Duy-Tin Vo and Yue Zhang. Proceedings of the 24 th International Joint Conference on Artifcial Intelligence (IJCAI 2015), Pages 1347-1353 Nagaoka University of Technology VO HUYNH QUOC VIET > Natural Language Processing Laboratory 2018 / 04 / 30
the use of syntax (e.g. parse trees and POS tags, etc.) , by extracting a rich set of automatic features. • Both sentiment-driven and standard embeddings are used, and a rich set of neural pooling functions are explored. • Sentiment lexicons are used as an additional source of information for feature extraction. 2
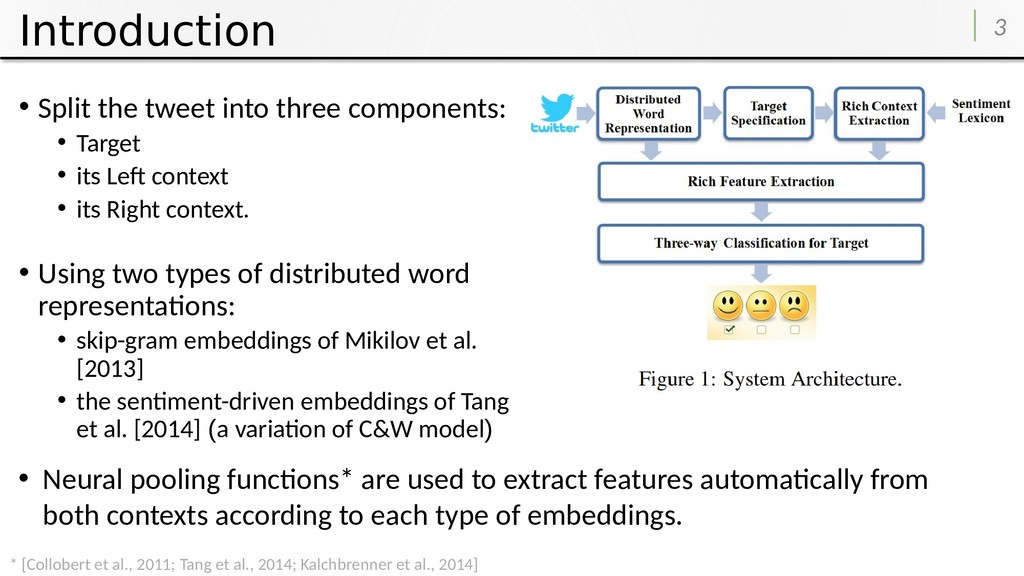
• its Left context • its Right context. • Using two types of distributed word representations: • skip-gram embeddings of Mikilov et al. [2013] • the sentiment-driven embeddings of Tang et al. [2014] (a variation of C&W model) 3 • Neural pooling functions* are used to extract features automatically from both contexts according to each type of embeddings. * [Collobert et al., 2011; Tang et al., 2014; Kalchbrenner et al., 2014]
specifc word embedding (SSWE) that automatic features can give the state-of-the-art accuracies on target- independent Twitter SA. Using the traditional ngram and POS features. • Jiang et al. [2011] analyze the dependency relationships between a given target and other words in a parse tree, considering them as additional features in the classical model of [Pang et al., 2002]. Using CRFs and POS features. • Dong et al. [2014] develop a novel deep learning approach based on automatically-parsed tweets, adaptively propagating sentiment signals to a specifc target using a recursive neural network.
