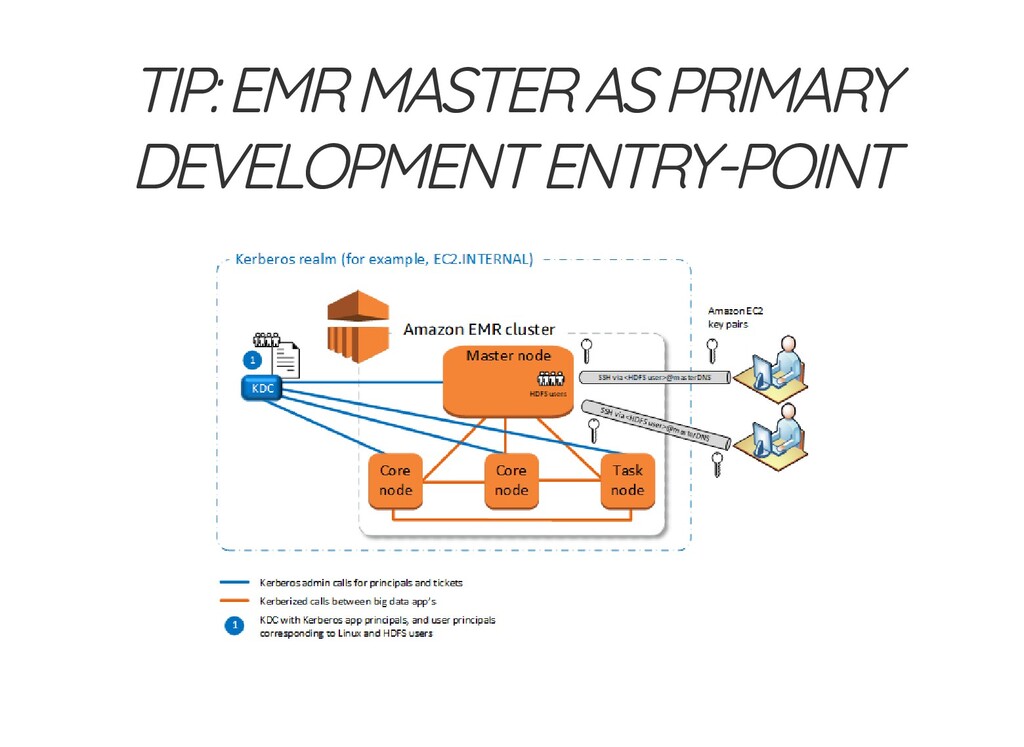
spark-submit (10min) take2: sbt build ⇨ scp ⇨ spark-submit (3-4min) take3: rsync source code to emr master option(hardcore): emacs/vim develop directly on emr master continuous rsync/lsyncd .. ok, this is good enough for me
