本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
紹介する論文は「VectorLLM: Human-like Extraction of Structured Building Contours via Multimodal LLMs」です。この研究では、人間が建物の輪郭を描くときと同様に建物の角を見つけ輪郭を描く手法を、マルチモーダル大規模言語モデルを用いて提案しています。学習を行った建物の輪郭抽出の精度が高いだけではなく、水域や道路といった学習を行っていない他の地物の輪郭も抽出できる汎用性を実現しています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
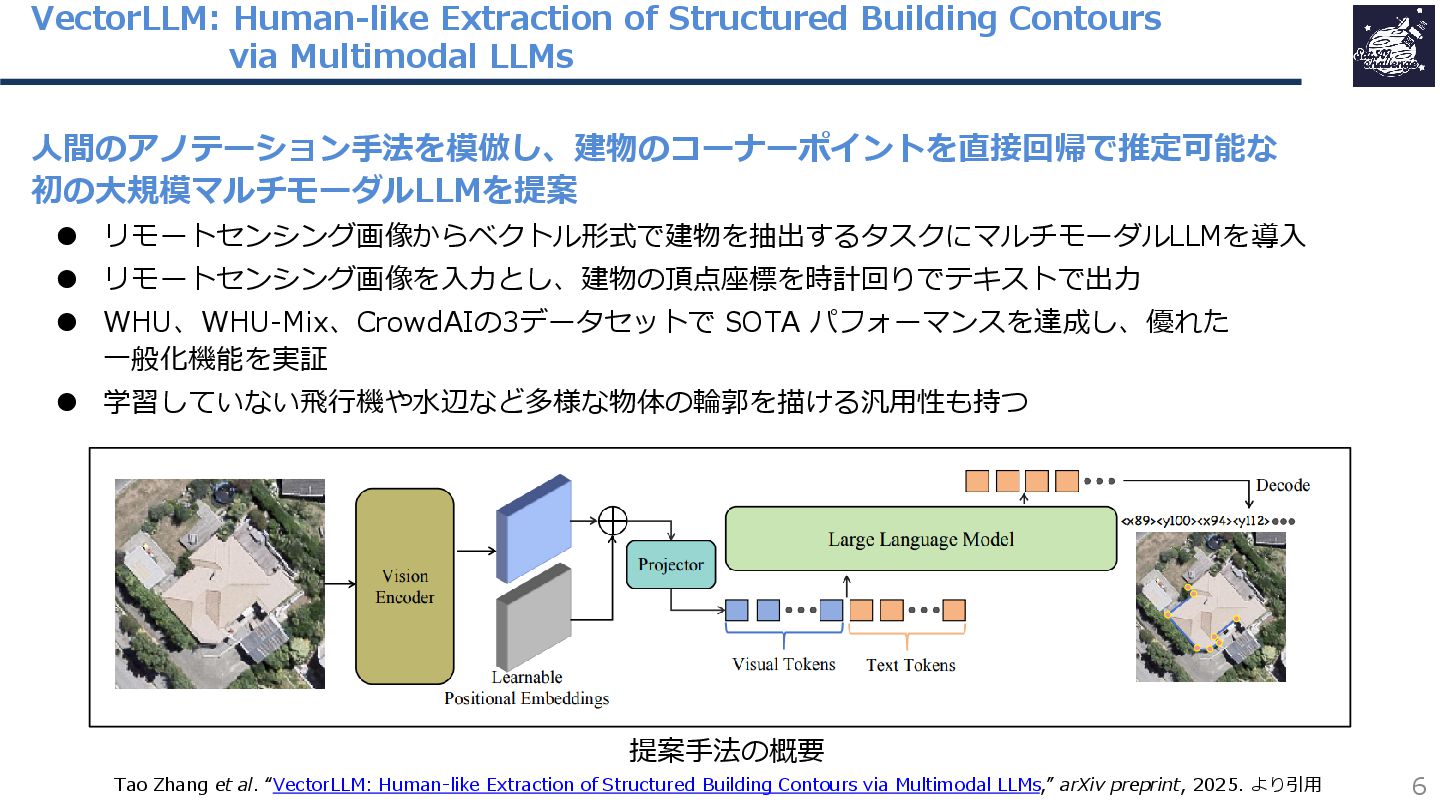{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
