Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
study-infra-0708
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
tenn25
July 08, 2018
Technology
75
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
study-infra-0708
データベースの仕組み
tenn25
July 08, 2018
More Decks by tenn25
See All by tenn25
DQ-Management3-1
tenn25
0
93
Azure-CICD.pdf
tenn25
0
100
study-infra-0526
tenn25
0
60
study-infra-0429
tenn25
0
86
Other Decks in Technology
See All in Technology
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
360
人とエージェントが高め合う協業設計
kintotechdev
0
1k
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
780
書籍セキュアAPIについて
riiimparm
0
360
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
220
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
300
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
1.1k
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
130
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
470
データエンジニアリングとドメイン駆動設計
masuda220
PRO
15
2.7k
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
160
最新IoT事例11選に学ぶ!現場の成功パターンと実践のコツ【SORACOM Discovery 2026】
soracom
PRO
0
110
Featured
See All Featured
Building AI with AI
inesmontani
PRO
1
1.1k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Done Done
chrislema
186
16k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Building Applications with DynamoDB
mza
96
7.1k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
A Modern Web Designer's Workflow
chriscoyier
698
190k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Speed Design
sergeychernyshev
33
1.9k
Docker and Python
trallard
47
4k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Transcript
データベースの仕組み #インフラ勉強会 2018/07/08 @tenn_25
社内SEとして運用やってます データベースが好きです ※どらくえ派です 自己紹介 2
目的 いま「分からん」「怖い」「触りたくもない」
目的 1時間後「データベースはいいぞ(^p^)」 ・どうやってSQLは実行されるの? →わかる ・どうやってデータ操作を正しく行ってるの? →わかる ・なぜ高速にデータが検索できるの? →わかる
アジェンダ ・データベース基本の「き」 ・データベースの構成要素 ・クエリを実行するまで - クエリの解析 - クエリの書き換え - 実行プランの作成
・データ処理の仕組み - トランザクション - ロック - キャッシュ - ログ ・まとめ
データベース基本の「き」 Q. データベースって何? A.「複数で共有、利用すること」と「検索、加工すること」を目的に整理されたデータの集 まり 出典:https://www.sejuku.net/blog/8763#MySQL Q.どうやってデータを検索したり更新したりできるの? A. SQLと呼ばれる言語をデータベースに対して実行する。 検索(SELECT),挿入(INSERT),更新(UPDATE),削除(DELETE)などが行える。
SELECT id,name FROM user WHERE id = ‘1024’; (例)userテーブルからidが 1024番の人のidと名前を検 索するSQL
