Maxime Beauchemin wrote an influential article, Functional Data Engineering — a modern paradigm for batch data processing. It is a significant step to bring Software Engineering concepts into Data Engineering. The principle utilizes the advancement from Hadoop.
Cloud object storage like S3 makes the storage a commodity.
The separate Storage & Compute, so both can scale independently. Yes, human life is too short for scaling storage and computing simultaneously.
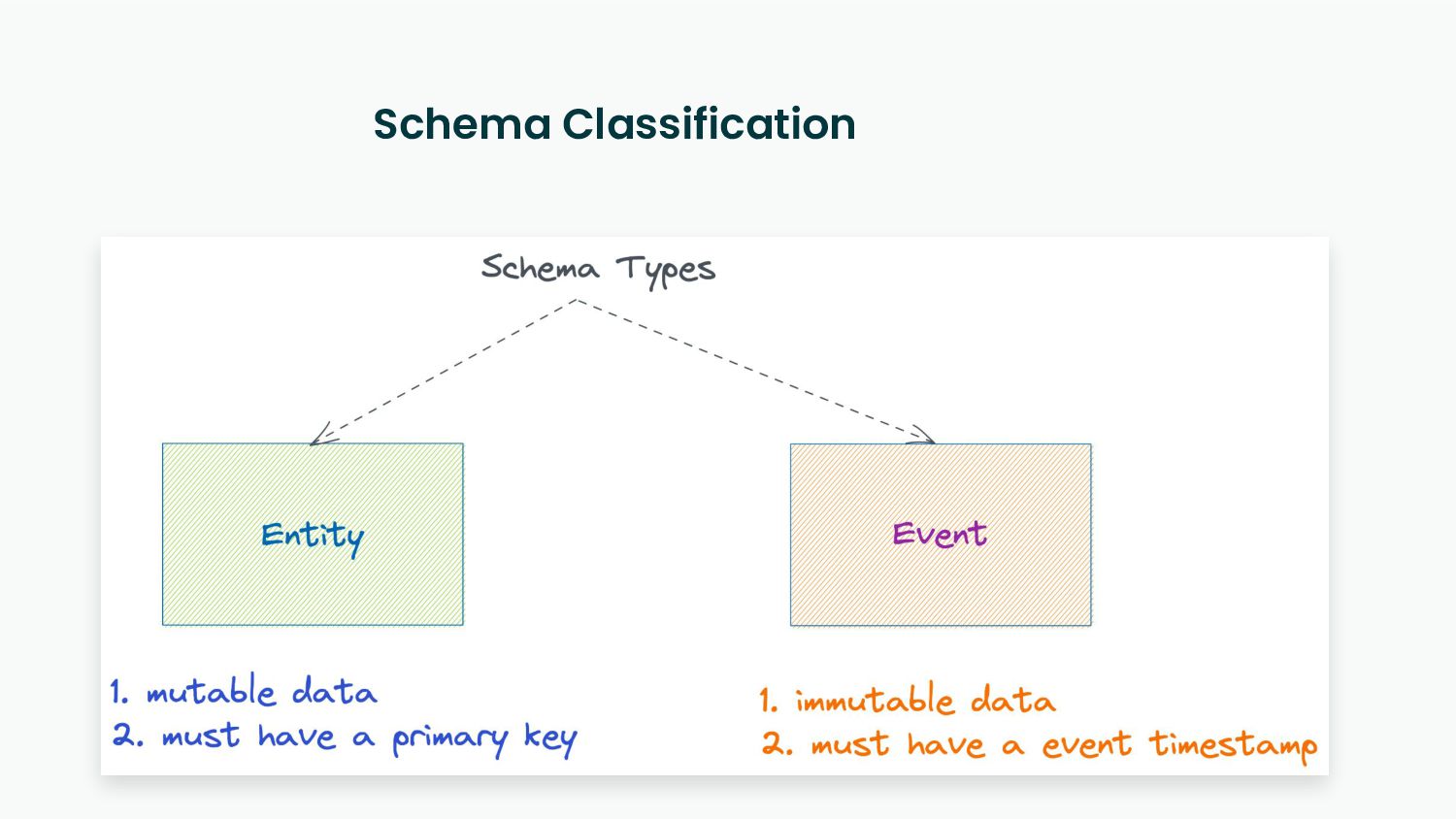
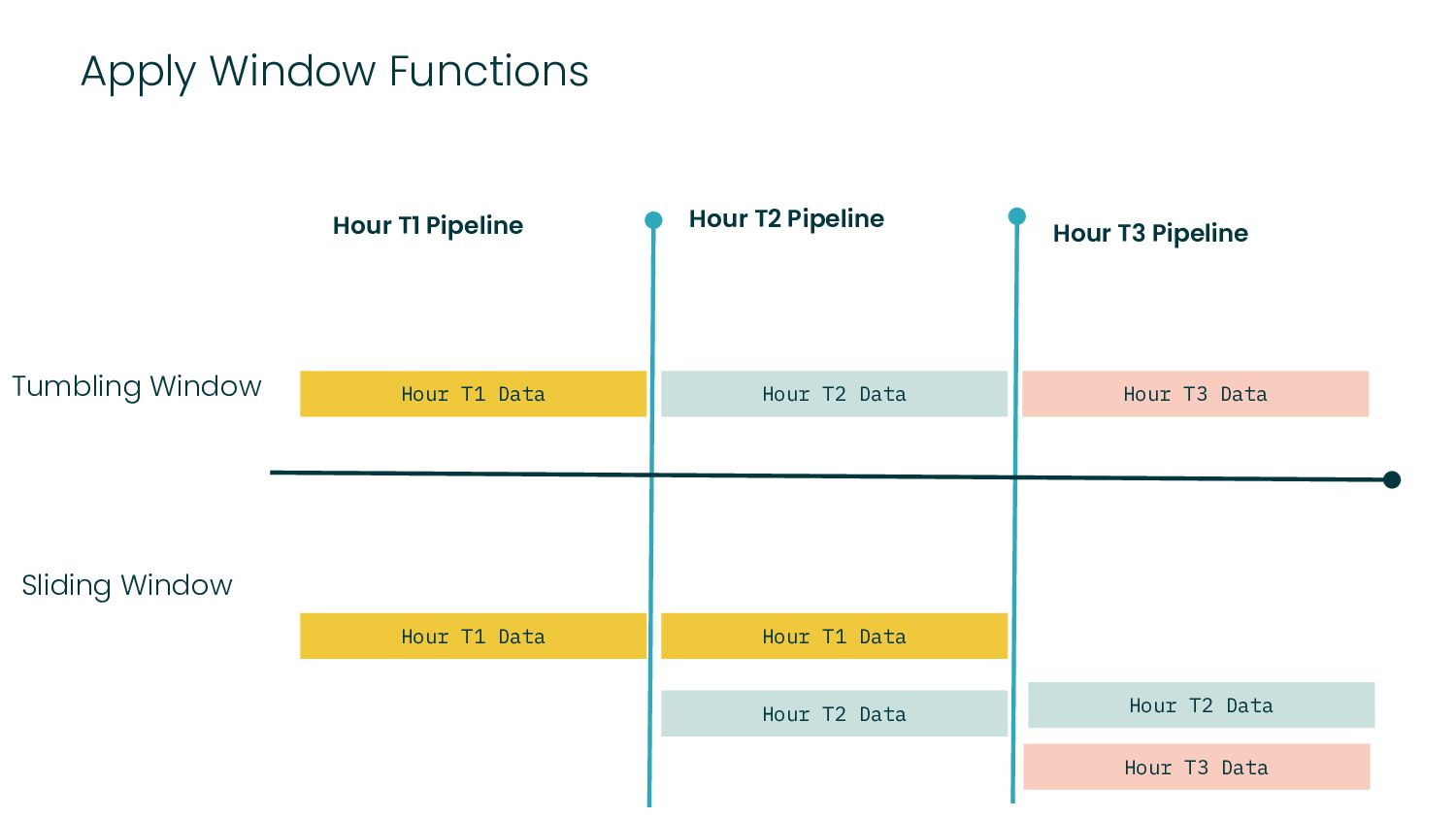
Functional data engineering follows two key principles.
