テーマ
LLM(大規模言語モデル)を使ったサービスの多言語対応の課題とプロンプト設計の戦略について。
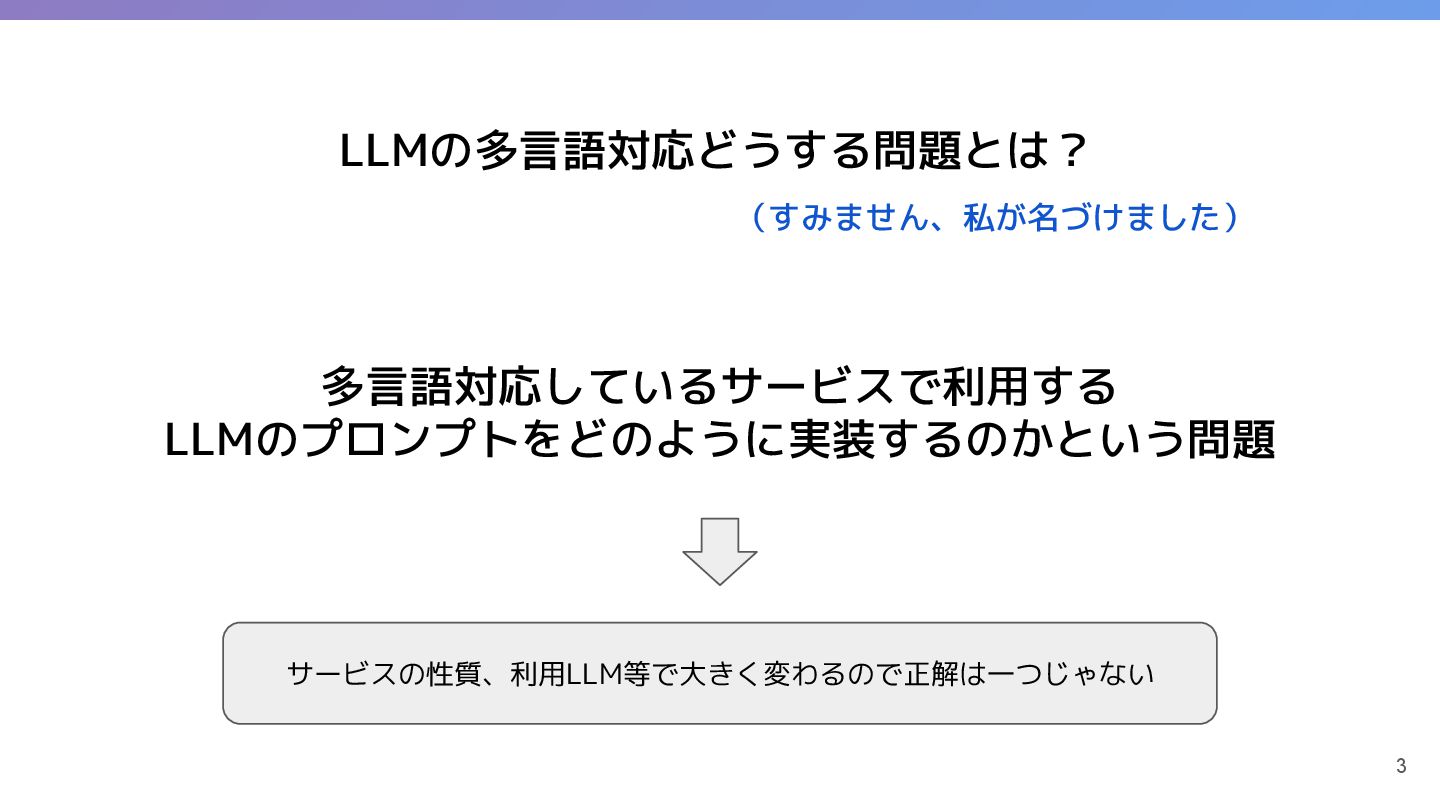
1. LLMの多言語対応の課題
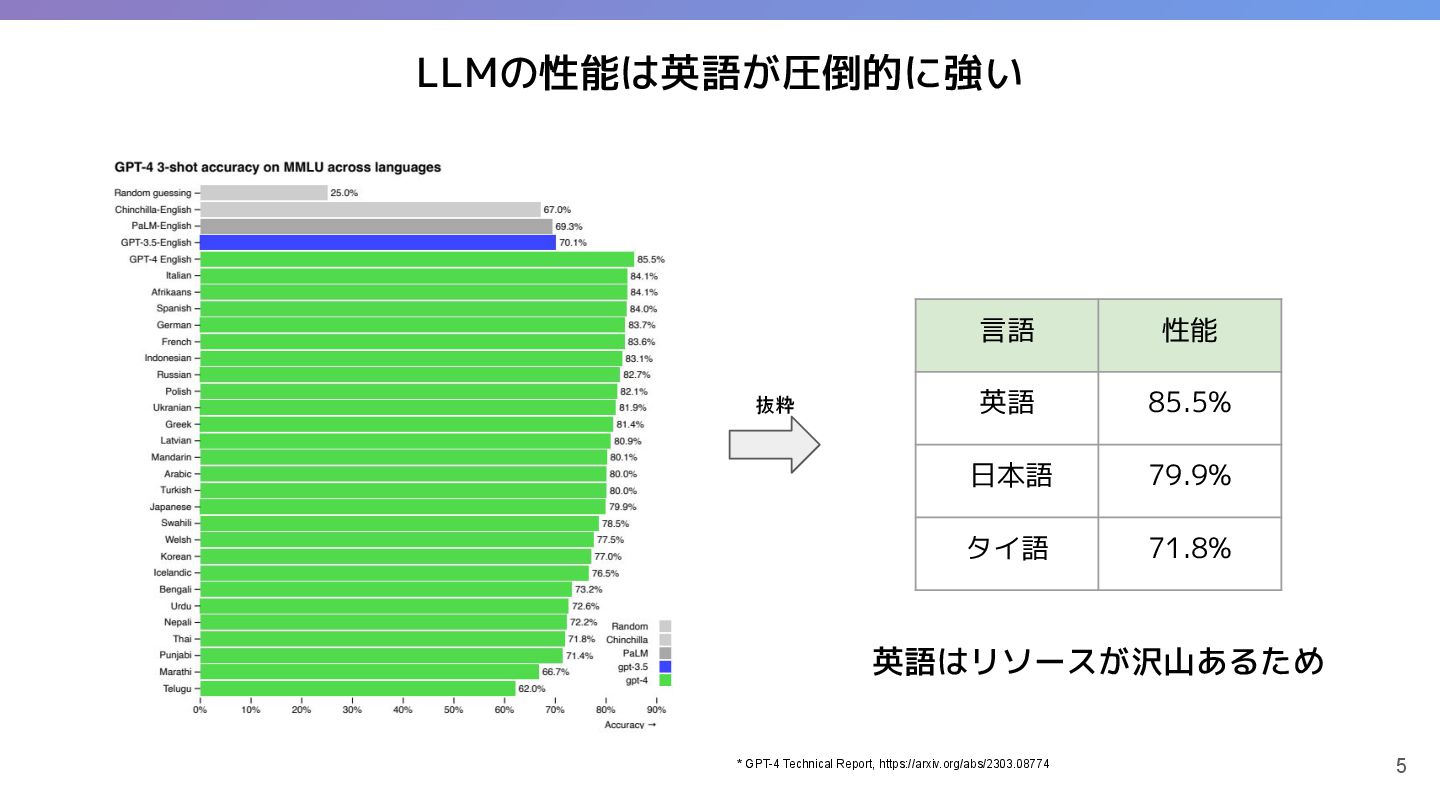
LLMの性能は言語によって異なり、英語が圧倒的に強い。
