line.to_f.round] end end class Reducer < Wukong::Streamer::ListReducer def finalize(line) yield [key, values.map(&:to_i).sum] end end Wukong::Script.new(Mapper, Reducer).run
or hadoop> <input> <output> Run on a 100 node cluster with 100 TB of input bin/round_and_sum --run=hadoop \ hdfs://datanode/numbers-*.txt \ hdfs://datanode/output \ --jobtracker=jobtracker
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1.2, 3.4, 5.6]. map(&:round). reduce(:+) # => 10 Input Map](https://files.speakerdeck.com/presentations/4ee90667d6985700490138bc/slide_4.jpg){kind=link}
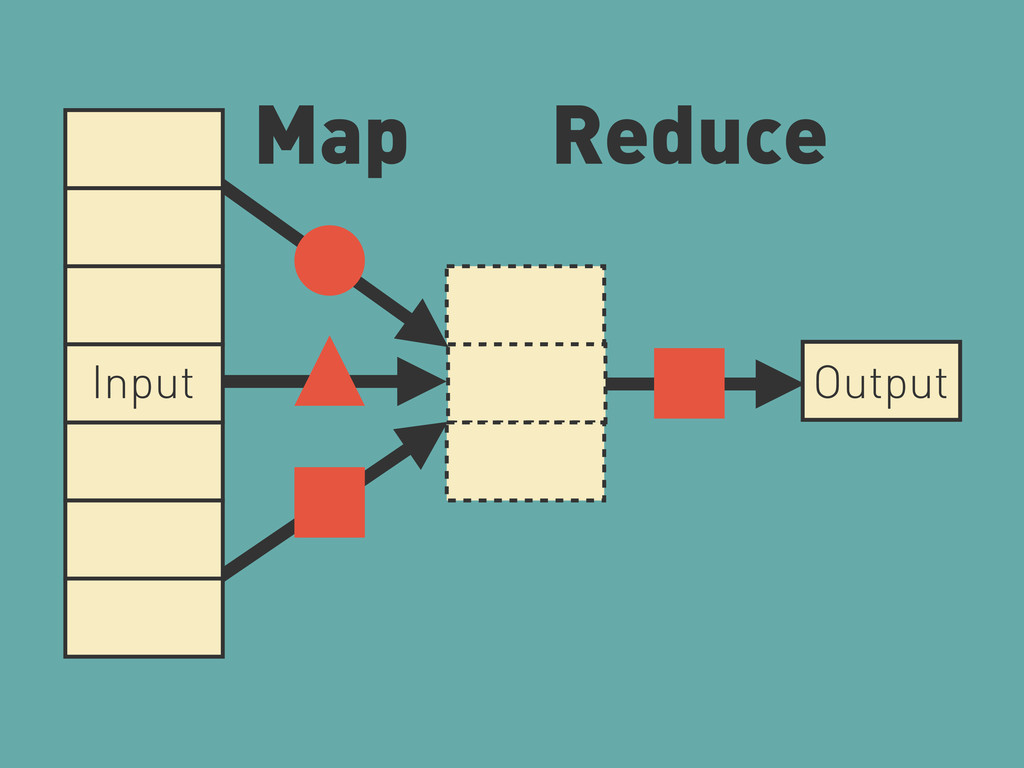{kind=link}
{kind=link}
{kind=link}
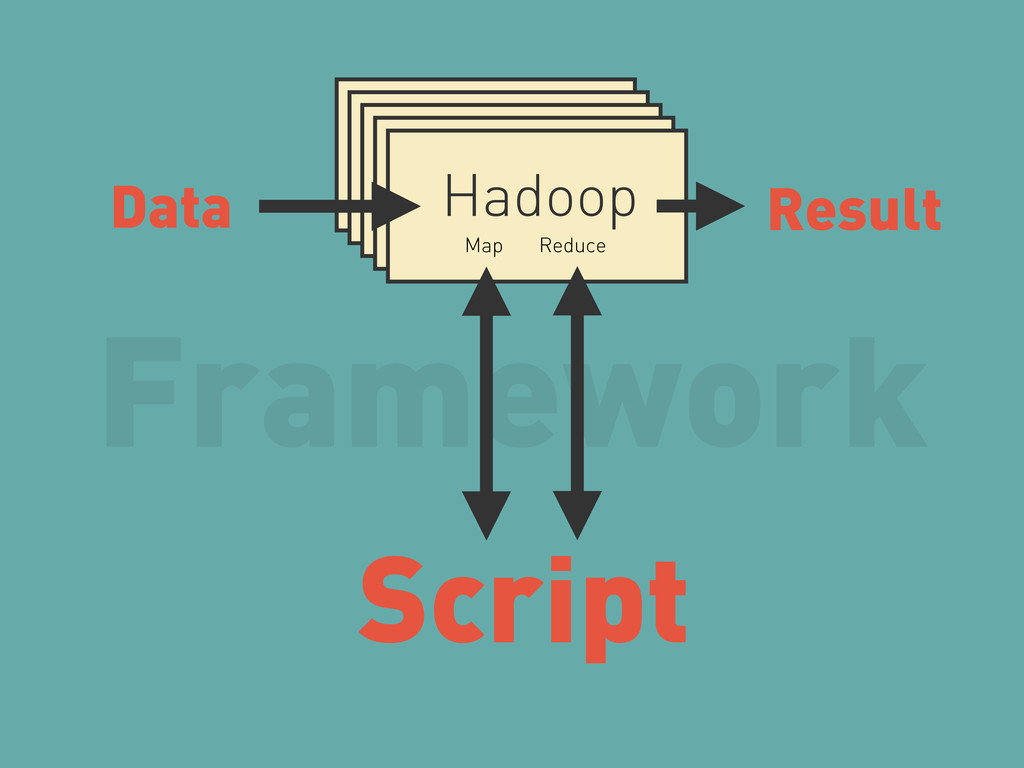{kind=link}
![[1.2, 3.4, 5.6]. map(&:round). reduce(:+) # => 10](https://files.speakerdeck.com/presentations/4ee90667d6985700490138bc/slide_9.jpg){kind=link}
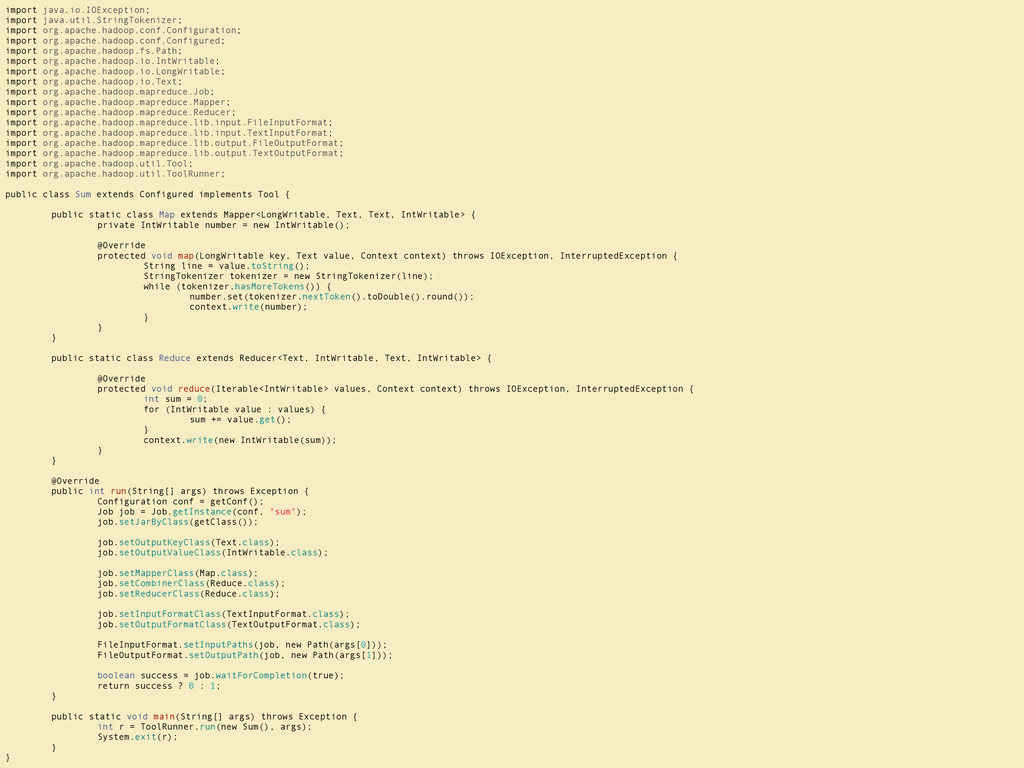{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}