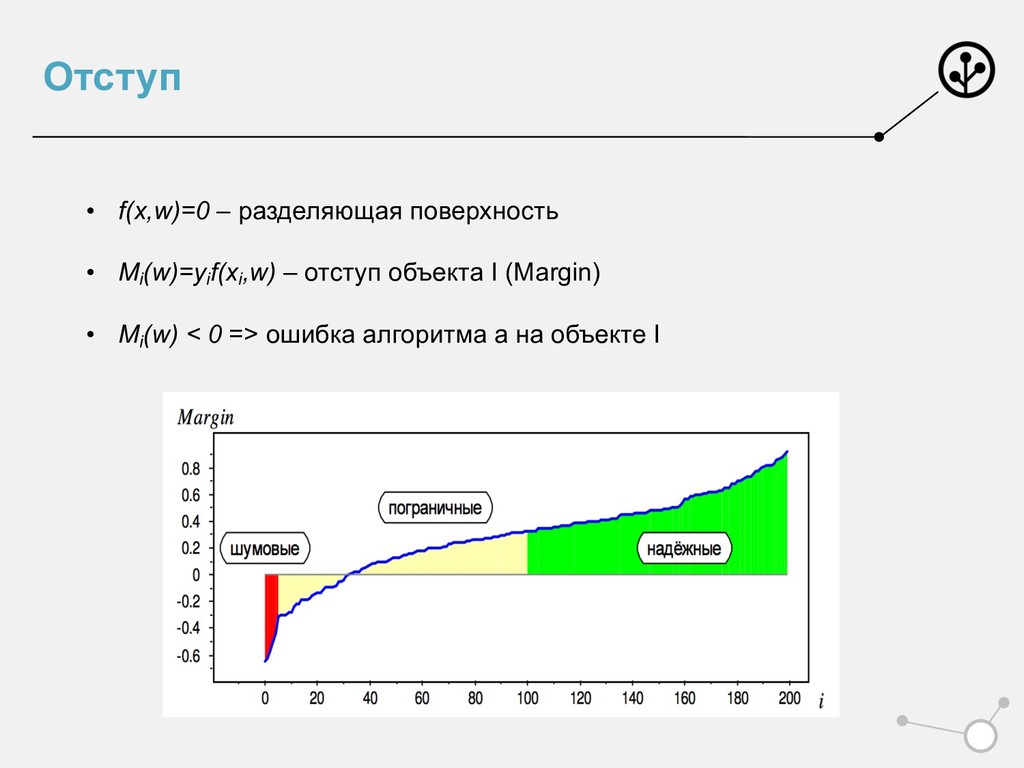
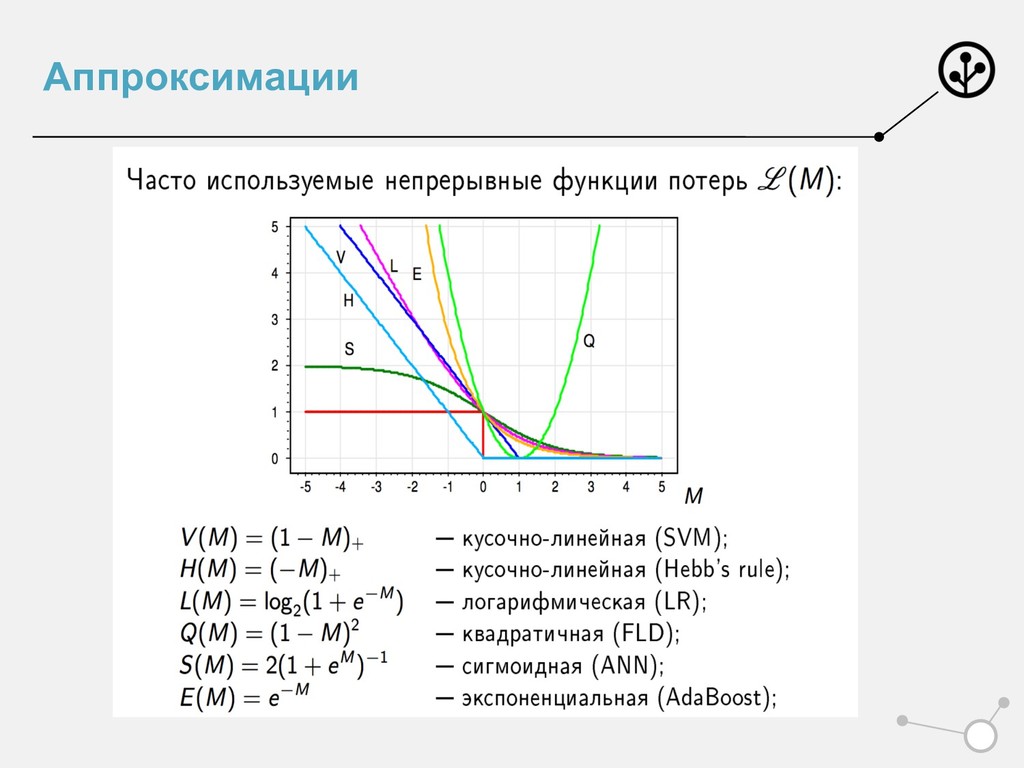
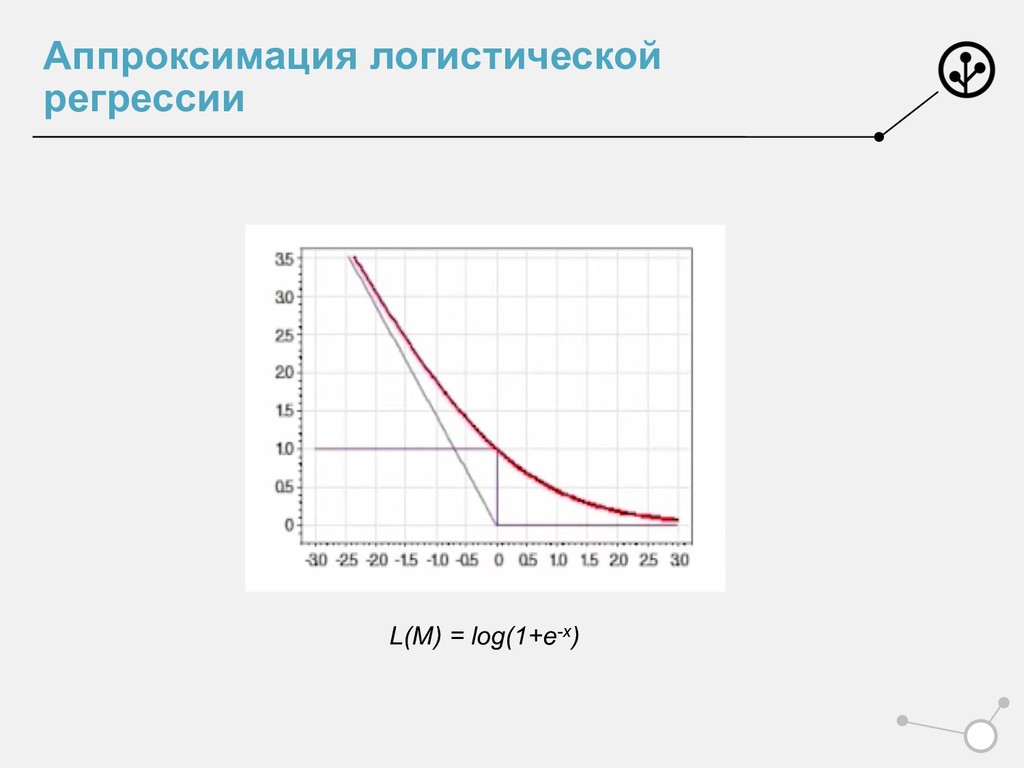
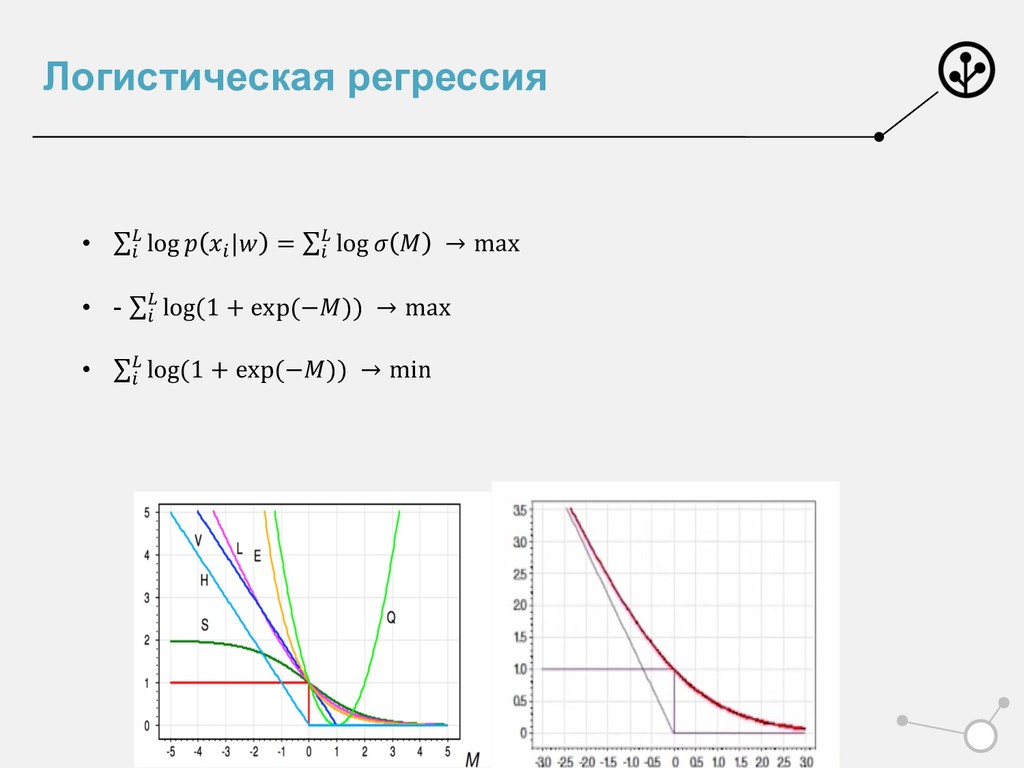
Сформировали лосс • Умеем оптимизировать • Умеем принимать решение • Но слишком много мы просто приняли на веру • Почему и откуда именно? • L = log(1+e-M) • ! " = $ $%&'((*+)
