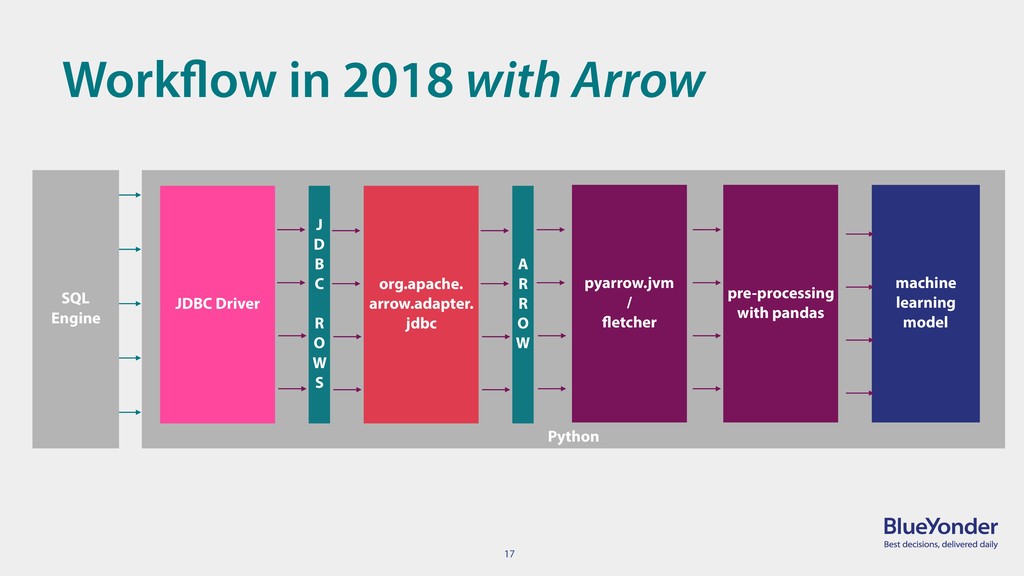
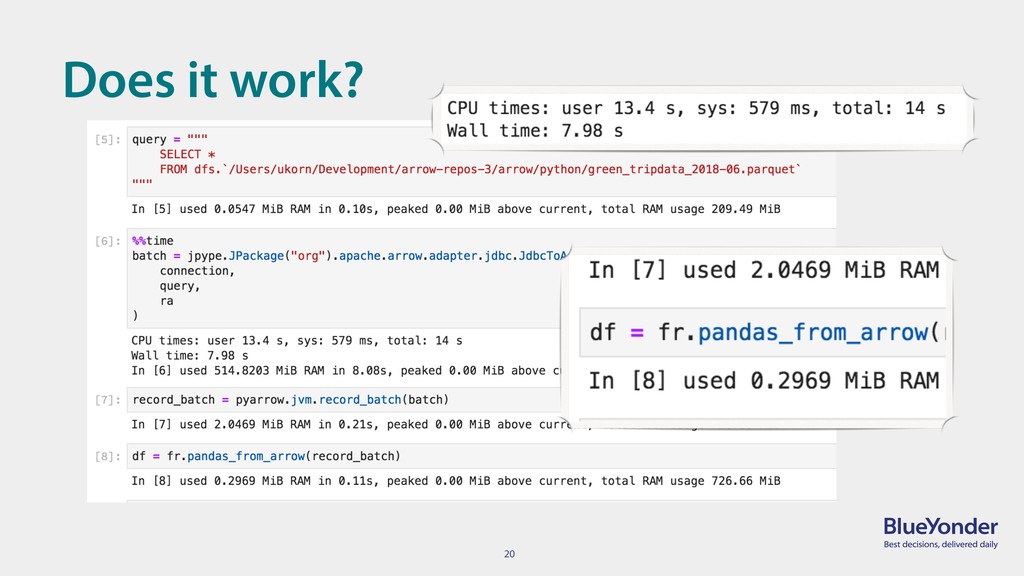
Apache Arrow's promise was to reduce the (serialization & copy) overhead of working with columnar data between different systems. Using the latest Pandas release and Arrow's ability to share memory between the JVM and Python as ingredients, we demonstrate that Arrow can fulfill this bold statement. The performance benefits of this will be shown using a typical data engineering use-case that produces data in the JVM and then passes it on to a Python-based machine learning model.
