, BERTによる文書分類器を学習 . 未拡張のデータセットによる学習と比較し , 高い性能を示した. • 2022年, Liuら[12]は, GPT-3によるテキスト拡張を 質問応答に応用. 質問文とGPT-3により生成した関連 知識をモデルへと入力 . 質問文のみを入力するベースラインと比較し , 高い性能を示した • 2023年, Pratt ら[13]は, CLIPによるゼロショット画像分類 に,大規模言語モデルによる テキスト拡張を応用した CuPLを提案. 画像キャプションのテキストを GPT-3により生成し, モデルに入力. テンプレート「a photo of a {}」ベースのキャプションを用いた手法と比較し ,高い性能を示した [10] K. M. Yoo et al., “GPT3Mix: Leveraging Large-scale Language Models for Text Augmentation,” in Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 2021, pp. 2225–2239. [11] T. B. Brown et al., “Language models are few-shot learners,” in Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, BC, Canada: Curran Associates Inc., 2020, pp. 1877–1901. [12] J. Liu et al., “Generated knowledge prompting for commonsense reasoning,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 2022, pp. 3154–3169. [13] S. Pratt, I. Covert, R. Liu, and A. Farhadi, “What does a platypus look like? Generating customized prompts for zero-shot image classification,” in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023, pp. 15 645–15 655.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• ニュース推薦: 各ユーザの閲覧履歴やプロフィール等に基づき, ユーザが好みそうな ニュース記事を推薦 • 深層学習を用いたニュース推薦手法[1]: ◦ 「ニュース記事」と「ユーザの嗜好情報」を同じ次元のベクトルに変換→ ベクト](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_4.jpg){kind=link}
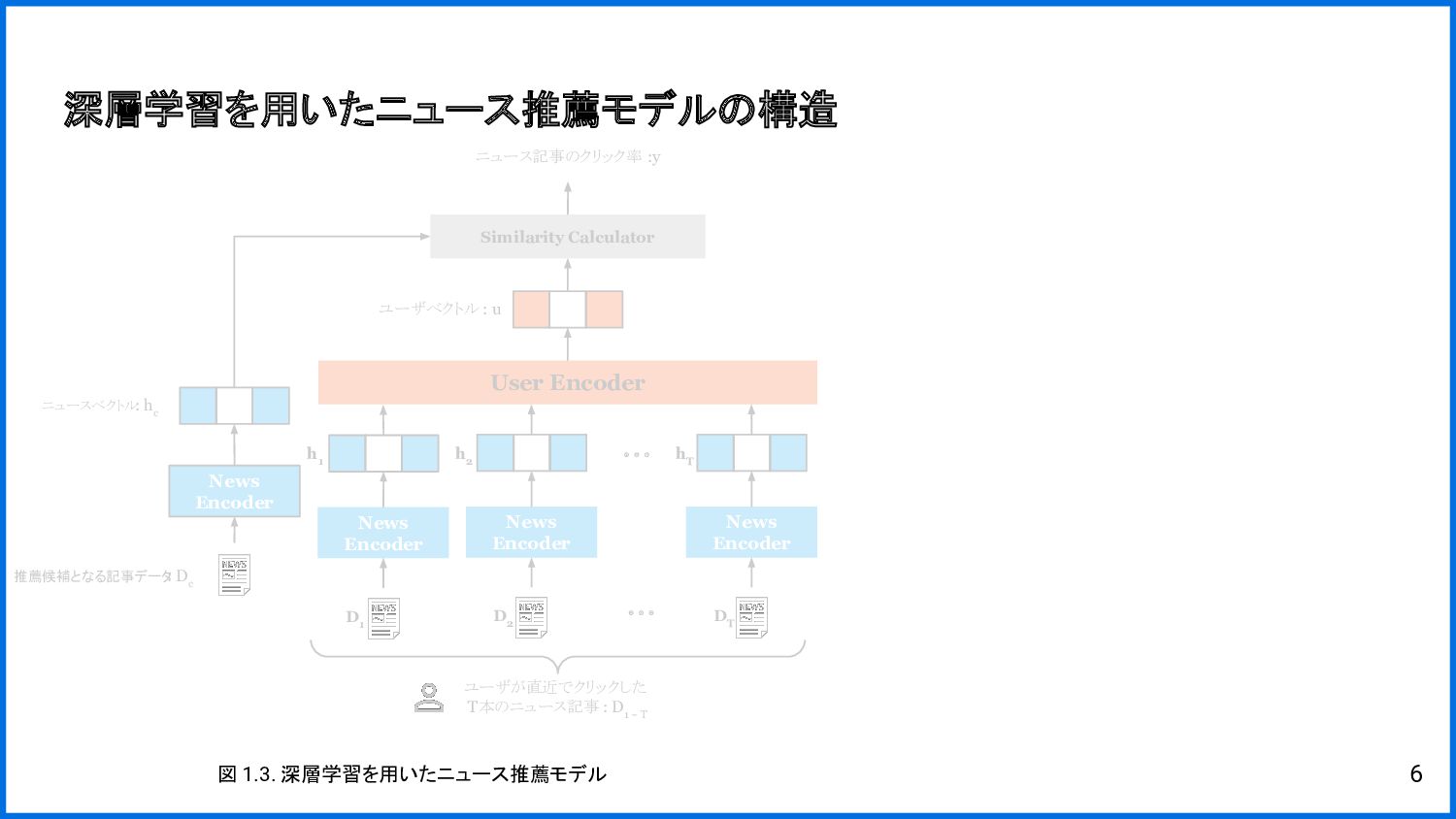{kind=link}
