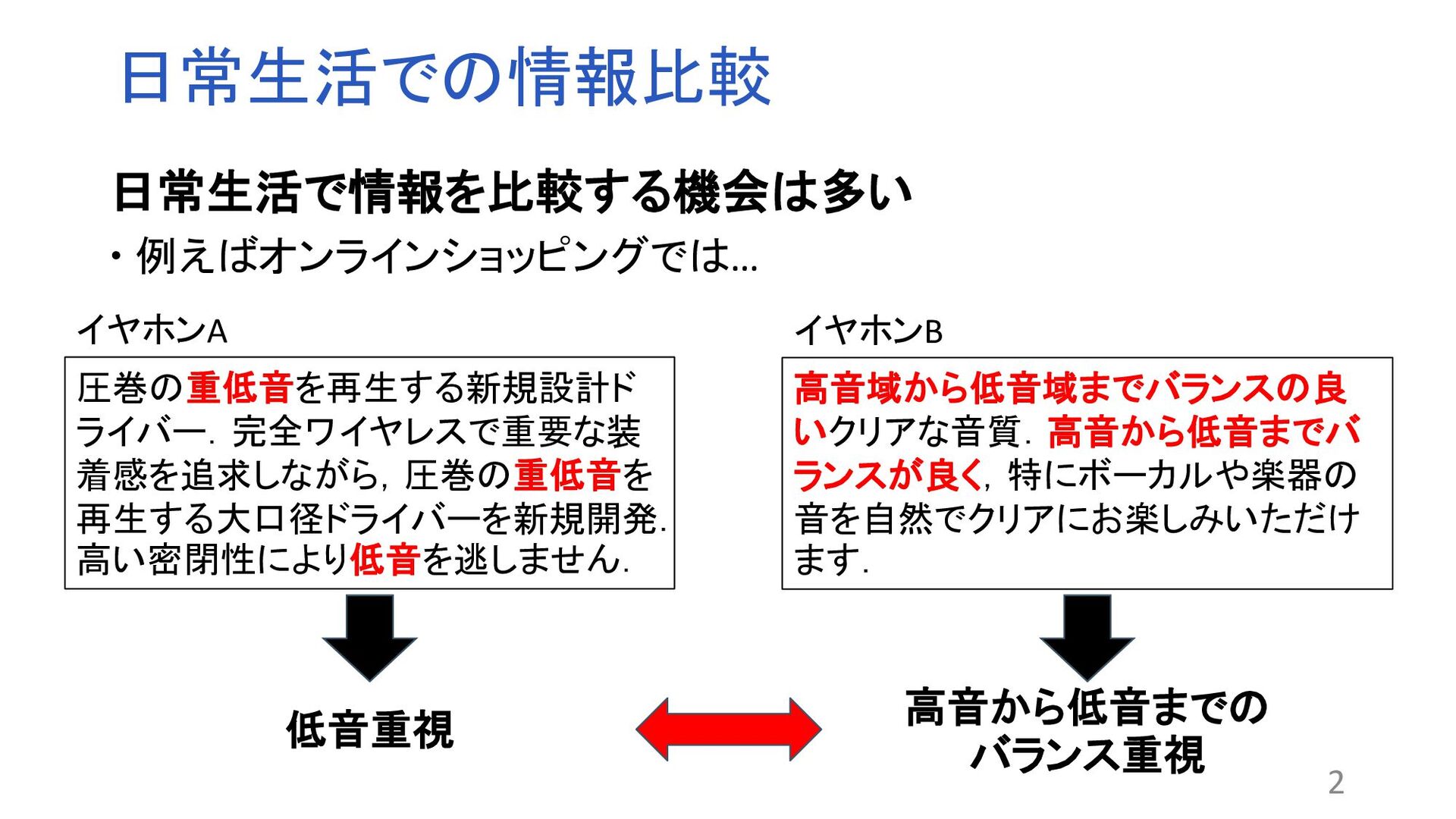
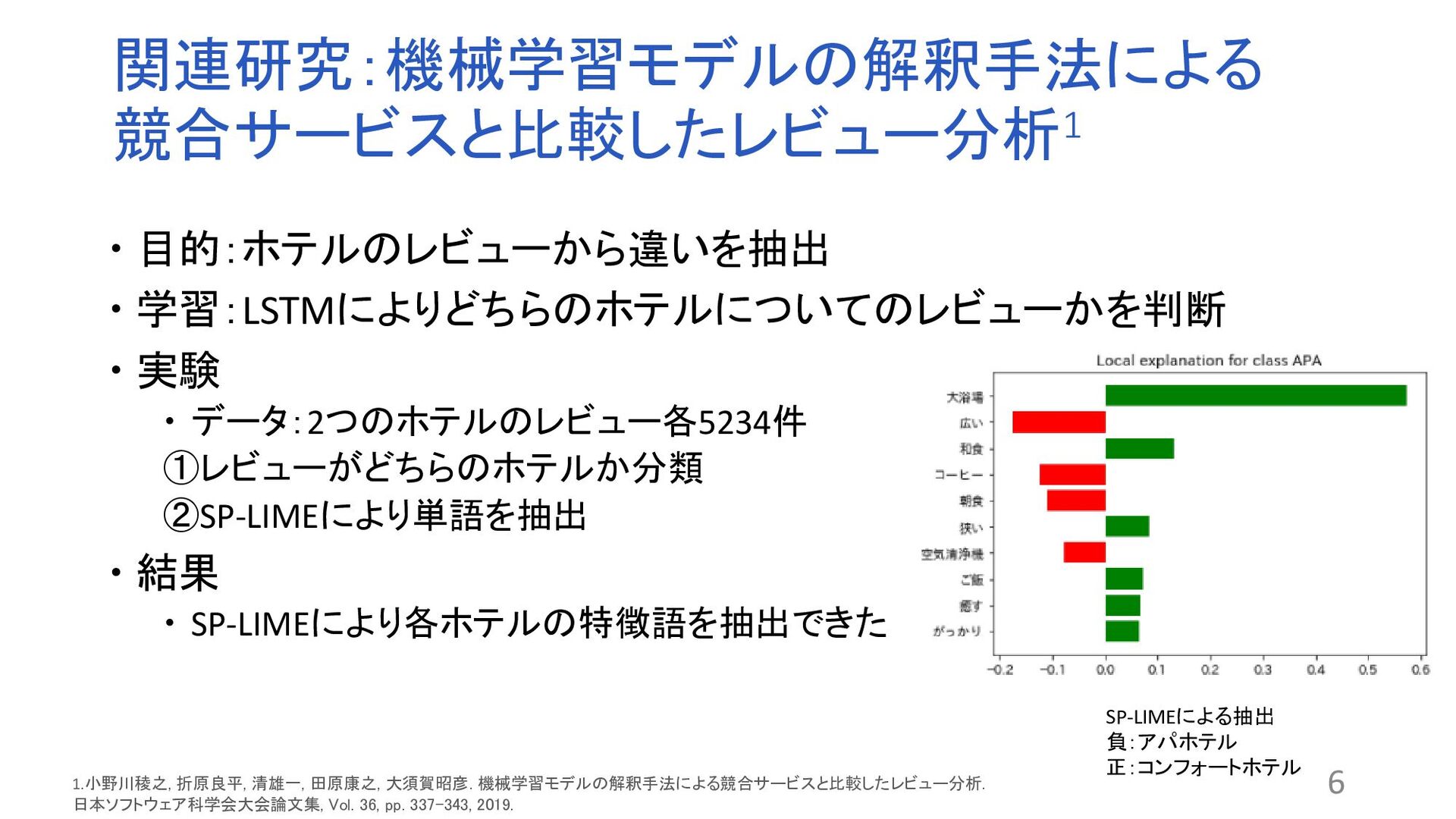
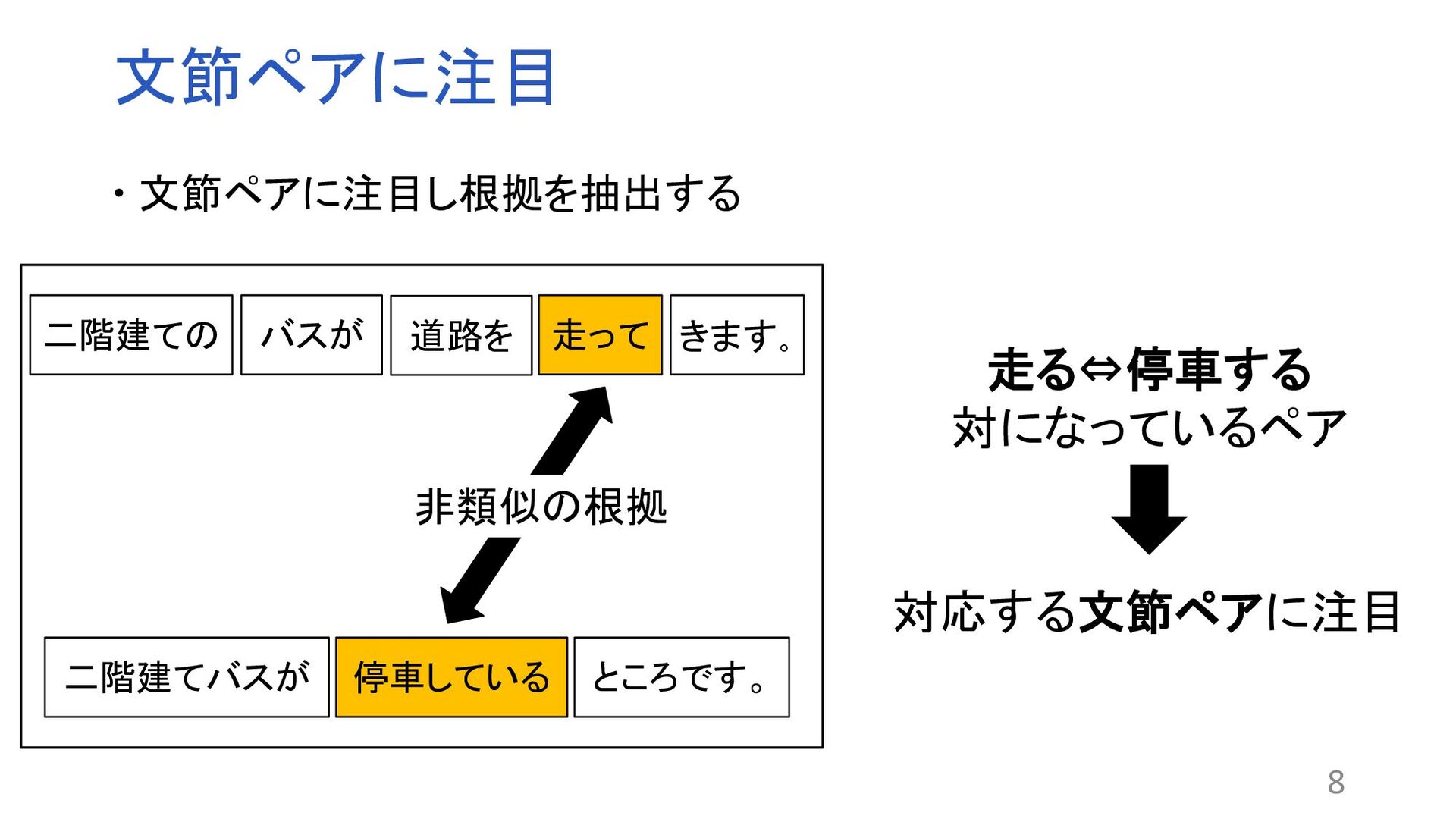
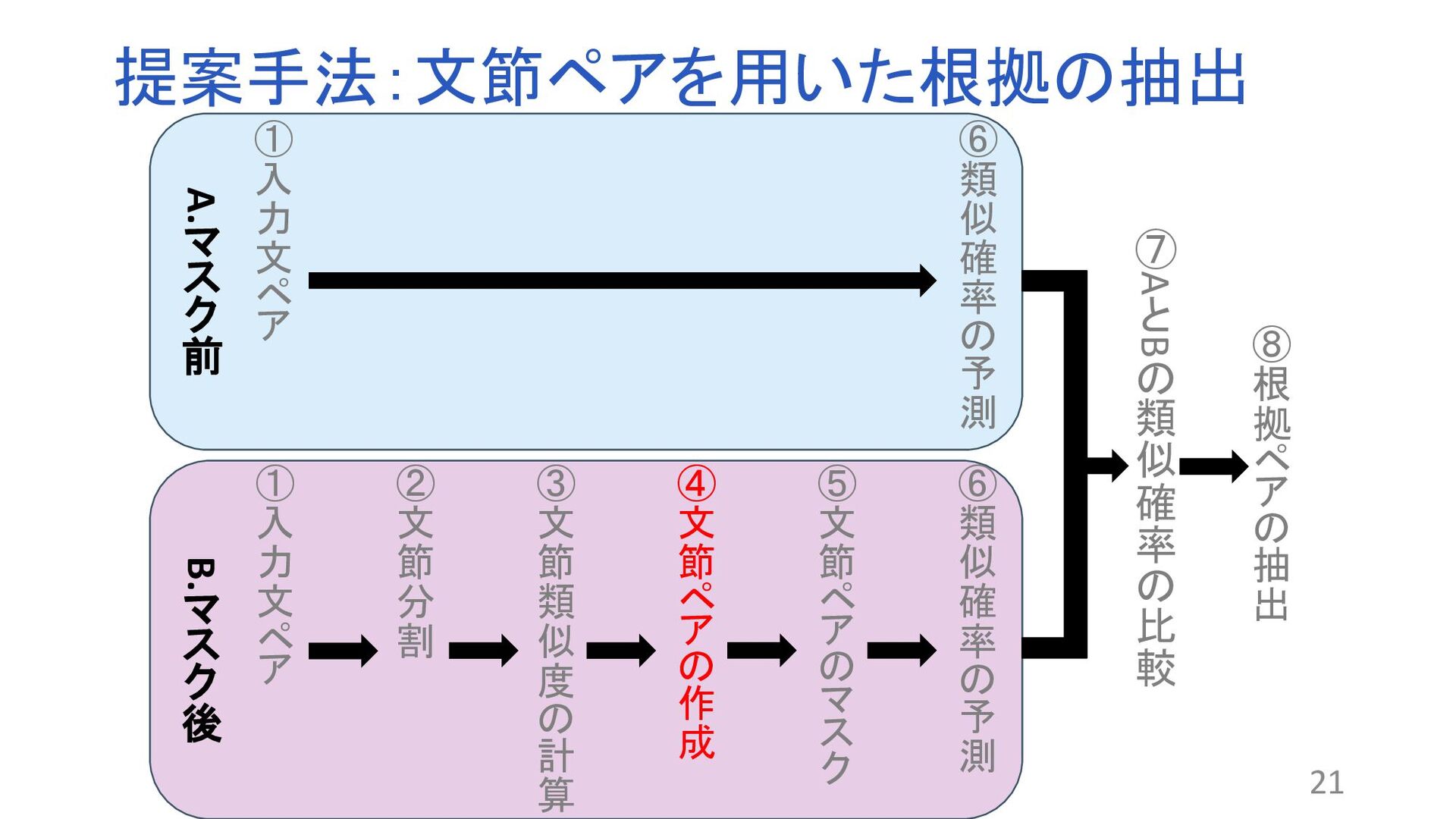
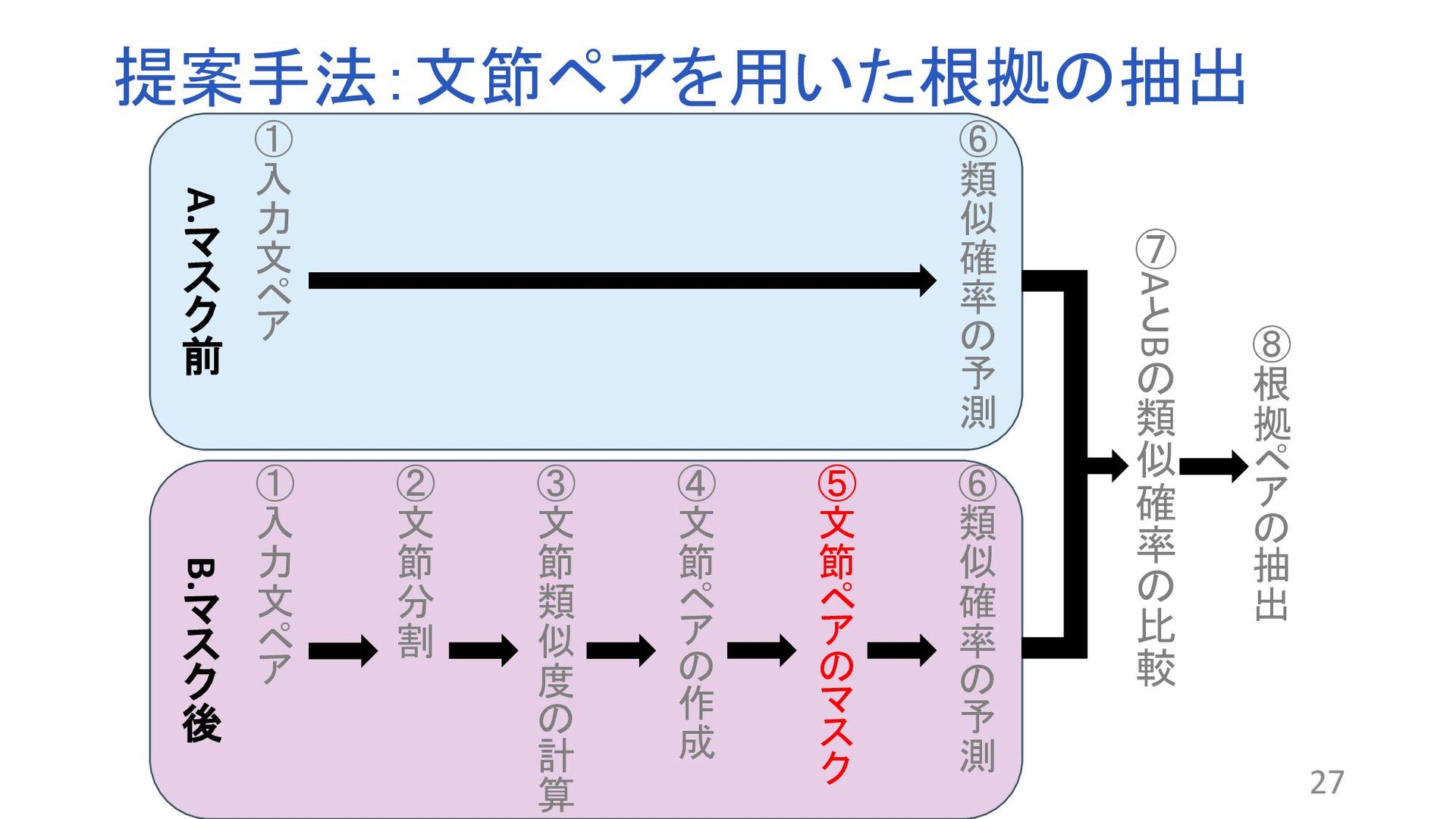
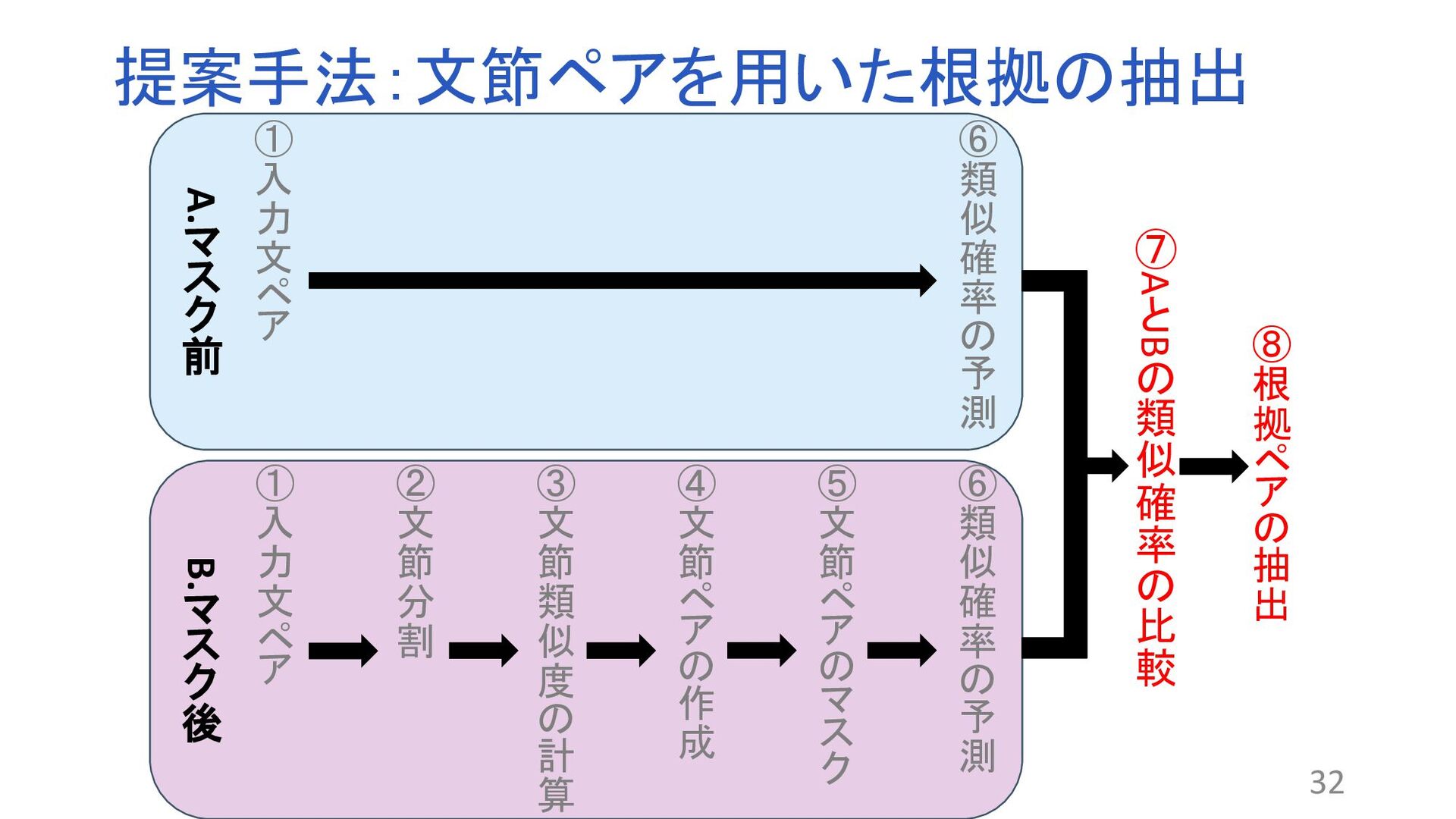
“Why Should I Trust You”:Explaining the Predictions of Any Classifier. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, pp. 97–101, 2016. 