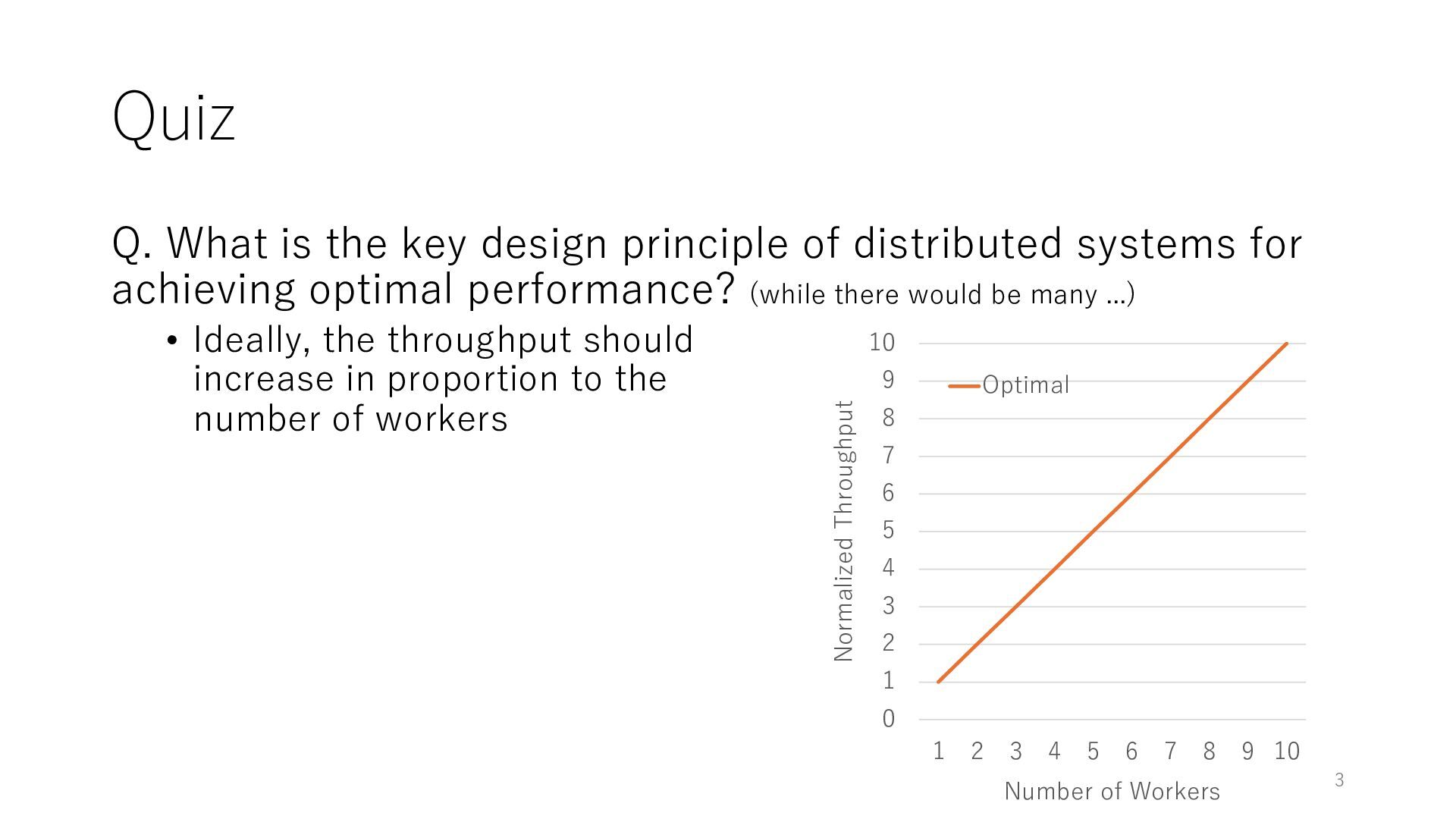
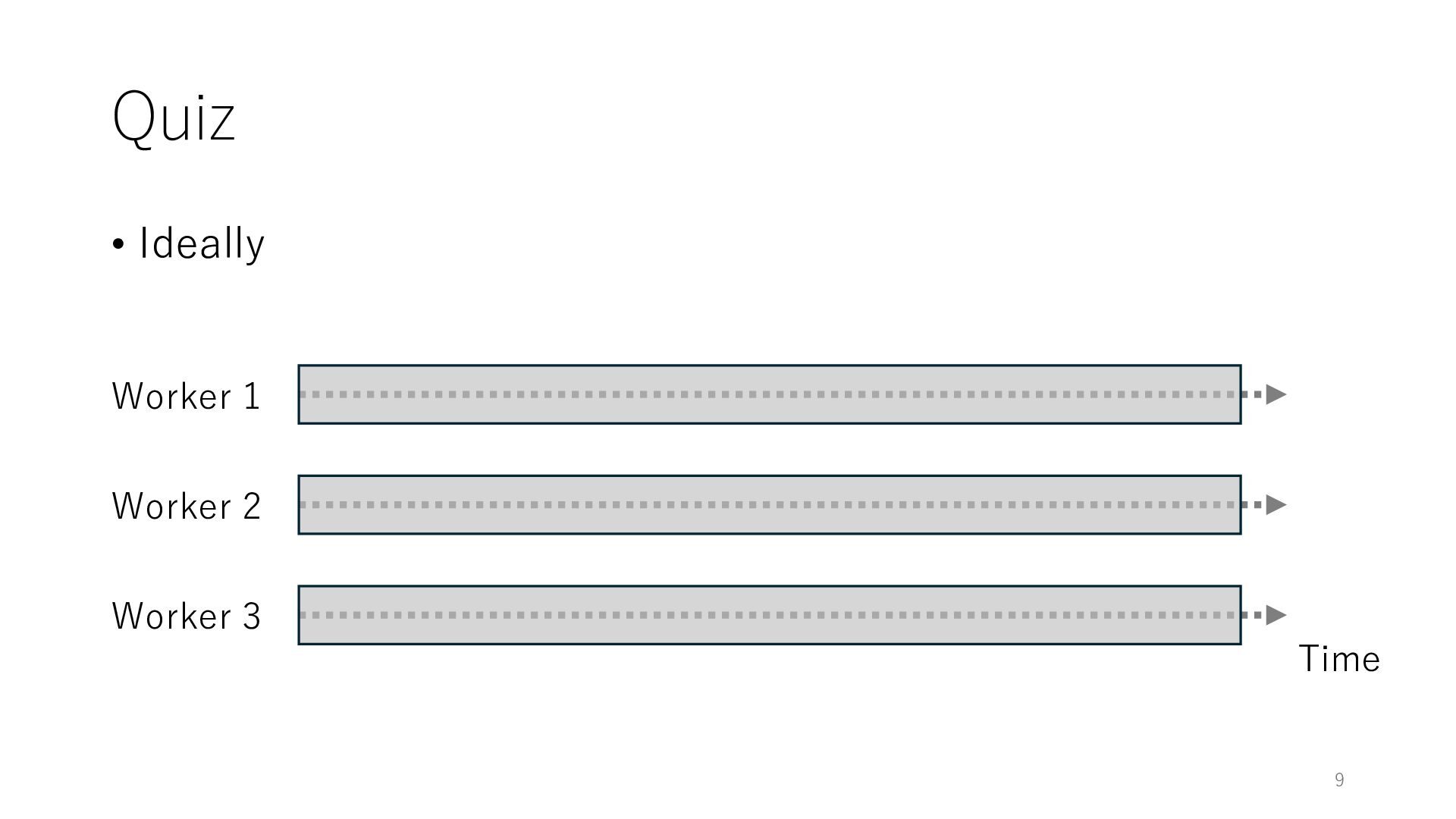
systems for achieving optimal performance? (while there would be many ...) • Ideally, the throughput should increase in proportion to the number of workers 3 0 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10 Normalized Throughput Number of Workers Optimal
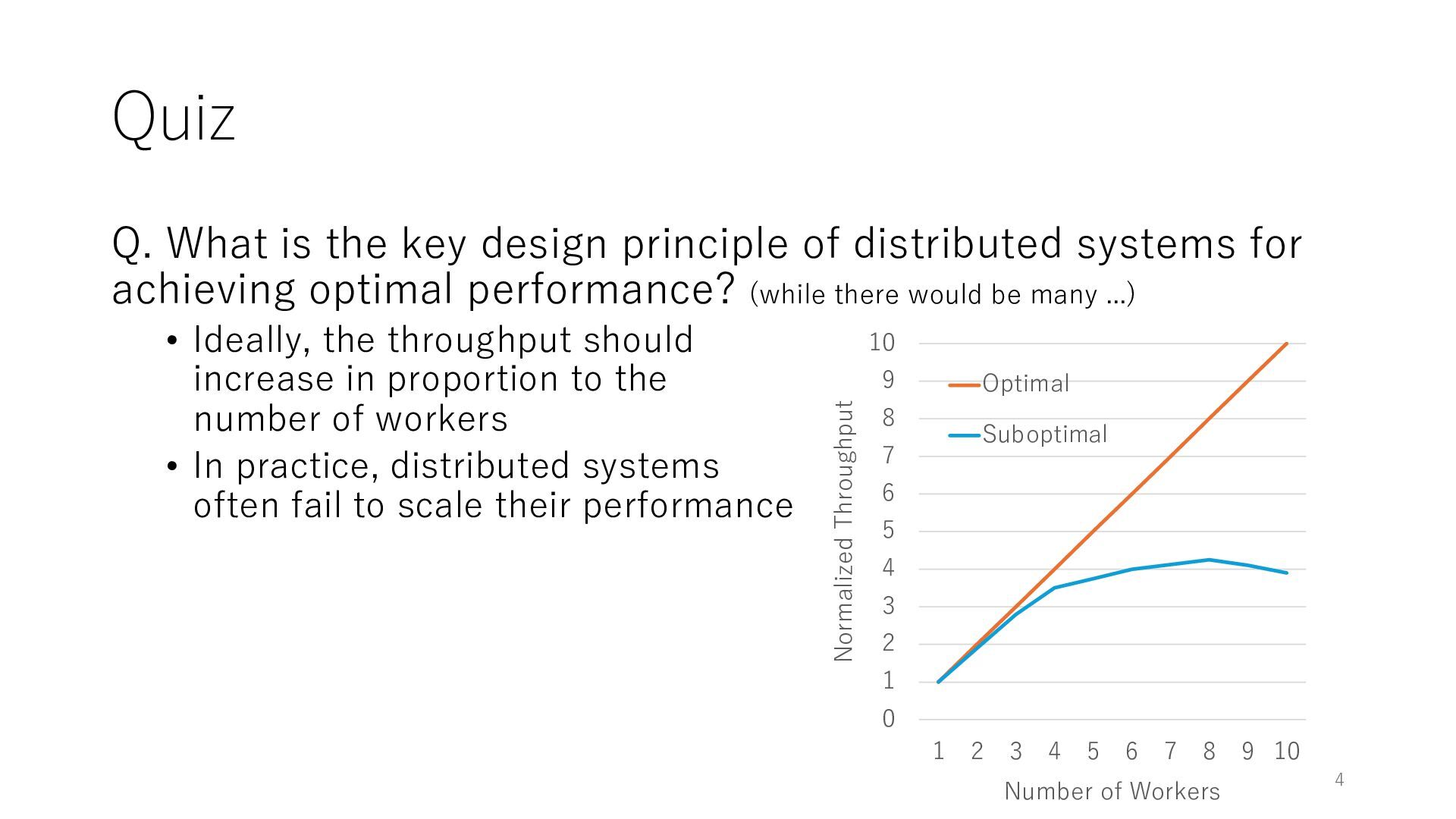
systems for achieving optimal performance? (while there would be many ...) • Ideally, the throughput should increase in proportion to the number of workers • In practice, distributed systems often fail to scale their performance 4 0 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10 Normalized Throughput Number of Workers Optimal Suboptimal
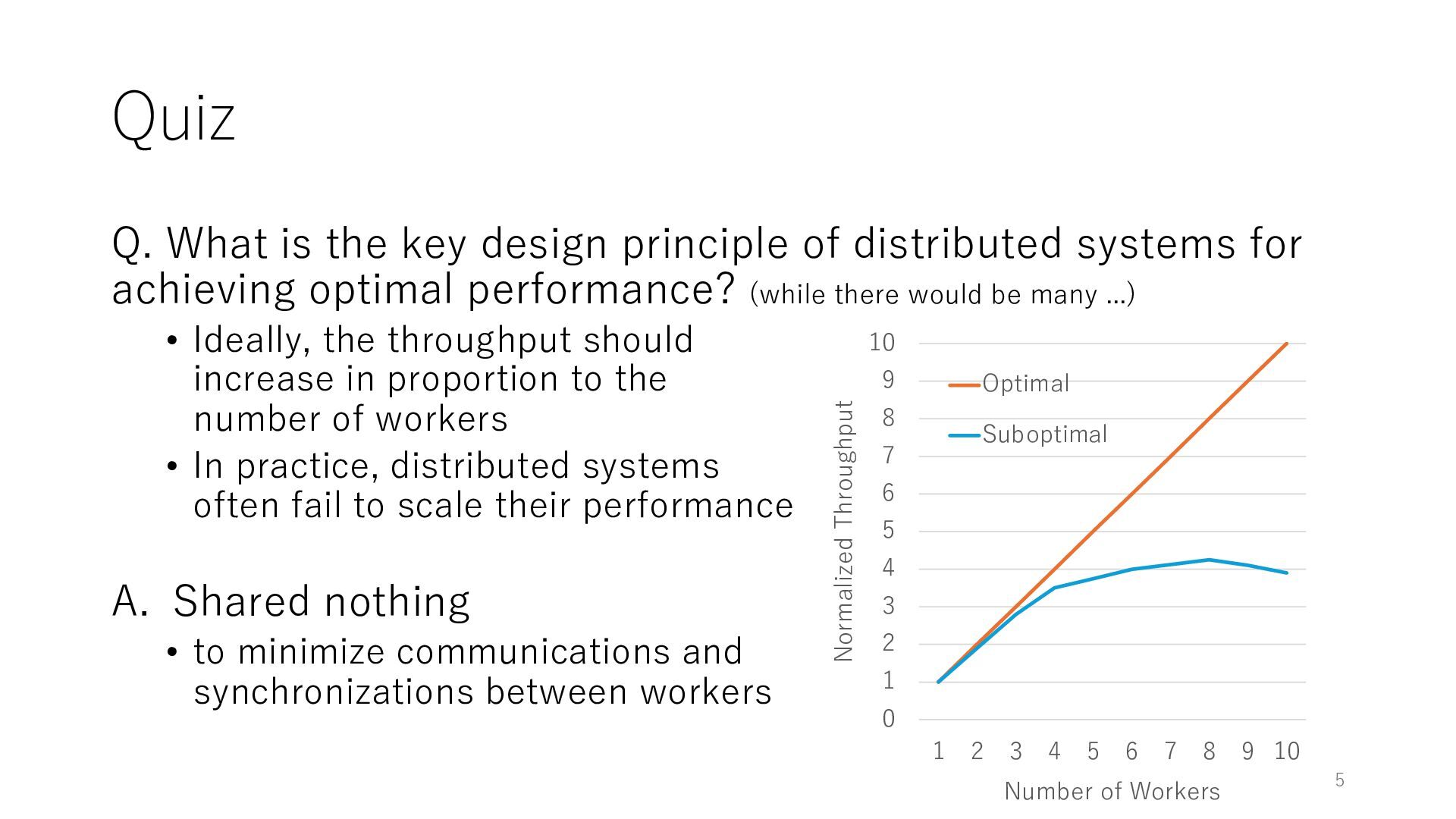
systems for achieving optimal performance? (while there would be many ...) • Ideally, the throughput should increase in proportion to the number of workers • In practice, distributed systems often fail to scale their performance A. Shared nothing • to minimize communications and synchronizations between workers 5 0 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10 Normalized Throughput Number of Workers Optimal Suboptimal
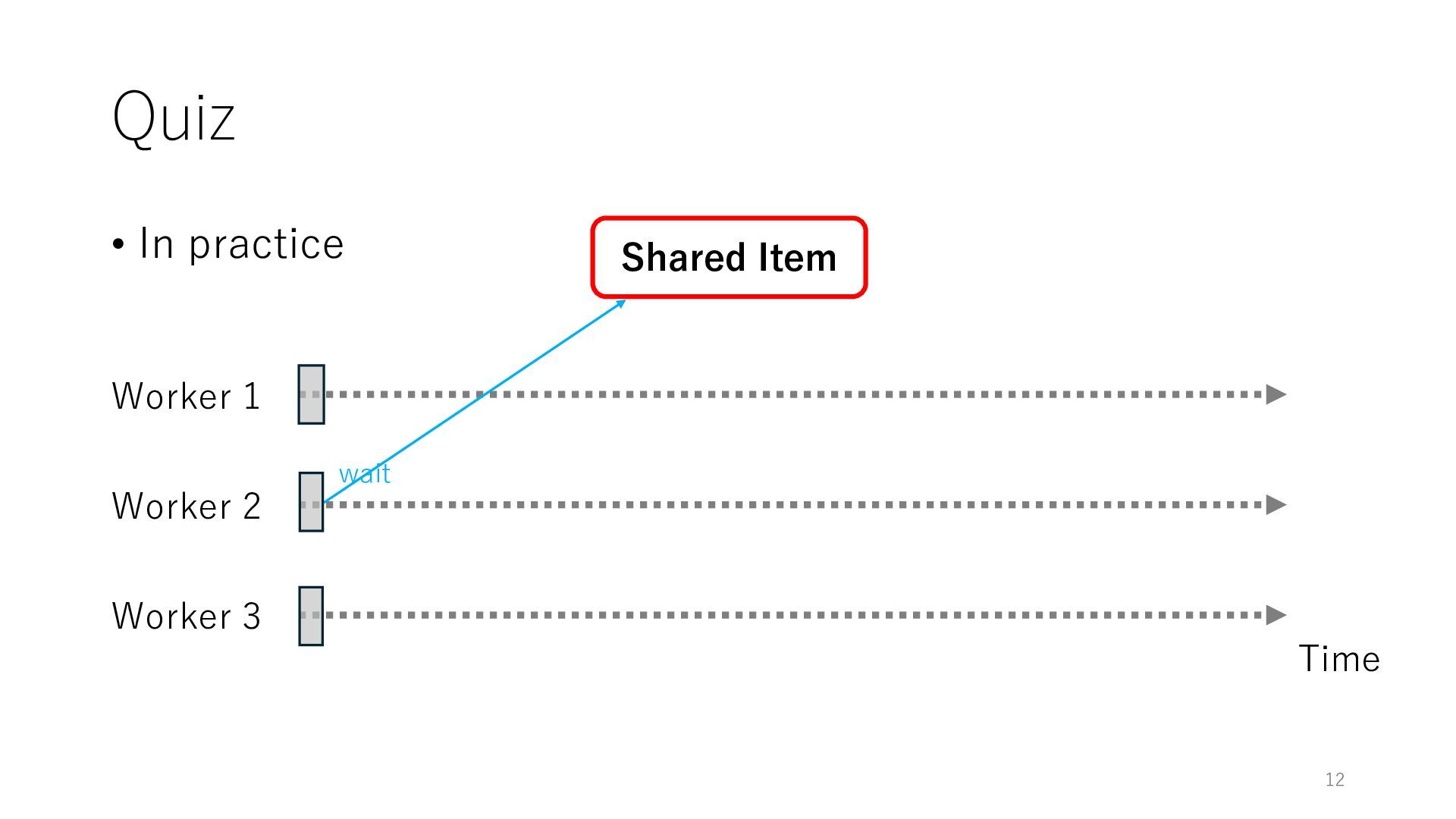
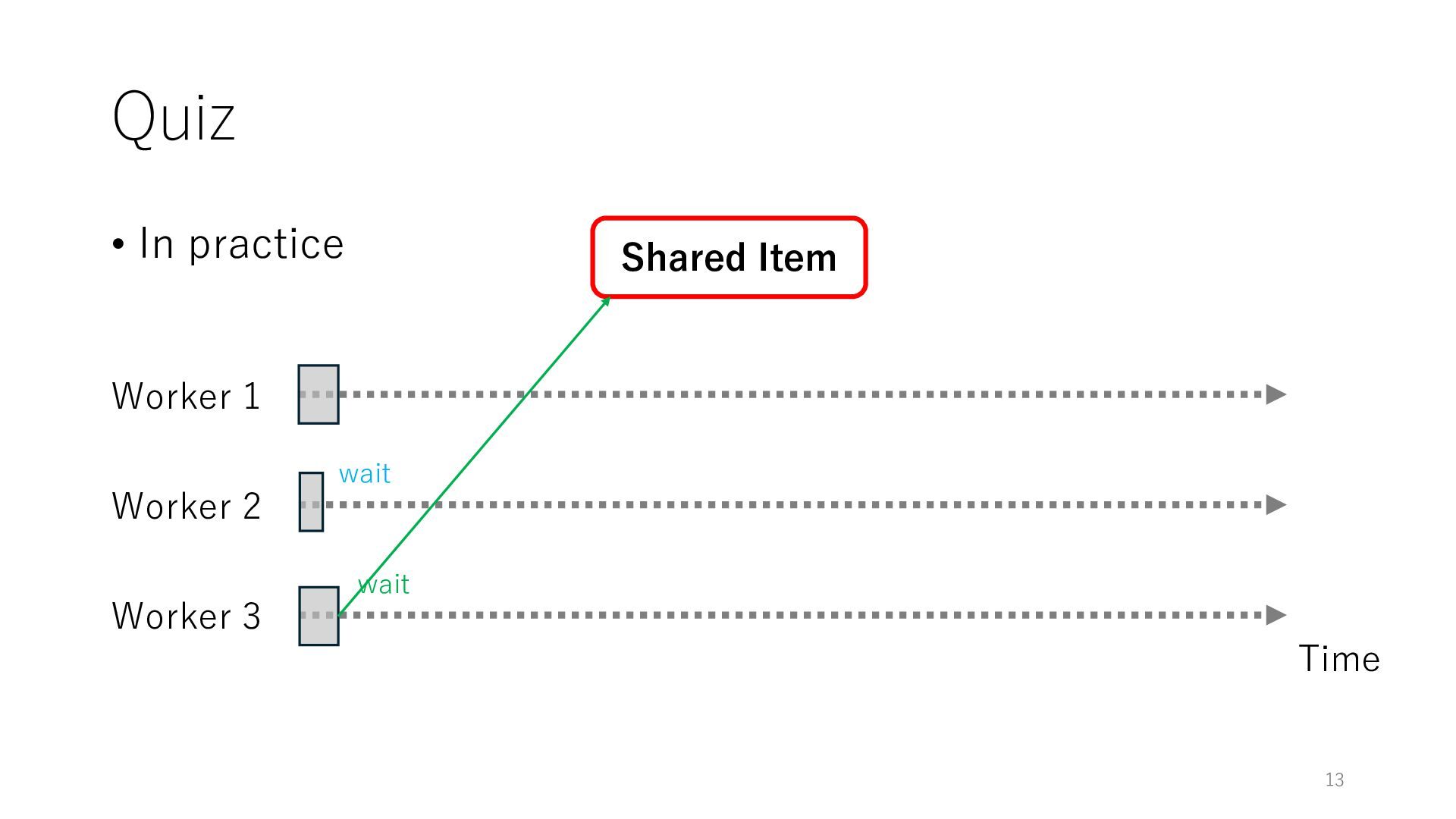
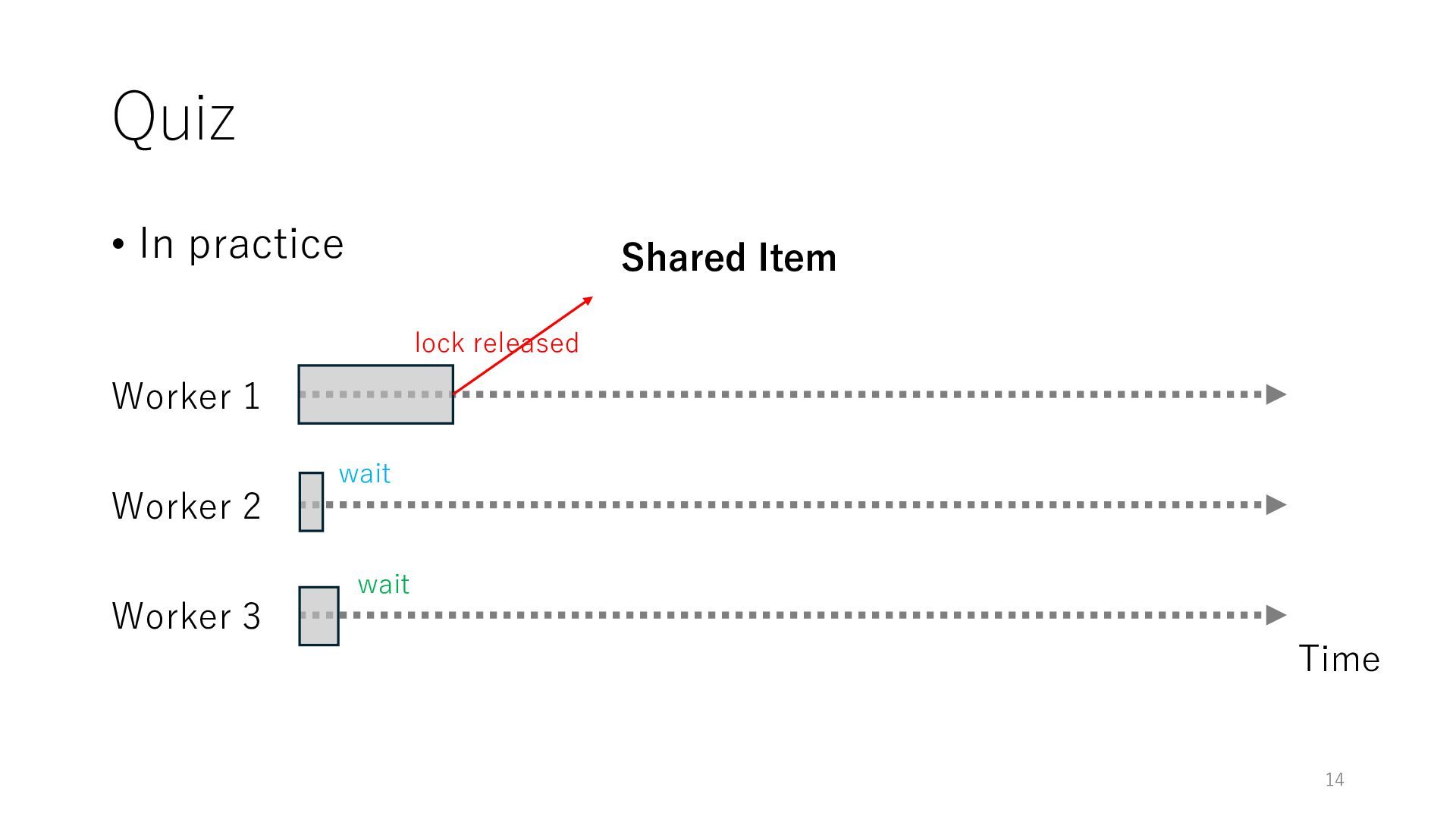
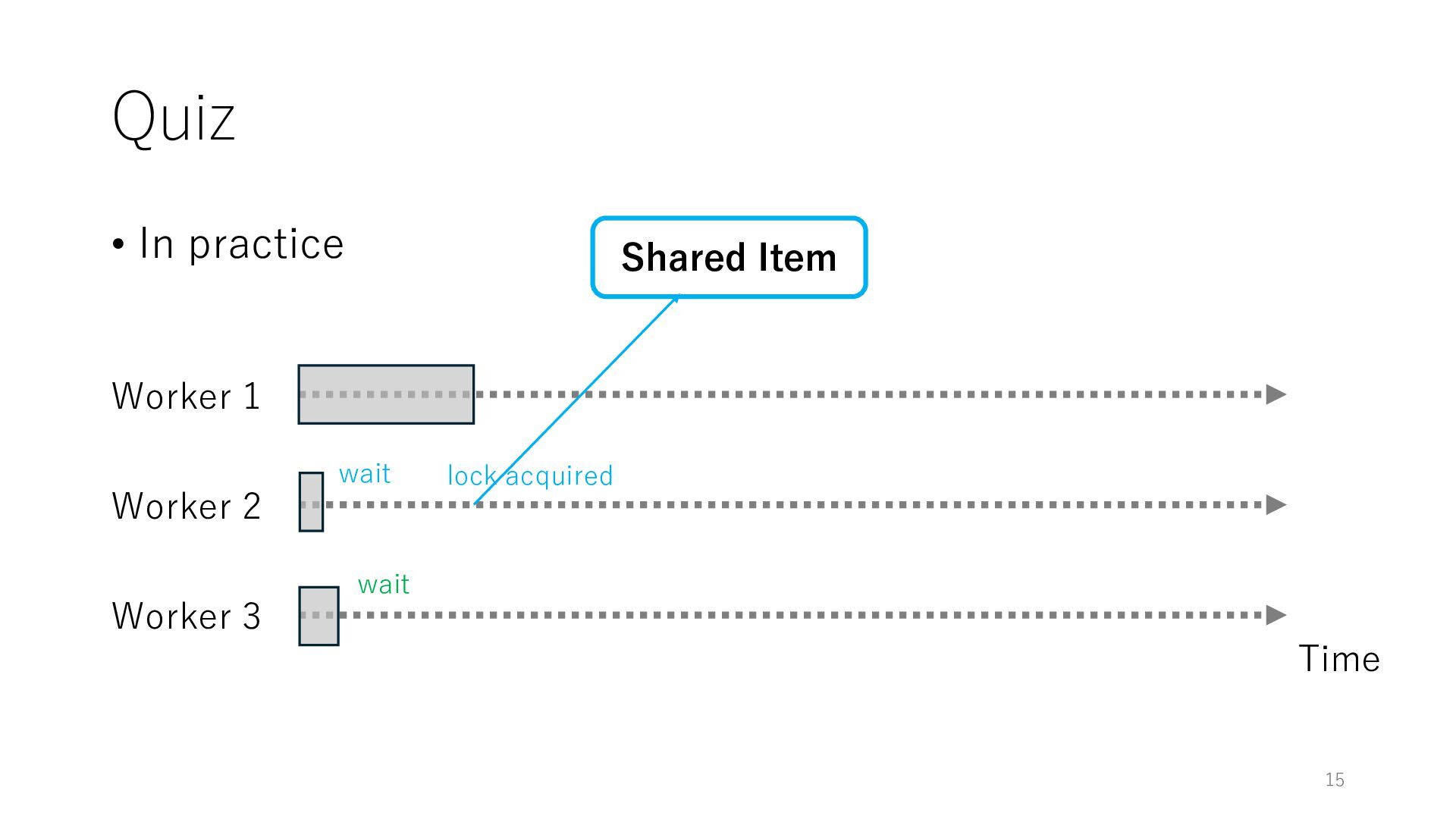