Сформировали лосс • Умеем оптимизировать • Умеем принимать решение • Но слишком много мы просто приняли на веру • Почему и откуда именно? • L = log(1+e-M) • ! " = $ $%&'((*+)
задачи • 6(8|:) –> 6 8 < • Оценить наиболее вероятные веса по выборке • Решение – методом ММП • <= = arg maxD E(F) • E(F) = ∏H I 6 8H |< → KL8 • E F → max => log E 8 → max
постановке xi – пара объект-ответ (xi ,yi ) • Пусть признаки – только бинарные {0,1} • Тогда порождающее распределение – Бернулли • Можно доказать, что для Бернулли • !(#,%&'(|*) !(#,%&,(|*) = exp(1, 2) • Доказательство (beyond the scope)
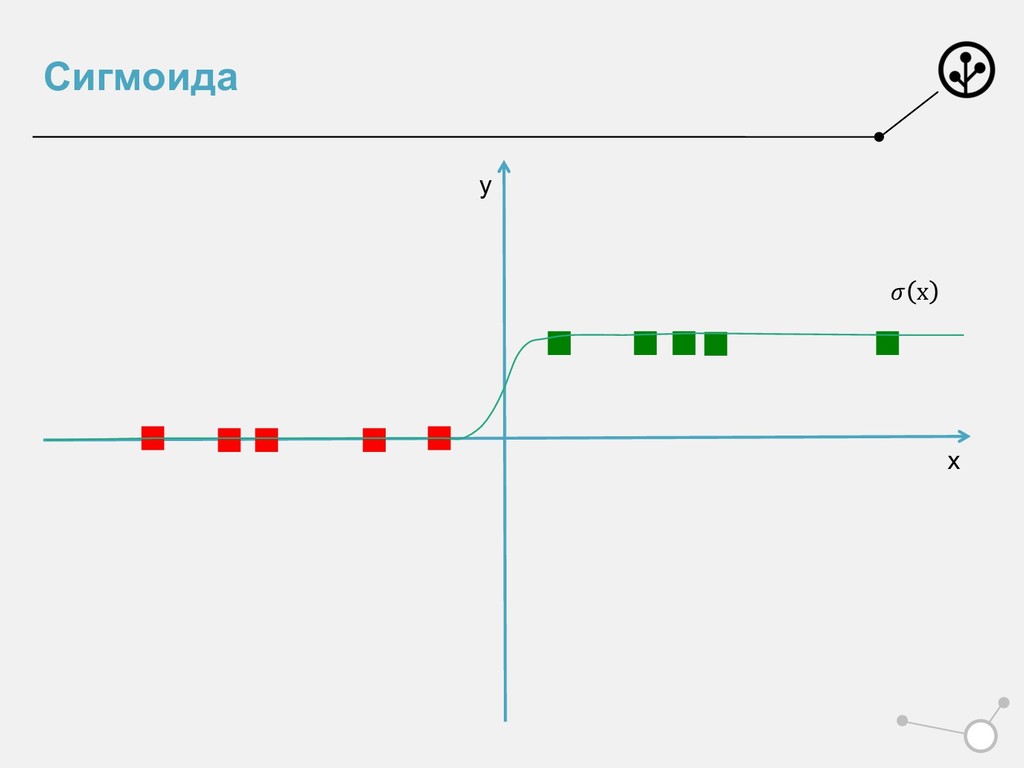
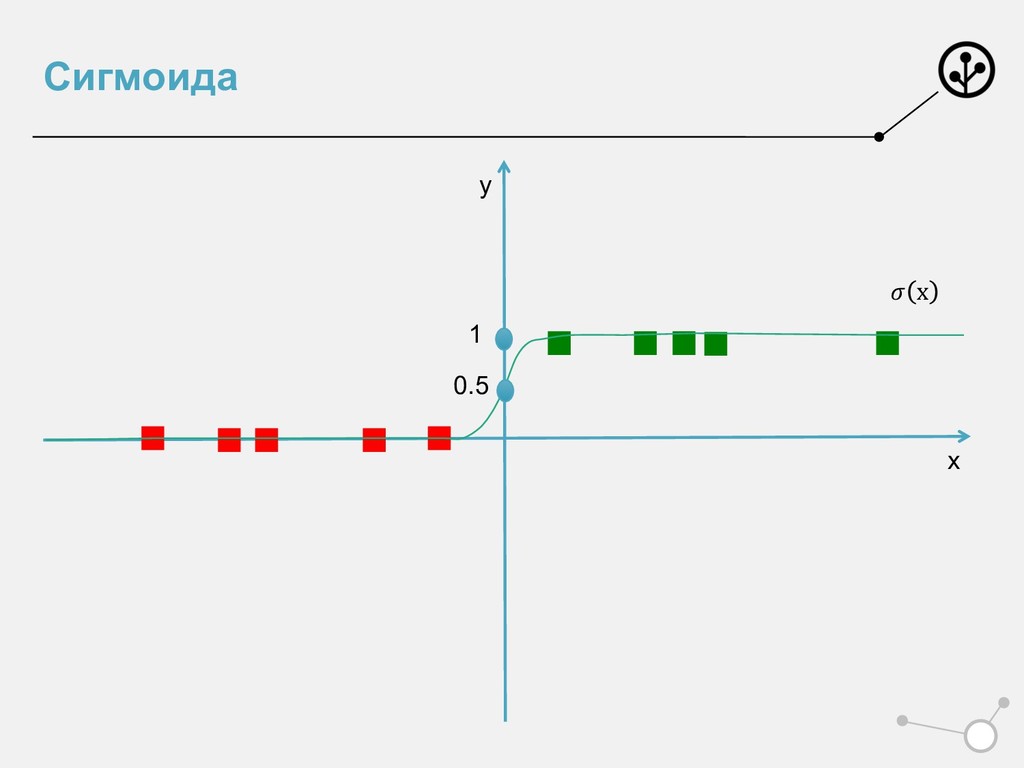
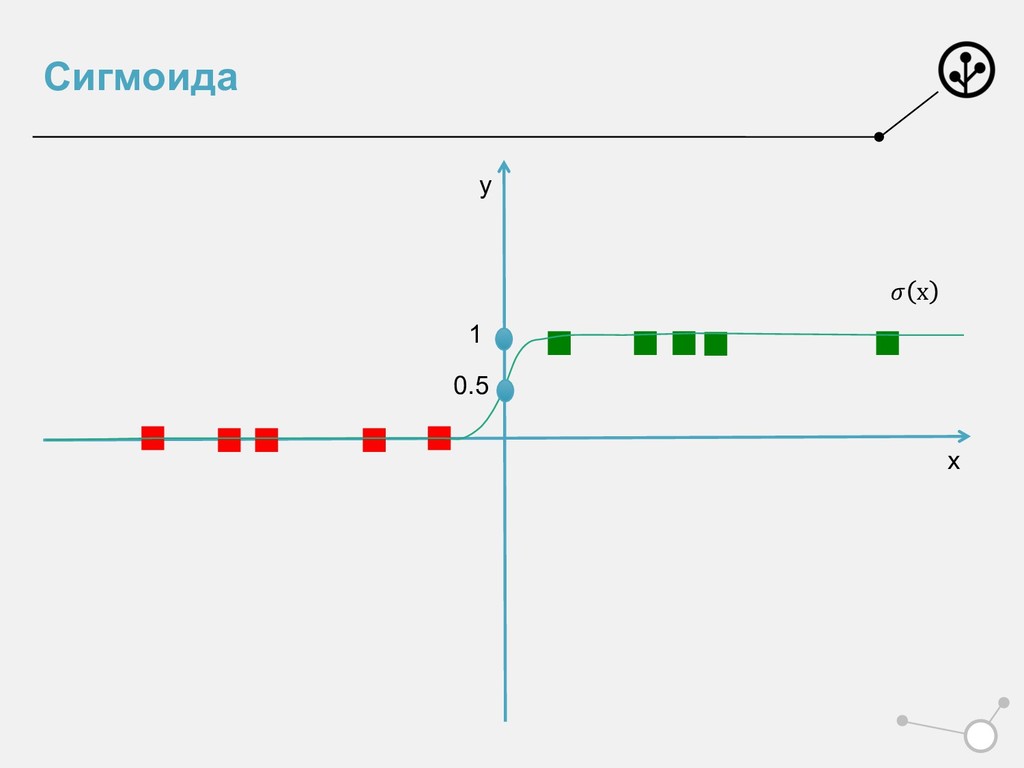
эмпирический риск лог-лоссом • ИЛИ порождает признаки из