Share
MapReduce 型の並列処理を取り入れた,大規模なコードベースに適用可能なスケーラビリティを持つタイプ 3 コードクローン(重複コード)検出手法を提案する.手法を実現するツールを, 4 億行規模のコードベースに対して適用する実験を行った.実験には 1 台の計算機(ただしメモリ 128GiB)を利用し,数時間程度でコードクローンを検出した.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
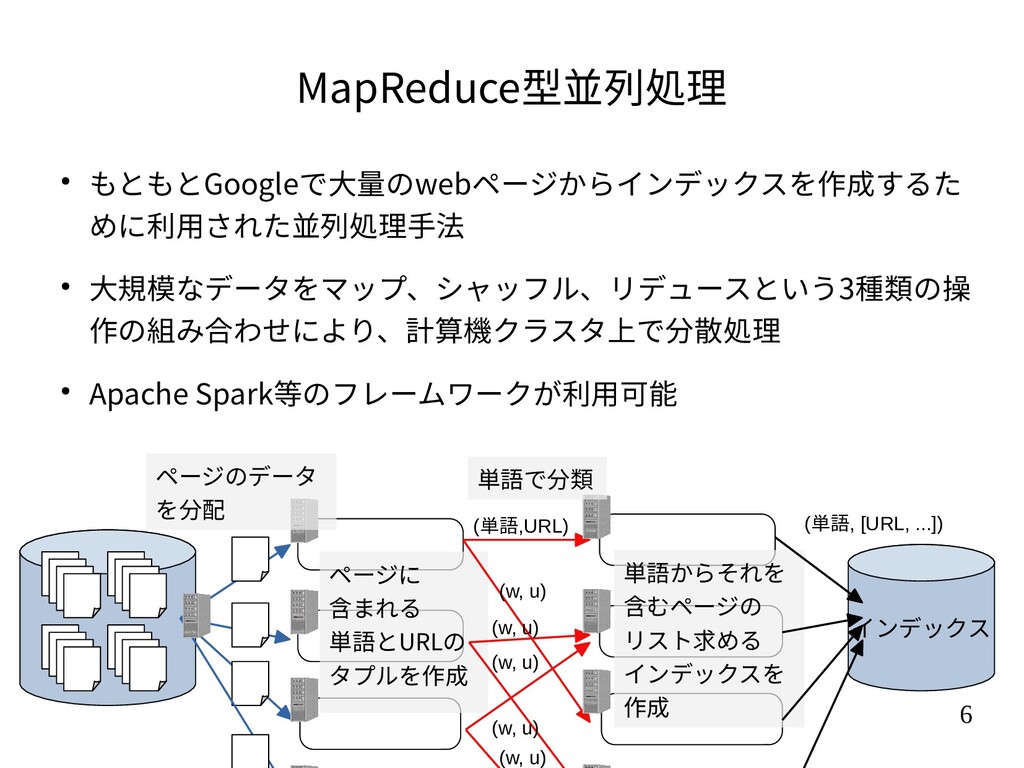{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
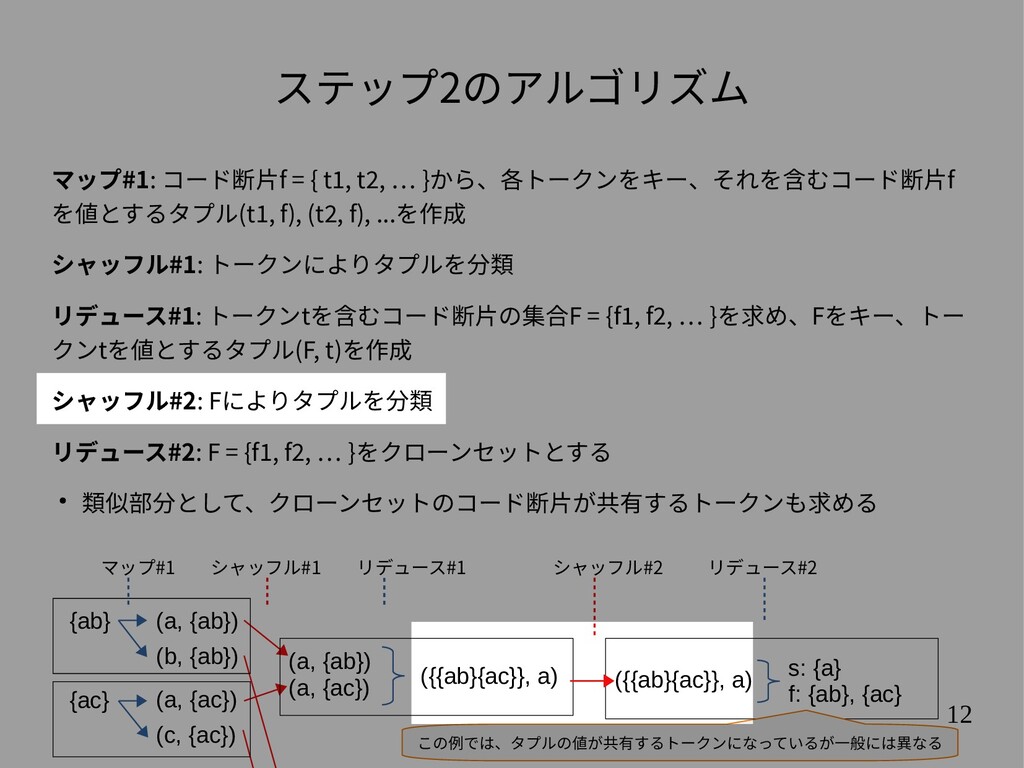{kind=link}
{kind=link}
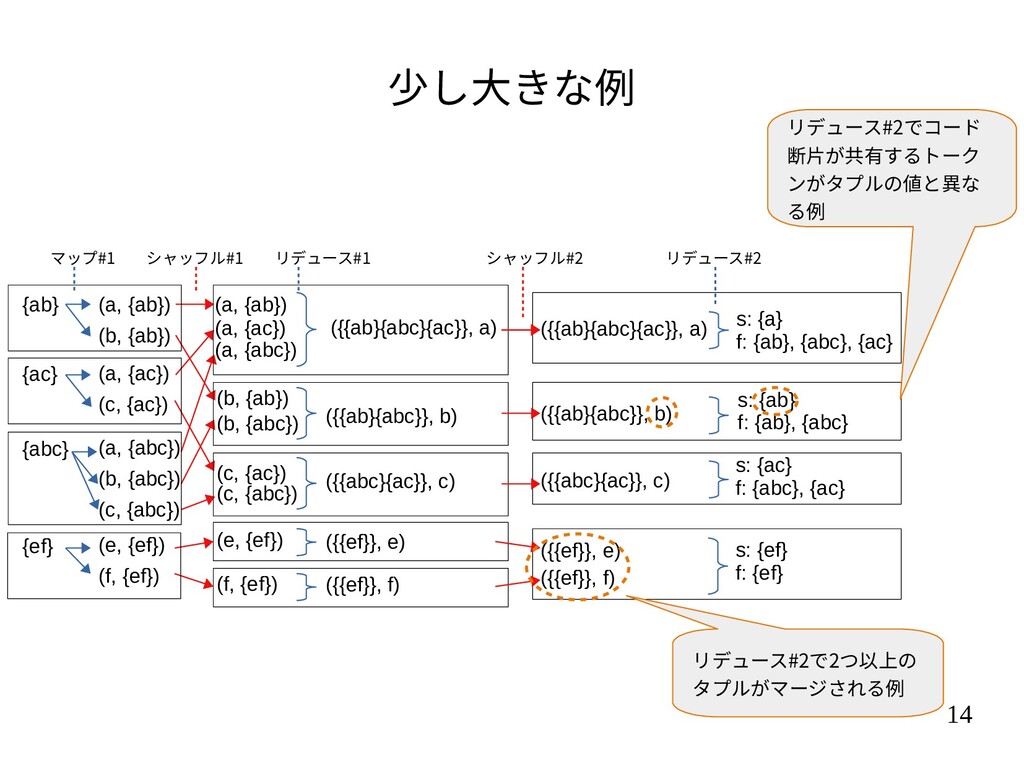{kind=link}
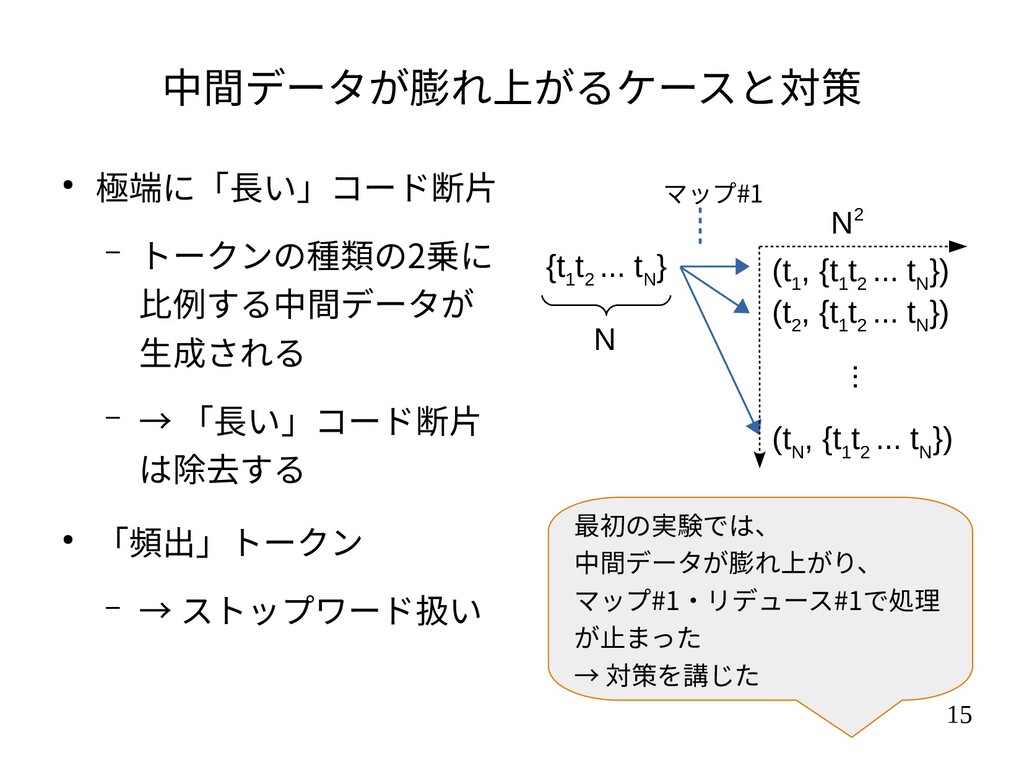{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}