Drake Don’t study, get drunk, drive too fast “Newest acronym you'll love to hate”, “Dumb” Drake apologized about culture's obnoxious adoption of the phrase, saying he had no idea it would become so big Judkis, Maura (February 25, 2011). "#YOLO: The Newest Acronym You'll Love to Hate". Washington Post Style Blog. Retrieved October 10, 2012 Walsh, Megan (May 17, 2012). "YOLO: The Evolution of the Acronym". Huffington Post. The Black Sheep Online Apology - In the opening monologue of Saturday Night Live on January 19, 2014
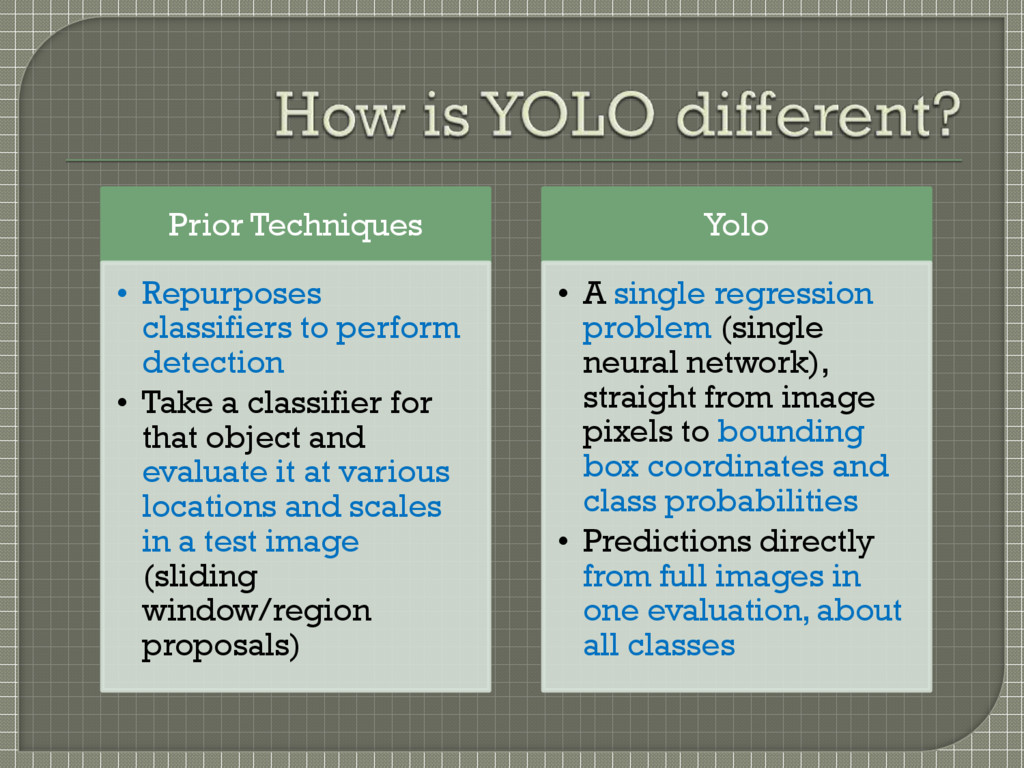
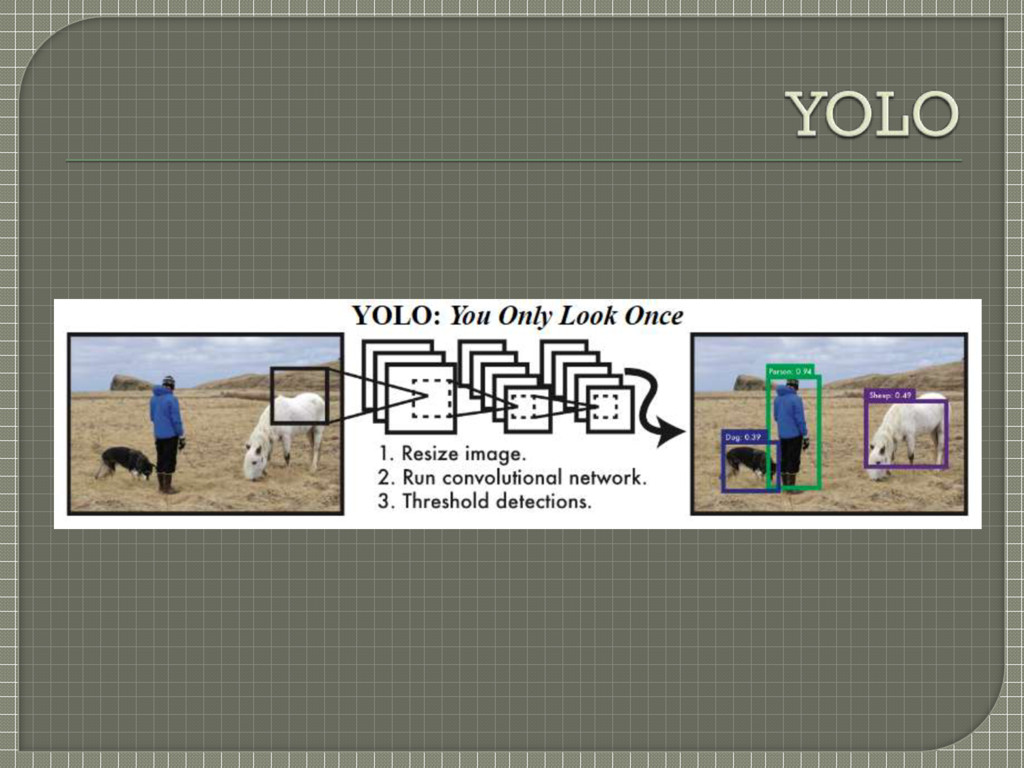
a classifier for that object and evaluate it at various locations and scales in a test image (sliding window/region proposals) Yolo • A single regression problem (single neural network), straight from image pixels to bounding box coordinates and class probabilities • Predictions directly from full images in one evaluation, about all classes
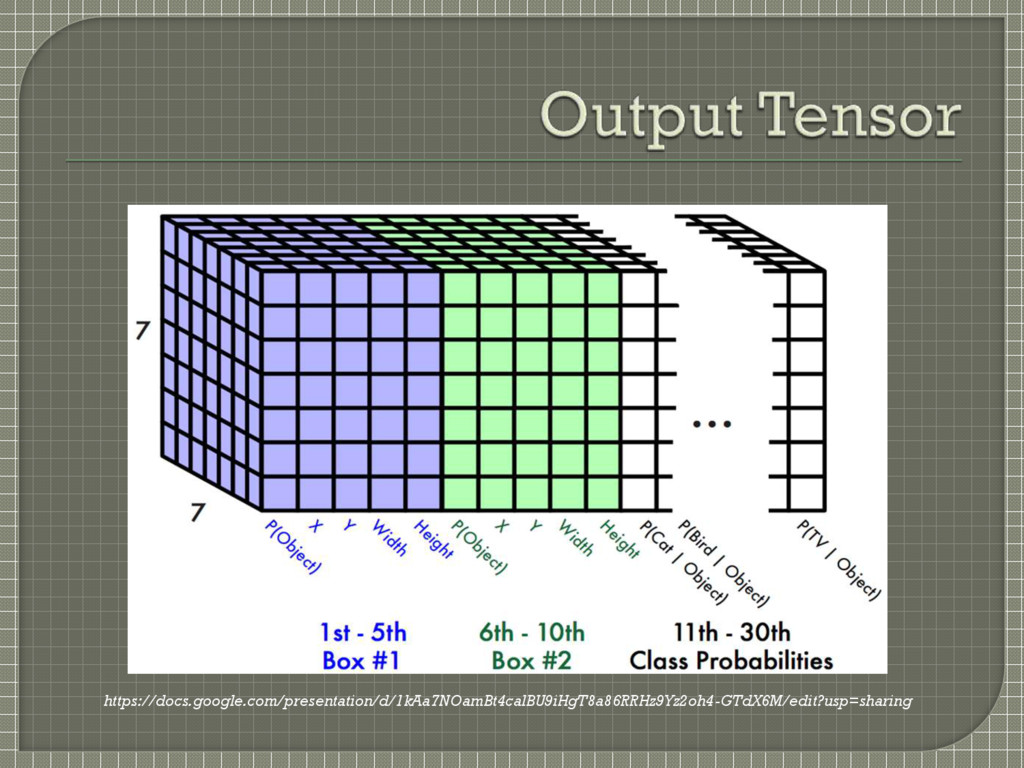
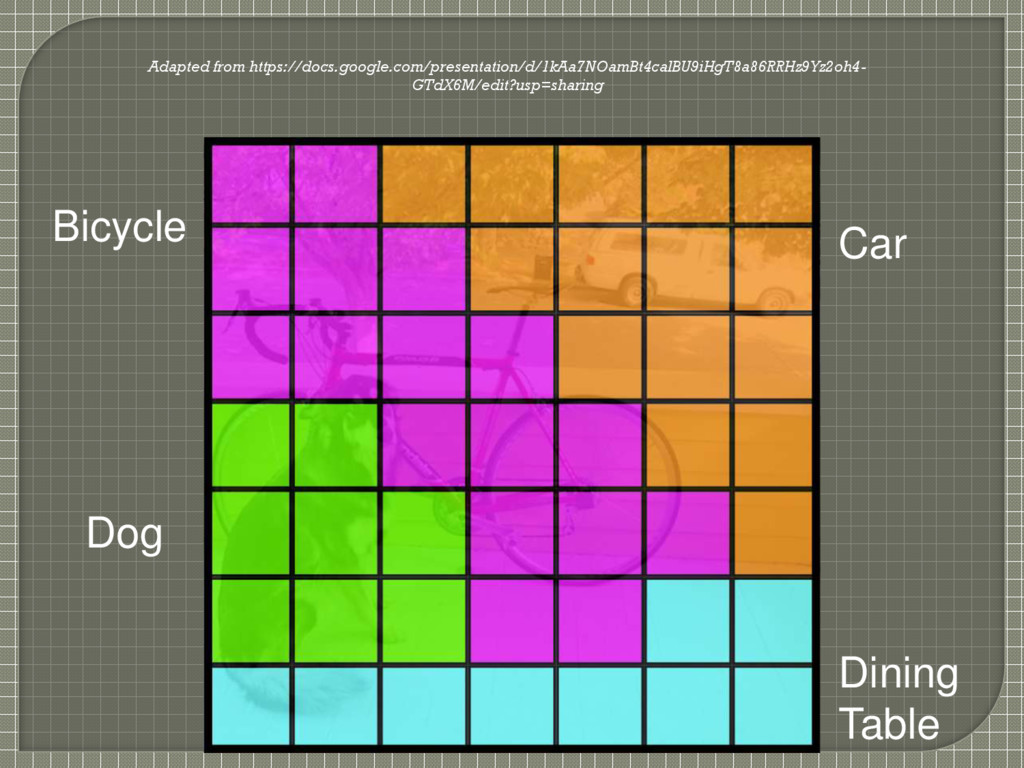
conditional class probabilities Pr(Classi | Object) Each bounding box consists of 5 predictions: x, y, w, h and confidence x,y center of box relative to bounds of grid cell [0,1] w,h relative to whole image [0,1] Confidence = Pr(Object) * IOU between the predicted box and ground truth These predictions are encoded as S X S X (B*5 + C) tensor
predictions to get class- specific confidence scores for each box • These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object
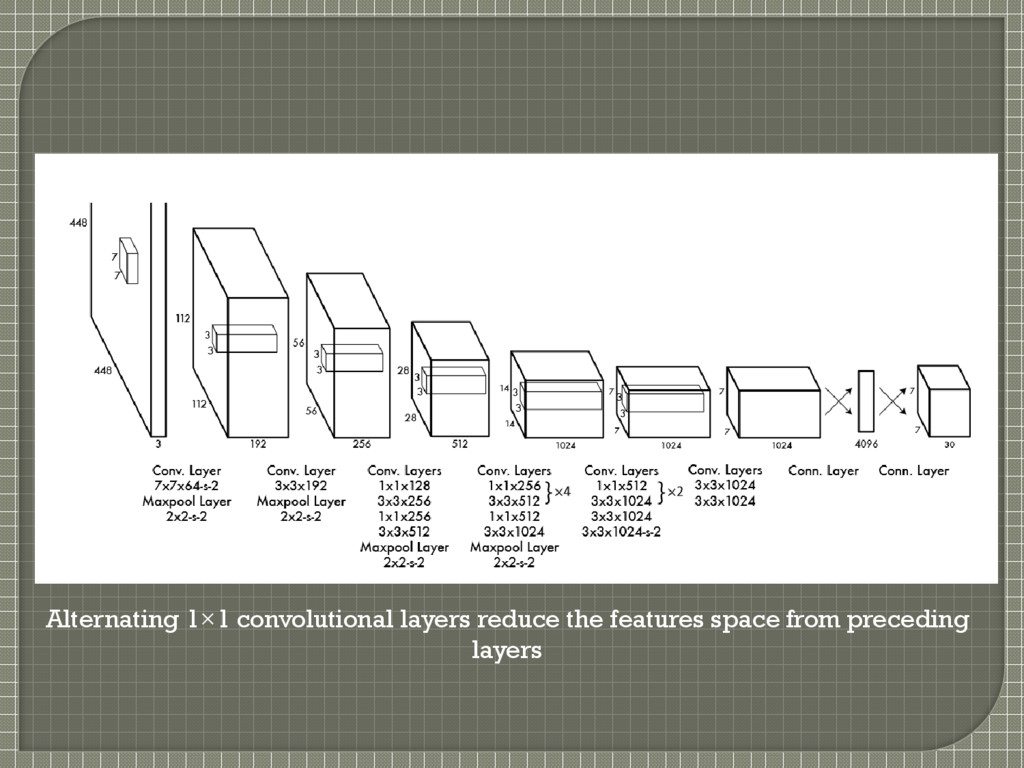
