HDFS MapReduce (Yarn) Ecosystem/Solution "Hadoop solution" vs classic RDBMS warehousing Ecosystem of tools and frameworks originated from Hadoop or its principles 3 . 1
le still occupies 64mb block) MapReduce is slow no ACID, append-only (or rewrite) only batch-processing highly complex (con guration & programming api) 10 . 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
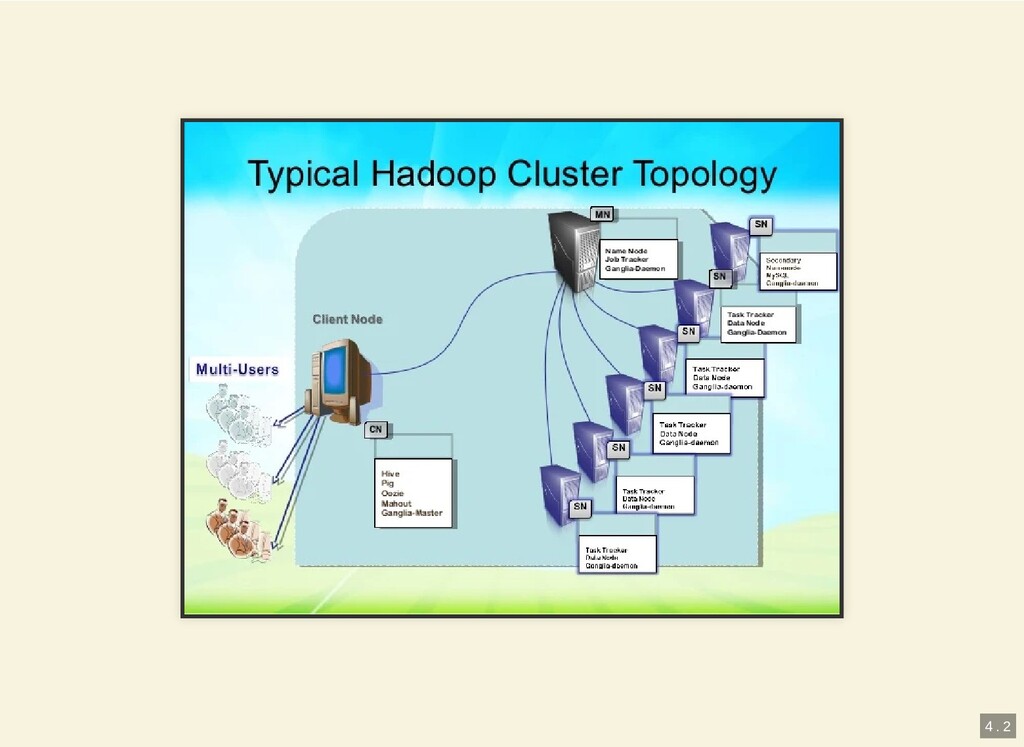{kind=link}
![HADOOP CHARACTERISTICS HADOOP CHARACTERISTICS open-source commodity hardware [semi/un]structured