Share
強化学習を用いたドローンの自律飛行タスクにおいて、シミュレーションによるデータと実世界データの性質の違いに着目してSim2Realの転移学習を行った論文(https://arxiv.org/abs/1902.03701 )のまとめスライドです。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
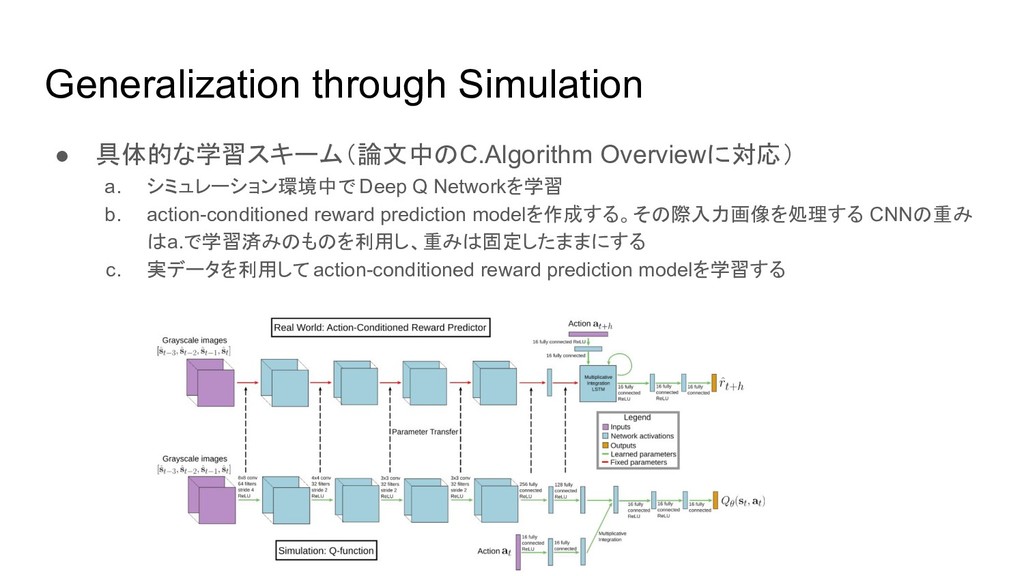{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
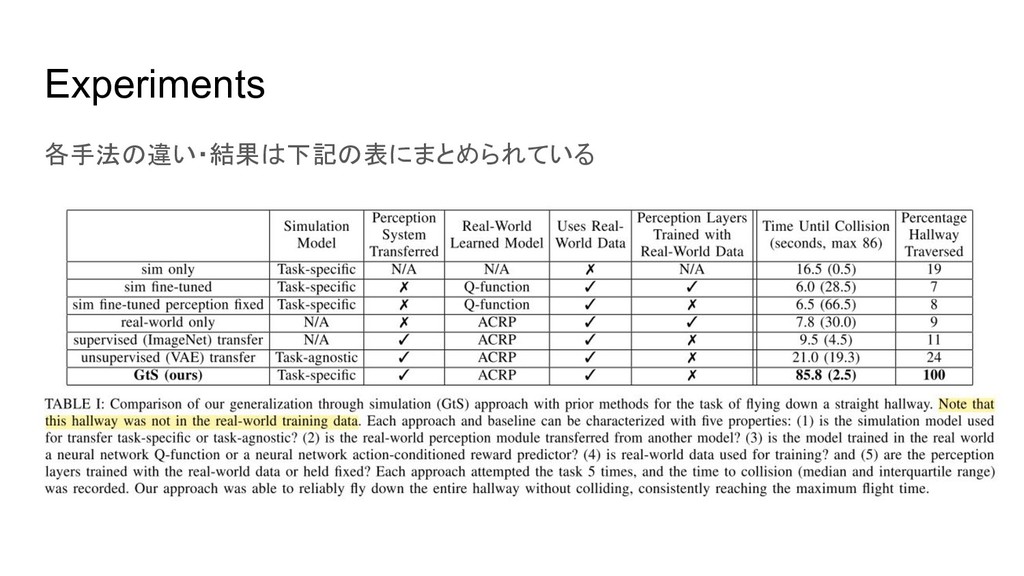{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}