{kind=link}
{kind=link}
{kind=link}
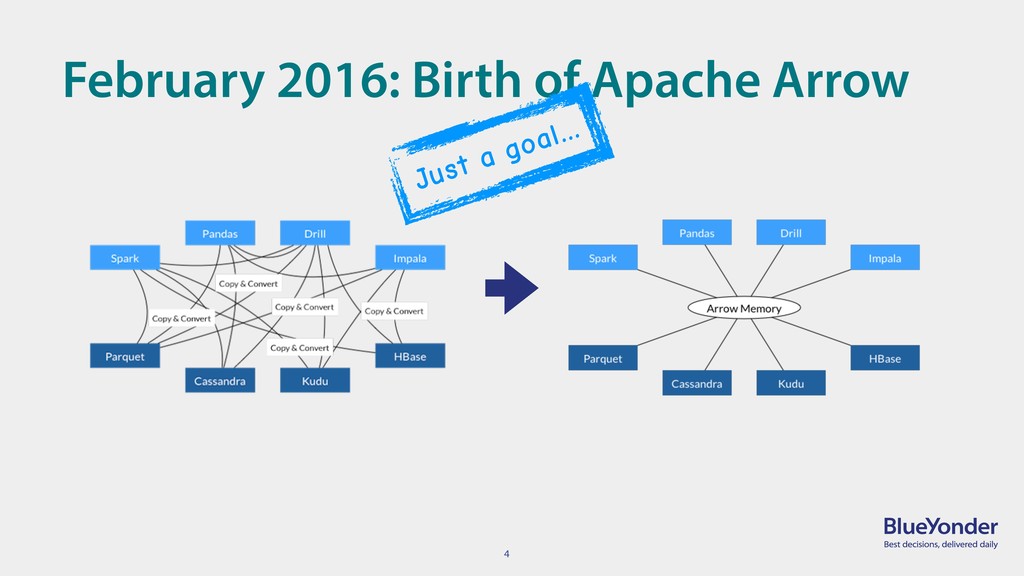{kind=link}
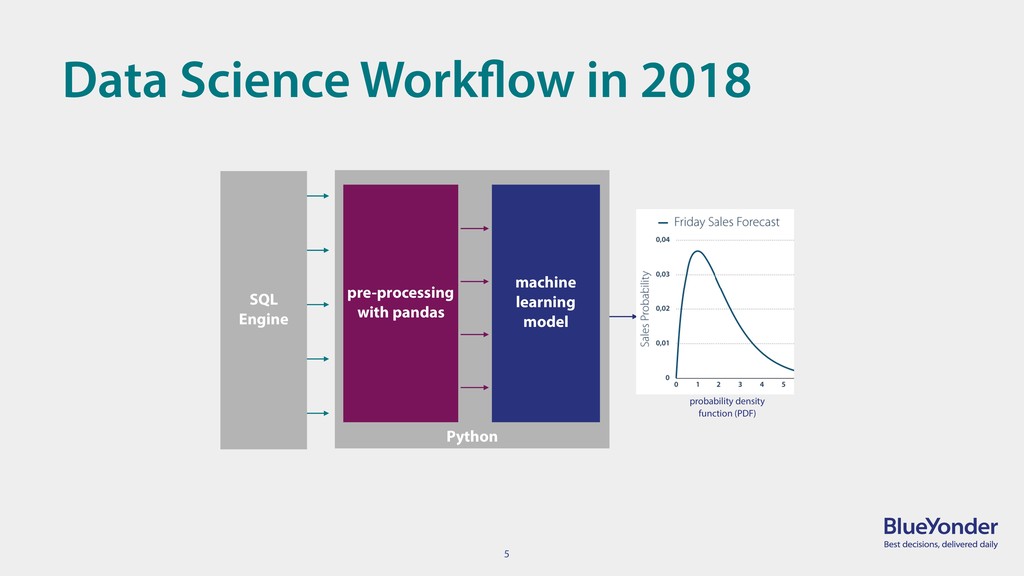{kind=link}
{kind=link}
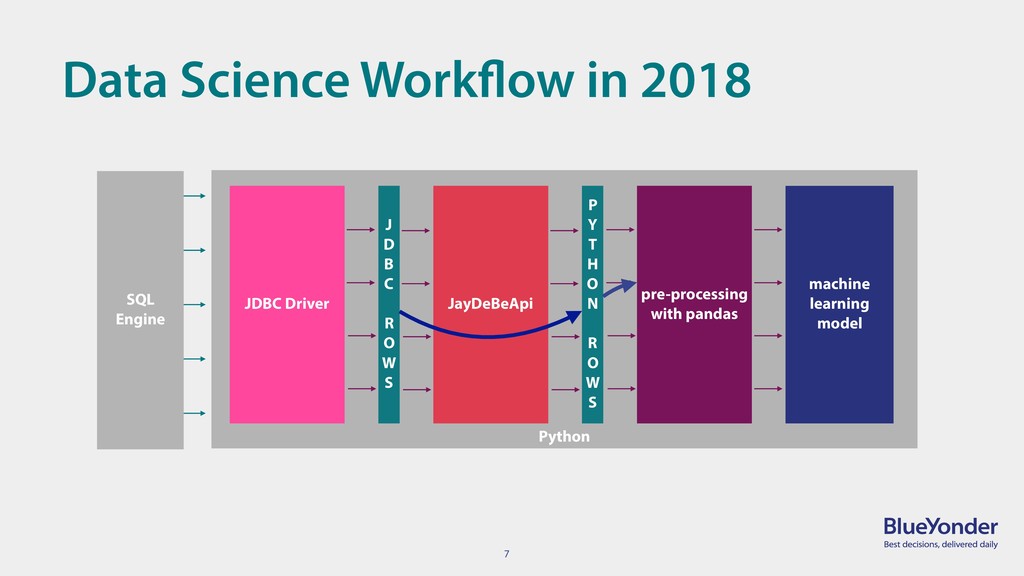{kind=link}
{kind=link}