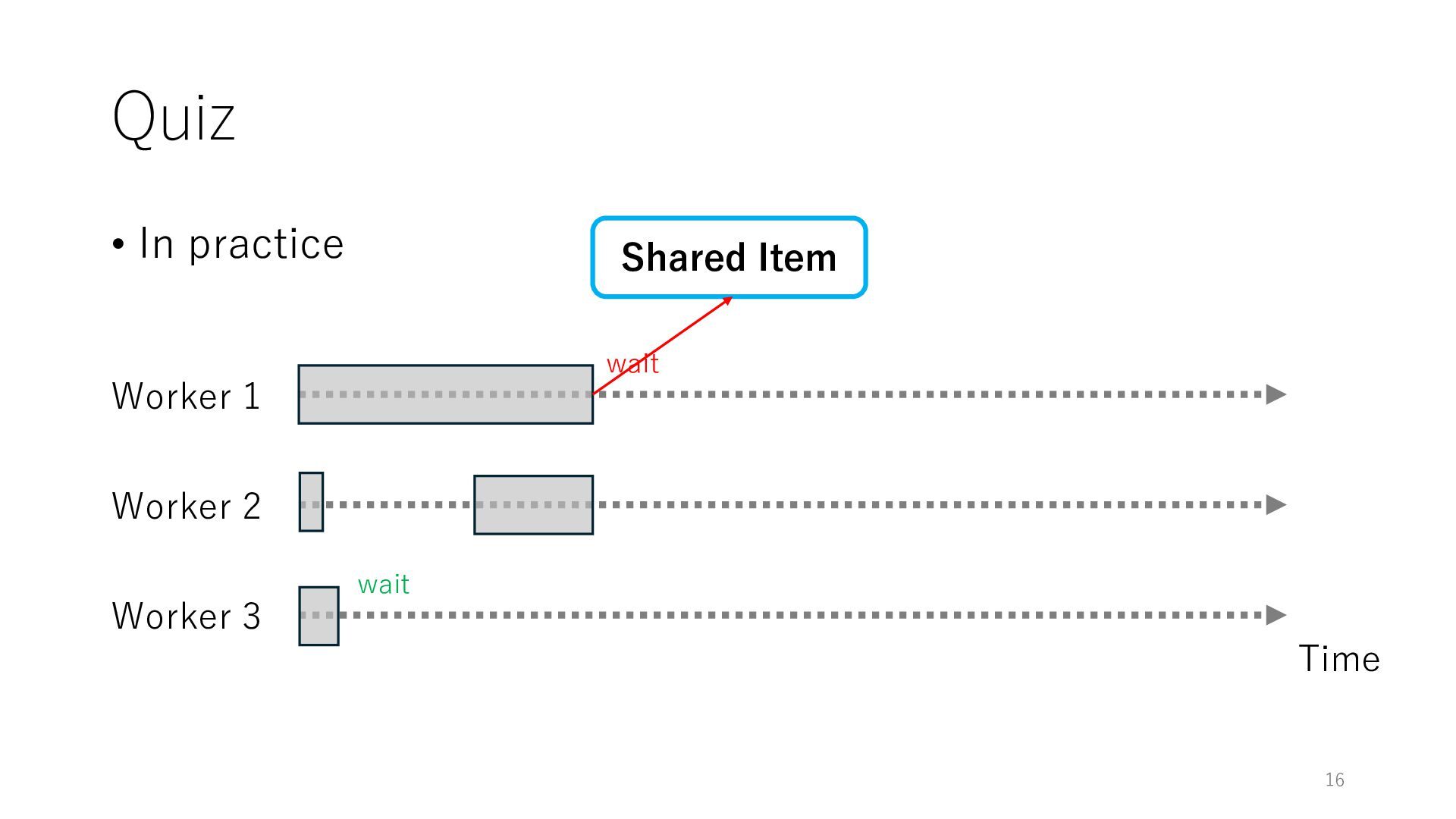
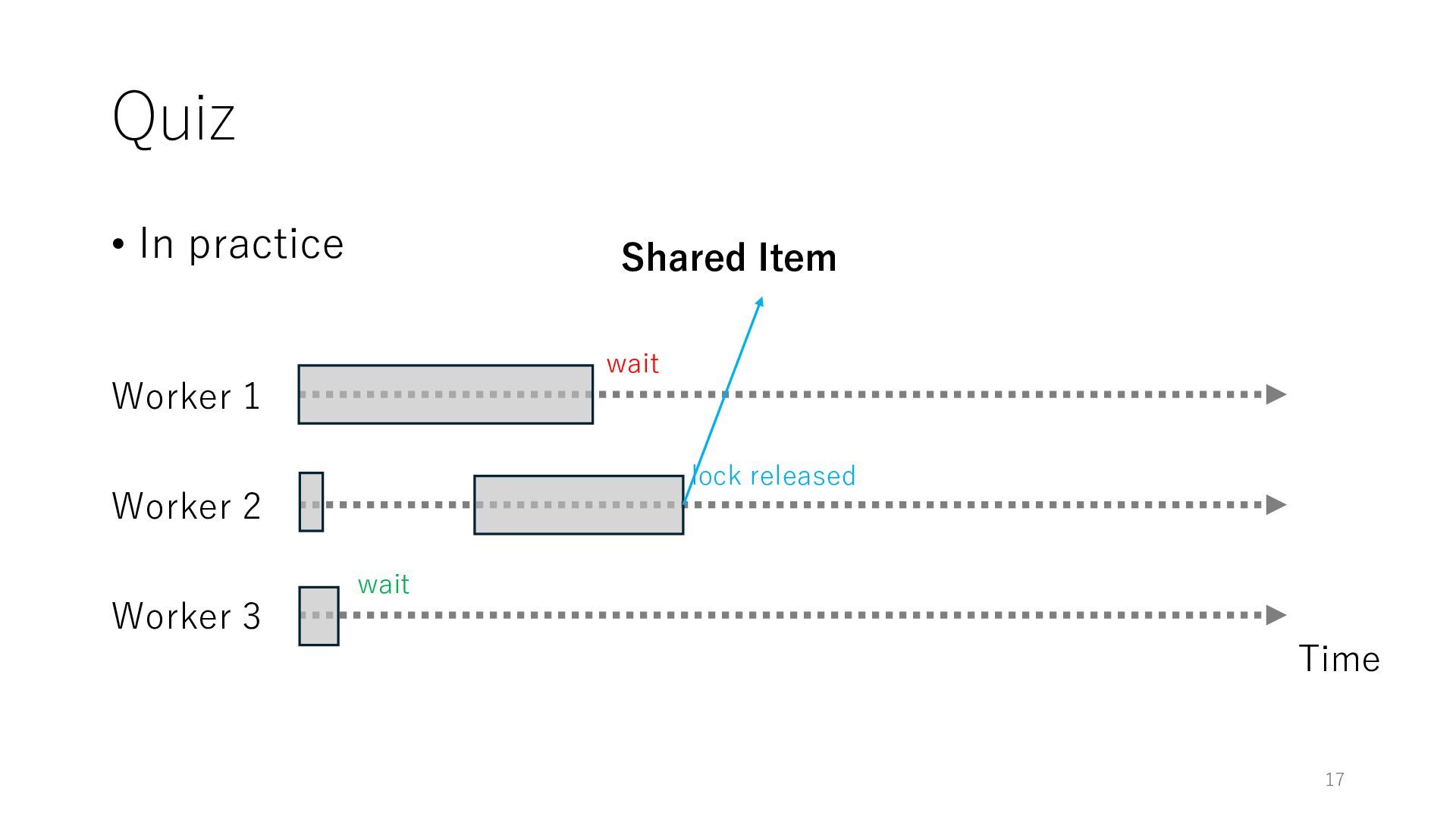
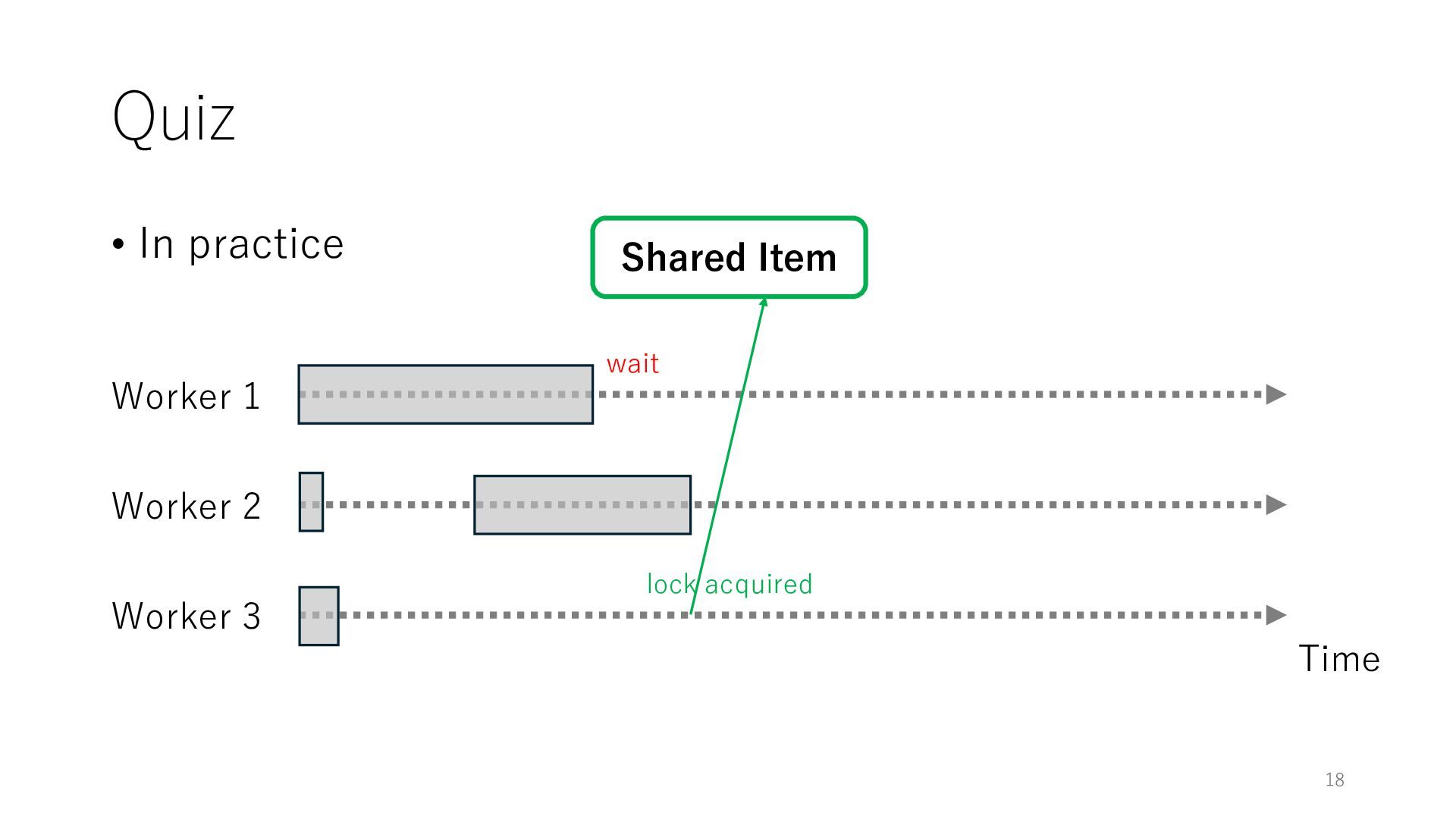
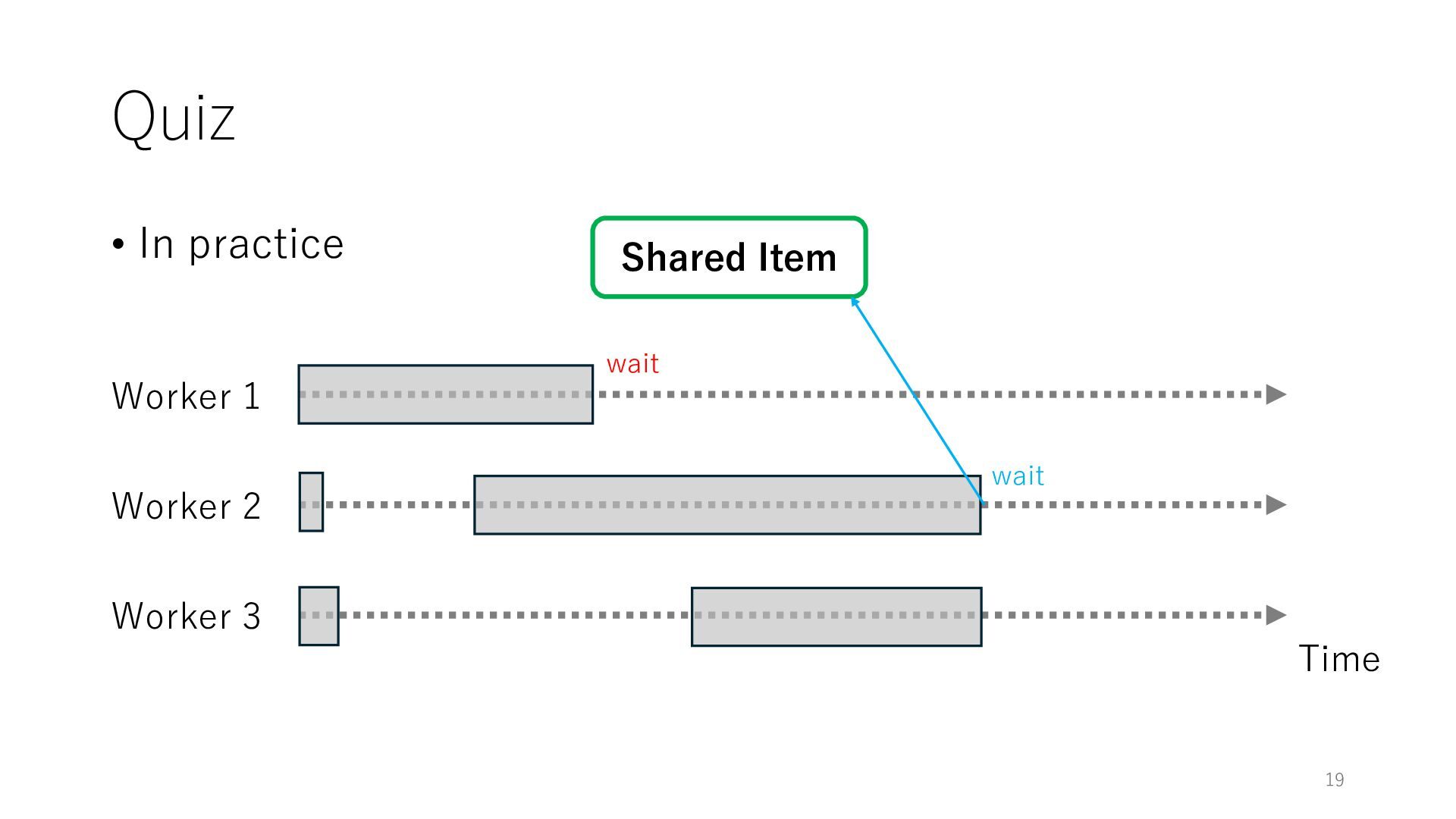
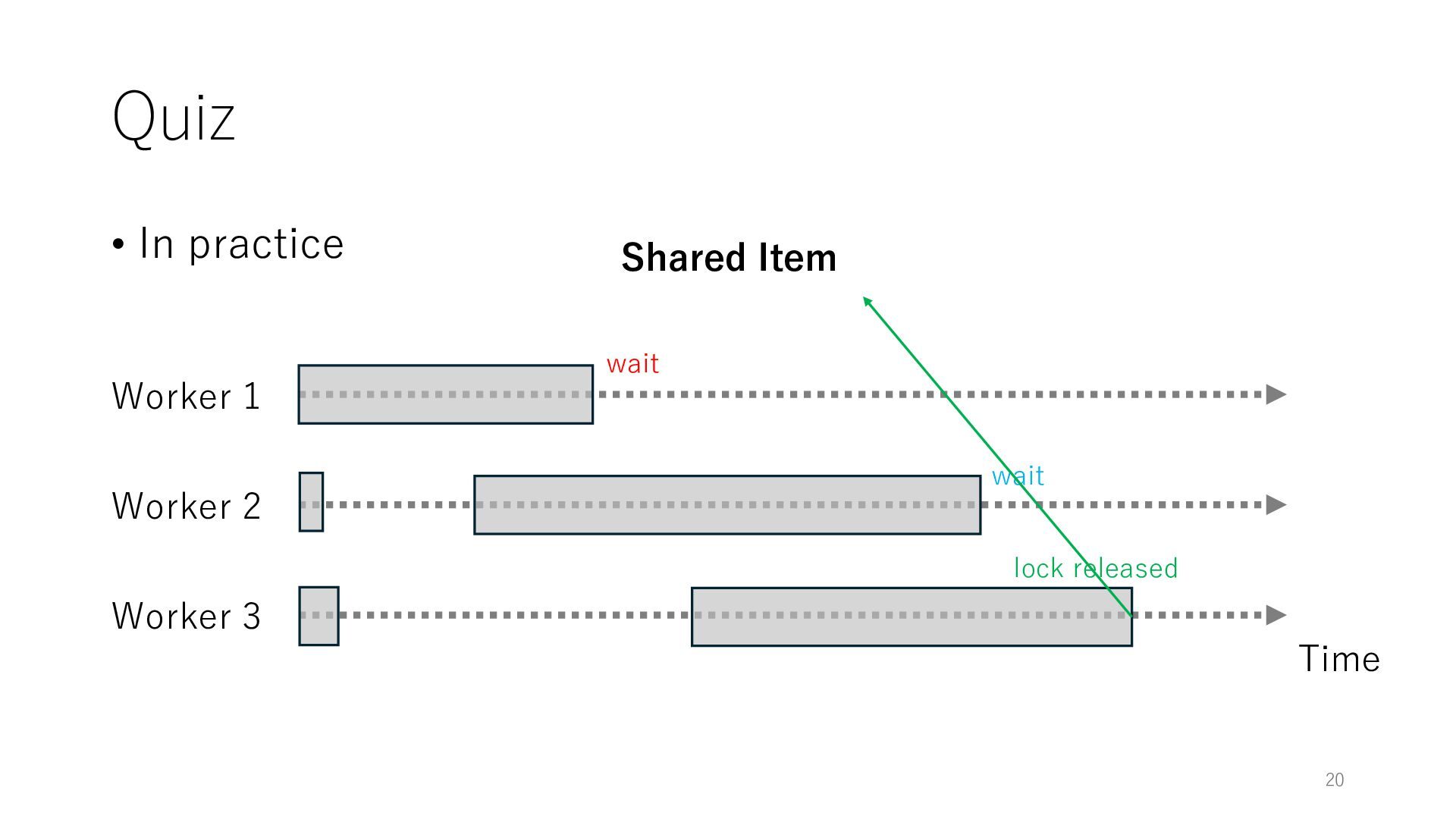
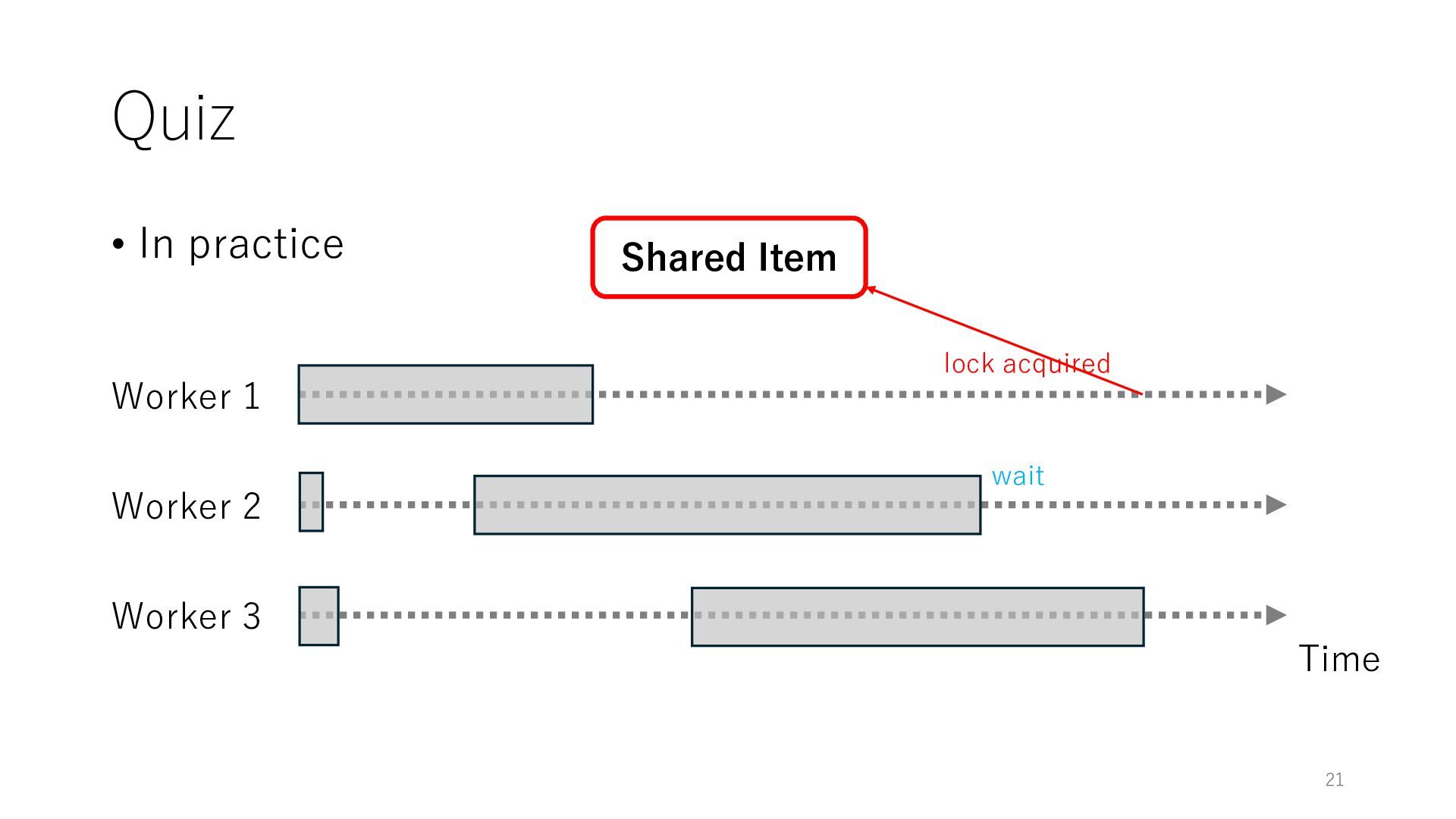
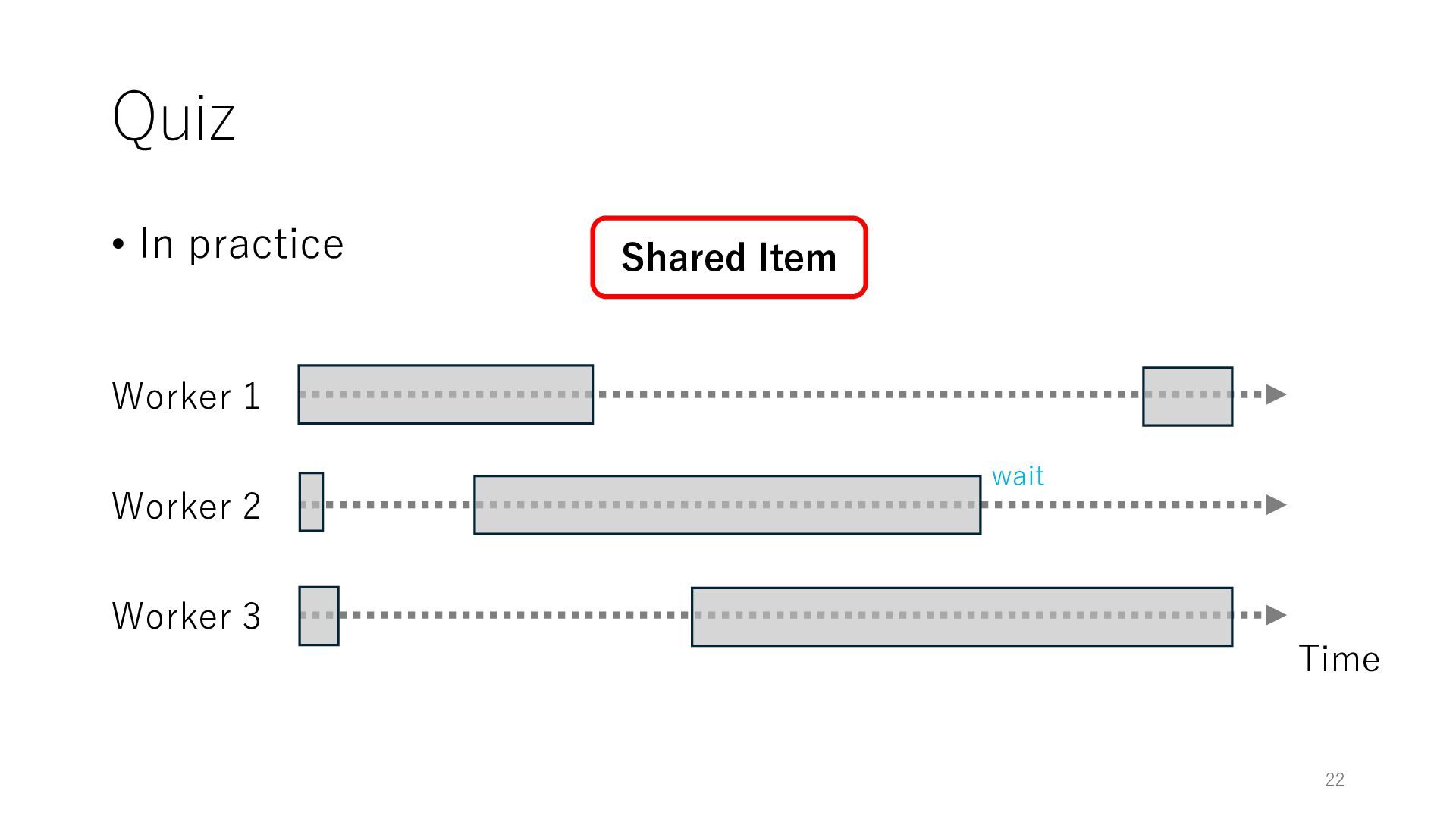
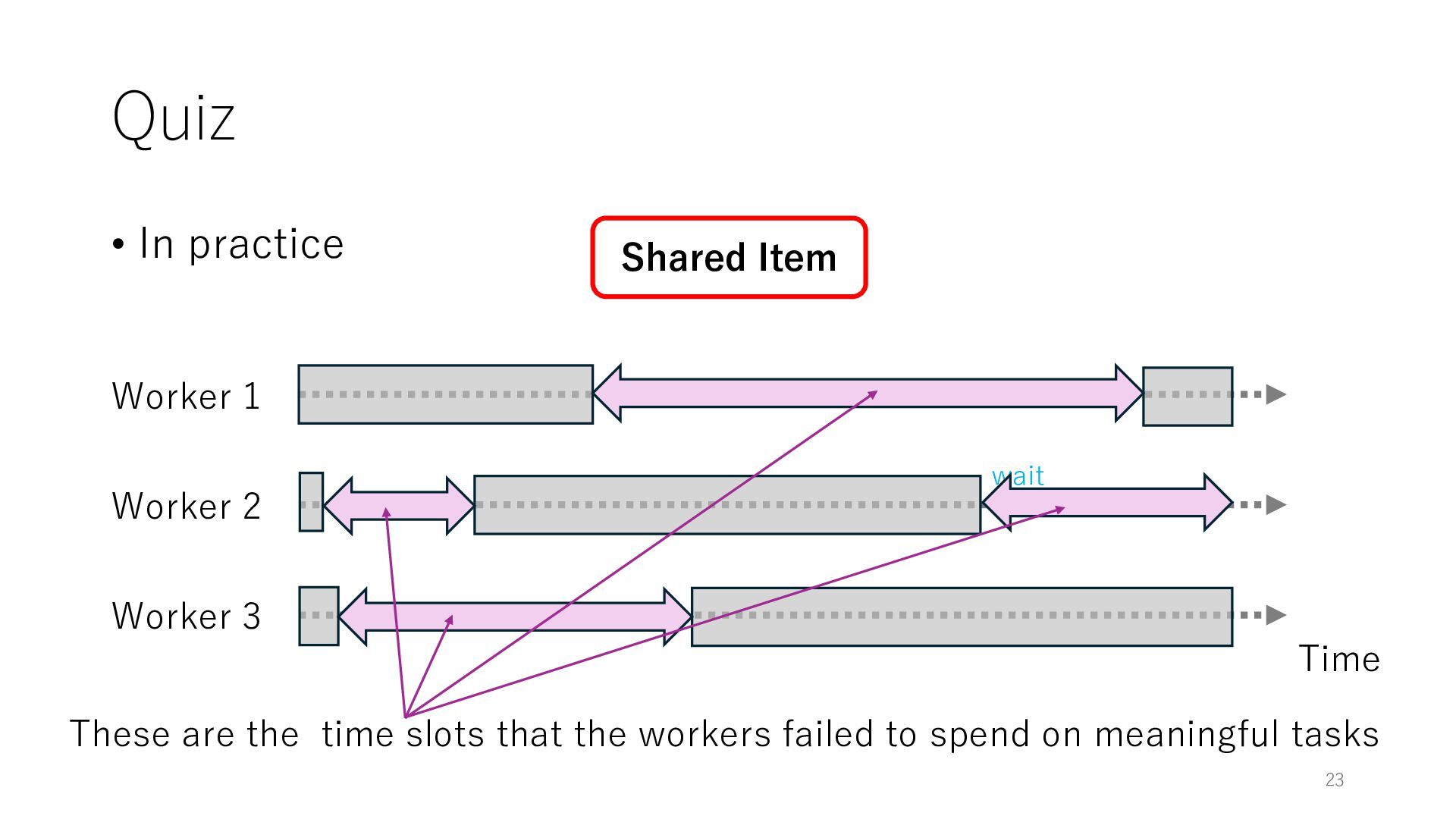
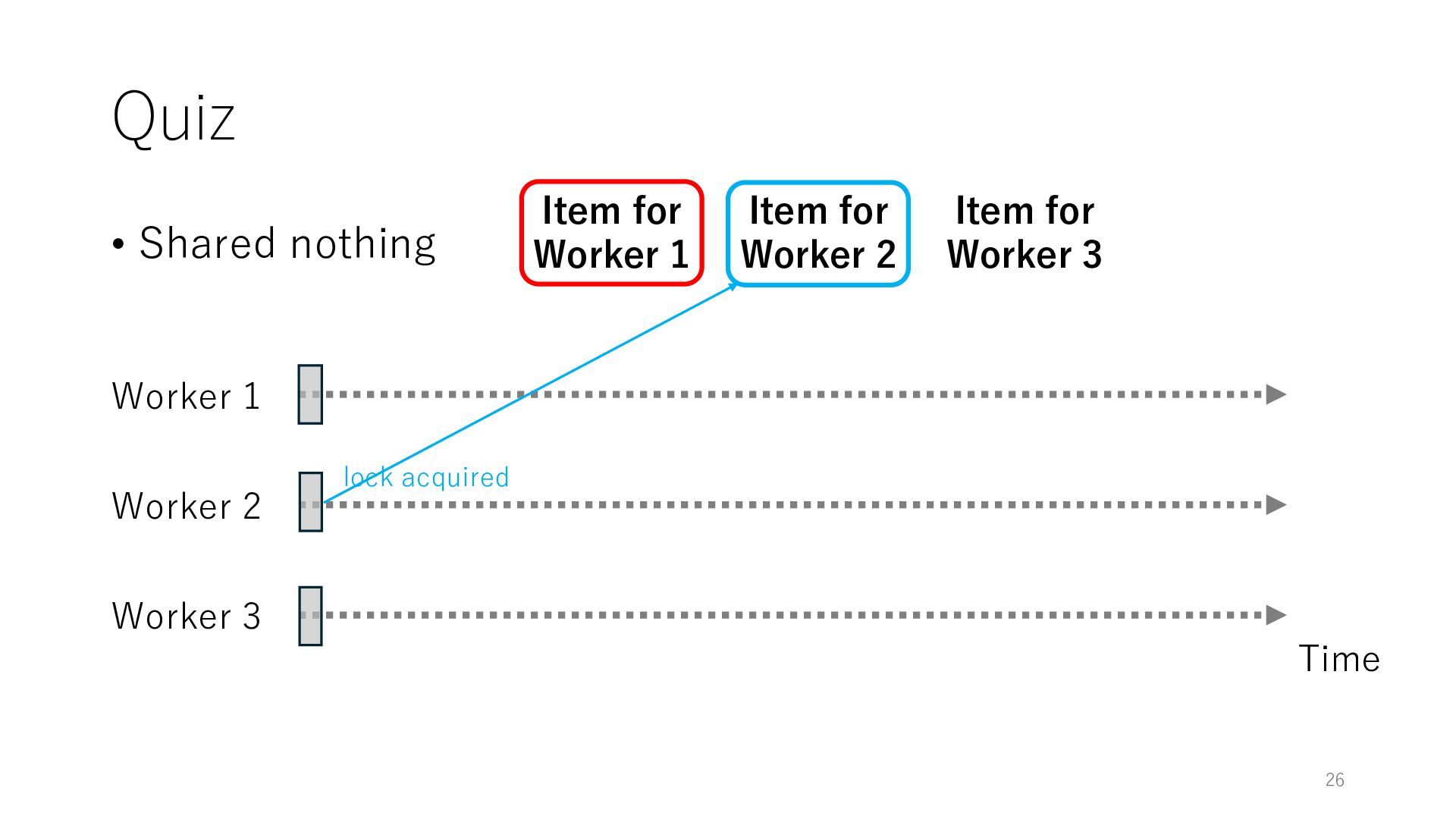
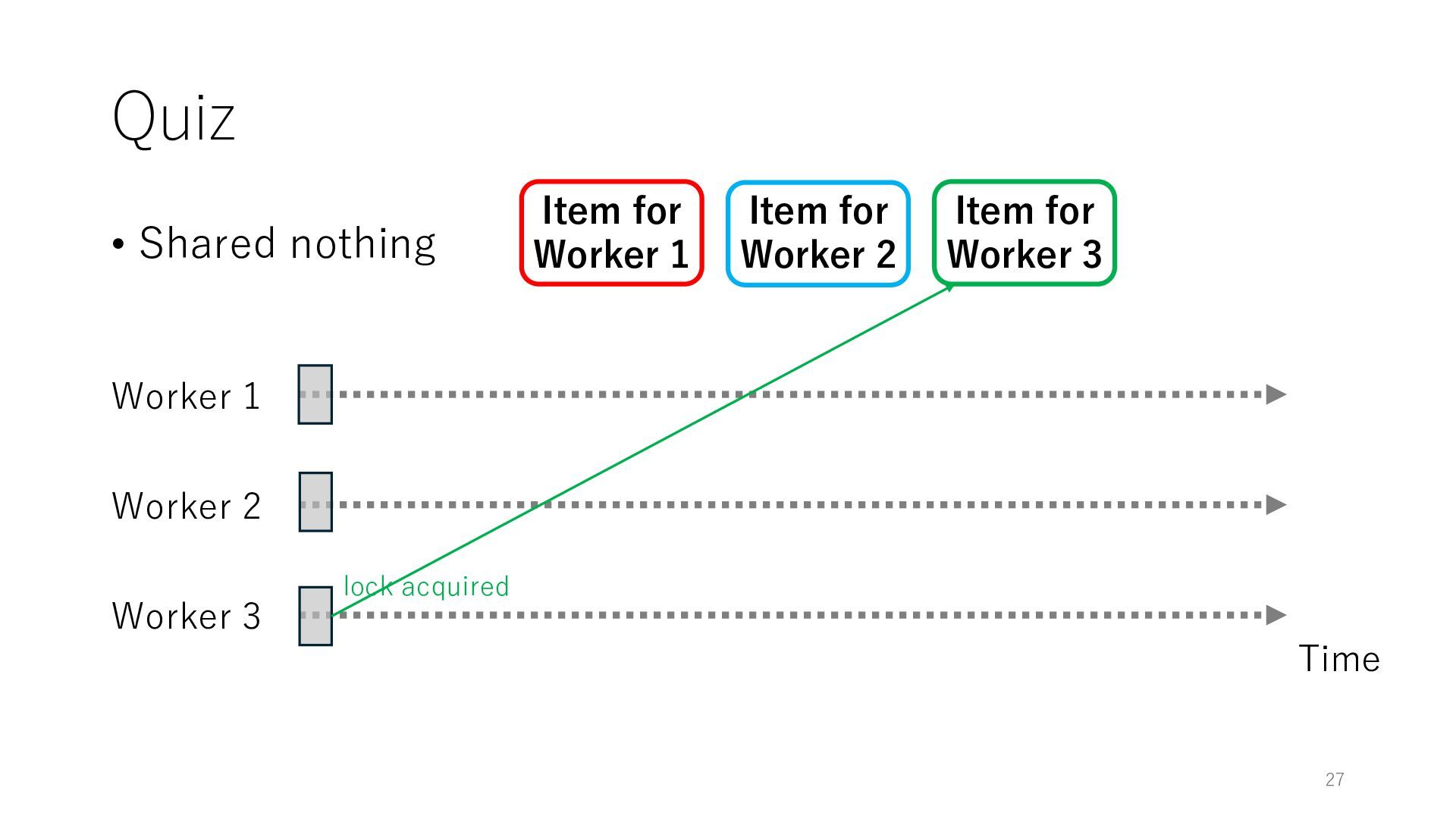
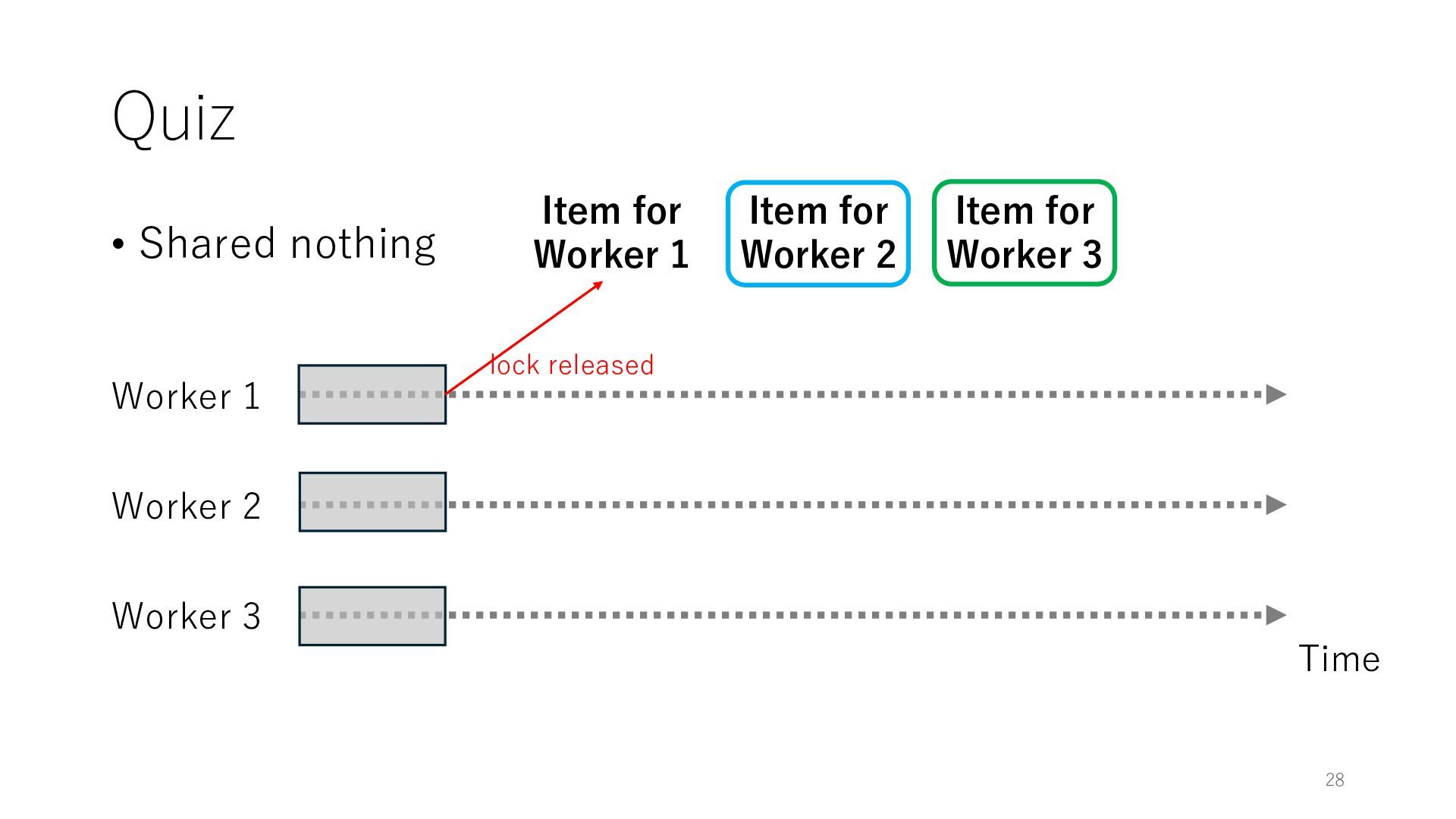
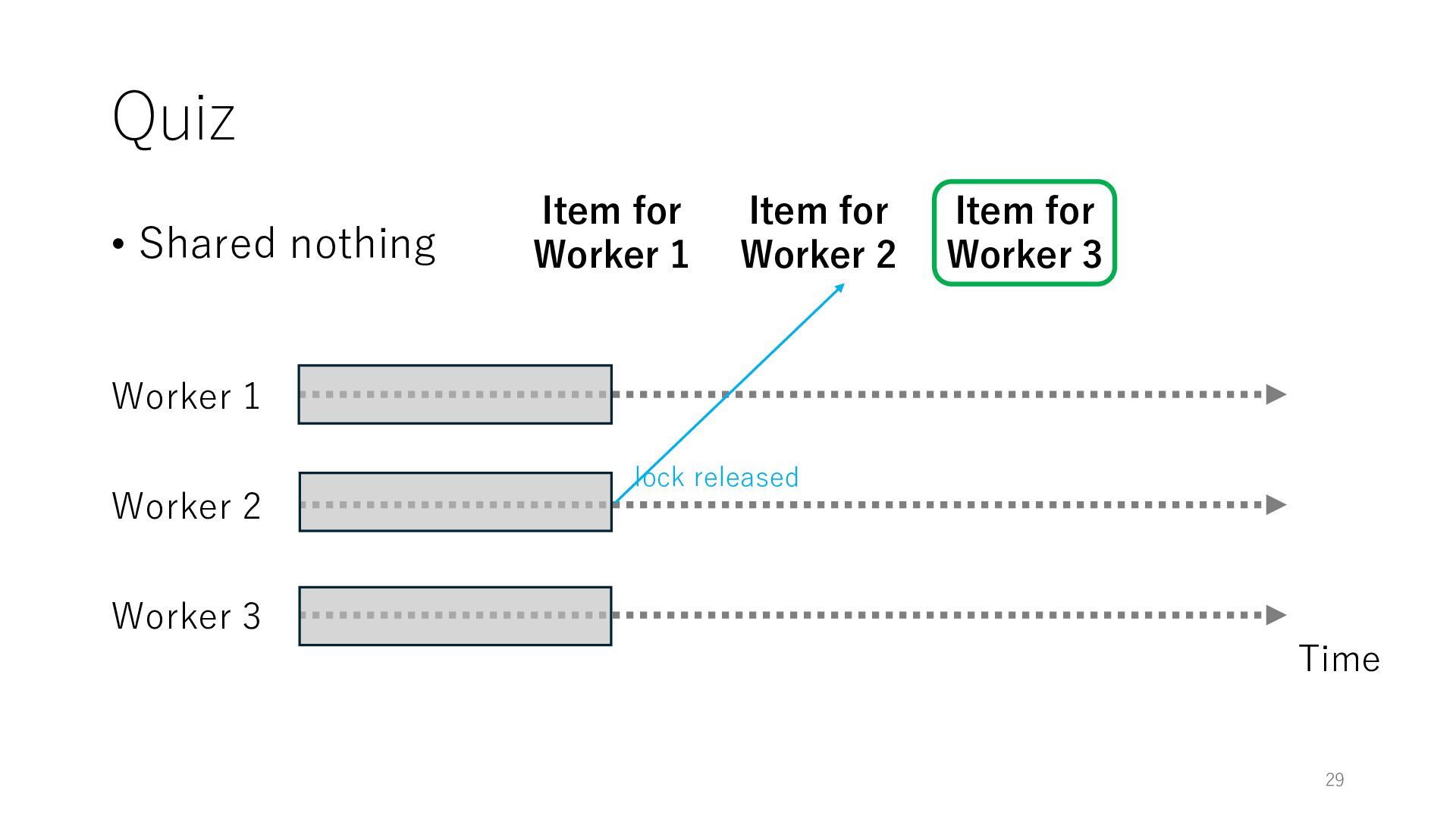
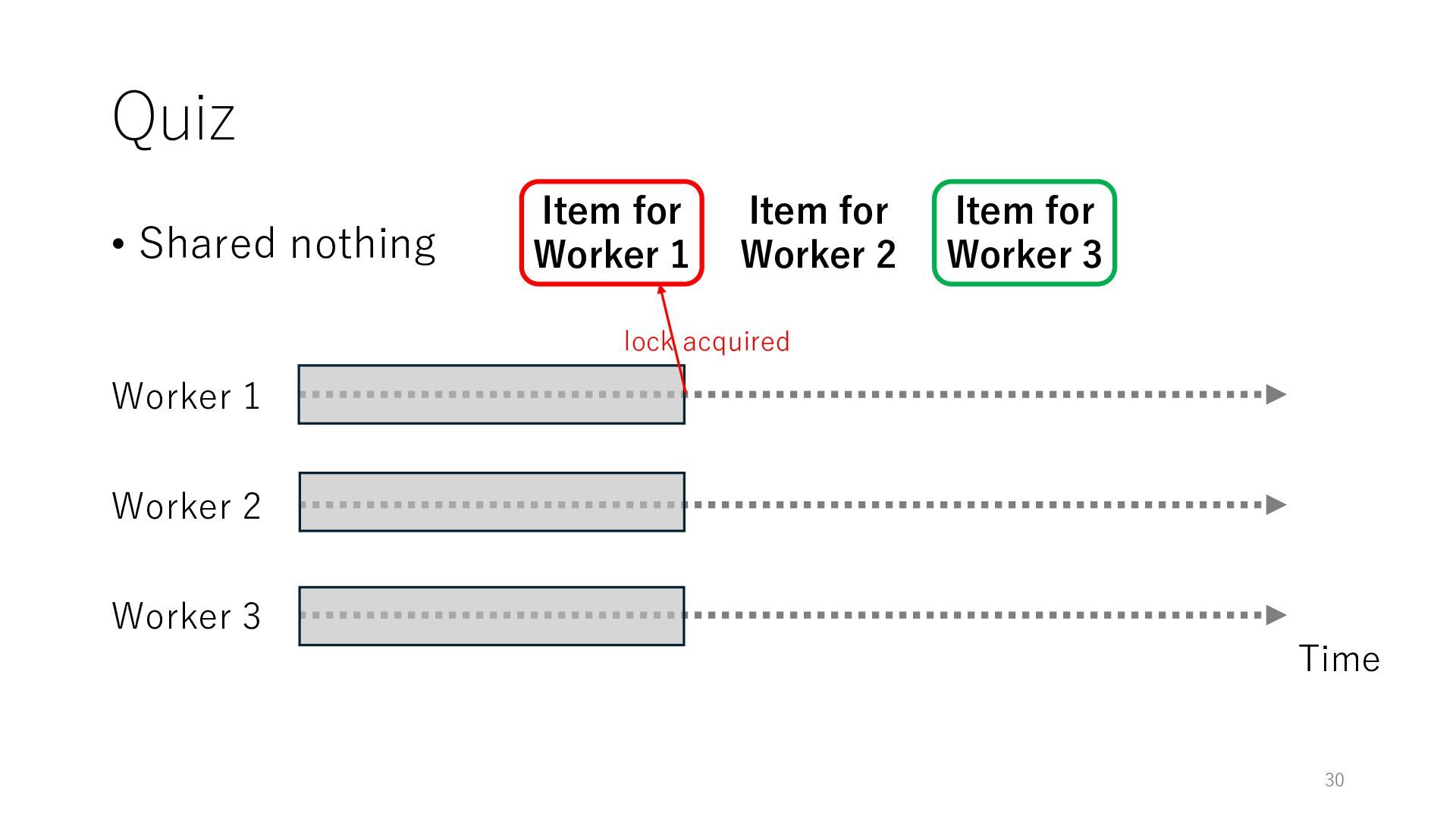
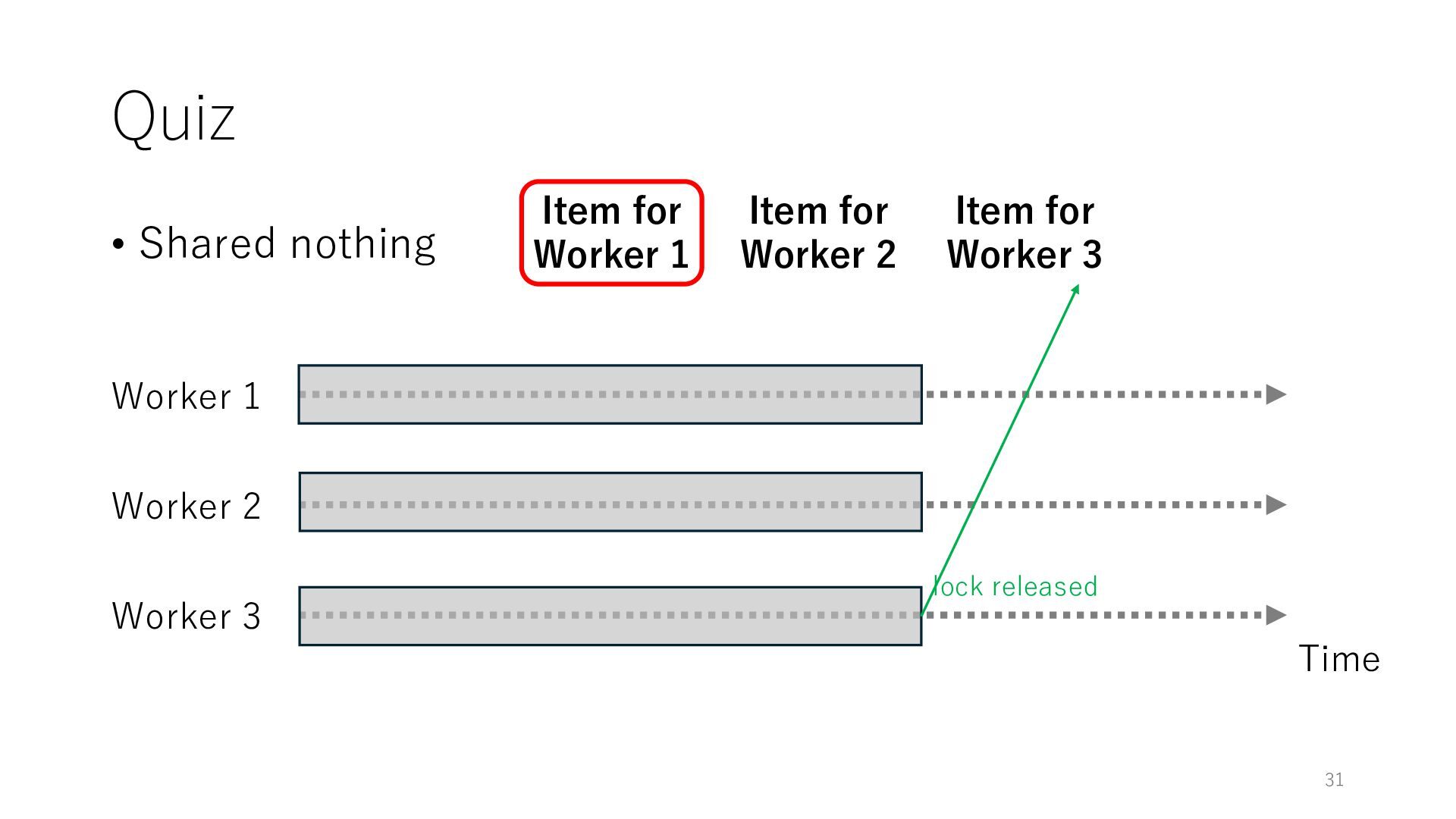
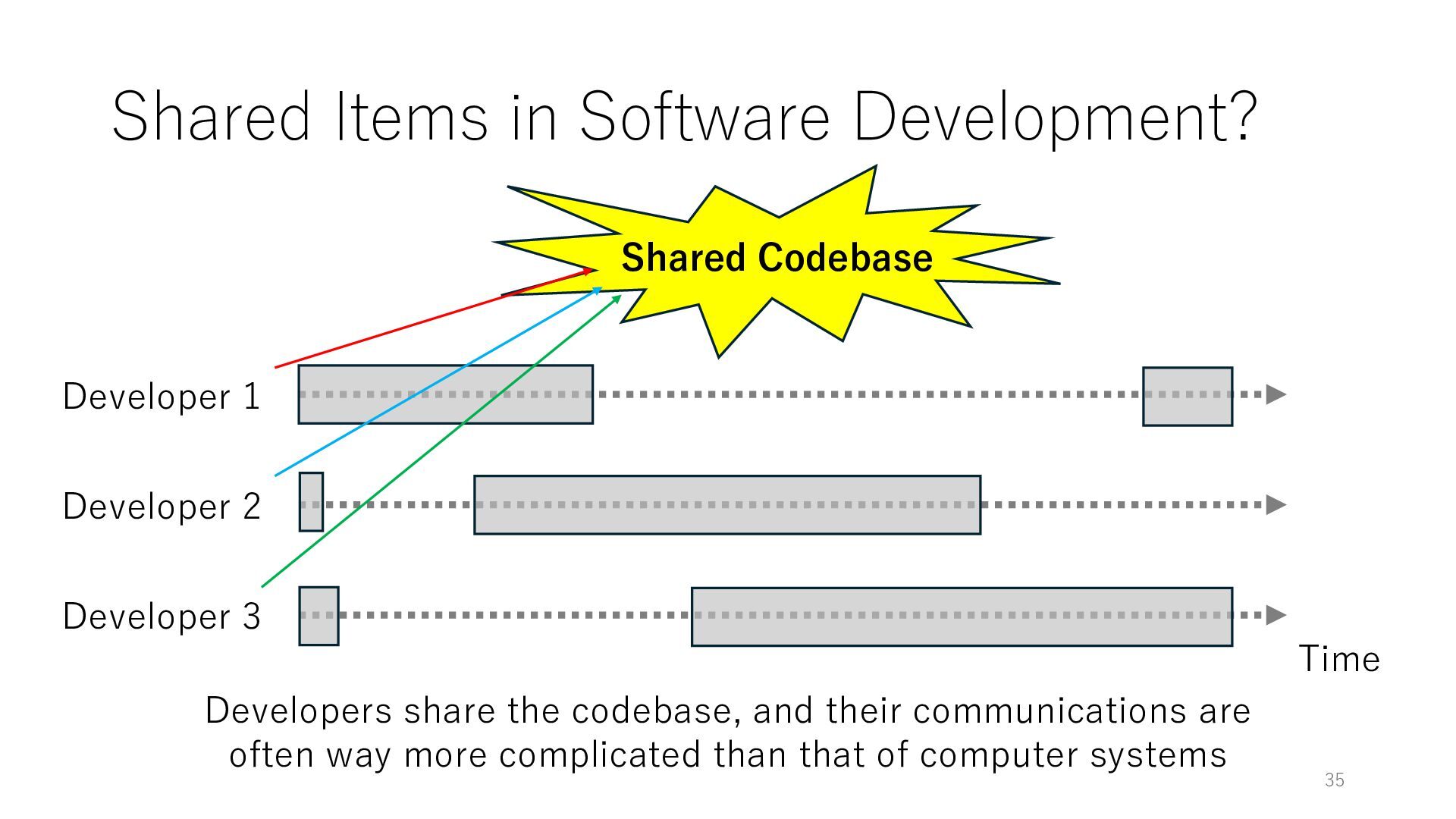
Worker 3 Item for Worker 1 Item for Worker 2 Item for Worker 3 The workers can spend all their time on meaningful tasks because they do not need to wait for each other to access a shared item
Worker 3 Item for Worker 1 Item for Worker 2 Item for Worker 3 The workers can spend all their time on meaningful tasks because they do not need to wait for each other to access a shared item In general, the designers of distributed systems try to reduce shared objects to achieve high throughput
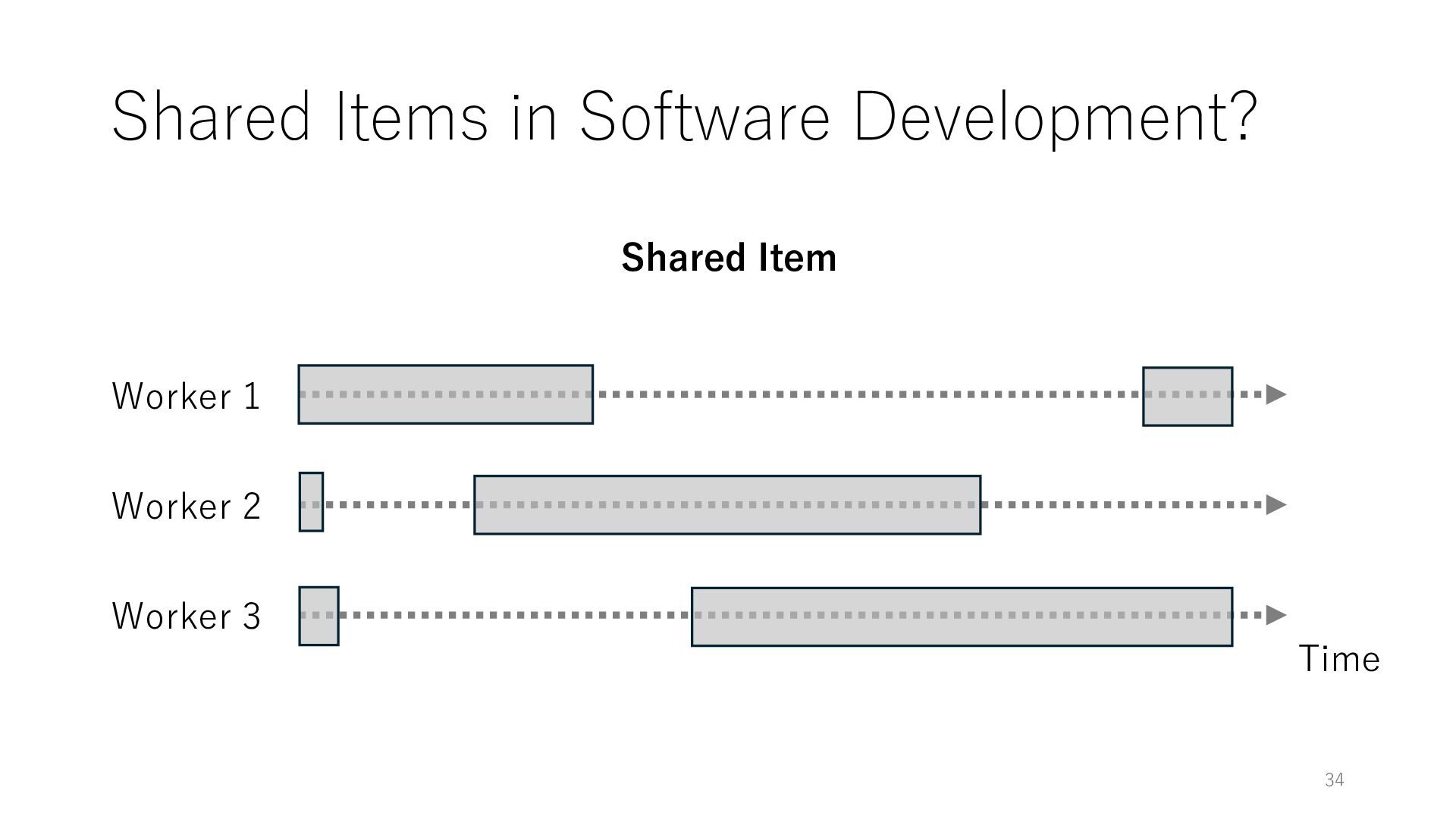
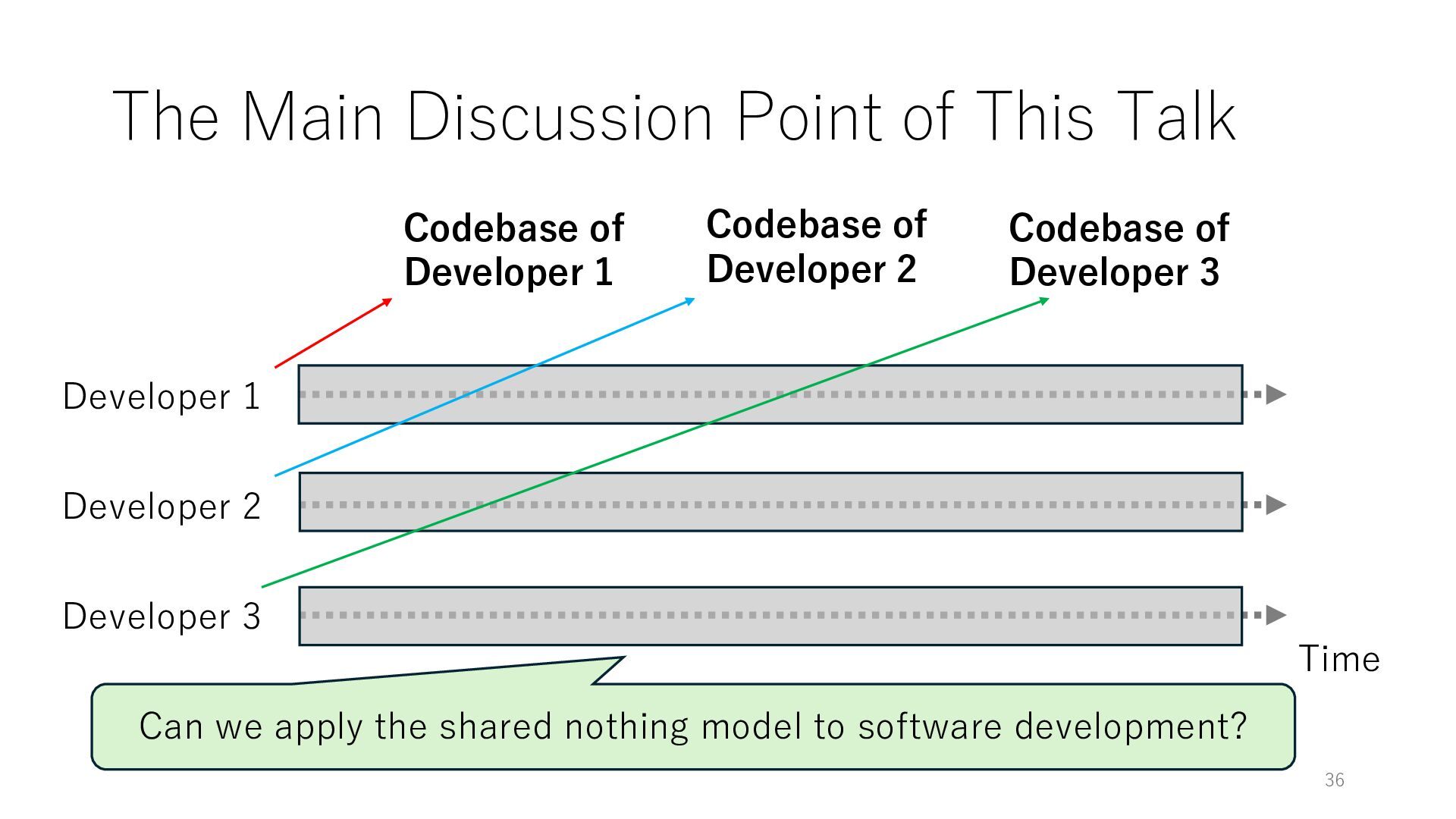
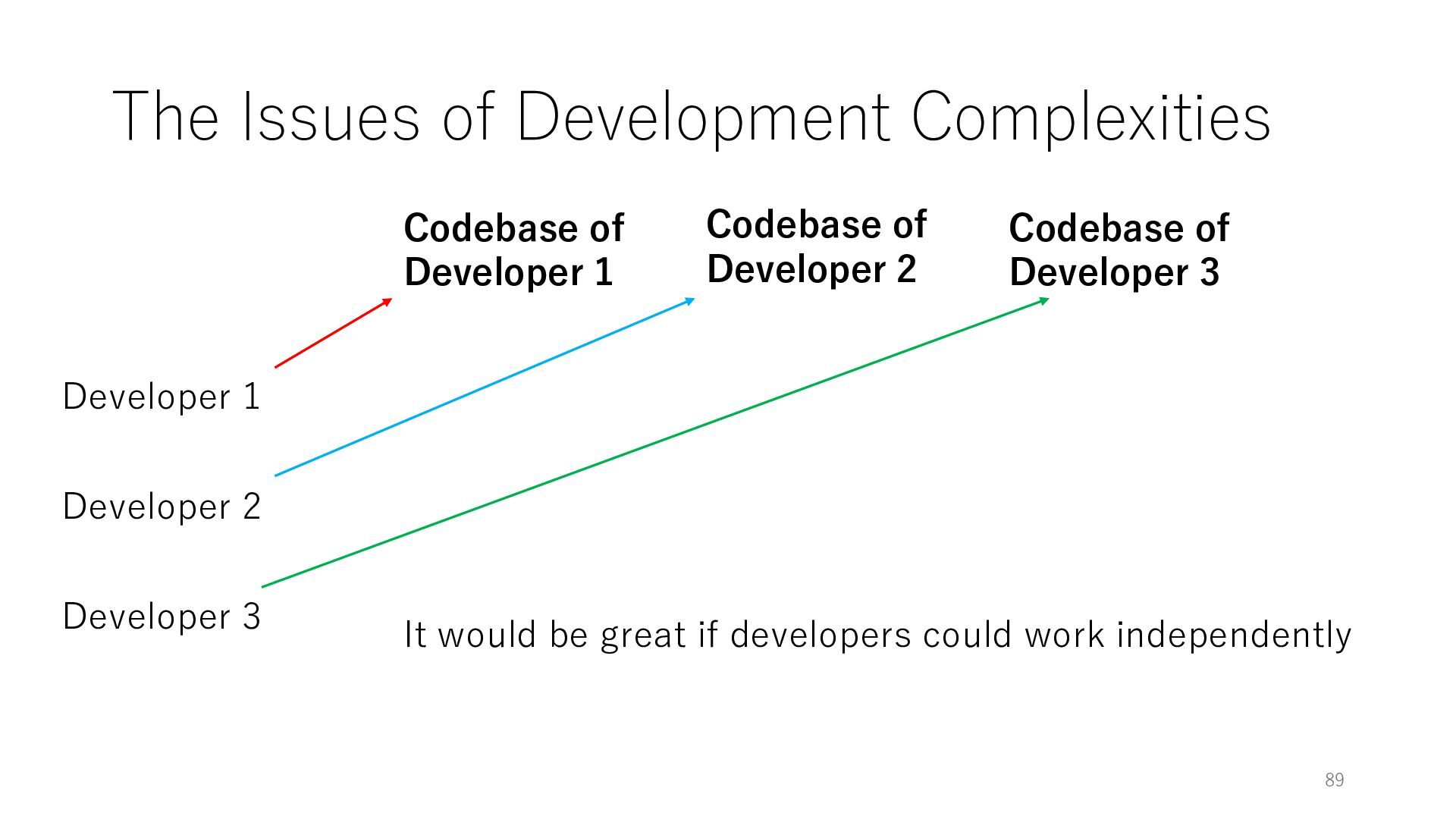
Time Developer 2 Developer 3 Codebase of Developer 1 Codebase of Developer 2 Codebase of Developer 3 Can we apply the shared nothing model to software development?