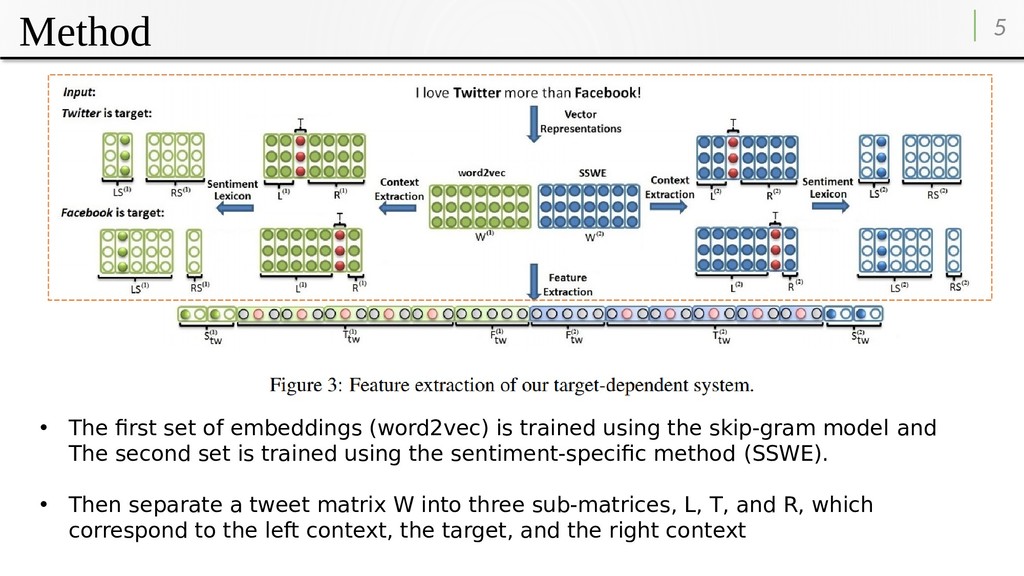
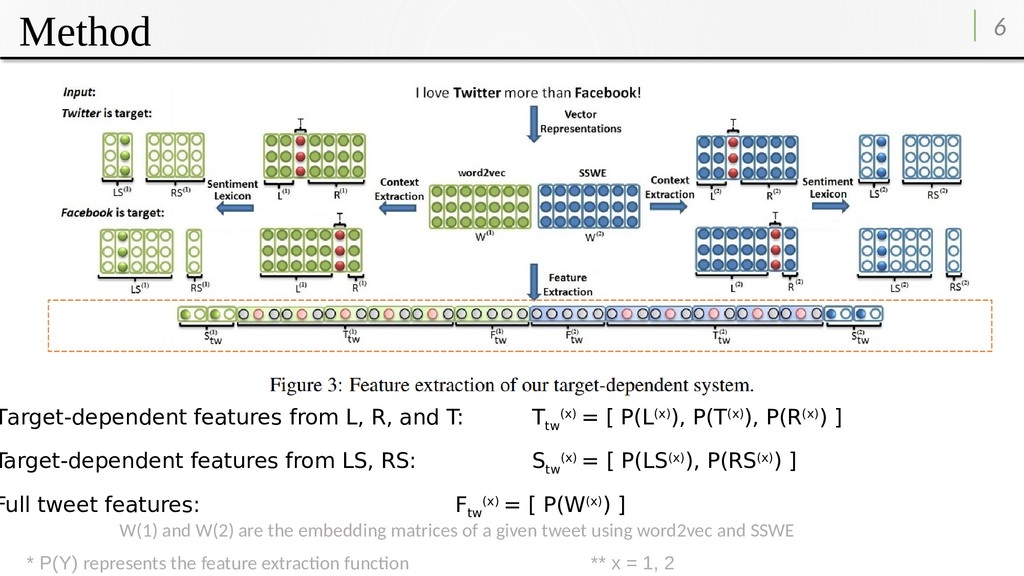
trained using the skip-gram model and The second set is trained using the sentiment-specific method (SSWE). • Then separate a tweet matrix W into three sub-matrices, L, T, and R, which correspond to the left context, the target, and the right context
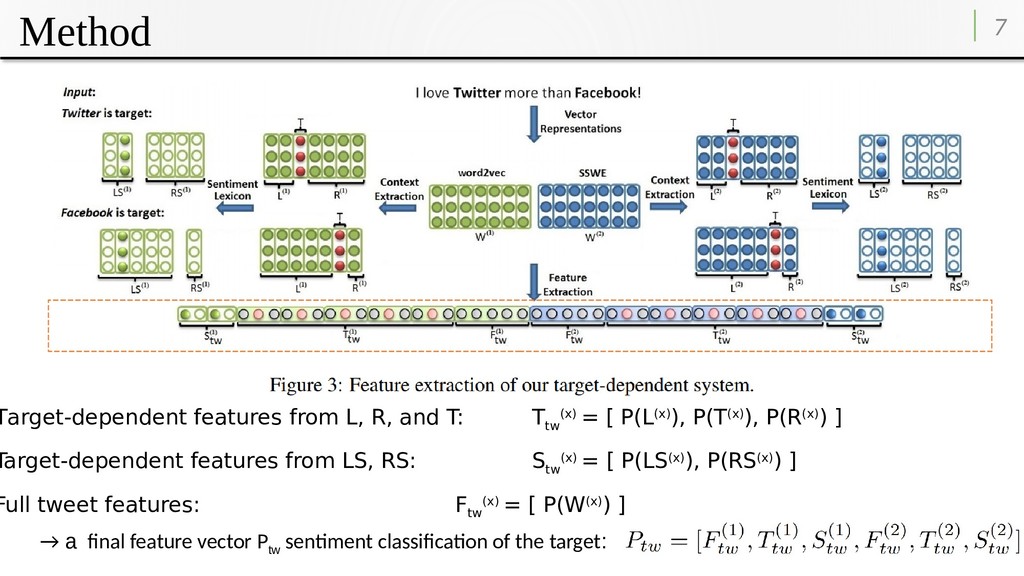
tw (x) = [ P(L(x)), P(T(x)), P(R(x)) ] Target-dependent features from LS, RS: S tw (x) = [ P(LS(x)), P(RS(x)) ] Full tweet features: F tw (x) = [ P(W(x)) ] * P(Y) represents the feature extraction function ** x = 1, 2 W(1) and W(2) are the embedding matrices of a given tweet using word2vec and SSWE