関連する文章を比較するモデルが存在する 関連文書の検索やコピペチェッカーなど 課題:ブラックボックス問題 ?なぜその結果が得られるのかわからない 解決策:XAI(説明可能なAI) BERT:Attentionの可視化やLIME1 問題点 トークン単位で抽出するため根拠として適切でない場合 (例:が、です) 2文の関連性を考慮していない
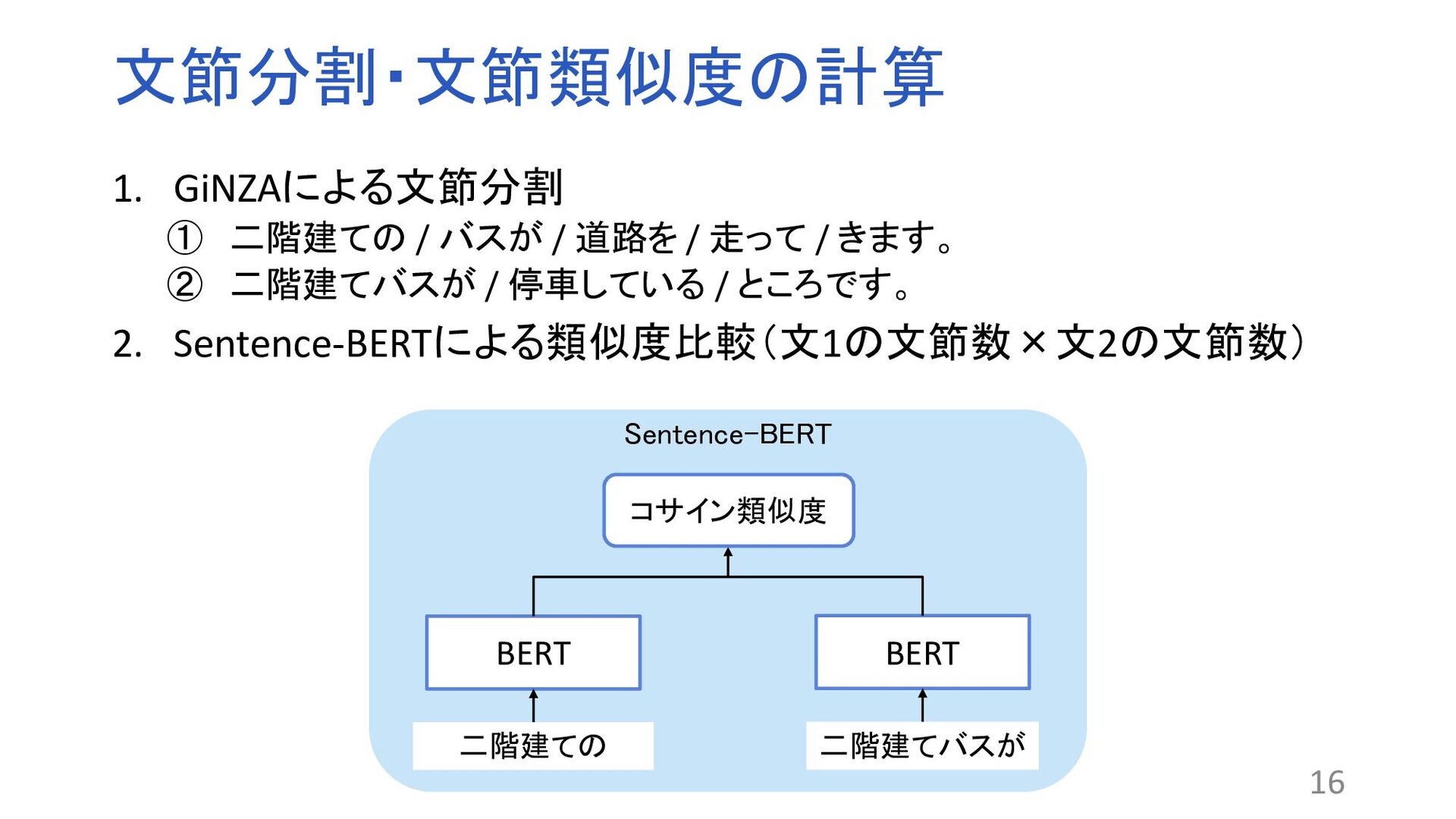
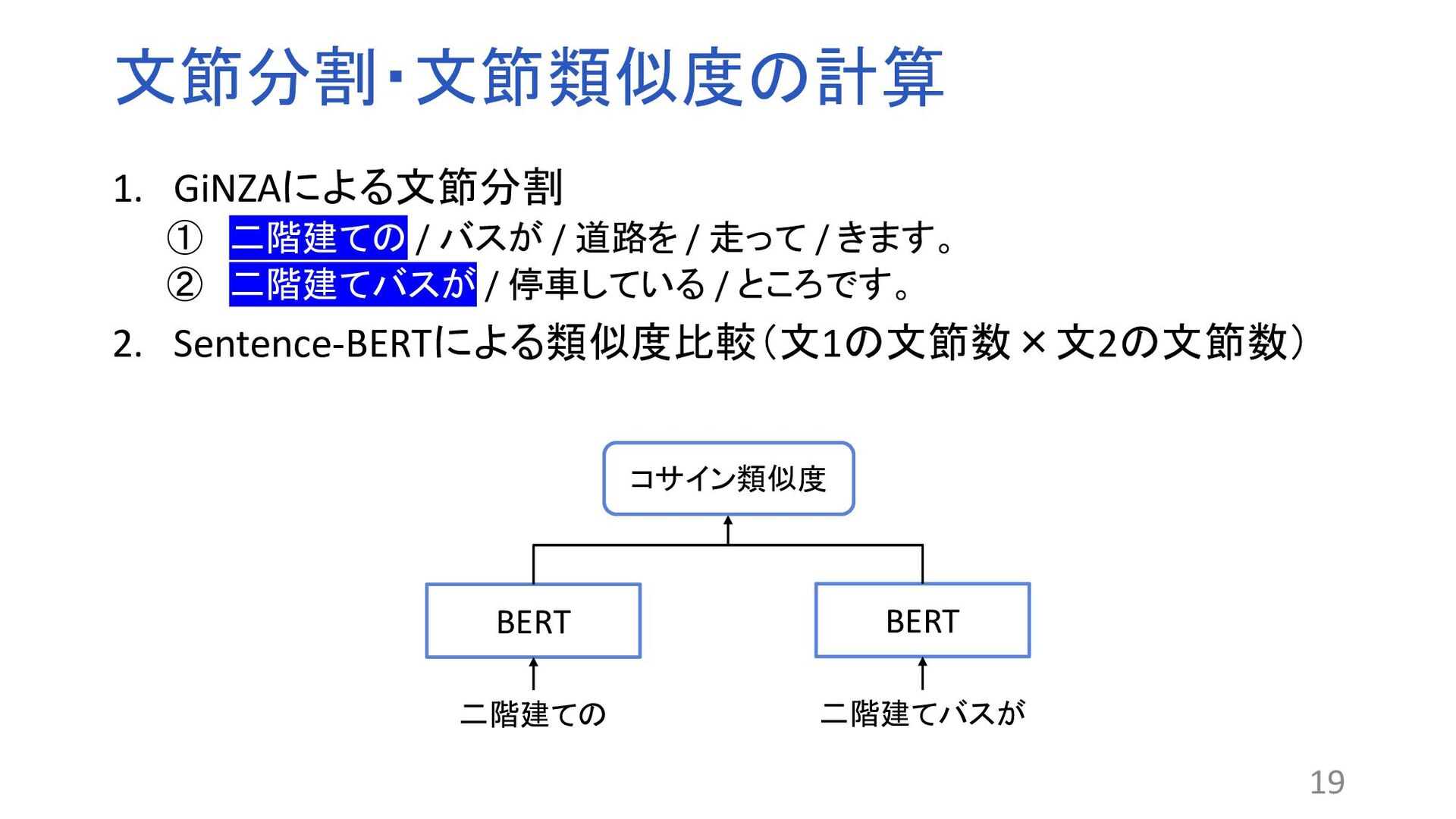
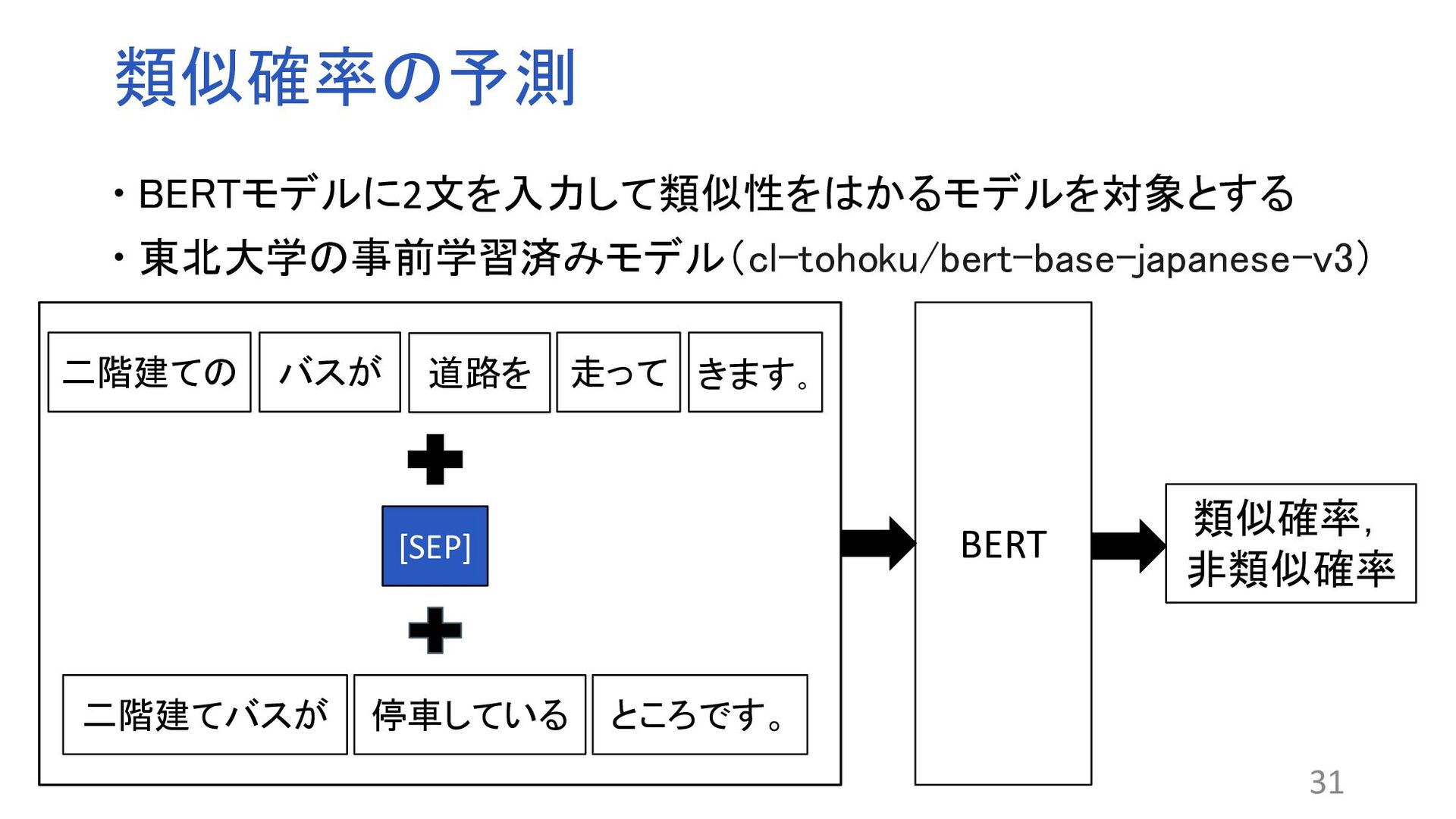