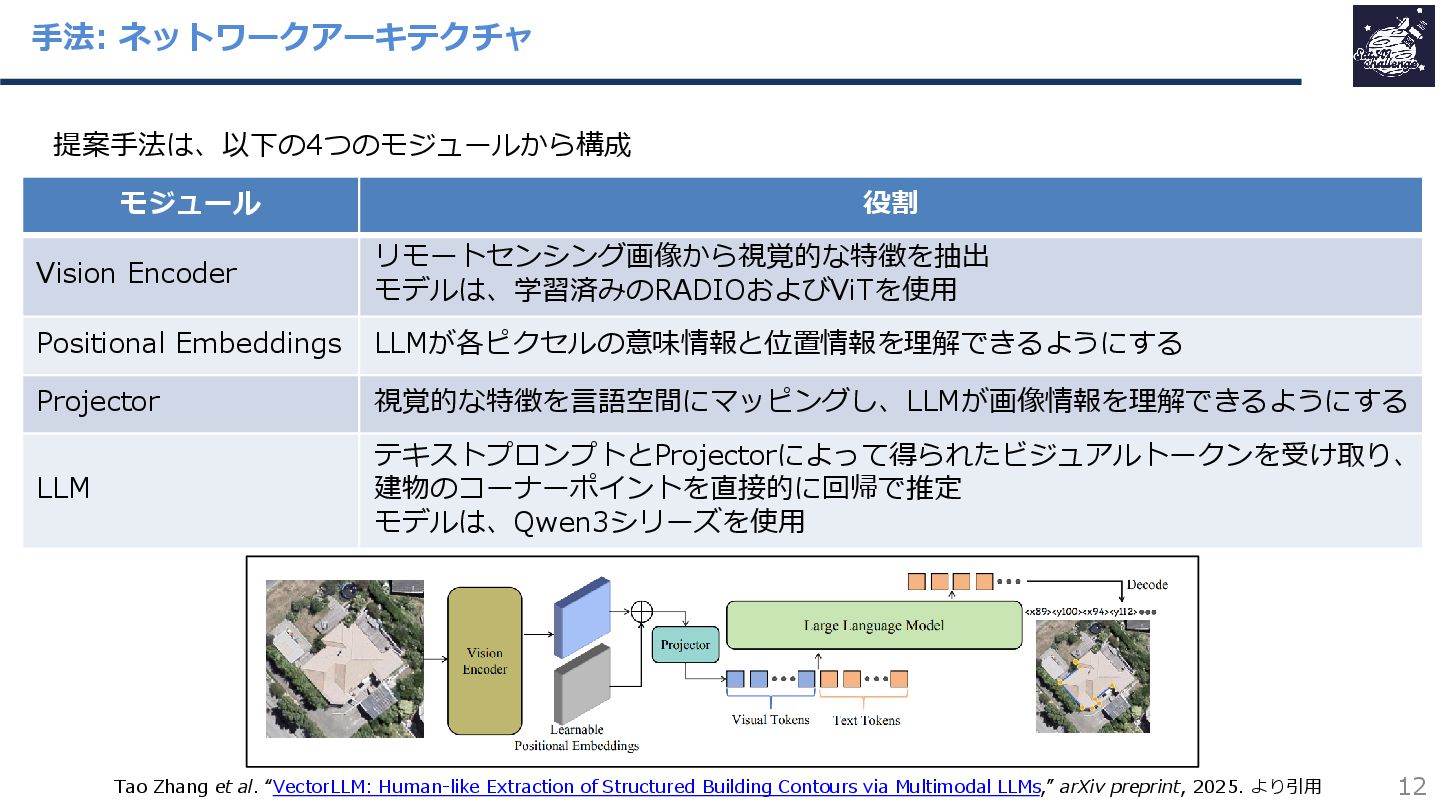{kind=link}
![手法: 学習戦略(事前トレーニング) 13 視覚的な特徴をテキスト空間に紐づけるだけでなく、 幾何学的推論能力をLLMに学習させるのが目的 事前学習データ例 “Input: [image]¥n[x85][y32][x160][y63][x135][y122] [x176][y139][x154][y191][x103][y169][x111] [y150][x46][y124][x85][y32].”](