data, schema-on-read](https://files.speakerdeck.com/presentations/3f7eea5fd8b04c00bb6f0ddcc936e0f2/slide_5.jpg){kind=link}
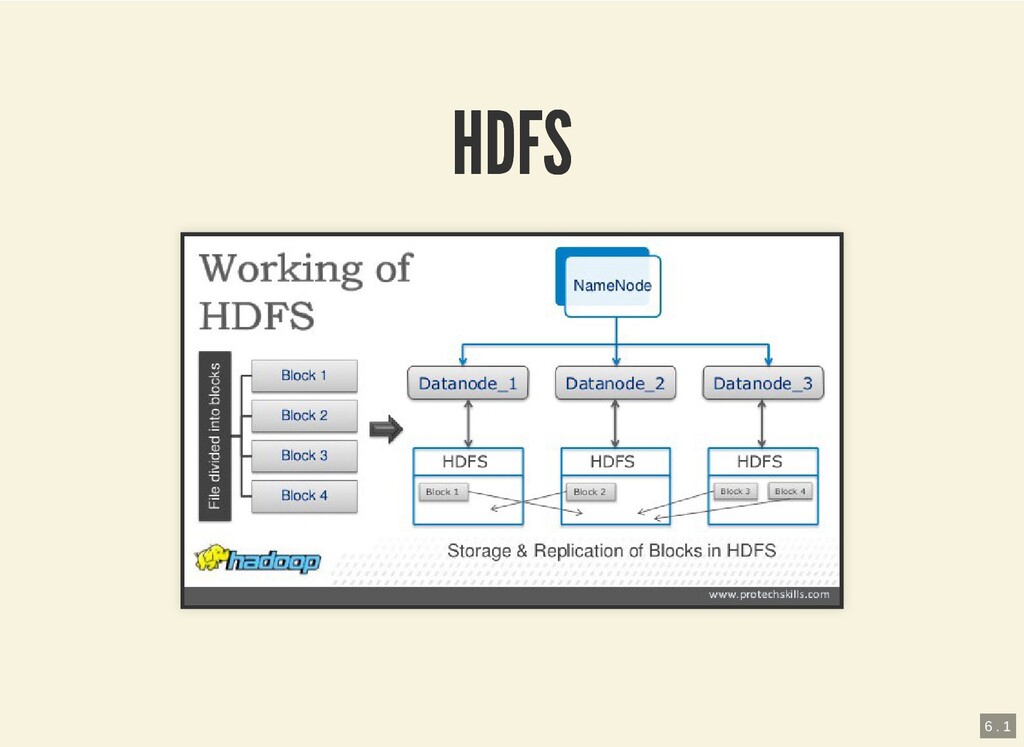{kind=link}