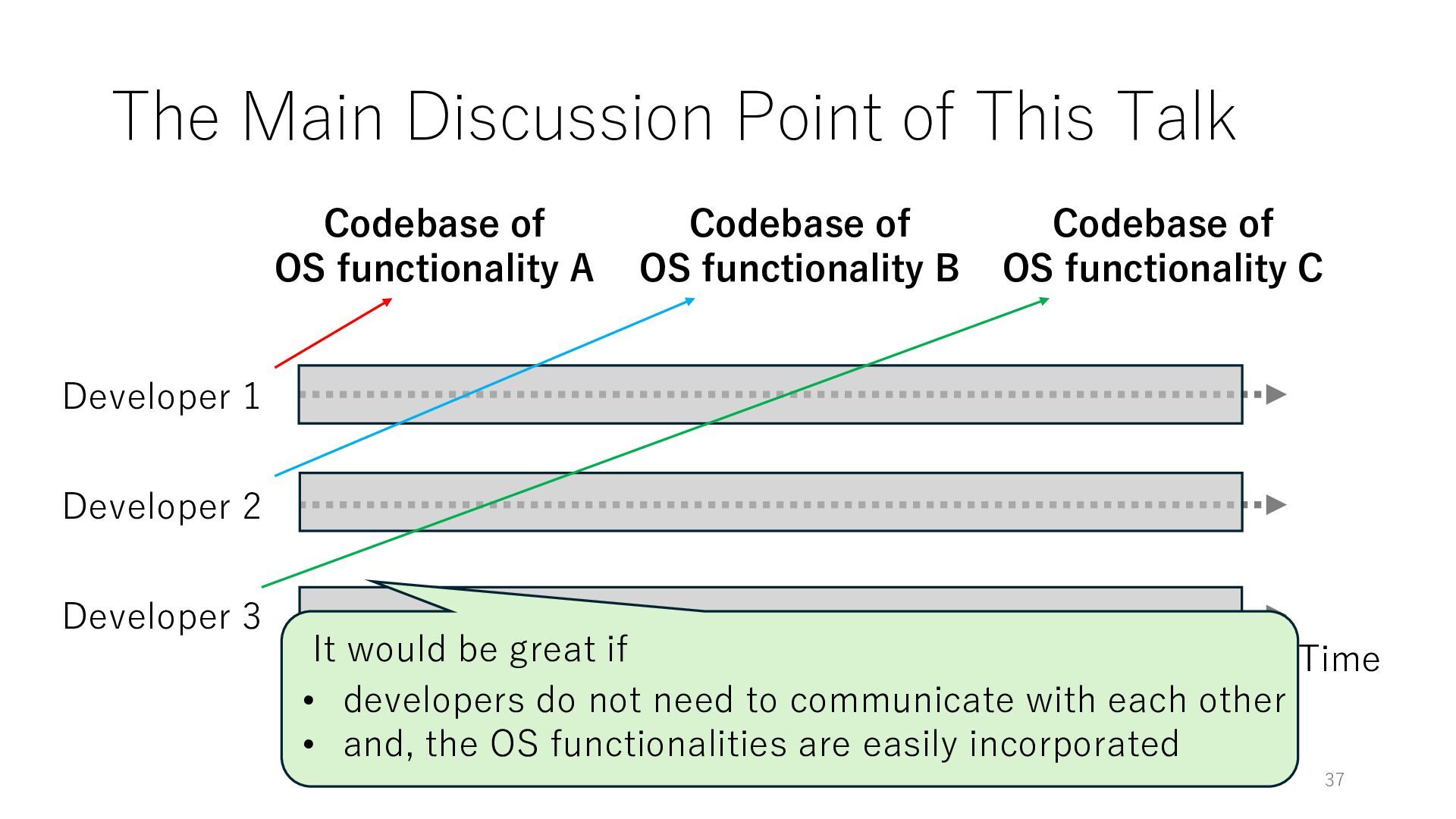
Time Developer 2 Developer 3 Codebase of OS functionality A Codebase of OS functionality B Codebase of OS functionality C It would be great if • developers do not need to communicate with each other • and, the OS functionalities are easily incorporated
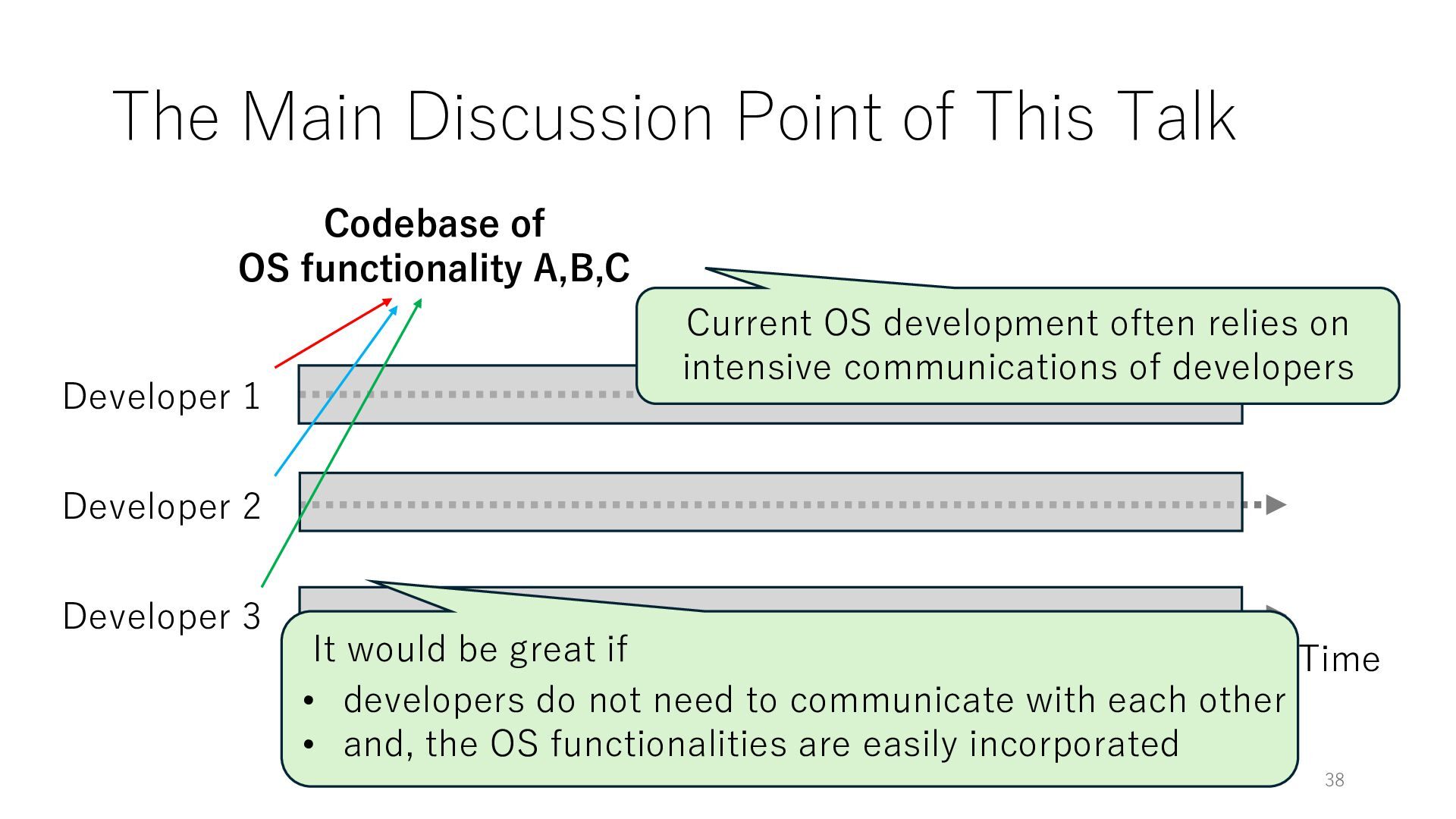
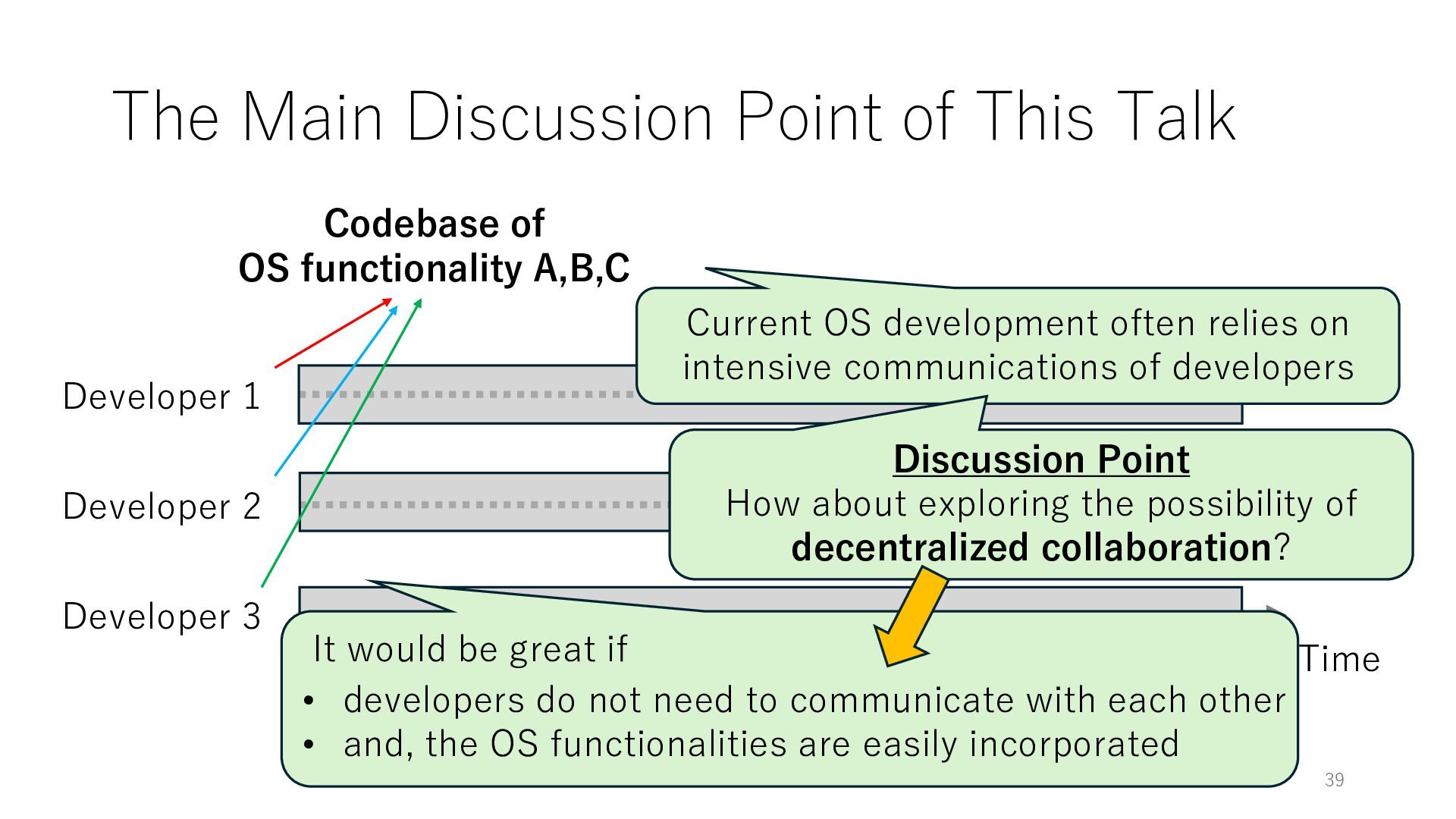
Time Developer 2 Developer 3 Codebase of OS functionality A,B,C Current OS development often relies on intensive communications of developers It would be great if • developers do not need to communicate with each other • and, the OS functionalities are easily incorporated
Time Developer 2 Developer 3 Codebase of OS functionality A,B,C Current OS development often relies on intensive communications of developers Discussion Point How about exploring the possibility of decentralized collaboration? It would be great if • developers do not need to communicate with each other • and, the OS functionalities are easily incorporated
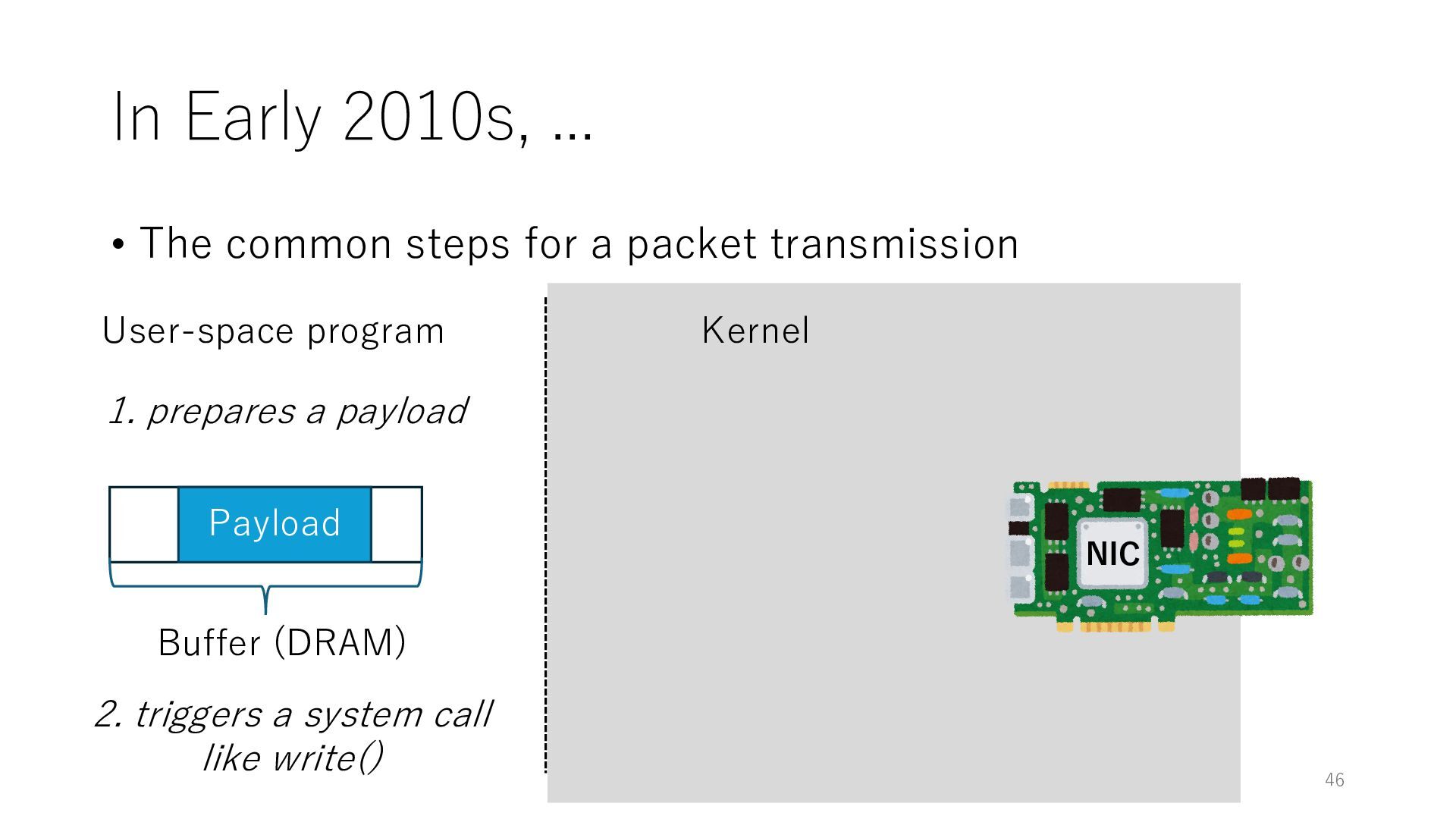
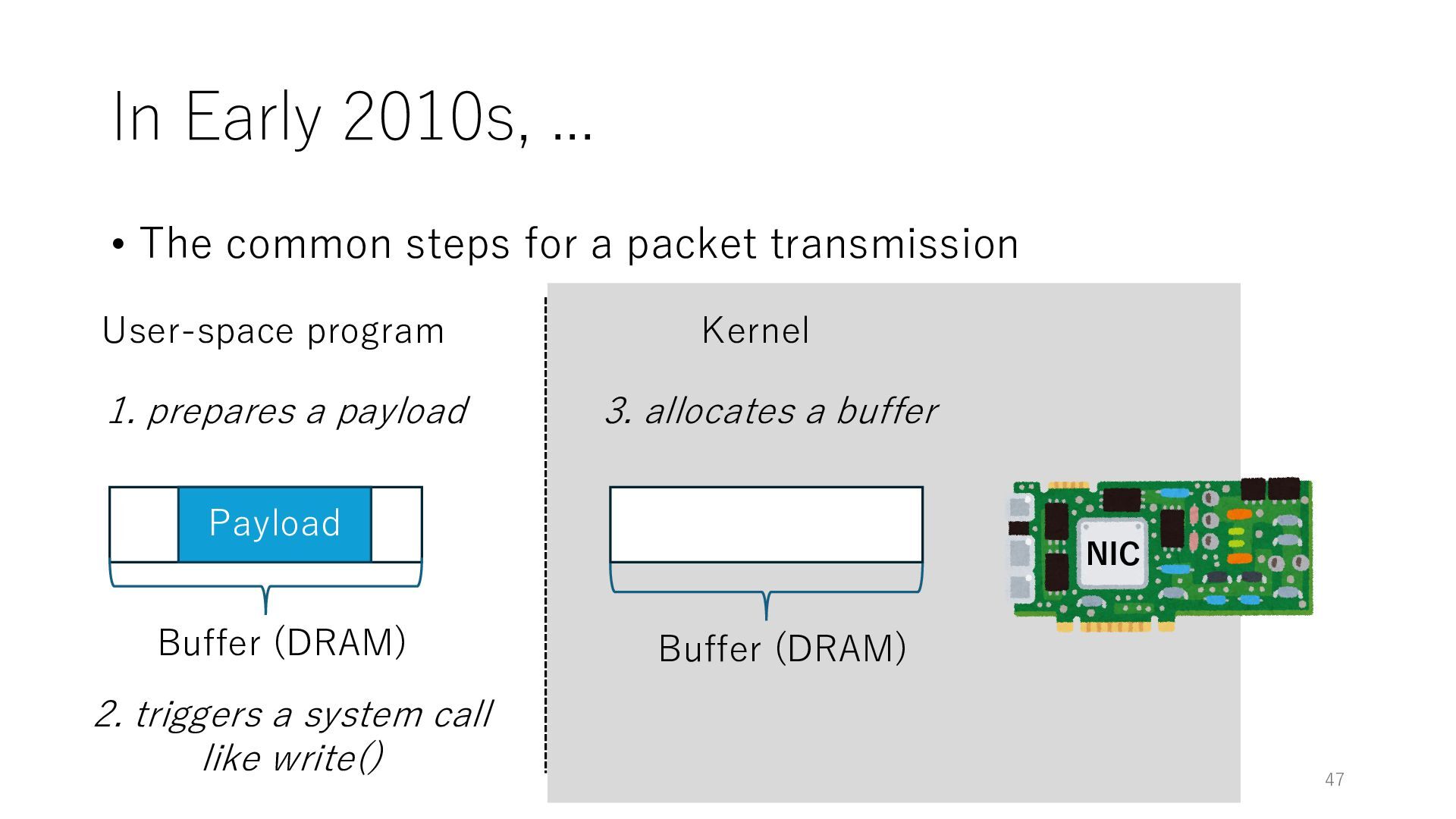
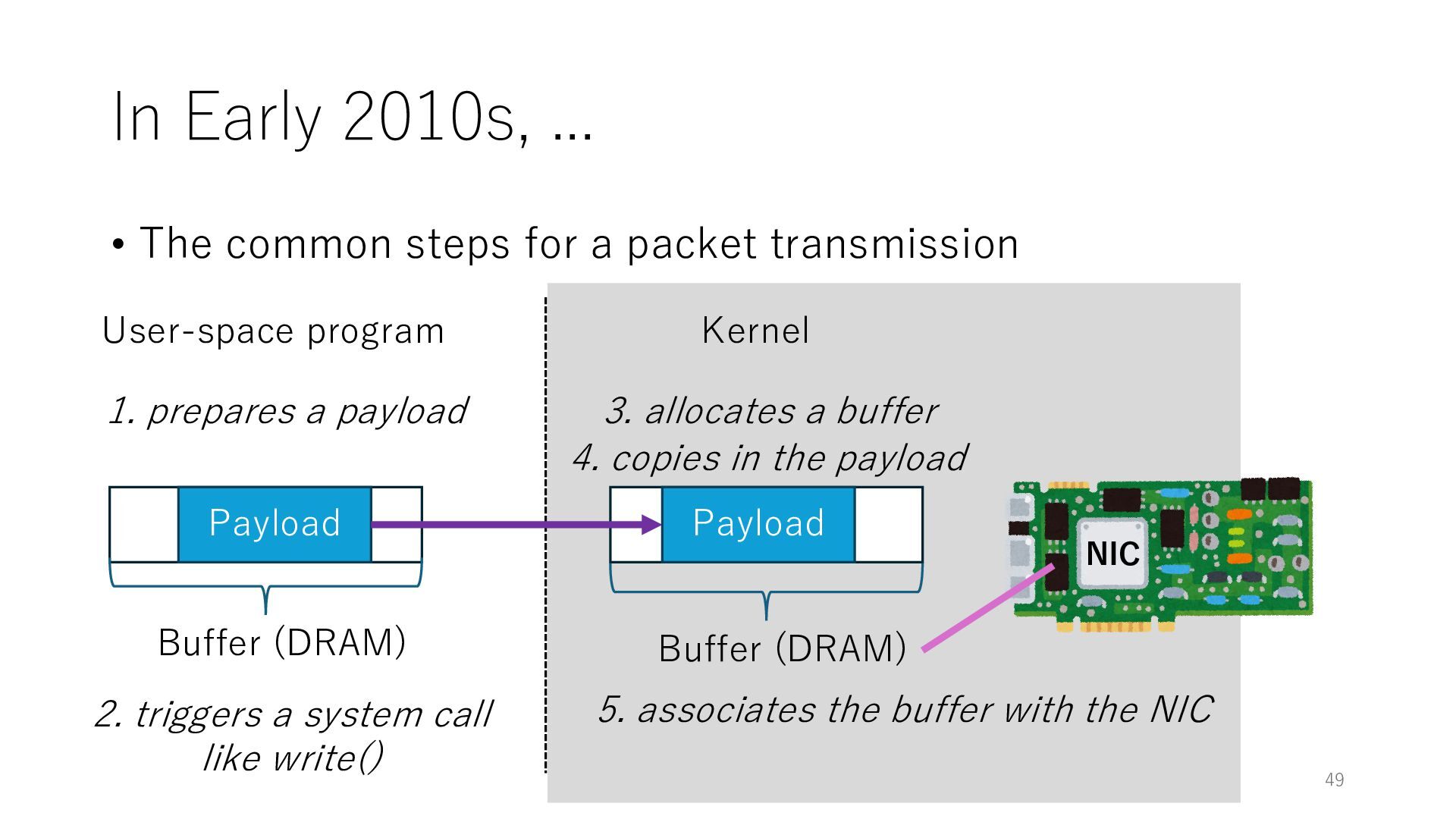
packet transmission NIC User-space program Kernel Payload Buffer (DRAM) 1. prepares a payload 2. triggers a system call like write() 3. allocates a buffer Buffer (DRAM) 47
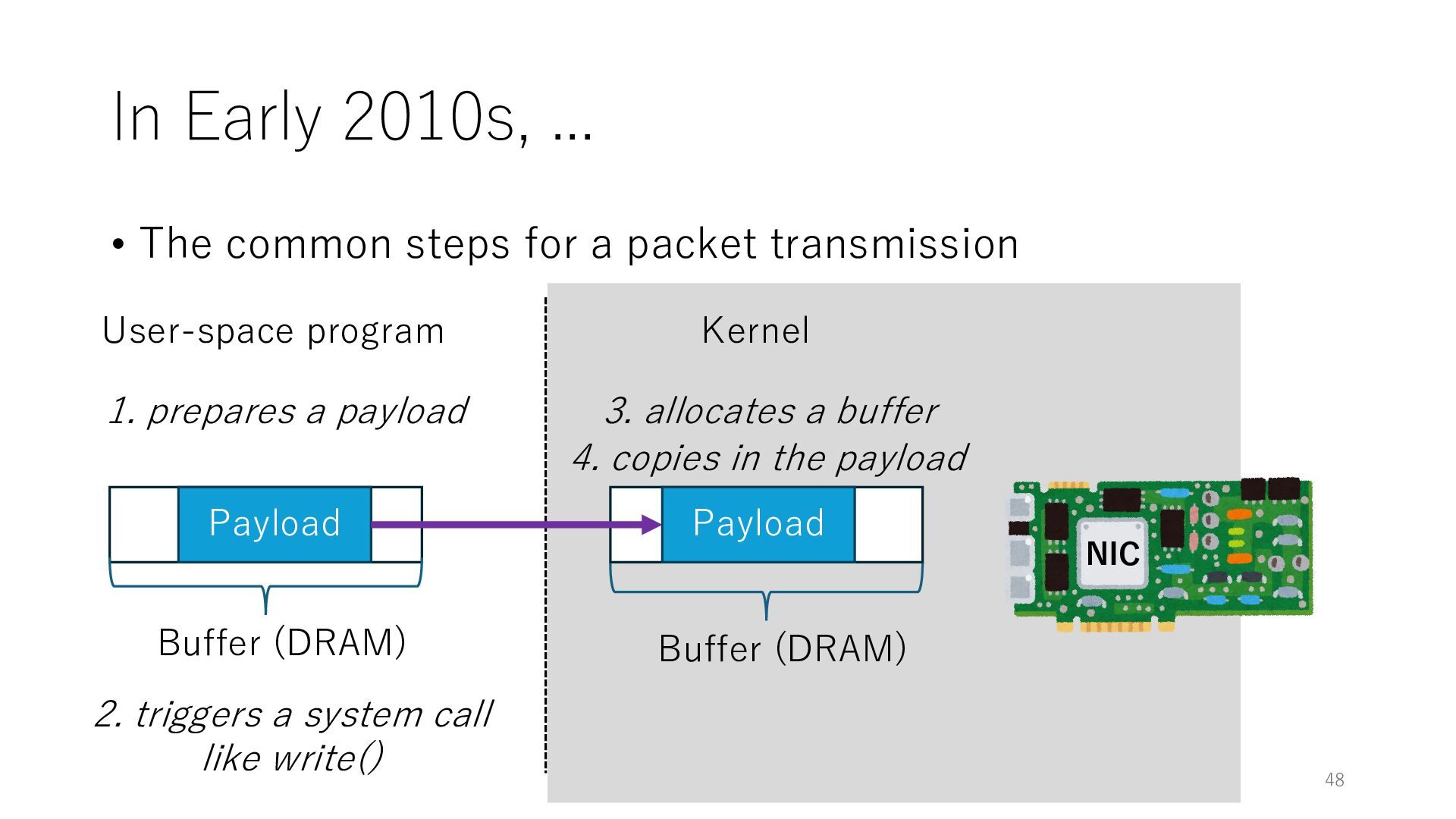
packet transmission NIC User-space program Kernel Payload Buffer (DRAM) 1. prepares a payload 2. triggers a system call like write() 3. allocates a buffer Buffer (DRAM) 4. copies in the payload Payload 48
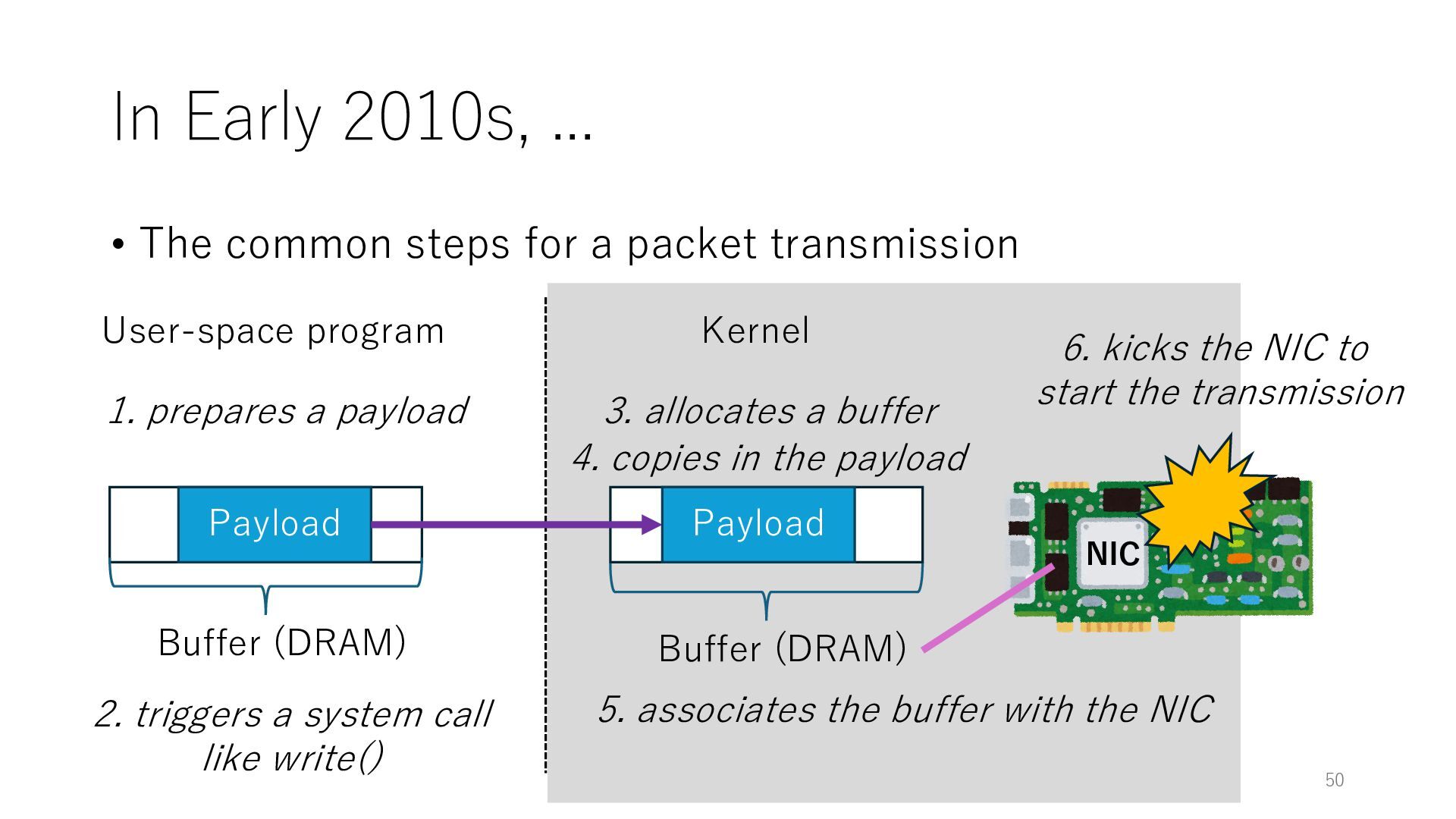
packet transmission NIC User-space program Kernel Payload Buffer (DRAM) 1. prepares a payload 2. triggers a system call like write() 3. allocates a buffer Buffer (DRAM) 4. copies in the payload Payload 5. associates the buffer with the NIC 49
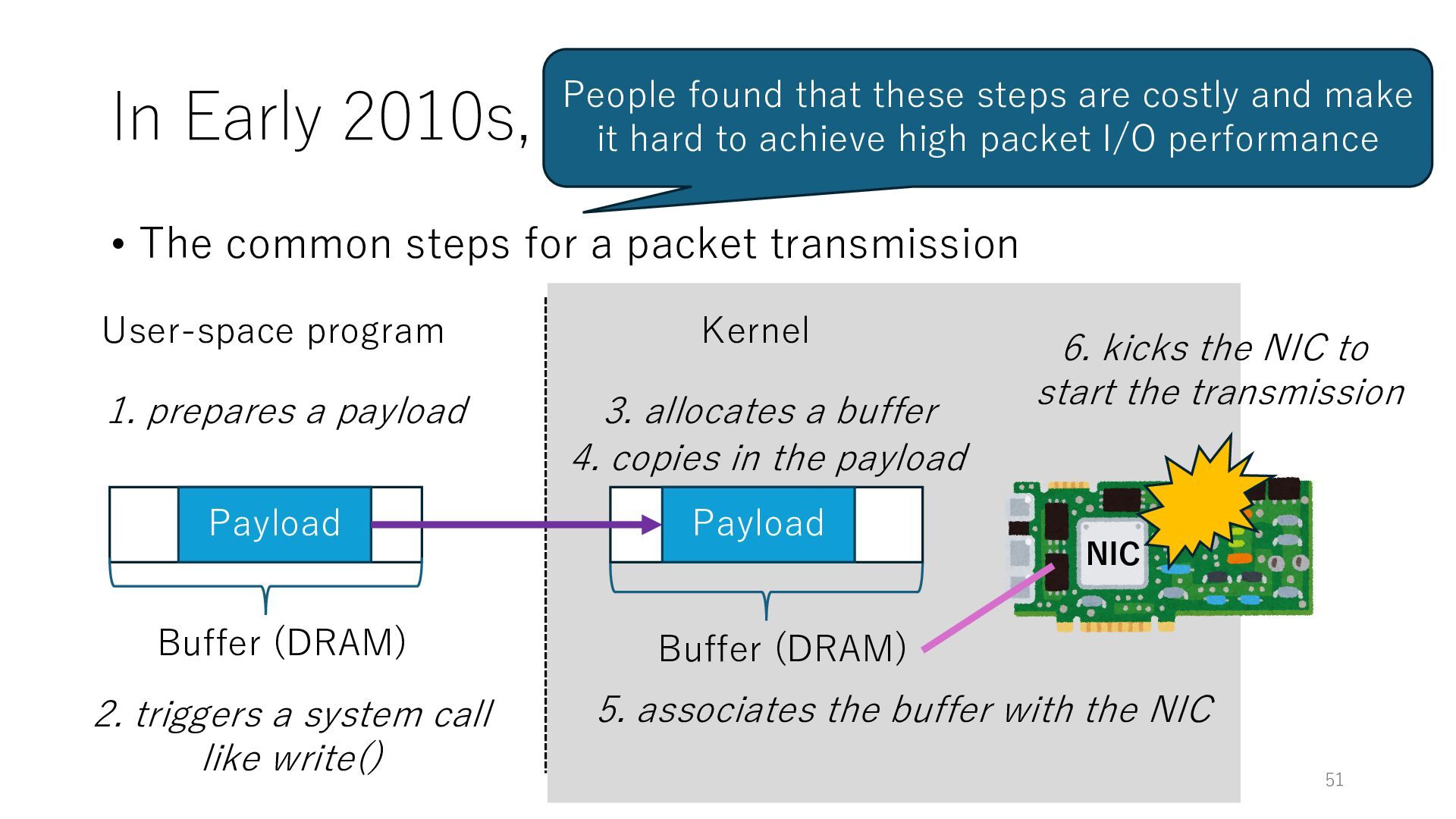
packet transmission NIC User-space program Kernel Payload Buffer (DRAM) 1. prepares a payload 2. triggers a system call like write() 3. allocates a buffer Buffer (DRAM) 4. copies in the payload Payload 5. associates the buffer with the NIC 6. kicks the NIC to start the transmission 50
packet transmission NIC User-space program Kernel Payload Buffer (DRAM) 1. prepares a payload 2. triggers a system call like write() 3. allocates a buffer Buffer (DRAM) 4. copies in the payload Payload 5. associates the buffer with the NIC 6. kicks the NIC to start the transmission 51 People found that these steps are costly and make it hard to achieve high packet I/O performance
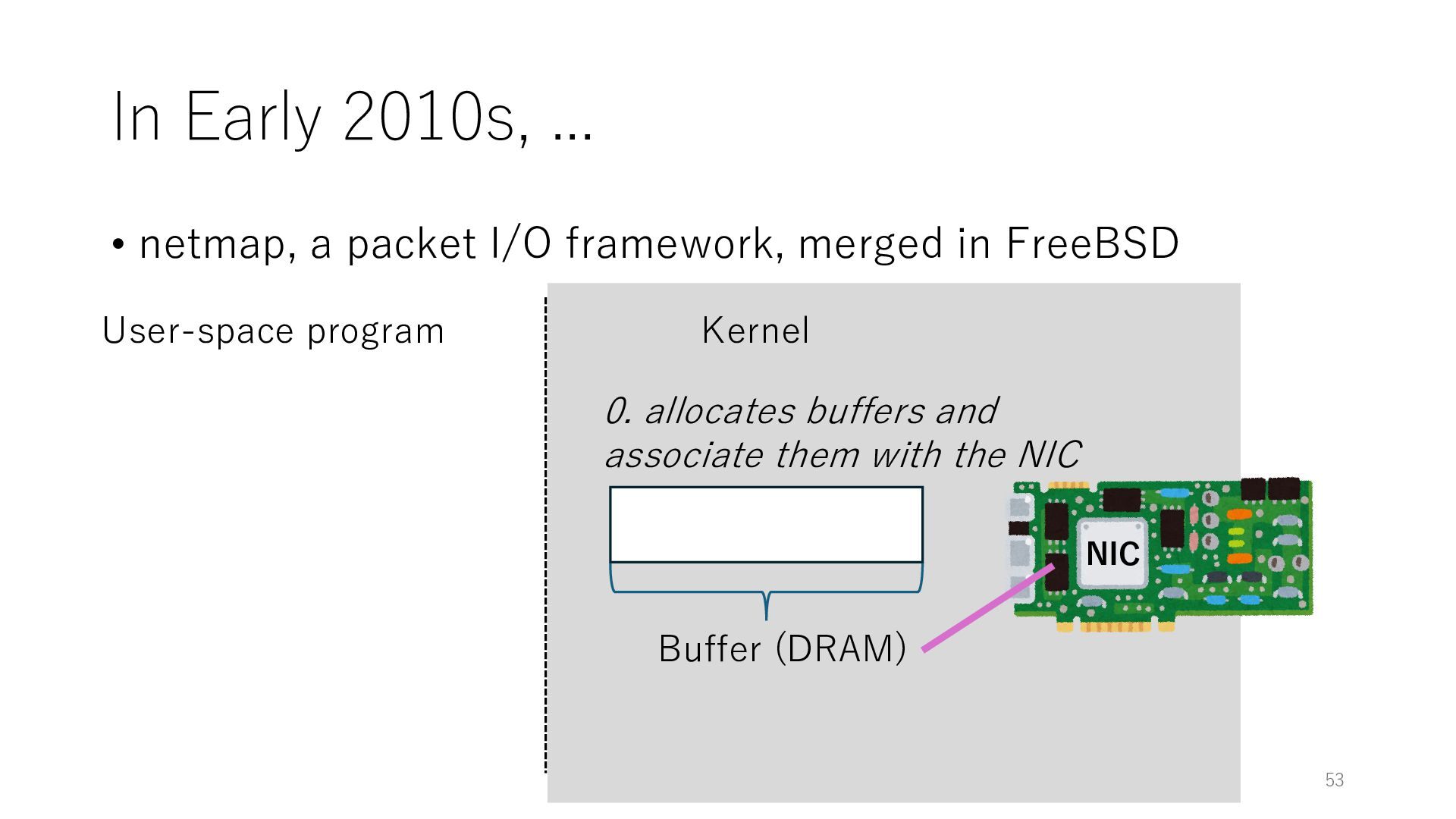
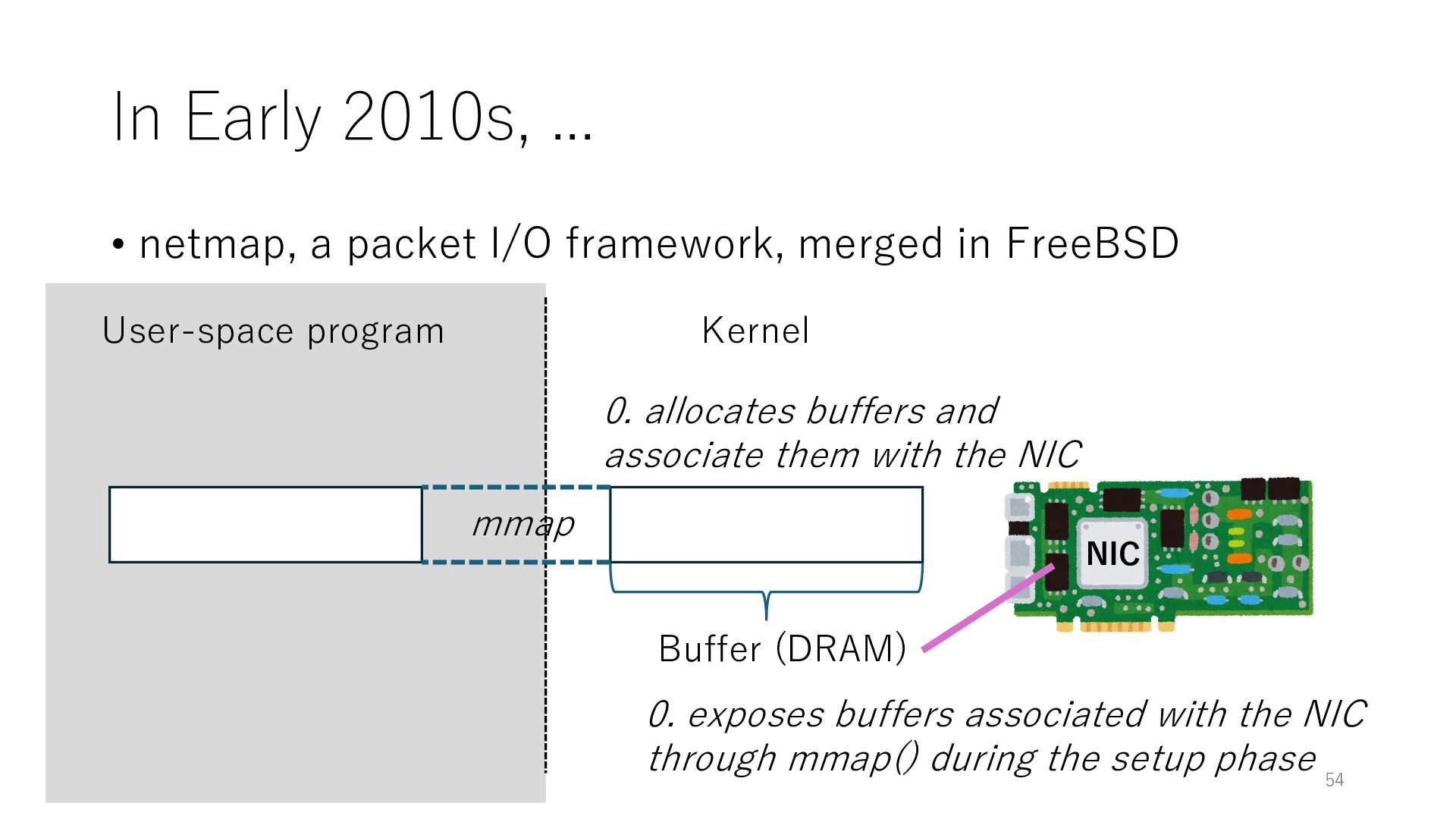
merged in FreeBSD NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap 54
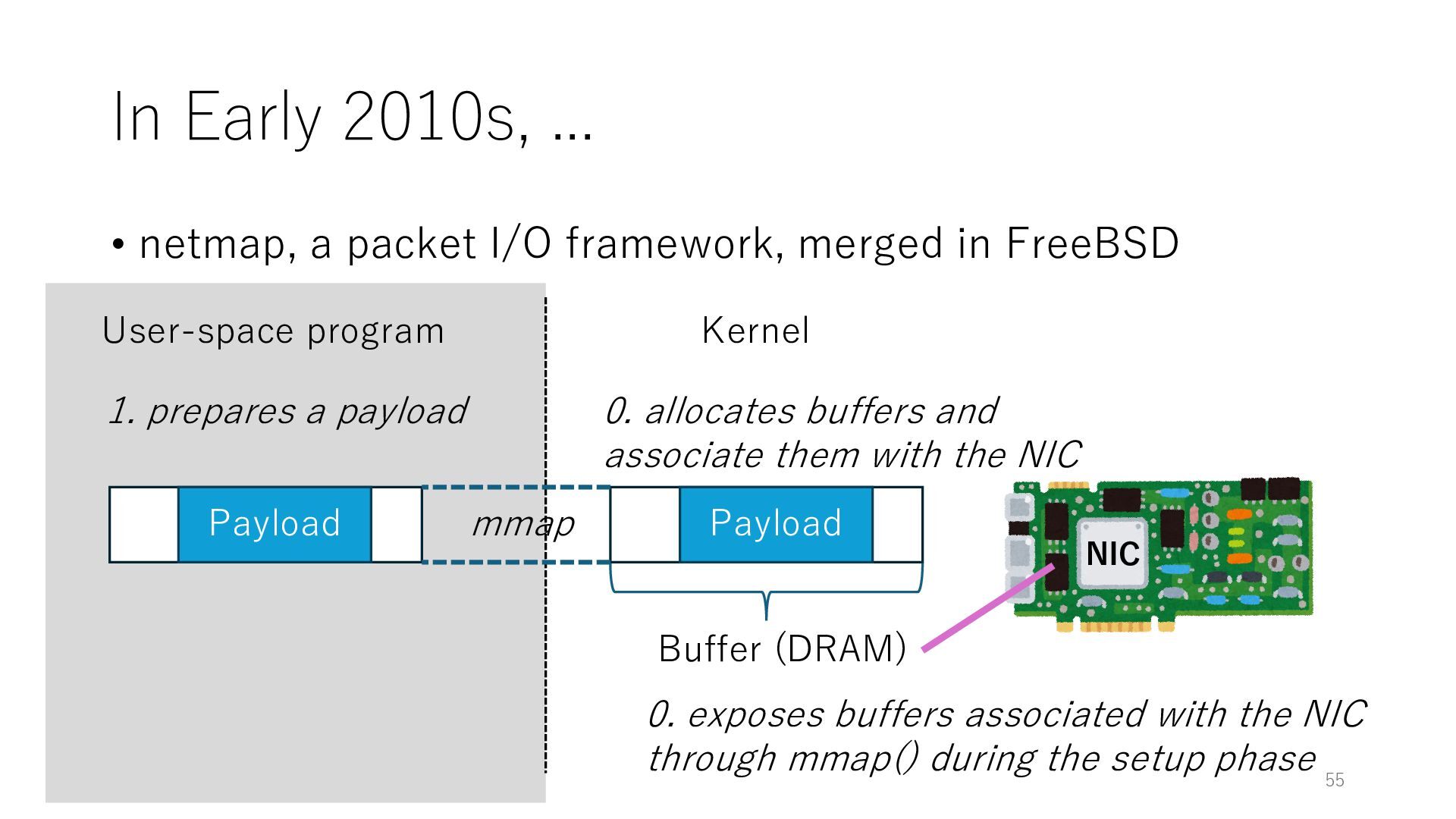
merged in FreeBSD NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload Payload 55
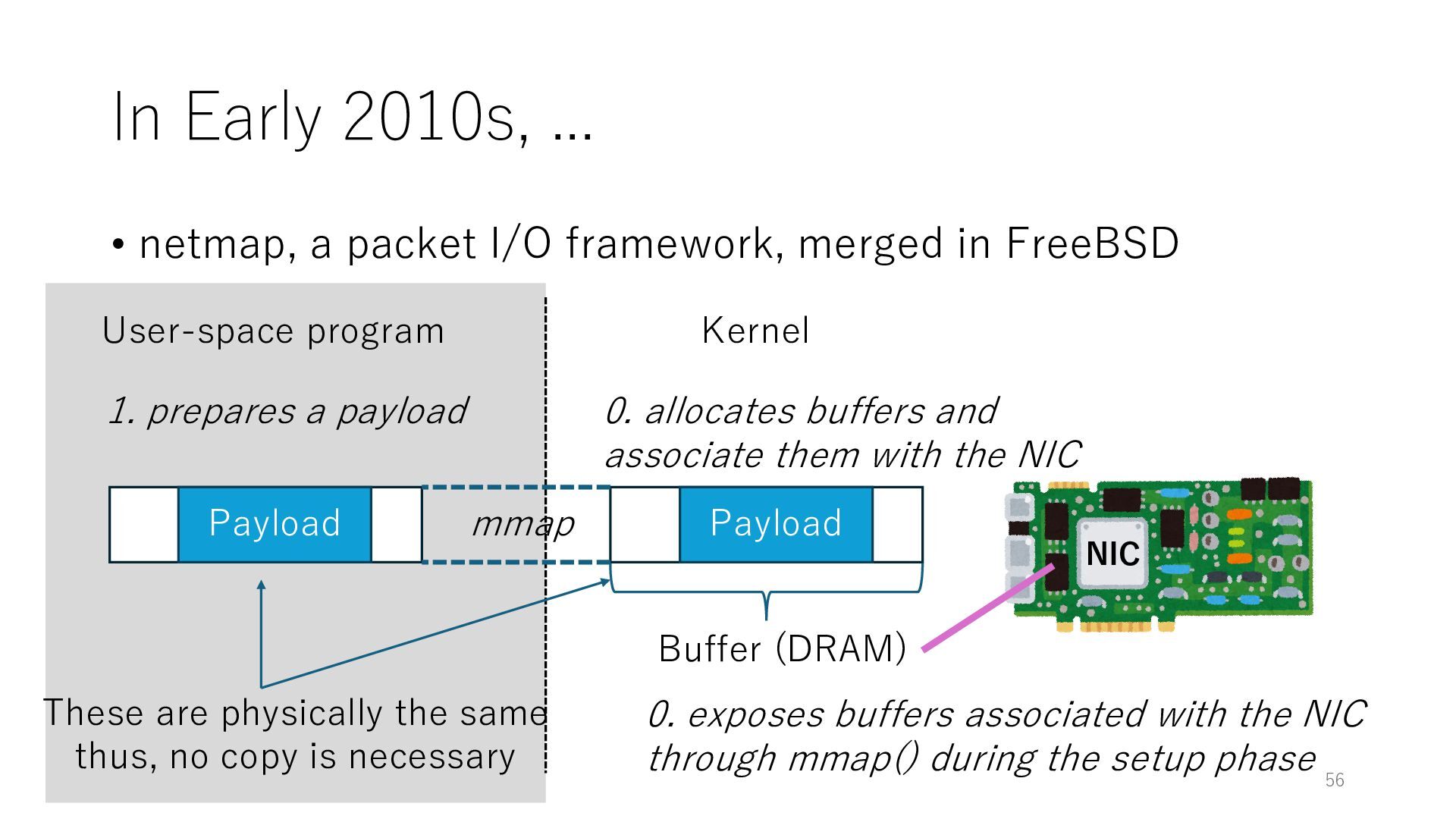
merged in FreeBSD NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload Payload 56 These are physically the same thus, no copy is necessary
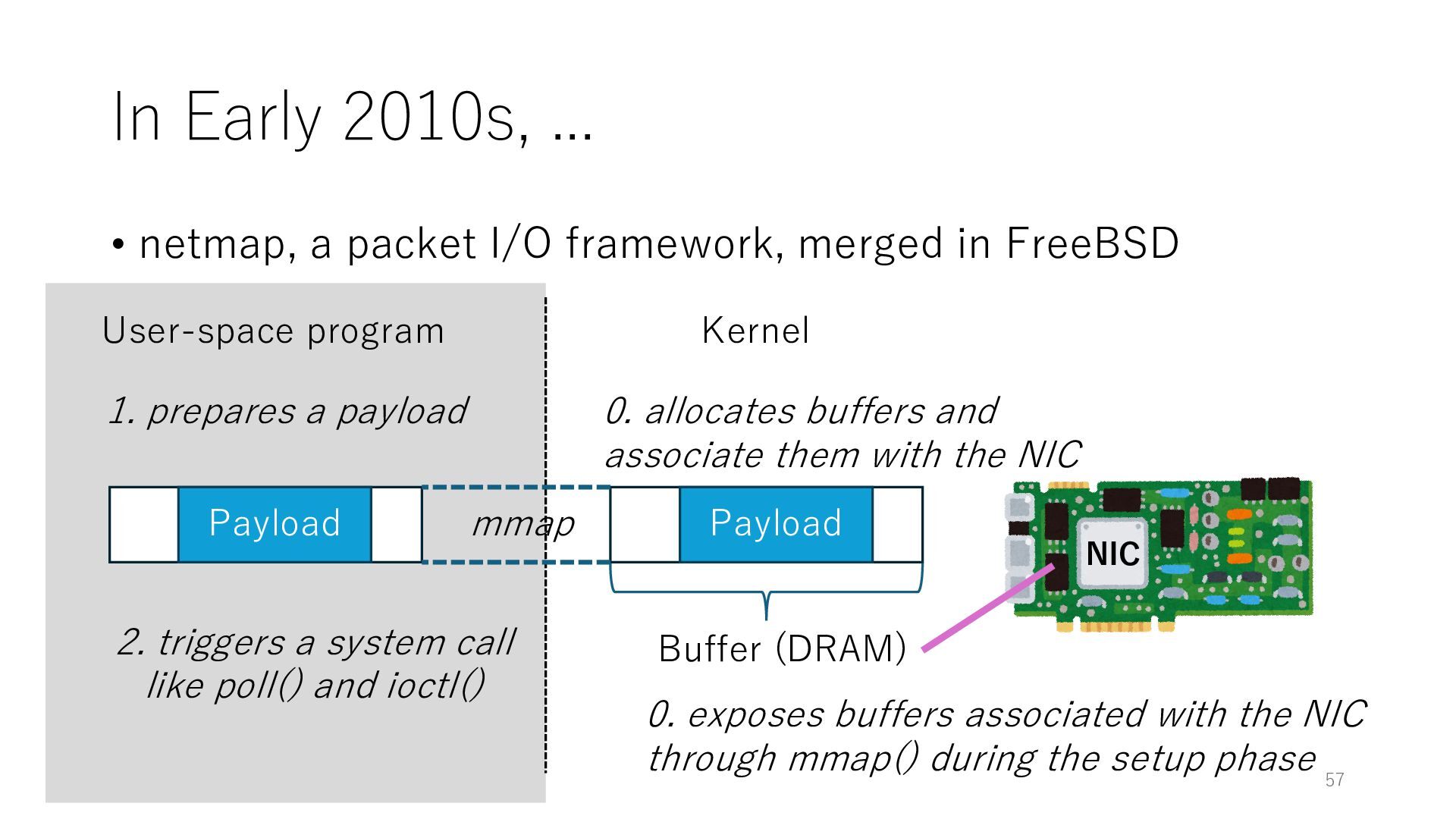
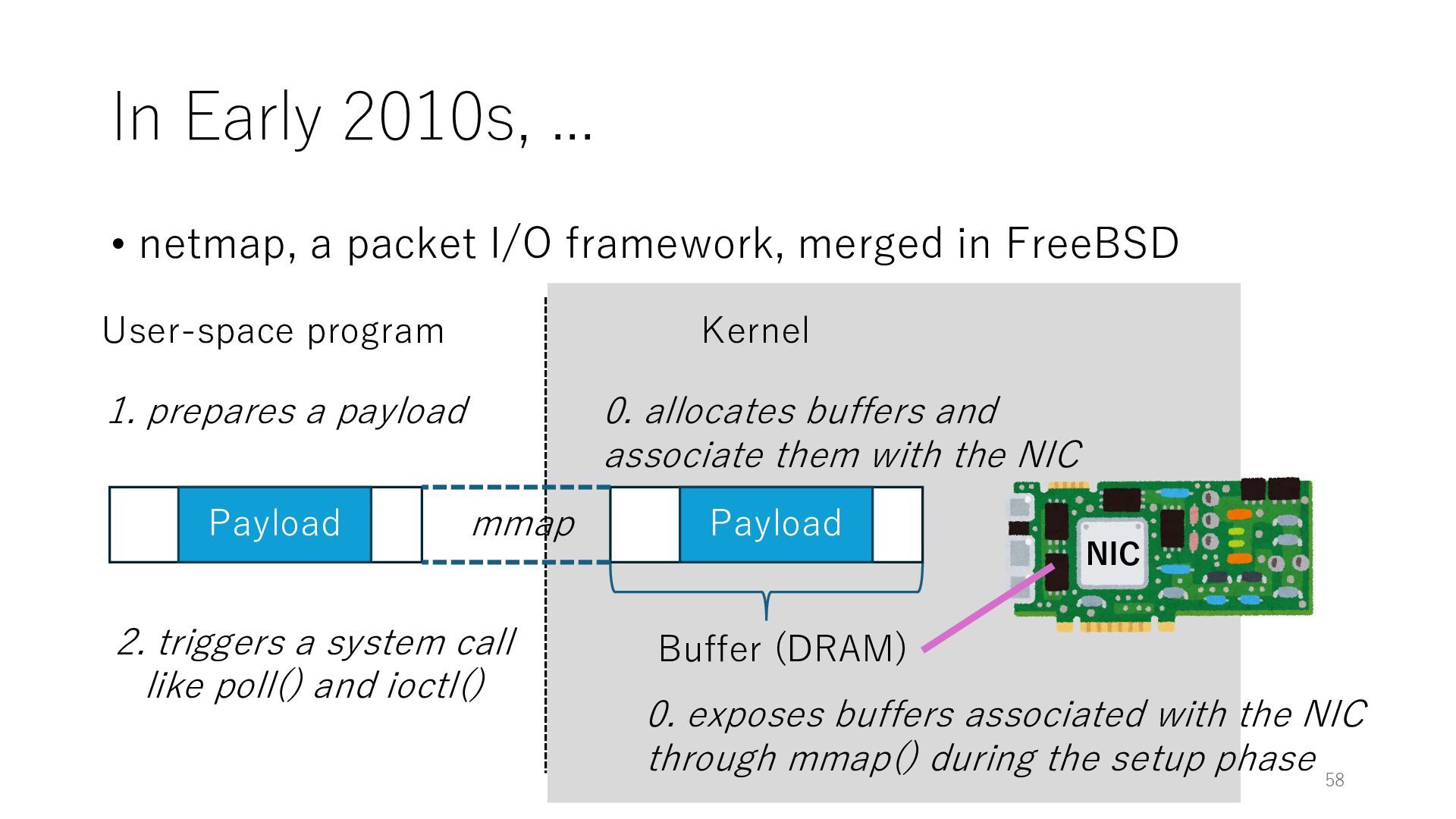
merged in FreeBSD NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload 2. triggers a system call like poll() and ioctl() Payload 57
merged in FreeBSD NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload 2. triggers a system call like poll() and ioctl() Payload 58
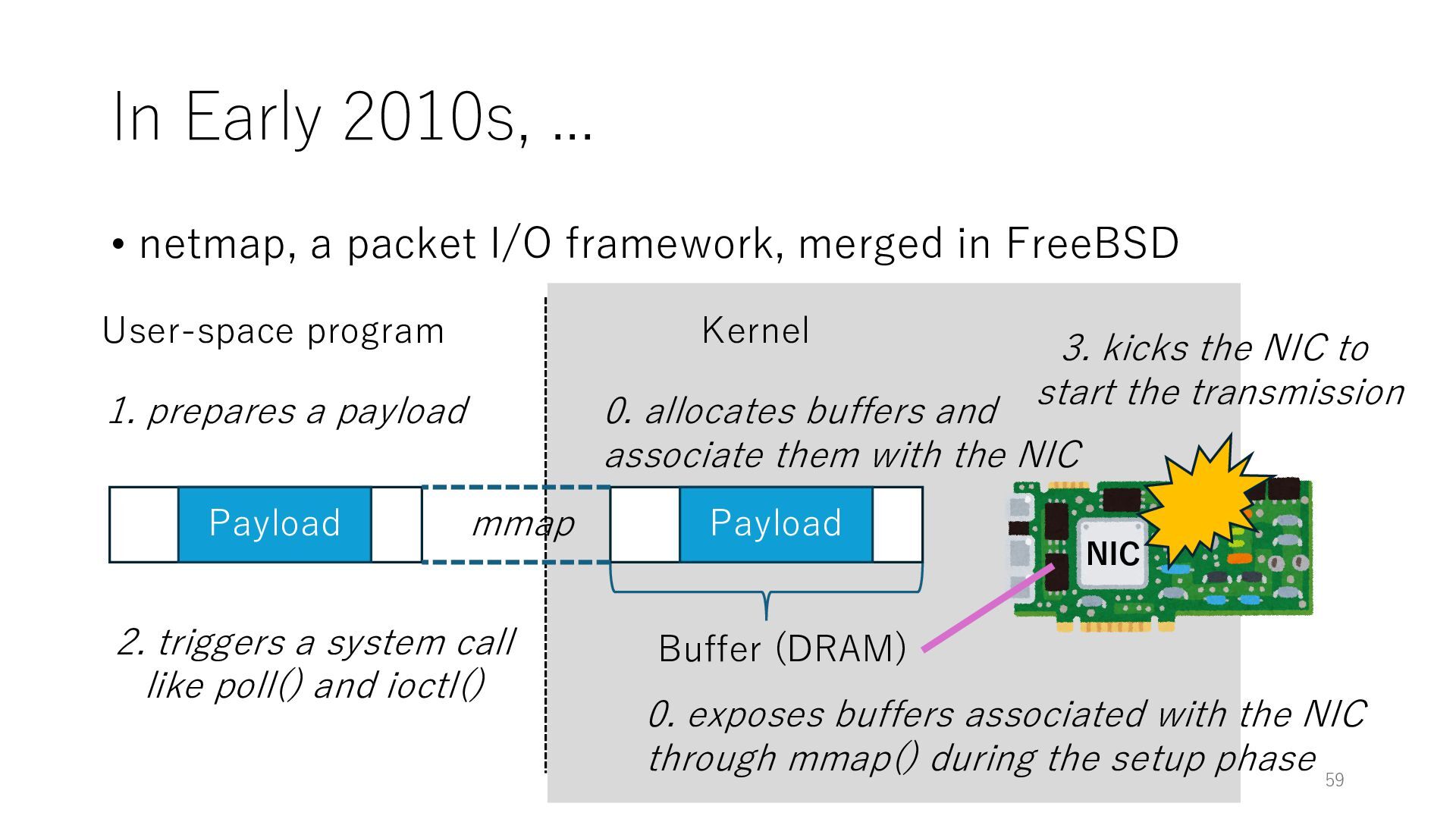
merged in FreeBSD NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload 2. triggers a system call like poll() and ioctl() 3. kicks the NIC to start the transmission Payload 59
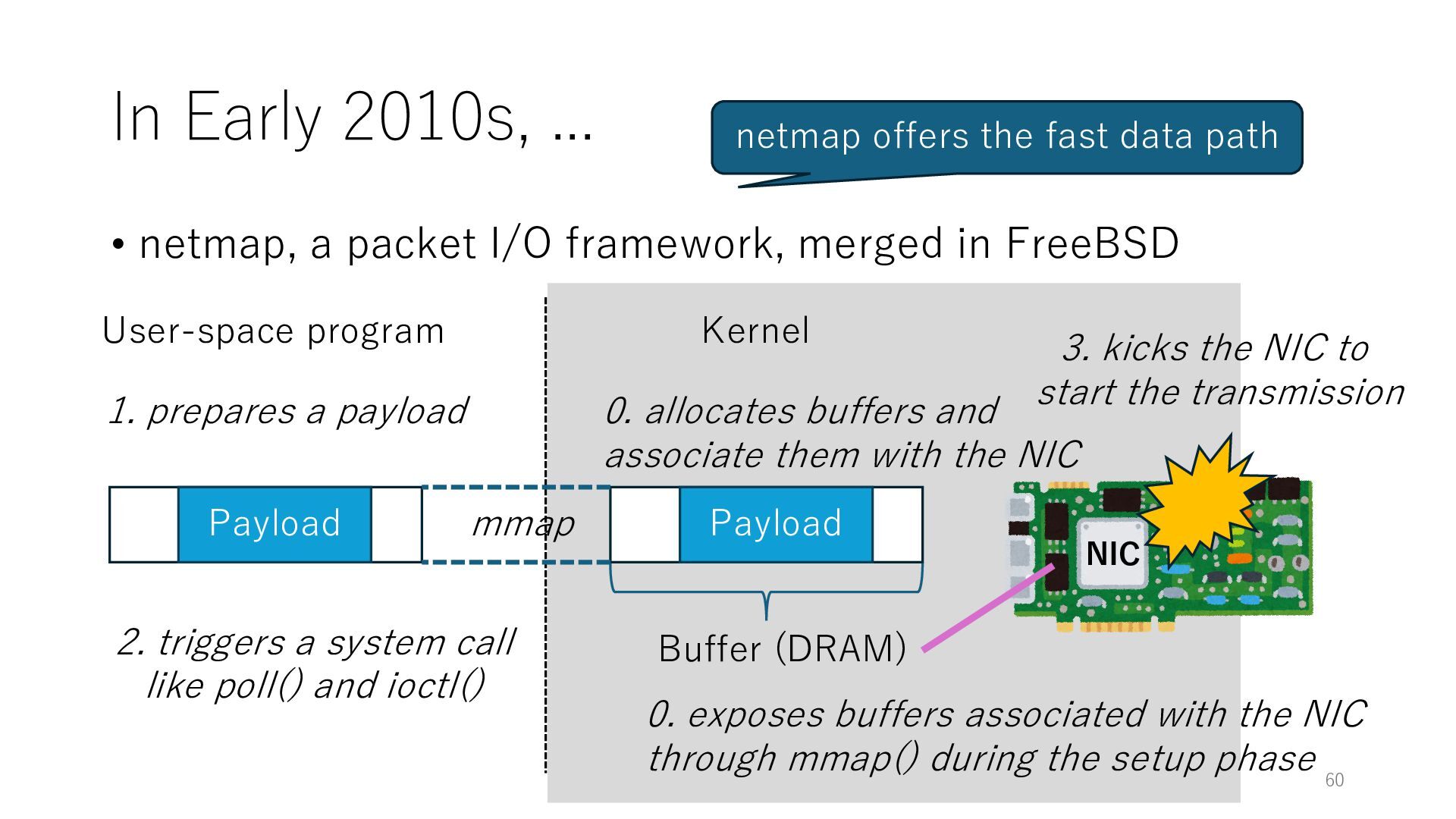
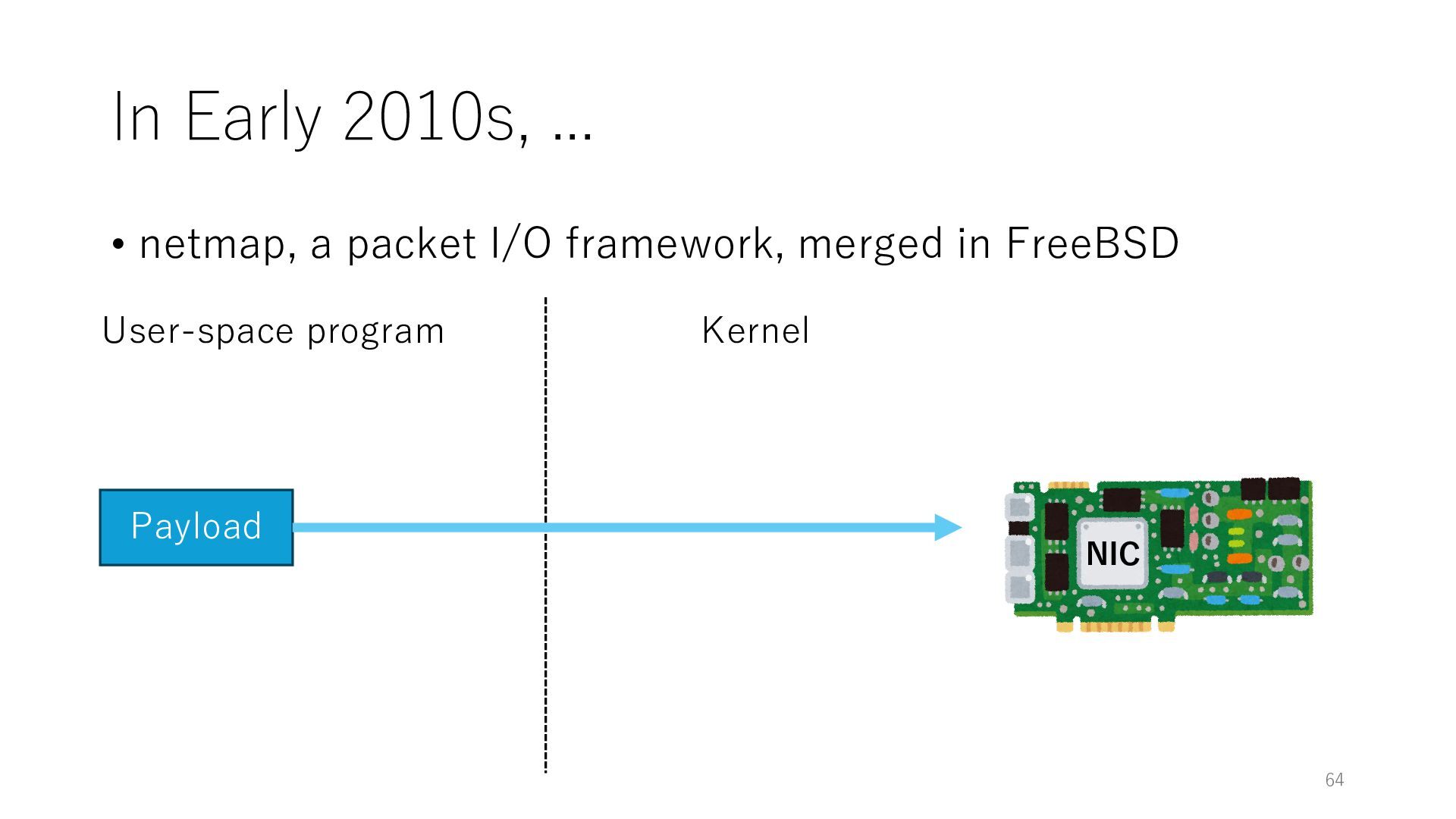
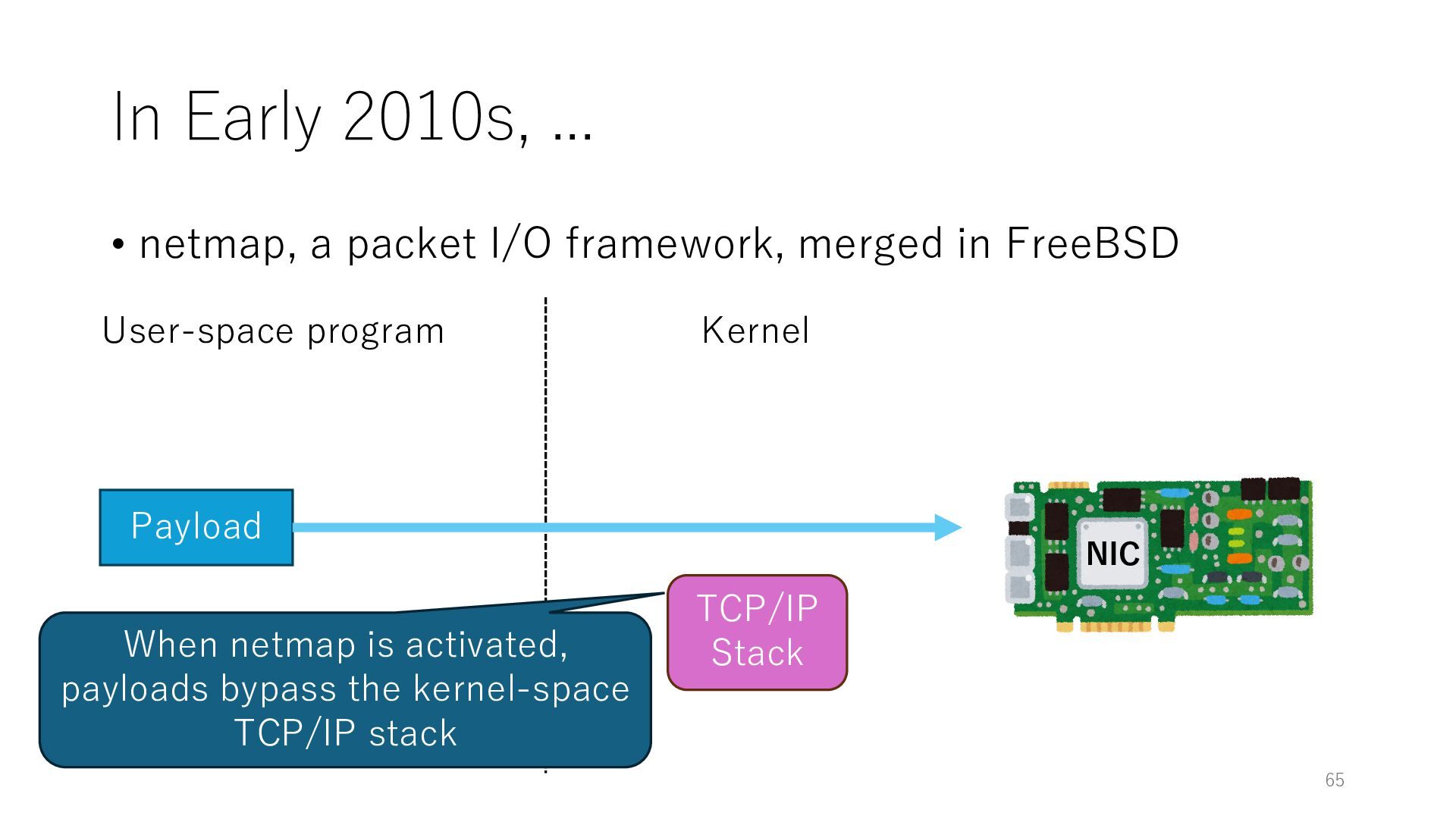
merged in FreeBSD NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload 2. triggers a system call like poll() and ioctl() 3. kicks the NIC to start the transmission Payload 60 netmap offers the fast data path
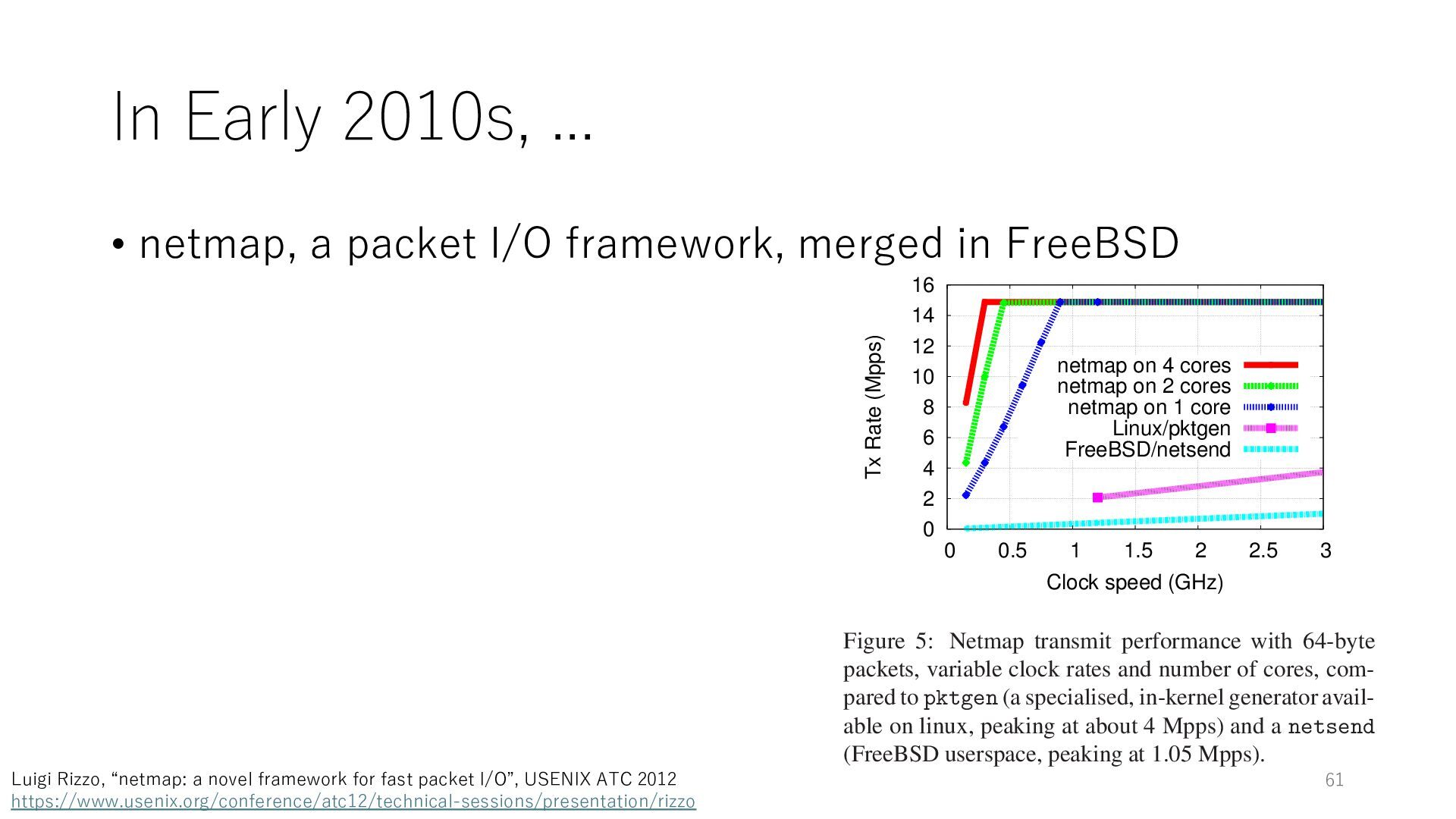
merged in FreeBSD application costs almost negligible: a packet generator which streams pre-generated packets, and a packet re- ceiver which just counts incoming packets. 5.2 Test equipment We have run most of our experiments on systems equipped with an i7-870 4-core CPU at 2.93 GHz (3.2 GHz with turbo-boost), memory running at 1.33 GHz, and a dual port 10 Gbit/s card based on the Intel 82599 NIC. The numbers reported in this paper refer to the netmap version in FreeBSD HEAD/amd64 as of April 2012. Experiments have been run using di- rectly connected cards on two similar systems. Results are highly repeatable (within 2% or less) so we do not report confidence intervals in the tables and graphs. netmap is extremely efficient so it saturates a 10 Gbit/s interface even at the maximum packet rate, and we need to run the system at reduced clock speeds to determine 0 2 4 6 8 10 12 14 16 0 0.5 1 1.5 2 2.5 3 Tx Rate (Mpps) Clock speed (GHz) netmap on 4 cores netmap on 2 cores netmap on 1 core Linux/pktgen FreeBSD/netsend Figure 5: Netmap transmit performance with 64-byte packets, variable clock rates and number of cores, com- pared to pktgen (a specialised, in-kernel generator avail- able on linux, peaking at about 4 Mpps) and a netsend (FreeBSD userspace, peaking at 1.05 Mpps). Luigi Rizzo, “netmap: a novel framework for fast packet I/O”, USENIX ATC 2012 https://www.usenix.org/conference/atc12/technical-sessions/presentation/rizzo 61