VOC detection dataset • Initial convolutional layers extract features from image • FC layers predict output probabilities and coordinates Inspired by GoogleNet • 24 convolutional layers followed by 2 FC layers • Instead of inception modules, simply use 1X1 reduction layers followed by 3X3 convolutional layers (as in NIN) M. Lin, Q. Chen, and S. Yan. Network in network. CoRR, abs/1312.4400, 201
and a fully connected layer • On the ImageNet 1000-class competition dataset They train this network for approximately a week and achieve a single crop top-5 accuracy of 88% on the ImageNet 2012 validation set, comparable to the GoogLeNet models in Caffe’s Model Zoo
improve performance Add four convolutional layers and two fully connected layers with randomly initialized weights Input resolution increased from 224X224 to 448X448 • Detection often requires fine grained visual information S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal net- Works. arXiv preprint arXiv:1506.01497, 2015
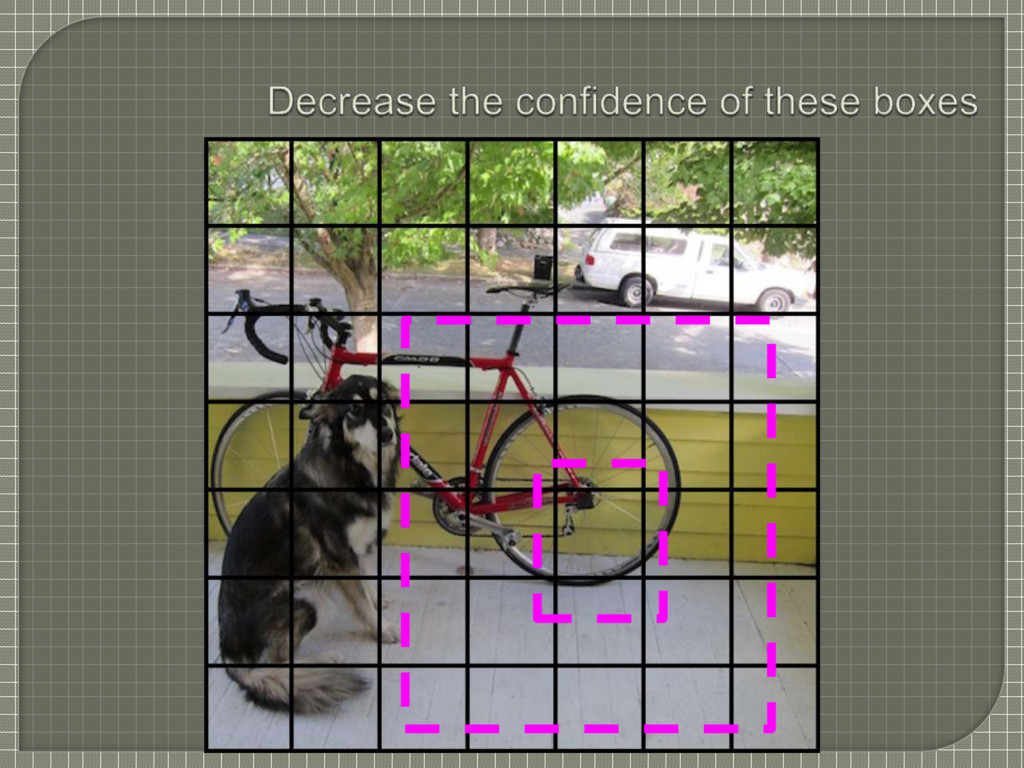
every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on
bounding box coordinate predictions (localization error) and decrease the loss from confidence predictions (classification error) for boxes that don’t contain objects λcoord = 5 λnoobj = 0.5
weighs errors in large boxes and small boxes Solution to Problem 3: Small deviations in large boxes matter less than in small boxes – predict square root of width and height of bounding box
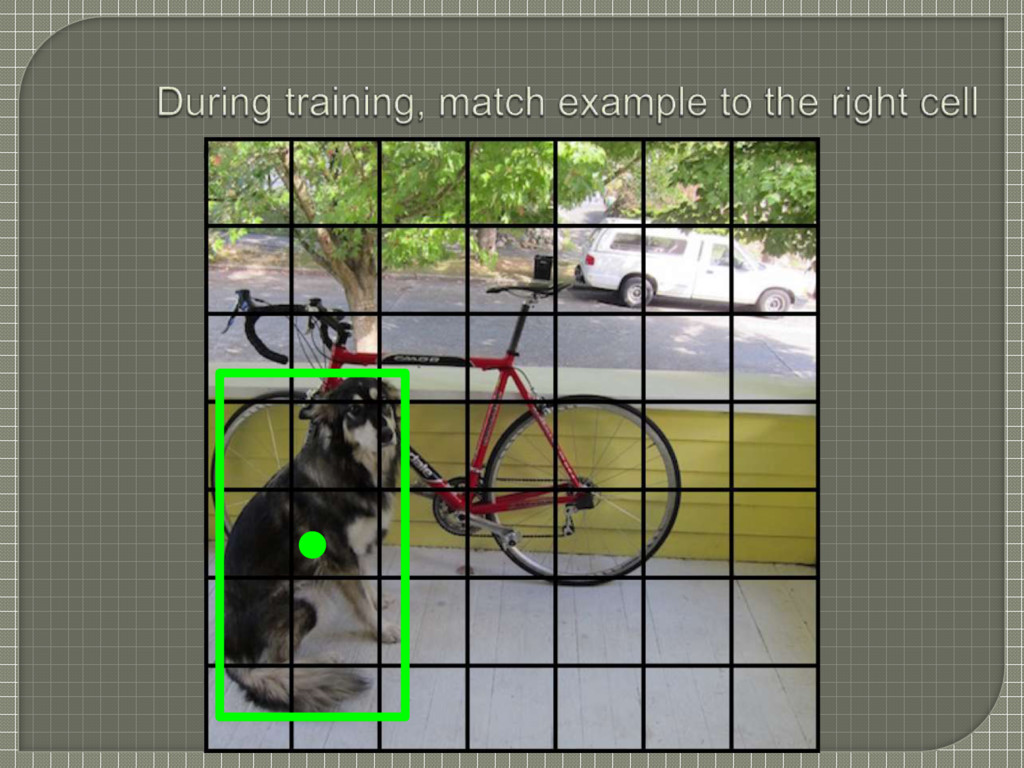
At training time we only want one bounding box predictor to be responsible for each object Assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth • Leads to specialization between the bounding box predictors • Each predictor gets better at predicting certain sizes, aspect ratios, or classes of object, improving overall recall
