Wu. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 3 (EMNLP '09), Vol. 3, pages 1533-1541. Nagaoka University of Technology VO HUYNH QUOC VIET Natural Language Processing Laboratory 2018 / 05 / 30 Phrase Dependency Parsing for Opinion Mining
product reviews. ⇒ to identify product features, expressions of opinions and its relations. • A concept of phrase dependency parsing is introduced ⇒ Extends traditional dependency parsing to phrase level. • Sentiment lexicons are used as an additional source of information for feature extraction. 2
product feature and express different opinions on each of them → The relation extraction is an important subtask of opinion mining. 1. I highly [recommend](1) the Canon SD500(1) to anybody looking for a compact camera that can take [good](2) pictures(2) . 2. This camera takes [amazing](3) image qualities(3) and its size(4) [cannot be beat](4). • Other works on relation extraction: use the headword to represent the whole phrase and extract features from the word level dependency tree. • “Image color is [disappointed]” 3
dependency parsing and propose an approach to construct it is introduced. • Because phrase dependency parsing naturally divides the dependencies into local and global, a novel tree kernel method has also been proposed. 4
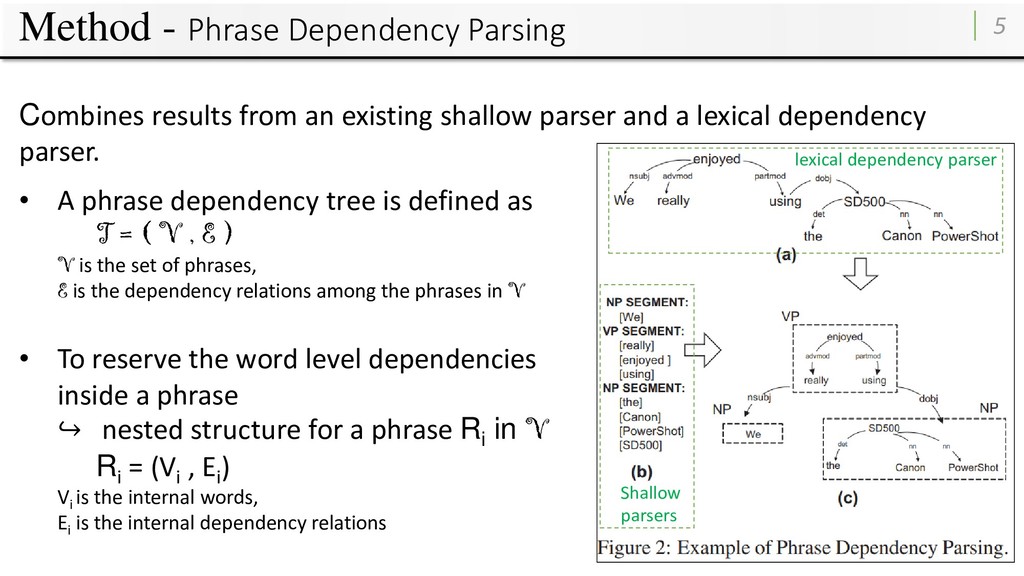
existing shallow parser and a lexical dependency parser. • A phrase dependency tree is defined as T = ( V , E ) V is the set of phrases, E is the dependency relations among the phrases in V • To reserve the word level dependencies inside a phrase ↪ nested structure for a phrase Ri in V Ri = (Vi , Ei ) Vi is the internal words, Ei is the internal dependency relations lexical dependency parser Shallow parsers
• More than 98% of product features are in a single phrase, which is either noun phrase (NP) or verb phrase (VP). ⇒ All NPs and VPs are selected as candidate product features. • The large amount of noise candidates occured: • The more likely a phrase to be a product feature, the more closely it related to the product review. • Each candidate NP or VP chunk in the output of shallow parser is scored by the model → cut off if its score is less than a threshold. • Use a dictionary which contains 8221 opinion expressions to select candidates → The tree distance between product feature and opinion expression in relation < 5 in the phrase dependency parsing tree
kernel over phrase dependency trees and incorporate this kernel within an SVM. (generalized the definition by Culotta and Sorensen, 2004 to fit the phrase dependency tree) Where Ti and Tj are two tree with root node Ri and Rj Fk = { f k } :Each tree node Tk ∈ Ti is augmented with a set of features F m(Ti , Tj ) :match function is defined on comparing a subset of nodes’ features s(Ti , Tj ) :similarity function
Tj): Kin (Ri ,Rj) is a kernel function over root node R = (Vr , Er )’s internal phrase structures Kc is a kernel function over R’s children. l(a) R’s children length as , bs is the s-th element in a, b the constant 0 < λ < 1 normalizes the effects of children subsequences’ length.