merged in FreeBSD • The speed of packet transmission over a raw socket is 1.05 Mpps • Mpps: million packets per second application costs almost negligible: a packet generator which streams pre-generated packets, and a packet re- ceiver which just counts incoming packets. 5.2 Test equipment We have run most of our experiments on systems equipped with an i7-870 4-core CPU at 2.93 GHz (3.2 GHz with turbo-boost), memory running at 1.33 GHz, and a dual port 10 Gbit/s card based on the Intel 82599 NIC. The numbers reported in this paper refer to the netmap version in FreeBSD HEAD/amd64 as of April 2012. Experiments have been run using di- rectly connected cards on two similar systems. Results are highly repeatable (within 2% or less) so we do not report confidence intervals in the tables and graphs. netmap is extremely efficient so it saturates a 10 Gbit/s interface even at the maximum packet rate, and we need to run the system at reduced clock speeds to determine 0 2 4 6 8 10 12 14 16 0 0.5 1 1.5 2 2.5 3 Tx Rate (Mpps) Clock speed (GHz) netmap on 4 cores netmap on 2 cores netmap on 1 core Linux/pktgen FreeBSD/netsend Figure 5: Netmap transmit performance with 64-byte packets, variable clock rates and number of cores, com- pared to pktgen (a specialised, in-kernel generator avail- able on linux, peaking at about 4 Mpps) and a netsend (FreeBSD userspace, peaking at 1.05 Mpps). 62 Luigi Rizzo, “netmap: a novel framework for fast packet I/O”, USENIX ATC 2012 https://www.usenix.org/conference/atc12/technical-sessions/presentation/rizzo
merged in FreeBSD • The speed of packet transmission over a raw socket is 1.05 Mpps • Mpps: million packets per second • netmap achieves the line rate (14.88 Mpps) with one CPU core application costs almost negligible: a packet generator which streams pre-generated packets, and a packet re- ceiver which just counts incoming packets. 5.2 Test equipment We have run most of our experiments on systems equipped with an i7-870 4-core CPU at 2.93 GHz (3.2 GHz with turbo-boost), memory running at 1.33 GHz, and a dual port 10 Gbit/s card based on the Intel 82599 NIC. The numbers reported in this paper refer to the netmap version in FreeBSD HEAD/amd64 as of April 2012. Experiments have been run using di- rectly connected cards on two similar systems. Results are highly repeatable (within 2% or less) so we do not report confidence intervals in the tables and graphs. netmap is extremely efficient so it saturates a 10 Gbit/s interface even at the maximum packet rate, and we need to run the system at reduced clock speeds to determine 0 2 4 6 8 10 12 14 16 0 0.5 1 1.5 2 2.5 3 Tx Rate (Mpps) Clock speed (GHz) netmap on 4 cores netmap on 2 cores netmap on 1 core Linux/pktgen FreeBSD/netsend Figure 5: Netmap transmit performance with 64-byte packets, variable clock rates and number of cores, com- pared to pktgen (a specialised, in-kernel generator avail- able on linux, peaking at about 4 Mpps) and a netsend (FreeBSD userspace, peaking at 1.05 Mpps). 63 Luigi Rizzo, “netmap: a novel framework for fast packet I/O”, USENIX ATC 2012 https://www.usenix.org/conference/atc12/technical-sessions/presentation/rizzo
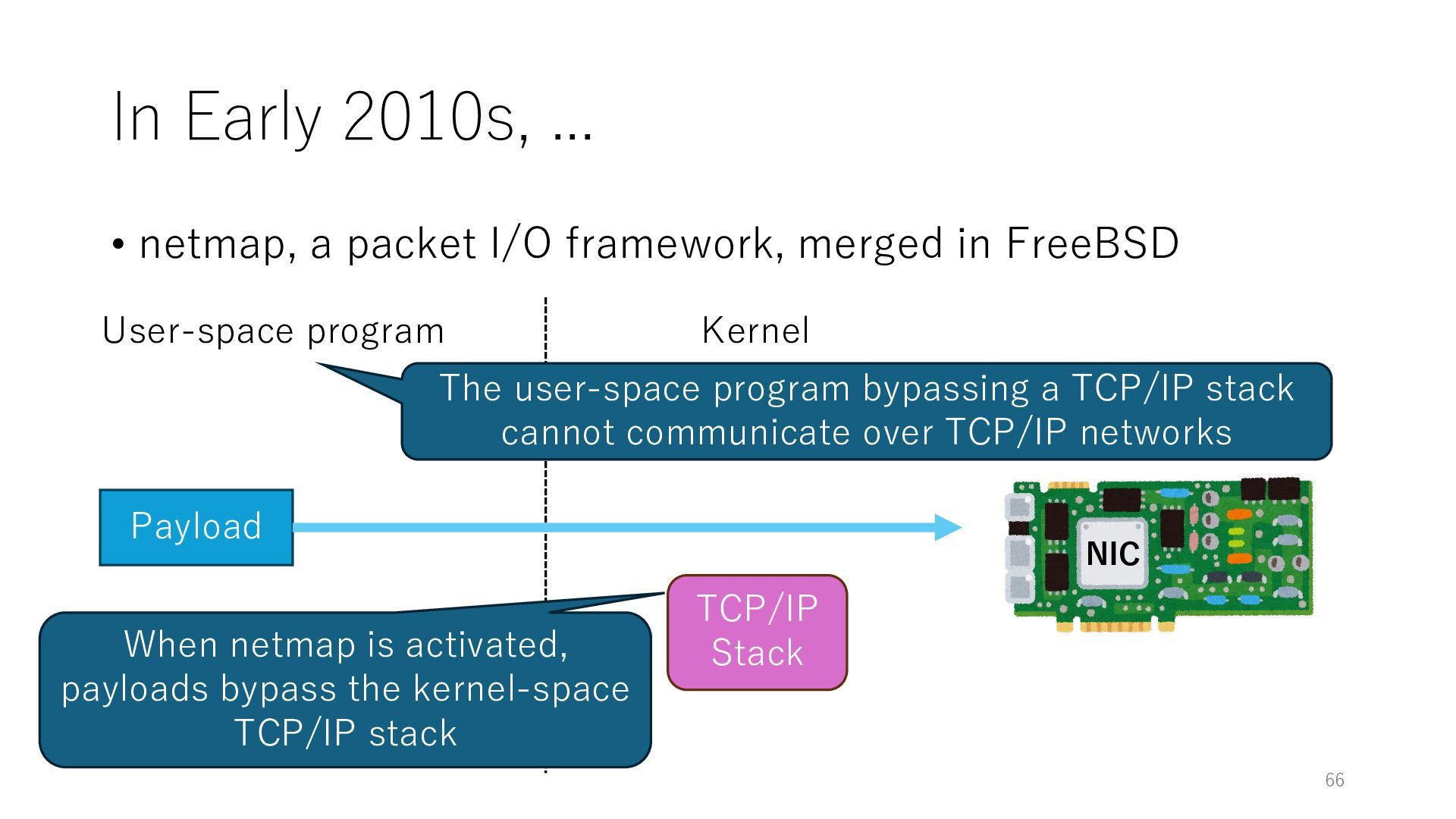
merged in FreeBSD NIC User-space program Kernel 66 Payload TCP/IP Stack When netmap is activated, payloads bypass the kernel-space TCP/IP stack The user-space program bypassing a TCP/IP stack cannot communicate over TCP/IP networks
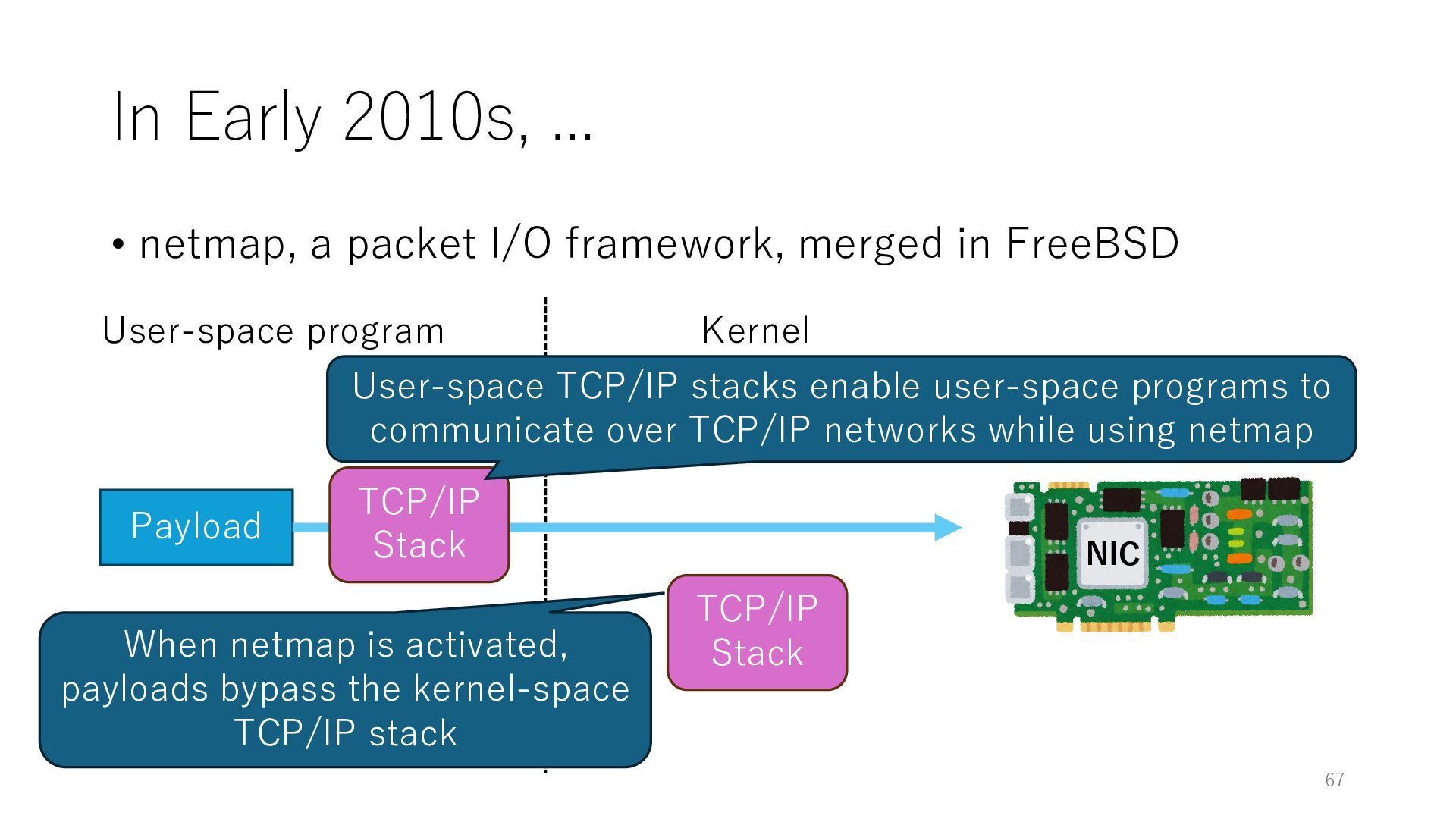
merged in FreeBSD NIC User-space program Kernel 67 Payload TCP/IP Stack When netmap is activated, payloads bypass the kernel-space TCP/IP stack TCP/IP Stack User-space TCP/IP stacks enable user-space programs to communicate over TCP/IP networks while using netmap
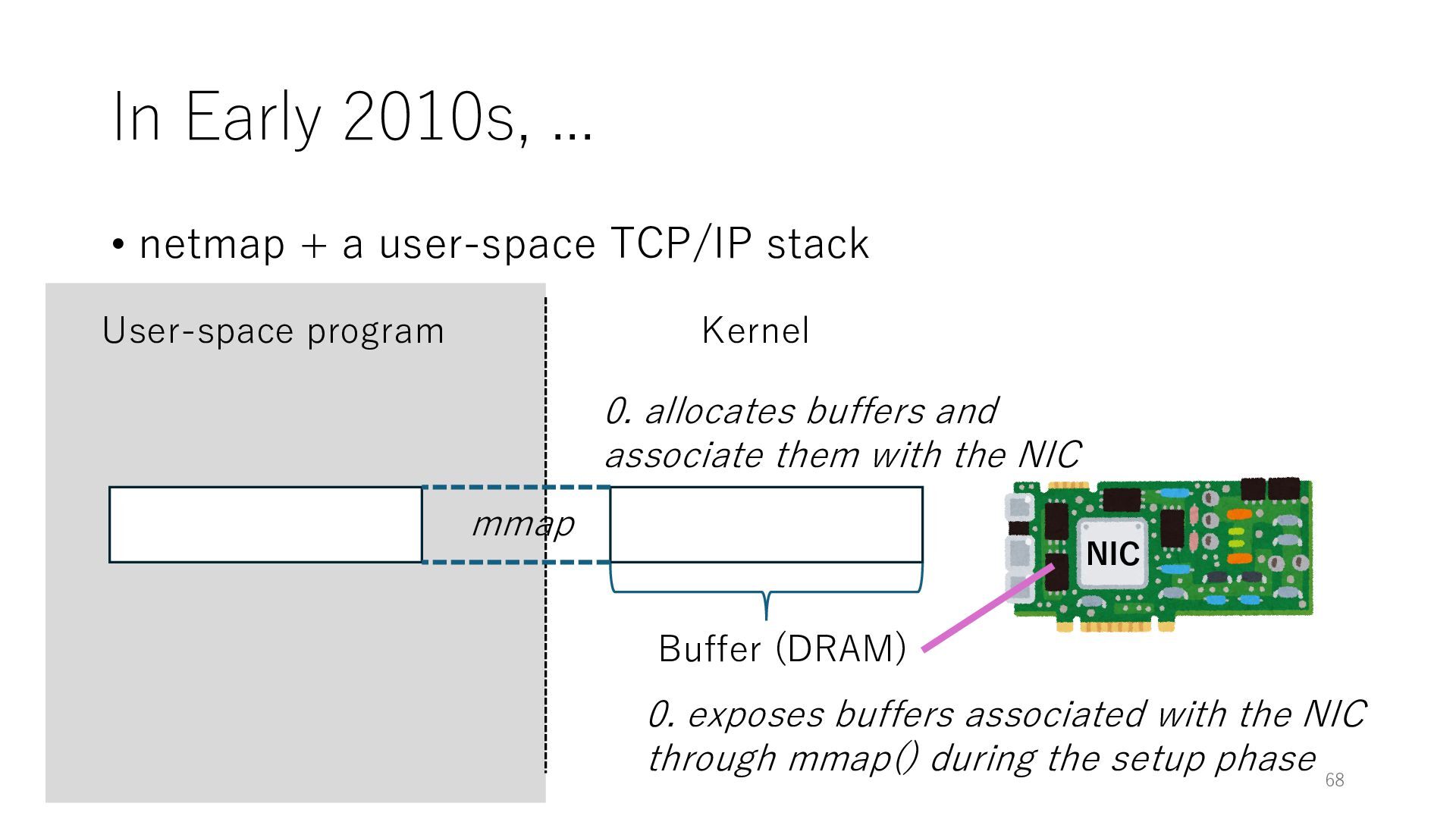
stack NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap 68
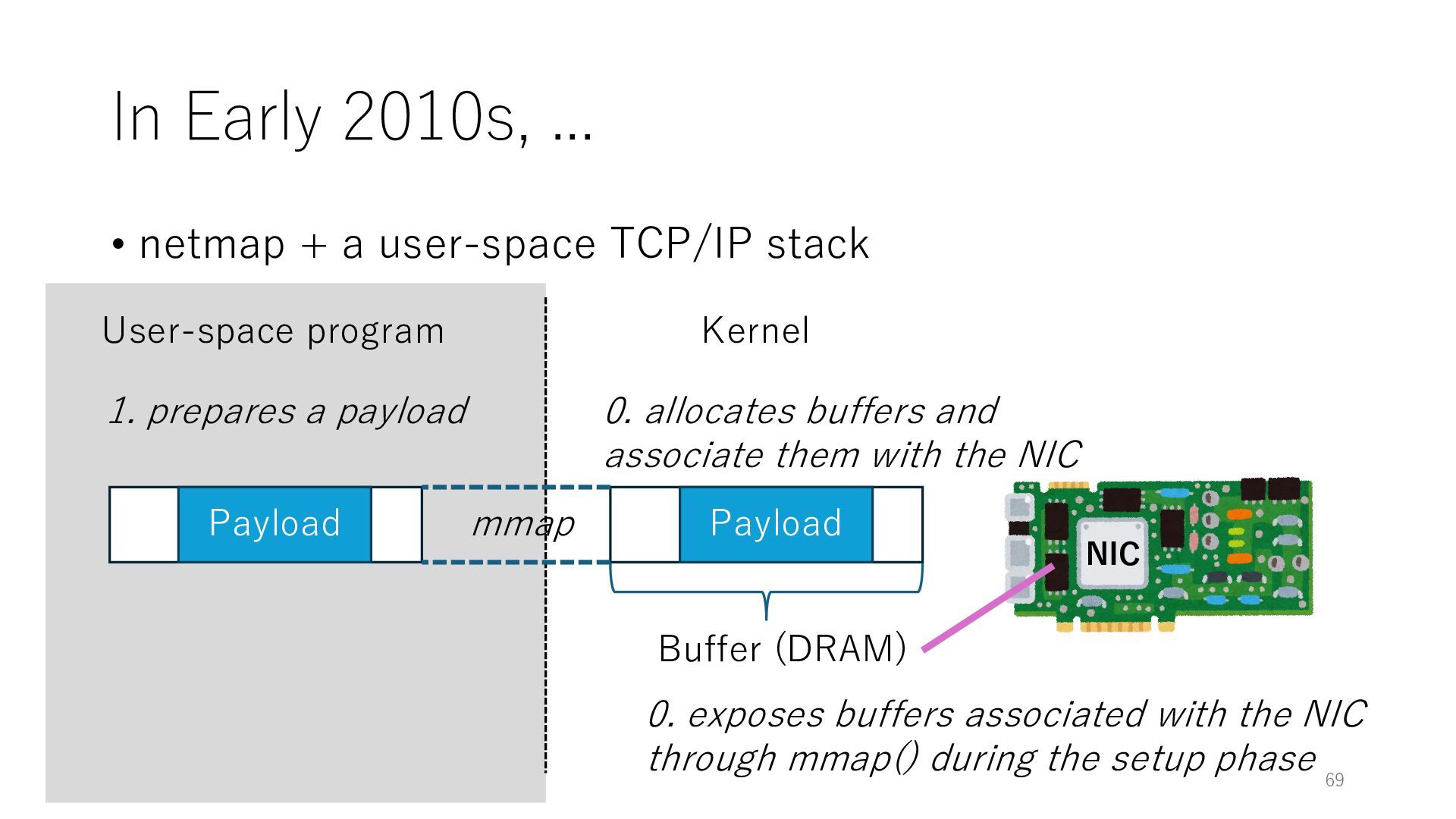
stack NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload Payload 69
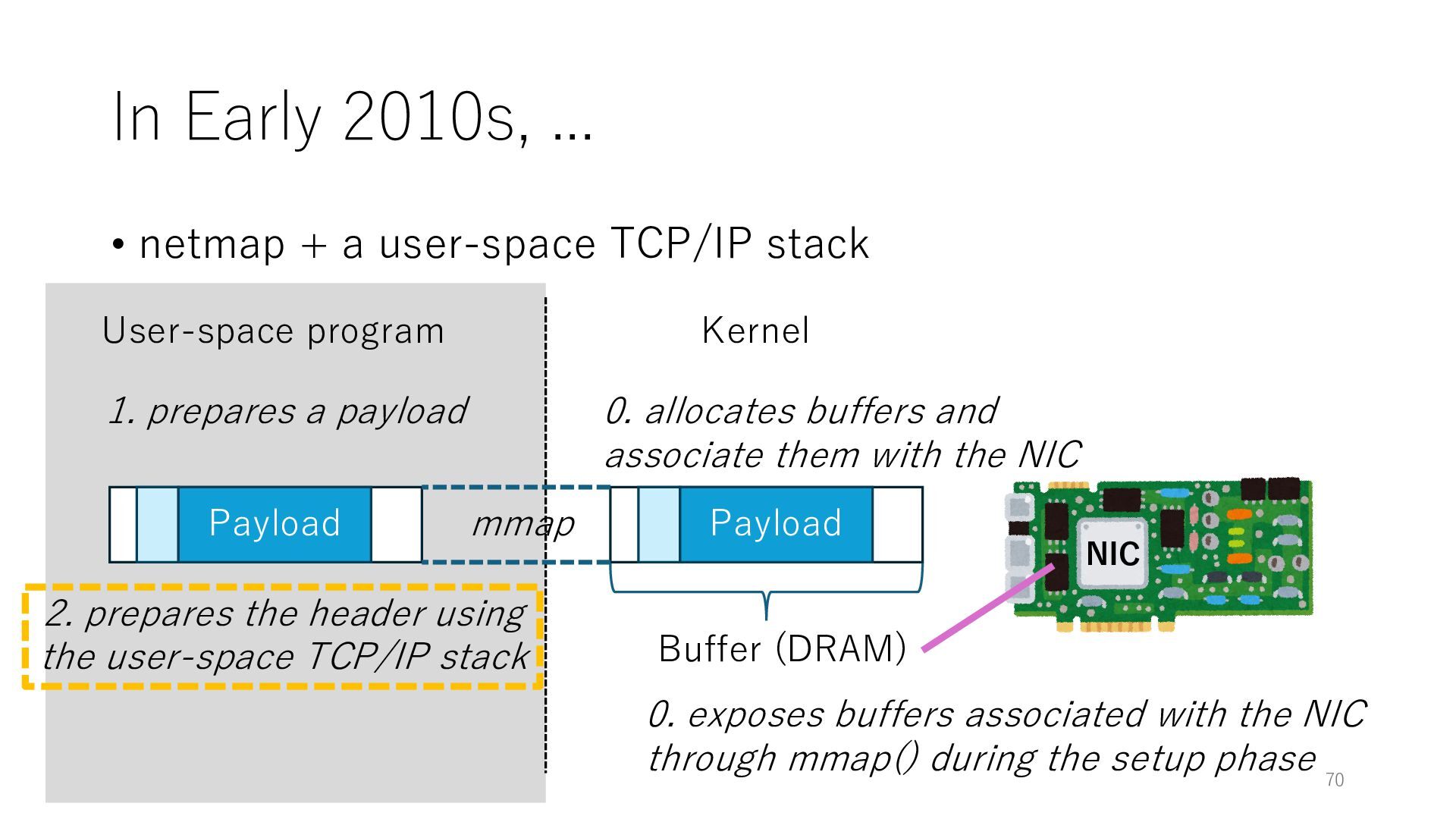
stack NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload Payload 2. prepares the header using the user-space TCP/IP stack 70
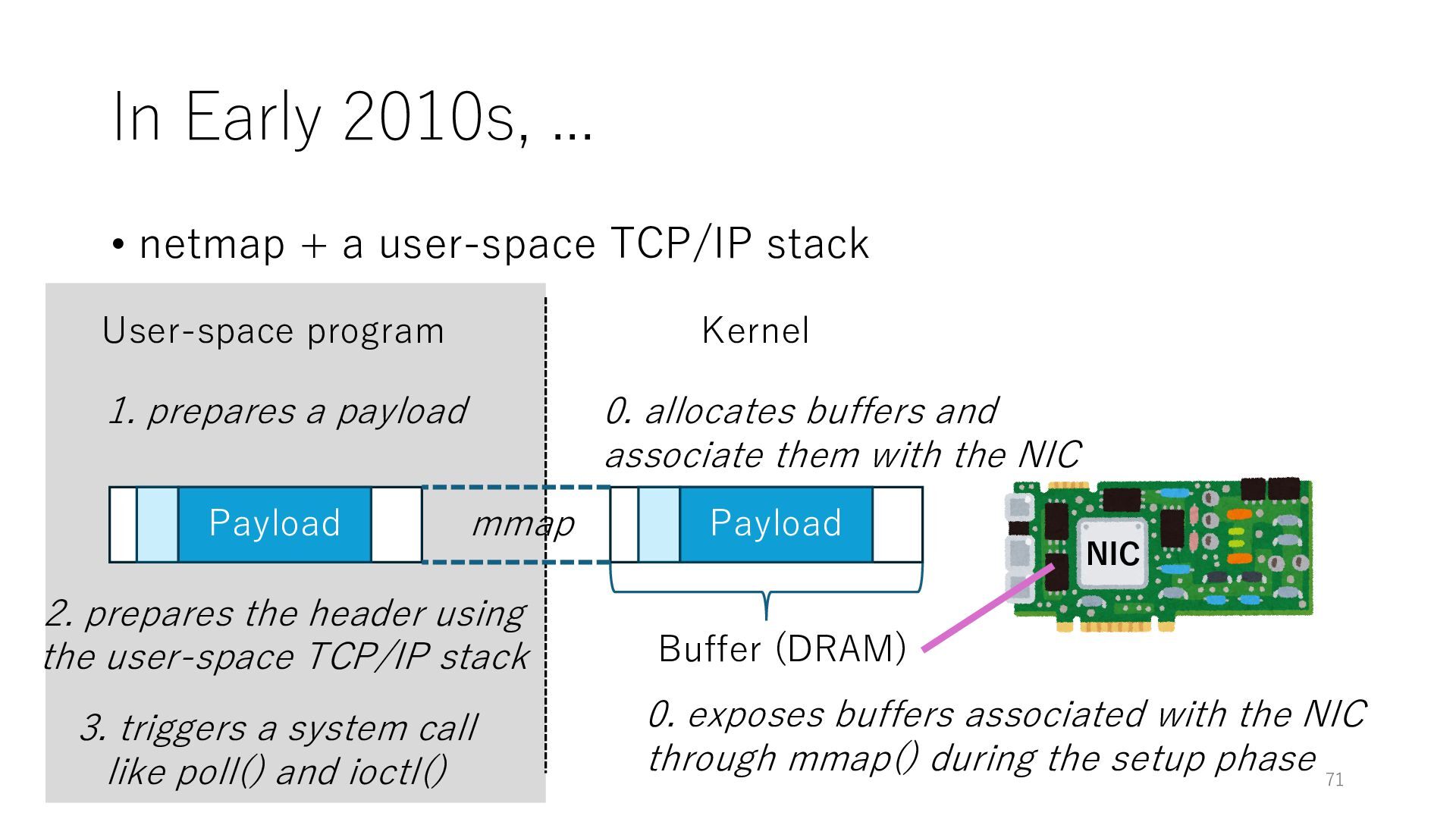
stack NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload 2. prepares the header using the user-space TCP/IP stack Payload 3. triggers a system call like poll() and ioctl() 71
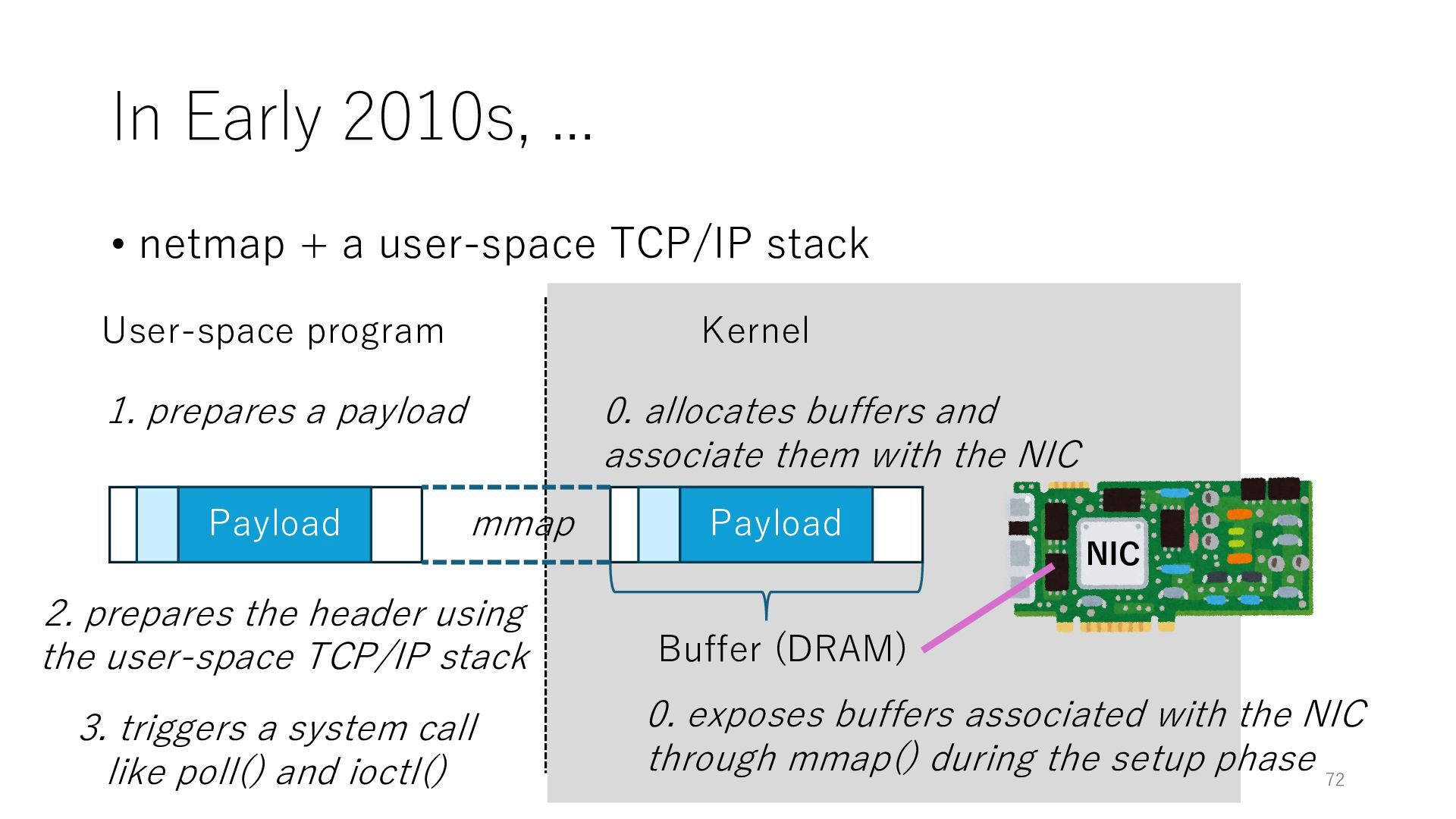
stack NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload 2. prepares the header using the user-space TCP/IP stack Payload 3. triggers a system call like poll() and ioctl() 72
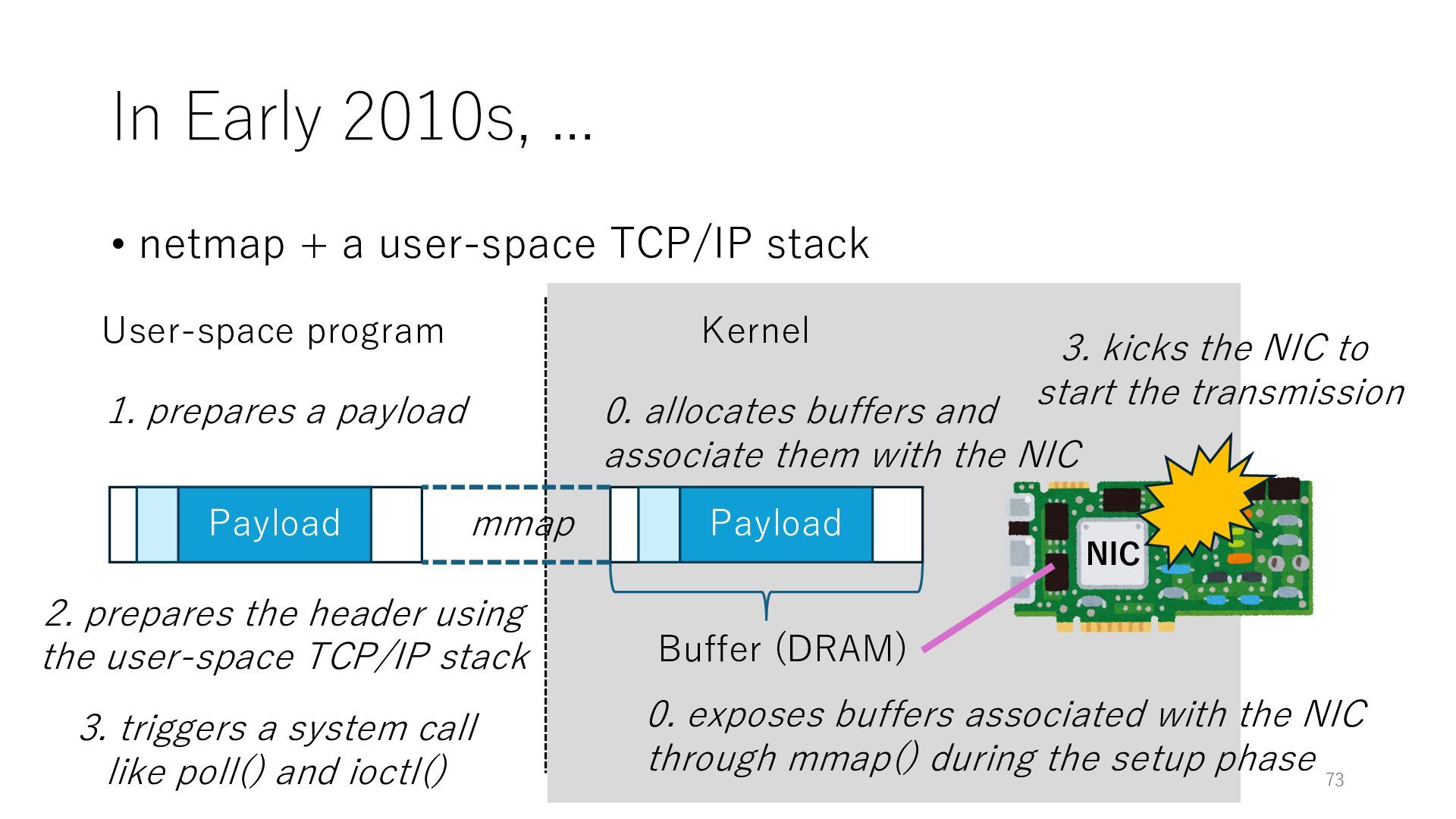
