Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
study-infra-0429
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
tenn25
April 29, 2018
Technology
86
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
study-infra-0429
ゼロから始める DBチューニング(再演)
tenn25
April 29, 2018
More Decks by tenn25
See All by tenn25
DQ-Management3-1
tenn25
0
93
Azure-CICD.pdf
tenn25
0
100
study-infra-0708
tenn25
0
75
study-infra-0526
tenn25
0
60
Other Decks in Technology
See All in Technology
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
180
AI驚き屋発見器
yama3133
1
370
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
240
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
380
Git 研修【MIXI 26新卒技術研修】#2
mixi_engineers
PRO
1
390
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.1k
新たなDBアーキテクチャ「LTAP」にDeep Dive!!
inoutk
0
100
人とエージェントが高め合う協業設計
kintotechdev
0
1k
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
160
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
500
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
750
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
220
Featured
See All Featured
GitHub's CSS Performance
jonrohan
1033
470k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Writing Fast Ruby
sferik
630
63k
Facilitating Awesome Meetings
lara
57
7k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
4k
Rails Girls Zürich Keynote
gr2m
96
14k
4 Signs Your Business is Dying
shpigford
187
22k
Leo the Paperboy
mayatellez
8
1.9k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Typedesign – Prime Four
hannesfritz
42
3.1k
The Spectacular Lies of Maps
axbom
PRO
1
870
Transcript
ゼロから始める DBチューニング(再演+α) #インフラ勉強会 2018/4/29 @tenn_25
@tenn_25 ・BtoC向けWebサービスの運用担当 ・2月に勉強会したけどネットが貧弱だった ・最近Jc•mと契約してネットは改善された ・どらくえ派 自己紹介 2
今回のゴール ・DBチューニングの観点を知る ・DBがどう動いているかを理解する ・インデックス、統計情報、実行プランを理解する 注意事項 ※今回はリレーショナルデータベースの話なのでNoSQLは違います ※各DB製品によっても細かいところが違います 3