tw (x) = [ P(L(x)), P(T(x)), P(R(x)) ] Target-dependent features from LS, RS: S tw (x) = [ P(LS(x)), P(RS(x)) ] Full tweet features: F tw (x) = [ P(W(x)) ] → a fnal feature vector P tw sentiment classifcation of the target:
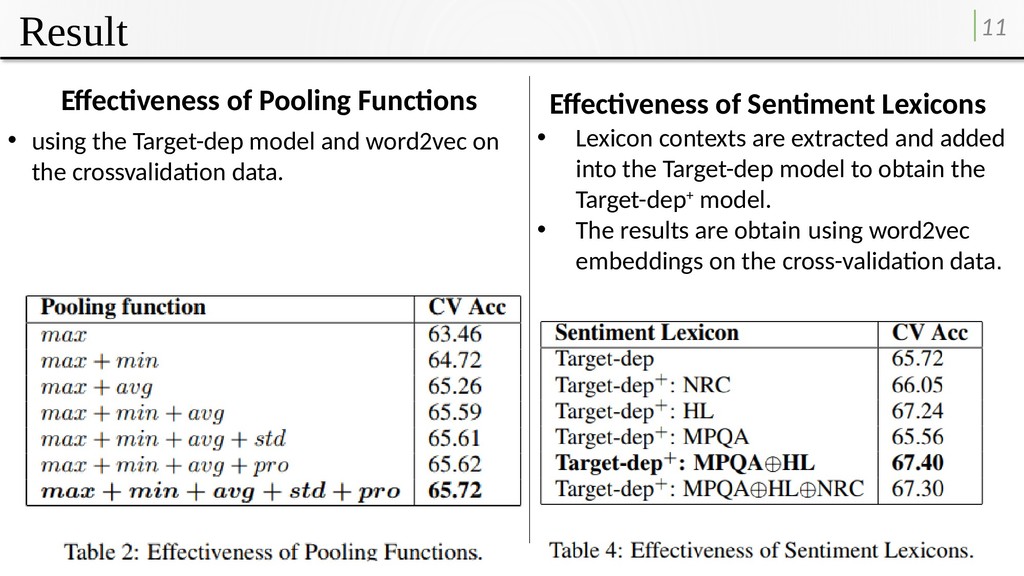
avg pooling functions to extract features from word embeddings. •Where x i , k is the ith feature of the k word (max) pooling p = ∞ (min) pooling p = - ∞ (avg) pooling p = 1 (std) Strandard deviation p = 2 (pro) is a variation of (avg), with larger contrast between positive and negative values.
