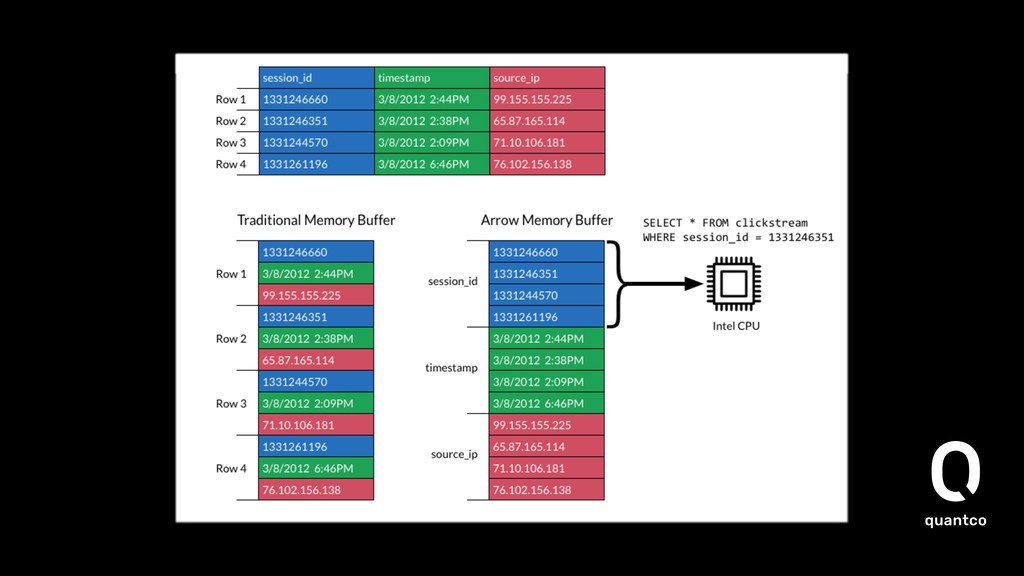
As a Data Scientist/Engineer in Python, we focus in our work to solve problems with large amounts of data but still stay in Python. This is where we are the most effective and feel comfortable. Libraries like Pandas and NumPy provide us with efficient interfaces to deal with this data while still getting optimal performance. The main problem appears when we have to deal with systems outside of our comfort ecosystem. We need to write cumbersome and mostly slow conversion code that ingests data from there into our pipeline until we can work efficiently. Using Apache Arrow and Parquet as base technologies, we get a set of tools that eases this interaction and also brings us a huge performance improvement. As part of the talk we will show a basic problem where we take data coming from a Java application through Python into using these tools.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}