Wenqi Shi, Yue Yu, Yuchen Zhuang, Yanqiao Zhu, May Dongmei Wang,Joyce C. Ho, Chao Zhang, and Carl Yang: BMRetriever: Tuning LargeLanguage Models as Better Biomedical Text Retrievers, In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 22234–22254, 2024
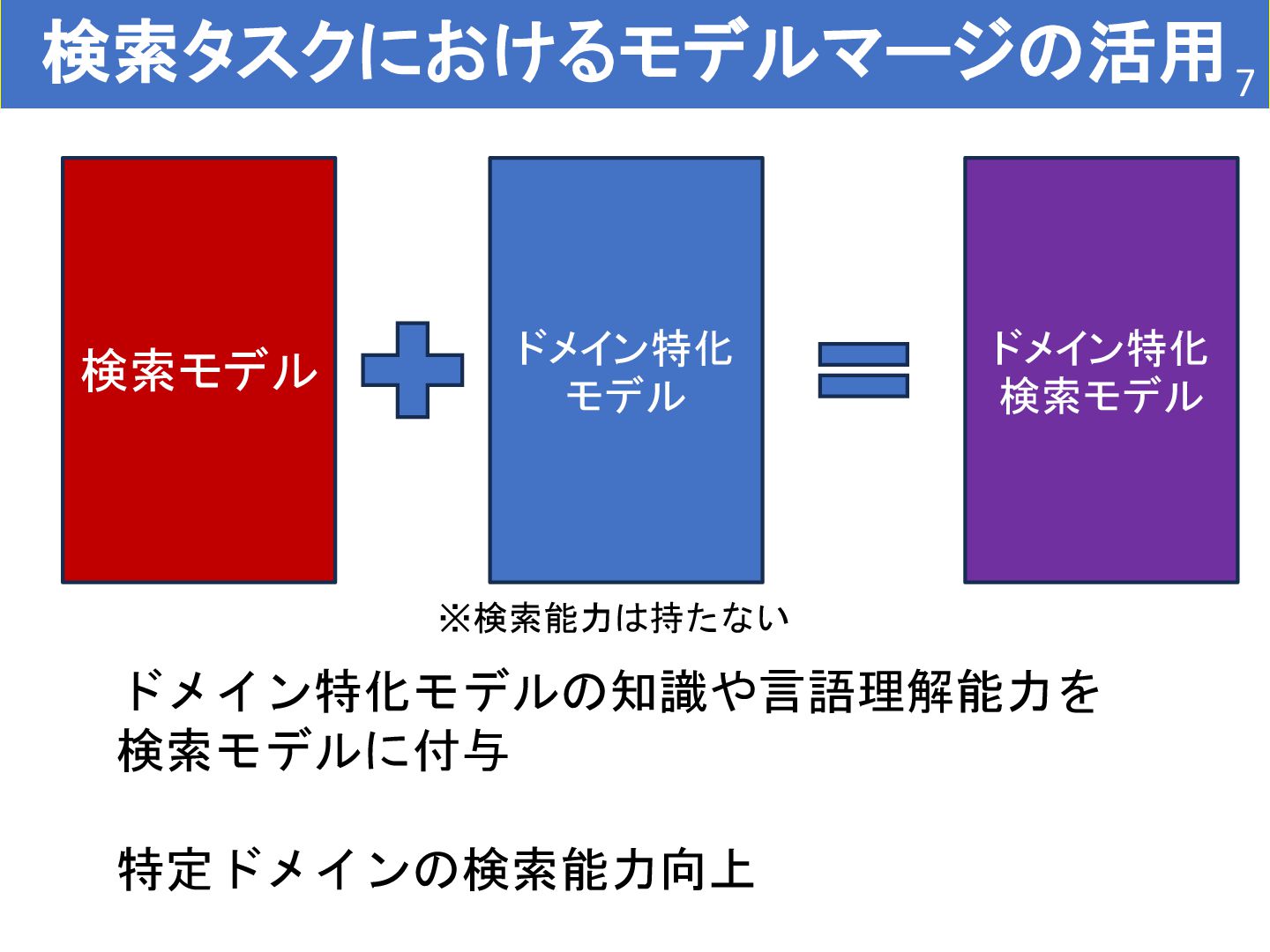
subject in any style by effectively merging loras." European Conference on Computer Vision. Springer, Cham, 2025. YU, Le, et al. Language models are super mario: Absorbing abilities