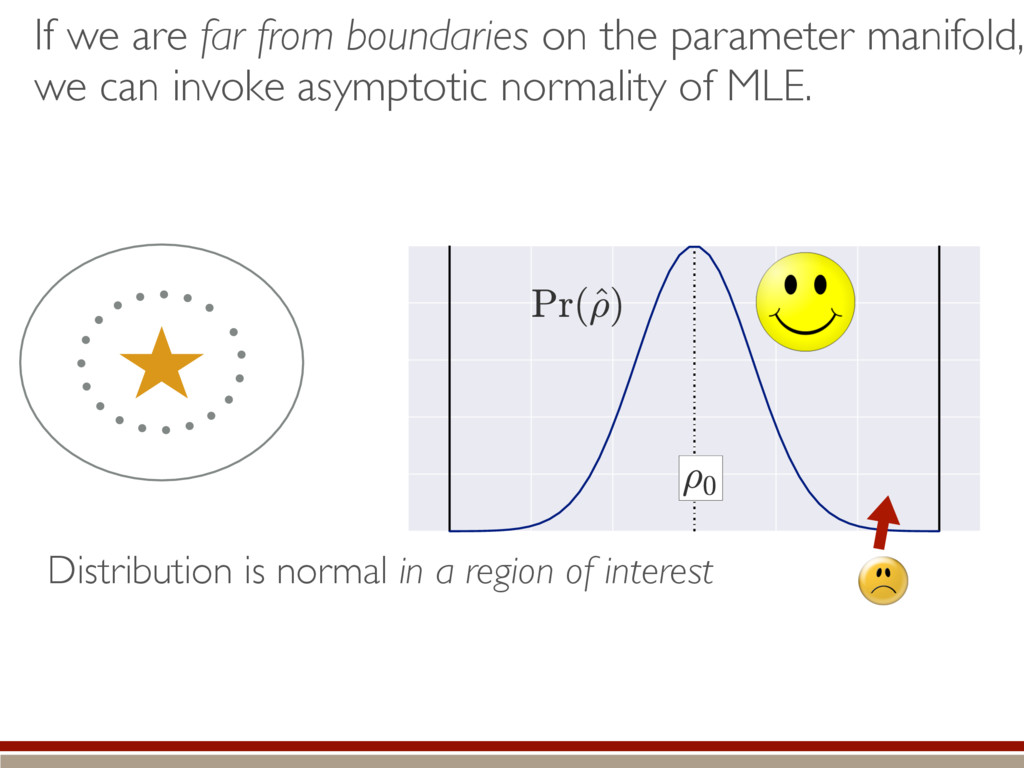
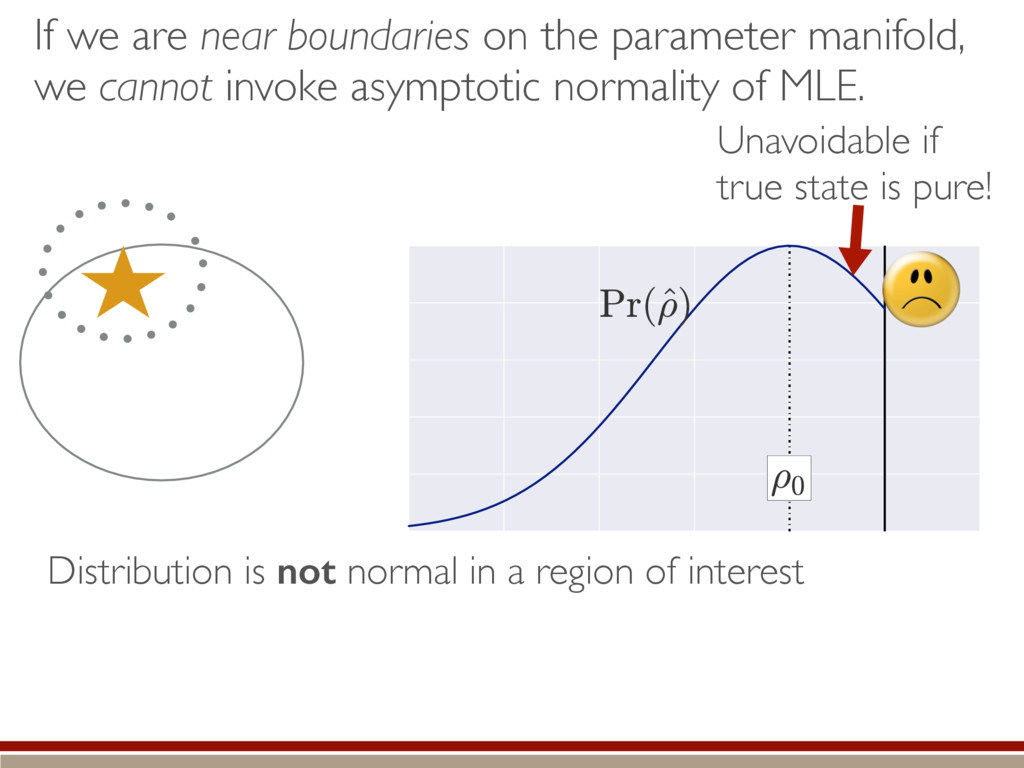
Quantum Information and Control, UNM Center for Computing Research, Sandia National Labs LFQIS-4 2016 June 21 Sandia National Laboratories is a multi-program laboratory managed and operated by Sandia Corporation, a wholly owned subsidiary of Lockheed Martin Corporation, for the U.S. Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000. CCR Center for Computing Research
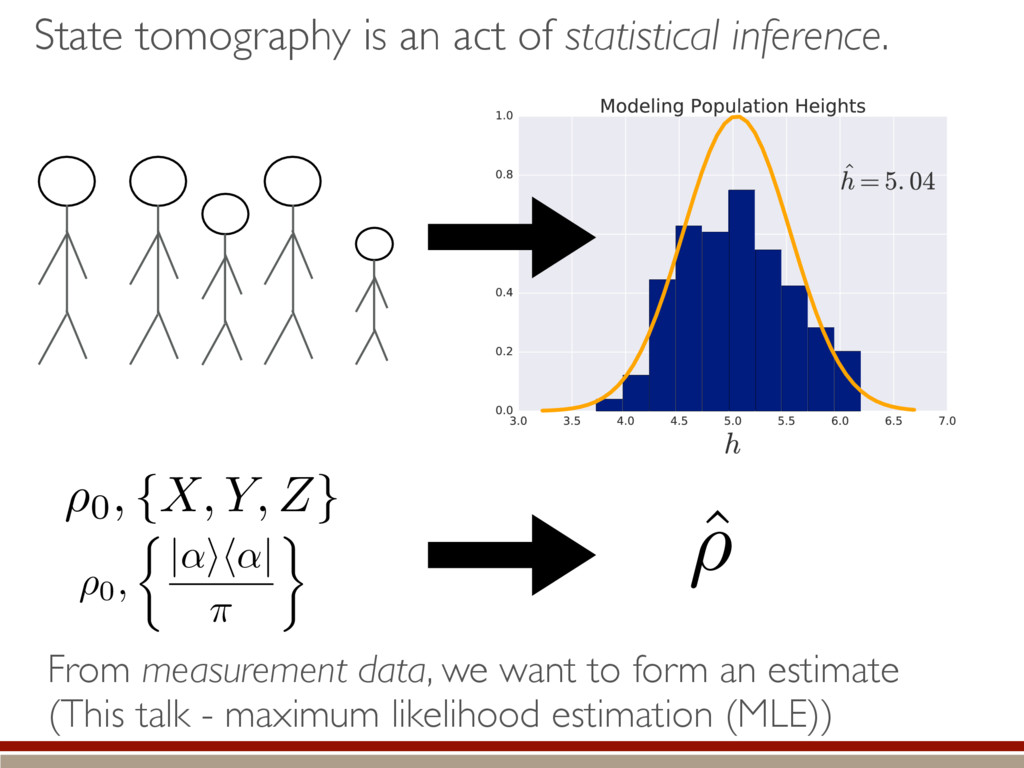
A model is fully described by its parameters: M = {⇢ | some conditions are satisfied } M = {⇢ | dim(⇢) = d} Examples: M = {⇢ | rank(⇢) = r} Pr(k|⇢) = Tr(⇢Ek) Model Parameter (assume POVM fixed)
(E1, n1), (E2, n2), · · · We may have different models for the same data… which one should we choose? How do we determine which model to use? We also have two models for the state: M1, M2 Two concepts: Fitting the data the best Being close to the truth Not the same!!