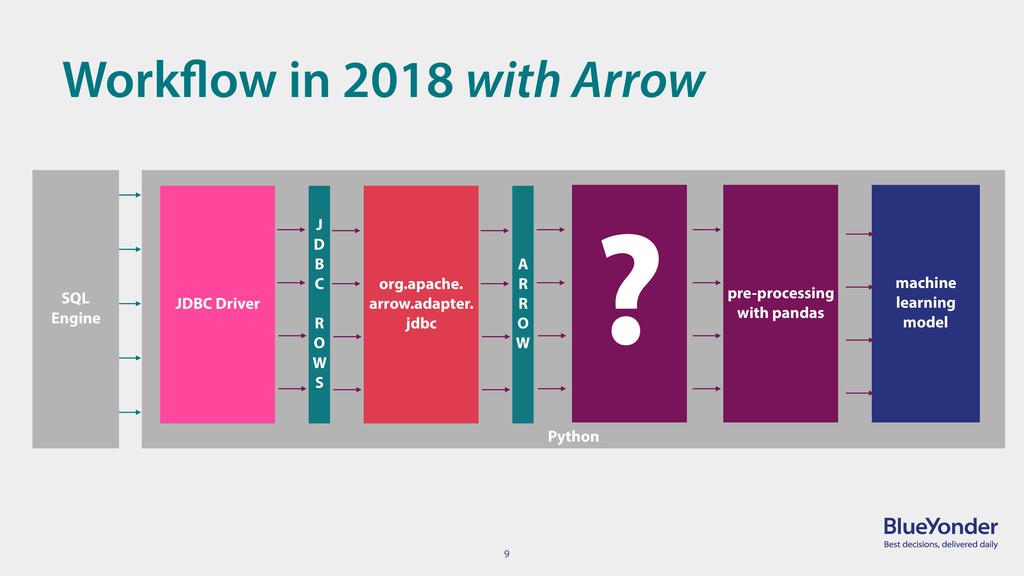{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cross language DataFrame library • Website: https://arrow.apache.org/ • ML: [email protected]](https://files.speakerdeck.com/presentations/6f3a322359174e4c9cd78304841e3294/slide_21.jpg){kind=link}