by stateless compute containers and modelled for an event-driven solution. (https://github.com/anaibol/awesome-serverless) • Serverless functions allow you to NOT think about servers. Which means you no longer have to deal with over/under capacity, deployments, scaling and fault tolerance, OS or language updates, metrics and logging. (https://github.com/anaibol/awesome-serverless) • Serverless functions are about running backend code without managing your own server systems or your own server applications. (https://martinfowler.com/articles/serverless.html)
No lock-in on a specific framework or library 3. Deployment can be as simple as uploading a zip file 4. Scaling is automatically handled by the provider 5. Functions are triggered by events (event-driven) 6. (Usually) easy integration with other services of the provider
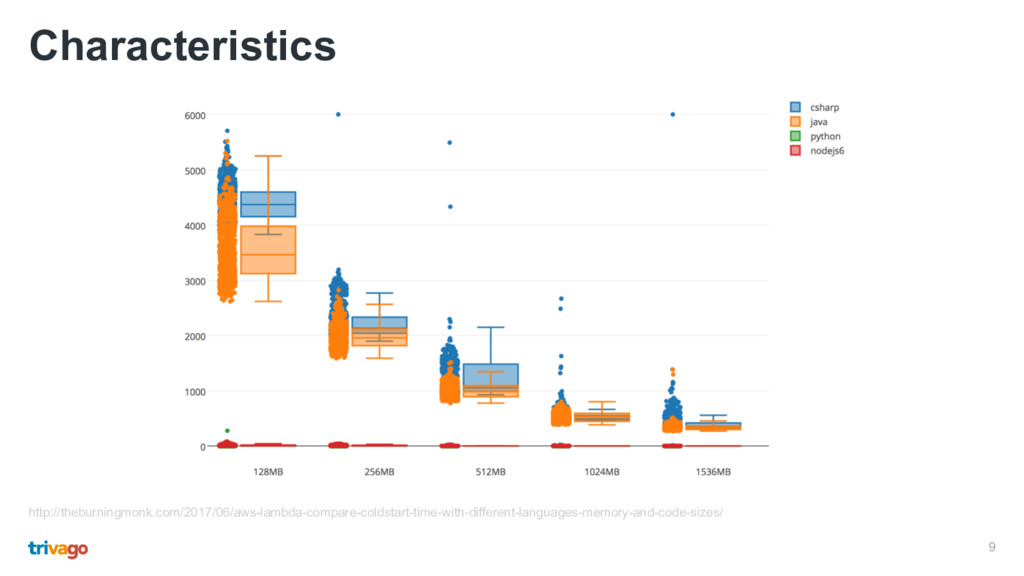
of input to output • Can use databases, caches or file storage (DynamoDb, Redis, S3) • Very short-lived • Usually only a couple hundred milliseconds or lower • There’s always some startup latency • Watch out for cold starts • Statically typed/compiled languages have a much higher startup time (up to 100x)
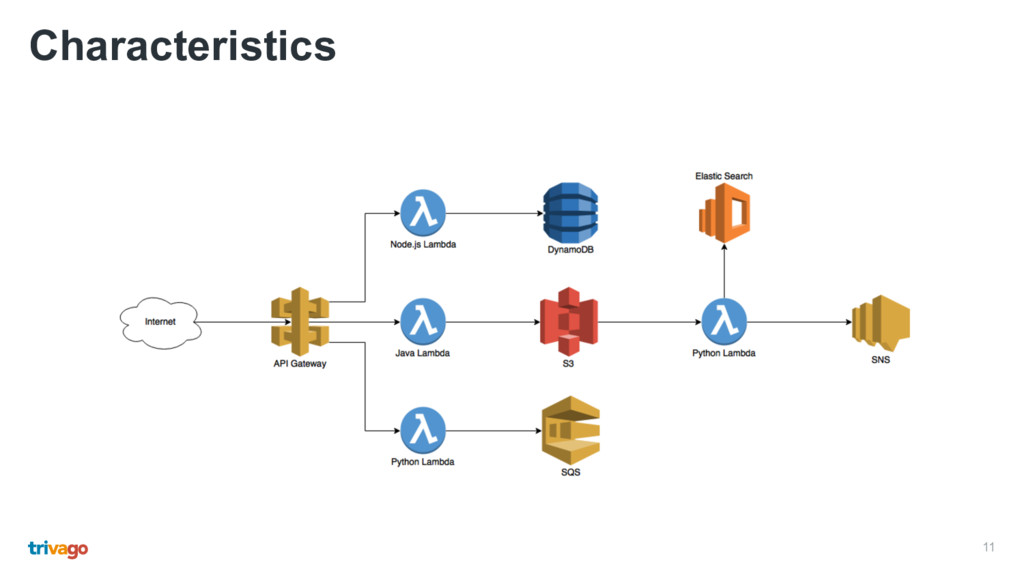
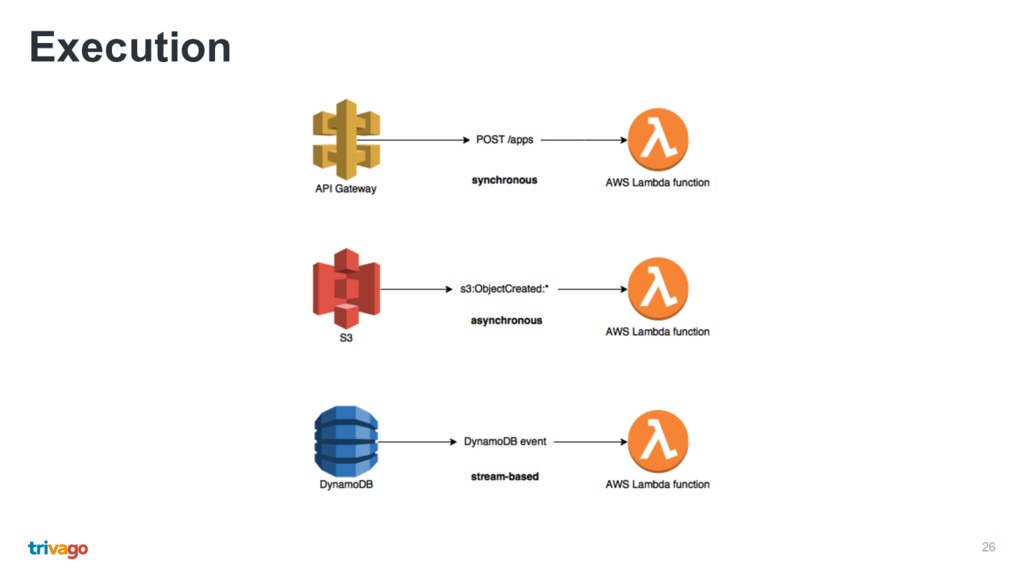
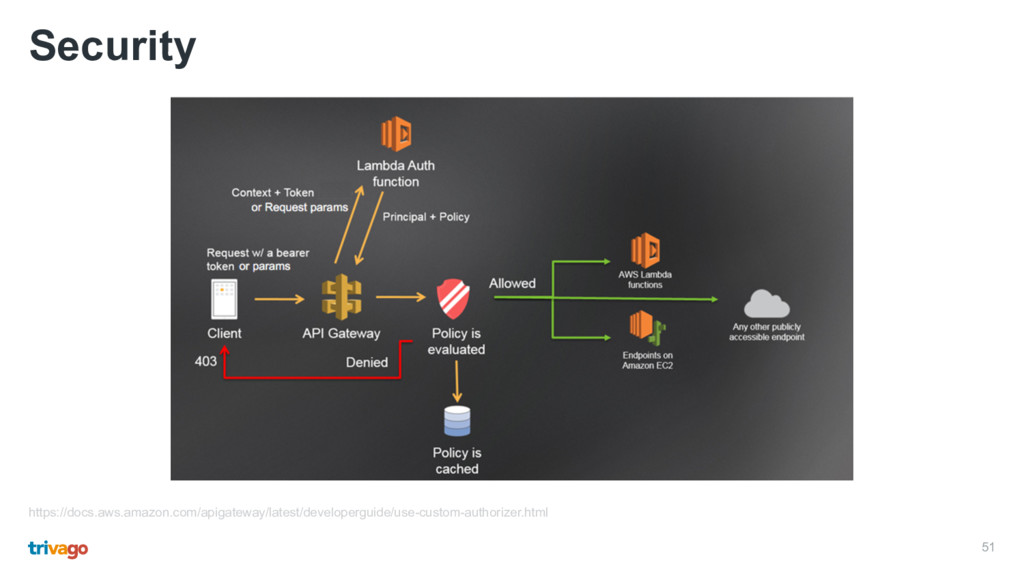
• The gateway maps HTTP requests and triggers the function with an event • Function call results are mapped to HTTP responses • You still need a good Ops culture • Debugging, monitoring and testing can be challenging • You only pay for what you actually use
create, deploy and operate serverless architectures • Supports multiple providers (AWS, Azure, IBM, Google Cloud) • Open-source (https://github.com/serverless/serverless) • Extensible with plugins (https://github.com/serverless/plugins) • Good community support (meetups, user groups, gitter, slack)
events and other resources • Defined in a serverless.yml template • Every project requires at least one service, more are possible • Initially created by running serverless create --template aws-nodejs --path sample • Every service translates to one CloudFormation template and stack with one API Gateway
service template • The handler property defines the file and the module that gets executed • The signature of a function is module.exports.handler = function(event, context, callback) {} • It’s possible to override provider settings on a function level • Permissions are defined on a provider level using the iamRoleStatements or role properties • The environment property defines environment variables • The onError property defines a SNS/SQS Dead Letter Queue (DLQ)