stack NIC User-space program Kernel 0. exposes buffers associated with the NIC through mmap() during the setup phase Buffer (DRAM) 0. allocates buffers and associate them with the NIC mmap Payload 1. prepares a payload 2. prepares the header using the user-space TCP/IP stack Payload 3. triggers a system call like poll() and ioctl() 3. kicks the NIC to start the transmission 73
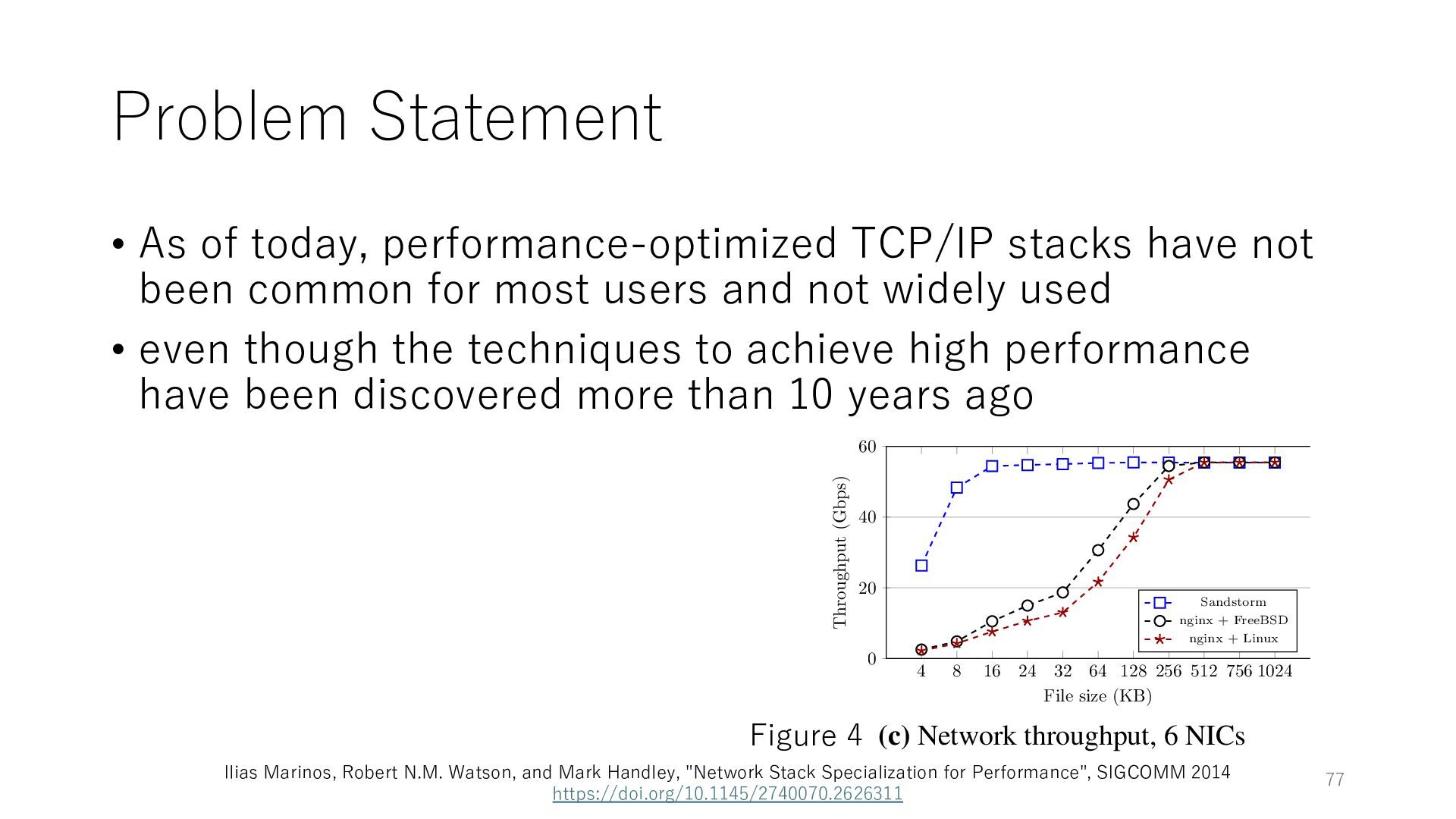
not been common for most users and not widely used • even though the techniques to achieve high performance have been discovered more than 10 years ago 76
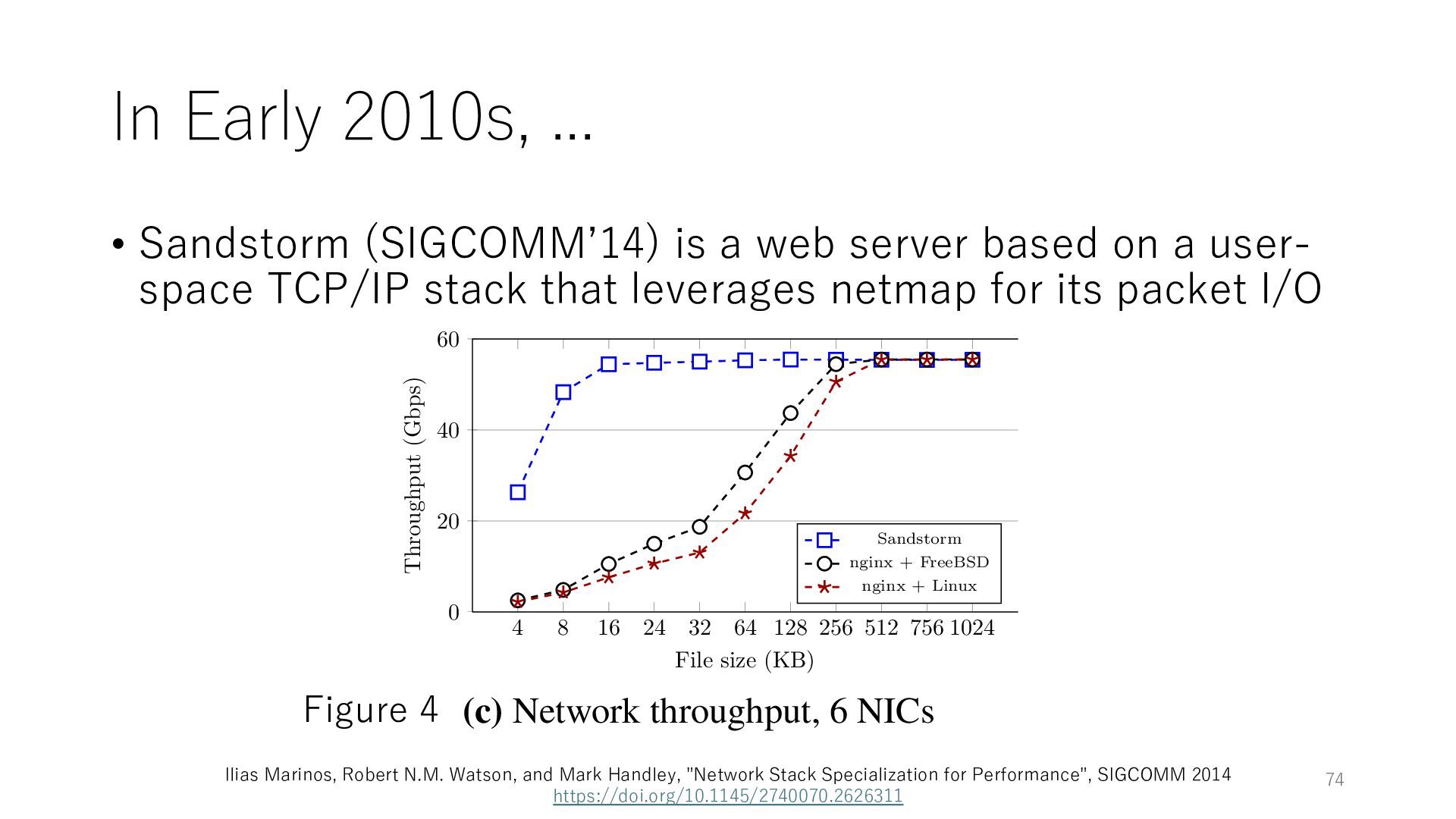
not been common for most users and not widely used • even though the techniques to achieve high performance have been discovered more than 10 years ago 32 64 128 256 512 756 1024 le size (KB) Sandstorm nginx + FreeBSD nginx + Linux roughput, 1 NIC 4 8 16 24 32 64 128 256 512 756 1024 0 20 40 60 File size (KB) Throughput (Gbps) Sandstorm nginx + FreeBSD nginx + Linux (b) Network throughput, 4 NICs 4 8 16 24 32 64 128 256 512 756 1024 0 20 40 60 File size (KB) Throughput (Gbps) Sandstorm nginx + FreeBSD nginx + Linux (c) Network throughput, 6 NICs Sandstorm 100 100 Figure 4 Ilias Marinos, Robert N.M. Watson, and Mark Handley, "Network Stack Specialization for Performance", SIGCOMM 2014 https://doi.org/10.1145/2740070.2626311 77
not been common for most users and not widely used • even though the techniques to achieve high performance have been discovered more than 10 years ago 32 64 128 256 512 756 1024 le size (KB) Sandstorm nginx + FreeBSD nginx + Linux roughput, 1 NIC 4 8 16 24 32 64 128 256 512 756 1024 0 20 40 60 File size (KB) Throughput (Gbps) Sandstorm nginx + FreeBSD nginx + Linux (b) Network throughput, 4 NICs 4 8 16 24 32 64 128 256 512 756 1024 0 20 40 60 File size (KB) Throughput (Gbps) Sandstorm nginx + FreeBSD nginx + Linux (c) Network throughput, 6 NICs Sandstorm 100 100 Figure 4 Ilias Marinos, Robert N.M. Watson, and Mark Handley, "Network Stack Specialization for Performance", SIGCOMM 2014 https://doi.org/10.1145/2740070.2626311 This gap persists for most users until an adequate solution is identified 78
not been common for most users and not widely used • even though the techniques to achieve high performance have been discovered more than 10 years ago 32 64 128 256 512 756 1024 le size (KB) Sandstorm nginx + FreeBSD nginx + Linux roughput, 1 NIC 4 8 16 24 32 64 128 256 512 756 1024 0 20 40 60 File size (KB) Throughput (Gbps) Sandstorm nginx + FreeBSD nginx + Linux (b) Network throughput, 4 NICs 4 8 16 24 32 64 128 256 512 756 1024 0 20 40 60 File size (KB) Throughput (Gbps) Sandstorm nginx + FreeBSD nginx + Linux (c) Network throughput, 6 NICs Sandstorm 100 100 Figure 4 Ilias Marinos, Robert N.M. Watson, and Mark Handley, "Network Stack Specialization for Performance", SIGCOMM 2014 https://doi.org/10.1145/2740070.2626311 This gap persists for most users until an adequate solution is identified I am exploring this 79
not commonly used despite their performance advantages? • There is a negative cycle • Many of the performance-optimized TCP/IP stacks are research prototypes, and their implementations are immature 82
not commonly used despite their performance advantages? • There is a negative cycle • Many of the performance-optimized TCP/IP stacks are research prototypes, and their implementations are immature • On one hand, users do not like to use immature TCP/IP stacks 83
not commonly used despite their performance advantages? • There is a negative cycle • Many of the performance-optimized TCP/IP stacks are research prototypes, and their implementations are immature • On one hand, users do not like to use immature TCP/IP stacks • On the other hand, usersʼ feedback and bug reports are essential for the maturity of the implementations 84
not commonly used despite their performance advantages? • There is a negative cycle • Many of the performance-optimized TCP/IP stacks are research prototypes, and their implementations are immature • On one hand, users do not like to use immature TCP/IP stacks • On the other hand, usersʼ feedback and bug reports are essential for the maturity of the implementations • So, immature TCP/IP stack implementations can never get mature 85
not commonly used despite their performance advantages? • There is a negative cycle • Many of the performance-optimized TCP/IP stacks are research prototypes, and their implementations are immature • On one hand, users do not like to use immature TCP/IP stacks • On the other hand, usersʼ feedback and bug reports are essential for the maturity of the implementations • So, immature TCP/IP stack implementations can never get mature 86
not commonly used despite their performance advantages? • There is a negative cycle • Many of the performance-optimized TCP/IP stacks are research prototypes, and their implementations are immature • On one hand, users do not like to use immature TCP/IP stacks • On the other hand, usersʼ feedback and bug reports are essential for the maturity of the implementations • So, immature TCP/IP stack implementations can never get mature 87 How can we break this negative cycle?