アジェンダ 1.チューニングのアプローチ 2.データベースの仕組み 3.データベースのデータ構造 4.インデックスの構造 5.その他の重要事項 6.デモ 4
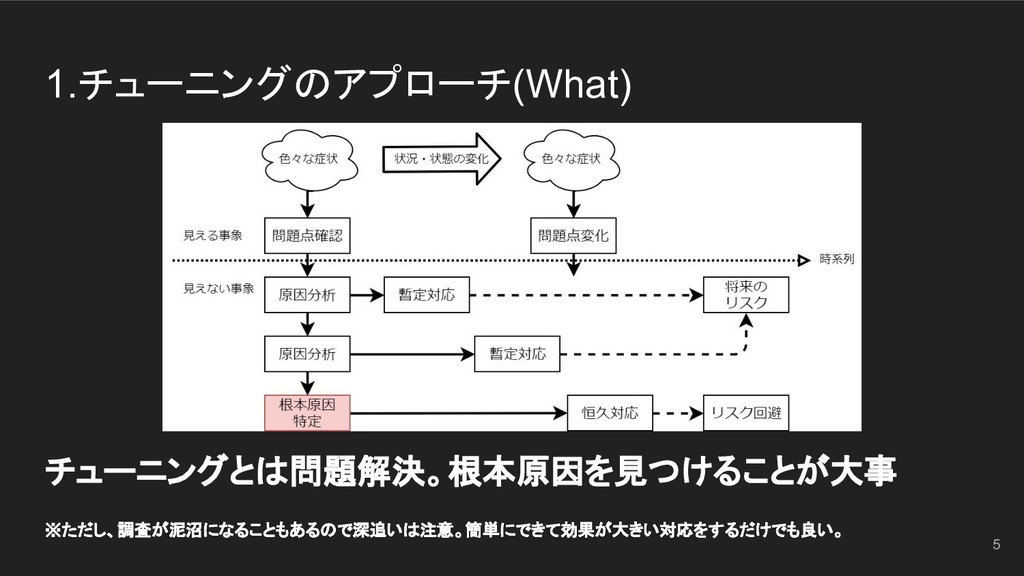
1.チューニングのアプローチ(What) チューニングとは問題解決。根本原因を見つけることが大事 ※ただし、調査が泥沼になることもあるので深追いは注意。簡単にできて効果が大きい対応をするだけでも良い。 5
DBチューニングの場合は、ボトルネックを見つけてそこを対処しよう ボトルネックの8割はディスクI/O(※個人調べ) まずは「いかにディスクI/Oを減らすか」の視点で! 1.チューニングのアプローチ(Where) 6
1.チューニングのアプローチ(原因分析のHow) ・データベースの症状、範囲を確認する(見える事象) - リソース使用量、クエリの実行時間、どんな変更をしたか、いつからか - 影響範囲(特定の処理だけ?特定のクエリだけ?特定のテーブルだけ?) ・データベースの内部情報を調べる(見えない事象) - 各DB製品ごとにツールや方法が違う。 -
SQLServerの場合…トレース(Profiler)、動的管理ビュー、パフォーマンスモニタ、クエリストア 7
1.チューニングのアプローチ(対応のHow) ・SQLの見直し - ループ処理、サブクエリ、 JOINなどの見直し ・論理設計の見直し - テーブル設計見直し、非正規化など ・DB内部の設定の見直し -DB内の細かい設定変更、インデックス
←今日の話はこれ ・物理設計の見直し -負荷分散、並列処理、 RAIDやファイル構成の見直し、スケールアップ /アウト(札束で殴r 8
1.チューニングのアプローチ(まとめ) 表面的な症状を見てるだけでは根本原因は分からない。 リソース負荷や症状はあくまで「予想の裏付け」程度の参考にする。 データベースの内部の情報を調べる必要がある(DB毎に違う) データベースの仕組みを知っている必要がある(今日はこれ) 9
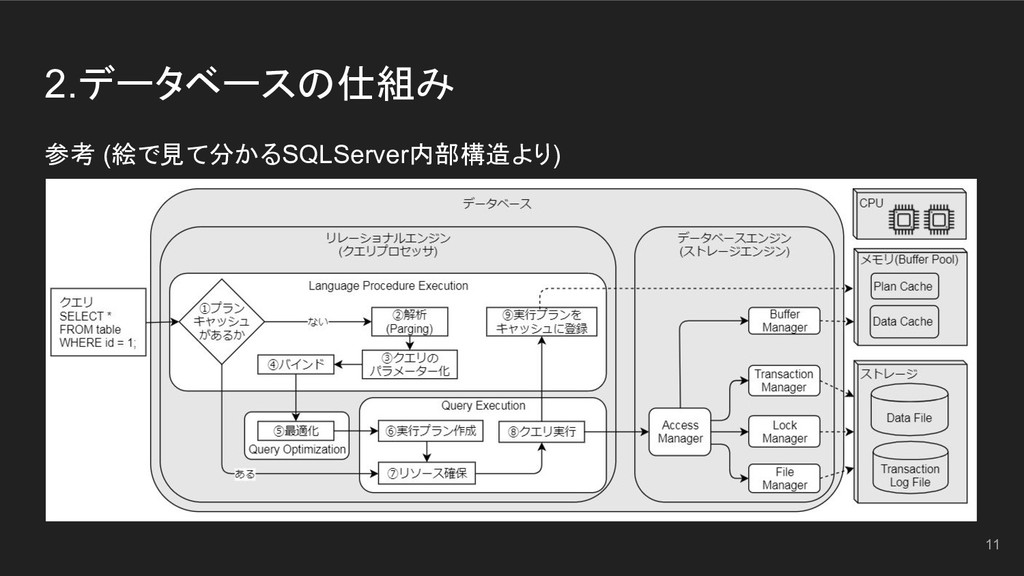