function • A function can be triggered by multiple events • Each event type requires specific information • An API Gateway http event requires path (/apps) and method (POST) • An S3 event requires bucket and event (s3:ObjectCreated:*)
Creates a single CloudFormation templates • Runs the template to create a stack plus an S3 bucket for the functions • Functions are packaged (zip-compressed) and uploaded to the bucket • The template is updated with roles, functions, events and other resources • The stack is updated based on the final template • To show deployment progress, use serverless deploy —verbose • To force a deployment, use serverless deploy —force • To deploy a single function only, use serverless deploy function --function handler • To update the configuration only, use serverless deploy --update-config
business logic from infrastructure code • Use dependency injection • Use serverless invoke or serverless invoke local to test your functions • Requires a —function/-f argument for the function name • Provides a —data/-d or —raw argument for event data • Provides a —log/-l argument to output logging data • Mock of run AWS services locally • DynamoDB Docker images, Kinesalite (https://github.com/mhart/kinesalite), AWS SDK Mock (https://www.npmjs.com/package/aws-sdk-mock)
in all regions • Regional service • Supports Node.js (v4.3 and v6.10), Java (v8), Go (v1.x), C# (.NET Core v1.0 and v2.0) and Python (v2.7 and 3.6) • Use Lambda@Edge (AWS CloudFront plus Lambda) for global, latency-sensitive services (only Node.js) • Free tier includes 1M requests and 400k GB-s per month (128 MB ~ 900h, 1024 MB ~ 100h) • Execution duration is rounded up to the nearest 100ms
• Containers based on Public Amazon Linux AMI, currently kernel version 4.9.75-25.55.amzn1.x86_64 • AWS SDK (JS, Python 2.7 and 3.6) and OpenJDK 8 available by default • Execution context is reused for some time (currently 30m, up from 5m) • Be aware of cold starts • Be aware of concurrent cold starts • Memory, language and package size affect cold start time
before being discarded • Define a Dead Letter Queue (DLQ) to send unprocessed events to an AWS SQS queue or AWS SNS topic • Environment variables can dynamically configure your Lambda functions • Automatically encrypted with AWS KMS after deployment and decrypted on invocation • Custom encryption with AWS KMS before deployment possible