https://files.speakerdeck.com/presentations/6f89fa85bdb64f8f9c02f63f43332e97/slide_12.jpg){kind=link}
![手法: 学習戦略(教師ありファインチューニング) 14 ユーザの指示に対応した回答を出力するように学習 学習データ例 既存の建物抽出データセットをVQA形式に再構成し使用 建物の左上隅を始点とし、時計回りに点を並べるように回答 を生成するように学習 “Input: [image]¥nPlease](https://files.speakerdeck.com/presentations/6f89fa85bdb64f8f9c02f63f43332e97/slide_13.jpg){kind=link}
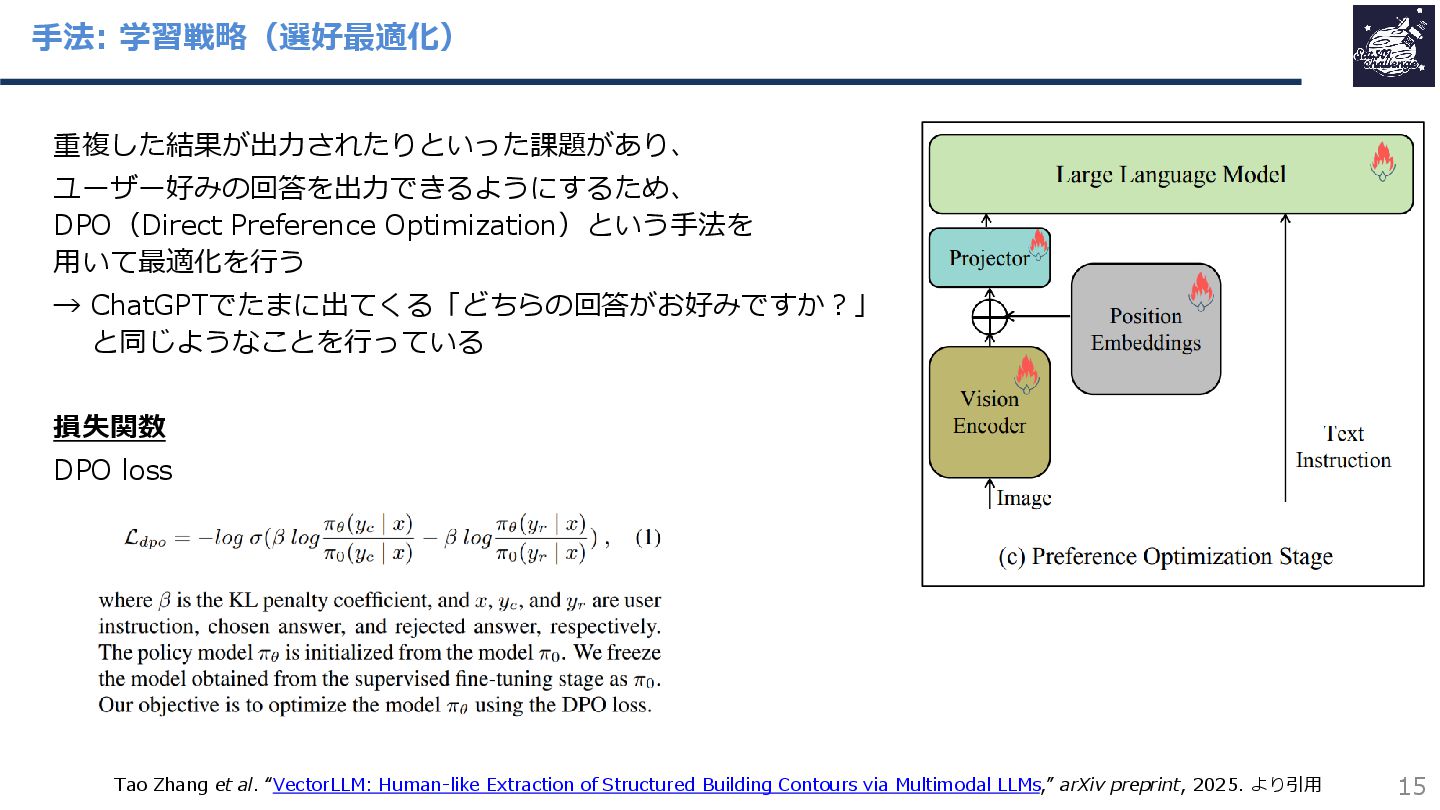{kind=link}
![学習データ例 好ましい回答:教師ありファインチューニングモデルの 推論結果でIoU0.8以上のもの 