Slack data platform evolves from the batch system to near real-time. I will also touch base on how Samza helps us to build low latency data pipelines & Experimentation framework.
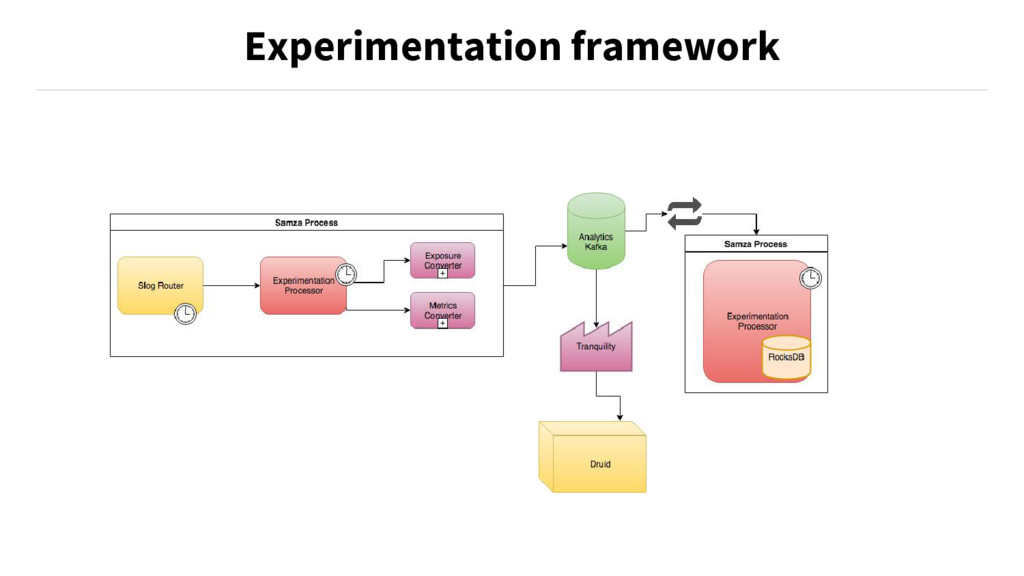
• RocksDB Store exposure table (team_users_experimentation mapping). • Metrics