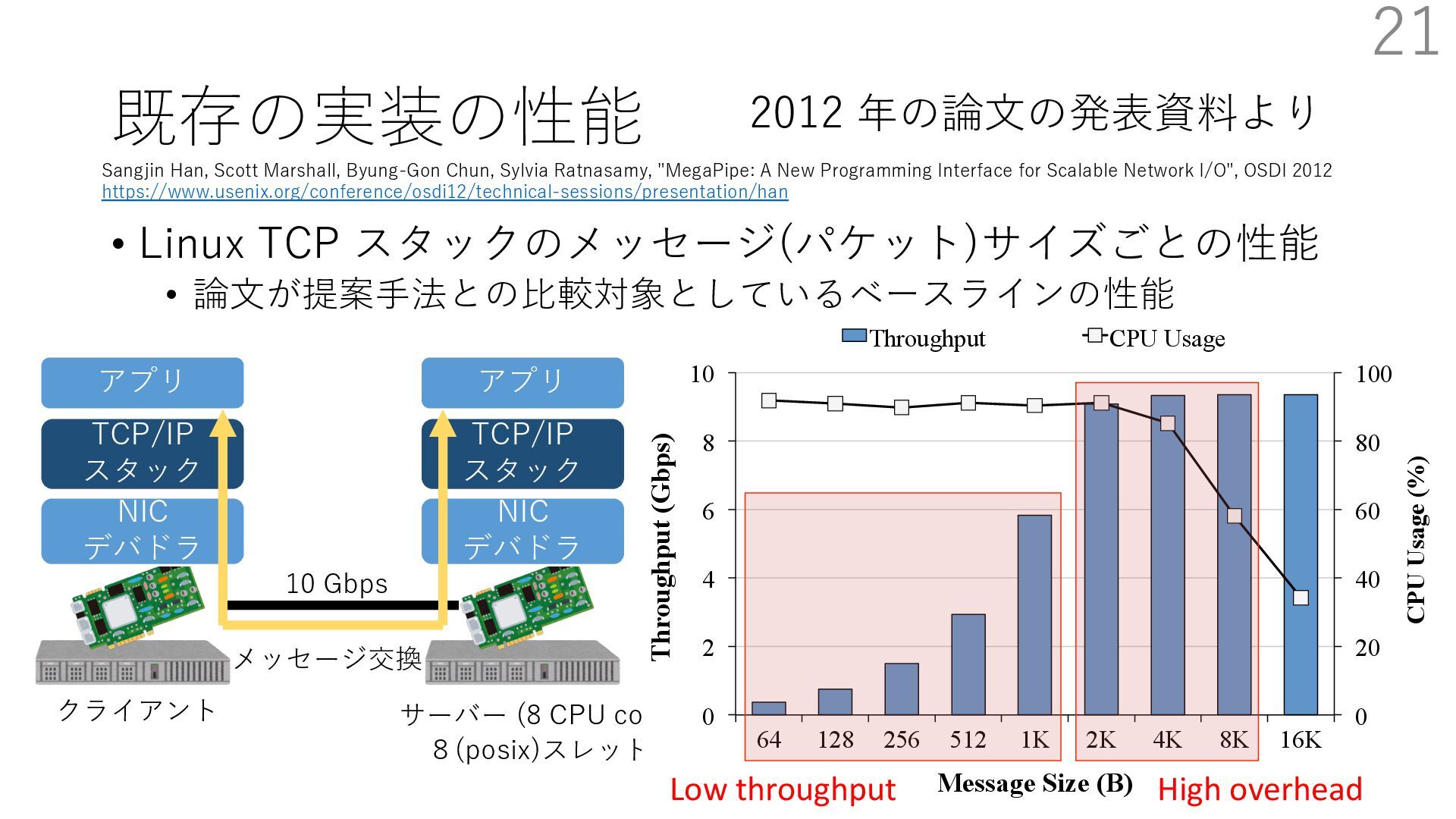
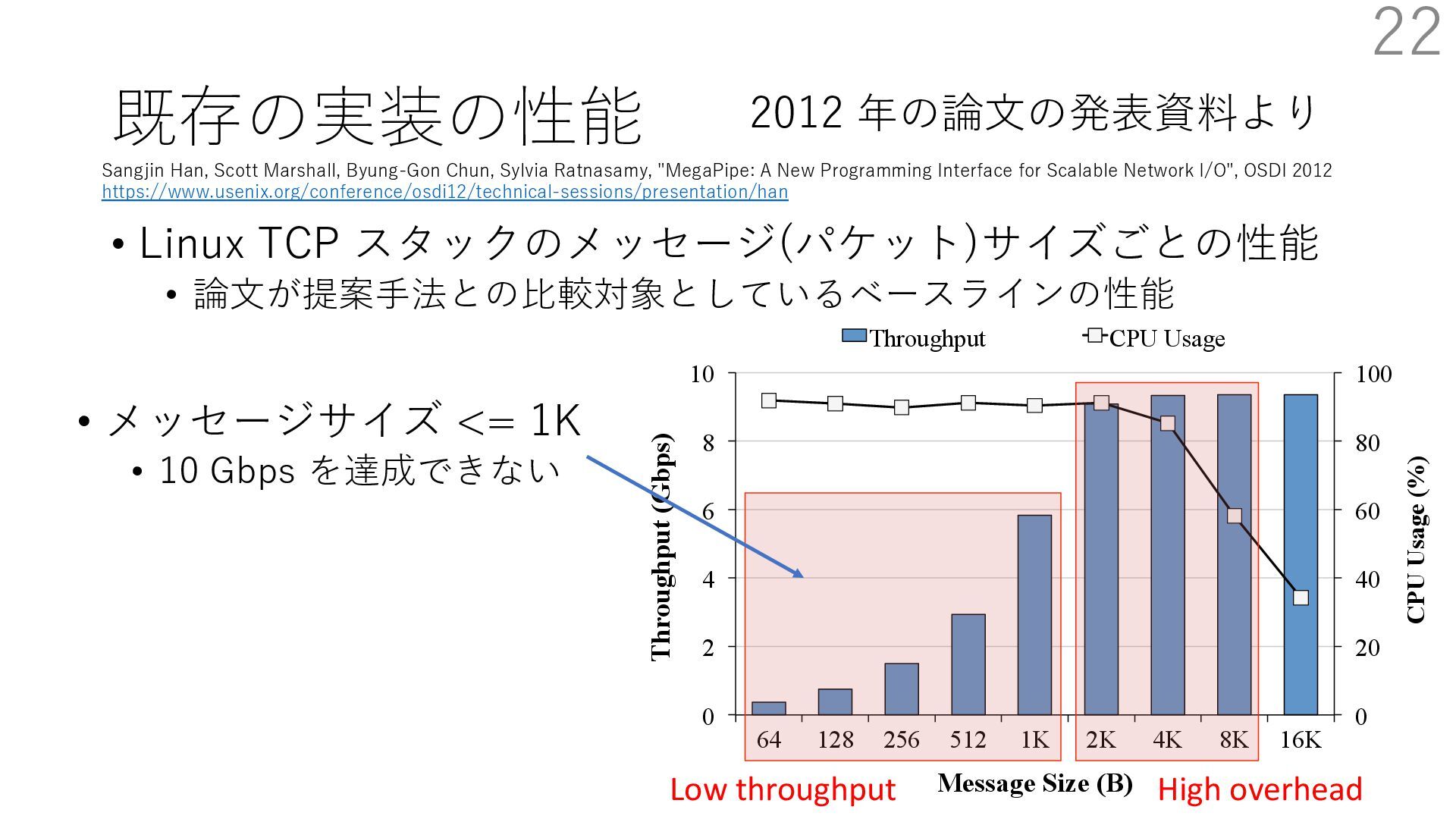
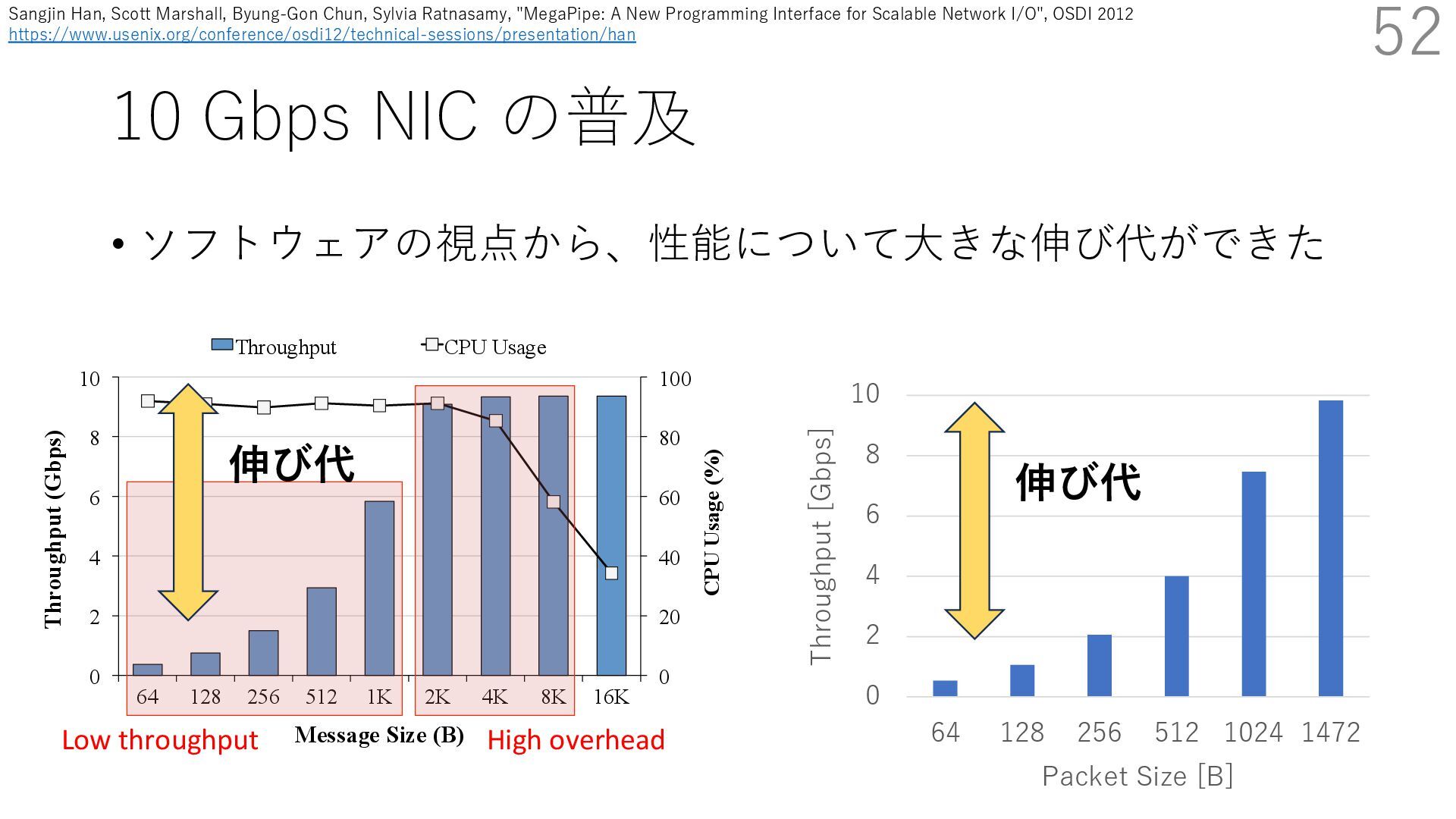
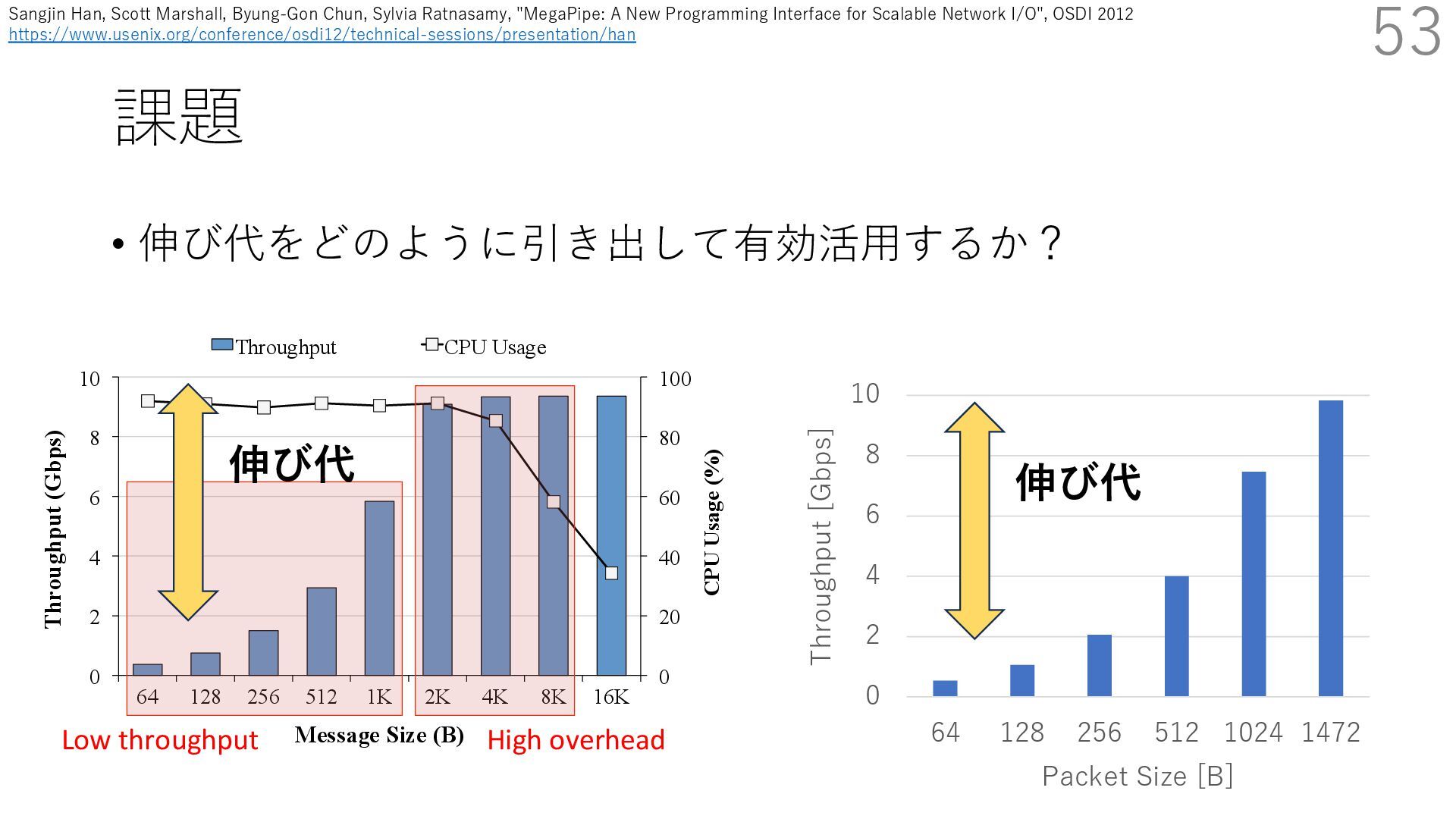
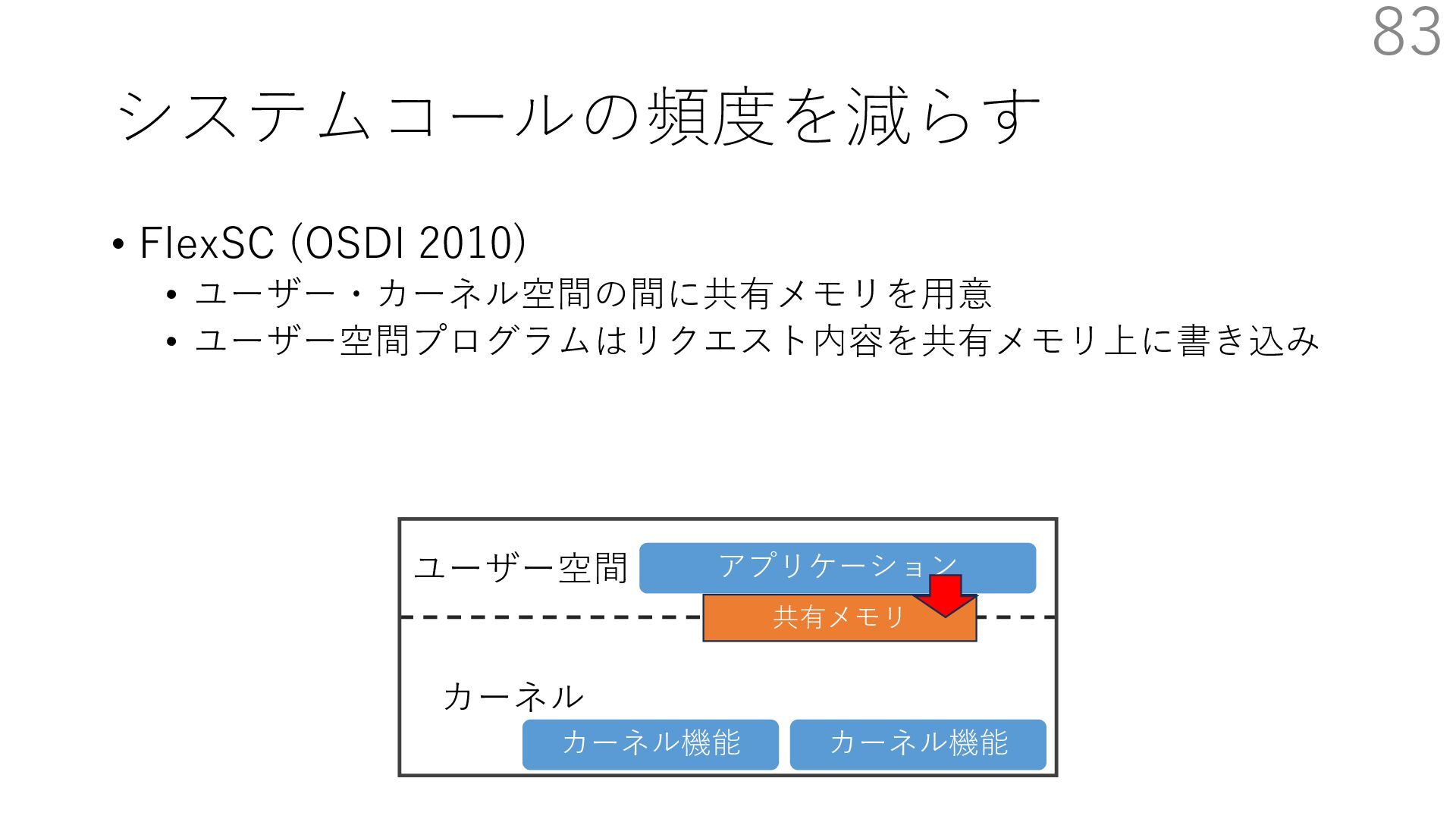
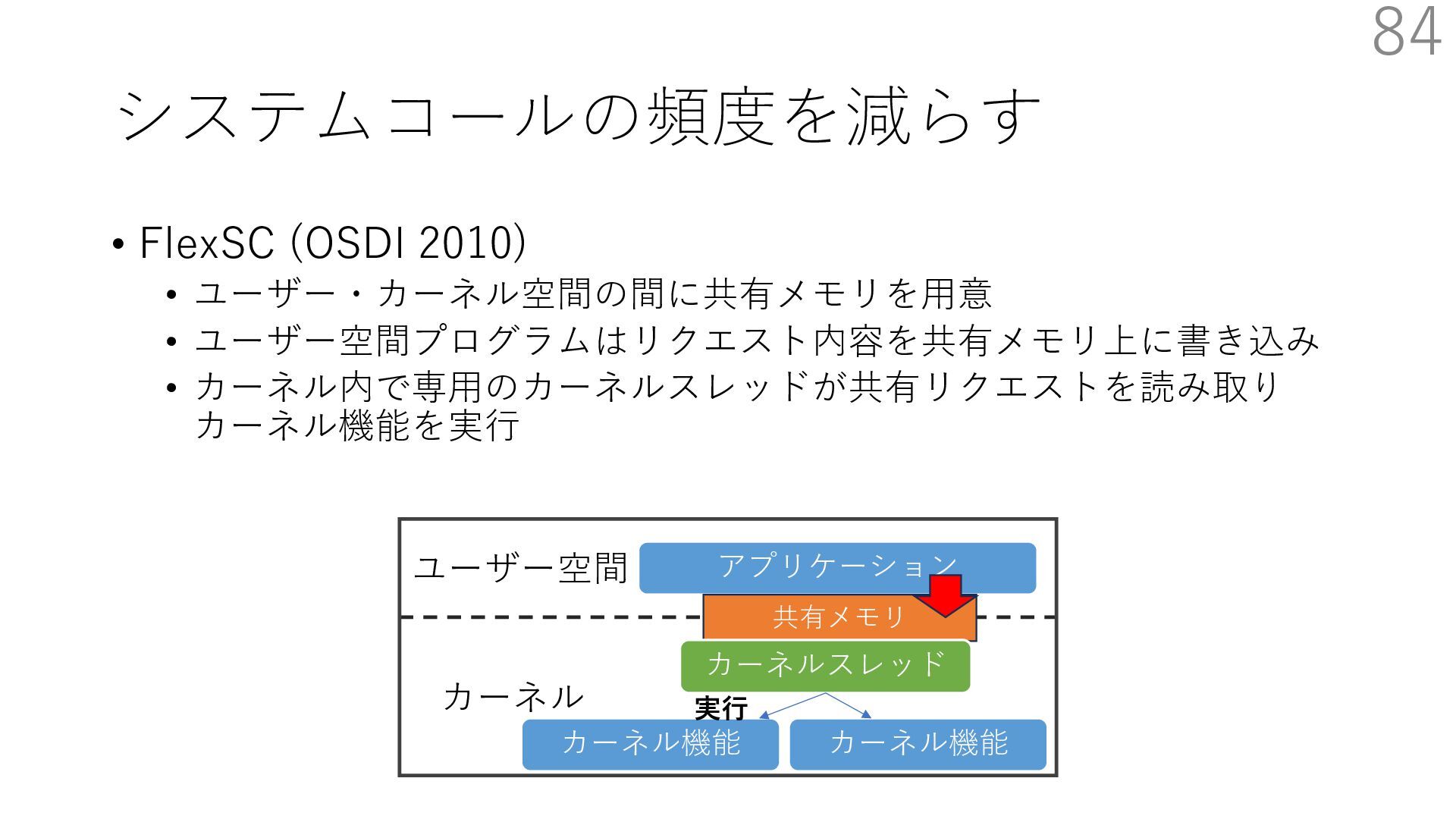
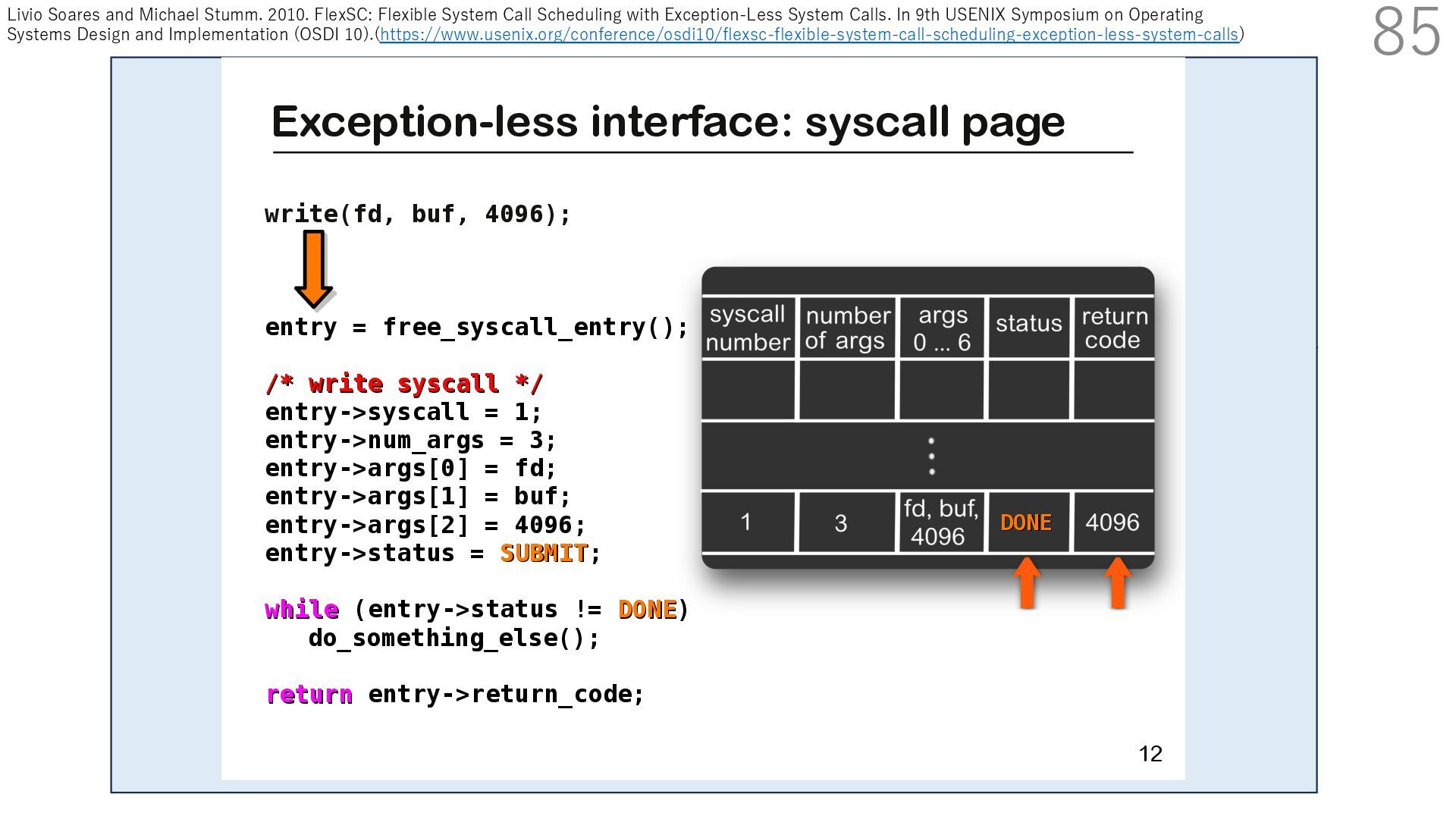
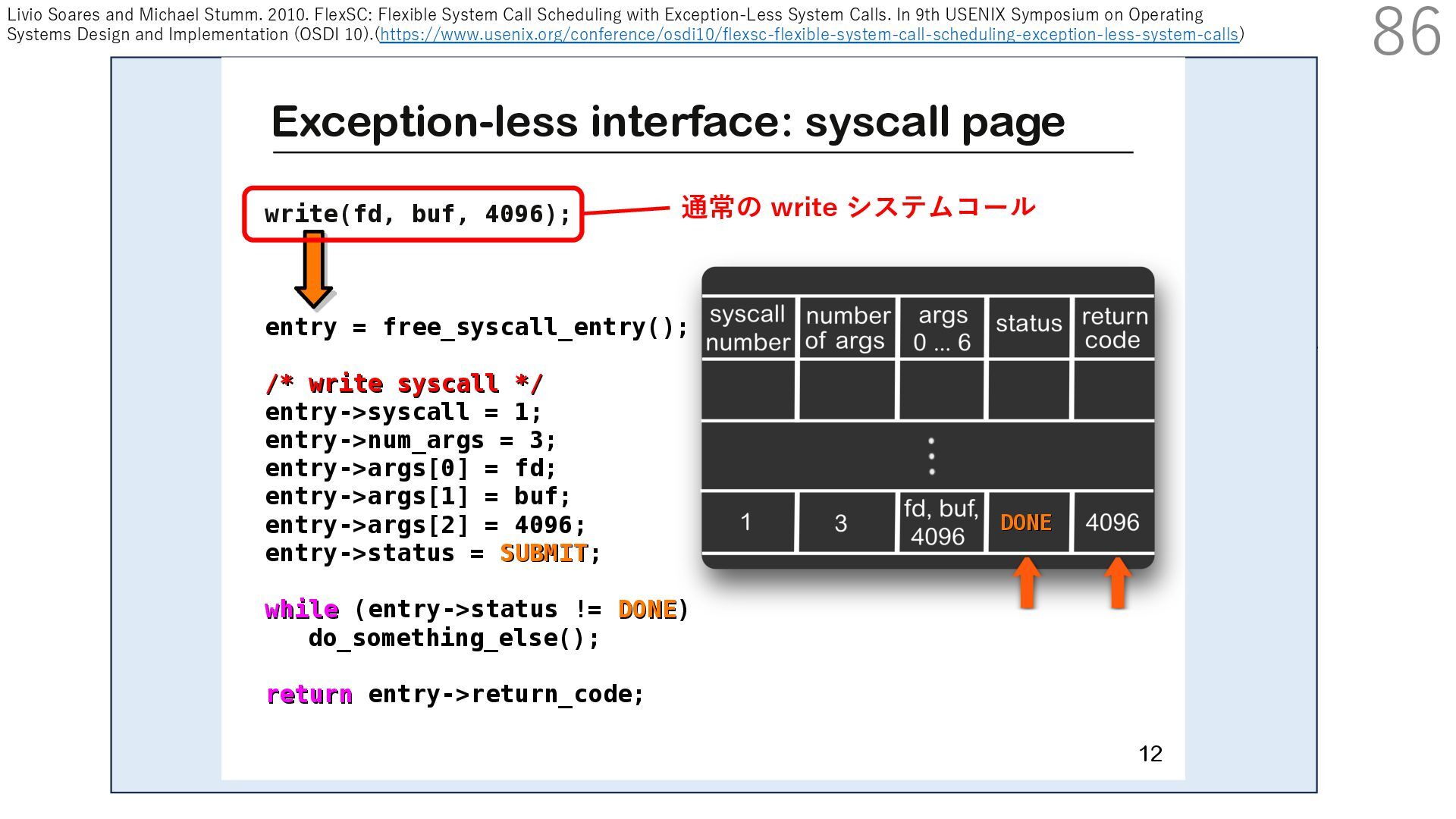
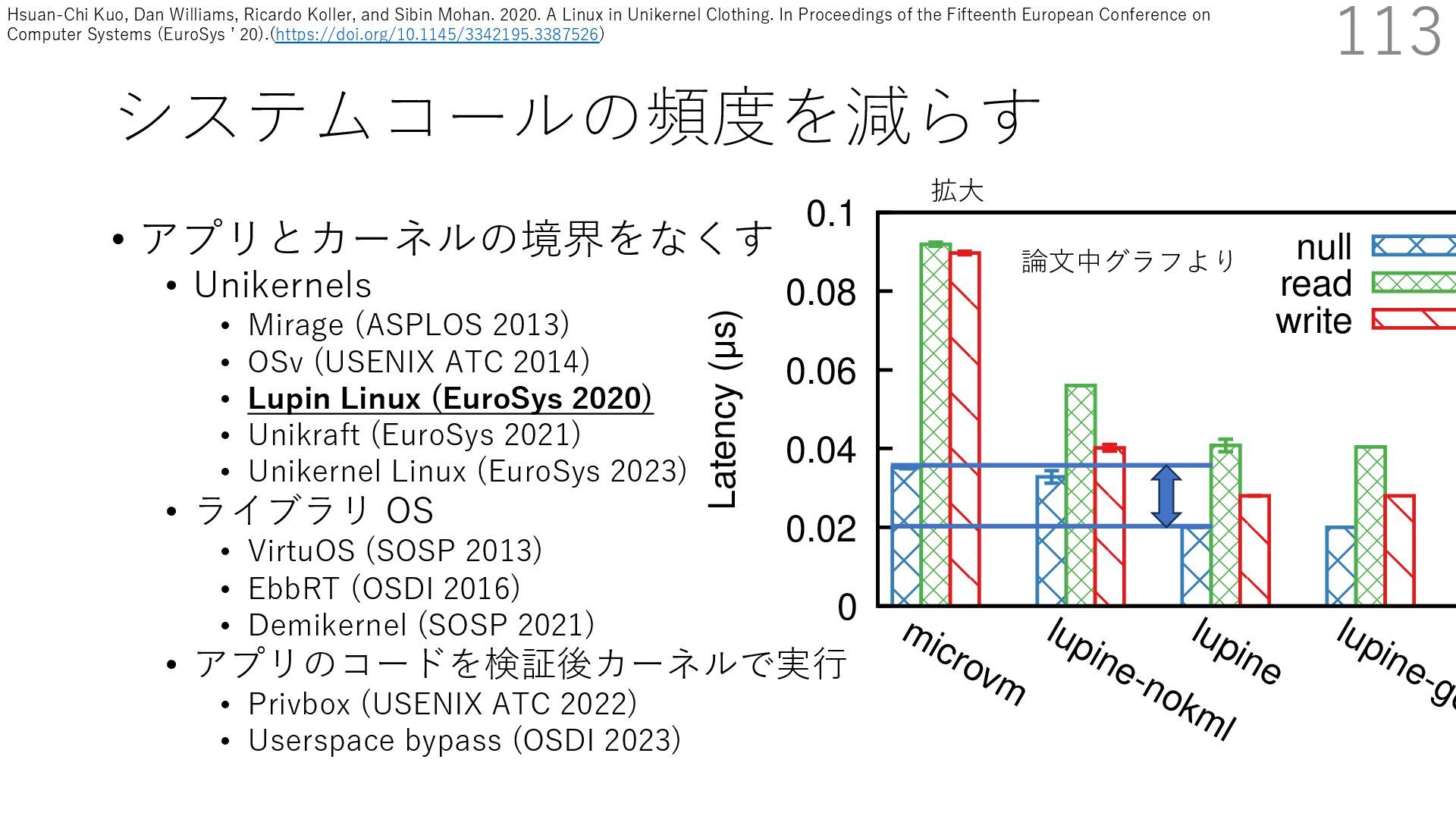
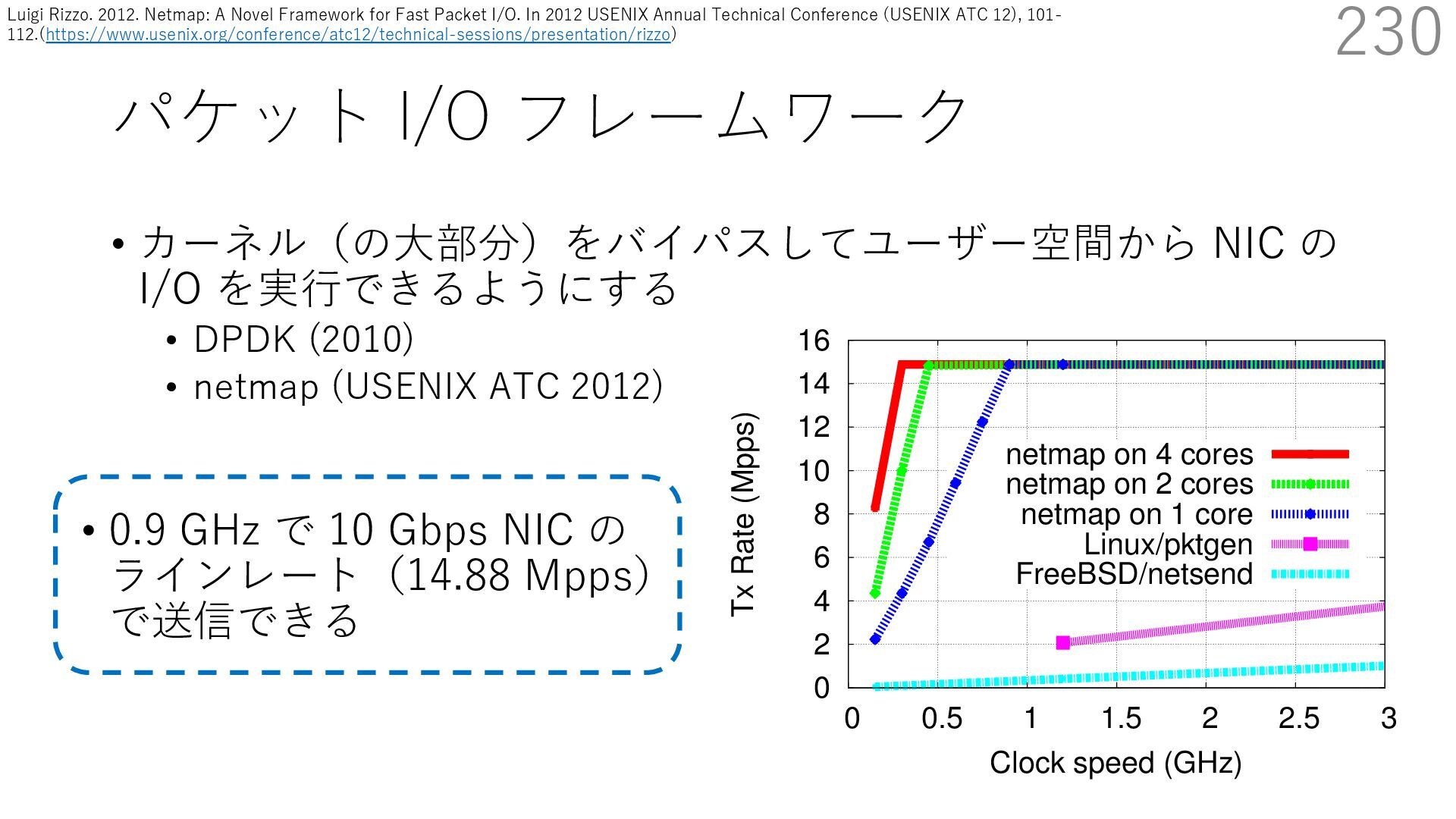
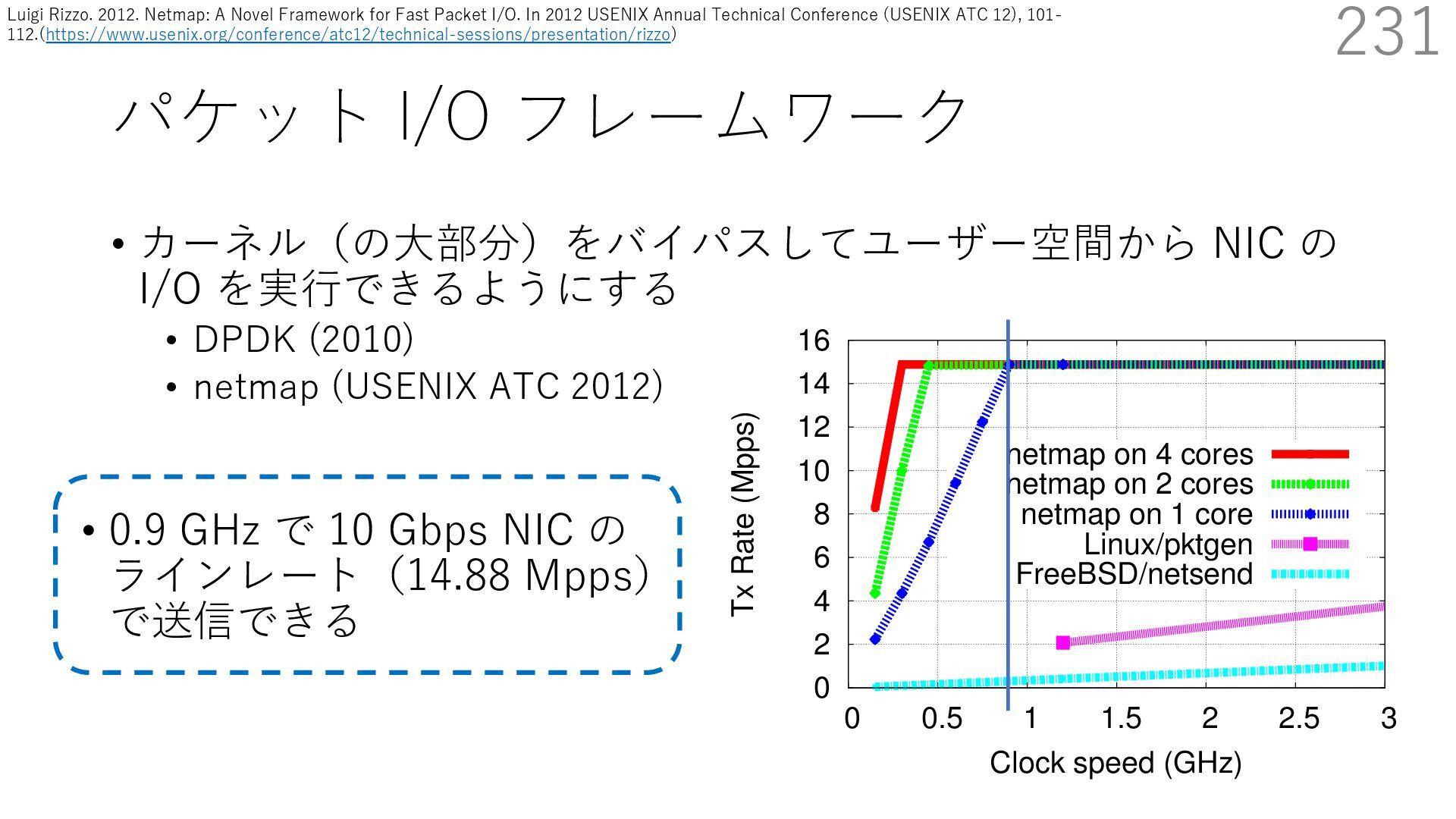
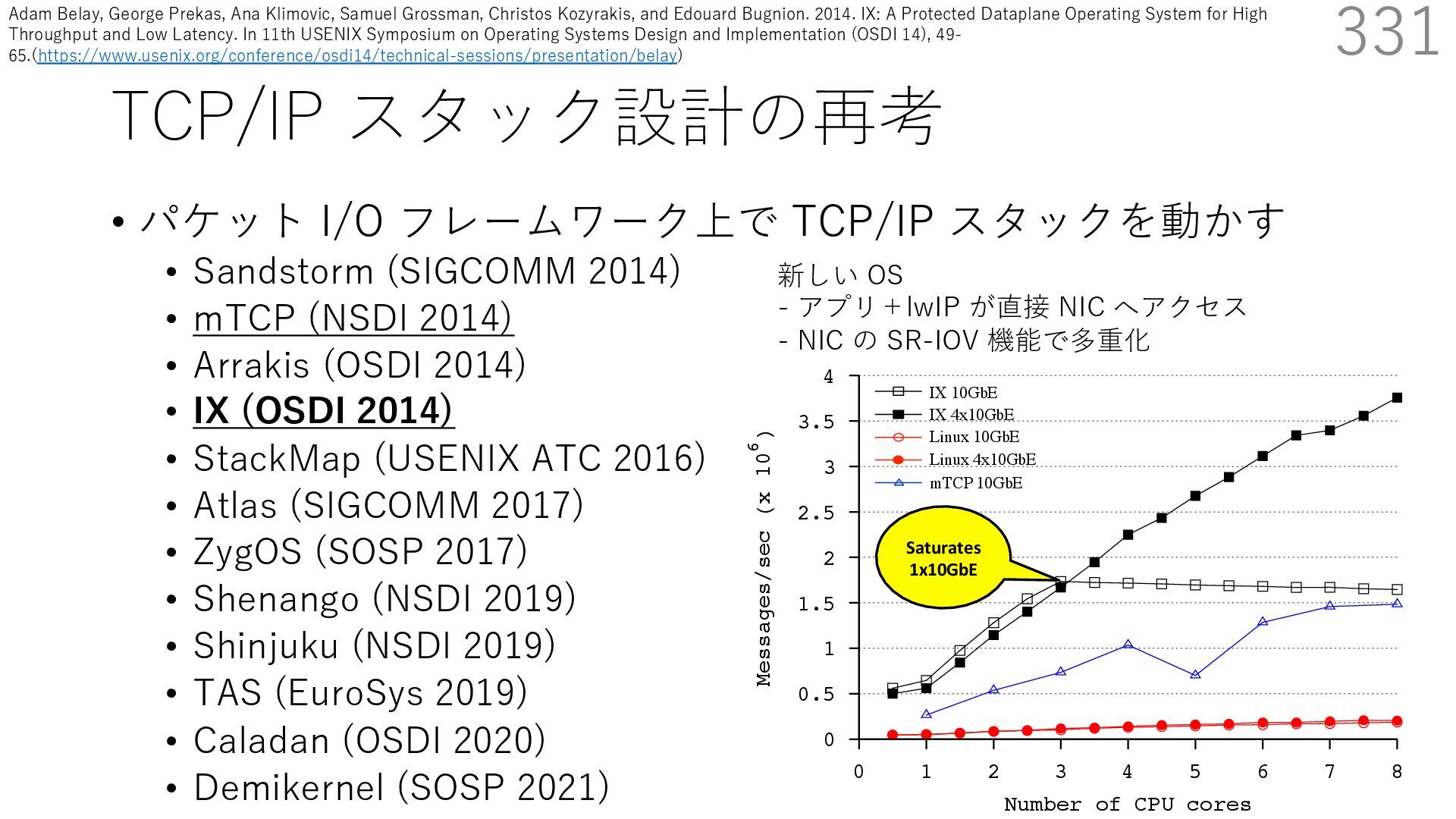
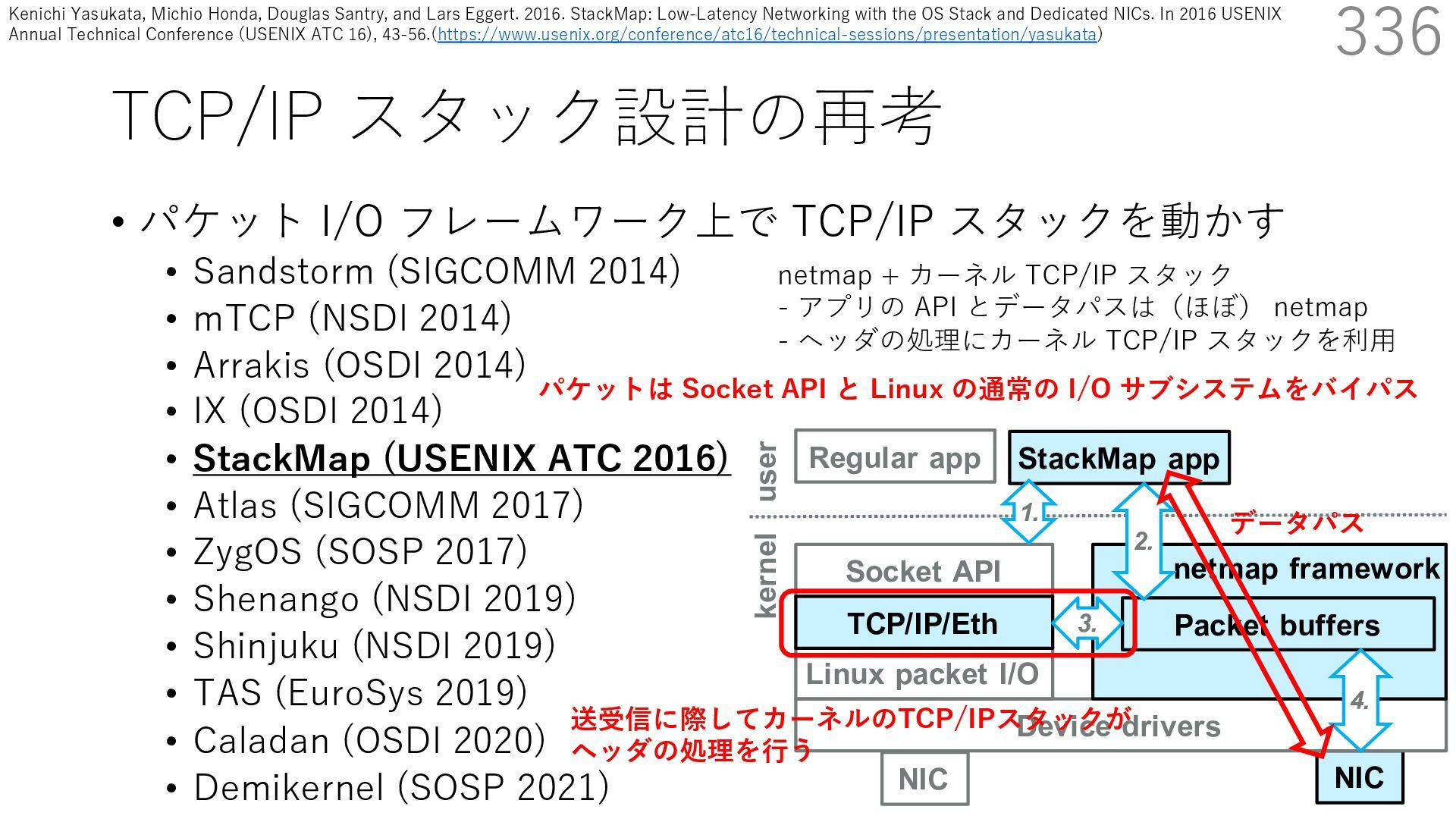
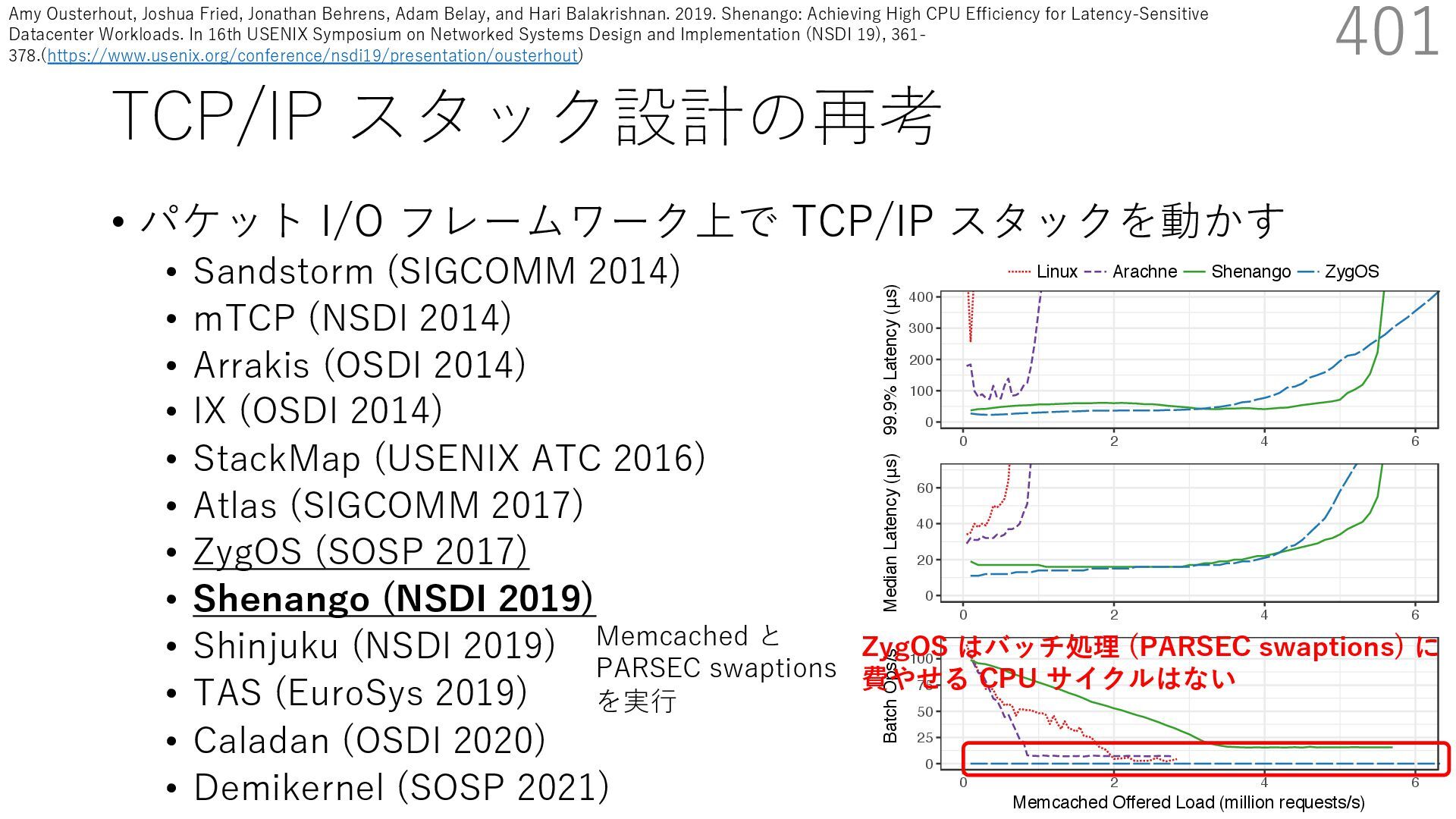
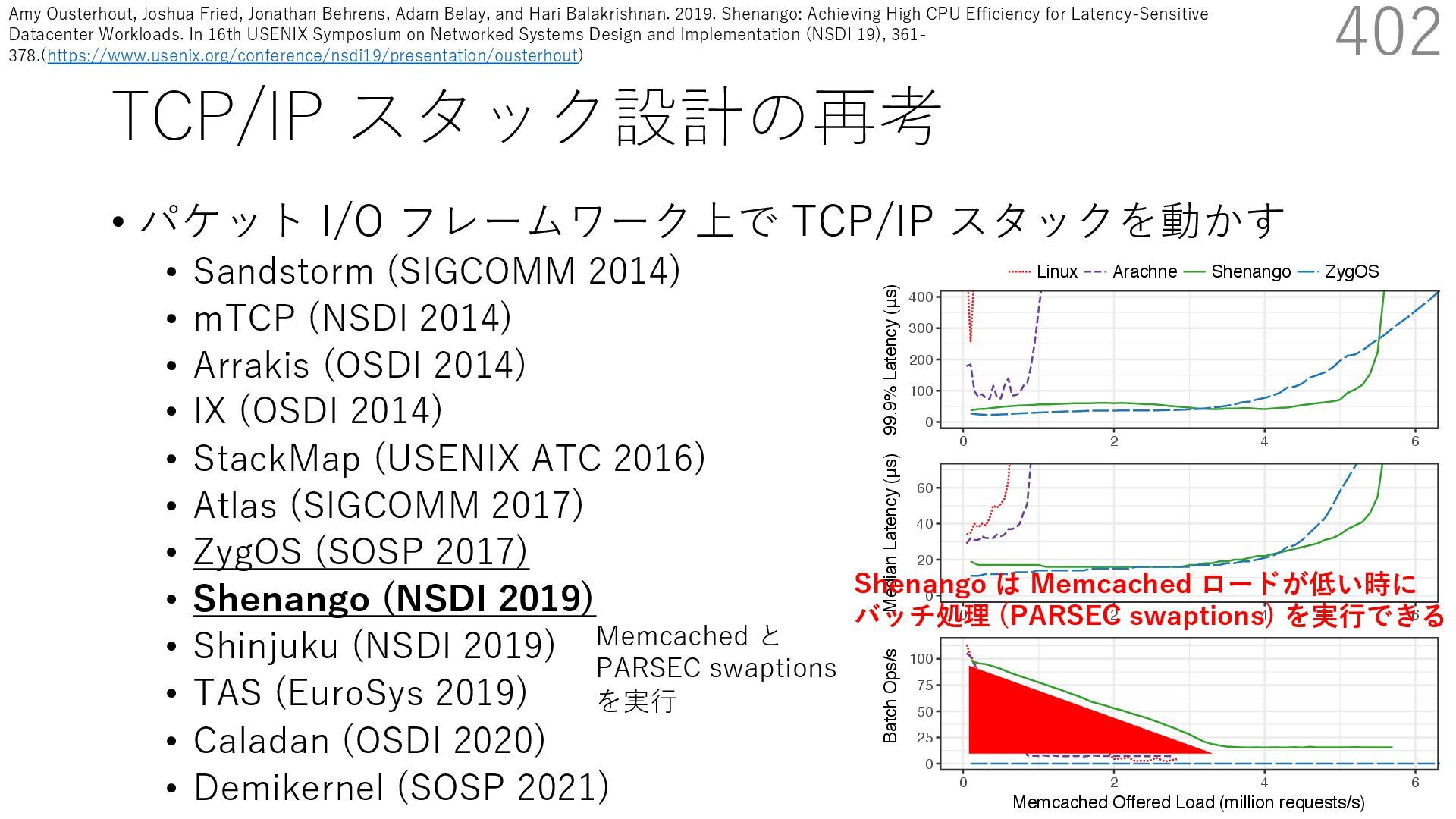
DPDK (2010) • netmap (USENIX ATC 2012) on costs almost negligible: a packet generator reams pre-generated packets, and a packet re- hich just counts incoming packets. est equipment e run most of our experiments on systems d with an i7-870 4-core CPU at 2.93 GHz Hz with turbo-boost), memory running at Hz, and a dual port 10 Gbit/s card based on the 599 NIC. The numbers reported in this paper the netmap version in FreeBSD HEAD/amd64 0 2 4 6 8 10 12 14 16 0 0.5 1 1.5 2 2.5 3 Tx Rate (Mpps) Clock speed (GHz) netmap on 4 cores netmap on 2 cores netmap on 1 core Linux/pktgen FreeBSD/netsend • 0.9 GHz で 10 Gbps NIC の ラインレート(14.88 Mpps) で送信できる 230 Luigi Rizzo. 2012. Netmap: A Novel Framework for Fast Packet I/O. In 2012 USENIX Annual Technical Conference (USENIX ATC 12), 101- 112.(https://www.usenix.org/conference/atc12/technical-sessions/presentation/rizzo)
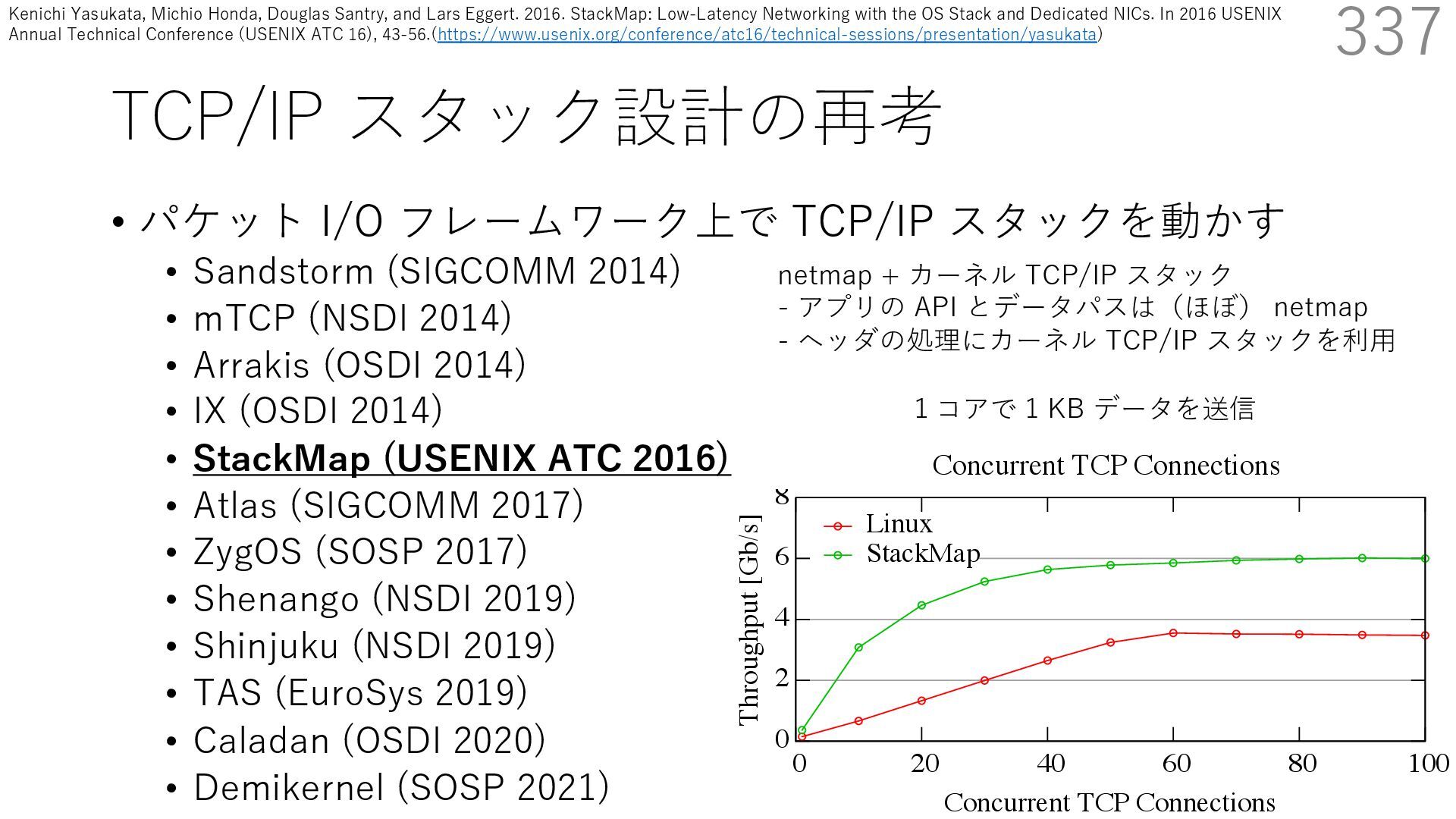
DPDK (2010) • netmap (USENIX ATC 2012) on costs almost negligible: a packet generator reams pre-generated packets, and a packet re- hich just counts incoming packets. est equipment e run most of our experiments on systems d with an i7-870 4-core CPU at 2.93 GHz Hz with turbo-boost), memory running at Hz, and a dual port 10 Gbit/s card based on the 599 NIC. The numbers reported in this paper the netmap version in FreeBSD HEAD/amd64 0 2 4 6 8 10 12 14 16 0 0.5 1 1.5 2 2.5 3 Tx Rate (Mpps) Clock speed (GHz) netmap on 4 cores netmap on 2 cores netmap on 1 core Linux/pktgen FreeBSD/netsend • 0.9 GHz で 10 Gbps NIC の ラインレート(14.88 Mpps) で送信できる 231 Luigi Rizzo. 2012. Netmap: A Novel Framework for Fast Packet I/O. In 2012 USENIX Annual Technical Conference (USENIX ATC 12), 101- 112.(https://www.usenix.org/conference/atc12/technical-sessions/presentation/rizzo)
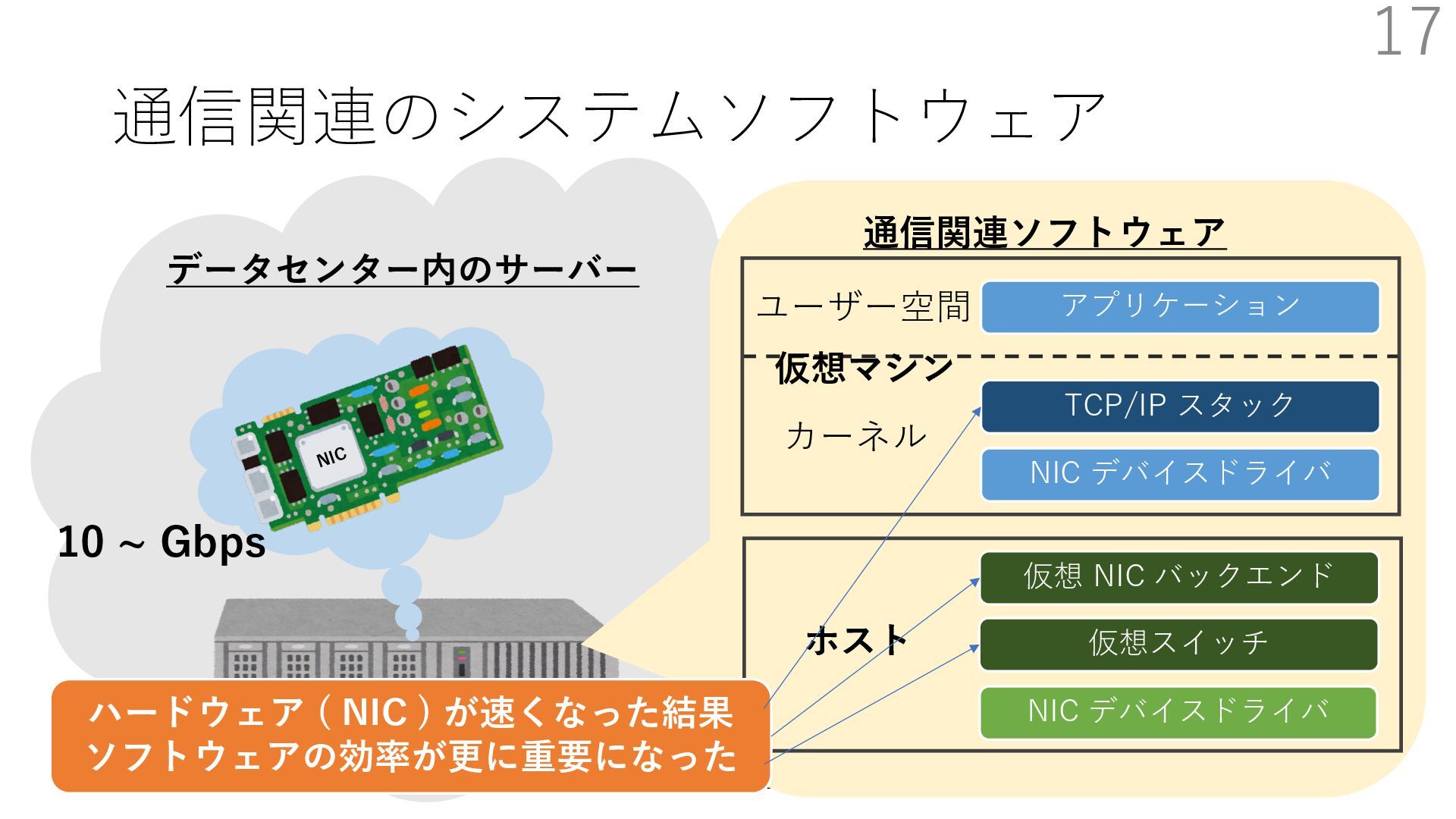
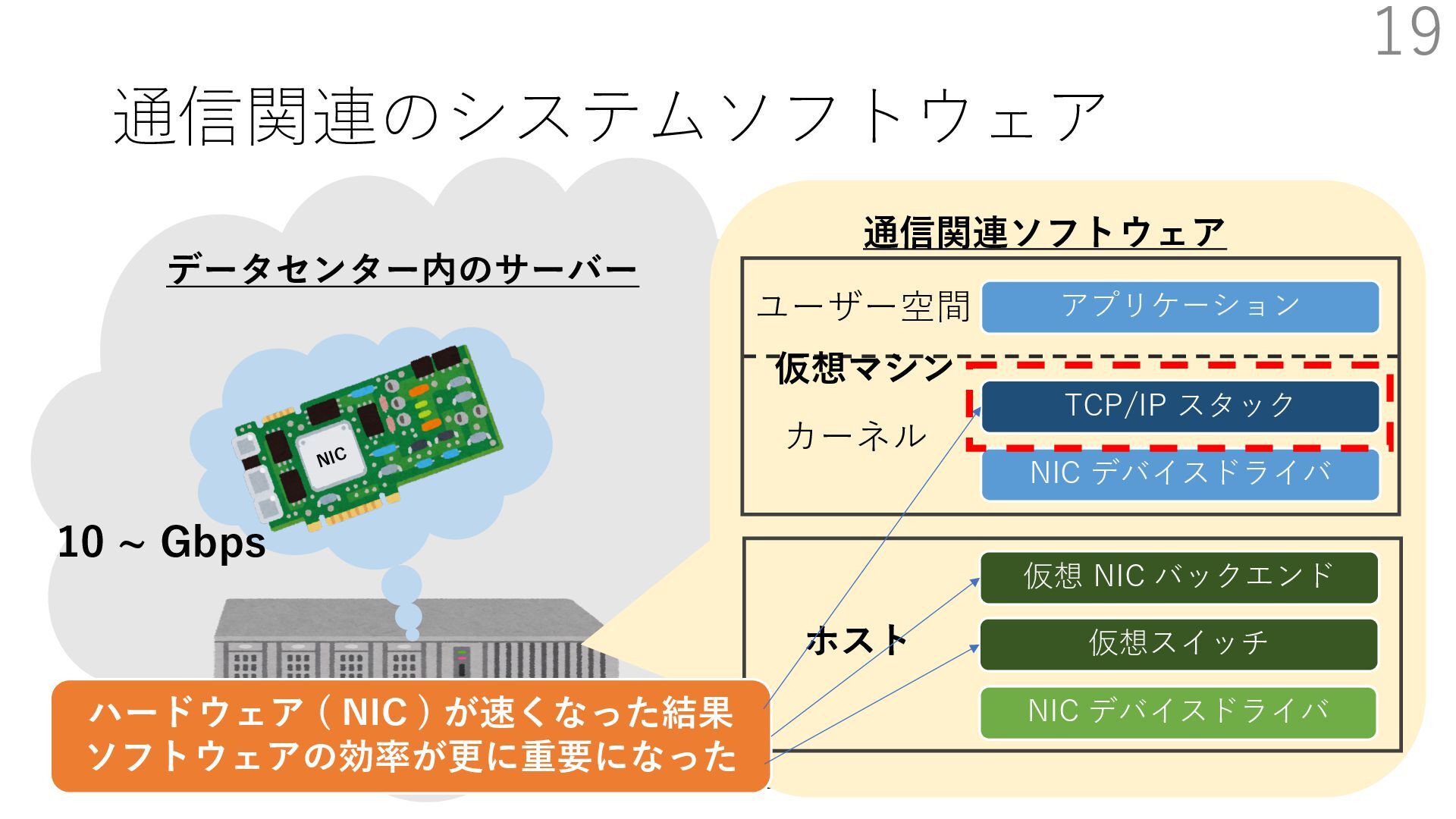
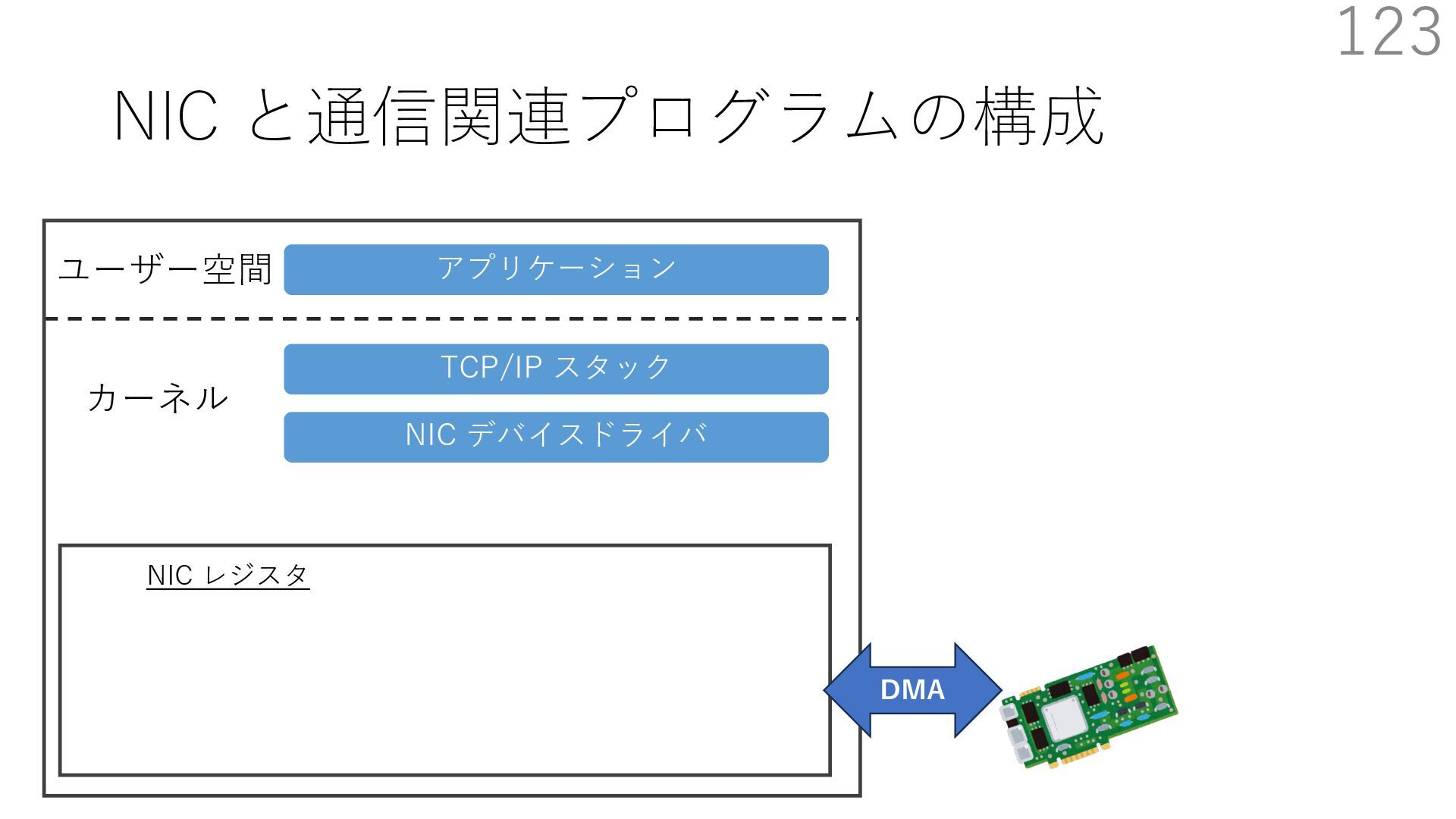
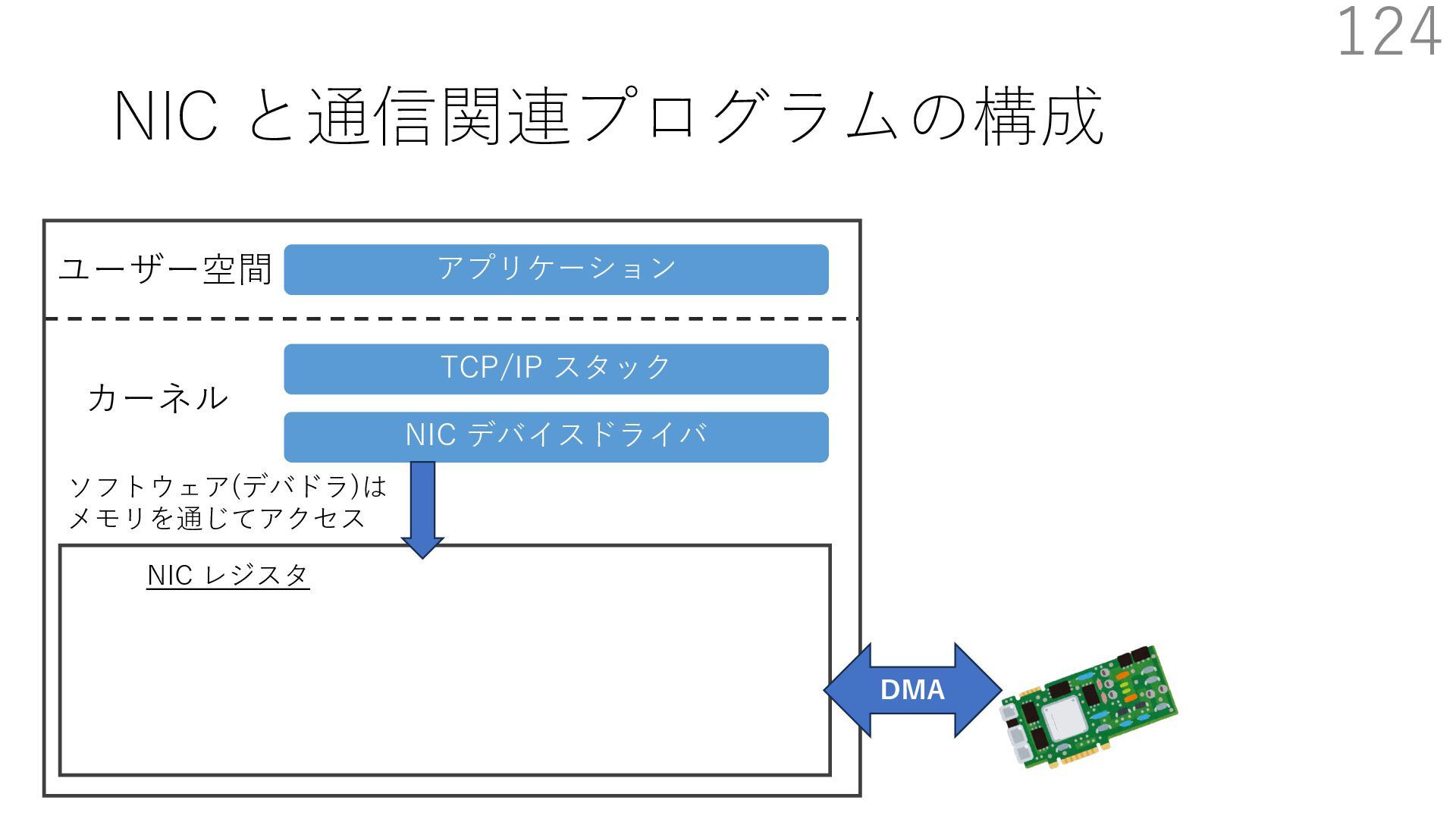
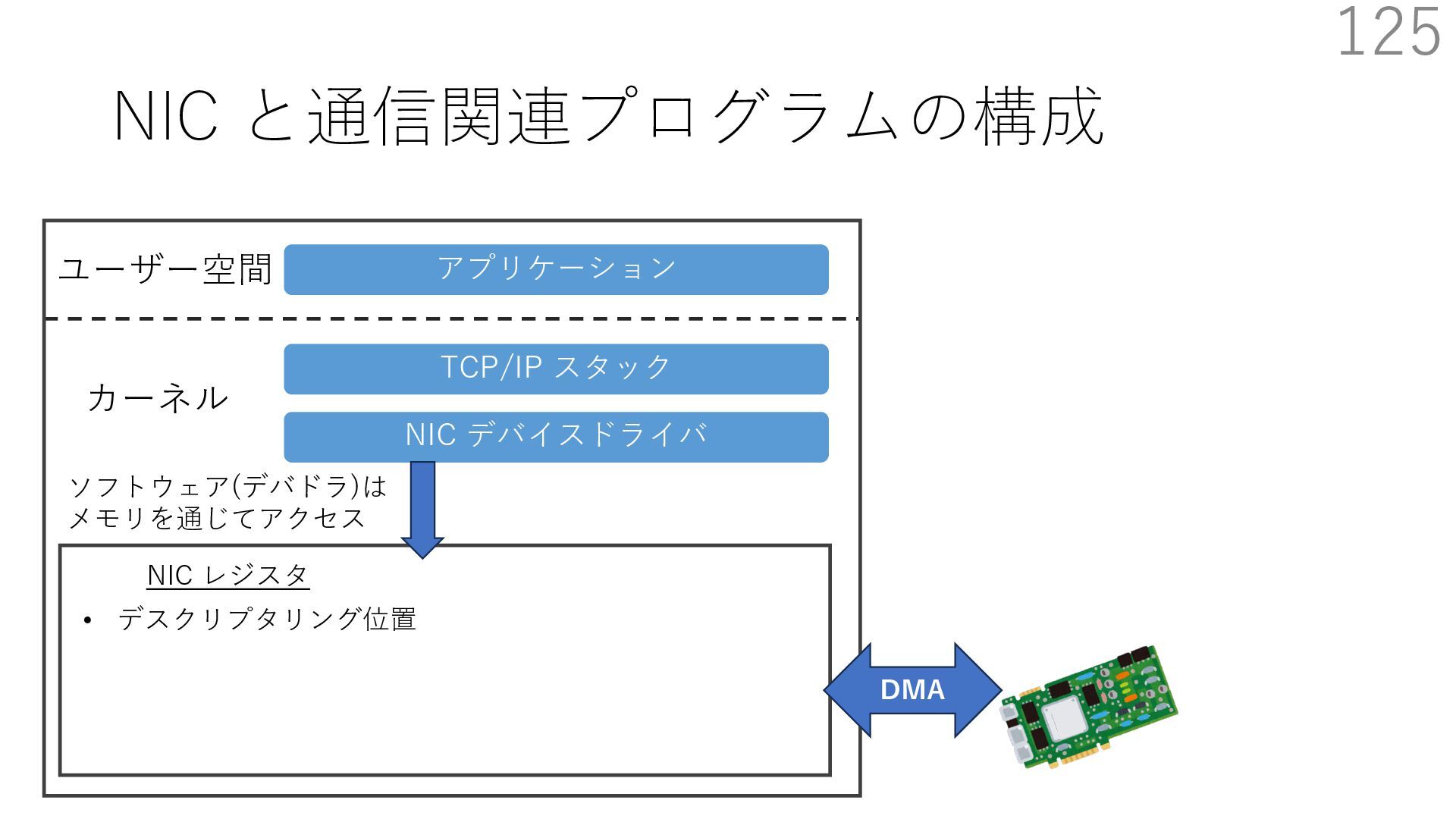
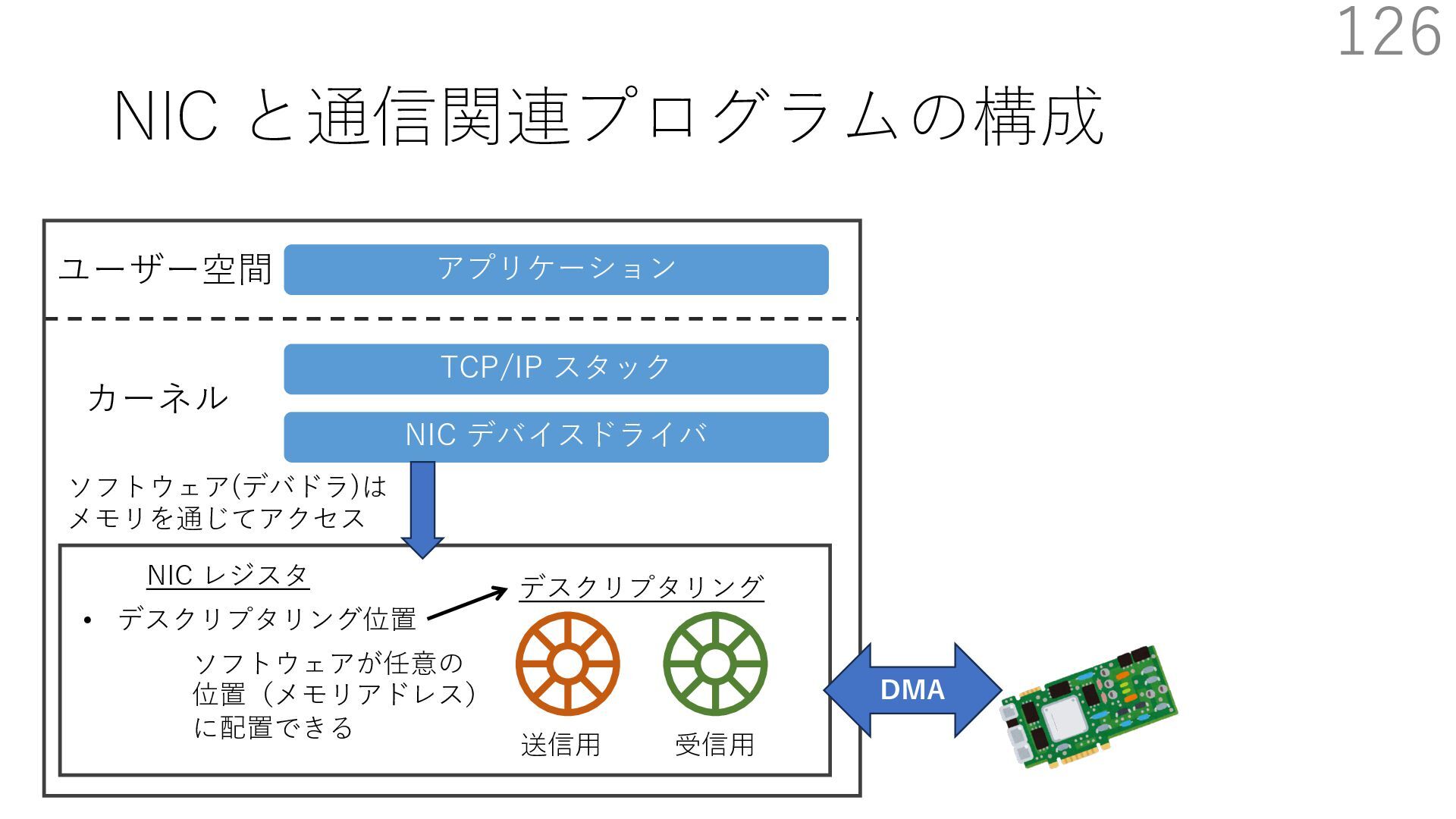
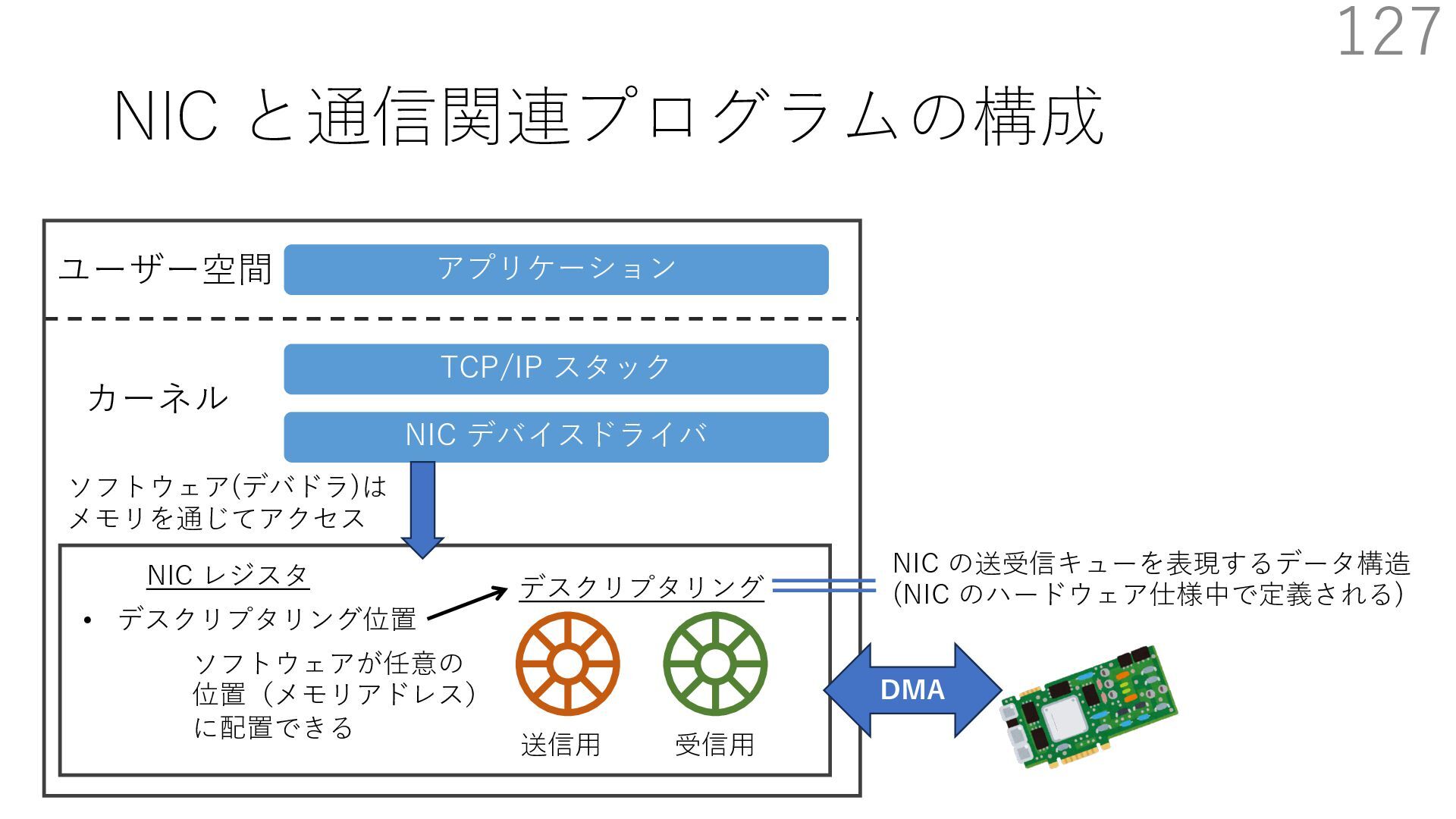
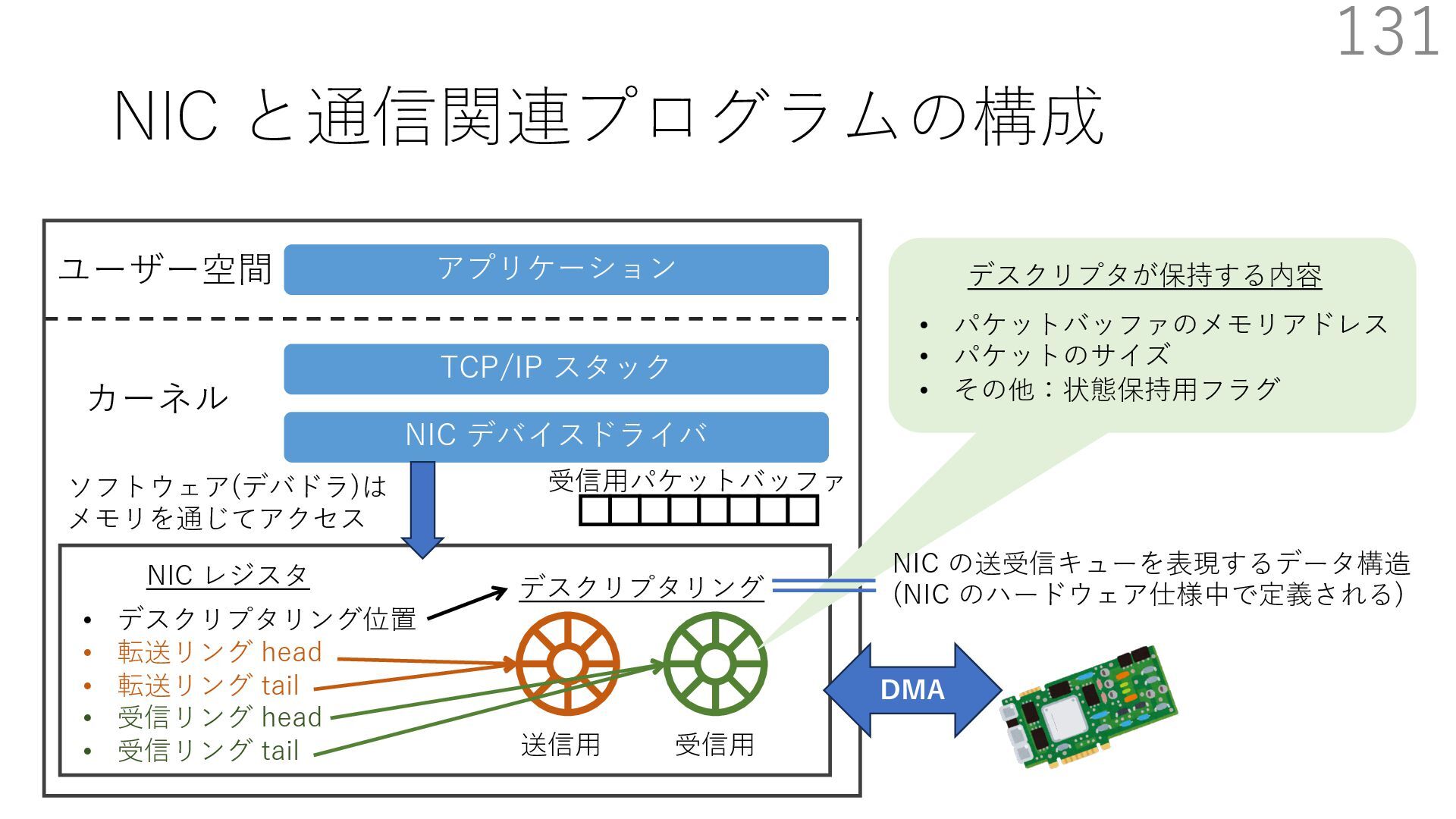
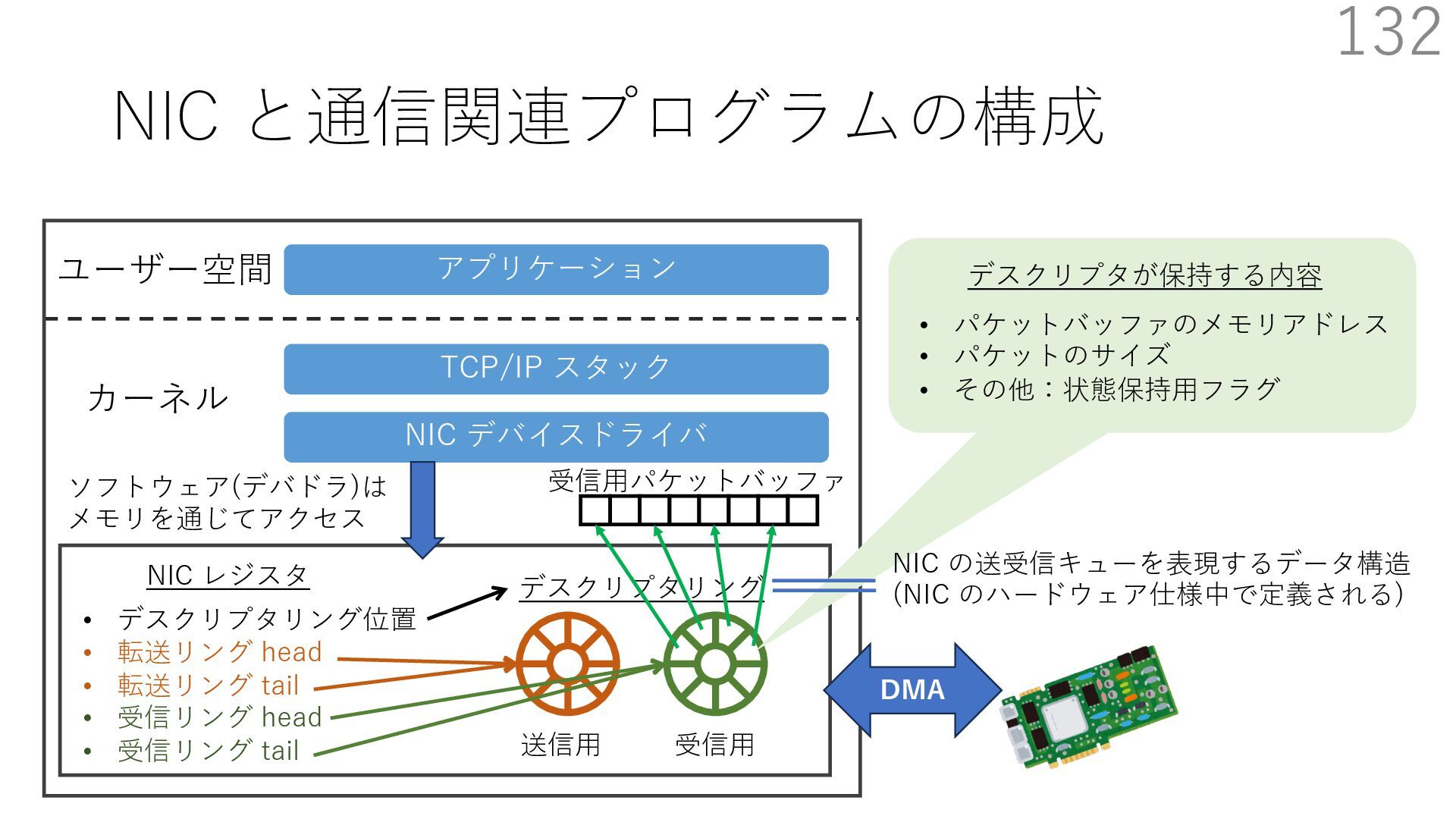
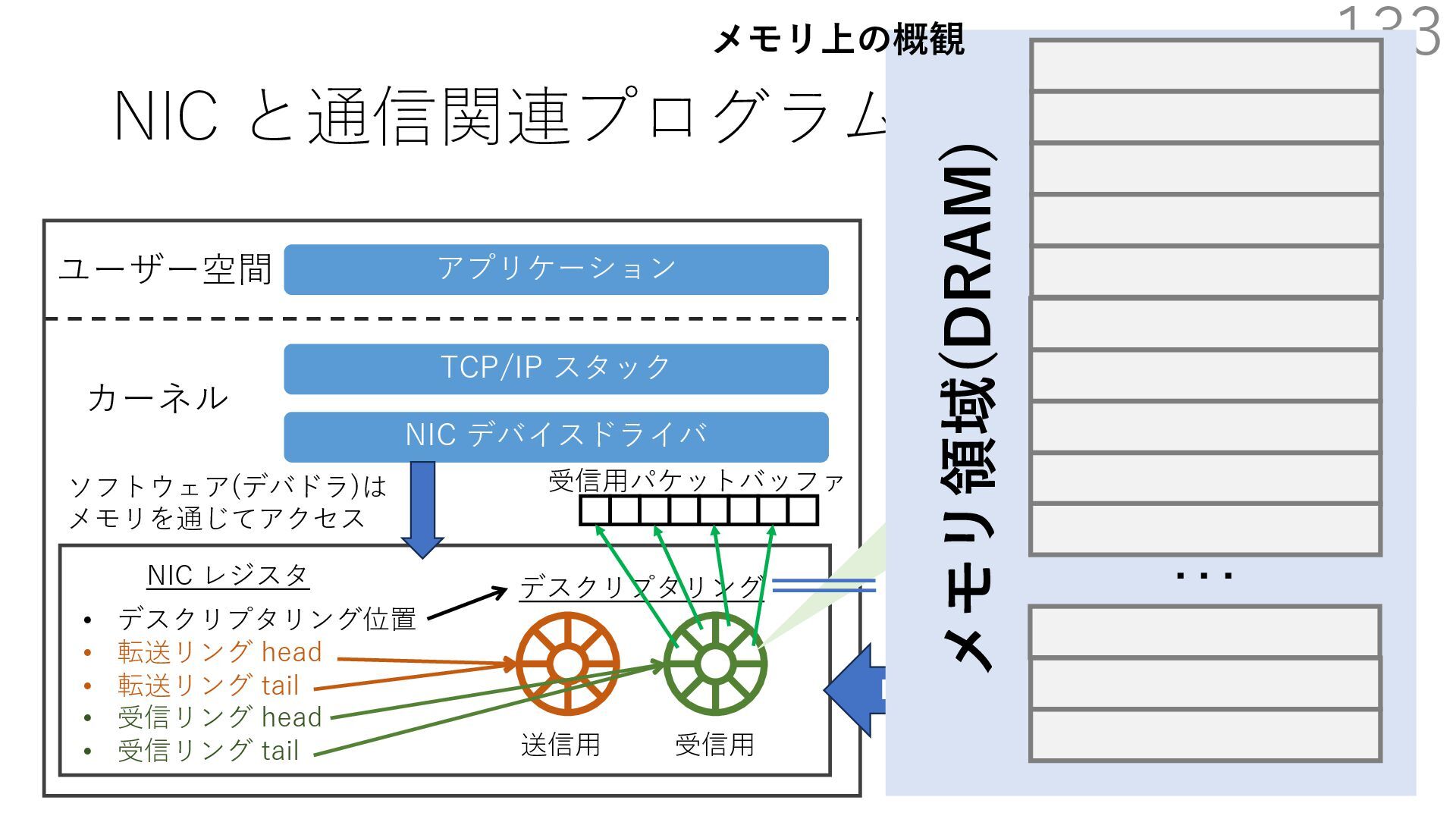
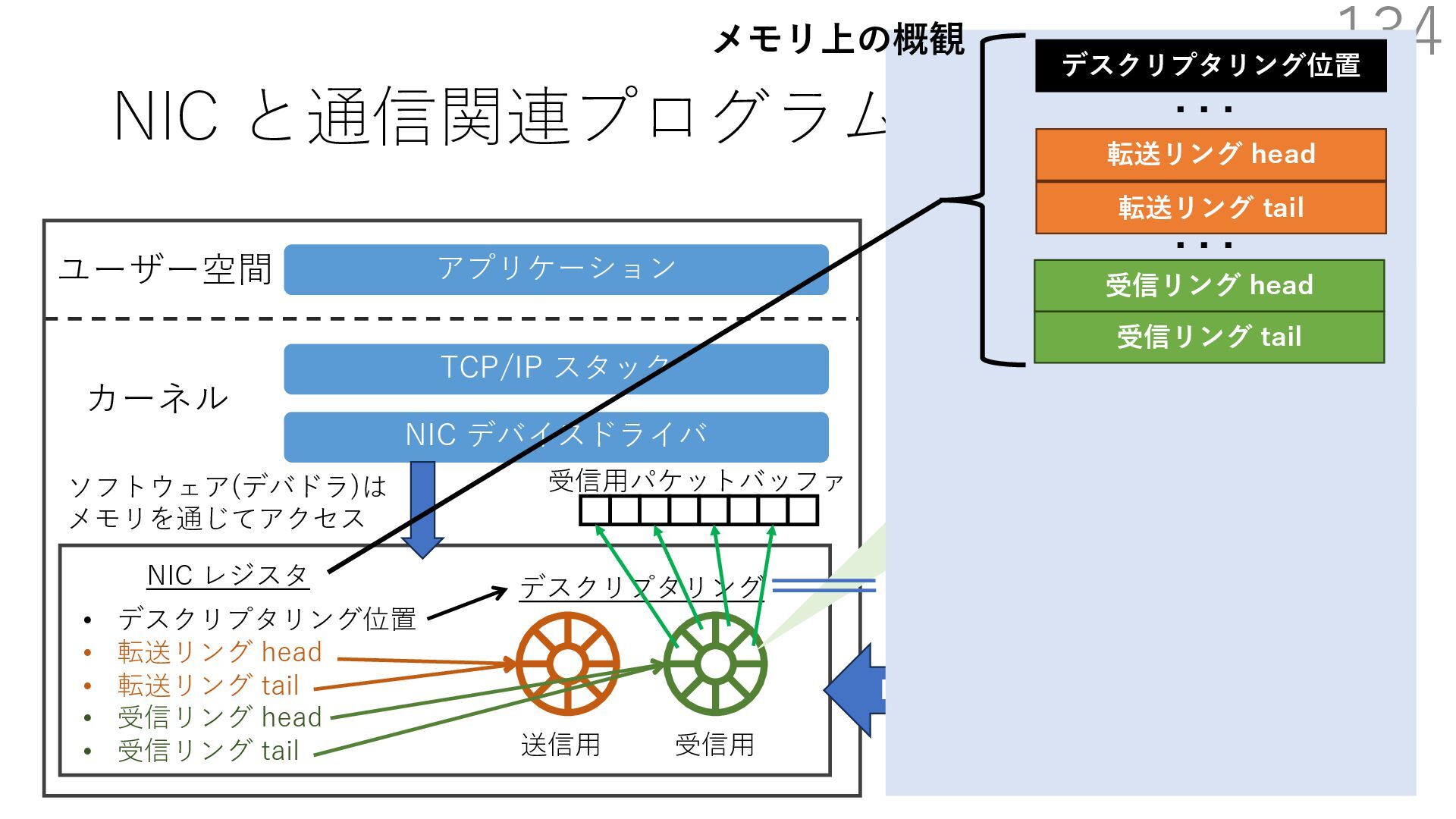
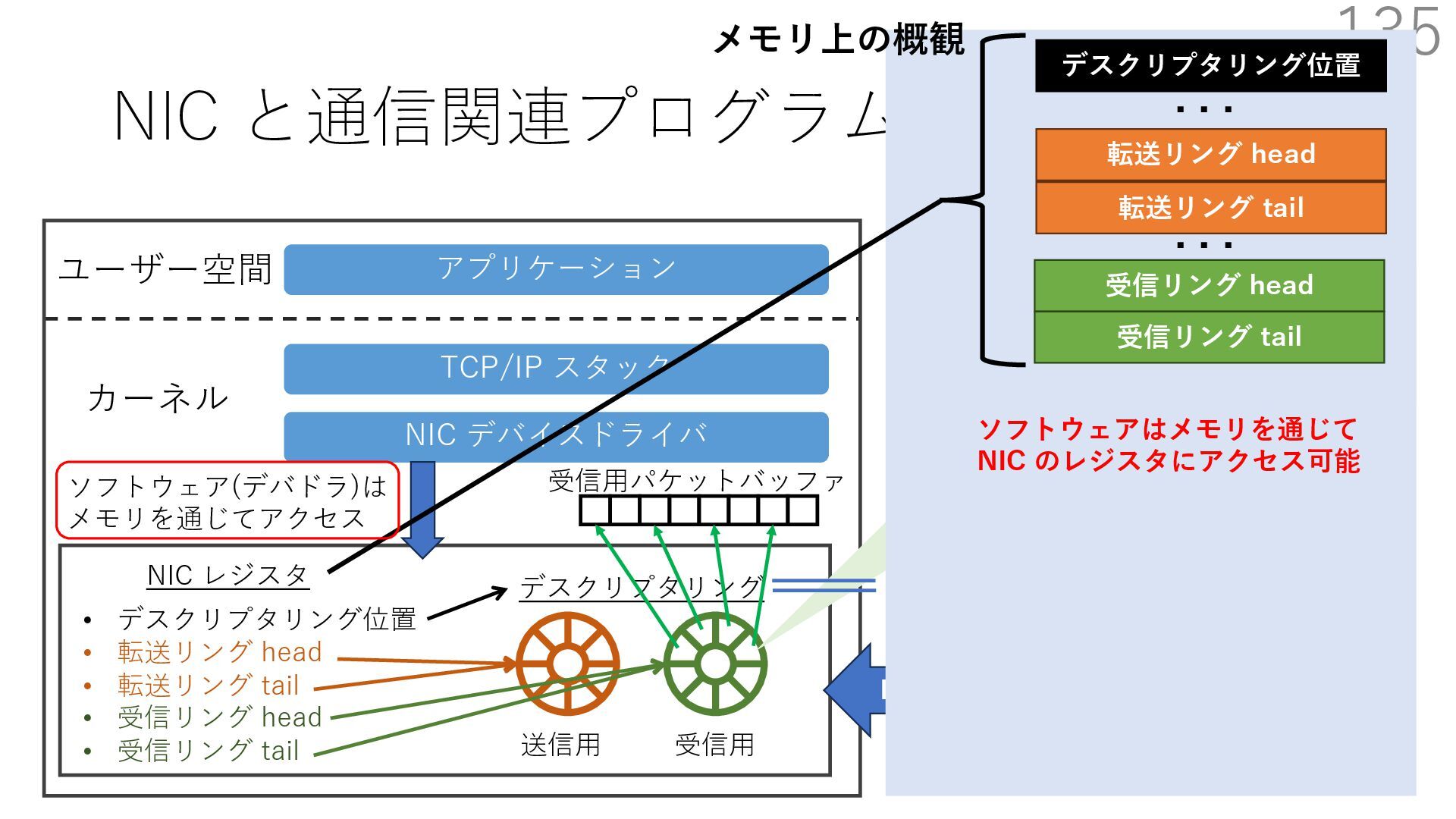
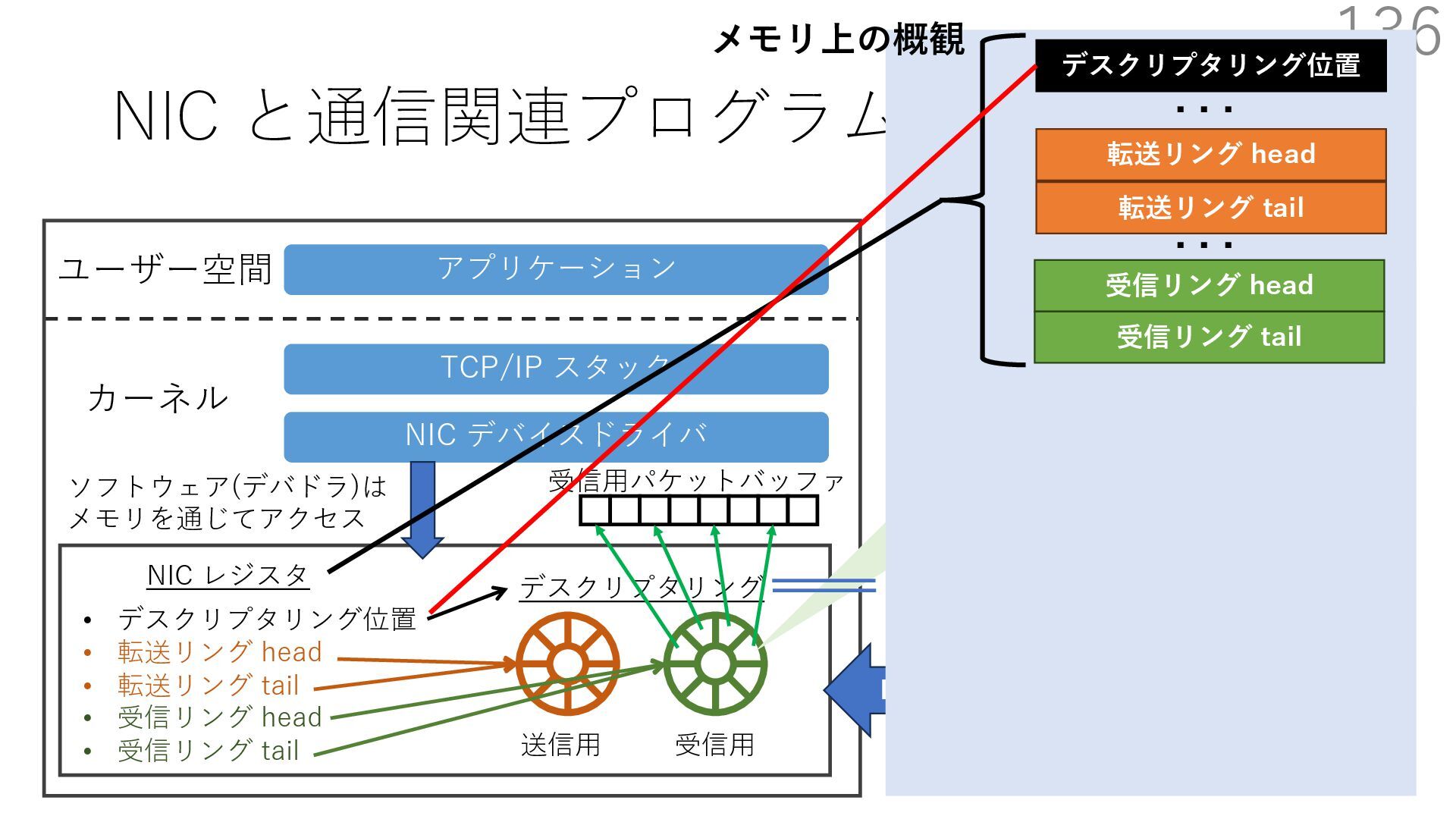
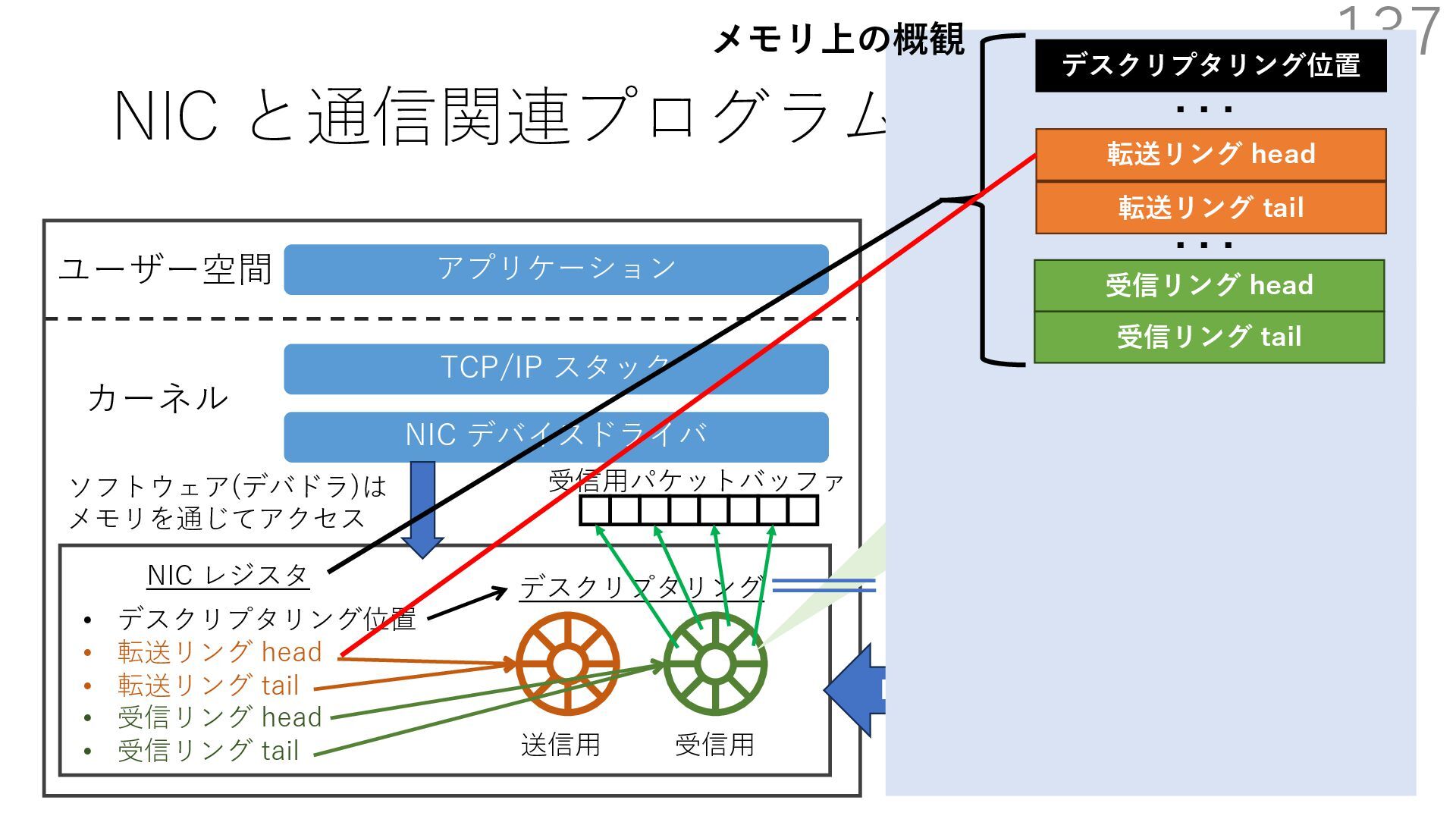
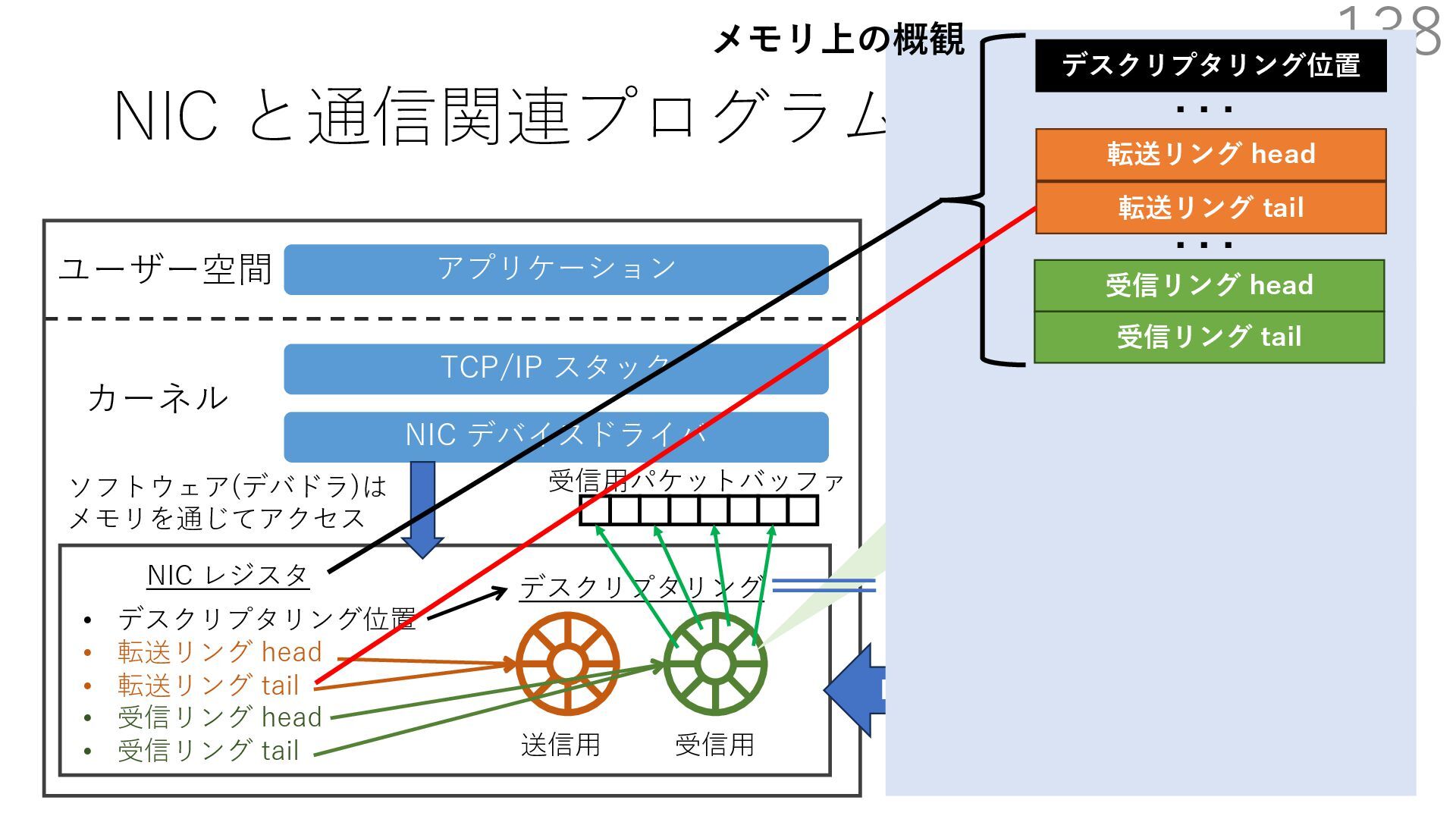
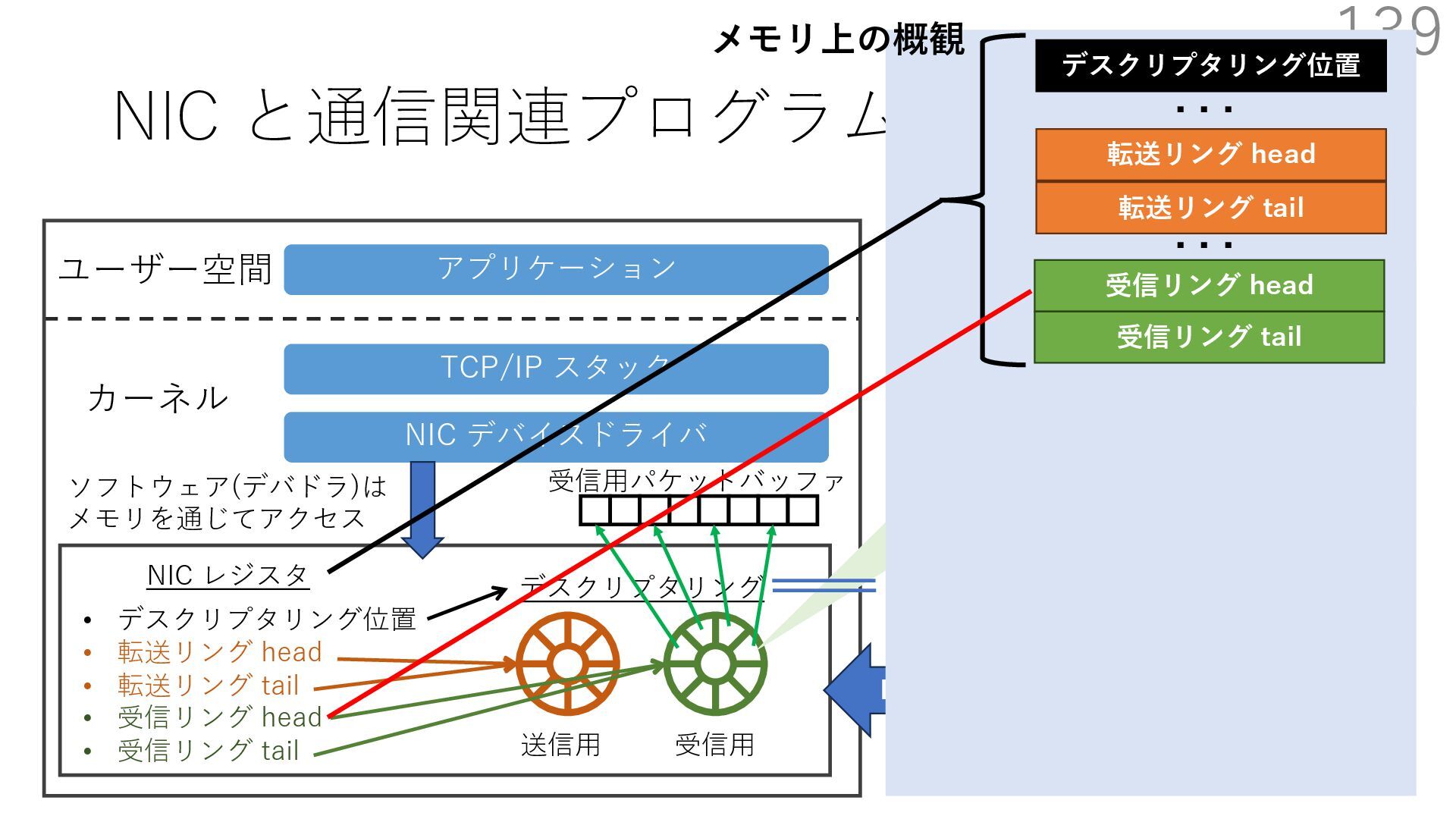
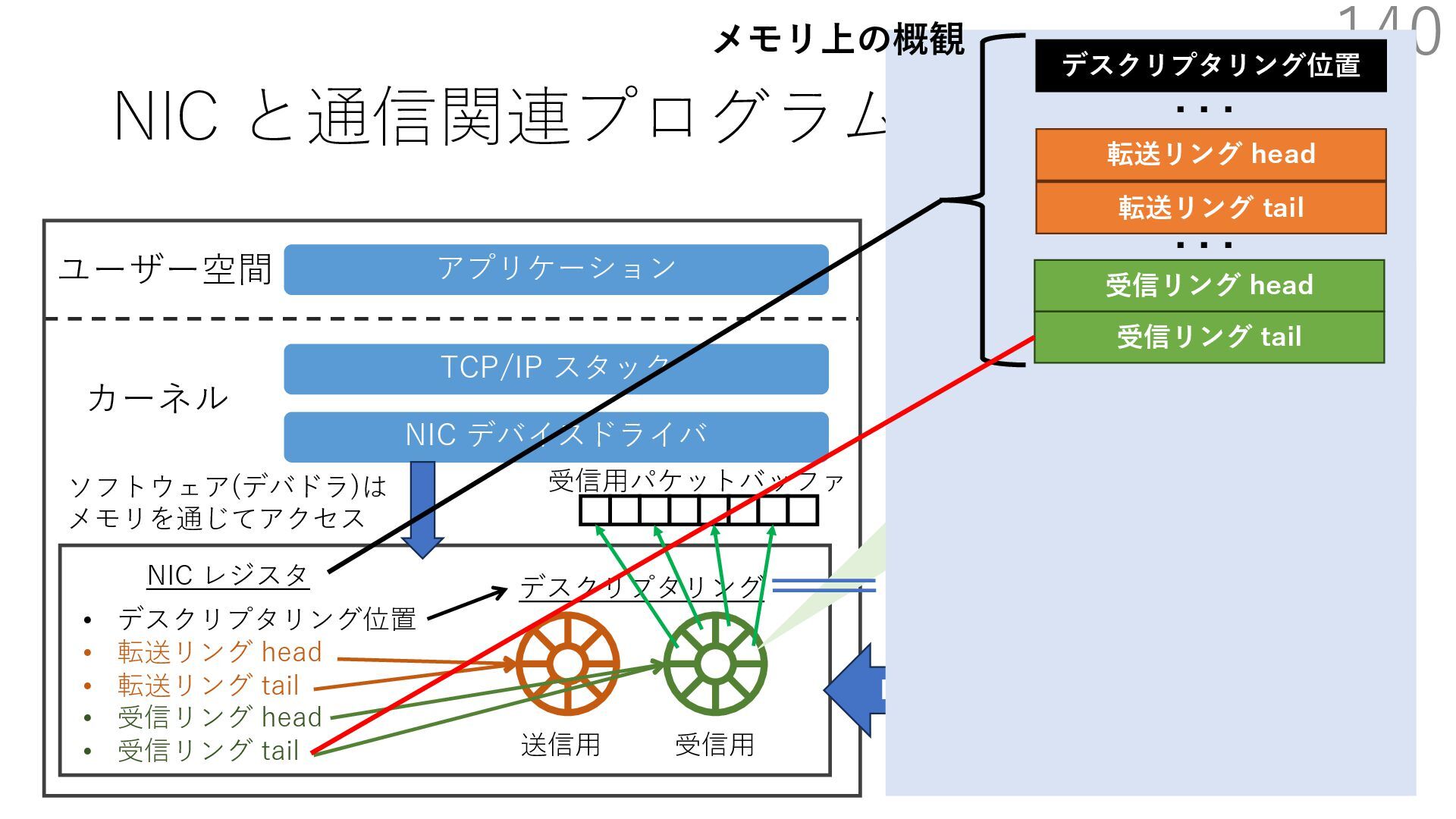
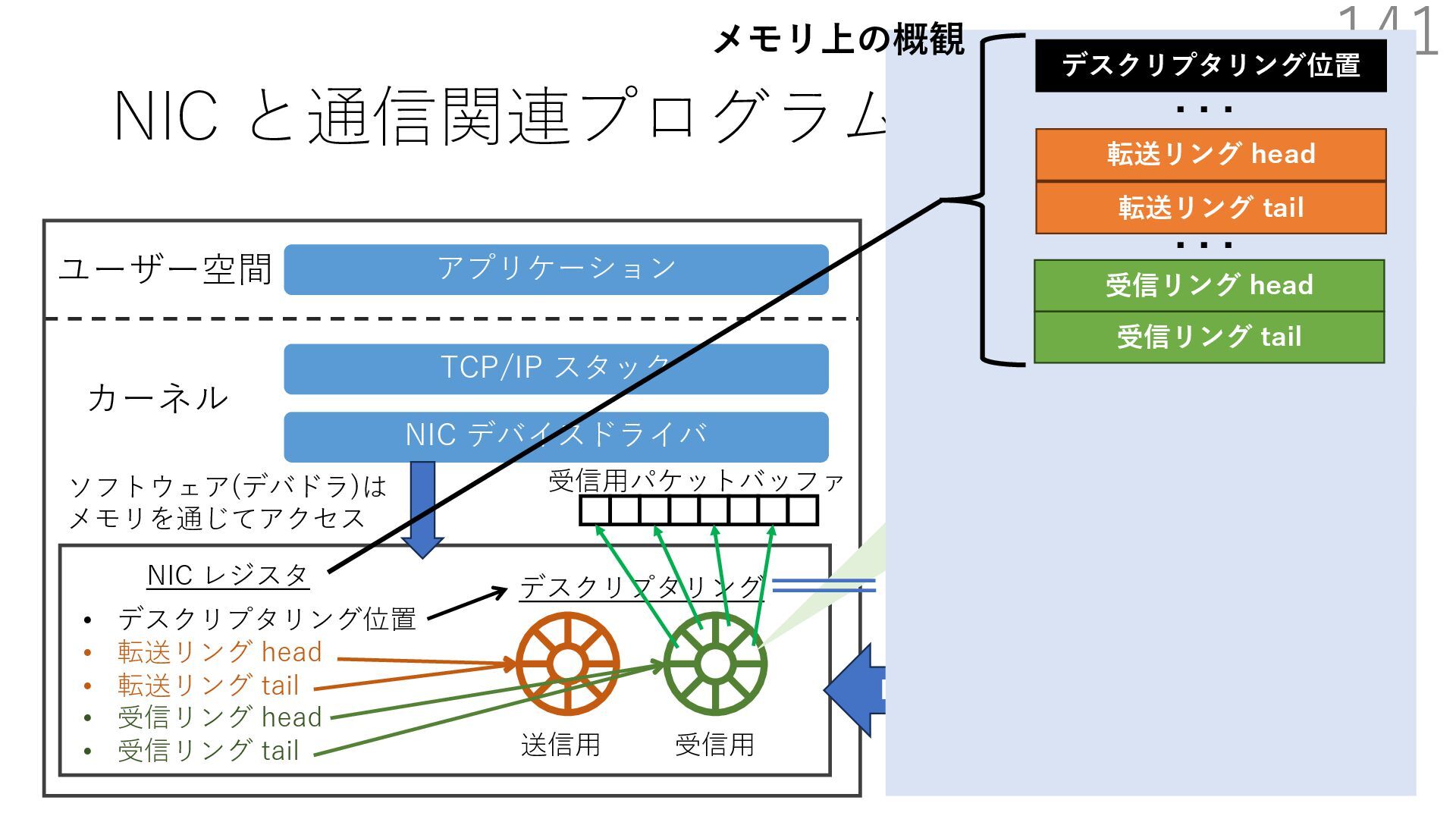
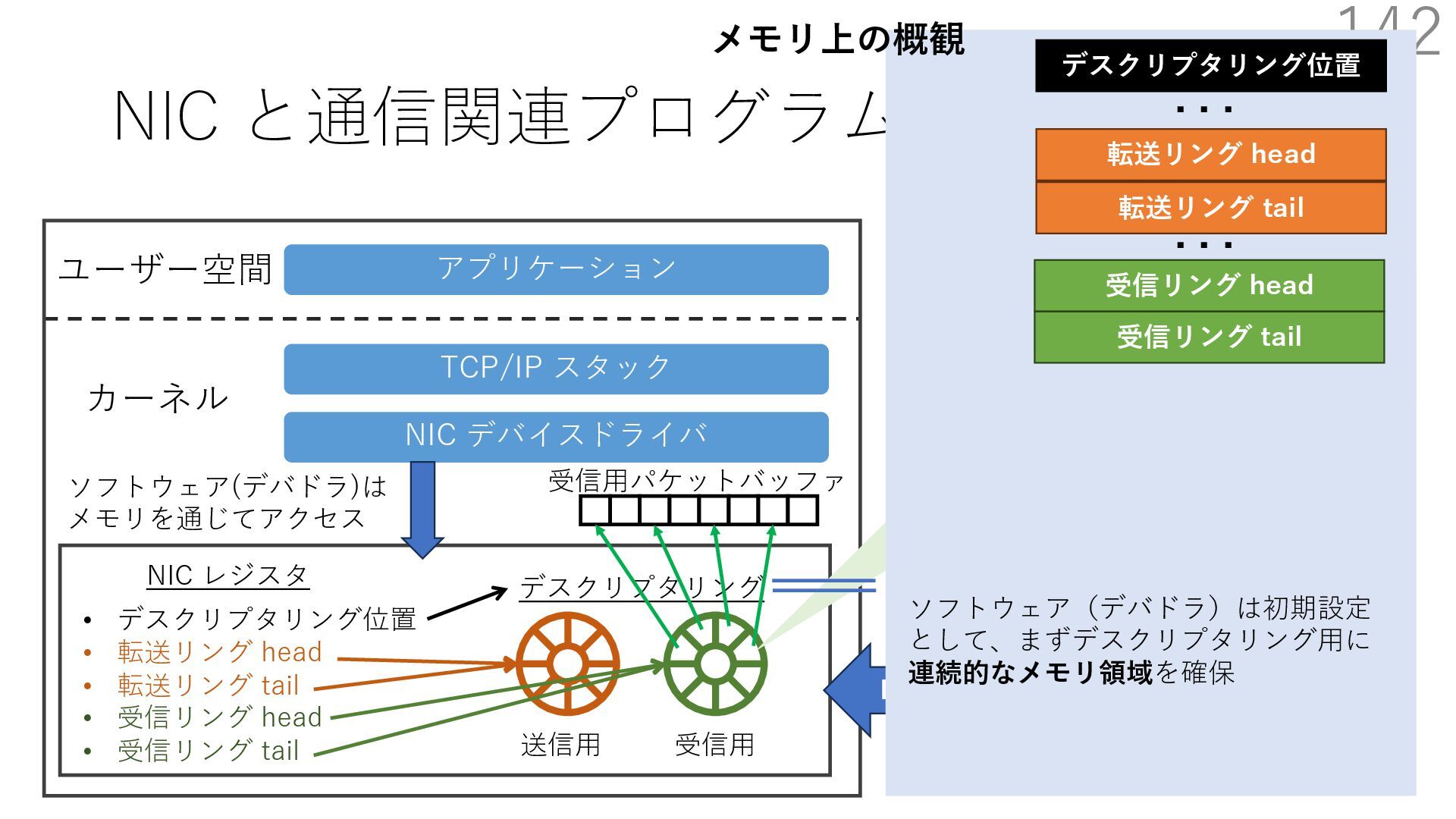
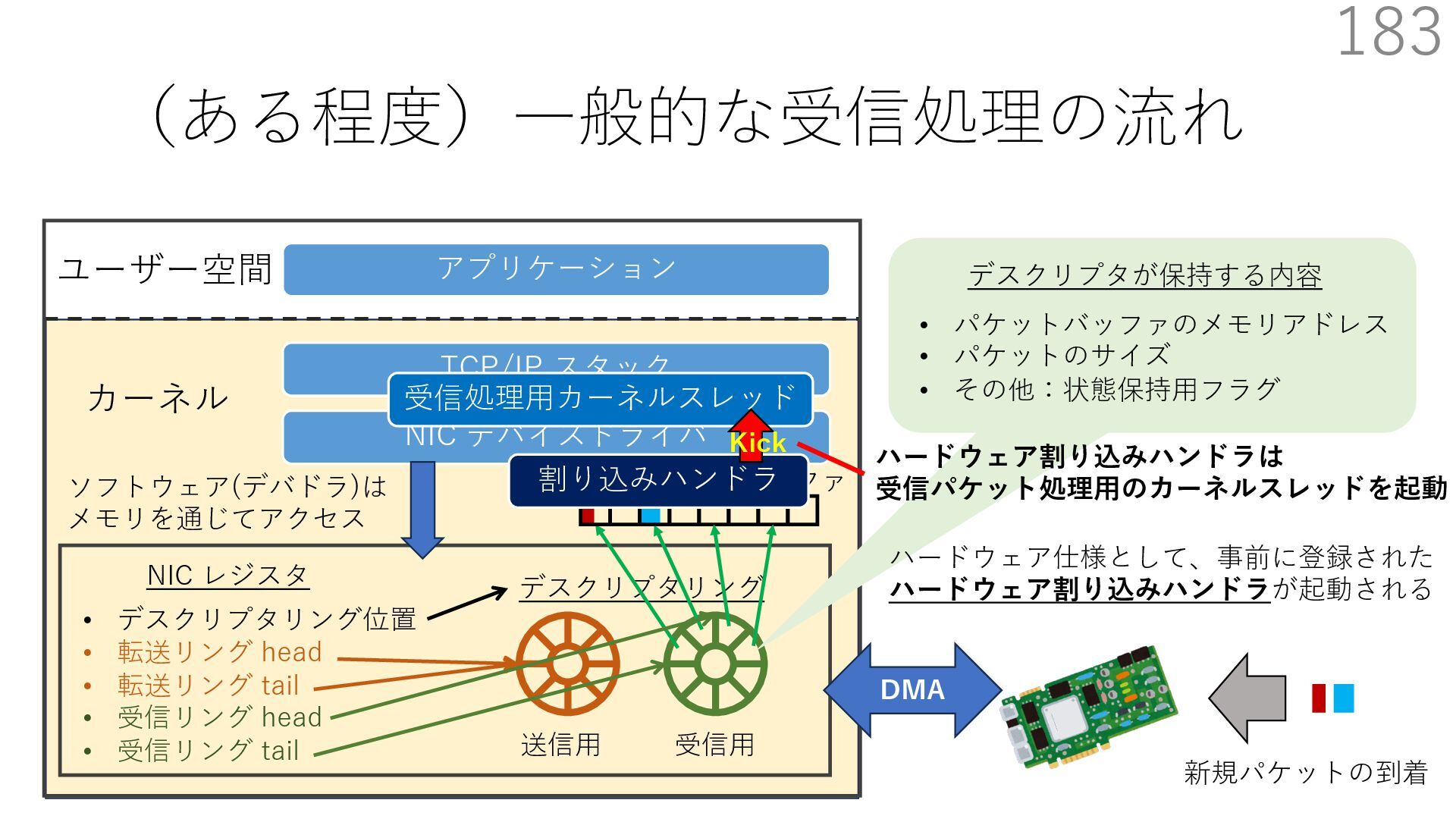
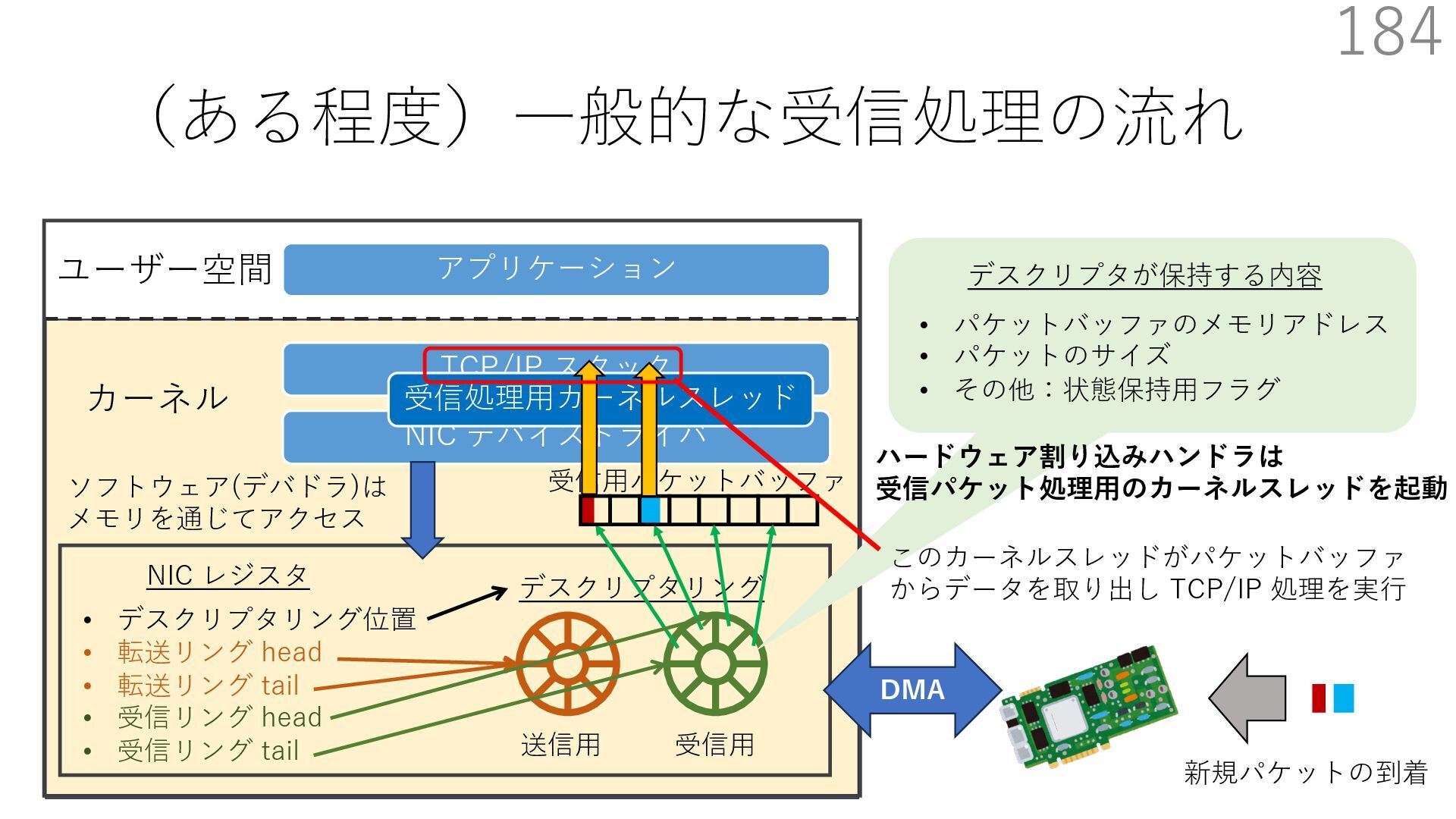
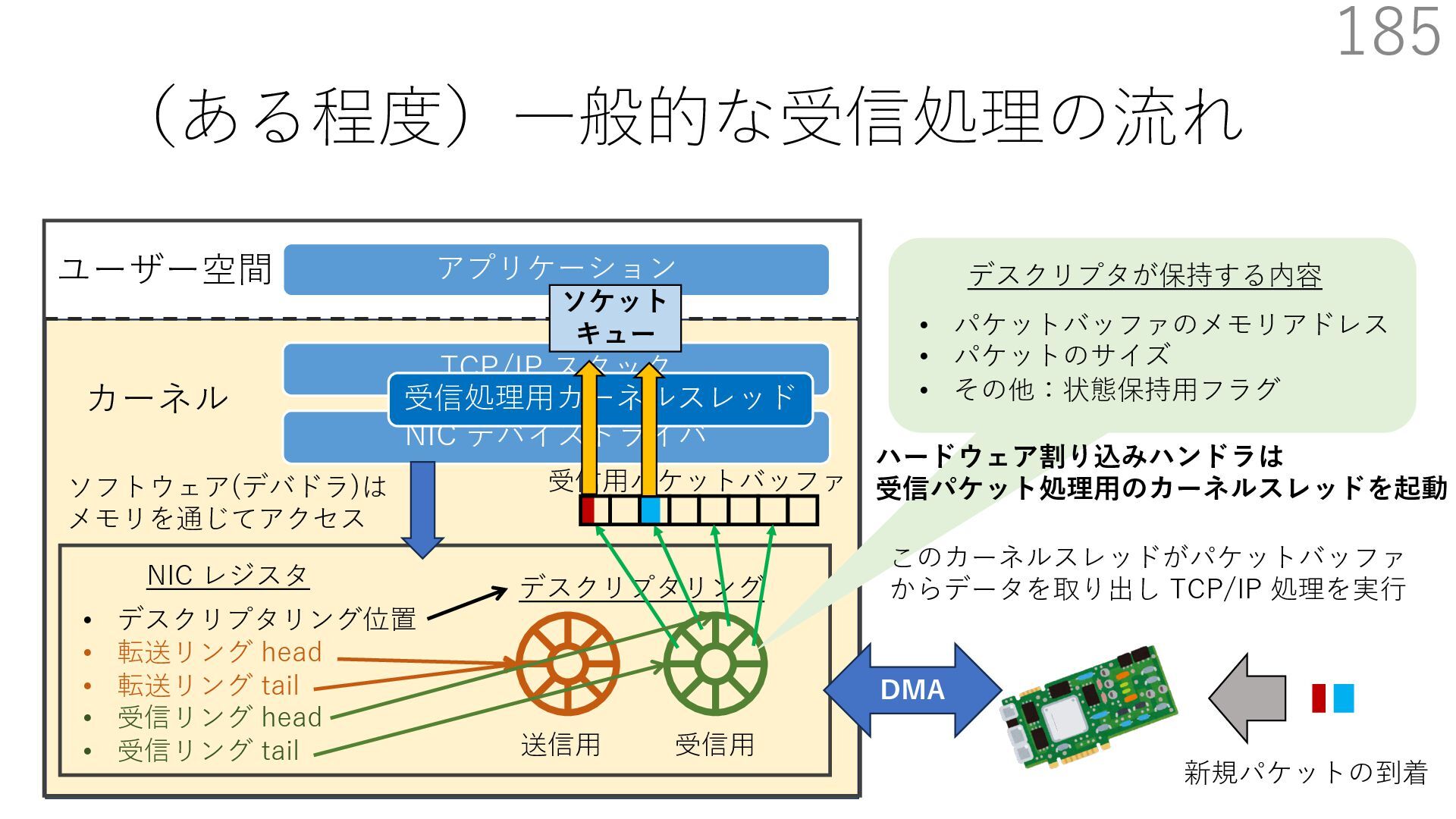
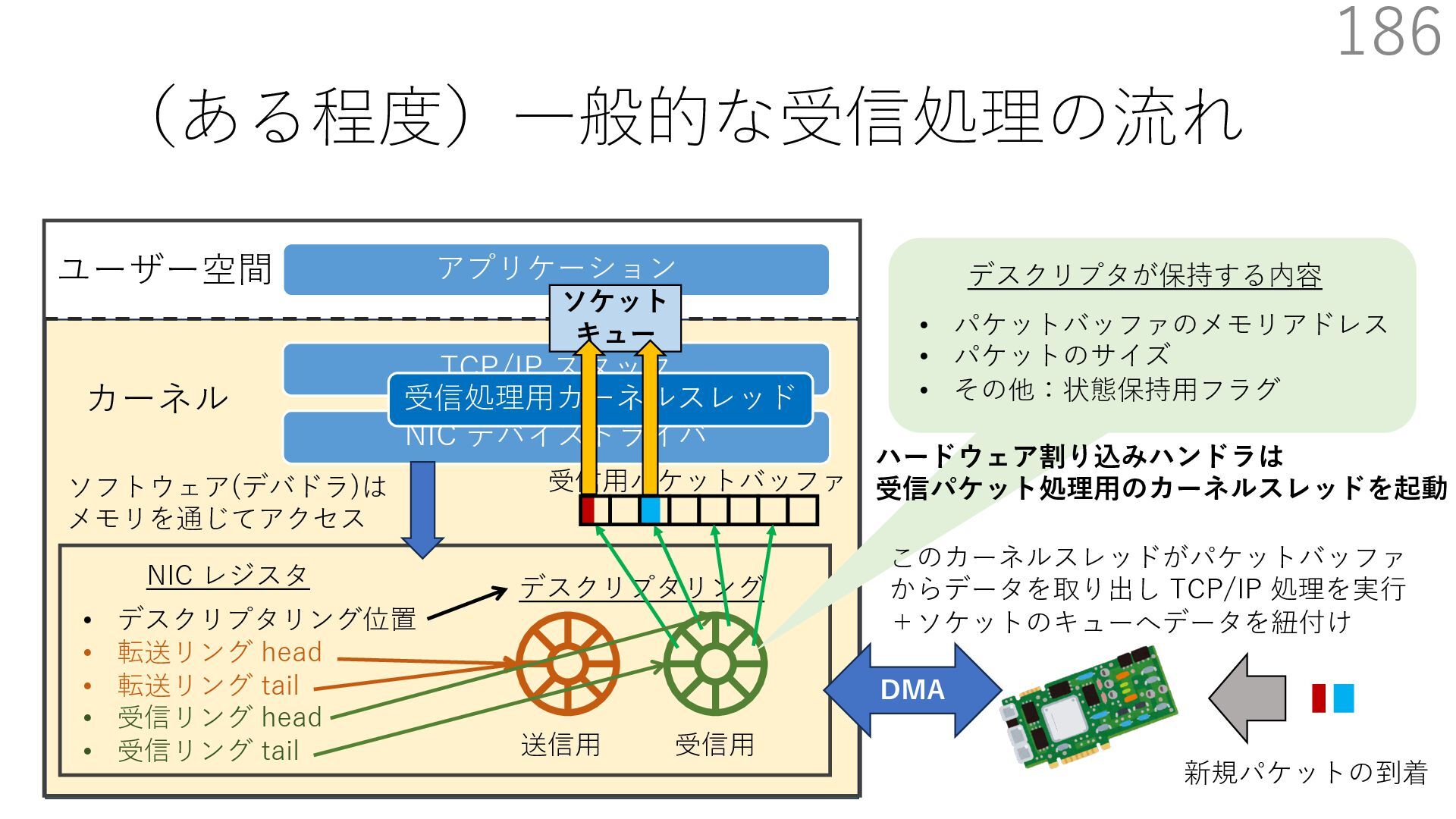
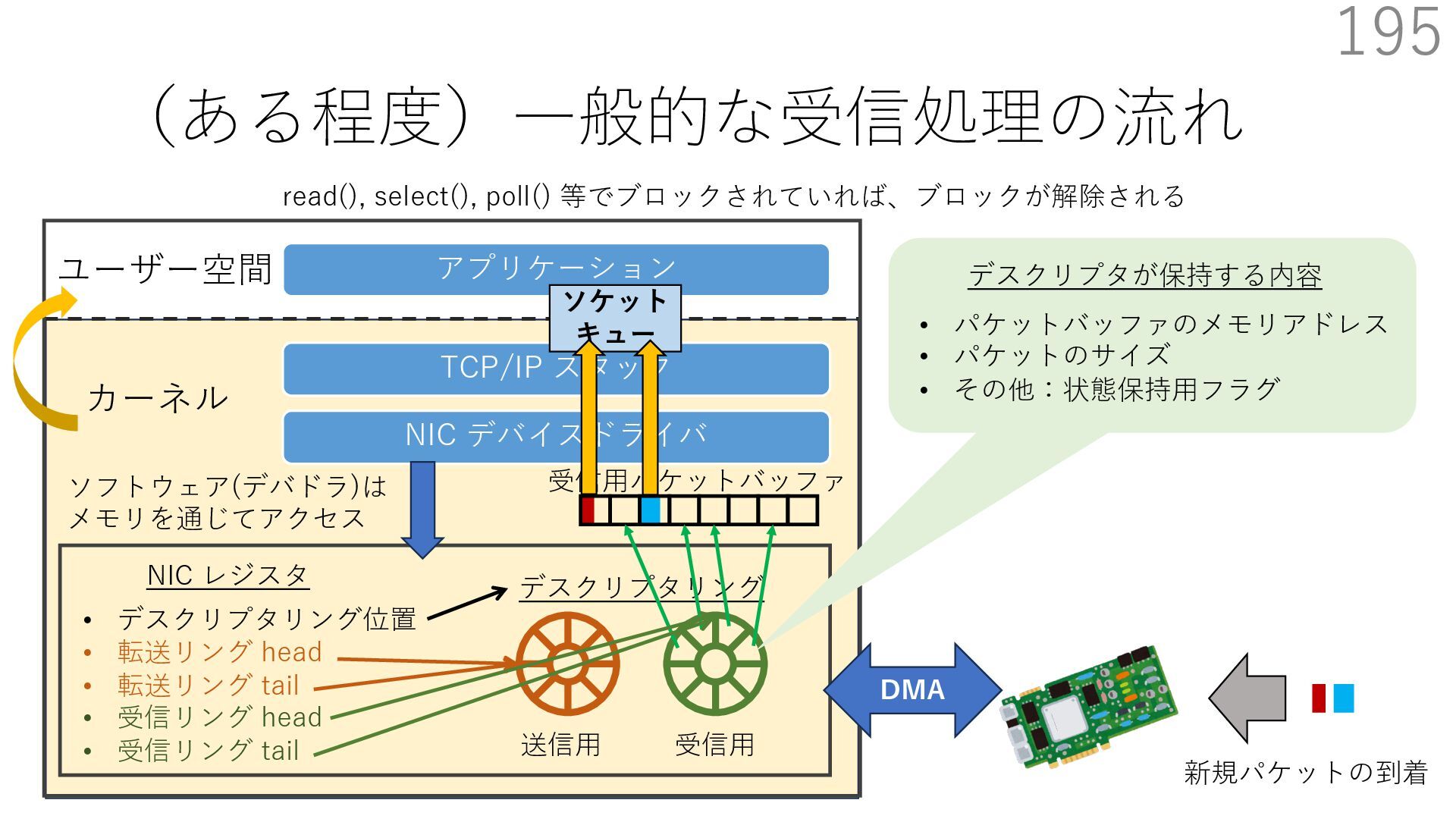
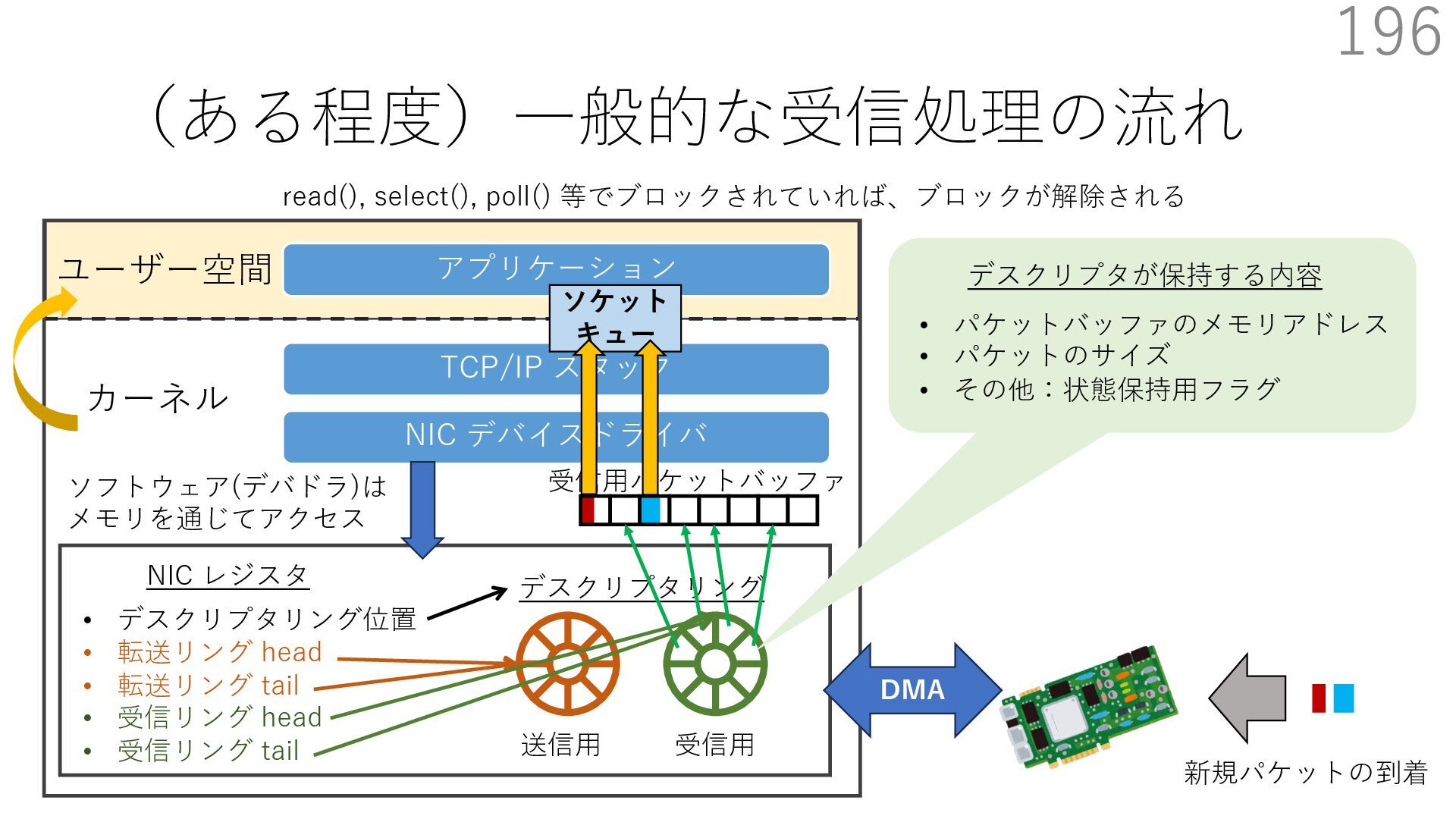
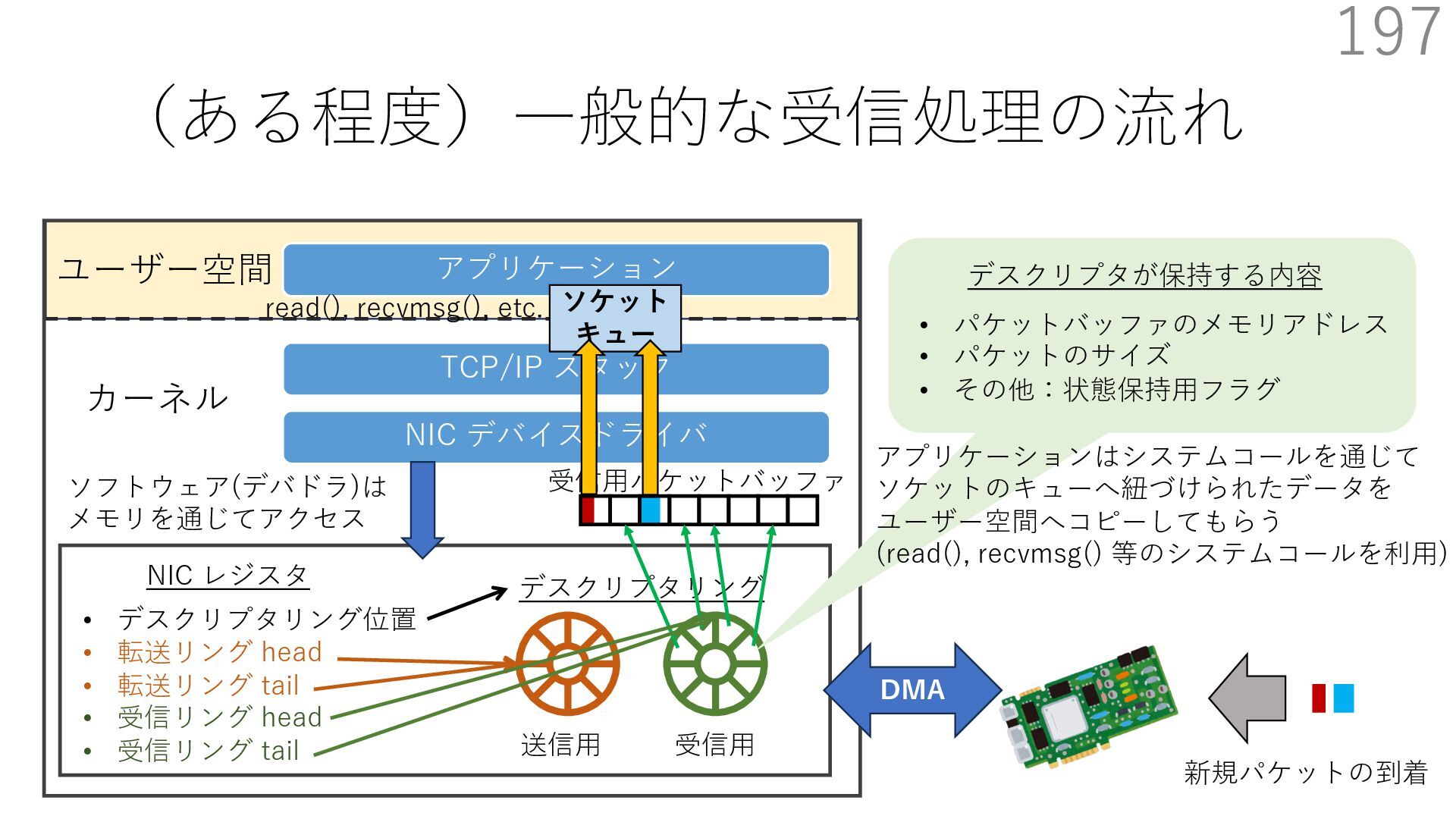
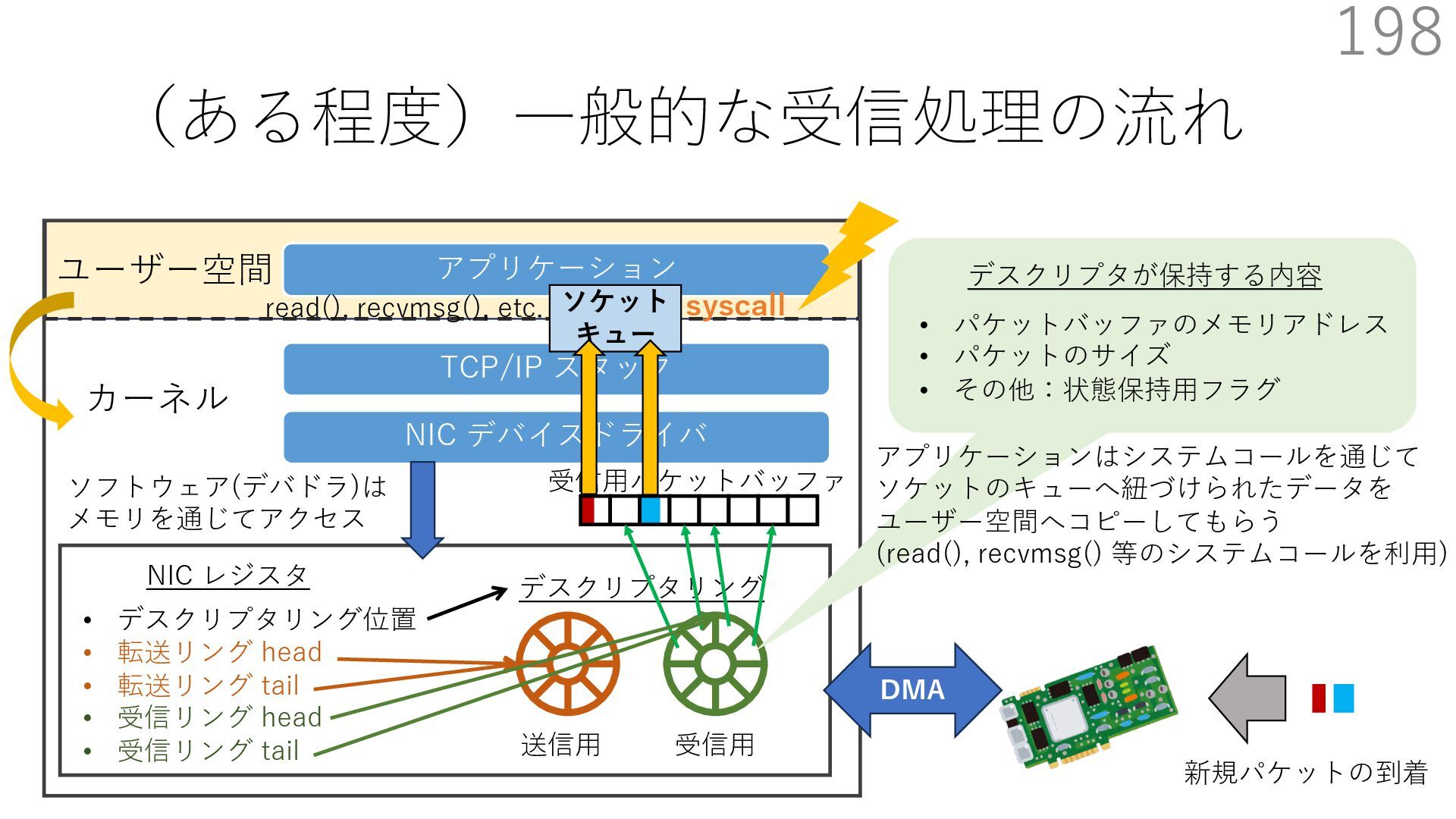
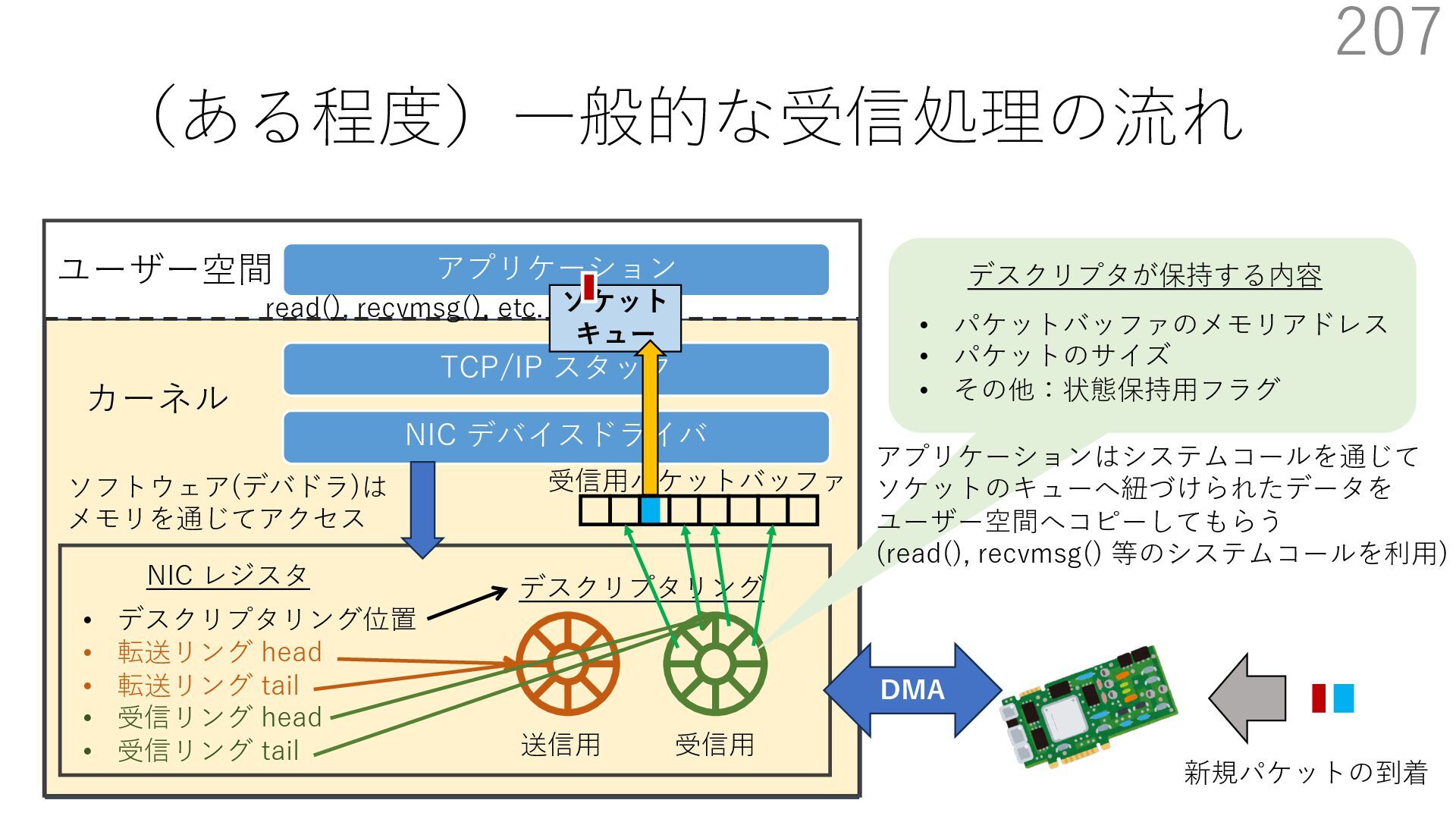
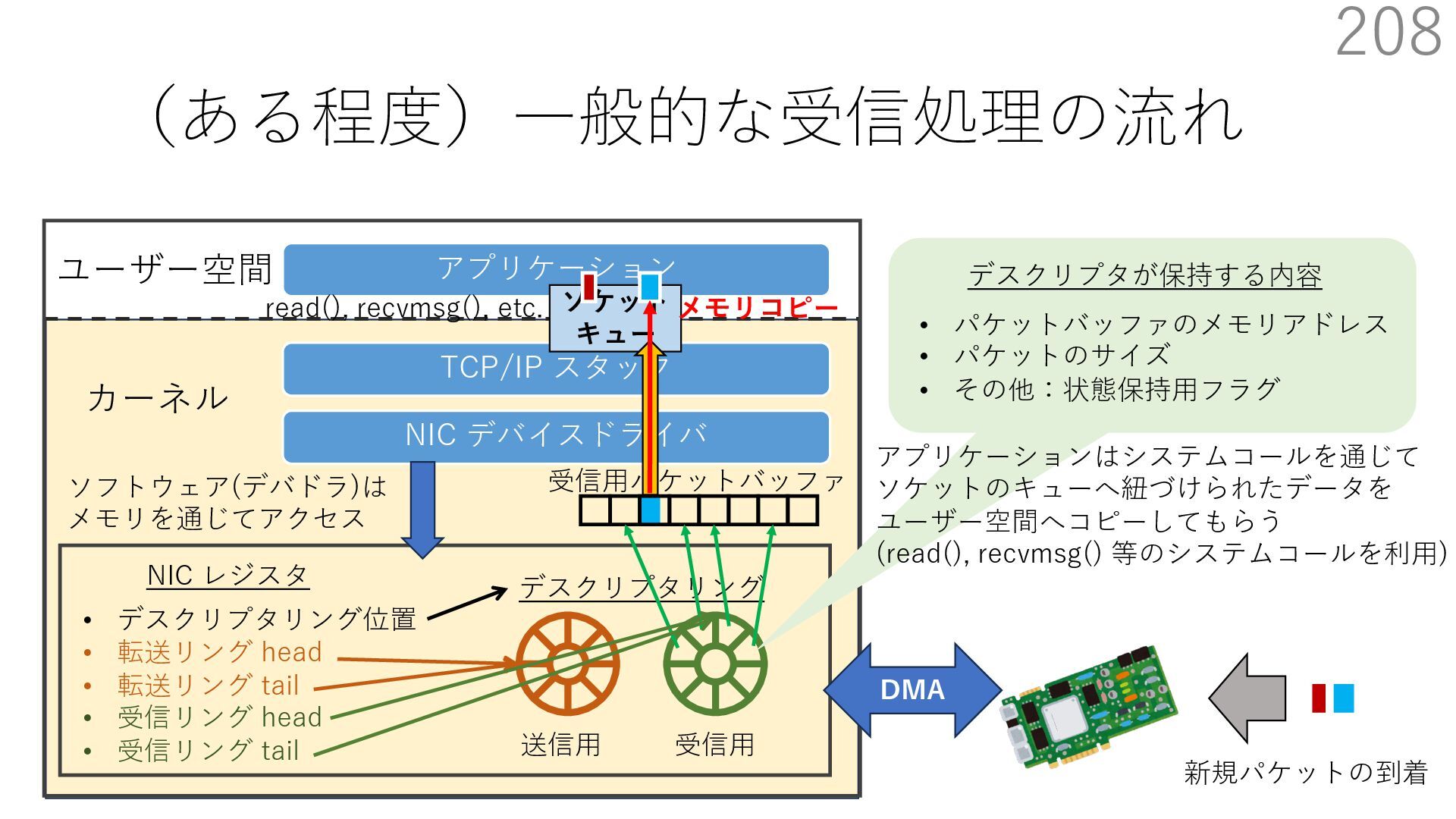
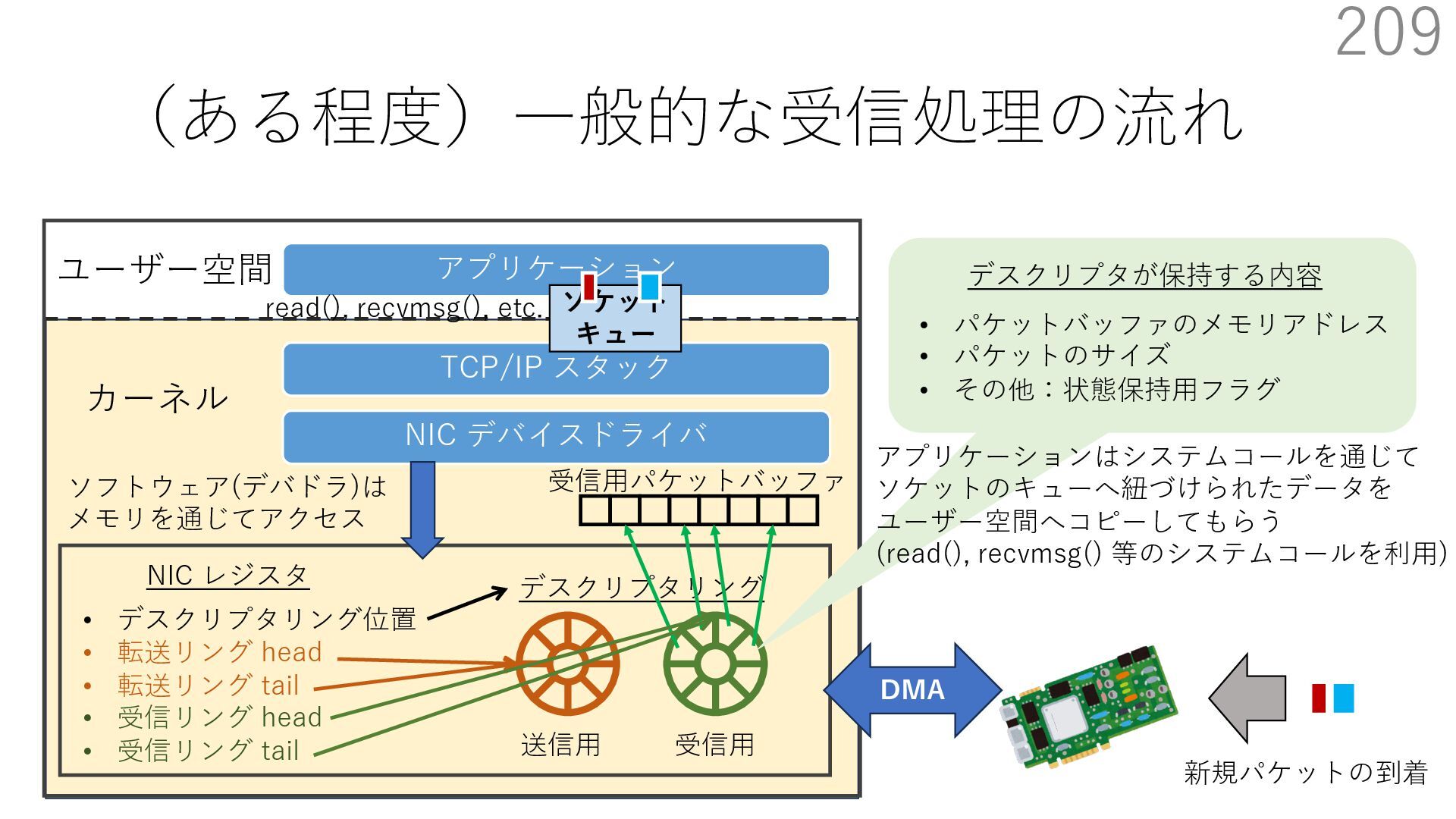
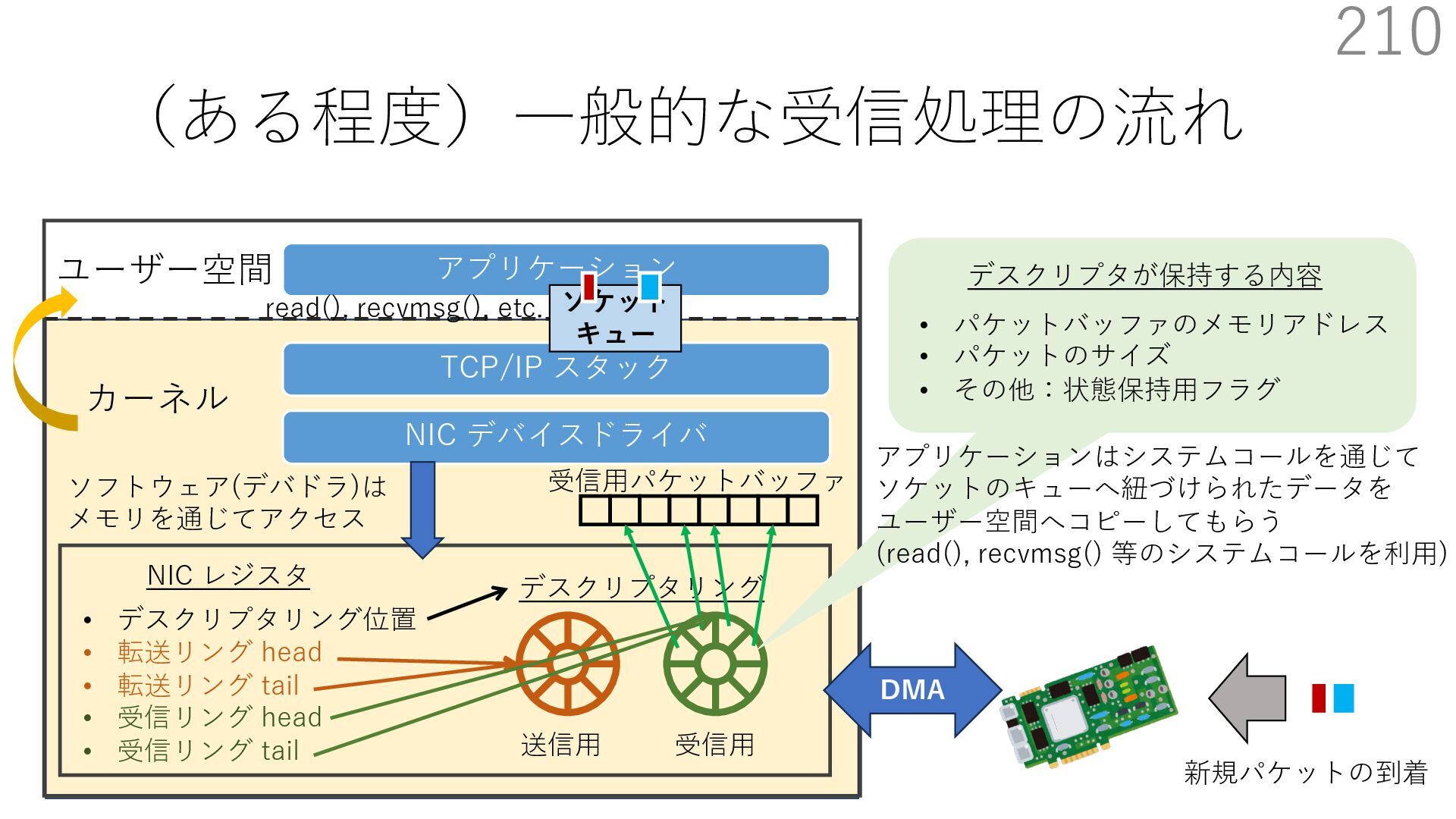
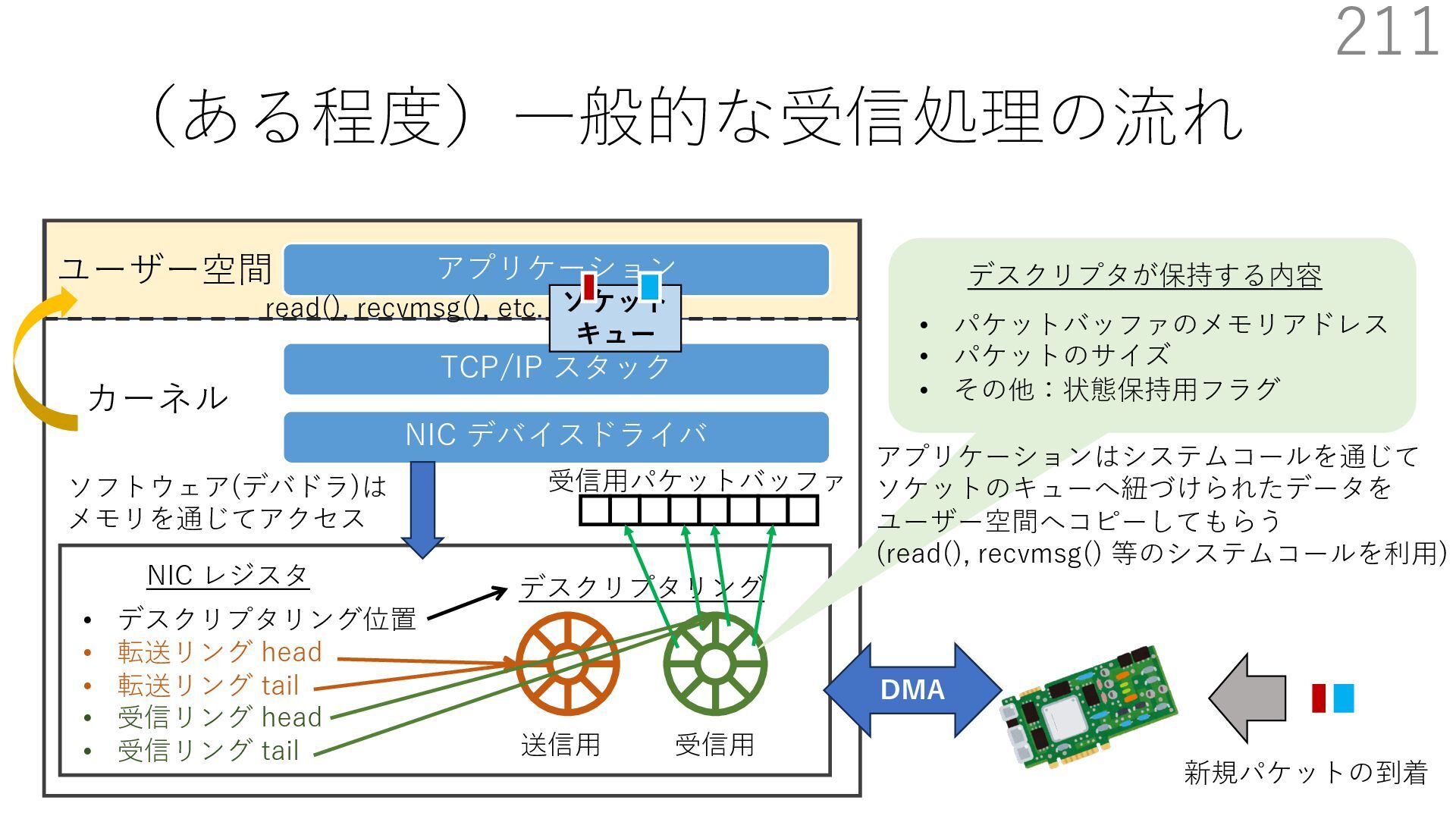
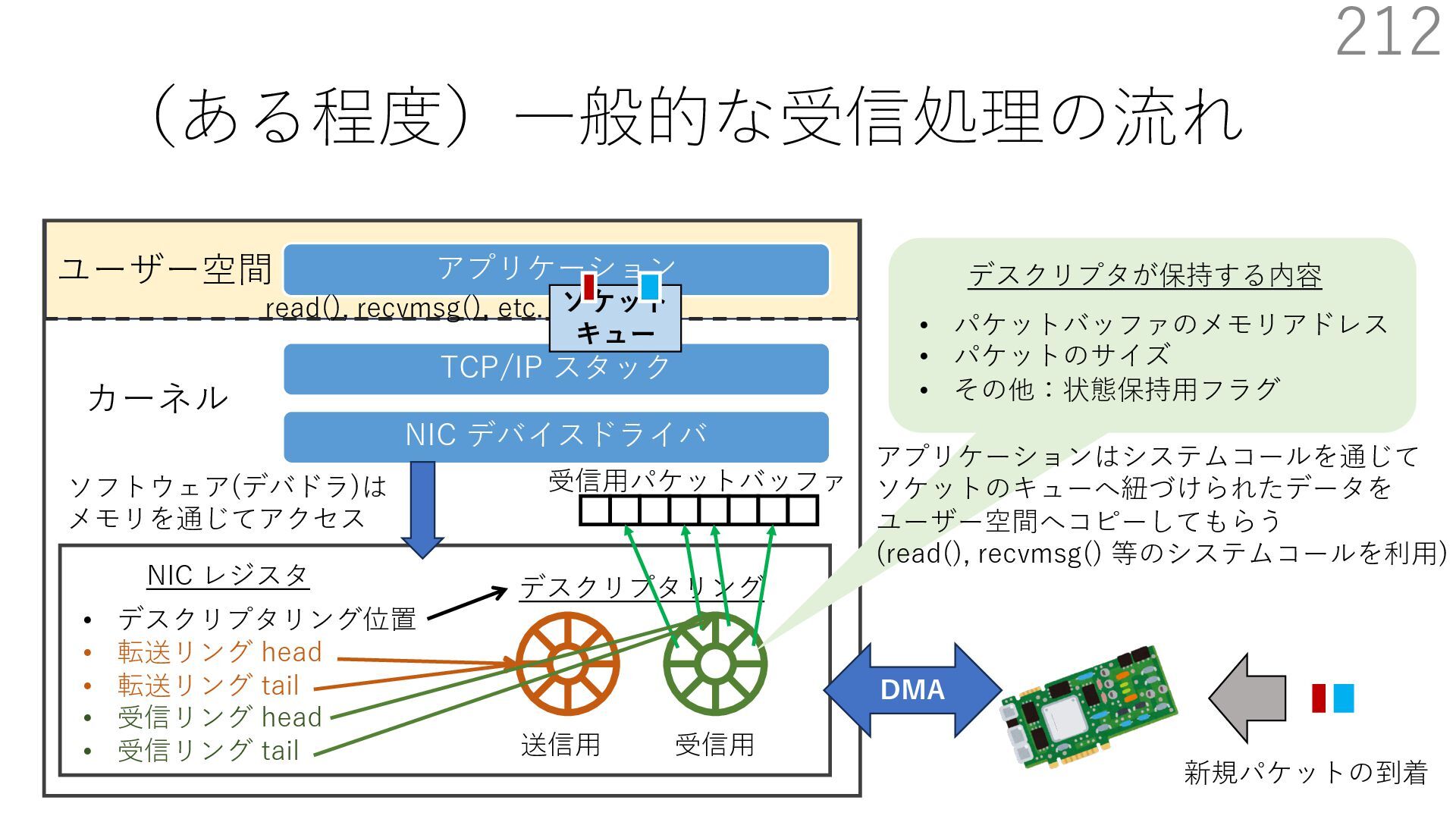
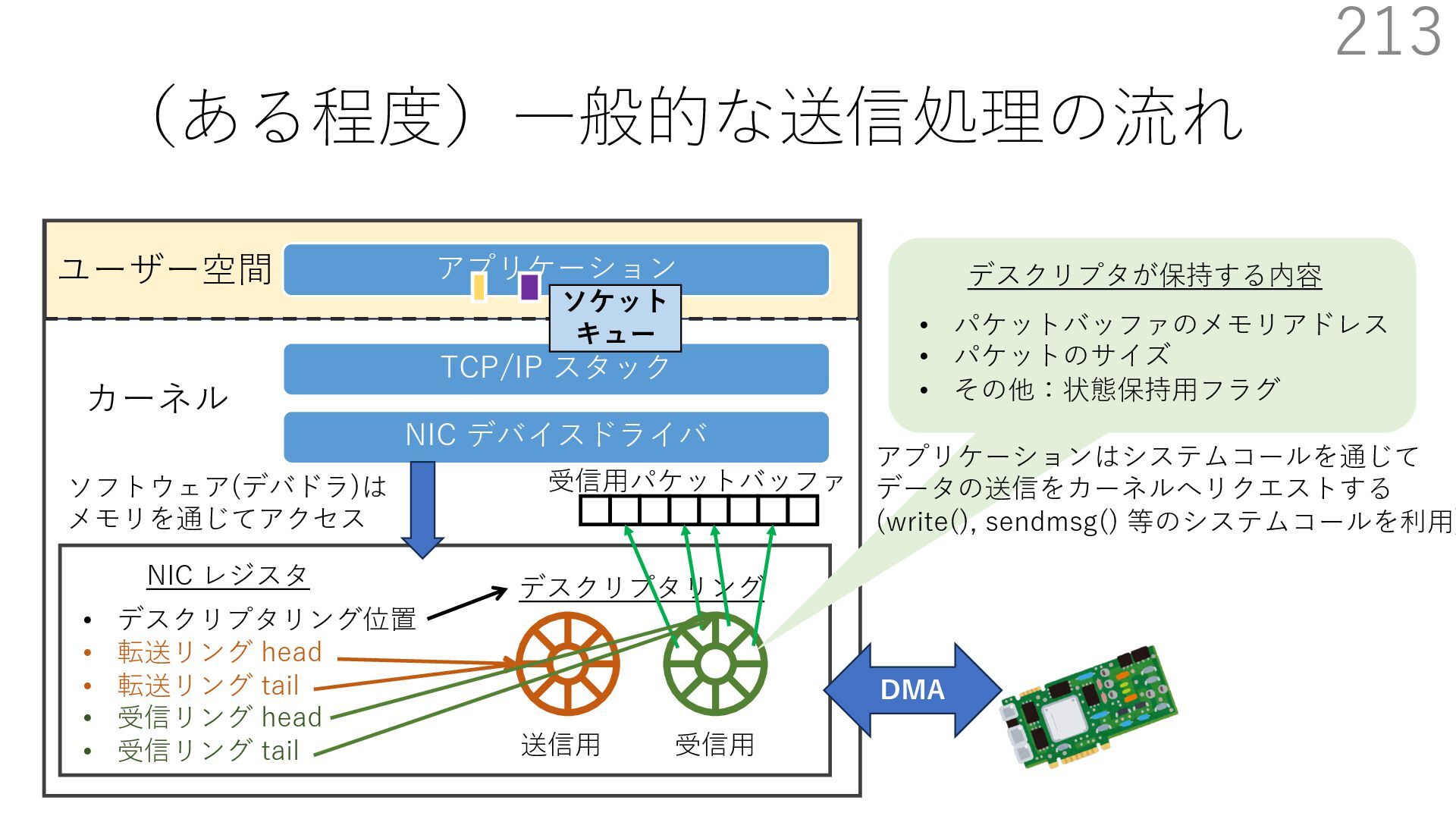
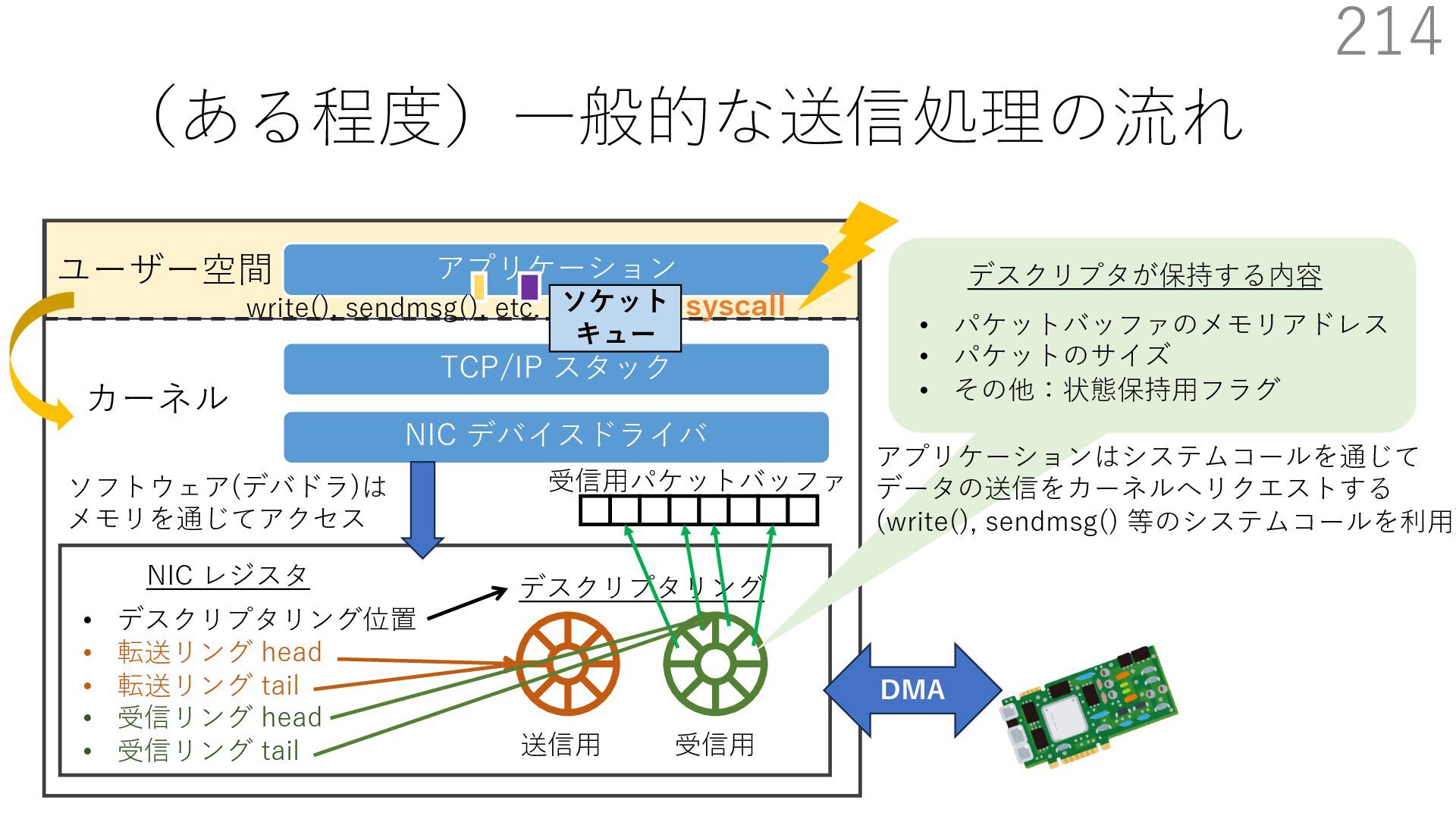
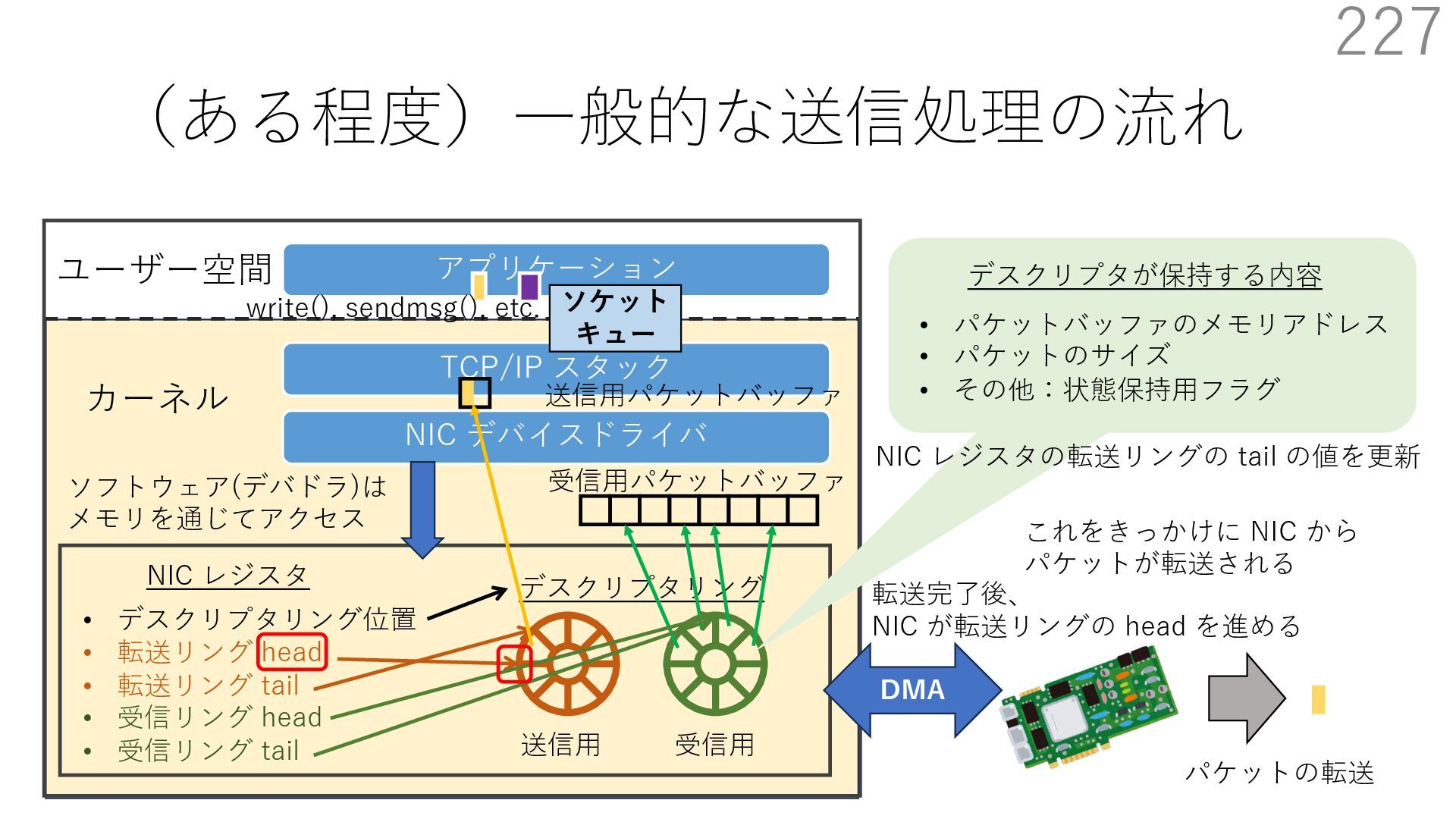
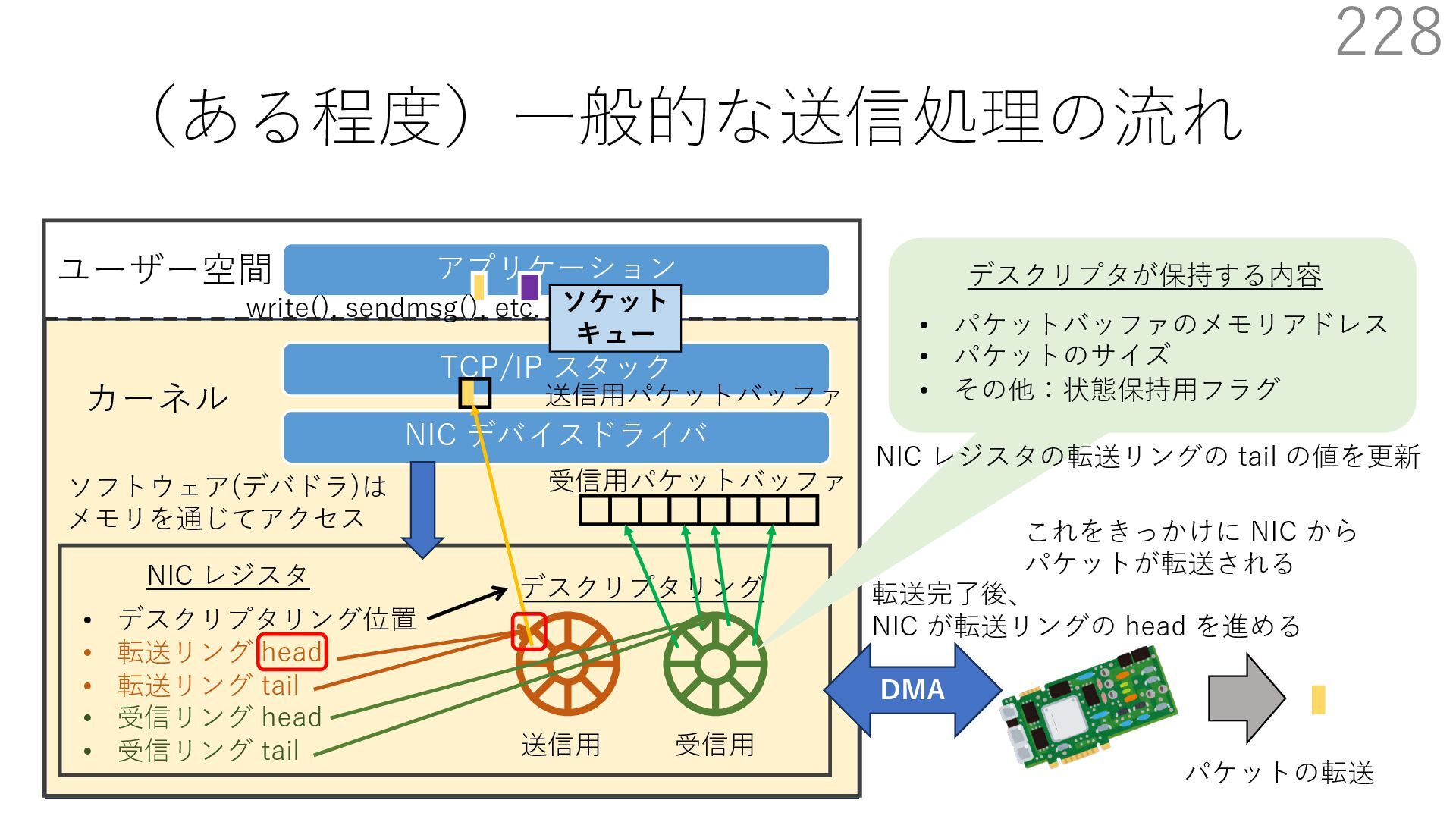
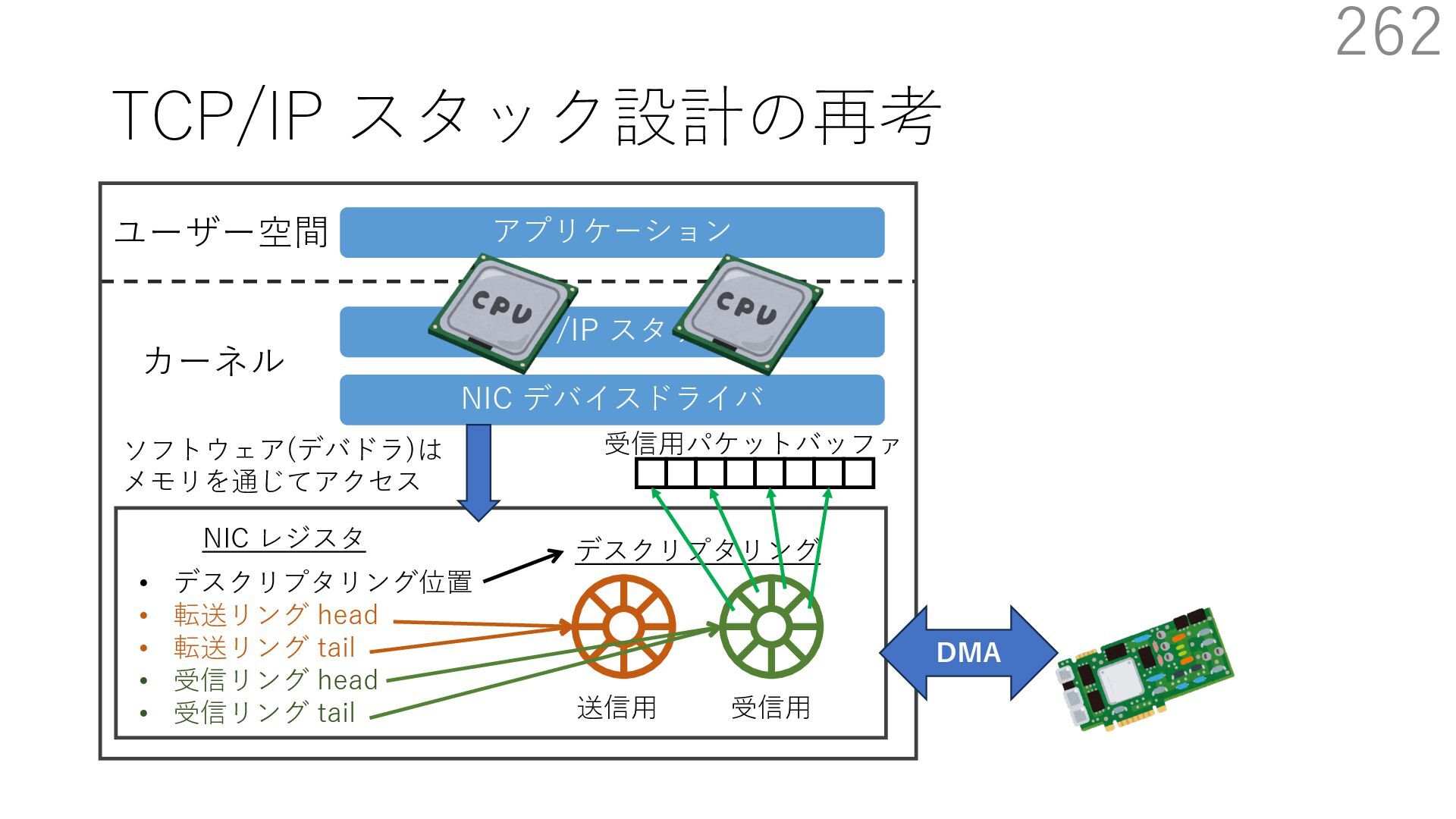
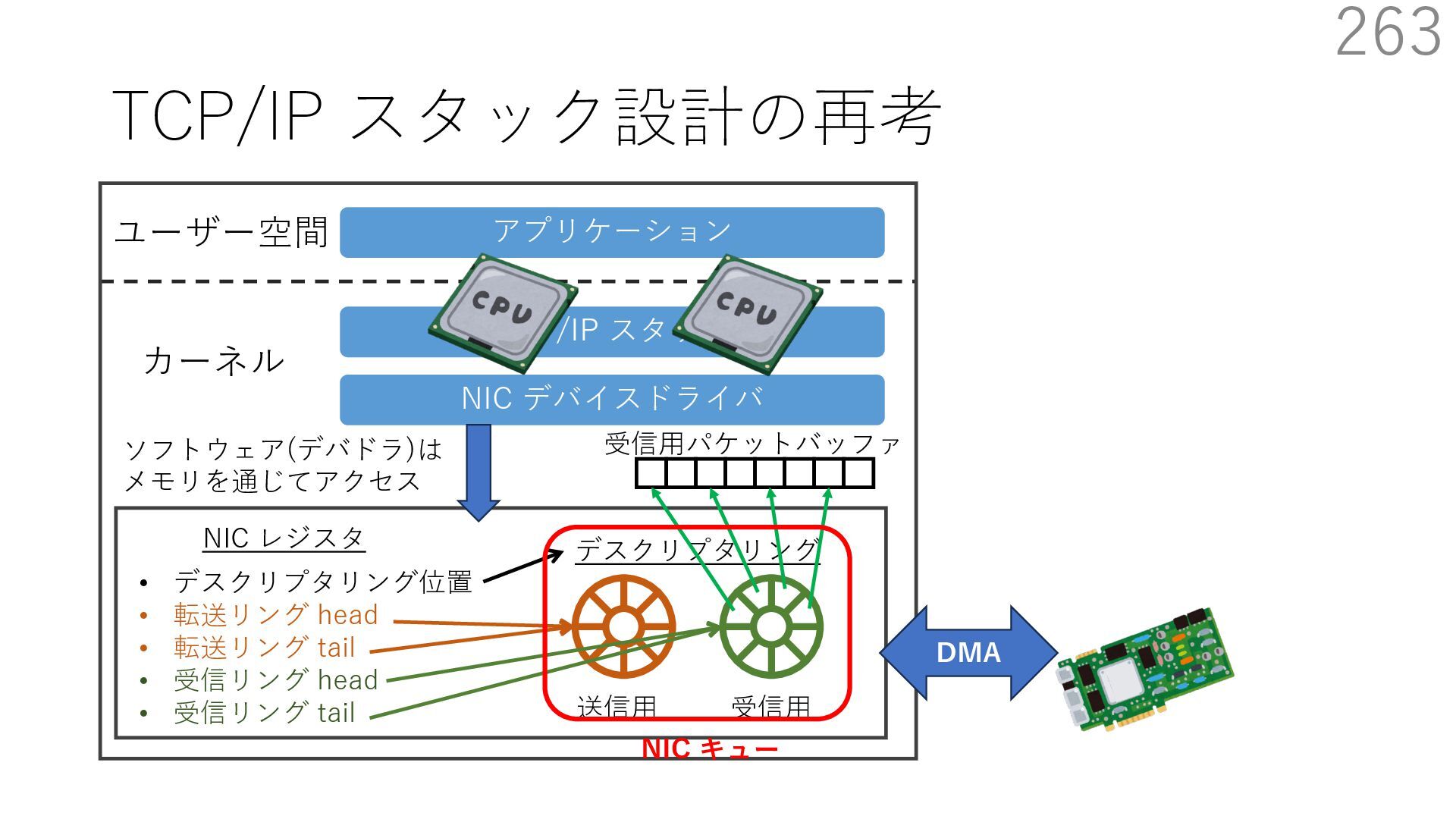
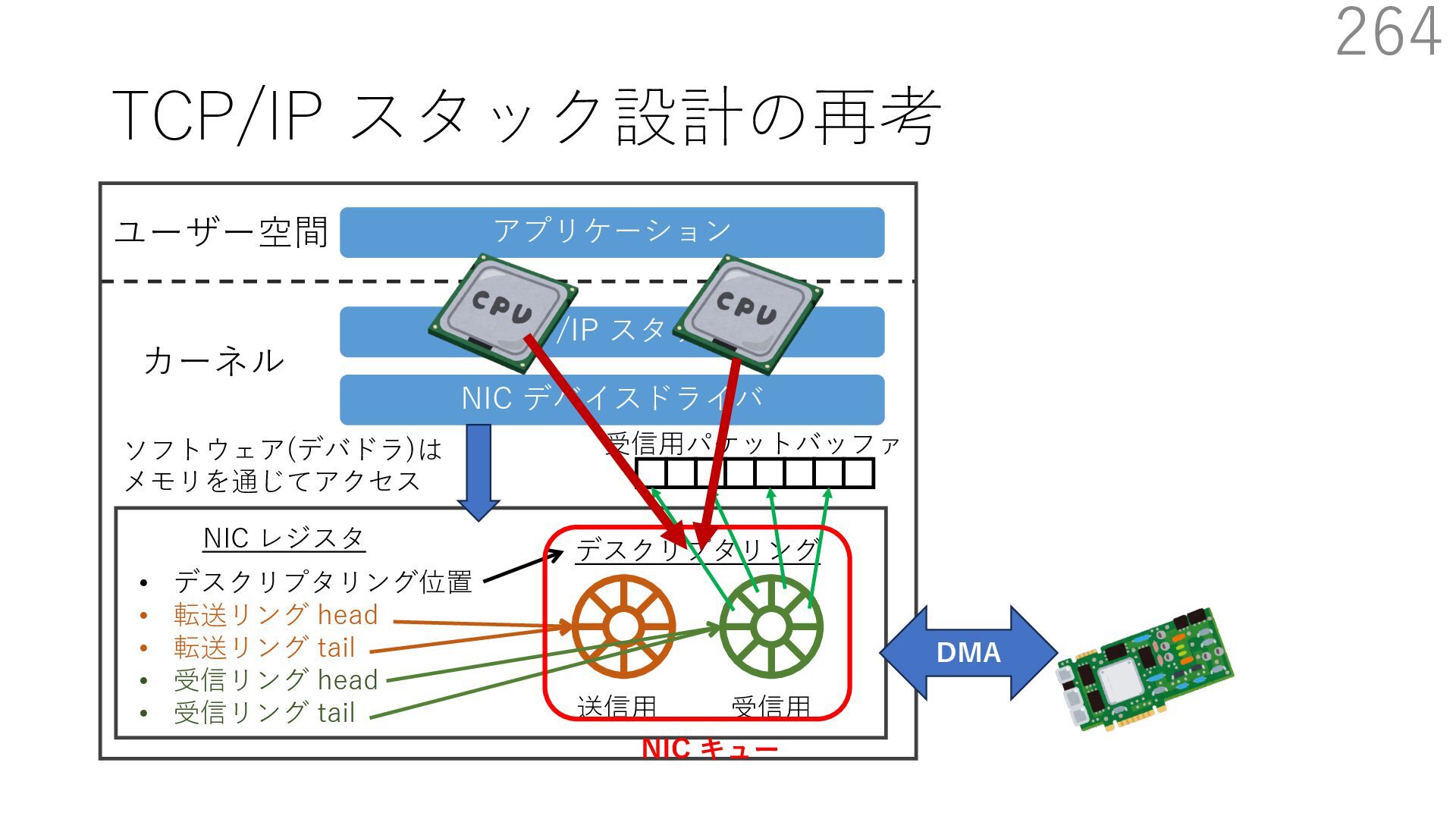
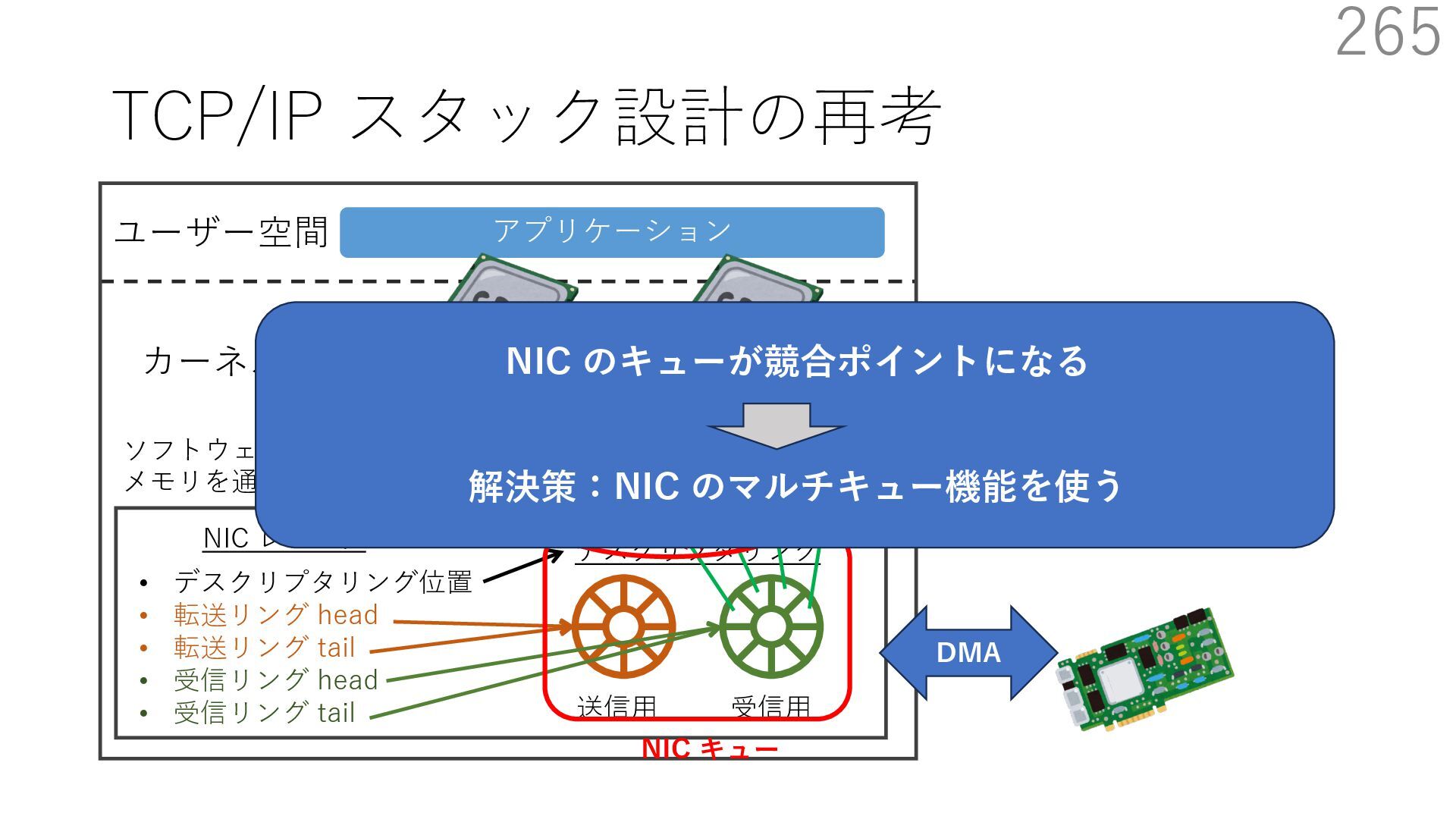
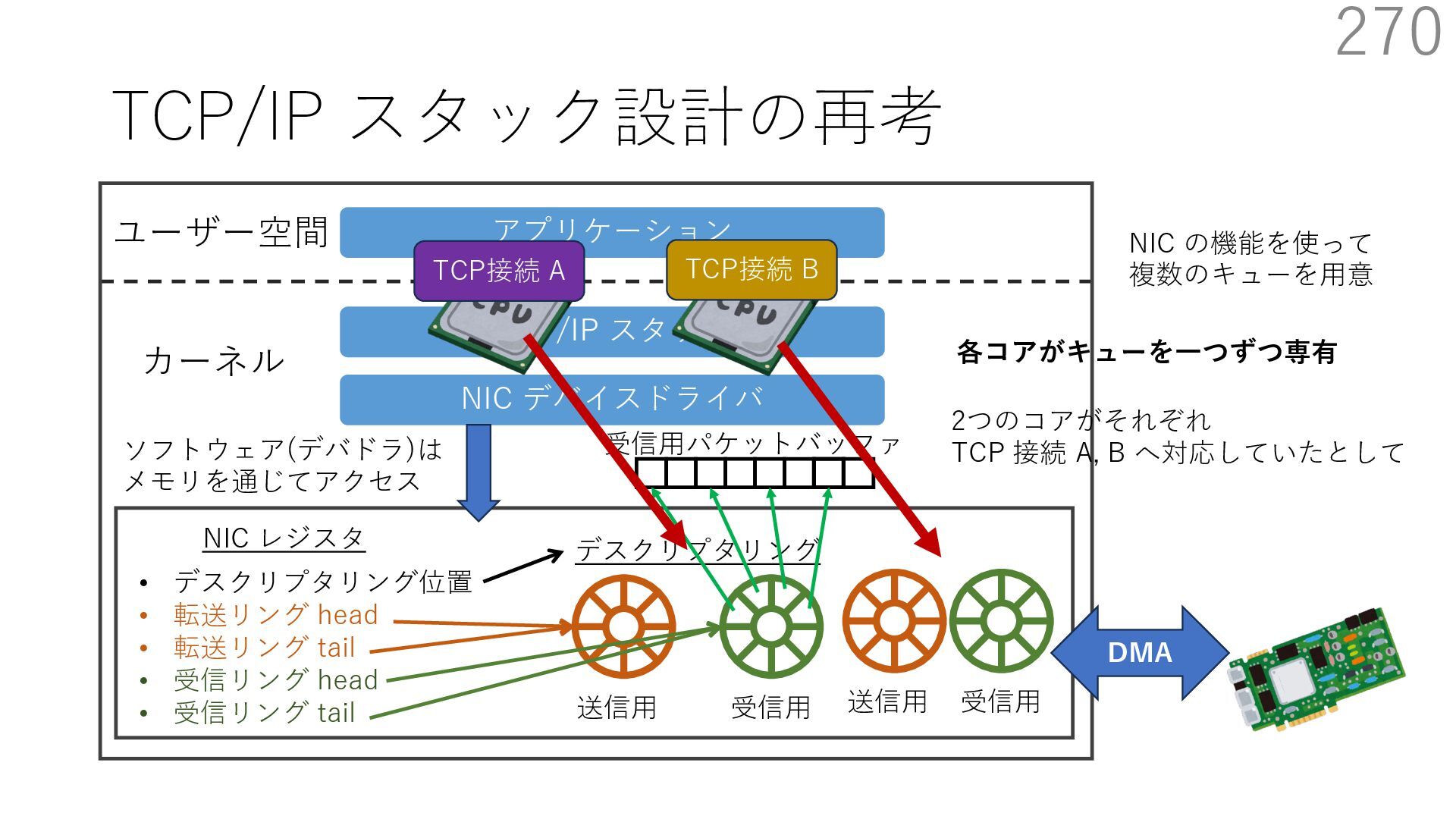