from homologous models as a free lunch. In: Forty-first International Conference on Machine Learning. 2024. 本物の犬とフィギュアを統合 数学能力とコーディング能力を持つLLM モデルマージを検索タスクに応用する研究はまだ無い。→検証
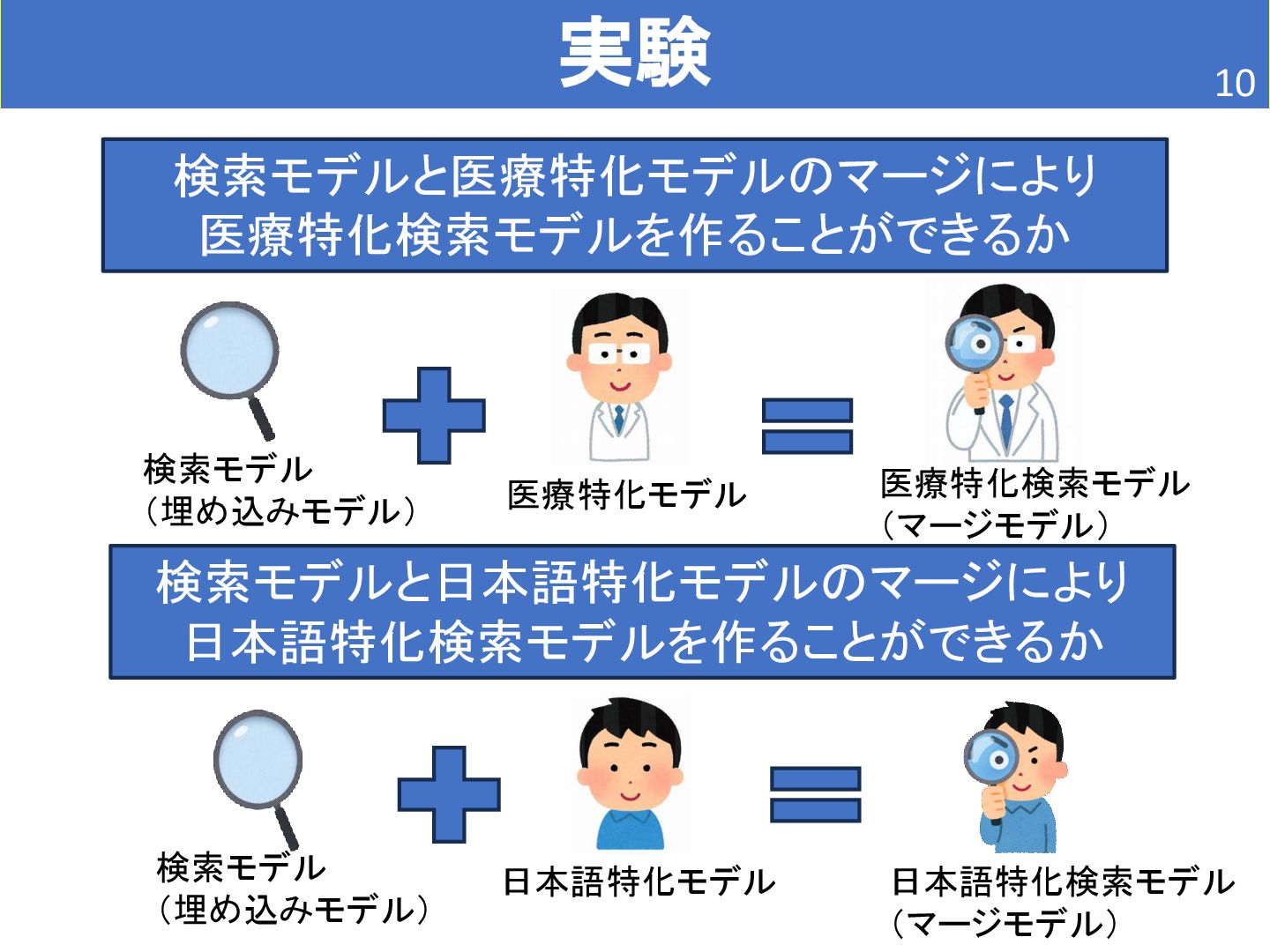
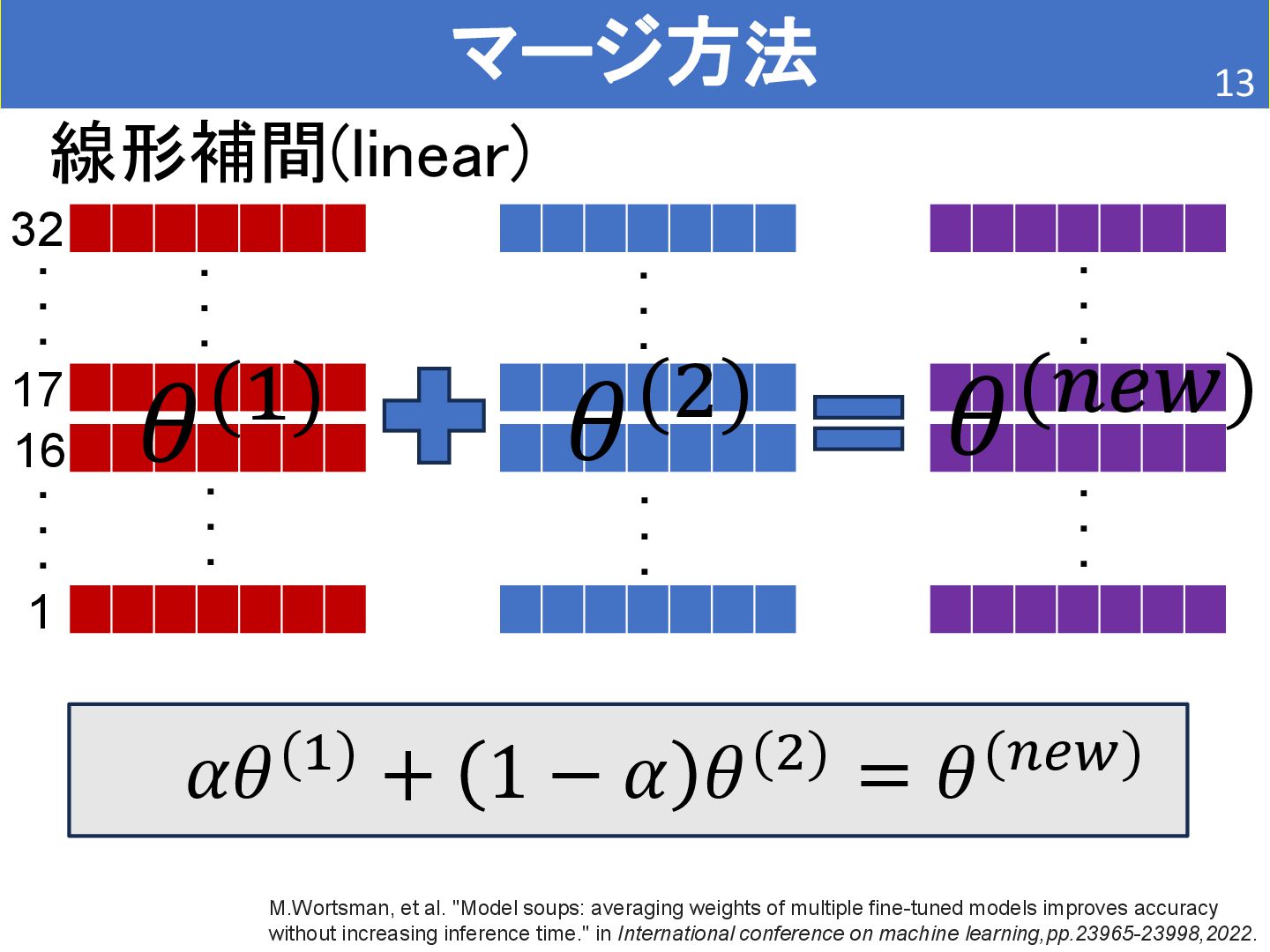
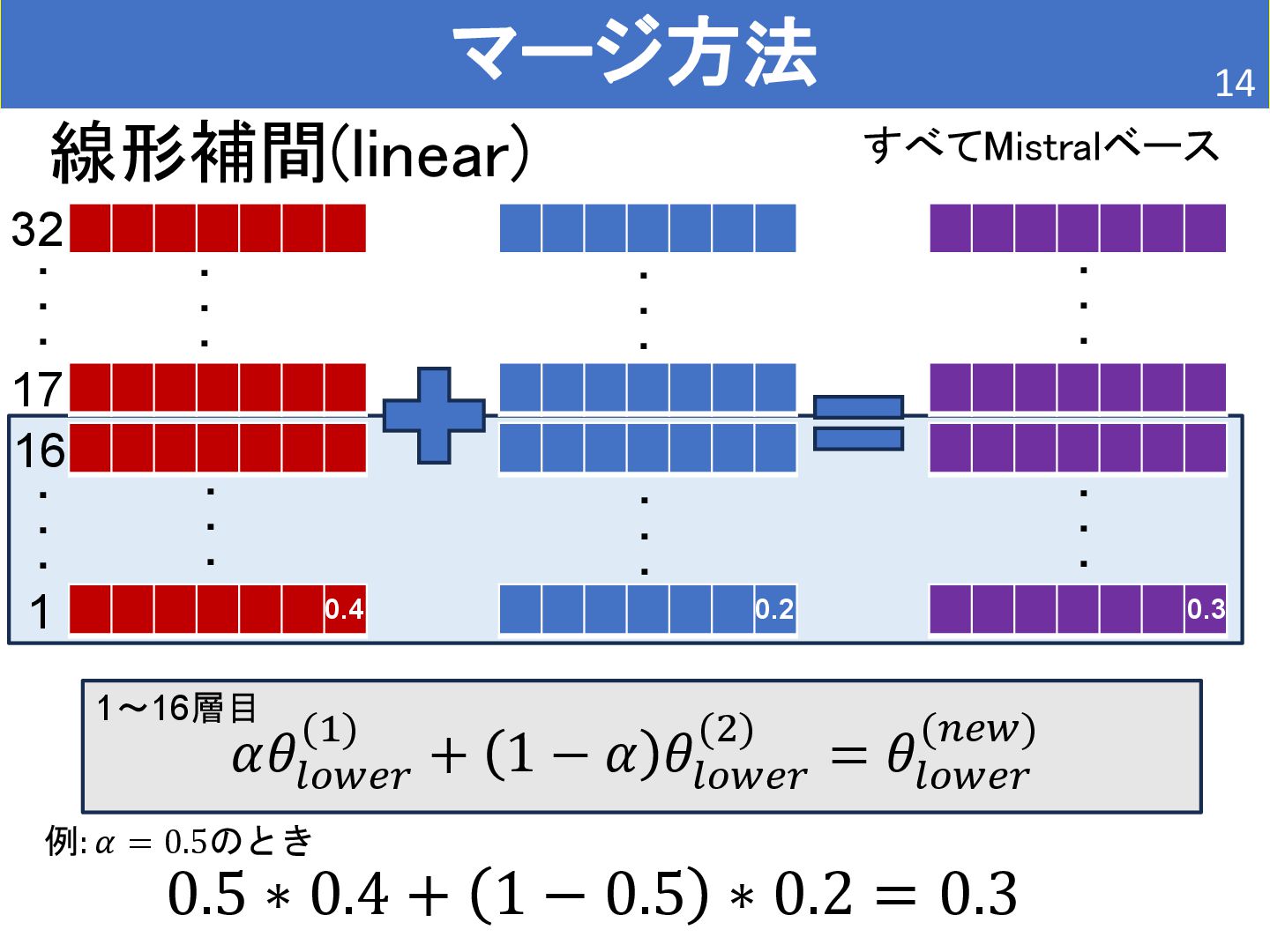
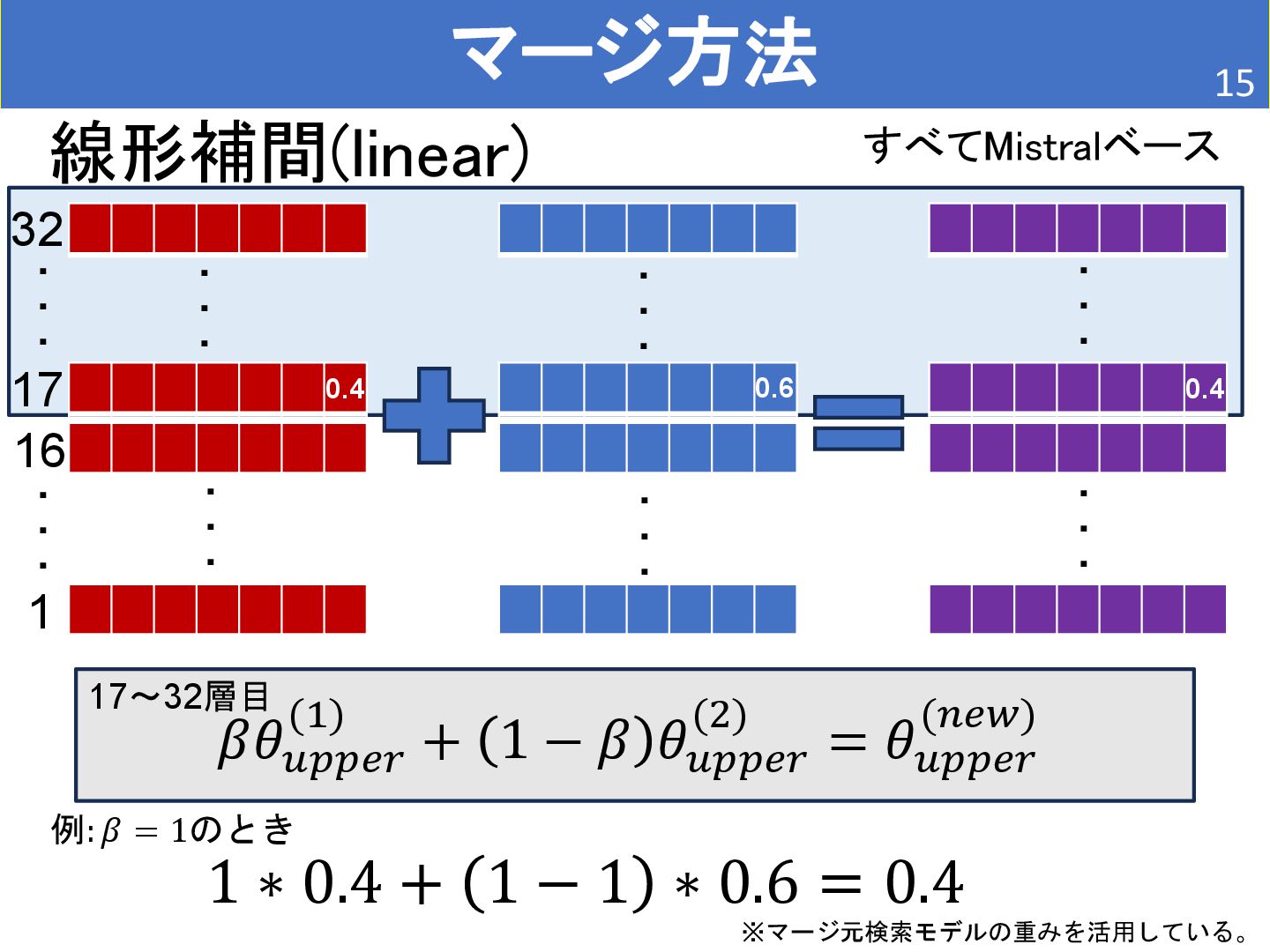
• BioMistral/BioMistral-7B • Mistralを医療文書で継続事前学習 • 検索能力は持たない。 [2] Labrak, Yanis, et al. "Biomistral: A collection of open-source pretrained large