which model fits the data better. ( M1, M2) = 2 log( L ( M1) /L ( M2)) The LLRS is defined as where the likelihood of a model is L ( M ) = max ⇢2M L ( ⇢ ) > 0 : M2 < 0 : M1 Decision rule:
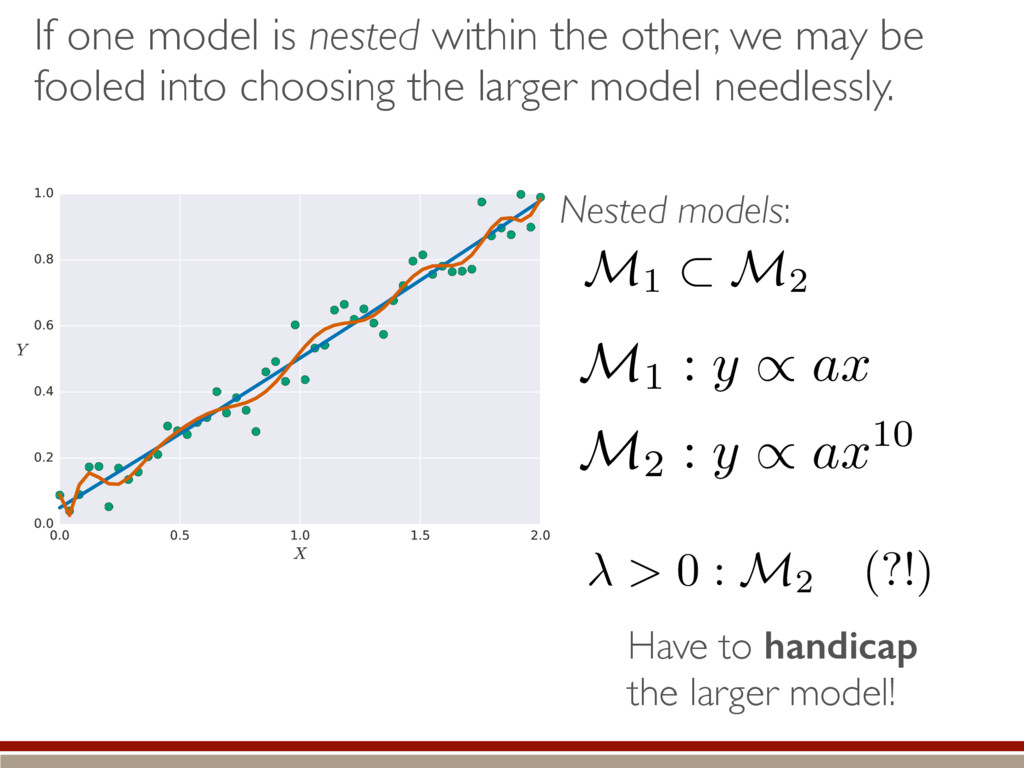
be fooled into choosing the larger model needlessly. Nested models: Have to handicap the larger model! M1 ⇢ M2 > 0 : M2 (?!) M1 : y / ax M2 : y / ax 10
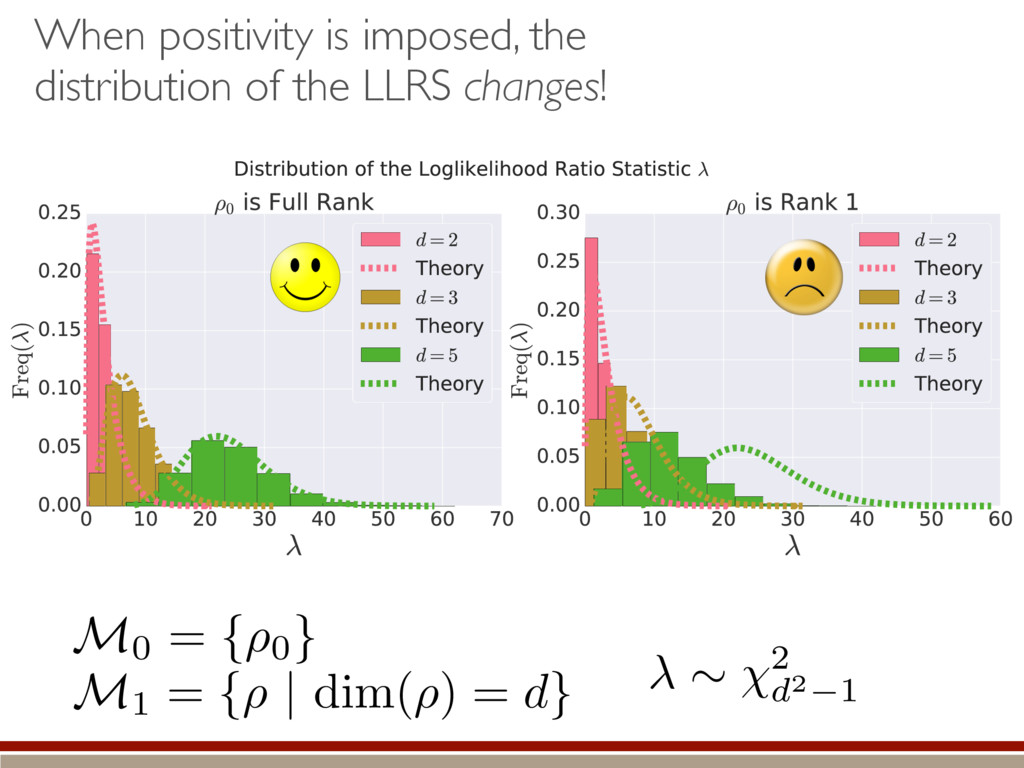
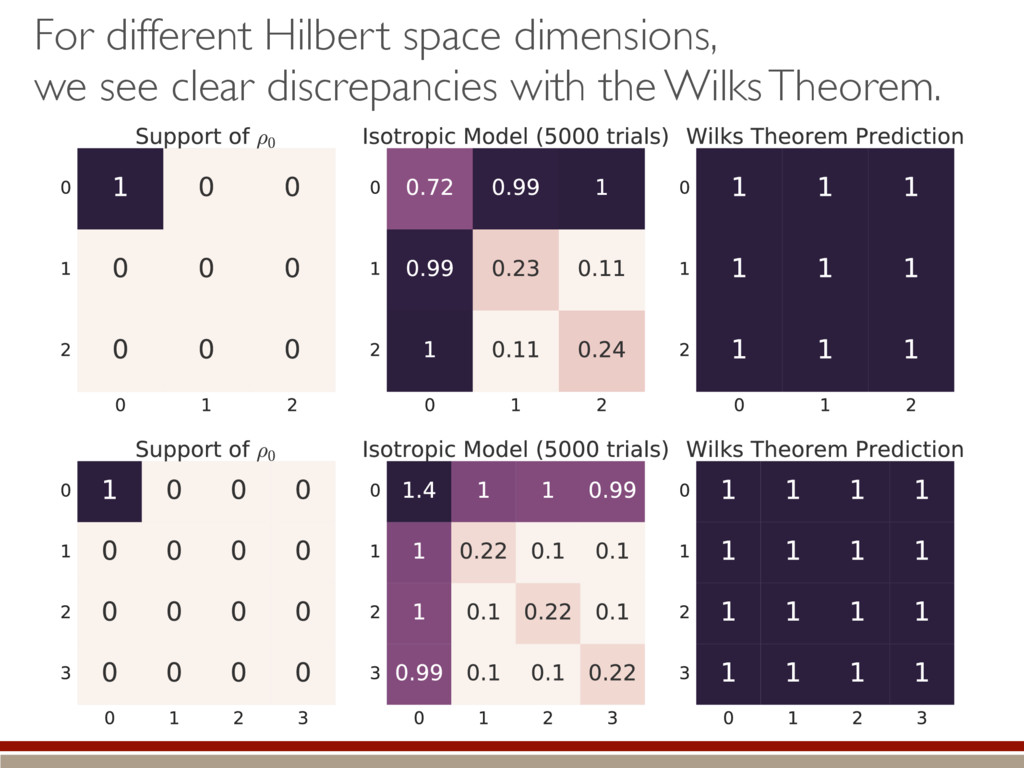
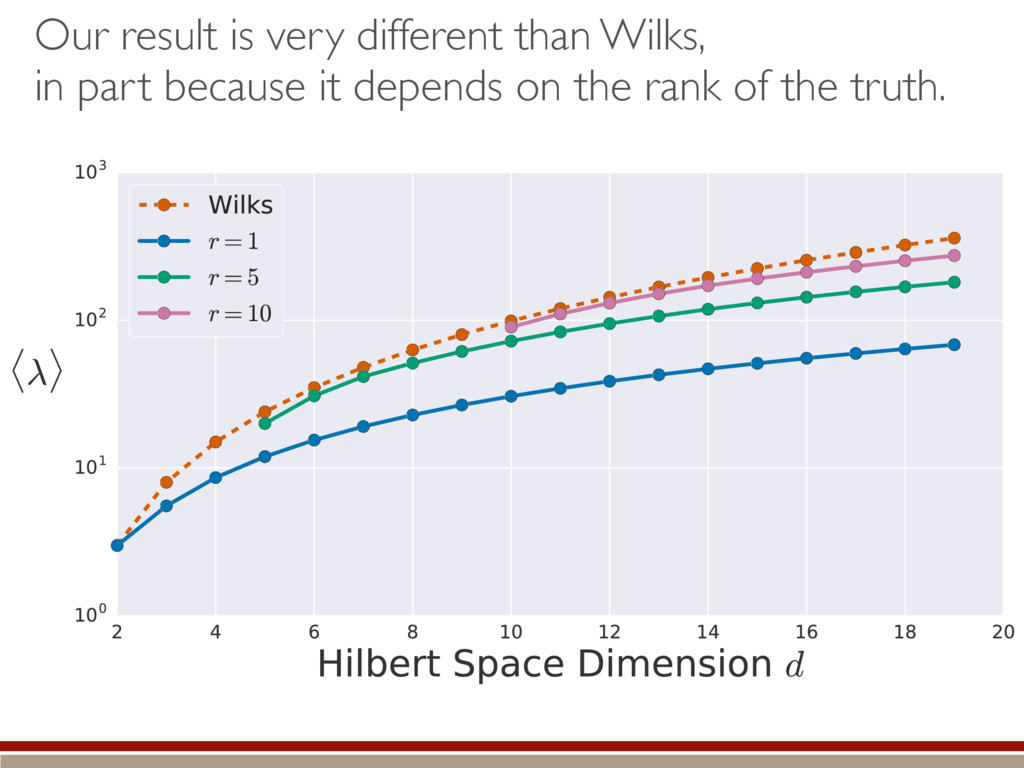
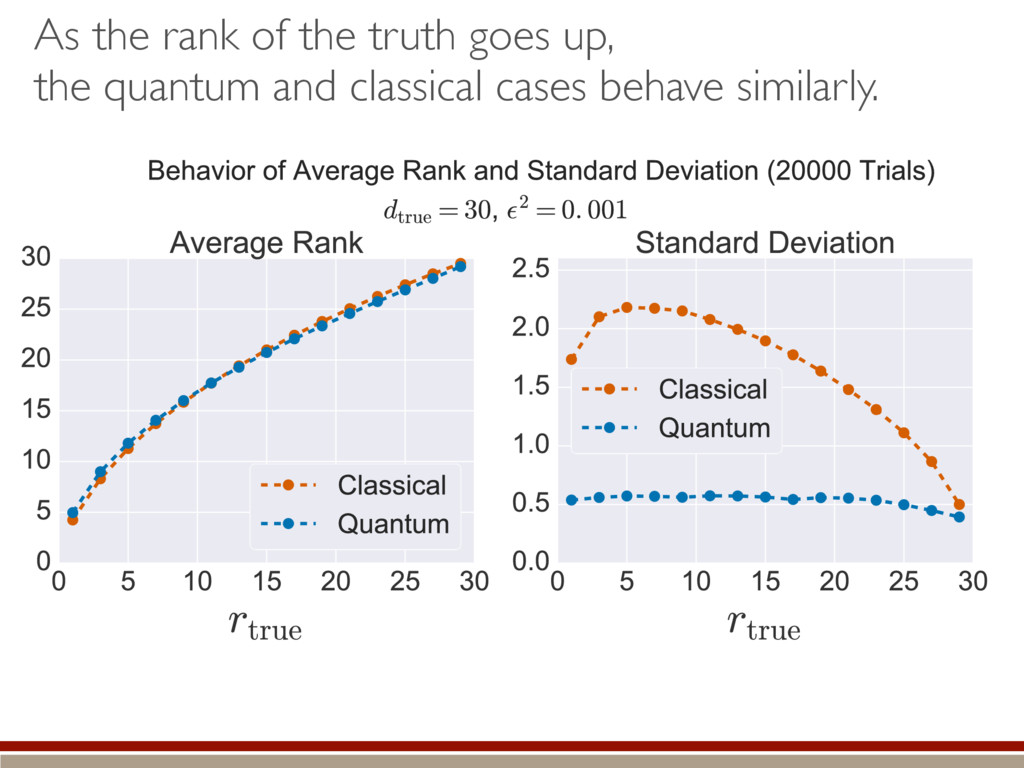
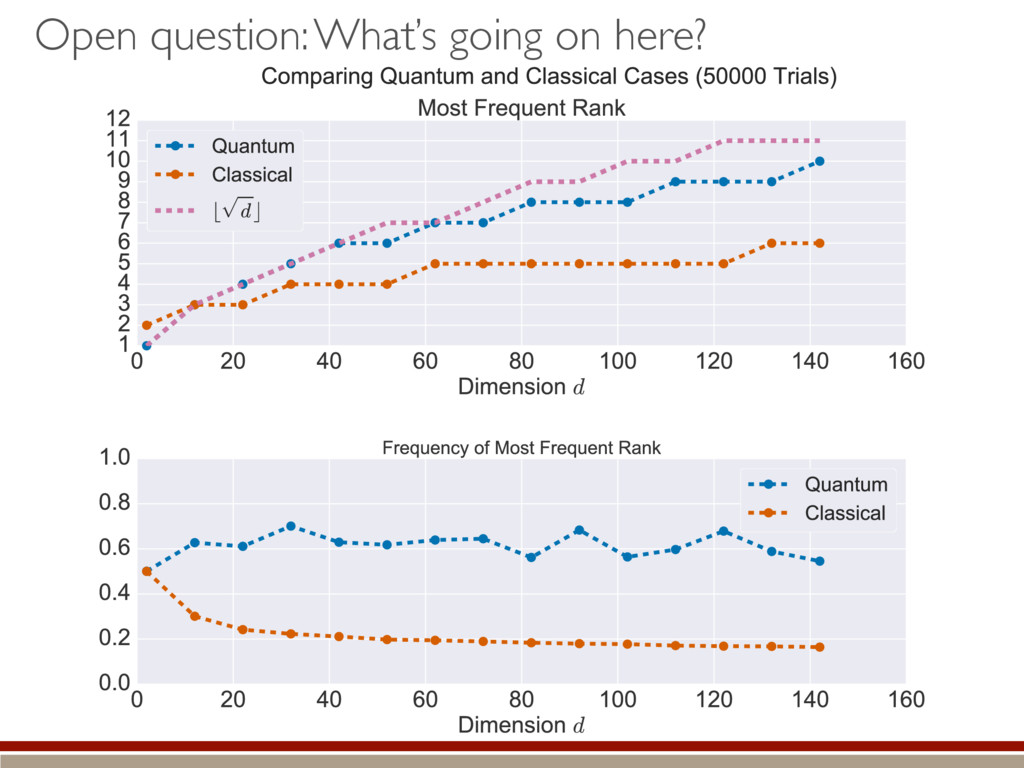