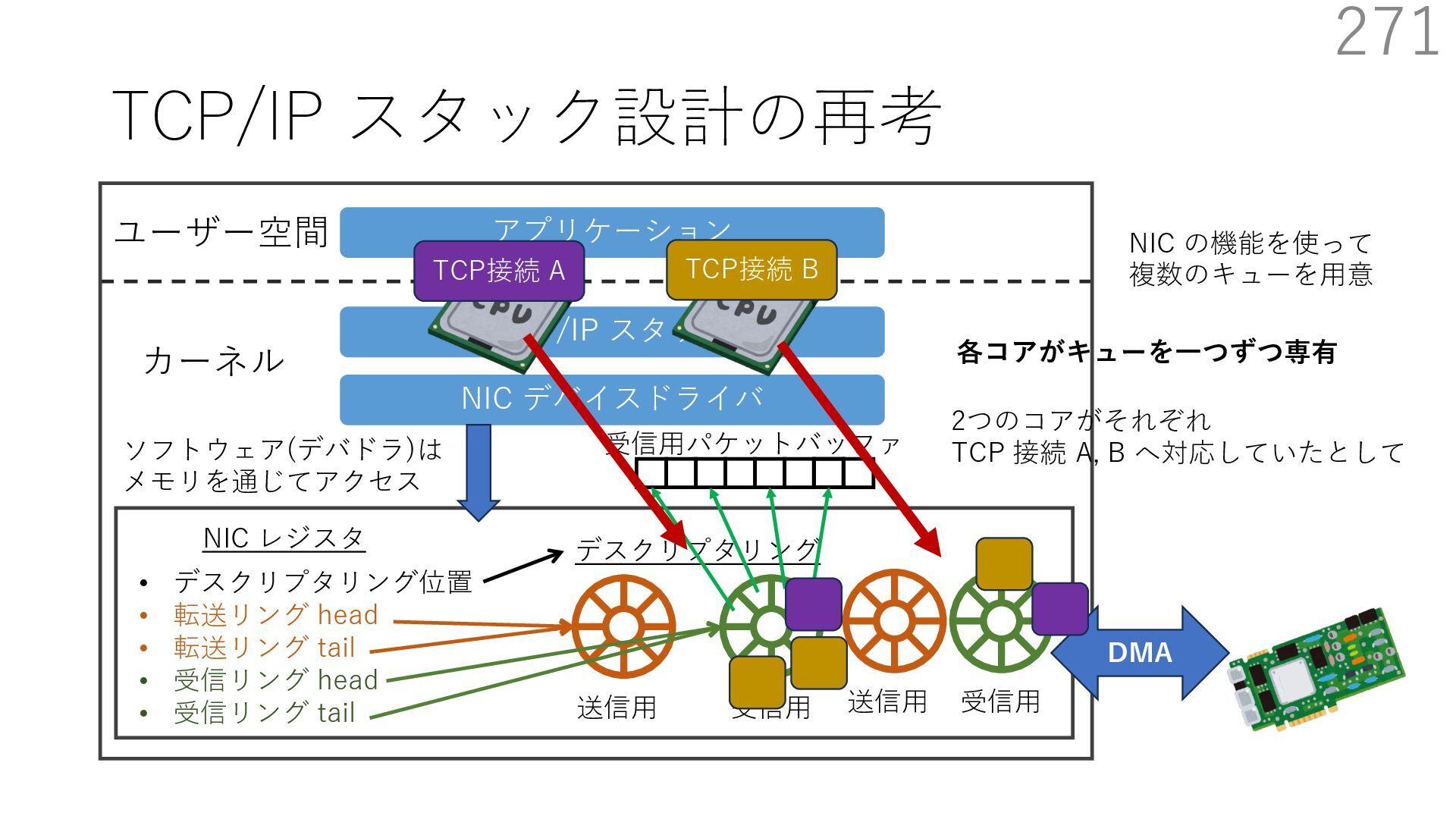
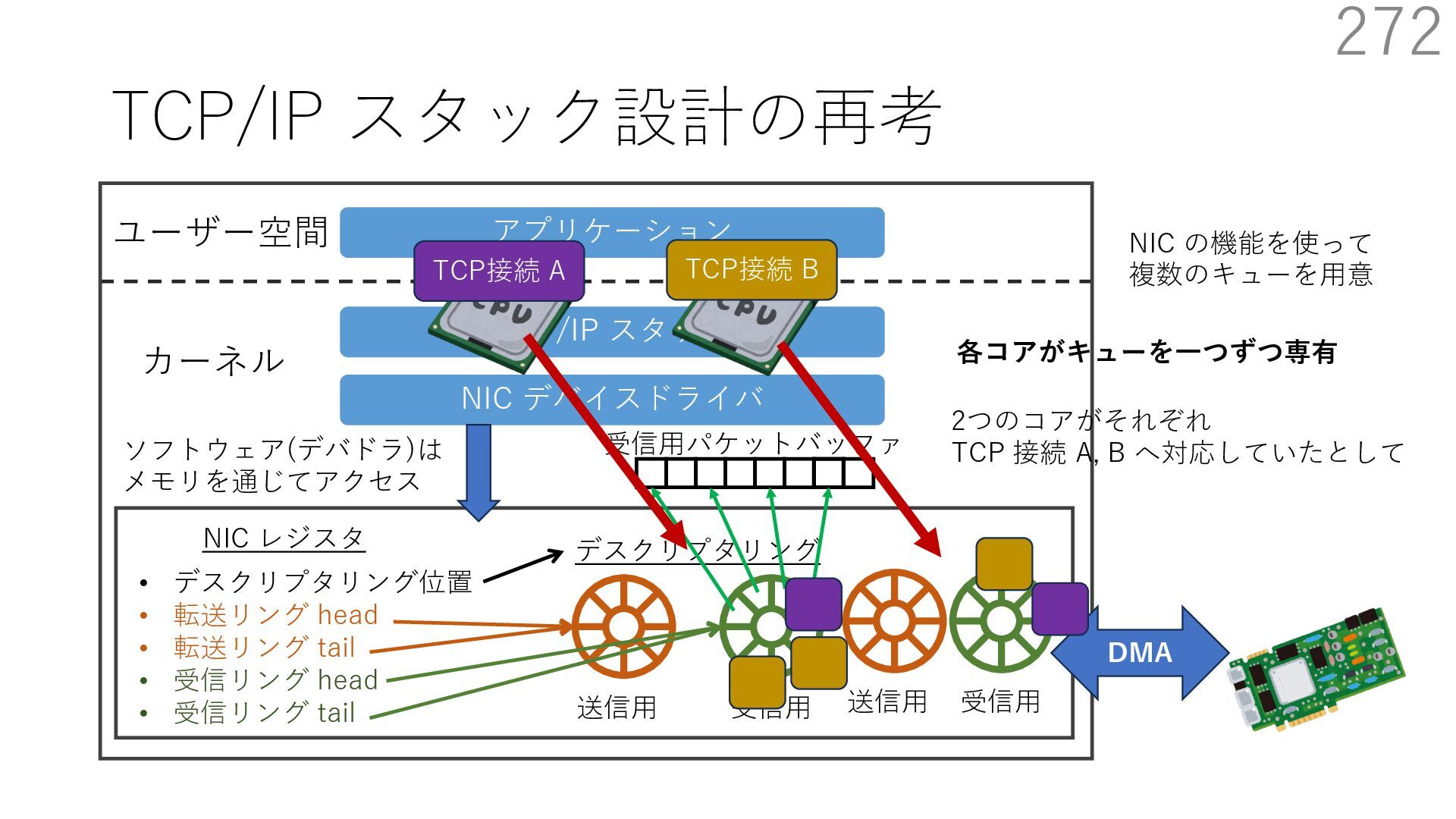
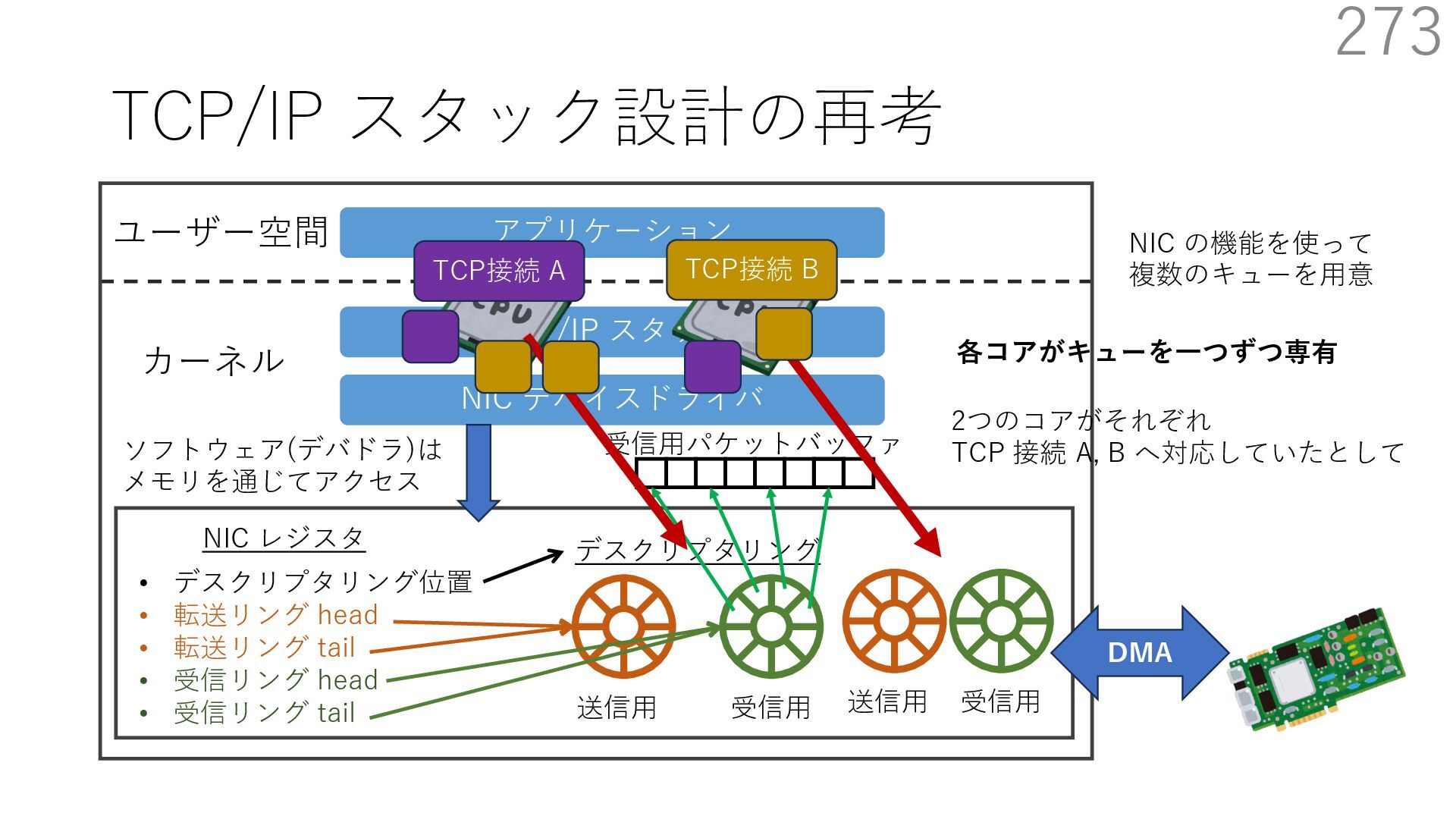
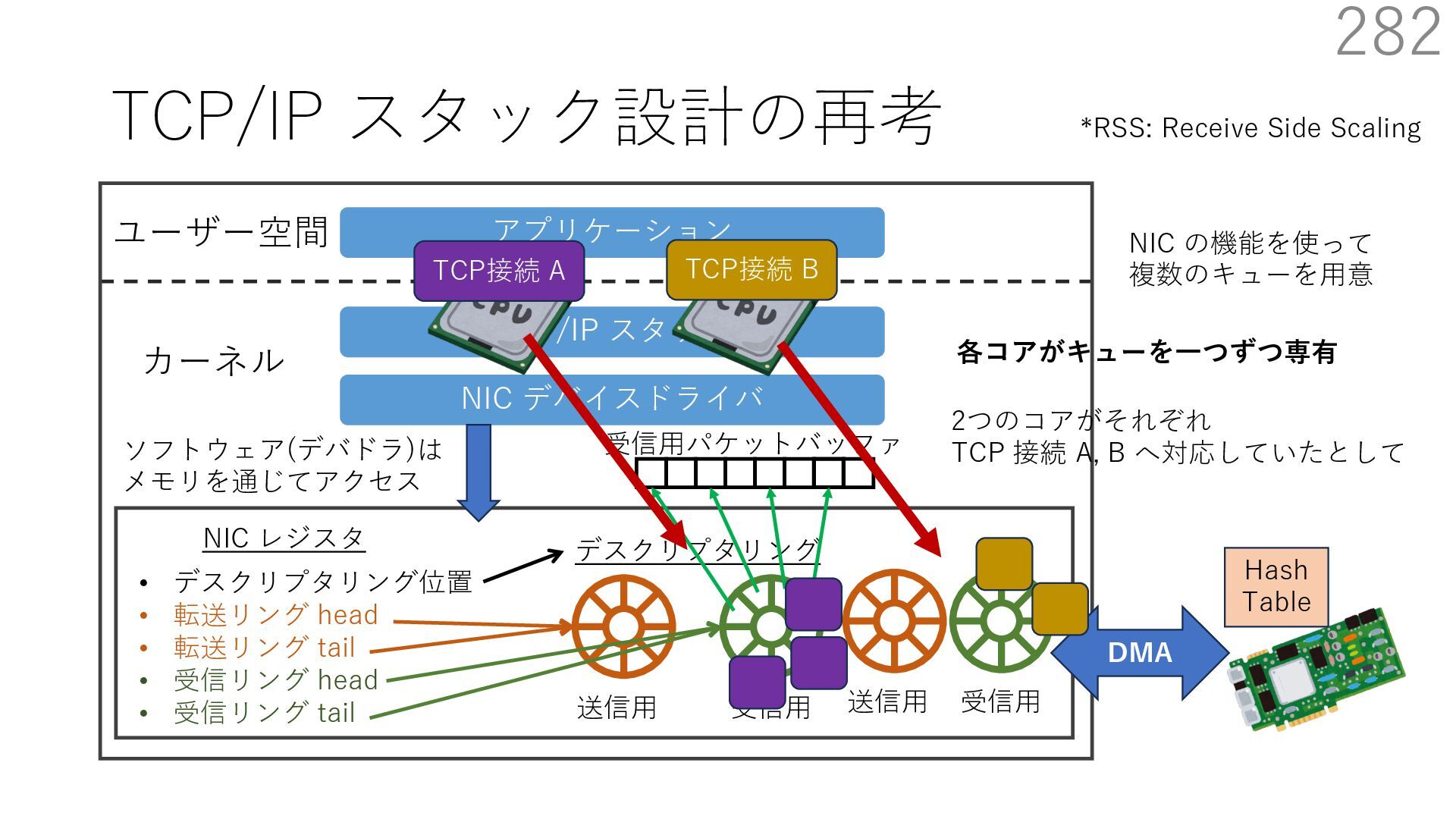
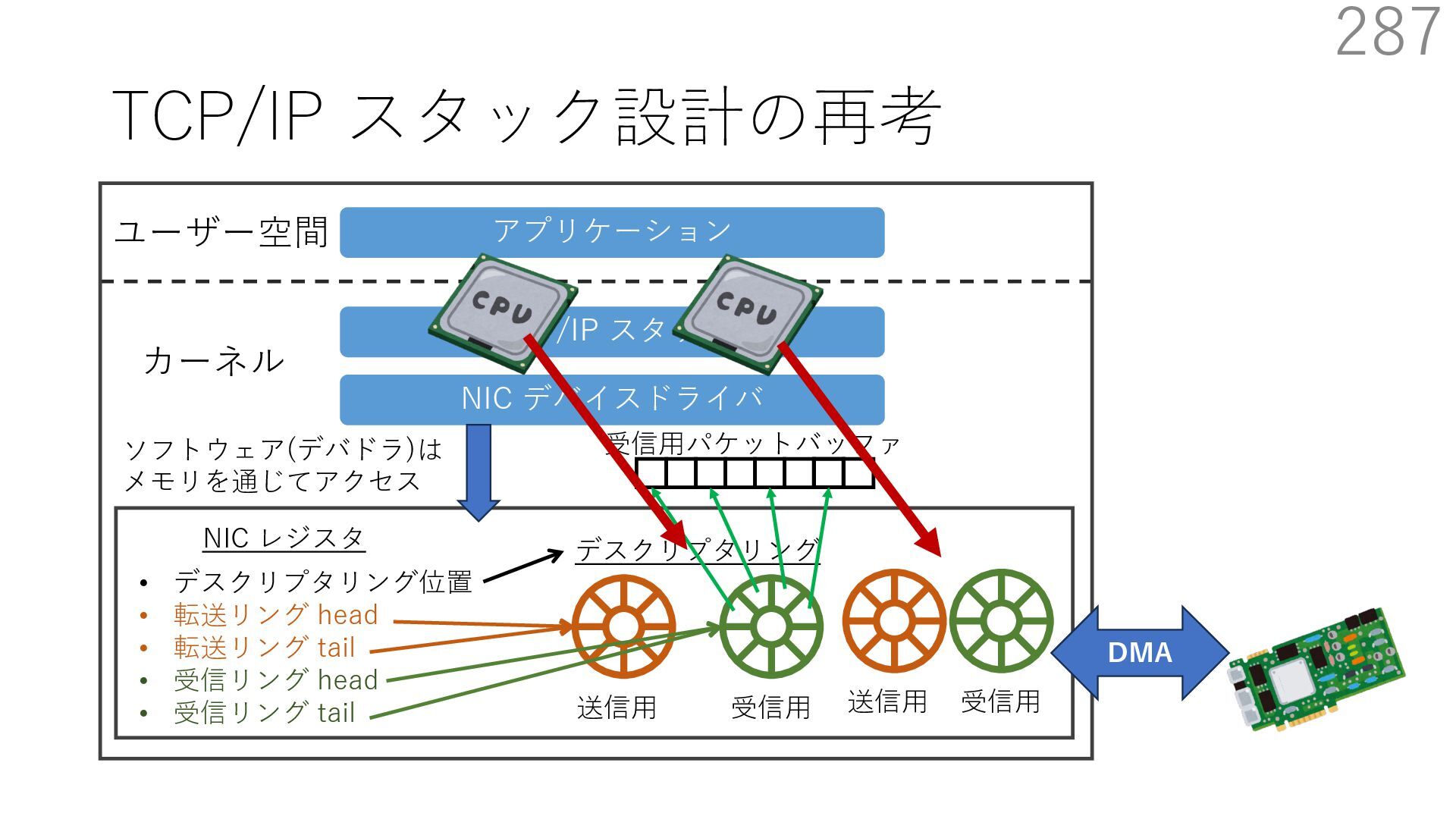
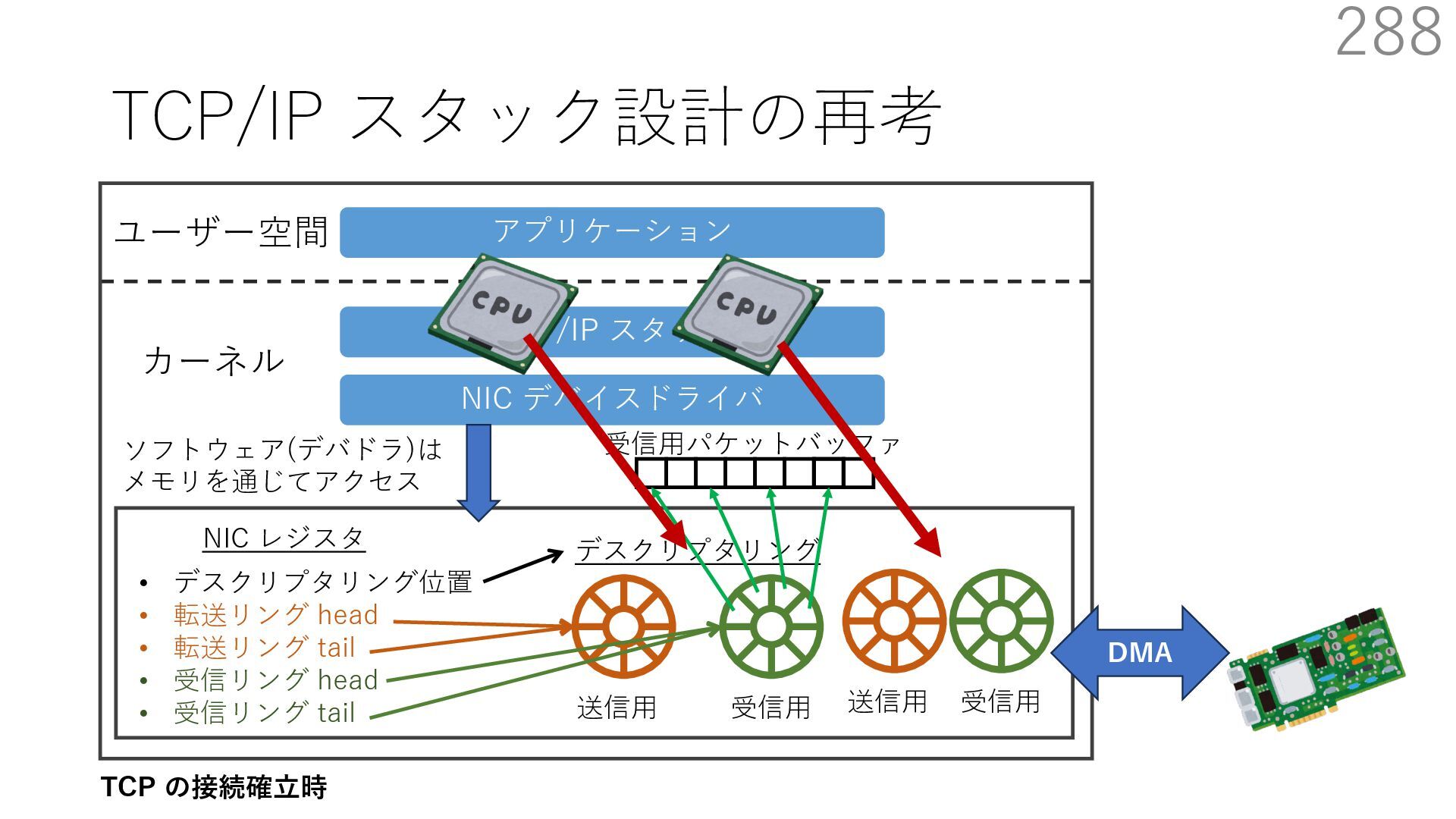
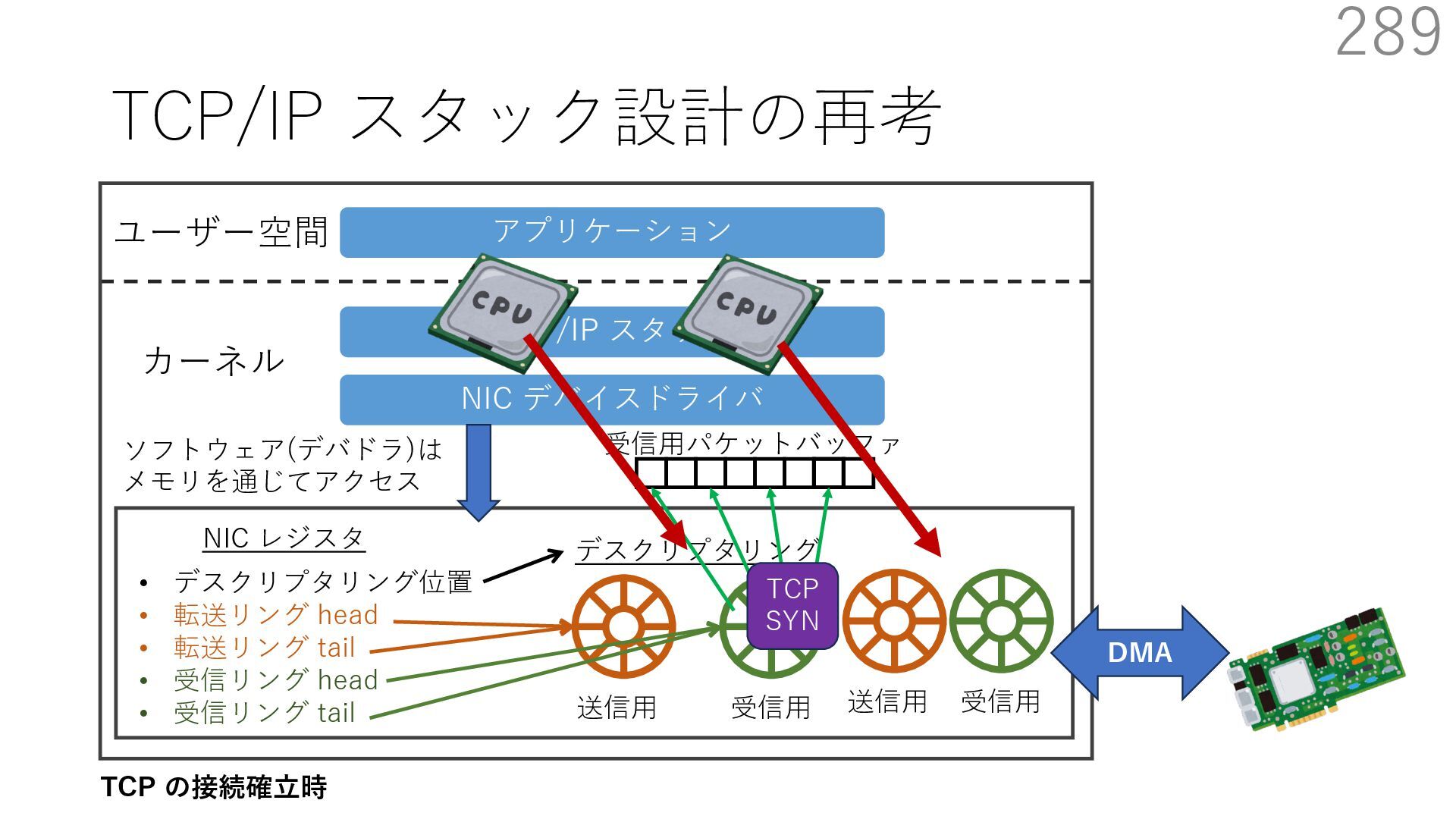
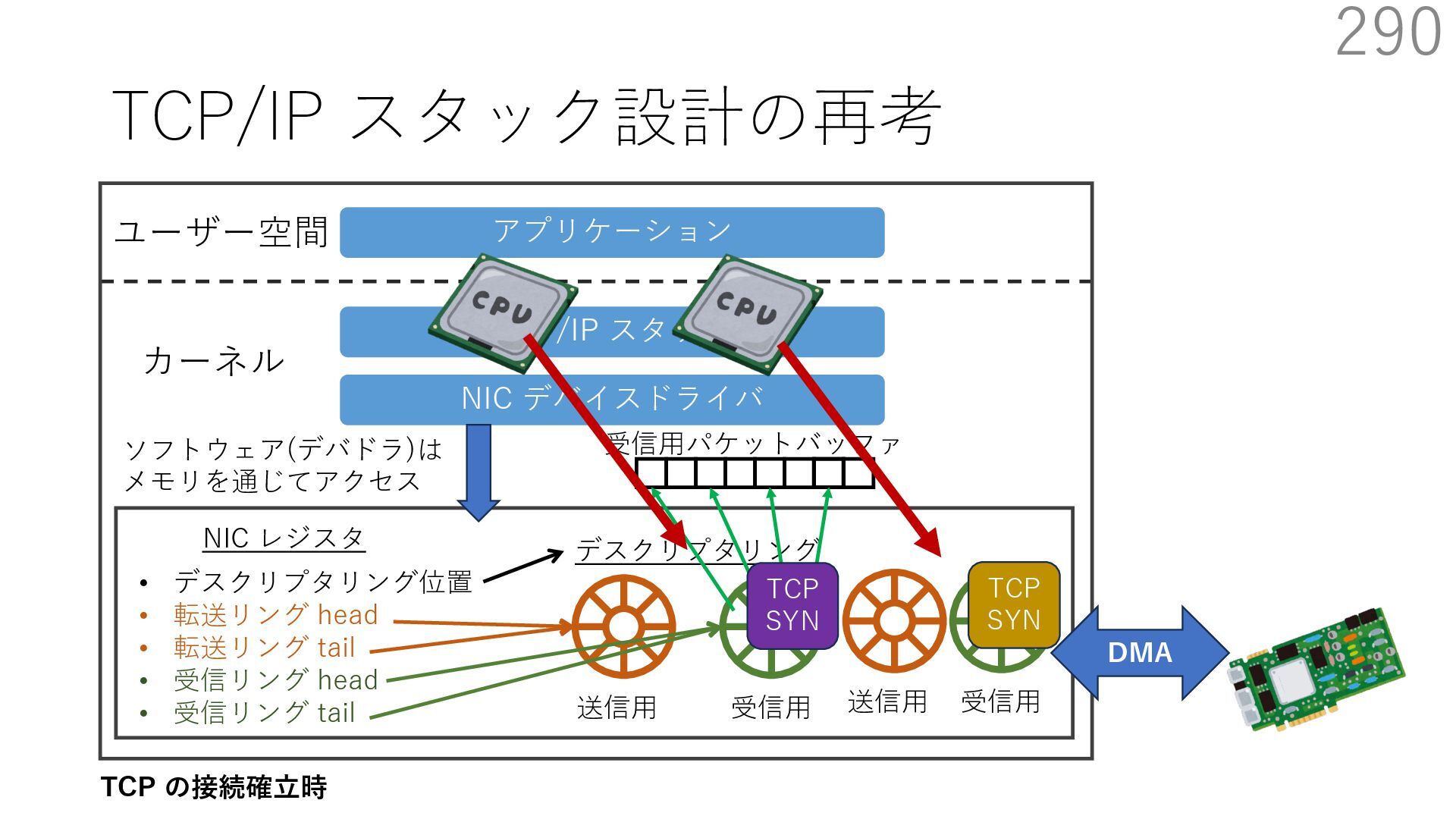
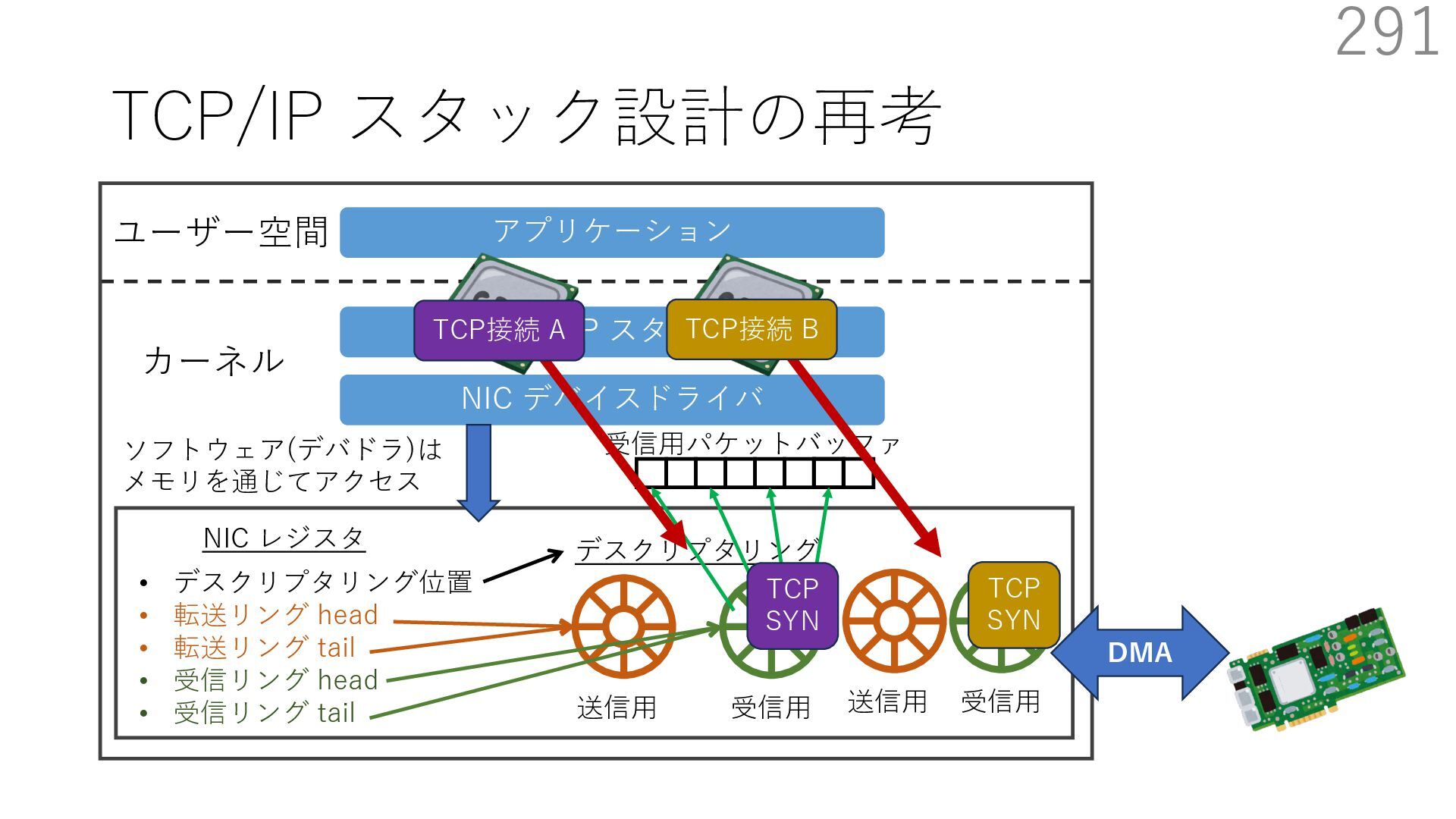
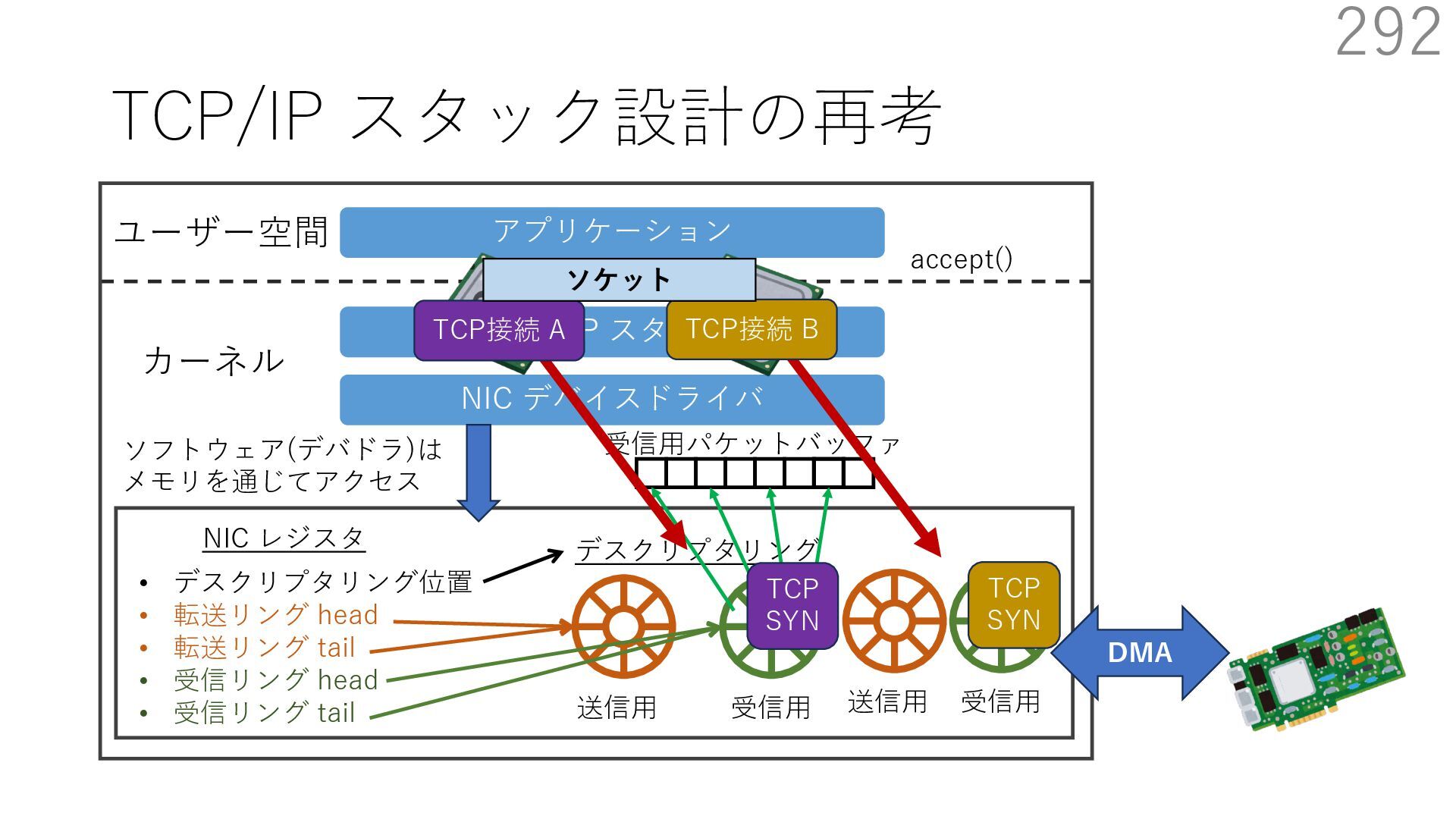
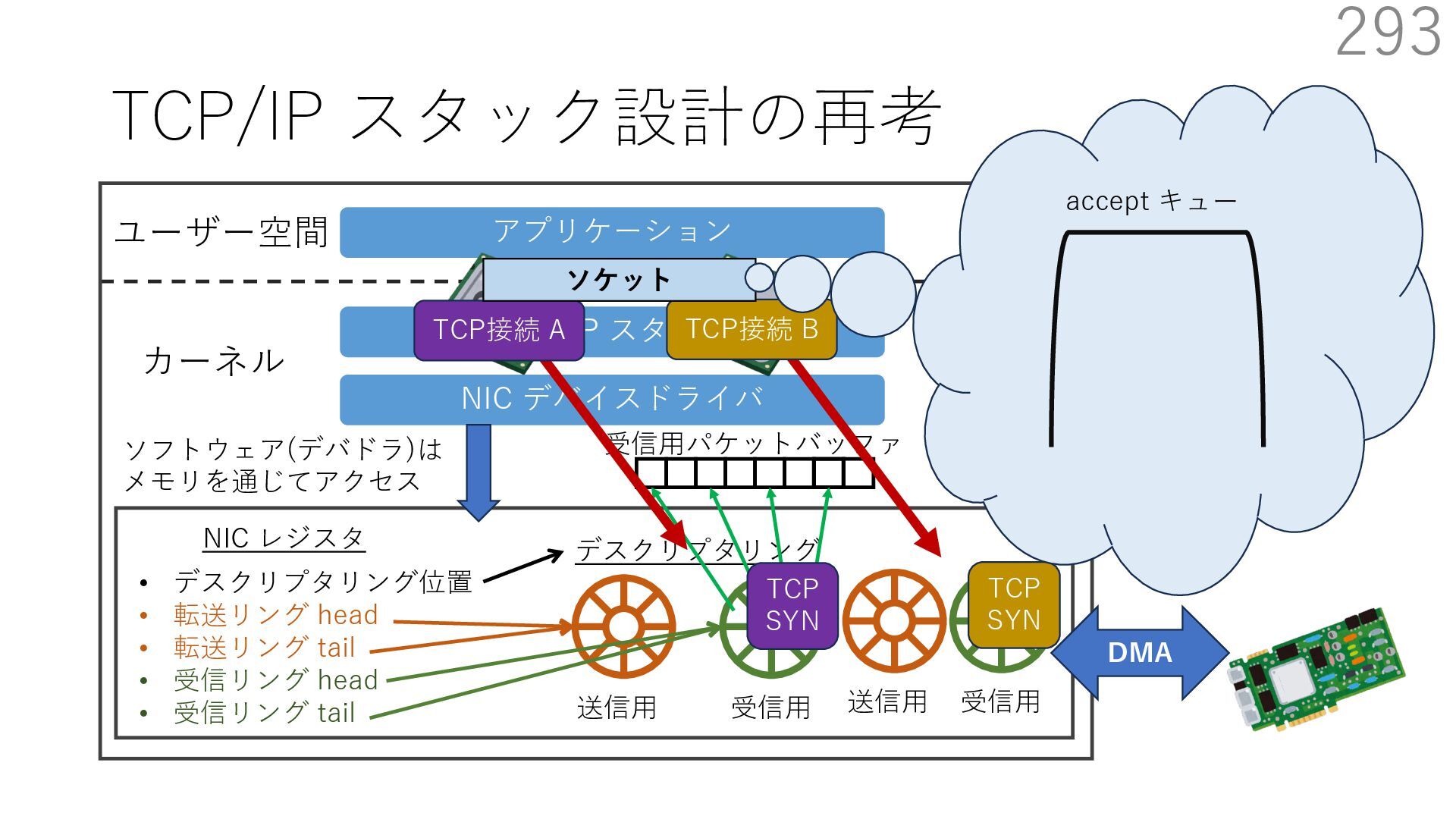
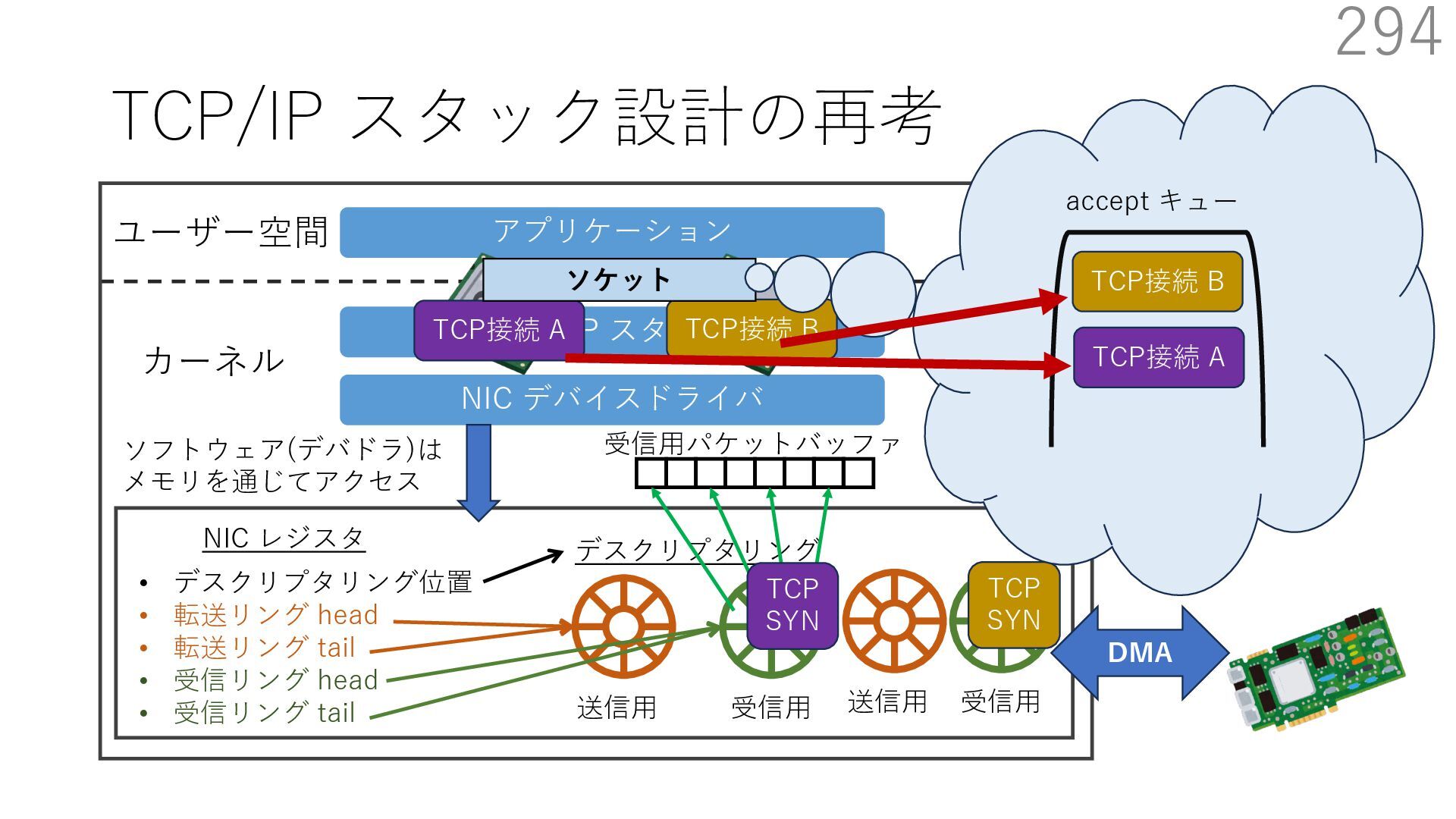
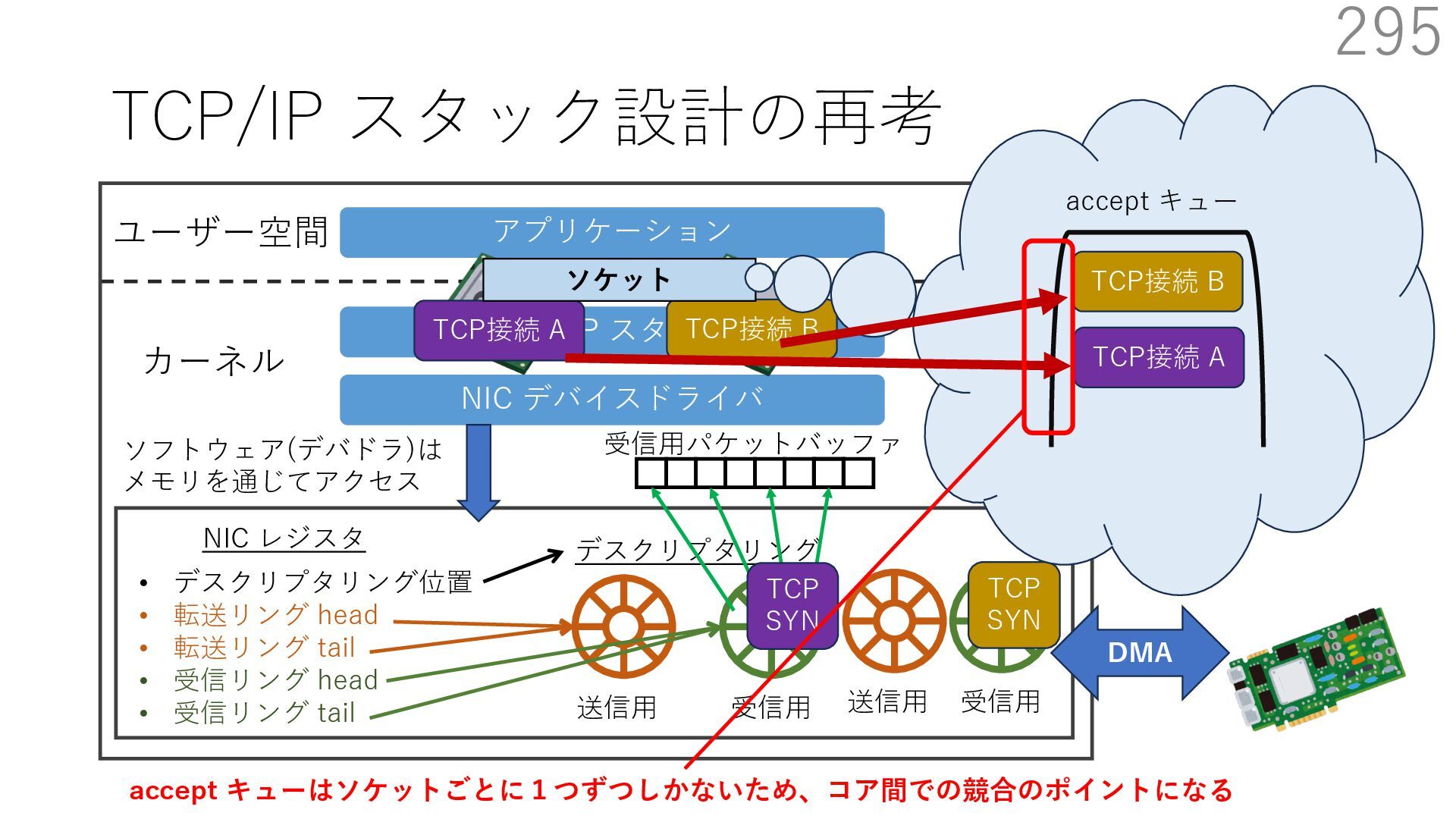
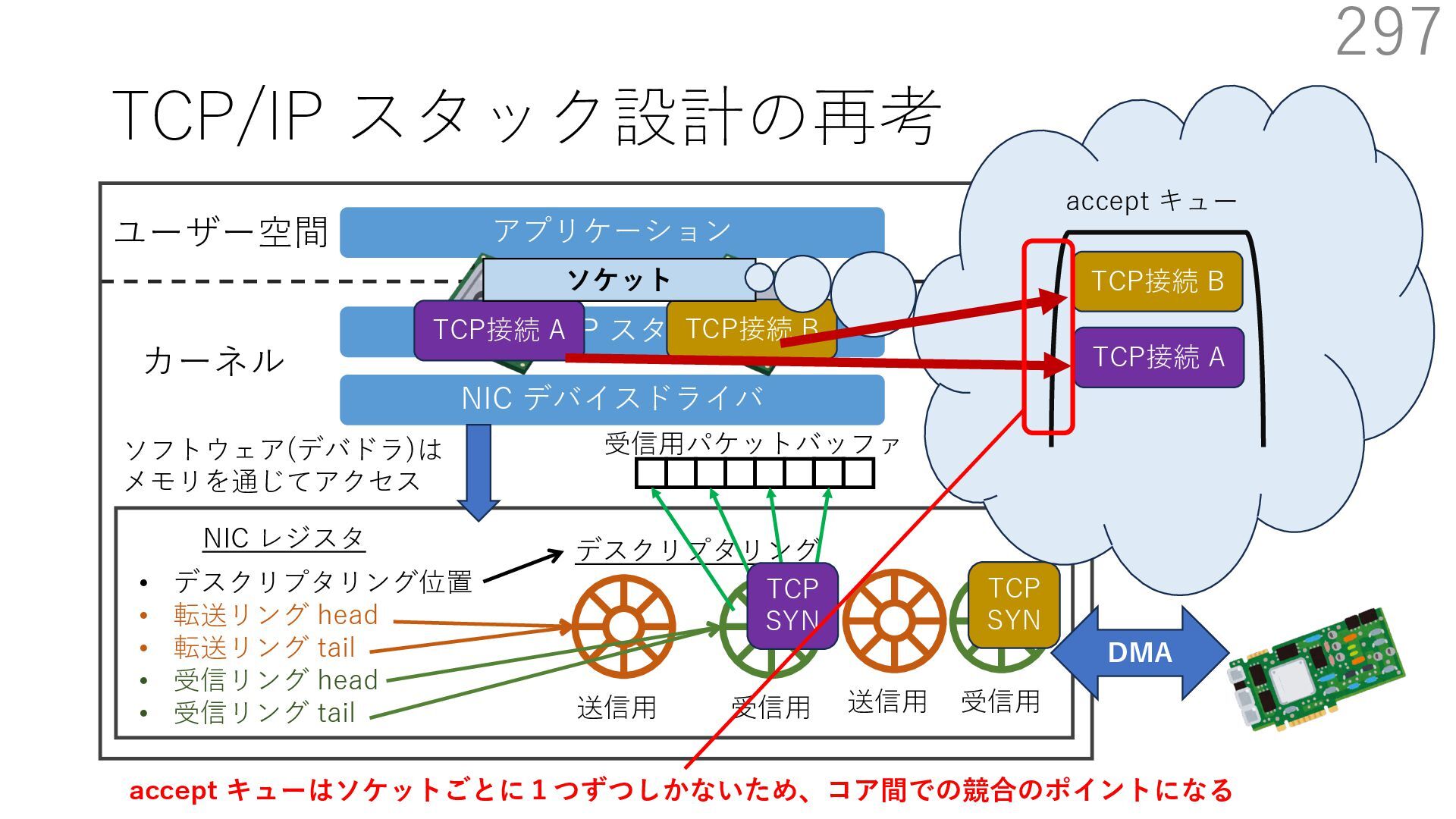
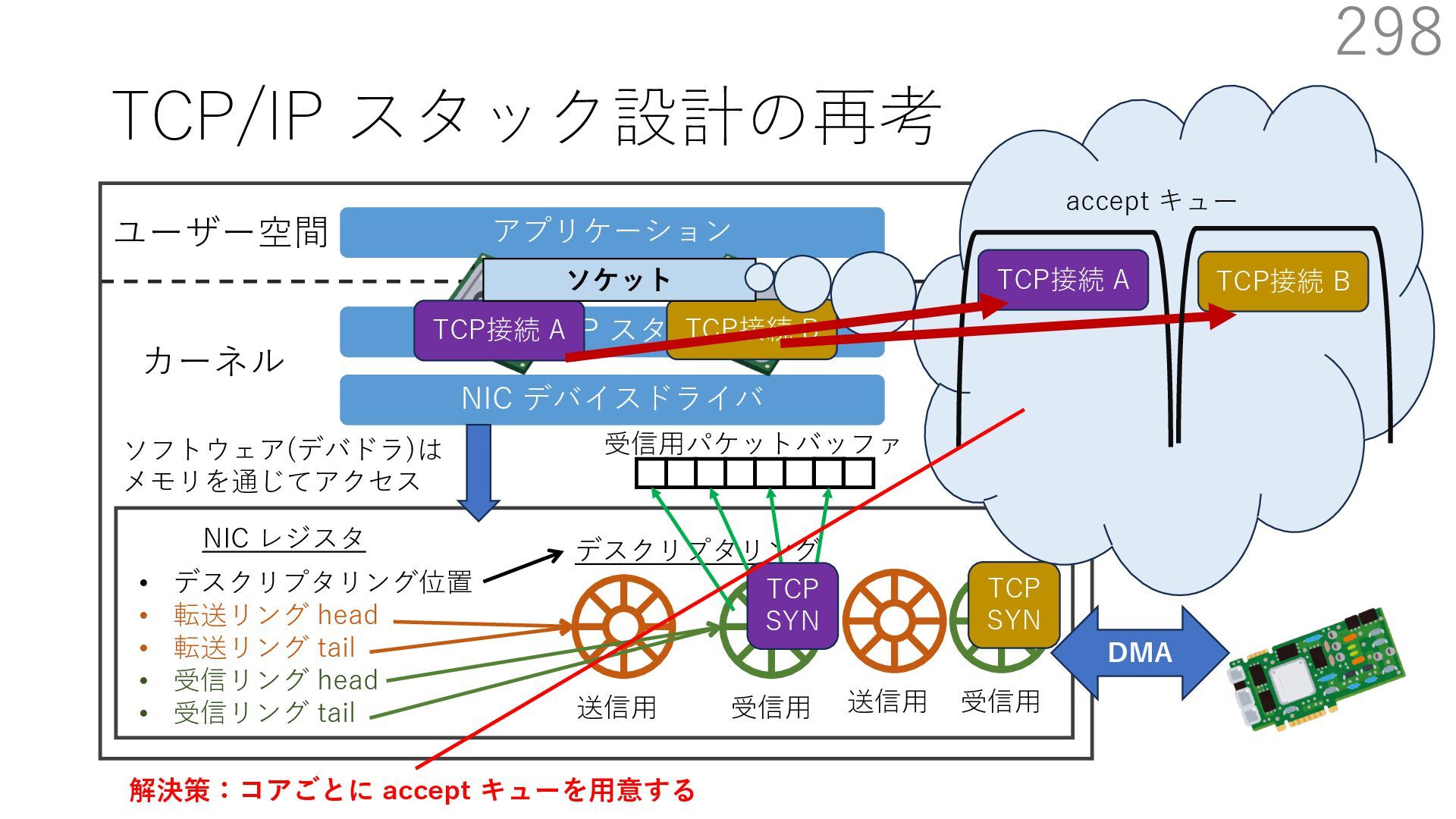
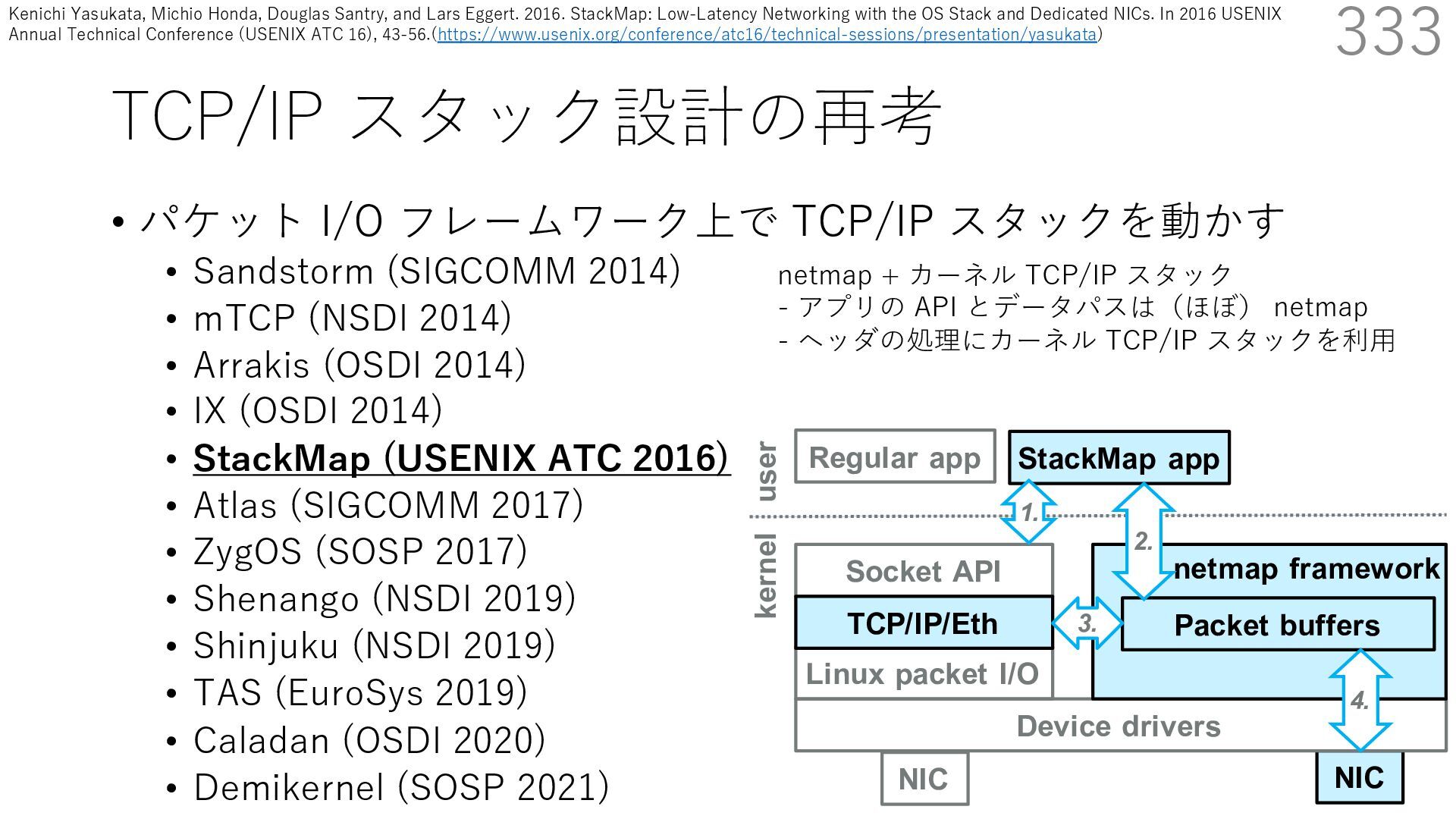
デバイスドライバ アプリケーション ユーザー空間 カーネル デスクリプタリング 受信⽤ NIC レジスタ • デスクリプタリング位置 • 転送リング head • 転送リング tail • 受信リング head • 受信リング tail 受信⽤パケットバッファ ソフトウェア(デバドラ)は メモリを通じてアクセス TCP/IP スタック 送信⽤ 受信⽤ DMA TCP SYN TCP SYN TCP接続 A TCP接続 B ソケット accept キュー TCP接続 B TCP接続 A
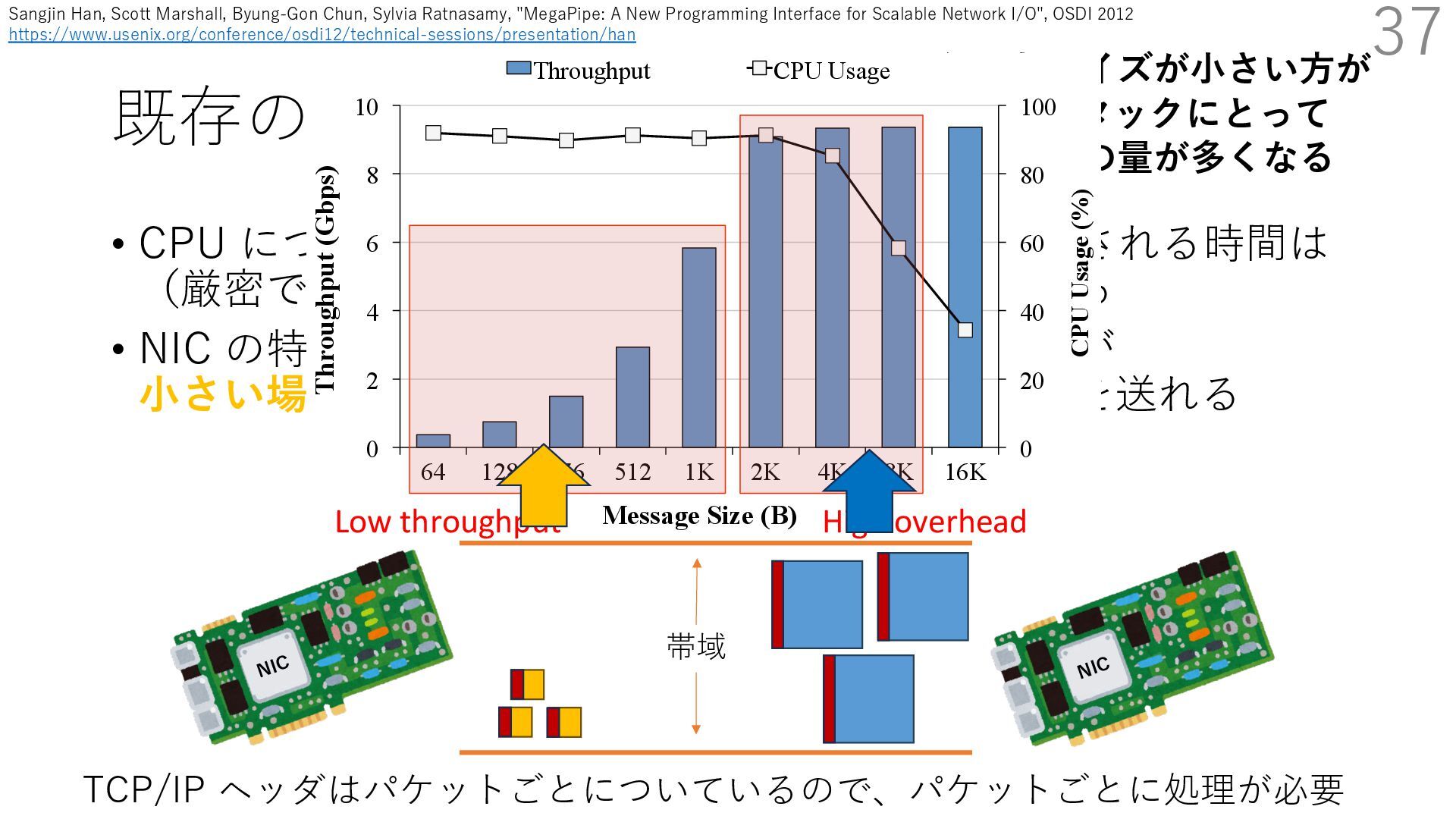
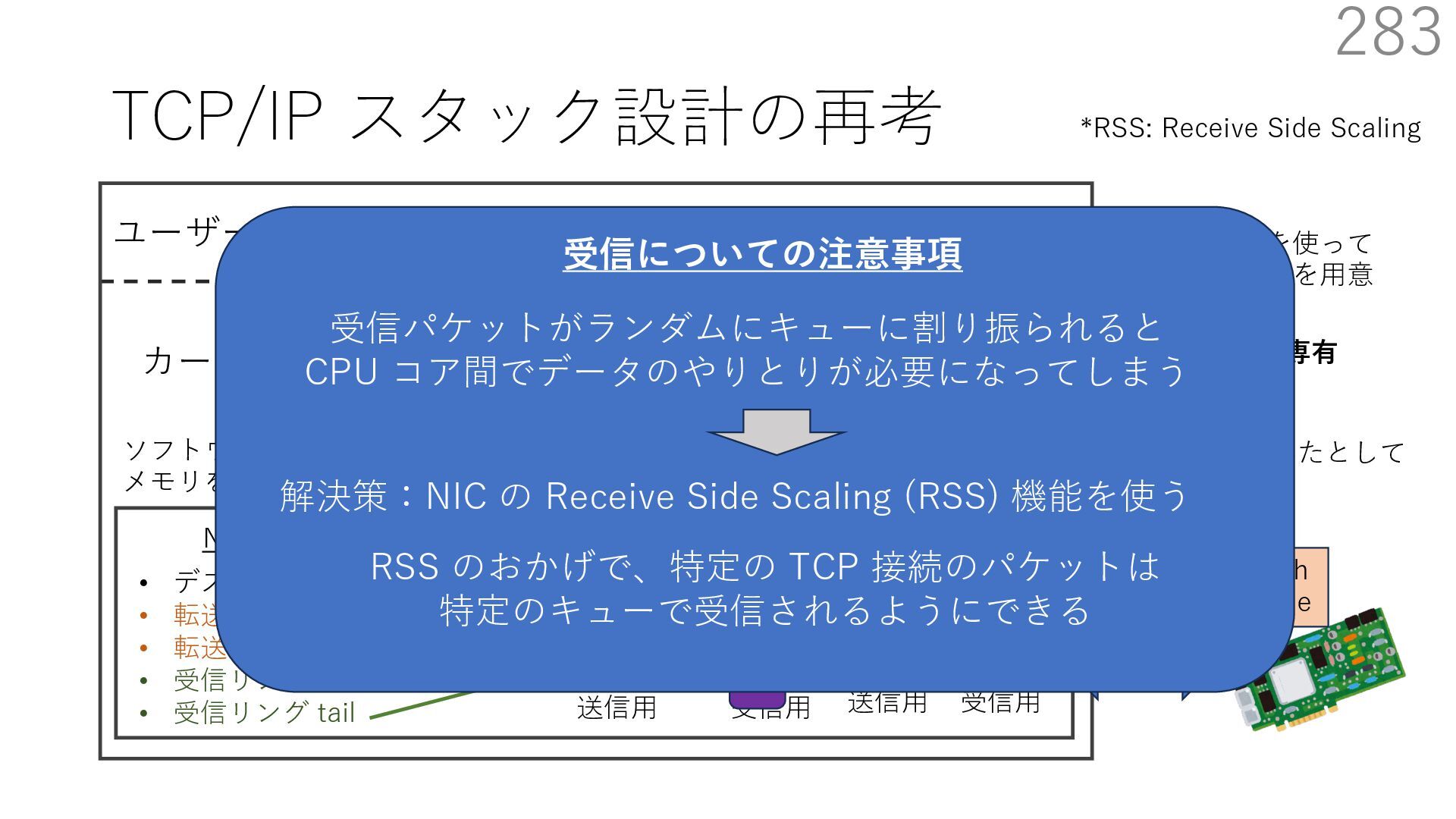
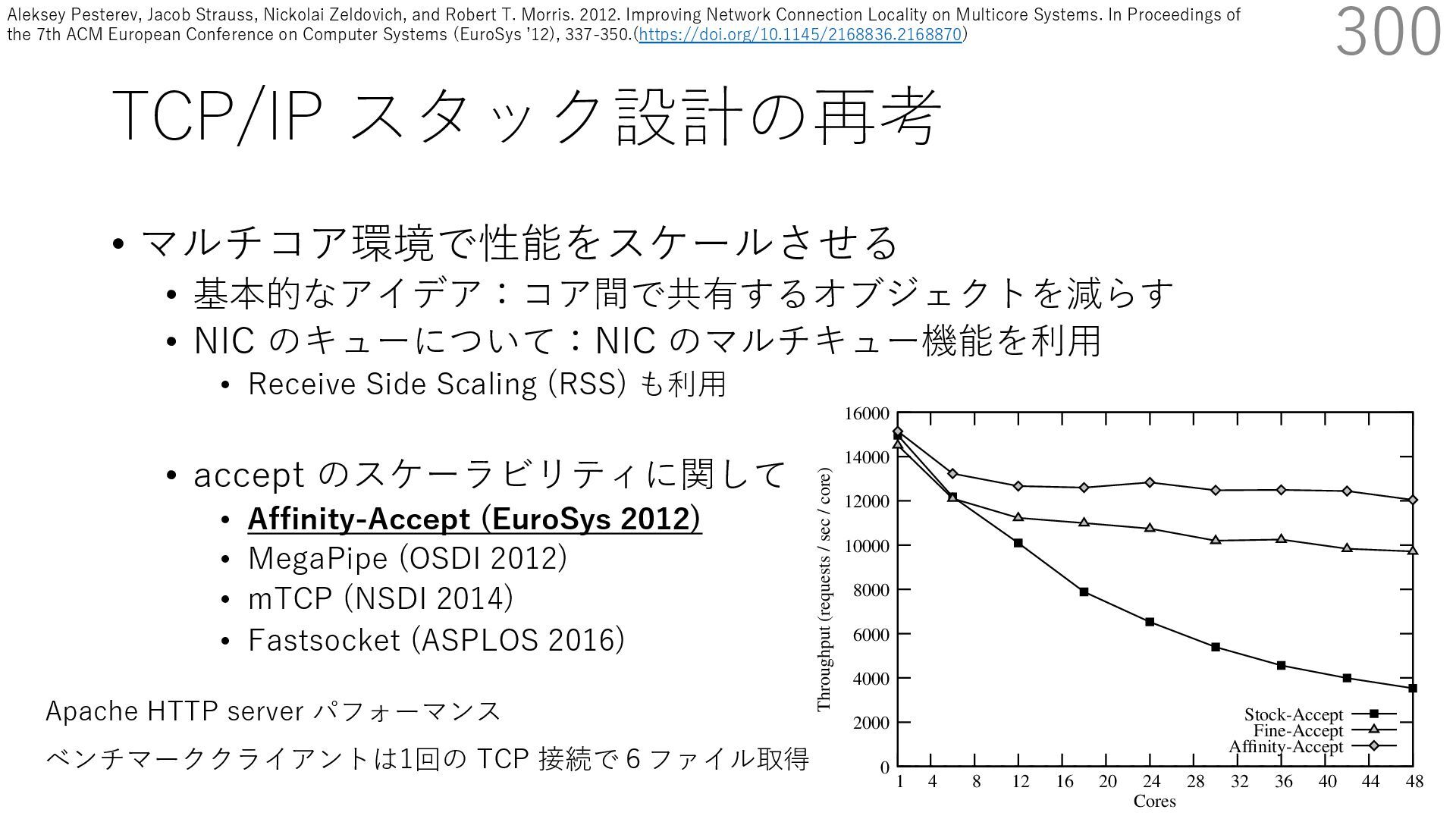
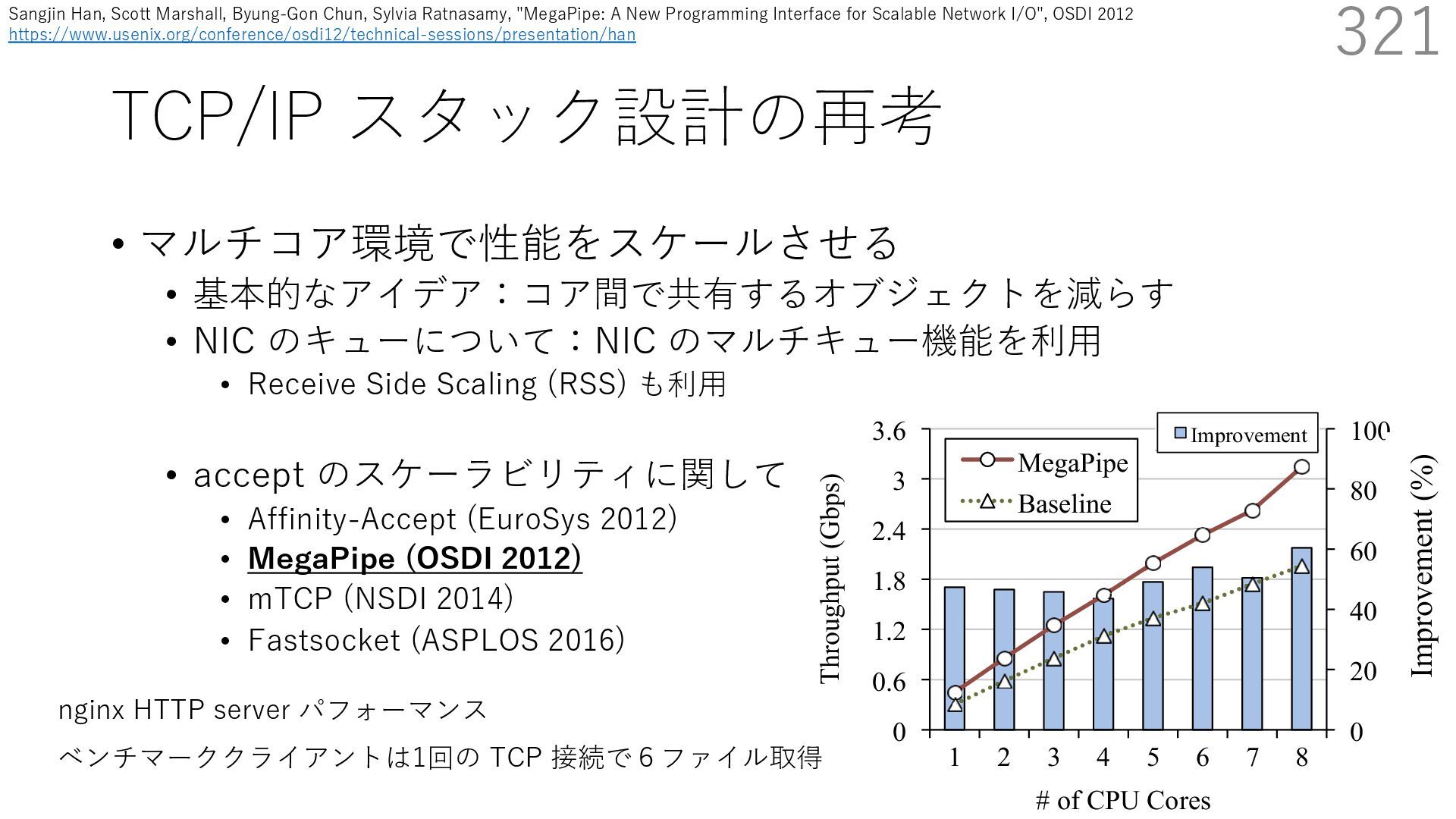
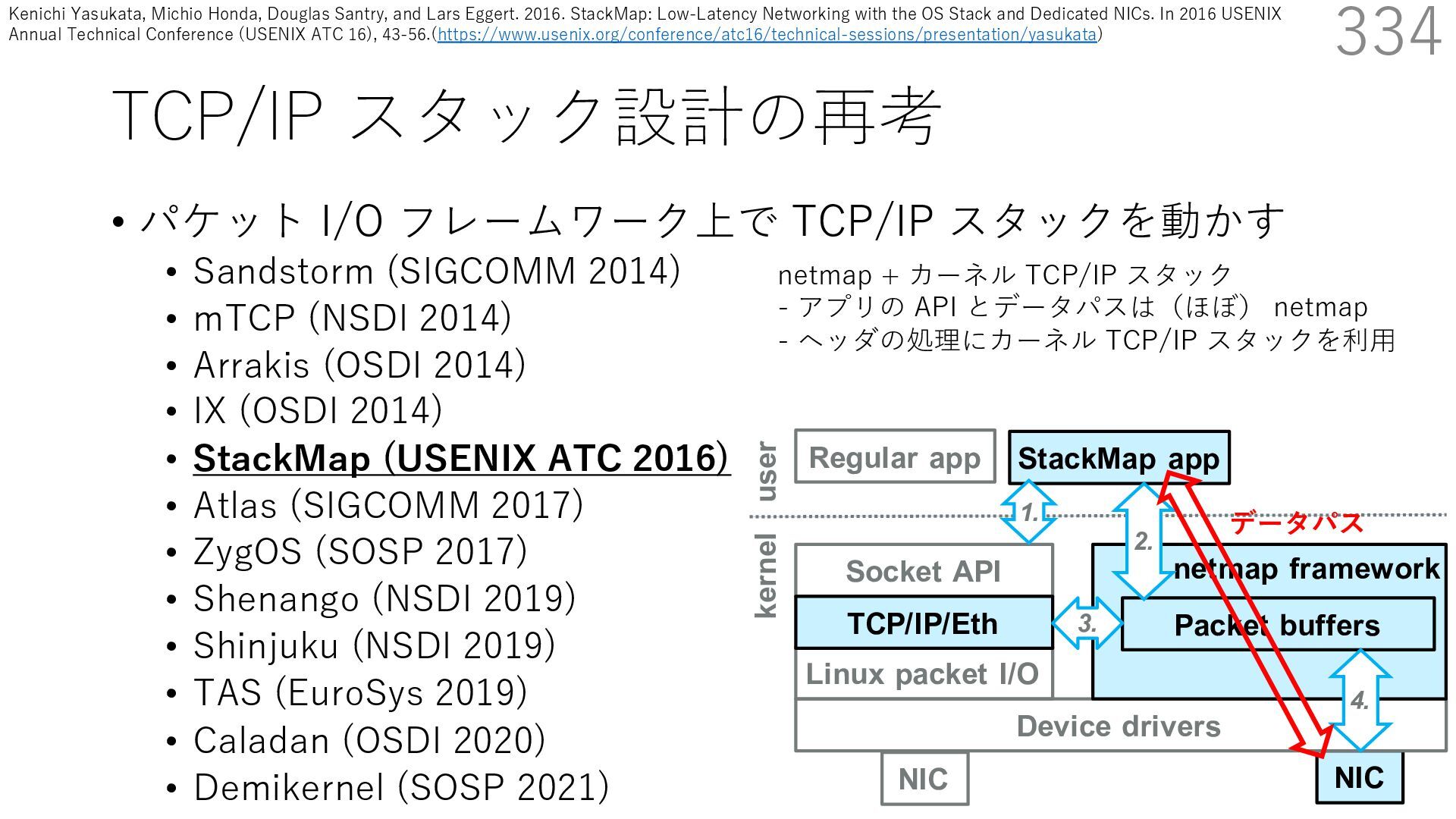
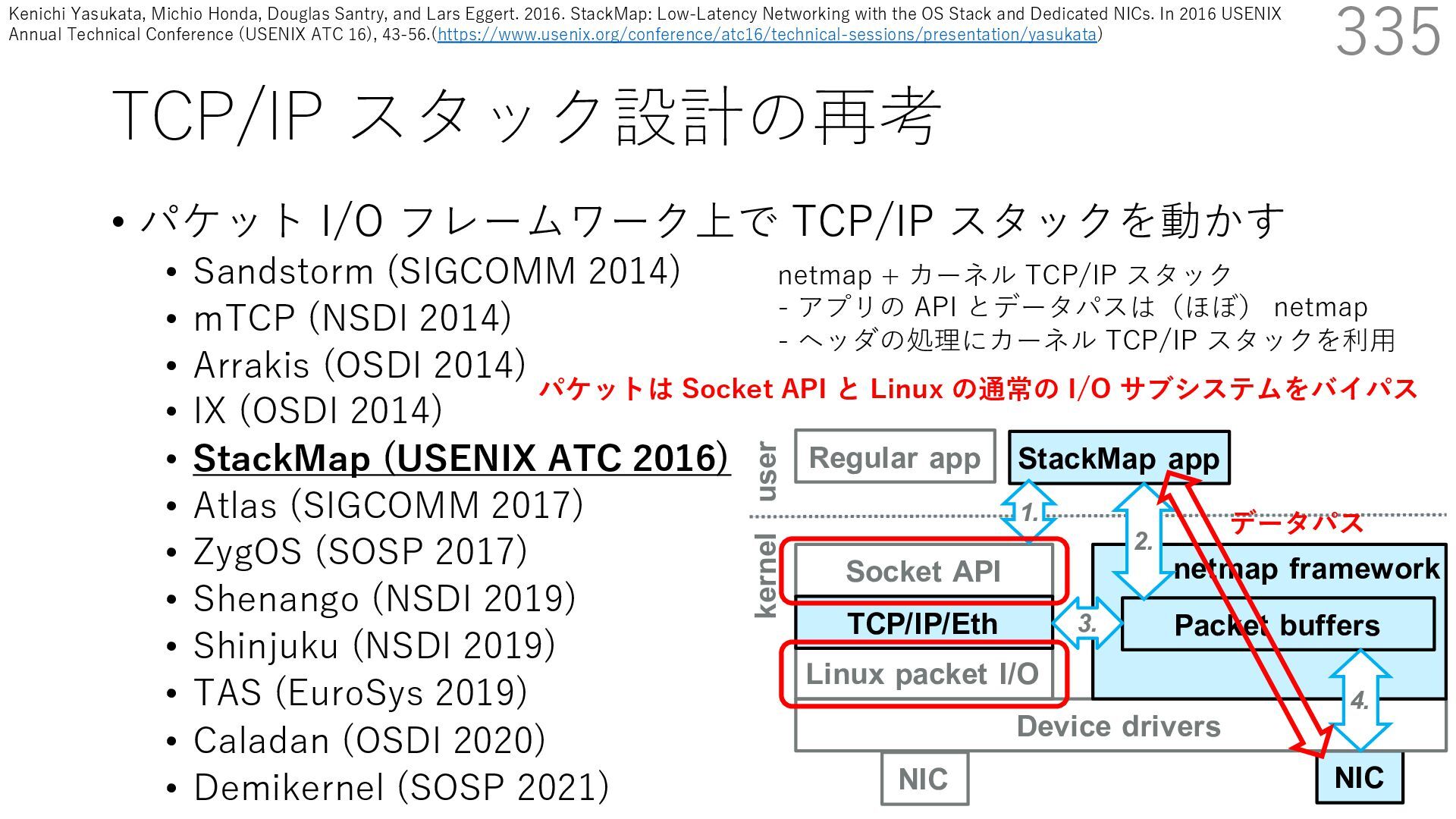
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 300 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
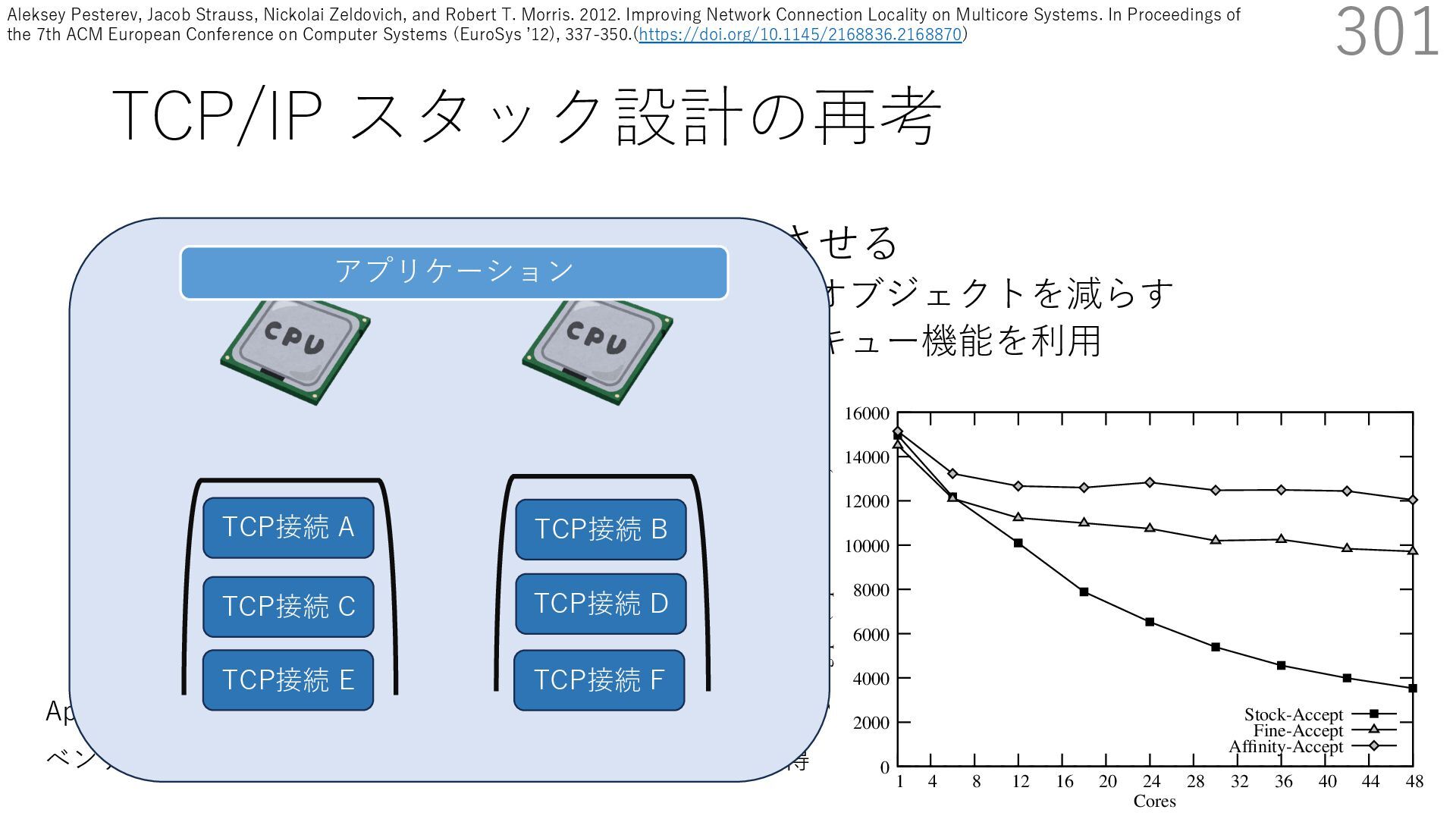
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 301 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 A TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
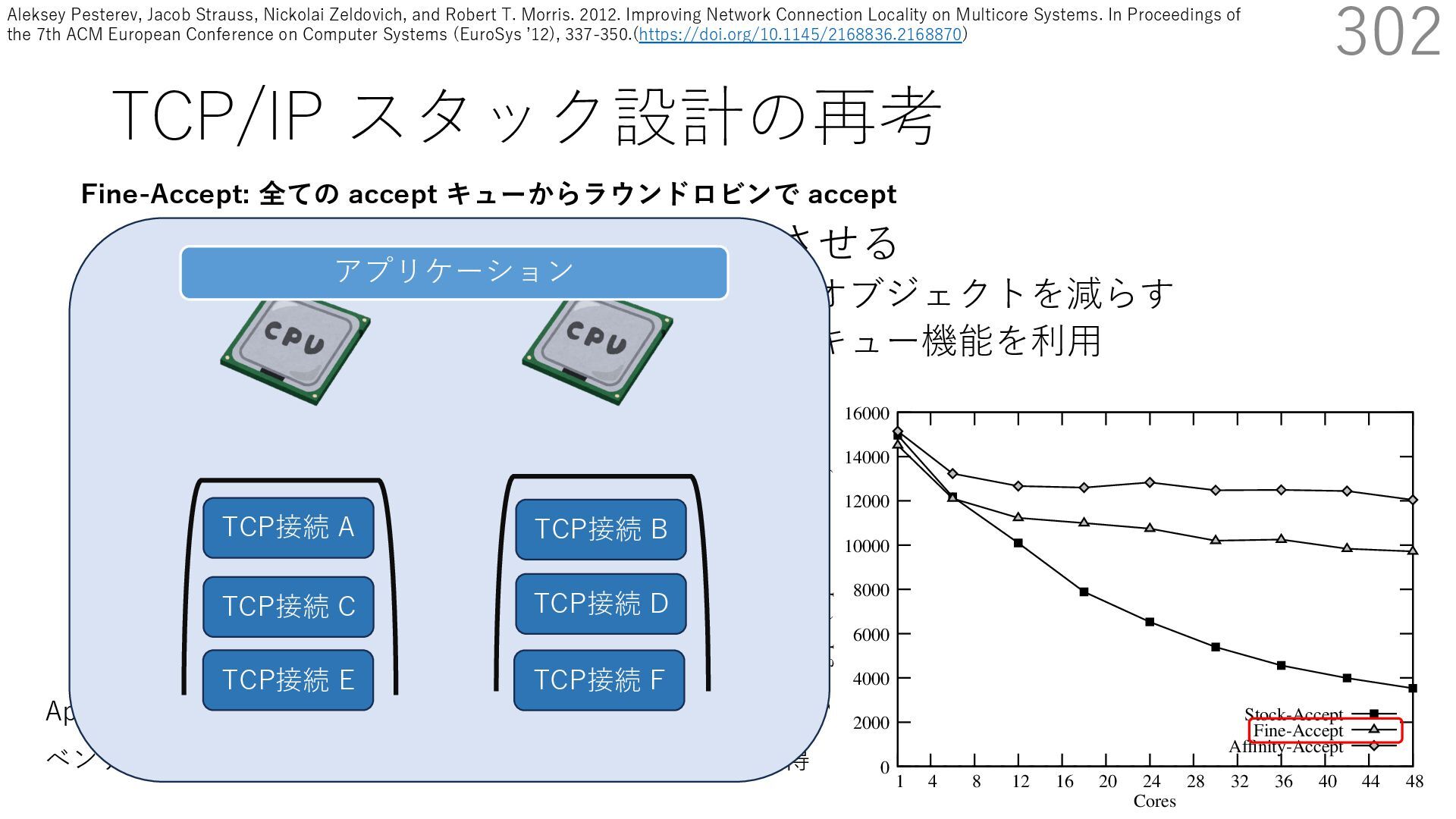
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 302 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 A TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
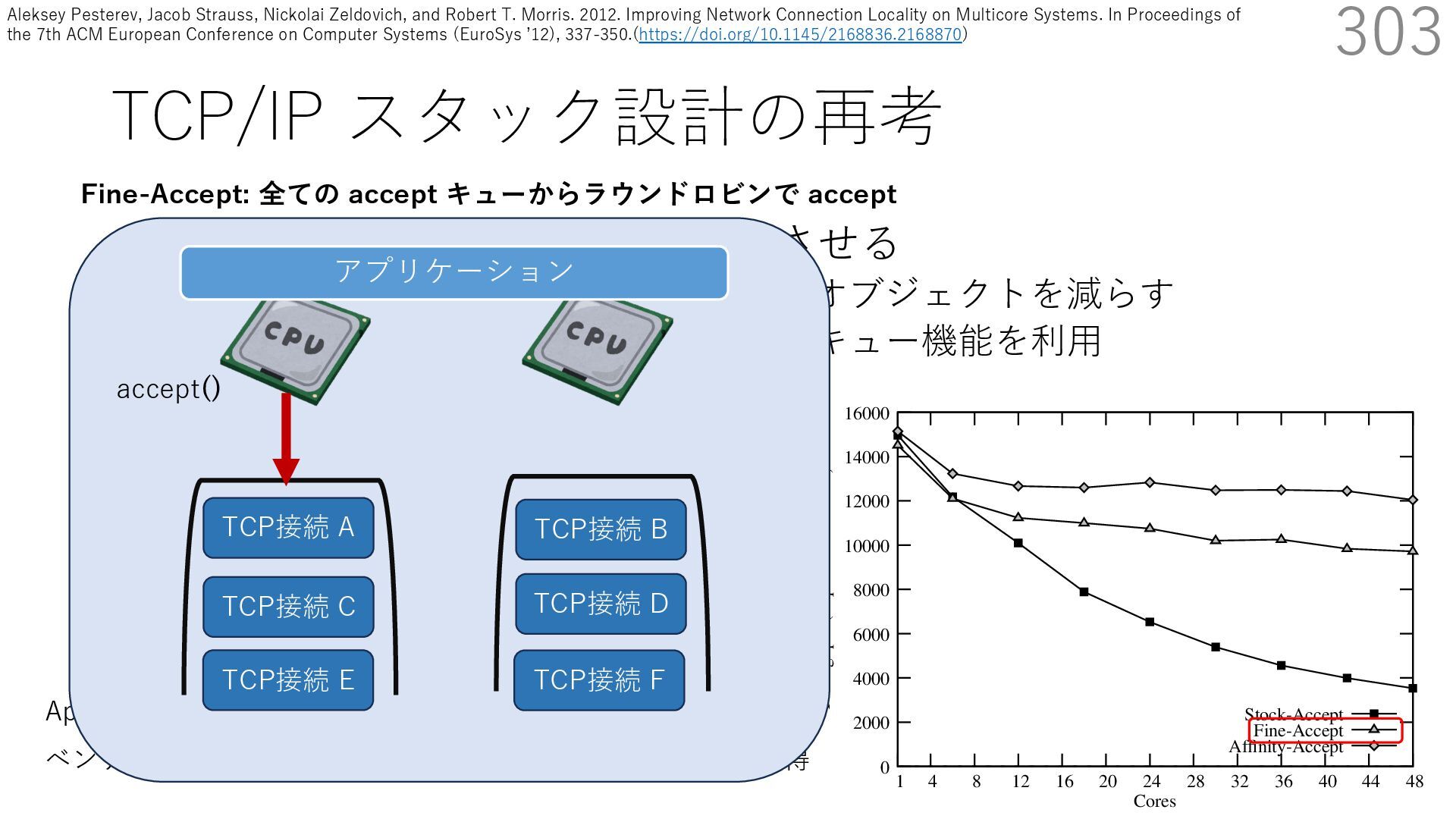
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 303 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 A TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept accept() Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
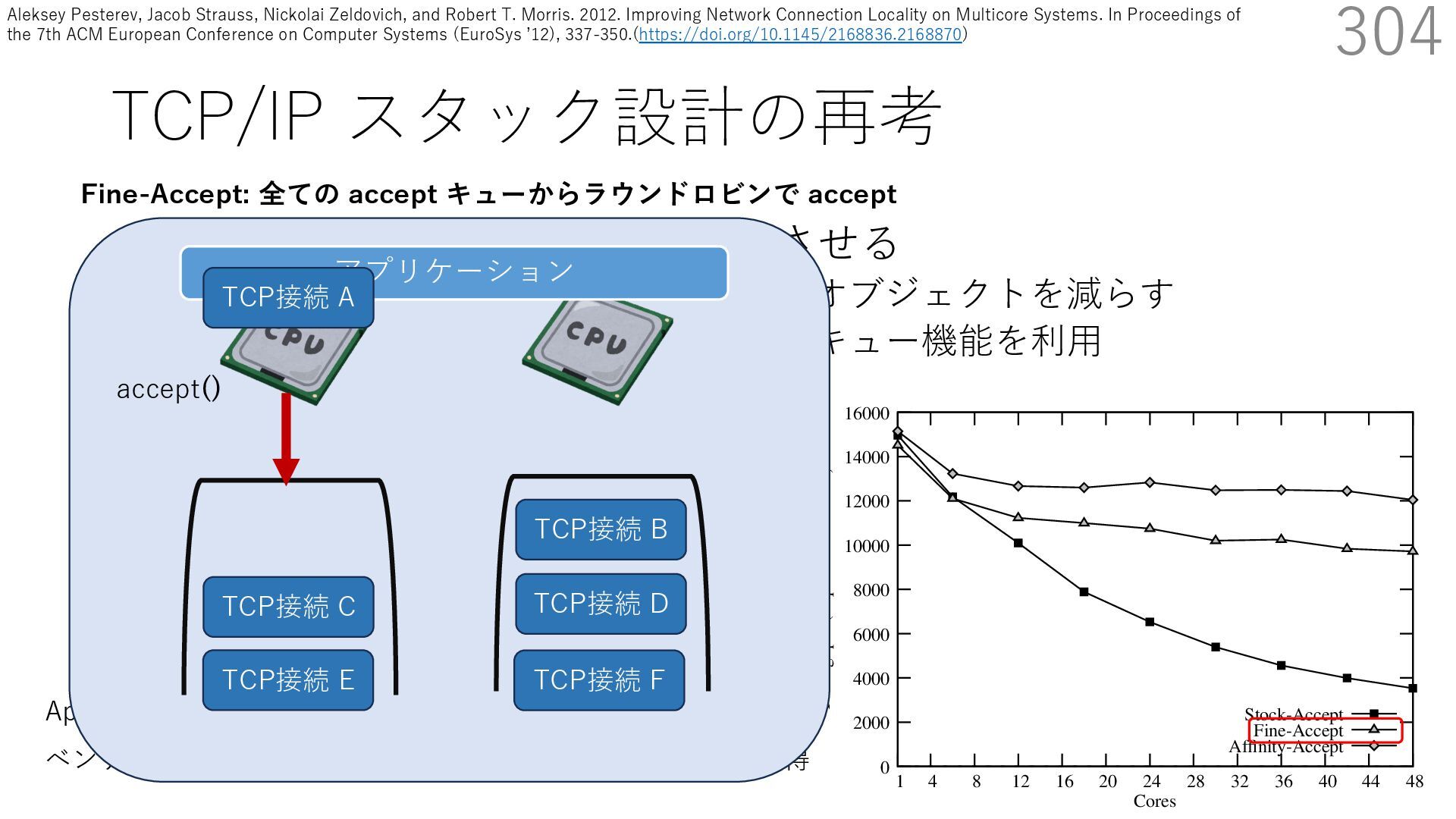
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 304 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept accept() TCP接続 A Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
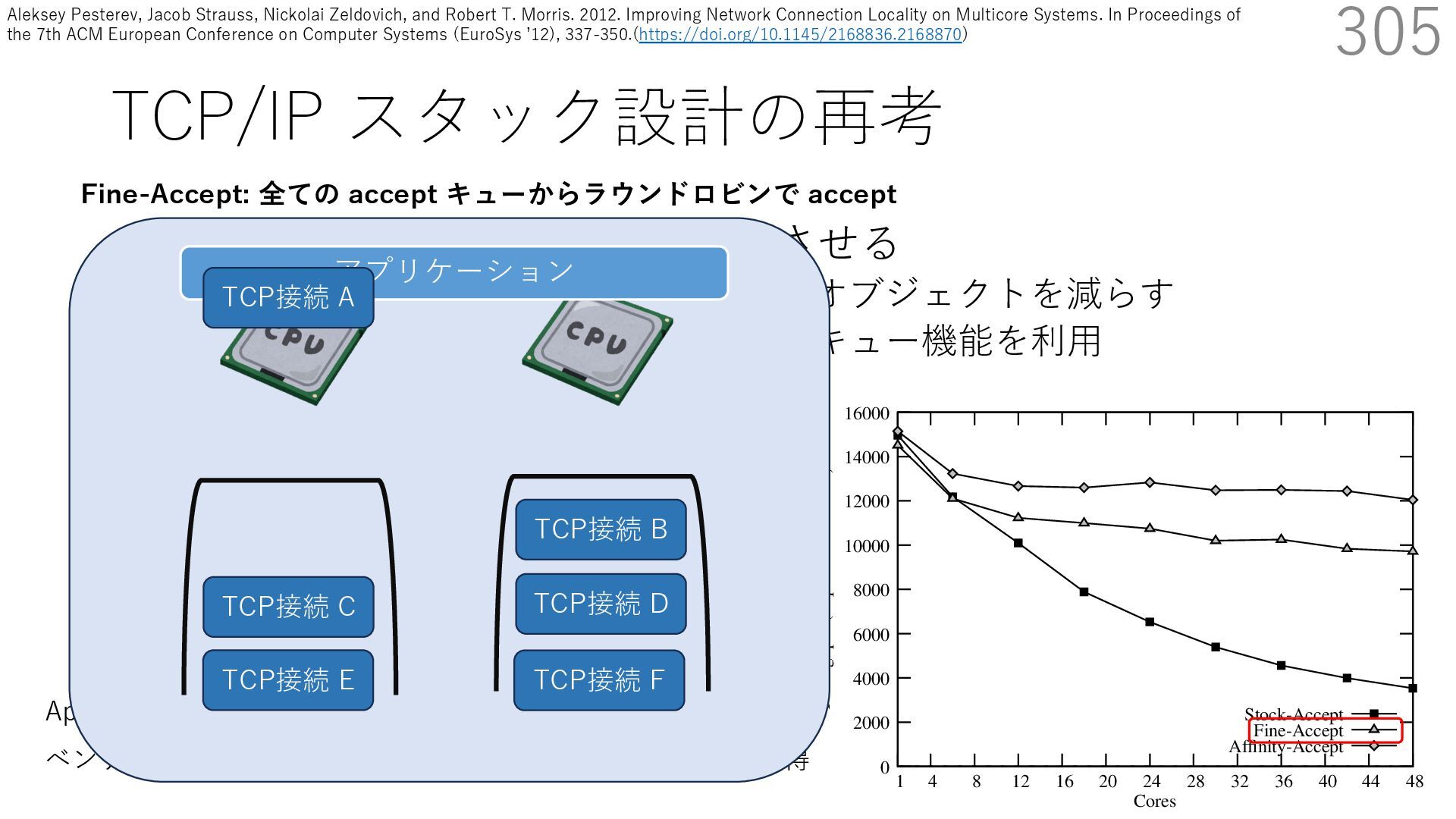
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 305 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept TCP接続 A Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
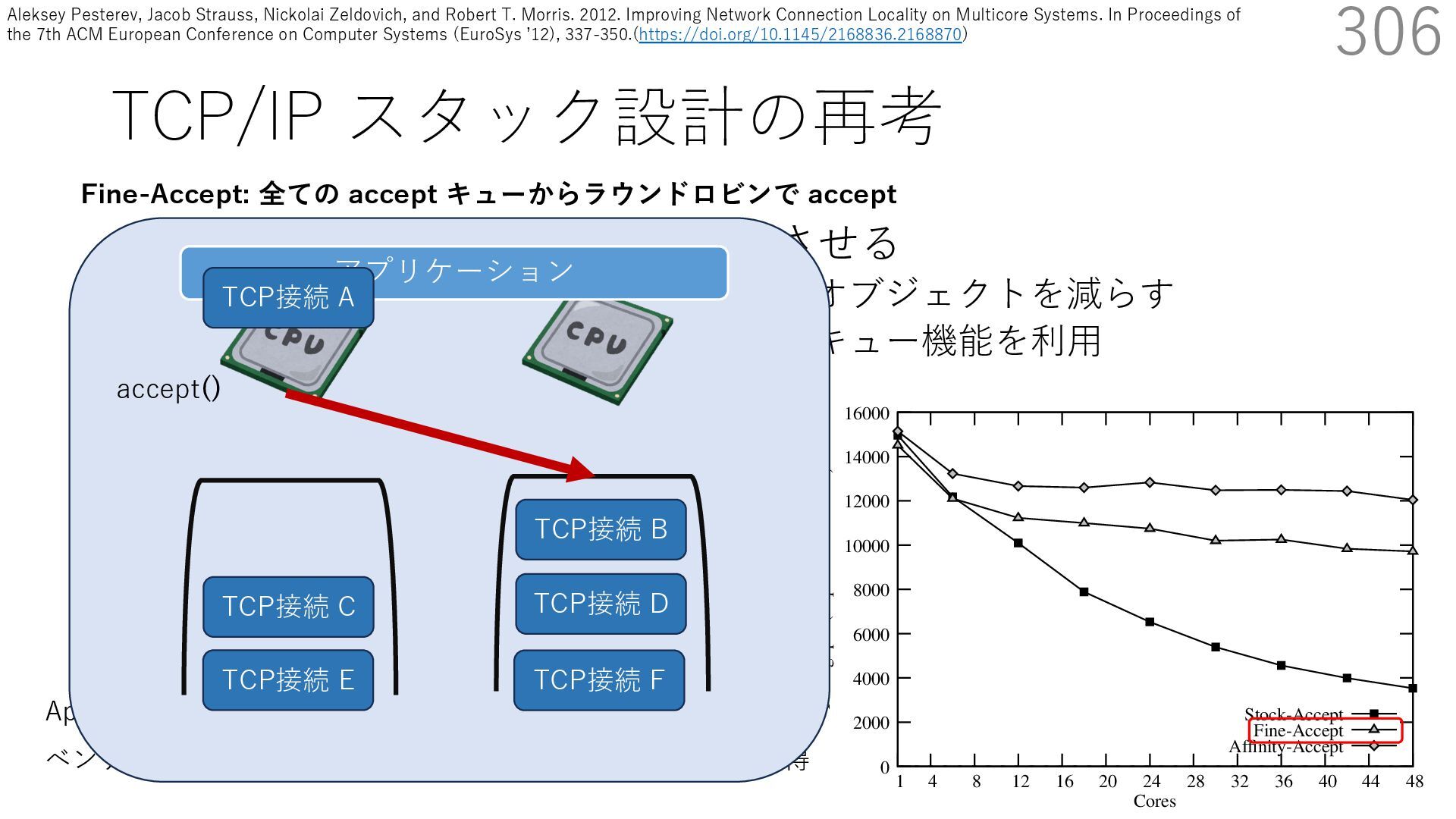
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 306 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept TCP接続 A accept() Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
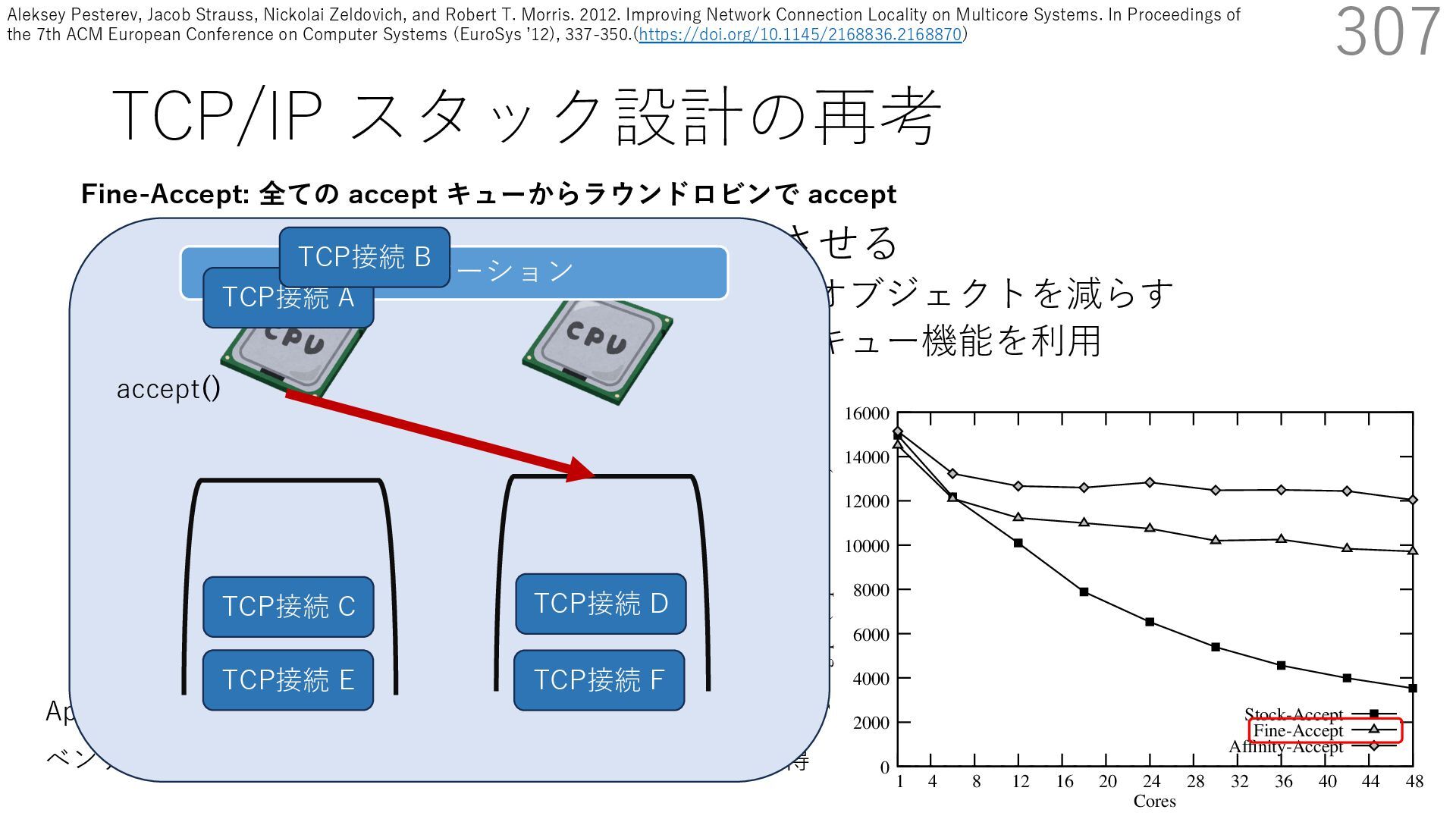
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 307 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept TCP接続 A accept() TCP接続 B Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
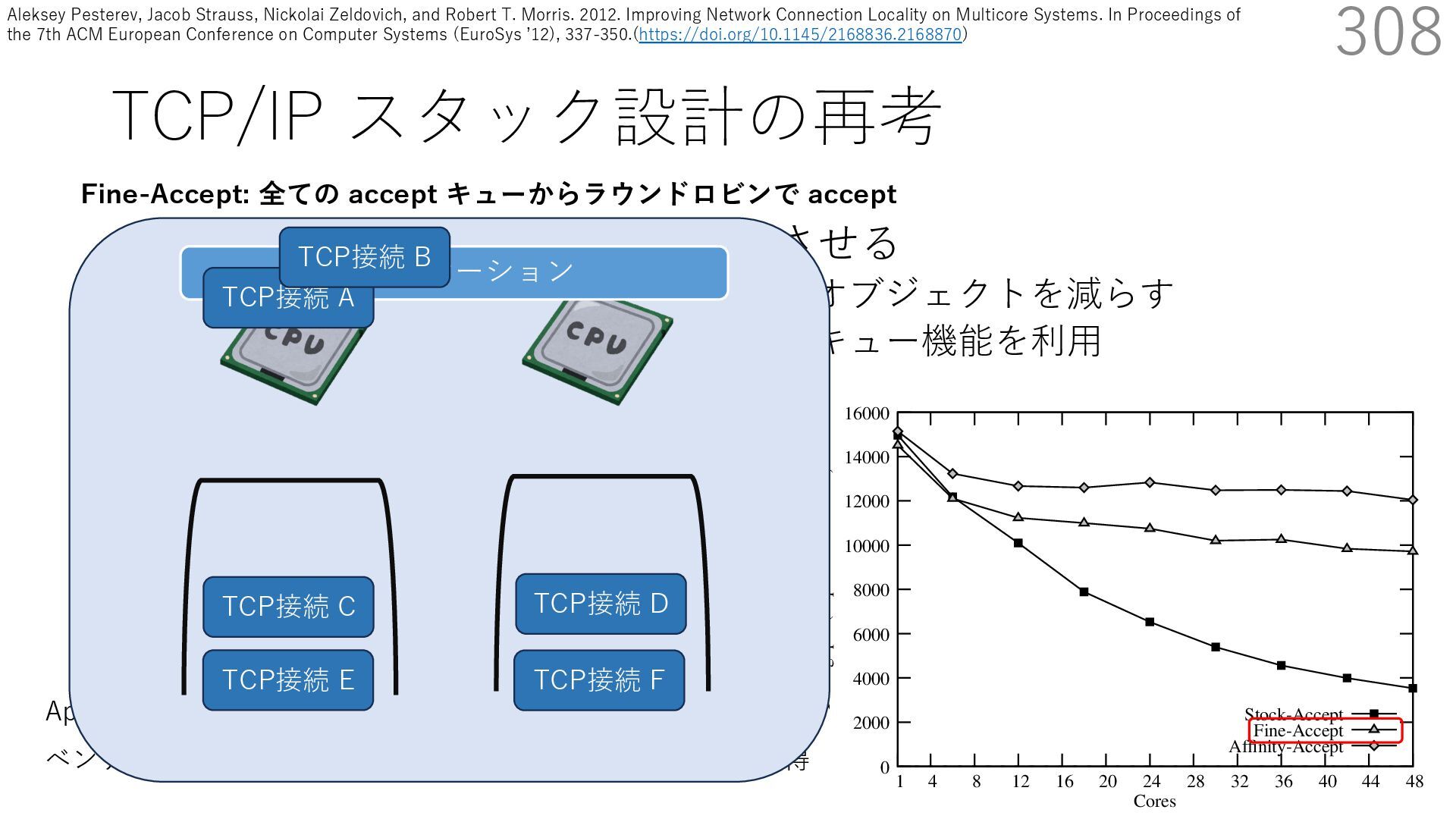
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 308 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept TCP接続 A TCP接続 B Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
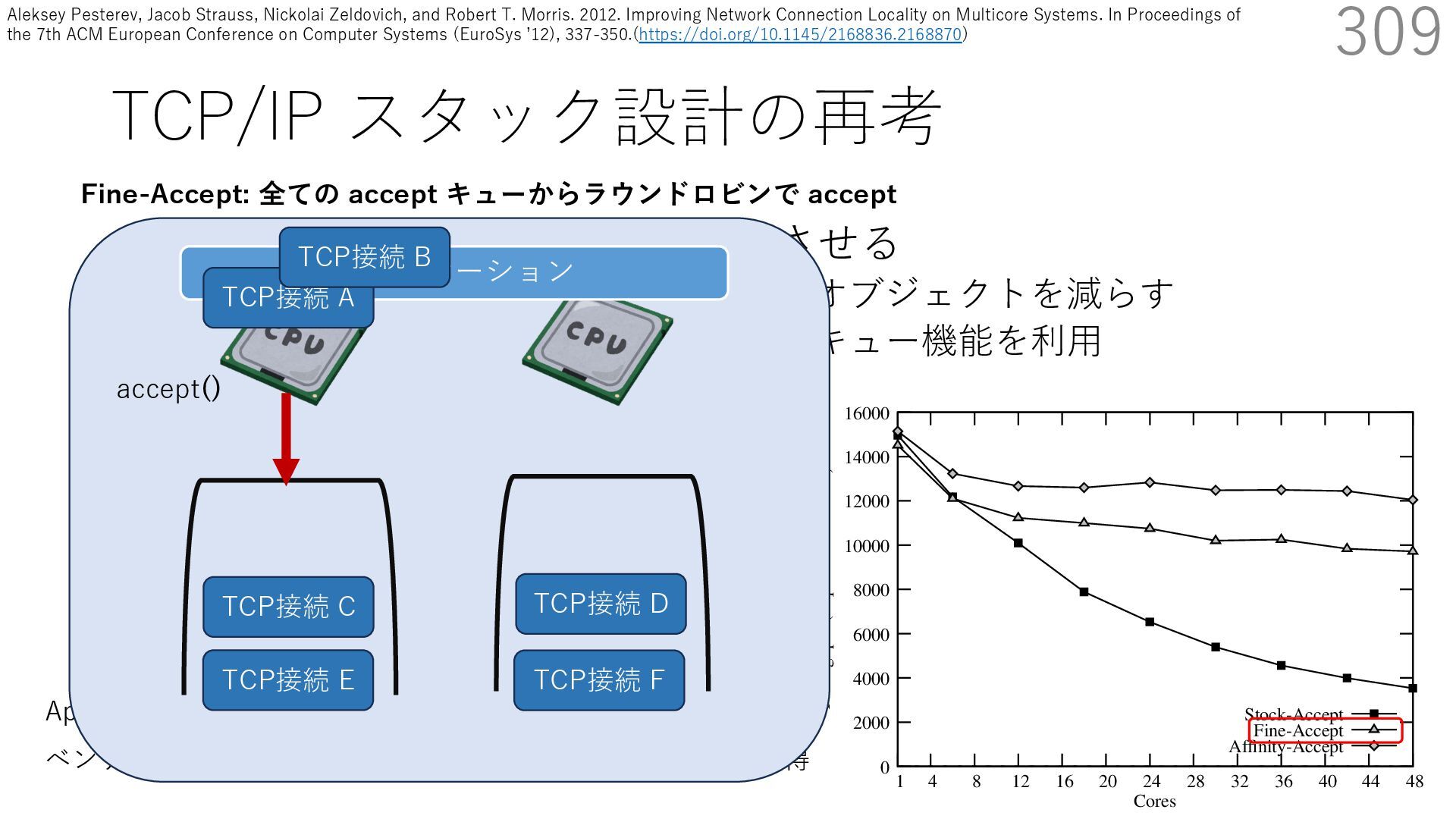
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 309 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept TCP接続 A TCP接続 B accept() Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
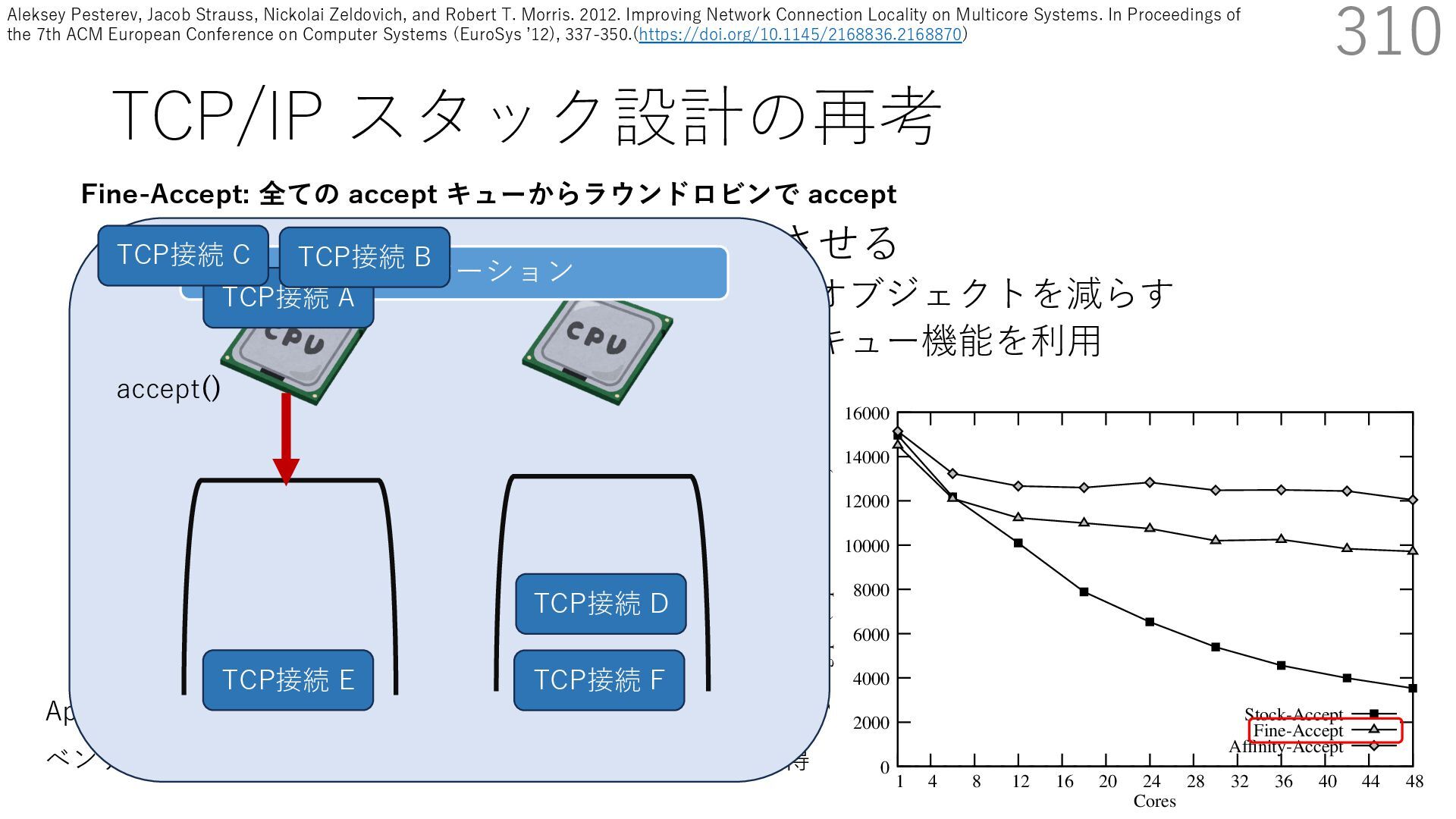
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 310 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 D TCP接続 E TCP接続 F アプリケーション Fine-Accept: 全ての accept キューからラウンドロビンで accept TCP接続 A TCP接続 B accept() TCP接続 C Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
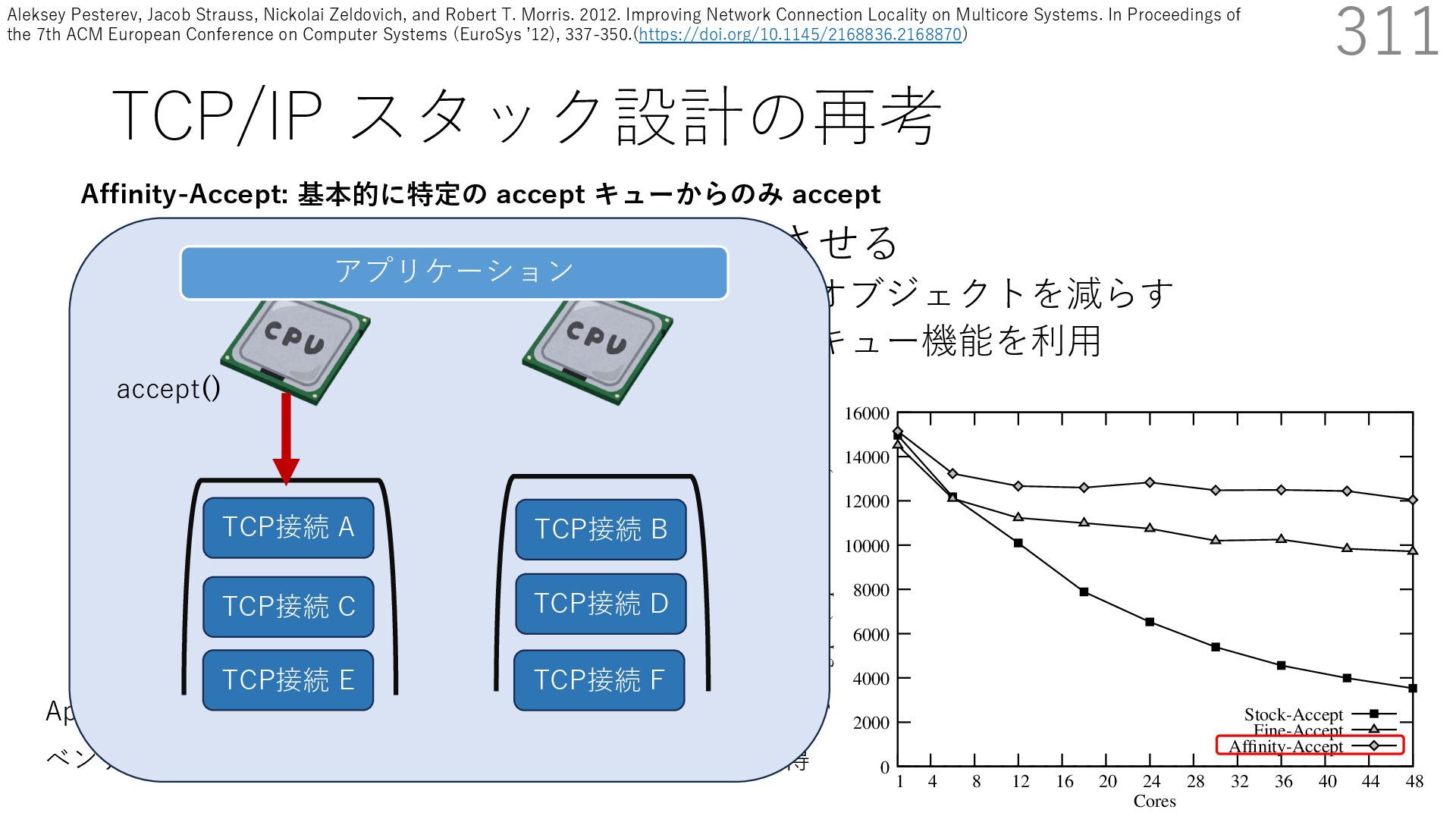
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 311 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 A TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Affinity-Accept: 基本的に特定の accept キューからのみ accept accept() Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
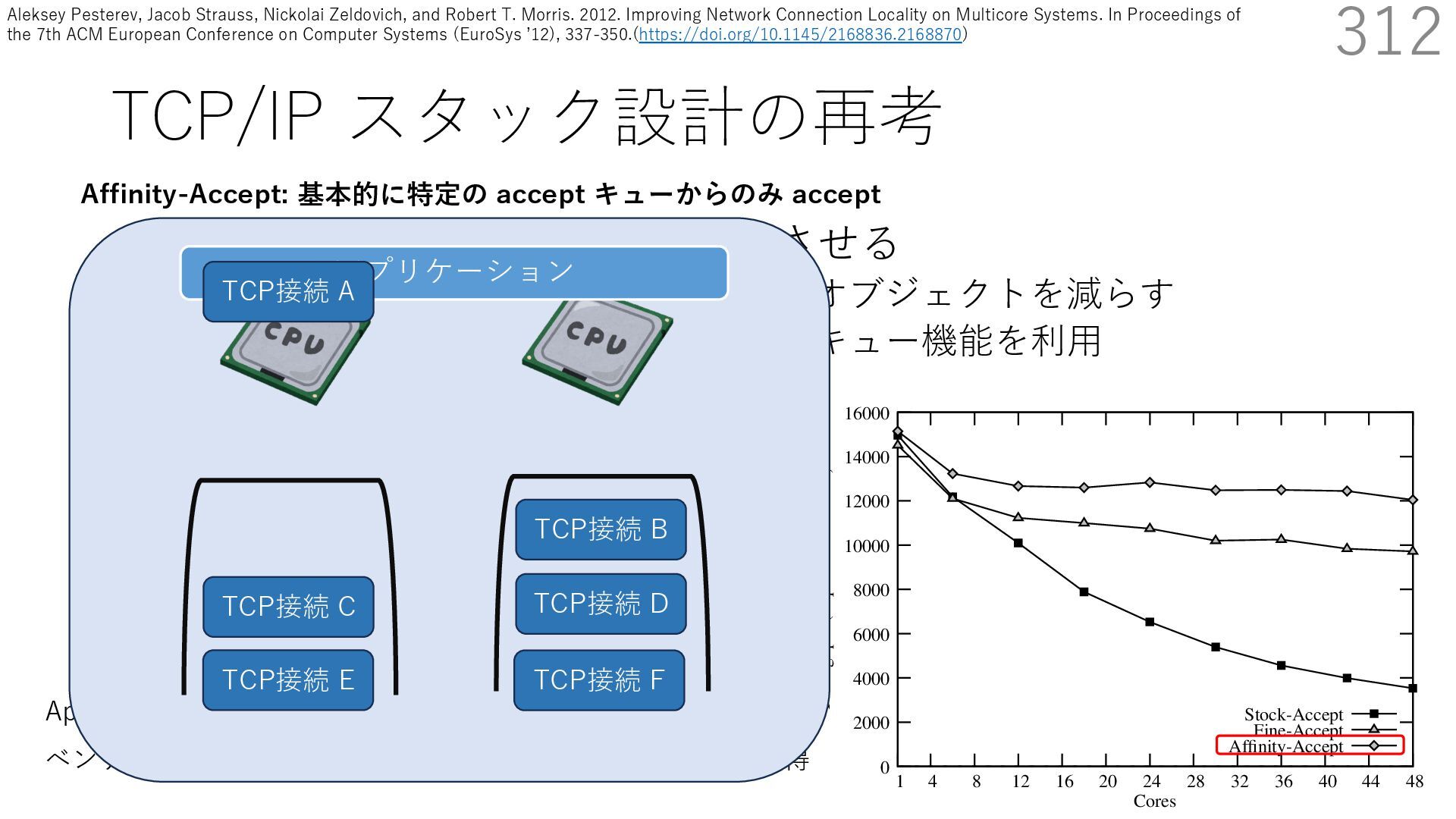
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 312 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Affinity-Accept: 基本的に特定の accept キューからのみ accept TCP接続 A Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
