A talk about three popular Ruby web servers at Amsterdam.rb. How and why are these servers different? Along the way we’ll learn some things about the options we have to let a Ruby program do multiple things at the same time.
(Unicorn) • Threading (Puma) • Event-driven (Thin) Disclaimer: For the sake of simplicity we will focus on the original strong point of each of these three servers, the story is a bit more complex in reality. There are other web servers out there too.
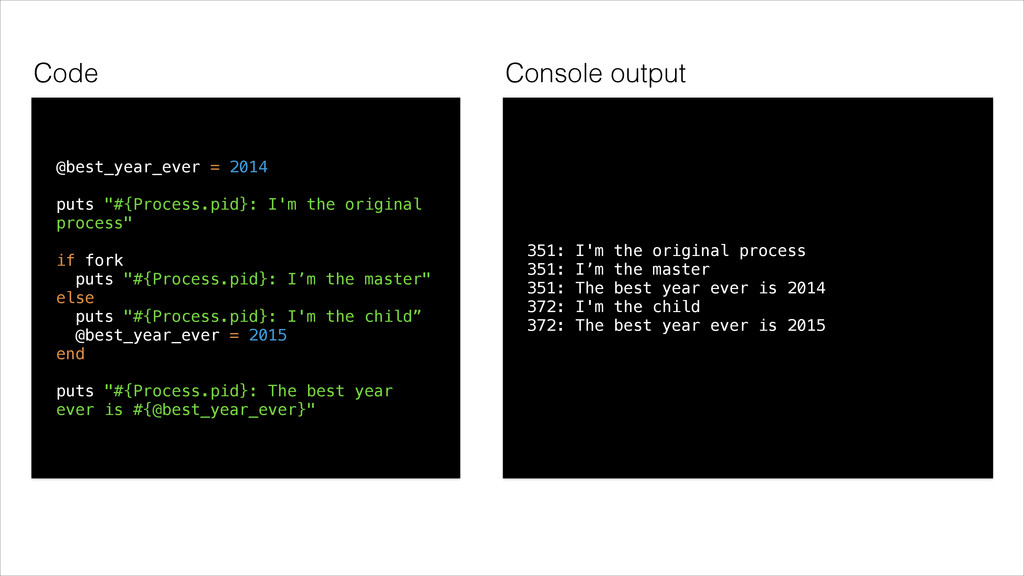
the original process" if fork puts "#{Process.pid}: I’m the master" else puts "#{Process.pid}: I'm the child” @best_year_ever = 2015 end puts "#{Process.pid}: The best year ever is #{@best_year_ever}" 351: I'm the original process 351: I’m the master 351: The best year ever is 2014 372: I'm the child 372: The best year ever is 2015
