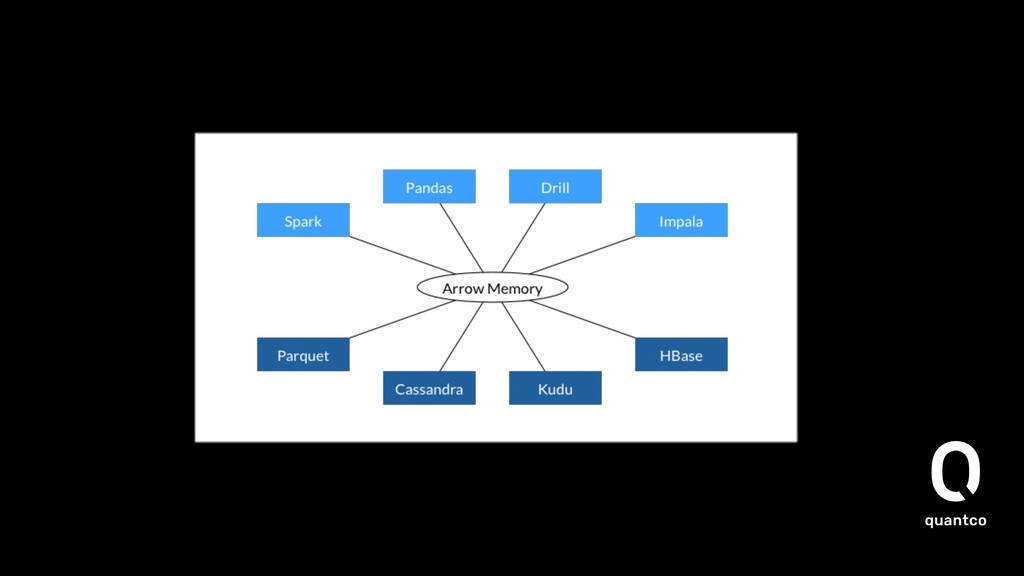
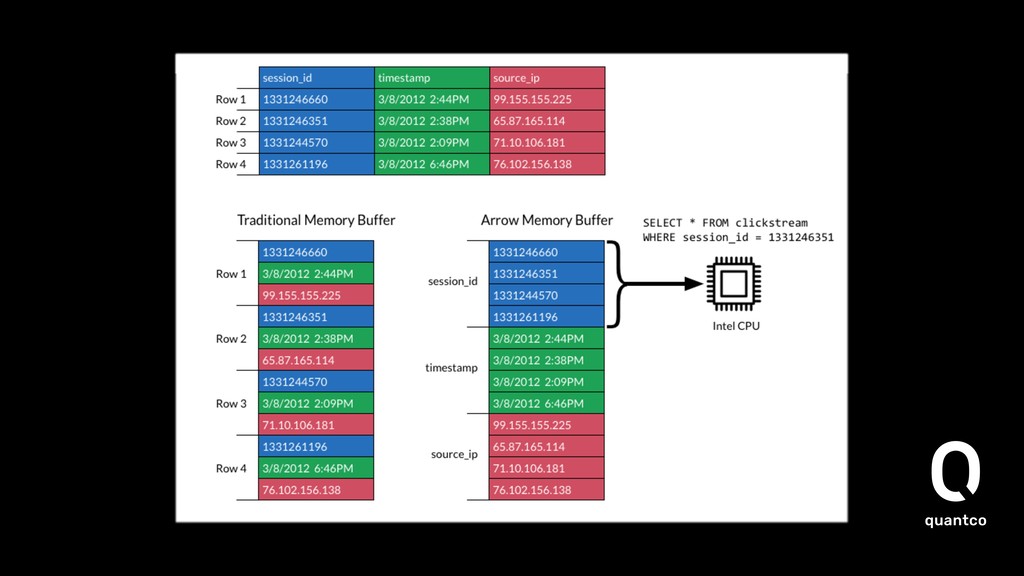
In the space of building products with data, either by dealing with huge amounts of data or by applying machine learning, many different ecosystems meet. Larger volumes of data have to be passed between these systems. The handling of the data is not only down to divide between systems written in Java that need to pass it on to the machine learning model in Python. When you take into account that you want to integrate with the existing business infrastructure, you also need to cater for legacy systems as well do you need to bring the large volumes of data to the user via UIs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}