![[6]C. Wu et al., “NPA: Neural News Recommendation with Personalized](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_6.jpg){kind=link}
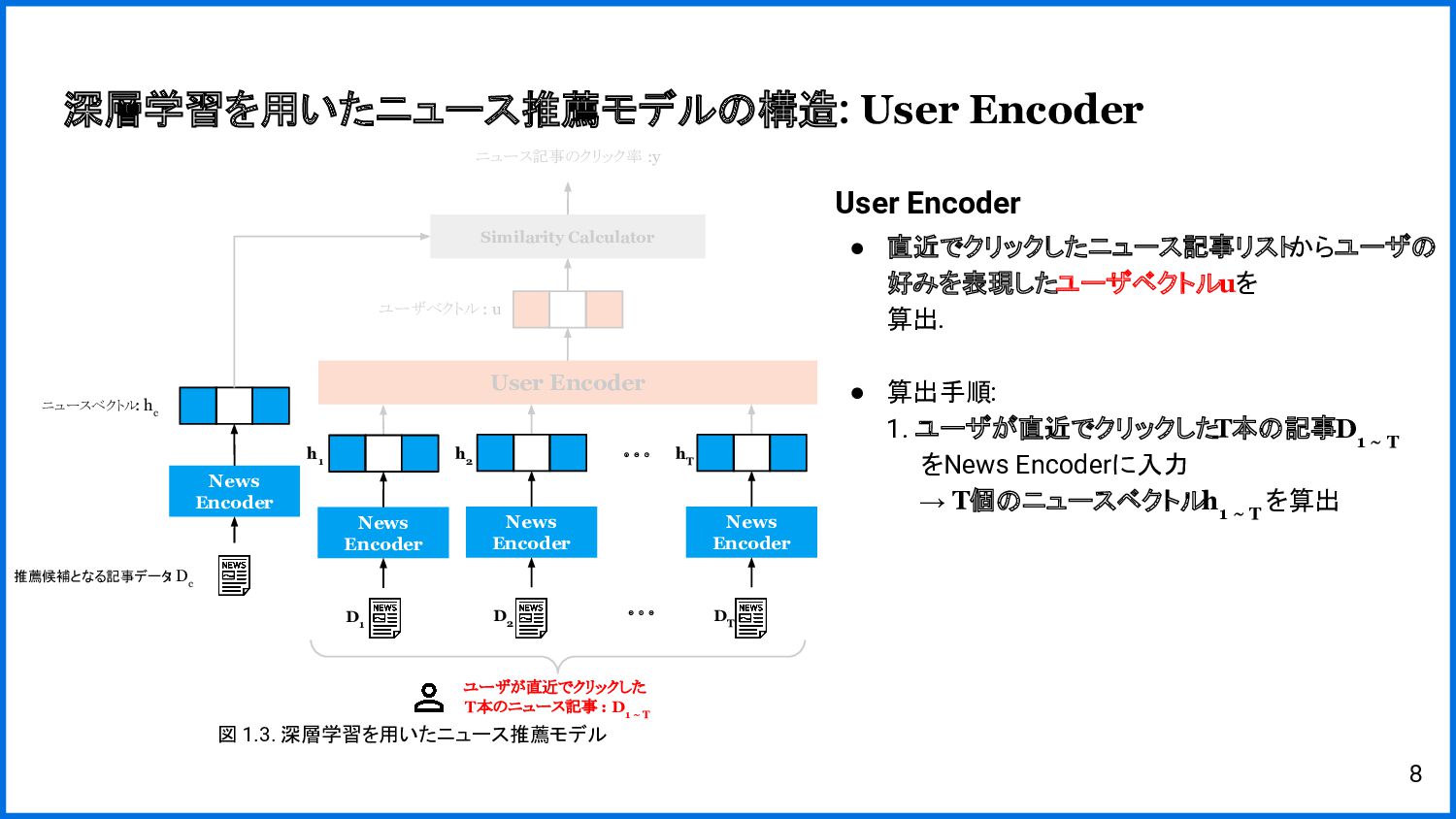{kind=link}
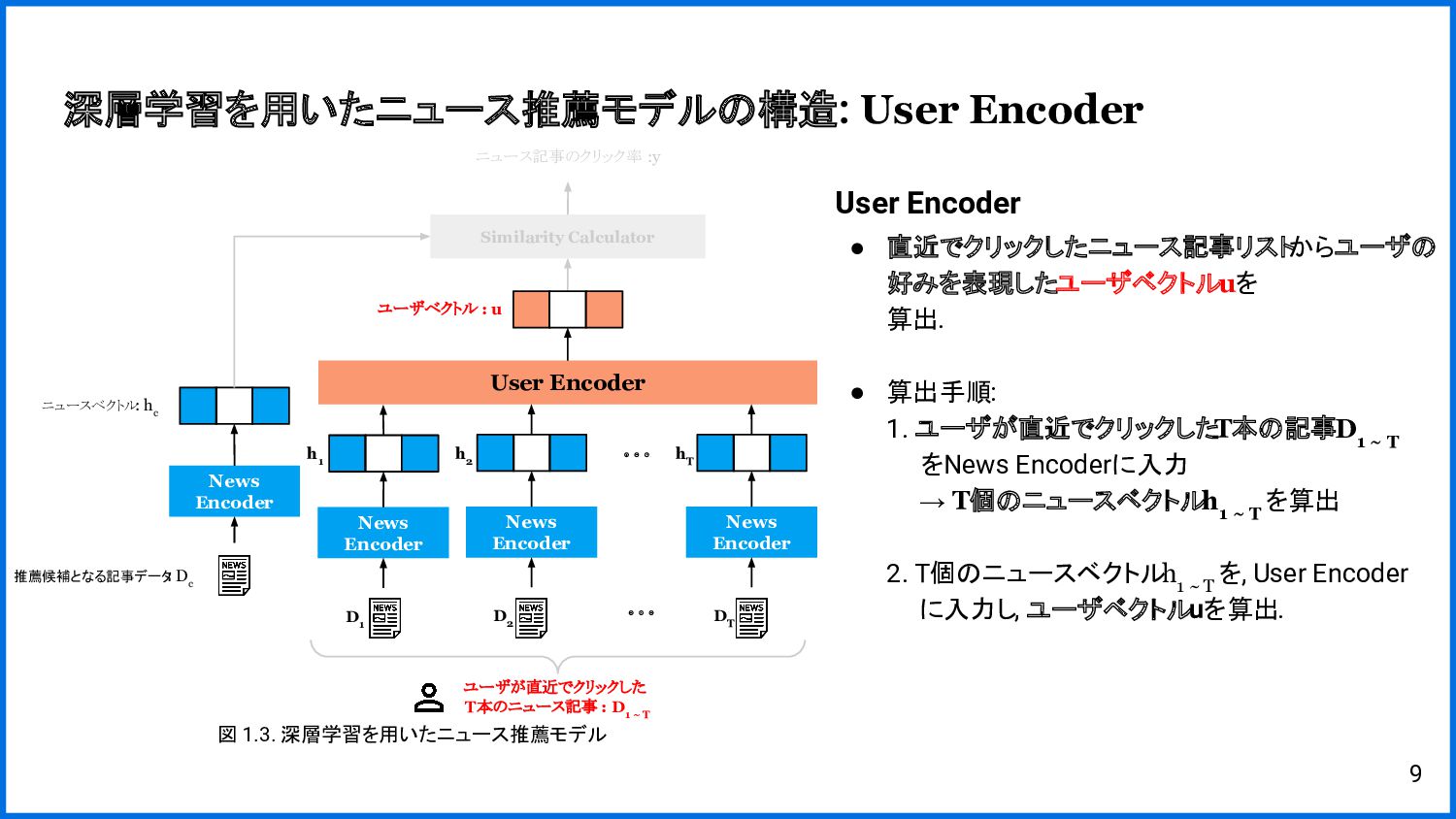{kind=link}
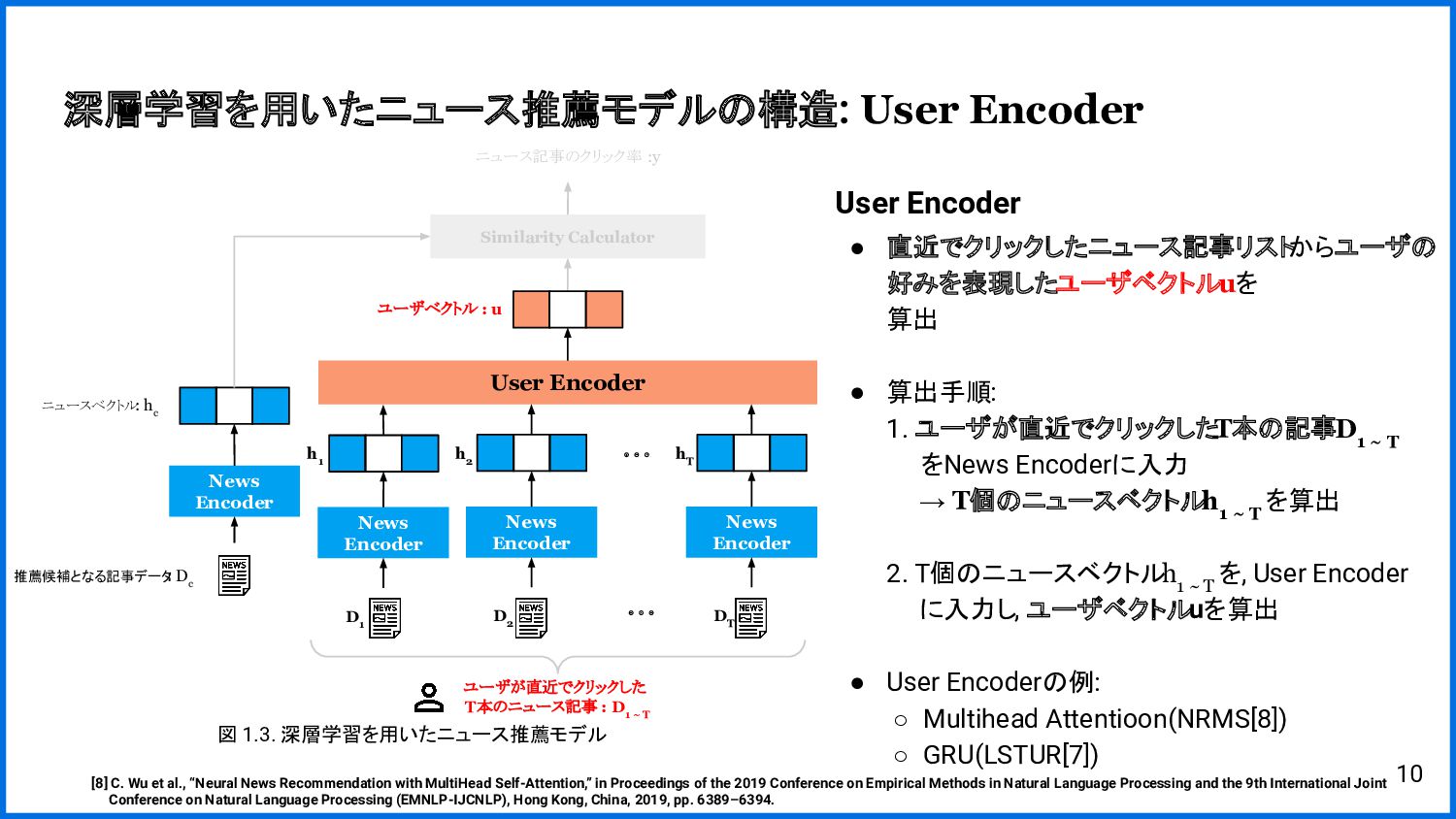{kind=link}
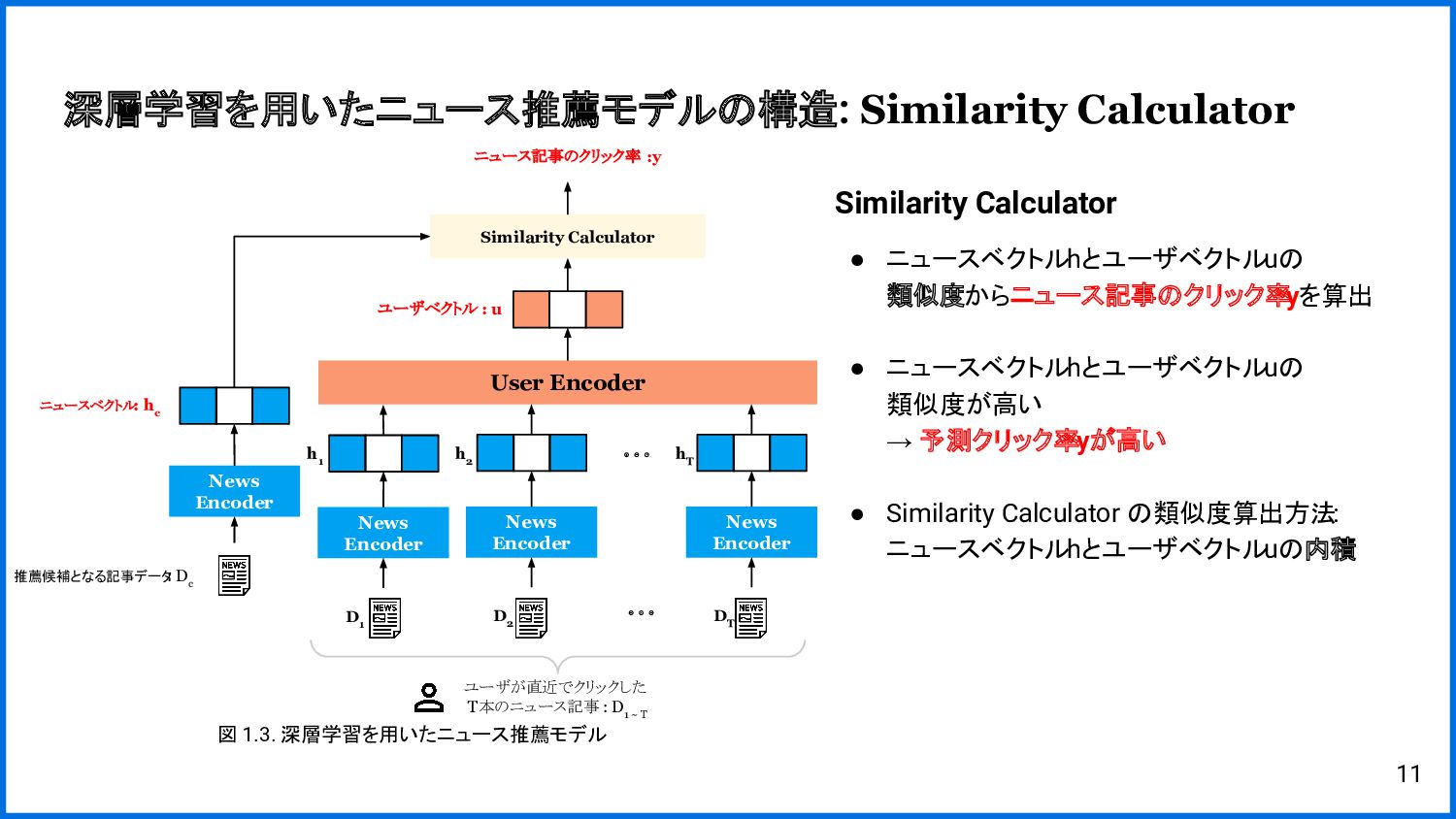{kind=link}
![• ニュース記事の内容や扱っているトピックに応じて決定される記事の分類 • MIND[2]データセットにおけるニュースカテゴリの具体例: finance-real-estate, tv-golden-globes, newspolitics, … etc ニュースの記事カテゴリ情報とその課題](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_11.jpg){kind=link}
