into a global destination for must-see videos. Building the best “go-to” experience where users can get their daily dose of must-see videos, and partners can leverage the latest tools to grow and monetise their audience.
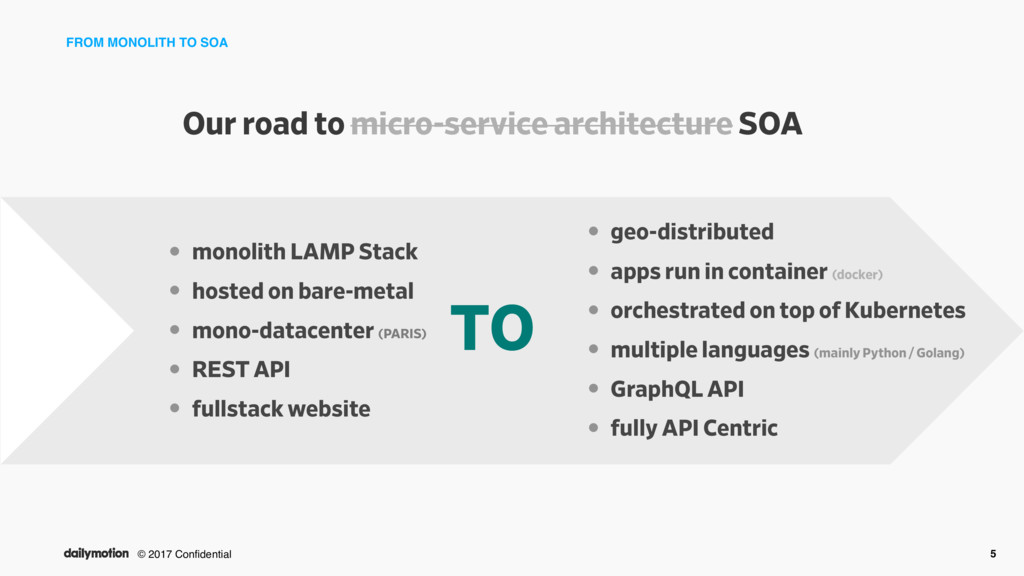
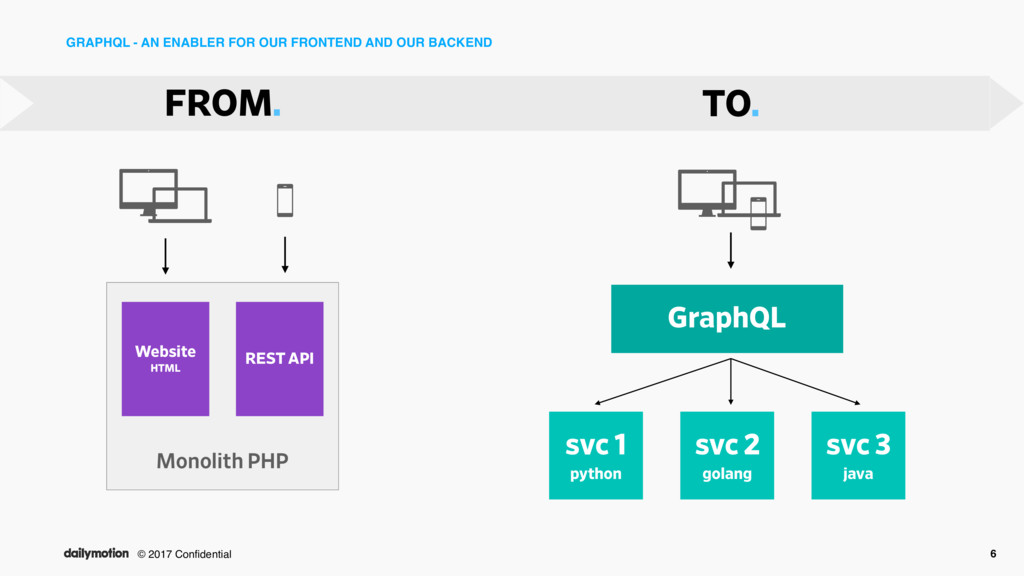
to micro-service architecture SOA • monolith LAMP Stack • hosted on bare-metal • mono-datacenter (PARIS) • REST API • fullstack website • geo-distributed • apps run in container (docker) • orchestrated on top of Kubernetes • multiple languages (mainly Python / Golang) • GraphQL API • fully API Centric TO
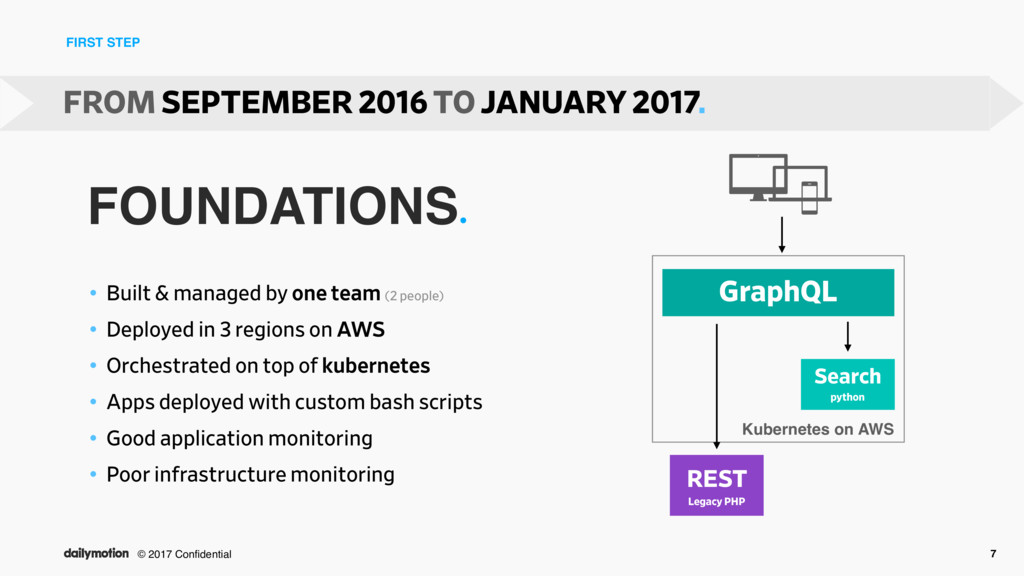
by one team (2 people) • Deployed in 3 regions on AWS • Orchestrated on top of kubernetes • Apps deployed with custom bash scripts • Good application monitoring • Poor infrastructure monitoring FROM SEPTEMBER 2016 TO JANUARY 2017. GraphQL REST Legacy PHP Search python Kubernetes on AWS FOUNDATIONS•
JANUARY 2017 TO JUNE 2017. People • from 2 to ~30 people. • from 1 to 5 teams Services • from 1 to ~15 services. • from 1 to ~10 languages / technologies Release • from an average of 1 deployment per day to more than 10
