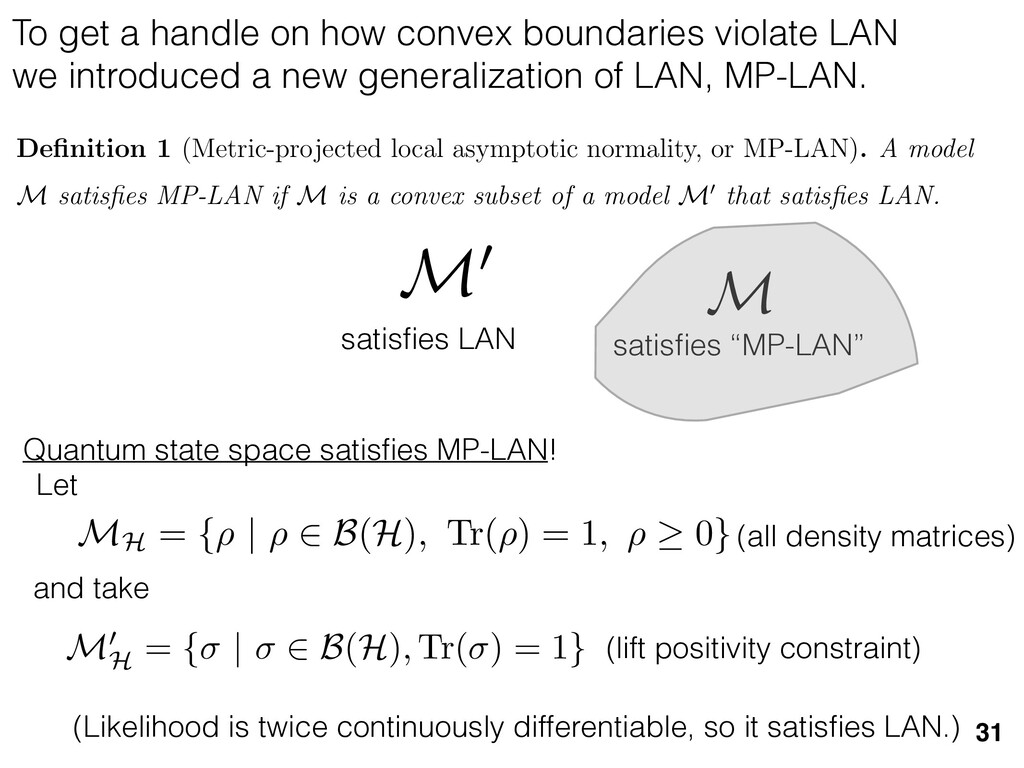
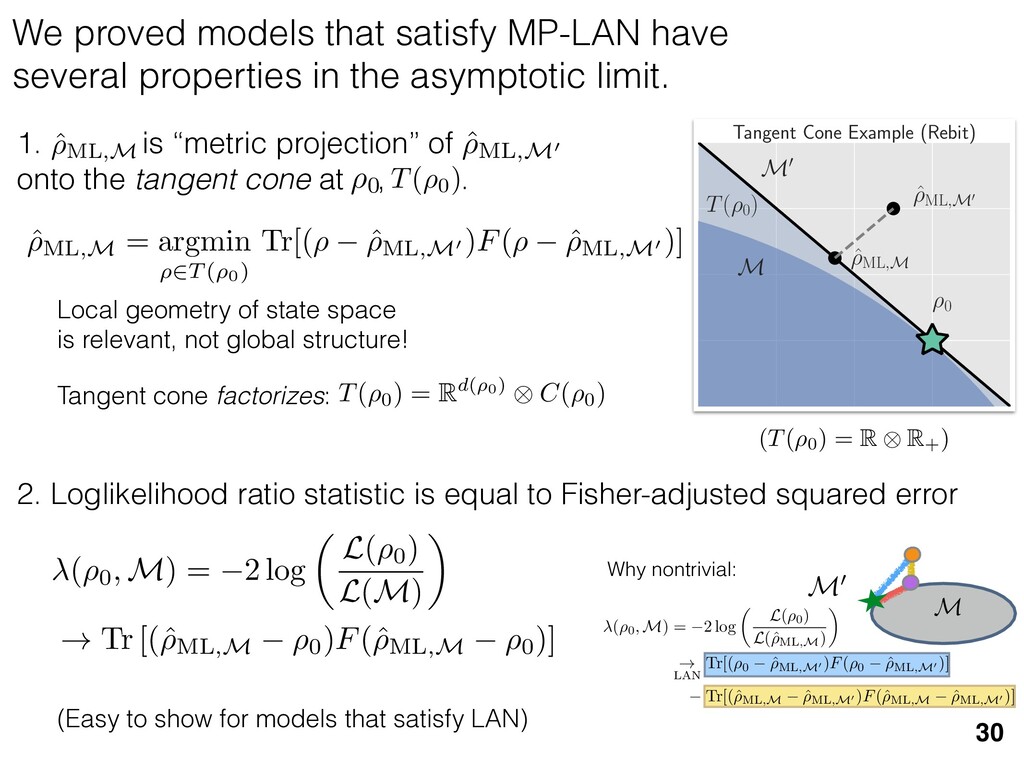
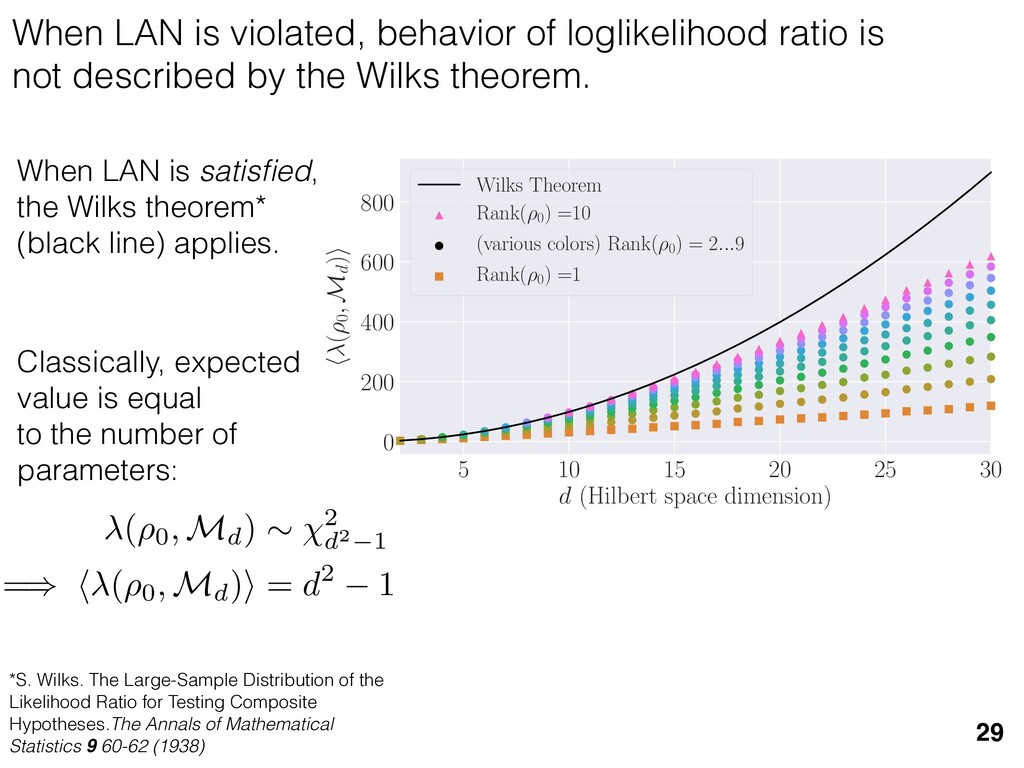
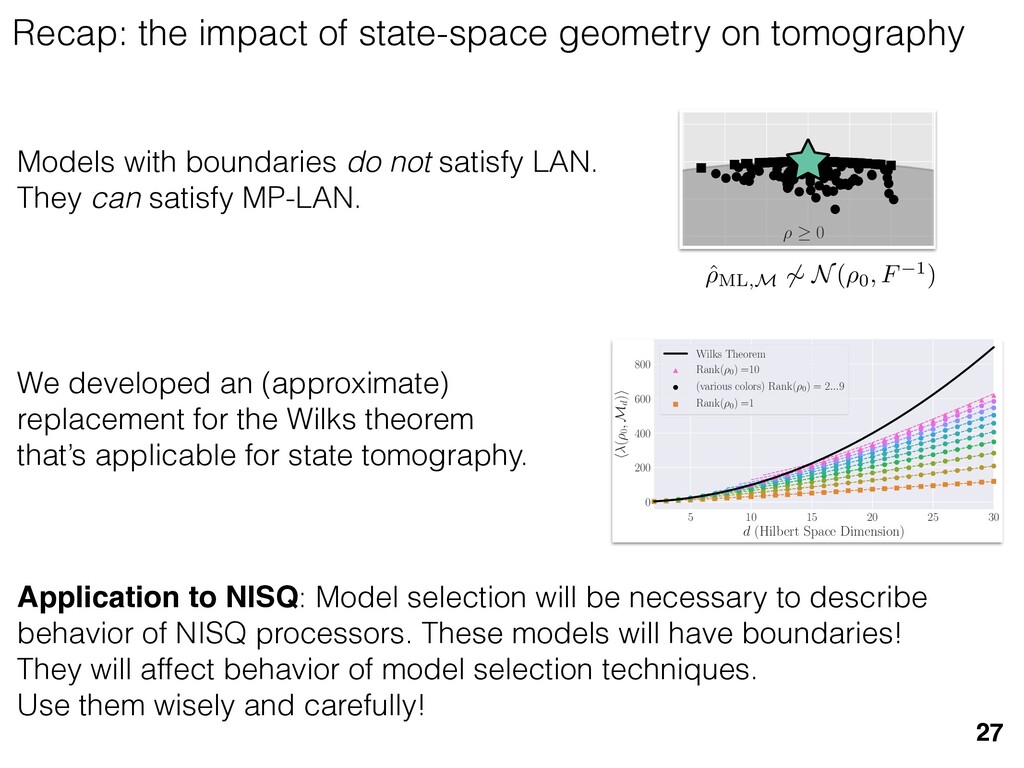
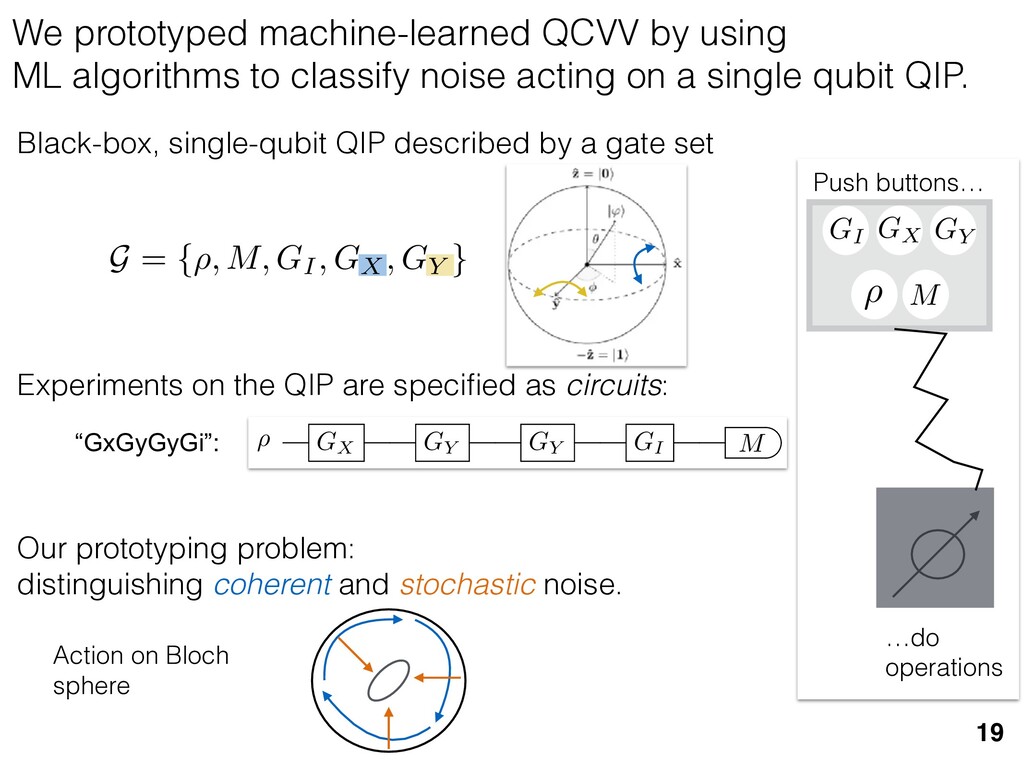
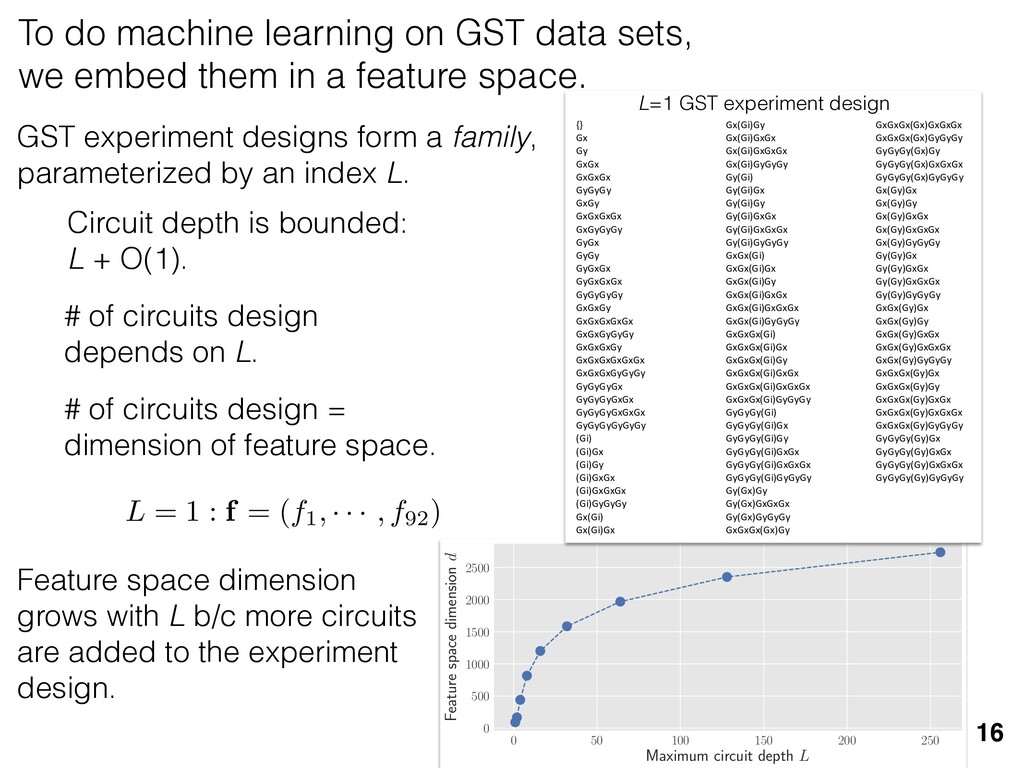
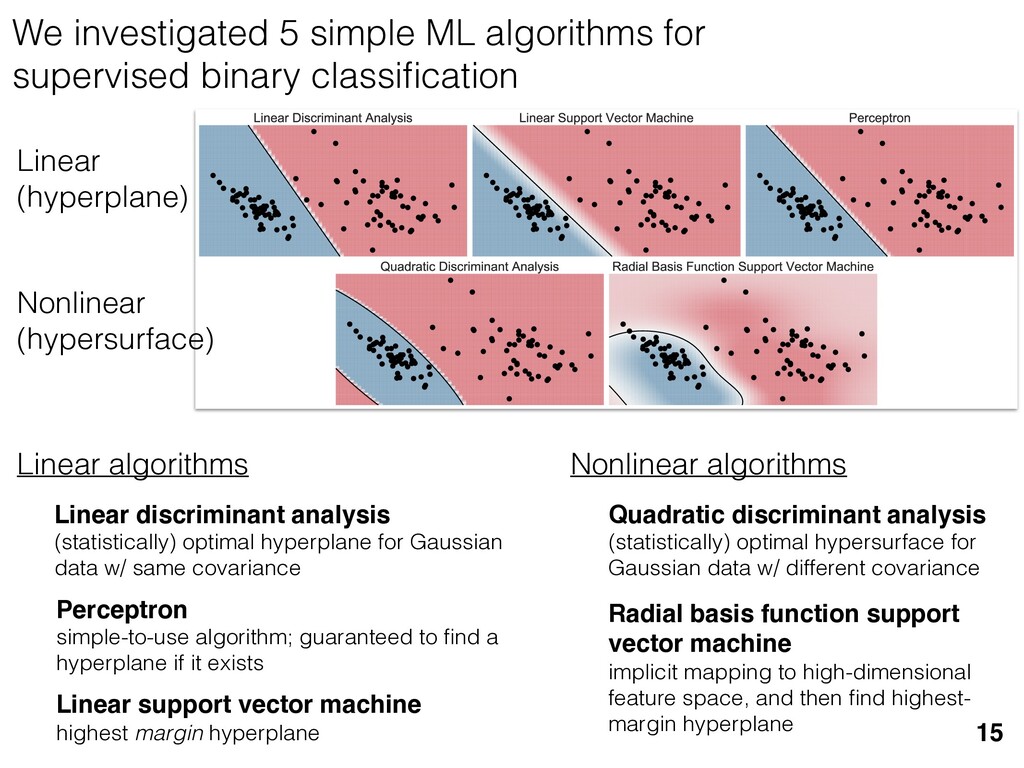
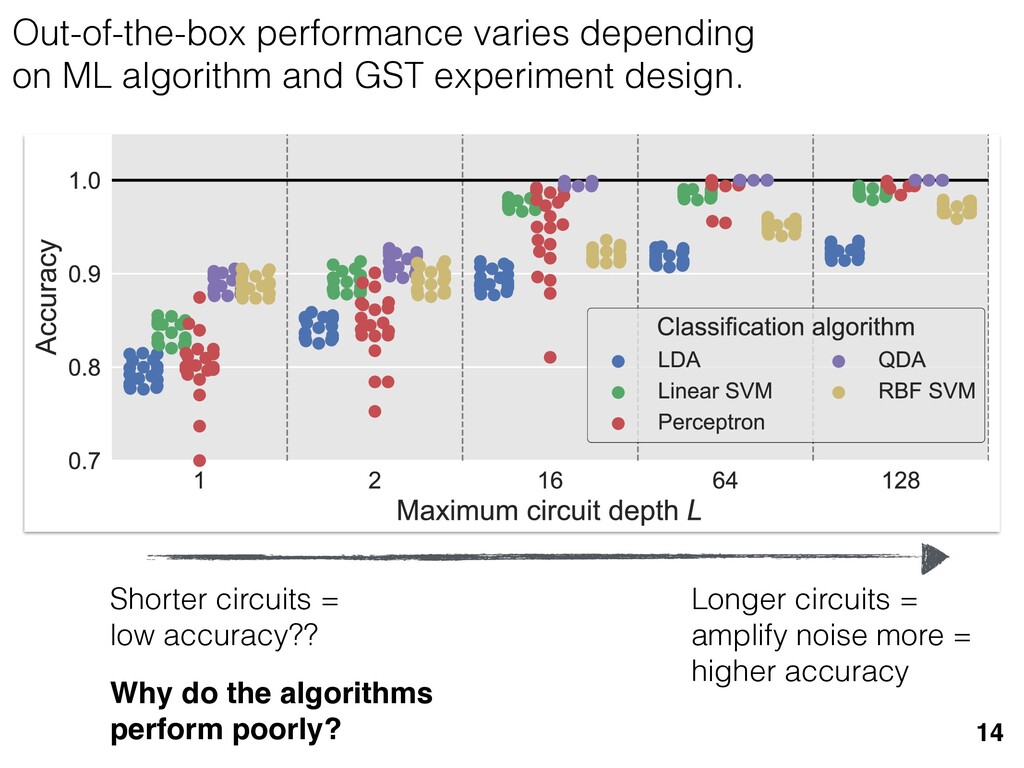
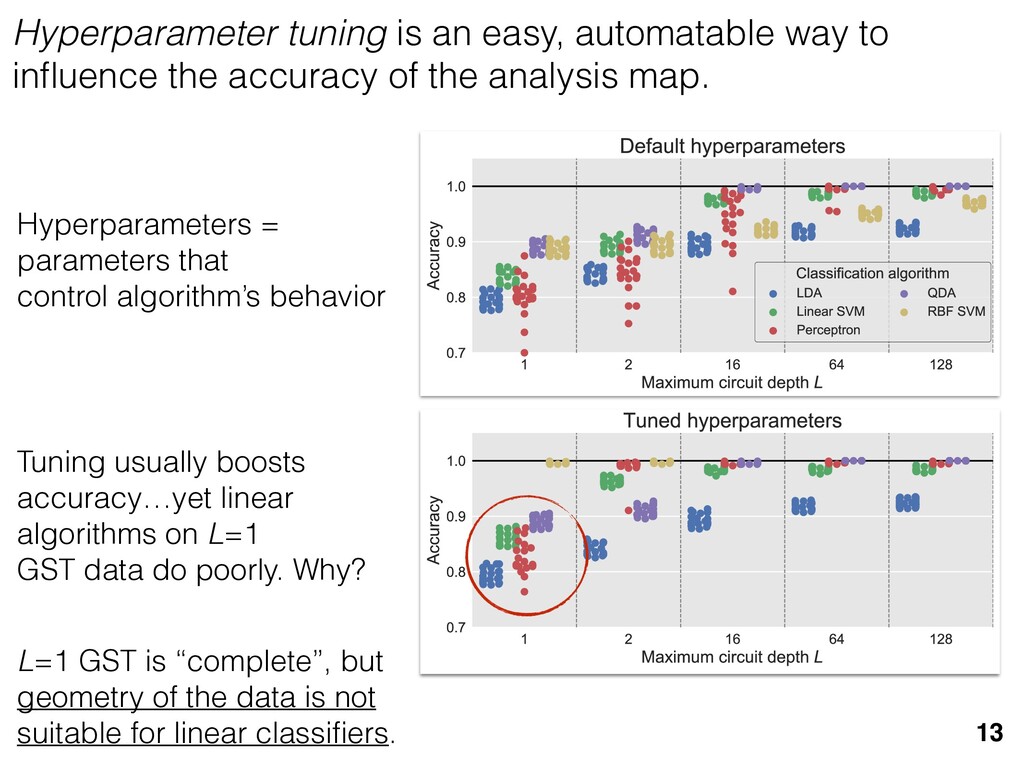
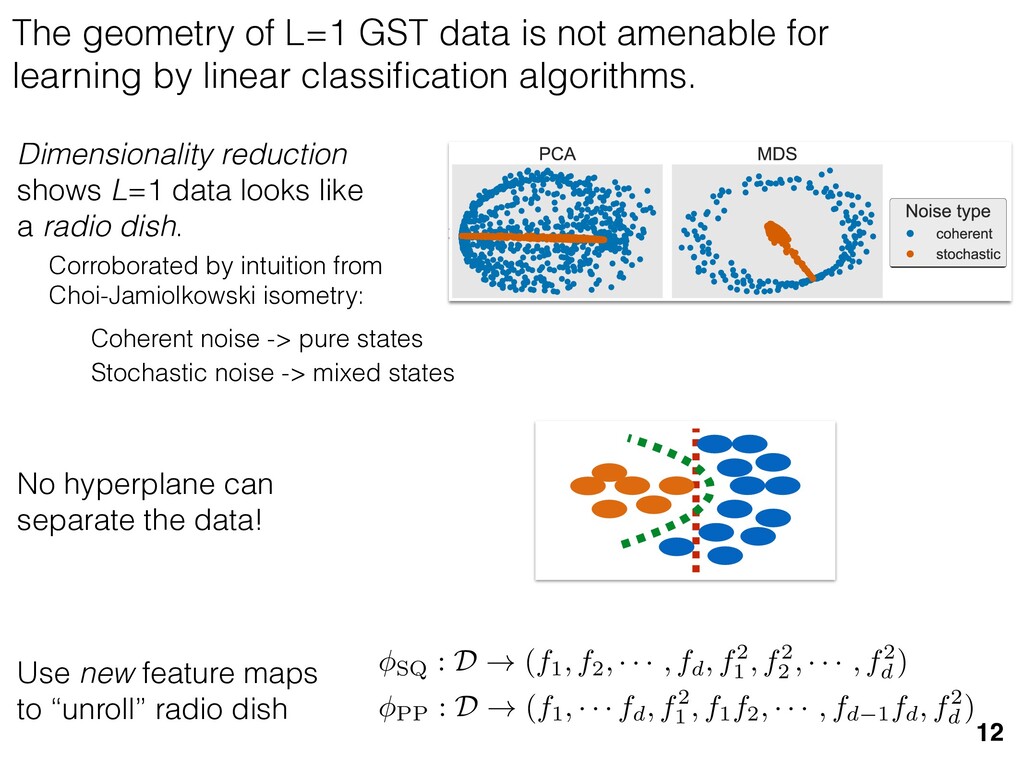
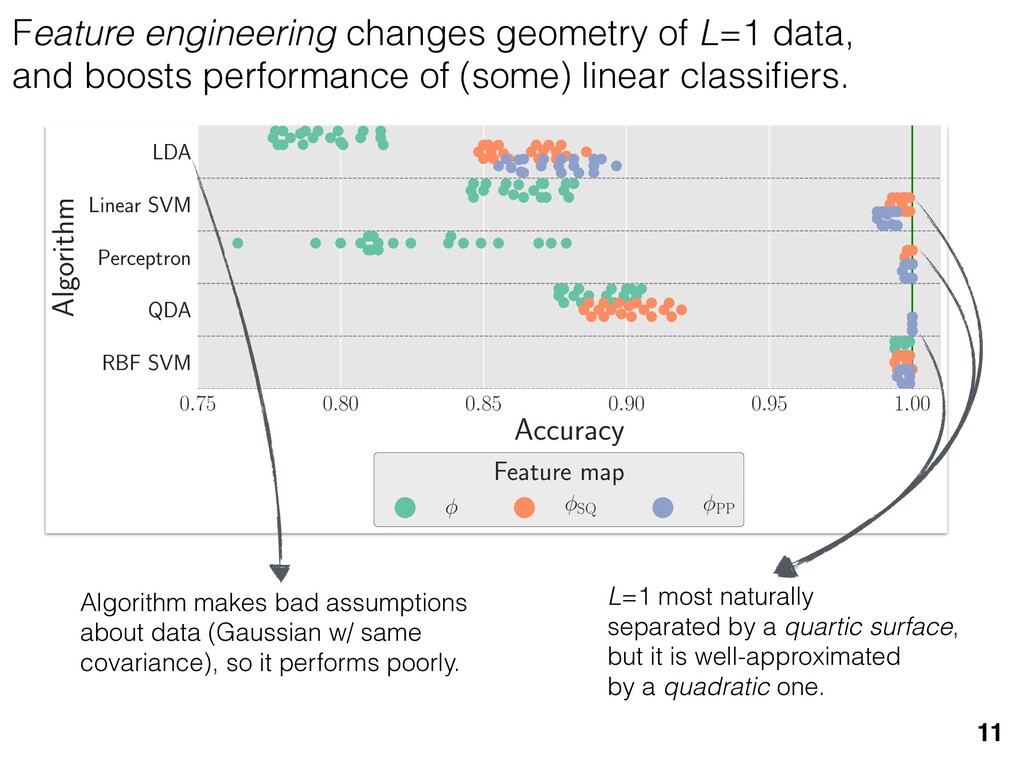
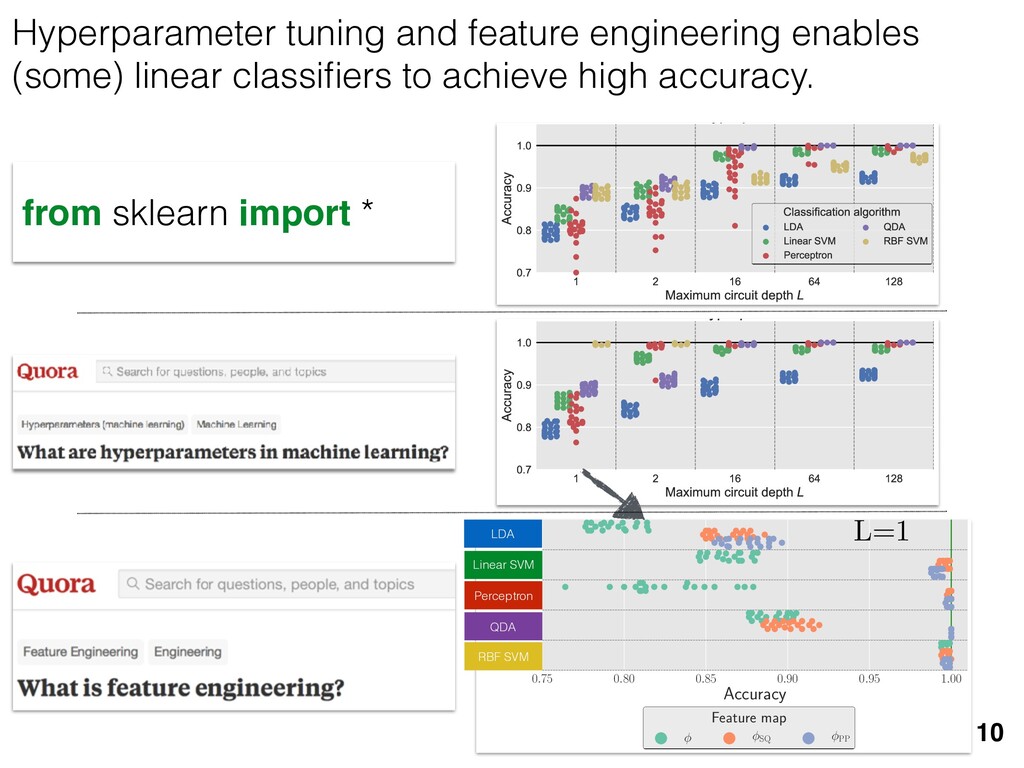
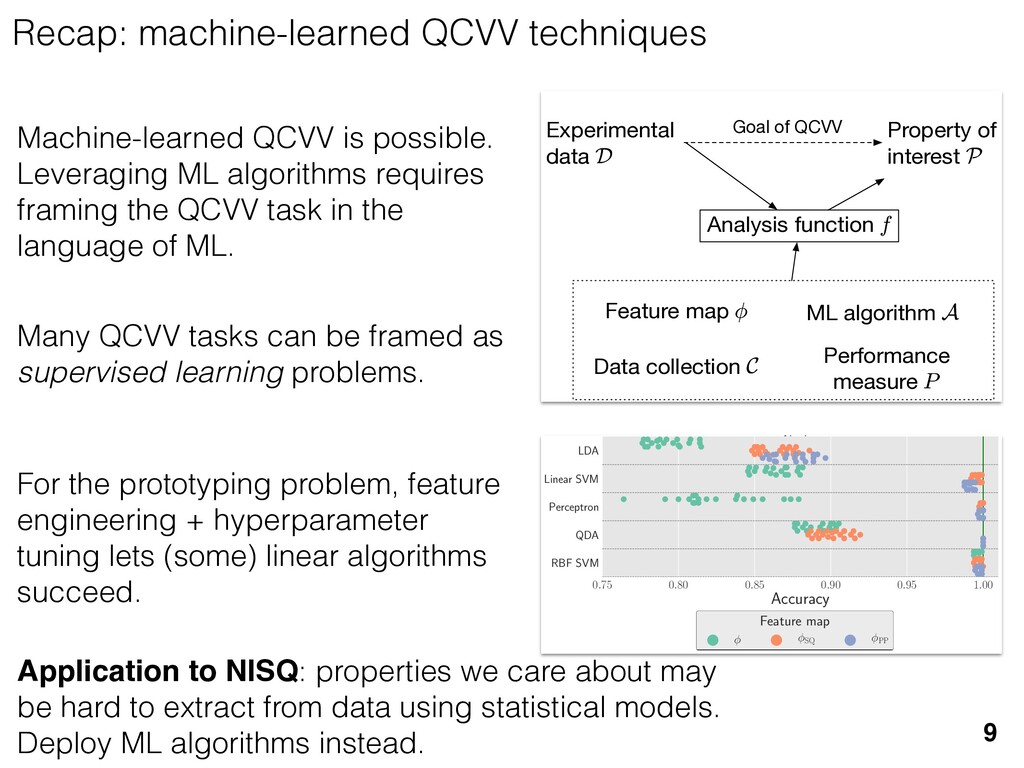
previous section allow us } [ {j } as the ansatz for the eigenvalues of here the pj are N(⇢jj , ✏2) random variables, j are the (fixed, smoothed) order statistics of semicircle distribution. In turn, the defining or q (Equation (12)) is well approximated as r X j =1 (pj q)+ + N X j =1 (j q)+ = 1. this equation, we observe that the j are ally distributed around = 0, so half of This equation is a quintic polynomial in q/✏, so by the Abel-Ru ni theorem, it has no algebraic solution. How- ever, as N ! 1, its roots have a well-defined algebraic approximation that becomes accurate quite rapidly (e.g., for d r > 4): z ⌘ q/✏ ⇡ 2 p d r ✓ 1 1 2 x + 1 10 x2 1 200 x3 ◆ , (17) where x = ⇣ 15 ⇡r 2( d r ) ⌘ 2 / 5. 3. Expression for h kite i 11 n allow us nvalues of variables, tatistics of e defining mated as This equation is a quintic polynomial in q/✏, so by the Abel-Ru ni theorem, it has no algebraic solution. How- ever, as N ! 1, its roots have a well-defined algebraic approximation that becomes accurate quite rapidly (e.g., for d r > 4): z ⌘ q/✏ ⇡ 2 p d r ✓ 1 1 2 x + 1 10 x2 1 200 x3 ◆ , (17) where x = ⇣ 15 ⇡r 2( d r ) ⌘ 2 / 5. 11 w us s of bles, s of ning as This equation is a quintic polynomial in q/✏, so by the Abel-Ru ni theorem, it has no algebraic solution. How- ever, as N ! 1, its roots have a well-defined algebraic approximation that becomes accurate quite rapidly (e.g., for d r > 4): z ⌘ q/✏ ⇡ 2 p d r ✓ 1 1 2 x + 1 10 x2 1 200 x3 ◆ , (17) where x = ⇣ 15 ⇡r 2( d r ) ⌘ 2 / 5. med N samples is su ciently large , the eigenvalues of ⇢ 0 are large bations jj and q. This implies nder this assumption, q is the (pj q) + N X j =1 (j q)+ = 1 Z 2 ✏ p N = q ( q)Pr()d = 0 h (q2 + 8N) p q2 + 4N ✓ ⇡ 2 sin 1 ✓ q 2 p N ◆◆ = 0, (15) N(0, r✏2) random variable. We rete sum (line 1) with an inte- ximation is valid when N 1, roximate a discrete collection of ers by a smooth density or