![• ニュース記事の内容や扱っているトピックに応じて決定される記事の分類 • MIND[2]データセットにおけるニュースカテゴリの具体例: finance-real-estate, tv-golden-globes, newspolitics, … etc ニュースの記事カテゴリ情報とその課題](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
![関連研究: ニュース推薦 16 • News Encoder/User Encoderに異なるニューラルネットを用いた手法が提案されている 深層学習を用いたニュース推薦 NAML[6] NPA[9]](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_15.jpg){kind=link}
![関連研究: ニュース推薦 17 • News Encoder/User Encoderに異なるニューラルネットを用いた手法が提案されている 深層学習を用いたニュース推薦 NAML[6] NPA[9]](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_16.jpg){kind=link}
{kind=link}
![[10] K. M. Yoo et al., “GPT3Mix: Leveraging Large-scale Language](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_18.jpg){kind=link}
![[10] K. M. Yoo et al., “GPT3Mix: Leveraging Large-scale Language](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_19.jpg){kind=link}
![関連研究: 大規模言語モデルによる生成文の応用 21 • 2021年, Yooら[10]は, GPT-3[11]によりテキスト拡張を 文書分類に応用するGPT3Mixを提案. GPT-3で 訓練データの拡張を行い](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
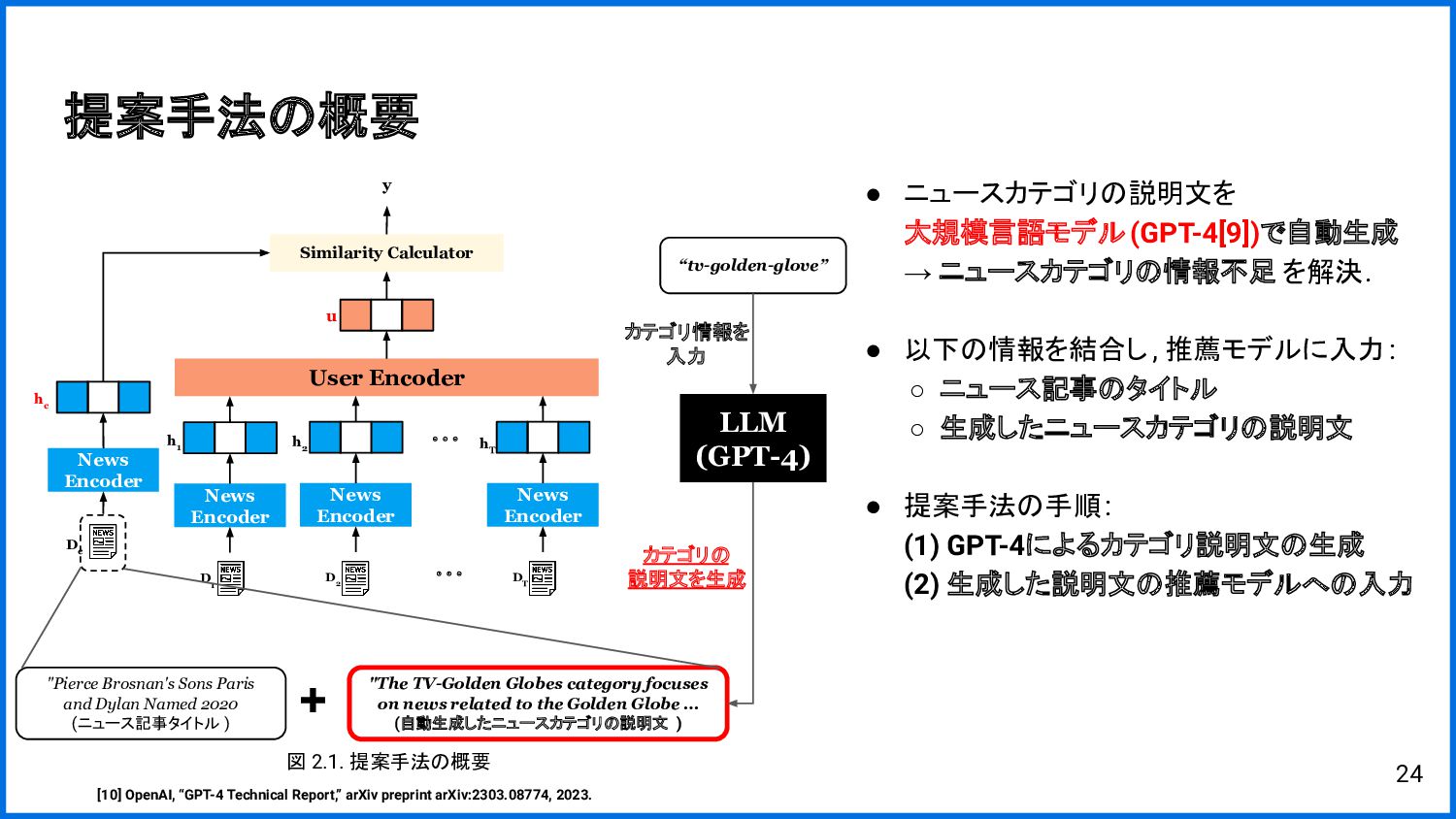{kind=link}
{kind=link}
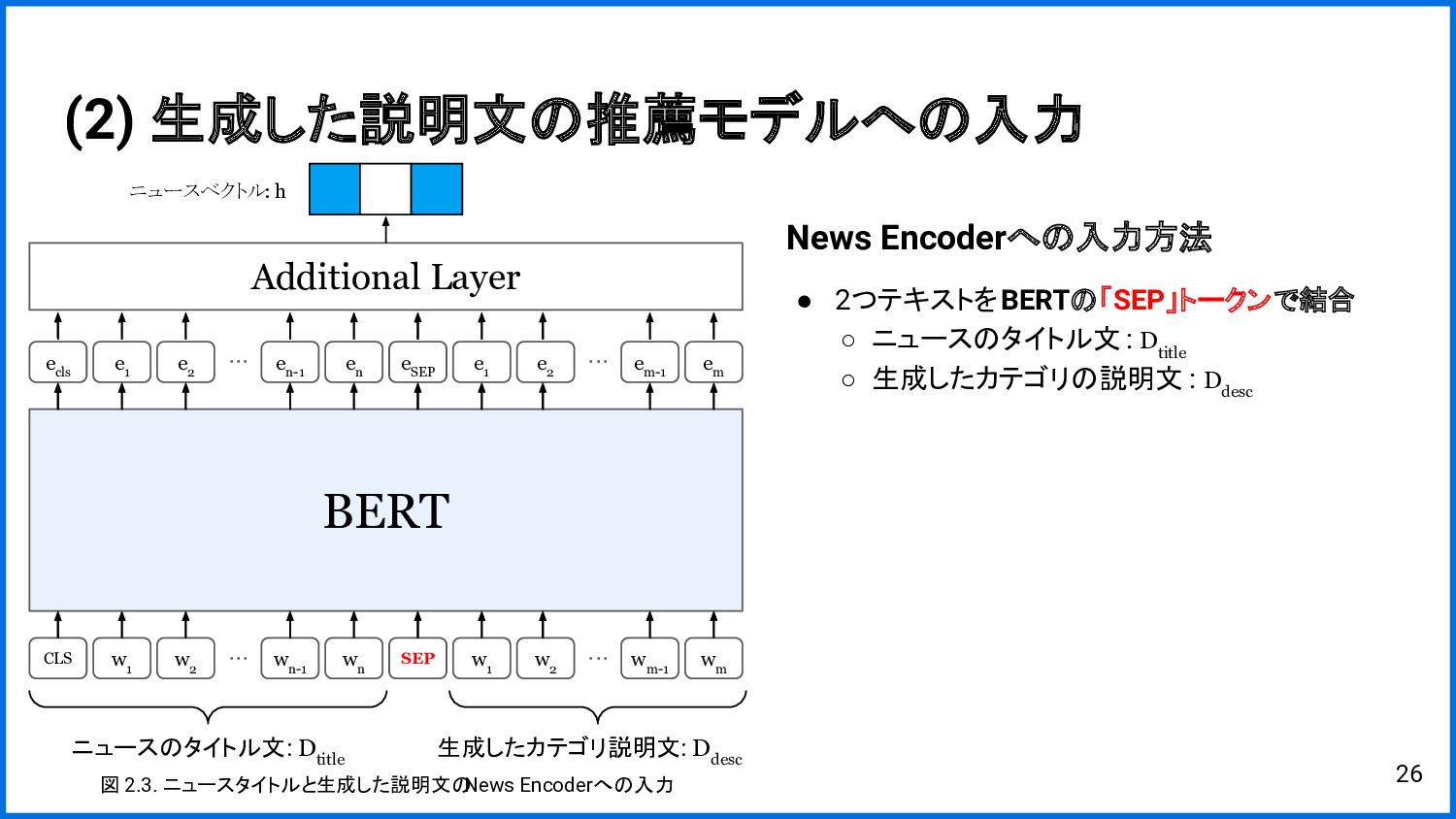{kind=link}
{kind=link}
![検証のための推薦モデル: NRMS(NRMS-BERT)[1,8] BERT Encoder Multihead Attention Multihead Attention Additive Attention](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_27.jpg){kind=link}