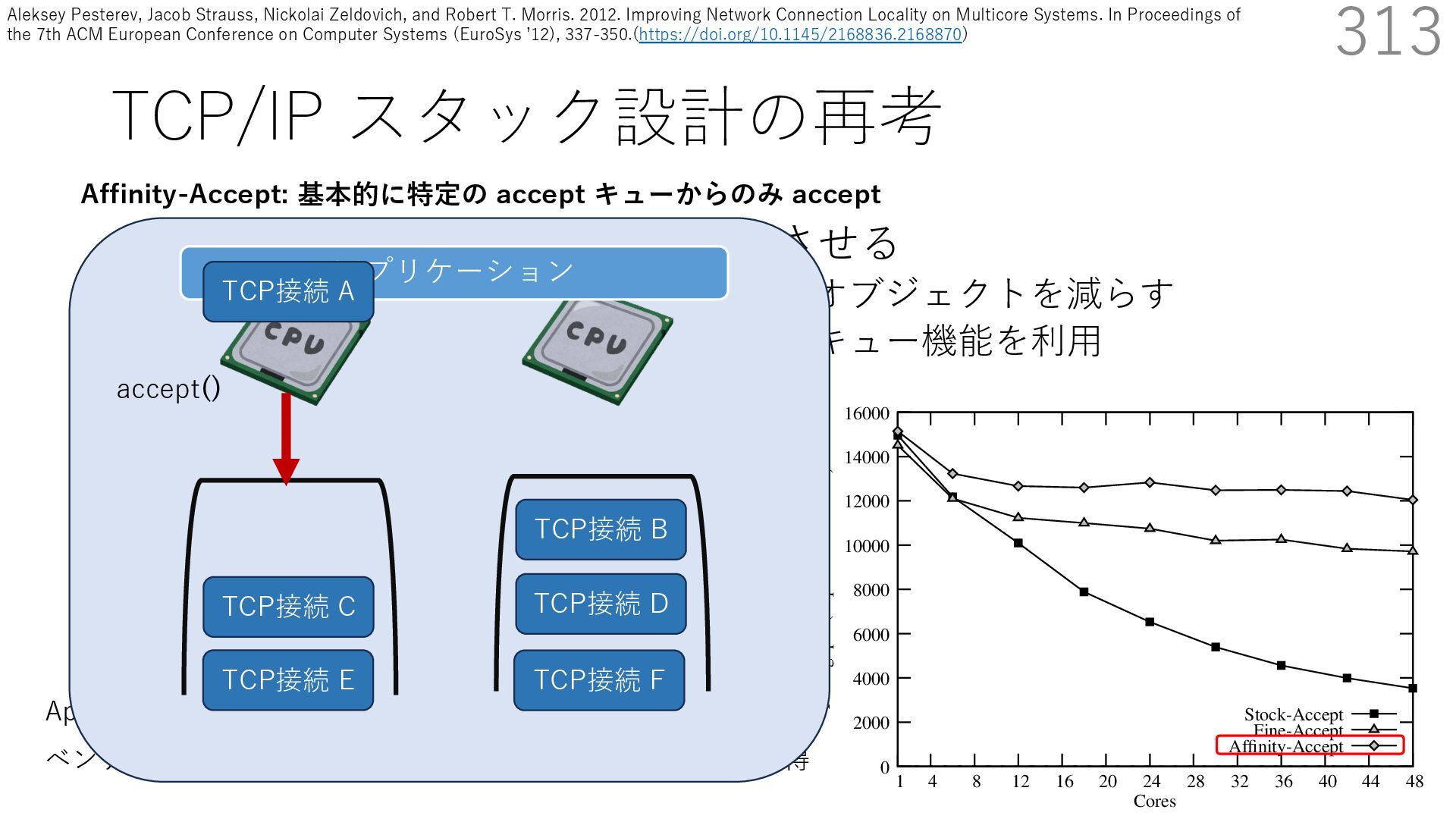
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 313 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 C TCP接続 D TCP接続 E TCP接続 F アプリケーション Affinity-Accept: 基本的に特定の accept キューからのみ accept TCP接続 A accept() Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
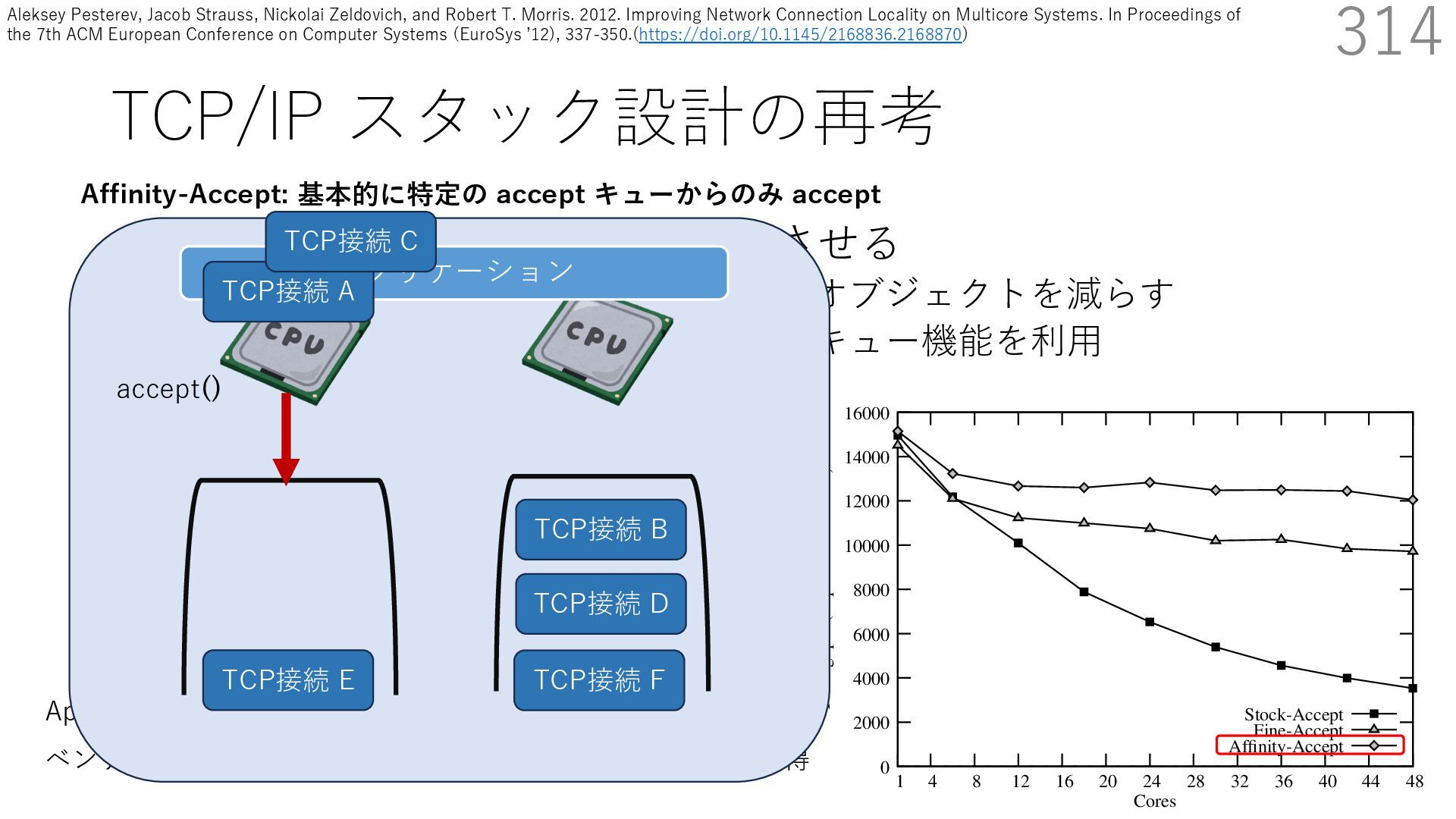
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 314 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 TCP接続 B TCP接続 D TCP接続 E TCP接続 F アプリケーション Affinity-Accept: 基本的に特定の accept キューからのみ accept TCP接続 A accept() TCP接続 C Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
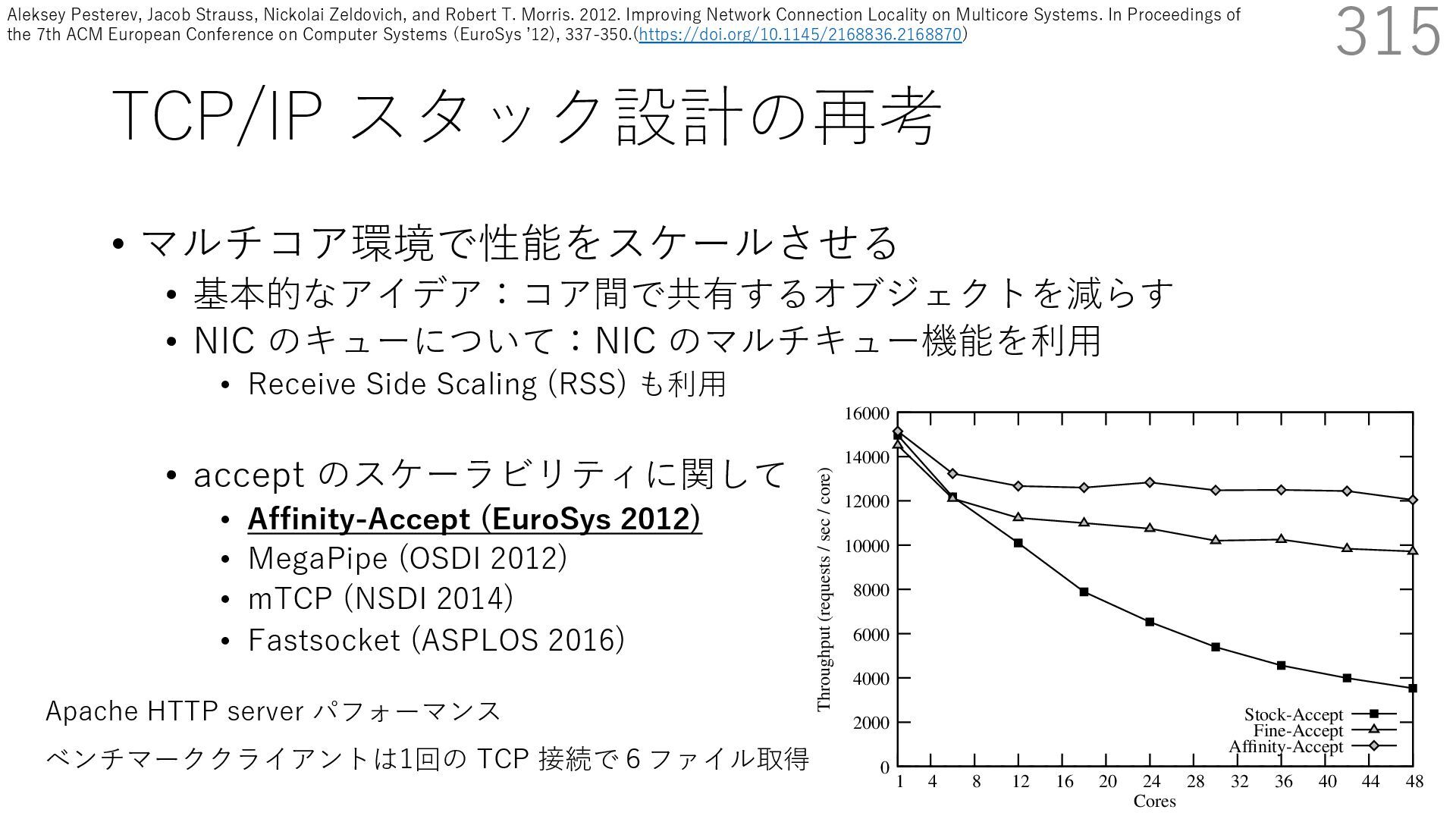
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 315 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
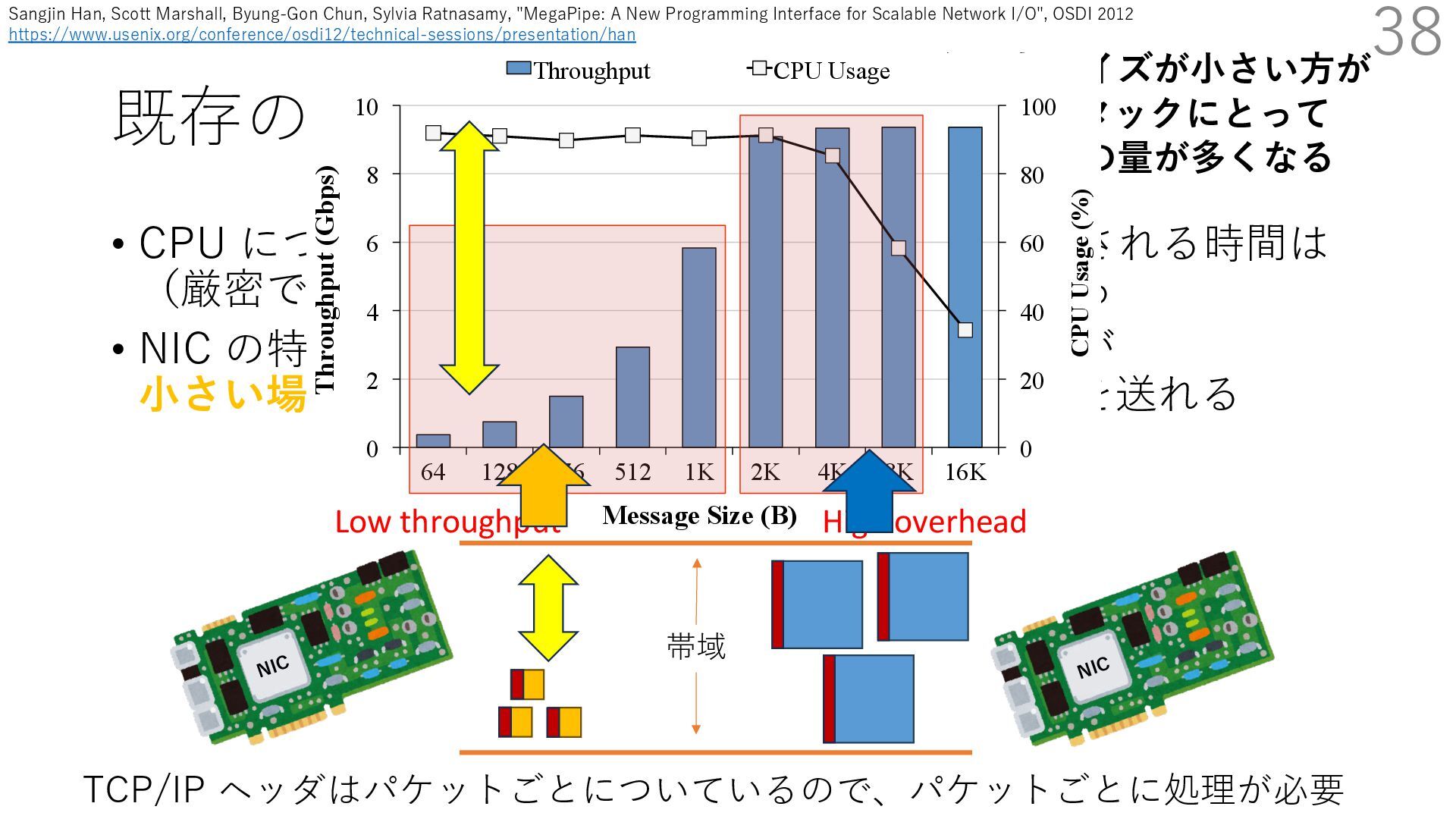
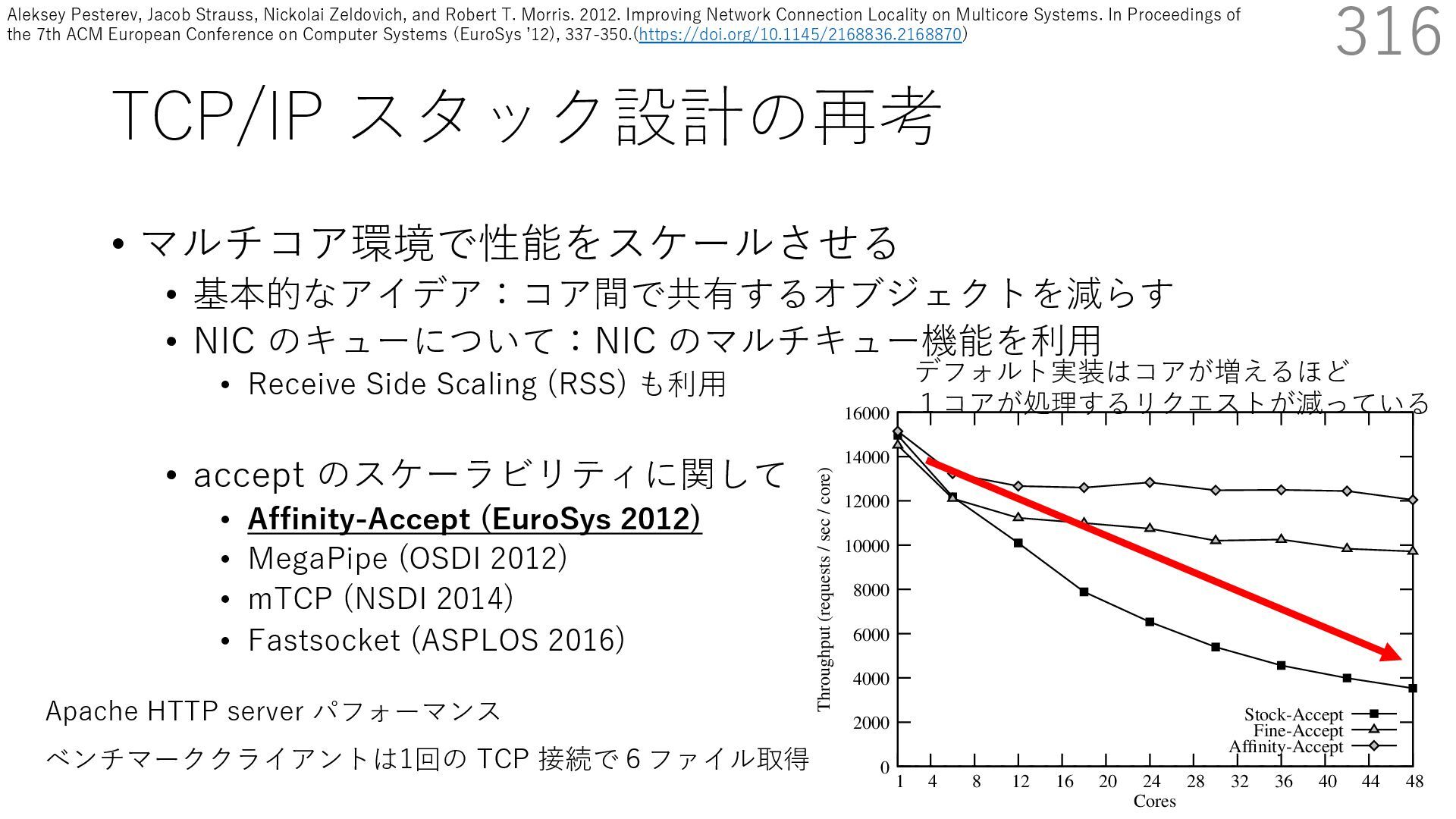
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 316 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 デフォルト実装はコアが増えるほど 1コアが処理するリクエストが減っている Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
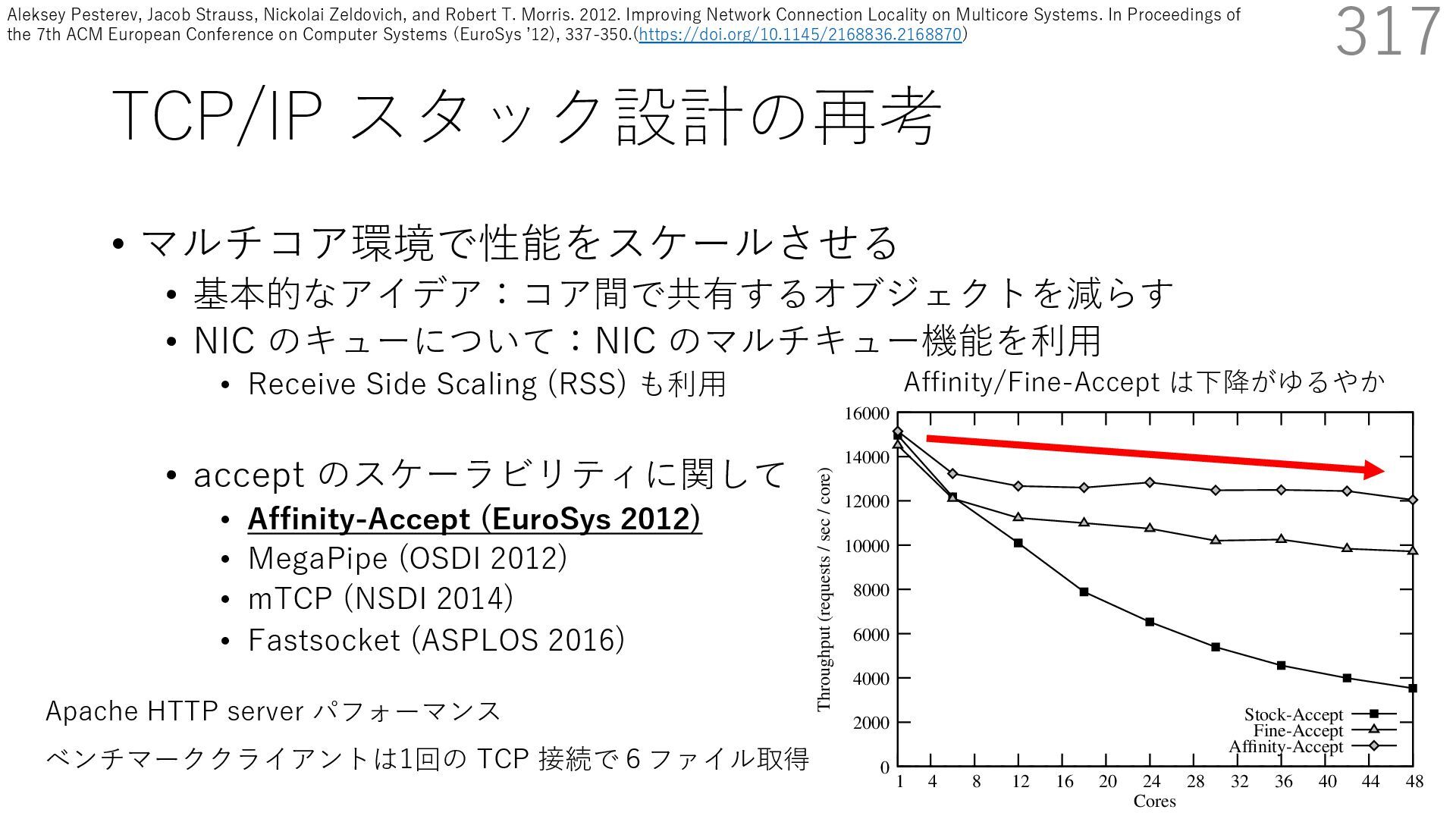
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 317 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 Affinity/Fine-Accept は下降がゆるやか Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
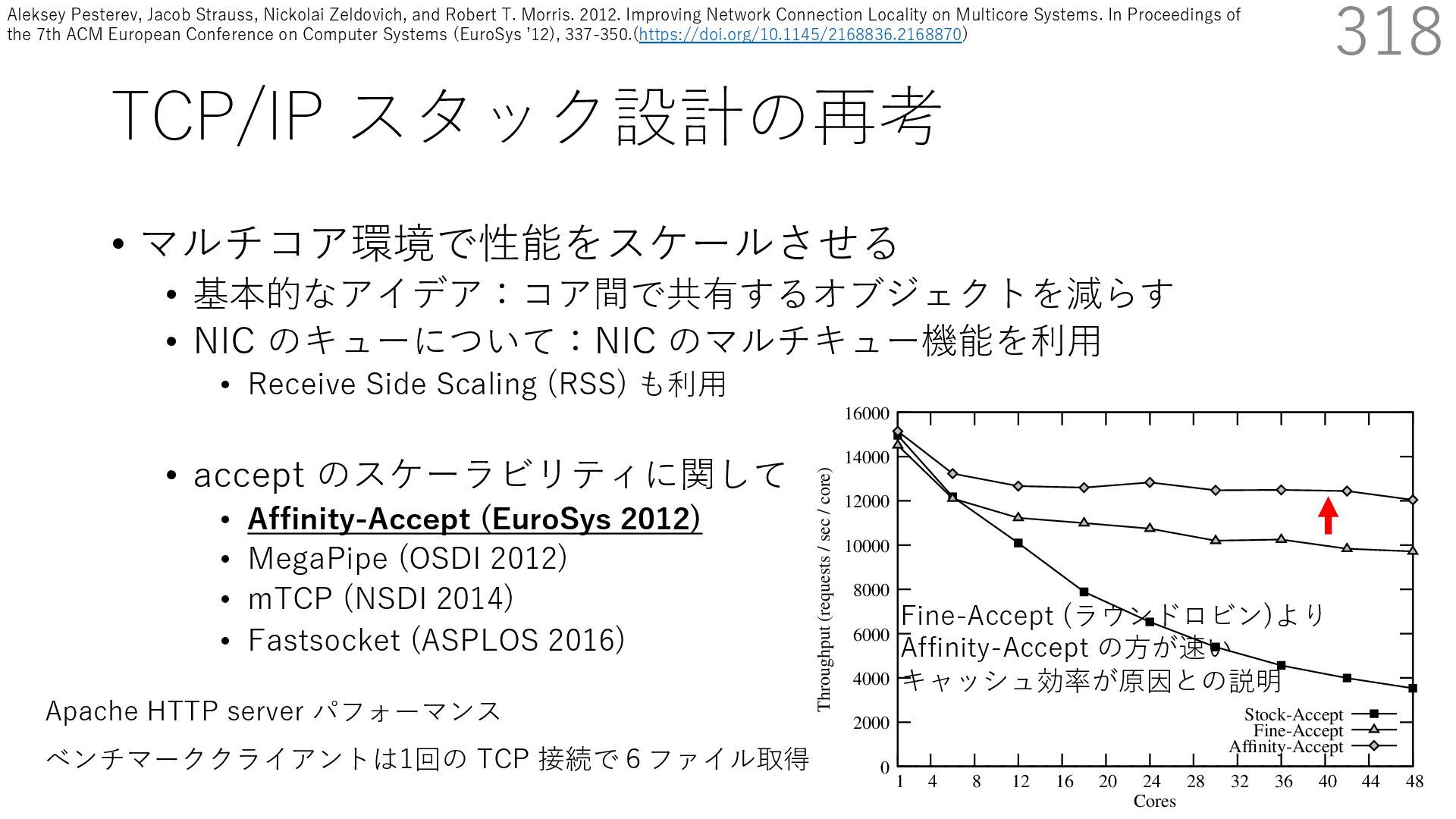
• Receive Side Scaling (RSS) も利⽤ • accept のスケーラビリティに関して • Affinity-Accept (EuroSys 2012) • MegaPipe (OSDI 2012) • mTCP (NSDI 2014) • Fastsocket (ASPLOS 2016) 318 ectly because it does not sufficiently stress the network ck: some requests involve performing SQL queries or ning PHP code, which stresses the disk and CPU more n the network stack. Applications that put less stress on network stack will see less pronounced improvements h Affinity-Accept. The files served range from 30 bytes to 70 bytes. The web server serves 30,000 distinct files, and ient chooses a file to request uniformly over all files. Unless otherwise stated, in all experiments a client re- ests a total of 6 files per connection with requests spaced by think time. First, a client requests one file and waits for Stock-Accept Fine-Accept Affinity-Accept 0 2000 4000 6000 8000 10000 12000 14000 16000 1 4 8 12 16 20 24 28 32 36 40 44 48 Throughput (requests / sec / core) Cores Apache HTTP server パフォーマンス ベンチマーククライアントは1回の TCP 接続で6ファイル取得 Fine-Accept (ラウンドロビン)より Affinity-Accept の⽅が速い キャッシュ効率が原因との説明 Aleksey Pesterev, Jacob Strauss, Nickolai Zeldovich, and Robert T. Morris. 2012. Improving Network Connection Locality on Multicore Systems. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys ʼ12), 337-350.(https://doi.org/10.1145/2168836.2168870)
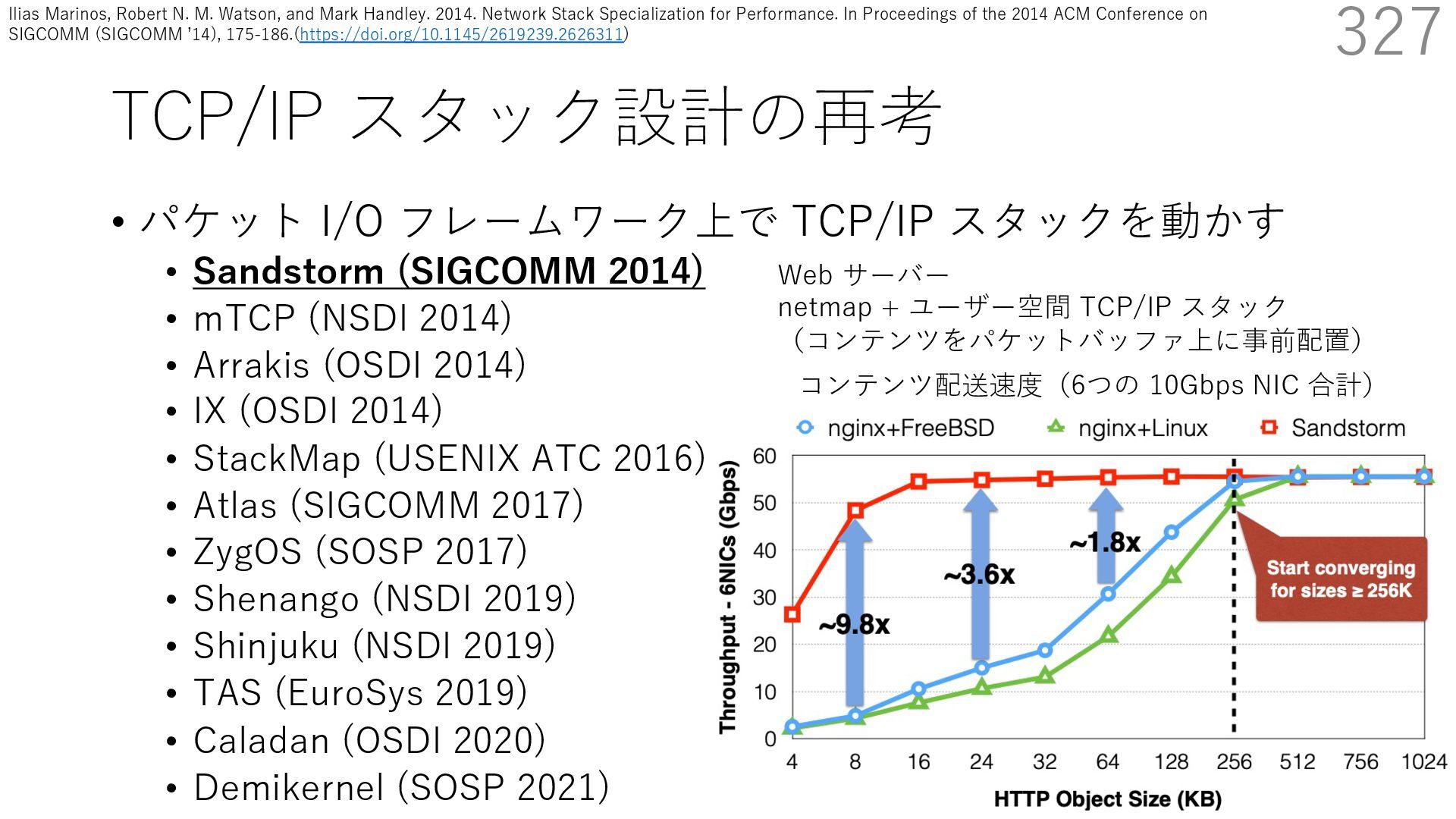
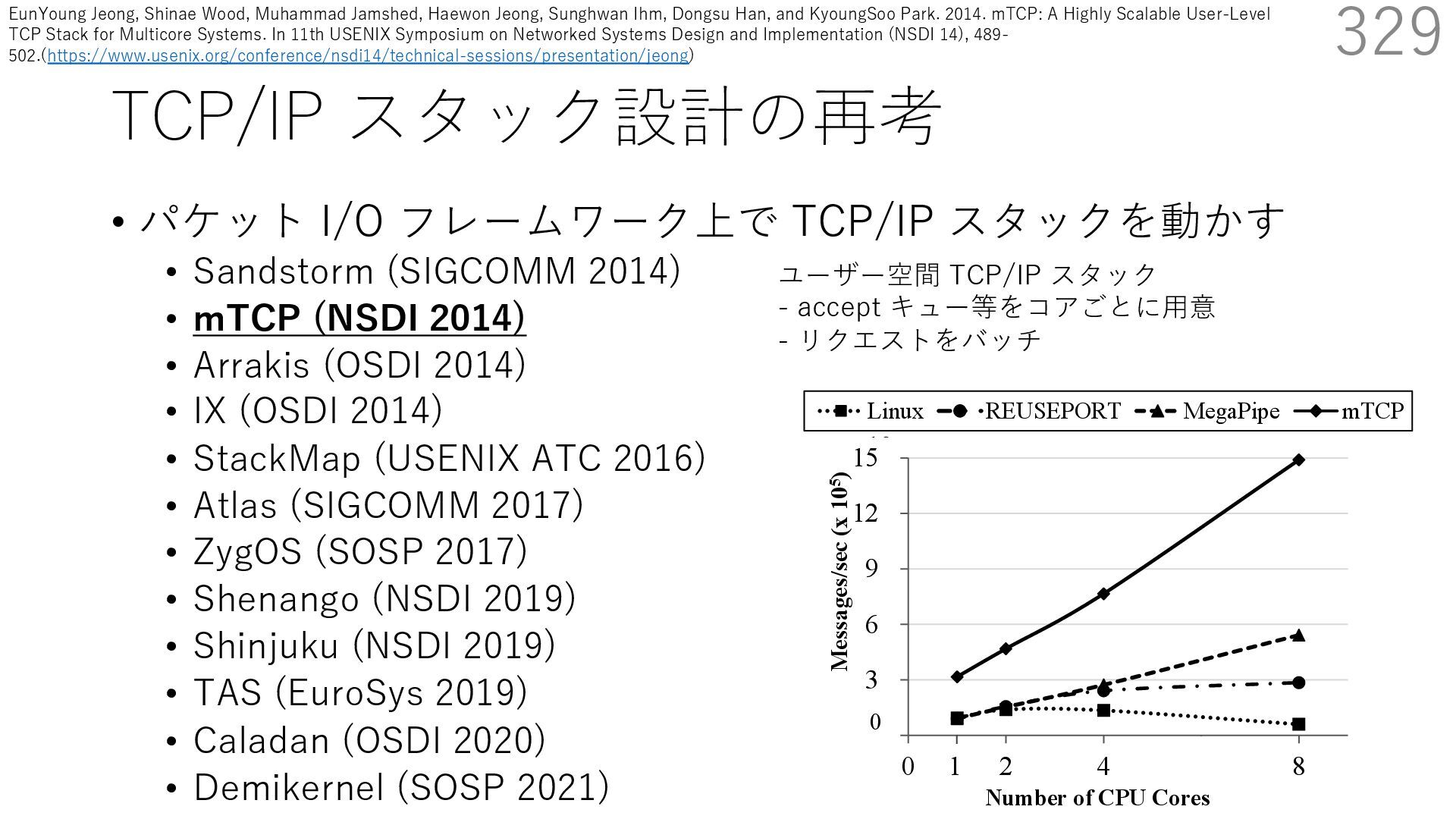
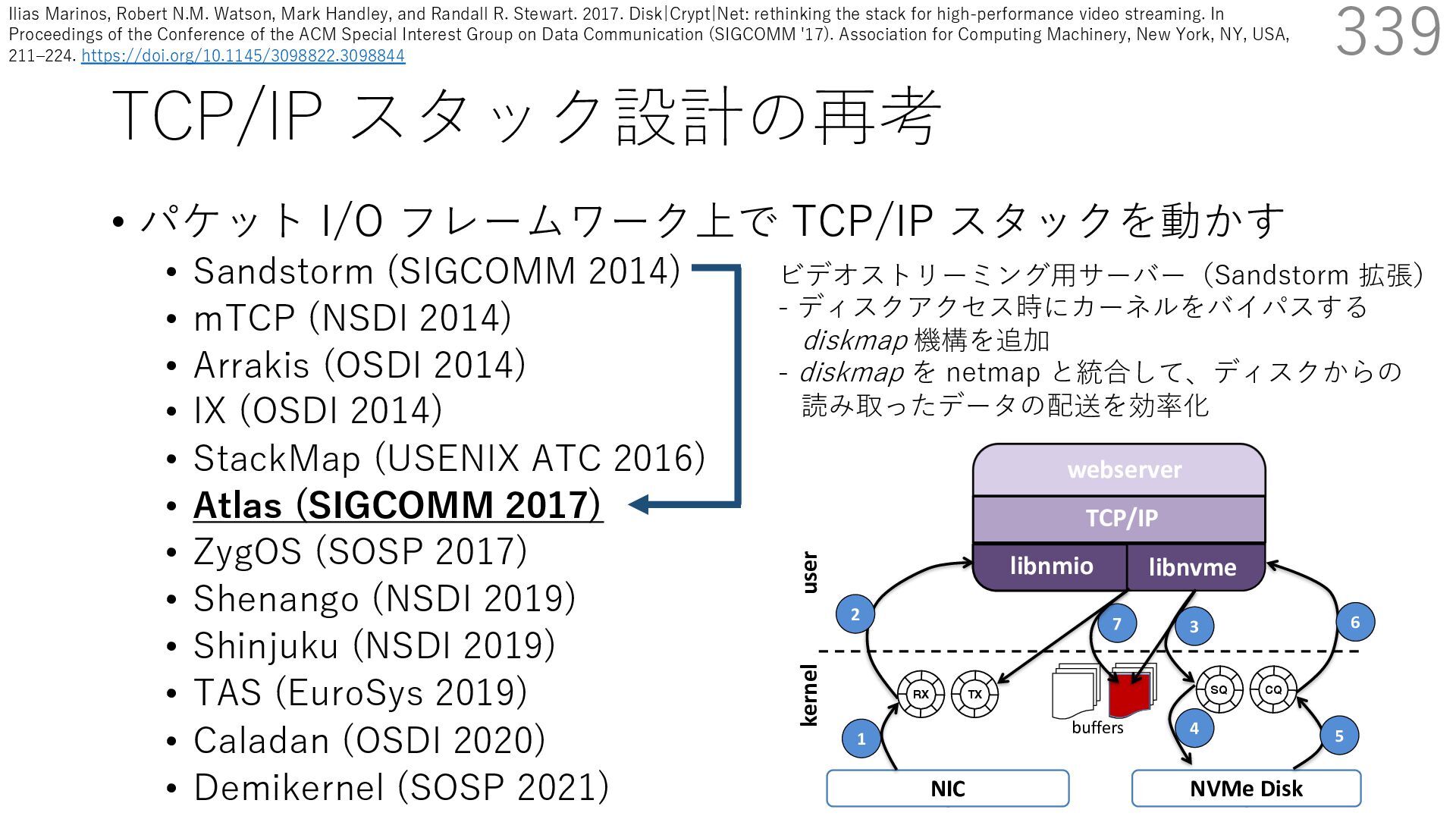
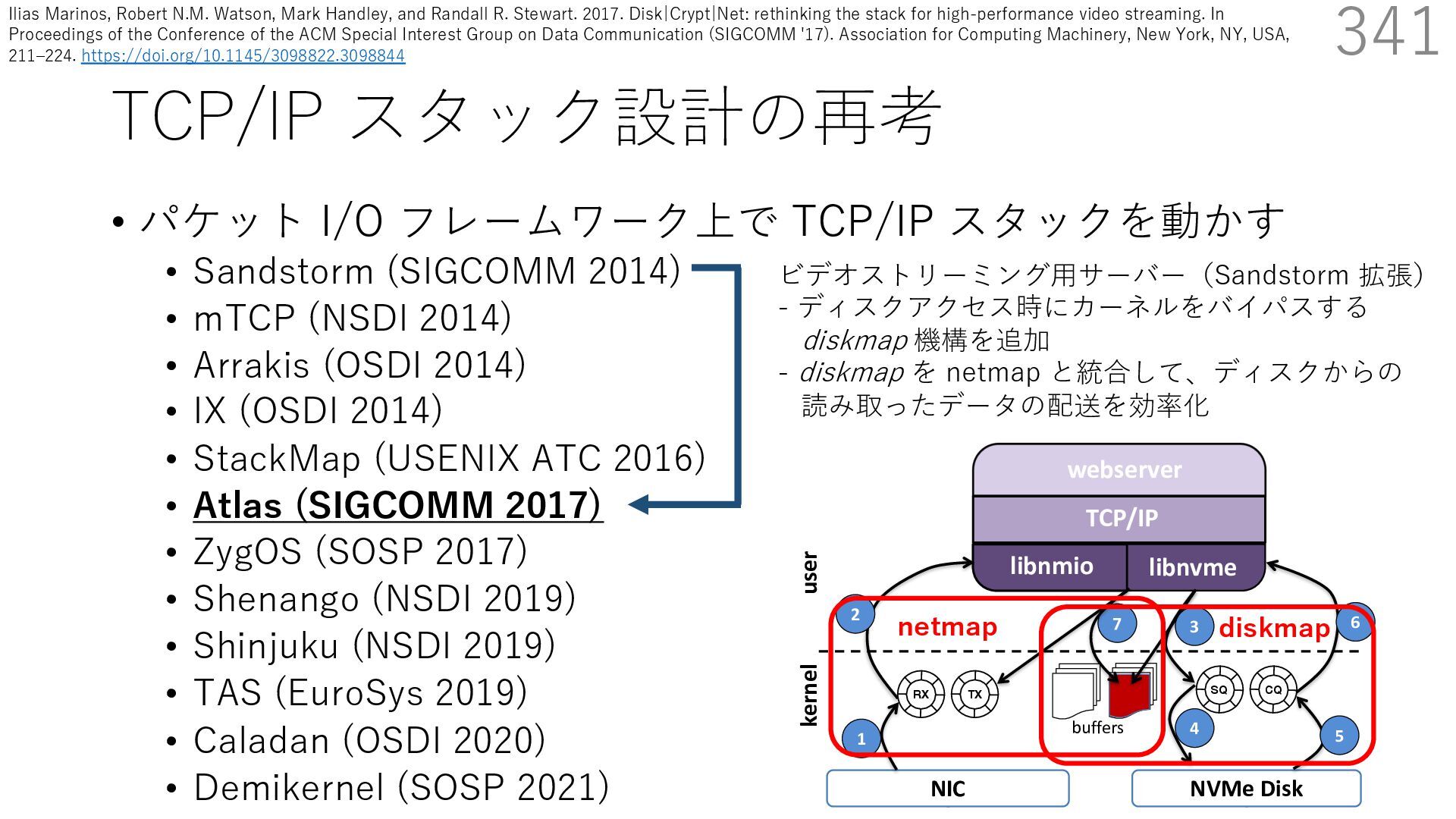
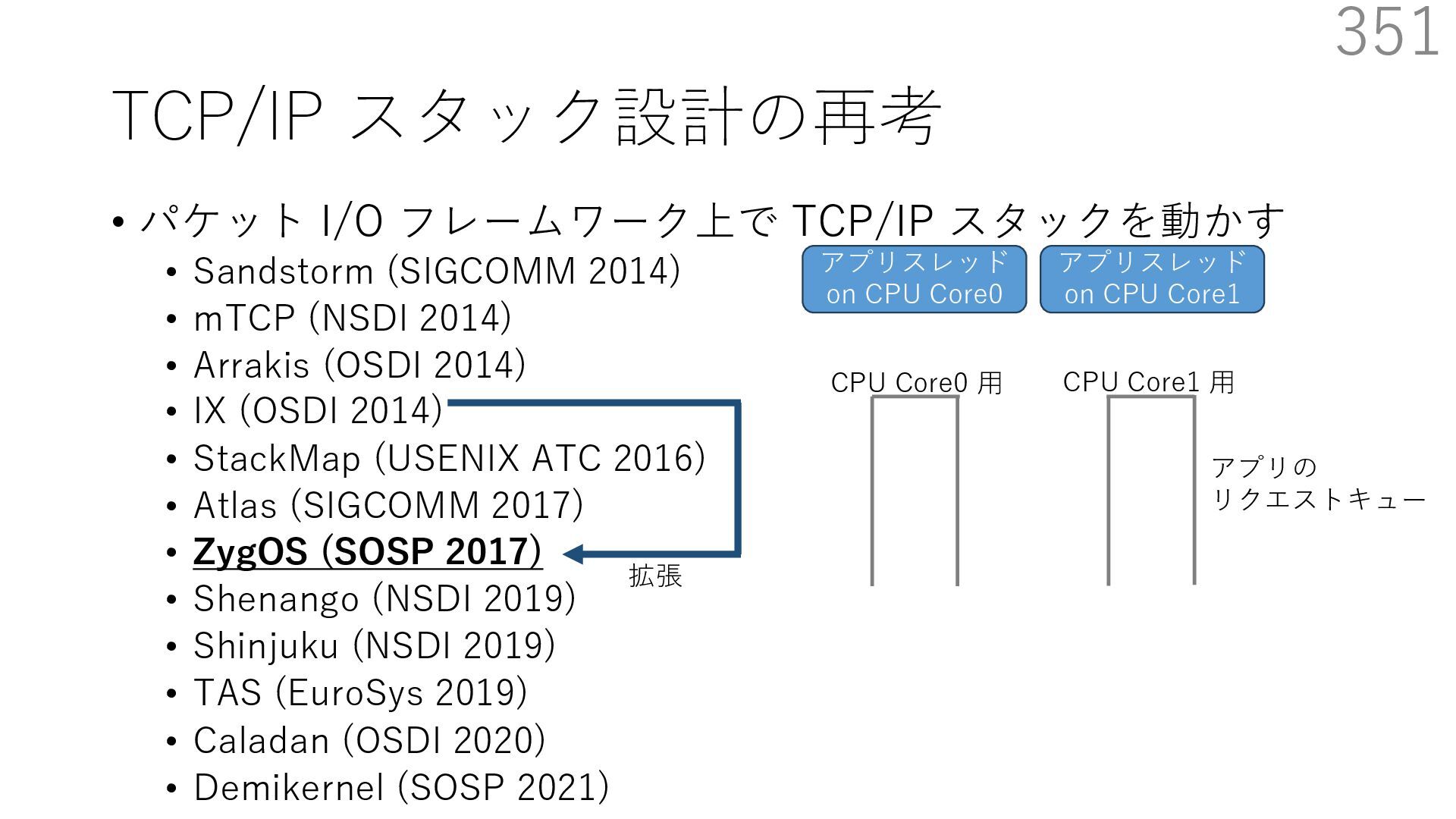
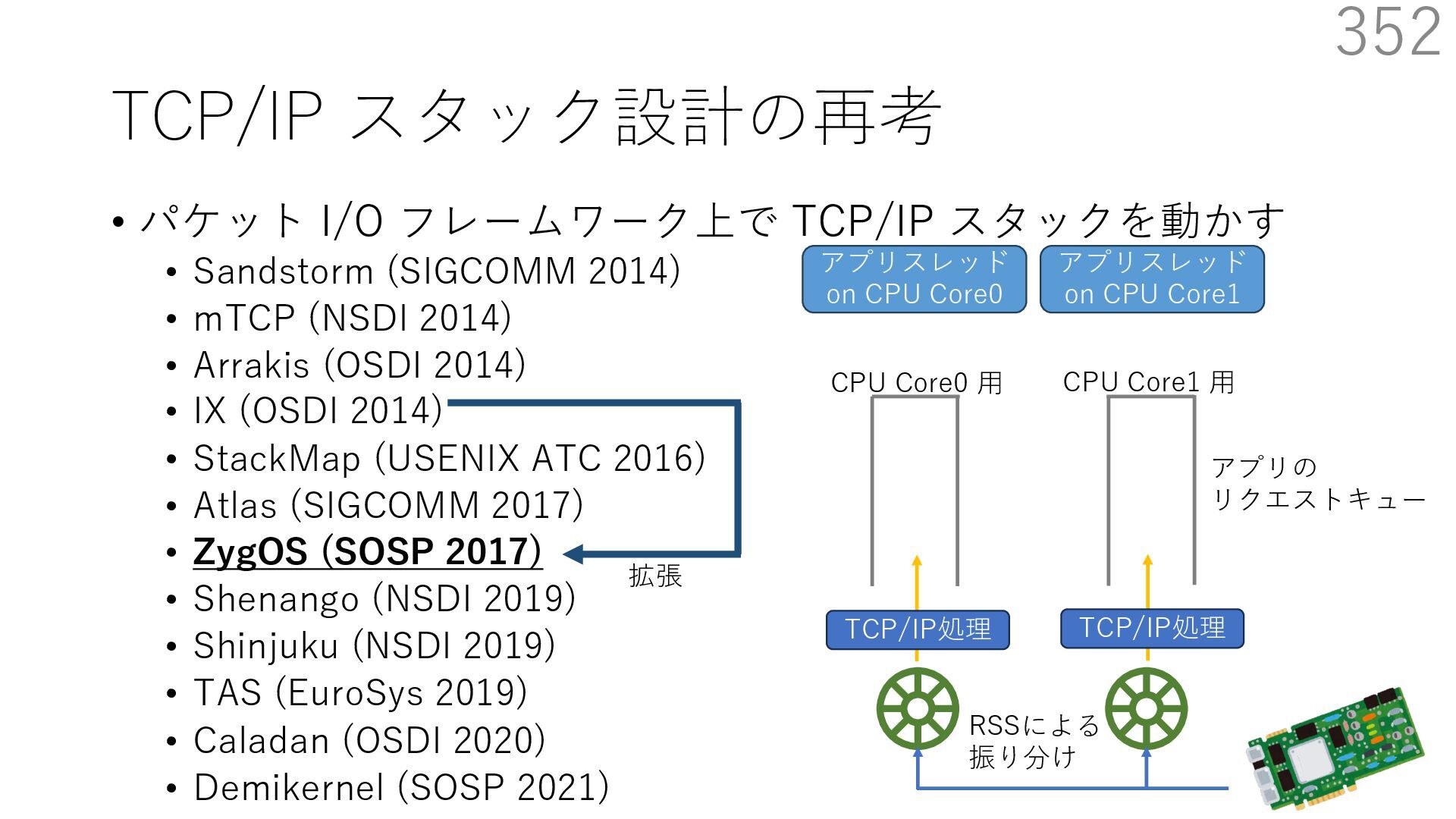
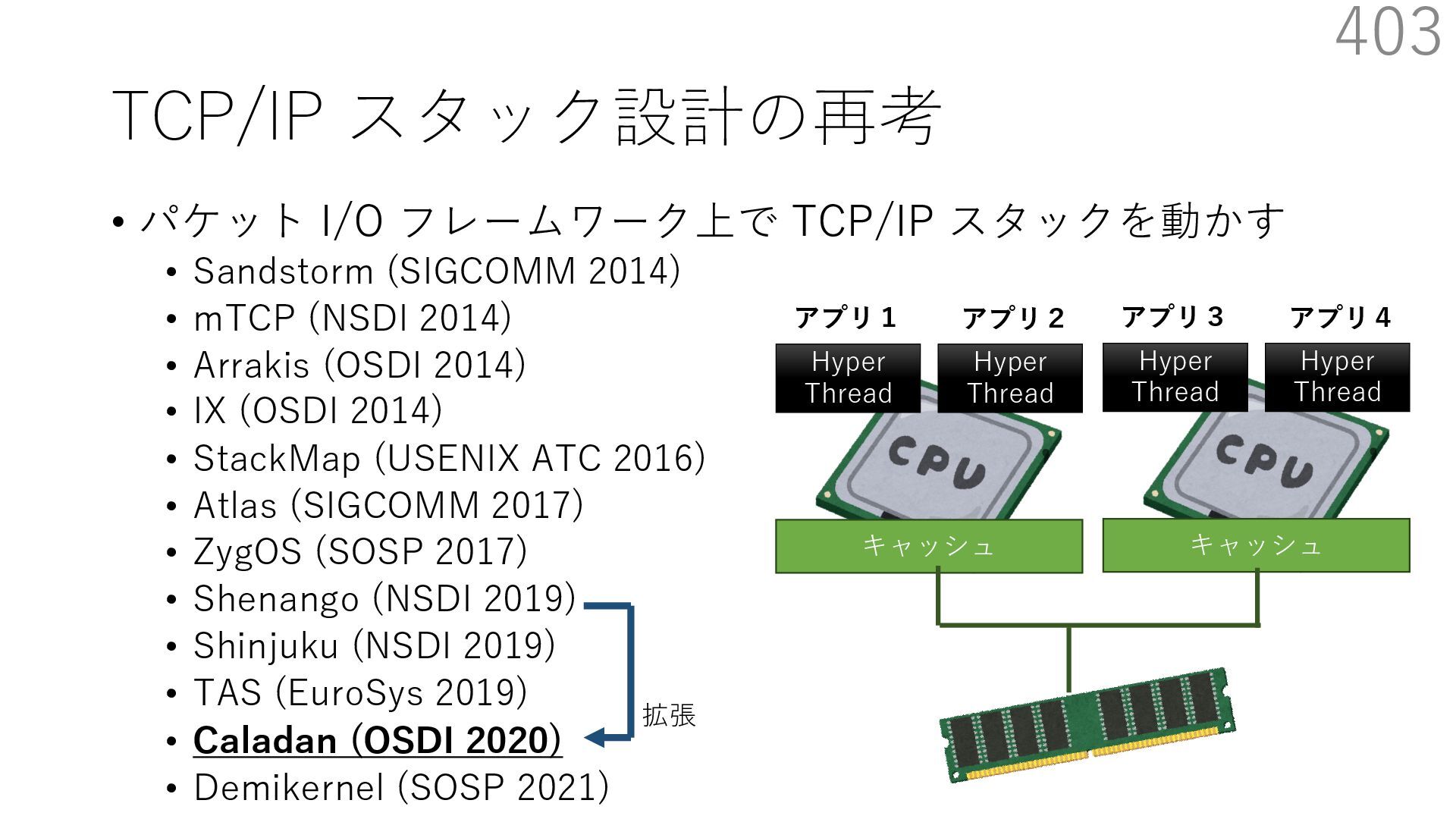
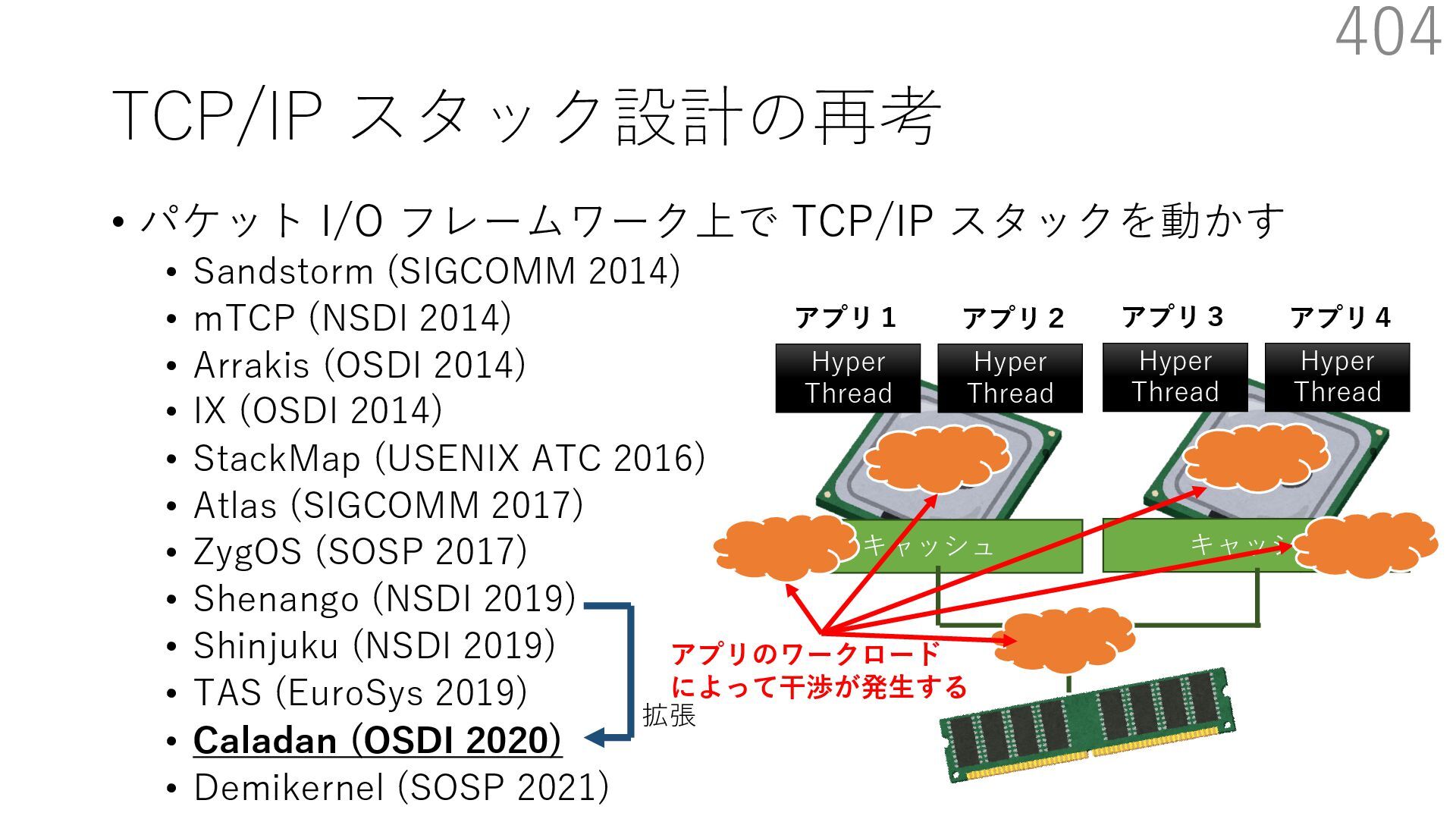
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 339 ビデオストリーミング⽤サーバー(Sandstorm 拡張) - ディスクアクセス時にカーネルをバイパスする diskmap 機構を追加 - diskmap を netmap と統合して、ディスクからの 読み取ったデータの配送を効率化 The Atlas Execution Pipeline SQ CQ NVMe Disk NIC RX TX kernel user webserver TCP/IP libnmio libnvme 1 2 4 buffers 5 6 3 7 Ilias Marinos, Robert N.M. Watson, Mark Handley, and Randall R. Stewart. 2017. Disk|Crypt|Net: rethinking the stack for high-performance video streaming. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM '17). Association for Computing Machinery, New York, NY, USA, 211‒224. https://doi.org/10.1145/3098822.3098844
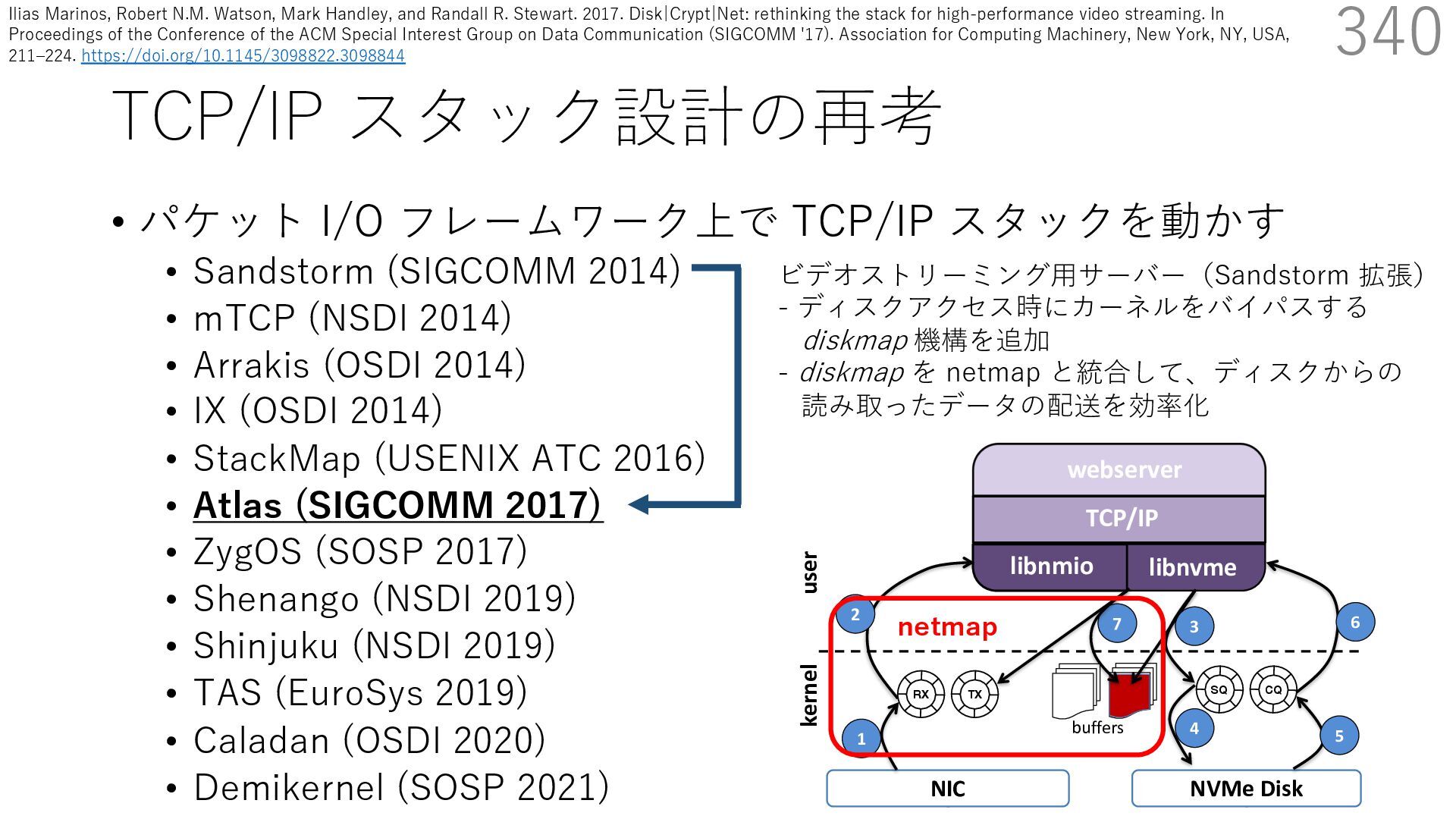
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 340 ビデオストリーミング⽤サーバー(Sandstorm 拡張) - ディスクアクセス時にカーネルをバイパスする diskmap 機構を追加 - diskmap を netmap と統合して、ディスクからの 読み取ったデータの配送を効率化 The Atlas Execution Pipeline SQ CQ NVMe Disk NIC RX TX kernel user webserver TCP/IP libnmio libnvme 1 2 4 buffers 5 6 3 7 netmap Ilias Marinos, Robert N.M. Watson, Mark Handley, and Randall R. Stewart. 2017. Disk|Crypt|Net: rethinking the stack for high-performance video streaming. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM '17). Association for Computing Machinery, New York, NY, USA, 211‒224. https://doi.org/10.1145/3098822.3098844