dis- umbers that has approximately remarkably accurate in practice. imation, we replace with its zero. We could obtain an even n by treating more carefully, tion turns out to be quite accu- ), it is necessary to further sim- pression resulting from the inte- we assume ⇢ 0 is relatively low- given in Equation (13): h kite i ⇡ 1 ✏2 * r X j =1 [⇢jj (pj q)+]2 + N X j =1 ⇥ (¯ j q)+ ⇤ 2 + ⇡ 1 ✏2 * r X j =1 [ jj + q]2 + N X j =1 ⇥ (¯ j q)+ ⇤ 2 + ⇡ r + rz2 + N ✏2 Z 2 ✏ p N = q Pr()( q)2d = r + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 ✓ z 2 p N ◆◆ z(z2 + 26N) 24⇡ p 4N z2 . (18) D. Complete Expression for h i The total expected value, h i = h L i + h kite i, is thus h (⇢ 0 , Md)i ⇡ 2rd r2 + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 ✓ z 2 p N ◆◆ z(z2 + 26N) 24⇡ p 4N z2 . (19) where z is given in Equation (17), N = d r, and r = Rank(⇢ 0 ). When LAN is violated, our result (dashed lines) applies. r X j =1 (pj q) + N X j =1 (j q)+ = 1 =) rq + + N Z 2 ✏ p N = q ( q)Pr()d = 0 ) rq + + ✏ 12⇡ h (q2 + 8N) p q2 + 4N 12qN ✓ ⇡ 2 sin 1 ✓ q 2 p N ◆◆ = 0, (15) = Pr j =1 jj is a N(0, r✏2) random variable. We to replace a discrete sum (line 1) with an inte- ine 2). This approximation is valid when N 1, can accurately approximate a discrete collection of spaced real numbers by a smooth density or dis- on over the real numbers that has approximately me CDF. It is also remarkably accurate in practice. et another approximation, we replace with its e value, which is zero. We could obtain an even accurate expression by treating more carefully, is crude approximation turns out to be quite accu- ready. olve