2.データベースの仕組み 10 欲しいデータがメモリに乗ってたら速い。 乗ってなかったら仕方なくデータ探しの旅へ…
2.データベースの仕組み 11 参考 (絵で見て分かるSQLServer内部構造より)
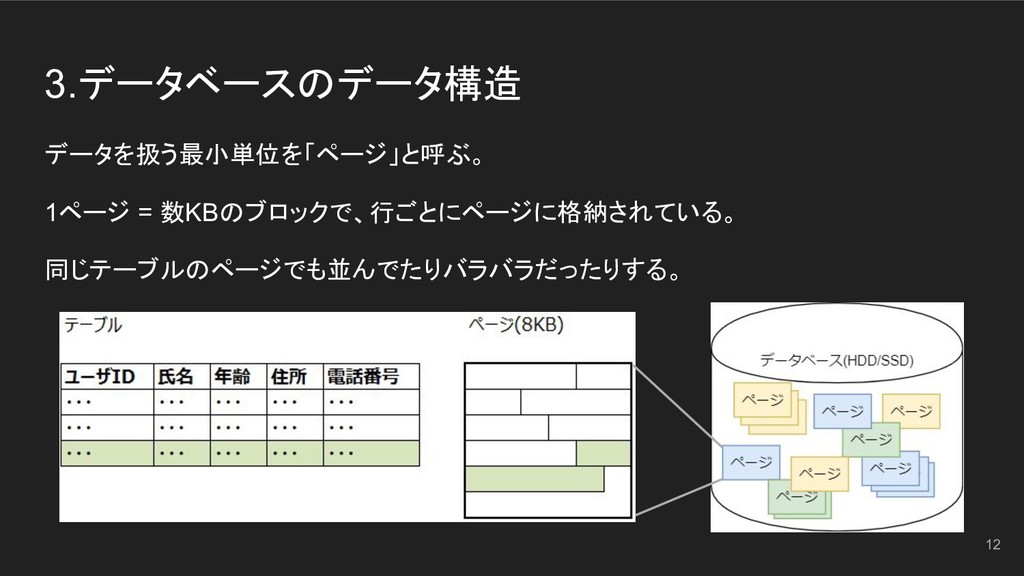
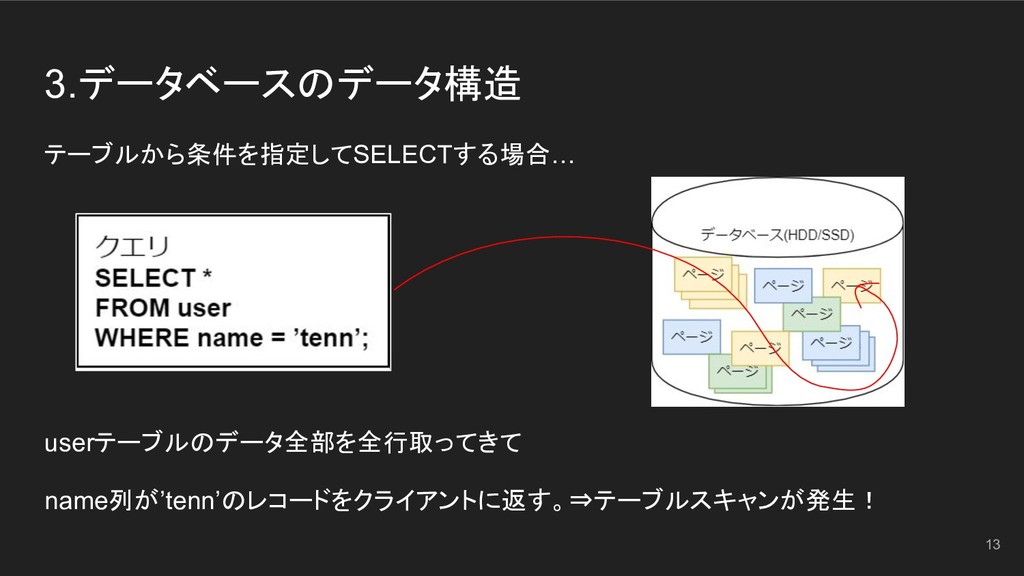
3.データベースのデータ構造 データを扱う最小単位を「ページ」と呼ぶ。 1ページ = 数KBのブロックで、行ごとにページに格納されている。 同じテーブルのページでも並んでたりバラバラだったりする。 12
3.データベースのデータ構造 テーブルから条件を指定してSELECTする場合… userテーブルのデータ全部を全行取ってきて name列が’tenn’のレコードをクライアントに返す。⇒テーブルスキャンが発生! 13
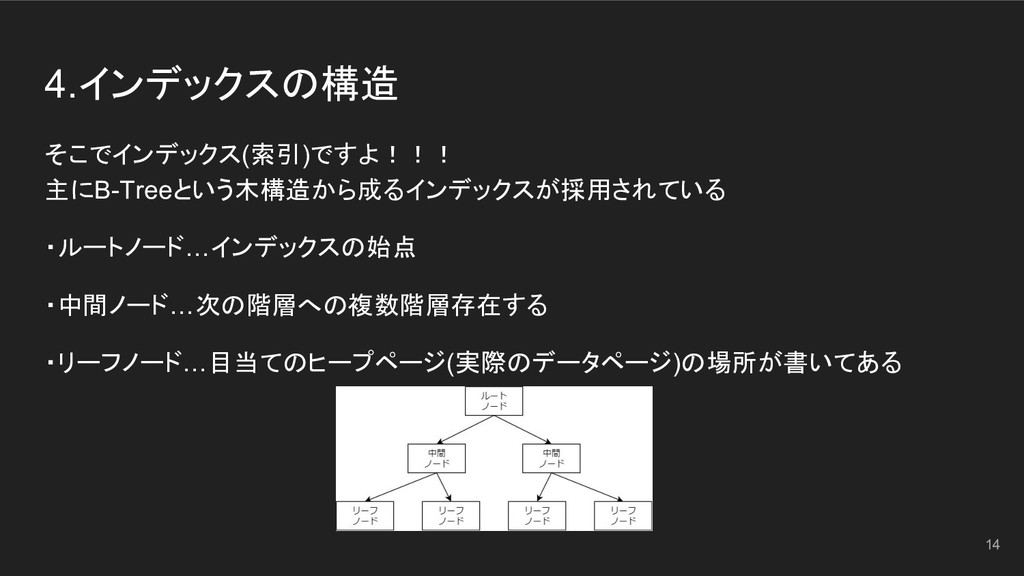
4.インデックスの構造 そこでインデックス(索引)ですよ!!! 主にB-Treeという木構造から成るインデックスが採用されている ・ルートノード…インデックスの始点 ・中間ノード…次の階層への複数階層存在する ・リーフノード…目当てのヒープページ(実際のデータページ)の場所が書いてある 14
4.インデックスの構造 テーブルにインデックス(索引)を付けると… インデックスを辿って 欲しいページだけにアクセスできる インデックス付与することで簡単にディスクIOが減らせる! 15
4.インデックスの構造 ヒープ…実データそのもののこと。ストレージ上でバラバラ。並んでない。 インデックス…検索を高速化させるためにテーブルに付与する情報。索引。 16
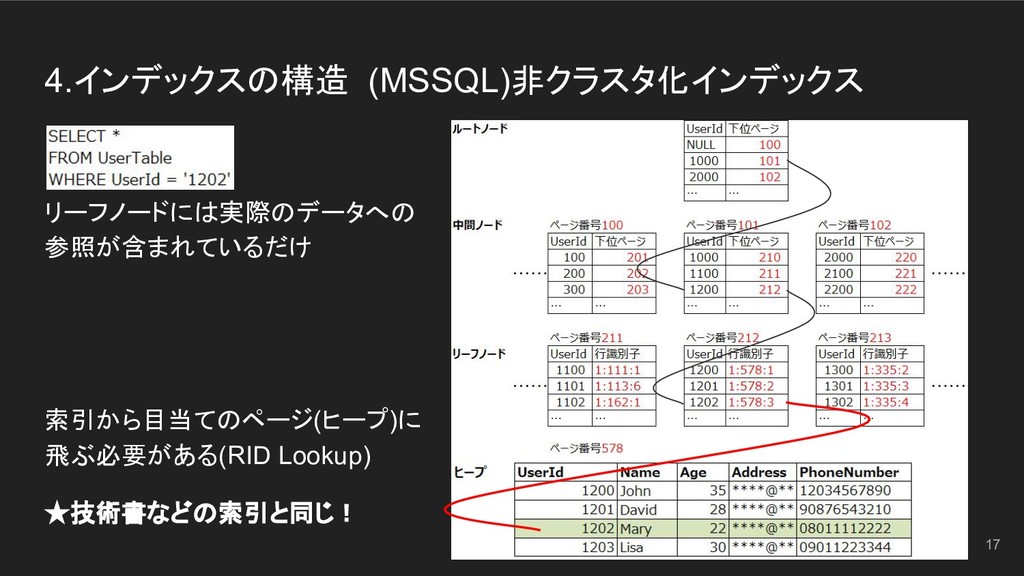
4.インデックスの構造 (MSSQL)非クラスタ化インデックス 17 リーフノードには実際のデータへの 参照が含まれているだけ 索引から目当てのページ(ヒープ)に 飛ぶ必要がある(RID Lookup) ★技術書などの索引と同じ!
