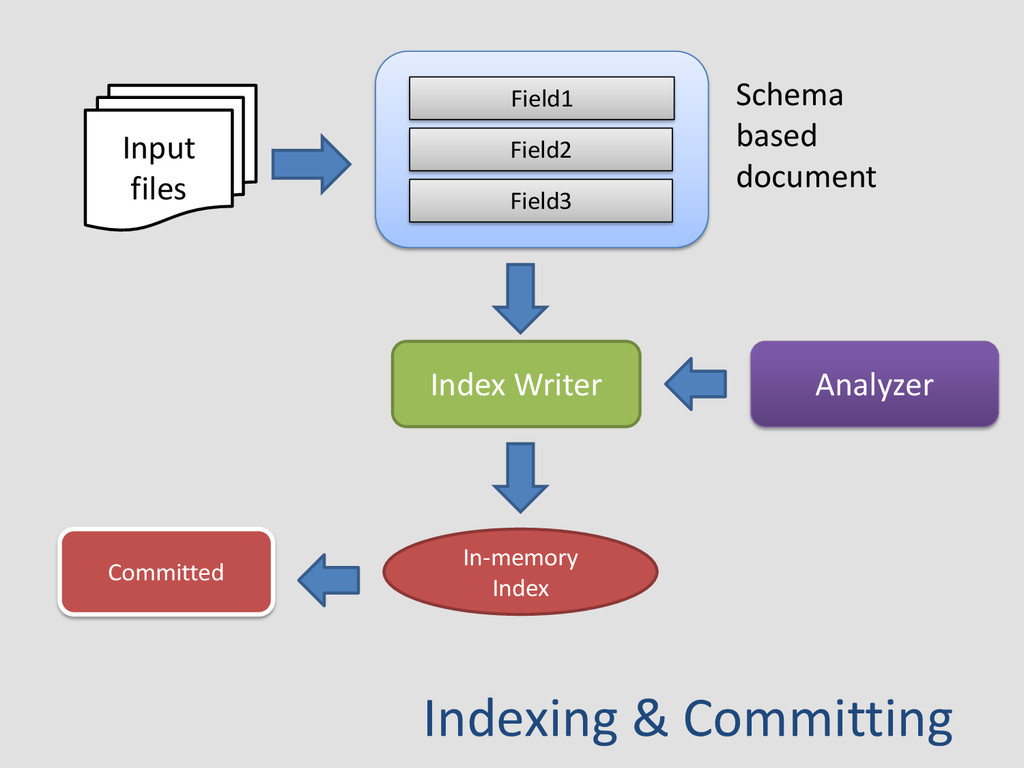
data as Documents and store them to index Document is a set of fields Field is a name=value pair {title = “python”, content = “computer”, tag = “language”} Analyzers "parse" each field of your data into index- able "tokens" or keywords. “Welcome to Pycon" it will produce list [“welcome", “to", “Pycon”]
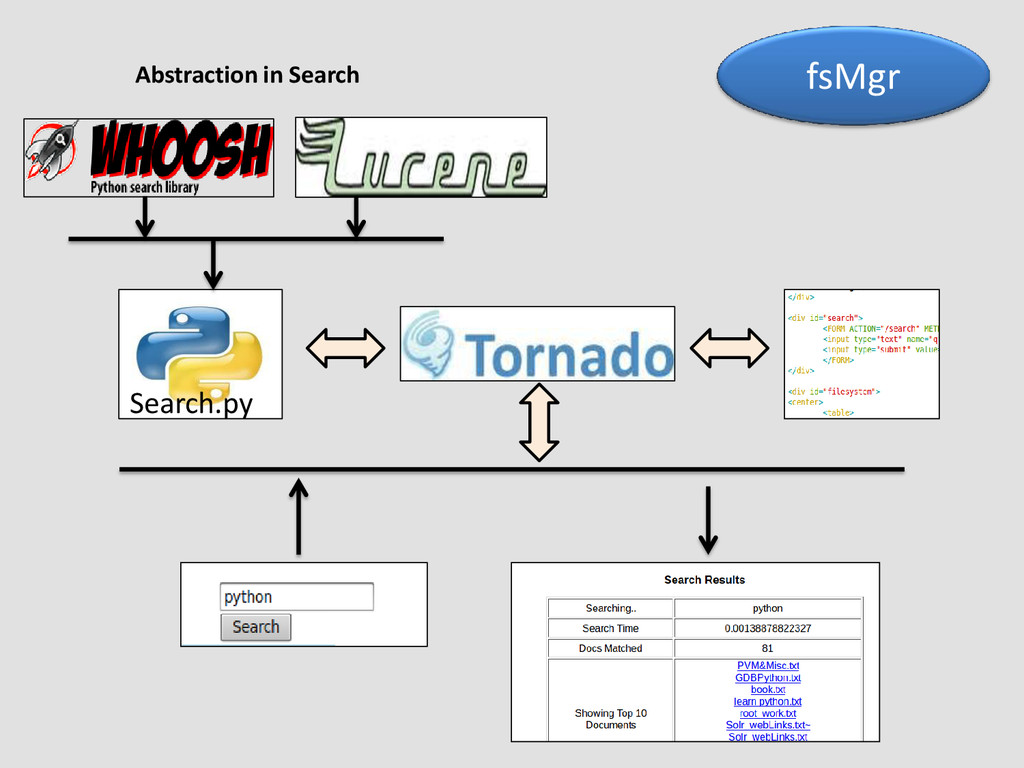
indexing and search One of the fastest Python search engine 100% Python code Extensible code No external dependency Active development and support
a small project. Limited scalability for search and indexing – A good beginning • Haystack is appropriate with Django • Xapian is ultra fast, but is not as feature rich as Solr • Lucene is not distributed; has external dependency