Equation (15), it is necessary to further sim- he complicated expression resulting from the inte- ine 3). To do so, we assume ⇢ 0 is relatively low- so r ⌧ d/2. In this case, the sum of the positive ⇡ ✏2 j =1 [ jj + q]2 + j =1 (¯ j q ⇡ r + rz2 + N ✏2 Z 2 ✏ p N = q Pr()( q)2 = r + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 z(z2 + 26N) 24⇡ p 4N z2 . D. Complete Expression for h The total expected value, h i = h L i + h h (⇢ 0 , Md)i ⇡ 2rd r2 + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 ✓ z(z2 + 26N) 24⇡ p 4N z2 . where z is given in Equation (17), N = d Rank(⇢ 0 ). V. COMPARISON TO NUMER kite i ⇡ 1 ✏2 * r X j =1 [⇢jj (pj q)+]2 + N X j =1 ⇥ (¯ j q)+ ⇤ 2 + ⇡ 1 ✏2 * r X j =1 [ jj + q]2 + N X j =1 ⇥ (¯ j q)+ ⇤ 2 + ⇡ r + rz2 + N ✏2 Z 2 ✏ p N = q Pr()( q)2d = r + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 ✓ z 2 p N ◆◆ z(z2 + 26N) 24⇡ p 4N z2 . (18) D. Complete Expression for h i The total expected value, h i = h L i + h kite i, is thus h (⇢ 0 , Md)i ⇡ 2rd r2 + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 ✓ z 2 p N ◆◆ z(z2 + 26N) 24⇡ p 4N z2 . (19) here z is given in Equation (17), N = d r, and r = on, q is the q)+ = 1 )d = 0 4N ◆◆ = 0, (15) variable. We ith an inte- hen N 1, collection of nsity or dis- proximately in practice. with its ain an even re carefully, e quite accu- further sim- ✏2 j =1 j =1 ⇡ 1 ✏2 * r X j =1 [ jj + q]2 + N X j =1 ⇥ (¯ j q)+ ⇤ 2 + ⇡ r + rz2 + N ✏2 Z 2 ✏ p N = q Pr()( q)2d = r + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 ✓ z 2 p N ◆◆ z(z2 + 26N) 24⇡ p 4N z2 . (18) D. Complete Expression for h i The total expected value, h i = h L