couple a months • Organised training sessions for newcomers • Optimised and reviewed our on-boarding process • Optimised the way to work on an SOA stack • Evangelised (GraphQL + Infrastructure) FROM 2 TO ~30 PEOPLE.
Simplify the technical on-boarding process • Simplify the project switching over our 500+ repositories • Use generic tasks name to launch code quality checks • Let developers use the technologies they want Gather. 10
network (subnets can be routed from one region to another) • Ingress anycast IP, easy to setup • A hosted Kubernetes managed service with cool features such as node autoscaling • Connection to Dailymotion’s private network in Paris • Currently deployed in 3 regions across the world (~80 nodes) FROM 1 SERVICE TO 10 SERVICES.
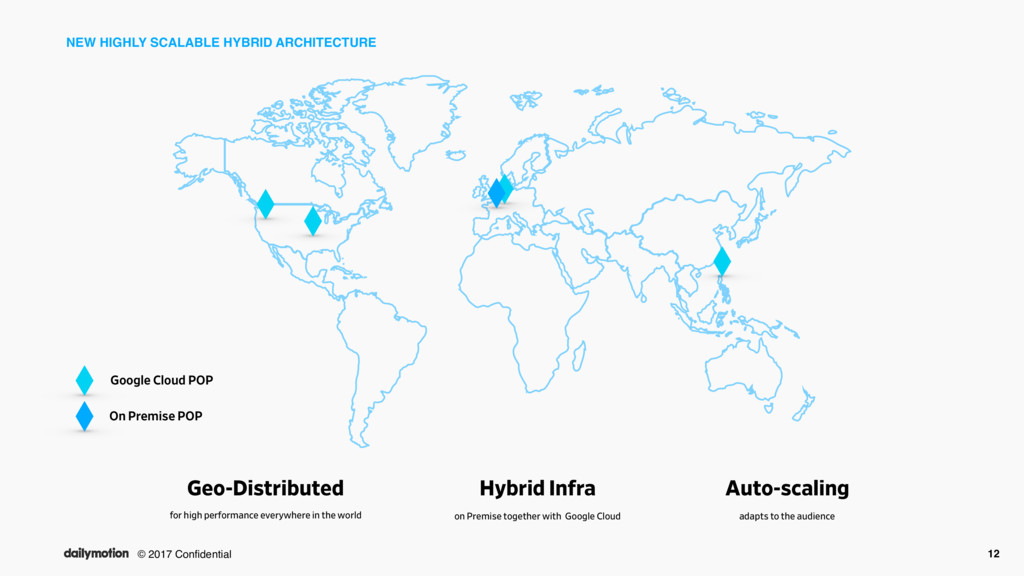
for high performance everywhere in the world Hybrid Infra on Premise together with Google Cloud Auto-scaling adapts to the audience Google Cloud POP On Premise POP
Implement continuous deployment (except production which needs human approval) • Let developers deploy by themselves • Delegate deployment workflow to developers through Jenkinsfile (Pipeline). • Enforce common interfaces, minimum code quality, deployment guidelines built by the devops team FROM 1 DEPLOYMENT PER DAY TO MORE THAN 10.