• The event that triggered the Lambda function • The context containing information about the current runtime • context.getRemainingTimeInMillis() returns the remaining execution time before timeout • context.functionName holds the name of the function • context. memoryLimitInMB holds the memory limit • contect.logGroupName/logStreamName hold CloudWatch logs information • An optional callback to return information to the caller
Not actually a database, just tables • Provides a HTTP RestAPI • Provides encryption at rest using AWS KMS (AES-256, us-east/west, eu-east) • Provides on-demand backups and restores (us-east/west, eu-east) • Provides TTL functionality • Runs on SSD and spread across multiple availability zones • Use global tables to keep them in sync across regions
for account and region, 3 to 255 characters (a-Z, 0-9, _, -, .) • Primary key: either single partition key or partition key and sort key • Throughout settings • Support the following data types: • Scalar: string, number (signed, 38 digits precision), binary, boolean, null • Document: lists (unordered) or maps (ordered), up to 32 levels deep • Sets: numbers, strings or binaries (unique type and values, ordered)
• Input to an internal hash function, determines the physical partition • Partition key value must be unique, allows efficient queries • Partition and sort key as composite primary key • Input to an internal hash function, determines the physical partition, sorted by sort key • Partition and sort key values combined must be unique, allow flexible queries • Can only be defined on table creation
consistent read per second for 1 item up to 4 KB (2 for eventual consistent reads) • Eventual consistent read are enabled by default • One write capacity is 1 write per second for 1 item up to 1 KB • Item size is rounded up to the next 4/1 KB • Reads/writes exceeding the throughput are throttled (retries with exponential backoff) • Throughput can be changed automatically (auto-scaling) or manually (AWS Console, CLI, API) • 10 PRCU = 10 SCR/s = 20 ECR/s (items <= 4 KB) • 10 PRCU = 5 SCR/s = 10 ECR/s (items > 4kB, <= 8 KB)
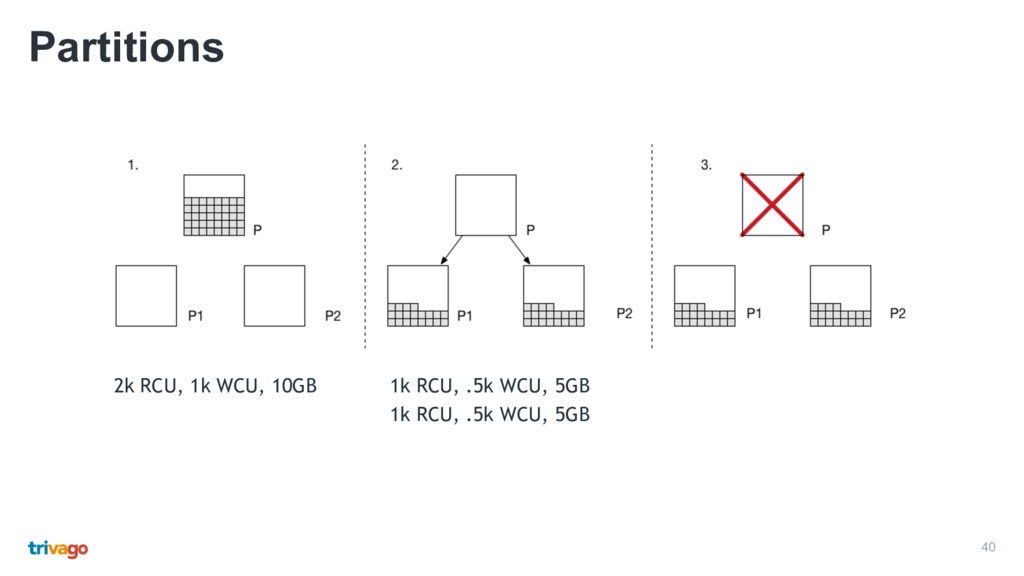
across multiple availability zones • Table data should be spread uniformly across all partitions • Selection and uniformity of the primary key • Workload patterns • A single partition supports up to 3k read capacity units or 1k write capacity units • Initial number of partitions: (RCP / 3k) + (WCU / 1k), (6k / 3k) + (.5k / 1k) = 2.5 ~ 3 • Partitions are split once provisioned throughput or storage requirements are changed • Once split, data and throughput is evenly distributed across new partitions
