の概要, https://docs.github.com/ja/copilot/using-github-copilot/getting-started-with-github-copilot AutoGen LLMでコードを生成し、生成したコード を実行して結果をLLMにより分析して、 結果をコード生成AIに戻してコードを修 正する・・・の繰り返し 文献: AutoGen: Enabling next-generation large language model applications, Microsoft Research, 2023-09-25 Blog https://www.microsoft.com/en-us/research/blog/autogen- enabling-next-generation-large-language-model- applications/ 3
簡単にはコンテキストを長くできない LLMで利用されているTransformer系のNNでは、アテンシ ョンという機構が用いられている アテンションは、LLMが応答の次のトークンを生成するた めに、コンテキスト中のトークンのどれに注目して次のト ークンを生成するべきかを決定する コンテキスト=プロンプトやこれまでに生成した応答 アテンションの実装にはアテンション行列が使われる。ア テンション行列の要素数=コンテキストの長の2乗 文献: J. Adrián, G. García-Mateos. "Preliminary Results on Different Text Processing Tasks Using Encoder-Decoder Networks and the Causal Feature Extractor" Applied Sciences 10, no. 17: 5772. https://doi.org/10.3390/app10175772 (2020). 7
a haystack)問題 アテンション行列を間引いて計算コストを下げることで、 コンテキスト長を大きくする工夫が種々提案されている ただし、 長いコンテキストを持つLLMであっても、入力テキスト が長くなるほどLLMの推論が低下すると報告されている 入力テキストの中から質問に答えるのに必要な箇所を 特定するのが、入力テキストが長いほど難しくなる 文献1: Jiayu Dingら, "LongNet: Scaling Transformers to 1,000,000,000 Tokens," https://www.microsoft.com/en-us/research/publication/longnet-scaling-transformers- to-1000000000-tokens/ , 2023. 文献2: M. Levy, A. Jacoby, Y. Goldberg, "Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models," arXiv:2402.14848v1, 2024. 8
◯(関数の呼び出し順) A ◯(アルファベット順) C × ◯(関数の呼び出し順) CA ◯(アルファベット順) T ◯ × 提案手法のプロンプトは「full」 変種「CA」では、コーツツリーが含まれず、ソースファイルもアルファベット 順であるため、関数の呼び出し順に関する情報が含まれない 「関数の呼び出し順」にソースコードを並べたものは、ある関数が異なる関数から呼ばれるときには、その関数のソースコード を複数回含める。アルファベット順では、関数のソースコードは1回しか含めない 15
{kind=link}
{kind=link}
{kind=link}
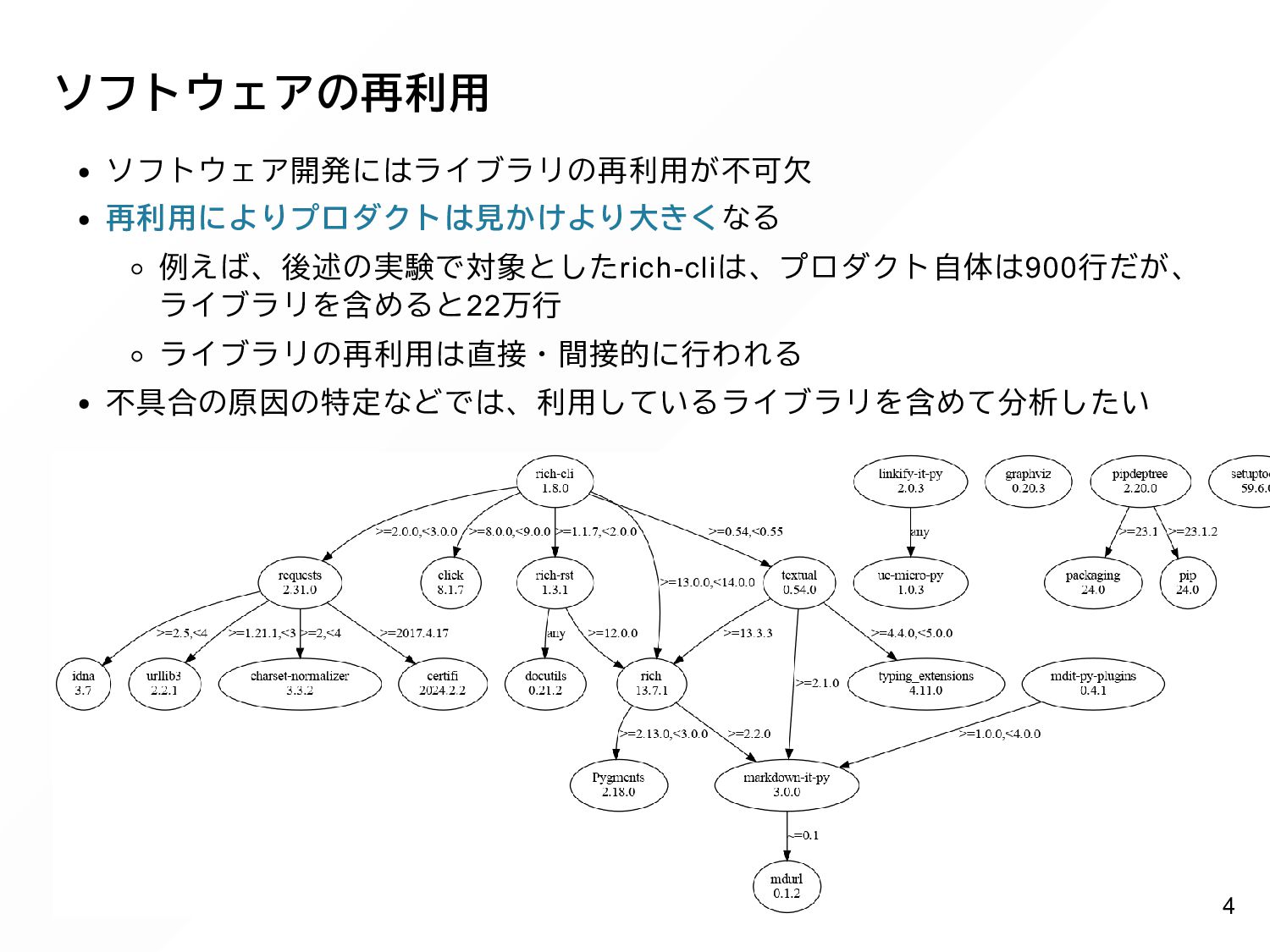{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}