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 341 ビデオストリーミング⽤サーバー(Sandstorm 拡張) - ディスクアクセス時にカーネルをバイパスする diskmap 機構を追加 - diskmap を netmap と統合して、ディスクからの 読み取ったデータの配送を効率化 The Atlas Execution Pipeline SQ CQ NVMe Disk NIC RX TX kernel user webserver TCP/IP libnmio libnvme 1 2 4 buffers 5 6 3 7 netmap diskmap Ilias Marinos, Robert N.M. Watson, Mark Handley, and Randall R. Stewart. 2017. Disk|Crypt|Net: rethinking the stack for high-performance video streaming. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM '17). Association for Computing Machinery, New York, NY, USA, 211‒224. https://doi.org/10.1145/3098822.3098844
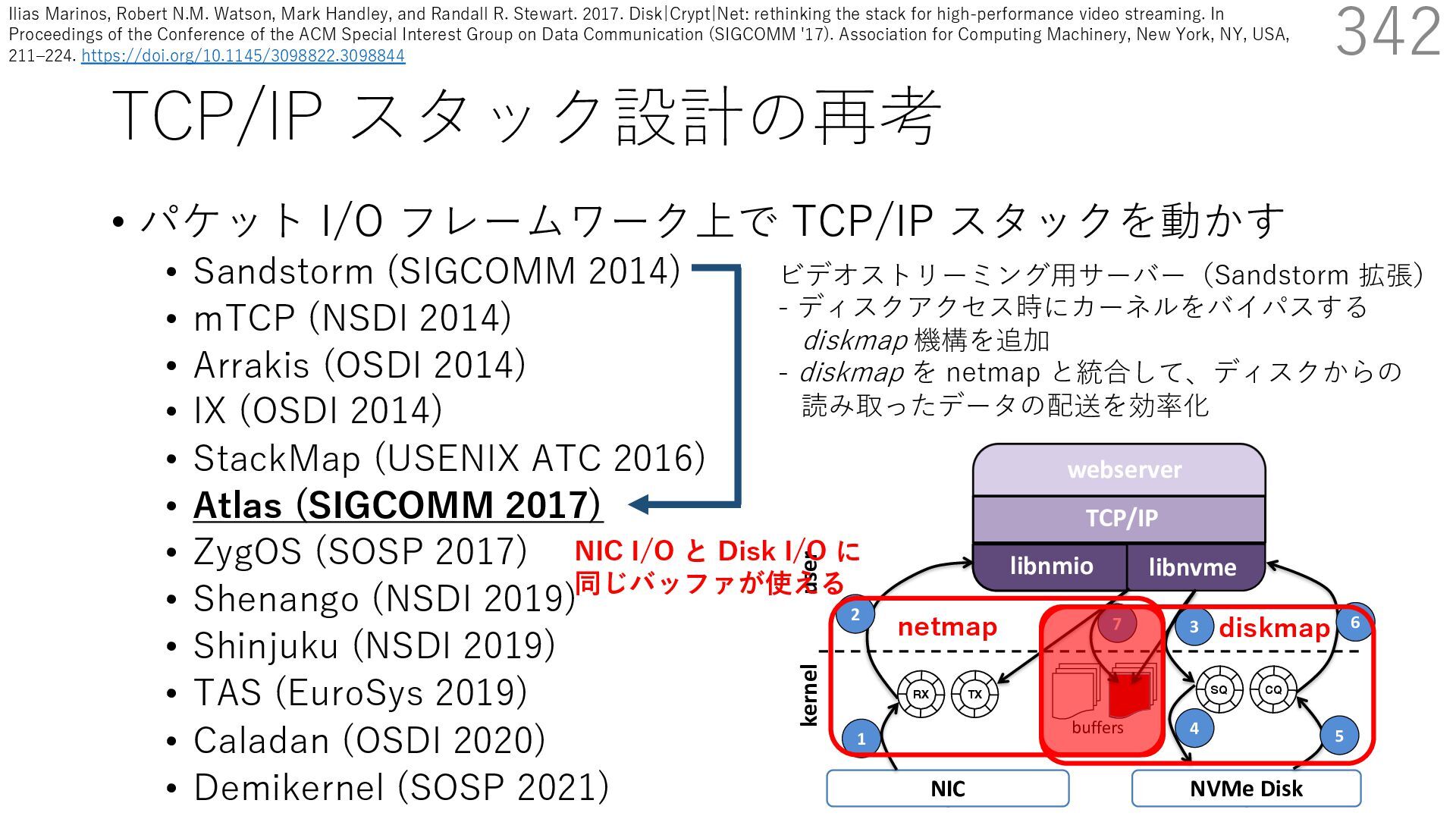
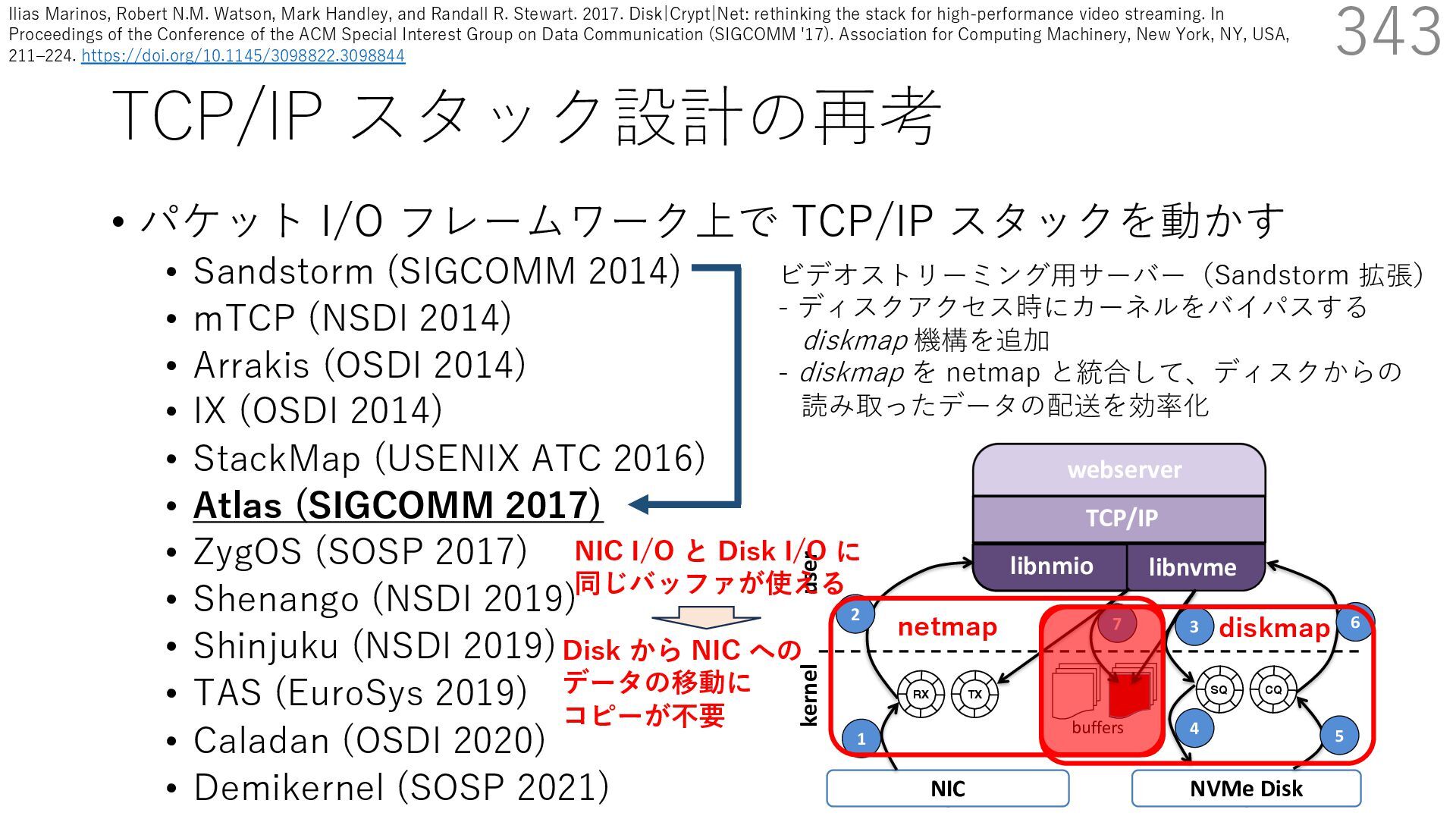
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 342 ビデオストリーミング⽤サーバー(Sandstorm 拡張) - ディスクアクセス時にカーネルをバイパスする diskmap 機構を追加 - diskmap を netmap と統合して、ディスクからの 読み取ったデータの配送を効率化 The Atlas Execution Pipeline SQ CQ NVMe Disk NIC RX TX kernel user webserver TCP/IP libnmio libnvme 1 2 4 buffers 5 6 3 7 netmap diskmap NIC I/O と Disk I/O に 同じバッファが使える Ilias Marinos, Robert N.M. Watson, Mark Handley, and Randall R. Stewart. 2017. Disk|Crypt|Net: rethinking the stack for high-performance video streaming. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM '17). Association for Computing Machinery, New York, NY, USA, 211‒224. https://doi.org/10.1145/3098822.3098844
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 343 ビデオストリーミング⽤サーバー(Sandstorm 拡張) - ディスクアクセス時にカーネルをバイパスする diskmap 機構を追加 - diskmap を netmap と統合して、ディスクからの 読み取ったデータの配送を効率化 The Atlas Execution Pipeline SQ CQ NVMe Disk NIC RX TX kernel user webserver TCP/IP libnmio libnvme 1 2 4 buffers 5 6 3 7 netmap diskmap NIC I/O と Disk I/O に 同じバッファが使える Disk から NIC への データの移動に コピーが不要 Ilias Marinos, Robert N.M. Watson, Mark Handley, and Randall R. Stewart. 2017. Disk|Crypt|Net: rethinking the stack for high-performance video streaming. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM '17). Association for Computing Machinery, New York, NY, USA, 211‒224. https://doi.org/10.1145/3098822.3098844
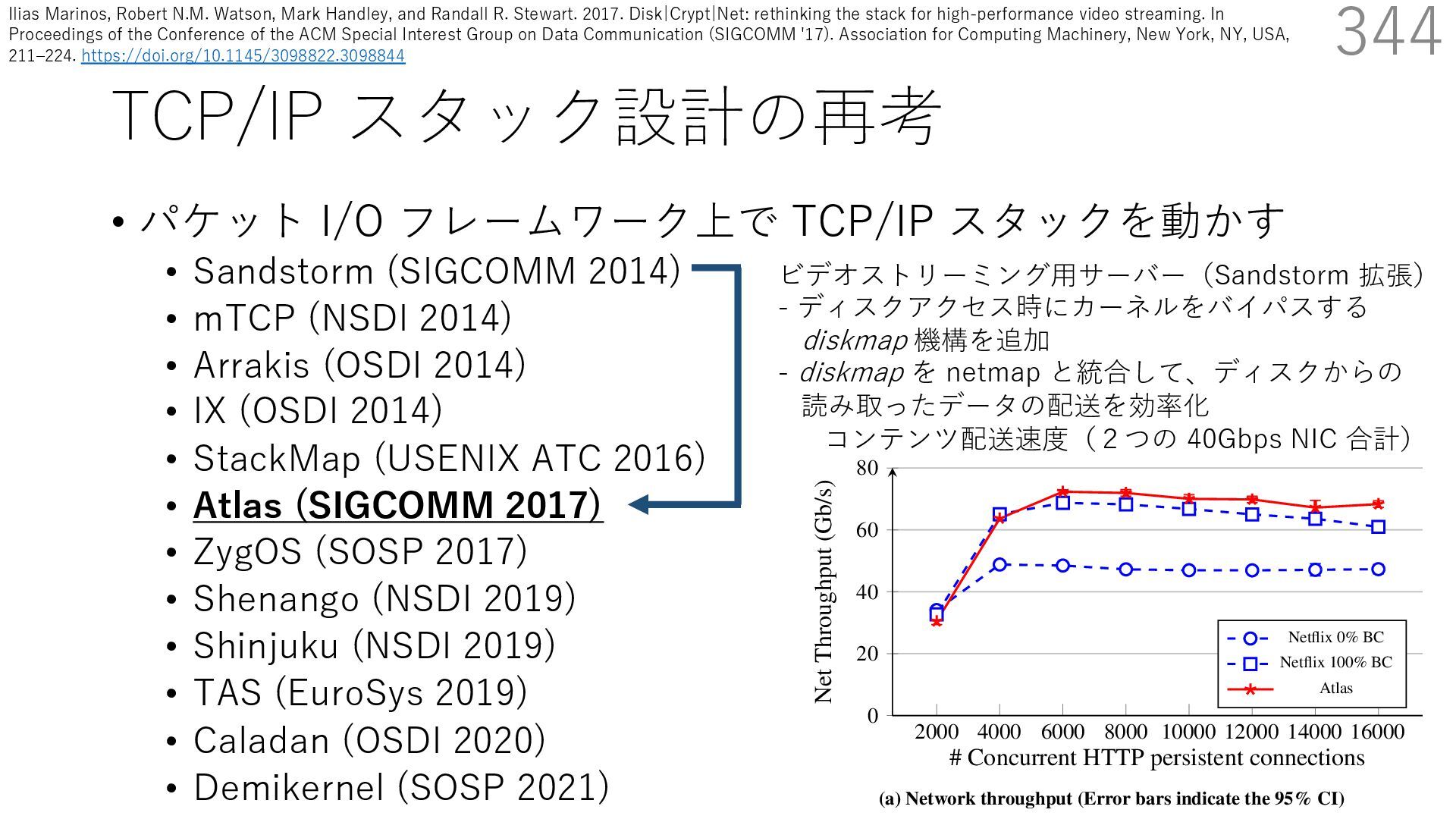
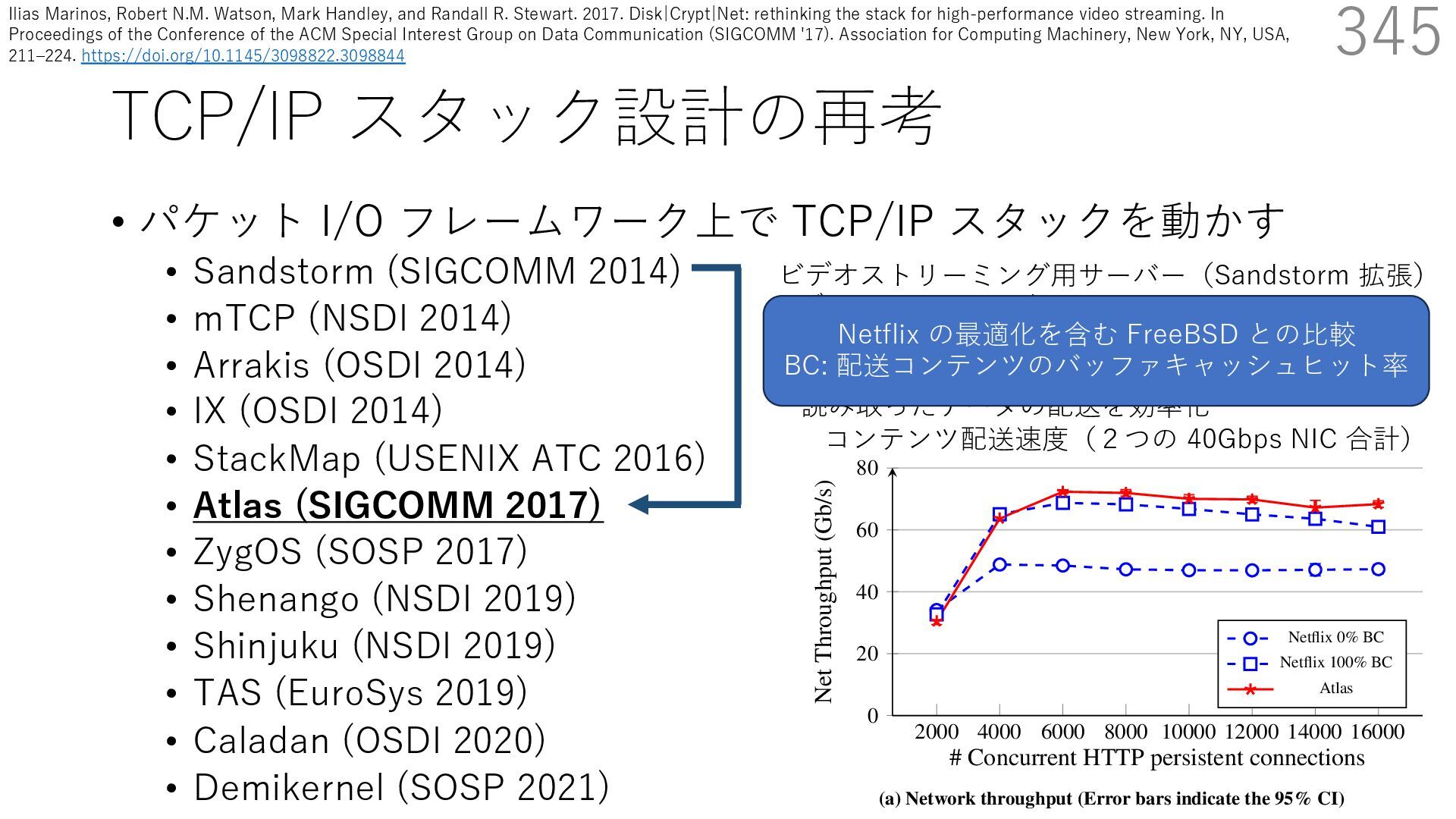
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 344 ビデオストリーミング⽤サーバー(Sandstorm 拡張) - ディスクアクセス時にカーネルをバイパスする diskmap 機構を追加 - diskmap を netmap と統合して、ディスクからの 読み取ったデータの配送を効率化 Disk|Crypt|Net: rethinking the stack for high-performance video streamin 2000 4000 6000 8000 10000 12000 14000 16000 0 20 40 60 80 # Concurrent HTTP persistent connections Net Throughput (Gb/s) Netflix 0% BC Netflix 100% BC Atlas (a) Network throughput (Error bars indicate the 95% CI) コンテンツ配送速度(2つの 40Gbps NIC 合計) Ilias Marinos, Robert N.M. Watson, Mark Handley, and Randall R. Stewart. 2017. Disk|Crypt|Net: rethinking the stack for high-performance video streaming. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM '17). Association for Computing Machinery, New York, NY, USA, 211‒224. https://doi.org/10.1145/3098822.3098844
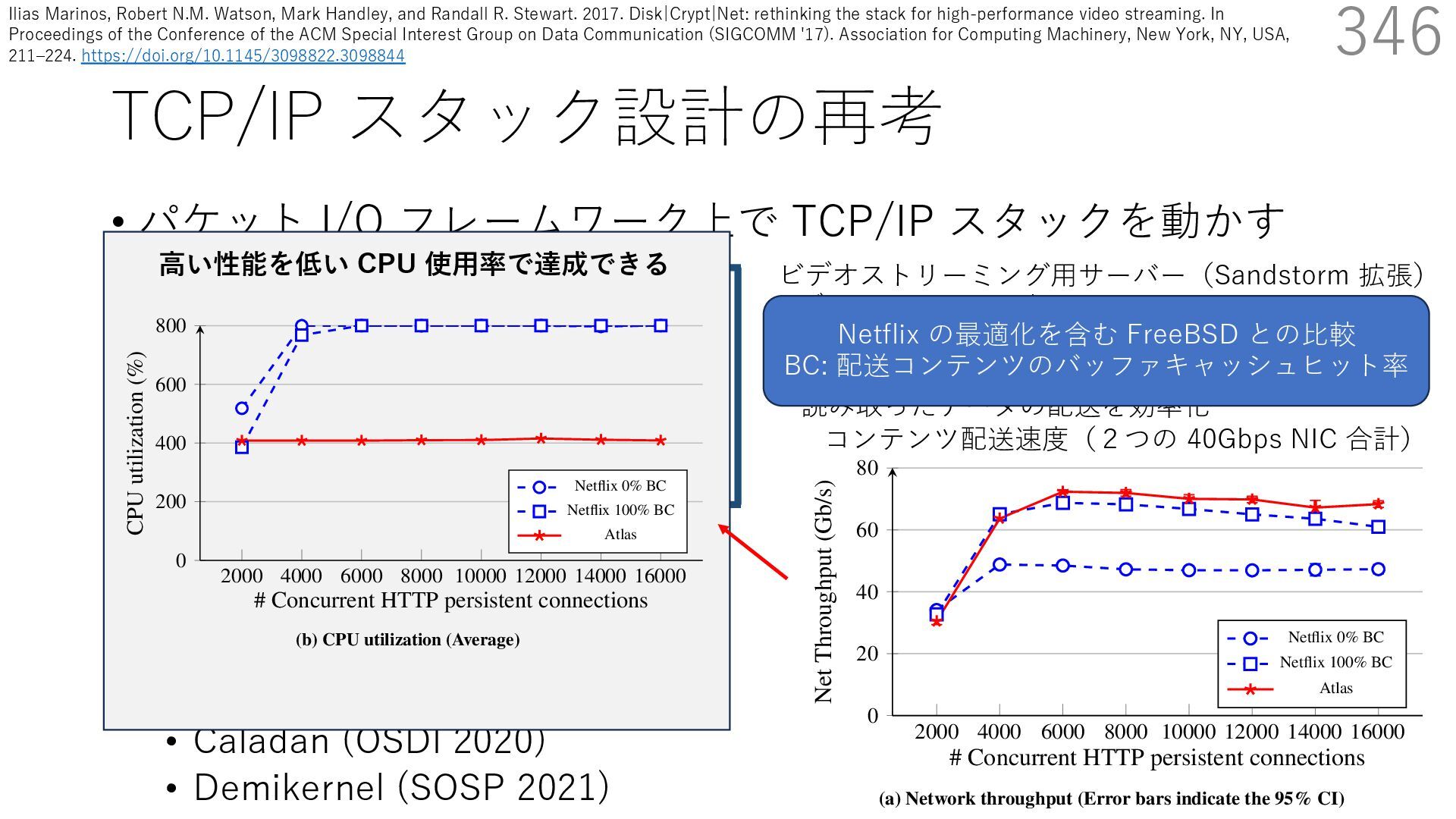
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 346 ビデオストリーミング⽤サーバー(Sandstorm 拡張) - ディスクアクセス時にカーネルをバイパスする diskmap 機構を追加 - diskmap を netmap と統合して、ディスクからの 読み取ったデータの配送を効率化 Disk|Crypt|Net: rethinking the stack for high-performance video streamin 2000 4000 6000 8000 10000 12000 14000 16000 0 20 40 60 80 # Concurrent HTTP persistent connections Net Throughput (Gb/s) Netflix 0% BC Netflix 100% BC Atlas (a) Network throughput (Error bars indicate the 95% CI) コンテンツ配送速度(2つの 40Gbps NIC 合計) Netflix の最適化を含む FreeBSD との⽐較 BC: 配送コンテンツのバッファキャッシュヒット率 実験時の CPU 使⽤率 少ない CPU 使⽤率で⾼い性能を達成 eo streaming SIGCOMM ’17, August 21-25, 2017, Los Angeles, CA, USA 16000 ns % BC % BC 2000 4000 6000 8000 10000 12000 14000 16000 0 200 400 600 800 # Concurrent HTTP persistent connections CPU utilization (%) Netflix 0% BC Netflix 100% BC Atlas (b) CPU utilization (Average) 100 150 ughput (Gb/s) ⾼い性能を低い CPU 使⽤率で達成できる Ilias Marinos, Robert N.M. Watson, Mark Handley, and Randall R. Stewart. 2017. Disk|Crypt|Net: rethinking the stack for high-performance video streaming. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM '17). Association for Computing Machinery, New York, NY, USA, 211‒224. https://doi.org/10.1145/3098822.3098844
