of the 55th Annual Meeting of the Association for Computational Linguistics, Volume 2 (abs/1705.00441), pages 441–447, July 2017. Nagaoka University of Technology VO HUYNH QUOC VIET Natural Language Processing Laboratory 2018 / 07 / 19 Learning Topic-Sensitive Word Representations
words in NLP tasks. • Most of the existing models generate one representation per word and do not consider different meanings of a word. • This paper introduced two approaches (unsupervised learning) to learn multiple topic- sensitive representations per word by using Hierarchical Dirichlet Process (HDP). ⇨ Able to distinguish between different meanings of a given word. 2 The polysemous word ⬌ Diverse contexts ⬌ Distinct topic distributions
to document modeling. • Uses a Dirichlet process to capture the unknow number of topics. • Assumed that topics and senses are interchangeable, and train individual models per word. 3 Example: the word “bat” in two different sentences: While the team at bat is trying to score run, the team in the field is attempting to record outs. The bat wing is membrane strtched acreoss four “extremely” elongated fingers.
by distributions over topics without assuming these concepts to be identical. • The contributions of this paper are: 1/ Proposed three unsupervised, language-independent approaches to approximate senses with topics and learn multiple topic-sensitive embeddings per word. 2/ Showed that in the Lexical Substitution ranking task our models outperform two competitive baselines. 4
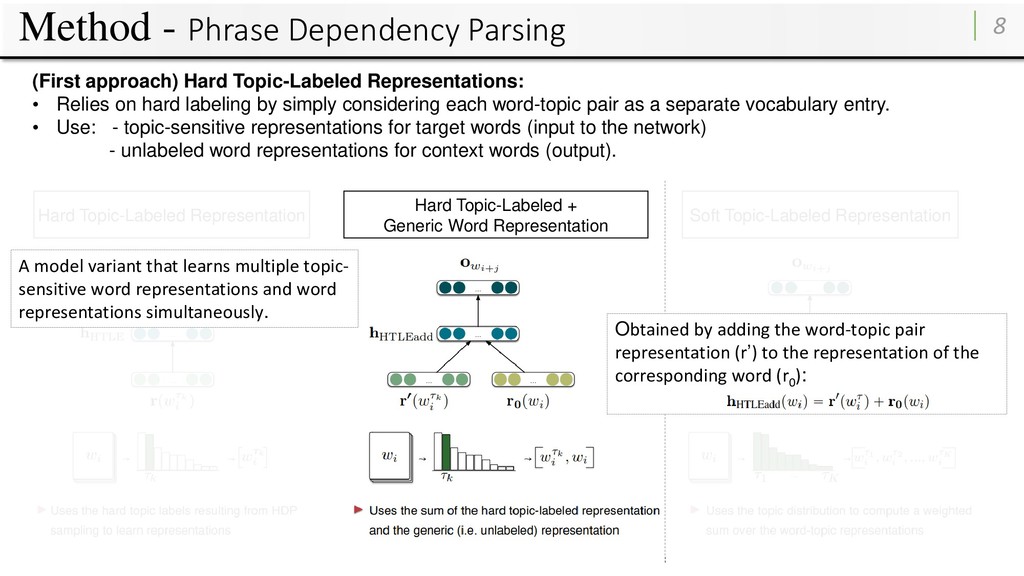
Topic-Labeled + Generic Word Representation Soft Topic-Labeled Representation (First approach) Hard Topic-Labeled Representations: • Relies on hard labeling by simply considering each word-topic pair as a separate vocabulary entry. • Use: - topic-sensitive representations for target words (input to the network) - unlabeled word representations for context words (output).
Topic-Labeled + Generic Word Representation Soft Topic-Labeled Representation The embedding of a word in context h(wi ) is obtained by extracting the row of the input lookup table (r) corresponding to the HDP-labeled word-topic pair: wi : context words ; wi τ : target word-topic pair shortcoming of the HTLE model is that: • the representations are trained separately and information is not shared between different topic-sensitive representations of the same word. (First approach) Hard Topic-Labeled Representations: • Relies on hard labeling by simply considering each word-topic pair as a separate vocabulary entry. • Use: - topic-sensitive representations for target words (input to the network) - unlabeled word representations for context words (output).
Topic-Labeled + Generic Word Representation Soft Topic-Labeled Representation A model variant that learns multiple topic- sensitive word representations and word representations simultaneously. Obtained by adding the word-topic pair representation (r’) to the representation of the corresponding word (r0 ): (First approach) Hard Topic-Labeled Representations: • Relies on hard labeling by simply considering each word-topic pair as a separate vocabulary entry. • Use: - topic-sensitive representations for target words (input to the network) - unlabeled word representations for context words (output).