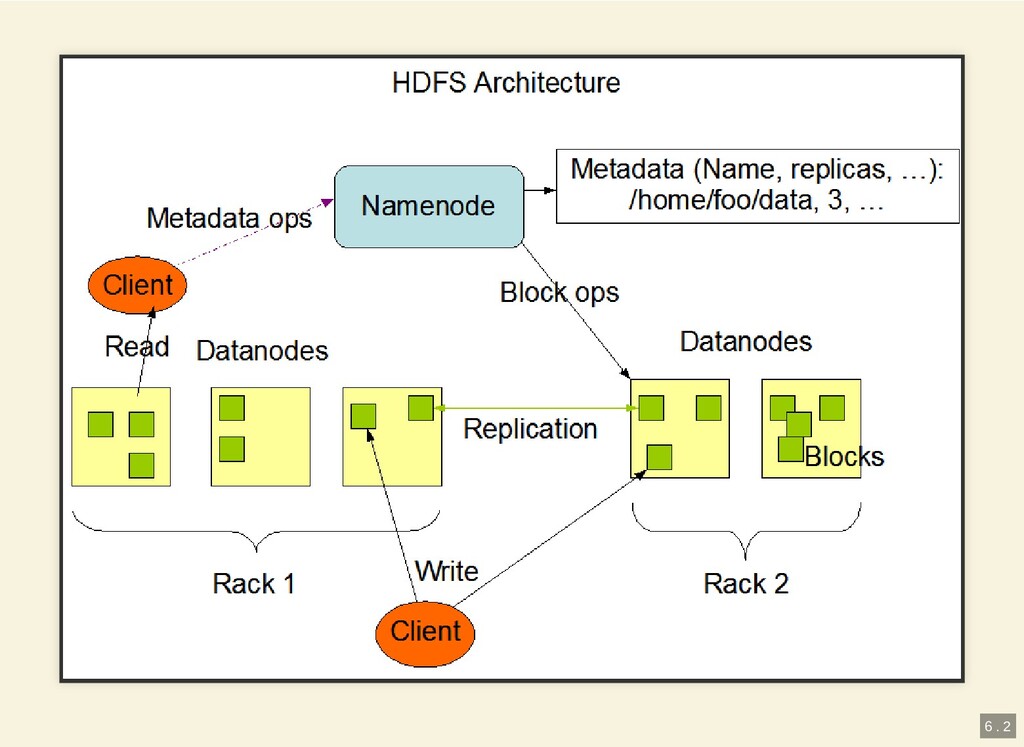{kind=link}
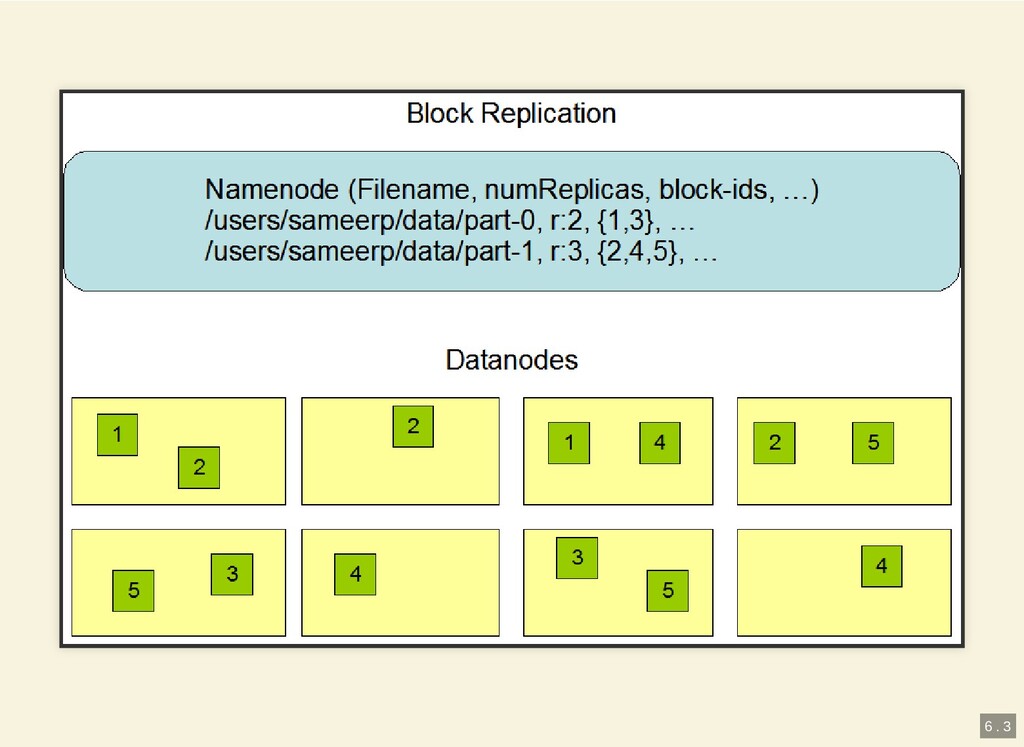{kind=link}
{kind=link}
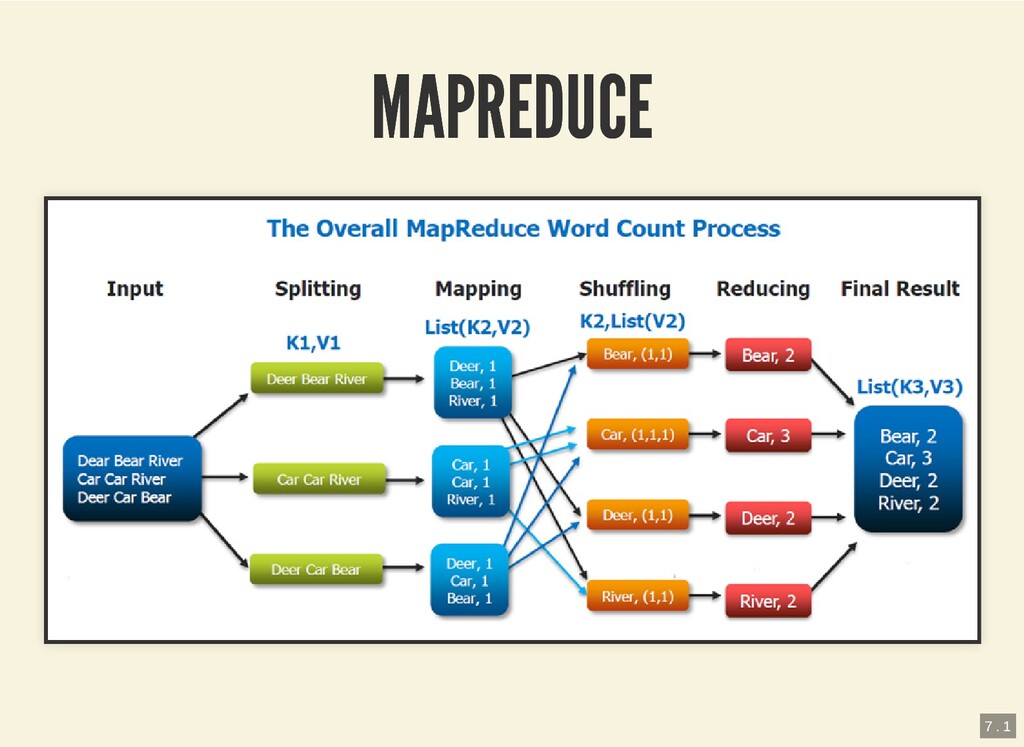{kind=link}