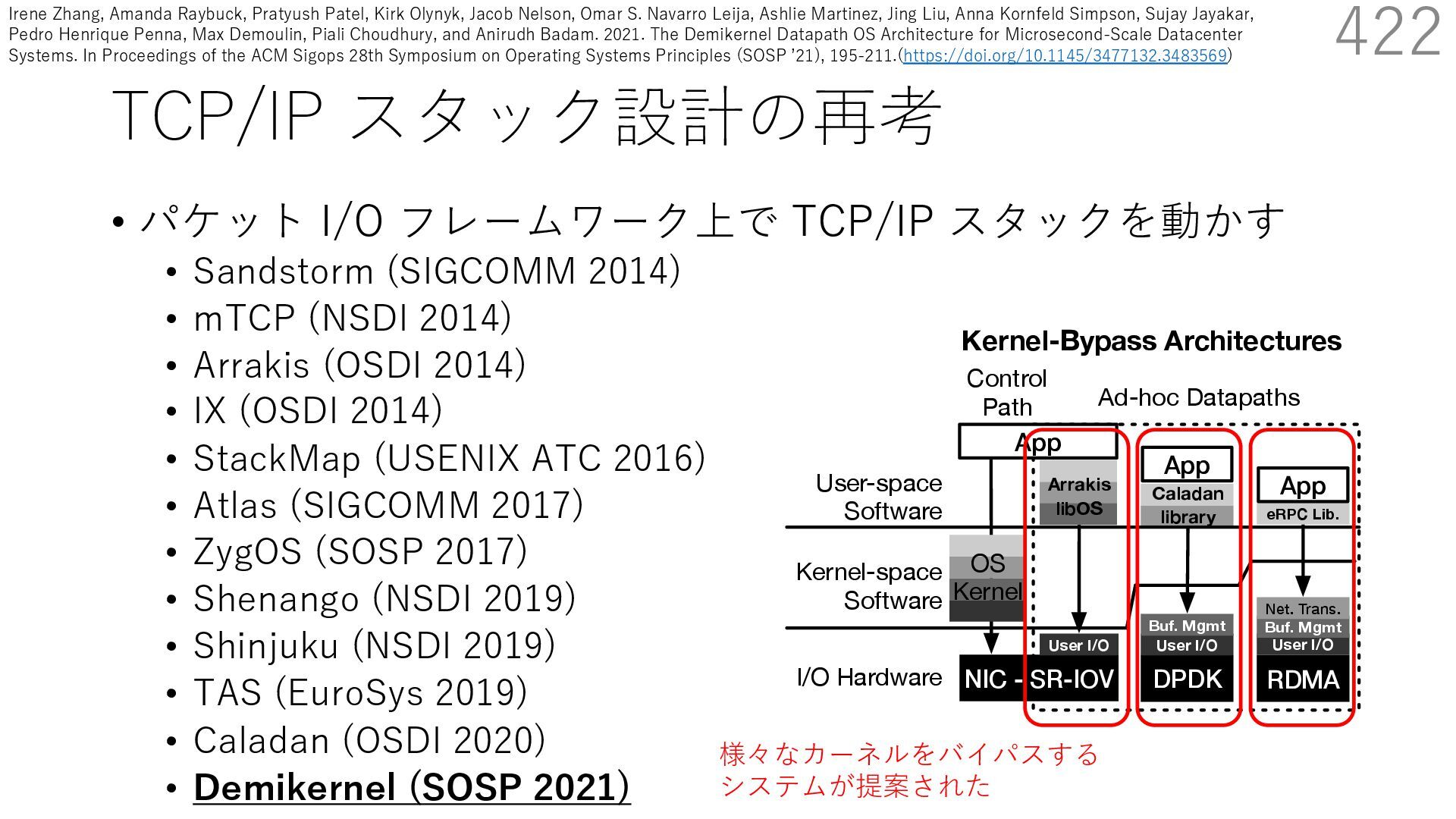
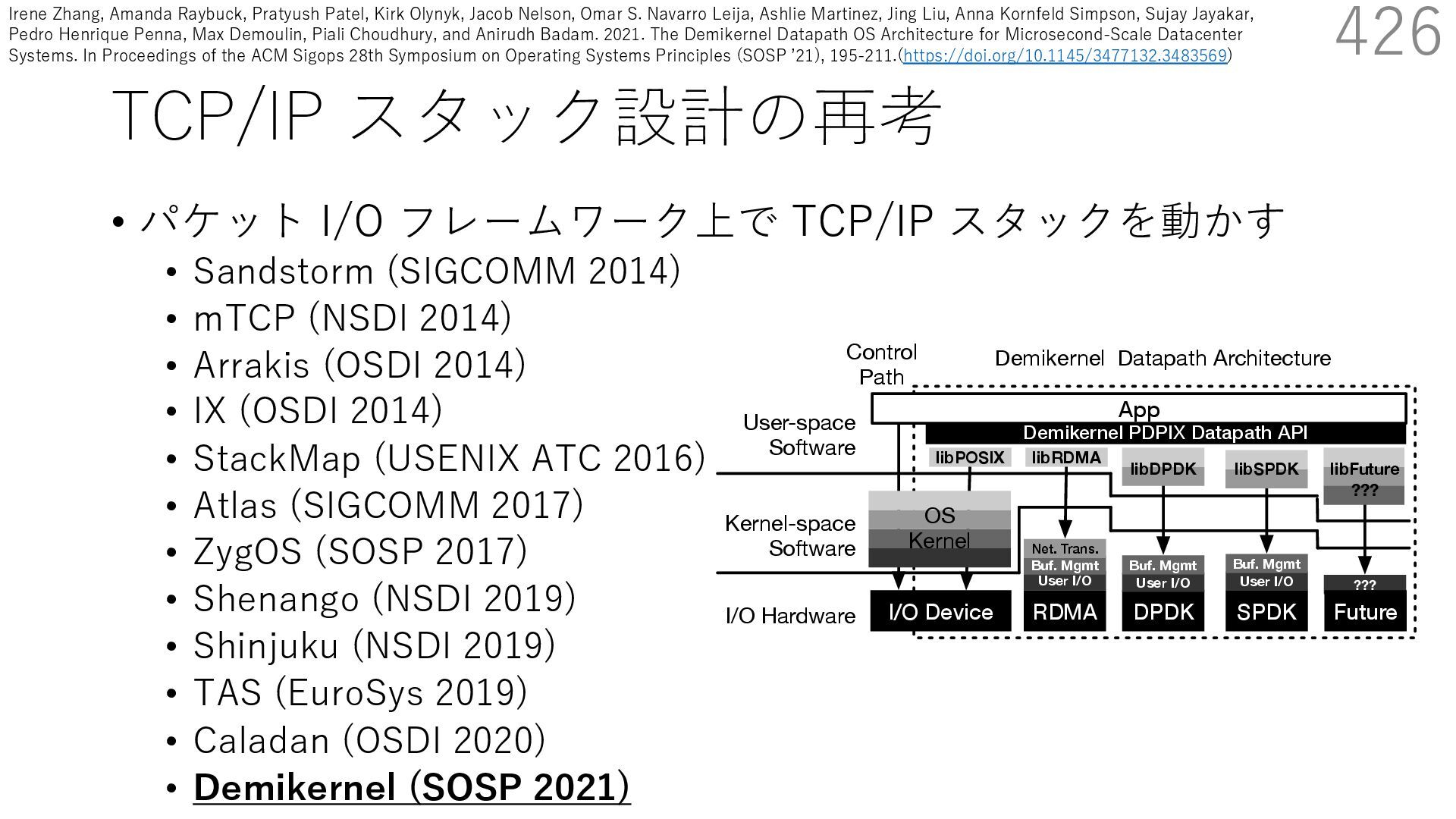
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 421 s devices. Demikernel datapath OSes run with trolplane kernel (e.g., Linux or Windows) and erchangeable library OSes with the same API, ent features and architecture. Each library OS is fic: it offloads to the kernel-bypass device when implements remaining OS management in a user- These libOSes aim to simplify the development atacenter systems across heterogenous kernel- es with while minimizing OS overheads. el follows a trend away from kernel-oriented ary-oriented datapath OSes, motivated by the User-space Software Kernel-space Software I/O Hardware D N Con Pa NIC - SR-IOV User I/O Arrakis libOS DPDK App User I/O Buf. Mgmt Caladan library Kernel-Bypass Architectures eRPC Lib. RDMA App User I/O Buf. Mgmt Net. Trans. OS Kernel Control Path Ad-hoc Datapaths App OS Kern Figure 1. Example kernel-bypass architectures. U ernel architecture (right), Arrakis [73], Caladan [23 Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ʼ21), 195-211.(https://doi.org/10.1145/3477132.3483569)
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 422 s devices. Demikernel datapath OSes run with trolplane kernel (e.g., Linux or Windows) and erchangeable library OSes with the same API, ent features and architecture. Each library OS is fic: it offloads to the kernel-bypass device when implements remaining OS management in a user- These libOSes aim to simplify the development atacenter systems across heterogenous kernel- es with while minimizing OS overheads. el follows a trend away from kernel-oriented ary-oriented datapath OSes, motivated by the User-space Software Kernel-space Software I/O Hardware D N Con Pa NIC - SR-IOV User I/O Arrakis libOS DPDK App User I/O Buf. Mgmt Caladan library Kernel-Bypass Architectures eRPC Lib. RDMA App User I/O Buf. Mgmt Net. Trans. OS Kernel Control Path Ad-hoc Datapaths App OS Kern Figure 1. Example kernel-bypass architectures. U ernel architecture (right), Arrakis [73], Caladan [23 様々なカーネルをバイパスする システムが提案された Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ʼ21), 195-211.(https://doi.org/10.1145/3477132.3483569)
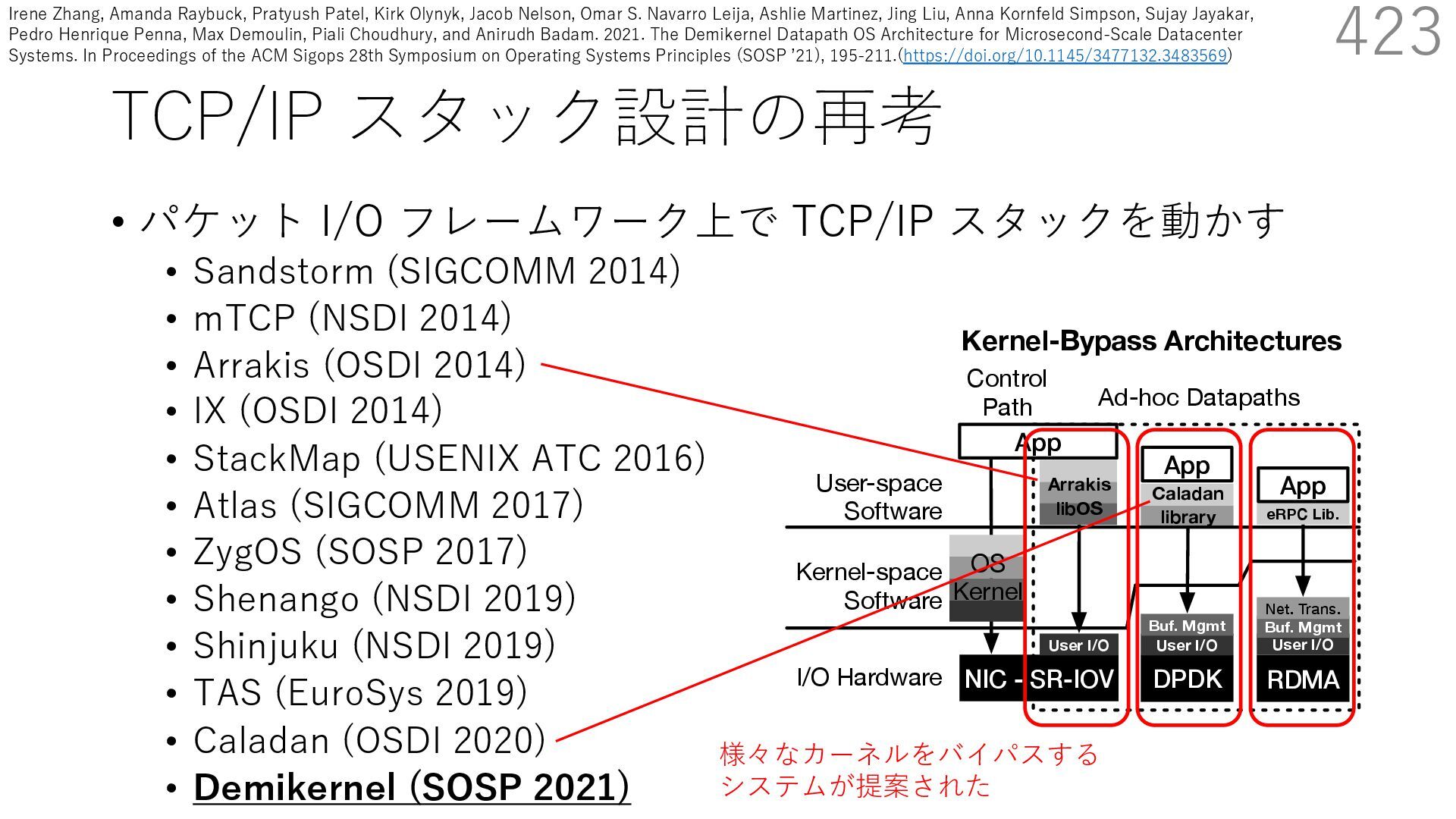
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 423 s devices. Demikernel datapath OSes run with trolplane kernel (e.g., Linux or Windows) and erchangeable library OSes with the same API, ent features and architecture. Each library OS is fic: it offloads to the kernel-bypass device when implements remaining OS management in a user- These libOSes aim to simplify the development atacenter systems across heterogenous kernel- es with while minimizing OS overheads. el follows a trend away from kernel-oriented ary-oriented datapath OSes, motivated by the User-space Software Kernel-space Software I/O Hardware D N Con Pa NIC - SR-IOV User I/O Arrakis libOS DPDK App User I/O Buf. Mgmt Caladan library Kernel-Bypass Architectures eRPC Lib. RDMA App User I/O Buf. Mgmt Net. Trans. OS Kernel Control Path Ad-hoc Datapaths App OS Kern Figure 1. Example kernel-bypass architectures. U ernel architecture (right), Arrakis [73], Caladan [23 様々なカーネルをバイパスする システムが提案された Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ʼ21), 195-211.(https://doi.org/10.1145/3477132.3483569)
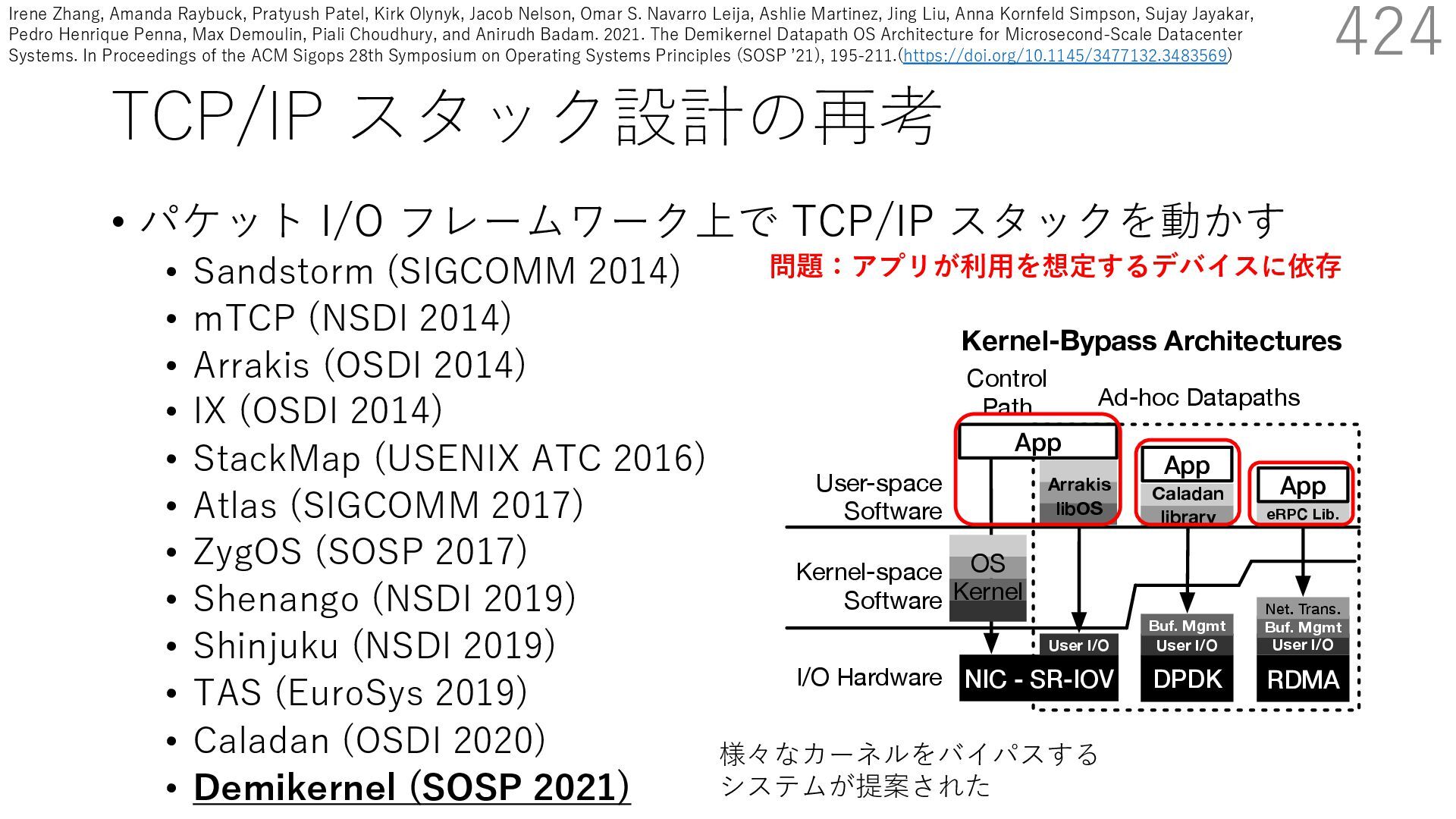