not commonly used despite their performance advantages? • There is a negative cycle • Many of the performance-optimized TCP/IP stacks are research prototypes, and their implementations are immature • On one hand, users do not like to use immature TCP/IP stacks • On the other hand, usersʼ feedback and bug reports are essential for the maturity of the implementations • So, immature TCP/IP stack implementations can never get mature 88 How can we break this negative cycle? My Approach How about lowering the bar for users to try out performance-optimize TCP/IP stacks to make it easier for them to gather user feedback?
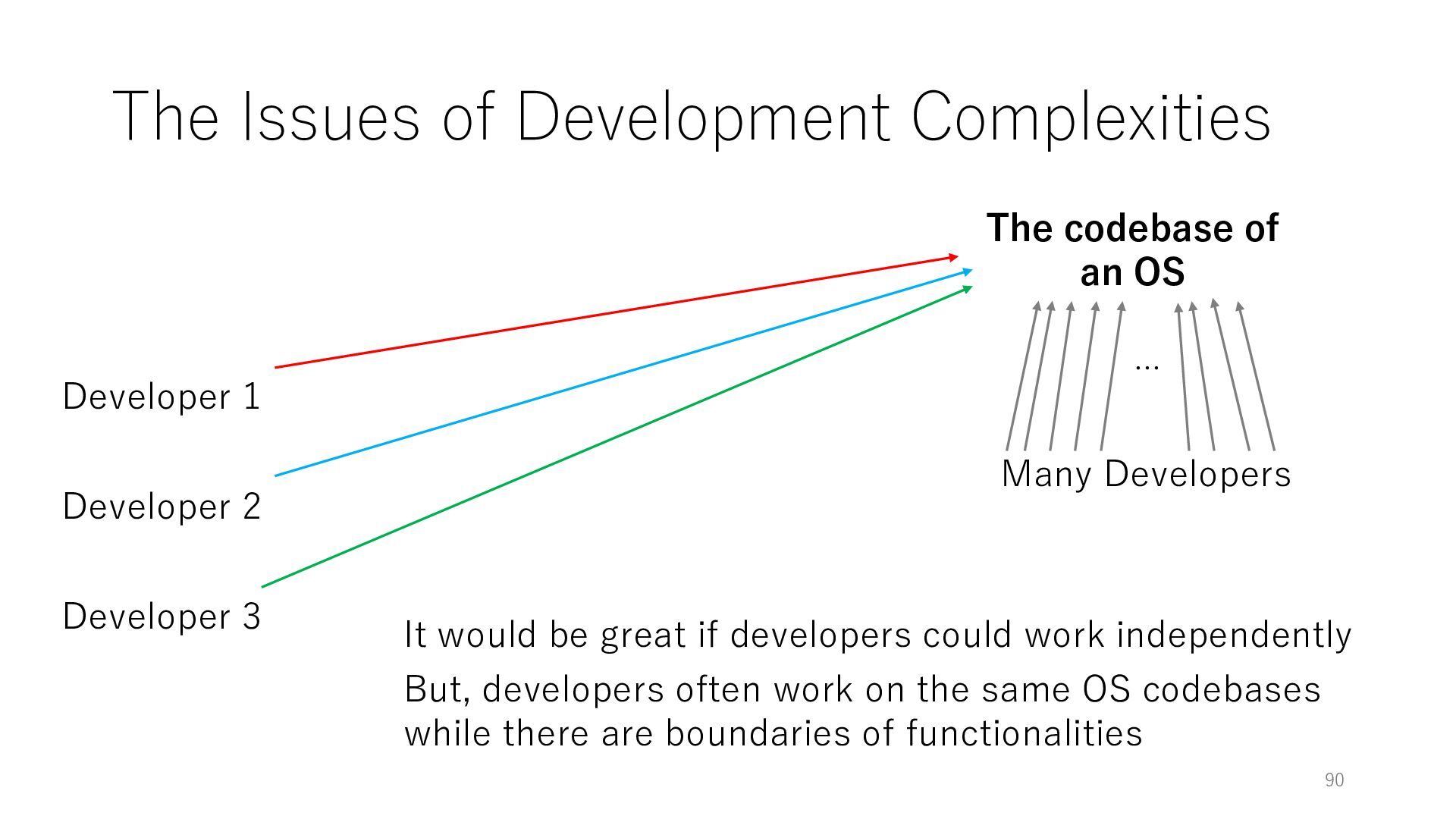
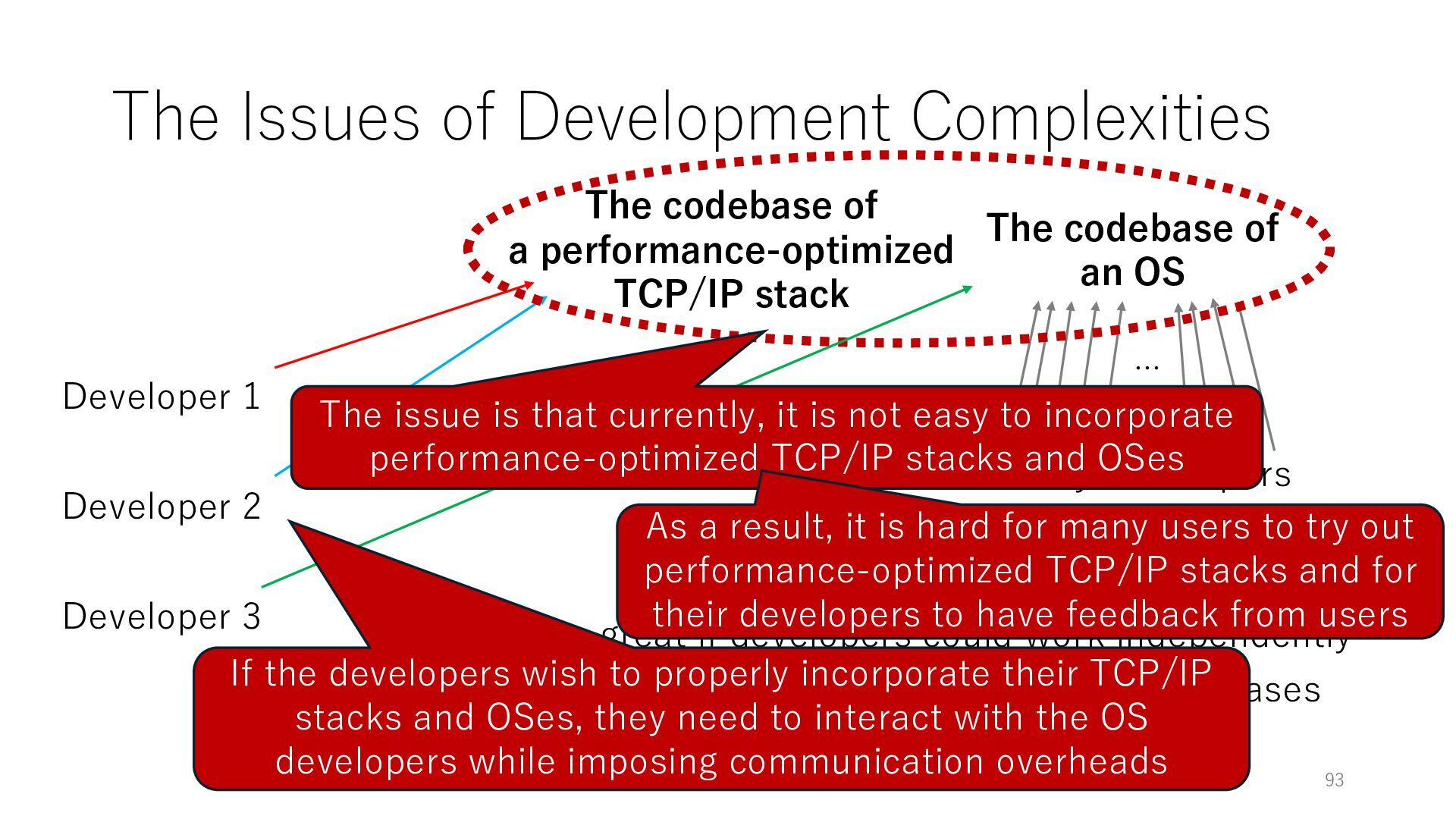
Developer 3 The codebase of an OS It would be great if developers could work independently Many Developers … But, developers often work on the same OS codebases while there are boundaries of functionalities
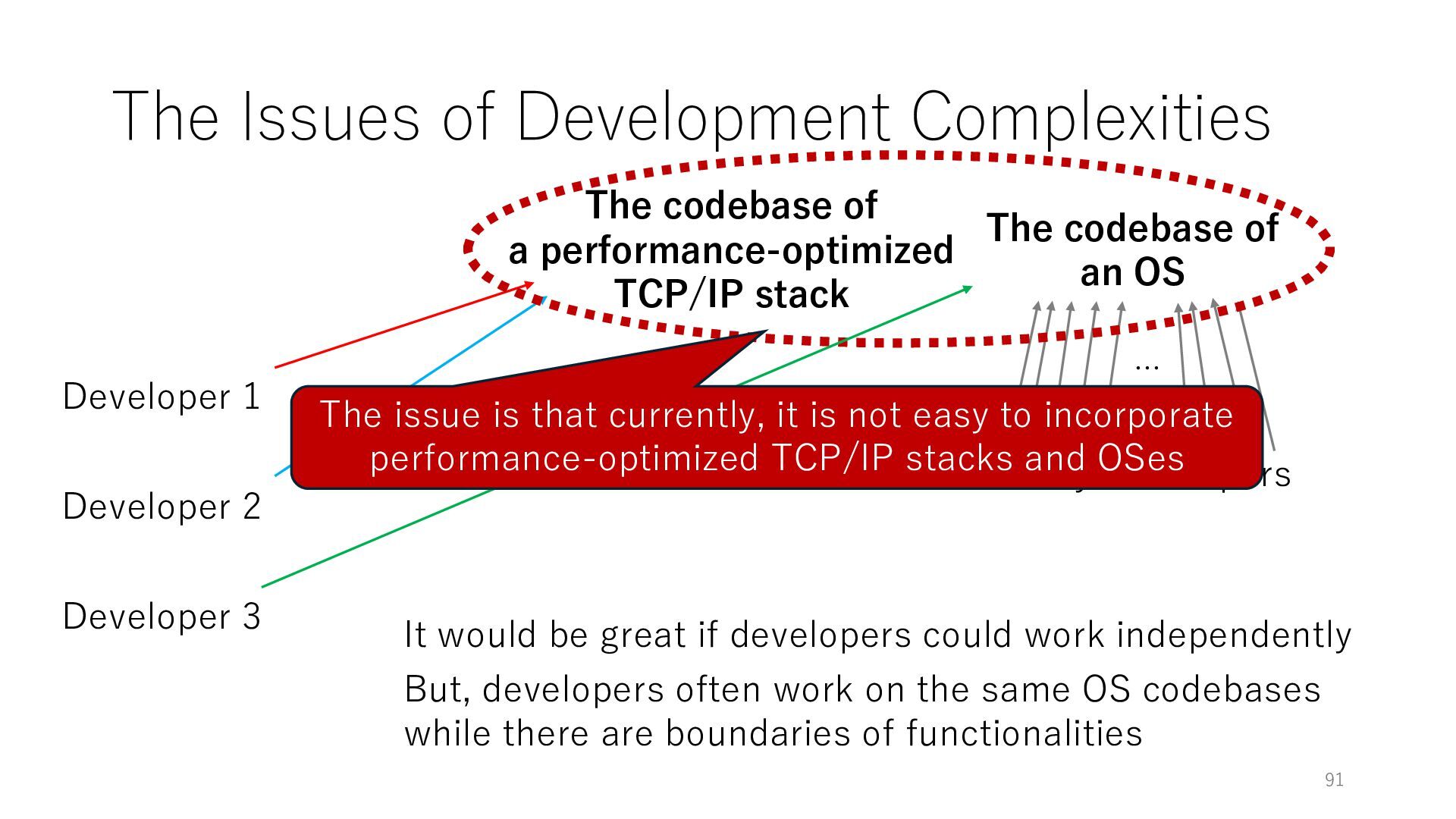
Developer 3 The codebase of an OS It would be great if developers could work independently Many Developers … But, developers often work on the same OS codebases while there are boundaries of functionalities The codebase of a performance-optimized TCP/IP stack The issue is that currently, it is not easy to incorporate performance-optimized TCP/IP stacks and OSes
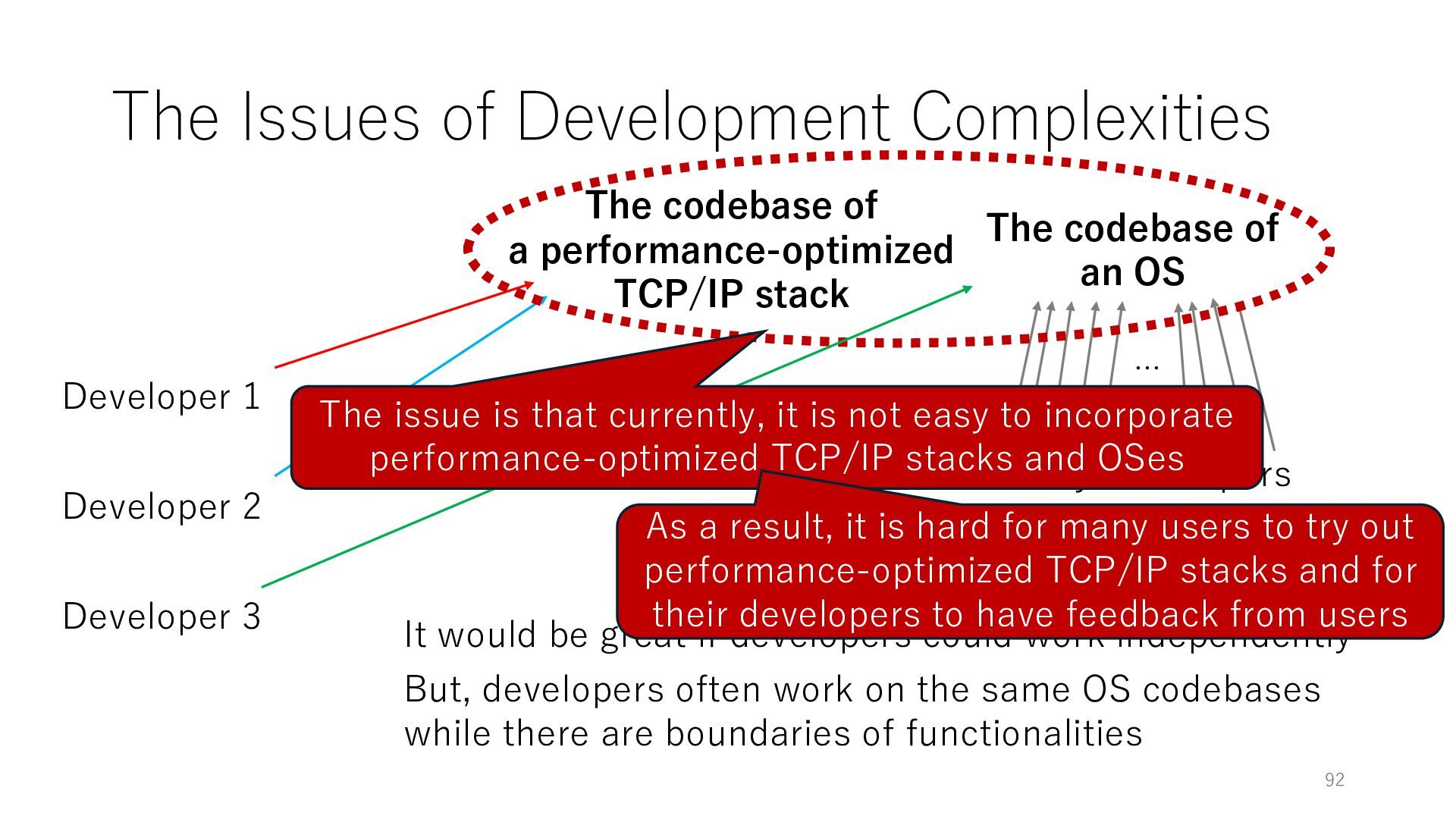
Developer 3 The codebase of an OS It would be great if developers could work independently Many Developers … But, developers often work on the same OS codebases while there are boundaries of functionalities The codebase of a performance-optimized TCP/IP stack The issue is that currently, it is not easy to incorporate performance-optimized TCP/IP stacks and OSes As a result, it is hard for many users to try out performance-optimized TCP/IP stacks and for their developers to have feedback from users
Developer 3 The codebase of an OS It would be great if developers could work independently Many Developers … But, developers often work on the same OS codebases while there are boundaries of functionalities The codebase of a performance-optimized TCP/IP stack The issue is that currently, it is not easy to incorporate performance-optimized TCP/IP stacks and OSes If the developers wish to properly incorporate their TCP/IP stacks and OSes, they need to interact with the OS developers while imposing communication overheads As a result, it is hard for many users to try out performance-optimized TCP/IP stacks and for their developers to have feedback from users
I believe OS development based on the decentralized collaboration model is beneficial for developers and users • It reduces communication overheads between developers • It makes it easier for users to try out emerging projects and for those projects to gather user feedback è Eventually, users will have many mature advanced products • The challenging part is the methods to incorporate OS subsystems independently developed by different parties • I would like to discuss solutions to the challenges with the BSD community, a key driver of OS development 94
like a TCP/IP stack, should be aware of portability for the compatibility with different OSes • Transparent integration: an OS subsystem should allow for transparent integration into an existing OS 97 The codebase of OS A The codebase of a TCP/IP stack The codebase of OS B The codebase of OS C Portability + Transparent integration I think these two are important for decentralized collaboration
like a TCP/IP stack, should be aware of portability for the compatibility with different OSes • Transparent integration: an OS subsystem should allow for transparent integration into an existing OS 98 The codebase of OS A The codebase of a TCP/IP stack The codebase of OS B The codebase of OS C Portability + Transparent integration Can we achieve high performance and portability simultaneously? I think these two are important for decentralized collaboration
of both performance and portability • Paper at SIGCOMM CCR • https://doi.org/10.1145/3687230.3687233 • nominated to be presented at the Best of CCR session in SIGCOMM 2024 • Source code • https://github.com/yasukata/iip 99 https://yasukata.github.io/presentation/2024/08/sigcomm2024/sigcomm2024ccr_slides_yasukata.pdf
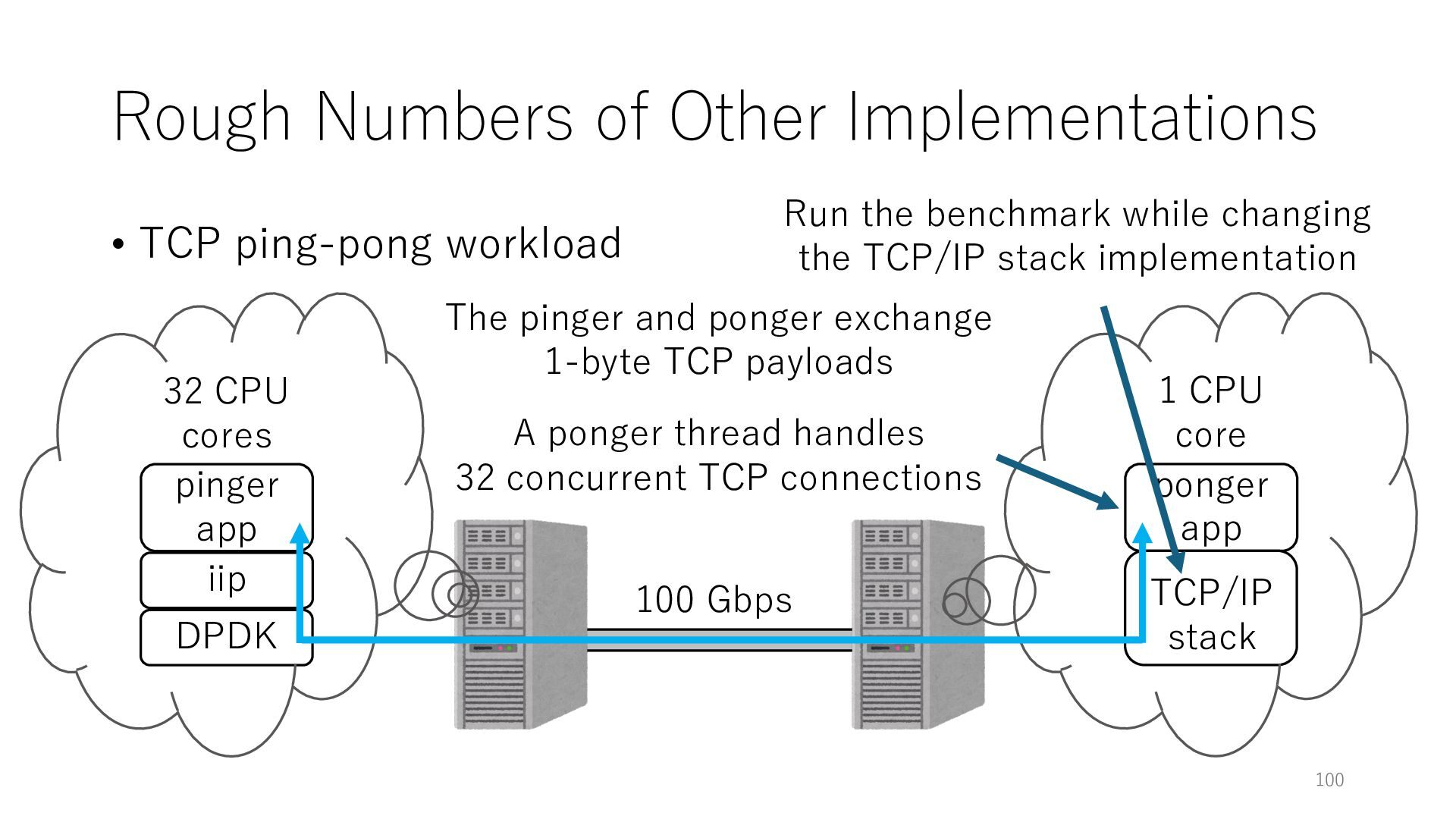
100 Gbps iip pinger app 32 CPU cores DPDK ponger app 1 CPU core The pinger and ponger exchange 1-byte TCP payloads A ponger thread handles 32 concurrent TCP connections Run the benchmark while changing the TCP/IP stack implementation TCP/IP stack
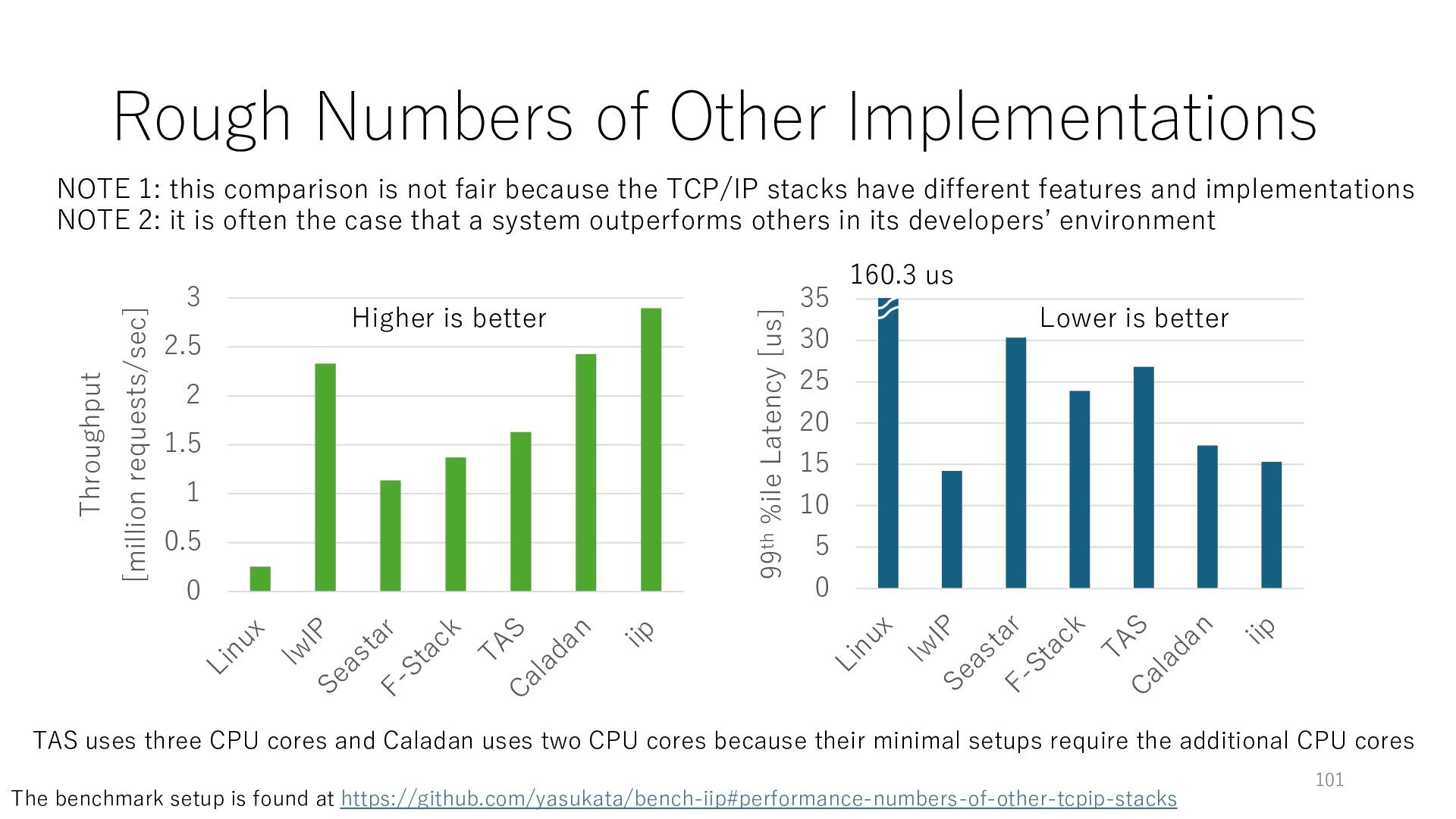