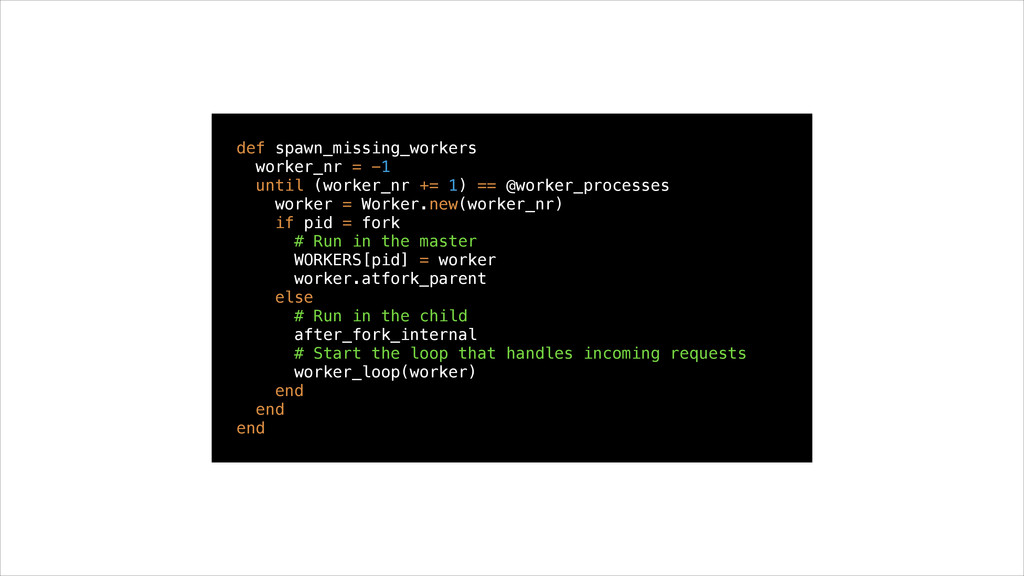
@worker_processes worker = Worker.new(worker_nr) if pid = fork # Run in the master WORKERS[pid] = worker worker.atfork_parent else # Run in the child after_fork_internal # Start the loop that handles incoming requests worker_loop(worker) end end end
• It does get copied when it’s written too • Therefore code used by frameworks and such occupies memory only once • Introduced in Ruby 2.0 (used to be available in REE too)
processes that handle requests • If you expect your workers to break it’s easy to kill them without affecting other workers • Concurrency is limited by the number of processes • Every process uses the full amount of memory. Copy on write helps, a bit.
Thread.new do sleep rand(5) puts "I'm thread #{i} and the best year ever is #{@best_year_ever}" end end sleep 2 @best_year_ever = 2015 sleep 30 