bounding boxes which are responsible for prediction (i.e. maximum overlap with ground truth box) • Highest weightage, hence multiplied by λcoord = 5 3rd term • Classification error of those bounding boxes which are responsible for prediction • Medium weightage, hence multiplied by 1 4th term • Classification error of those boxes which are NOT responsible for prediction • Least weightage, hence multiplied by λobj = 0.5 5th term • Penalizes classification error if an object is present in that grid cell • Hence the notion of conditional class probability
validation data sets from PASCAL VOC 2007 and 2012 SGD Batch size of 64 Momentum of 0.9 Decay of 0.0005 Learning rate • First epochs: slowly increase from 10-3 to 10-2 otherwise model often diverges due to unstable gradients • Continue for 75 epochs • 10-3 for 30 epochs • 10-4 for 30 epochs
the first connected layer prevents co-adaptation between layers Extensive data augmentation • Random scaling and translations of up to 20% of the original image size • Randomly adjust the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space
Often it is clear which grid cell an object falls in to and the network only predicts one box for each object However, some large objects or objects near the border of multiple cells can be well localized by multiple cells • Non-maximal suppression to fix multiple detections As in R-CNN and DPM • Quick operation and yet adds 2-3% to mAP
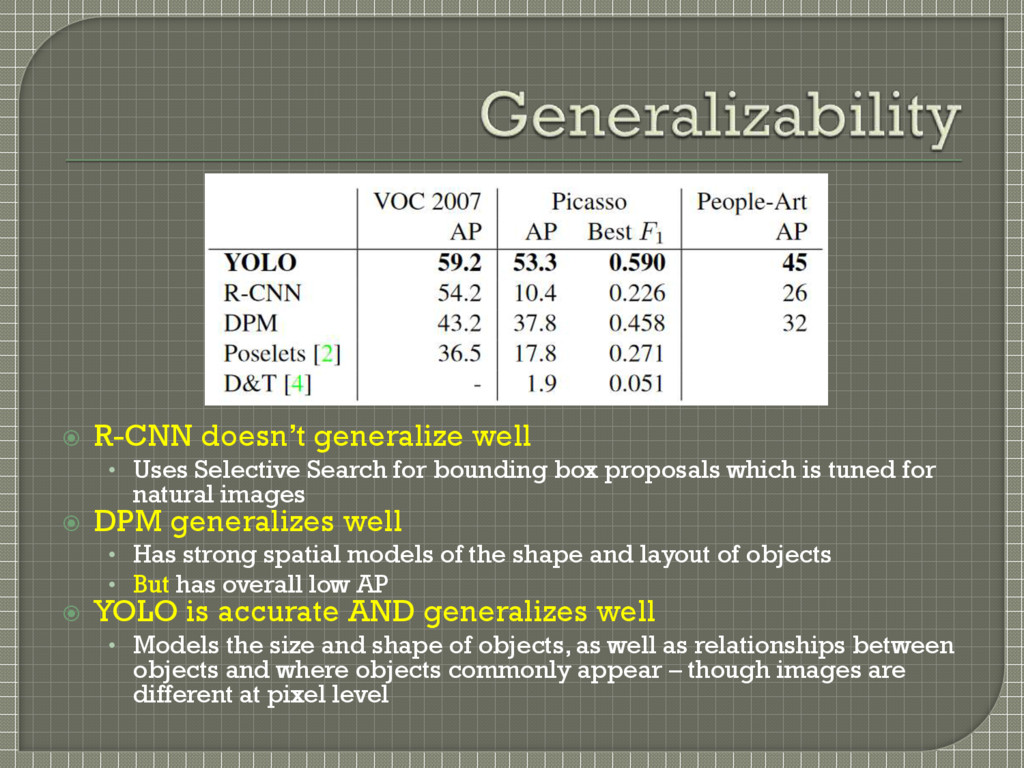