language models for medical domains." arXiv preprint arXiv:2402.10373 (2024). [1] L. Wang, et al. Improving Text Embeddings with Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pp. 11897–11916, 2024. どちらもMistralベース(Mistralは32個の層で構築されている。)
• stabilityai/japanese-stablelm-base-gamma-7b • Mistralを日本語文書で継続事前学習 • 検索能力は持たない。 [1] L. Wang, et al. Improving Text Embeddings with Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pp. 11897–11916, 2024.
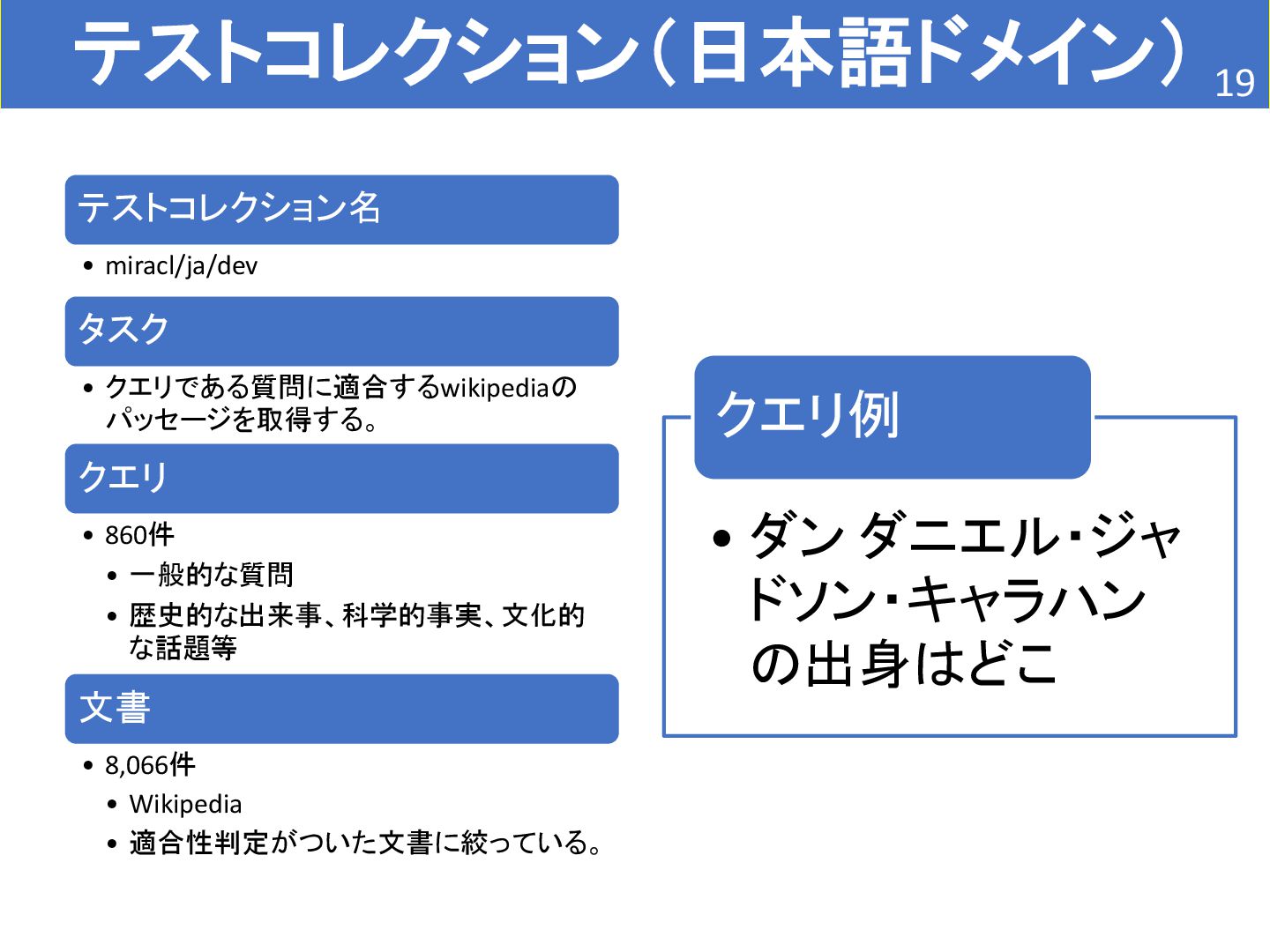
