Share
電子情報通信学会知能ソフトウェア工学研究会(IEICE KBSE)2024年1月研究会発表. 開発者が必要なソースコードやドキュメントを効率的に特定できるようにするためのトレーサ ビリティリンク回復手法について,成果物の構造を考慮した木構造の包含関係によるフィルタリングと逆ランキング ペナルティと名付けたランキングのためのメトリックを提案する.提案手法を OSS のプロダクトにて適用する実験 により評価する.
{kind=link}
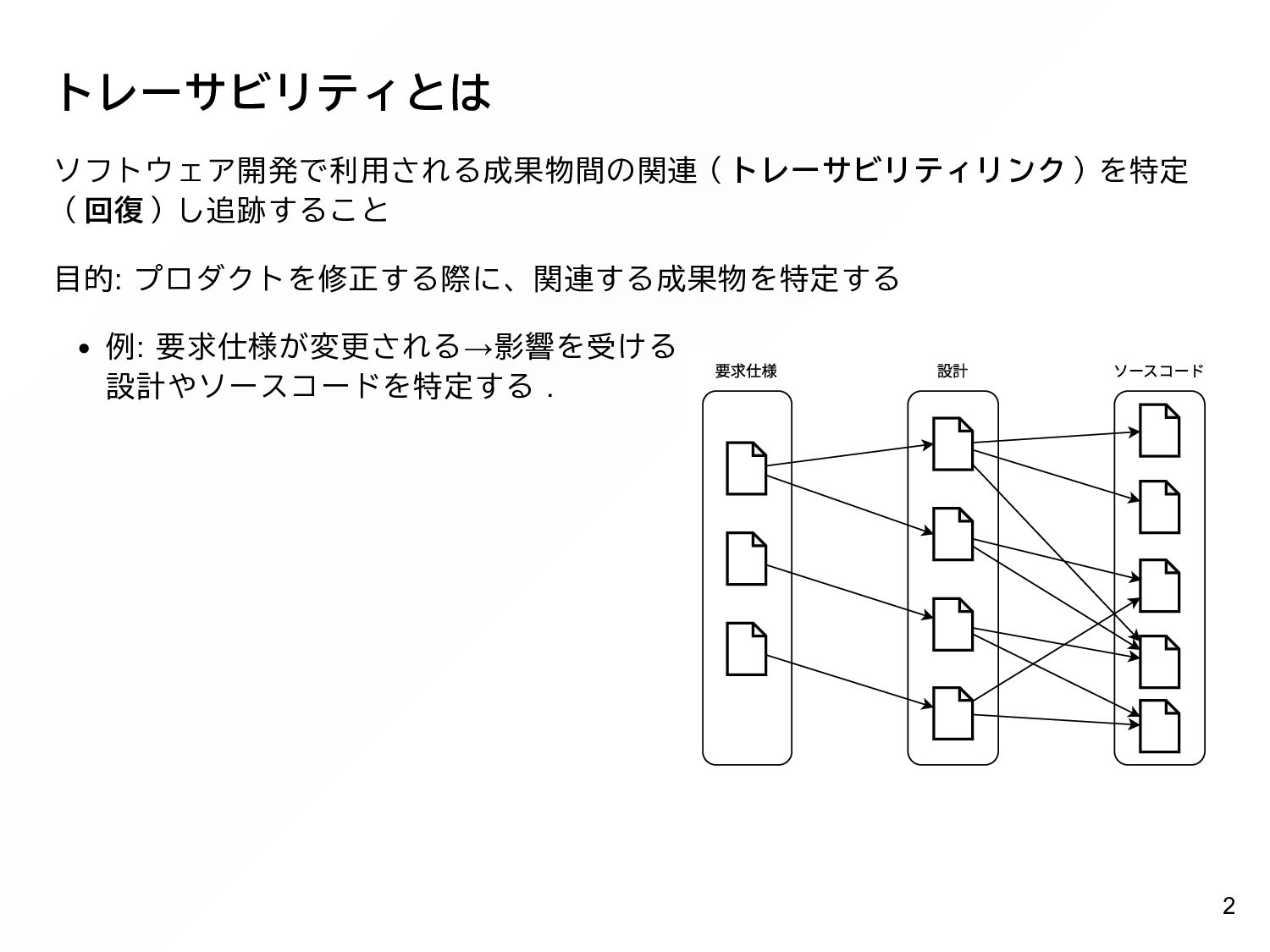{kind=link}
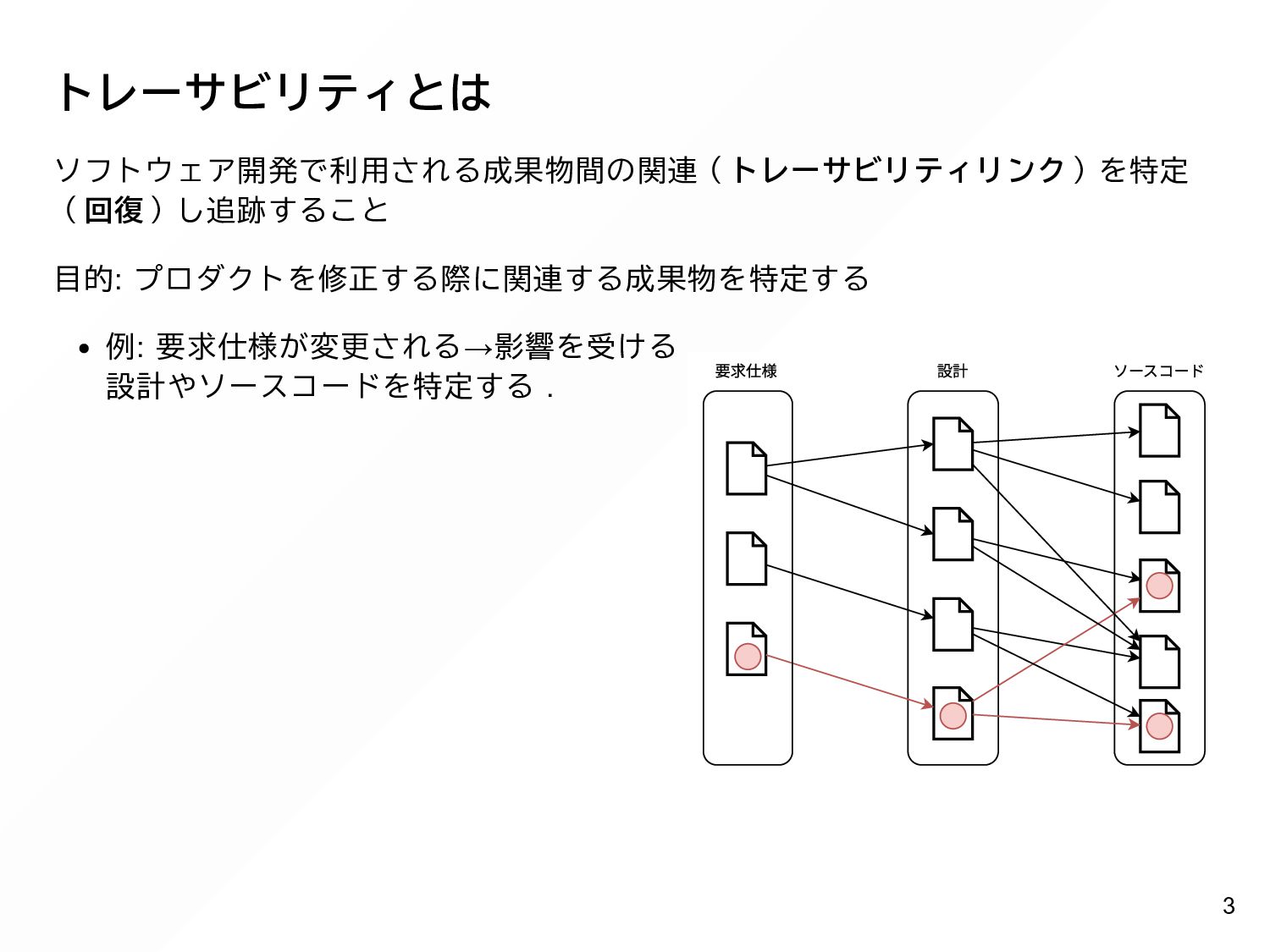{kind=link}