methods, including DPM and R-CNN by wide margin, when generalizing from natural images to other domains like artwork • Less likely to break down when applied to new domains or unexpected inputs
the image) when making predictions • Thus implicitly encodes contextual information about classes as well as their appearance • Makes less than half the number of background errors compared to Fast R-CNN which mistakes background patches in an image for objects because it can’t see the larger context
(especially for small objects) • Imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class • Limits the number of nearby objects that can be predicted • Small objects that appear in groups, such as flocks of birds
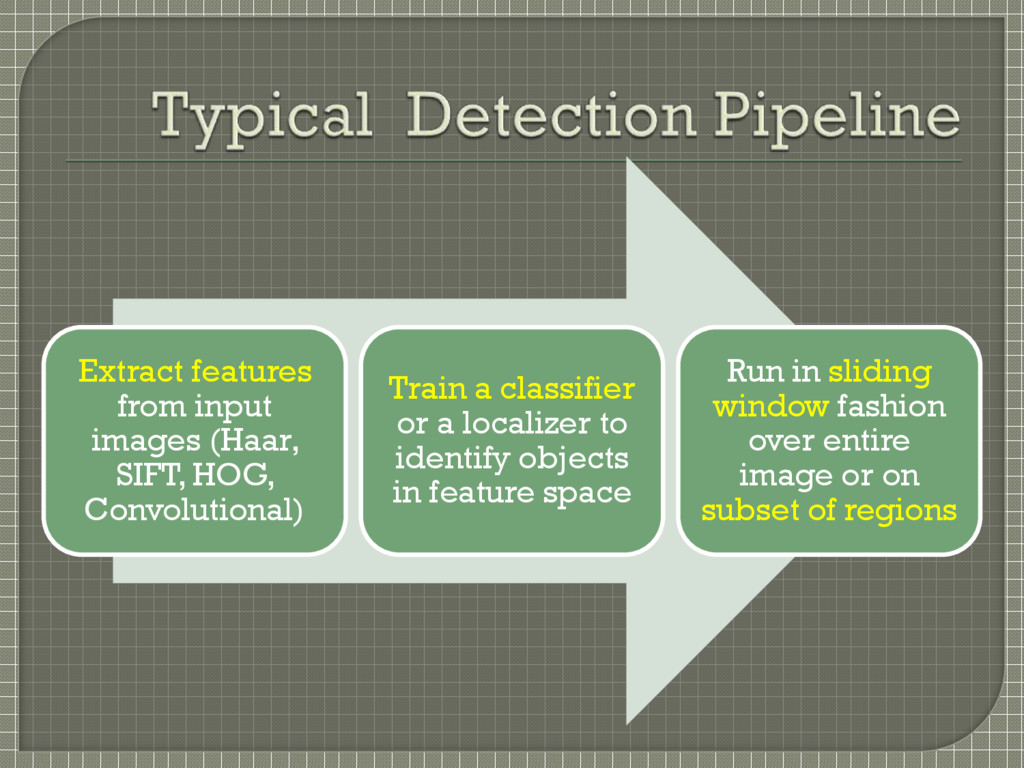
features, classify regions, predict bounding boxes for high scoring regions, etc. Static features The network performs feature extraction, bounding box prediction, non- maximal suppression, and contextual reasoning all concurrently Network trains the features in-line and optimizes them for the detection task Faster, more accurate model
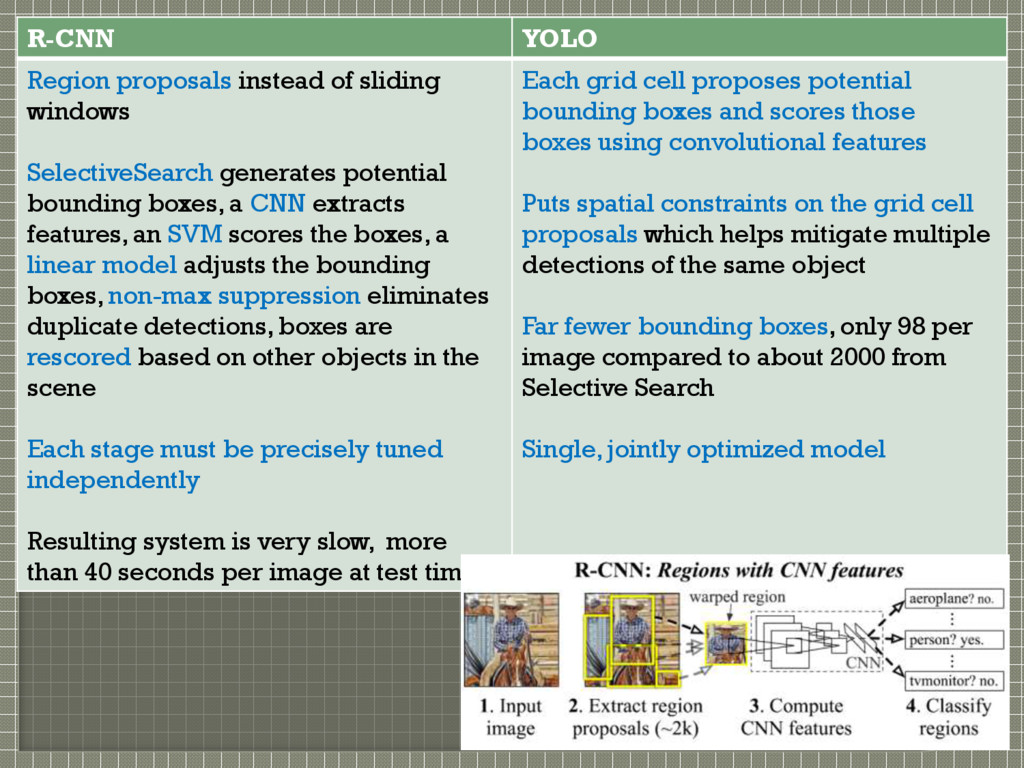
potential bounding boxes, a CNN extracts features, an SVM scores the boxes, a linear model adjusts the bounding boxes, non-max suppression eliminates duplicate detections, boxes are rescored based on other objects in the scene Each stage must be precisely tuned independently Resulting system is very slow, more than 40 seconds per image at test time Each grid cell proposes potential bounding boxes and scores those boxes using convolutional features Puts spatial constraints on the grid cell proposals which helps mitigate multiple detections of the same object Far fewer bounding boxes, only 98 per image compared to about 2000 from Selective Search Single, jointly optimized model