valid to make a good decision! If both contain true state… larger appears to fit data better… …actually just fitting noise Nested models: M1 ⇢ M2 M1 = {⇢ | dim(⇢) = d} M2 = {⇢ | dim(⇢) = d + 1} What’s the behavior of the LLRS when both are equally valid? ⇢0 M1 M2 & h i =) M2
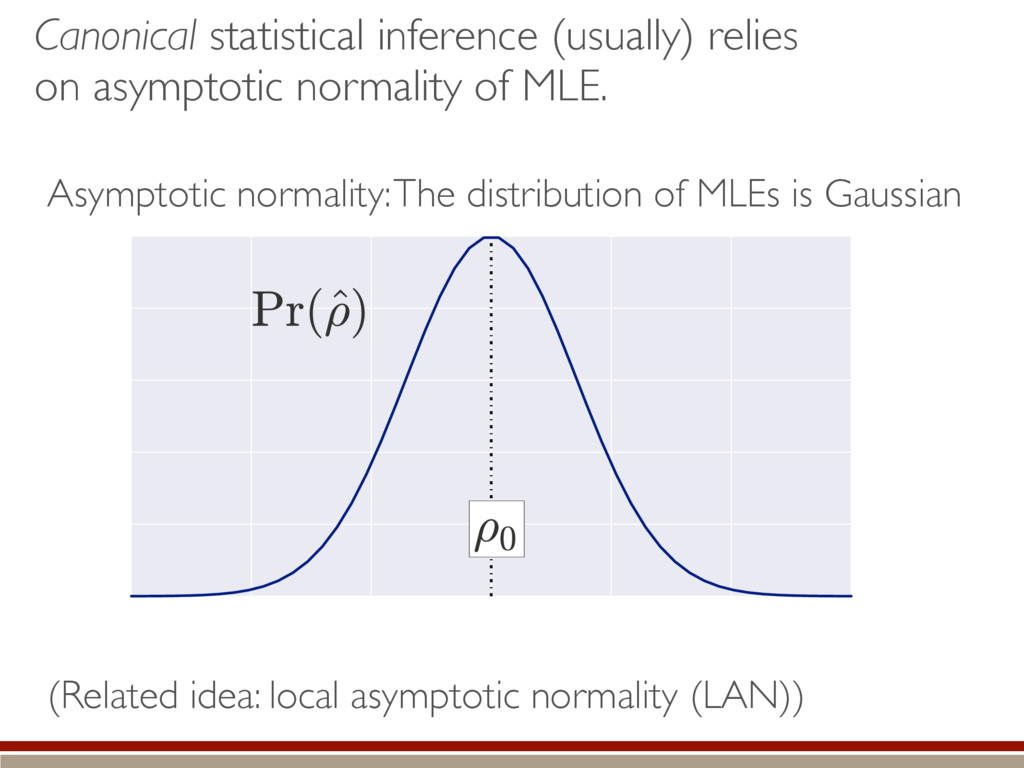
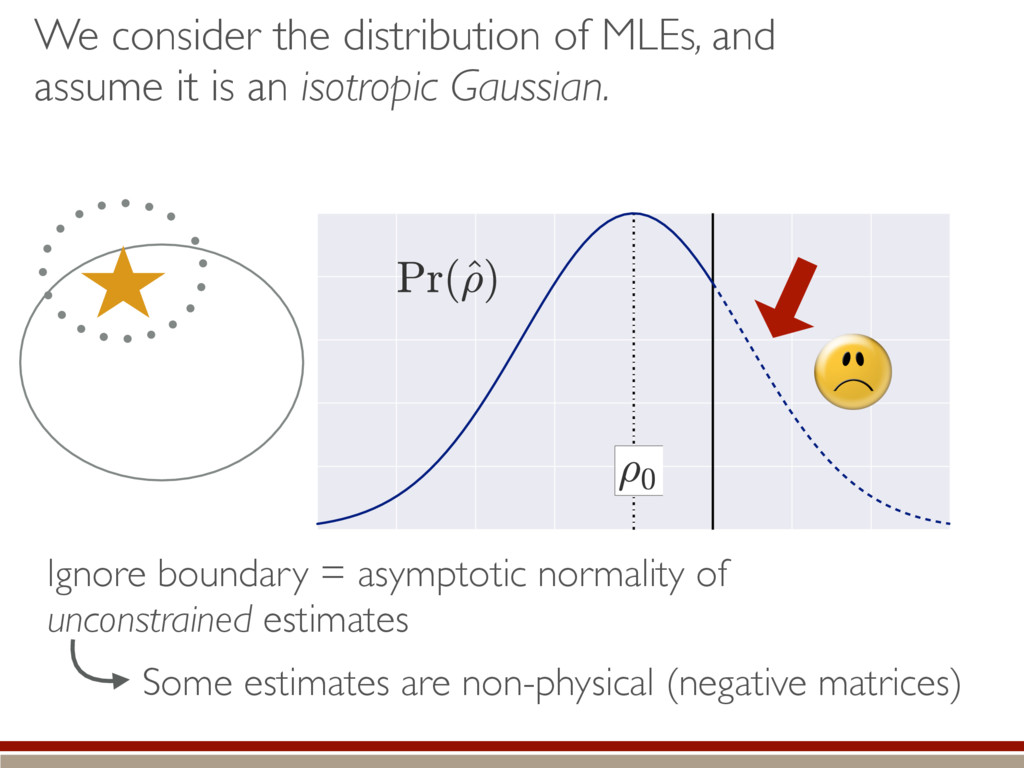
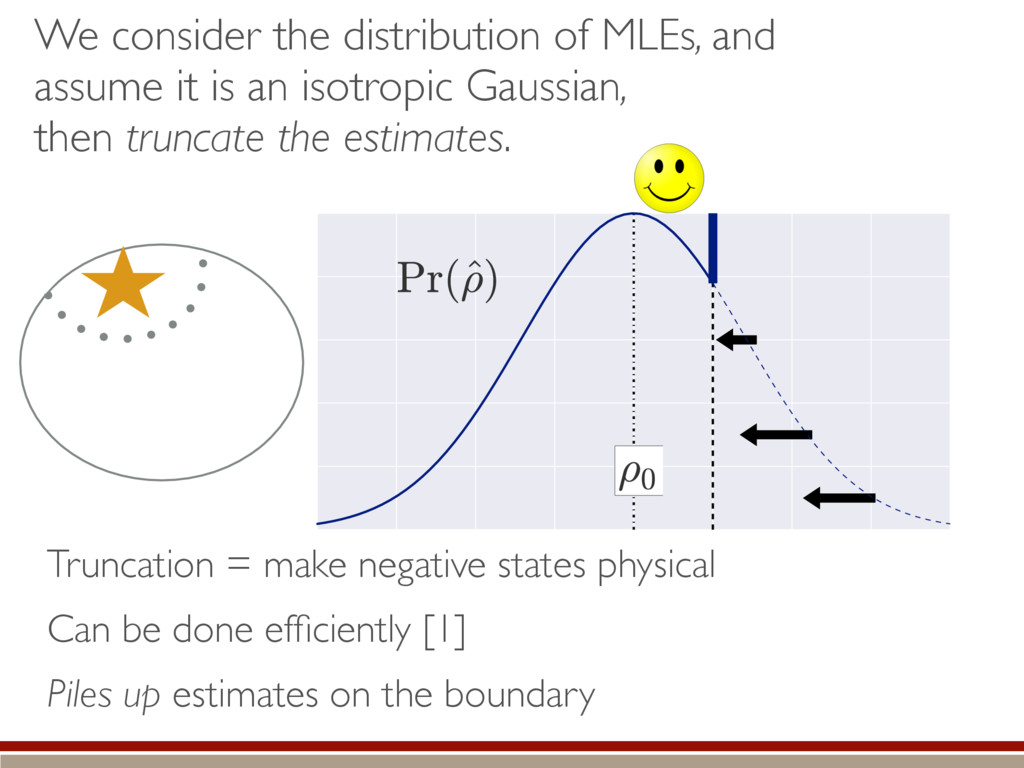
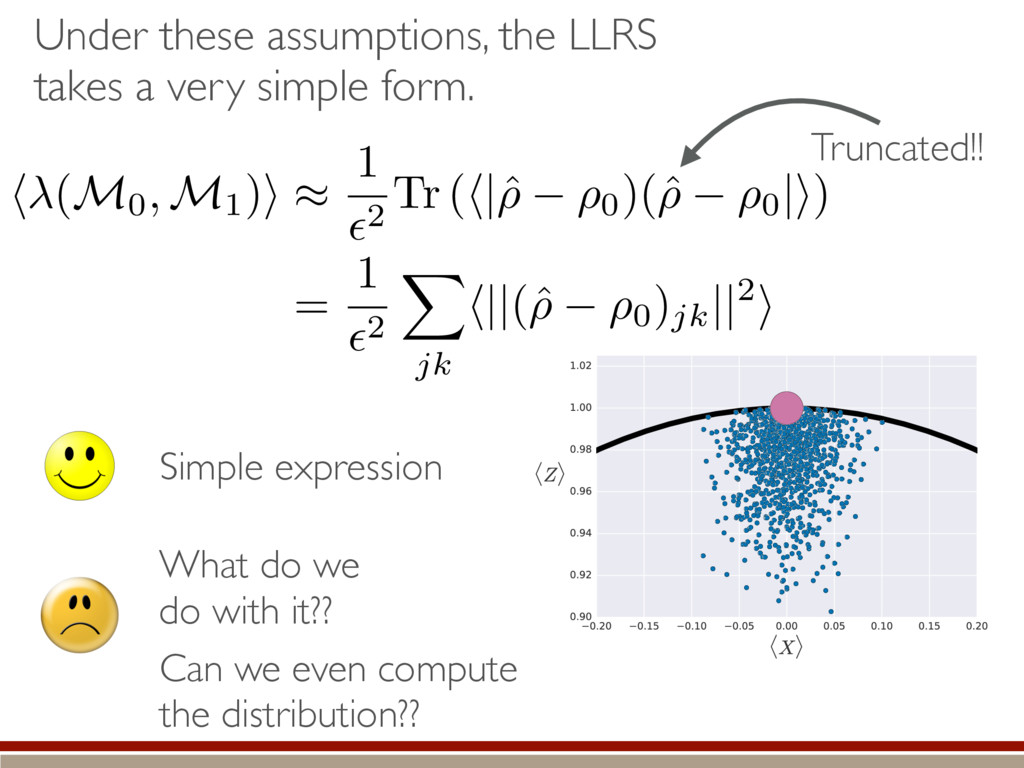
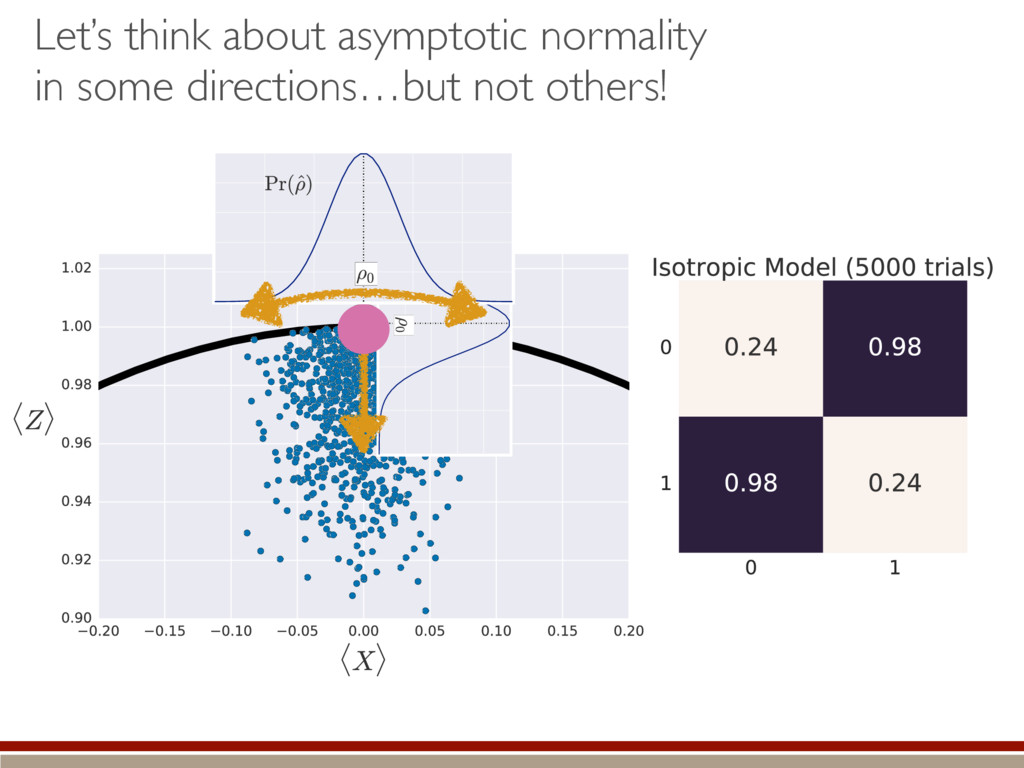
are present, we make several assumptions. We can do a Taylor series: The Fisher information is isotropic (in Hilbert-Schmidt basis): Unconstrained estimates are normally distributed and asymptotically efficient: Non-physical estimates are truncated back to positive states. h (M0 , M1)i ⇡ Tr (hH|ˆ ⇢ ⇢0)(ˆ ⇢ ⇢0 |i) ˆ ⇢ ⇠ N(⇢0, I 1) I = ✏2I
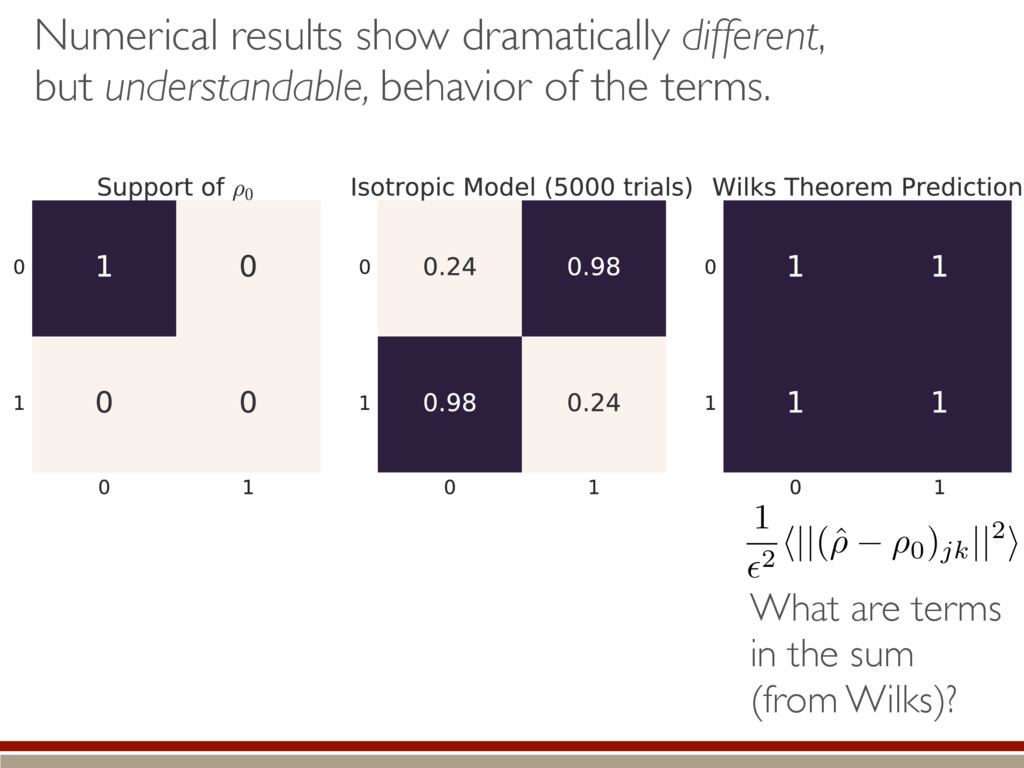
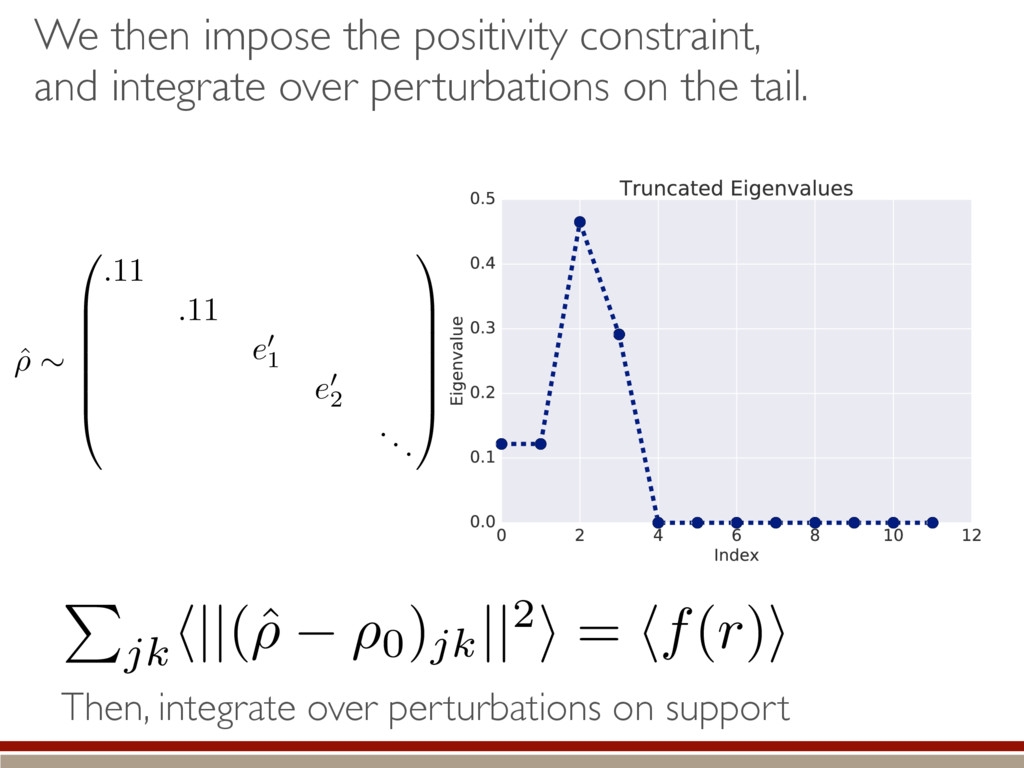
Simple expression What do we do with it?? Can we even compute the distribution?? Truncated!! h (M0, M1)i ⇡ 1 ✏2 Tr (h|ˆ ⇢ ⇢0)(ˆ ⇢ ⇢0 |i) = 1 ✏2 X jk h||(ˆ ⇢ ⇢0)jk ||2i
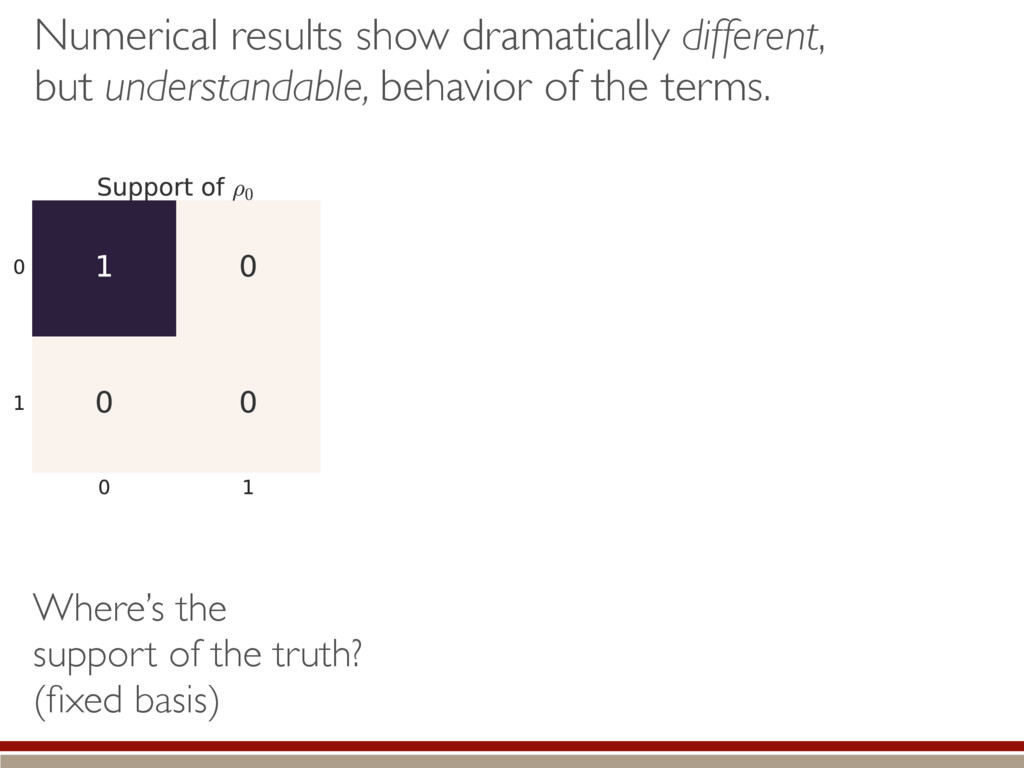
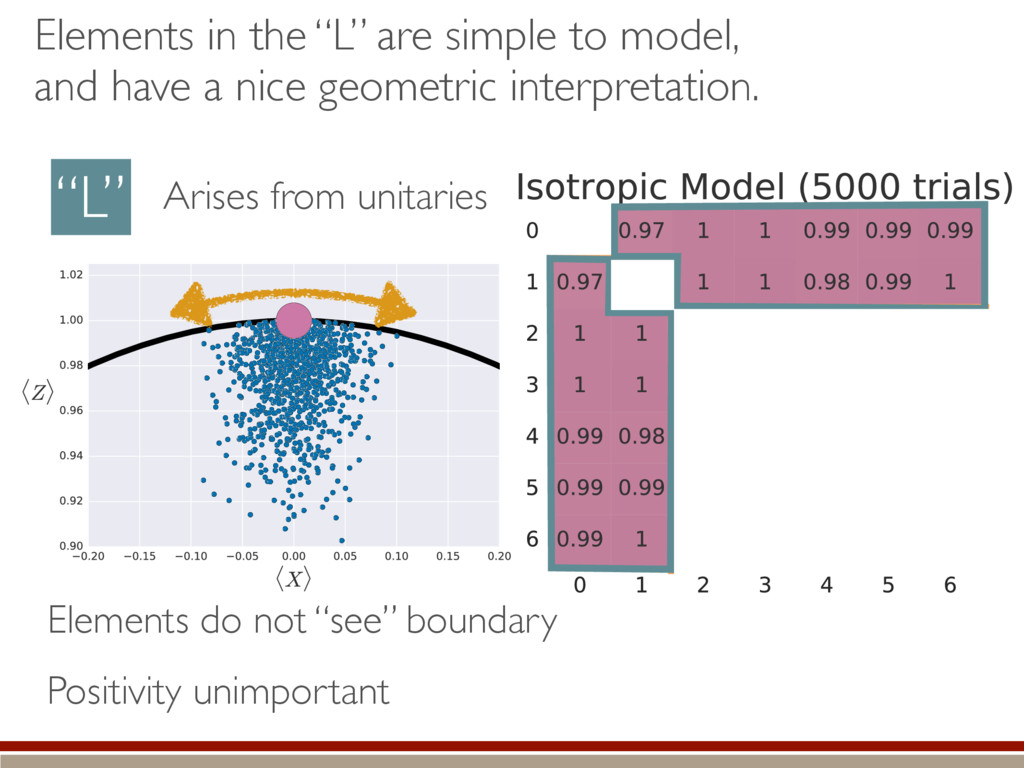