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 424 s devices. Demikernel datapath OSes run with trolplane kernel (e.g., Linux or Windows) and erchangeable library OSes with the same API, ent features and architecture. Each library OS is fic: it offloads to the kernel-bypass device when implements remaining OS management in a user- These libOSes aim to simplify the development atacenter systems across heterogenous kernel- es with while minimizing OS overheads. el follows a trend away from kernel-oriented ary-oriented datapath OSes, motivated by the User-space Software Kernel-space Software I/O Hardware D N Con Pa NIC - SR-IOV User I/O Arrakis libOS DPDK App User I/O Buf. Mgmt Caladan library Kernel-Bypass Architectures eRPC Lib. RDMA App User I/O Buf. Mgmt Net. Trans. OS Kernel Control Path Ad-hoc Datapaths App OS Kern Figure 1. Example kernel-bypass architectures. U ernel architecture (right), Arrakis [73], Caladan [23 様々なカーネルをバイパスする システムが提案された 問題:アプリが利⽤を想定するデバイスに依存 Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ʼ21), 195-211.(https://doi.org/10.1145/3477132.3483569)
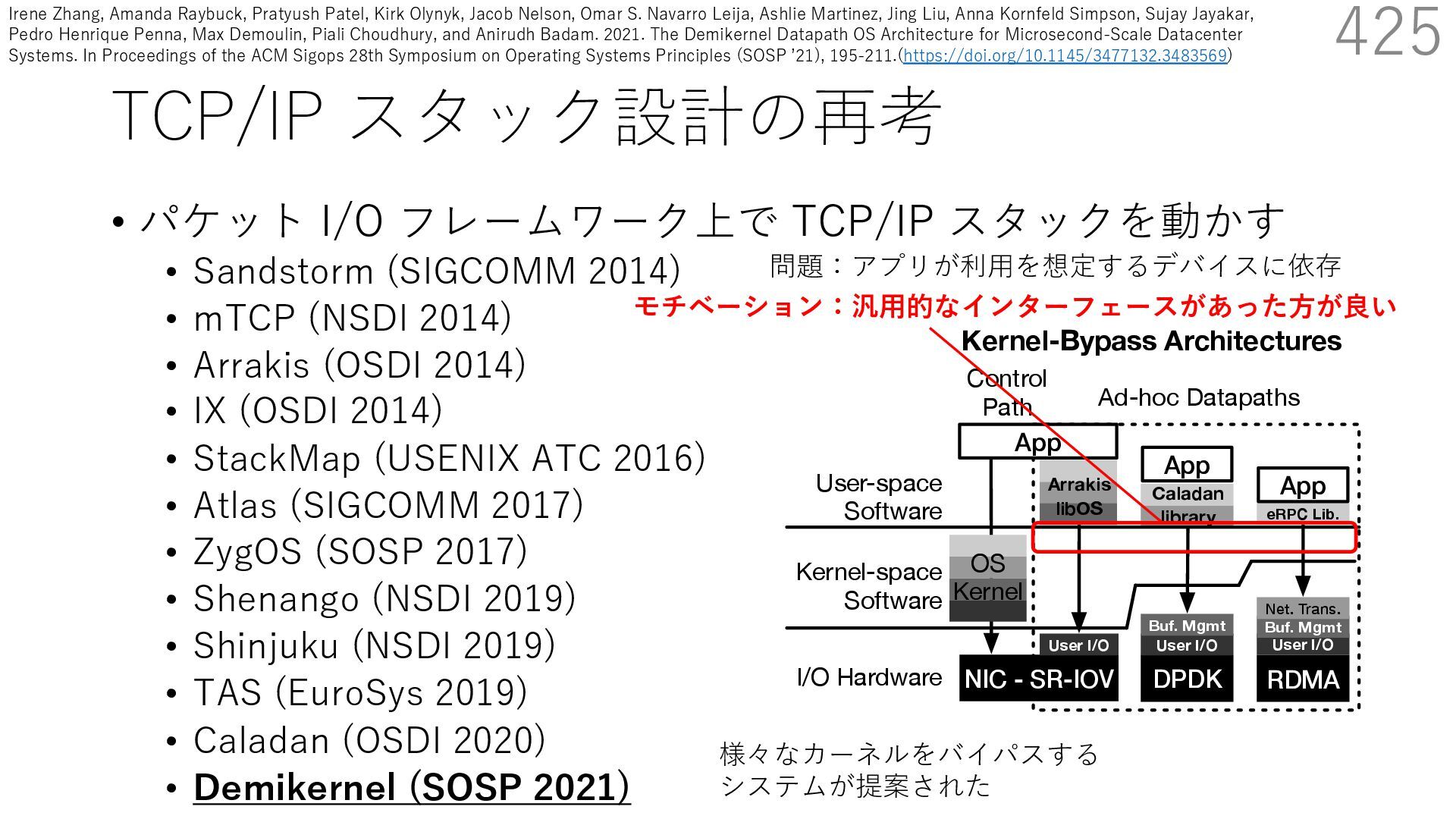
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 425 s devices. Demikernel datapath OSes run with trolplane kernel (e.g., Linux or Windows) and erchangeable library OSes with the same API, ent features and architecture. Each library OS is fic: it offloads to the kernel-bypass device when implements remaining OS management in a user- These libOSes aim to simplify the development atacenter systems across heterogenous kernel- es with while minimizing OS overheads. el follows a trend away from kernel-oriented ary-oriented datapath OSes, motivated by the User-space Software Kernel-space Software I/O Hardware D N Con Pa NIC - SR-IOV User I/O Arrakis libOS DPDK App User I/O Buf. Mgmt Caladan library Kernel-Bypass Architectures eRPC Lib. RDMA App User I/O Buf. Mgmt Net. Trans. OS Kernel Control Path Ad-hoc Datapaths App OS Kern Figure 1. Example kernel-bypass architectures. U ernel architecture (right), Arrakis [73], Caladan [23 様々なカーネルをバイパスする システムが提案された 問題:アプリが利⽤を想定するデバイスに依存 モチベーション:汎⽤的なインターフェースがあった⽅が良い Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ʼ21), 195-211.(https://doi.org/10.1145/3477132.3483569)
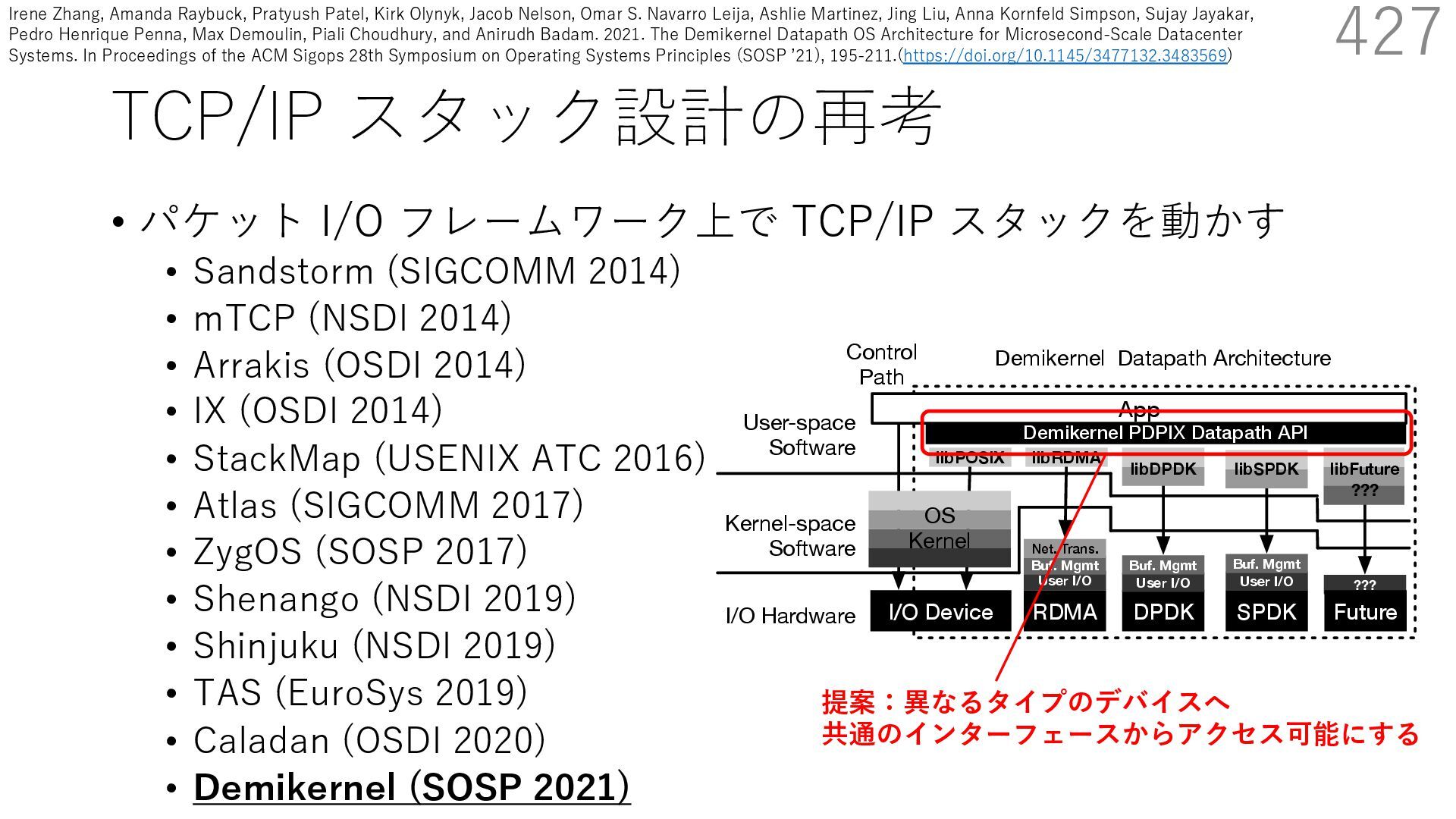
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 426 into a single library for both devices (e.g., RDMAxSPDK). We implemented the bulk of our library OS code in Rust. We initially prototyped several libOSes in C++; however, we found that Rust performs competitively with C++ and achieves ns-scale latencies while offering additional benefits. First, Rust enforces memory safety through language fea- tures and its compiler. Though our libOSes use unsafe code to bind to C/C++ kernel-bypass libraries and applications, User-space Software Kernel-space Software I/O Hardware I/O Device ??? libFuture ??? DPDK User I/O Buf. Mgmt libRDMA RDMA User I/O Buf. Mgmt Net. Trans. OS Kernel Control Path Demikernel Datapath Architecture App libPOSIX libDPDK SPDK User I/O Buf. Mgmt libSPDK Future Demikernel PDPIX Datapath API Figure 3. Demikernel kernel-bypass architecture. Demikernel ac- commodates heterogenous kernel-bypass devices, including poten- tial future hardware, with a flexible library OS-based datapath ar- chitecture.We include a libOS that goes through the OS kernel for Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ʼ21), 195-211.(https://doi.org/10.1145/3477132.3483569)
(SIGCOMM 2014) • mTCP (NSDI 2014) • Arrakis (OSDI 2014) • IX (OSDI 2014) • StackMap (USENIX ATC 2016) • Atlas (SIGCOMM 2017) • ZygOS (SOSP 2017) • Shenango (NSDI 2019) • Shinjuku (NSDI 2019) • TAS (EuroSys 2019) • Caladan (OSDI 2020) • Demikernel (SOSP 2021) 427 into a single library for both devices (e.g., RDMAxSPDK). We implemented the bulk of our library OS code in Rust. We initially prototyped several libOSes in C++; however, we found that Rust performs competitively with C++ and achieves ns-scale latencies while offering additional benefits. First, Rust enforces memory safety through language fea- tures and its compiler. Though our libOSes use unsafe code to bind to C/C++ kernel-bypass libraries and applications, User-space Software Kernel-space Software I/O Hardware I/O Device ??? libFuture ??? DPDK User I/O Buf. Mgmt libRDMA RDMA User I/O Buf. Mgmt Net. Trans. OS Kernel Control Path Demikernel Datapath Architecture App libPOSIX libDPDK SPDK User I/O Buf. Mgmt libSPDK Future Demikernel PDPIX Datapath API Figure 3. Demikernel kernel-bypass architecture. Demikernel ac- commodates heterogenous kernel-bypass devices, including poten- tial future hardware, with a flexible library OS-based datapath ar- chitecture.We include a libOS that goes through the OS kernel for 提案:異なるタイプのデバイスへ 共通のインターフェースからアクセス可能にする Irene Zhang, Amanda Raybuck, Pratyush Patel, Kirk Olynyk, Jacob Nelson, Omar S. Navarro Leija, Ashlie Martinez, Jing Liu, Anna Kornfeld Simpson, Sujay Jayakar, Pedro Henrique Penna, Max Demoulin, Piali Choudhury, and Anirudh Badam. 