i + h kite i, is thus h (⇢ 0 , Md)i ⇡ 2rd r2 + rz2 + N(N + z2) ⇡ ✓ ⇡ 2 sin 1 ✓ z 2 p N ◆◆ z(z2 + 26N) 24⇡ p 4N z2 . (19) where z is given in Equation (17), N = d r, and r = Rank(⇢ 0 ). Constrained models have an “effective” number of parameters We used MP-LAN to compute an accurate formula for the expected value of the loglikelihood ratio statistic. (Details: 2018 New J. Phys. 20 023050) 28 5 10 15 20 25 30 d (Hilbert space dimension) 0 200 400 600 800 h (⇢0 , Md )i Wilks Theorem Rank(⇢0 ) =10 (various colors) Rank(⇢0 ) = 2...9 Rank(⇢0 ) =1
{kind=link}
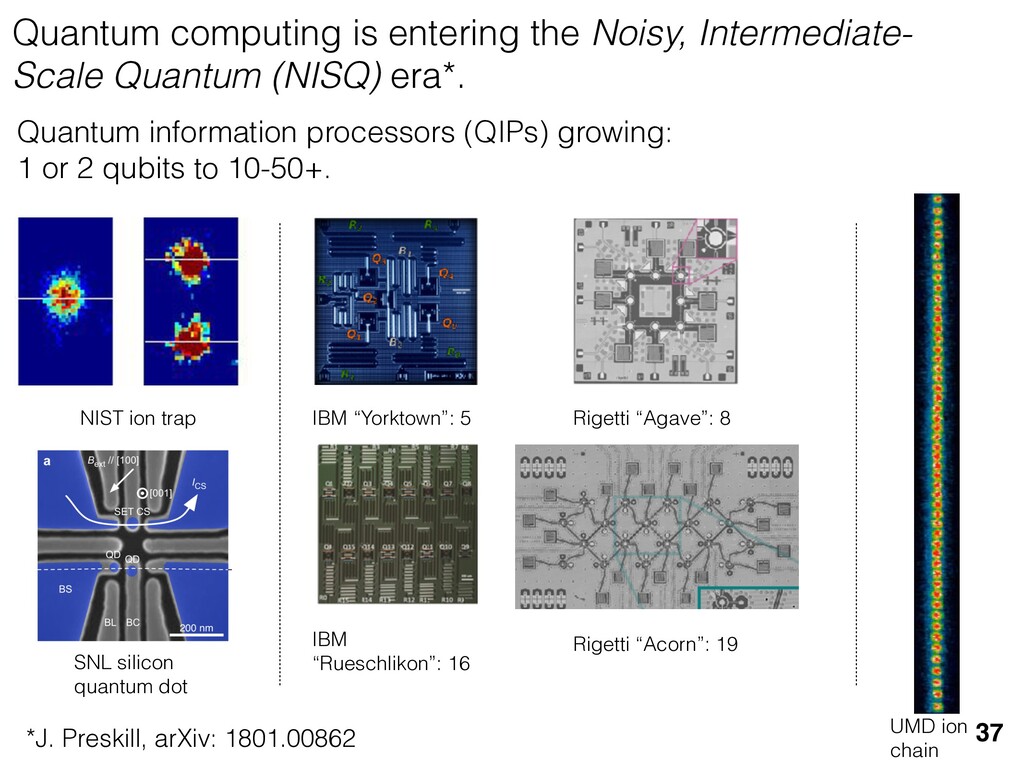{kind=link}
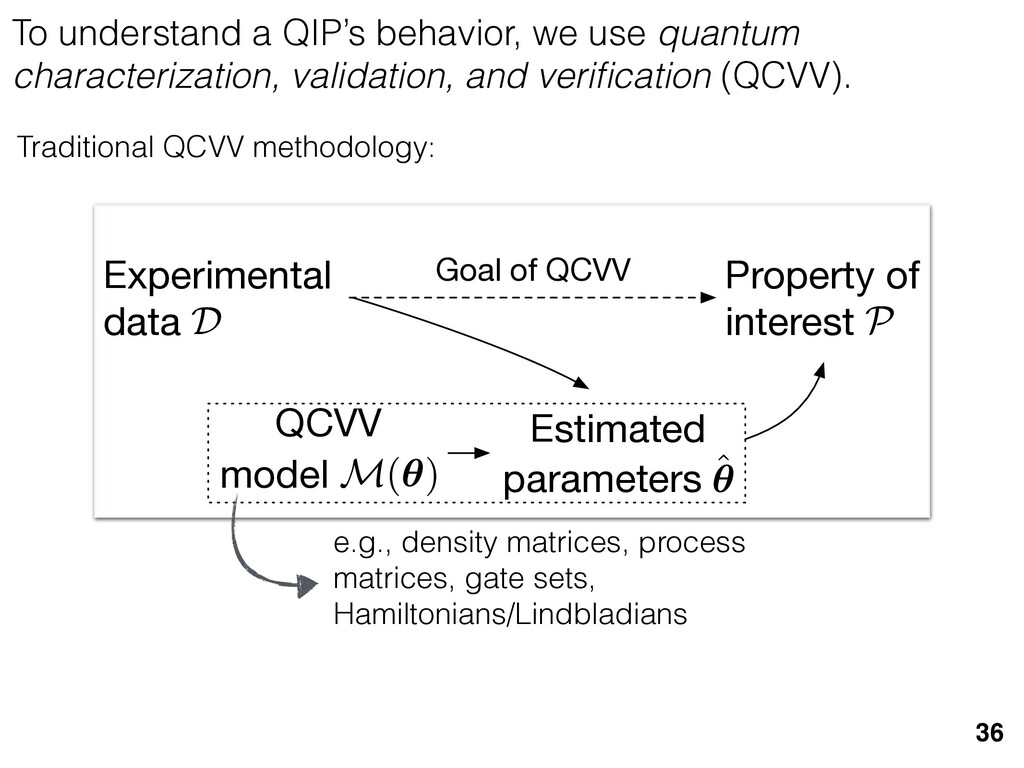{kind=link}
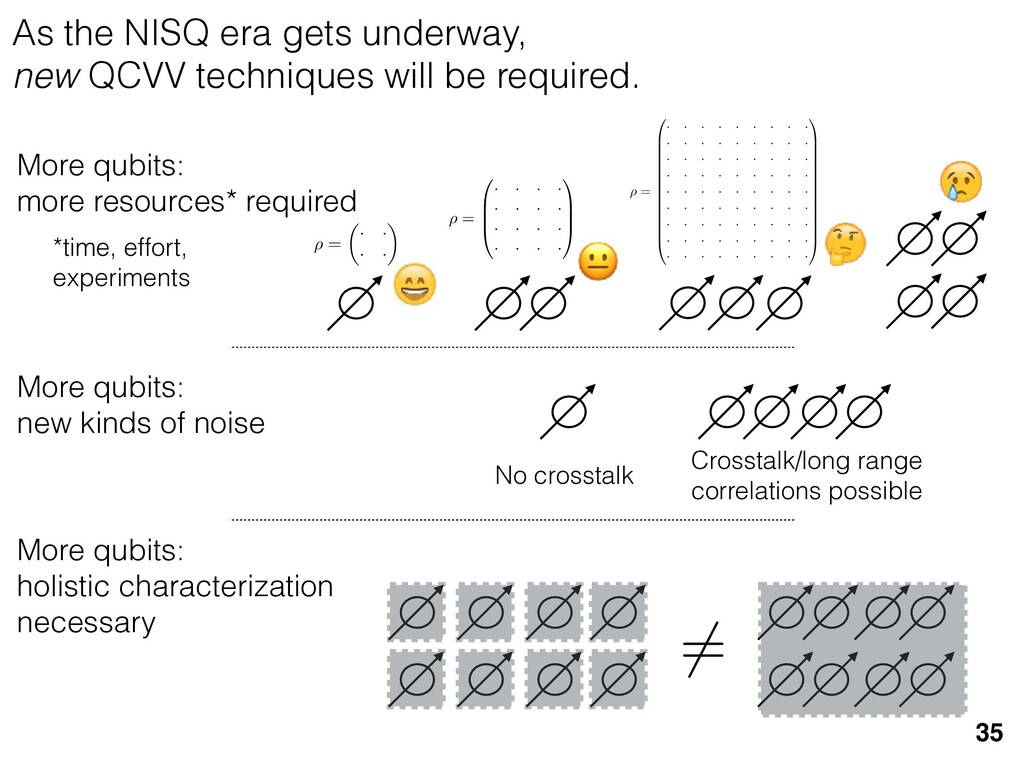{kind=link}
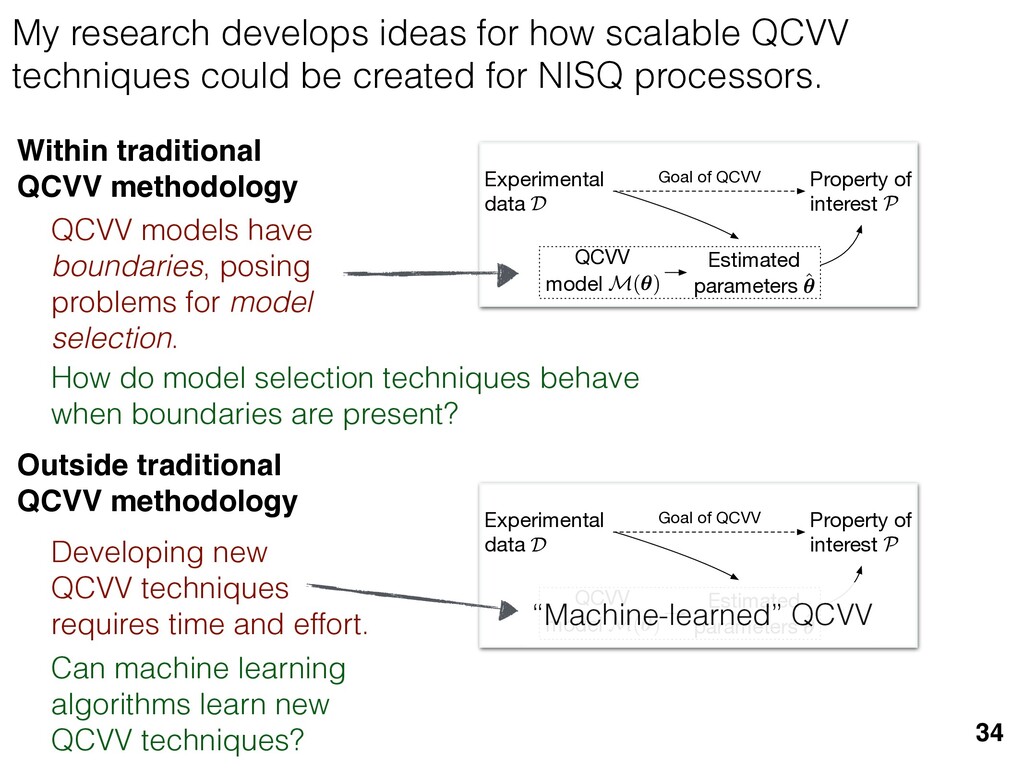{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}