Share
神谷 年洋, “コードレビュー向けコメント行位置予測ツールの試作,” 信学技報, vol. 120, no. 193, SS2020-12, DC2020-29, pp. 43-48, 2020年10月.
![コードレビュー向け コメント行位置予測ツールの試作 神谷年洋 島根大学 [email protected] 神谷 年洋 , “ コードレビュー向けコメント行位置予測ツールの試作](https://files.speakerdeck.com/presentations/70abda6a19764ffbaa0189f862d065af/slide_0.jpg){kind=link}
![2 コメントによるソースコード理解の補助 ソースコード理解にはコメントが重要である • ソースコードを扱う時間の半分以上は理解 [10][12] • 理解を助けるためにコメントは効果的 [18][17] ⬇](https://files.speakerdeck.com/presentations/70abda6a19764ffbaa0189f862d065af/slide_1.jpg){kind=link}
{kind=link}
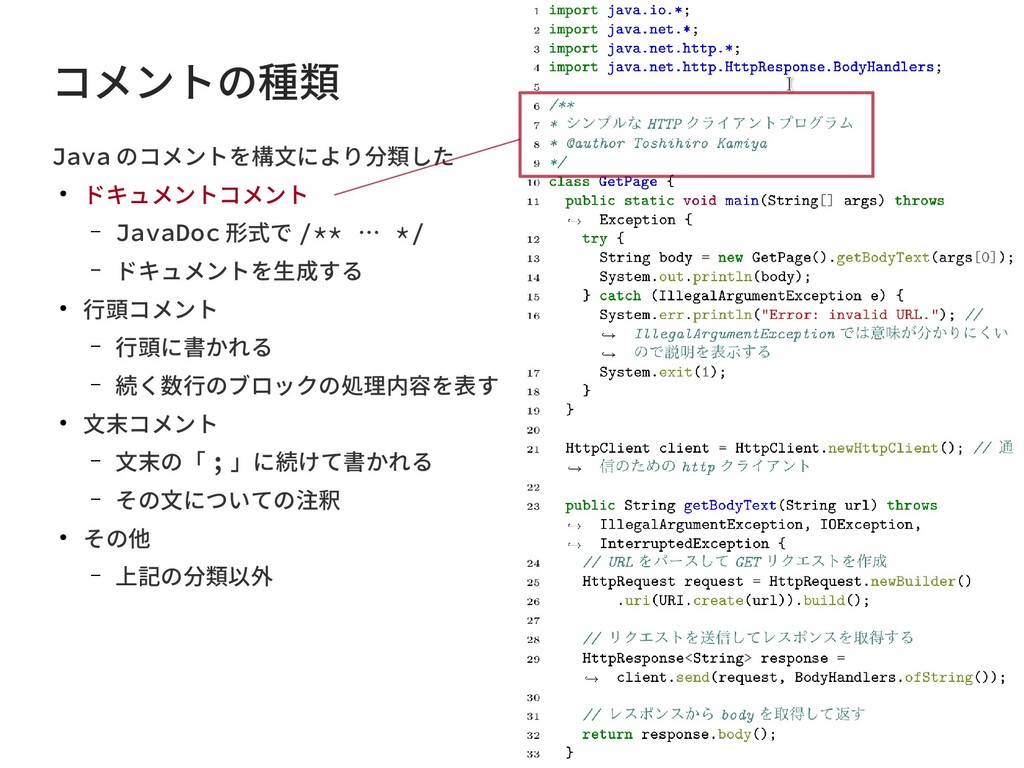{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
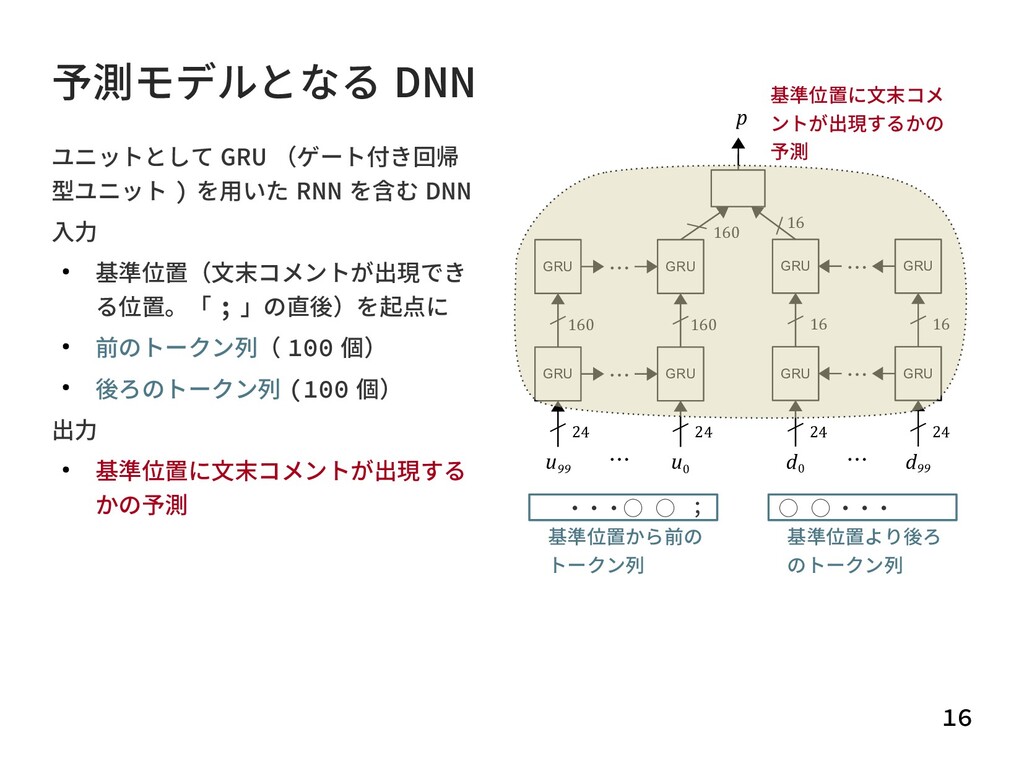{kind=link}
{kind=link}
{kind=link}
![19 実験の手順 対象データ • GitHub Java コーパス [1] のうち 5000](https://files.speakerdeck.com/presentations/70abda6a19764ffbaa0189f862d065af/slide_18.jpg){kind=link}