is not fair because the TCP/IP stacks have different features and implementations NOTE 2: it is often the case that a system outperforms others in its developersʼ environment TAS uses three CPU cores and Caladan uses two CPU cores because their minimal setups require the additional CPU cores 0 5 10 15 20 25 30 35 Linux lw IP Seastar F-Stack TAS Caladan iip 99th %ile Latency [us] 0 0.5 1 1.5 2 2.5 3 Linux lw IP Seastar F-Stack TAS Caladan iip Throughput [million requests/sec] Higher is better Lower is better 160.3 us The benchmark setup is found at https://github.com/yasukata/bench-iip#performance-numbers-of-other-tcpip-stacks
https://github.com/yasukata/mimicached 102 The benchmark setup is found at https://github.com/yasukata/mimicached#rough-performance-numbers • set 10% get 90% • zipfian distribution • 1 million key-value items • key size is 8 bytes • value size is 8 bytes • text protocol Workload
like a TCP/IP stack, should be aware of portability for the compatibility with different OSes • Transparent integration: an OS subsystem should allow for transparent integration into an existing OS 103 The codebase of OS A The codebase of a TCP/IP stack The codebase of OS B The codebase of OS C Portability + Transparent integration Can we achieve high performance and portability simultaneously? I think these two are important for decentralized collaboration
like a TCP/IP stack, should be aware of portability for the compatibility with different OSes • Transparent integration: an OS subsystem should allow for transparent integration into an existing OS 104 The codebase of OS A The codebase of a TCP/IP stack The codebase of OS B The codebase of OS C Portability + Transparent integration Portable TCP/IP stacks can be compiled and run on a wide range of OSes but, we need a mechanism to transparently integrate them into OSes I think these two are important for decentralized collaboration
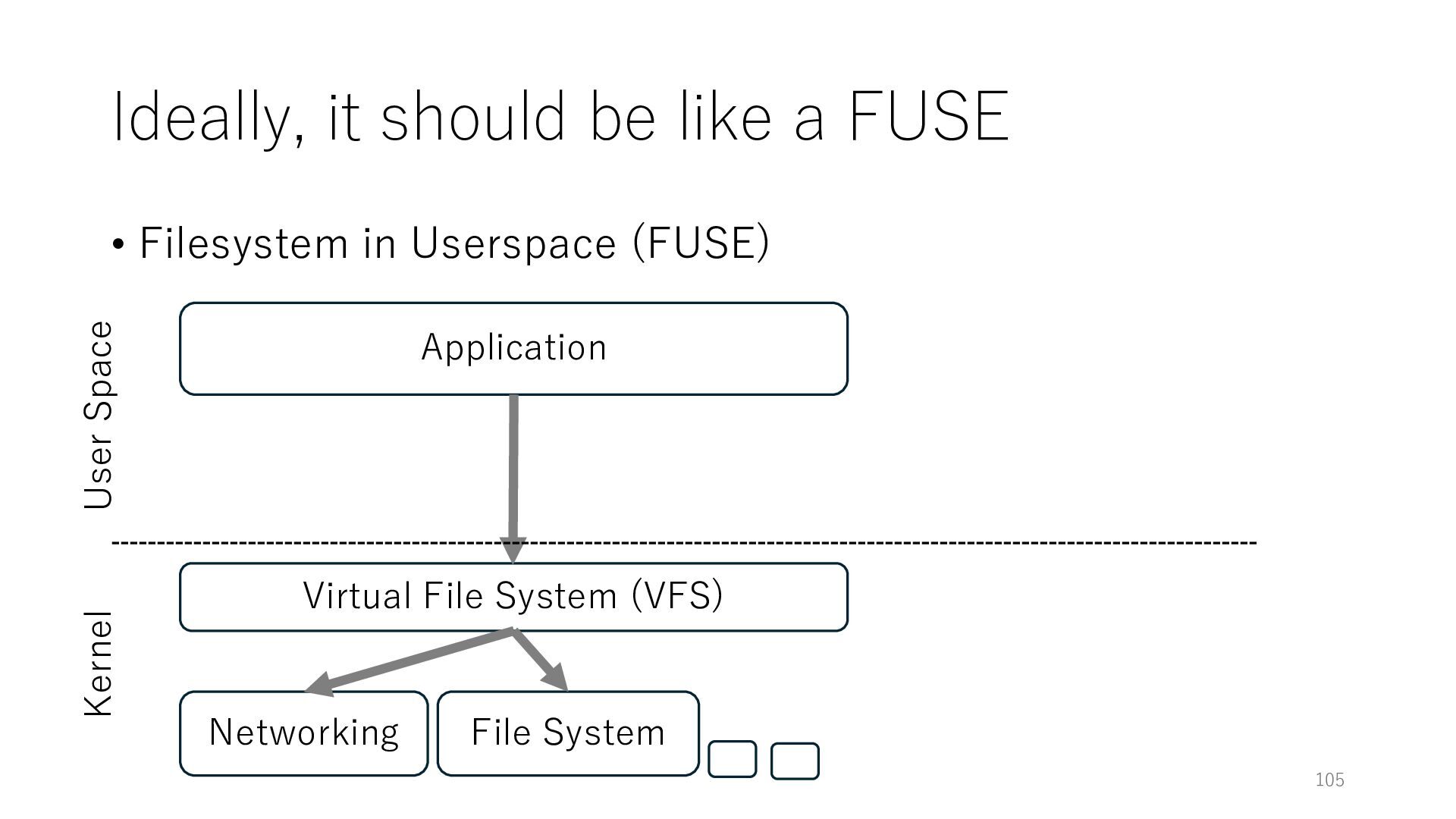
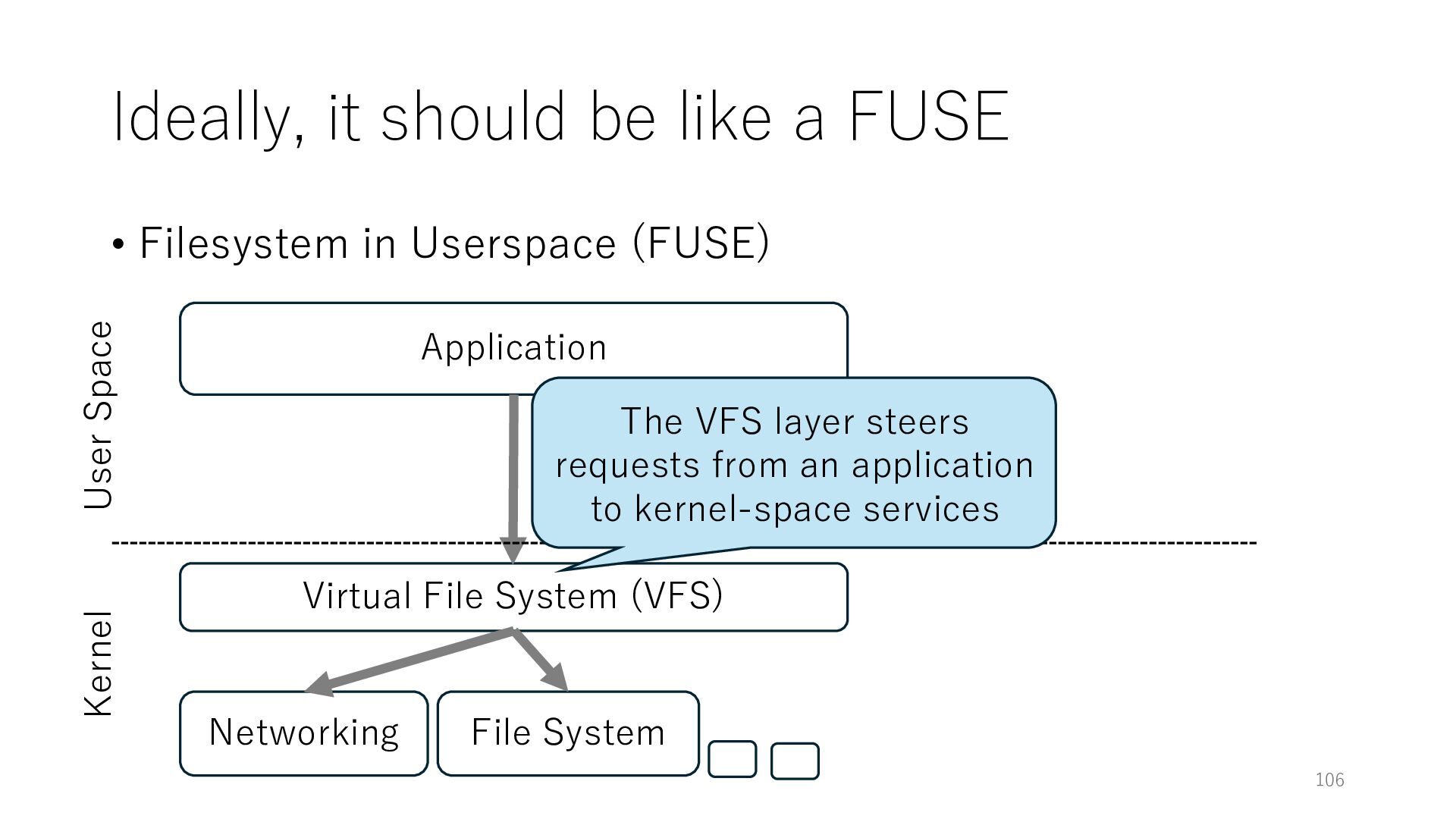
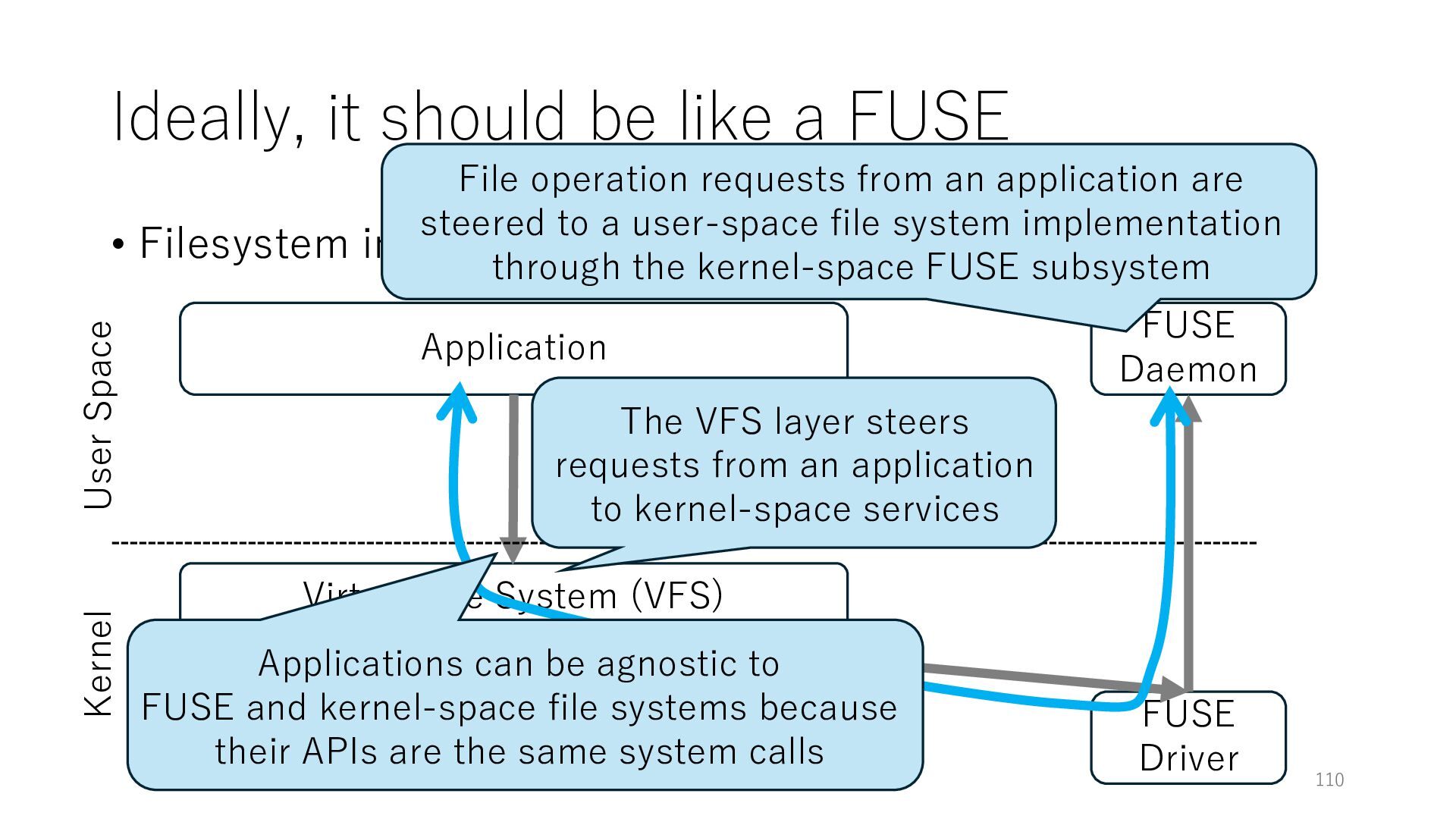
Userspace (FUSE) Application Networking Virtual File System (VFS) File System 106 User Space Kernel The VFS layer steers requests from an application to kernel-space services
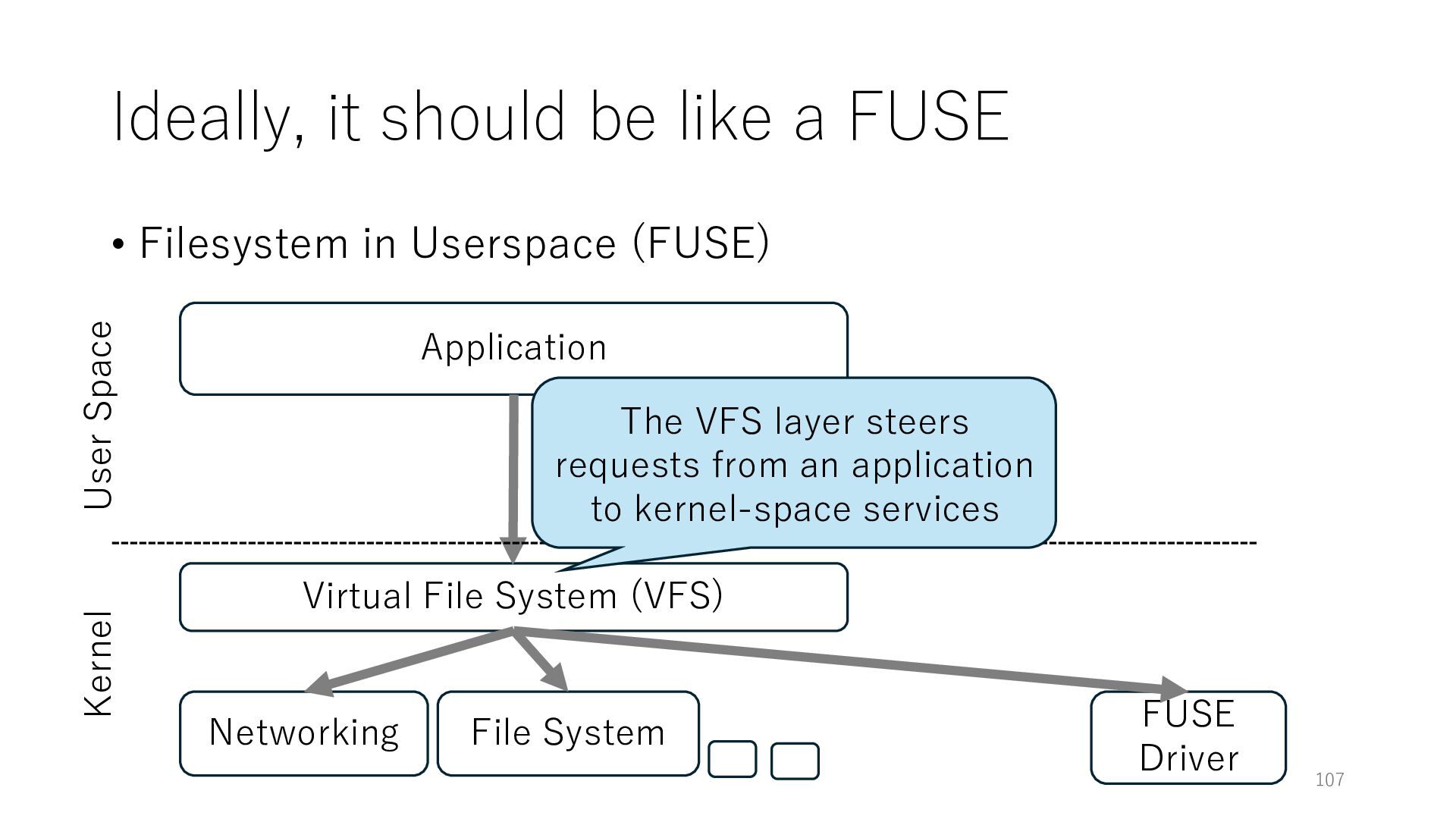
Userspace (FUSE) Application Networking Virtual File System (VFS) File System 107 User Space Kernel The VFS layer steers requests from an application to kernel-space services FUSE Driver
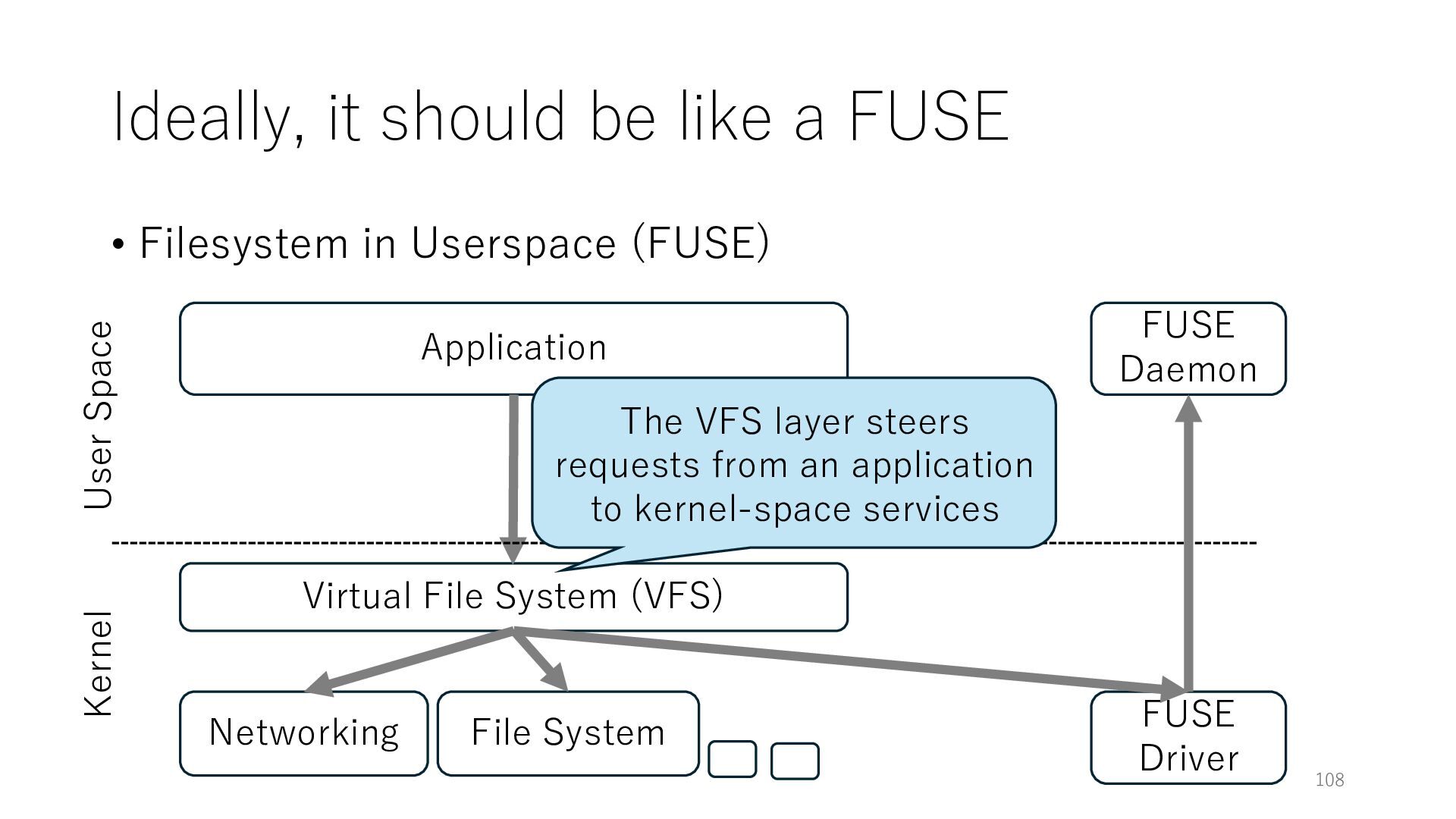
Userspace (FUSE) Application Networking Virtual File System (VFS) File System 108 User Space Kernel The VFS layer steers requests from an application to kernel-space services FUSE Daemon FUSE Driver
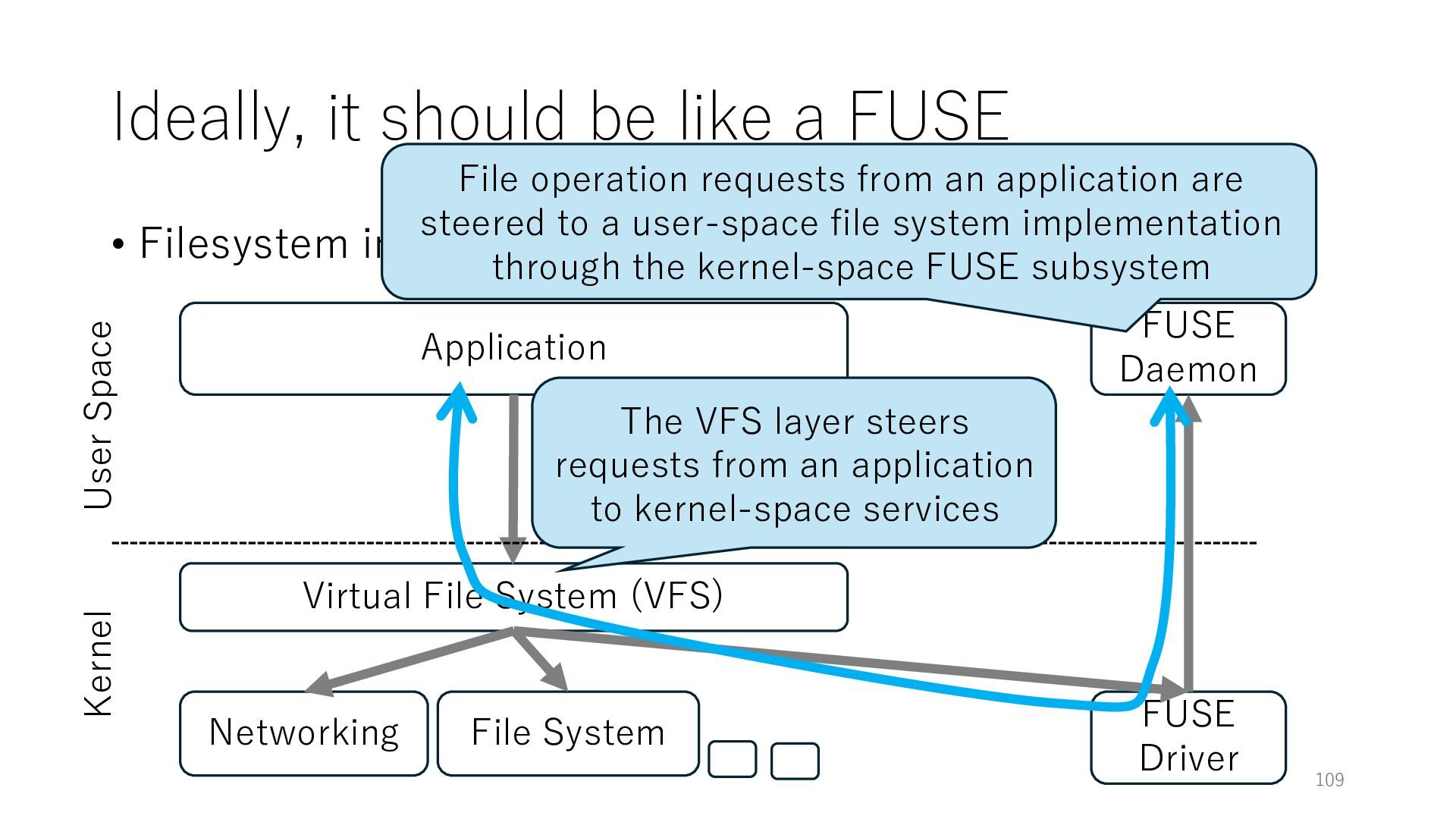
Userspace (FUSE) Application Networking Virtual File System (VFS) File System 109 User Space Kernel The VFS layer steers requests from an application to kernel-space services FUSE Daemon FUSE Driver File operation requests from an application are steered to a user-space file system implementation through the kernel-space FUSE subsystem
Userspace (FUSE) Application Networking Virtual File System (VFS) File System 110 User Space Kernel The VFS layer steers requests from an application to kernel-space services FUSE Daemon FUSE Driver File operation requests from an application are steered to a user-space file system implementation through the kernel-space FUSE subsystem Applications can be agnostic to FUSE and kernel-space file systems because their APIs are the same system calls
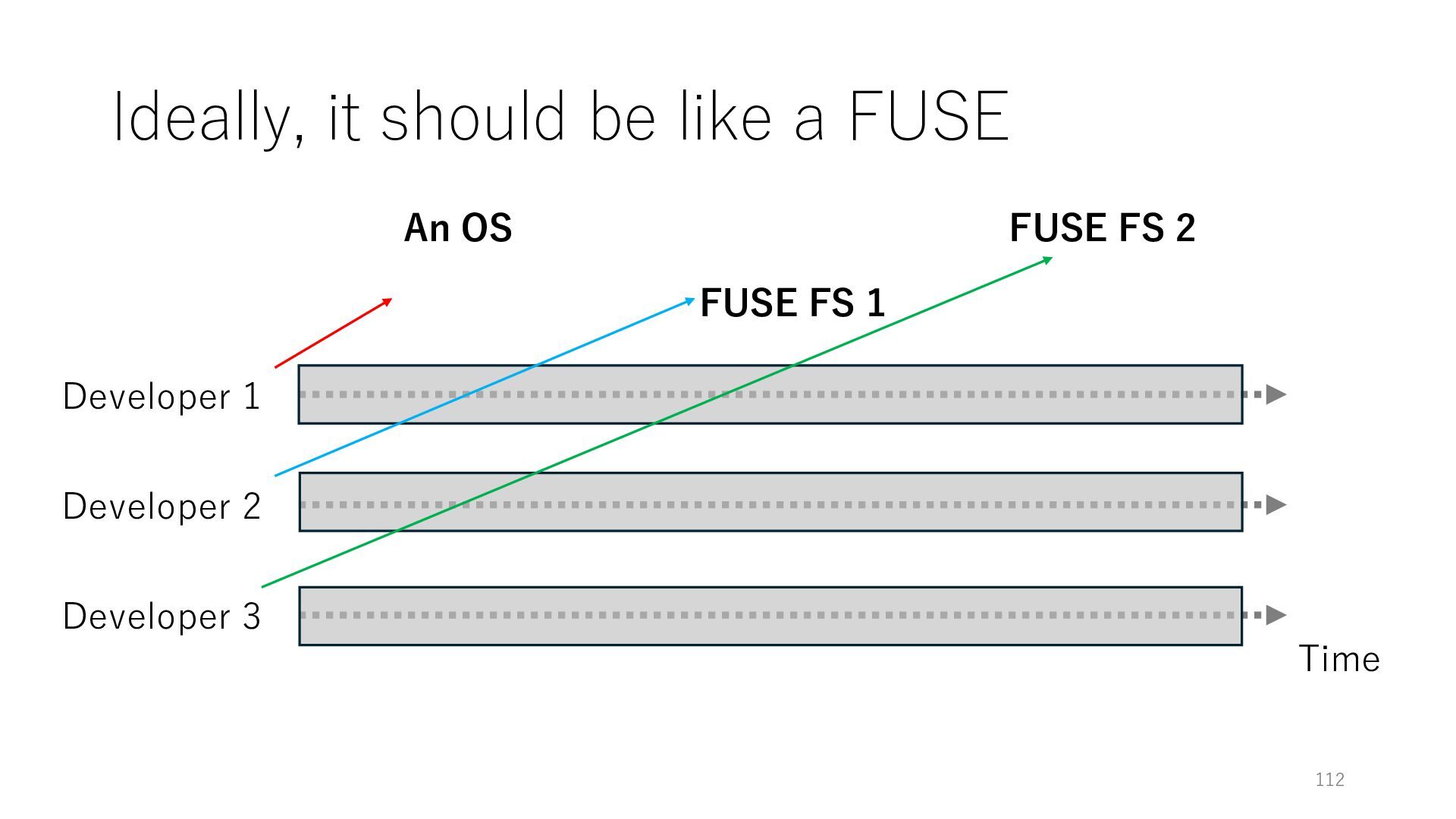
Time Developer 2 Developer 3 Codebase of OS functionality A Codebase of OS functionality B Codebase of OS functionality C Coming back to ... It would be great if • developers do not need to communicate with each other • and, the OS functionalities are easily incorporated
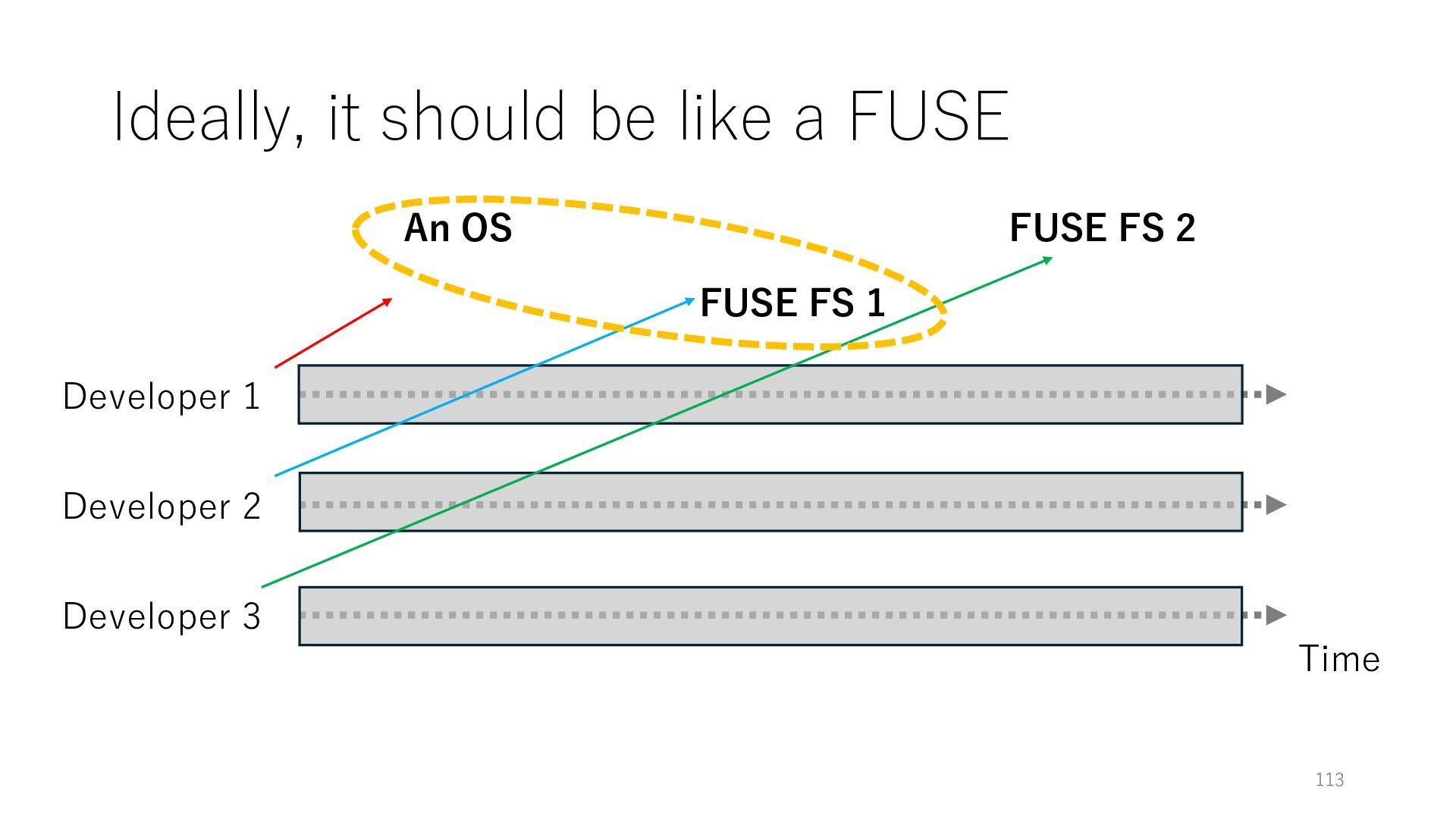
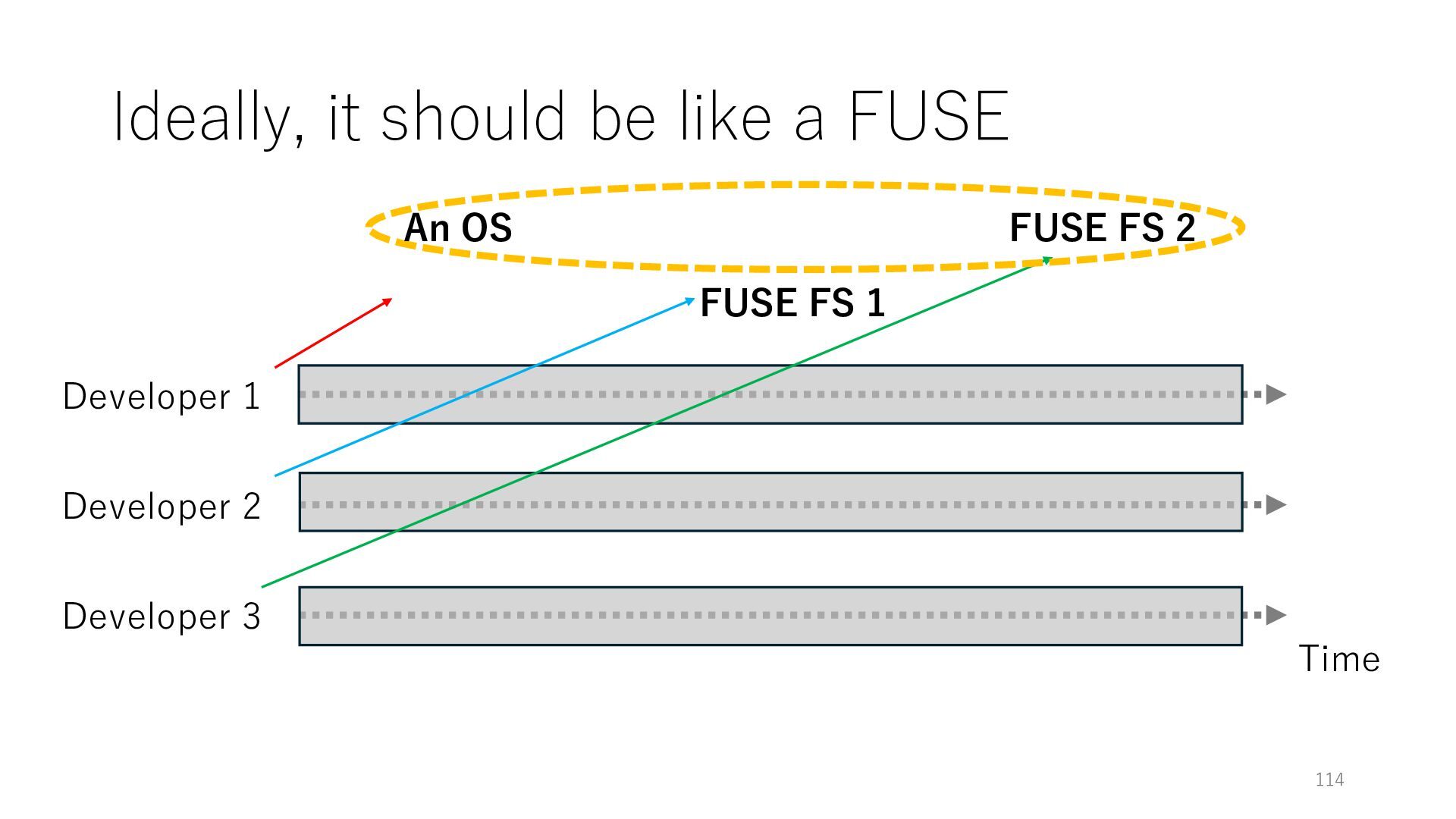
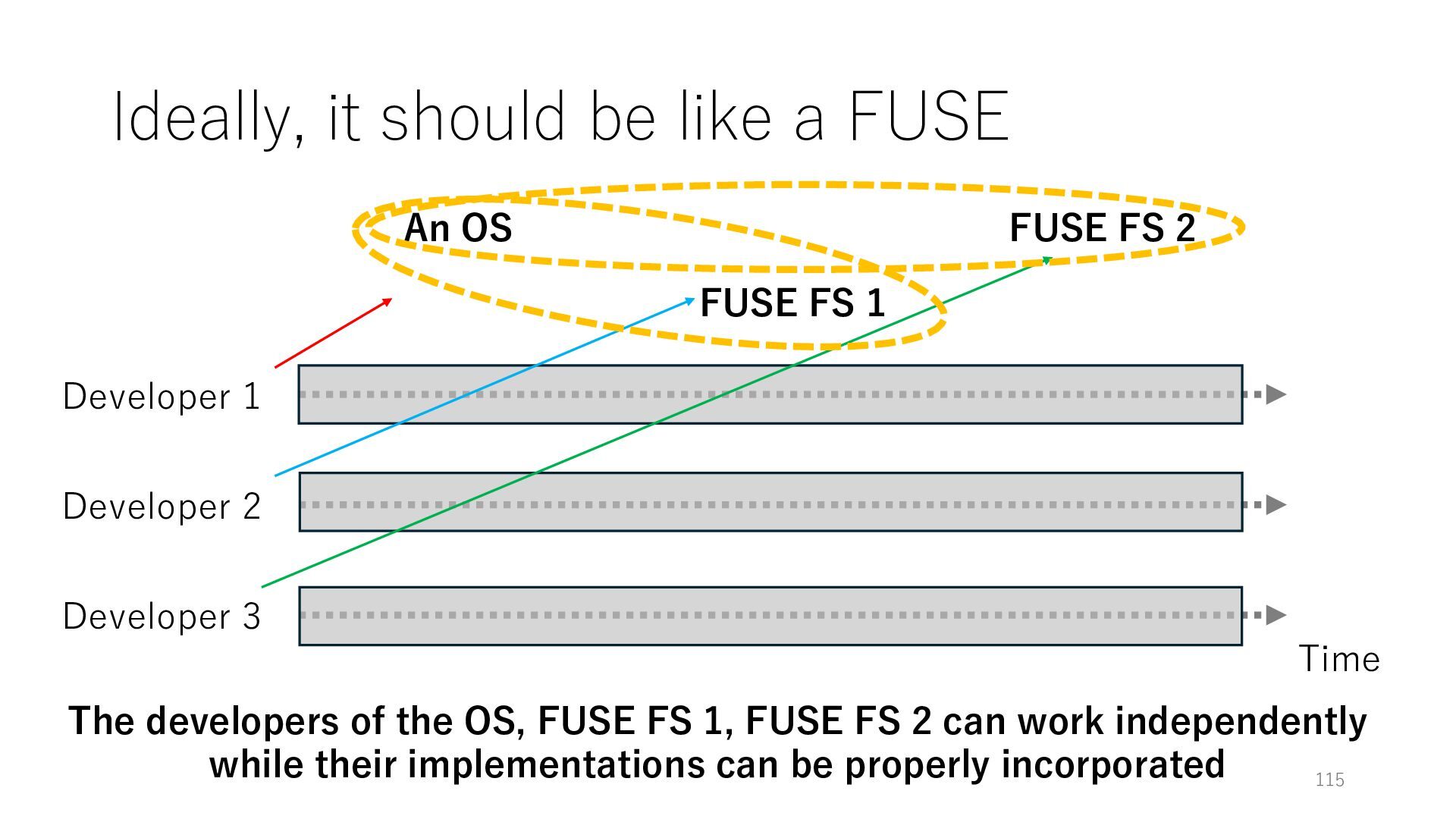
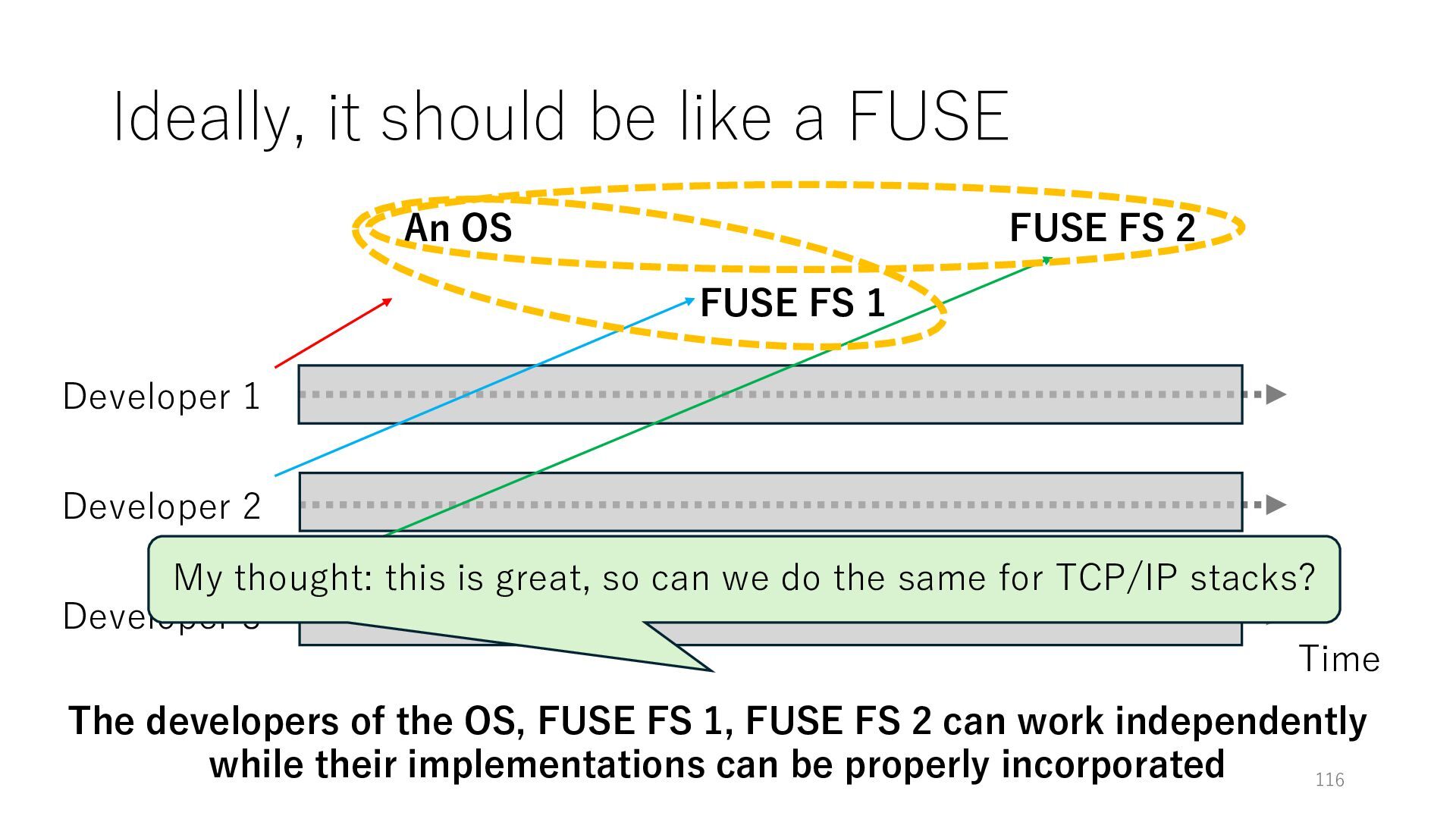
Time Developer 2 Developer 3 An OS FUSE FS 1 FUSE FS 2 The developers of the OS, FUSE FS 1, FUSE FS 2 can work independently while their implementations can be properly incorporated
Time Developer 2 Developer 3 An OS FUSE FS 1 FUSE FS 2 The developers of the OS, FUSE FS 1, FUSE FS 2 can work independently while their implementations can be properly incorporated My thought: this is great, so can we do the same for TCP/IP stacks?
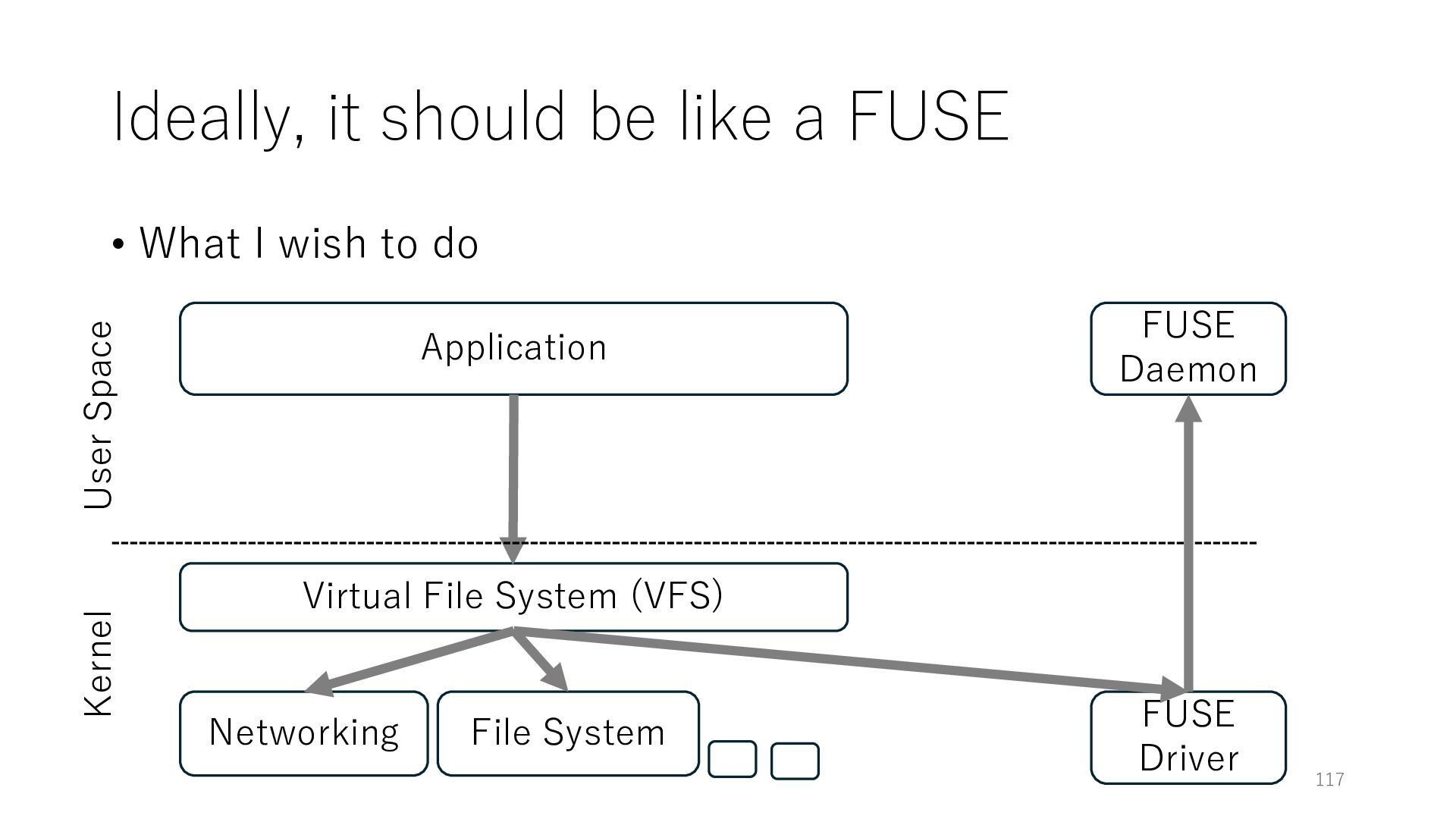
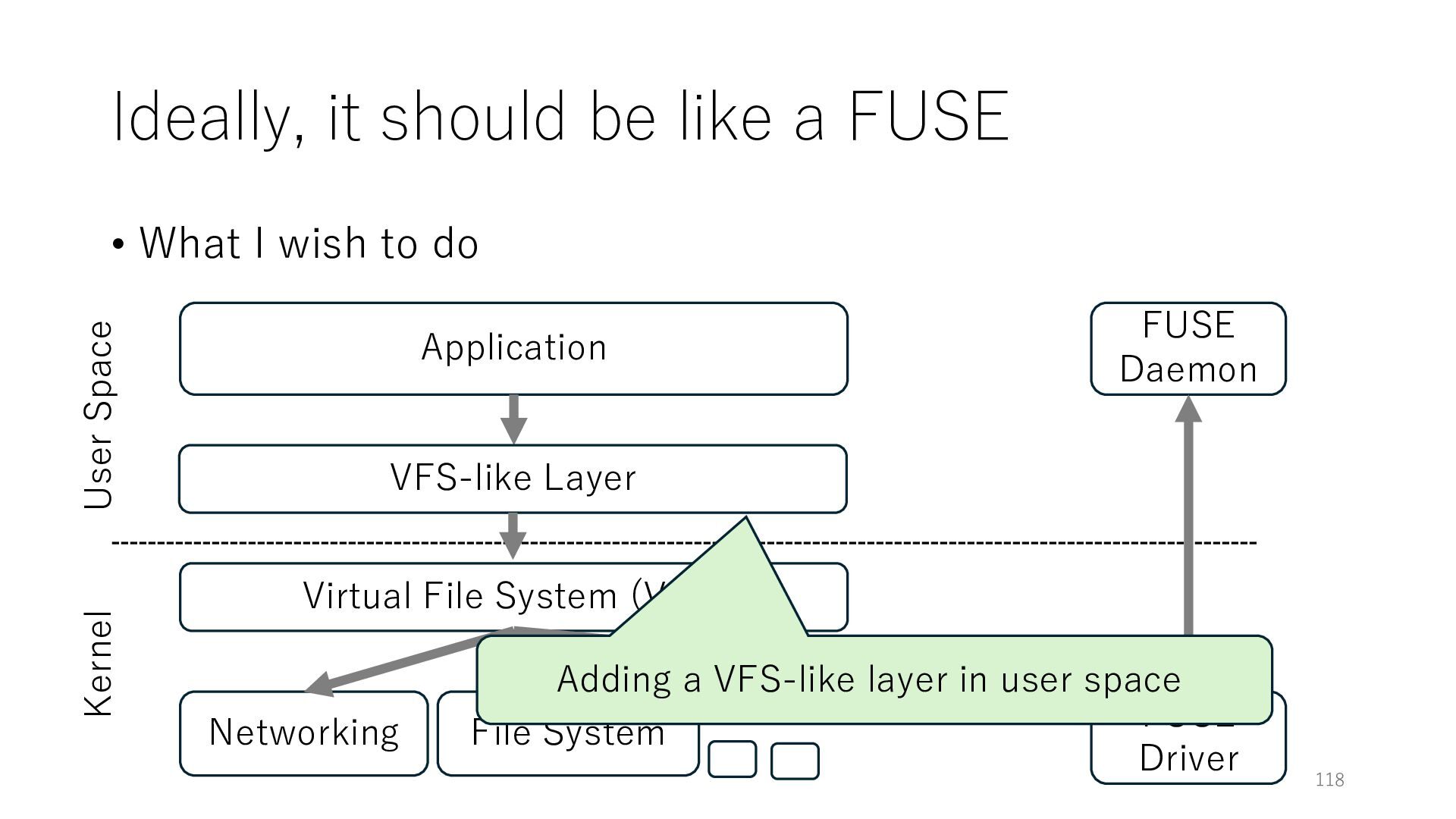
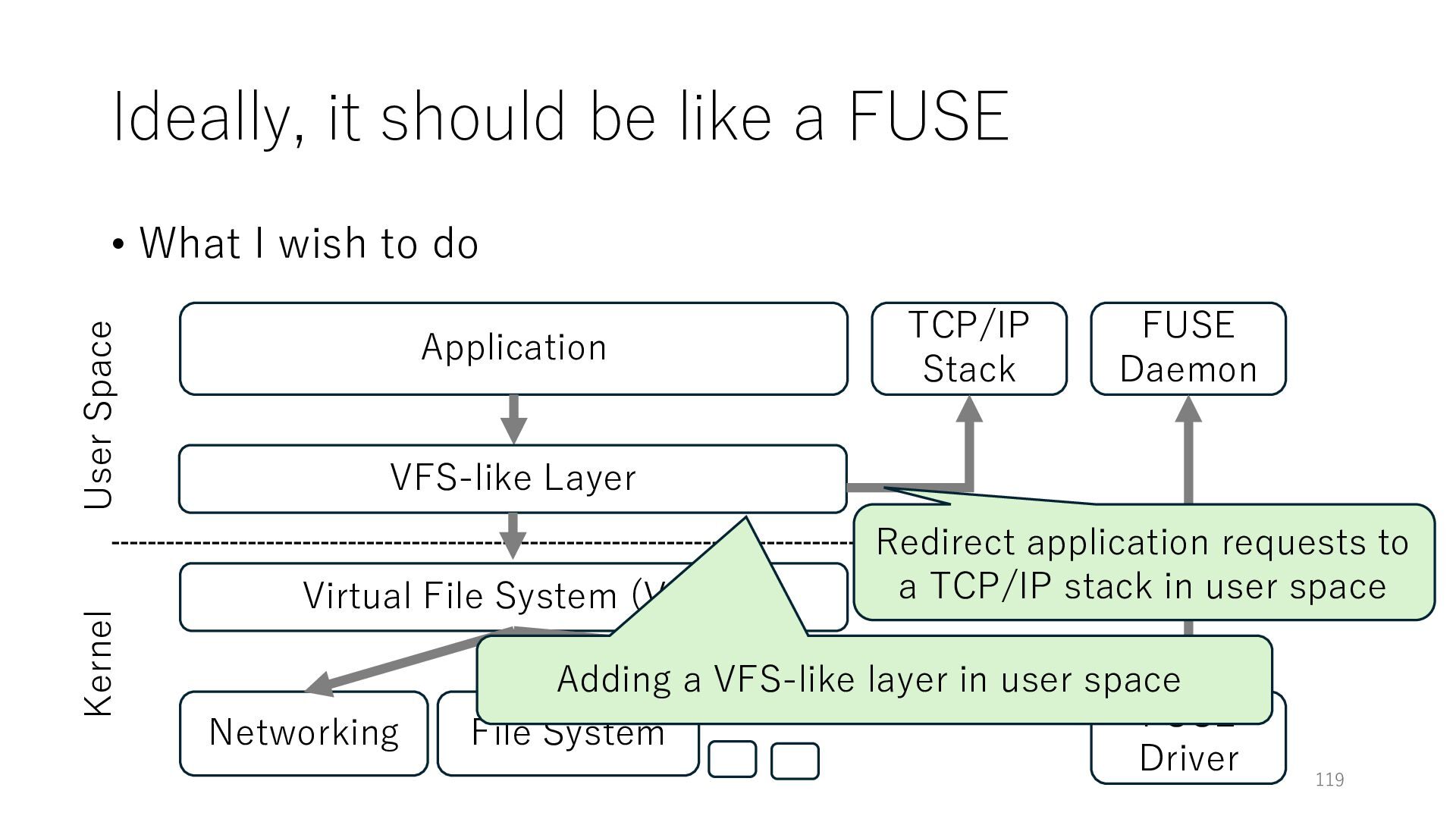
wish to do Application Networking Virtual File System (VFS) File System 118 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer Adding a VFS-like layer in user space
wish to do Application Networking Virtual File System (VFS) File System 119 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack Adding a VFS-like layer in user space Redirect application requests to a TCP/IP stack in user space
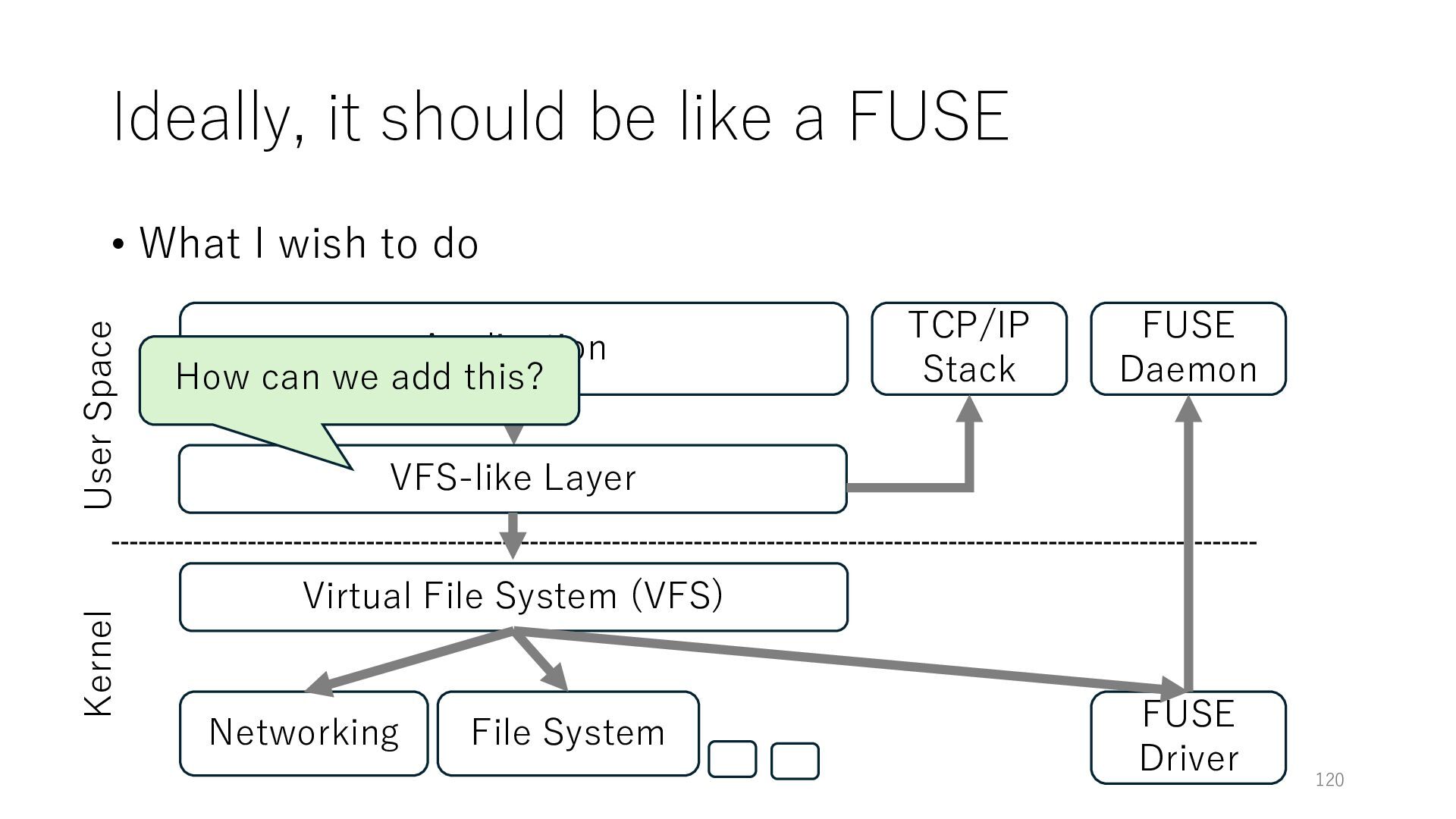
wish to do Application Networking Virtual File System (VFS) File System 120 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack How can we add this?