![対象となる成果物[12] 要求仕様、設計、テスト、ソースコ ード等 非形式的なドキュメント、リリース ノート、イシュー(問題の報告)等 解析方法(IRに限定して)[12] キーワード(TFIDF等) 埋め込みベクトル DNN 表現](https://files.speakerdeck.com/presentations/7a5f3ac364ff43f5b2915ec2946d3ac5/slide_3.jpg){kind=link}
{kind=link}
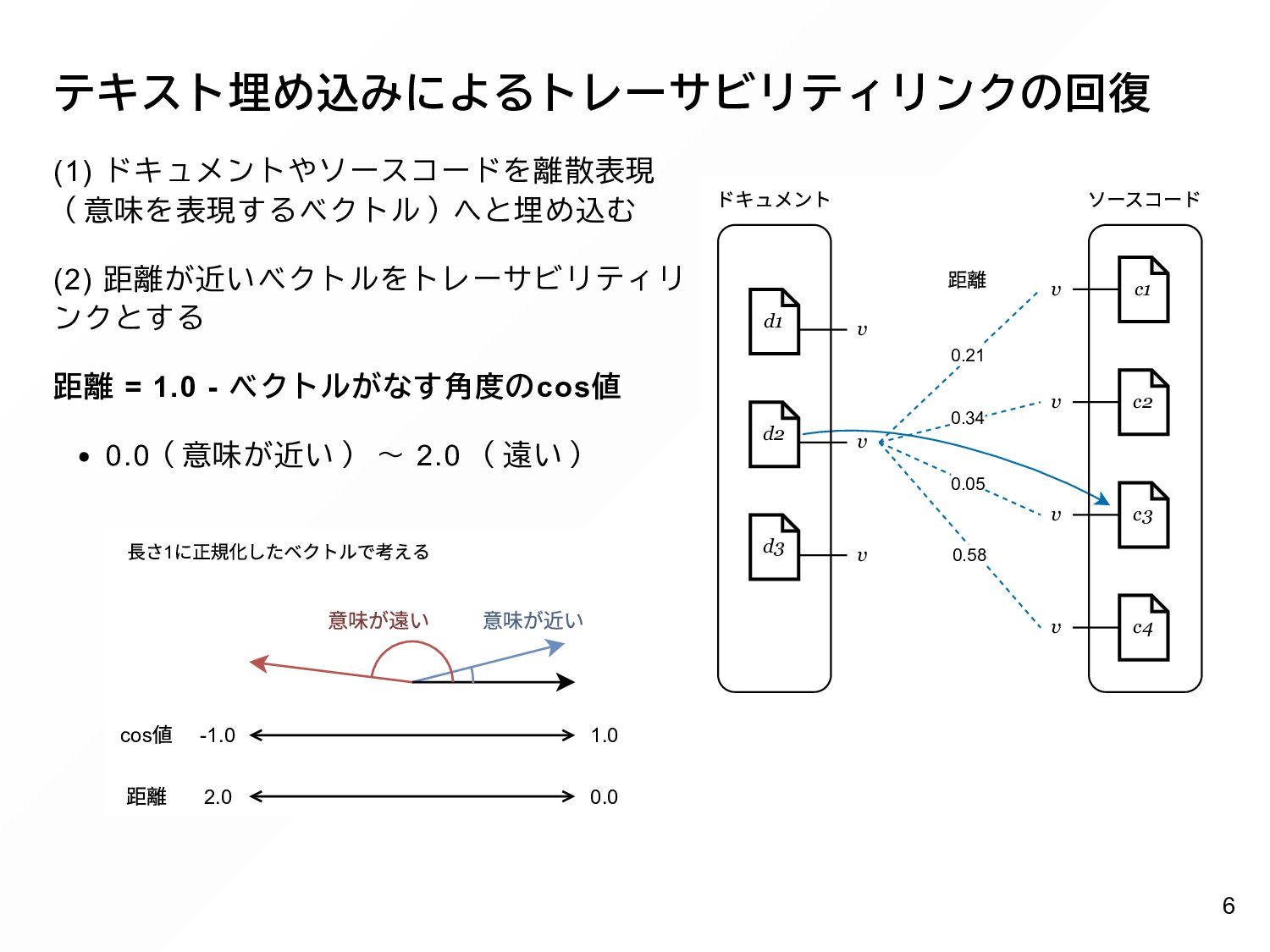{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