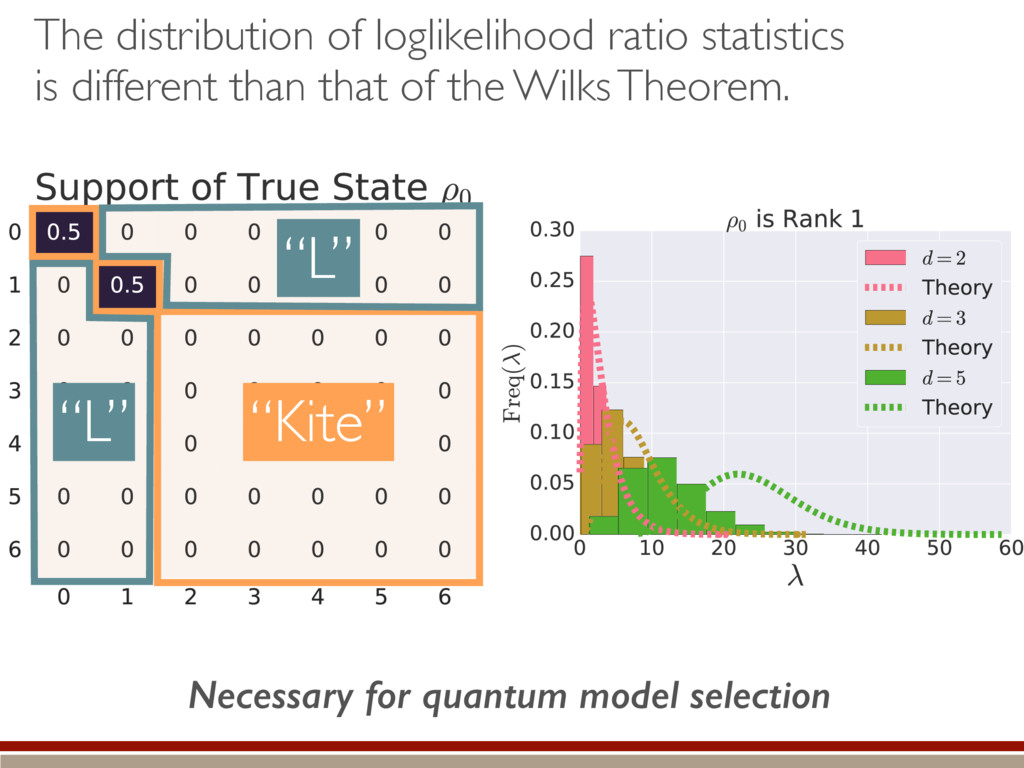
individual terms in the sum. What are the individual terms? Depending on the support of the true state, how does imposing positivity change the terms? How do they compare to the Wilks Theorem? Time for some numerics! h (M0, M1)i ⇡ 1 ✏2 X jk h||(ˆ ⇢ ⇢0)jk ||2i
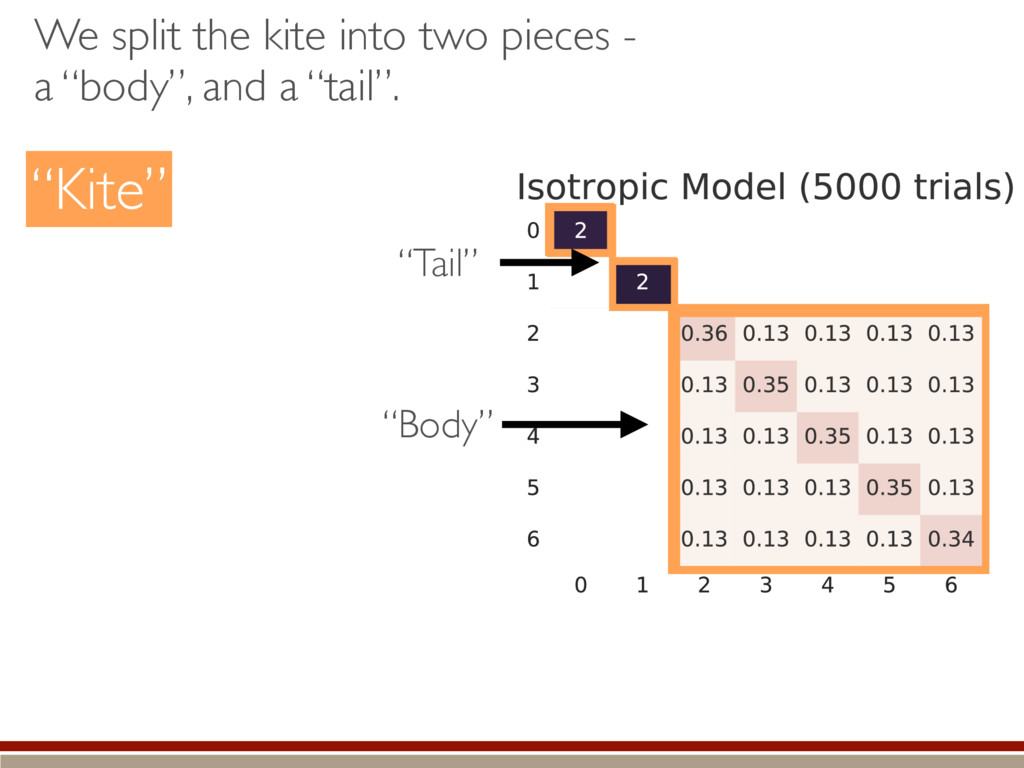
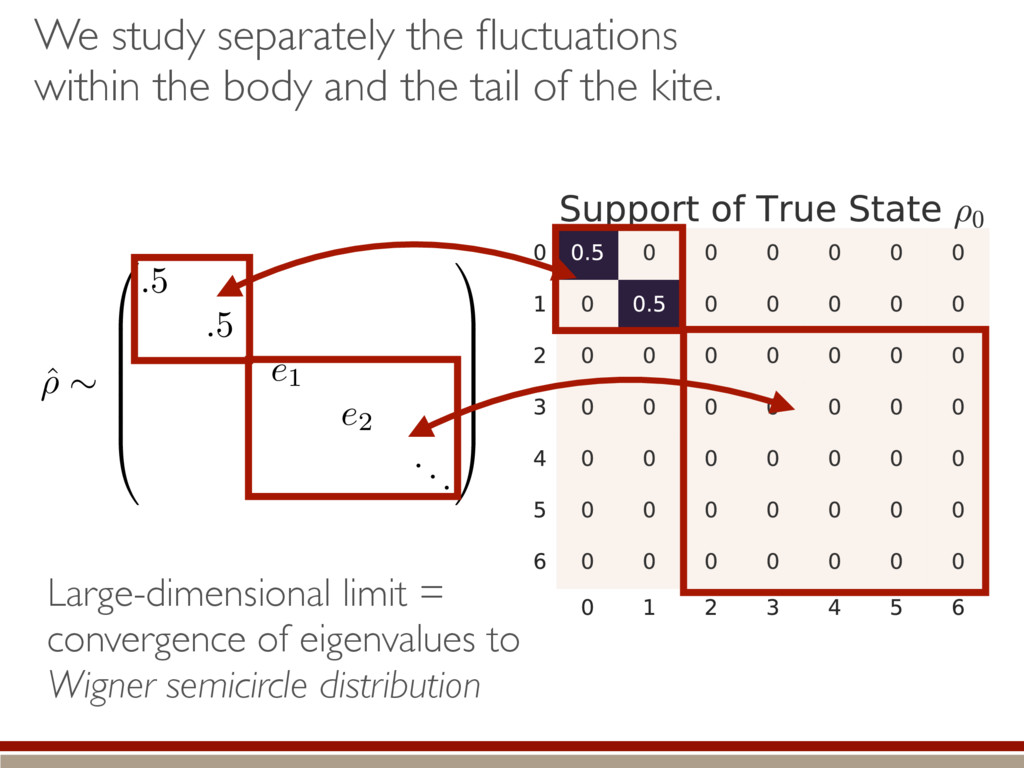
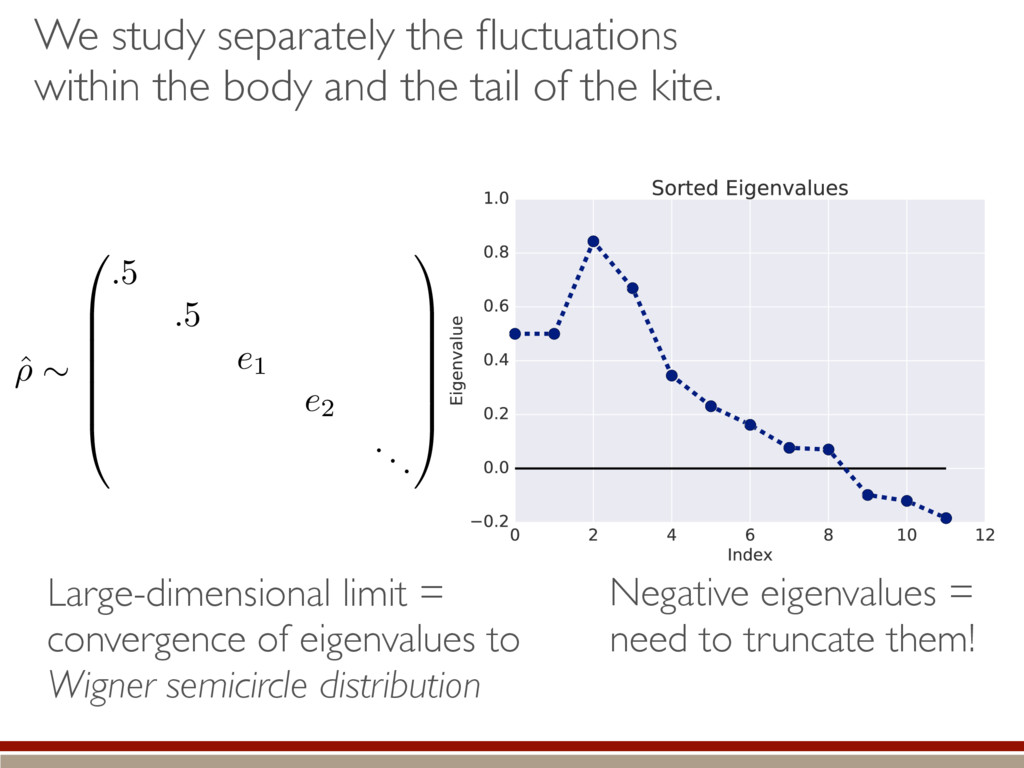
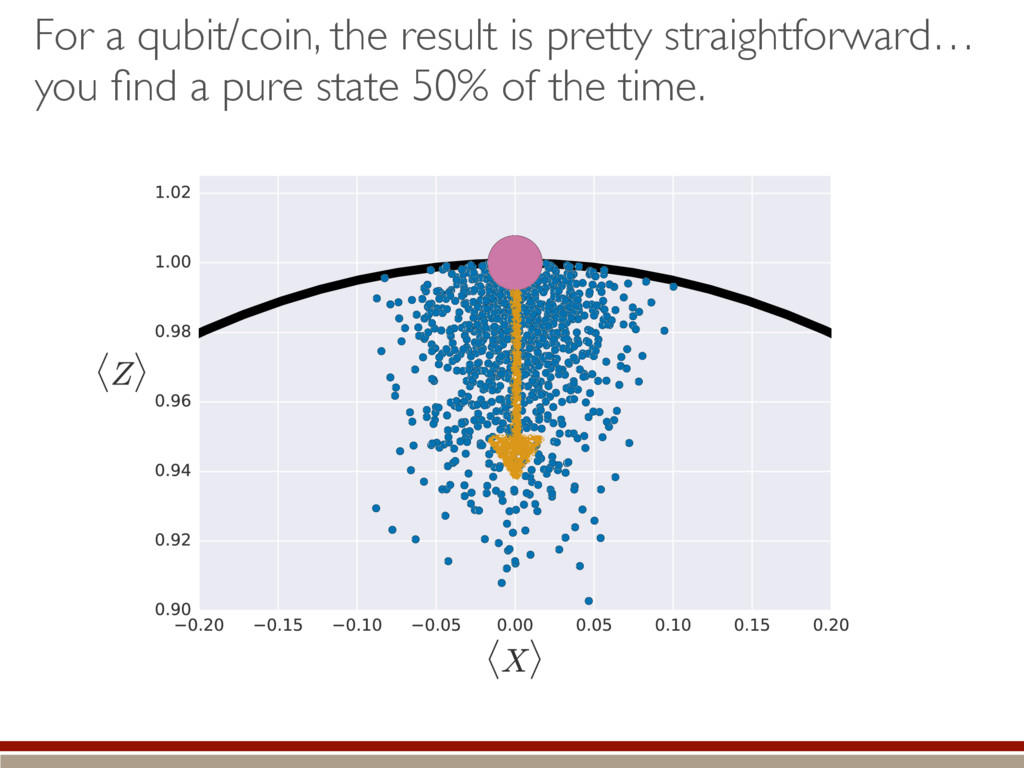
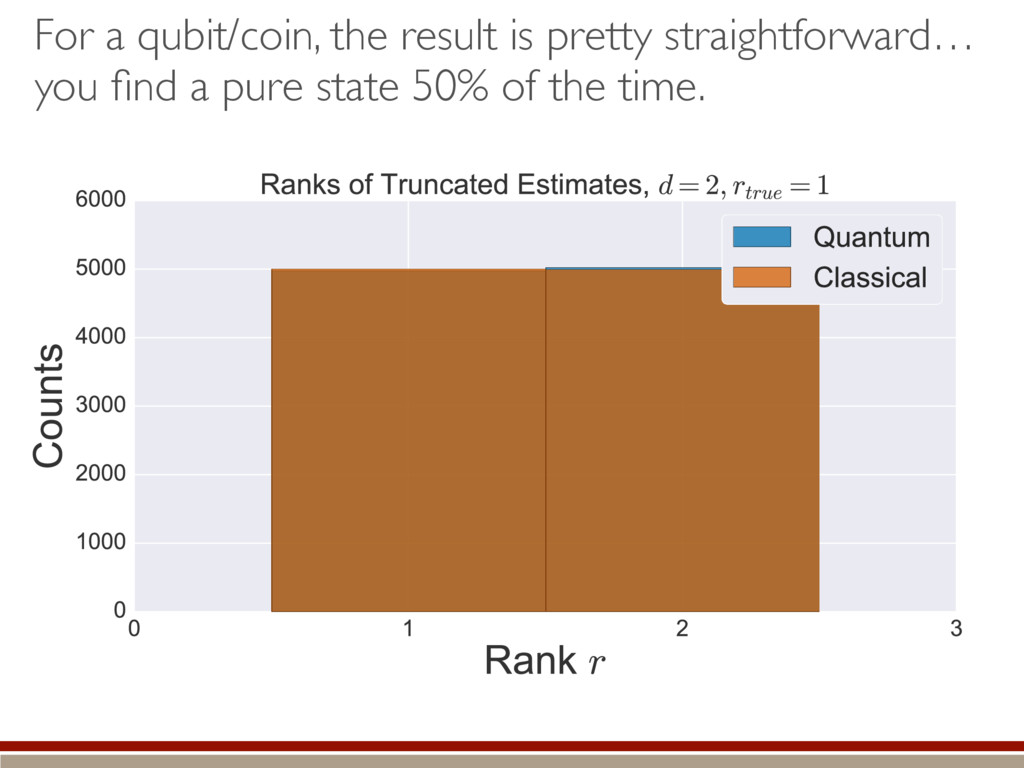
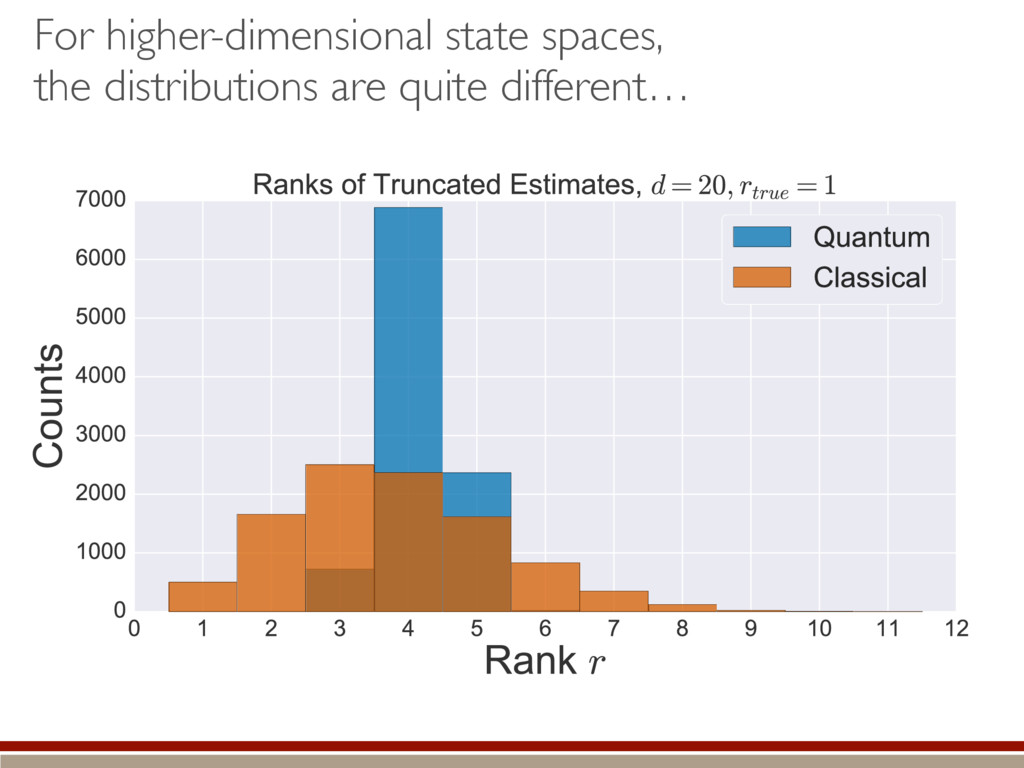
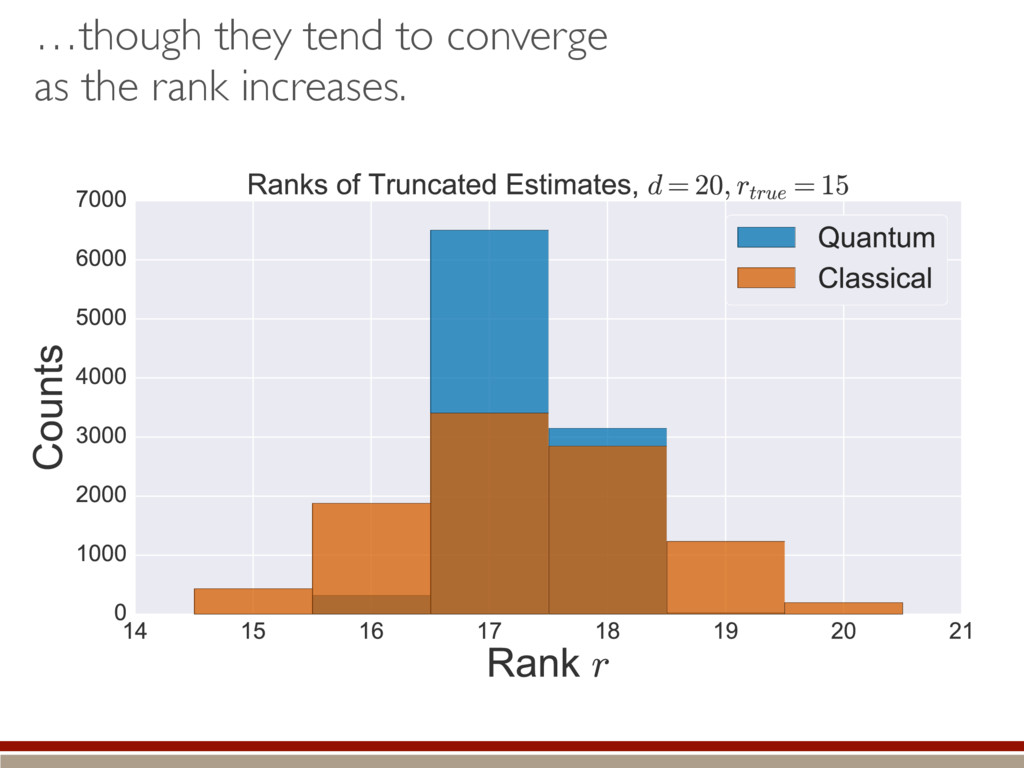