bad input will happen much faster effect of bug may take weeks, months until noticed distributed system effects huge data what you can automate and what you cannot divide & conquer know your library: how to test structured streaming - SparkTest
start money, do not forget to shut it down same prod cluster? interfering with existing jobs isolation: yarn queues (complex) data input: kafka offload data into some topic data output - parameterize/mock
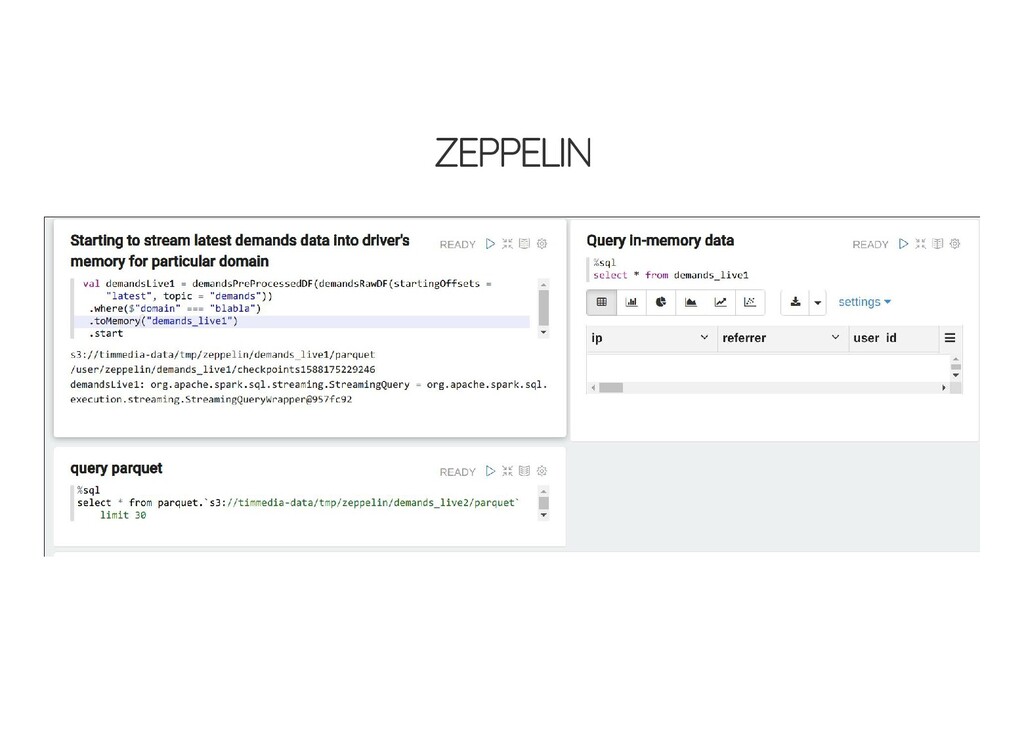
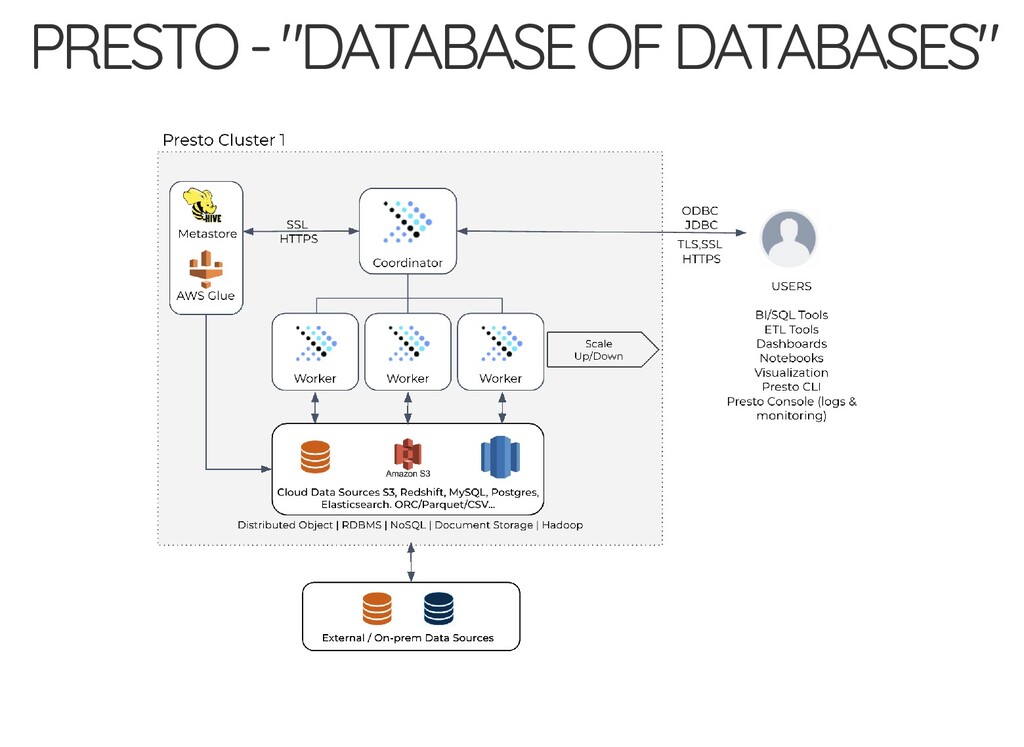
of custom code presto is much faster presto: much easier to glue different storages thrift-server & sql clients beauty of spark sql structured streaming spark: sql vs scala api?