with Gaussian Processes, NIPS, 2011 → MaxEntモデルを⾮線形・連続なものに対応させたよ • Continuous Inverse Optimal Control with Locally Optimal Examples, ICML, 2012 → MaxEntモデルをよりscalable(広い連続領域)にしたよ → 直接近似とLQRの両⽅の枠組みで共通の式を導出したよ • Inverse Optimal Control for Humanoid Locomotion, RSS, 2013 → ⾼次元なものに対しても⼯夫するだけで応⽤できるよ → しかも未知環境においても⼈らしい歩⾏を実現できるよ なーんだ、同じ⼿法で3つ出したんか・・・ ではなく、それぞれすごい・・・・・
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
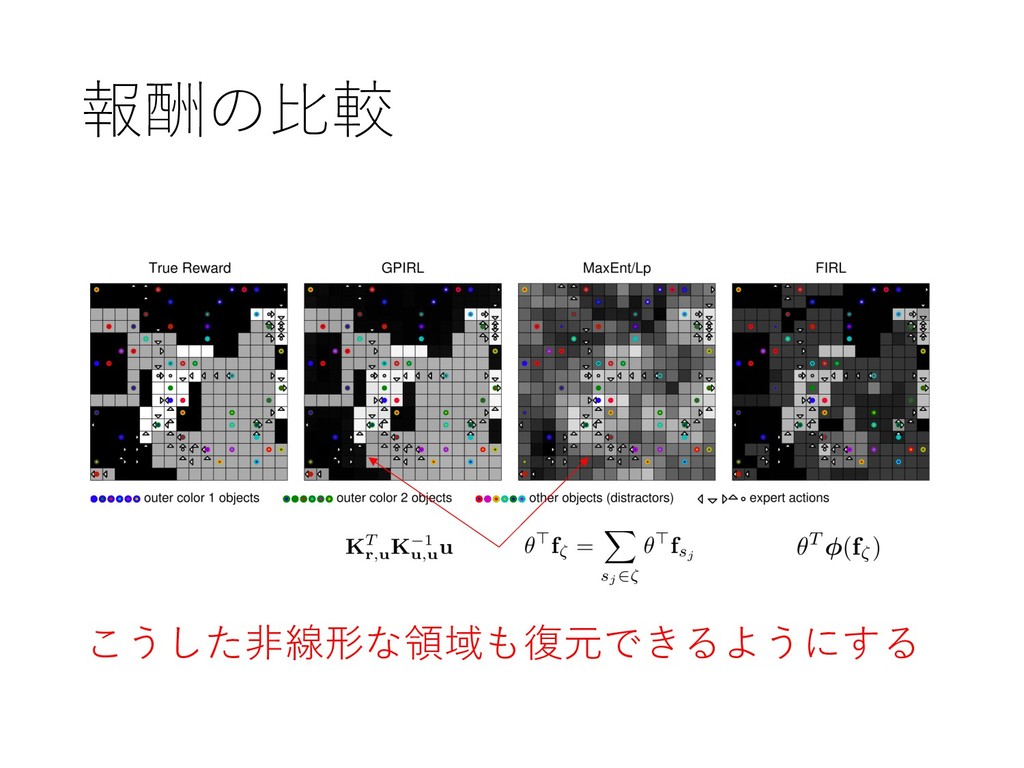{kind=link}
{kind=link}
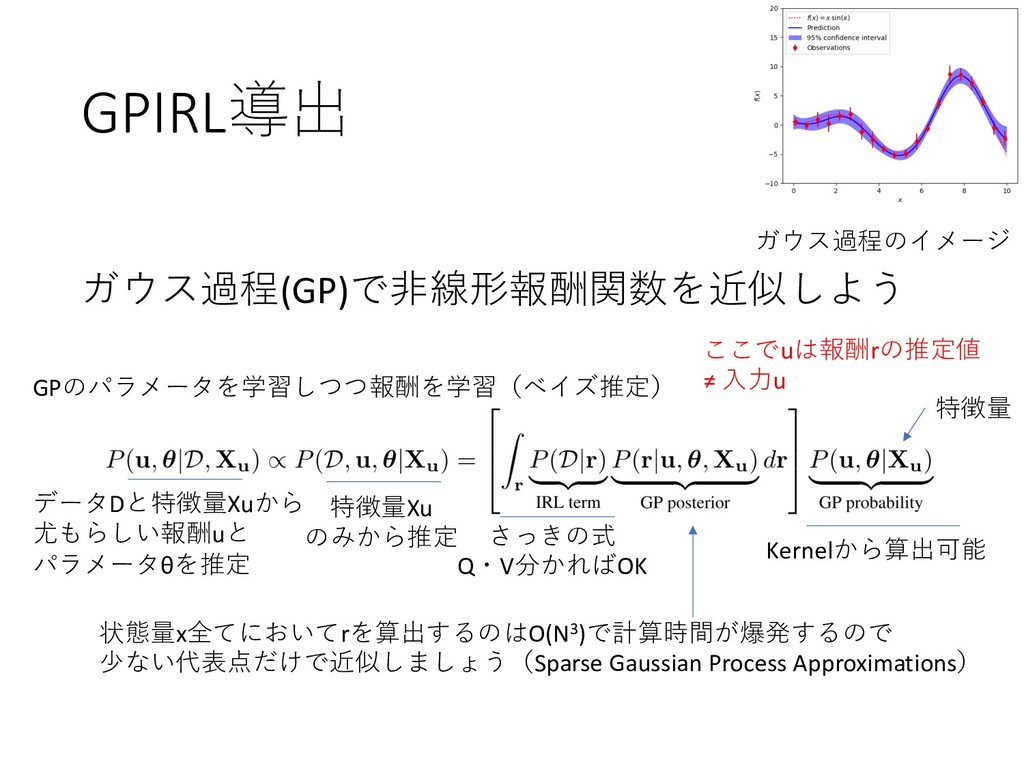{kind=link}
{kind=link}
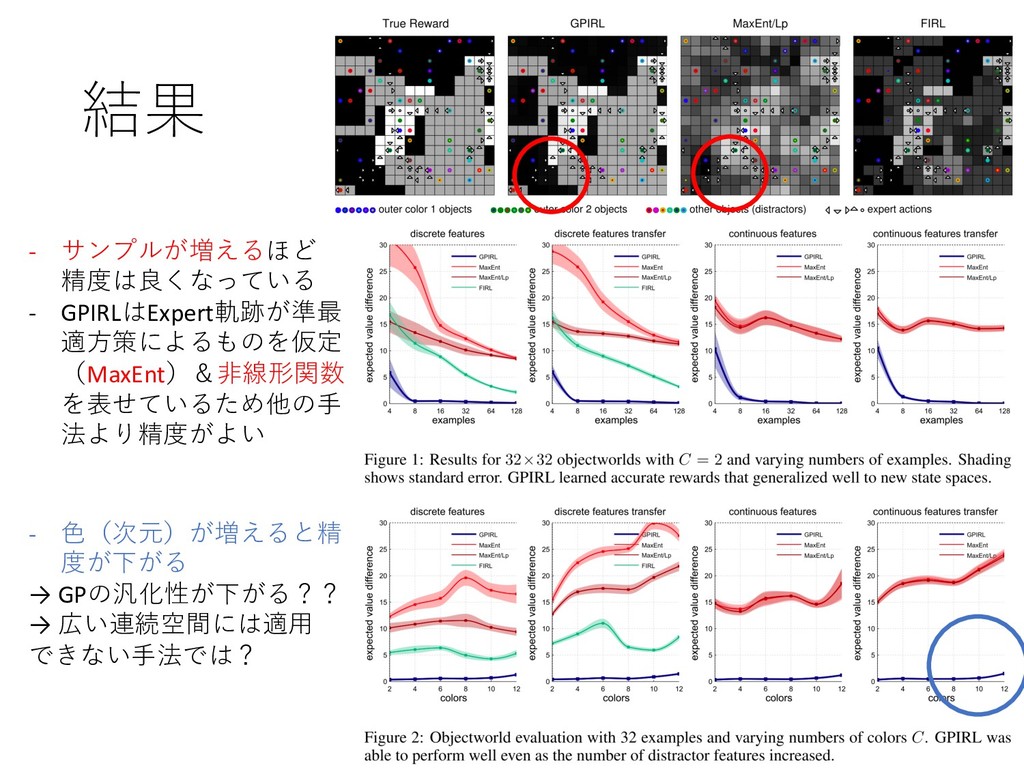{kind=link}
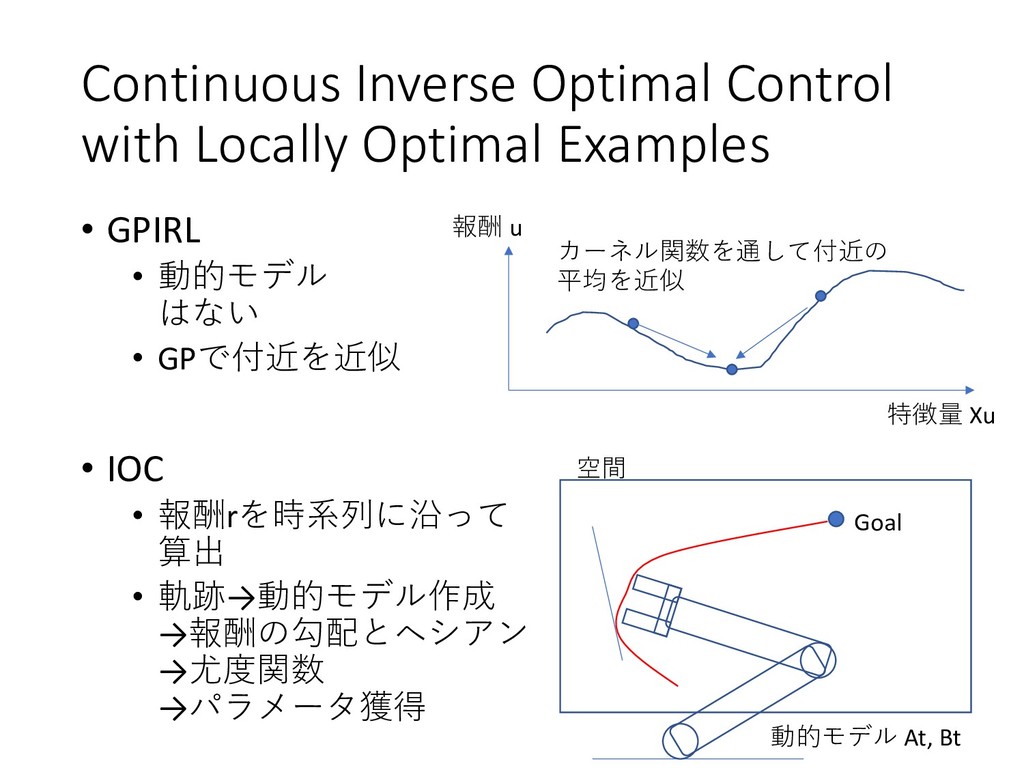{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}