вероятностного пространства • Показали для Бернулли – бинарных признаков • Но не для всех – сигмоиду нельзя трактовать как чистую вероятность. Но можно применять =) • Оптимизирует лог-лосс • Или решает задачу ММП • Удобна для задач скоринга, спама • Важен не только аутпут, но и мера принадлежности
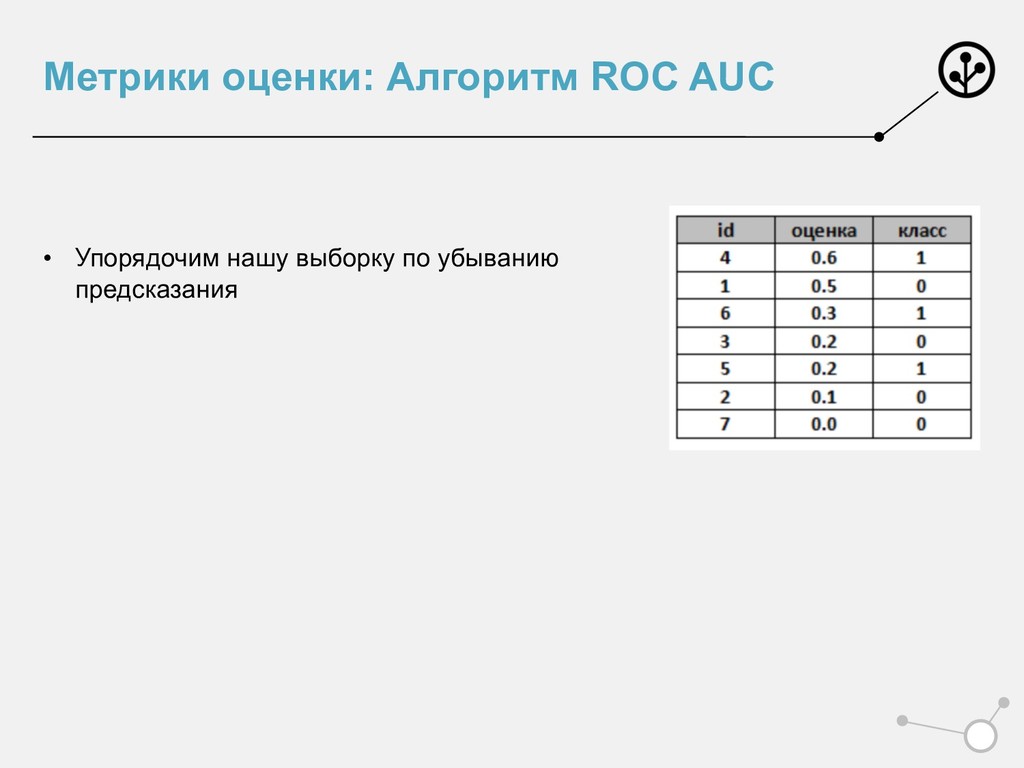
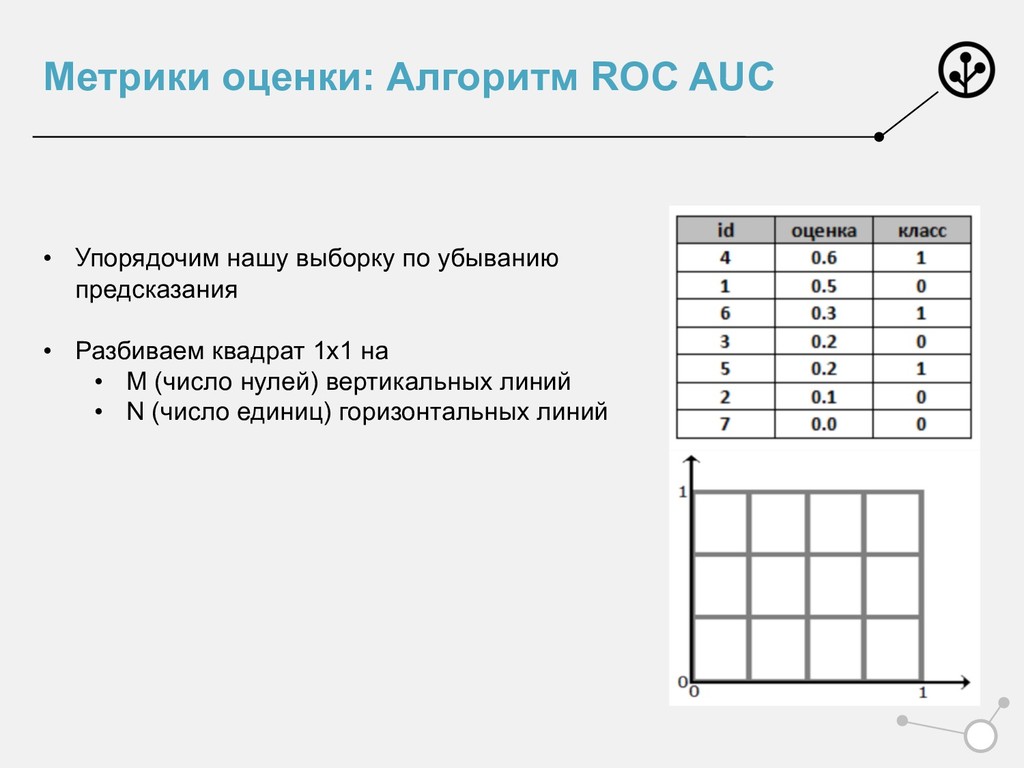