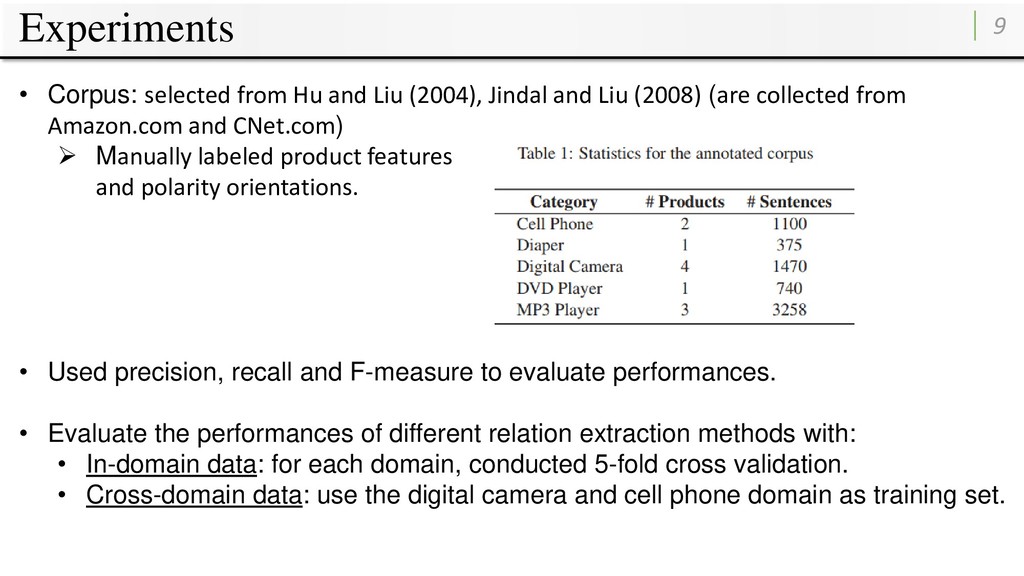
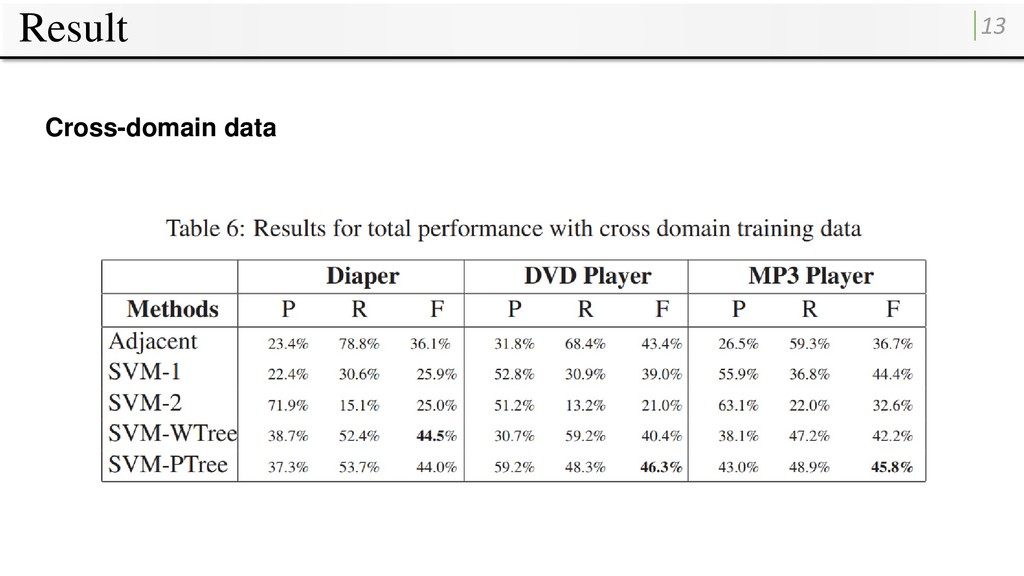
Jindal and Liu (2008) (are collected from Amazon.com and CNet.com) Manually labeled product features and polarity orientations. • Used precision, recall and F-measure to evaluate performances. • Evaluate the performances of different relation extraction methods with: • In-domain data: for each domain, conducted 5-fold cross validation. • Cross-domain data: use the digital camera and cell phone domain as training set.
