Share
■イベント Google Cloud Next Tokyo '23 https://cloudonair.withgoogle.com/events/next-tokyo
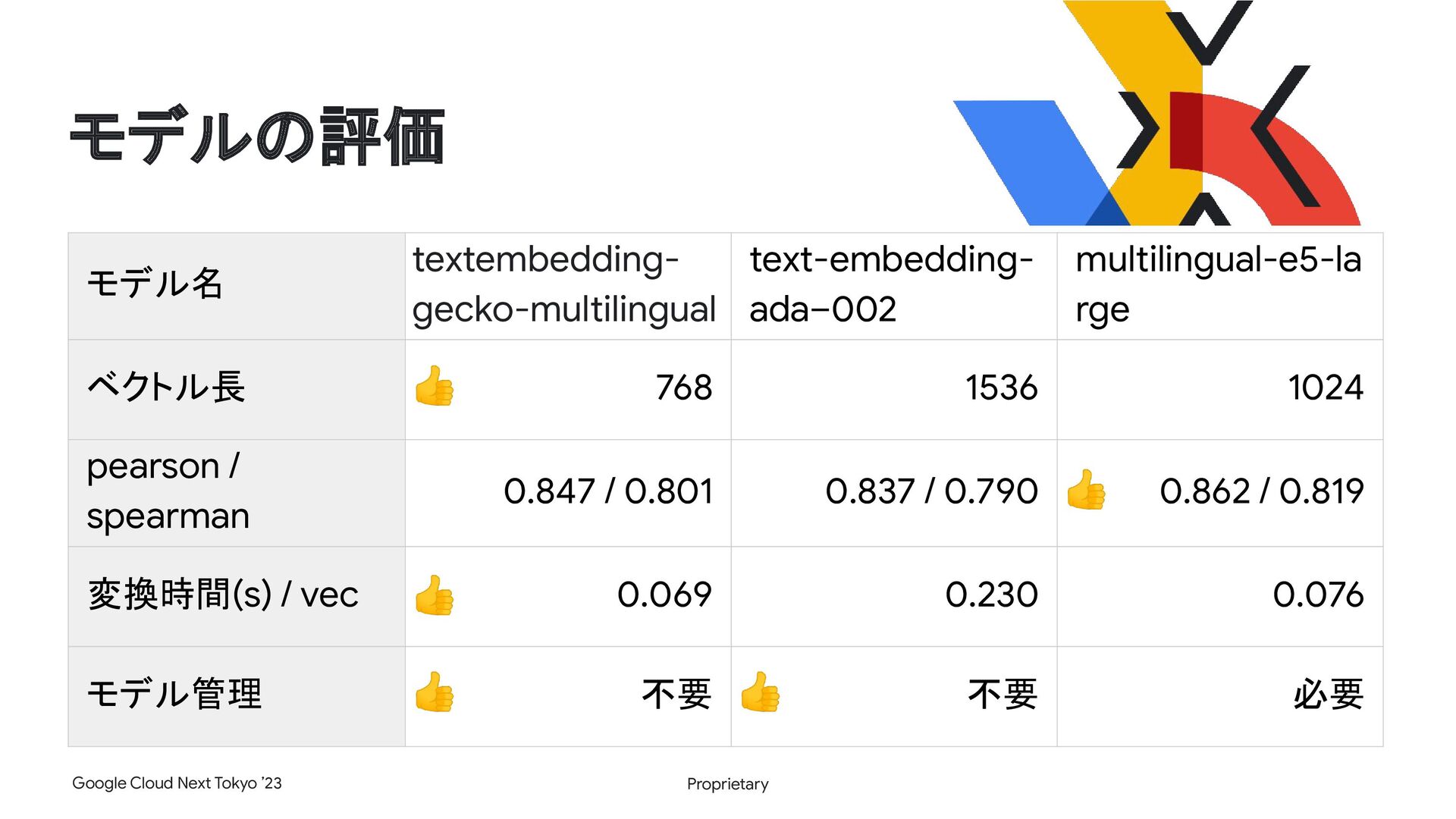
■登壇概要 タイトル:AI エージェントの記憶検索における Vertex AI の活用
■Gaudiy採用ページ https://site.gaudiy.com/recruit
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}