好ましくない回答: IoUが0.8未満の推論結果 わざとランダムに破損させた推論結果 “Input: [image]¥nPlease extract the](https://files.speakerdeck.com/presentations/6f89fa85bdb64f8f9c02f63f43332e97/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
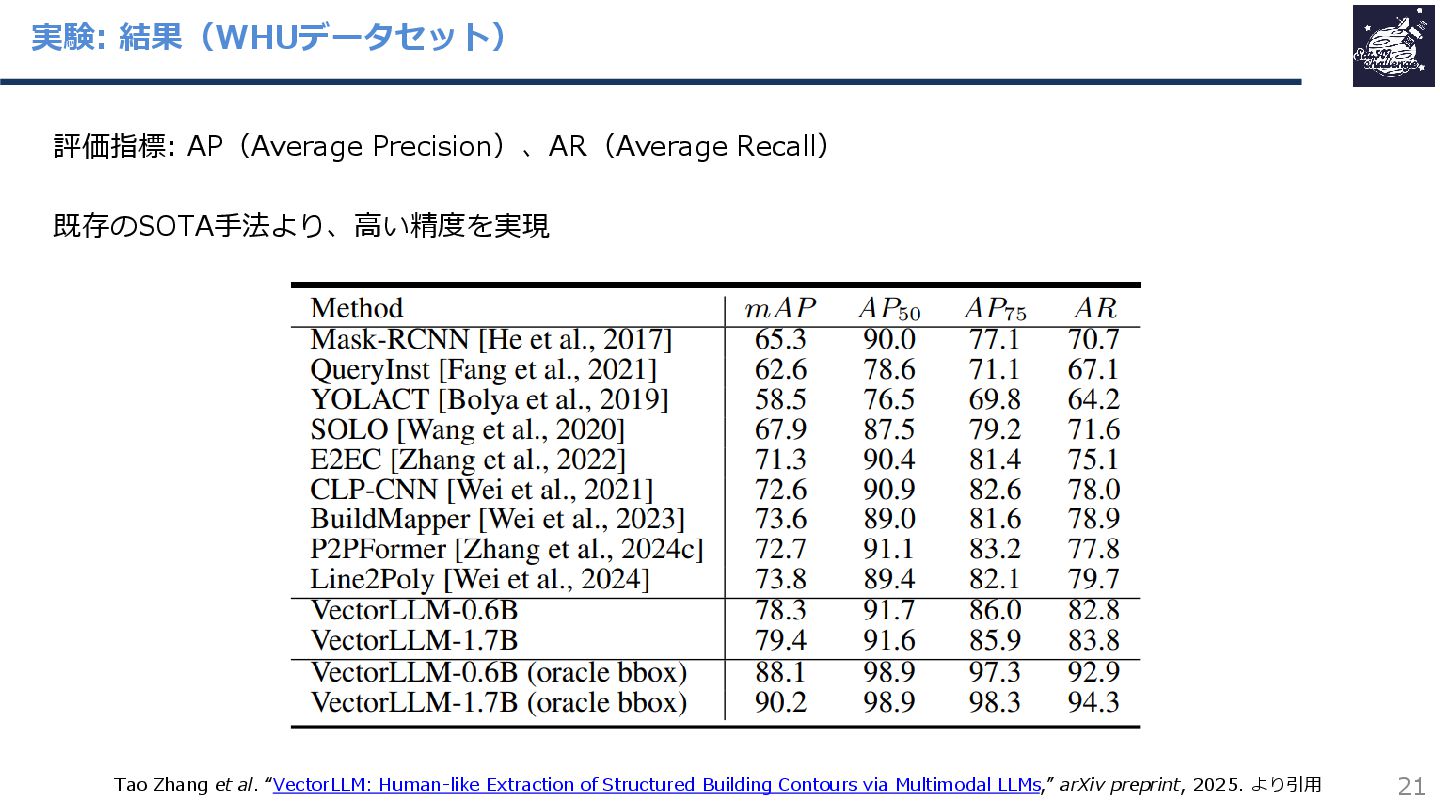{kind=link}
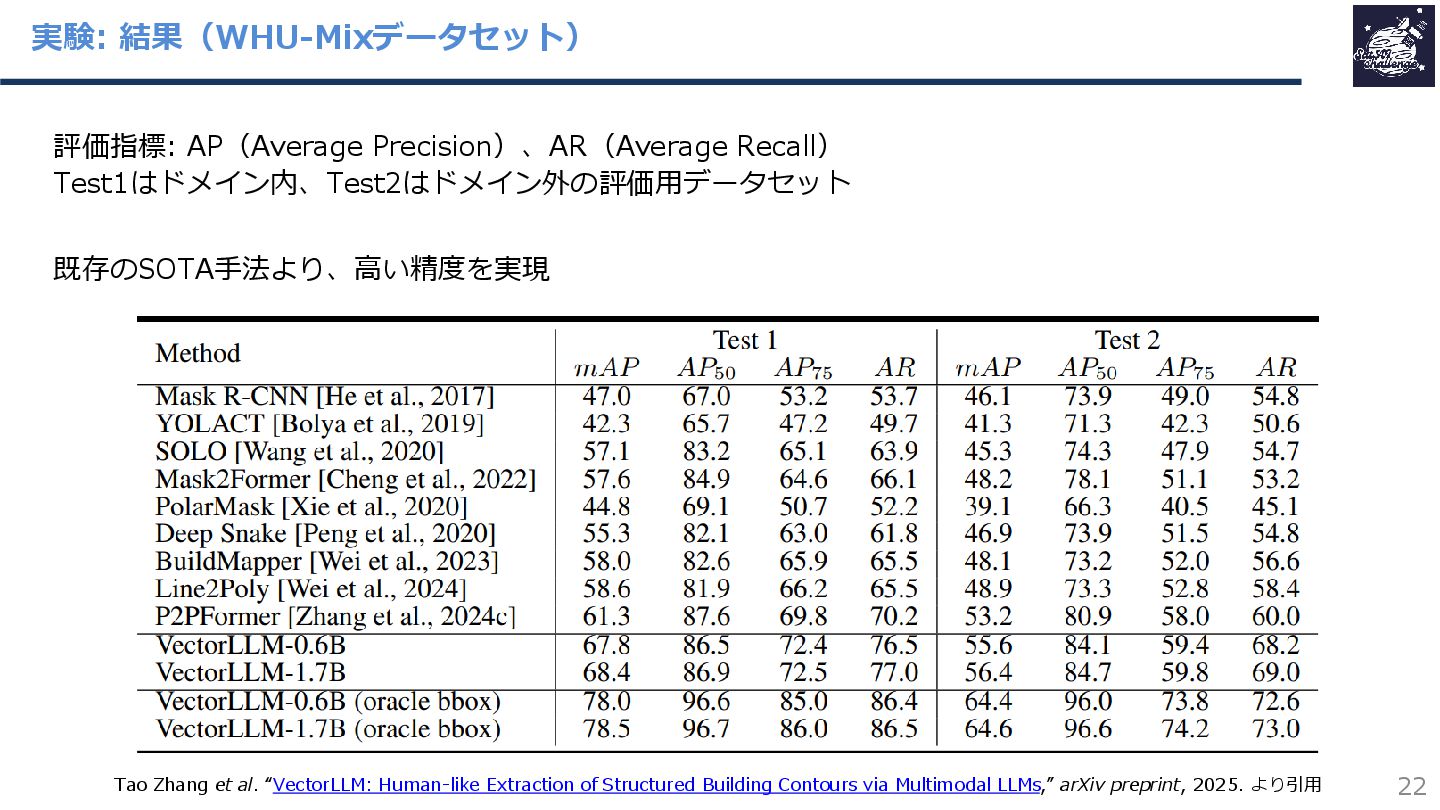{kind=link}
{kind=link}
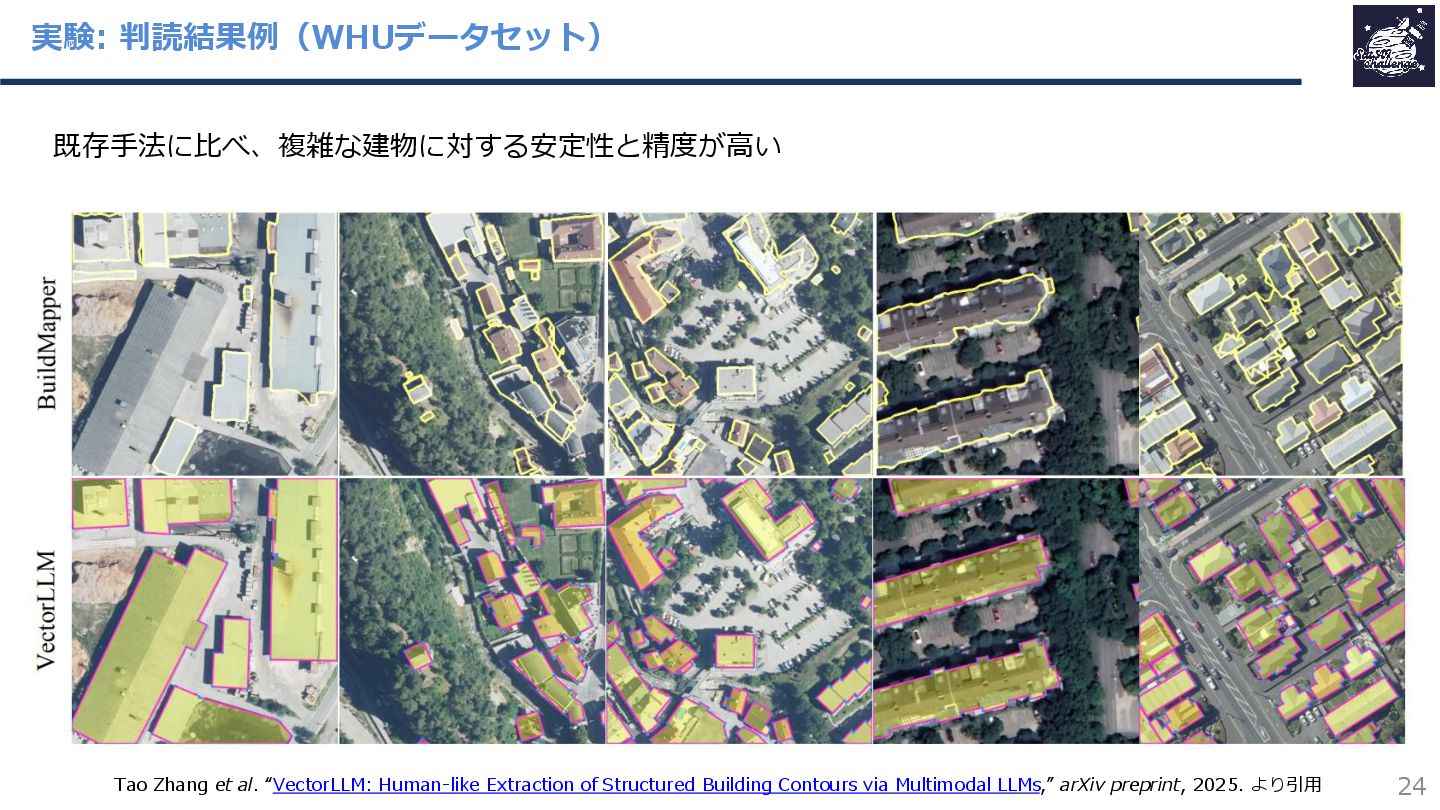{kind=link}
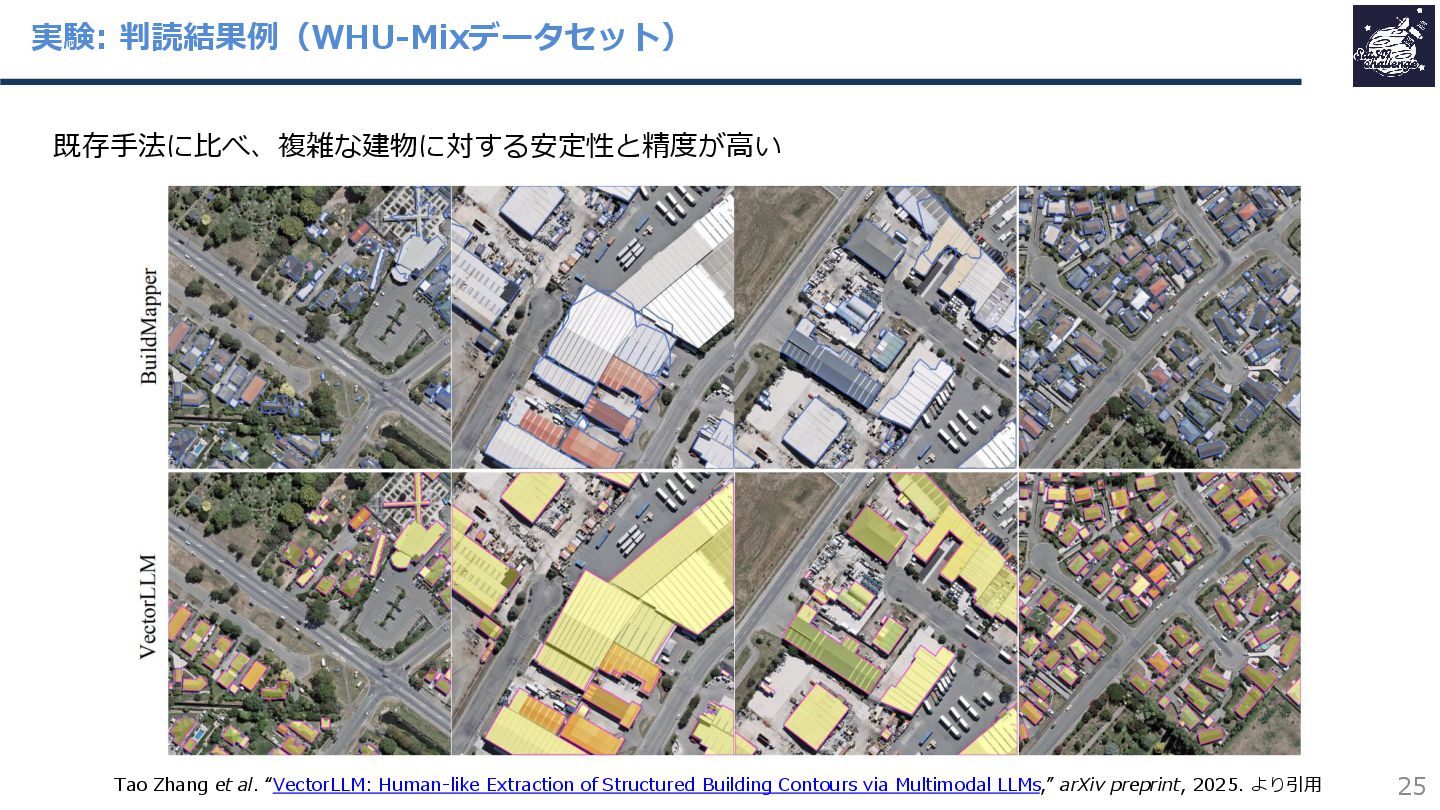{kind=link}
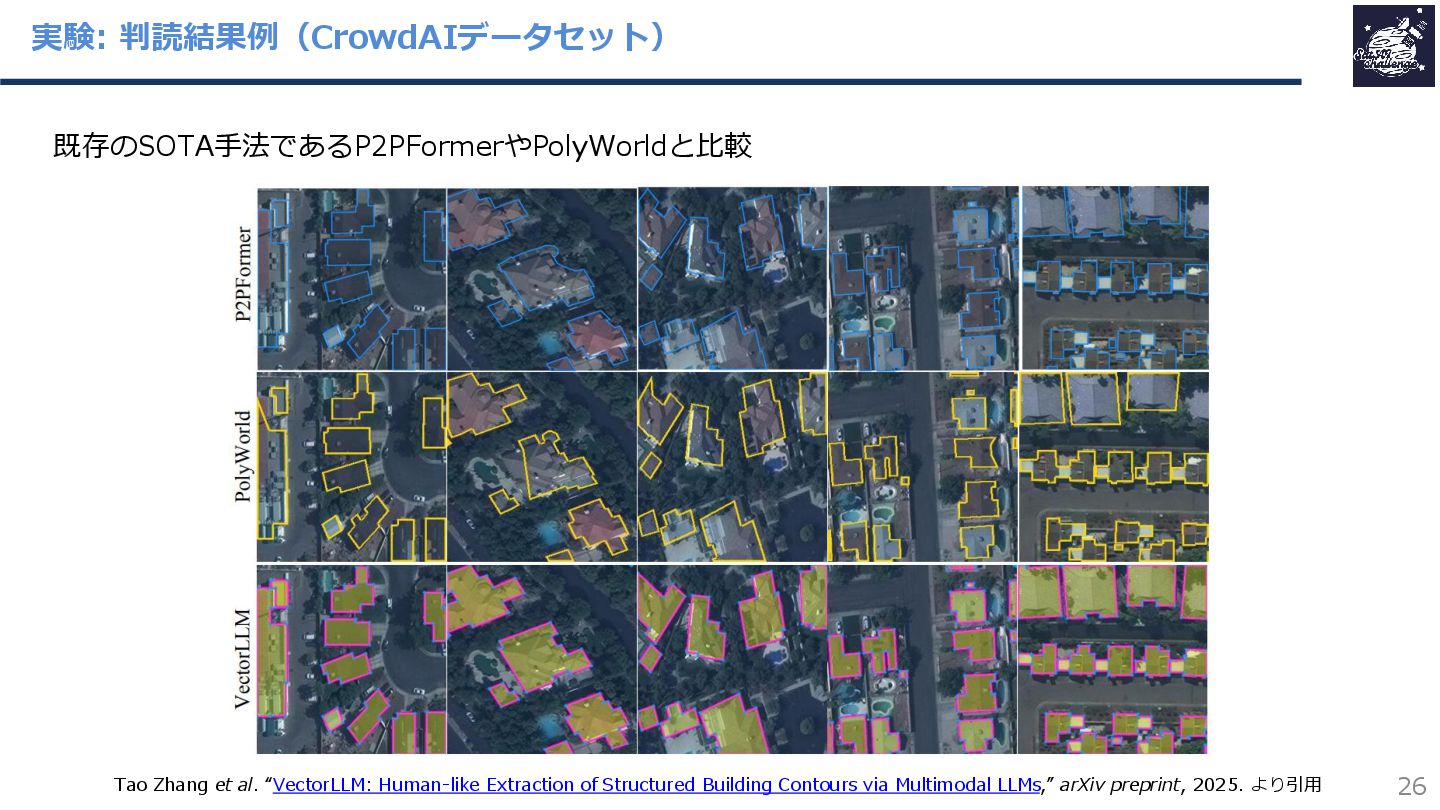{kind=link}
