In practice, structural nested models with multiple parameters have rarely been used. • In fact, structural nested models of any type have rarely been used, partly because of the lack of user-friendly software and partly because the extension of these models to survival analysis requires some additional considerations (see Chapter 17). We now review two methods that are arguably the most commonly used approaches to adjust for confounding: outcome regression and propensity scores. • g-estimationの真の姿は、part IIIまで待ちましょう。 19
has two parameters, 1 and 2, we also need to include two parameters in the IP weighted logistic model.” • 大事なこと:g-estimationはconditional exchangeabilityを確かめるものではなく、 conditional exchangeabilityが成立していることを前提とした手法(p178 コラム) • conditional exchangeabilityが成立する限りにおいて、Lの任意の部分集合V’につい て2′ † ’を追加しても、† = においては2′ = 0と推定されるはず。 • しかし、現実にはサンプル数の限界や誤差があるので全てのが同時にゼロになる とは限らず、困ってしまいそう。 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
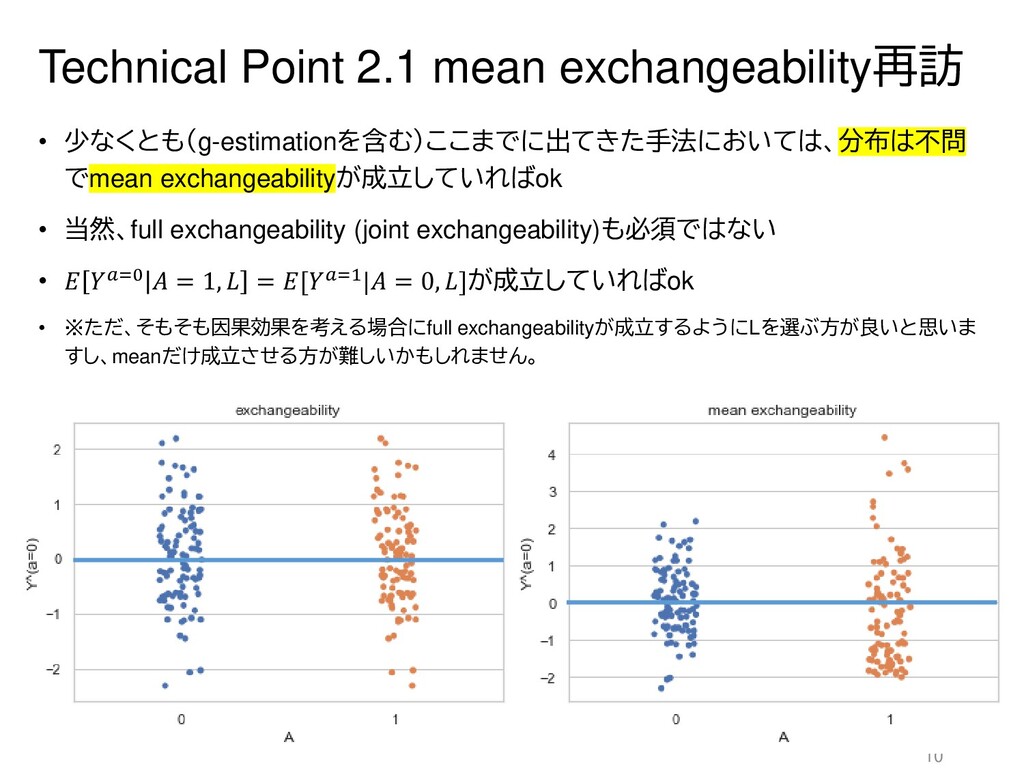{kind=link}
{kind=link}
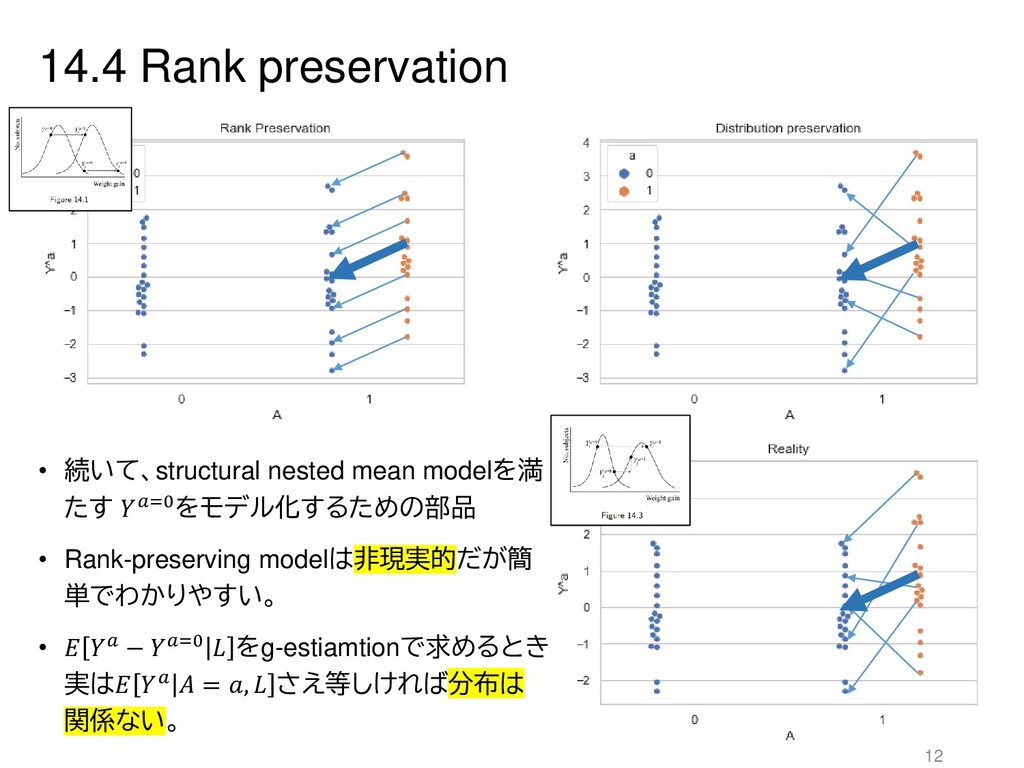{kind=link}
{kind=link}
{kind=link}
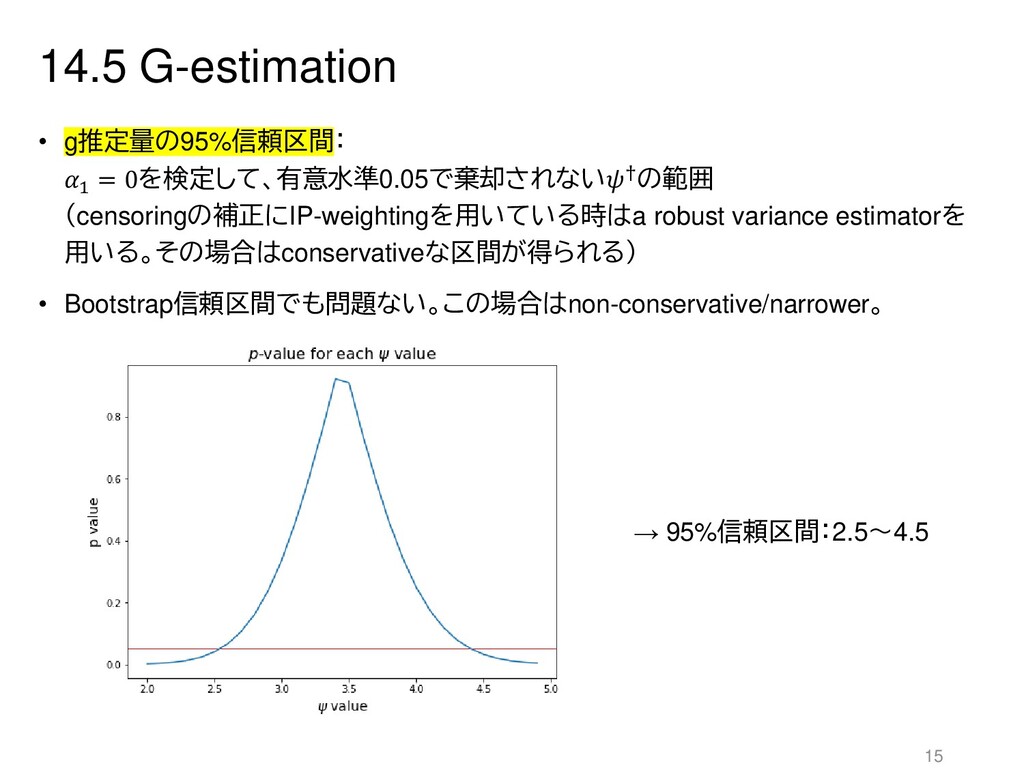{kind=link}
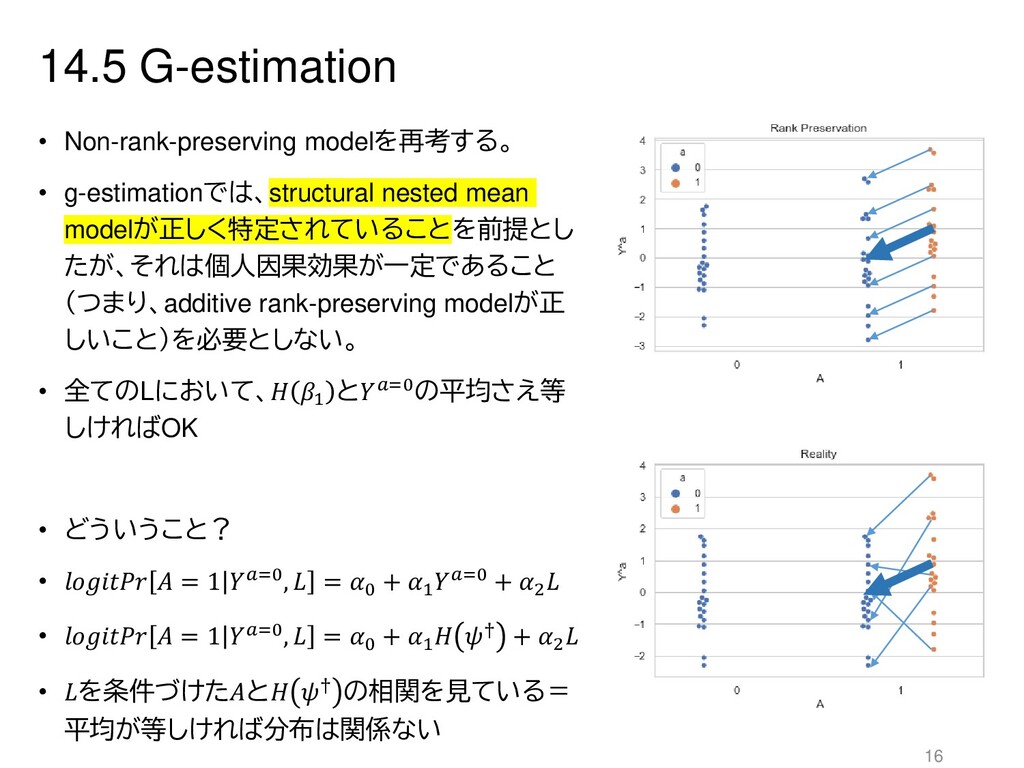{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}