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
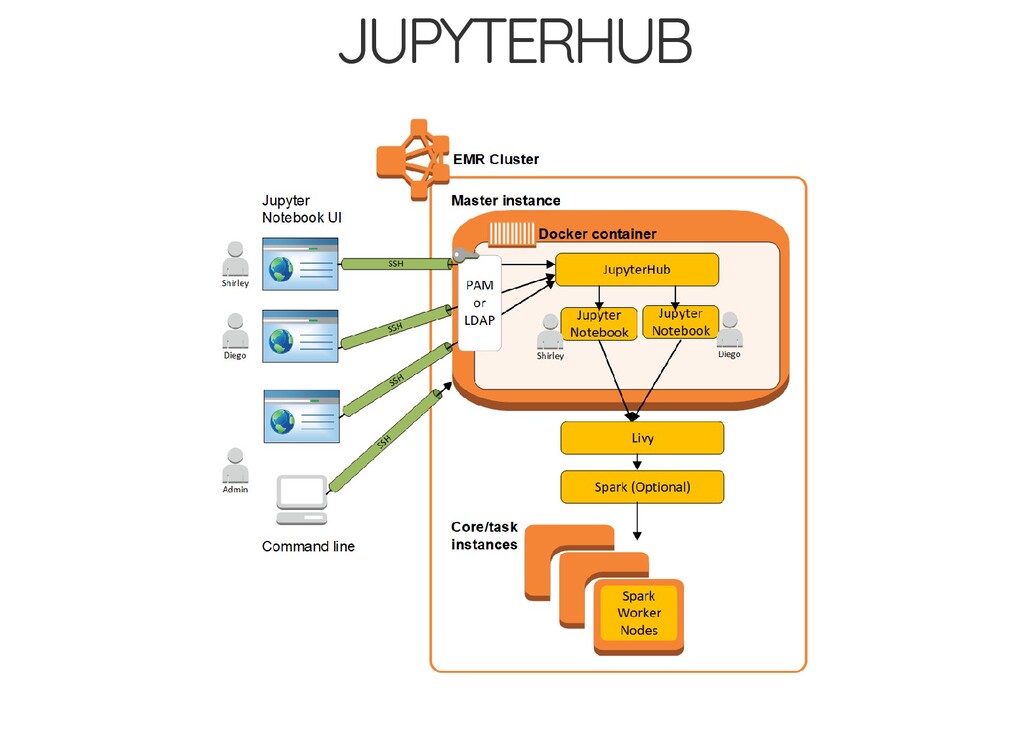{kind=link}
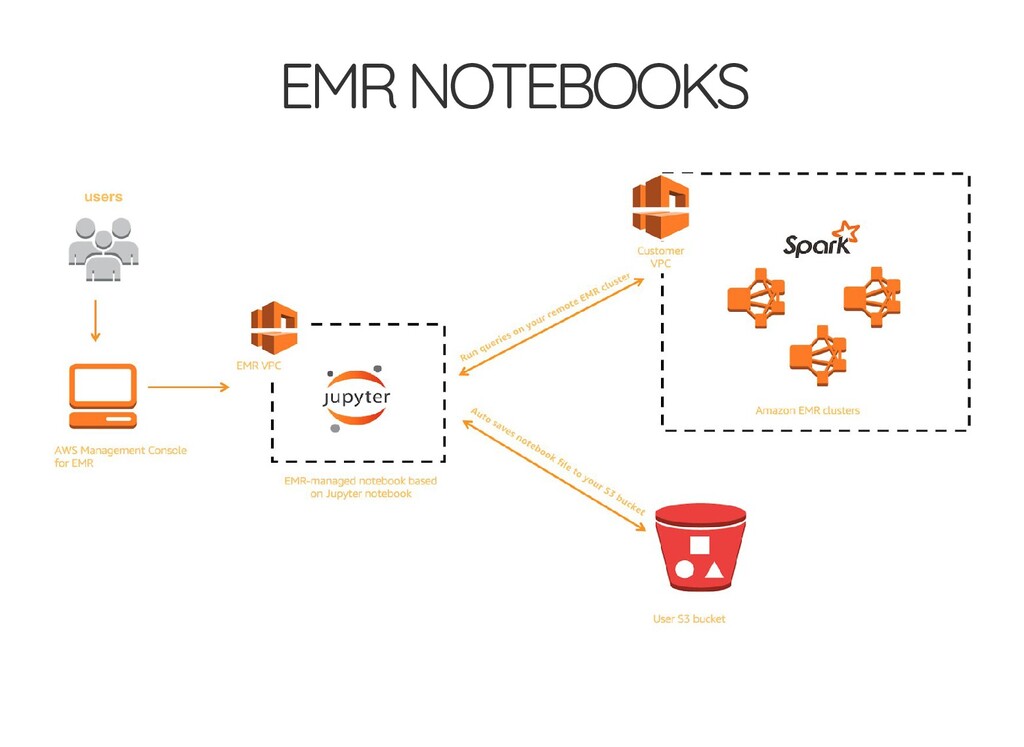{kind=link}
{kind=link}
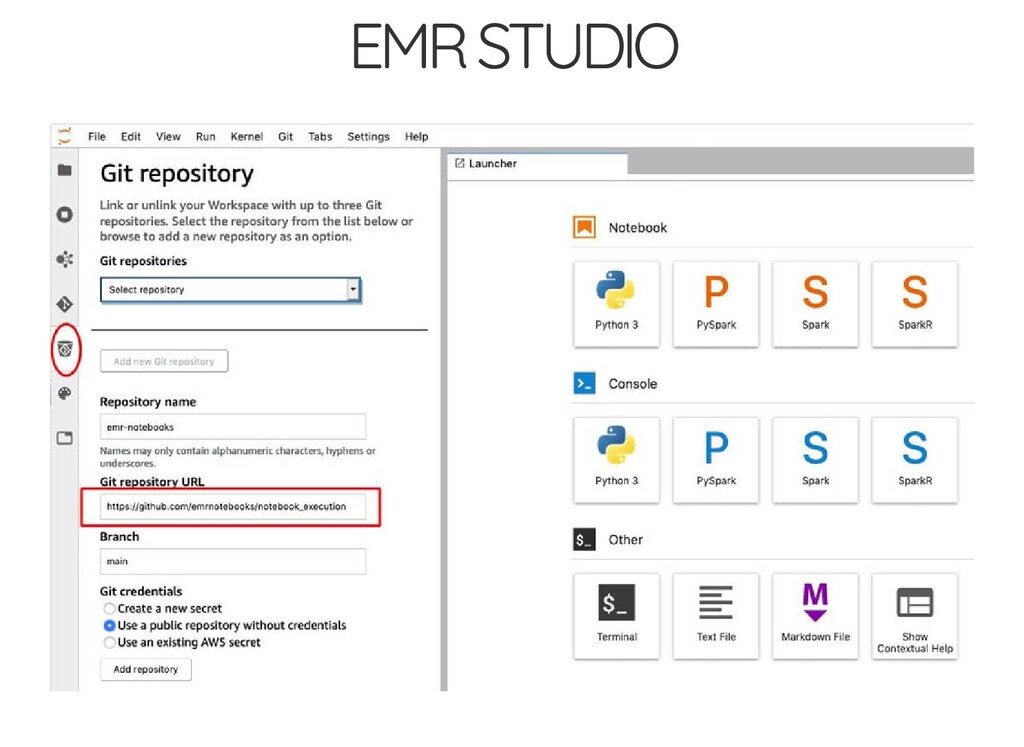{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}