key and (optional) sort key both different from the base table • Global as in spanning all the data of the base table • Local secondary indexes (LSI) • Partition key same as base table, sort key different • Local as in scoped to the partition of the partition key in the base table • Only string, number or binary attributes of the base table • Changes to the base table are distributed automatically • GSI requires additional attributes to be projected • GSI can be created on-the-fly
capacity units per table, 80k per account • others: 10k read/write capacity units per table, 20k per account • Tables: 256 per account • Indexes: 5 local and global secondary indexes per table • Keys: • partition keys: 1 Byte to 2 KByte • sort keys: 1 Byte to 1 KByte
and manage RESTful API • Exposes HTTP endpoints, AWS Lambda functions or other AWS services • API endpoints can be edge-optimised (default) or regional • Supports custom domain names • Supports versioning • Supports usage plans, API keys and custom authorisation
patterns • Supports mapping templates • Method response • Defines outgoing status code and mapping of integration response headers and body • Supports mapping templates and models • Can be pass-through • Possible to define a designated error handling response
the end user • Each deployment refers to a stage • Stages are snapshots including all resources and allow for proper versioning • Each stage enables caching, default throttling and SDK generation (Java, JavaScript, Objective-C, Swift and Ruby) • Supports canary releases (percentage-based)
or a Lambda function • User pools authorisation excepts an identity token as a header • Custom Lambda functions offer two possibilities: • Token-based expecting a custom header (JWT, OAuth) • Request-based expecting a custom header, query string or context parameter • Policies returned by a Lambda function can be cached • Usage plans and API keys enforce rate limits and quota • API keys can be added to usage plans, usage plans can be added to stages
using the restapi:import API action or apigateway import-rest- api CLI command • Export a Swagger API definition by using apigateway get-export or the console • Update an API Gateway by using the restapi:put API action • Supports merge and overwrite modes • API Gateway defines various different Swagger extensions • x-amazon-apigateway-authorizer • x-amazon-apigateway-gateway-responses • x-amazon-apigateway-integration
{kind=link}
![Email: [email protected] Twitter: https://twitter.com/heinrichtorsten Senior Software Engineer trivago Leipzig Torsten](https://files.speakerdeck.com/presentations/caebb5d1c9e64cb38d4ccf3c5761be58/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}