![• MIND(Microsoft News Dataset)[2]: Microsoft Newsの実際の行動ログ・ニュースデータから構築されたデータセット • 収録内容 ◦ 約6.5万件の英文ニュース記事データ](https://files.speakerdeck.com/presentations/cf6477f2e51c4494b29e7d2c6227599c/slide_28.jpg){kind=link}
{kind=link}
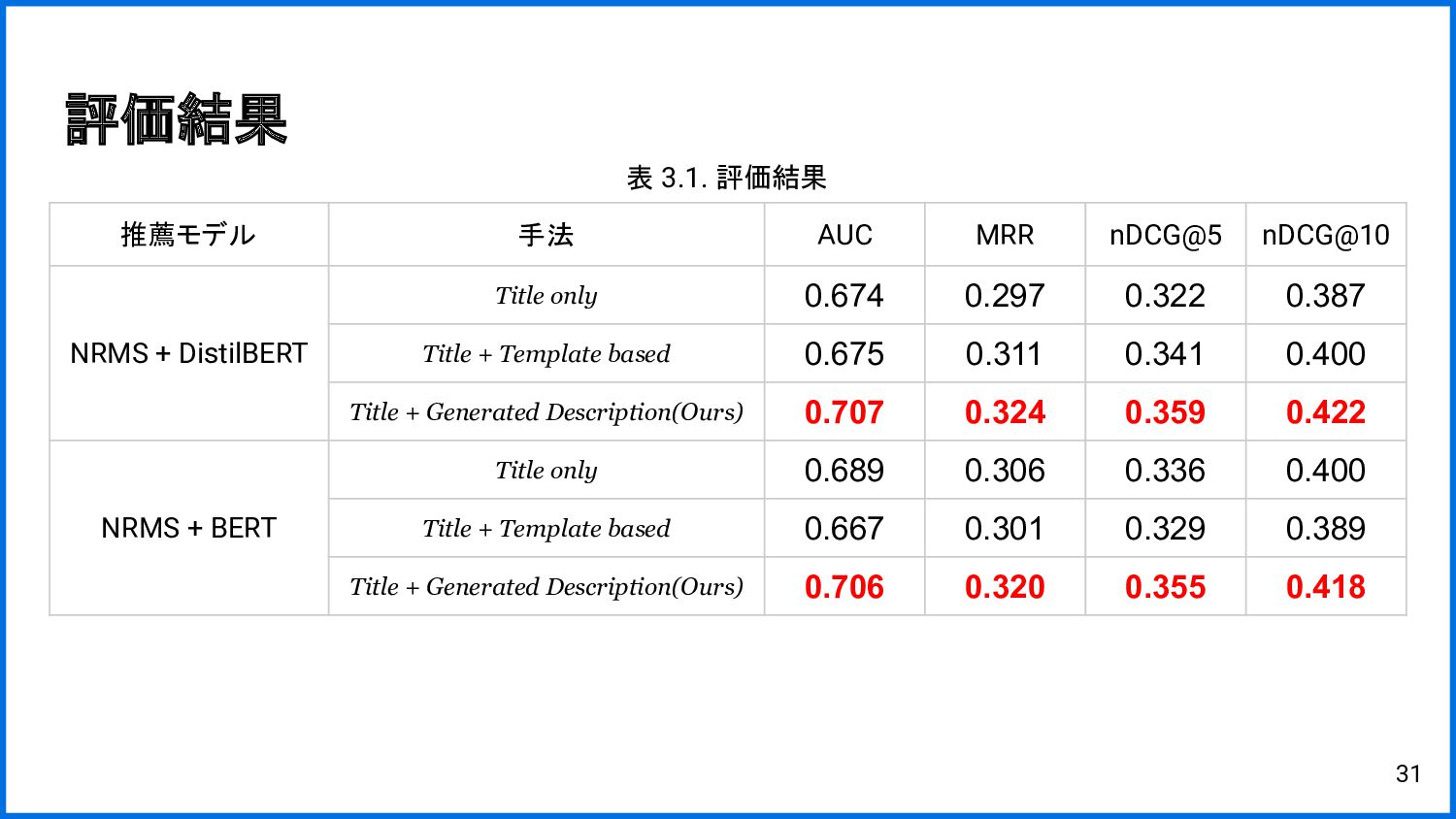{kind=link}
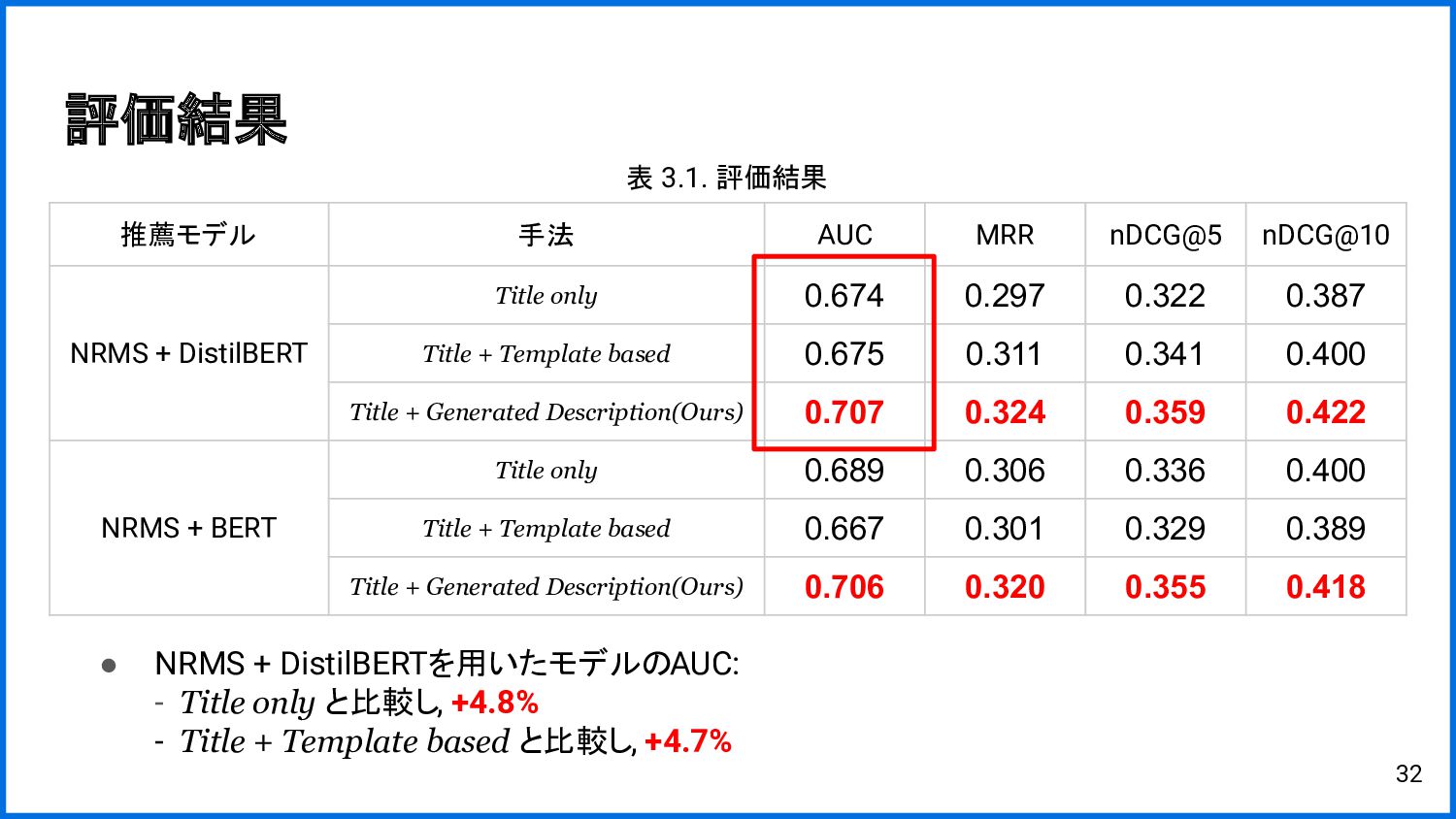{kind=link}
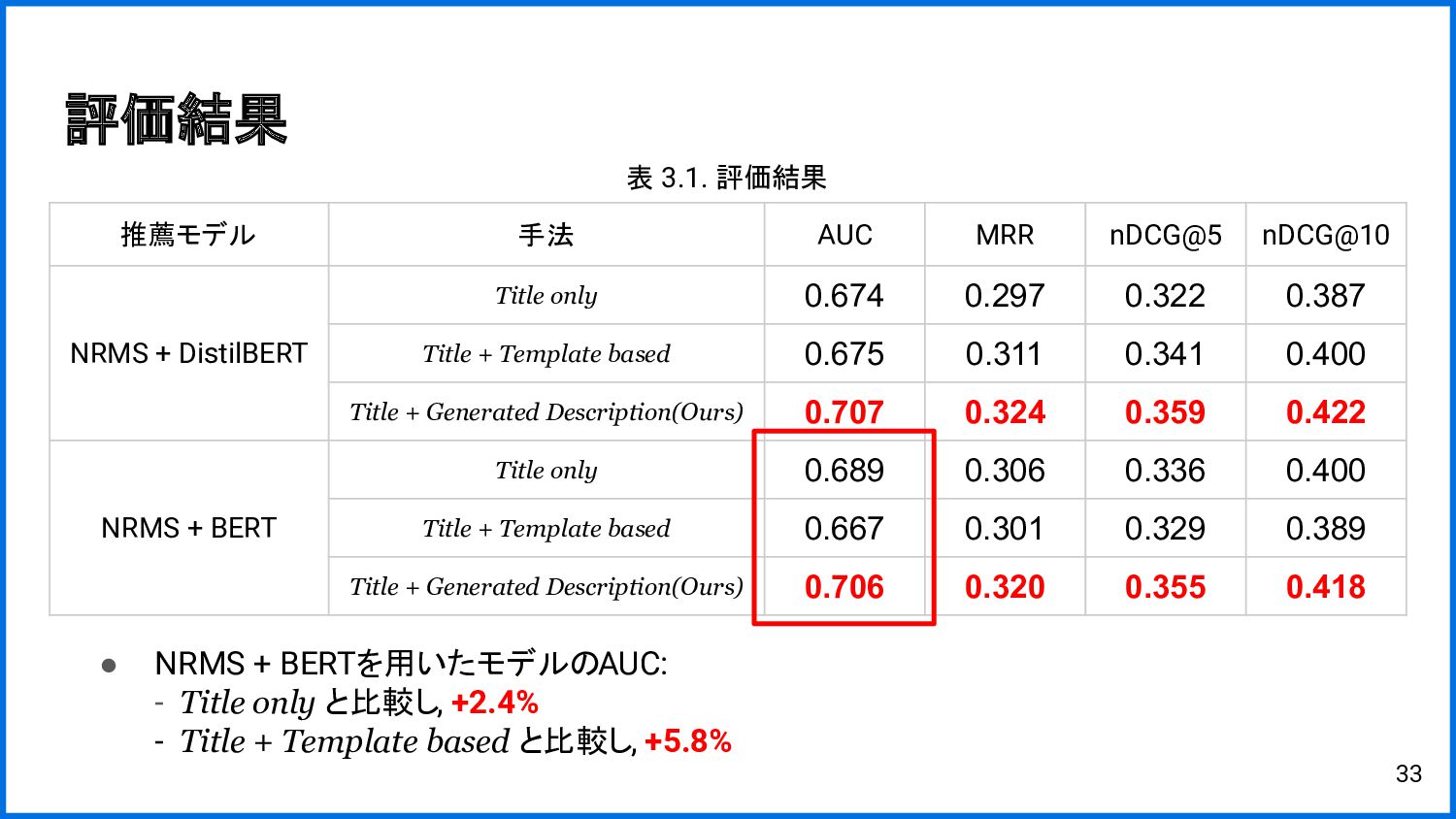{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
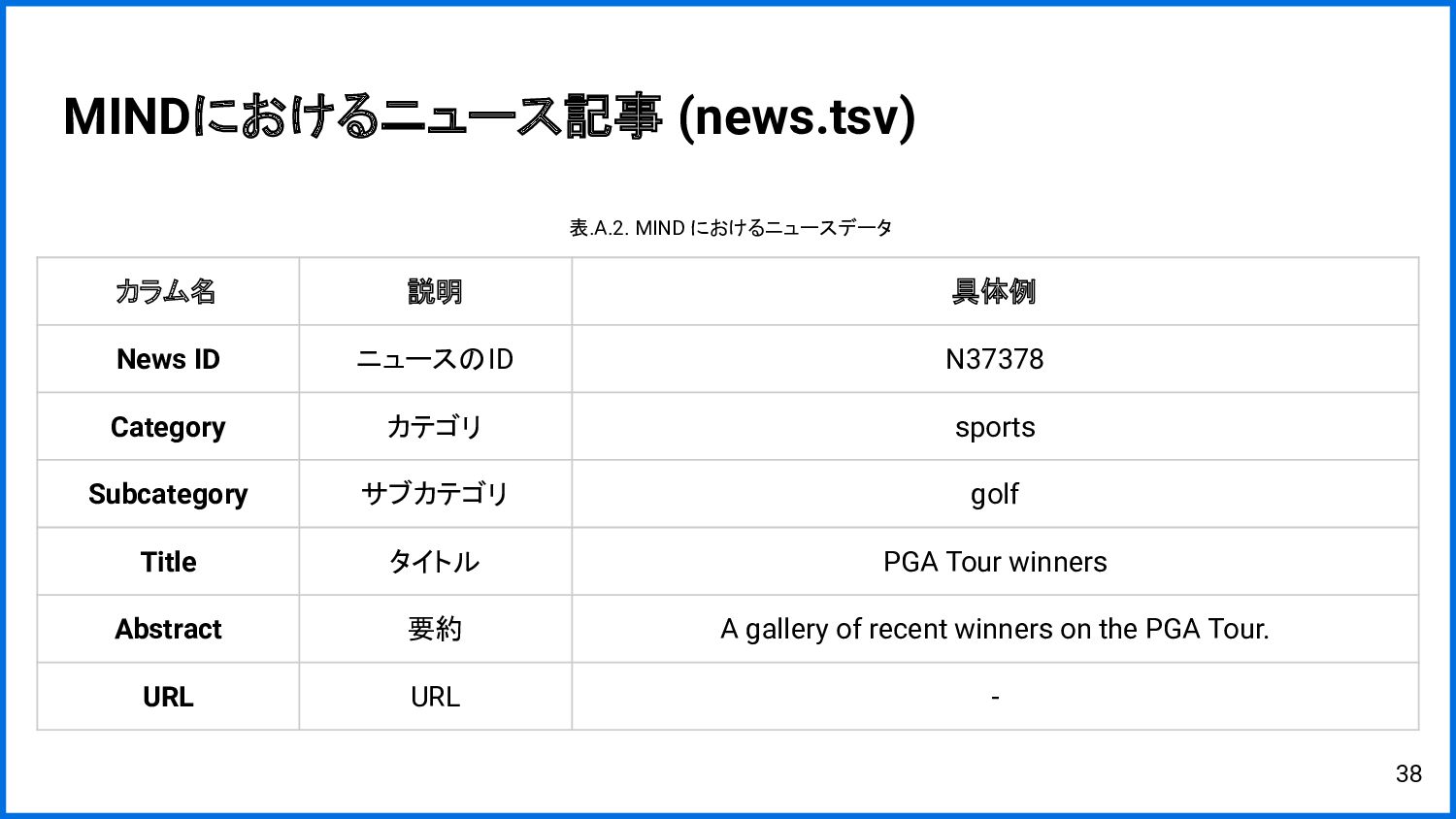{kind=link}
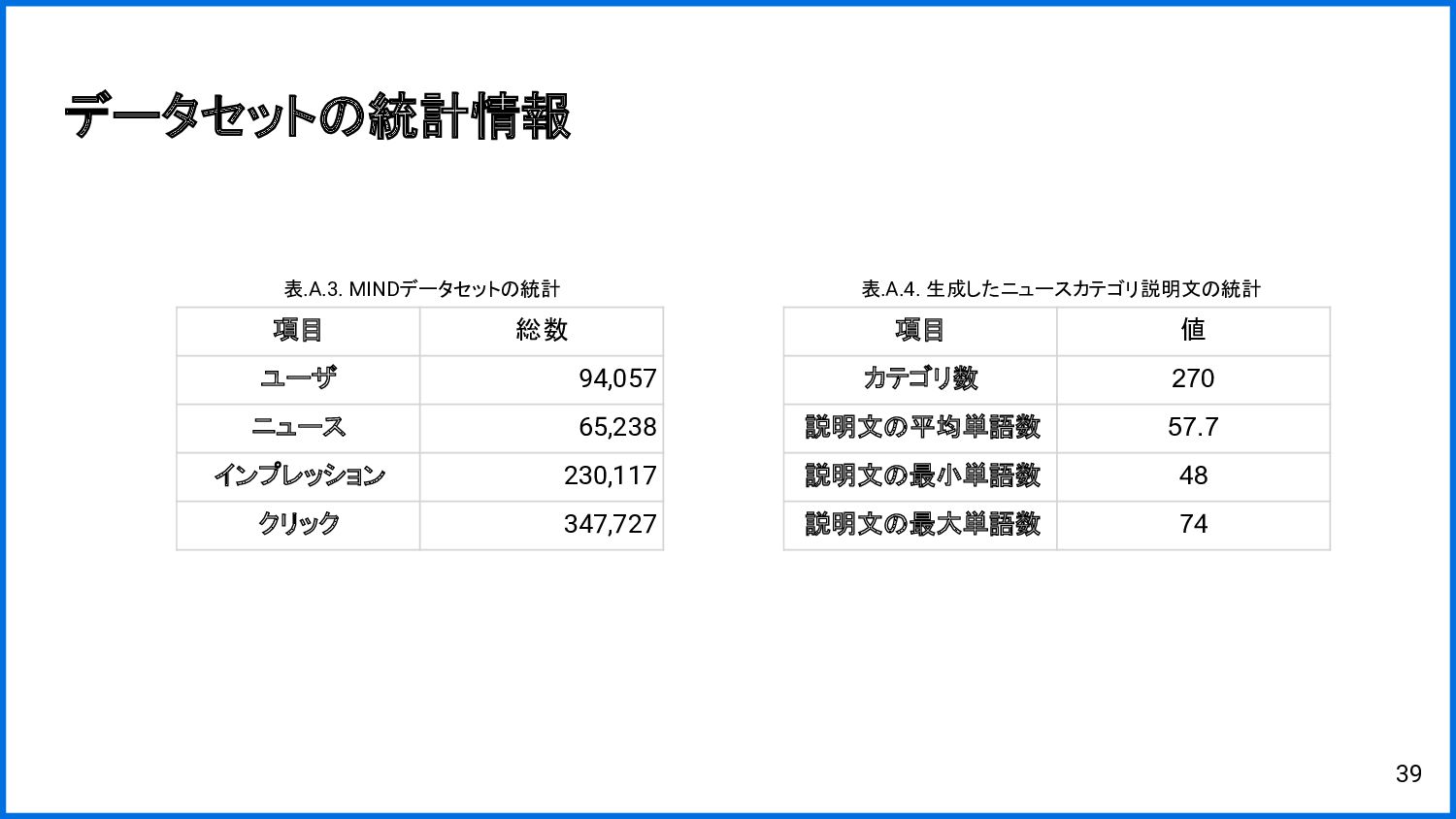{kind=link}
{kind=link}