I'm thread 2 and the best year ever is 2014 I'm thread 4 and the best year ever is 2014 I'm thread 0 and the best year ever is 2014 I'm thread 1 and the best year ever is 2015 I'm thread 3 and the best year ever is 2015
100.times do |i| Thread.new do sleep rand(0.5) @lock.synchronize do snapshot_of_total = @total sleep rand(0.5) @total = snapshot_of_total + 1 end end end sleep 60 puts @total 100
a line of Ruby code it locks • IO operations are run outside of the GIL • If you run operations on hashes, for example, in multiple threads your program will still only utilize one CPU core • Rubinius and jRuby don’t have a GIL
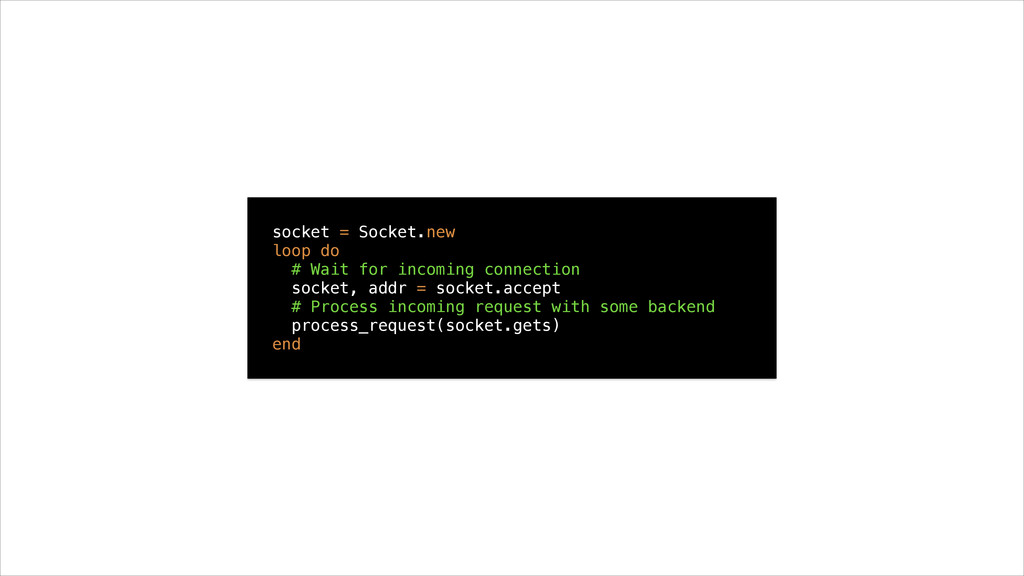
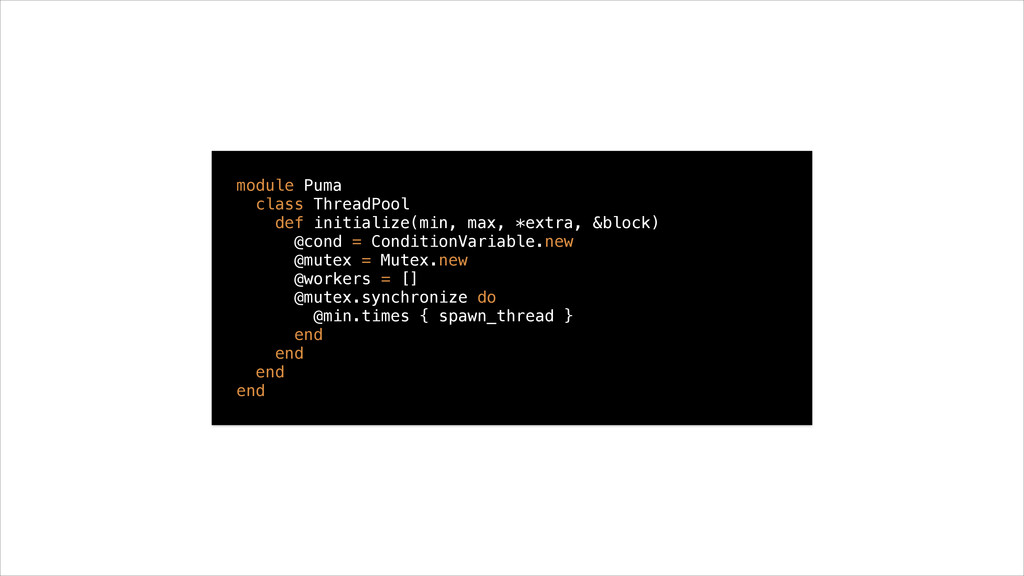
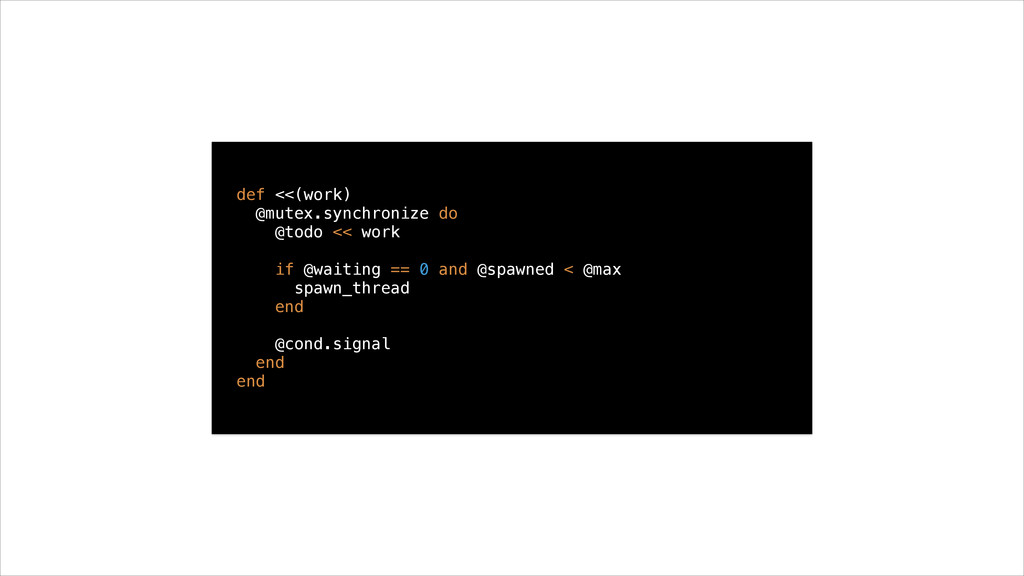
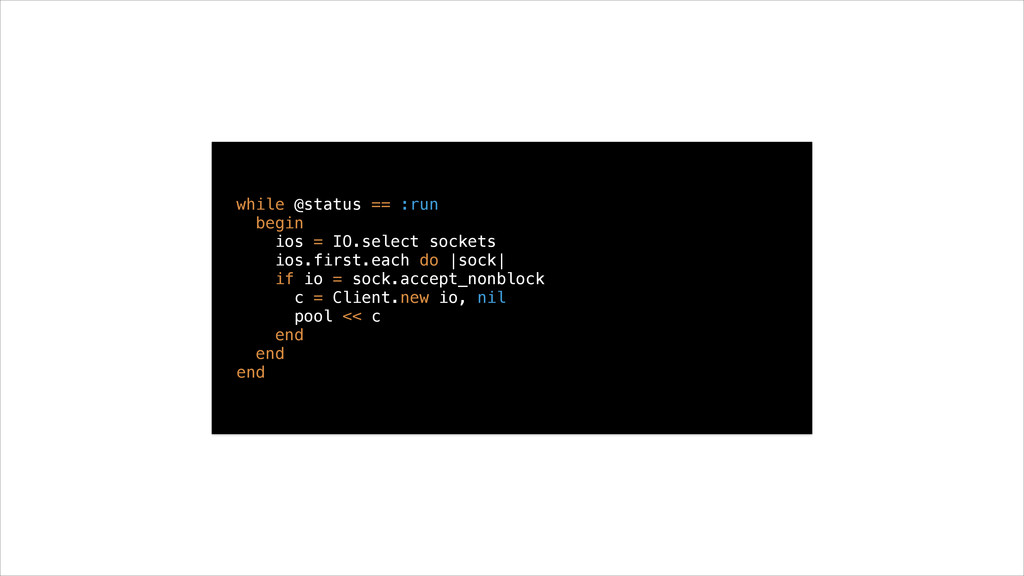