リーフノードには実際のデータが格納さ れており、インデックスのキーでソートさ れている。 五十音順に辿って行くと、 目当て の言葉に直接辿りつく! ★辞書と同じ 4.インデックスの構造 (MSSQL)クラスタ化インデックス 18
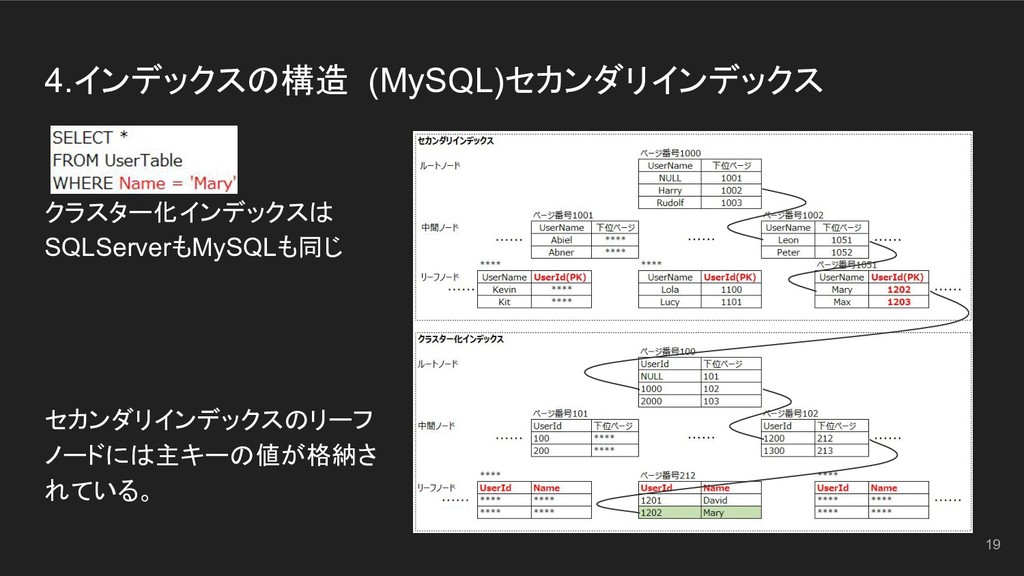
クラスター化インデックスは SQLServerもMySQLも同じ セカンダリインデックスのリーフ ノードには主キーの値が格納さ れている。 4.インデックスの構造 (MySQL)セカンダリインデックス 19
どうやってそのSQLを実行するか(データ検索手順書みたいなもの) 複雑なクエリになった時に実行プランは色々考えられる 実行プランは統計情報を基に決める 5.その他の重要事項 実行プラン(クエリプラン) 20
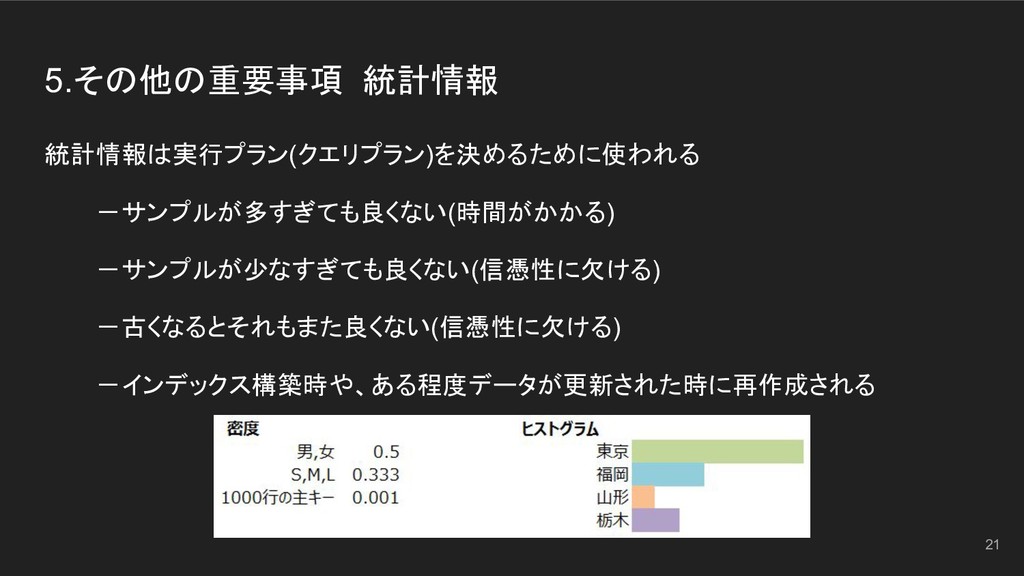
5.その他の重要事項 統計情報 統計情報は実行プラン(クエリプラン)を決めるために使われる -サンプルが多すぎても良くない(時間がかかる) -サンプルが少なすぎても良くない(信憑性に欠ける) -古くなるとそれもまた良くない(信憑性に欠ける) -インデックス構築時や、ある程度データが更新された時に再作成される 21
6.デモ SQLServerでデモします(画面共有) あるテーブルにインデックスを付けてみてIOコストが減ることを確認する ・テーブルスキャン…ヒープを全件検索(遅い) ・インデックススキャン…インデックスのリーフノードを全件検索(遅い) ・インデックスシーク…インデックスを辿って最短経路で検索(速い) 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}