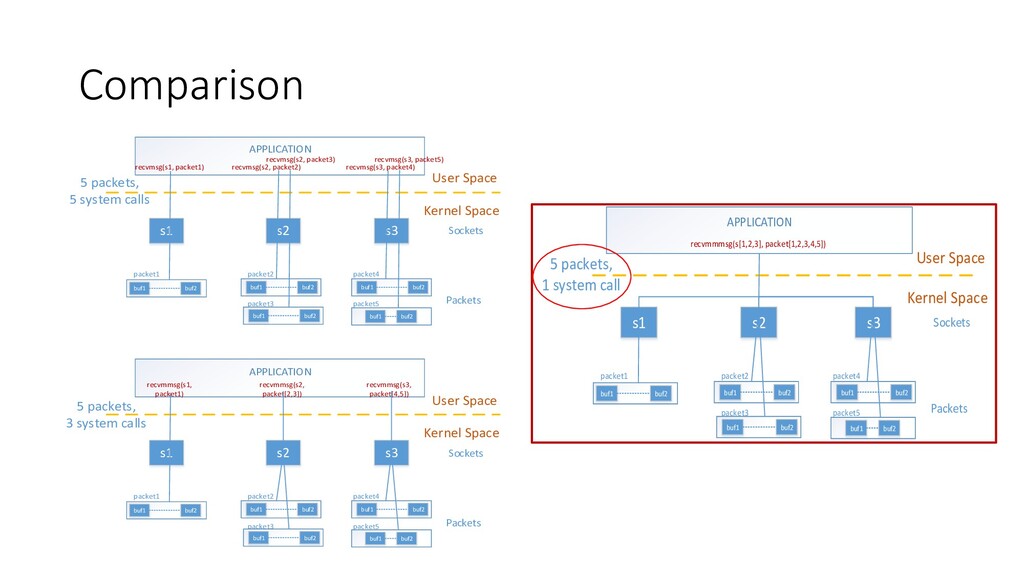
Space recvmsg(s1, packet1) Sockets buf1 buf2 buf1 buf2 buf1 buf2 packet3 packet4 packet5 buf1 buf2 packet1 packet2 recvmsg(s2, packet2) recvmsg(s2, packet3) recvmsg(s3, packet4) recvmsg(s3, packet5) Packets APPLICATION s1 s2 s3 buf1 buf2 Kernel Space User Space recvmmsg(s1, packet1) Sockets buf1 buf2 buf1 buf2 buf1 buf2 packet3 packet4 packet5 buf1 buf2 packet1 packet2 recvmmsg(s2, packet[2,3]) recvmmsg(s3, packet[4,5]) Packets 5 packets, 5 system calls 5 packets, 3 system calls APPLICATION s1 s2 s3 buf1 buf2 Kernel Space User Space recvmmmsg(s[1,2,3], packet[1,2,3,4,5]) Sockets buf1 buf2 buf1 buf2 buf1 buf2 packet3 packet4 packet5 buf1 buf2 packet1 packet2 Packets 5 packets, 1 system call
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}