Transformer Encoderによって構成される自然言語処理モデル ファインチューニングにより分類や質問応答など様々なタスクに おいて高精度な処理を行うことができる 17 BERT CLSベクトル シグモイド関数 類似、非類似 1.Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional trans- formers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1, pp. 4171–4186, 2019. 階 建て 二 階 建て バス ところ き
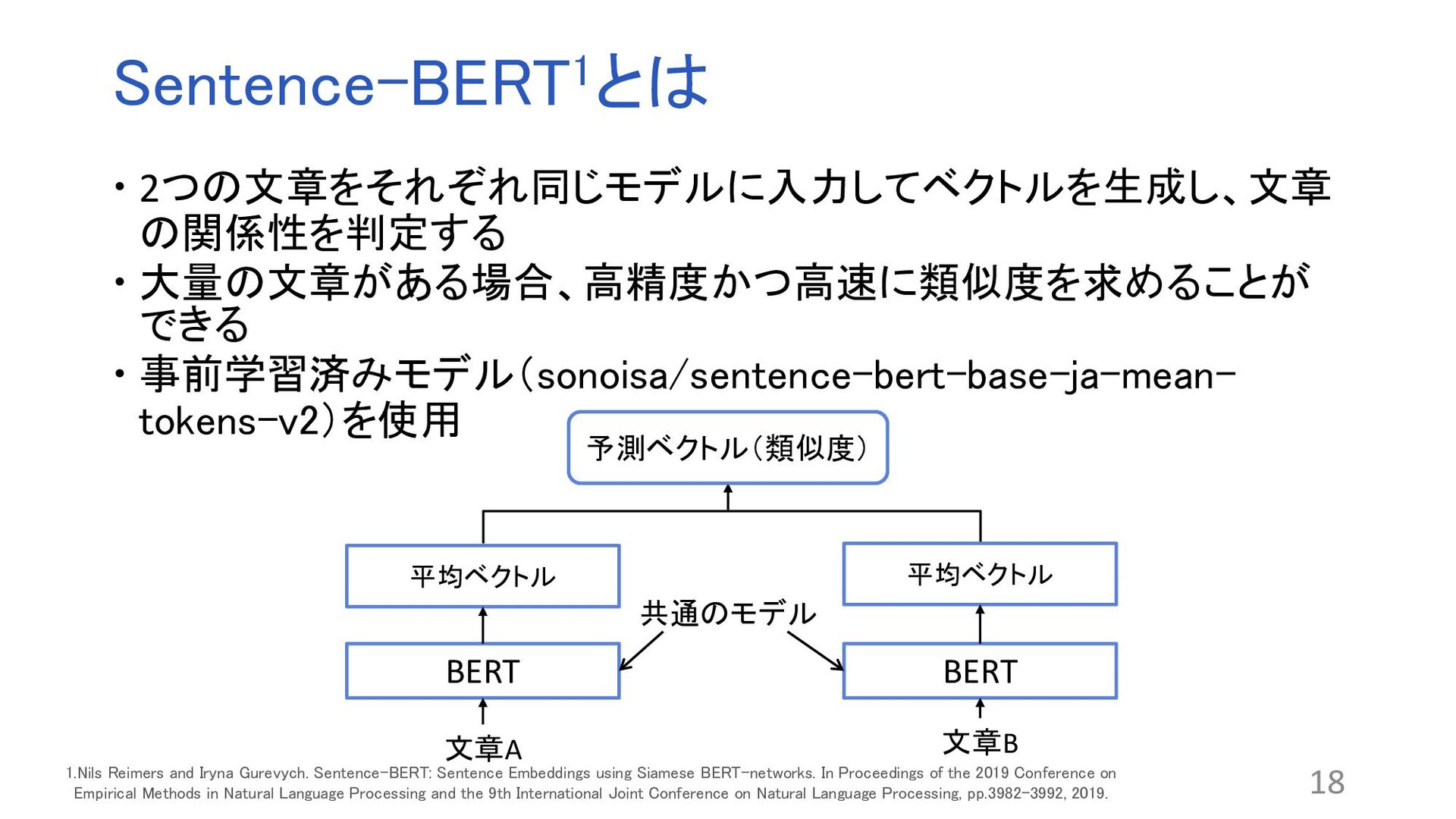
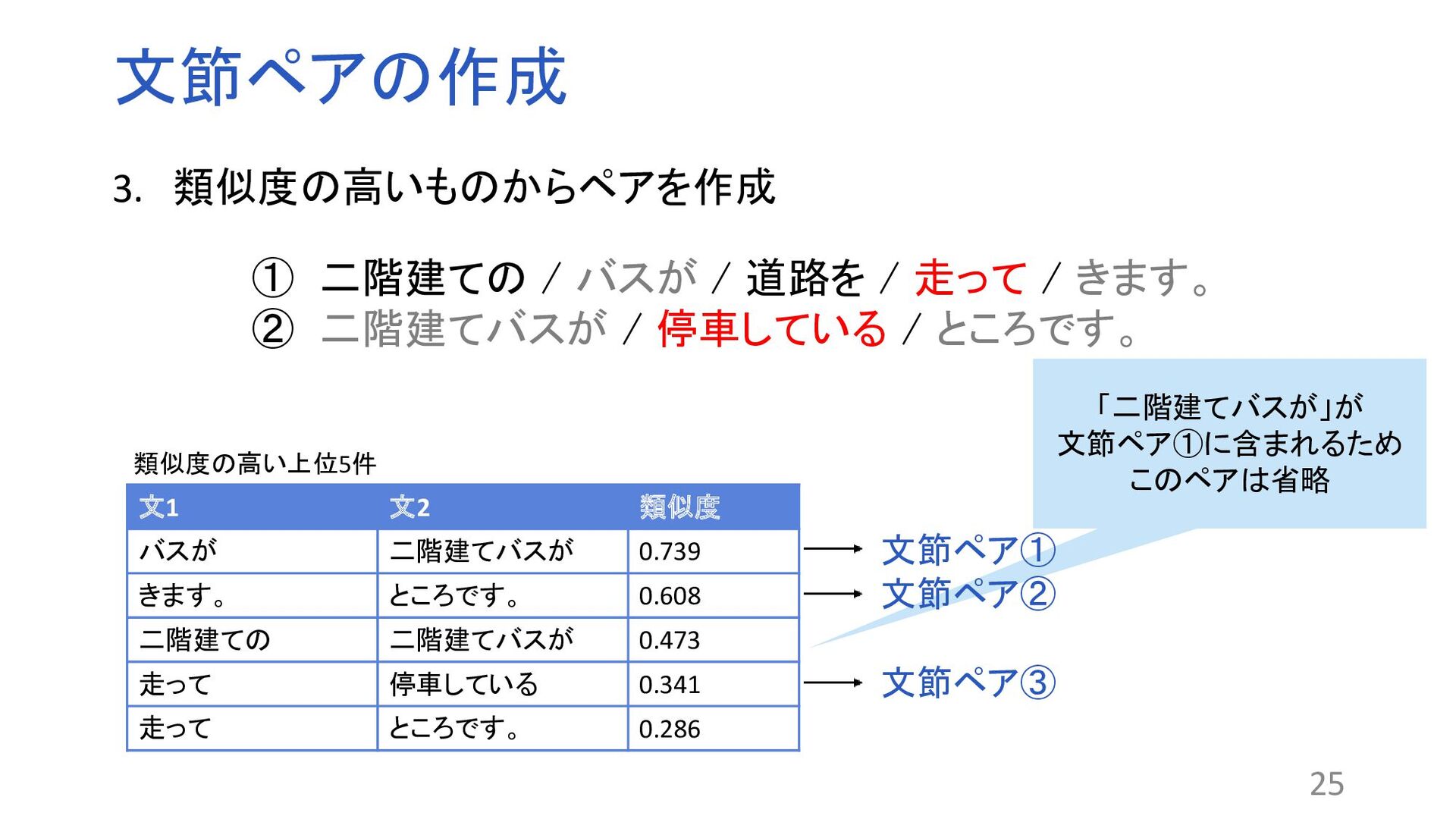