CNN to predict regions of interest instead of using Selective Search Cannot perform general object detection and is still just a piece in a larger detection pipeline, requiring further image patch classification Use a CNN to predict bounding boxes Complete end-to-end detection system for several objects at once
to perform localization and adapt that localizer to perform detection Efficiently performs sliding window detection but it is still a disjoint system Optimizes for localization, not detection performance Like DPM, the localizer only sees local information when making a prediction. Cannot reason about global context and thus requires significant post-processing to pro- duce coherent detections Both together Optimized for detection Reasons globally
the MultiGrasp system for regression to grasps Grasp detection is a much simpler task than object detection • Only needs to predict a single graspable region for an image containing one object • Doesn’t have to estimate the size, location, or boundaries of the object or predict it’s class, only find a region suitable for grasping But YOLO: bounding boxes and class probabilities for multiple objects of multiple classes in an image . Redmon and A. Angelova. Real-time grasp detection using convolutional neural networks. ICRA 2015
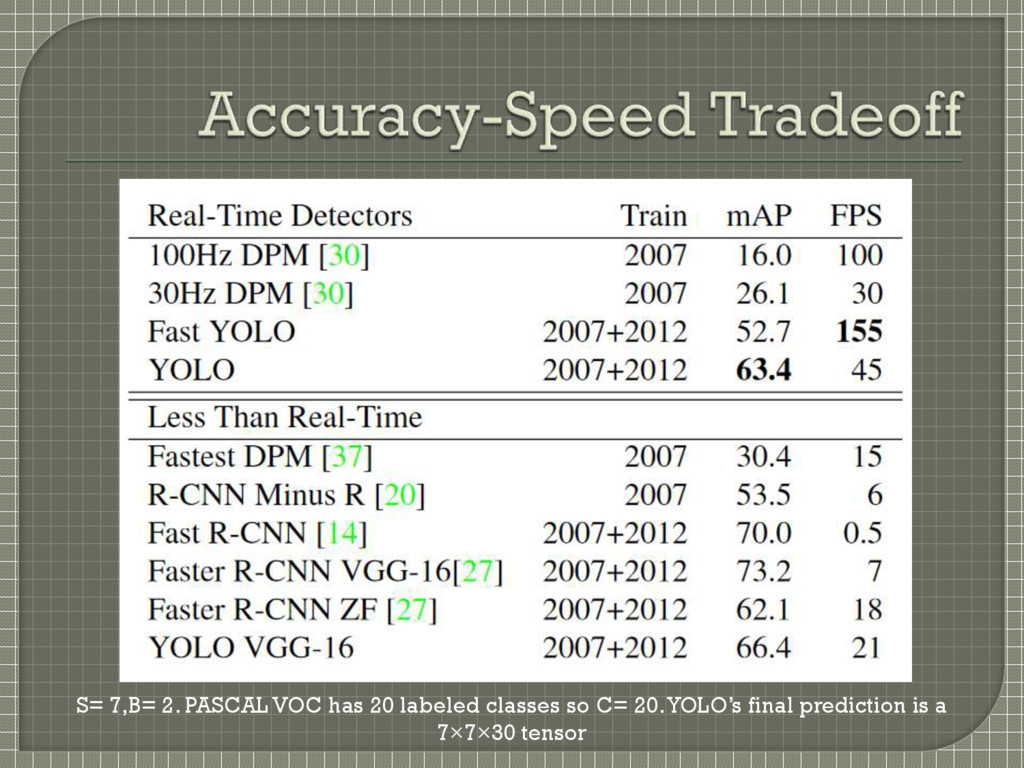
SelectiveSearch with static bounding box proposals • Fast R-CNN – 0.5 FPS Speeds up classification stage, still relies on SelectiveSearch which is slow (~2 seconds per image) • Faster RCNN – 7 FPS / 18 FPS Using neural networks to propose regions instead of Selective Search Similar to DeepMultiBox