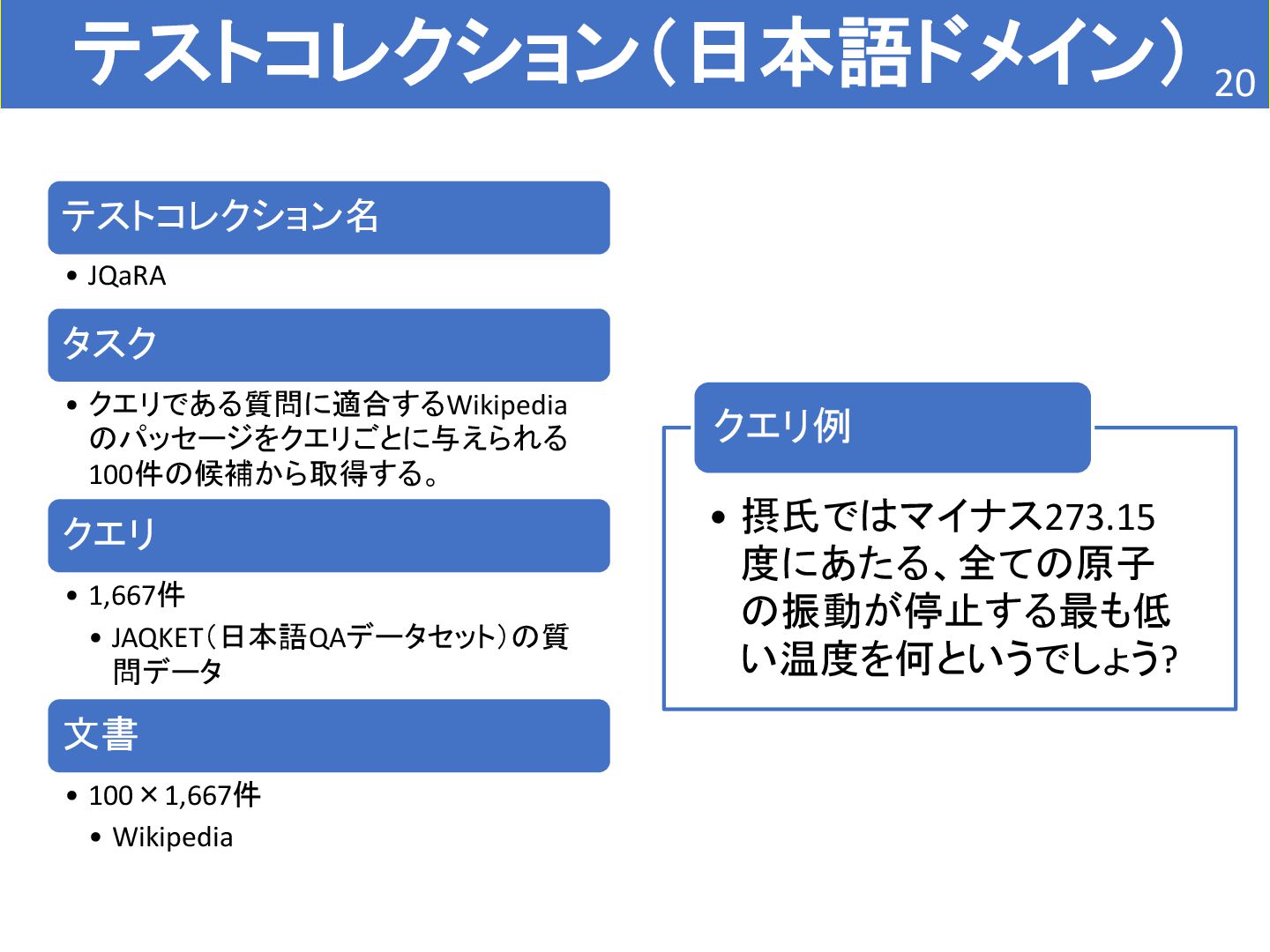
• 75件 • 患者の情報 文書 • 26,162件 • 臨床試験の情報 • 適合性判定がついた文書に絞っている。 • Patient is a 45-year-old man with a history of anaplastic astrocytoma of the spine complicated by severe lower extremity weakness and urinary retention s/p Foley catheter, high-dose steroids, hypertension, and chronic pain. The tumor is located in the T-L spine, unresectable anaplastic astrocytoma s/p radiation. Complicated by progressive lower extremity weakness