{kind=link}
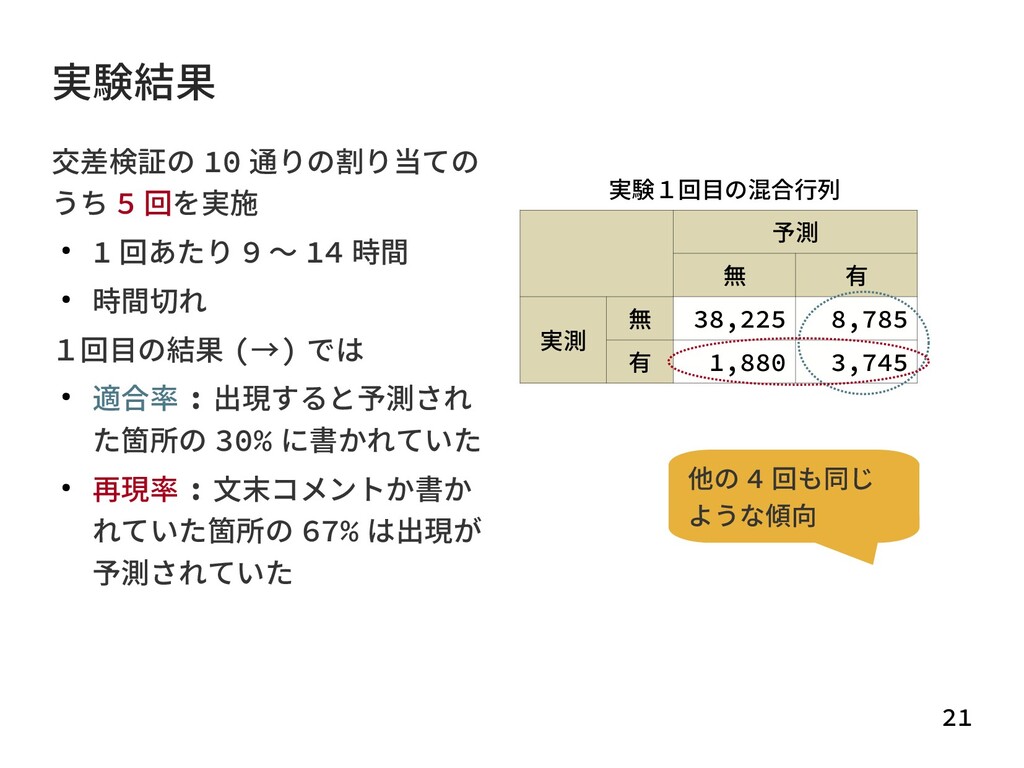{kind=link}
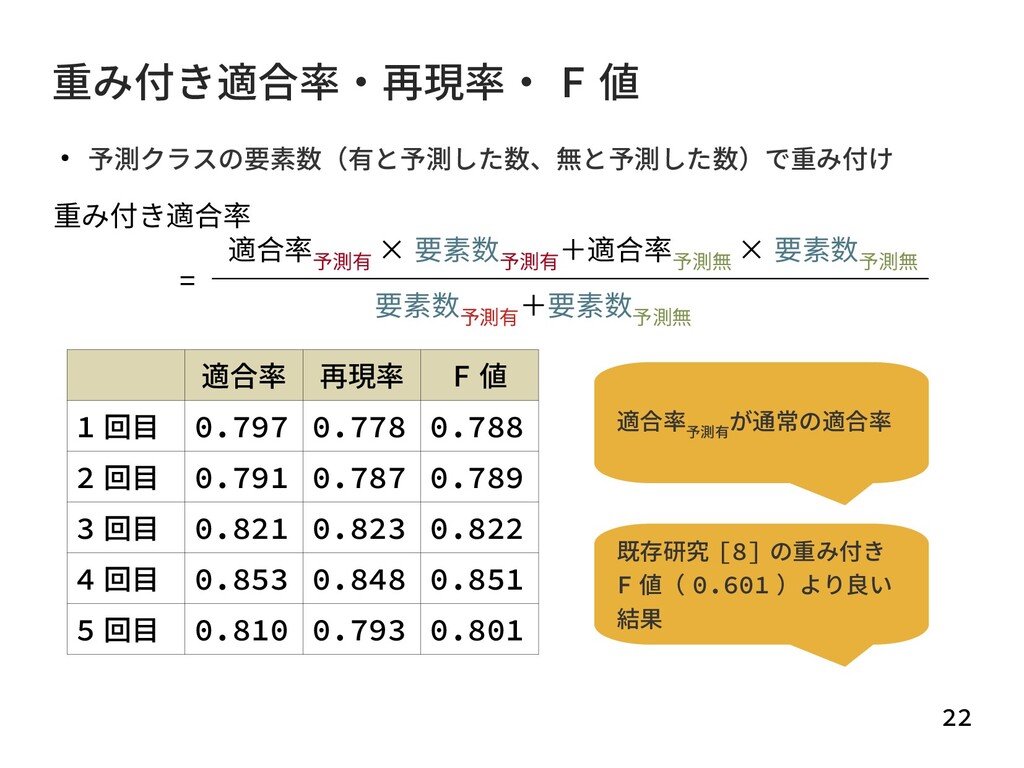{kind=link}
{kind=link}
{kind=link}
![25 Huang らの手法 [8] • 機械学習による手法 • 3種のコンテキストを入力とする予 測 –](https://files.speakerdeck.com/presentations/70abda6a19764ffbaa0189f862d065af/slide_24.jpg){kind=link}
{kind=link}
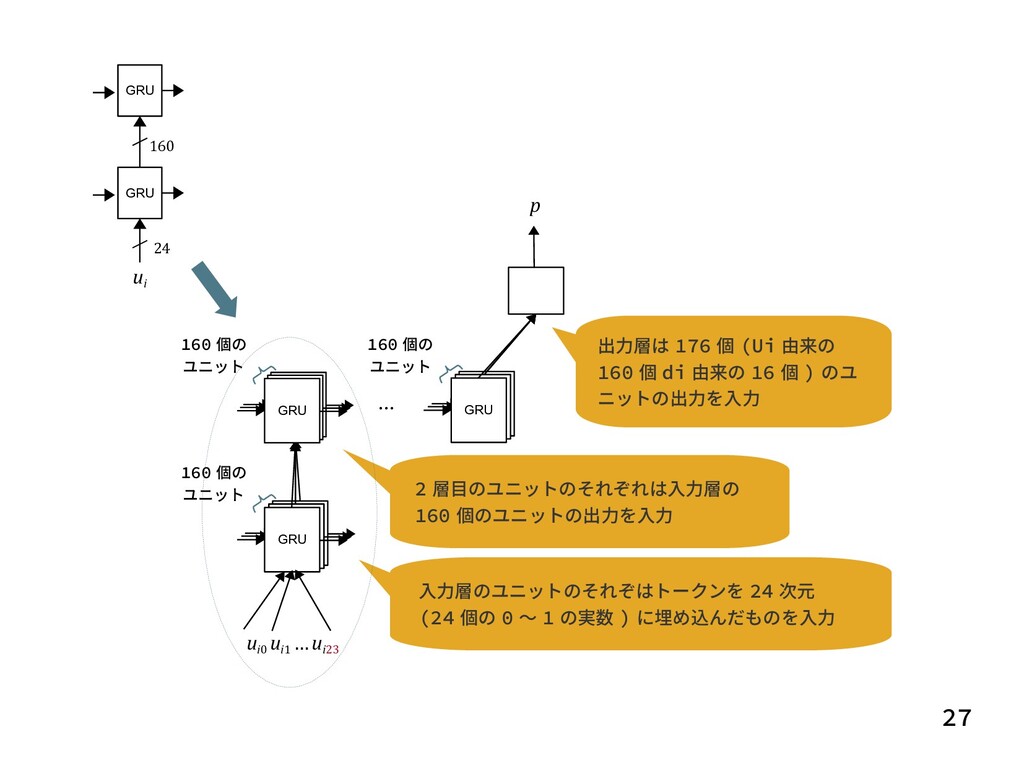{kind=link}