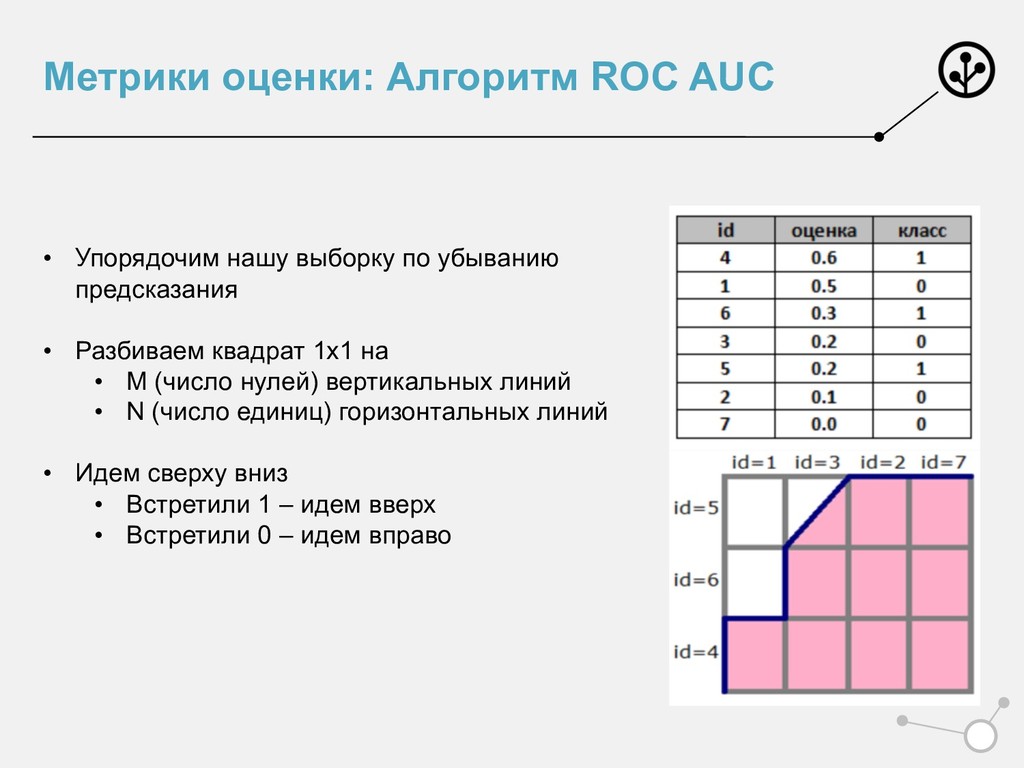
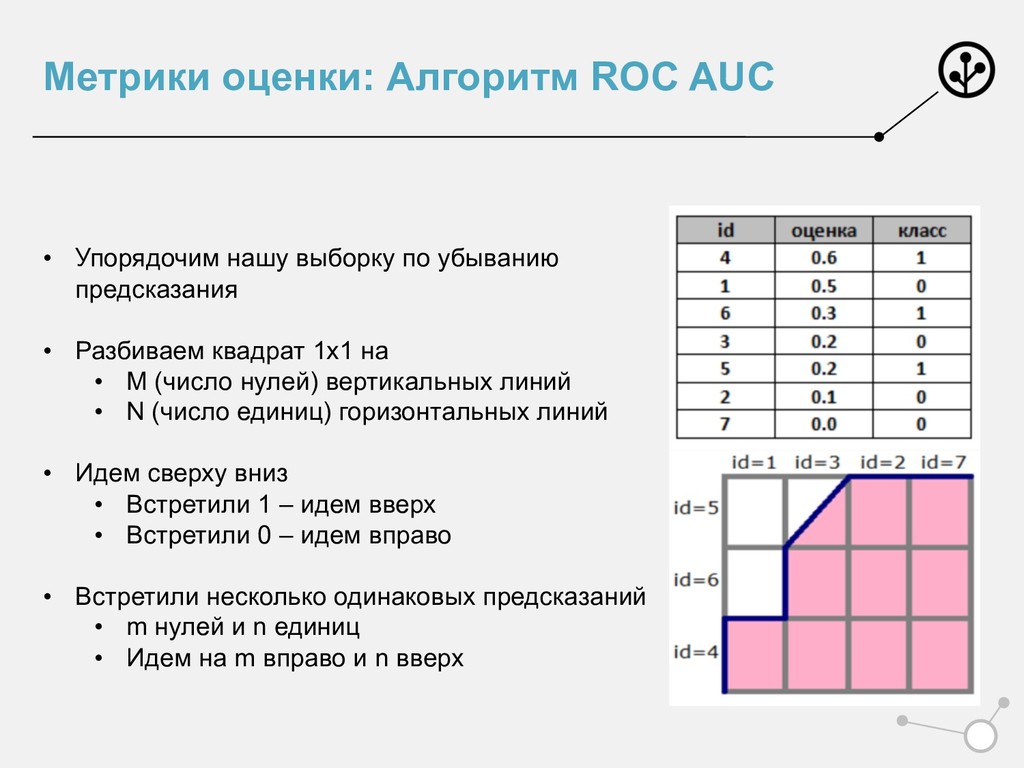
убыванию предсказания • Разбиваем квадрат 1х1 на • M (число нулей) вертикальных линий • N (число единиц) горизонтальных линий • Идем сверху вниз • Встретили 1 – идем вверх • Встретили 0 – идем вправо
убыванию предсказания • Разбиваем квадрат 1х1 на • M (число нулей) вертикальных