events range join with exposure table. • A periodic snapshot of RocksDB to quality check with batch system Experimentation Framework
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
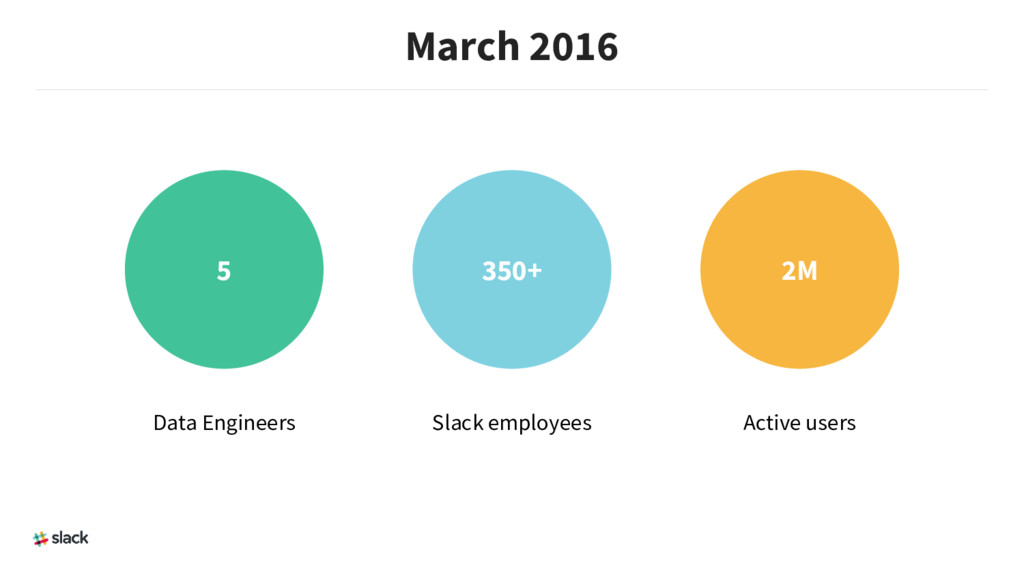{kind=link}
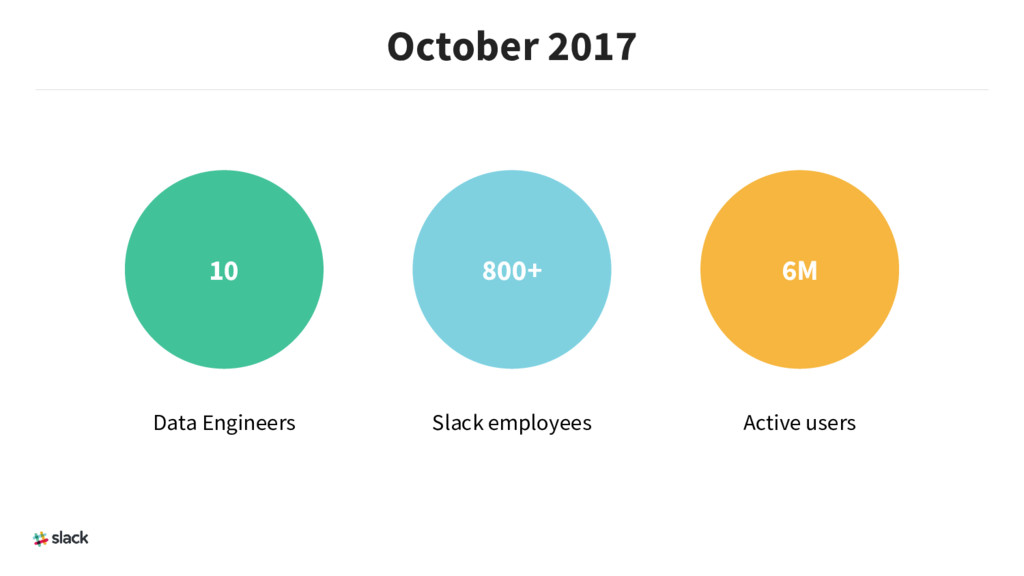{kind=link}