Dai. Diagnosing error in object detectors. In Computer Vision–ECCV 2012 , pages 340–353. Springer, 2012 Correct: correct class and IOU > .5 Localization: correct class, .1<IOU< .5 Similar: class is similar, IOU> .1 Other: class is wrong, IOU > .1 Background: IOU< .1 for any object Percentage of localization and background errors in the top N detections for various categories (N = # objects in that category)
every bounding box that R-CNN predicts • Check if YOLO predicts a similar box • If it does, give that prediction a boost based on the probability predicted by YOLO and the overlap between the two boxes
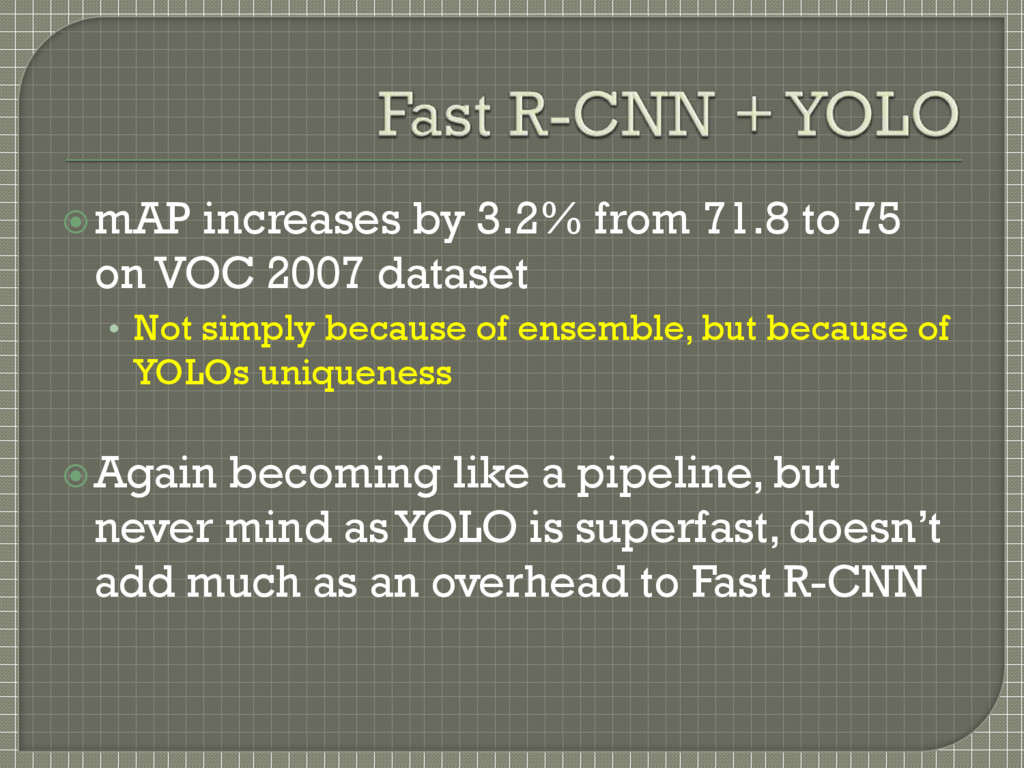
2007 dataset • Not simply because of ensemble, but because of YOLOs uniqueness Again becoming like a pipeline, but never mind as YOLO is superfast, doesn’t add much as an overhead to Fast R-CNN
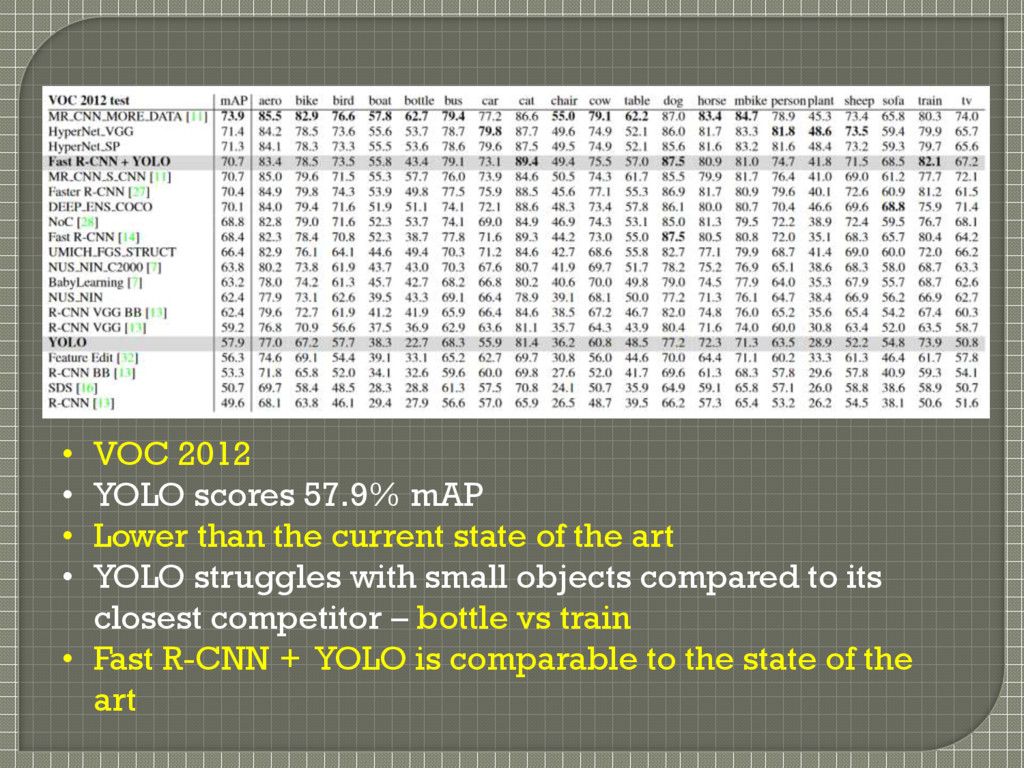
than the current state of the art • YOLO struggles with small objects compared to its closest competitor – bottle vs train • Fast R-CNN + YOLO is comparable to the state of the art
bounding box proposals which is tuned for natural images DPM generalizes well • Has strong spatial models of the shape and layout of objects • But has overall low AP YOLO is accurate AND generalizes well • Models the size and shape of objects, as well as relationships between objects and where objects commonly appear – though images are different at pixel level
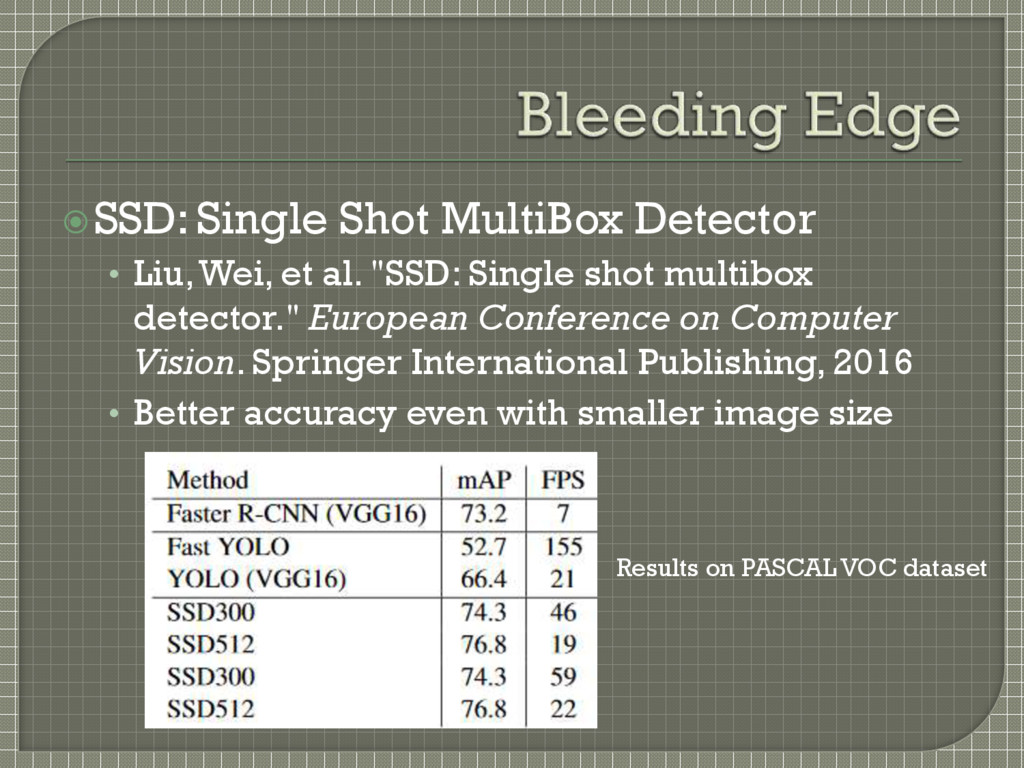
"SSD: Single shot multibox detector." European Conference on Computer Vision. Springer International Publishing, 2016 • Better accuracy even with smaller image size Results on PASCAL VOC dataset
