A talk I gave at the Quantum Artificial Intelligence (QAI) workshop, co-located with IEEE Quantum Week 2021 (QCE21).
Abstract:
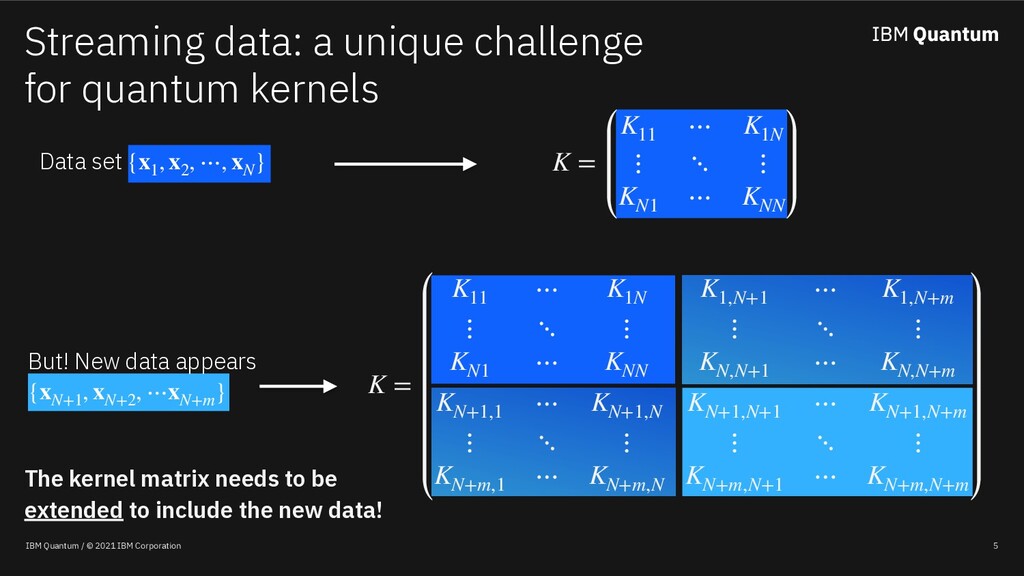
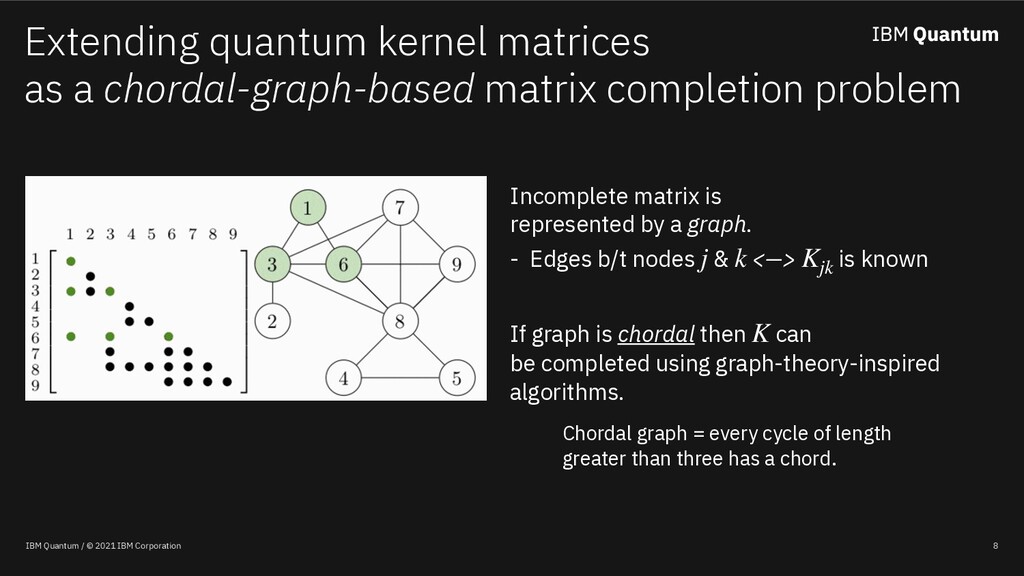
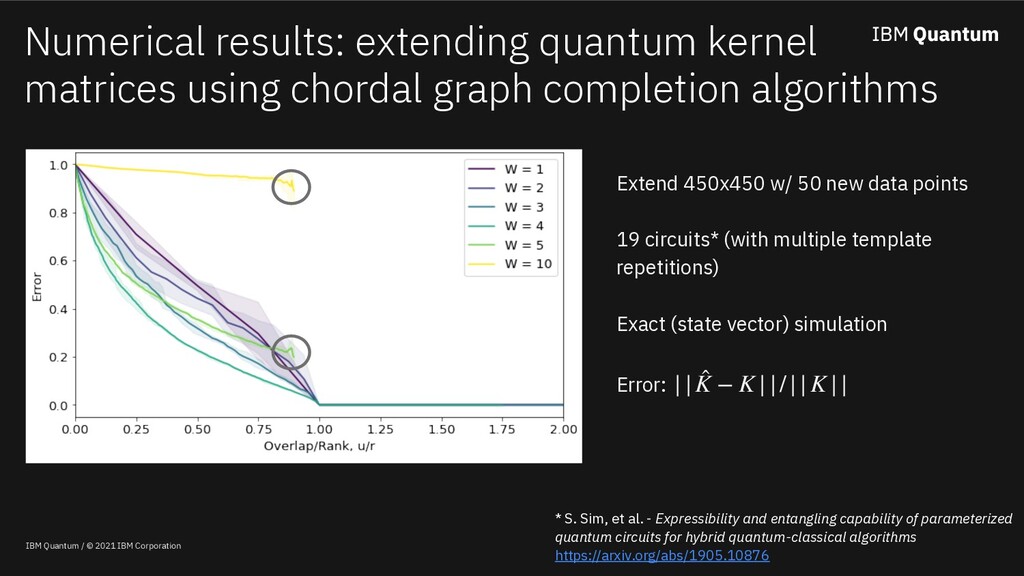
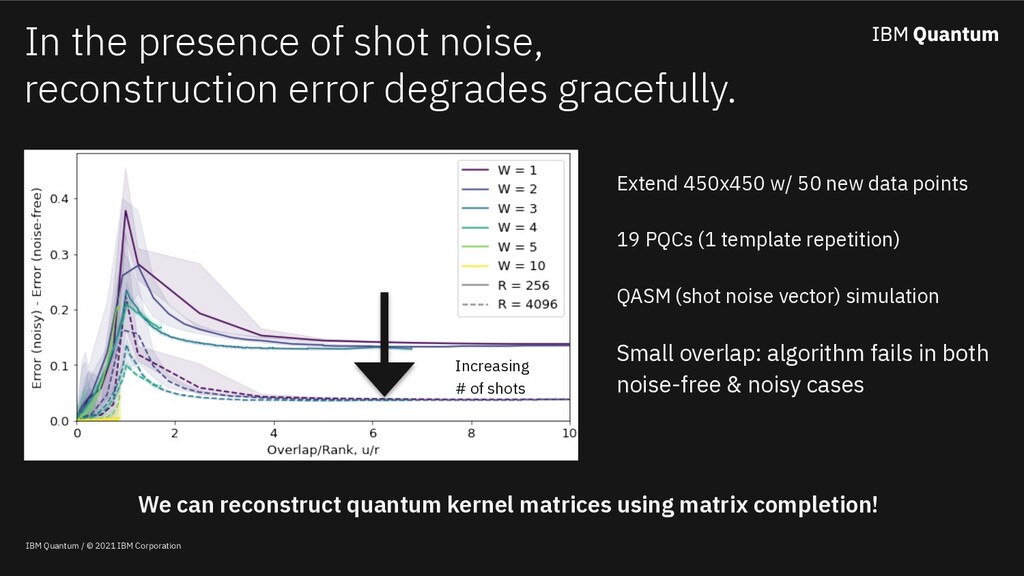
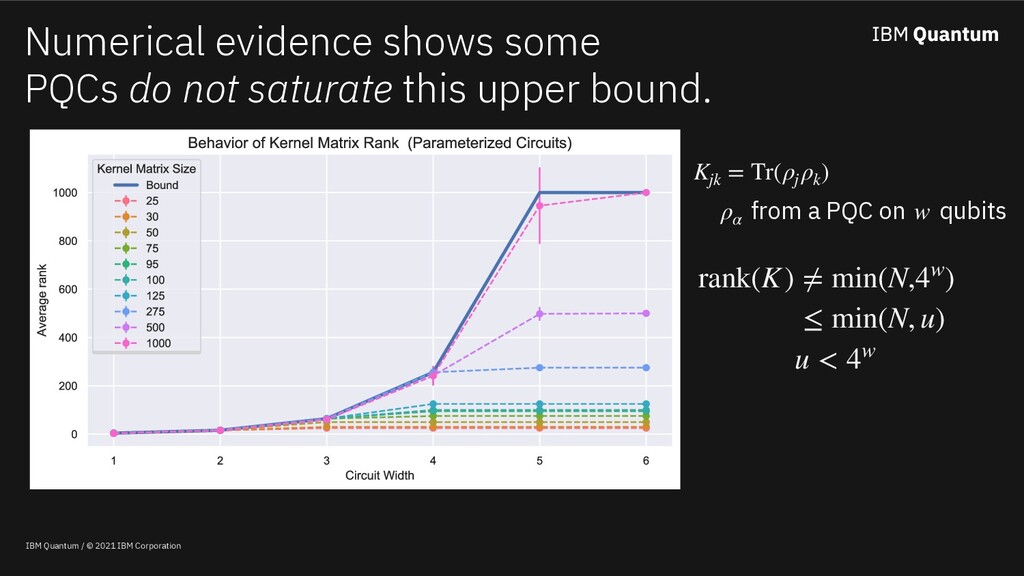
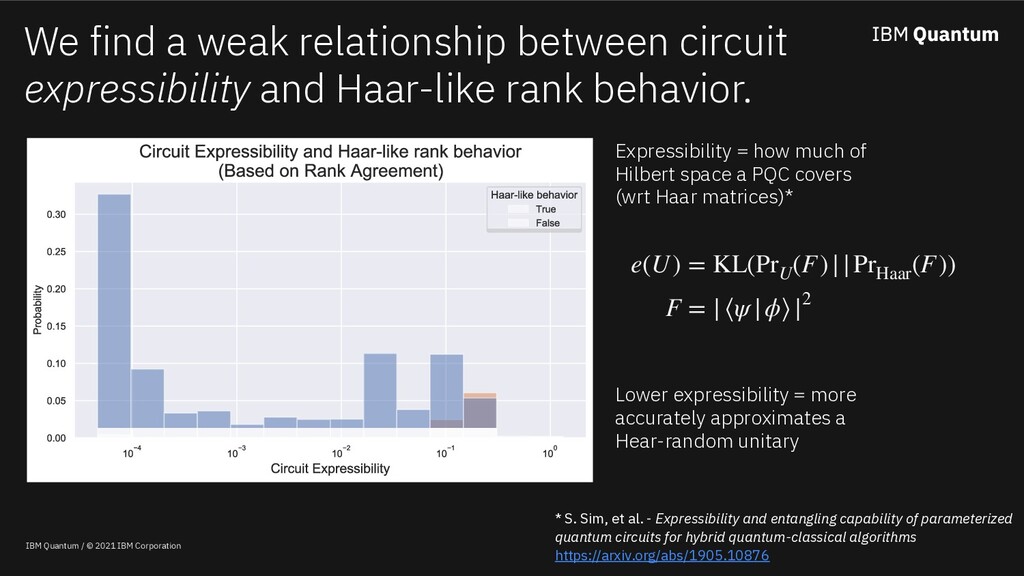
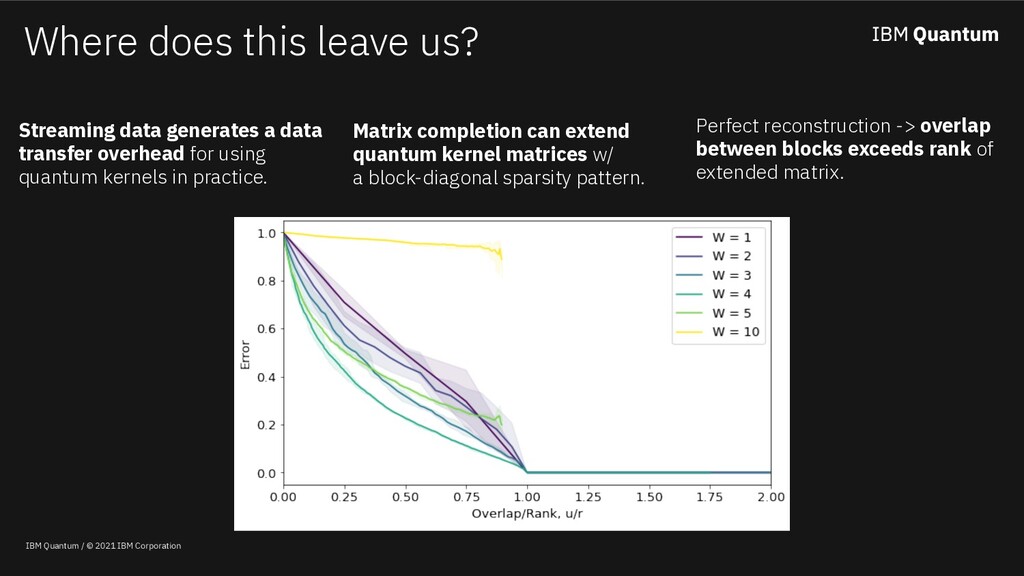