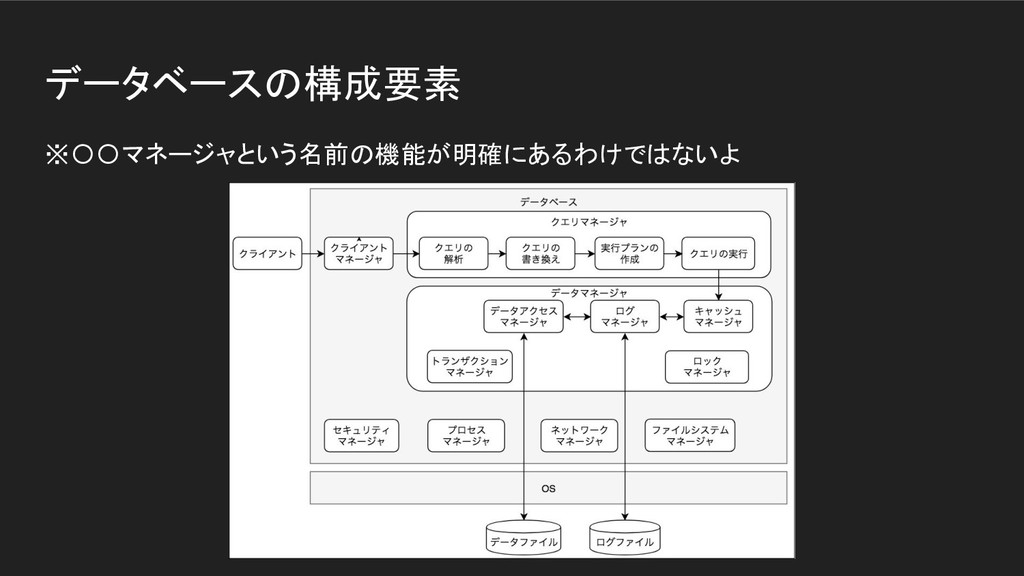
データベースの構成要素 ※〇〇マネージャという名前の機能が明確にあるわけではないよ
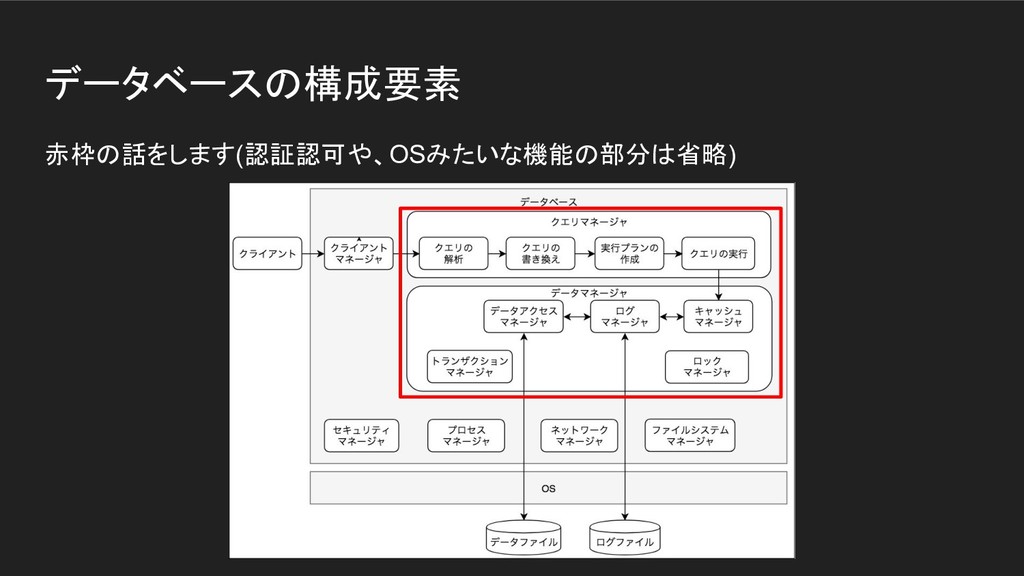
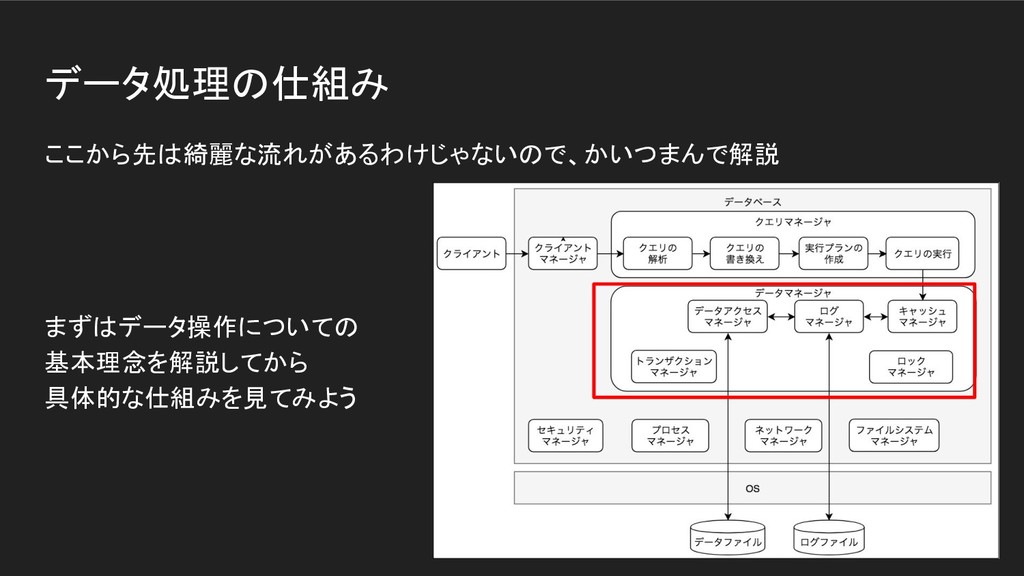
データベースの構成要素 赤枠の話をします(認証認可や、OSみたいな機能の部分は省略)
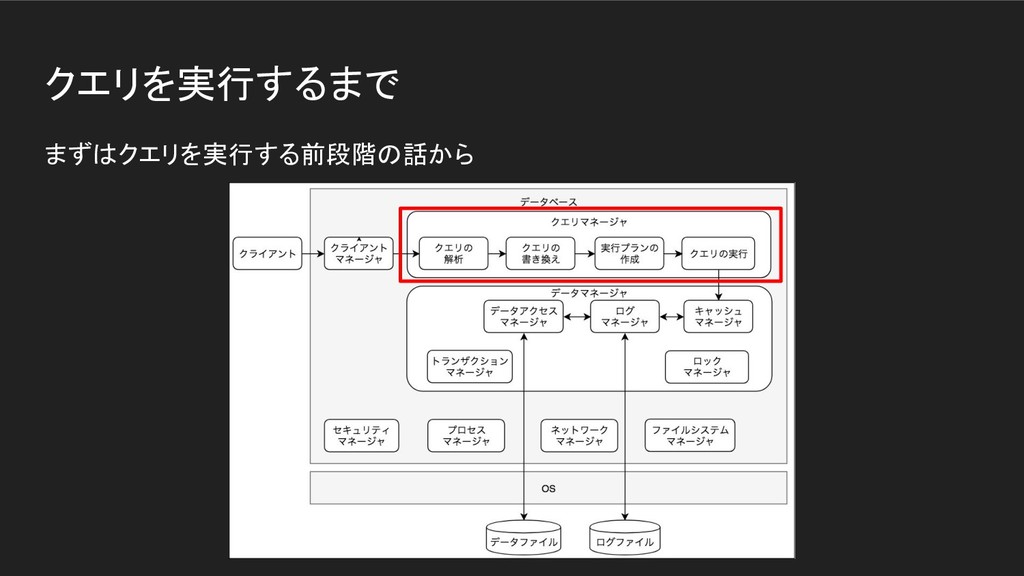
クエリを実行するまで まずはクエリを実行する前段階の話から
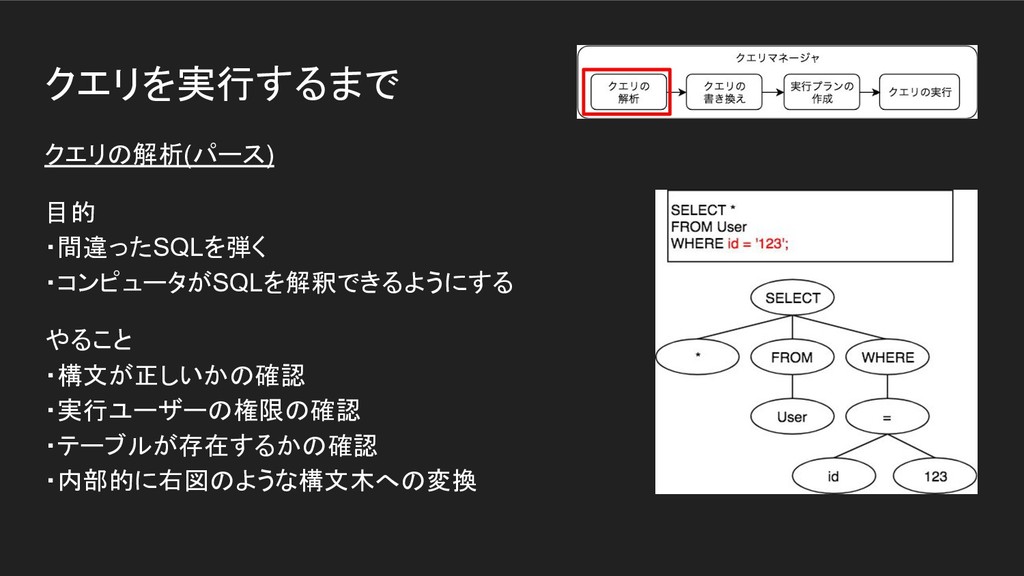
クエリを実行するまで クエリの解析(パース) 目的 ・間違ったSQLを弾く ・コンピュータがSQLを解釈できるようにする やること ・構文が正しいかの確認 ・実行ユーザーの権限の確認 ・テーブルが存在するかの確認 ・内部的に右図のような構文木への変換
クエリを実行するまで クエリの書き換え(リライタ) 目的 ・不要な演算を回避して少しでも高速化させる ・より最適な実行プラン(後述)を見つける やること ・一定のルールに従って構文木を変換
クエリを実行するまで 実行プランの作成(オプティマイズ) 目的 ・SQLには「どう実行するか」の情報が必要なため ・高速にデータを処理できそうな方法を考えるため やること ・統計情報を元にディスクIOやCPU,メモリの使用量を推定 ・統計情報をもとにSQLをどう実行するかを考える(様々な最適化アルゴリズム)
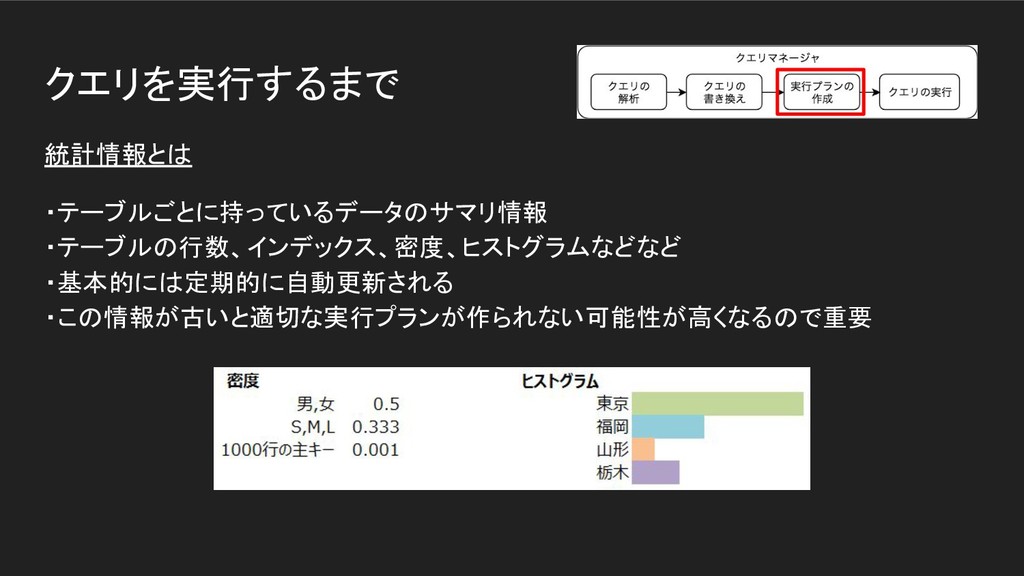