• They wait for work to come in and process it outside of the server’s main lock • Concurrency is limited by size of thread pool • Worker threads use little memory compared to processes
EM.run do 5.times do |i| EM.add_timer(rand(5)) do puts "I'm callback #{i} and” the best year ever is #{@best_year_ever}" end end EM.add_timer(2) do @best_year_ever = 2015 end end I'm callback 1 and the best year ever is 2014 I'm callback 3 and the best year ever is 2014 I'm callback 0 and the best year ever is 2015 I'm callback 2 and the best year ever is 2015 I'm callback 4 and the best year ever is 2015
EM.run do 100.times do |i| EM.add_timer(rand(0.5)) do snapshot_of_total = @total EM.add_timer(rand(0.5)) do @total = snapshot_of_total + 1 end end end EM.add_timer(5) do puts @total end end 4
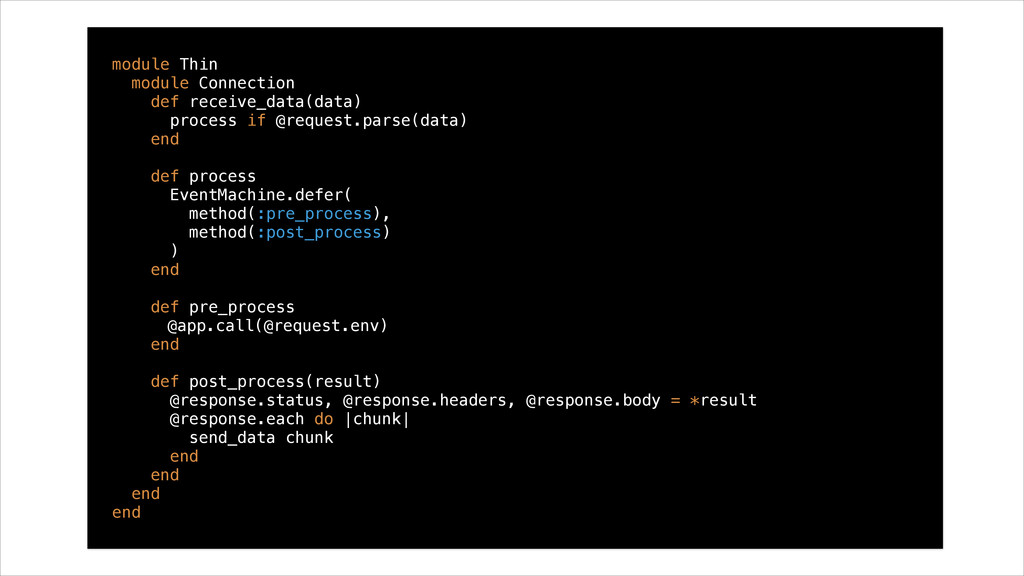
