stored • R replicas are required for a successful read • W replicas are required for a successful write • R, W and DW can specified per-request • Version conflicts are detected with vclocks and may be resolved by the application • But! By default, this is done for you using “latest wins”
• Keys must fit in memory, no secondary indexes LevelDB • Data compression, secondary indexes • Slower than Bitcask Memory • No persistence, good for testing Multi • Configure backend per bucket
Content-Type • Vclock (if the object already exists) • Links, indexes, metadata (if any) • Quorum size: W , DW • Content Content can be arbitrary data, but something like JSON is best for search, etc.
n val, allow mult, postcommit, etc. • Warning! Don’t have too many • Can’t delete (but I’m working on that) • “List keys” supported, but very expensive
int • Orthogonal to object value • Query on exact value or range • Query on one index only • Returns keys, not objects • Can feed map/reduce operations
Index distributed by term (high performance, possible latency hit) • Solr API • Search key/value data • Set precommit hook for indexer • JSON and XML are indexed by field name • Can feed map/reduce operations
• Basho officially supports C/C++, Erlang, Java, PHP, Python, Ruby • We maintain Riakasaurus (Python/Twisted) • We wrote a hybrid sync/async ORM-sort-of-thing which needs a cool name
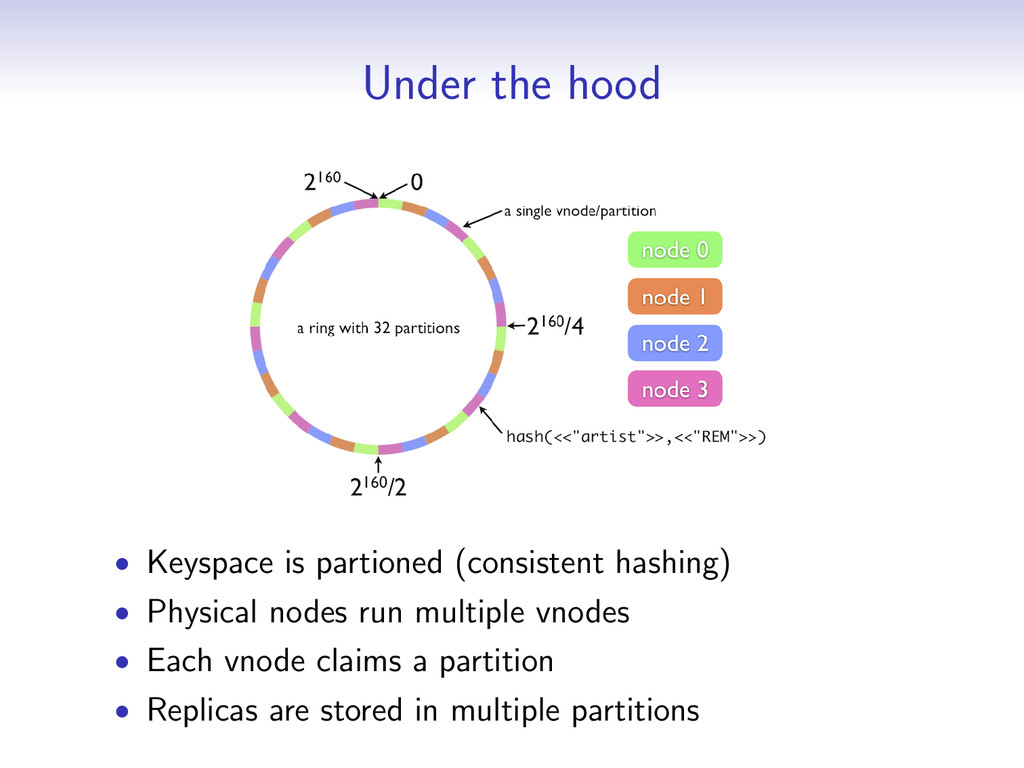
will do • All nodes are equal (no master) • Nodes can go away with no downtime (as long as there’s still a quorum) • Adding nodes is completely transparent • For best performance, use dedicated boxes with good I/O
that. . . • has high performance reads and writes • doesn’t require a devops army • can store relations (in a limited way) • works well with non-relational data • allows full-text searching
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}