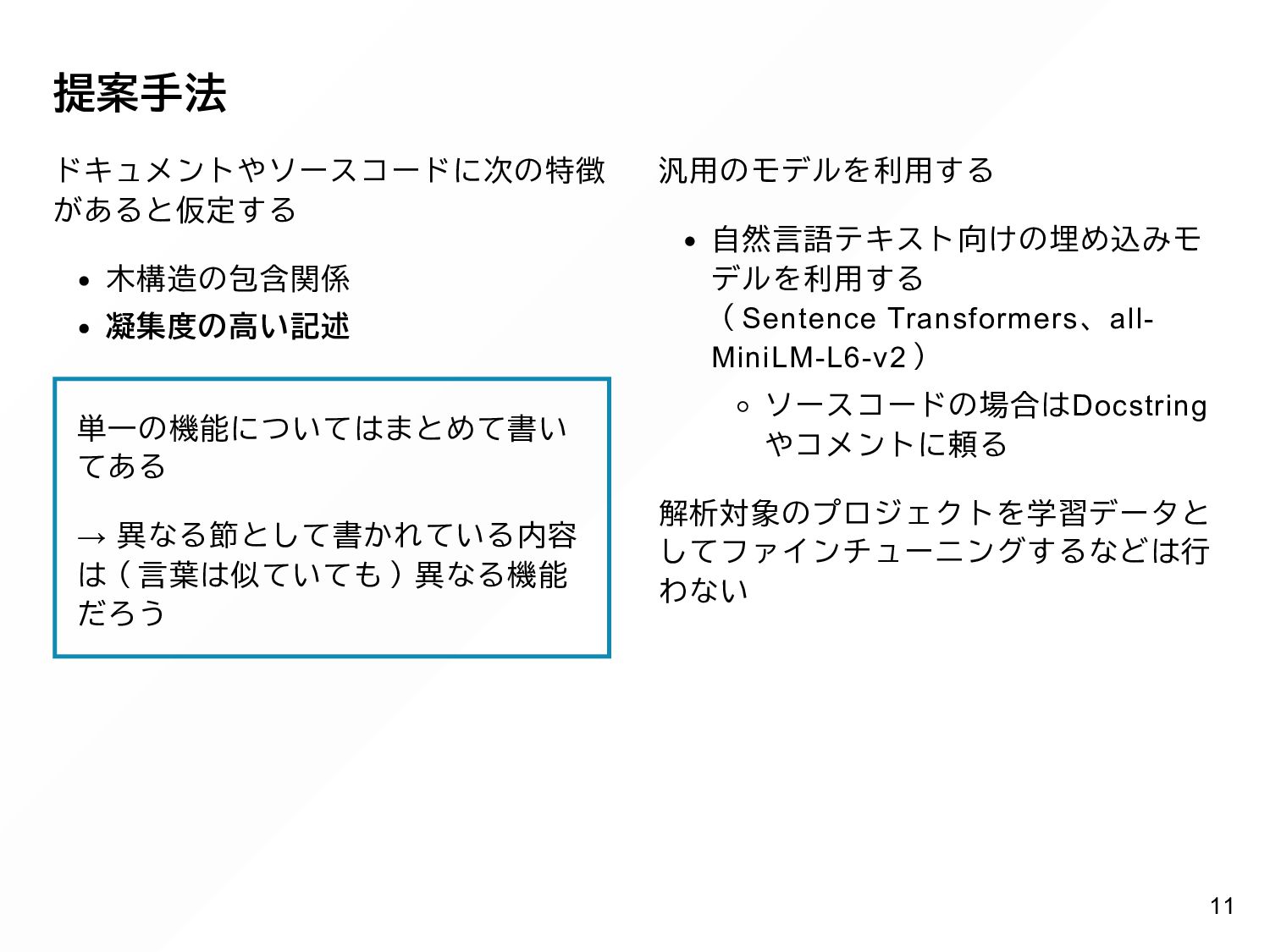{kind=link}
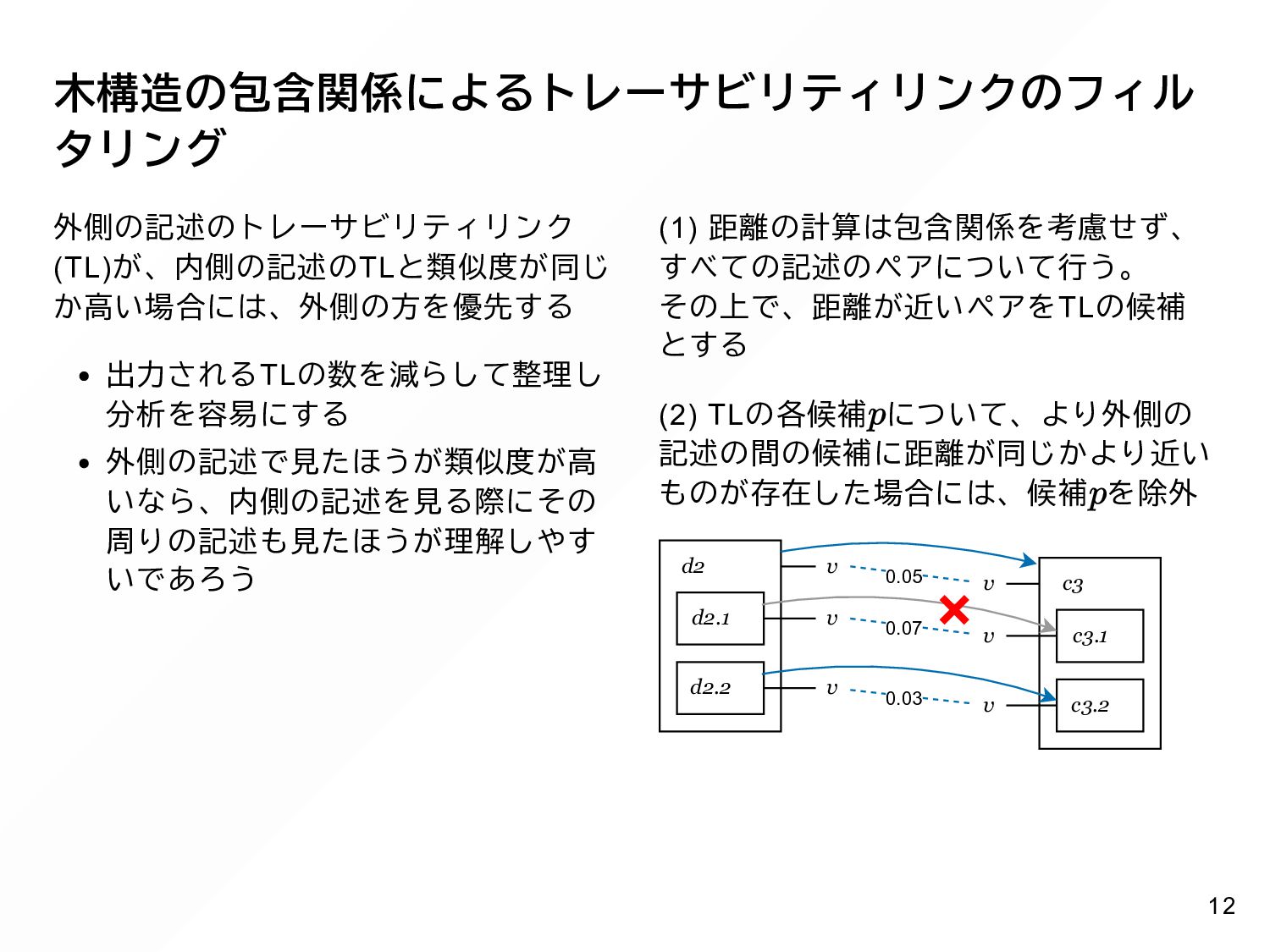{kind=link}
{kind=link}