Better, Faster, Stronger." arXiv preprint arXiv:1612.08242 (2016). • YOLOv2: employs some tricks and uses multi scale training method • YOLO9000 jointly optimizes detection and classification Allows to predict detections for object classes that don’t have labeled detection data – uses WordTree to combine data from various sources
function? Any studies on depth perception in images? • This perhaps good give clues for good prior as well! YOLO claims to generalize well to other domains but has tested itself only for person detection in artworks! Who knows it didn't do well in other domains?
by GoogleNet? Have they said anything about the choice of S? • No. They have used S=7 for their experiments but have not commented on how they got that number Thought process behind their network architecture? • Not revealed, except that it is inspired by GoogLeNet
grid cell and the object it is center of, do we really need four parameters, x, y, w and h? A: Yes, because given a grid cell, the bounding boxes that it predicts could be anywhere and of any size. x and y marks the center of the bounding box, relative to the grid cell (normalized as an offset between 0 and 1)
object portions of that object are also labelled as the whole? For example, face of the dog labeled as "dog" and the whole body also labeled as "dog" in the same image for the same dog A: It does detect any object appearing in different forms. Plus it does label objects inside objects. Given these two I believe there is no reason YOLO will not do well on the question asked.
Yes, as the output, is a complete tensor with info about all boxes, hence calling for a post processing step (which is quick and doesn't require any optimization as against the separate optimization required in R-CNN for adjusting the bounding boxes).
YOLO doing the same by eliminating that complex pipeline? A: No. YOLO is only bothered about detection and is modeling that as an end-to-end regression problem. The effect of classification is getting implicitly created by the CNN. YOLO 9000 on the other hand has the ability to jointly train on classification data and detection data. Quoting them, "... uses images labelled for detection to learn detection- specific information like bounding box coordinate prediction and objectness as well as how to classify common objects. It uses images with only class labels to expand the number of categories it can detect”
network robust to running on images of different sizes by training this aspect into the model. YOLO 9000 implements this. They argue that since their model only uses convolutional and pooling layers it can be resized on the fly. They change the network every few iterations. Every 10 batches their network randomly chooses a new image dimension size. This technique forces the network to learn to predict well across a variety of input dimensions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Deep MultiBox [Szegedy et al CVPR 2014] YOLO Train a](https://files.speakerdeck.com/presentations/95db654ac5ca4d75af0791f496d5f9cb/slide_74.jpg){kind=link}
![OverFeat [Sermanet et al, ICLR 2014] YOLO Train a CNN](https://files.speakerdeck.com/presentations/95db654ac5ca4d75af0791f496d5f9cb/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}