{kind=link}
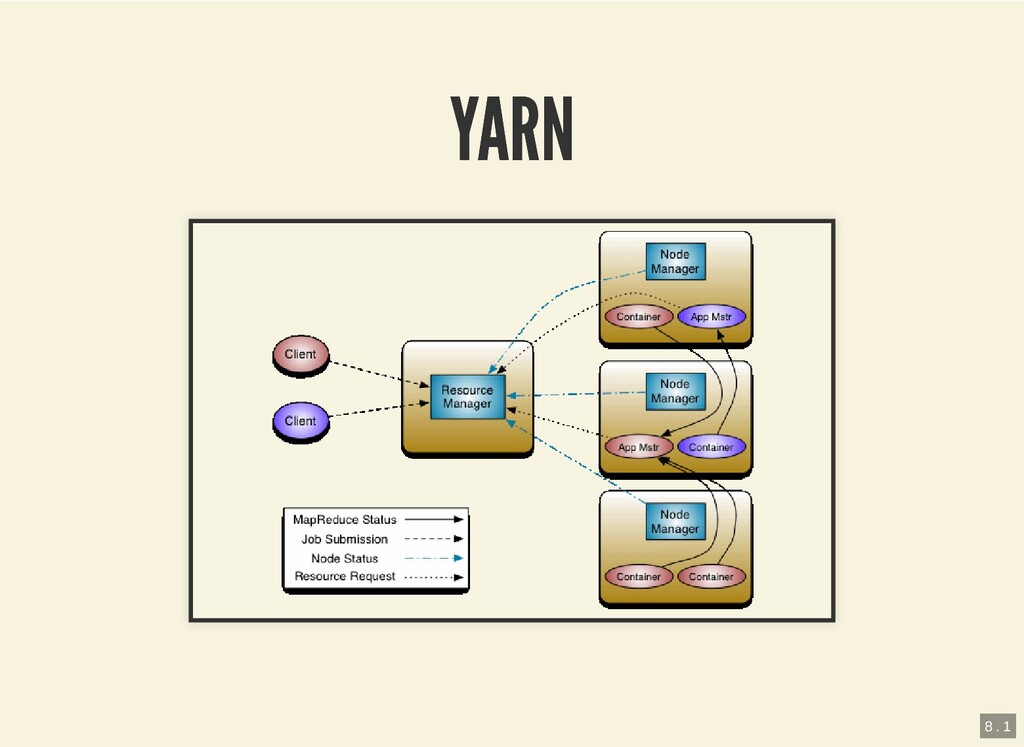{kind=link}
{kind=link}
{kind=link}
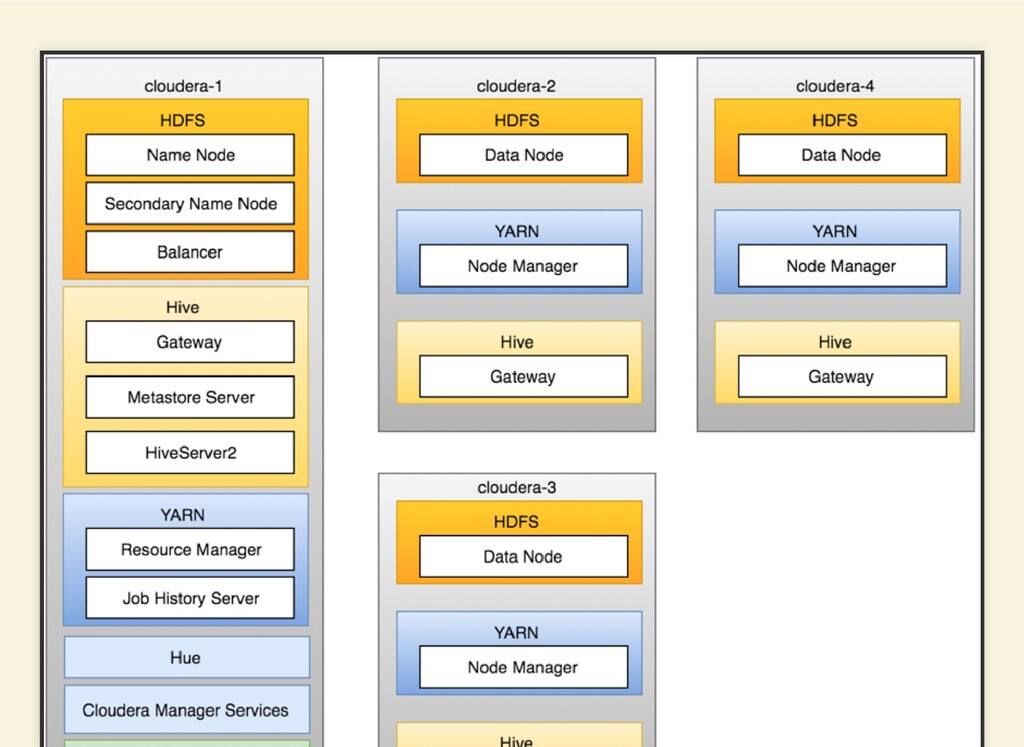{kind=link}
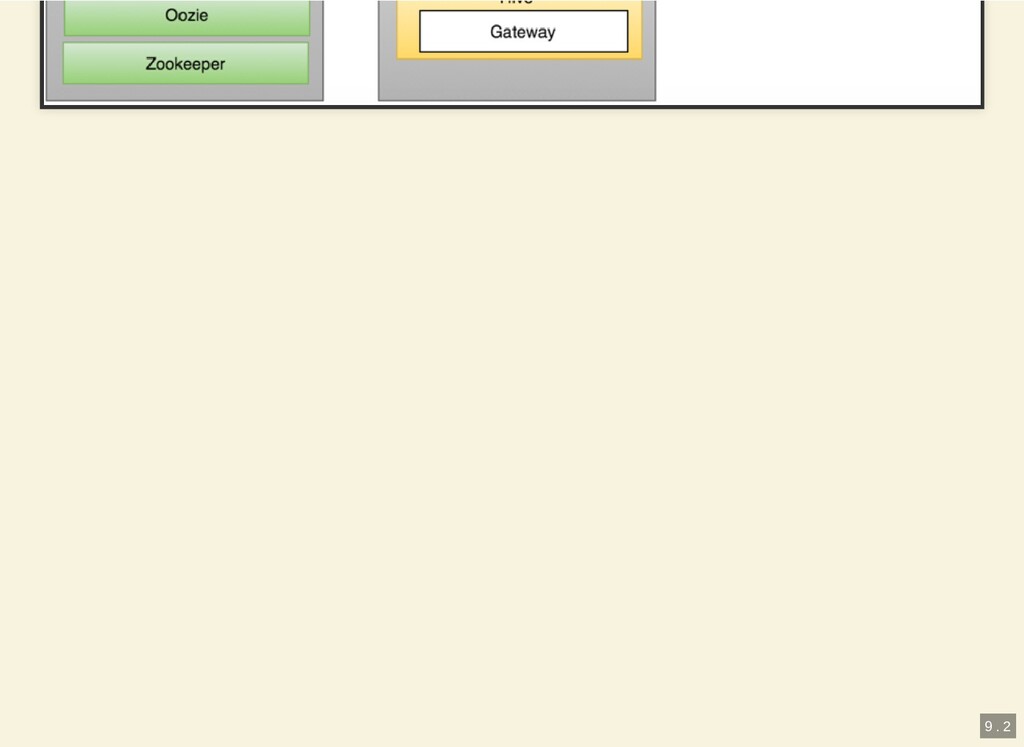{