18 BERT BERT 予測ベクトル(類似度) 文章A 文章B 平均ベクトル 平均ベクトル 共通のモデル 1.Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pp.3982–3992, 2019.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
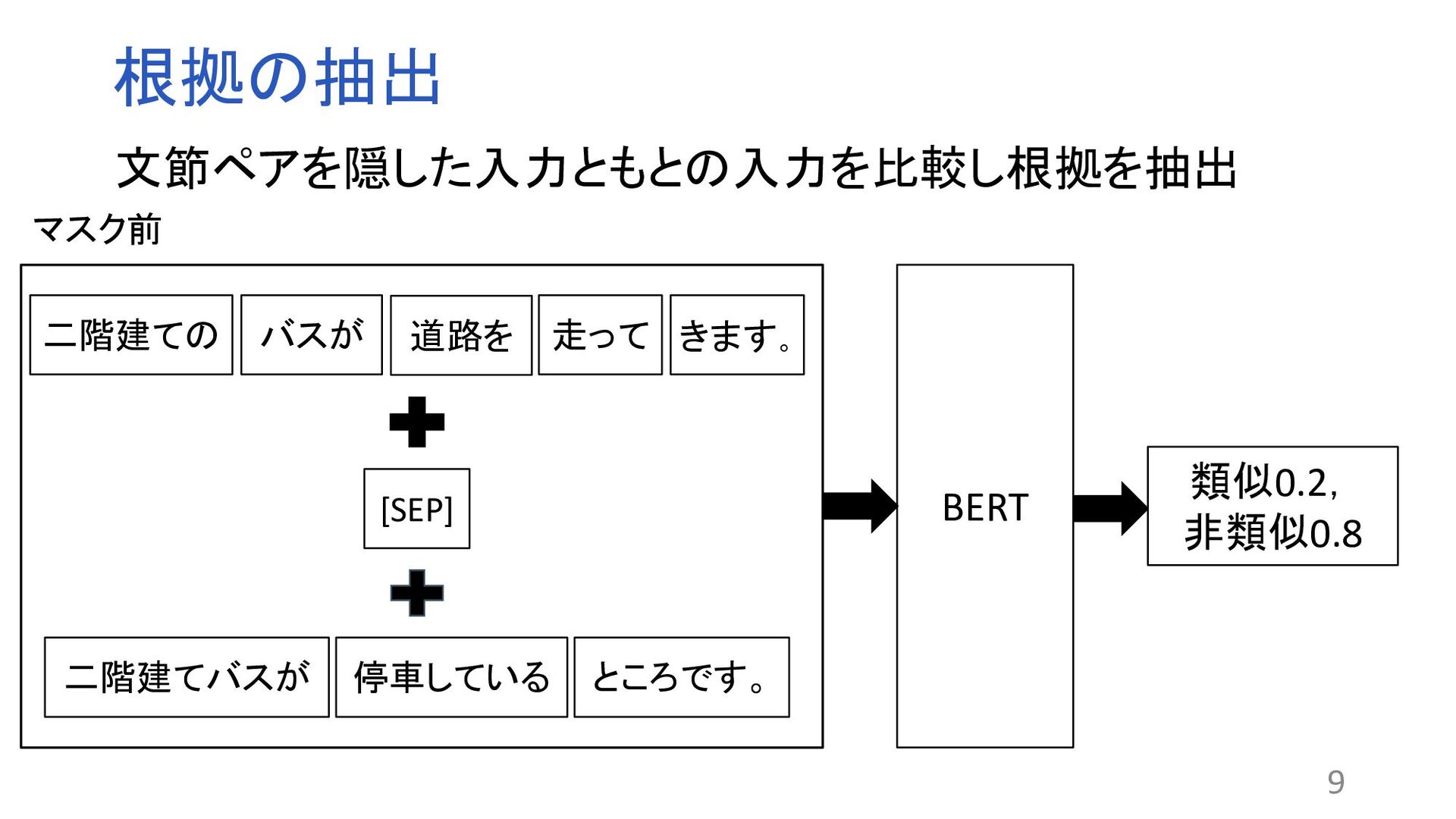
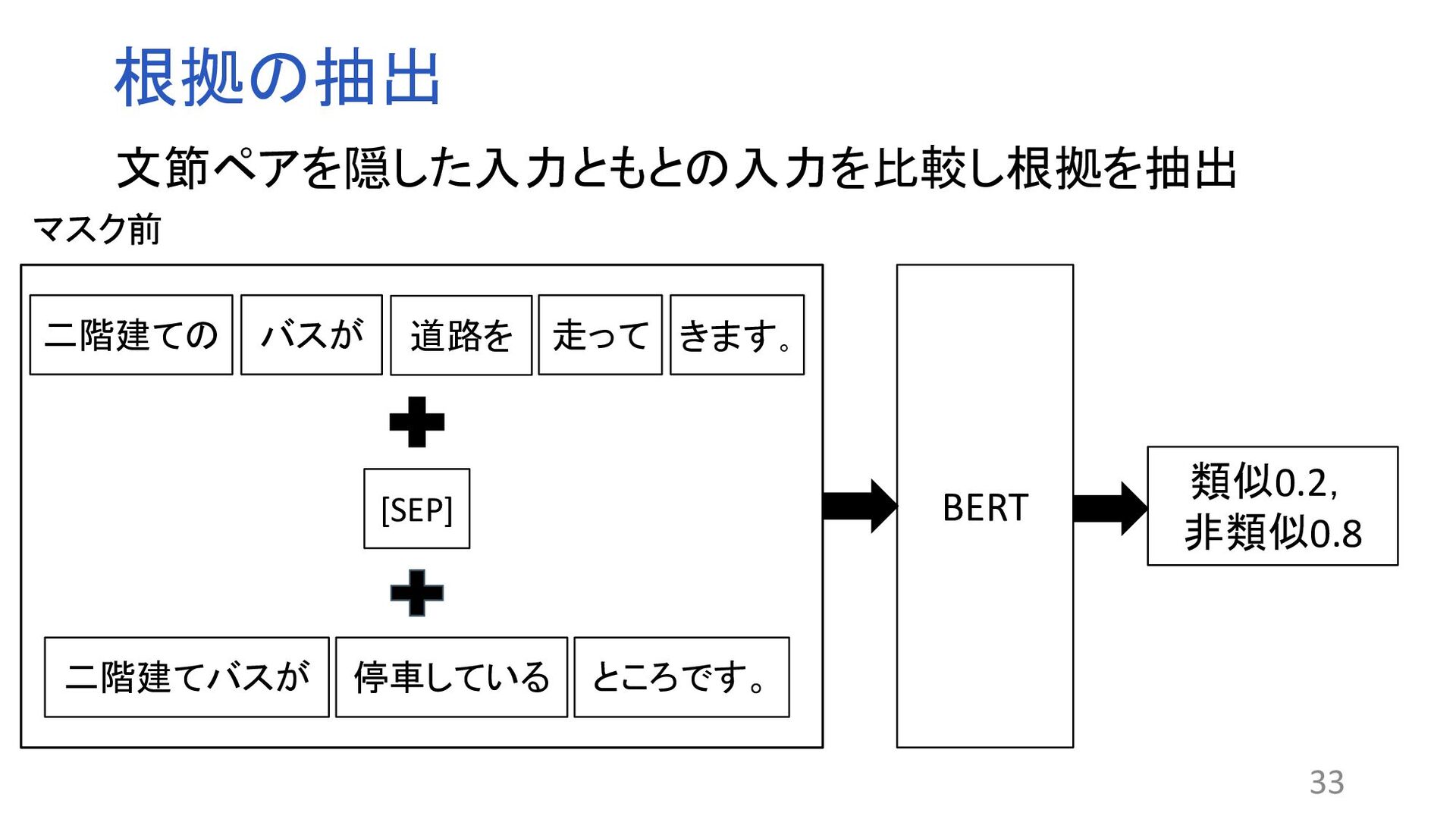
![根拠の抽出 類似0.7, 非類似0.3 BERT 二階建ての バスが 道路を [MASK] きます。 