and urinary retention. Patient initially presented with RLE weakness where his right knee gave out with difficulty walking and right anterior thigh numbness. MRI showed a spinal cord conus mass which was biopsied and found to be anaplastic astrocytoma. Therapy included field radiation t10- l1 followed by 11 cycles of temozolomide 7 days on and 7 days off. This was followed by CPT-11 Weekly x4 with Avastin Q2 weeks/ 2 weeks rest and repeat cycle. クエリ例
{kind=link}
{kind=link}
{kind=link}
![ドメイン特化検索モデルの必要性 4 一般的な文書でファインチューニングされたモデル は特定ドメインの文書検索性能に限界がある[1]。 ドメイン特化検索モデルが必要 [1] Ji Ma, et al.](https://files.speakerdeck.com/presentations/1615b6a94fc54c99adf733ca48278f56/slide_3.jpg){kind=link}
![ドメイン特化検索モデル構築のコスト 5 ドメイン特化検索モデルの構築には、特定ドメインの 適合性判定データを利用して、ファインチューニング することが一般的[1] 適合性判定データ収集コスト GPU計算コスト [1] Ran Xu,](https://files.speakerdeck.com/presentations/1615b6a94fc54c99adf733ca48278f56/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![マージ元モデル(医療ドメイン) 11 検索モデル[1] • intfloat/e5-mistral-7b-instruct • Mistralを埋め込みタスク用にファインチュー ニングしたバイエンコーダモデル。多くの検 索タスクベンチマークで上位にランクイン 医療特化モデル[2]](https://files.speakerdeck.com/presentations/1615b6a94fc54c99adf733ca48278f56/slide_10.jpg){kind=link}
![マージ元モデル(日本語ドメイン) 12 検索モデル[1] • intfloat/e5-mistral-7b-instruct • Mistralを埋め込みタスク用にファインチュー ニングしたバイエンコーダモデル。多くの検 索タスクベンチマークで上位にランクイン 日本語特化モデル](https://files.speakerdeck.com/presentations/1615b6a94fc54c99adf733ca48278f56/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