2021. The Demikernel Datapath OS Architecture for Microsecond-Scale Datacenter Systems. In Proceedings of the ACM Sigops 28th Symposium on Operating Systems Principles (SOSP ʼ21), 195-211.(https://doi.org/10.1145/3477132.3483569)
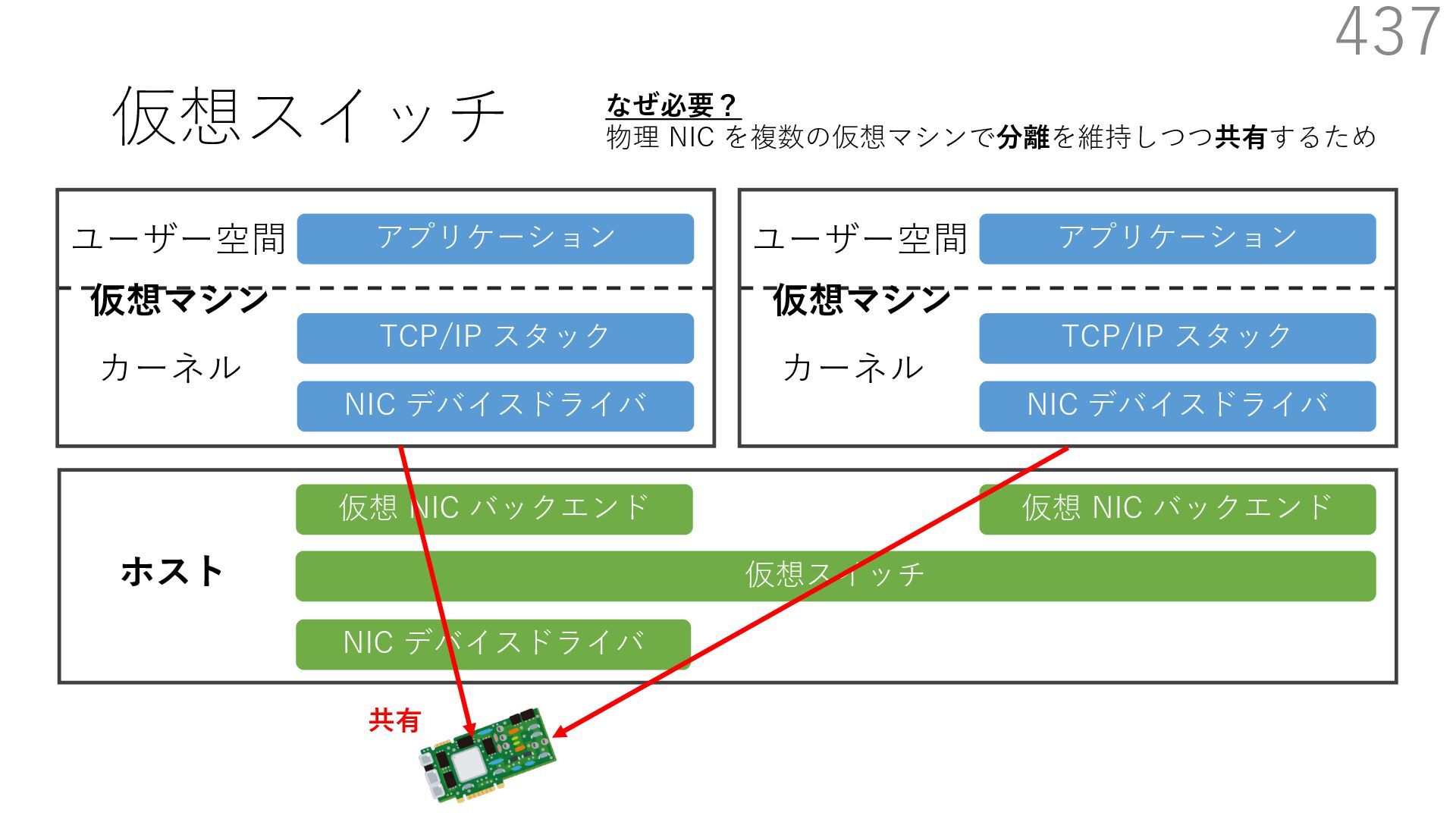
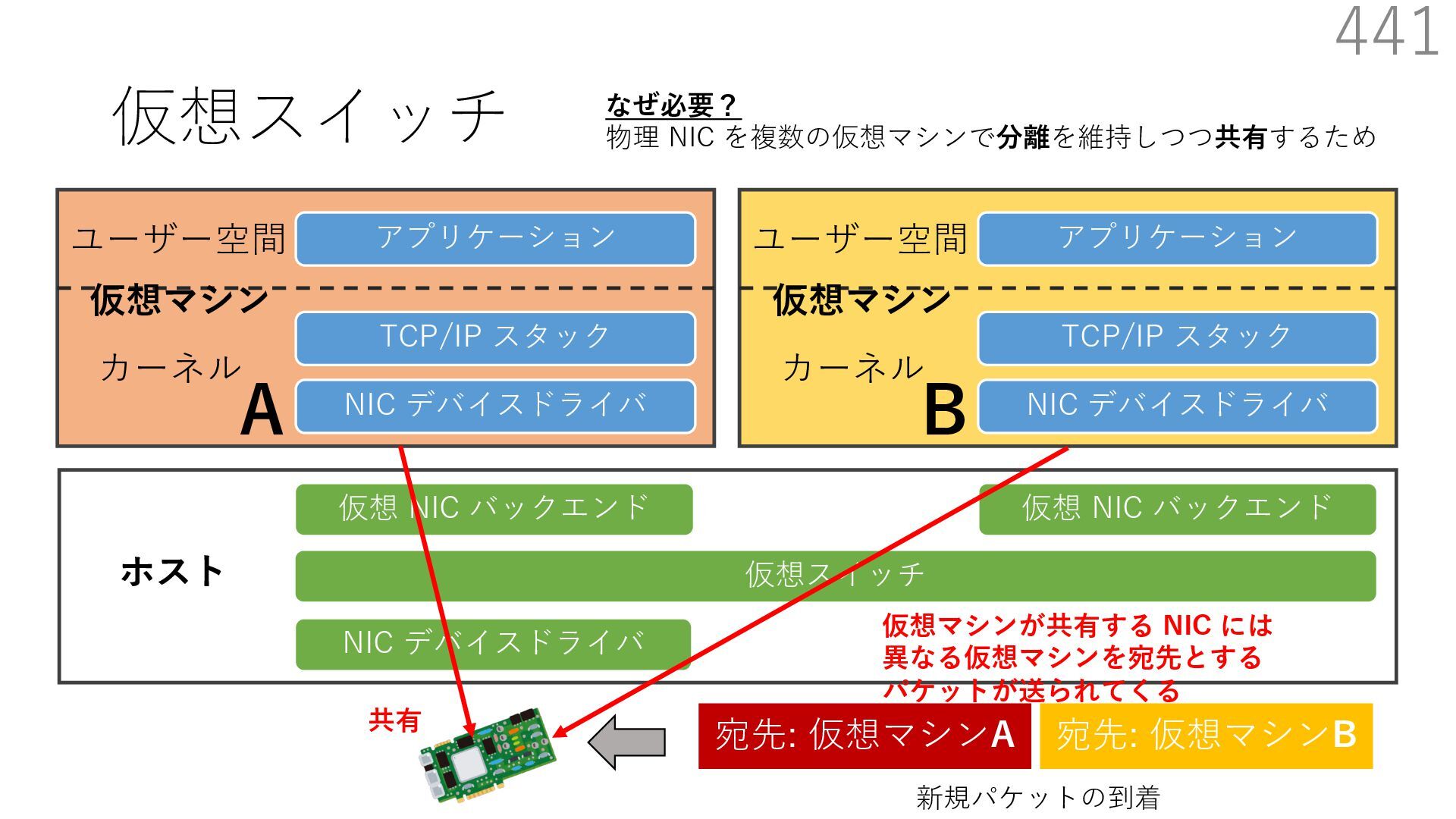
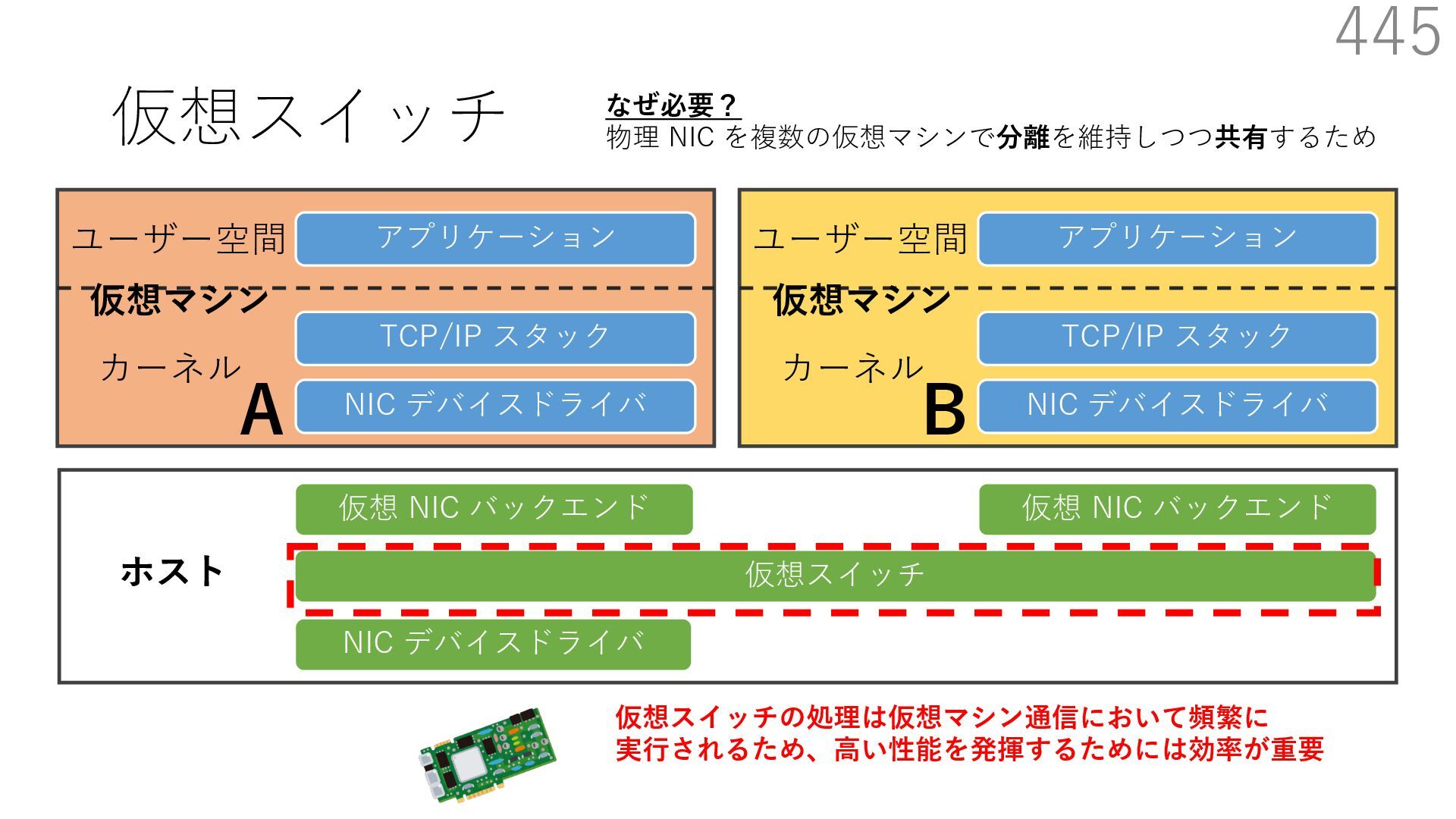
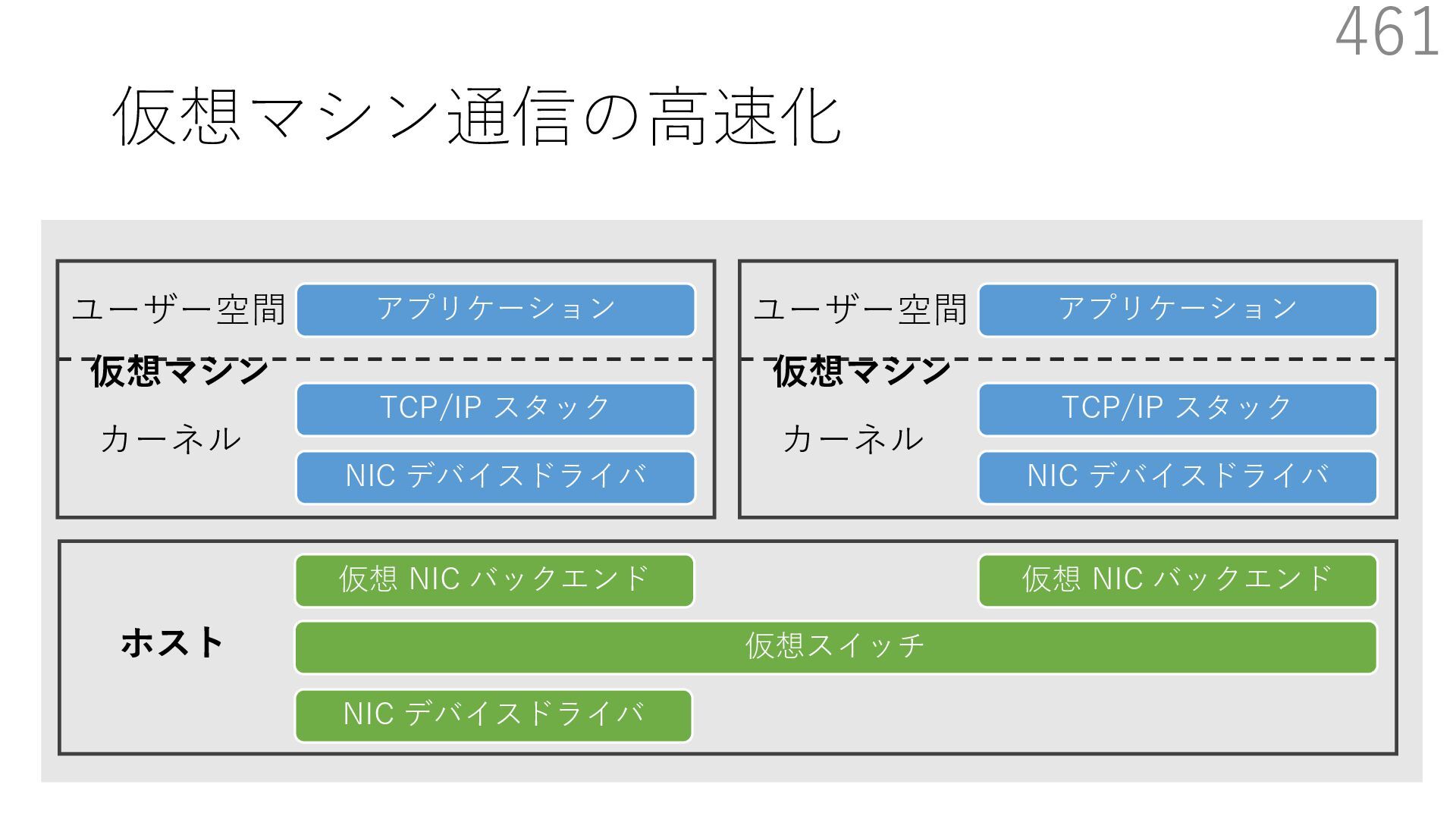
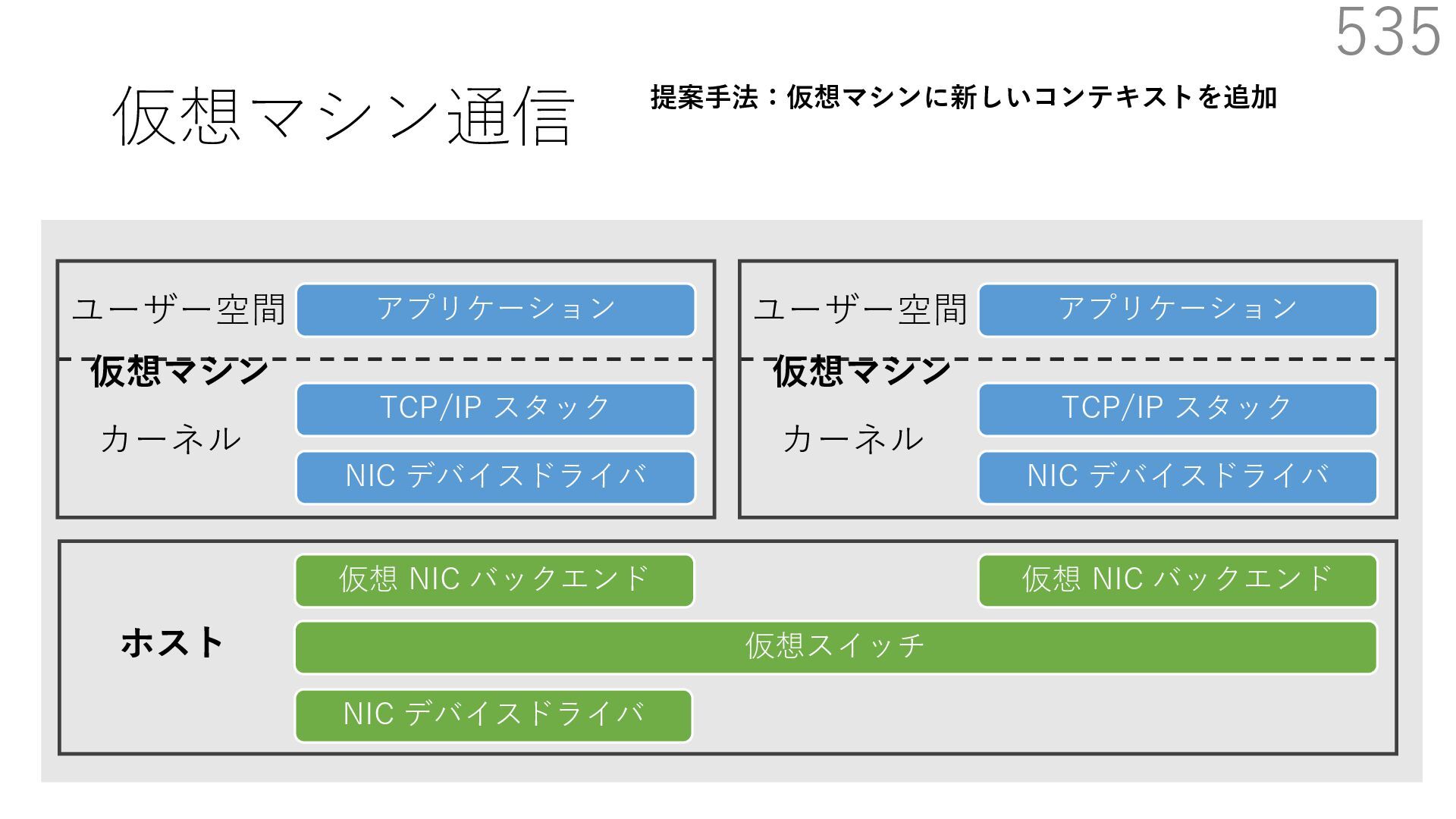
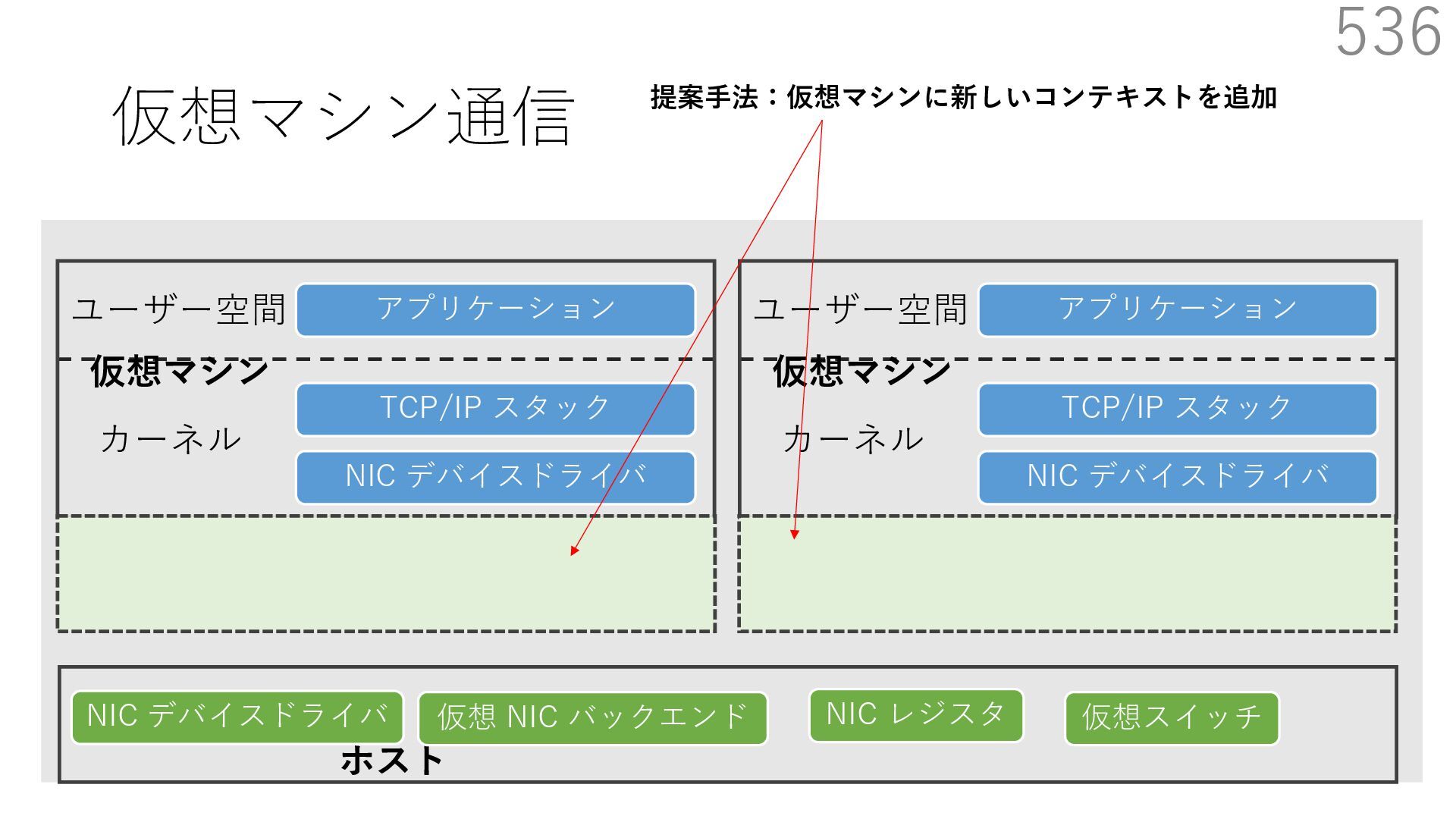
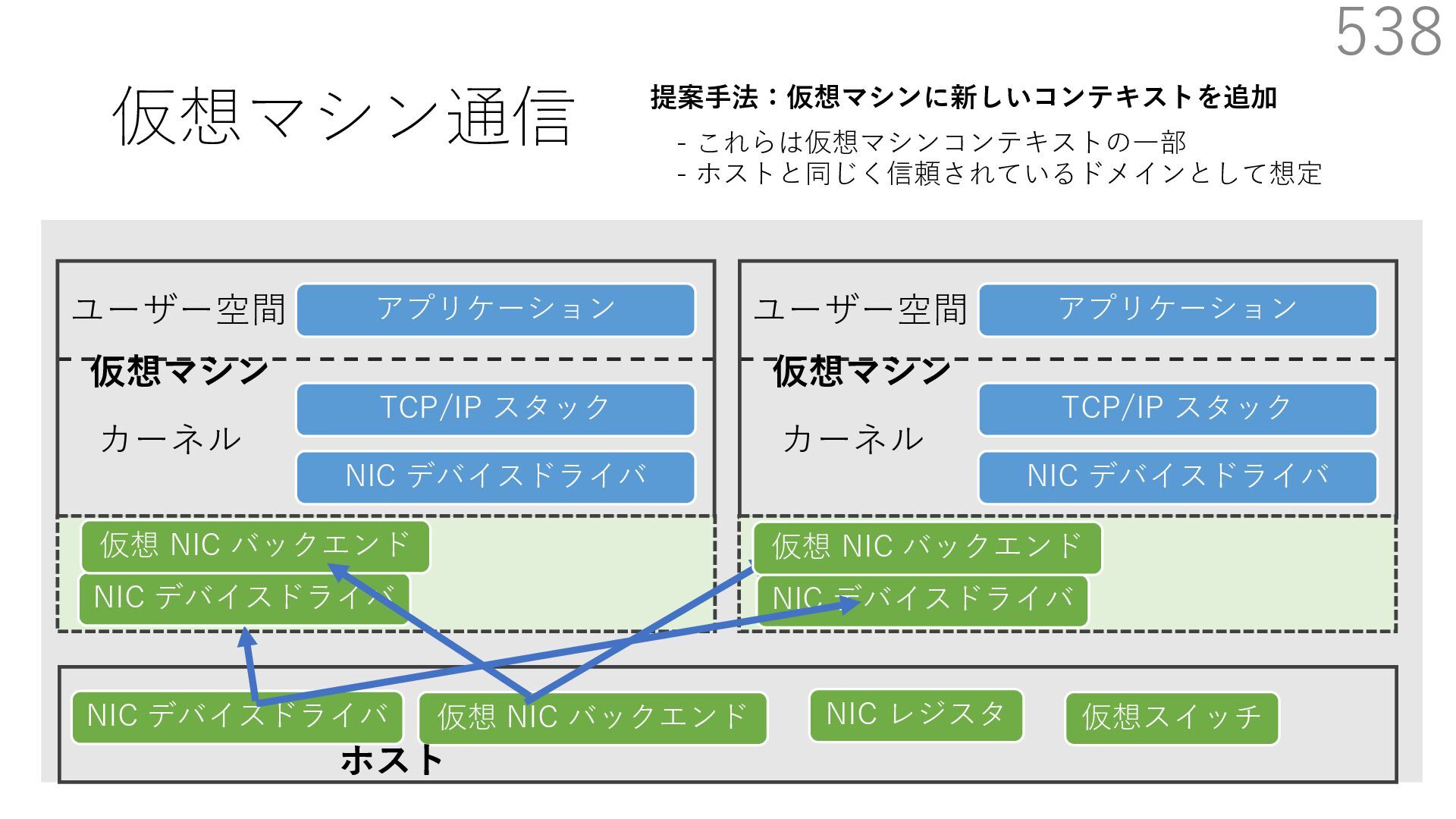
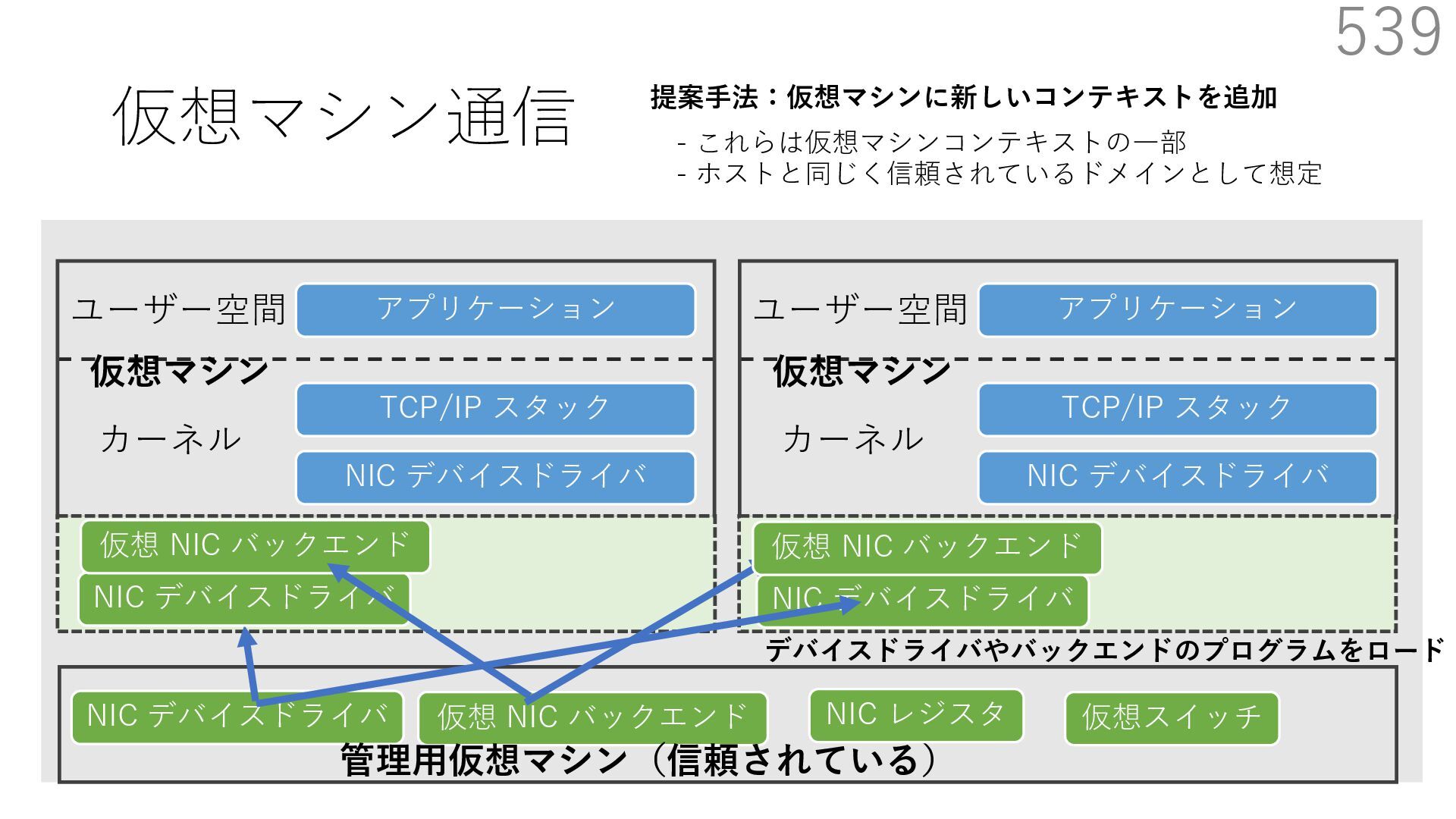
仮想 NIC バックエンド ユーザー空間 カーネル ホスト 仮想マシン NIC デバイスドライバ TCP/IP スタック アプリケーション ユーザー空間 カーネル 仮想マシン 仮想 NIC バックエンド なぜ必要? 物理 NIC を複数の仮想マシンで分離を維持しつつ共有するため A B 宛先: 仮想マシンA 新規パケットの到着 宛先: 仮想マシンB 共有
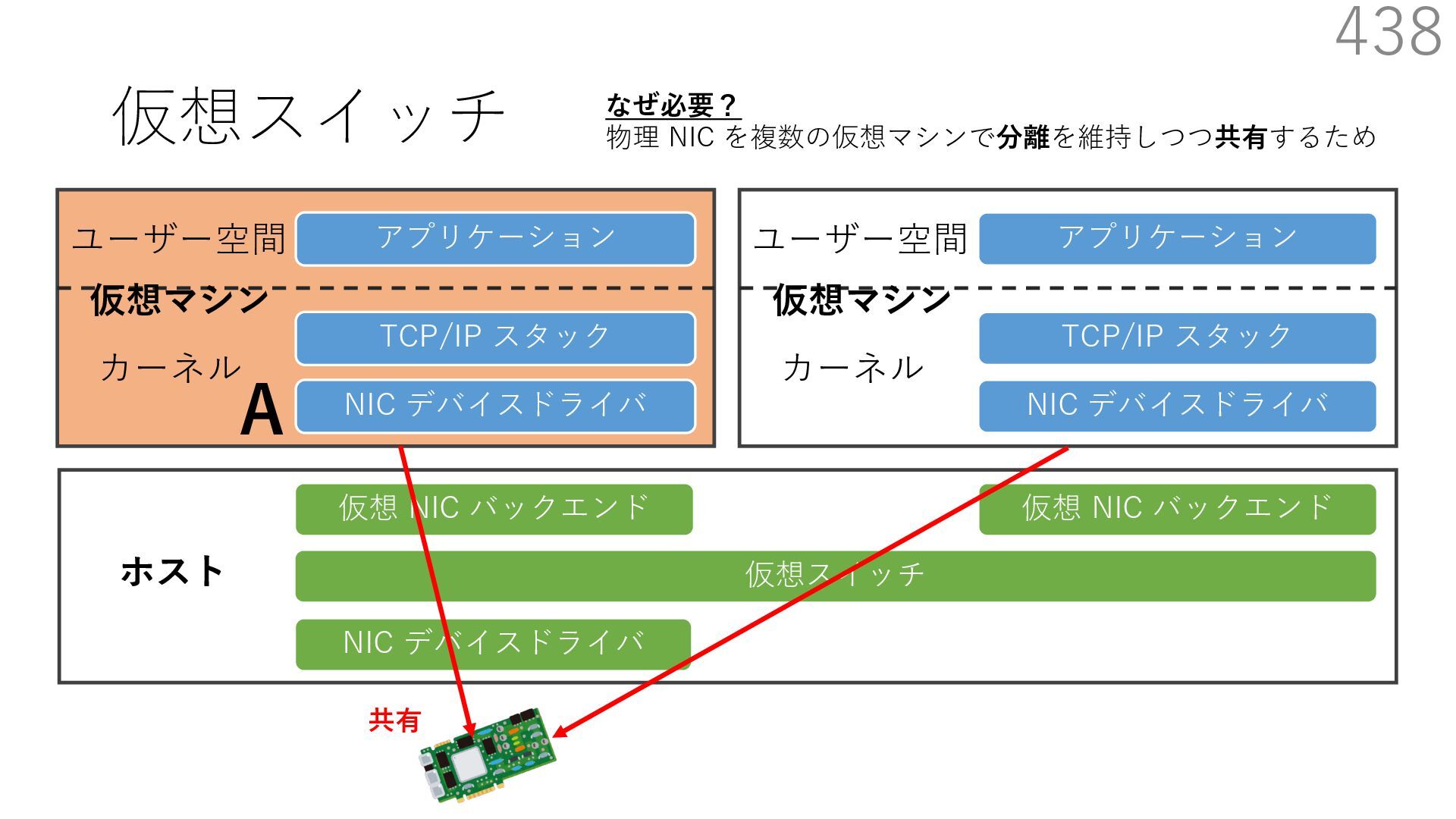
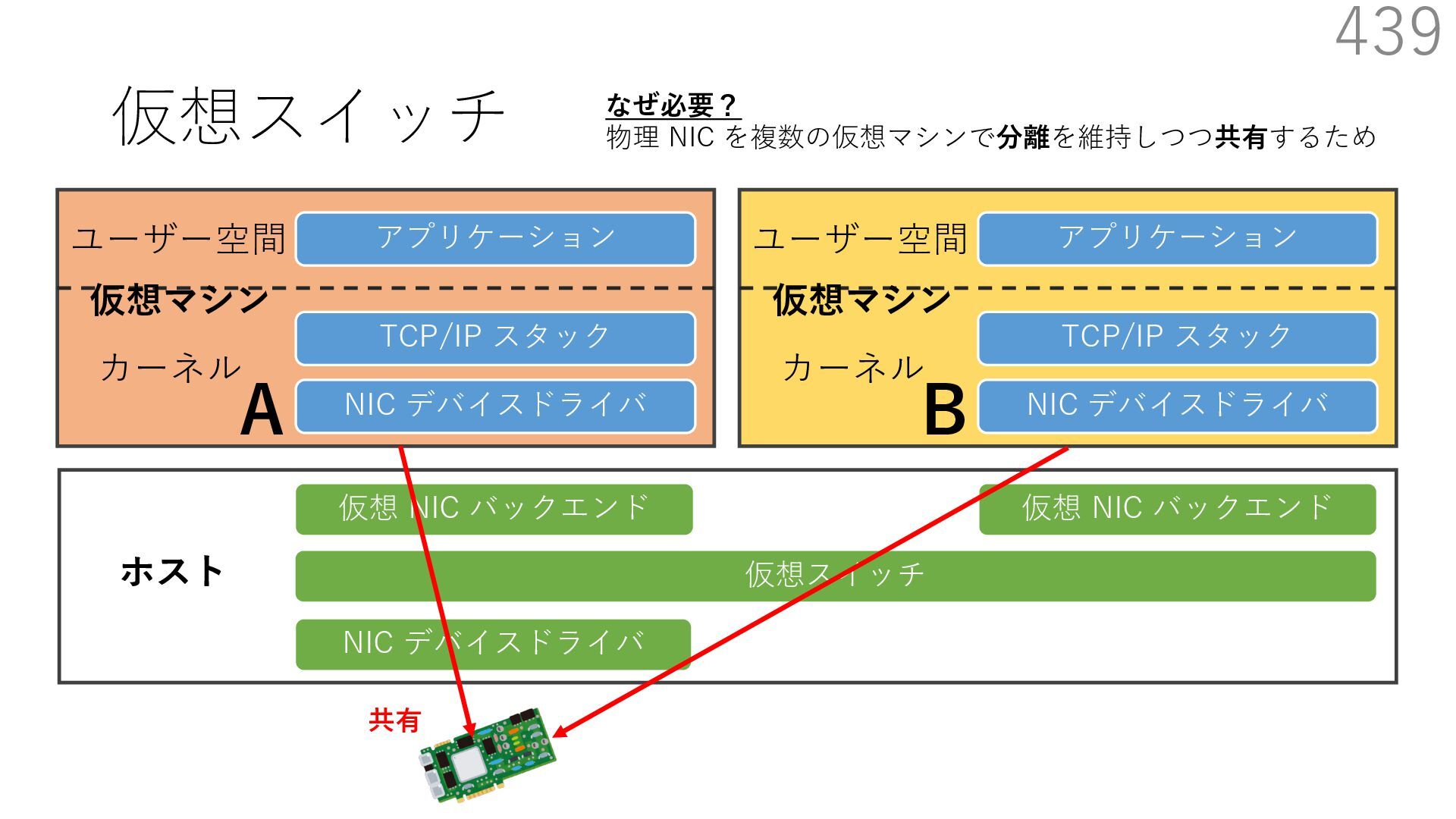
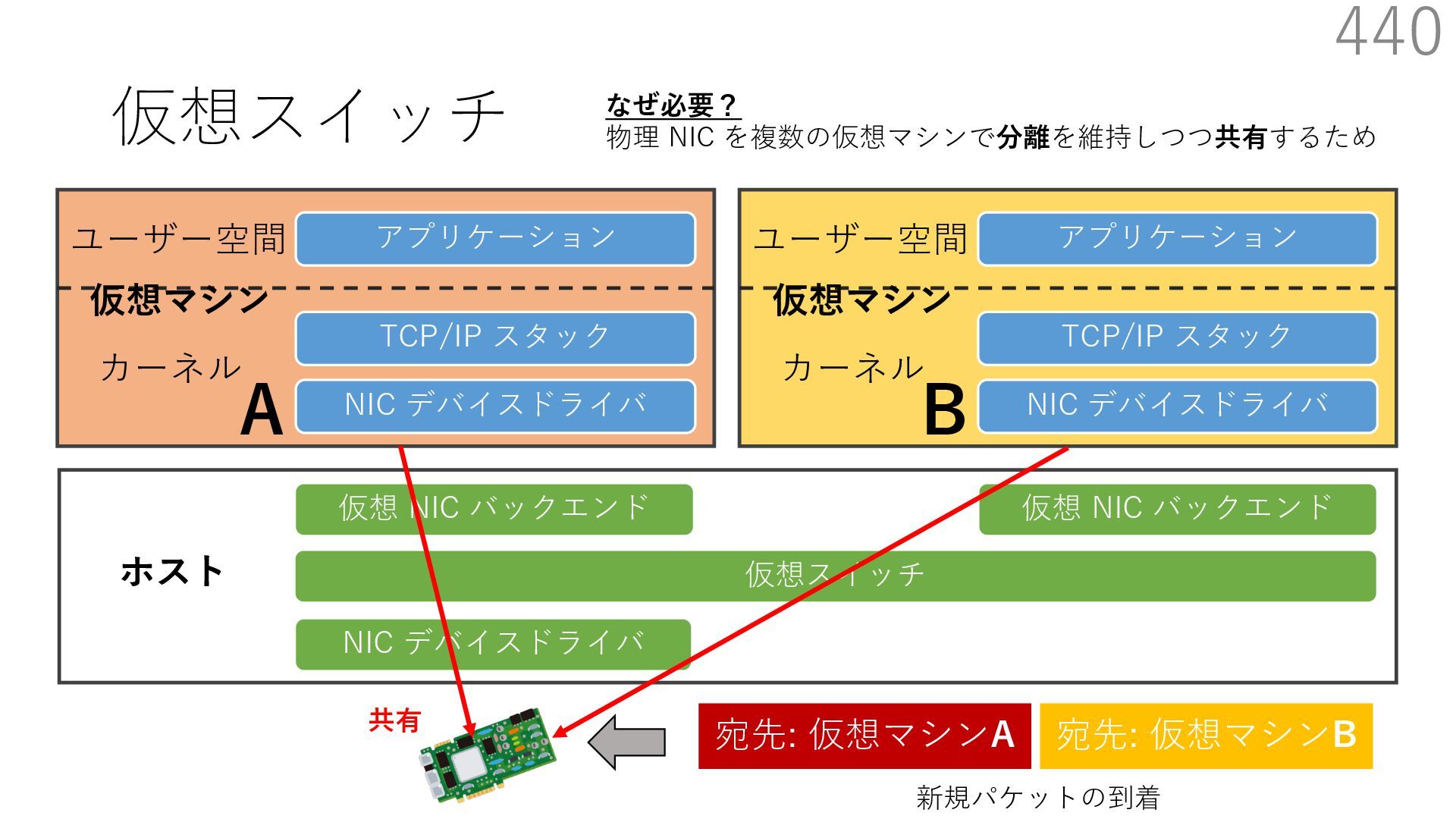
仮想 NIC バックエンド ユーザー空間 カーネル ホスト 仮想マシン NIC デバイスドライバ TCP/IP スタック アプリケーション ユーザー空間 カーネル 仮想マシン 仮想 NIC バックエンド なぜ必要? 物理 NIC を複数の仮想マシンで分離を維持しつつ共有するため A B 宛先: 仮想マシンA 新規パケットの到着 宛先: 仮想マシンB 共有 仮想マシンが共有する NIC には 異なる仮想マシンを宛先とする パケットが送られてくる
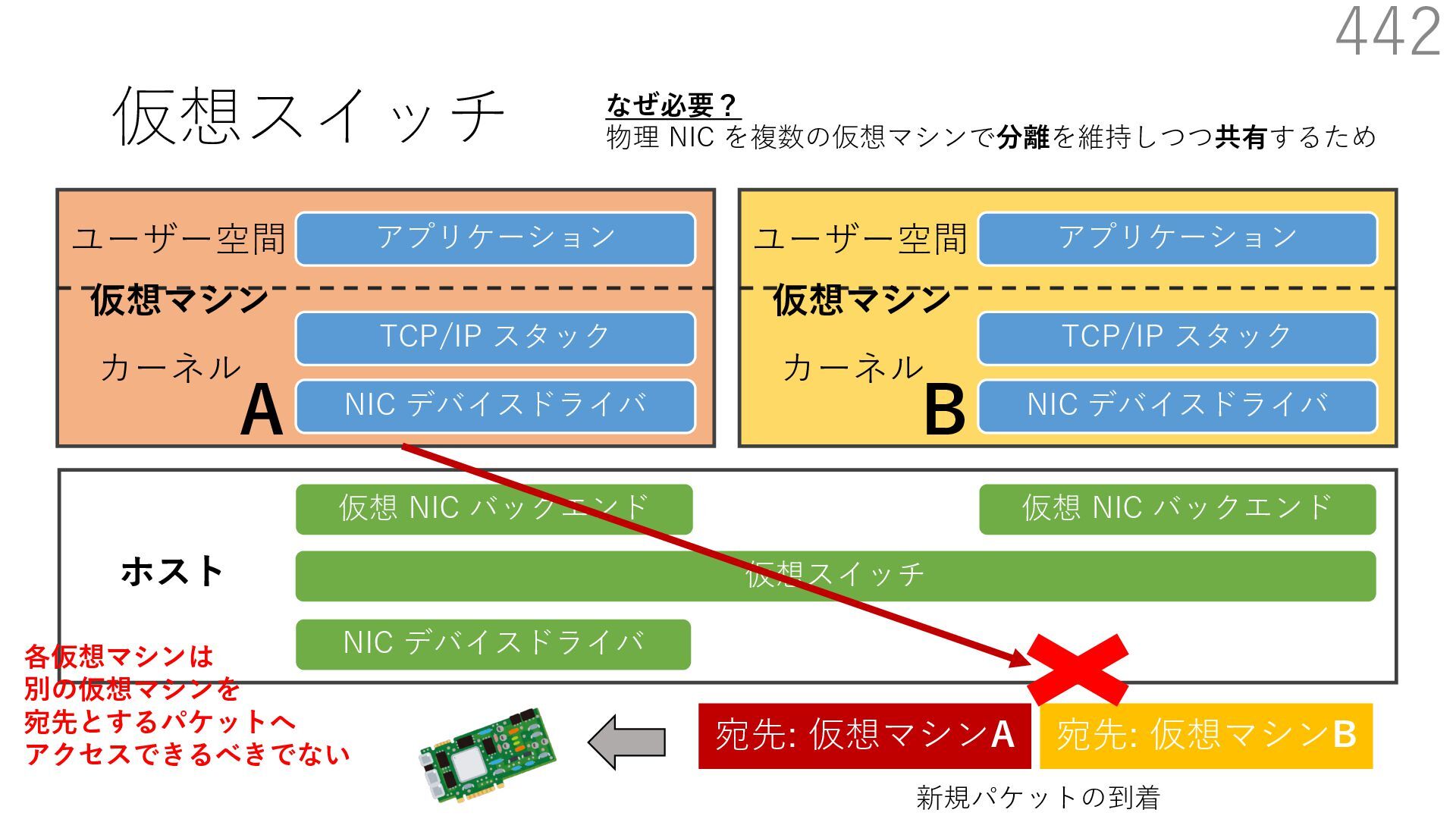
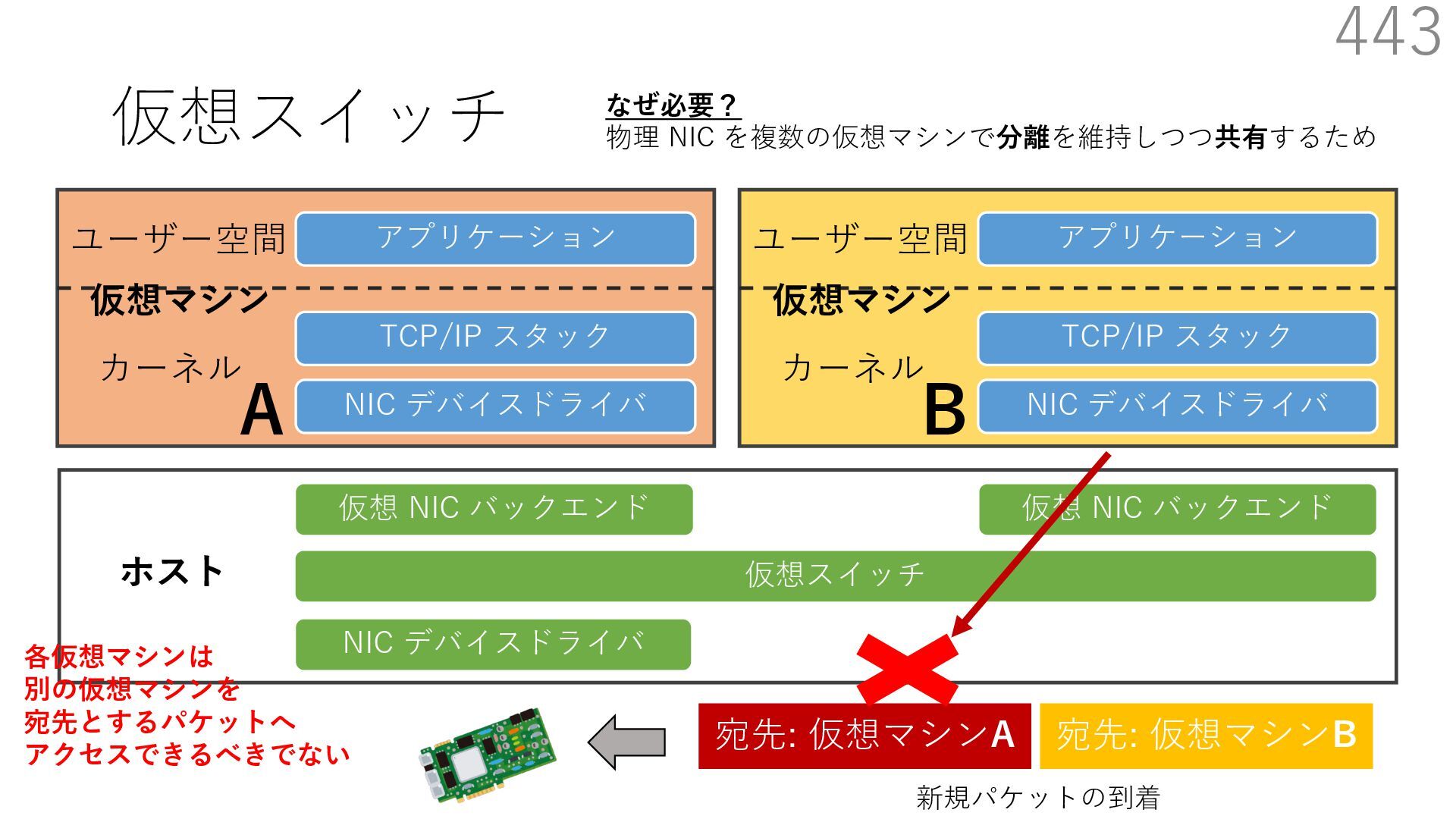
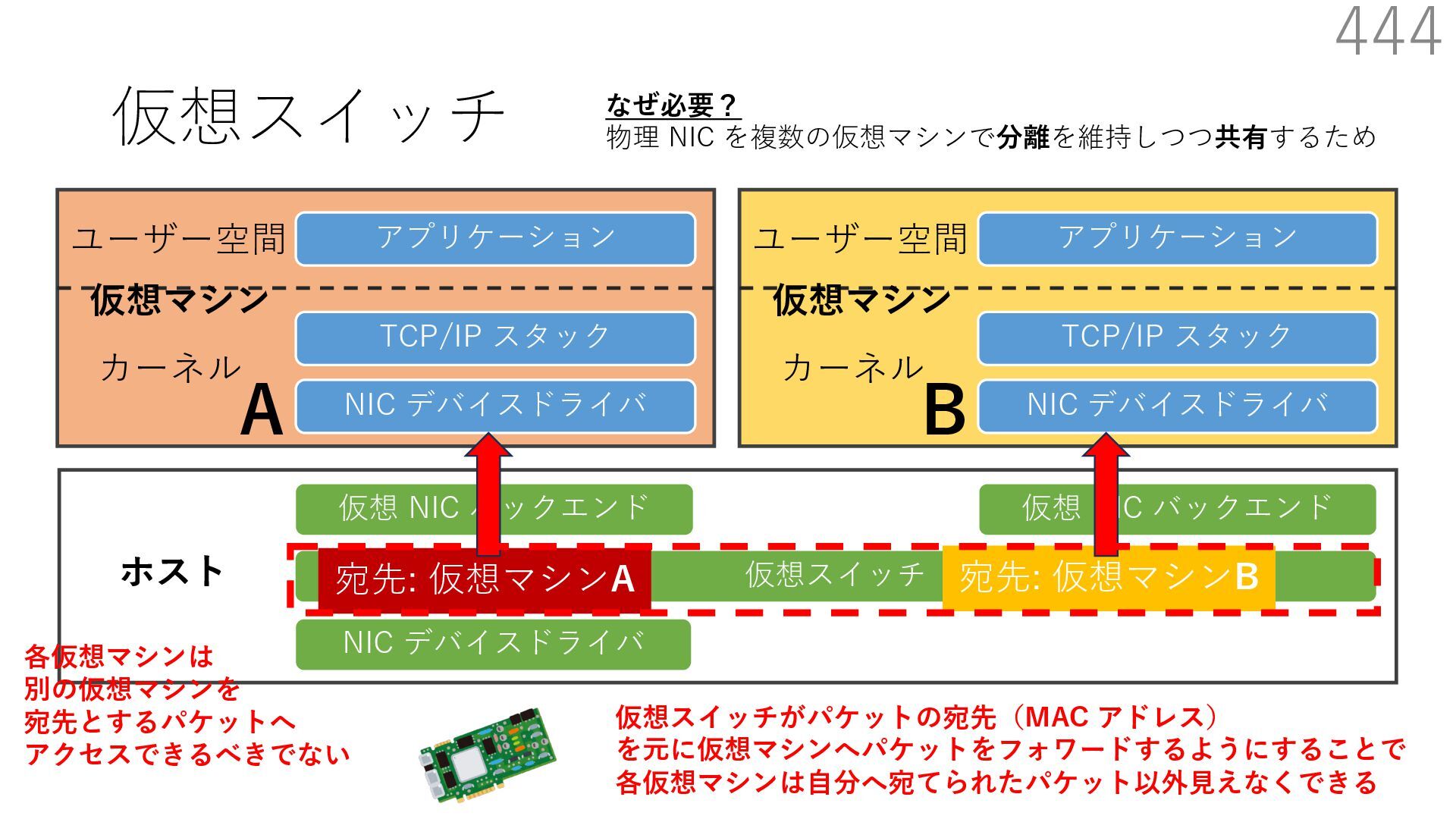
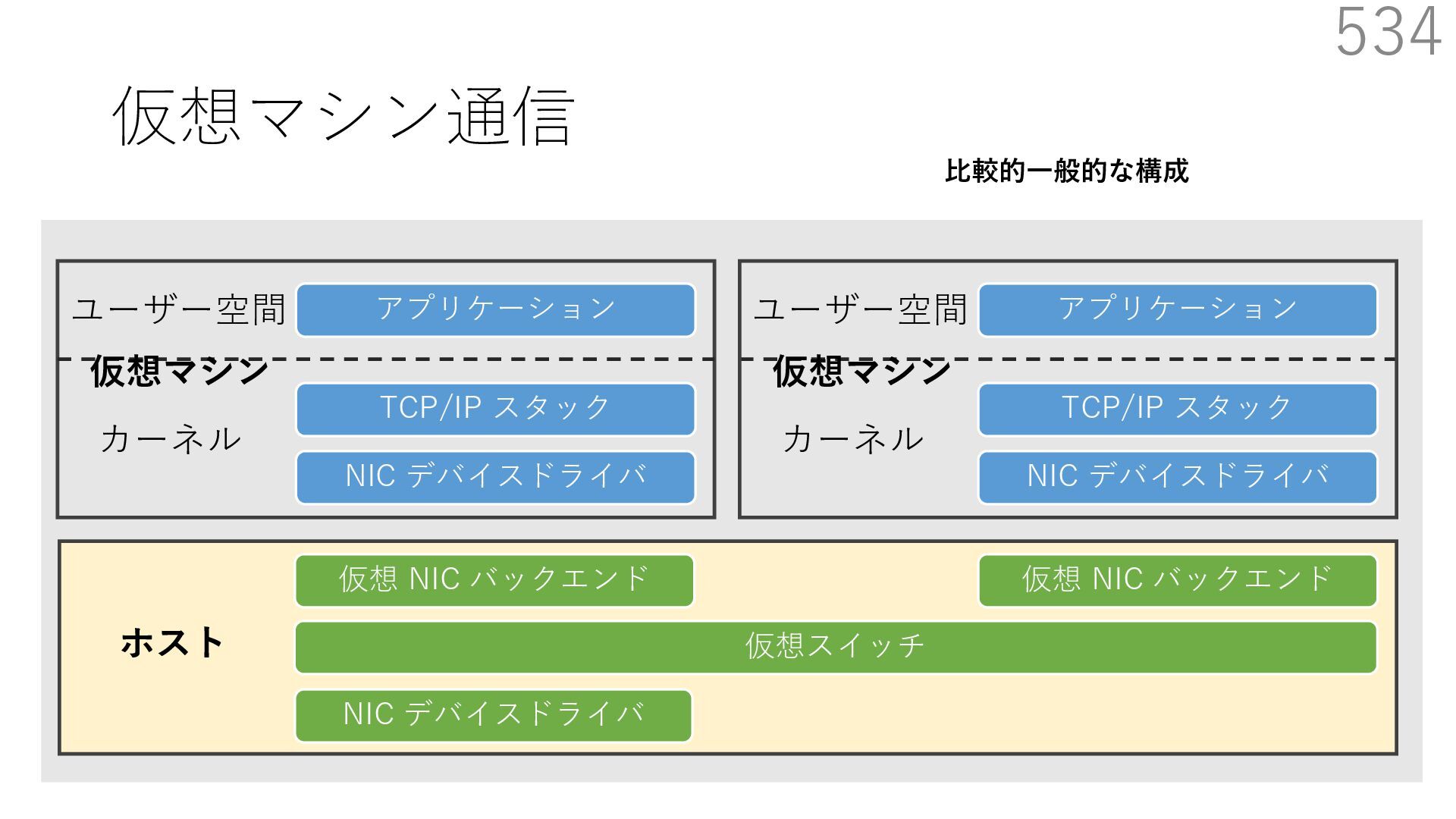
仮想 NIC バックエンド ユーザー空間 カーネル ホスト 仮想マシン NIC デバイスドライバ TCP/IP スタック アプリケーション ユーザー空間 カーネル 仮想マシン 仮想 NIC バックエンド なぜ必要? 物理 NIC を複数の仮想マシンで分離を維持しつつ共有するため A B 仮想スイッチの処理は仮想マシン通信において頻繁に 実⾏されるため、⾼い性能を発揮するためには効率が重要
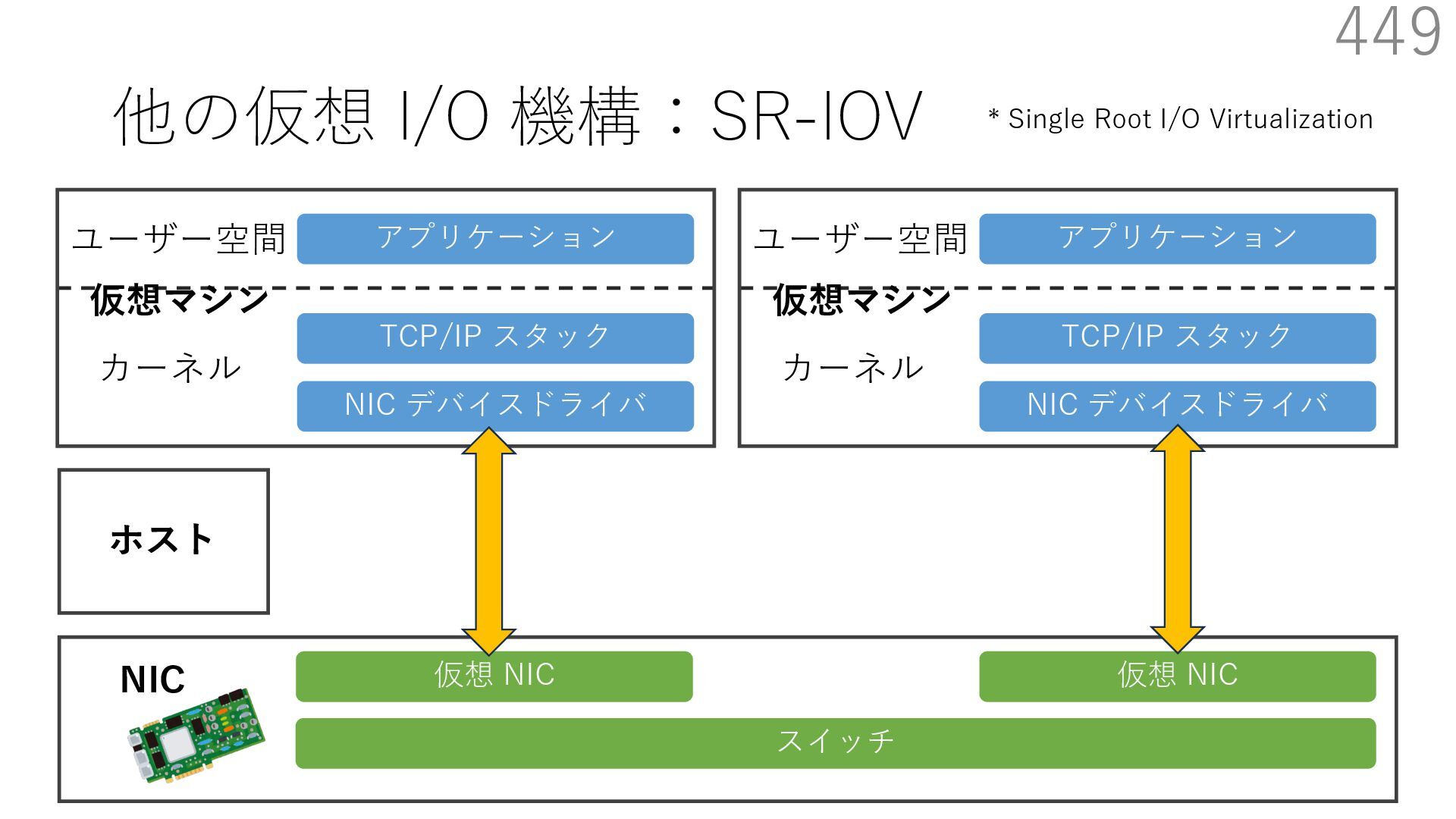
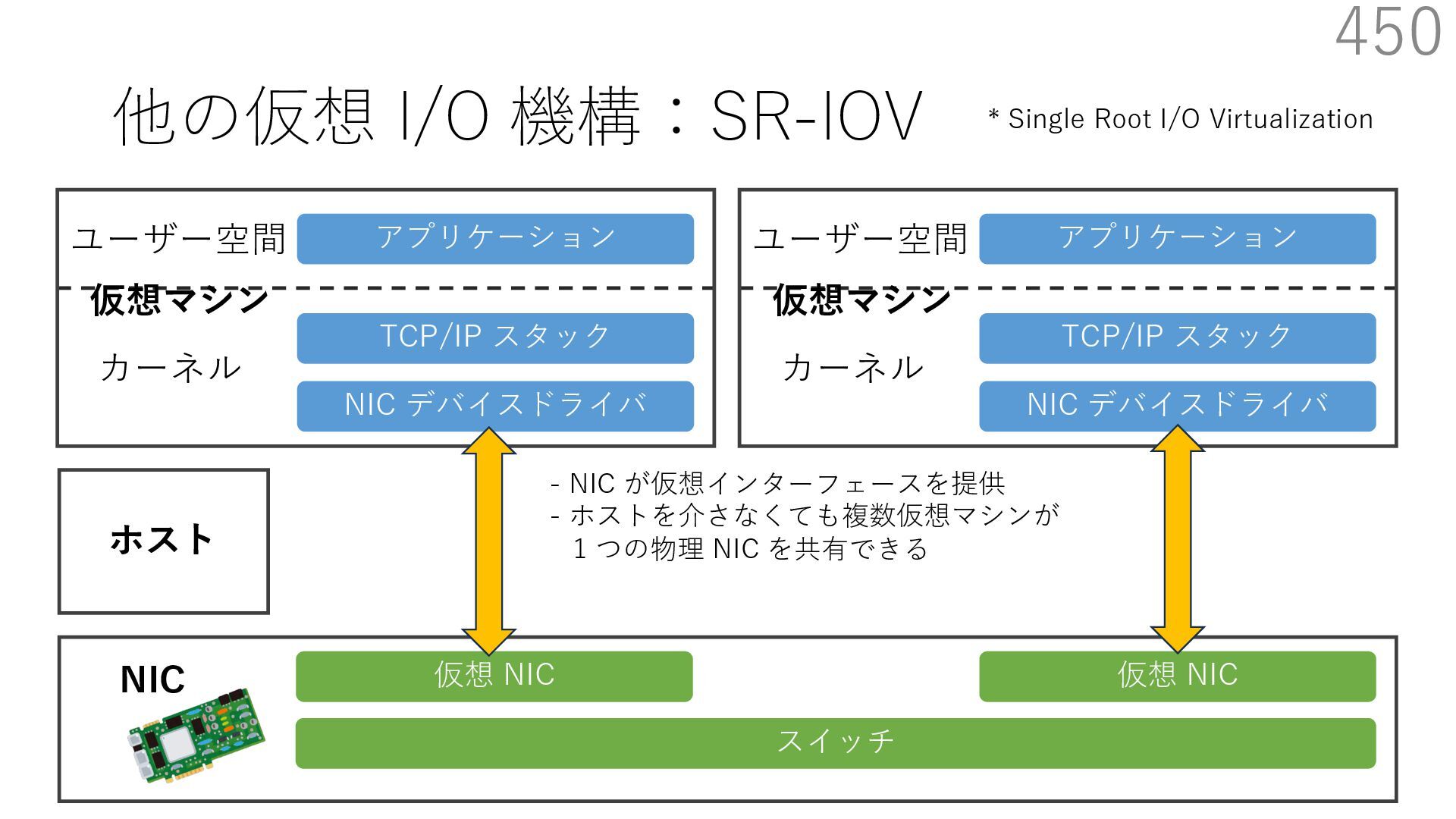
仮想 NIC ユーザー空間 カーネル NIC 仮想マシン NIC デバイスドライバ TCP/IP スタック アプリケーション ユーザー空間 カーネル 仮想マシン 仮想 NIC ホスト - NIC が仮想インターフェースを提供 - ホストを介さなくても複数仮想マシンが 1 つの物理 NIC を共有できる * Single Root I/O Virtualization
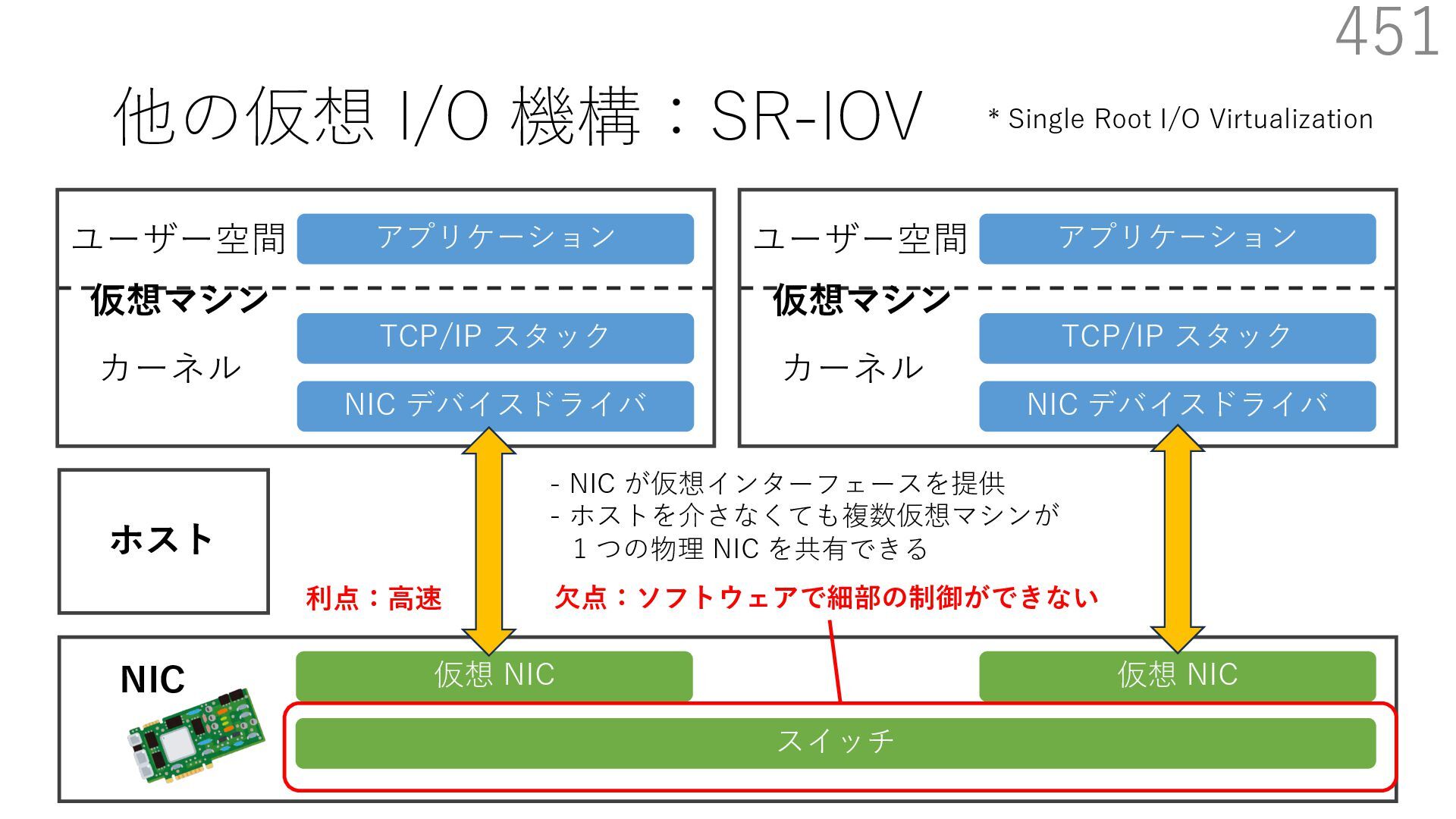
仮想 NIC ユーザー空間 カーネル NIC 仮想マシン NIC デバイスドライバ TCP/IP スタック アプリケーション ユーザー空間 カーネル 仮想マシン 仮想 NIC ホスト - NIC が仮想インターフェースを提供 - ホストを介さなくても複数仮想マシンが 1 つの物理 NIC を共有できる 利点:⾼速 ⽋点:ソフトウェアで細部の制御ができない * Single Root I/O Virtualization
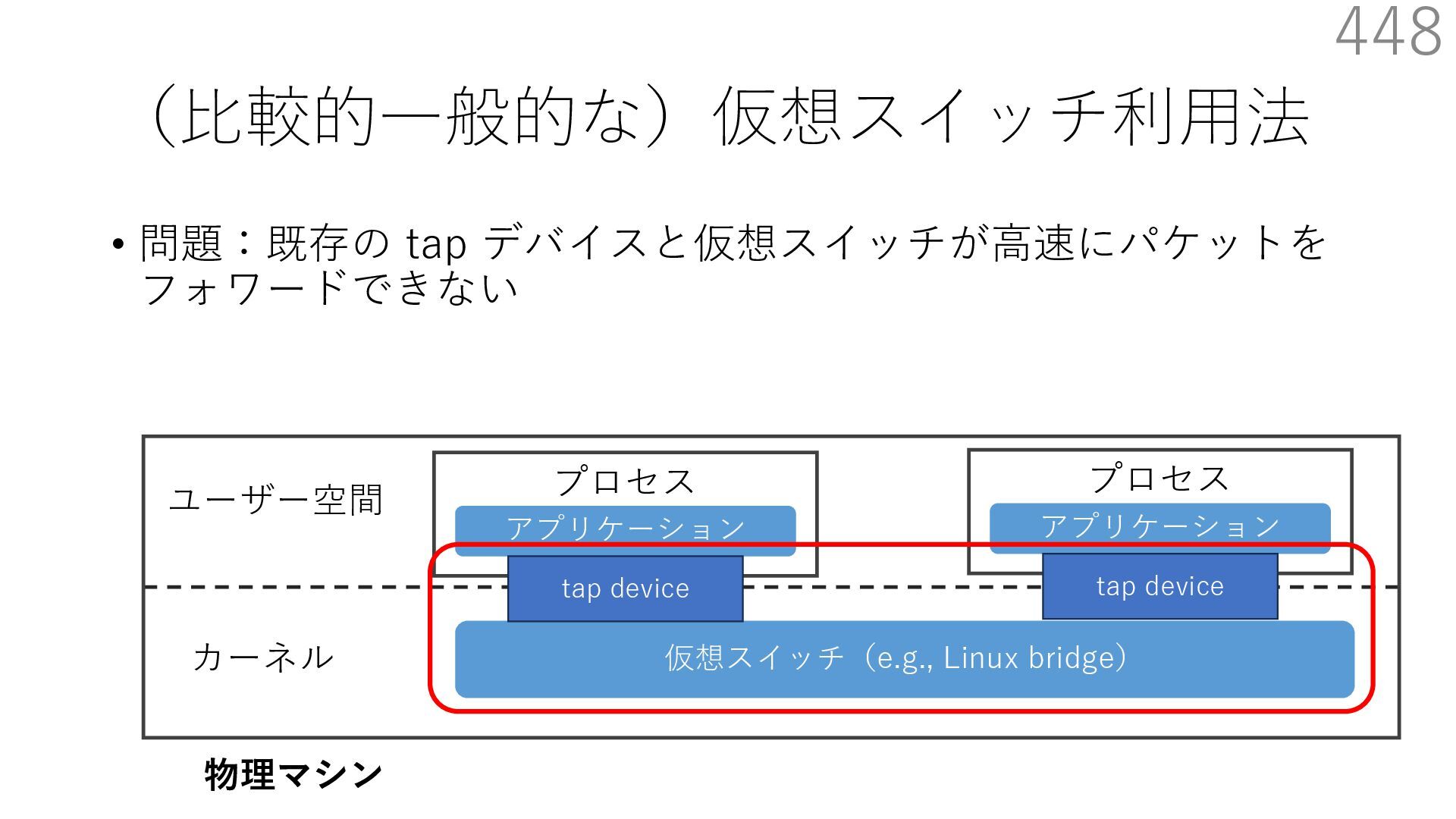
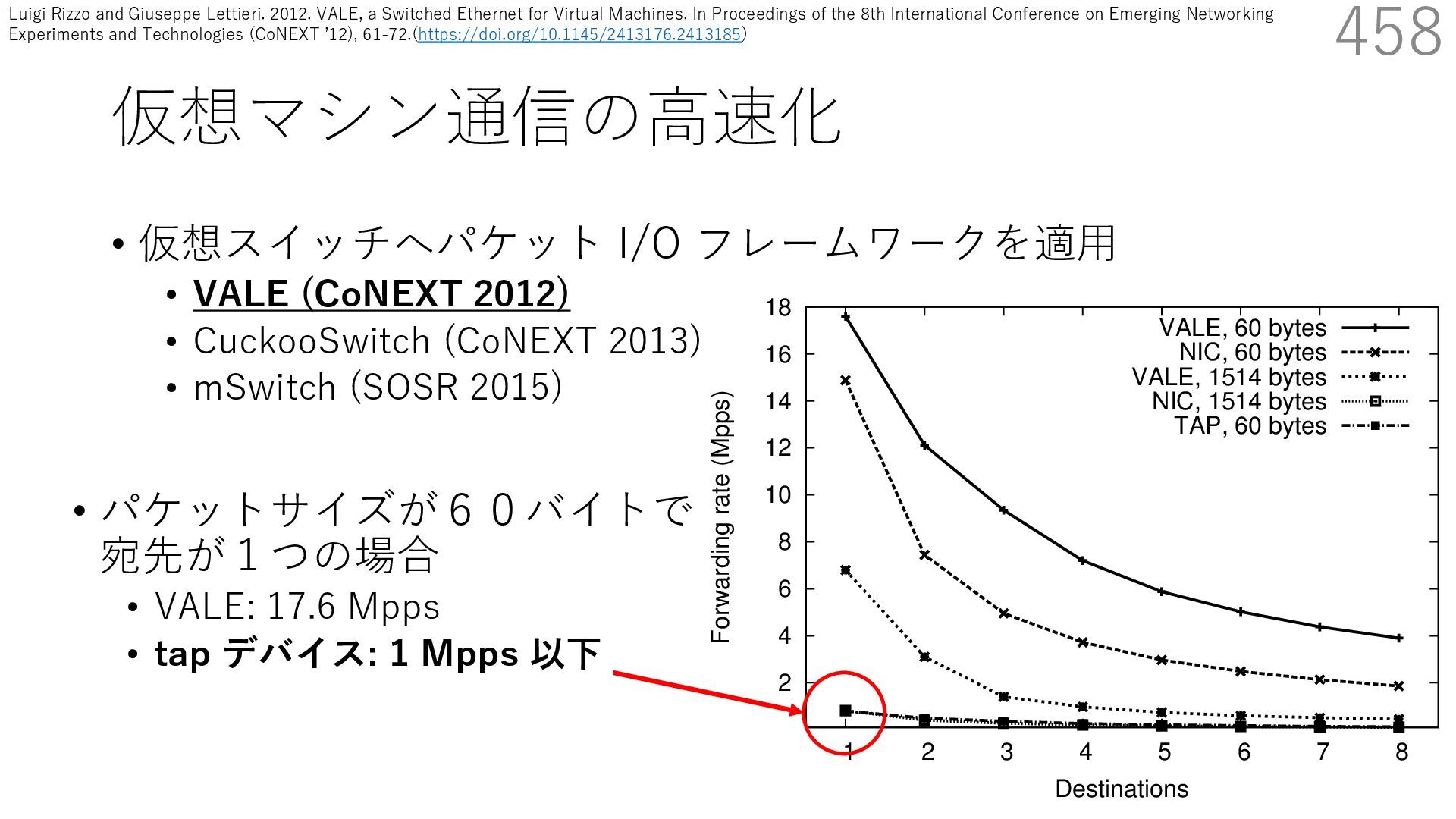
CuckooSwitch (CoNEXT 2013) • mSwitch (SOSR 2015) 456 responding pps rates are between 1/6 and 1/150 of tho shown here. The traffic received by a bridge should normally go to single destination, but there are cases (multicast or unknow destinations) where the bridge needs to replicate packets t multiple ports. Hence the number of active ports impac the throughput of the system. 2 4 6 8 10 12 14 16 18 1 2 3 4 5 6 7 8 Forwarding rate (Mpps) Destinations VALE, 60 bytes NIC, 60 bytes VALE, 1514 bytes NIC, 1514 bytes TAP, 60 bytes Luigi Rizzo and Giuseppe Lettieri. 2012. VALE, a Switched Ethernet for Virtual Machines. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies (CoNEXT ʼ12), 61-72.(https://doi.org/10.1145/2413176.2413185)
CuckooSwitch (CoNEXT 2013) • mSwitch (SOSR 2015) 457 responding pps rates are between 1/6 and 1/150 of tho shown here. The traffic received by a bridge should normally go to single destination, but there are cases (multicast or unknow destinations) where the bridge needs to replicate packets t multiple ports. Hence the number of active ports impac the throughput of the system. 2 4 6 8 10 12 14 16 18 1 2 3 4 5 6 7 8 Forwarding rate (Mpps) Destinations VALE, 60 bytes NIC, 60 bytes VALE, 1514 bytes NIC, 1514 bytes TAP, 60 bytes • パケットサイズが60バイトで 宛先が1つの場合 • VALE: 17.6 Mpps • tap デバイス: 1 Mpps 以下 Luigi Rizzo and Giuseppe Lettieri. 2012. VALE, a Switched Ethernet for Virtual Machines. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies (CoNEXT ʼ12), 61-72.(https://doi.org/10.1145/2413176.2413185)