query types that RDBMSs in general do not support without vendor extensions: • Fuzzy queries, in which "fuzzy" and "wuzzy" are considered matches • Word stemming queries, which consider "take," "took," and "taken" to be identical • Sound-like queries, which consider "cat" and "kat" to be identical • Synonym queries, which consider "jump," "hop," and "leap" to be identical • Queries on binary BLOB data types, such as PDF documents, Microsoft Word or Excel documents, or HTML and XML documents • More disappointingly, SQL search results are not ranked by match- relevance scores. The SQL standard is simply not intended for full- text querying.
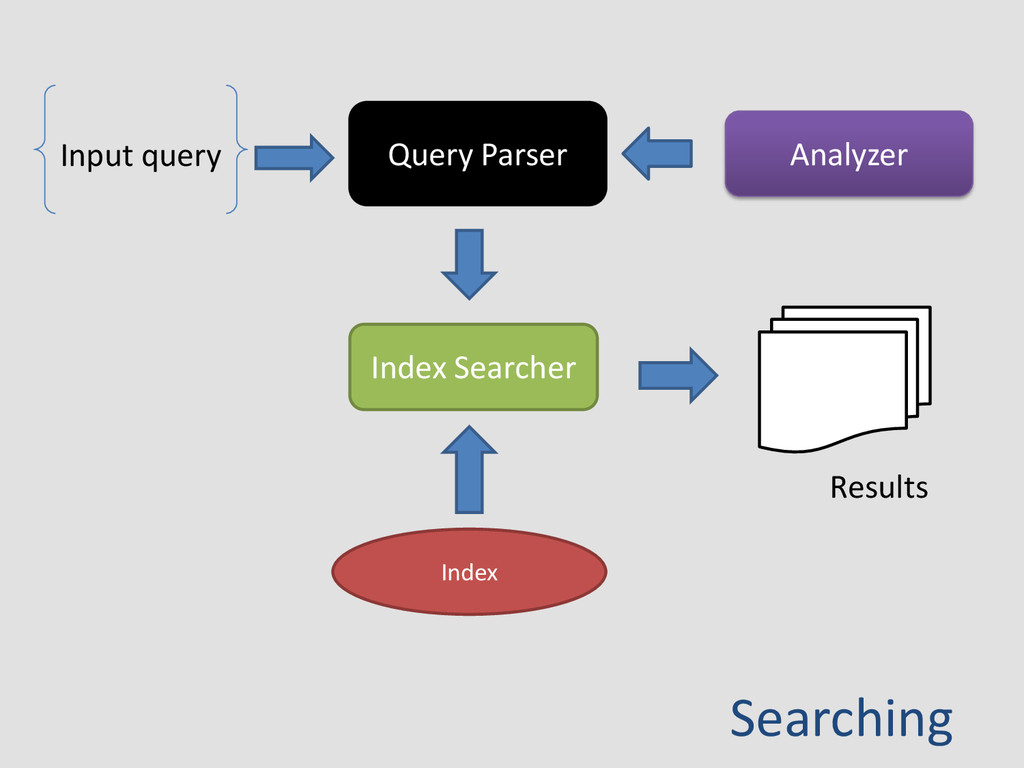
format for quick look up – Fast random access to stored words • Searching – Specify keywords • Displaying – Lookup documents that are relevant – Ranking – Different types of queries
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}