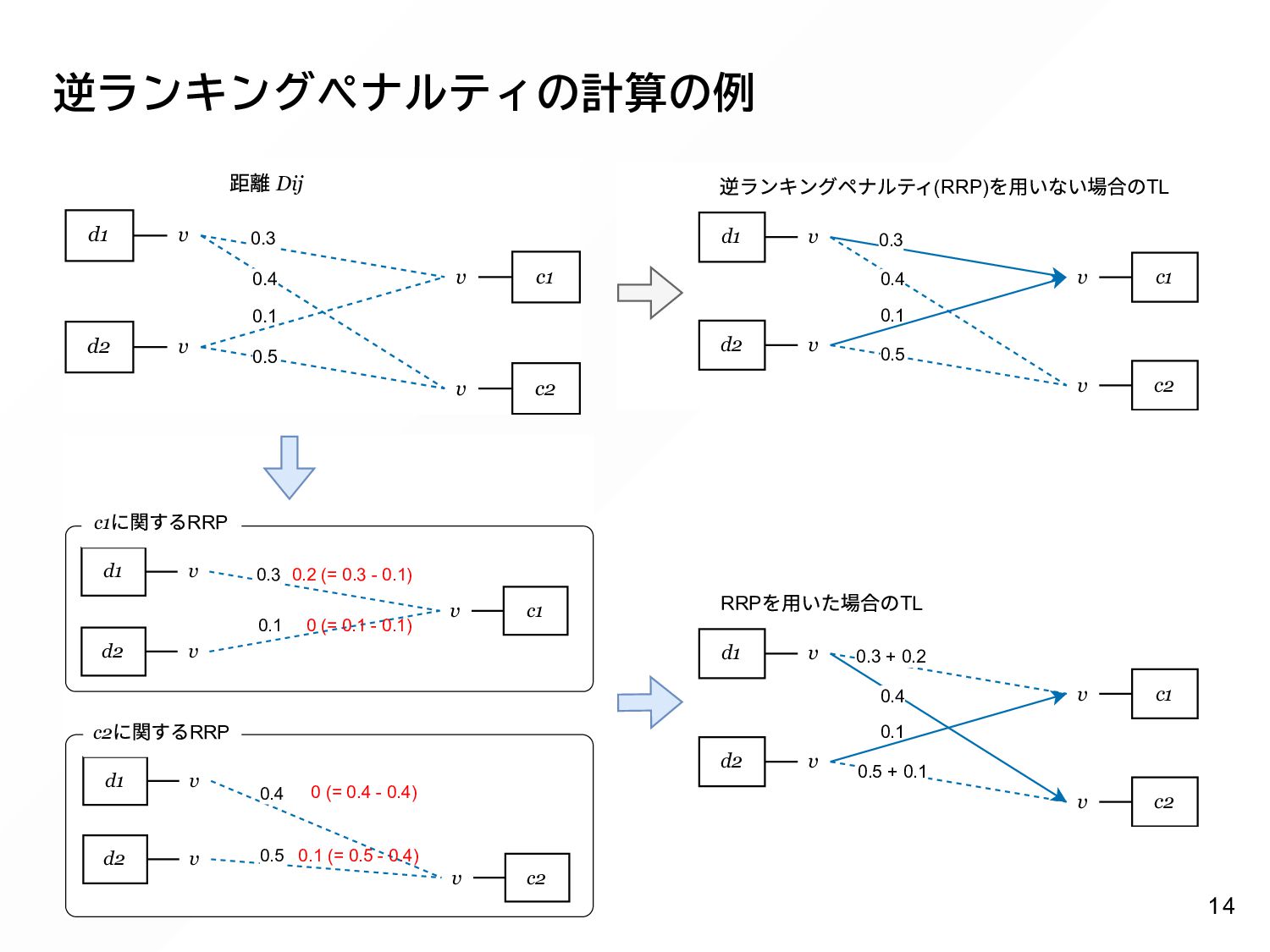{kind=link}
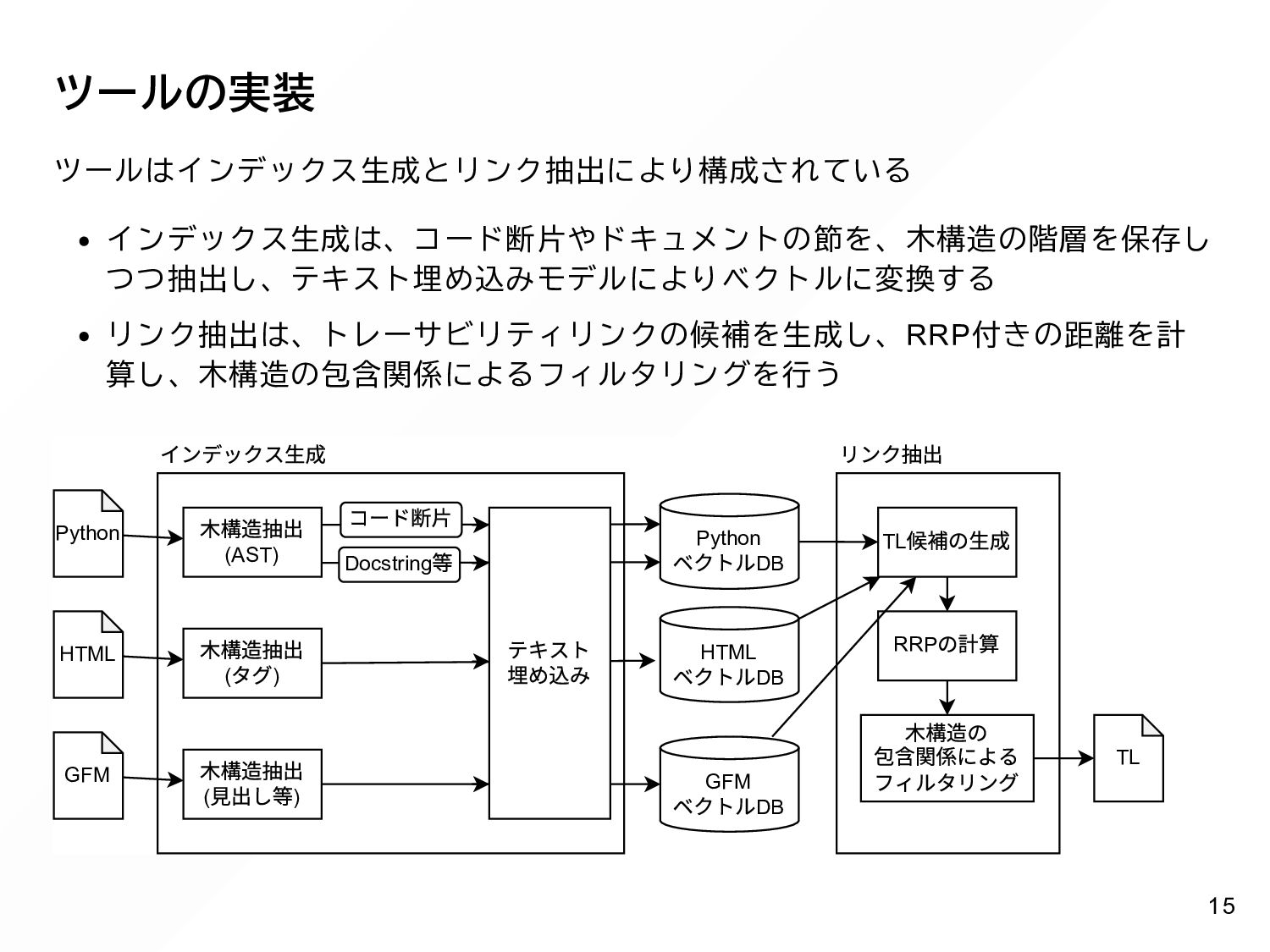{kind=link}
{kind=link}
{kind=link}
{kind=link}
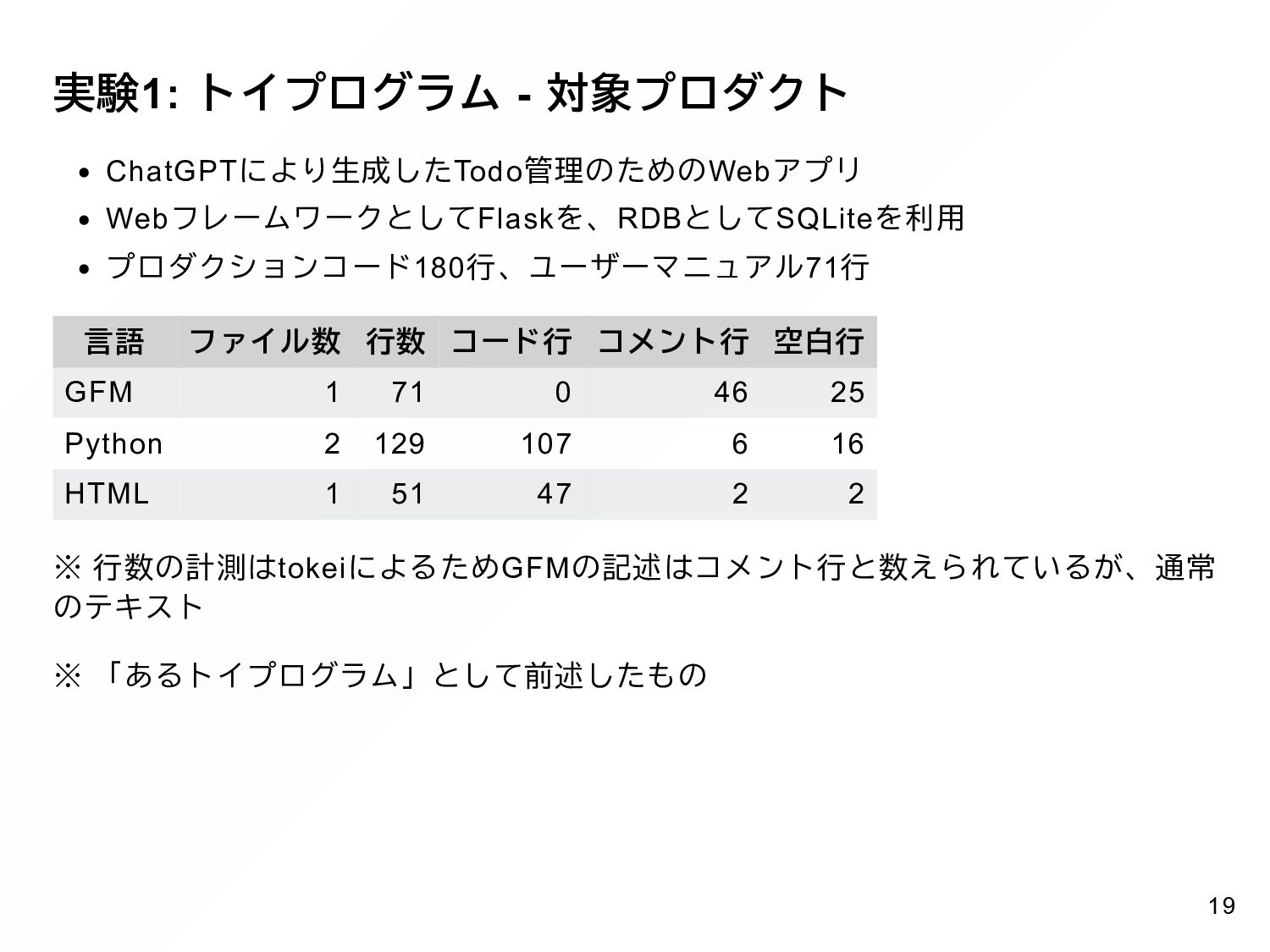{kind=link}