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
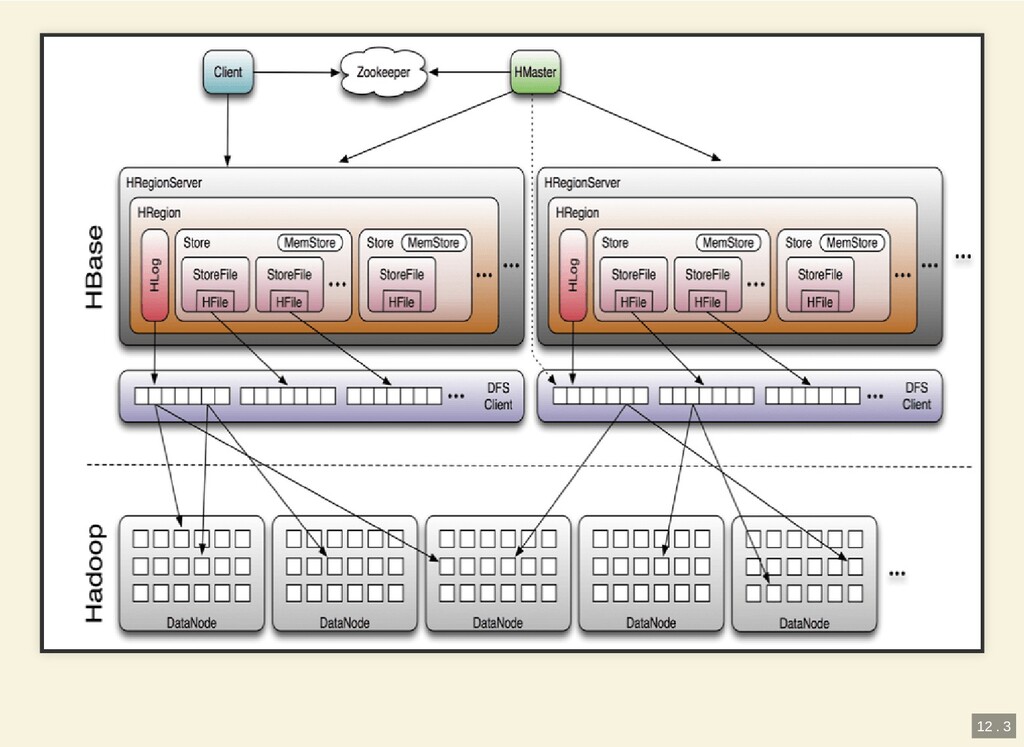{kind=link}
{kind=link}
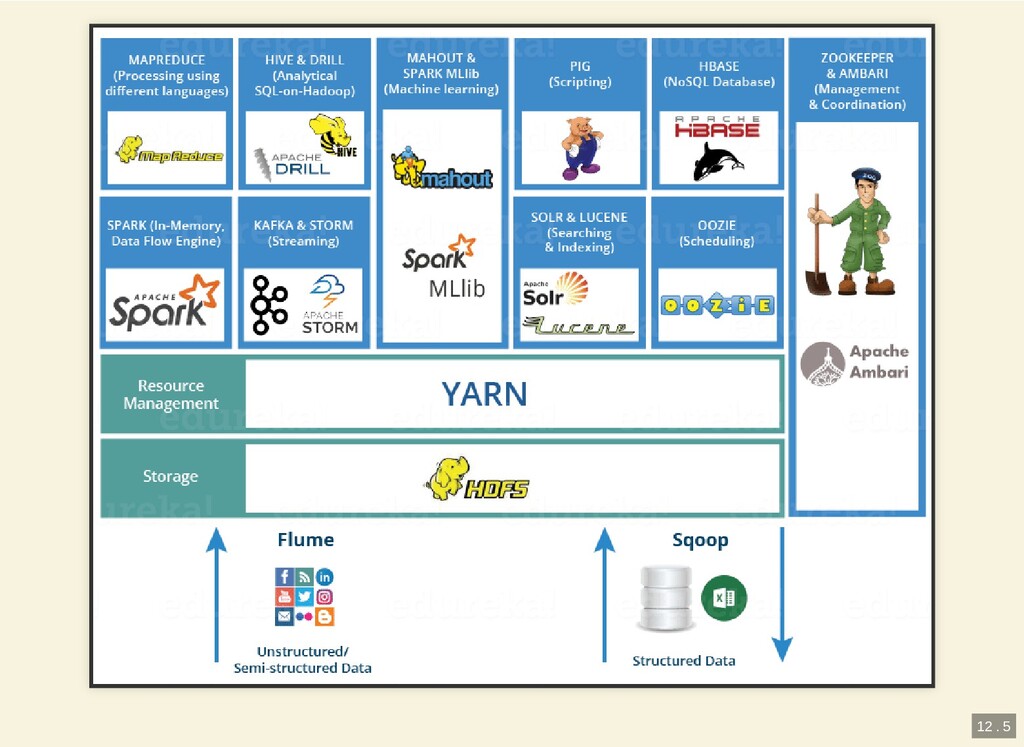{kind=link}
{kind=link}