Topic-Labeled + Generic Word Representation Soft Topic-Labeled Representation (Second approach) Soft Topic-Labeled Representations: • Directly include the topic distributions estimated by HDP for each document. For each update, use the topic distribution to compute a weighted sum over the word-topic representations (r’’) T : the total number of topics di : the document containing wi p(τk |di ) : the probability assigned to topic τk by HDP in document di
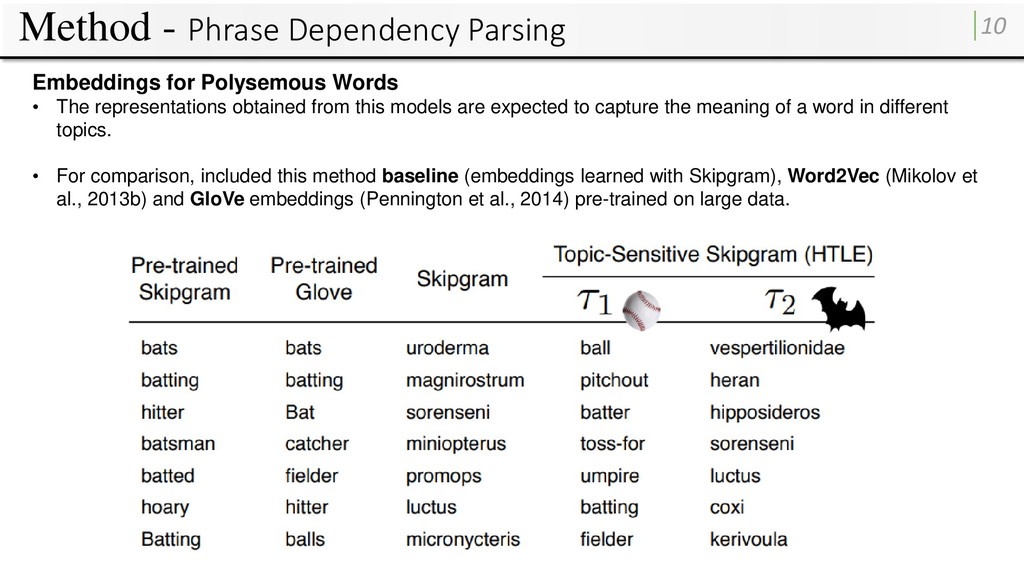
• The representations obtained from this models are expected to capture the meaning of a word in different topics. • For comparison, included this method baseline (embeddings learned with Skipgram), Word2Vec (Mikolov et al., 2013b) and GloVe embeddings (Pennington et al., 2014) pre-trained on large data.
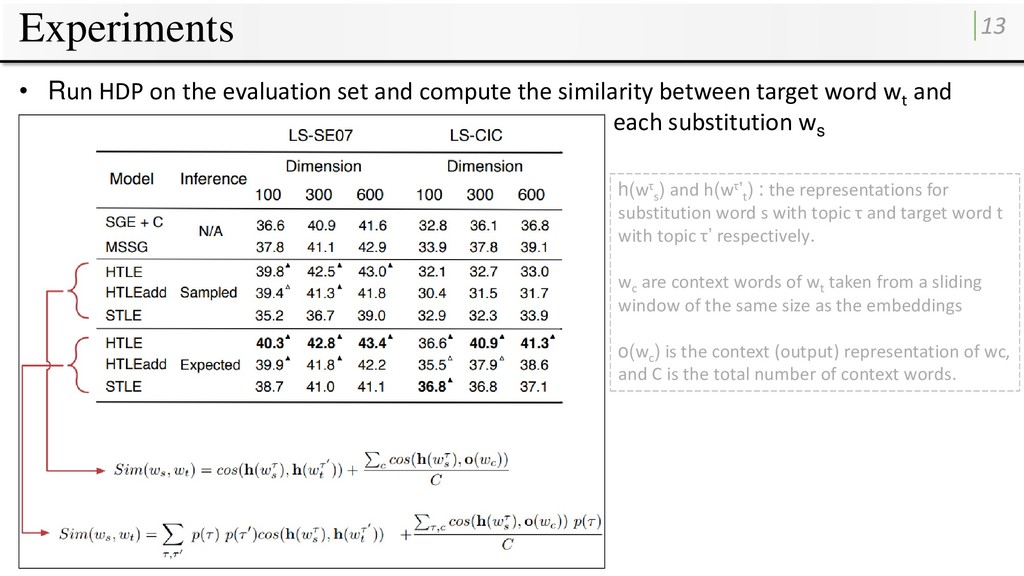
English Wikipedia corpus containing 4.8M documents. • Run HDP on the whole corpus to obtain the word-topic labeling (1st approach) and the document-level topic distributions (2nd approach) • Window size c = 10 and different embedding sizes (100, 300, 600) • Compare this models to several baselines: • Skipgram (SGE) • Multisense embeddings model per word type (MSSG) (Neelakantan et al., 2014). (All model are trained on the same training data with the same settings)
one to identify the best replacements for a word in a sentential context. • The presence of many polysemous target words makes this task more suitable for evaluating sense embedding. • Used two evaluation sets: • LS-SE07 (McCarthy and Navigli, 2007) • LS-CIC (Kremer et al., 2014). • The evaluation is performed by computing the Generalized Average Precision (GAP) score
compute the similarity between target word wt and each substitution w s h(wτ s ) and h(wτ’t ) : the representations for substitution word s with topic τ and target word t with topic τ’ respectively. wc are context words of wt taken from a sliding window of the same size as the embeddings o(wc ) is the context (output) representation of wc, and C is the total number of context words.
exploits the document-level context of words and does not require annotated data. • Obtain statistically significant improvements in the lexical substitution task while not using any syntactic information.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}