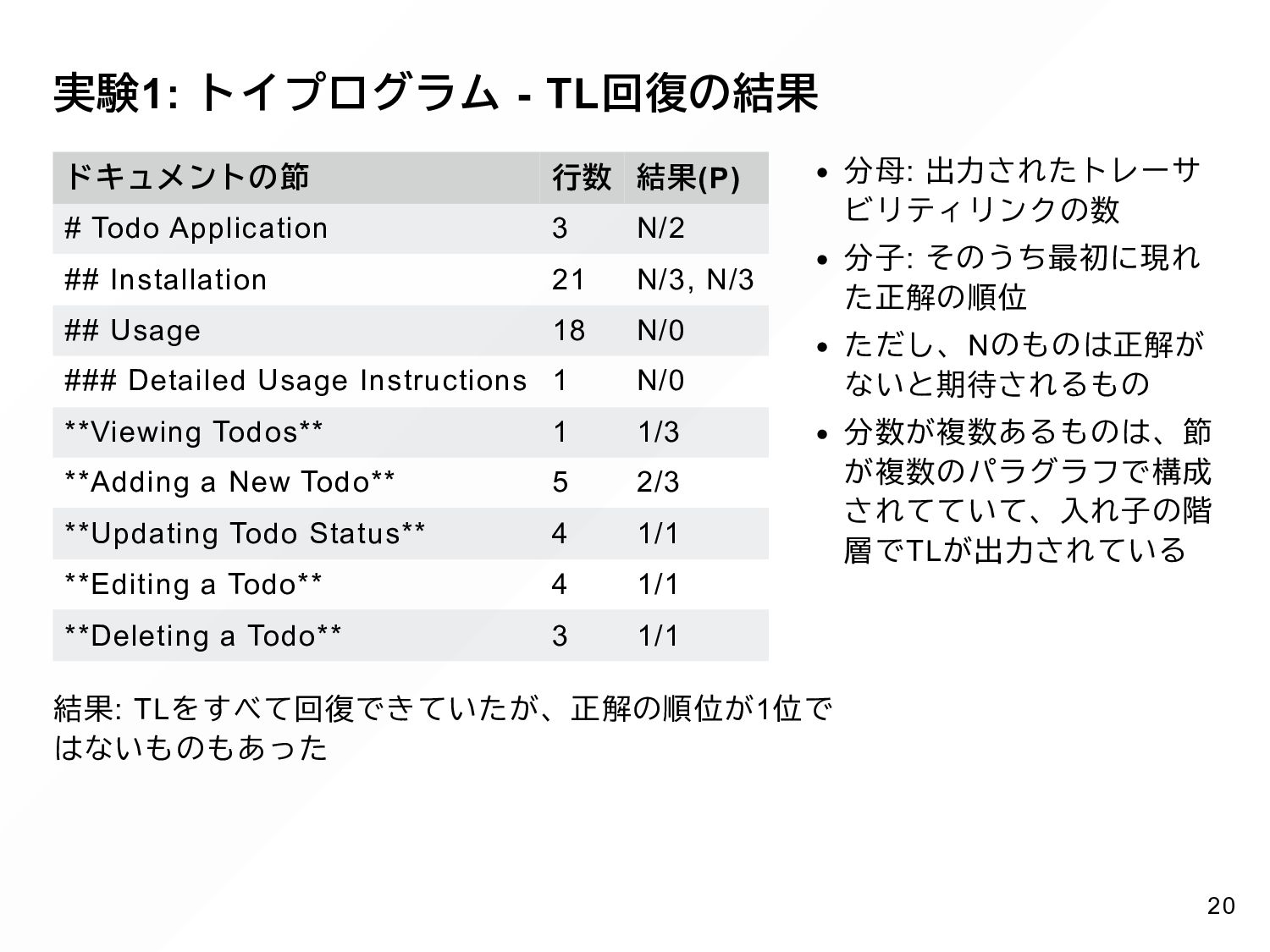{kind=link}
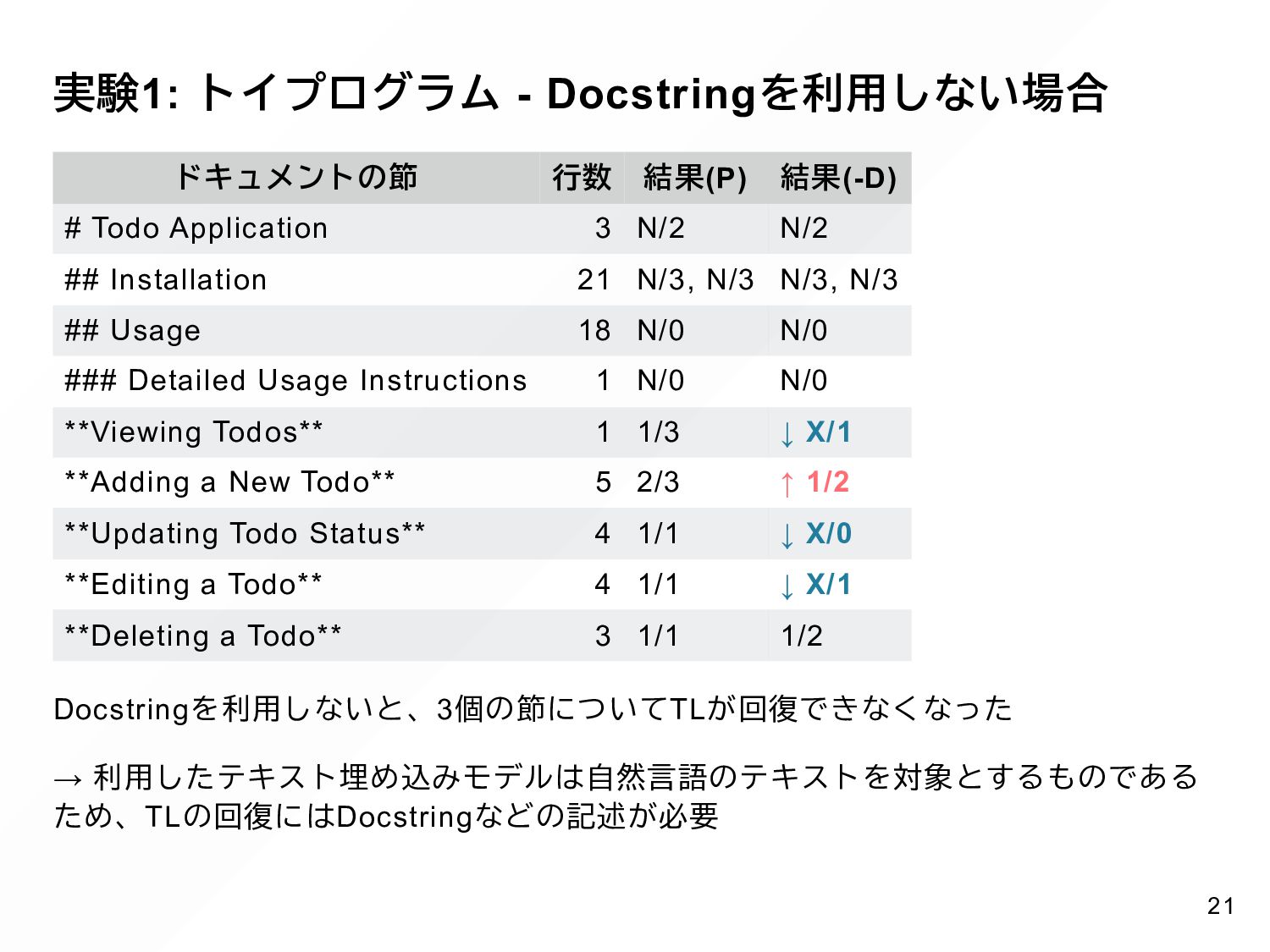{kind=link}
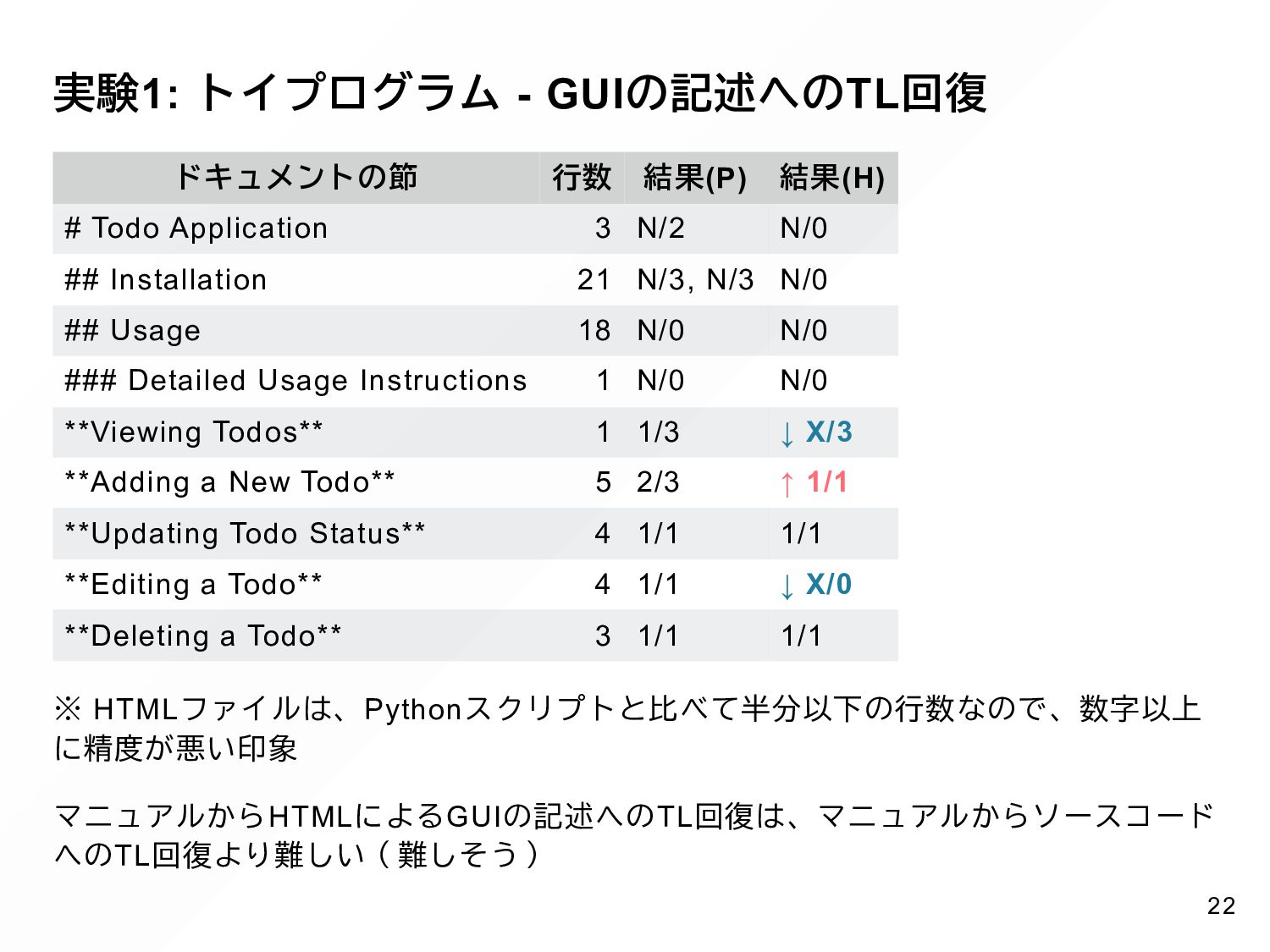{kind=link}