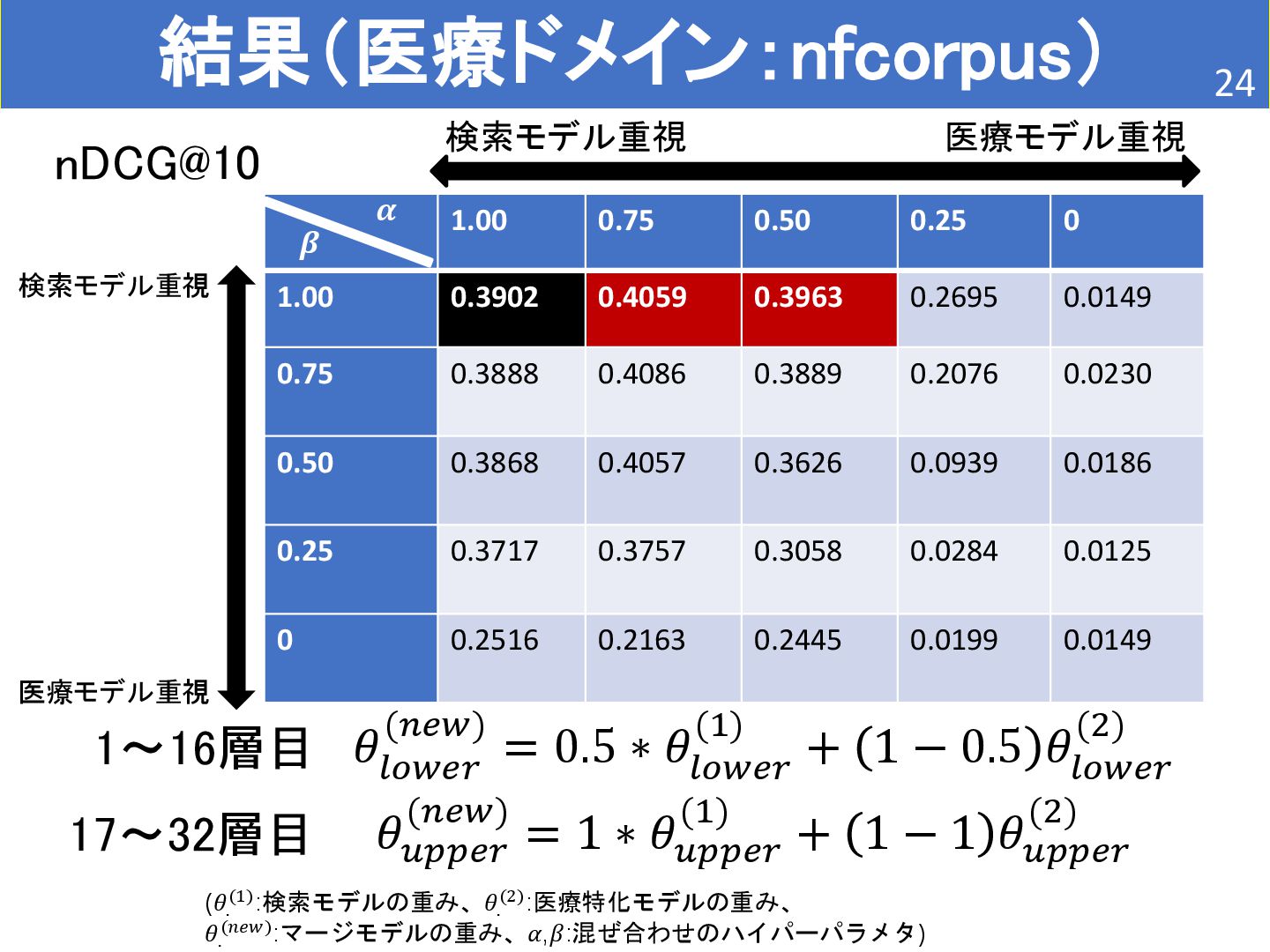
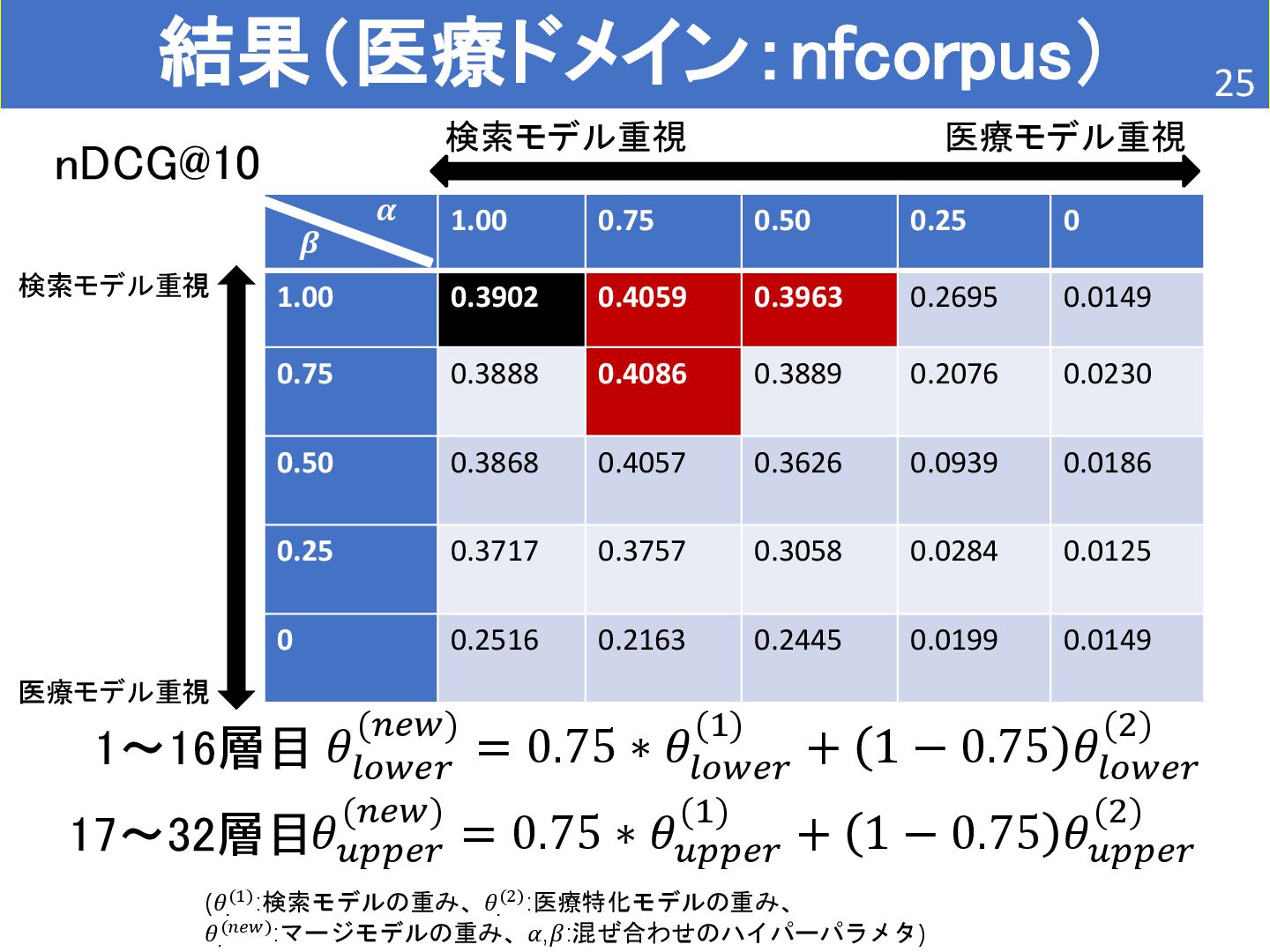
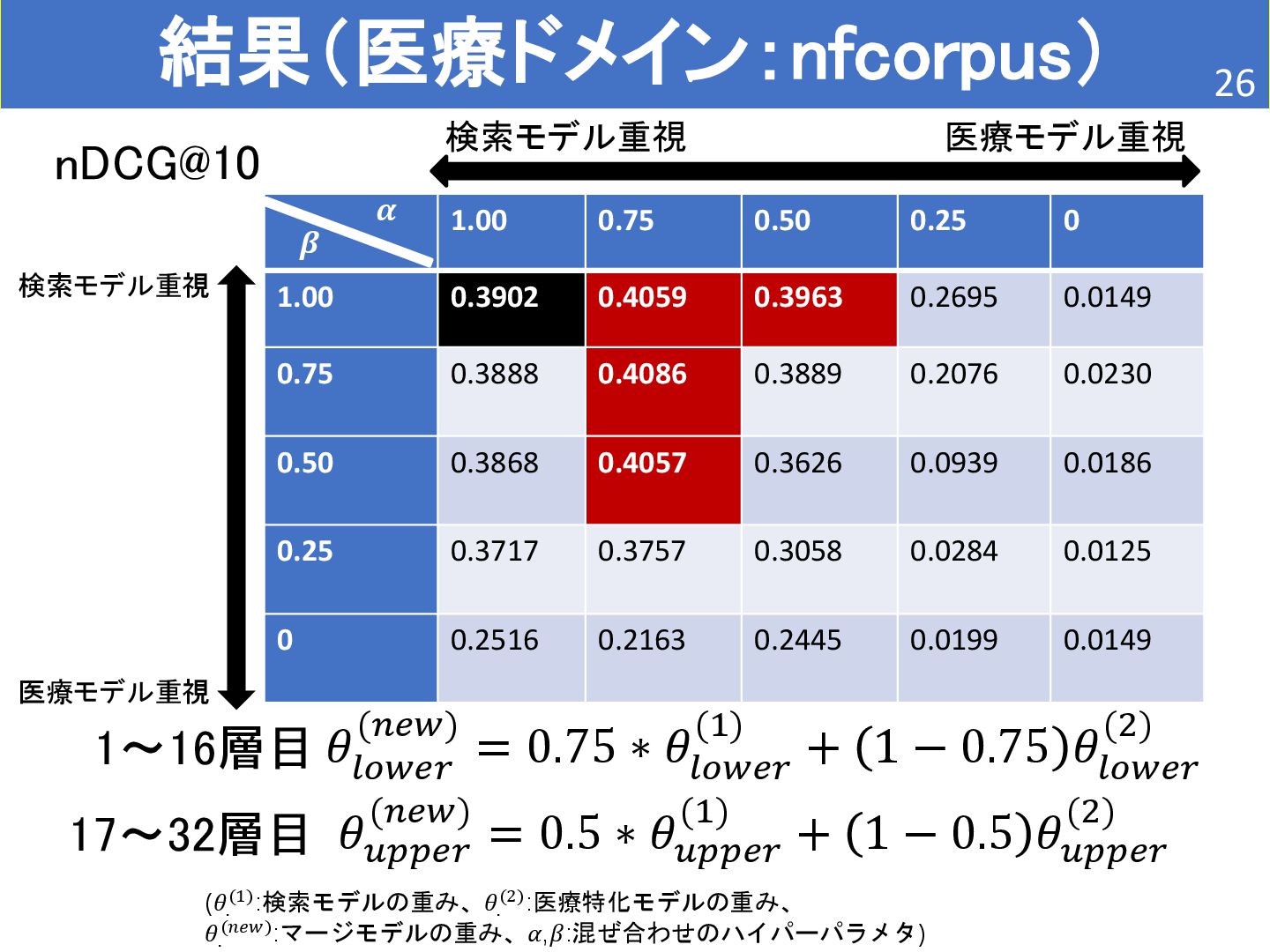
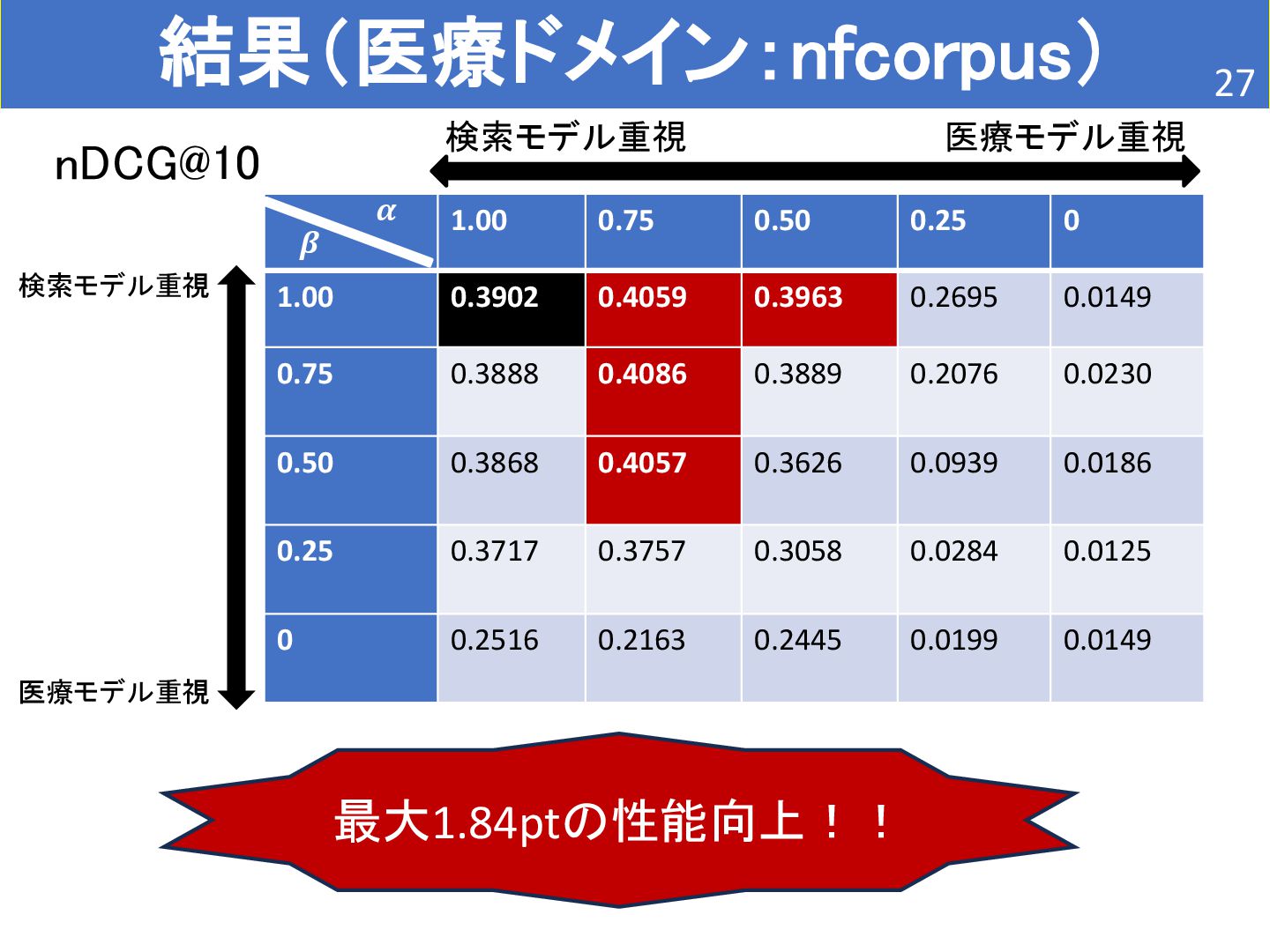
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![進化的モデルマージ 35 ・Sakana AIが提案[1] ・ユーザが指定した能力に長けた新しい基盤モデル を進化的アルゴリズムを用いて、自動的に作成する マージ方法 ・従来のマージが人間の直感に頼っていた問題を解決 [1] Akiba,](https://files.speakerdeck.com/presentations/1615b6a94fc54c99adf733ca48278f56/slide_34.jpg){kind=link}
{kind=link}