def process EventMachine.defer( method(:pre_process), method(:post_process) ) end def pre_process @app.call(@request.env) end def post_process(result) @response.status, @response.headers, @response.body = *result @response.each do |chunk| send_data chunk end end end end @port, Connection )
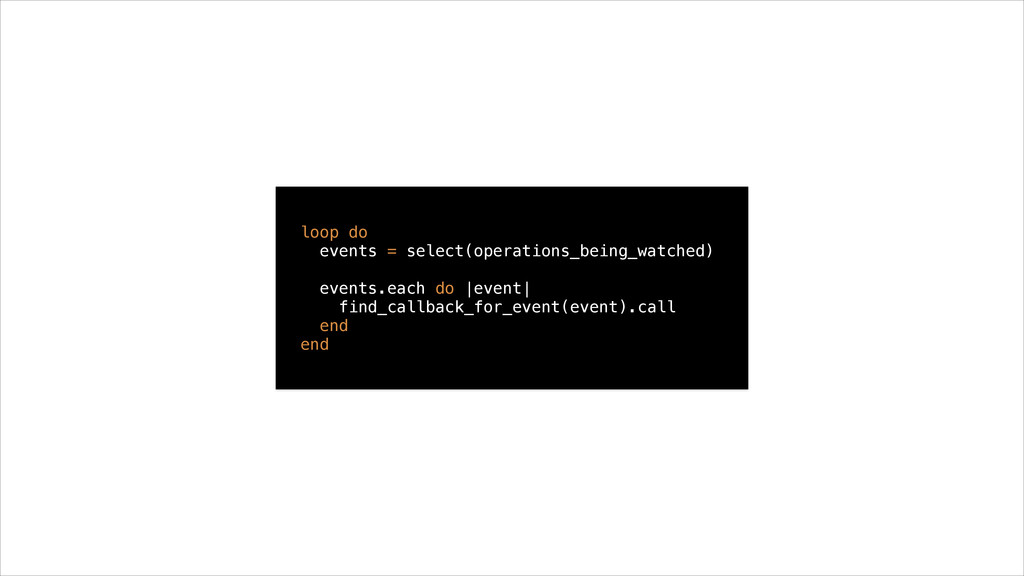
of operations and callbacks • Whenever an operation has to wait for something it stops, a callback gets called when the wait is over • Hardly any memory is used by the callbacks, they’re just Ruby blocks • Concurrency is an order of magnitude bigger than the other two models • All code running in the loop has to be event-driven
to (slowly) be moving this way. • If you run highly concurrent apps with long-running streams event-driven allows you to scale • If you don’t have a high-traffic site or you expect your workers to break go for good old multi-process
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}