多言語対応する際のプロンプトの設計が課題。
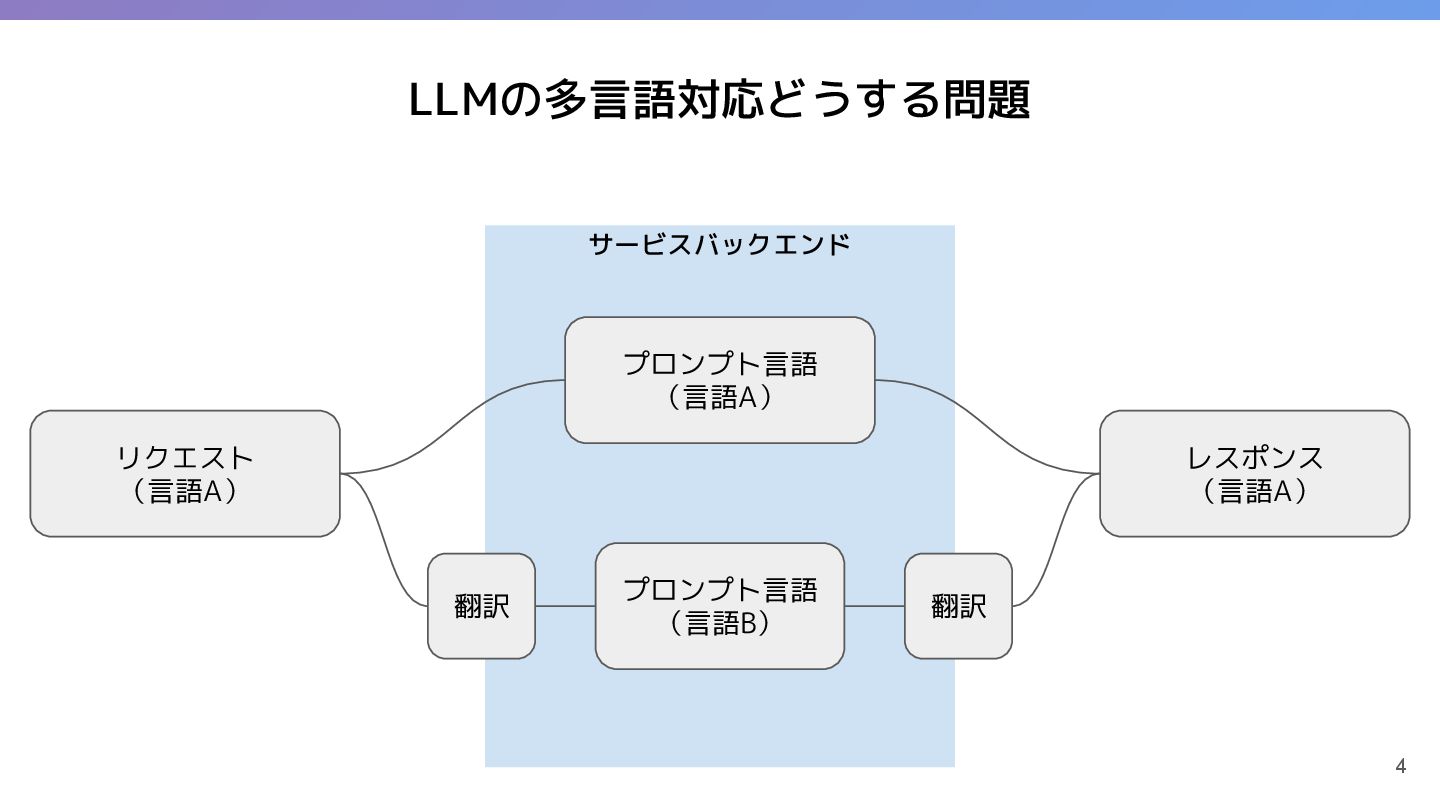
2. プロンプト設計の戦略
① ユーザーの言語でプロンプトを作成
メリット: 実装が簡単
デメリット: 言語ごとの対応負荷が高い、精度が低い可能性
② 英語でプロンプトを作り、結果を翻訳
メリット: 精度が高い(英語モデルの性能が高いため)
デメリット: 事前翻訳・事後翻訳が必要、呼び出し回数が増える
③ 英語でプロンプトを作成し、翻訳指示を埋め込む
メリット: 精度が高く、呼び出し回数を抑えられる
デメリット: 指示を無視して英語で出力されるリスク
結論 → 「プロンプトは全部英語で書くのが良い!」
3. 具体例:Tripia(AI旅行プラン生成アプリ)
AIが旅行プランを自動生成
課題: マイナーなエリアの情報を正しく取得できるか?