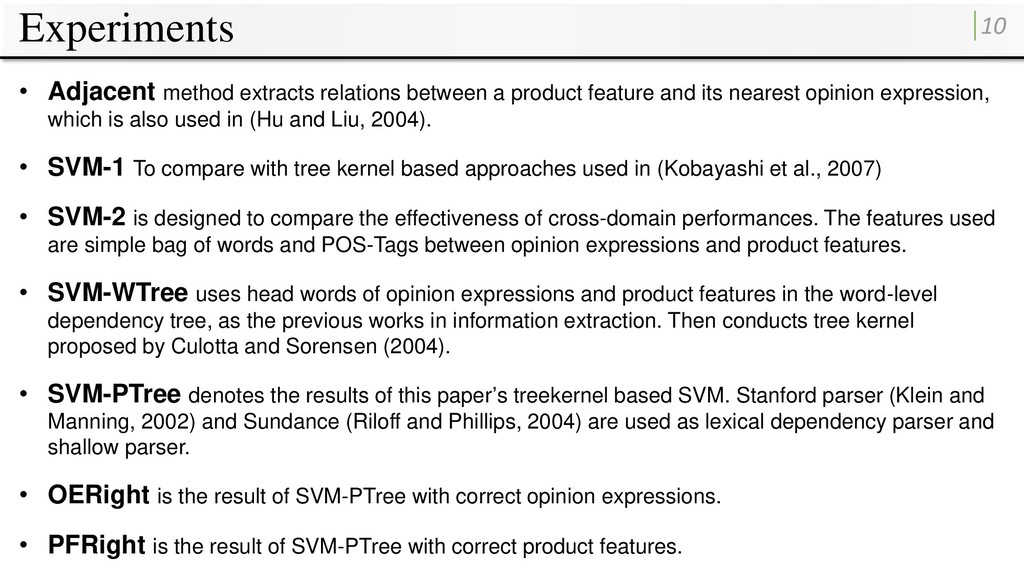
feature and its nearest opinion expression, which is also used in (Hu and Liu, 2004). • SVM-1 To compare with tree kernel based approaches used in (Kobayashi et al., 2007) • SVM-2 is designed to compare the effectiveness of cross-domain performances. The features used are simple bag of words and POS-Tags between opinion expressions and product features. • SVM-WTree uses head words of opinion expressions and product features in the word-level dependency tree, as the previous works in information extraction. Then conducts tree kernel proposed by Culotta and Sorensen (2004). • SVM-PTree denotes the results of this paper’s treekernel based SVM. Stanford parser (Klein and Manning, 2002) and Sundance (Riloff and Phillips, 2004) are used as lexical dependency parser and shallow parser. • OERight is the result of SVM-PTree with correct opinion expressions. • PFRight is the result of SVM-PTree with correct product features.
from unstructured documents. • Focused on extracting relations between product features and opinion expressions. Defined the phrase dependency parsing and proposed an approach to construct the phrase dependency trees Proposed a new tree kernel function to model the phrase dependency trees. • Experimental results show that this approach improved the performances of the mining task.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}