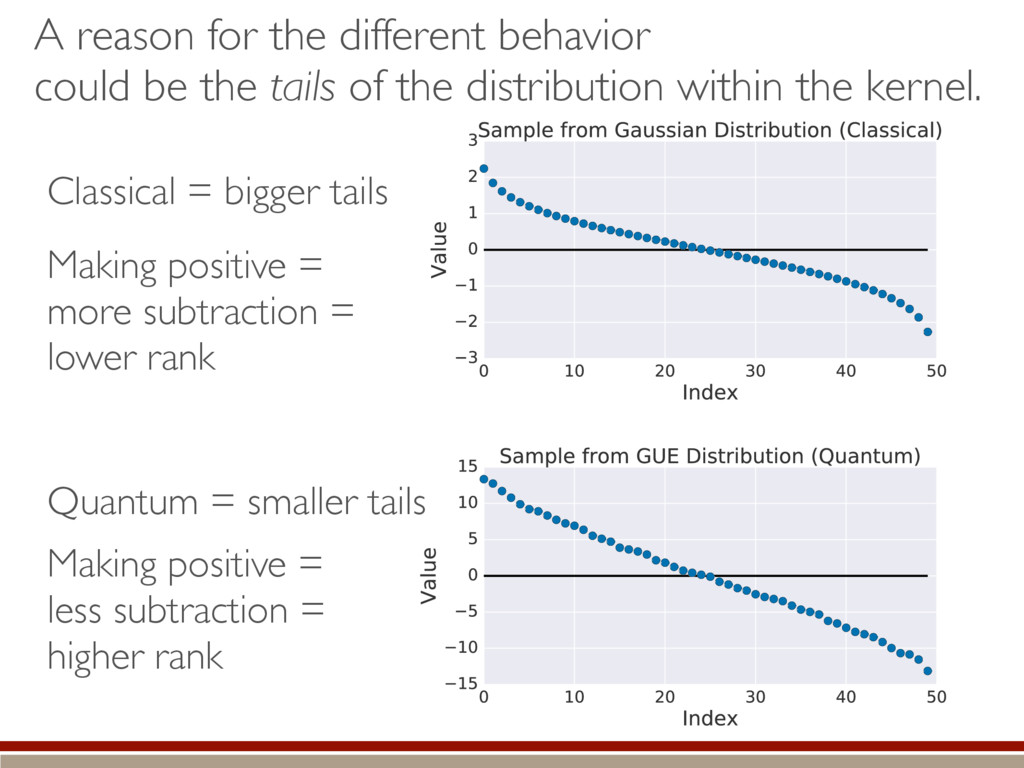
the fluctuations within the body and the tail of the kite. ˆ ⇢ ⇠ 0 B B B B B @ .5 .5 e1 e2 ... 1 C C C C C A Large-dimensional limit = convergence of eigenvalues to Wigner semicircle distribution
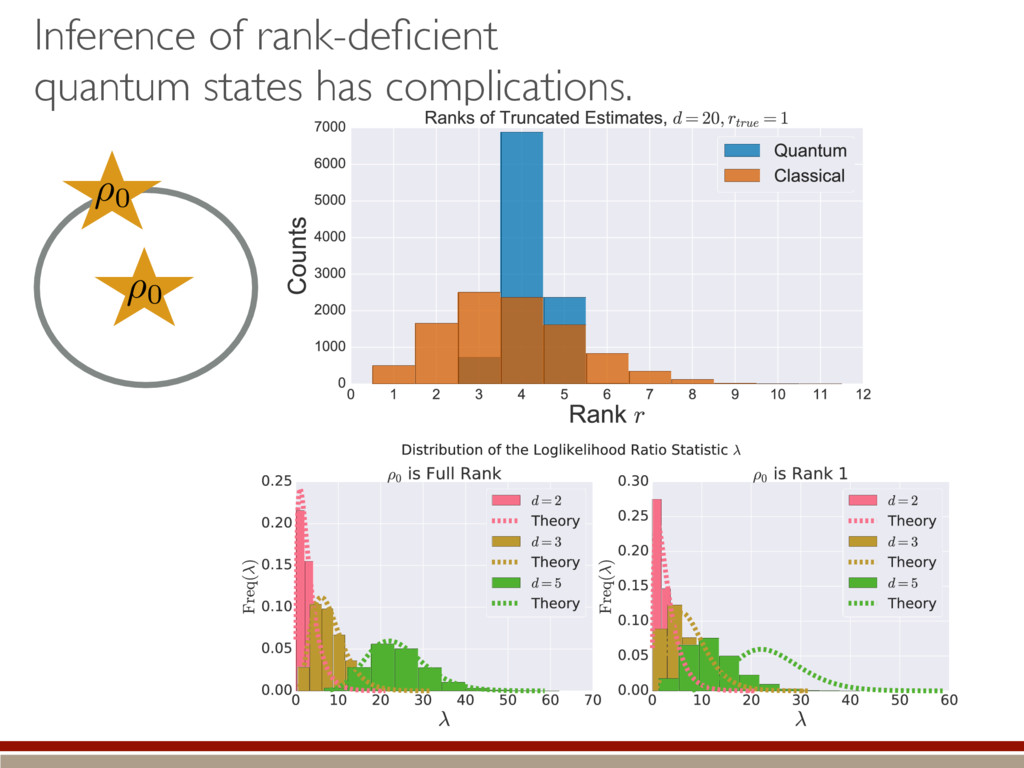
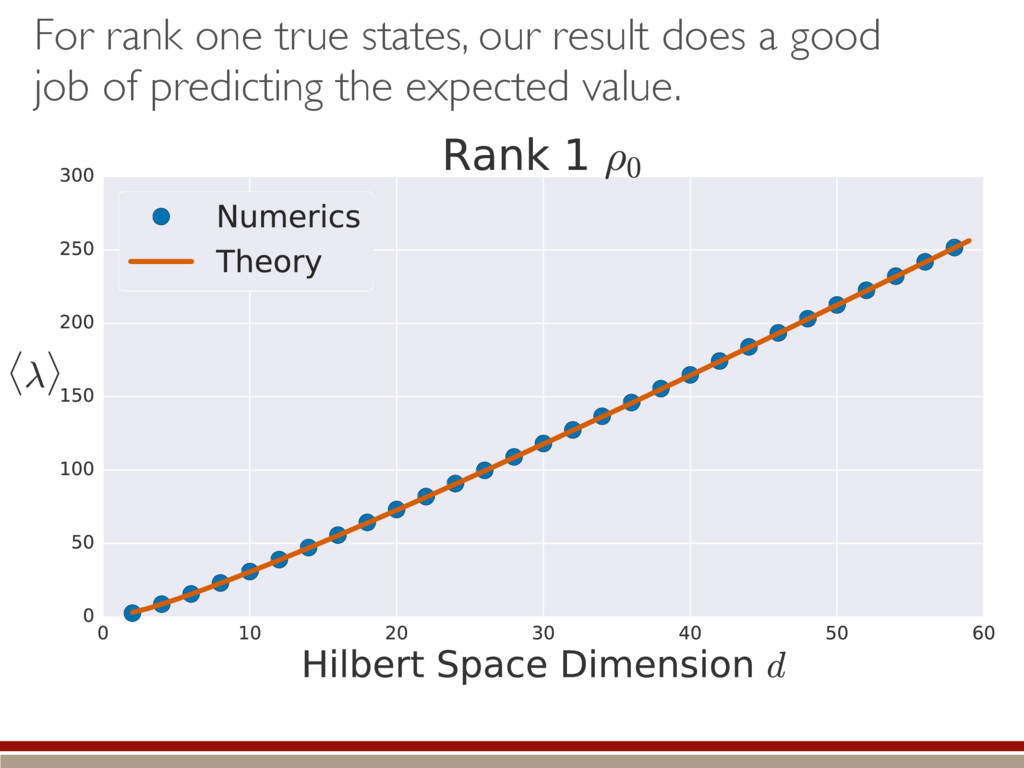
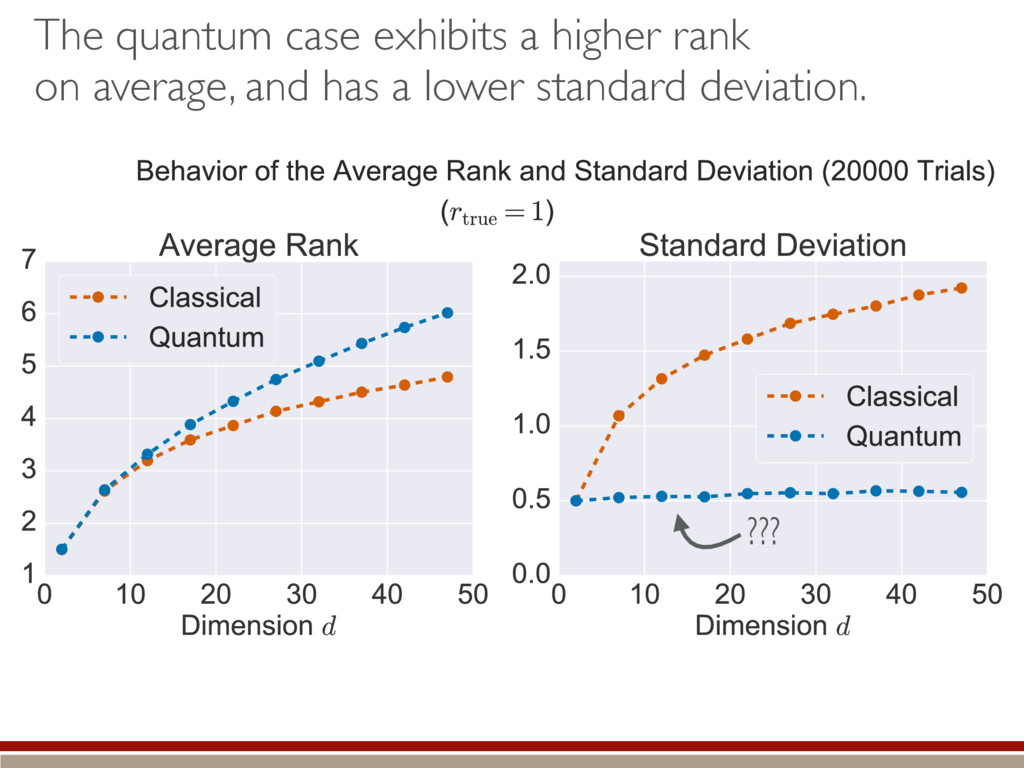
the expected value. A complicated, but straightforward formula! Dramatically different than Wilks’ result! Valid for rank-deficient states h (M0, M1)i ⇡ 2rd r(r + 1) + g(r) M0 = {⇢0 } M1 = {⇢ | dim(⇢) = d} r = rank(⇢0) “Kite” “L”