二階建てバスが](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![二 ・・・ ます ・・・ です [SEP] [SEP] [CLS] BERT1とは ](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![文節ペアのマスク 文節ペア 「走って」と「停車している」の場合 ① 二階建てのバスが道路を[MASK]きます。 ② 二階建てバスが[MASK]ところです。 28 二階建ての バスが](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_27.jpg){kind=link}
![文節ペアのマスク 対応なし 「道路を」の場合 ① 二階建てのバスが[MASK]走ってきます。 ② 二階建てバスが停車しているところです。 29 二階建ての バスが](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![根拠ペアの抽出 類似0.7, 非類似0.3 BERT 二階建ての バスが 道路を [MASK] きます。 二階建てバスが](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_33.jpg){kind=link}
![根拠ペアの抽出 類似0.3, 非類似0.7 BERT 二階建ての [MASK] 道路を 走って きます。 [MASK]](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_34.jpg){kind=link}
{kind=link}
![非類似文ペアを入力した際の根拠の抽出 37 LIME (比較手法) 二階建てのバスが道路を走ってきます。 [SEP]二階建てバスが停車しているところです。 文節ペア (提案手法) 二階建てのバスが道路を走ってきます。 [SEP]二階建てバスが停車しているところです。](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_36.jpg){kind=link}
![類似文ペアを入力した際の根拠の抽出 38 〇「ジャンプしている」=「ジャンプしています。」という共通して いるペアを類似の根拠として抽出できた 文節ペア (提案手法) LIME (比較手法) スケートボードでジャンプしている男性がいます。 [SEP]男性がスケートボードでジャンプしています。](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_37.jpg){kind=link}
![非類似を類似と誤分類した際の根拠の抽出 39 共通する文節が類似という誤分類に影響を与えている 「芝生の」と「道路の」という違いに注目していない 芝生の真ん中に、消火栓が設置されています。 [SEP]道路の真ん中に、消火栓が設置されています。 文節ペア (提案手法)](https://files.speakerdeck.com/presentations/50138cfcaac64d59a9df03ed626461bc/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}