クエリを実行するまで 統計情報とは ・テーブルごとに持っているデータのサマリ情報 ・テーブルの行数、インデックス、密度、ヒストグラムなどなど ・基本的には定期的に自動更新される ・この情報が古いと適切な実行プランが作られない可能性が高くなるので重要
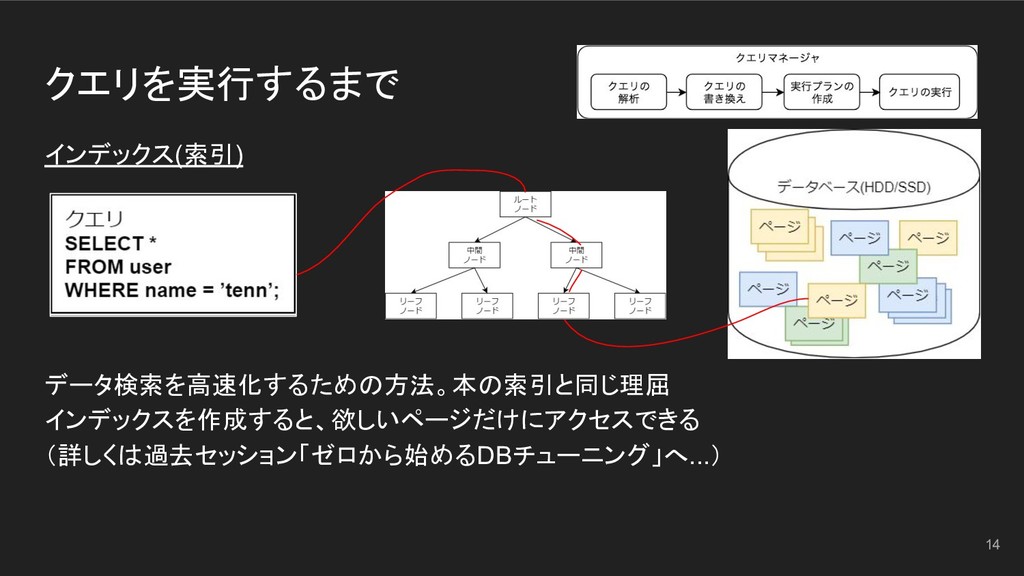
クエリを実行するまで インデックス(索引) データ検索を高速化するための方法。本の索引と同じ理屈 インデックスを作成すると、欲しいページだけにアクセスできる (詳しくは過去セッション「ゼロから始めるDBチューニング」へ...) 14
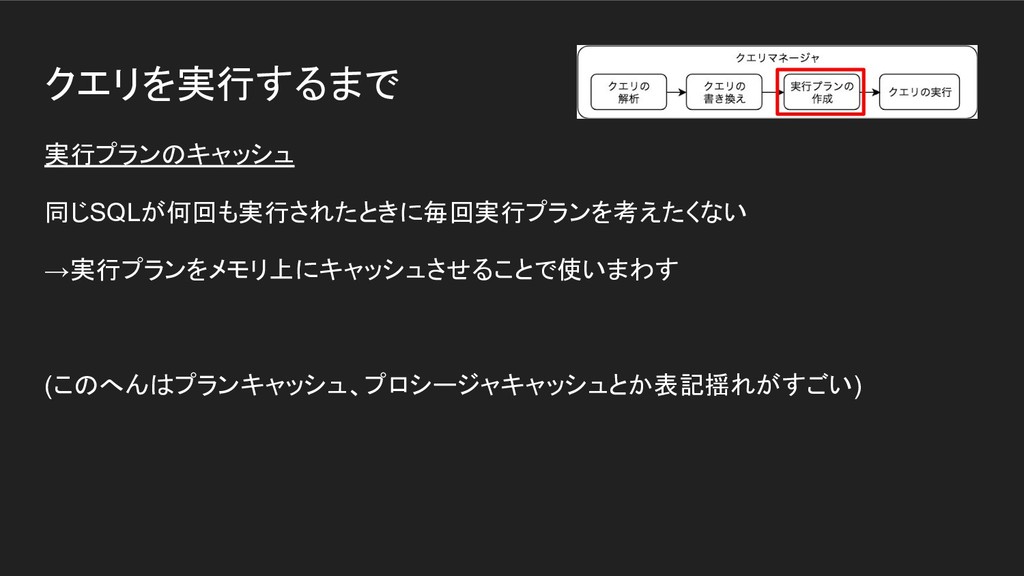
クエリを実行するまで 実行プランのキャッシュ 同じSQLが何回も実行されたときに毎回実行プランを考えたくない →実行プランをメモリ上にキャッシュさせることで使いまわす (このへんはプランキャッシュ、プロシージャキャッシュとか表記揺れがすごい)
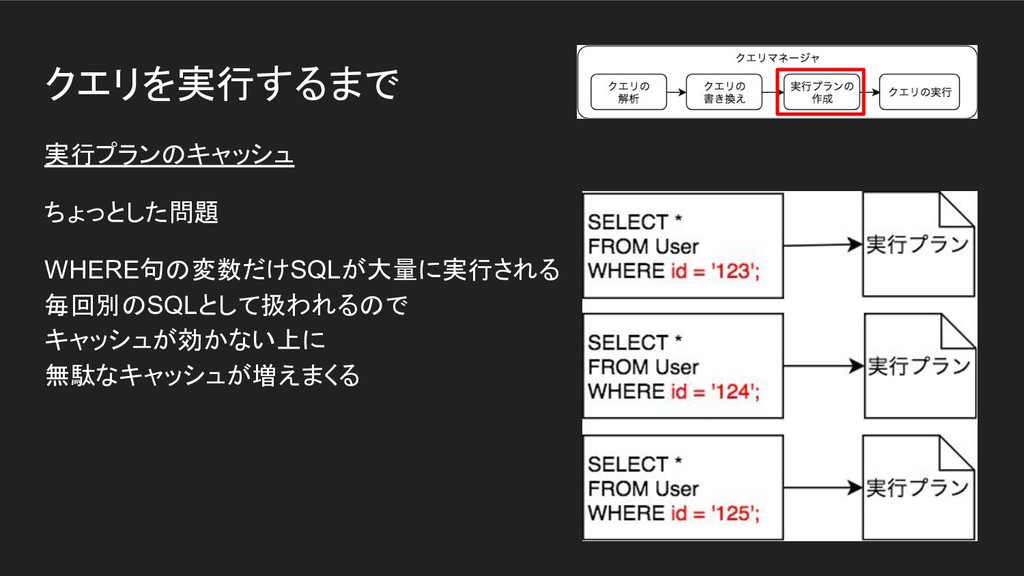
クエリを実行するまで 実行プランのキャッシュ ちょっとした問題 WHERE句の変数だけSQLが大量に実行される 毎回別のSQLとして扱われるので キャッシュが効かない上に 無駄なキャッシュが増えまくる
クエリを実行するまで 実行プランのキャッシュ そこでパラメータクエリですよ! 変数の部分以外は一緒なので使い回せる(SQLインジェクション対策にもなる)
クエリを実行するまで 実行プランのキャッシュ さらに問題が...(細かい話なので割愛) 実行プランのキャッシュとパラメータクエリをつかうことによって、 「何もしてないのにある日突然クエリが遅くなった!」 という事象が起こる(パラメータスニッフィング ) (この名前はSQLServer用語っぽい...?)