STEP #1: First we deployed our applications sequentially, region by region using bash scripts STEP #2: We wanted to manage our cluster from a single API endpoint : Federation Some API objects were missing in the Federation → mixed deployment methods : some objects in the Federation and others deployed region by region. STEP #3 (déjà-vu): Now, we’re deploying our applications sequentially region by region using Helm FROM 1 DEPLOYMENT PER DAY TO MORE THAN 10.
between our applications. • Deploy a complete stack with a single command. • Help us to manage different environments/regions within a chart. • Easy to rollback: each deployment has a unique revision id • Ongoing : Provision a staging environment per pull request FROM 1 DEPLOYMENT PER DAY TO MORE THAN 10.
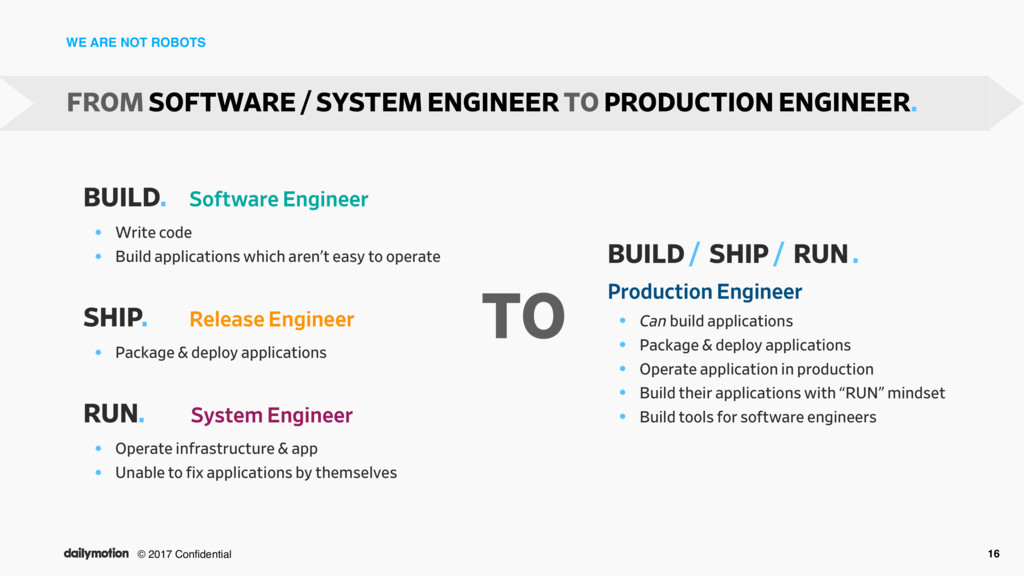
Engineer • Write code • Build applications which aren’t easy to operate SHIP. Release Engineer • Package & deploy applications RUN. System Engineer • Operate infrastructure & app • Unable to fix applications by themselves FROM SOFTWARE / SYSTEM ENGINEER TO PRODUCTION ENGINEER. BUILD / SHIP / RUN . Production Engineer • Can build applications • Package & deploy applications • Operate application in production • Build their applications with “RUN” mindset • Build tools for software engineers TO
APM with Open Tracing Specification • Logging Specification for each service • Monitoring / Alerting • Feature Flipping, Progressive rollout, Experimentation (A/B) HOW WE OPERATE OUR PLATFORM?
WHAT: Bad parameter applied on helm command • 3 clusters emptied (~ 1 300 containers) • All our products were unusable AND: We were down during 19 minutes • ~10 minutes to be notified • ~7 minutes to understand • ~2 minutes to recover from scratch the entire architecture NOW: Grow up • Wrap destructive commands • Improve monitoring
(on premises) • Stateful use cases: manage volume provisioning in the same way we orchestrate applications • Performance improvements (Service mesh) • Security: user authentication and auditing, secrets encryption. • Open Source our GraphQL Engine (Python, performance oriented) AND NOW ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}