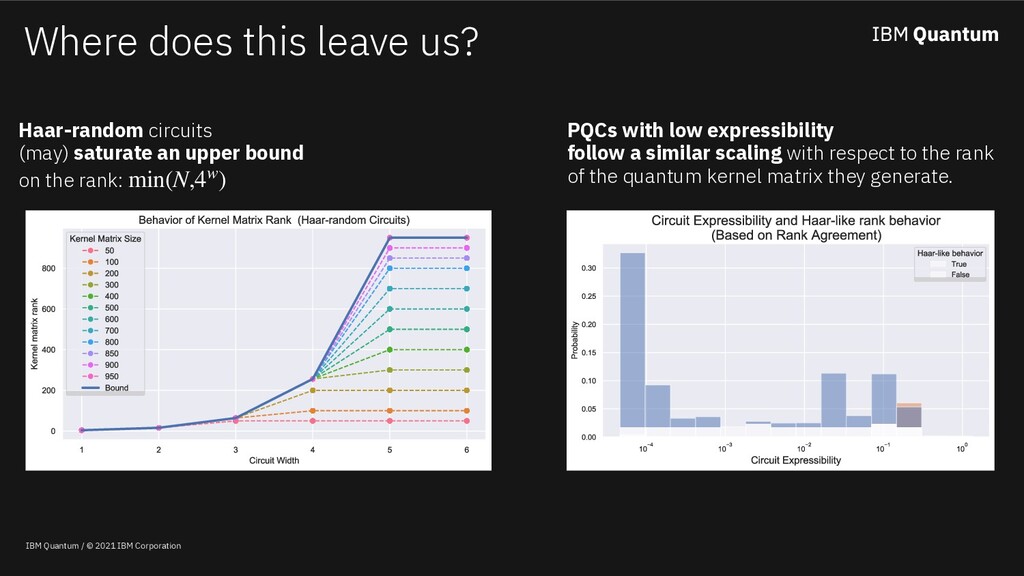
Classical machine learning algorithms can be enhanced by access to quantum computers. One such enhancement -- based on quantum kernel matrices -- defines novel similarity measures between pieces of data based on the transition probability of a parameterized quantum circuit (PQC). Utilizing quantum kernels in practice suffers from the problem that extending a kernel matrix to accommodate new data incurs a data transfer cost linear with the number of original data points. Although efficient from a complexity standpoint, in practice data transfer will introduce inefficiencies into the overall quantum-enhanced machine learning workflow. This work shows (a) that given access to kernel values involving a sample of the old data (along with the new), classical matrix completion algorithms can reconstruct with zero error the unsampled quantum kernel matrix entries (in a zero-noise regime) based on a quantity which depends on the rank of the extended kernel matrix, (b) in the presence of shot noise, the reconstruction error degrades gracefully, and (c) that the rank of quantum kernel matrices can be predicted given information about the PQC.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}