クエリを実行するまで そんなこんなありましたが、 ここまでやって、めでたくSQLが実行されます。
データ処理の仕組み ここから先は綺麗な流れがあるわけじゃないので、かいつまんで解説 まずはデータ操作についての 基本理念を解説してから 具体的な仕組みを見てみよう
データの処理の仕組み ACID特性 データベース界の法律! リレーショナルデータベースはこれらの特性を保証している。 ・原子性(Atomicity) ある1つの操作が中途半端に実行されることはない。 ・一貫性(Consistency) 制約に違反せずデータの整合性が担保されている。 ・独立性(Isolation) 2つの処理が同時に起こってもお互い影響しない。 ・耐久性(Durability)
ある処理が完了した後にそのデータは消えない。
データの処理の仕組み ACID特性(具体例) 処理1(T1)…口座Aから口座Xに100万円振り込む。 処理2(T2)…口座Bから口座Xに50万円振り込む。 ・原子性…T1実行中に障害が起きても、「口座 Aから100万円減ったが口座Bは増えていない」という事態 にならないこと。処理はロールバックされ振込が無かったことになること。 ・一貫性…預金が100万円未満の時には振り込めないこと。「預金額はマイナスにならない」という制約に 違反しないこと。 ・独立性…T1とT2が同時に実行された際、「片方の処理が影響を受けてうまく処理されず、講座
Xに50万 円しか入金されていない」という事態にならないこと。 ・耐久性…T1が正常に完了した後に障害が起きても、お金が無くなったりしないこと。
データの処理の仕組み トランザクション 1つのまとまった処理を「トランザクション」と呼ぶ。 例:AさんがBさんに100万円を振り込む 1. トランザクション開始 2. Aさんの口座の預金額を-100万円 3. Bさんの口座の預金額を+100万円
4. トランザクション終了(コミットorロールバック) ※ロールバックした場合は1~4の処理は無かったことになる。
データの処理の仕組み トランザクションと独立性 もし、同時に1つのトランザクションしか処理されないのであれば 独立性は保証される。 しかし、実際のデータベースは 複数のトランザクションが「同時に」「同じデータに」アクセスする。 だからアレコレ工夫しなくてはならない。