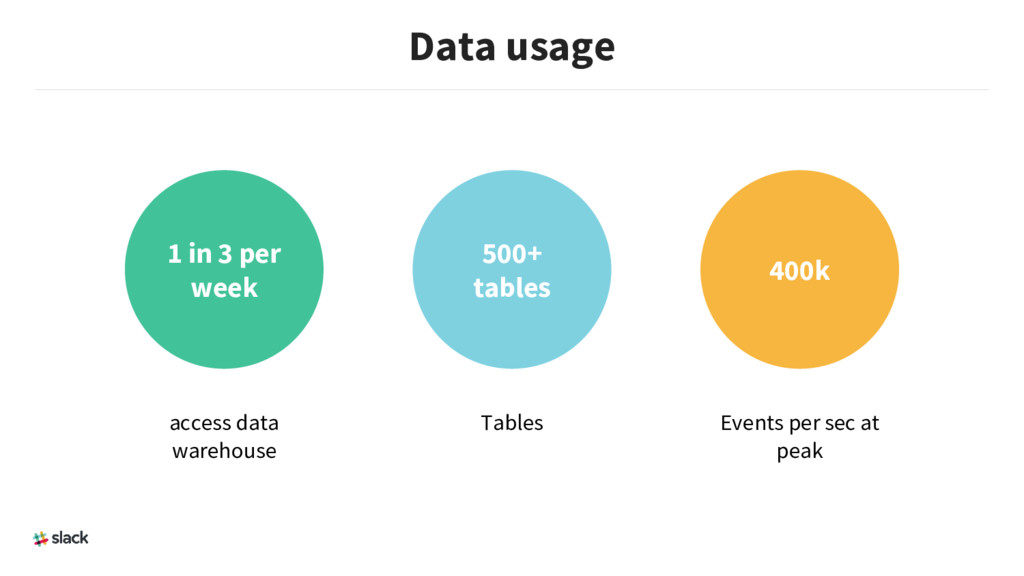{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
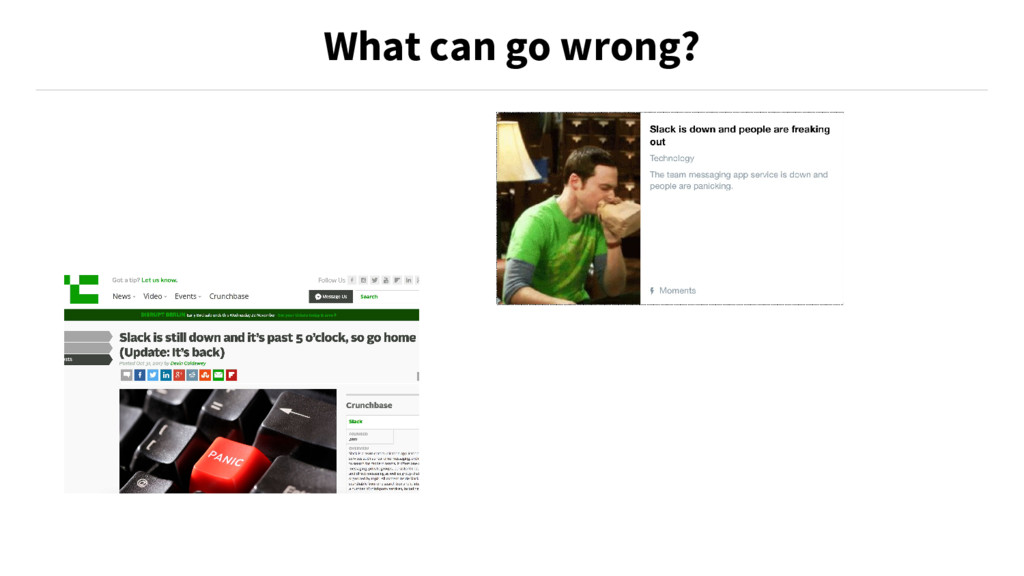{kind=link}
{kind=link}
{kind=link}
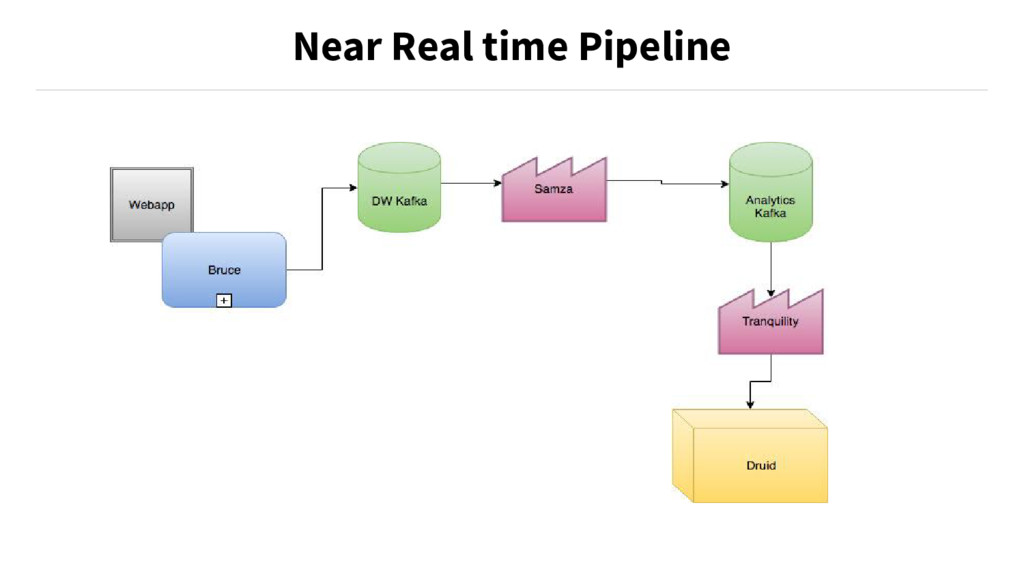{kind=link}
{kind=link}
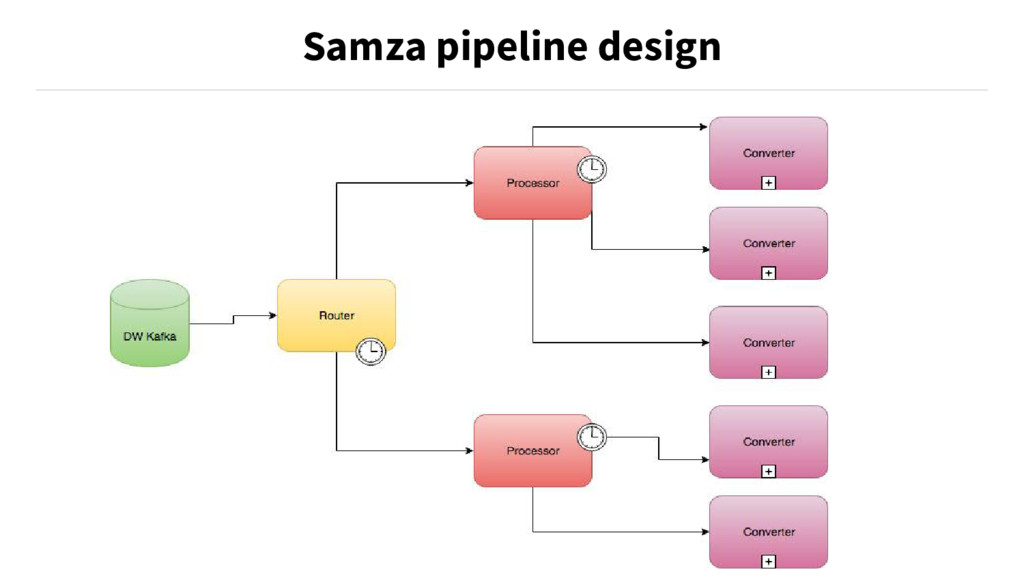{kind=link}
{kind=link}