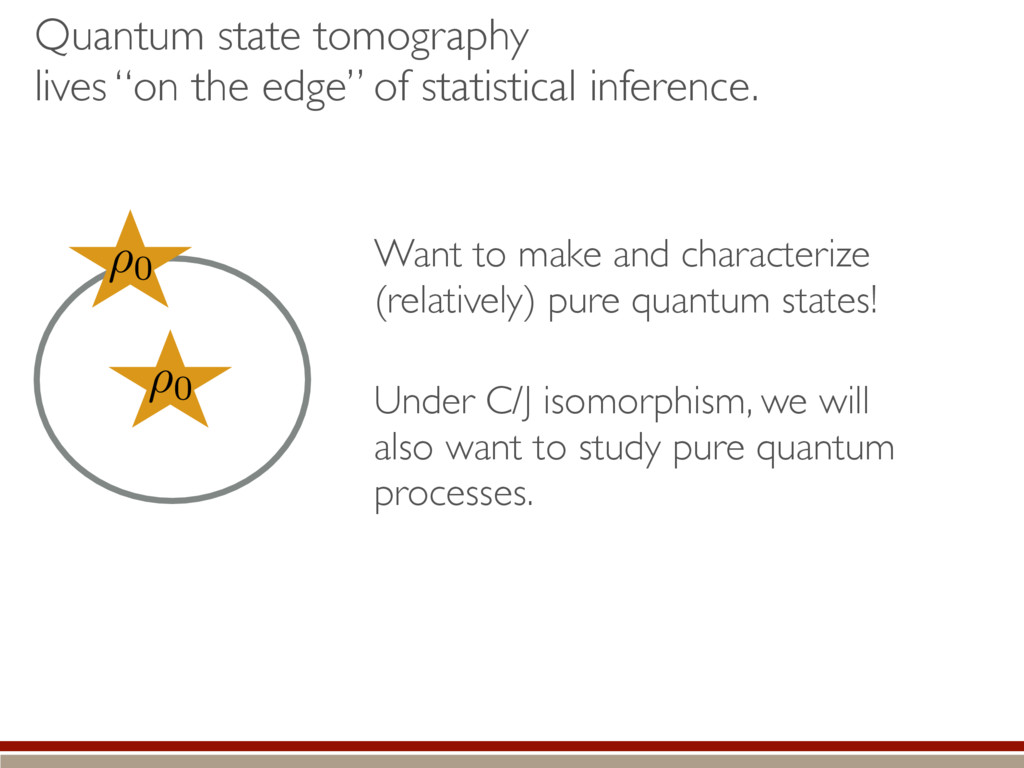
robustness to noise, and sample complexity [2-4] Recently, the importance of the positivity constraint has been investigated Provides guarantees on recovery! Suggests geometry of quantum state space is important [5] What, if anything, does this model have to say about compressed sensing? tomography of low-rank states
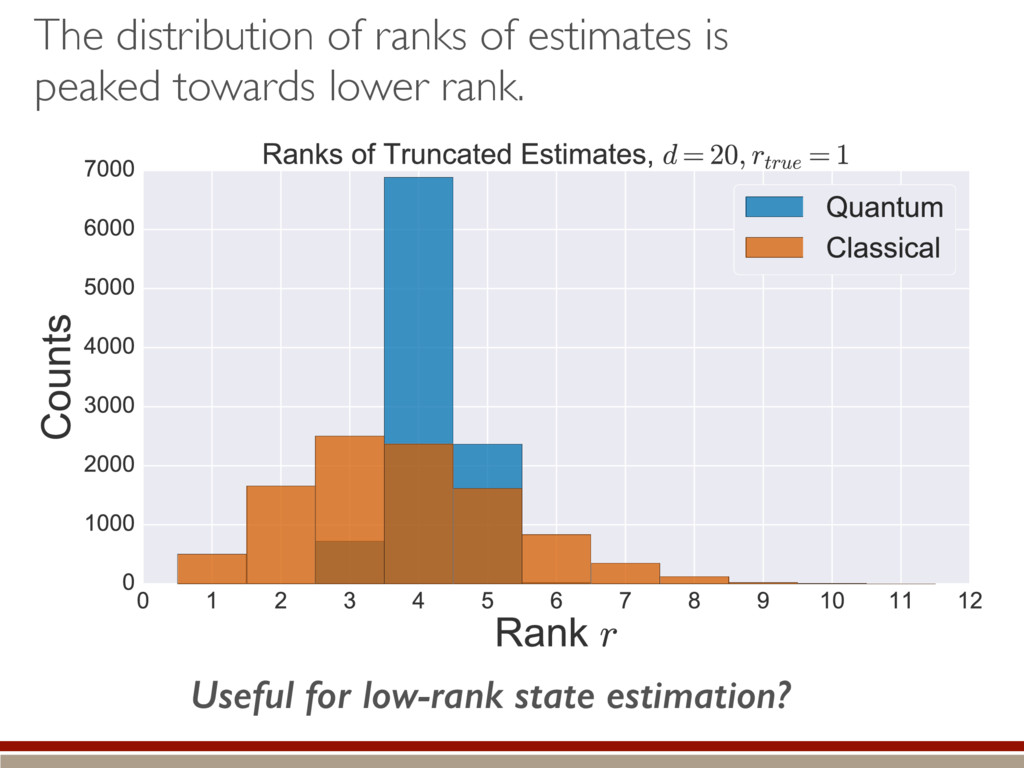
of the distribution within the kernel. Classical = bigger tails Making positive = less subtraction = higher rank Quantum = smaller tails Making positive = more subtraction = lower rank
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Suppose we have data [(POVM, counts)] from a true state](https://files.speakerdeck.com/presentations/c245d8afbf2a4179b8474c480bc9c2c2/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1] http://arxiv.org/abs/1106.5458 [2] http://journals.aps.org/prl/abstract/10.1103/PhysRevLett.105.150401 [3] http://iopscience.iop.org/article/10.1088/1367-2630/14/9/095022/meta [4] http://arxiv.org/abs/1410.6913 [5]](https://files.speakerdeck.com/presentations/c245d8afbf2a4179b8474c480bc9c2c2/slide_66.jpg){kind=link}
{kind=link}
{kind=link}