линий • N (число единиц) горизонтальных линий • Идем сверху вниз • Встретили 1 – идем вверх • Встретили 0 – идем вправо • Встретили несколько одинаковых предсказаний • m нулей и n единиц • Идем на m вправо и n вверх
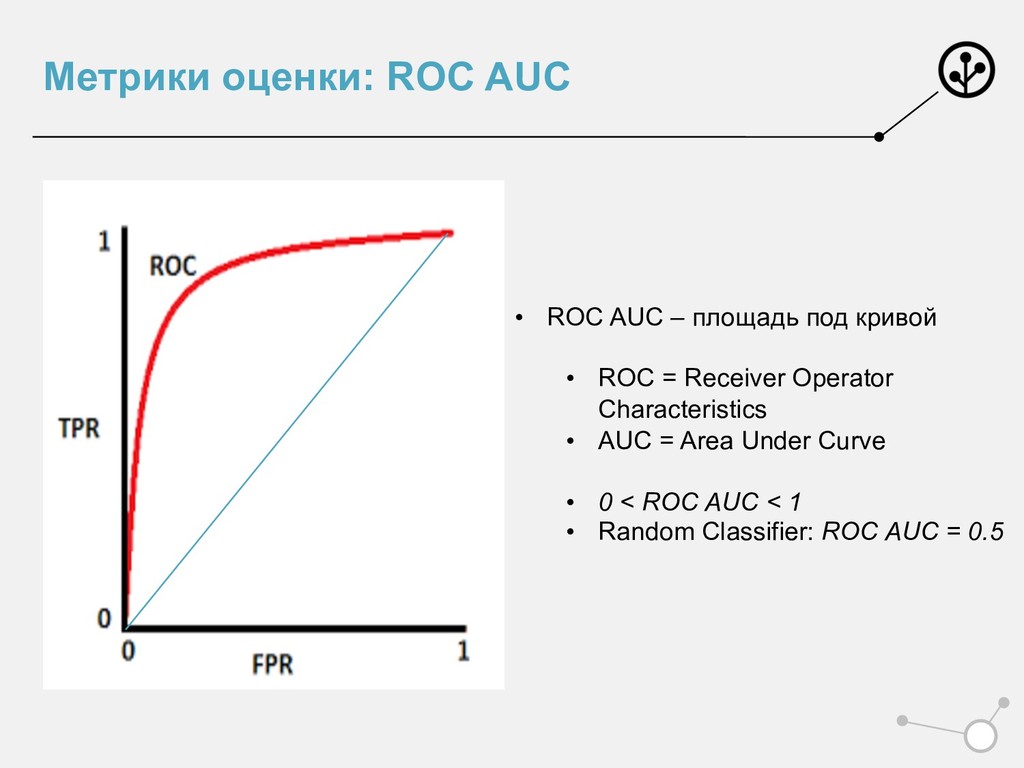
точек 1 и 0 из выборки • ROC отделяет верно упорядоченные алгоритмом пары точек • ROC AUC – число верно отранжированных