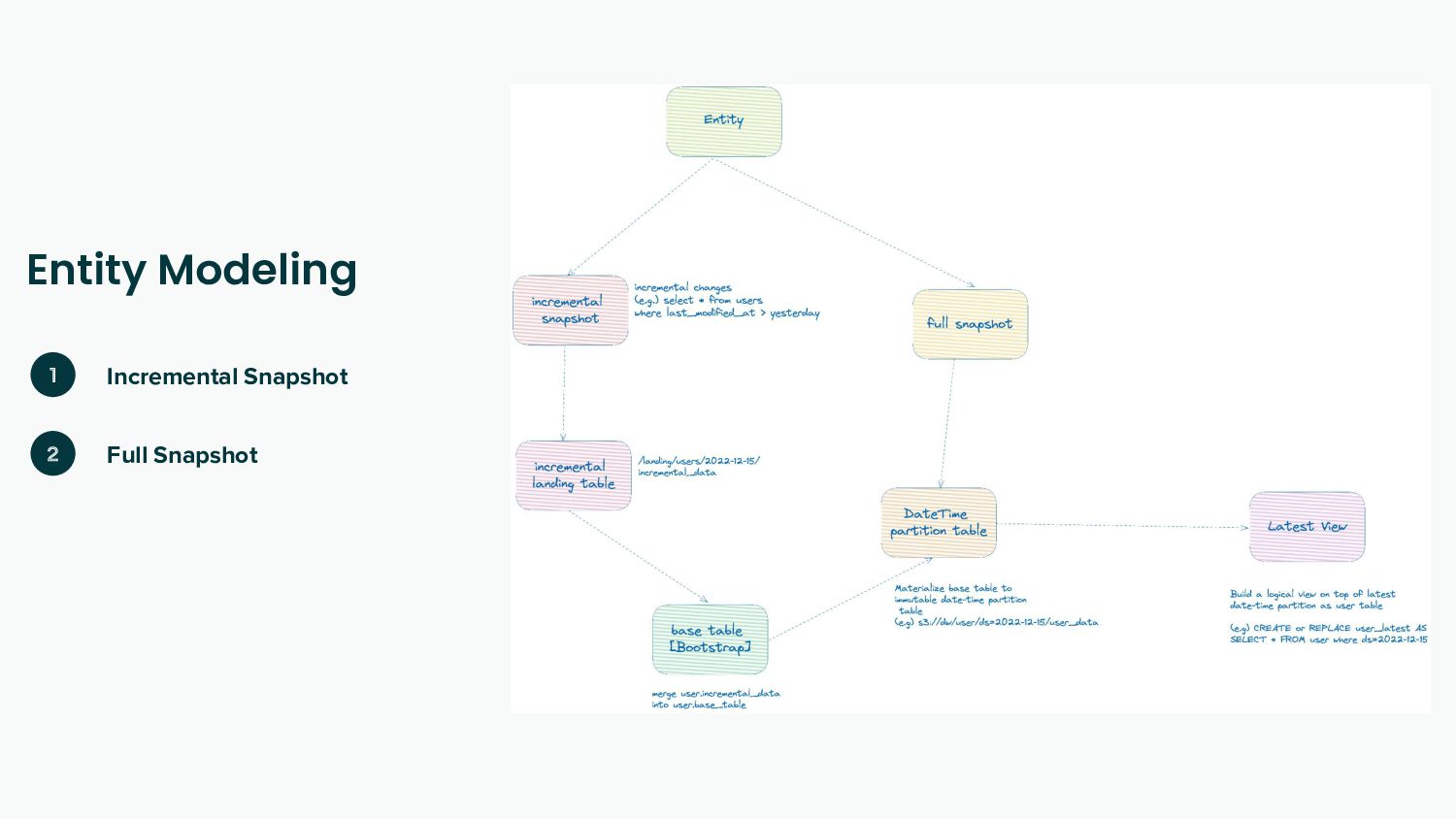
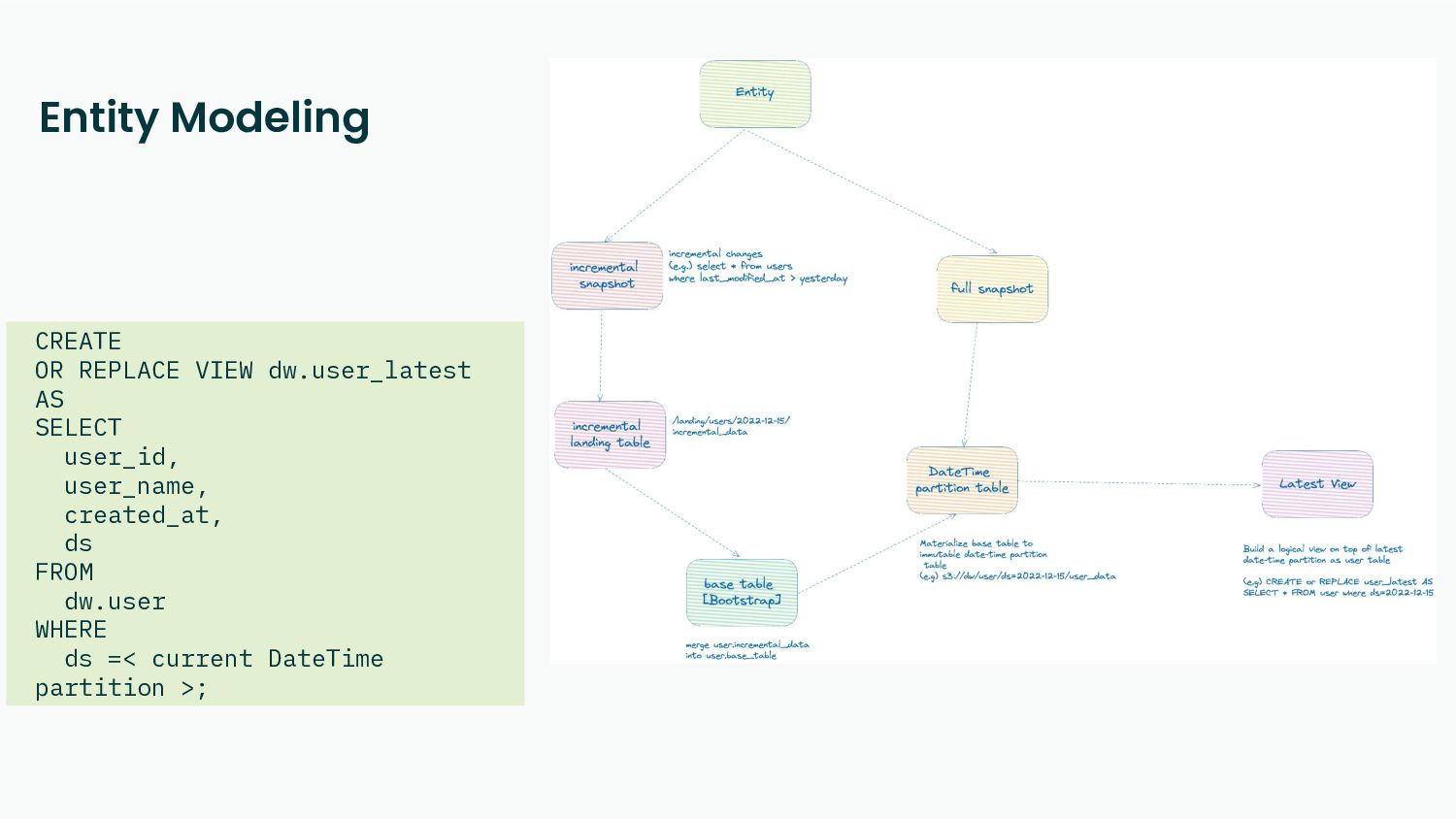
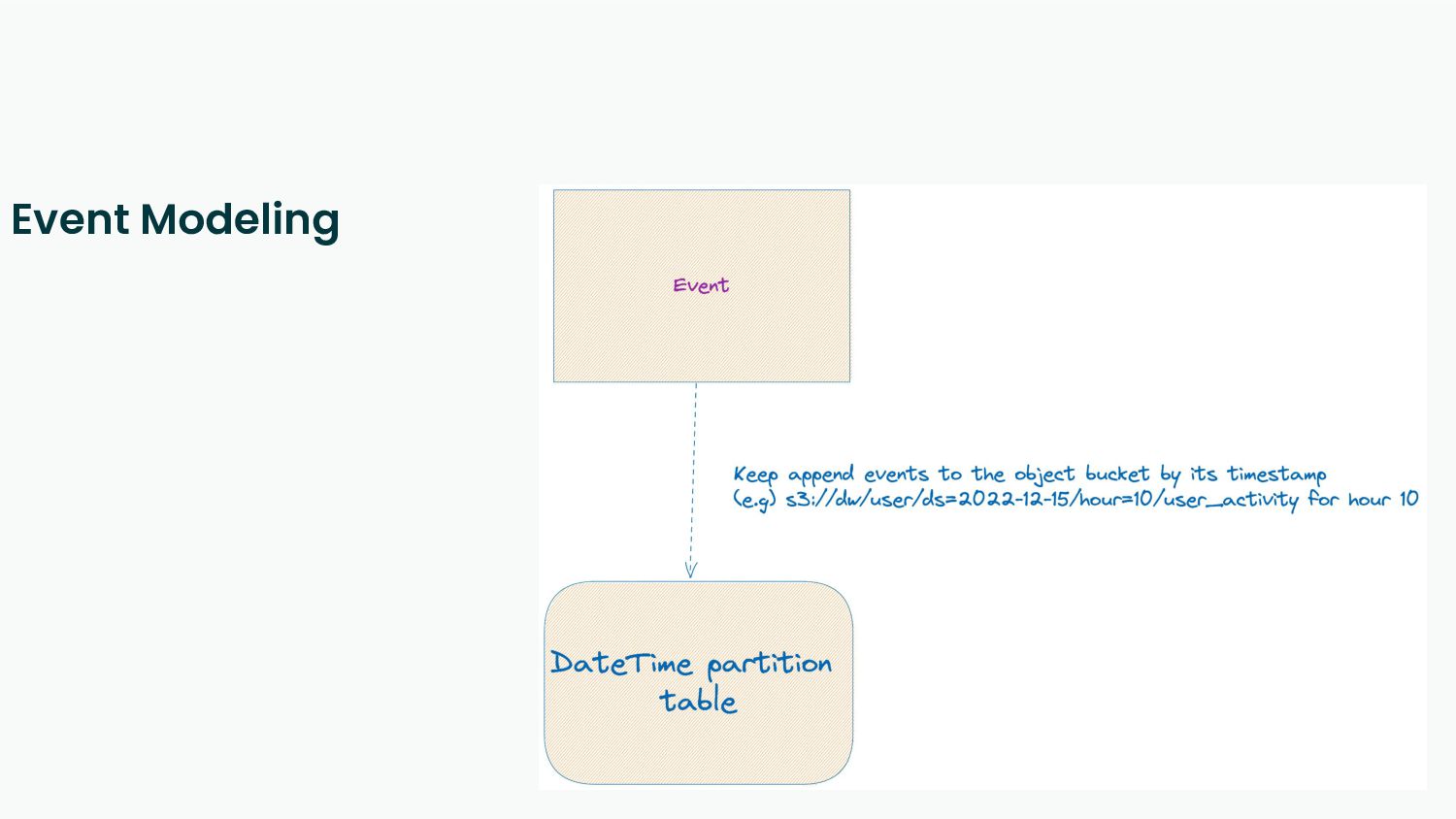
Reproducibility - Every task in the data pipeline should be deterministic and idempotent.
Re-Computability - Business logic changes over time, and bugs happen. The data pipeline should be able to recompute the desired state.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![https://schemata.app https://www.linkedin.com/in/ananthdurai [email protected]](https://files.speakerdeck.com/presentations/51b3ebc3185f487e96ecb05c04e77050/slide_14.jpg){kind=link}