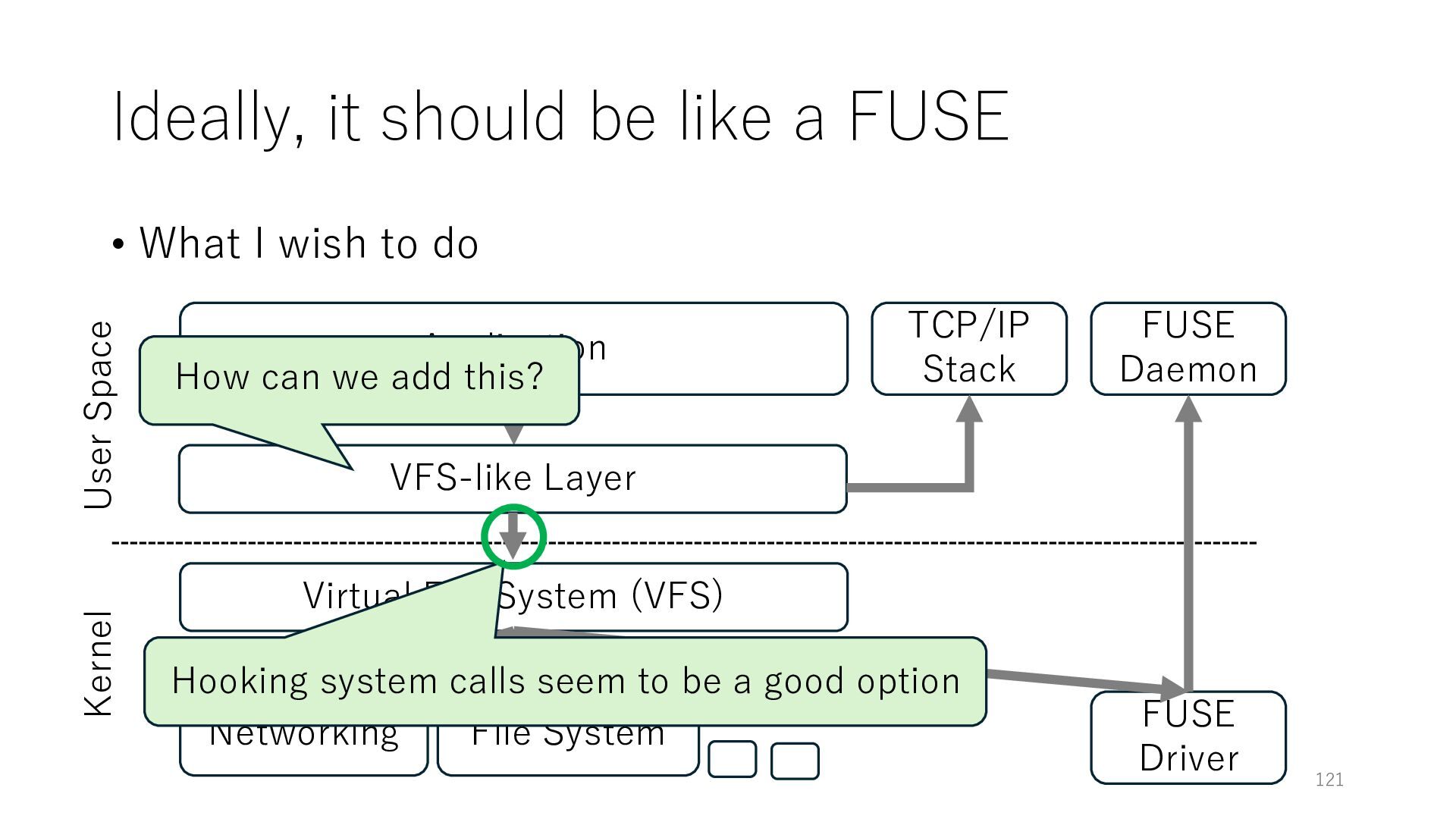
wish to do Application Networking Virtual File System (VFS) File System 121 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack How can we add this? Hooking system calls seem to be a good option
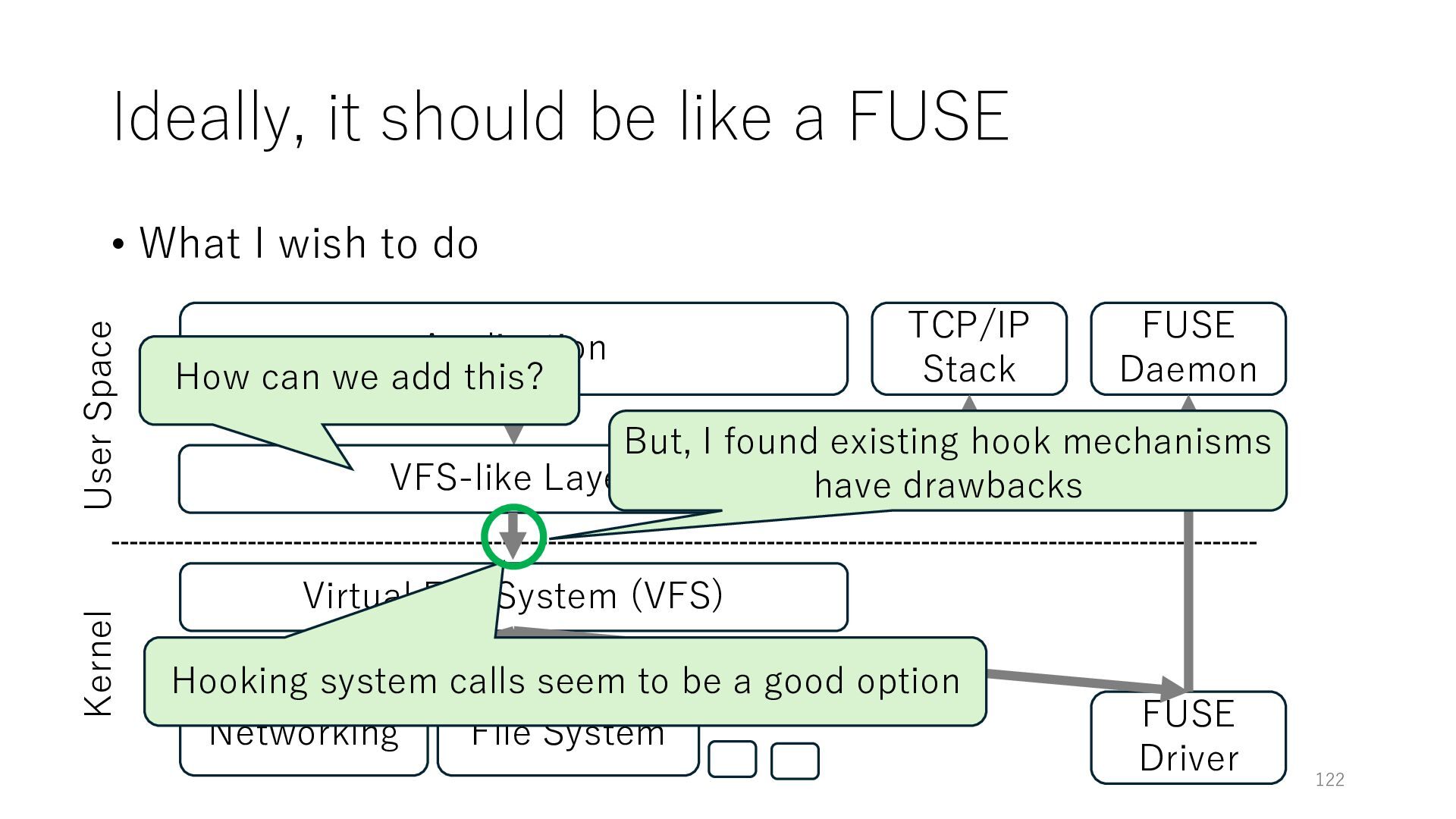
wish to do Application Networking Virtual File System (VFS) File System 122 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack How can we add this? Hooking system calls seem to be a good option But, I found existing hook mechanisms have drawbacks
hook mechanism for x86-64 based on binary rewriting • Paper at USENIX ATC 2023 • https://www.usenix.org/conference/atc23/presentation/yasukata • received a Best Paper Award • Source code • https://github.com/yasukata/zpoline 123
hook mechanism for ARM64 based on binary rewriting • Paper at ACM/IFIP Middleware 2025 • https://dl.acm.org/doi/10.1145/3721462.3770771 • Source code • https://github.com/retrage/svc-hook 124 https://speakerdeck.com/retrage/svc-hook-hooking-system-calls-on-arm64-by-binary-rewriting
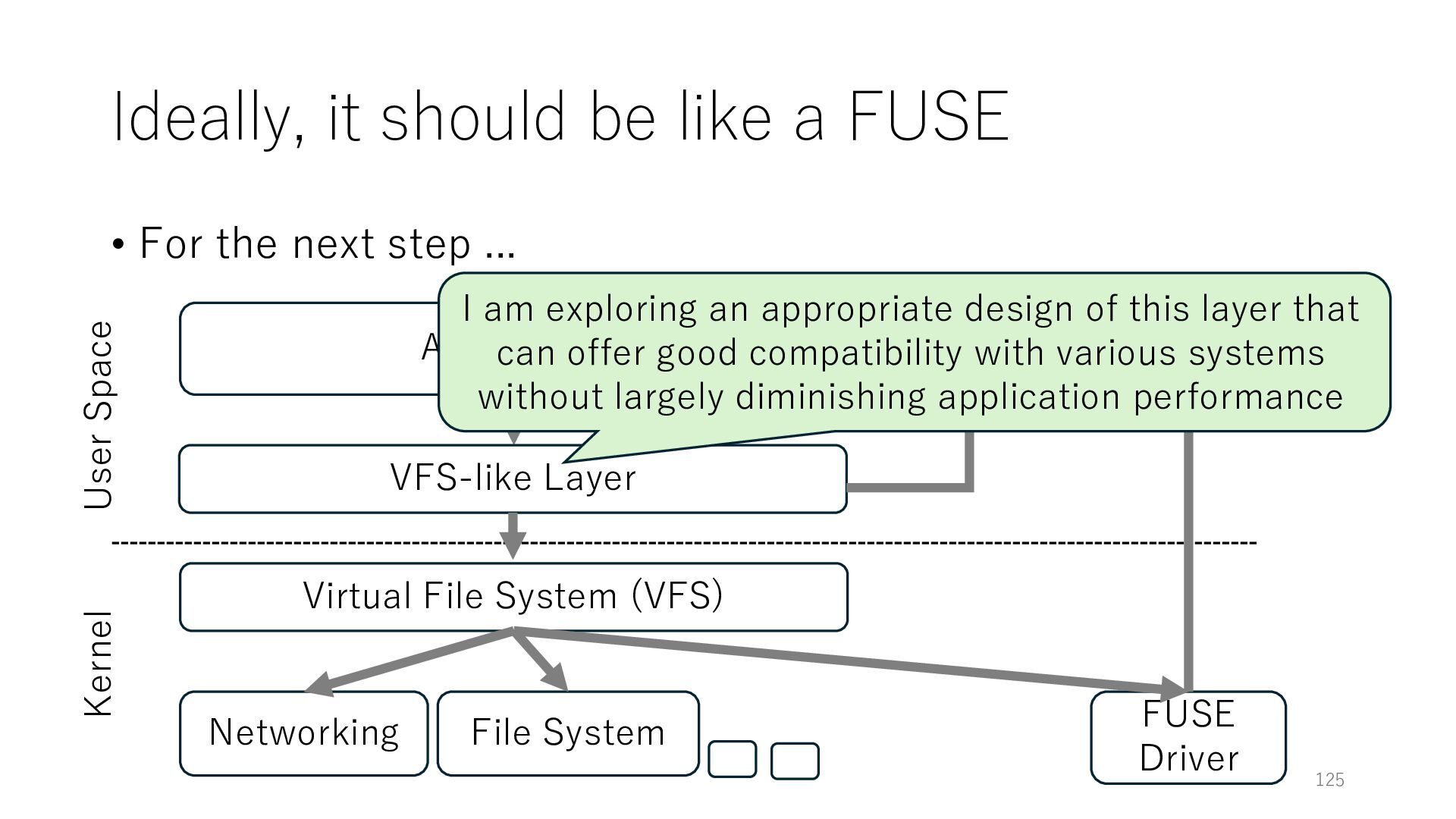
next step ... Application Networking Virtual File System (VFS) File System 125 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack I am exploring an appropriate design of this layer that can offer good compatibility with various systems without largely diminishing application performance
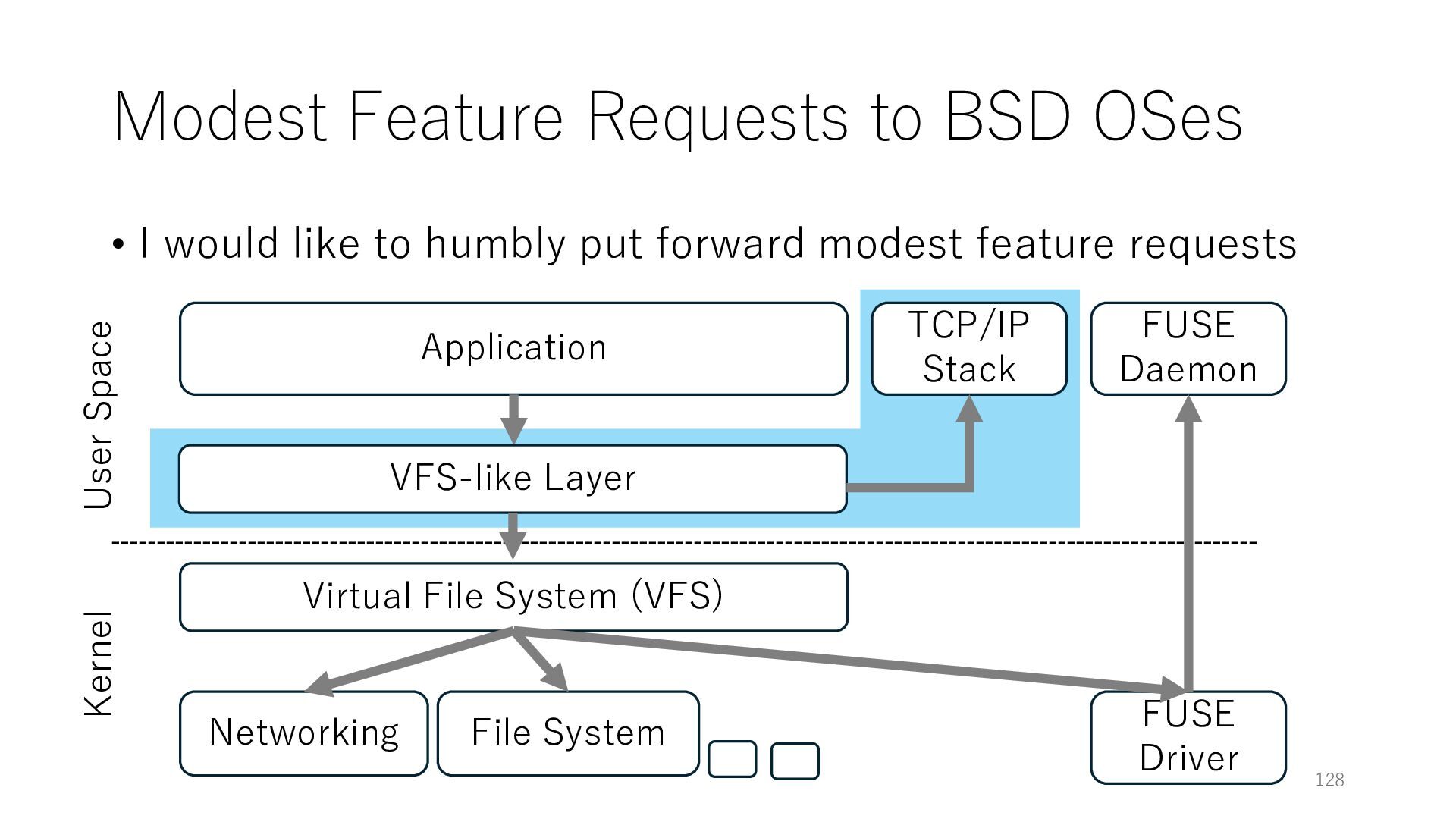
to humbly put forward modest feature requests Application Networking Virtual File System (VFS) File System 128 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack
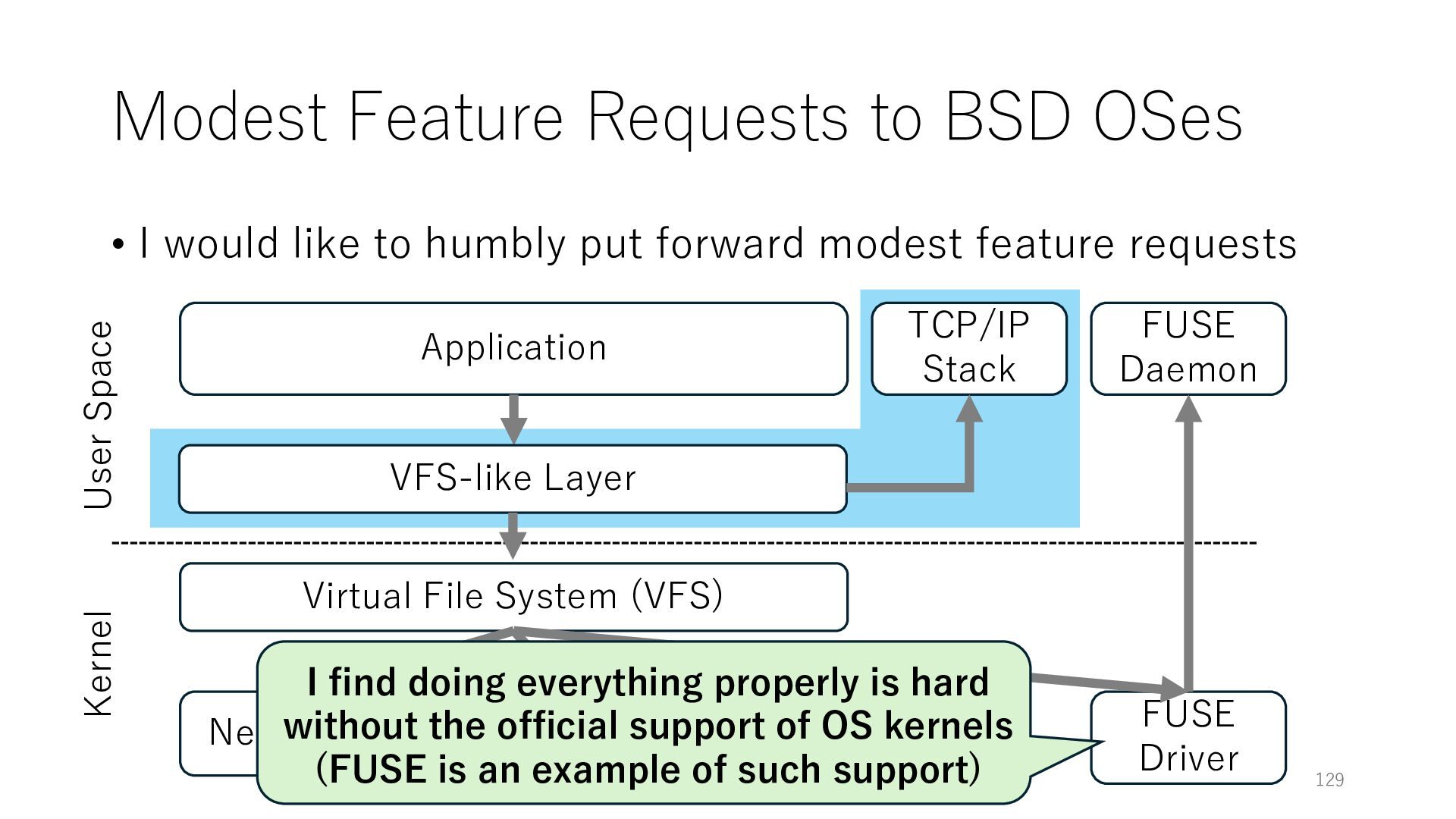
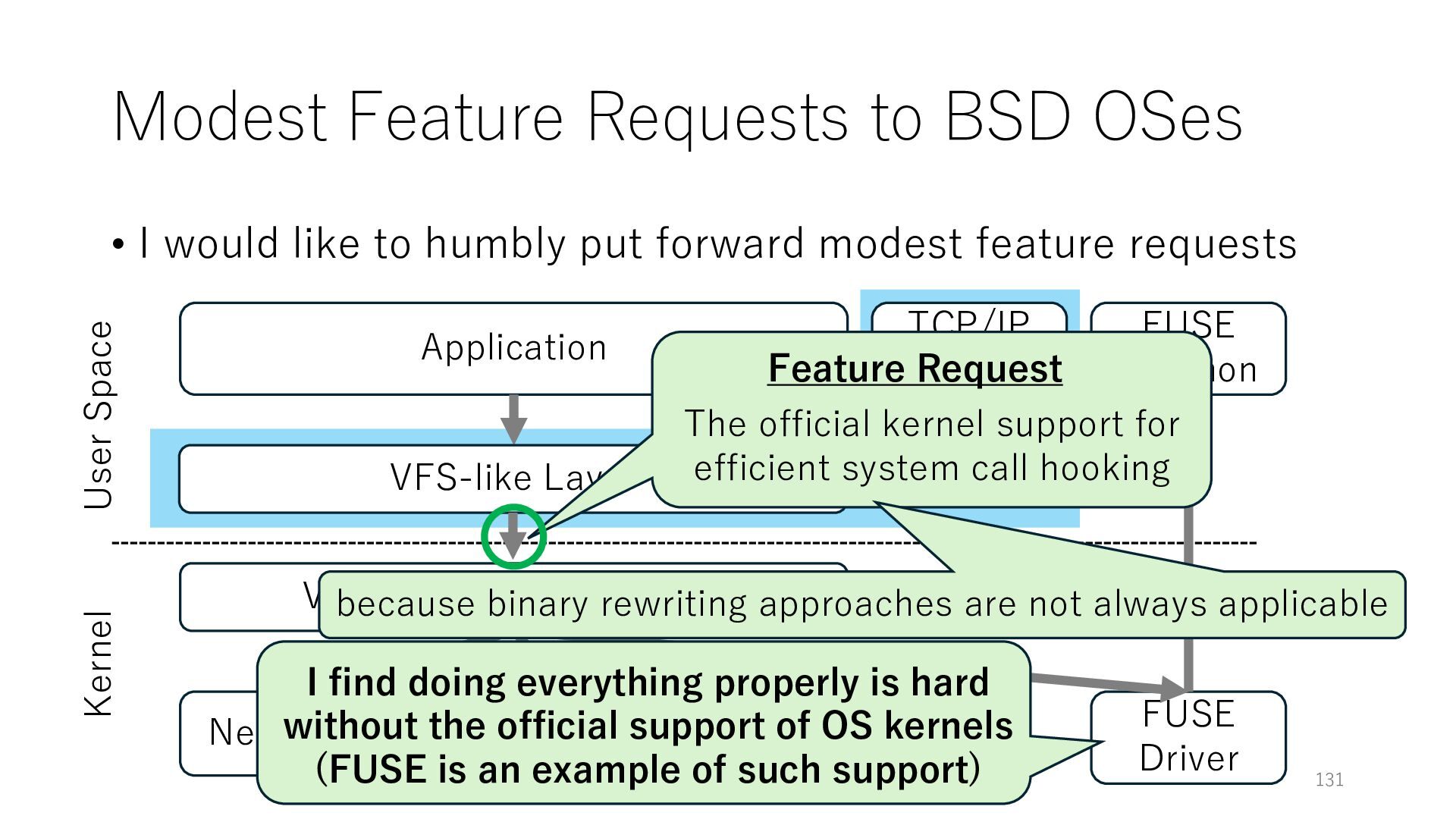
to humbly put forward modest feature requests Application Networking Virtual File System (VFS) File System 129 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack I find doing everything properly is hard without the official support of OS kernels (FUSE is an example of such support)
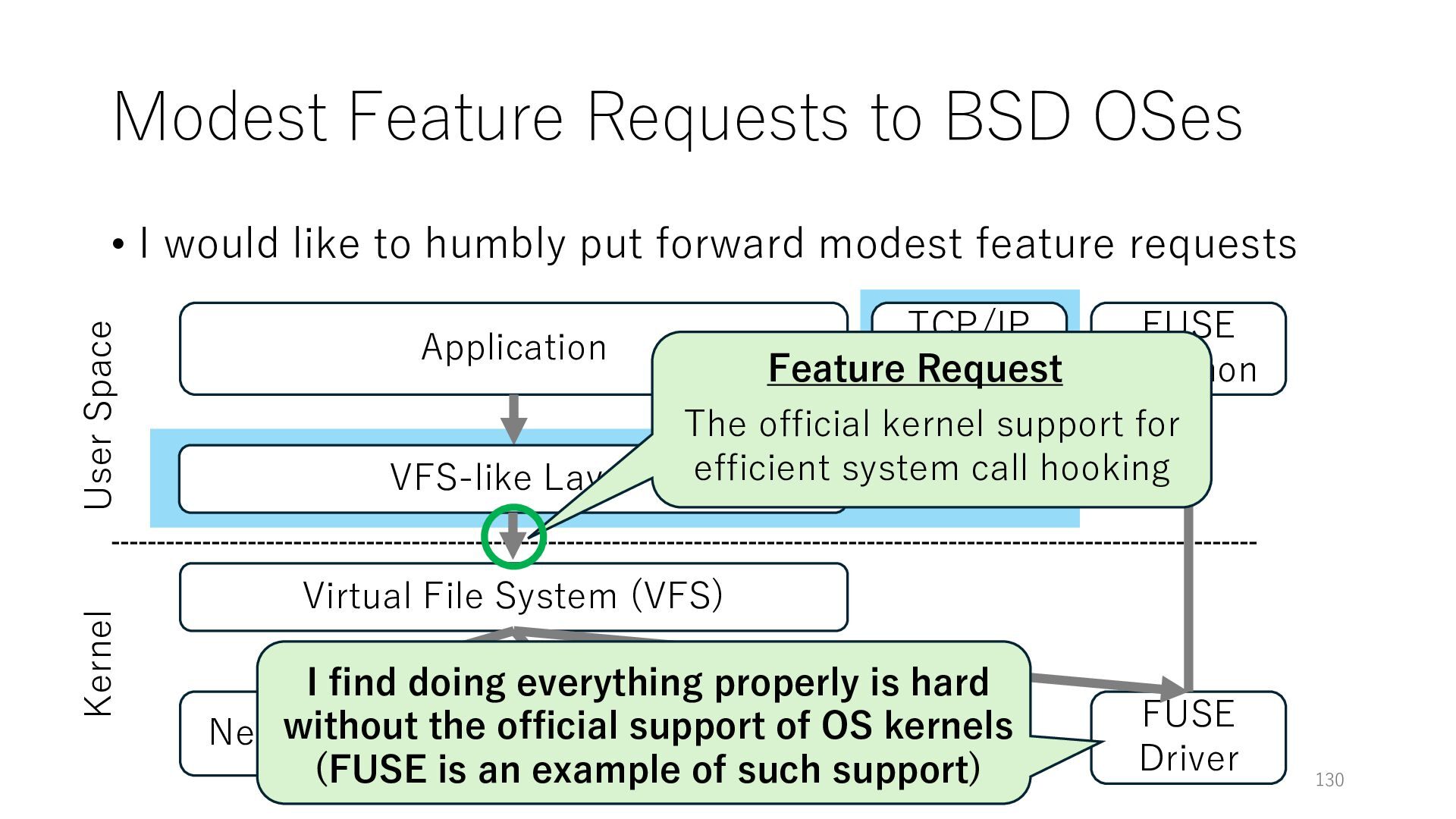
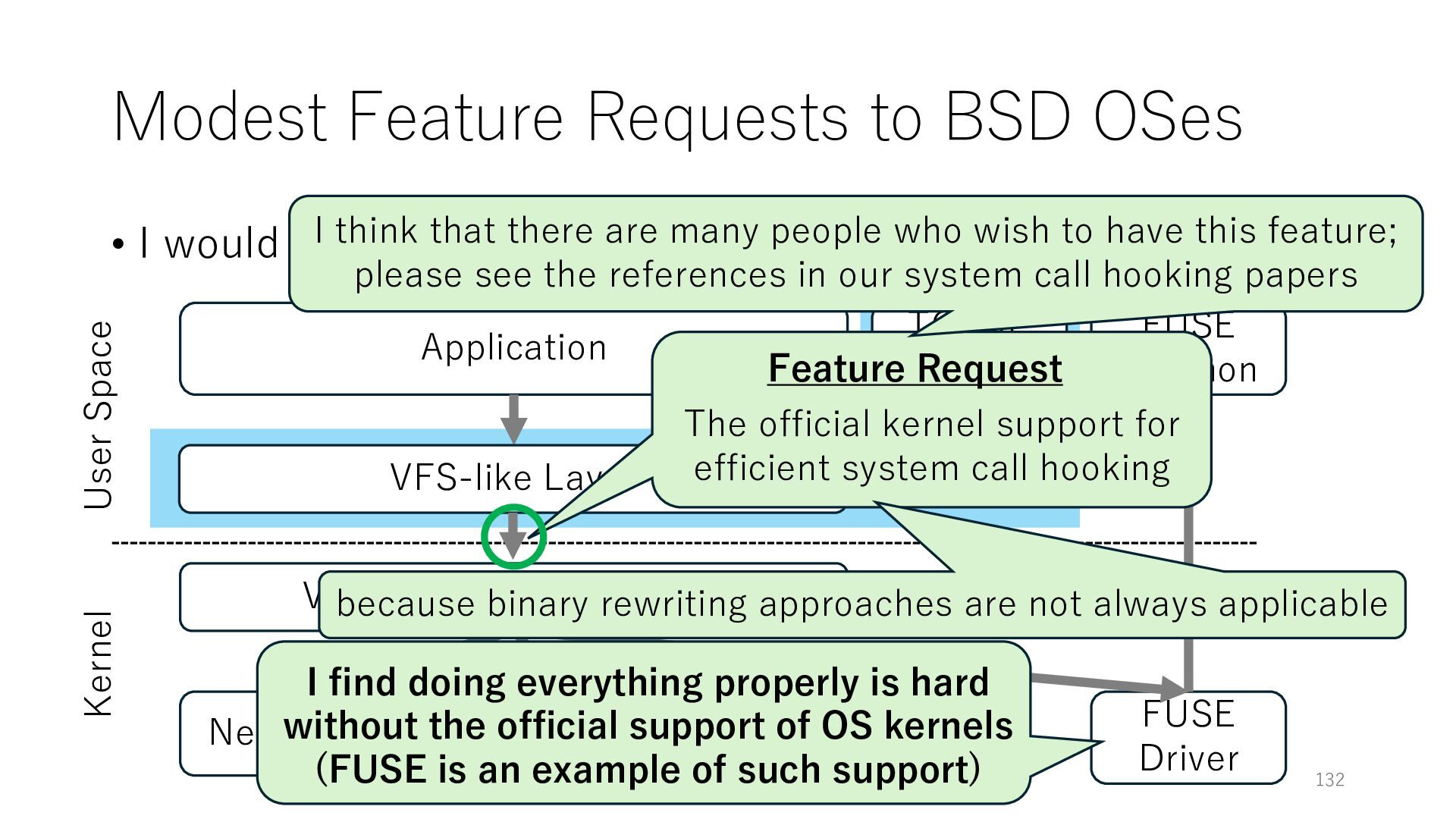
to humbly put forward modest feature requests Application Networking Virtual File System (VFS) File System 130 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack I find doing everything properly is hard without the official support of OS kernels (FUSE is an example of such support) Feature Request The official kernel support for efficient system call hooking
to humbly put forward modest feature requests Application Networking Virtual File System (VFS) File System 131 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack I find doing everything properly is hard without the official support of OS kernels (FUSE is an example of such support) Feature Request The official kernel support for efficient system call hooking because binary rewriting approaches are not always applicable
to humbly put forward modest feature requests Application Networking Virtual File System (VFS) File System 132 User Space Kernel FUSE Daemon FUSE Driver VFS-like Layer TCP/IP Stack I find doing everything properly is hard without the official support of OS kernels (FUSE is an example of such support) Feature Request The official kernel support for efficient system call hooking because binary rewriting approaches are not always applicable I think that there are many people who wish to have this feature; please see the references in our system call hooking papers
the kernel support for system call hooking 133 Application User Space Kernel syscall Immediately getting back to user space while jumping to a memory address preliminarily configured through a designated control interface
the kernel support for system call hooking 134 Application User Space Kernel syscall Immediately getting back to user space while jumping to a memory address preliminarily configured through a designated control interface It would be nice if users could use a BPF-like mechanism to choose whether getting back to user space or executing the kernel-space system call, at run time BPF program
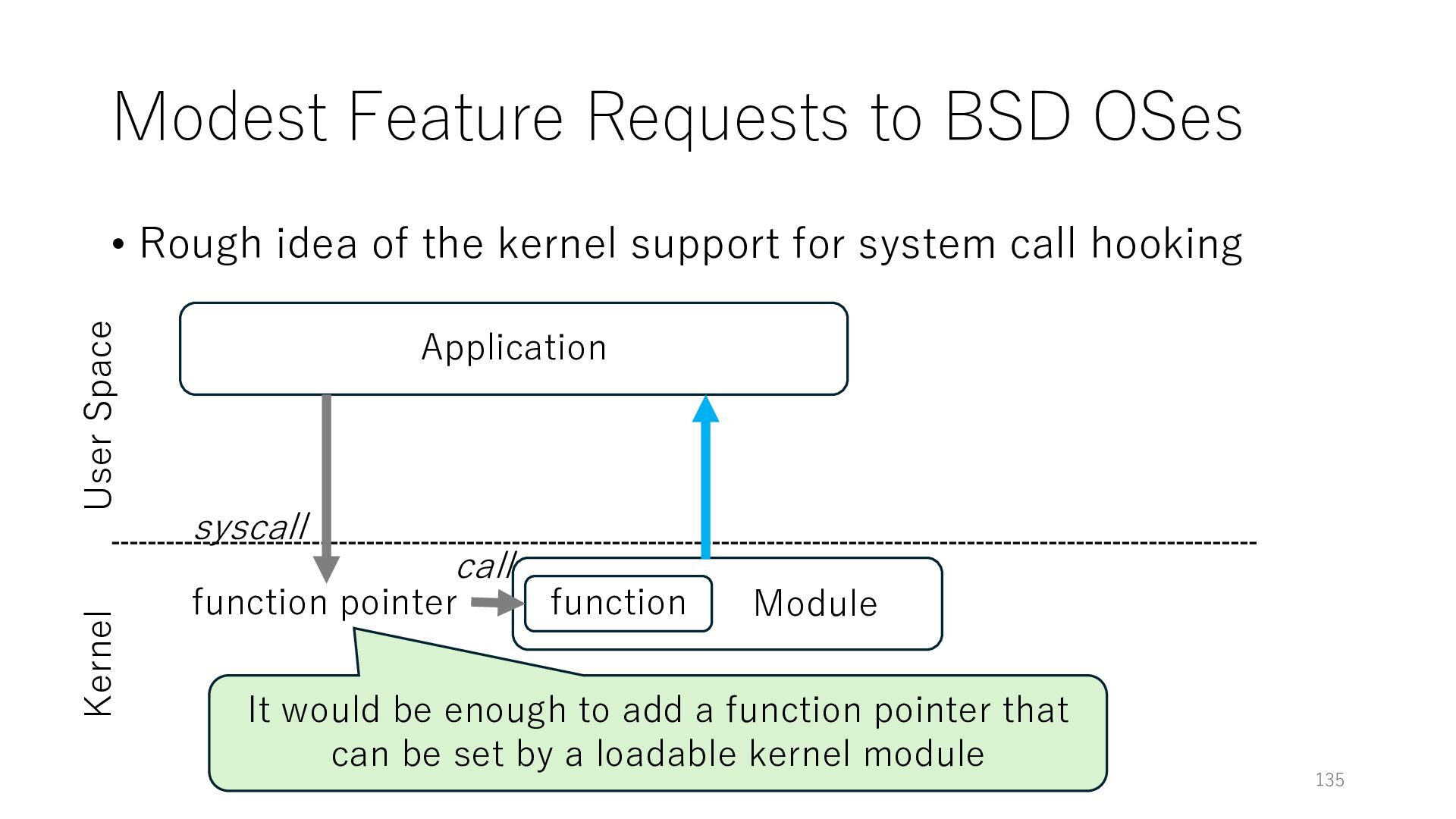
the kernel support for system call hooking 135 Application User Space Kernel syscall function pointer function Module It would be enough to add a function pointer that can be set by a loadable kernel module call
the kernel support for system call hooking Discussion point • What security implications should we consider? è Can we apply the same assumptions as ptrace? 136
be developed in a decentralized manner while still being easily incorporated • The OS designs have a significant impact on how OSes are developed, and there would be well-suited designs • If certain features were officially supported by major OS kernels, it could drive substantial progress in this area 138
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}