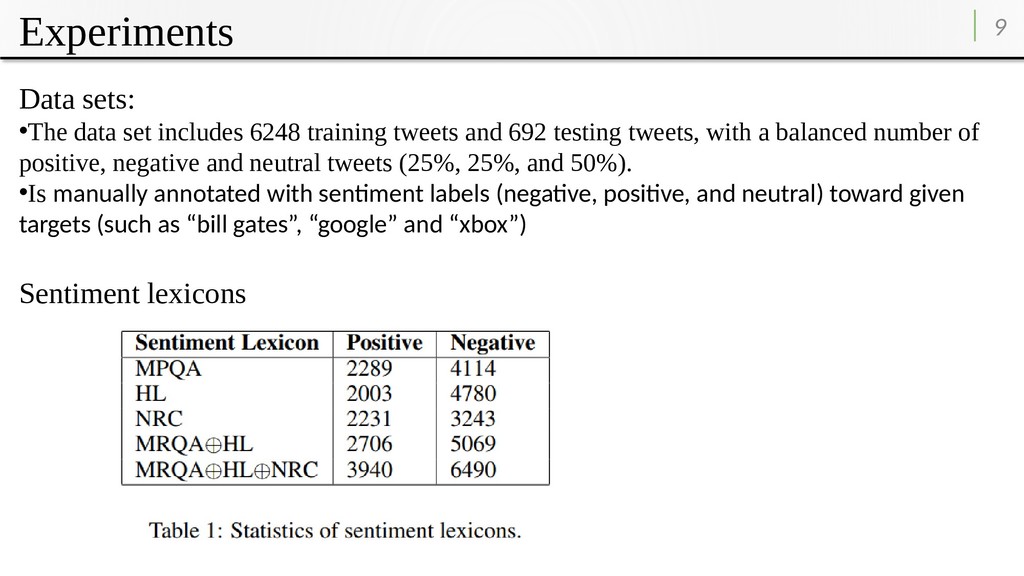
tweets and 692 testing tweets, with a balanced number of positive, negative and neutral tweets (25%, 25%, and 50%). •Is manually annotated with sentiment labels (negative, positive, and neutral) toward given targets (such as “bill gates”, “google” and “xbox”) Sentiment lexicons
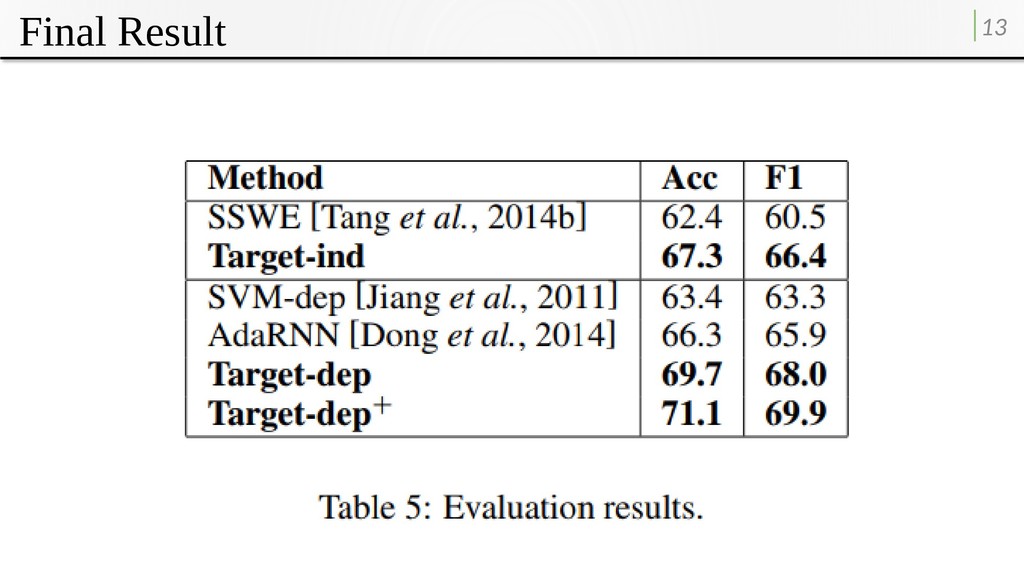
full tweet features (F tw ); •Target-dep−: A pure targeted method, which makes use of target-dependent features (T tw ); •Target-dep: This method combines features of both Target-ind and Target-dep−; •Target-dep+: The method uses Target-dep features and target-dependent sentiment features (S tw ).
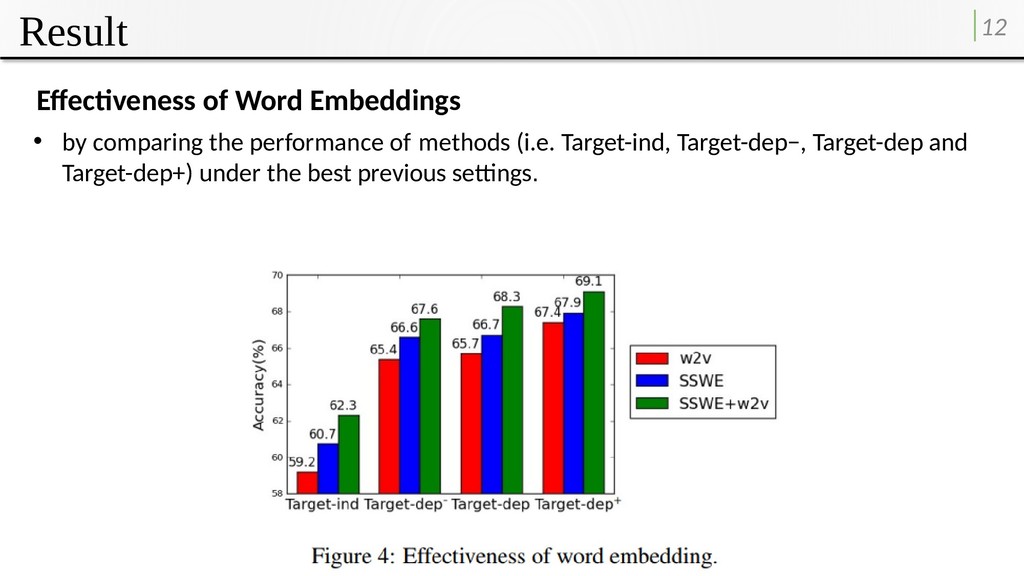
model and word2vec on the crossvalidation data. • Lexicon contexts are extracted and added into the Target-dep model to obtain the Target-dep+ model. • The results are obtain using word2vec embeddings on the cross-validation data. Effectiveness of Sentiment Lexicons
analyzers, gives better performance compared to the best previous method that uses syntax. • The method solves the potential limitation of syntaxbased method by avoiding the influence of noise by automatic syntactic analyzer. • Proved that multiple embeddings, multiple sentiment lexicons offer rich sources of feature information, which leads to significant improvement on accuracies.
{kind=link}
{kind=link}
{kind=link}
![Related work 4 • Tang et al. [2014] demonstrate sentiment](https://files.speakerdeck.com/presentations/056d964564c0420c8e7016b04cdd9199/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}