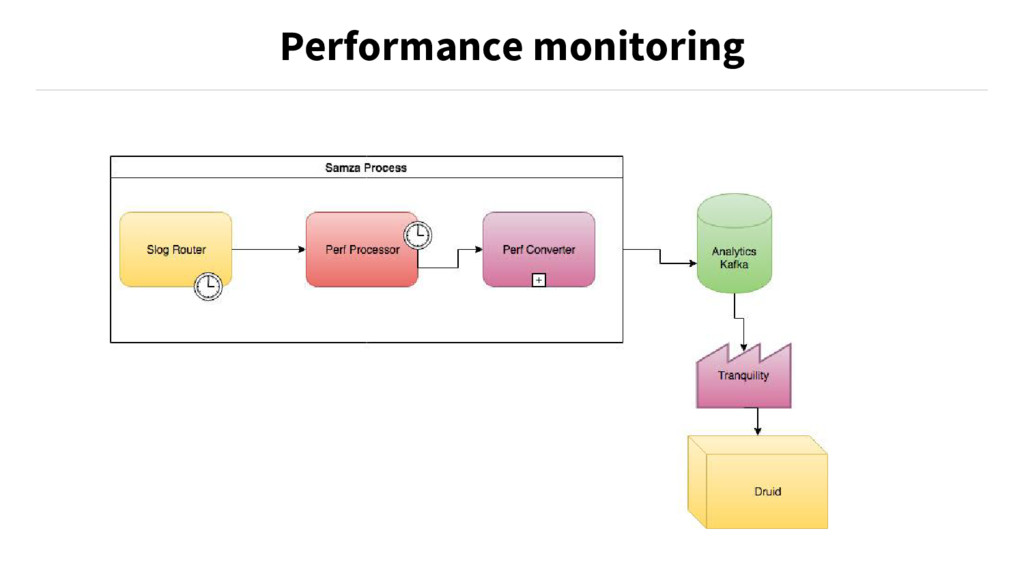{kind=link}
![• Approx percentile using Druid Histogram extension [http://jmlr.org/papers/volume11/ben-haim10a/ben-haim10a.pdf] • Unique](https://files.speakerdeck.com/presentations/c5cba1dca01947029a893df9654c2c12/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}