пар • Исчерпывающая интерпретация: • Вероятность, что алгоритм верно упорядочит случайно выбранную пару (1,0)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Метрики оценки: точность [precision] precision = tp tp+ fp](https://files.speakerdeck.com/presentations/26198b0cba5b4adbbe8739f35e45aef2/slide_46.jpg){kind=link}
![Метрики оценки: полнота [recall] precision = tp tp+ fn](https://files.speakerdeck.com/presentations/26198b0cba5b4adbbe8739f35e45aef2/slide_47.jpg){kind=link}
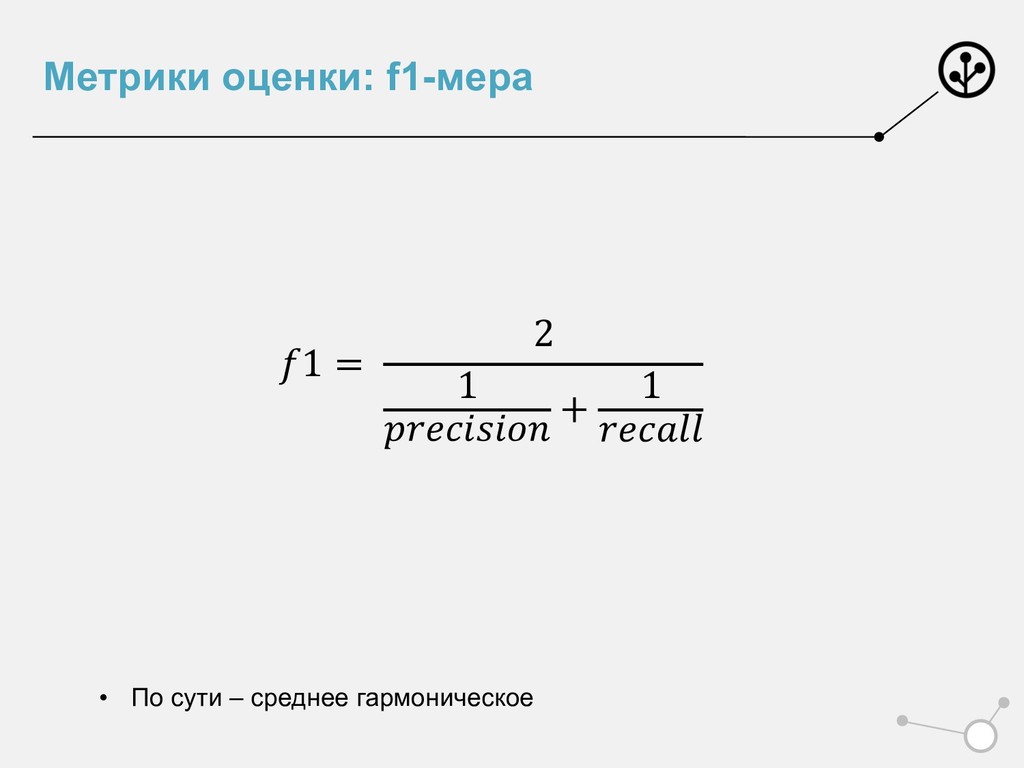{kind=link}
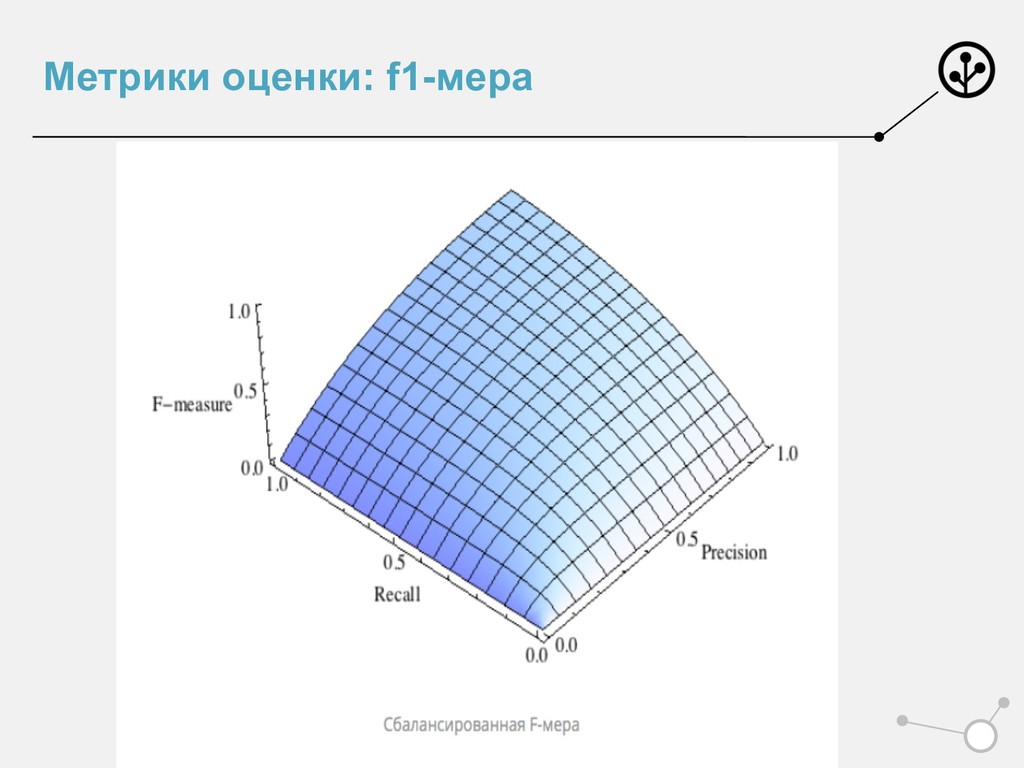{kind=link}
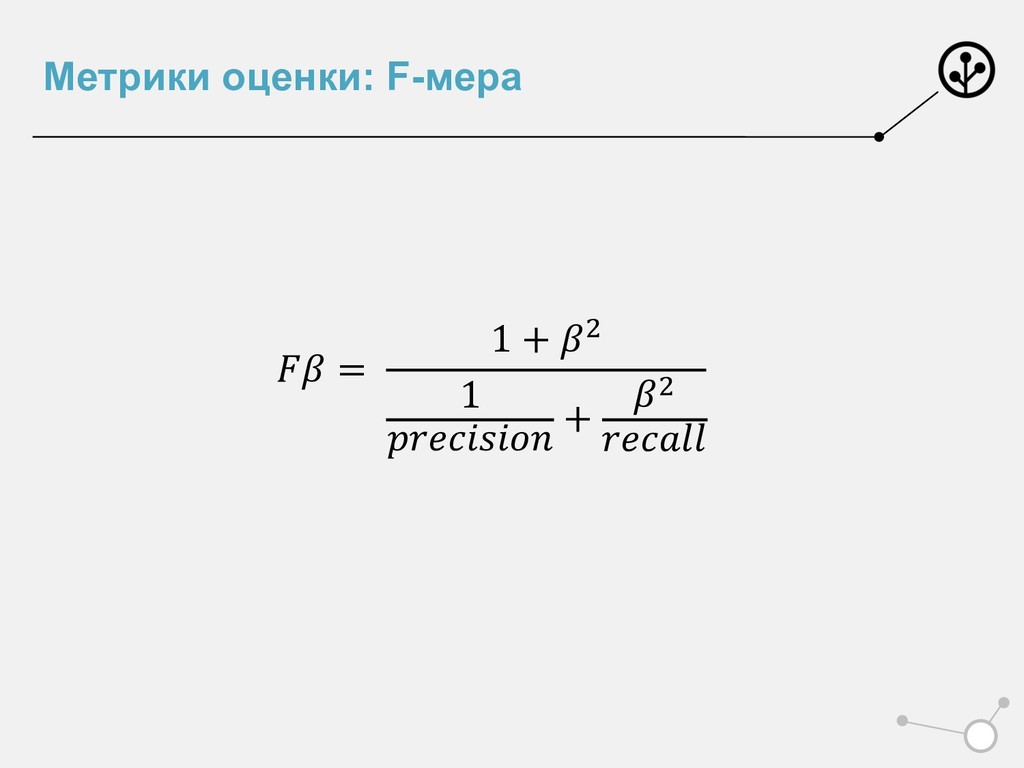{kind=link}
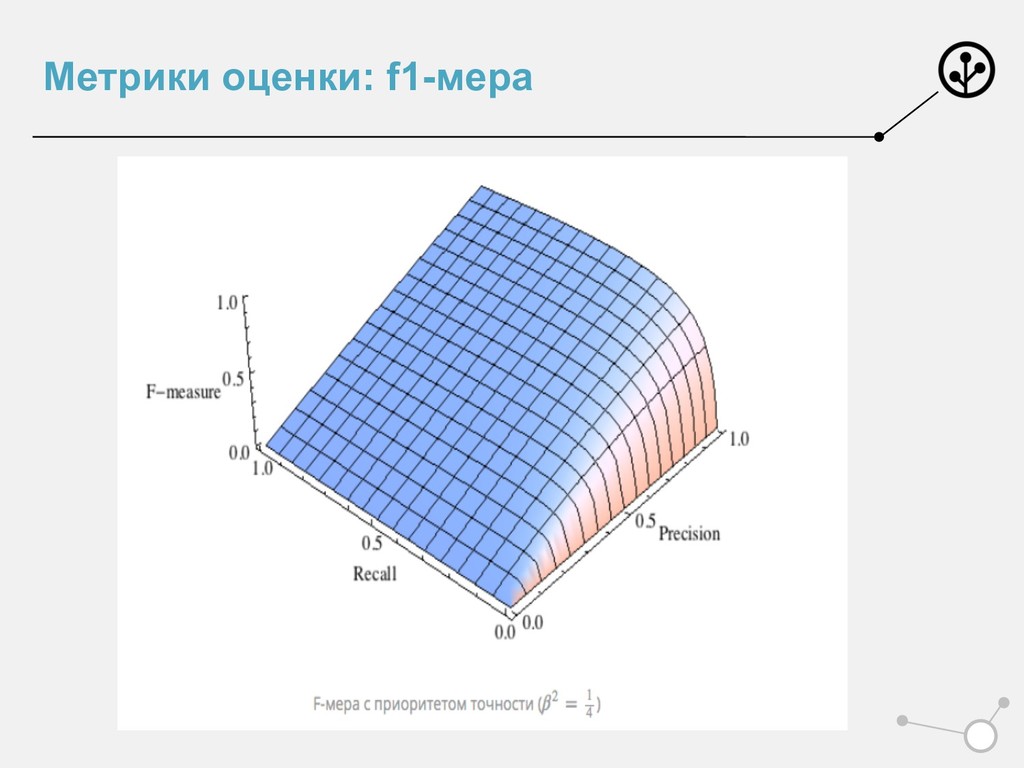{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}