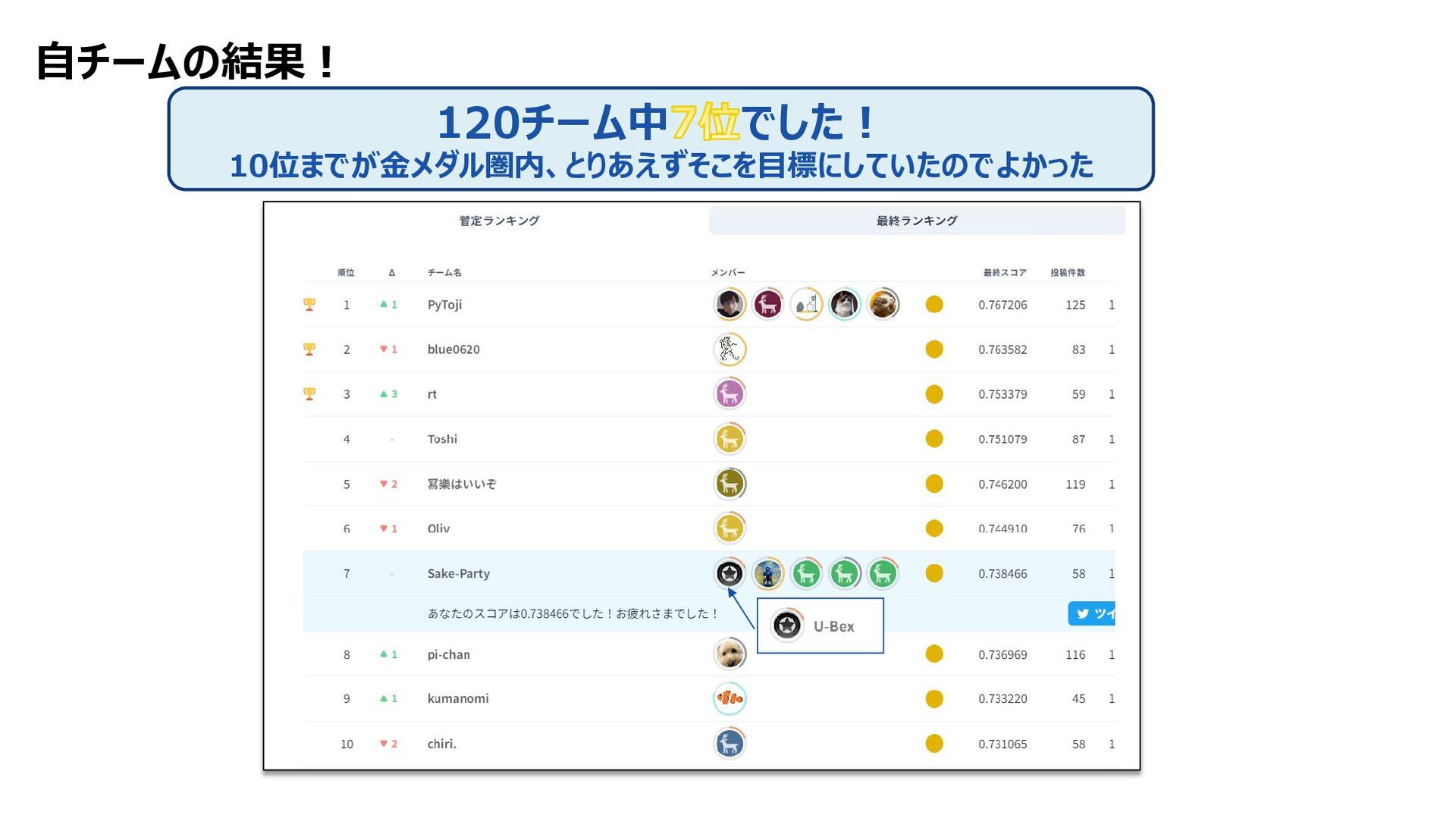
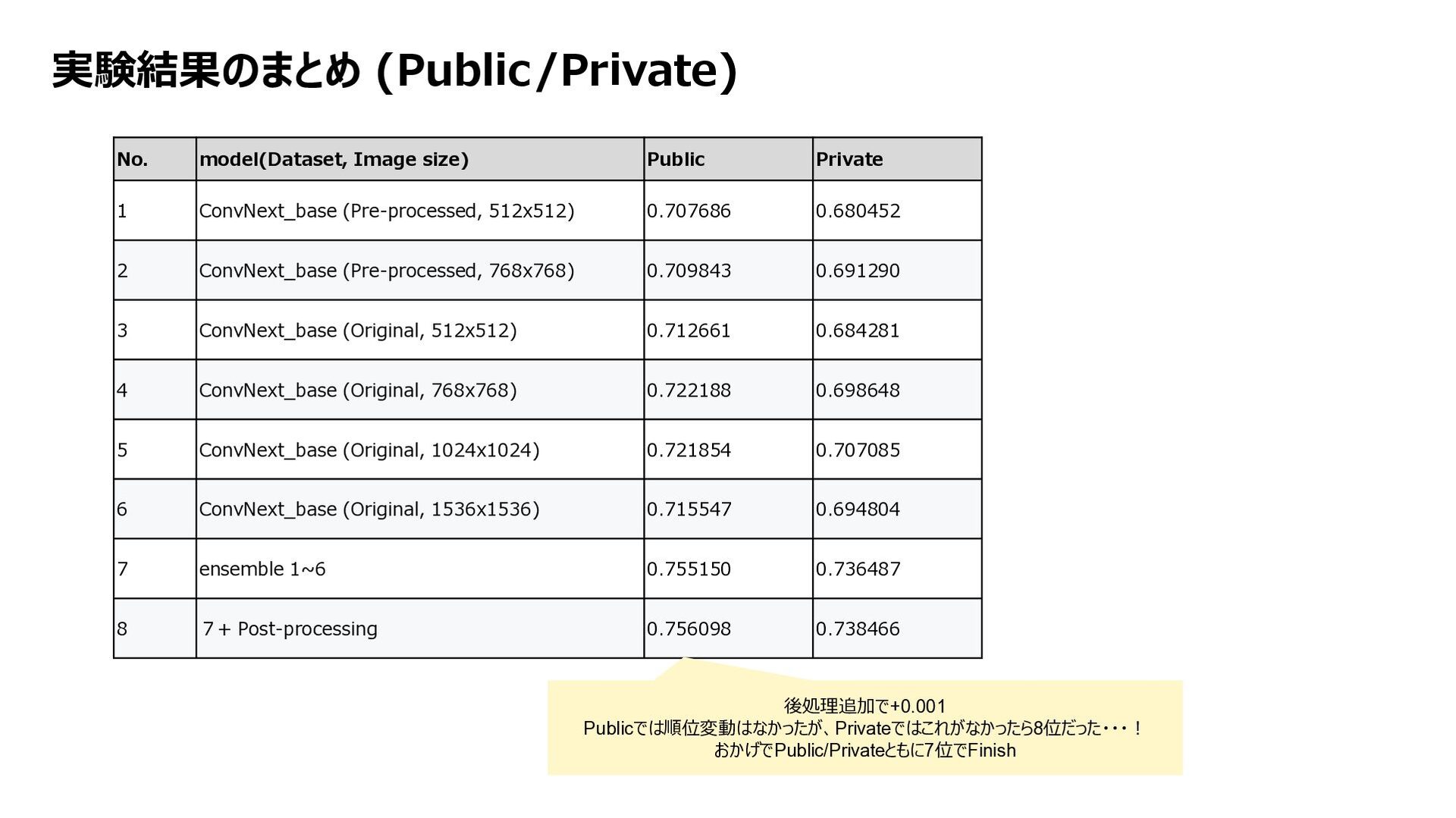
(Pre-processed, 512x512) 0.707686 0.680452 2 ConvNext_base (Pre-processed, 768x768) 0.709843 0.691290 3 ConvNext_base (Original, 512x512) 0.712661 0.684281 4 ConvNext_base (Original, 768x768) 0.722188 0.698648 5 ConvNext_base (Original, 1024x1024) 0.721854 0.707085 6 ConvNext_base (Original, 1536x1536) 0.715547 0.694804 7 ensemble 1~6 0.755150 0.736487 8 7+ Post-processing 0.756098 0.738466 後処理追加で+0.001 Publicでは順位変動はなかったが、Privateではこれがなかったら8位だった・・・! おかげでPublic/Privateともに7位でFinish
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}