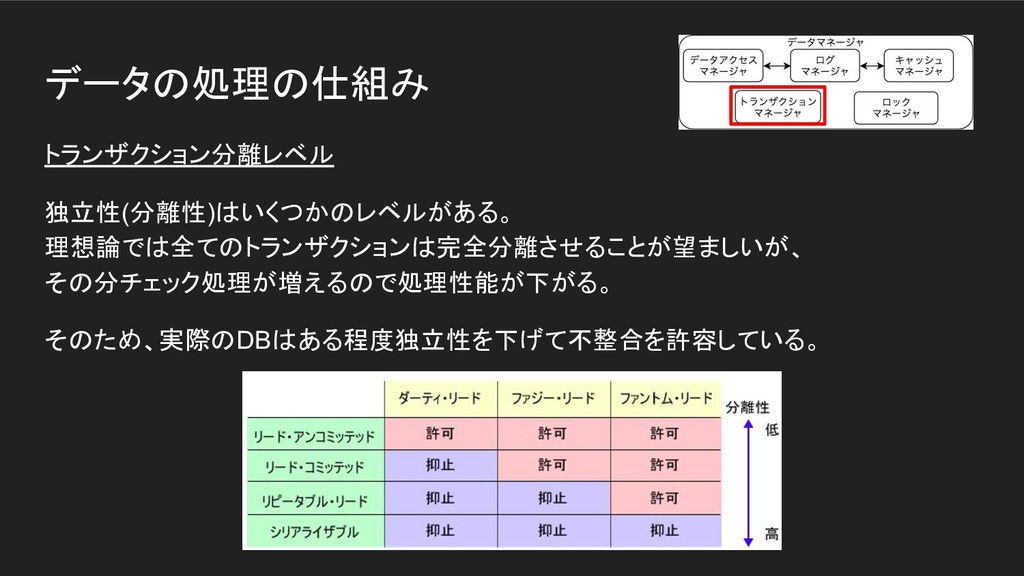
データの処理の仕組み トランザクション分離レベル 独立性(分離性)はいくつかのレベルがある。 理想論では全てのトランザクションは完全分離させることが望ましいが、 その分チェック処理が増えるので処理性能が下がる。 そのため、実際のDBはある程度独立性を下げて不整合を許容している。
データの処理の仕組み ロック 複数のトランザクションが「同時に」「同じデータに」アクセスする。 この平行性の制御のために、トランザクション内ではデータをロックする。 共有ロックと占有ロックがある。 (例)トランザクション①②③ の順に平行して動く場合
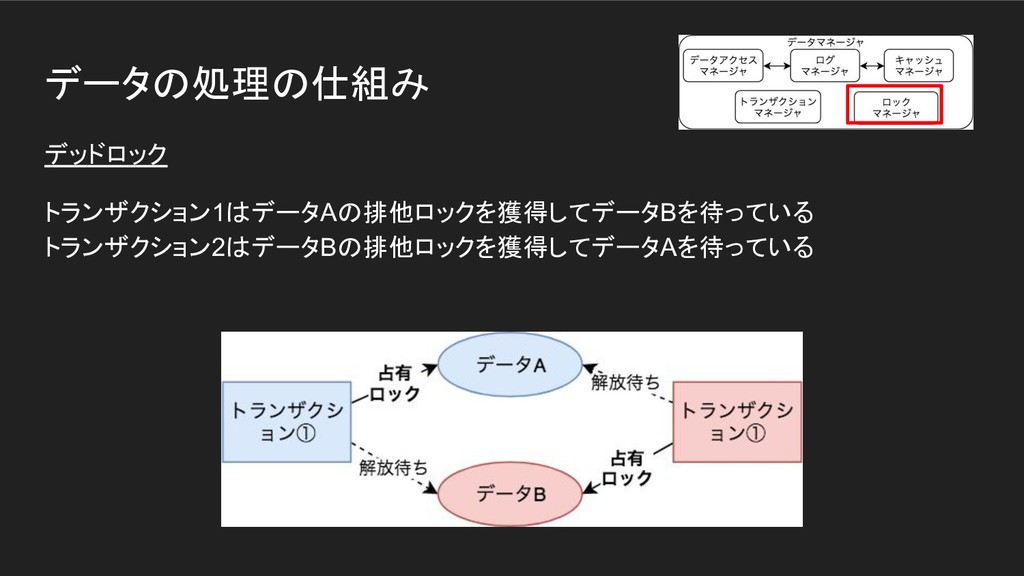
データの処理の仕組み デッドロック トランザクション1はデータAの排他ロックを獲得してデータBを待っている トランザクション2はデータBの排他ロックを獲得してデータAを待っている
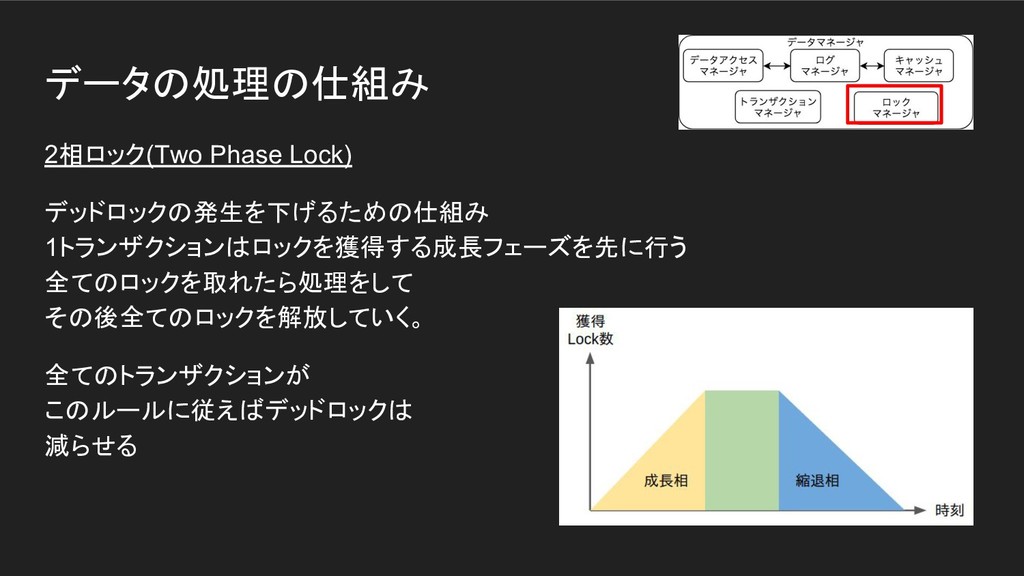
データの処理の仕組み 2相ロック(Two Phase Lock) デッドロックの発生を下げるための仕組み 1トランザクションはロックを獲得する成長フェーズを先に行う 全てのロックを取れたら処理をして その後全てのロックを解放していく。 全てのトランザクションが このルールに従えばデッドロックは
減らせる
データの処理の仕組み キャッシュ(メモリ・バッファ) データの操作は必ずメモリ上で行われるので読み込む必要がある。 ディスクに比べ高速なため、必要なデータをできるだけ効率良く読み込む やっていること ・必要なデータをメモリ上のバッファプールに格納する。 ・不要なデータをメモリ上のバッファプールから削除する
データの処理の仕組み 効率的にバッファプールに読み込ませる方法 高速化のため、データを処理するよりも前にバッファに読み込ませておく。 1,3,5と読み込まれたら次は7,9,11だろうと推測する方法も(投機的プリフェッチ) (※この仕組みはDBに限った話ではありません) データ1読み込み → データ1処理 データ2読み込み →