仮説: LLMはマイナーエリアの知識が英語では弱く、日本語では精度が高い可能性
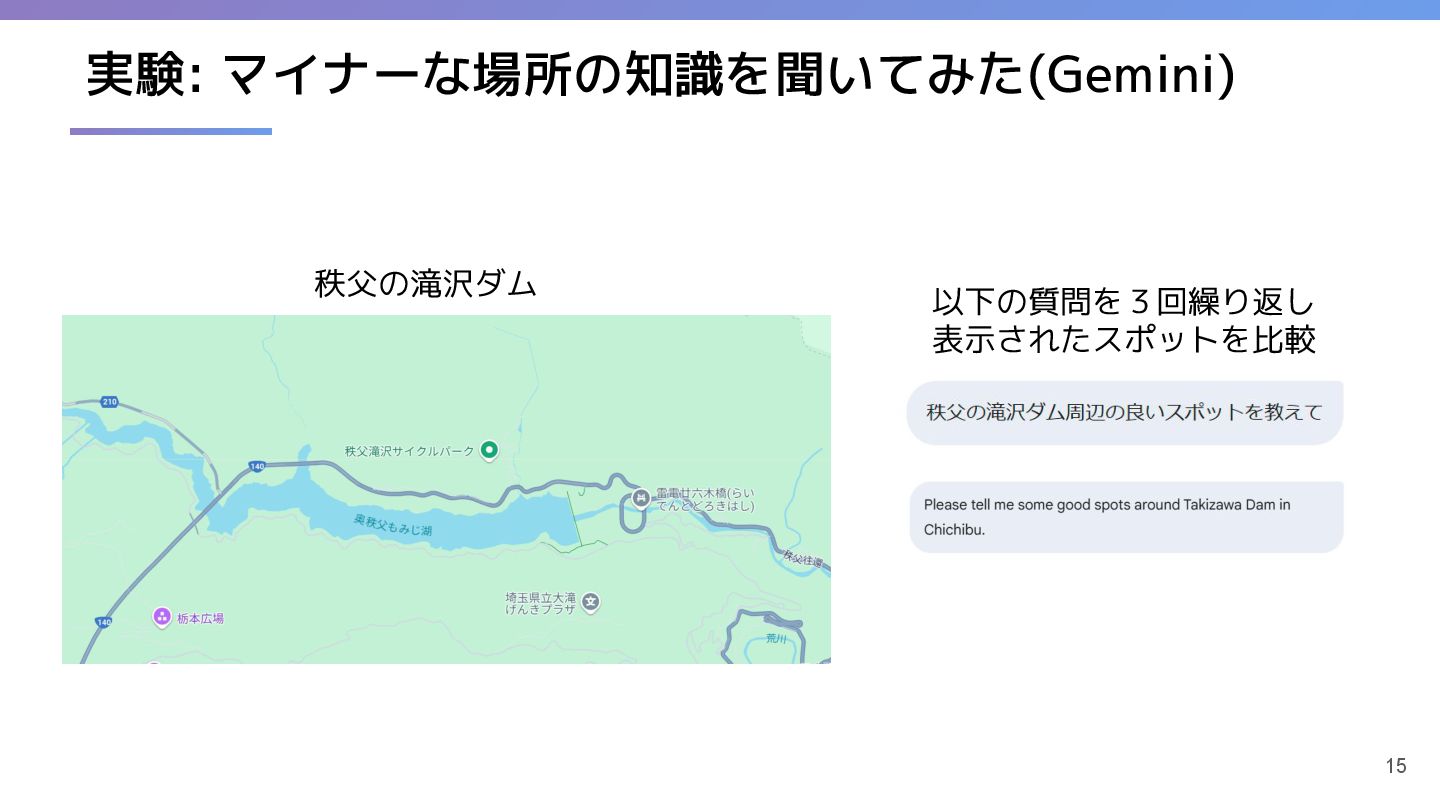
4. 実験:LLMに日本のマイナーなエリアについて質問
対象: 秩父の滝沢ダム
結果:
日本語のプロンプト: ダム近くのスポットを提示
英語のプロンプト: 広い範囲(秩父全体)のスポットを提示
結論: 言語によって取得できる情報に差がある
5. まとめ
多言語対応のプロンプト設計は**「英語で統一」**が基本。
ただし、特定言語に偏った情報(例: 日本のマイナーエリア)では、日本語の方が有利な場合もある。
LLMを使う際は、サービスに合わせて評価実験を行うことが重要!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}