{kind=link}
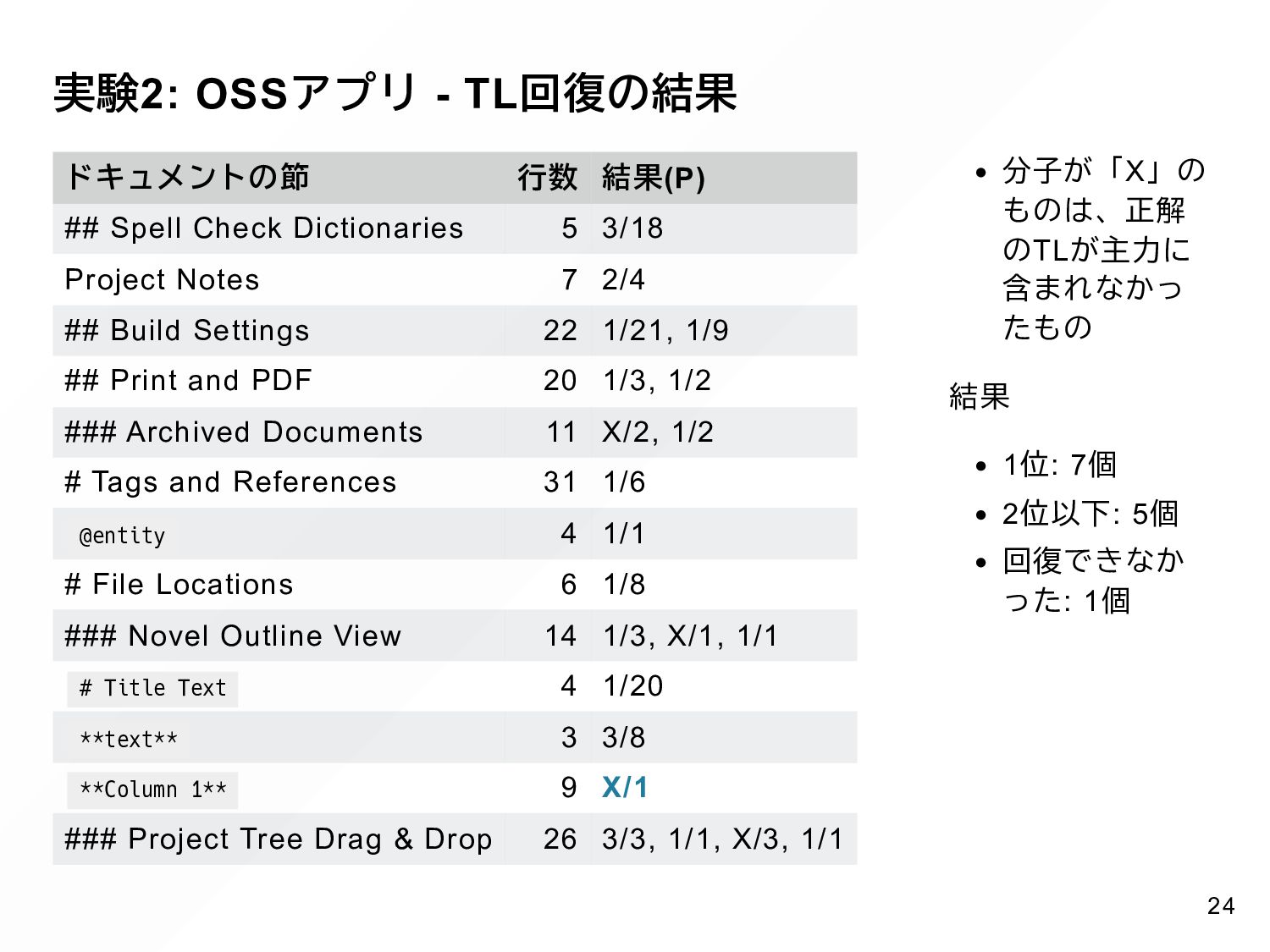{kind=link}
{kind=link}
{kind=link}
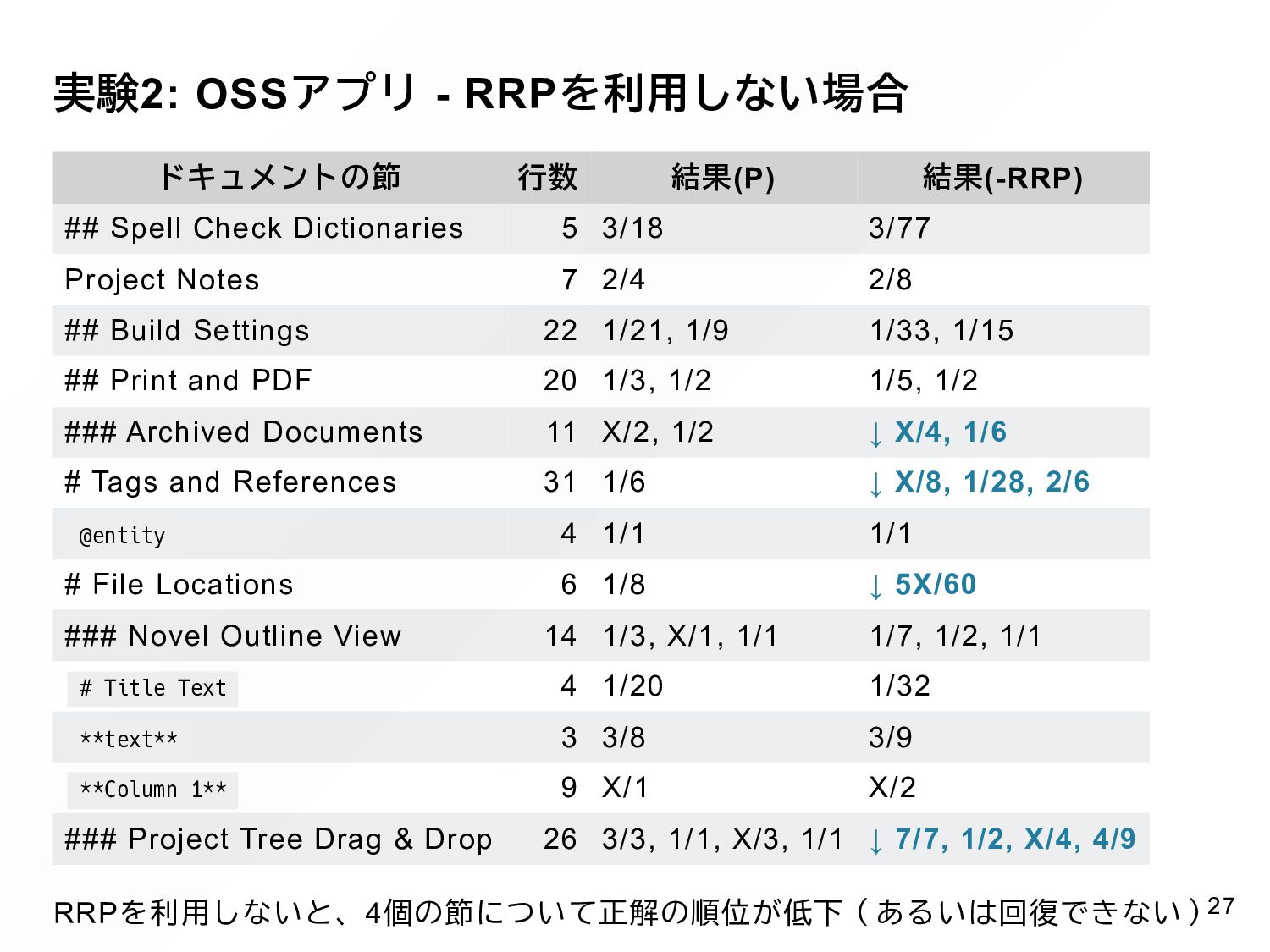{kind=link}
{kind=link}