データ2処理 データ3読み込み → データ3処理 時間
データの処理の仕組み どのデータをバッファから削除するか 一番有名なのはLRUアルゴリズム(Least Recently Used) 各キャッシュのページ(DBデータを扱う最小単位)はカウントを持っており、 時間経過によって減っていく。閾値を下回ったらバッファから削除。 キャッシュが利用されるとカウント数が上がる。 ※さっき出た実行プランのキャッシュも同じ方法で削除されます。
データの処理の仕組み ログ 処理するたびに実データを書き換えてたら、元に戻せない! トランザクションのロールバックには必要不可欠。 トランザクションの全ての操作はログファイルとして書き込まれる。 処理途中に障害が起きた場合にログによってデータを元に戻せる。
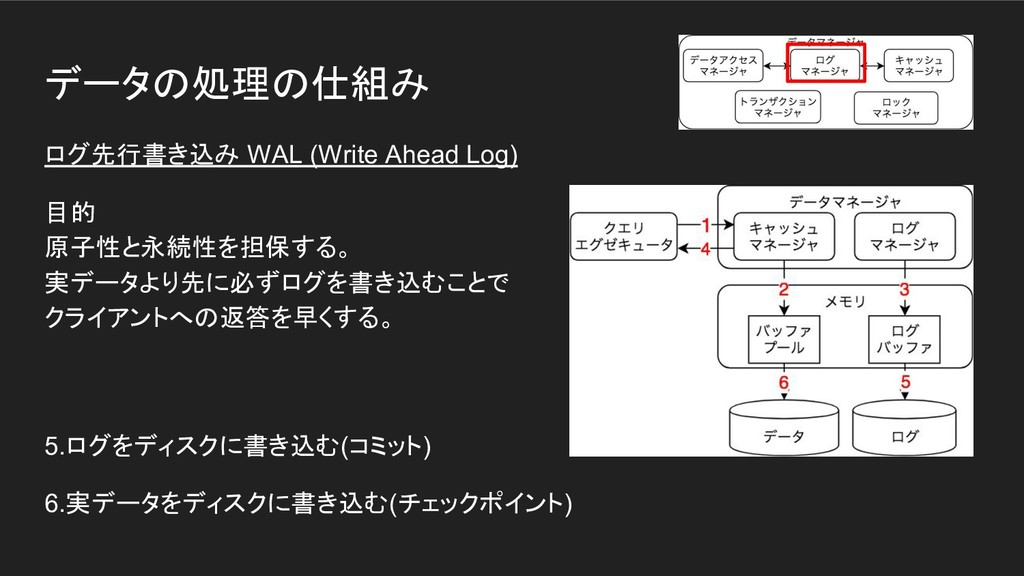
データの処理の仕組み ログ先行書き込み WAL (Write Ahead Log) 目的 原子性と永続性を担保する。 実データより先に必ずログを書き込むことで クライアントへの返答を早くする。
5.ログをディスクに書き込む(コミット) 6.実データをディスクに書き込む(チェックポイント)
データの処理の仕組み ログ先行書き込み WAL (Write Ahead Log) Force/No Force コミット前にデータをディスクに書き込む処理を行うのがForce コミット後にデータをディスクに書き込むのがNo
Force Steal/No Steal トランザクション内で随時ディスクに書き込めるのがSteal それを許容せず、データをまとめて更新するのがNo Steal Steal/NoForceがもっともパフォーマンスが高い分、管理は複雑 障害時はトランザクションログが必須になる。
まとめ ・データベースは様々な仕組みが組み合わさった叡智の結晶 ・データベースはデータがおかしくならないような仕組みを兼ね備えている ・「データのACID性」と「処理速度」はトレードオフ!意図的に一貫性の一部を許容したり 両立させるための仕組みを備えている ・データベースの仕組みを知るとめっちゃ深い!面白い!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}