{kind=link}
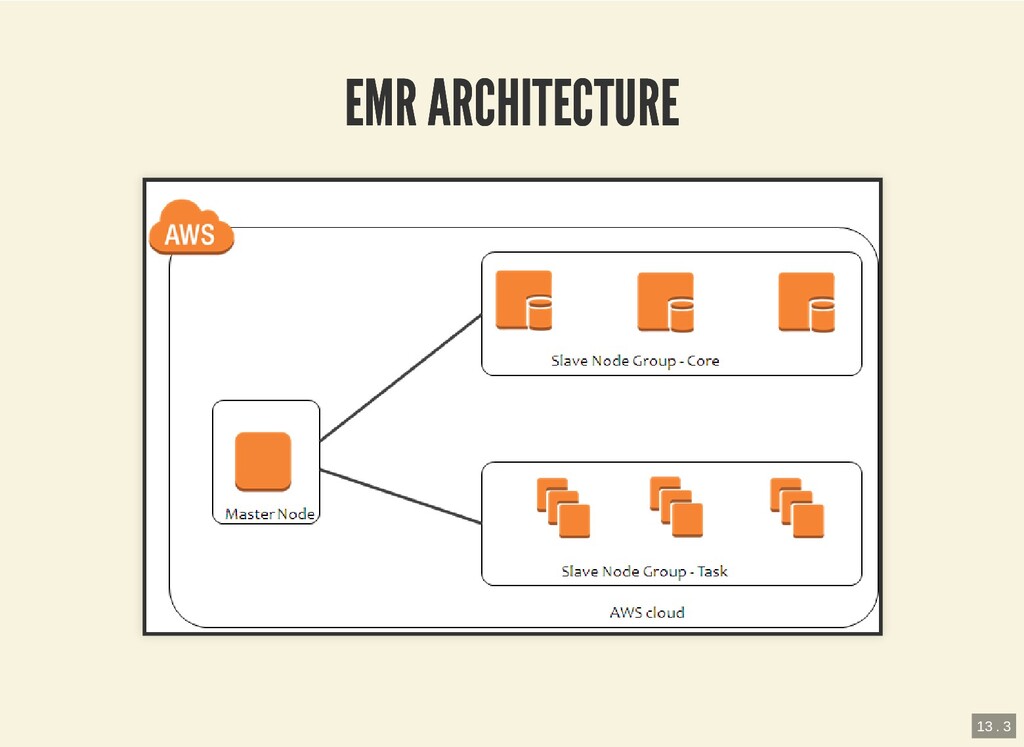{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
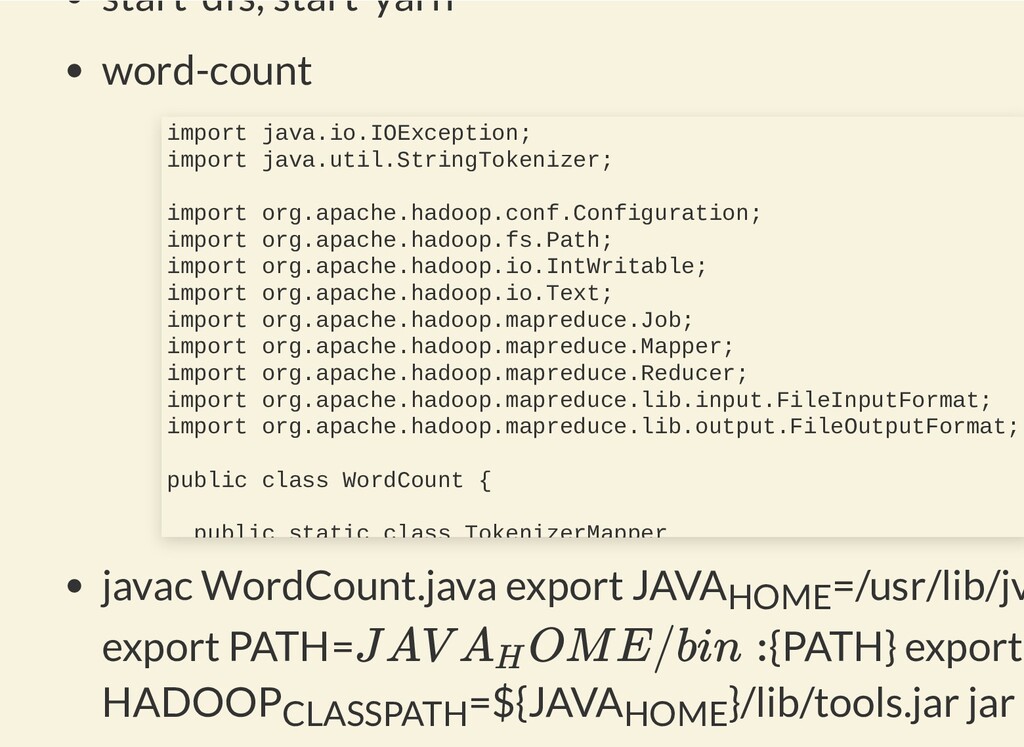{kind=link}
{kind=link}