{kind=link}
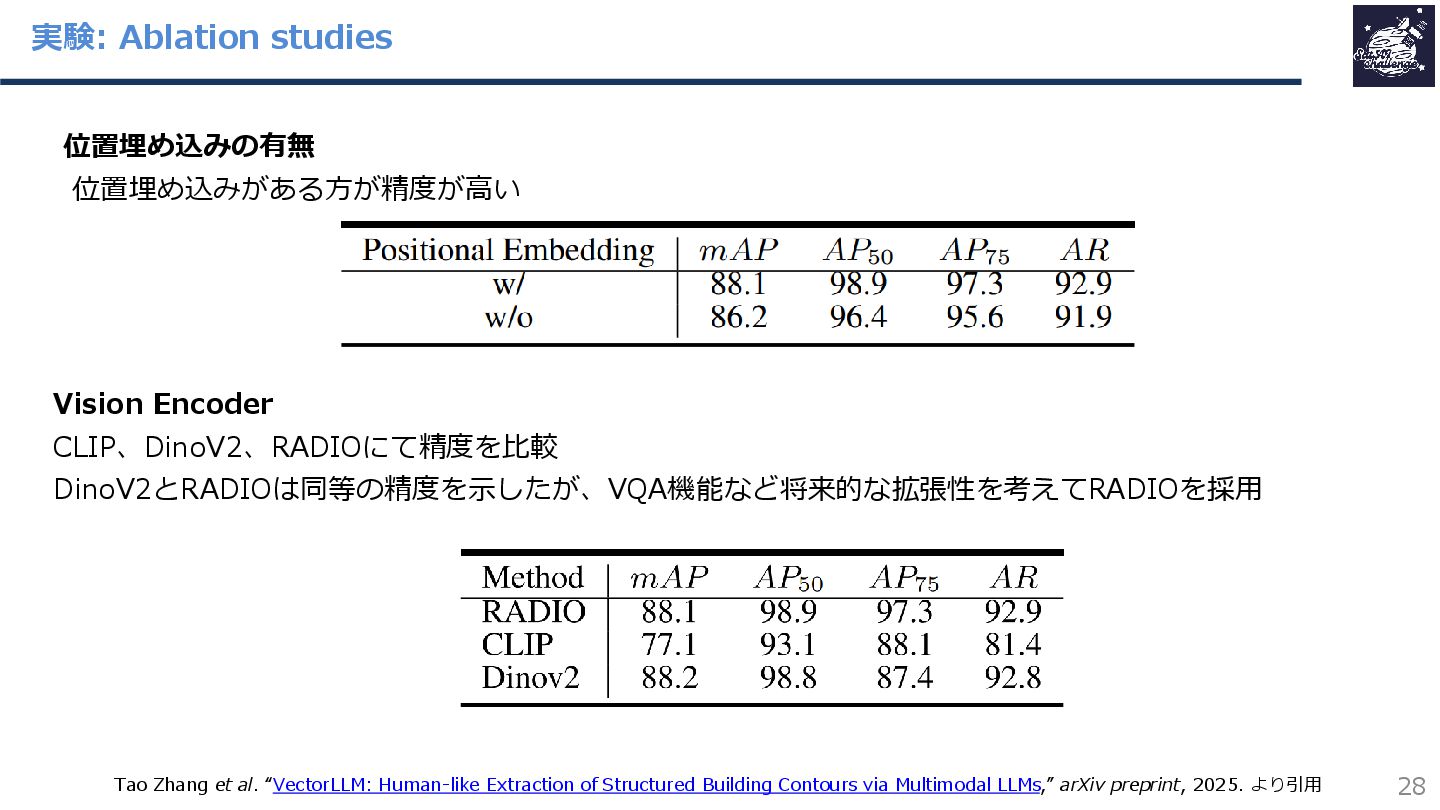{kind=link}
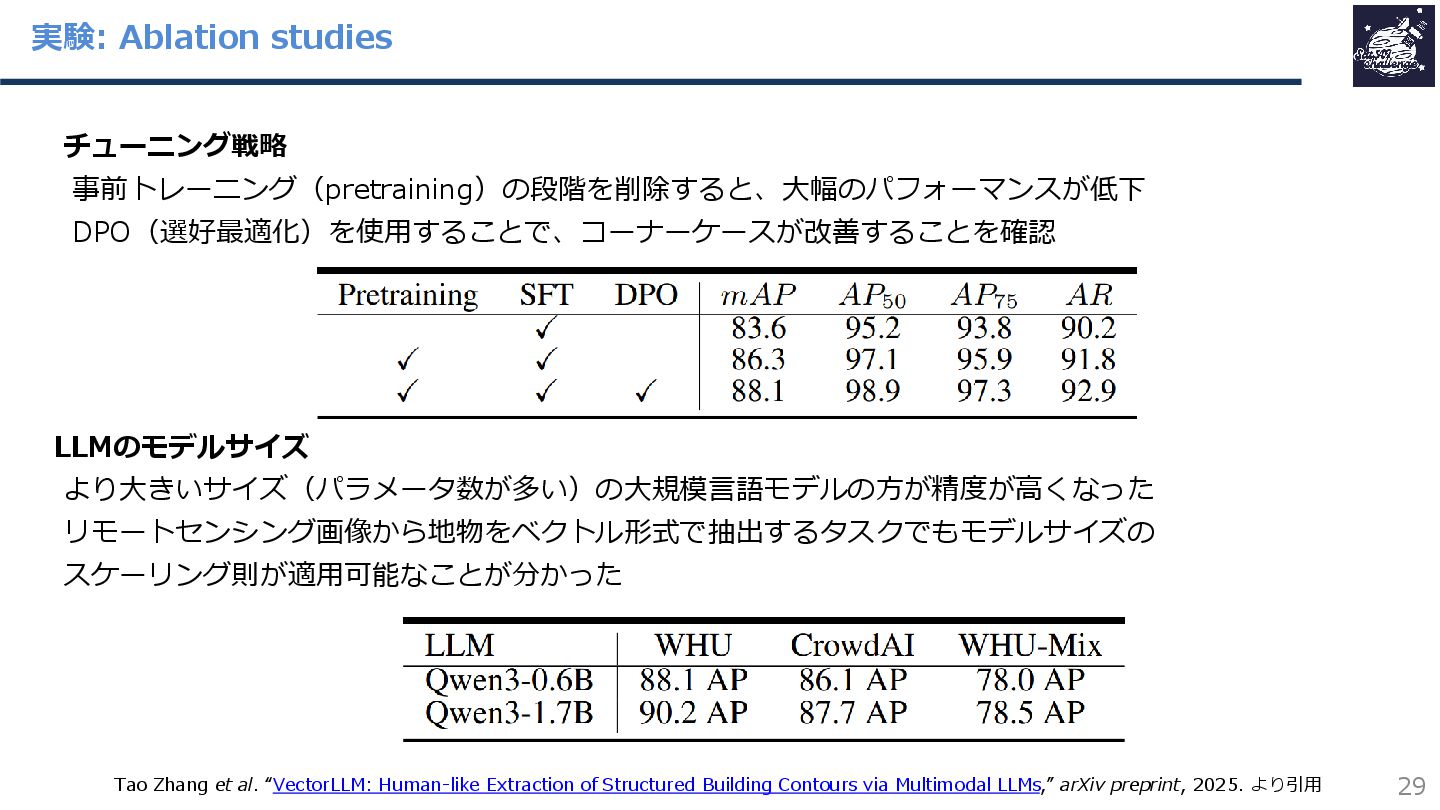{kind=link}
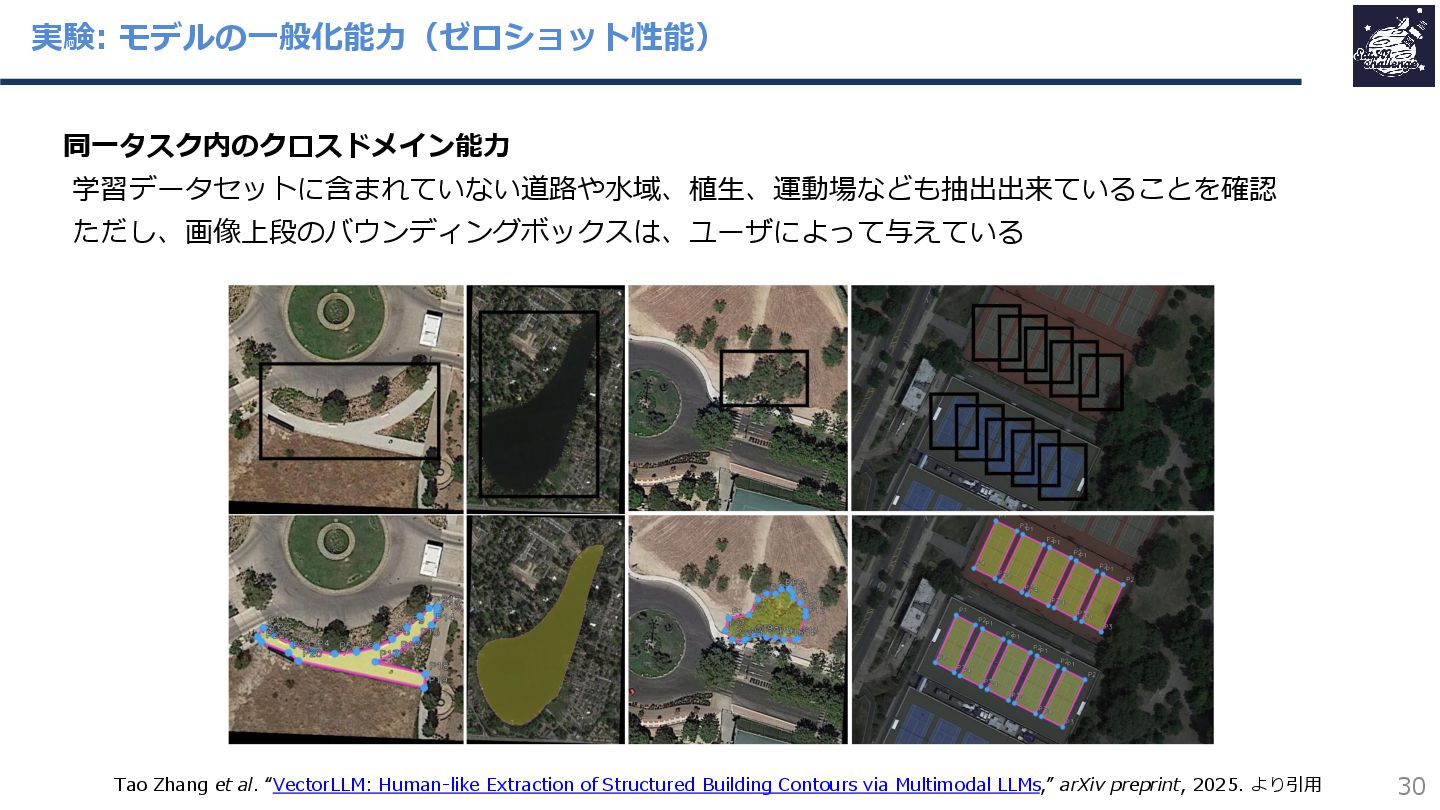{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}