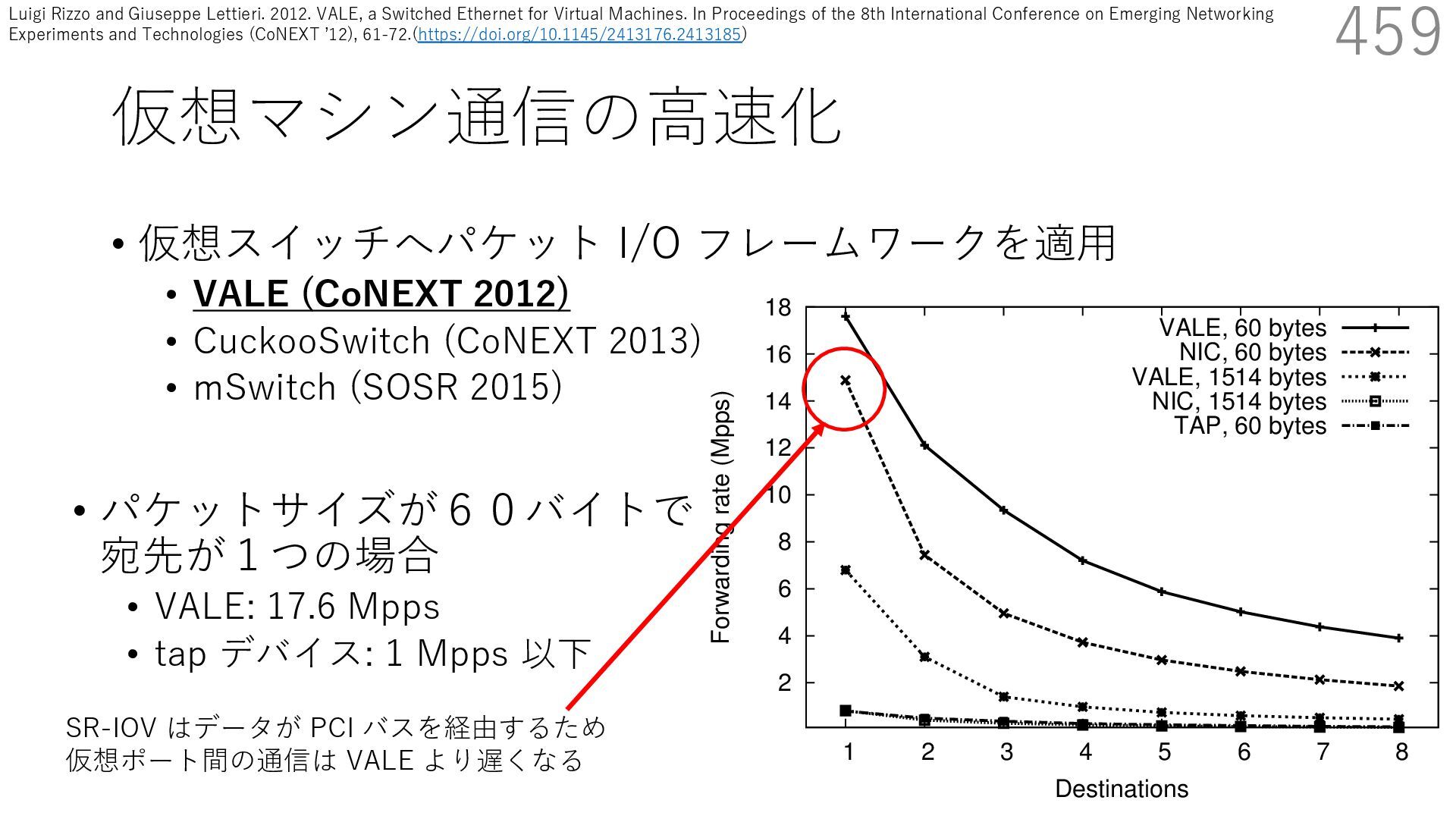
CuckooSwitch (CoNEXT 2013) • mSwitch (SOSR 2015) 458 responding pps rates are between 1/6 and 1/150 of tho shown here. The traffic received by a bridge should normally go to single destination, but there are cases (multicast or unknow destinations) where the bridge needs to replicate packets t multiple ports. Hence the number of active ports impac the throughput of the system. 2 4 6 8 10 12 14 16 18 1 2 3 4 5 6 7 8 Forwarding rate (Mpps) Destinations VALE, 60 bytes NIC, 60 bytes VALE, 1514 bytes NIC, 1514 bytes TAP, 60 bytes • パケットサイズが60バイトで 宛先が1つの場合 • VALE: 17.6 Mpps • tap デバイス: 1 Mpps 以下 Luigi Rizzo and Giuseppe Lettieri. 2012. VALE, a Switched Ethernet for Virtual Machines. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies (CoNEXT ʼ12), 61-72.(https://doi.org/10.1145/2413176.2413185)
CuckooSwitch (CoNEXT 2013) • mSwitch (SOSR 2015) 459 responding pps rates are between 1/6 and 1/150 of tho shown here. The traffic received by a bridge should normally go to single destination, but there are cases (multicast or unknow destinations) where the bridge needs to replicate packets t multiple ports. Hence the number of active ports impac the throughput of the system. 2 4 6 8 10 12 14 16 18 1 2 3 4 5 6 7 8 Forwarding rate (Mpps) Destinations VALE, 60 bytes NIC, 60 bytes VALE, 1514 bytes NIC, 1514 bytes TAP, 60 bytes • パケットサイズが60バイトで 宛先が1つの場合 • VALE: 17.6 Mpps • tap デバイス: 1 Mpps 以下 SR-IOV はデータが PCI バスを経由するため 仮想ポート間の通信は VALE より遅くなる Luigi Rizzo and Giuseppe Lettieri. 2012. VALE, a Switched Ethernet for Virtual Machines. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies (CoNEXT ʼ12), 61-72.(https://doi.org/10.1145/2413176.2413185)
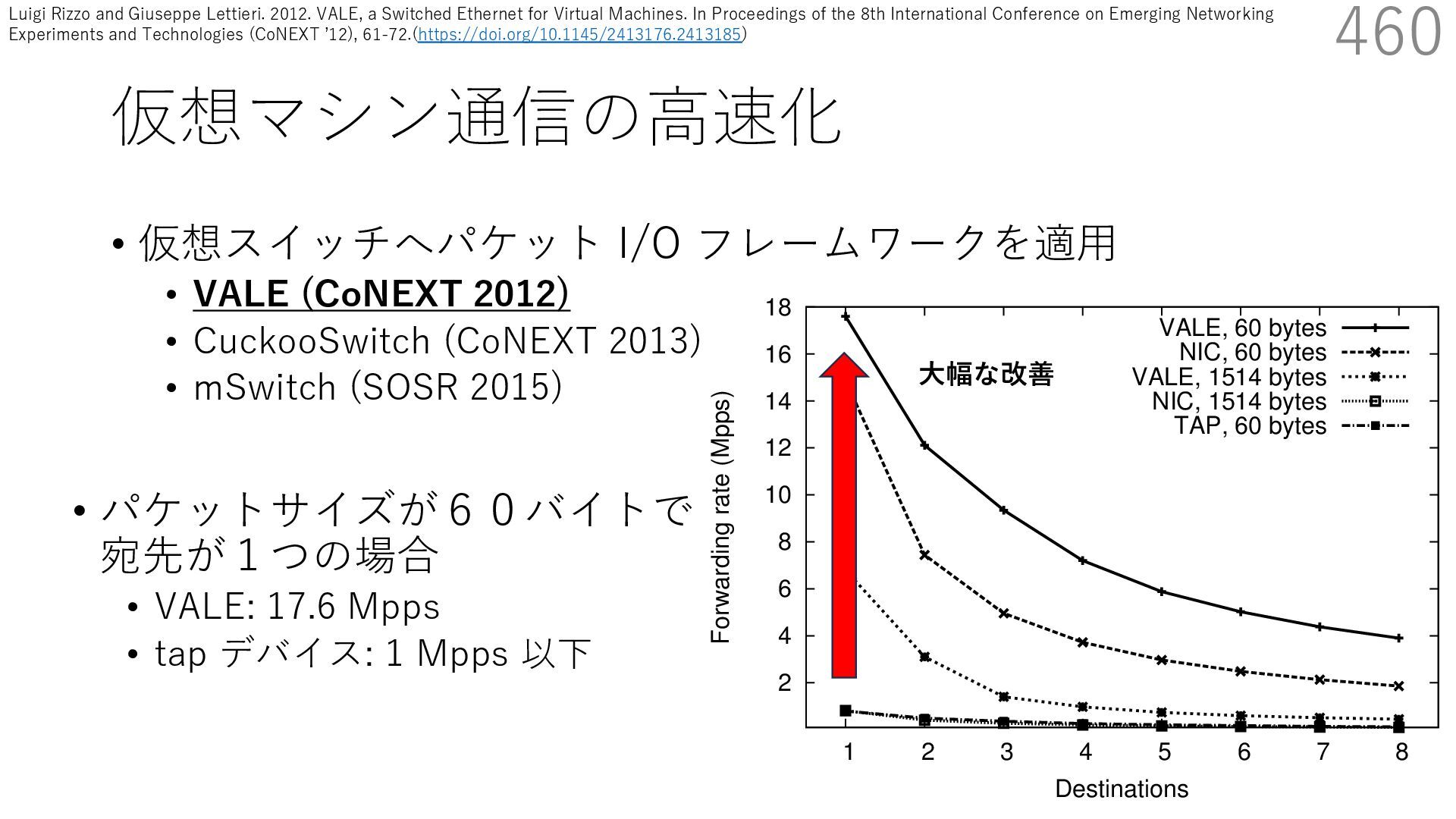
CuckooSwitch (CoNEXT 2013) • mSwitch (SOSR 2015) 460 responding pps rates are between 1/6 and 1/150 of tho shown here. The traffic received by a bridge should normally go to single destination, but there are cases (multicast or unknow destinations) where the bridge needs to replicate packets t multiple ports. Hence the number of active ports impac the throughput of the system. 2 4 6 8 10 12 14 16 18 1 2 3 4 5 6 7 8 Forwarding rate (Mpps) Destinations VALE, 60 bytes NIC, 60 bytes VALE, 1514 bytes NIC, 1514 bytes TAP, 60 bytes • パケットサイズが60バイトで 宛先が1つの場合 • VALE: 17.6 Mpps • tap デバイス: 1 Mpps 以下 ⼤幅な改善 Luigi Rizzo and Giuseppe Lettieri. 2012. VALE, a Switched Ethernet for Virtual Machines. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies (CoNEXT ʼ12), 61-72.(https://doi.org/10.1145/2413176.2413185)
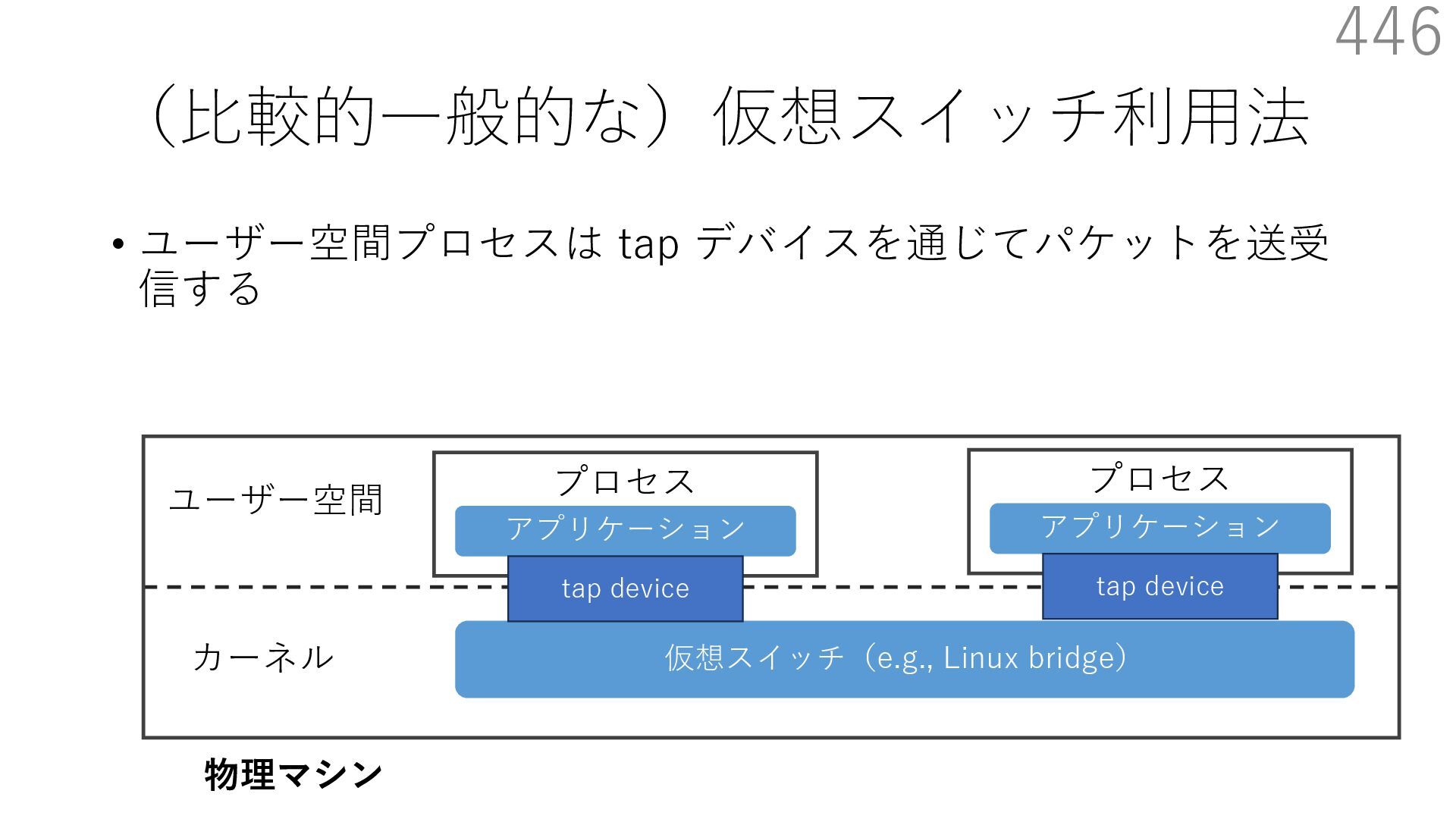
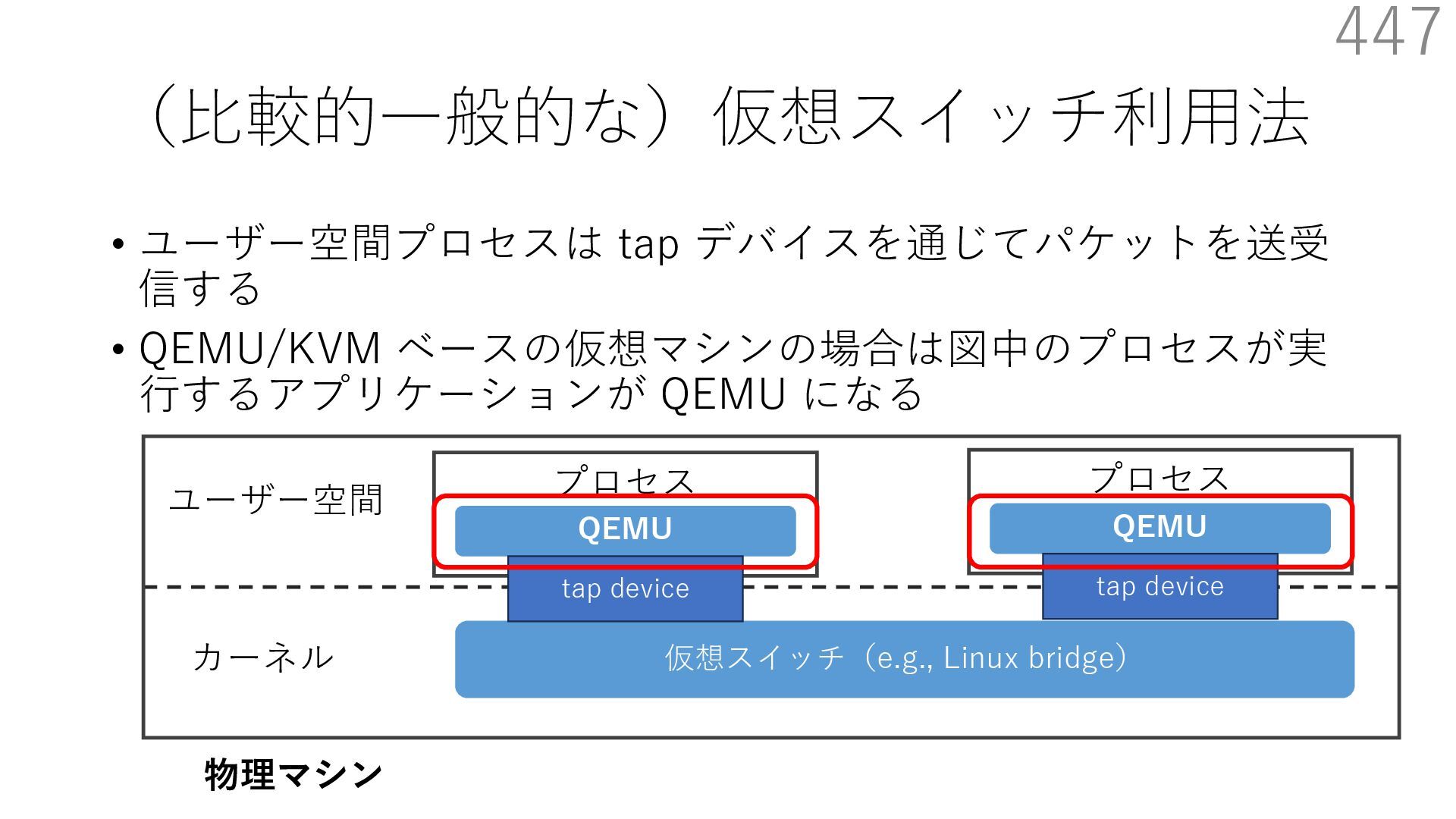
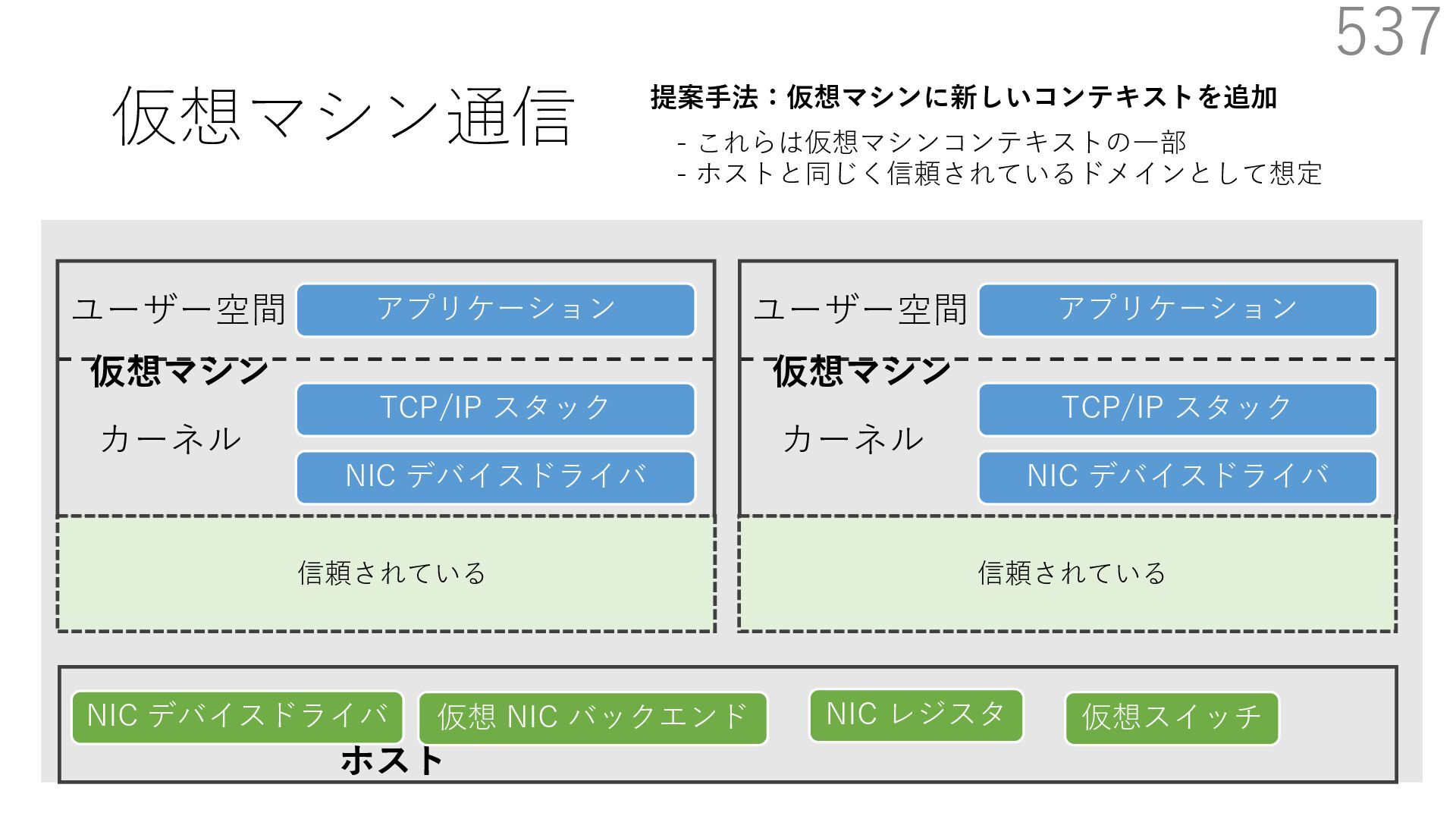
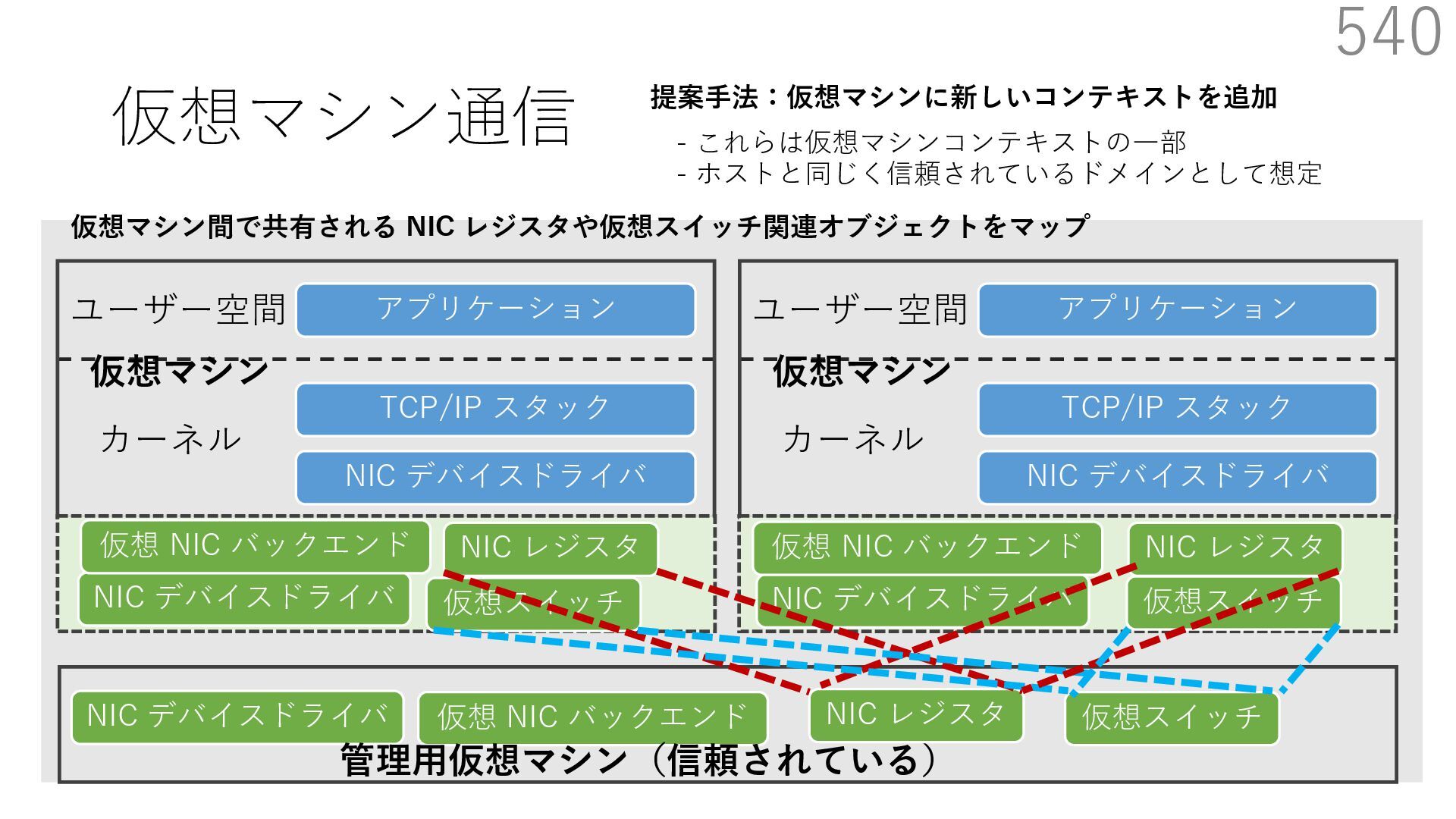
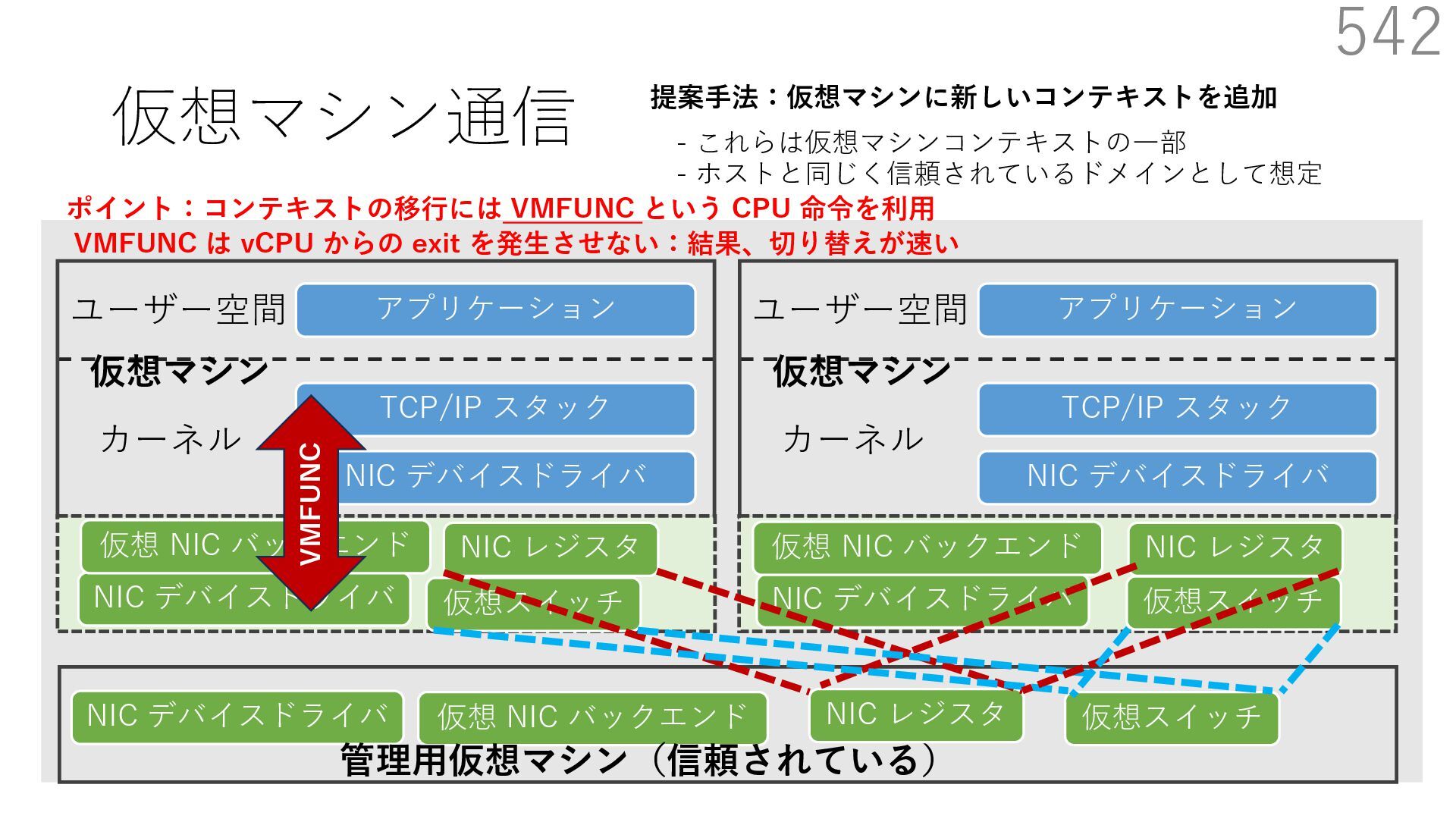
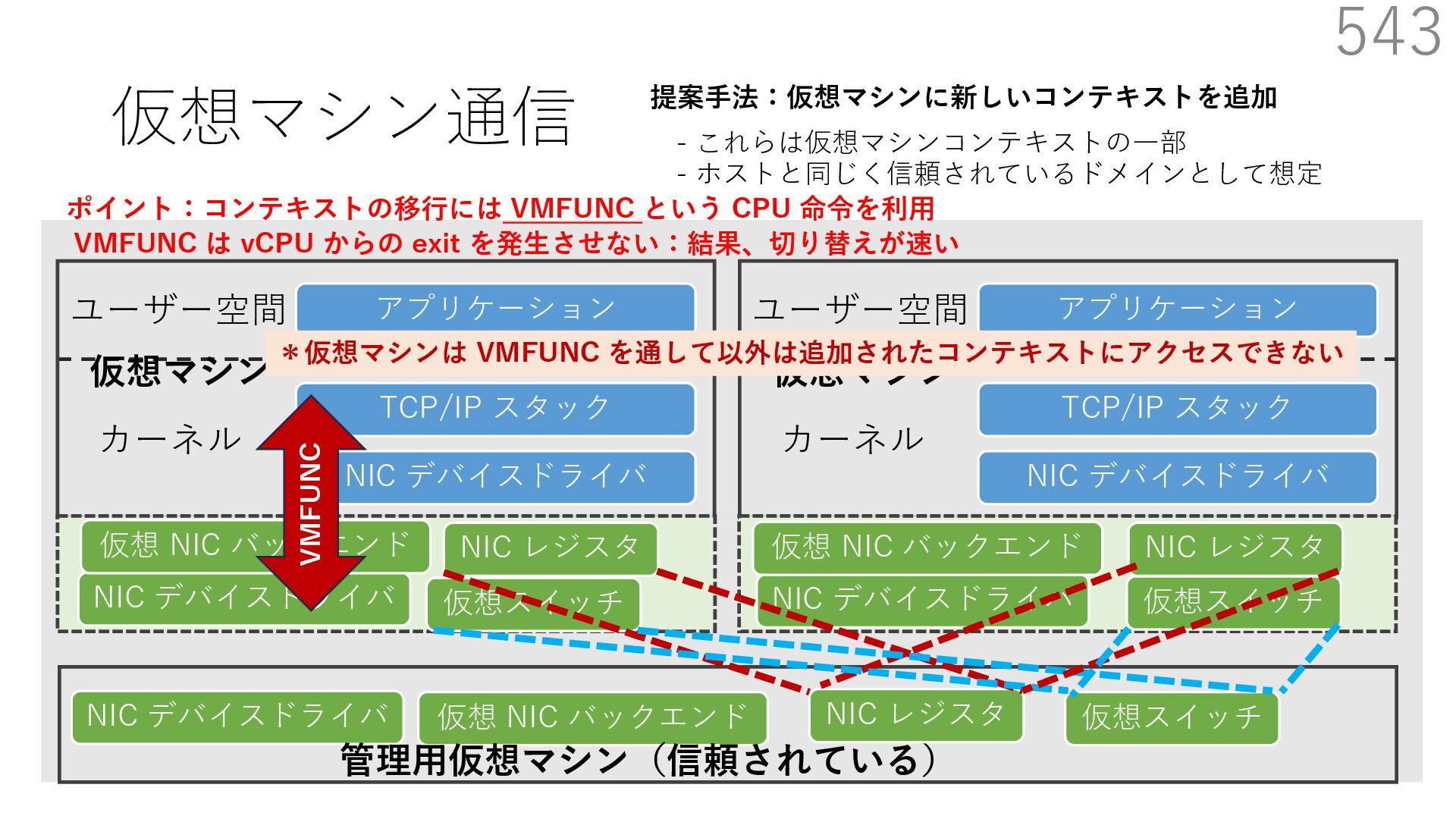
CuckooSwitch (CoNEXT 2013) • mSwitch (SOSR 2015) 540 NIC デバイスドライバ TCP/IP スタック アプリケーション NIC デバイスドライバ 仮想スイッチ 仮想 NIC バックエンド ユーザー空間 カーネル 管理⽤仮想マシン(信頼されている) 仮想マシン NIC デバイスドライバ TCP/IP スタック アプリケーション ユーザー空間 カーネル 仮想マシン 提案⼿法:仮想マシンに新しいコンテキストを追加 - これらは仮想マシンコンテキストの⼀部 - ホストと同じく信頼されているドメインとして想定 NIC デバイスドライバ 仮想 NIC バックエンド NIC デバイスドライバ 仮想 NIC バックエンド NIC レジスタ NIC レジスタ 仮想スイッチ NIC レジスタ 仮想スイッチ 仮想マシン間で共有される NIC レジスタや仮想スイッチ関連オブジェクトをマップ
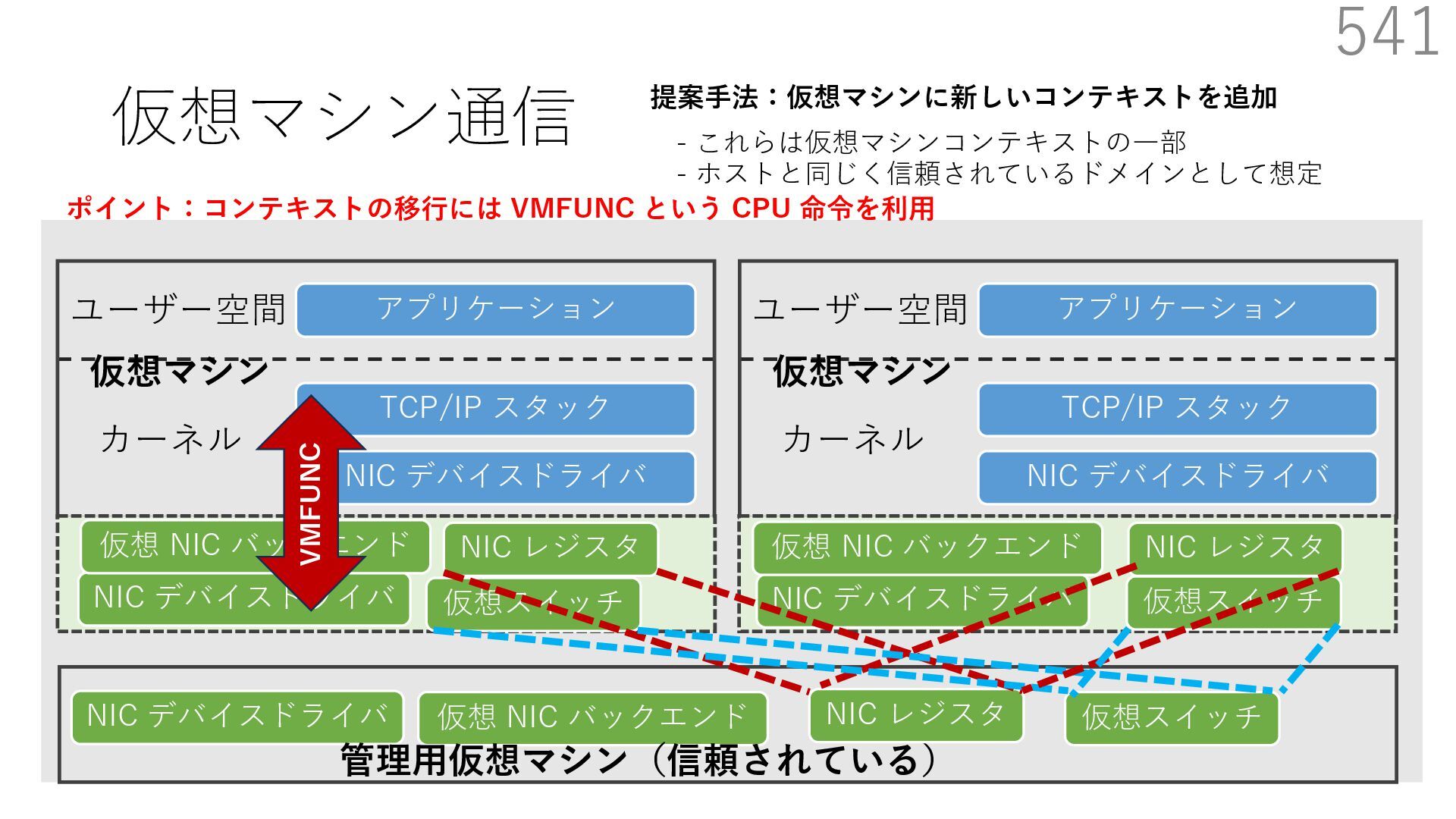
CuckooSwitch (CoNEXT 2013) • mSwitch (SOSR 2015) 541 NIC デバイスドライバ TCP/IP スタック アプリケーション NIC デバイスドライバ 仮想スイッチ 仮想 NIC バックエンド ユーザー空間 カーネル 管理⽤仮想マシン(信頼されている) 仮想マシン NIC デバイスドライバ TCP/IP スタック アプリケーション ユーザー空間 カーネル 仮想マシン 提案⼿法:仮想マシンに新しいコンテキストを追加 - これらは仮想マシンコンテキストの⼀部 - ホストと同じく信頼されているドメインとして想定 NIC デバイスドライバ 仮想 NIC バックエンド NIC デバイスドライバ 仮想 NIC バックエンド NIC レジスタ NIC レジスタ 仮想スイッチ NIC レジスタ 仮想スイッチ ポイント:コンテキストの移⾏には VMFUNC という CPU 命令を利⽤ VMFUNC
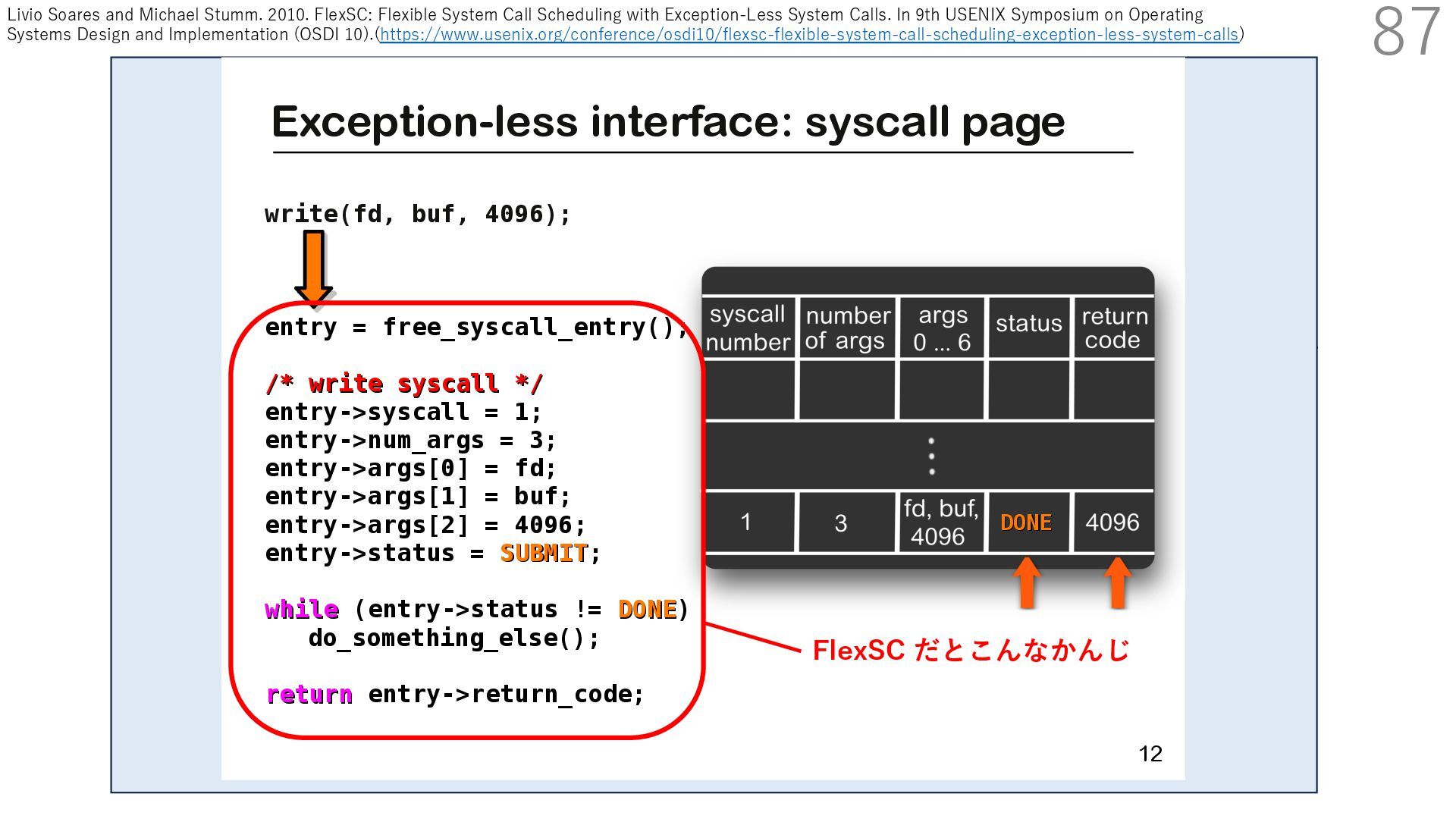
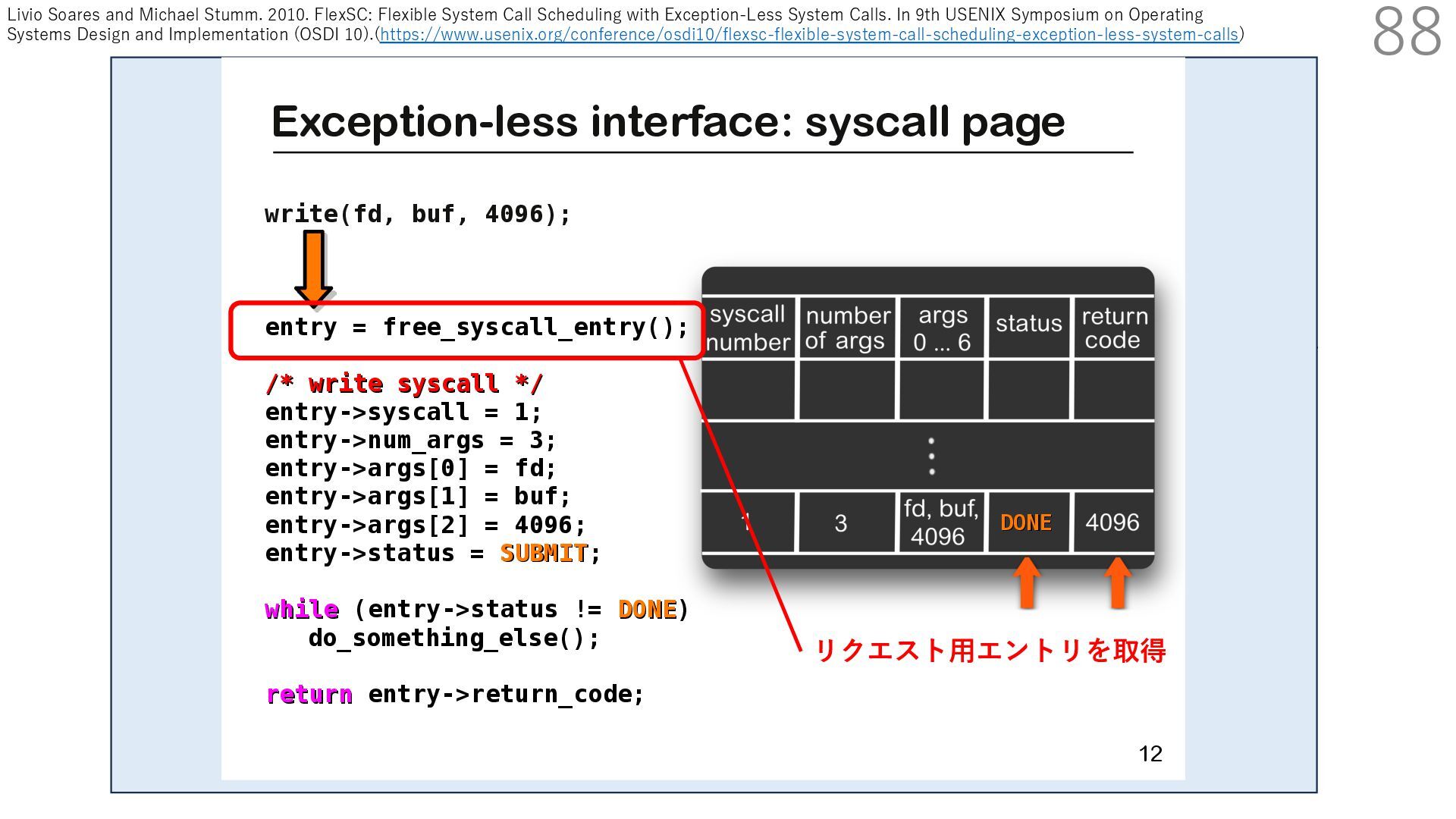
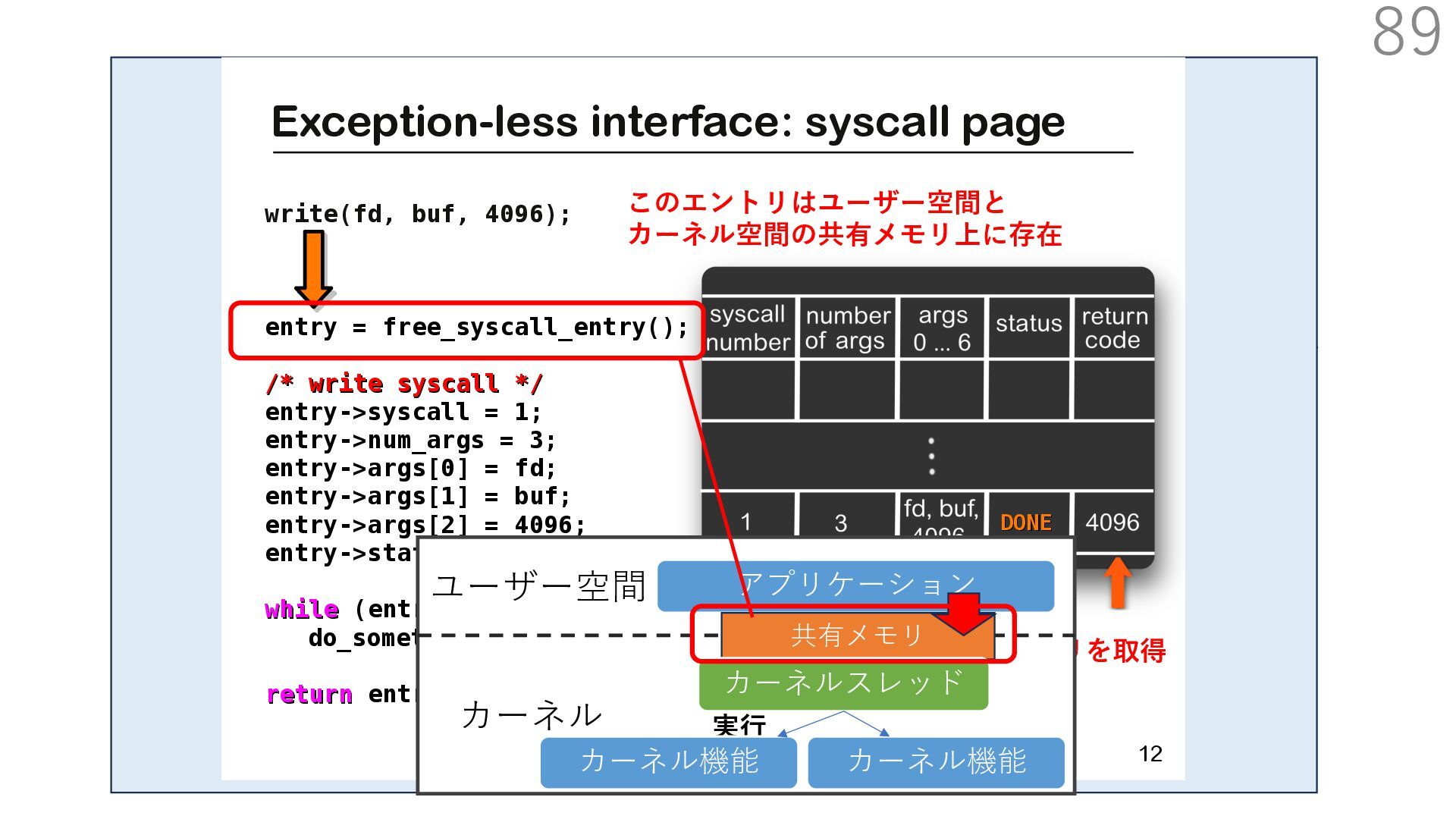
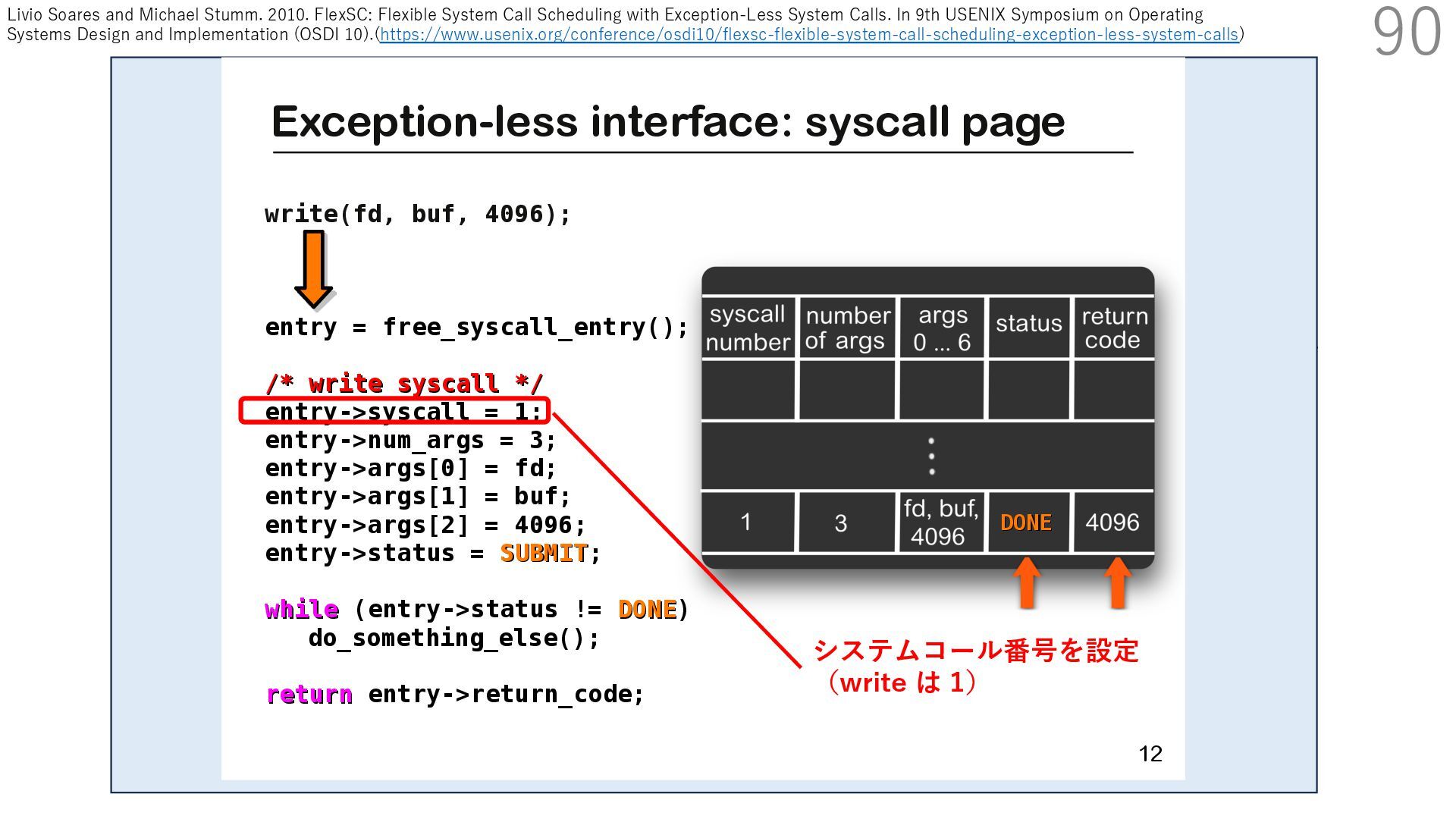
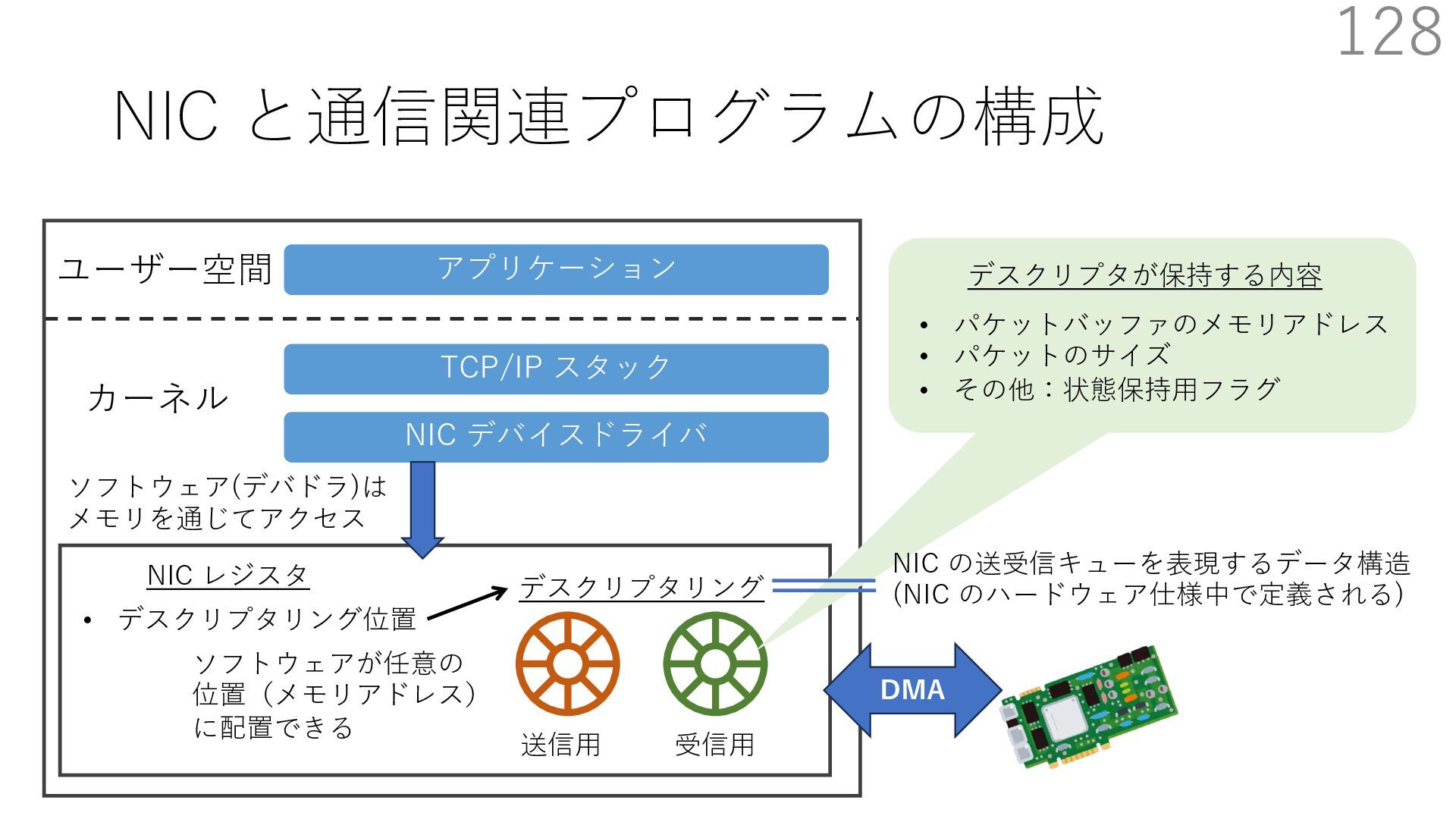
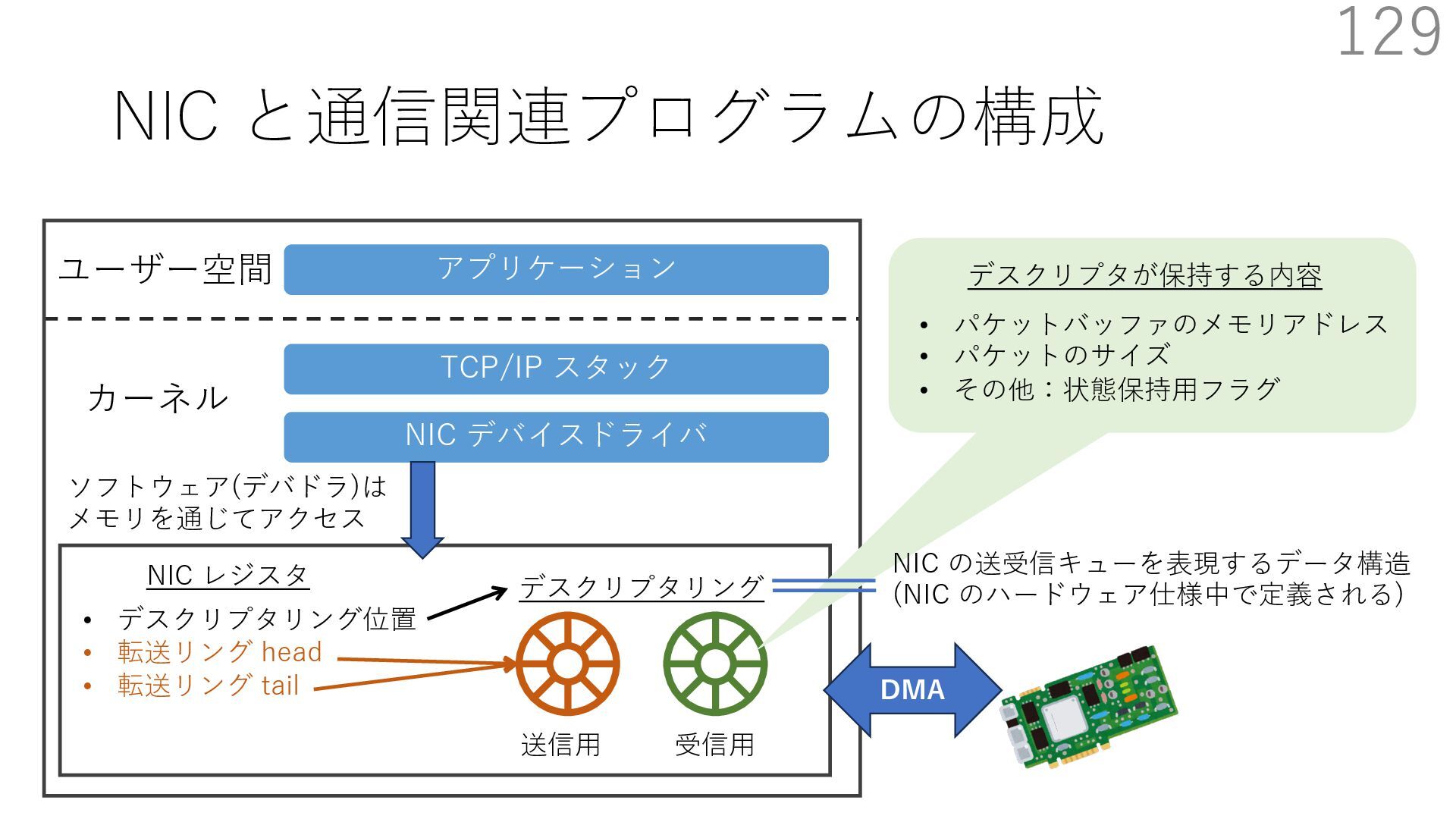
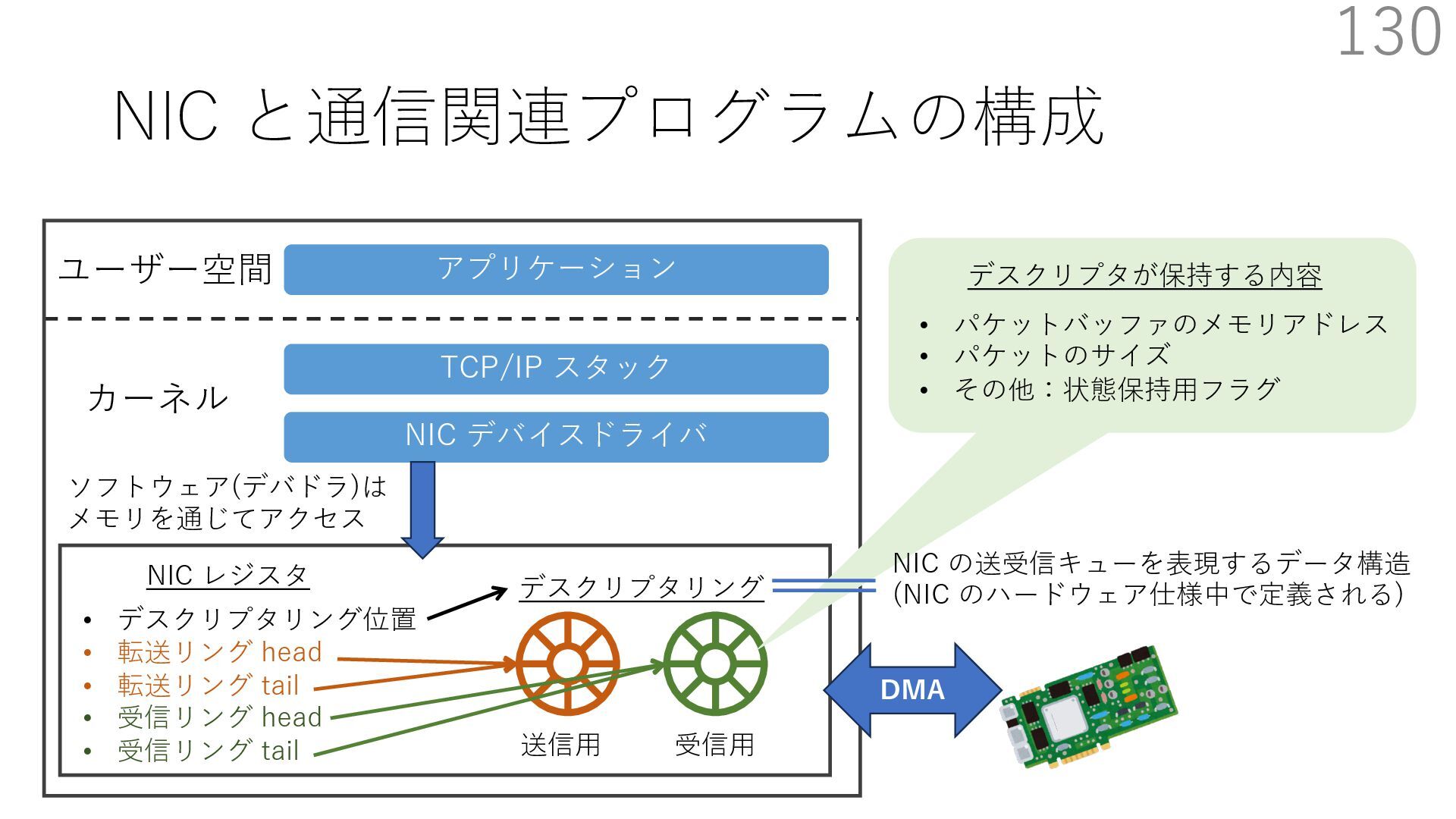
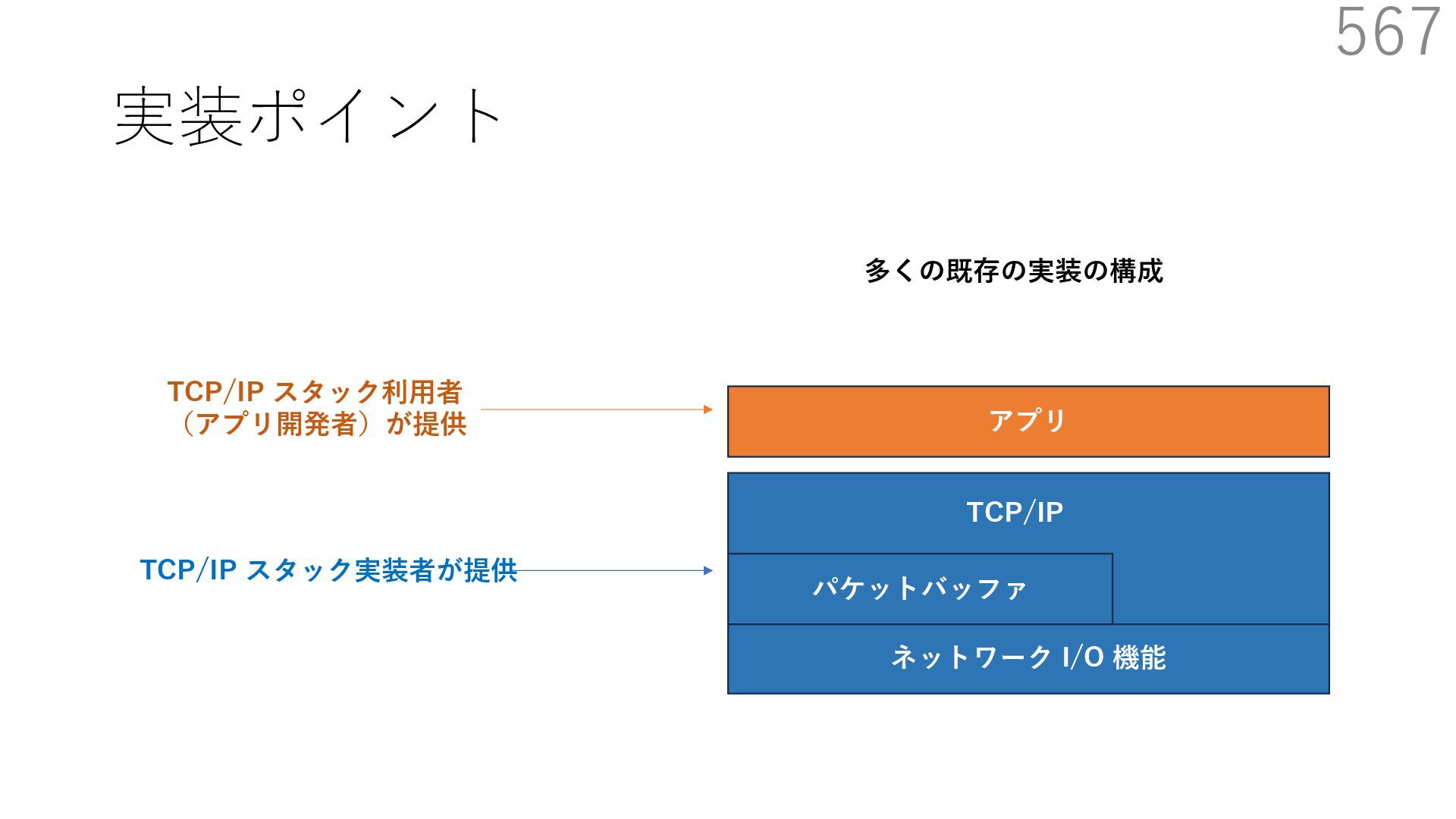
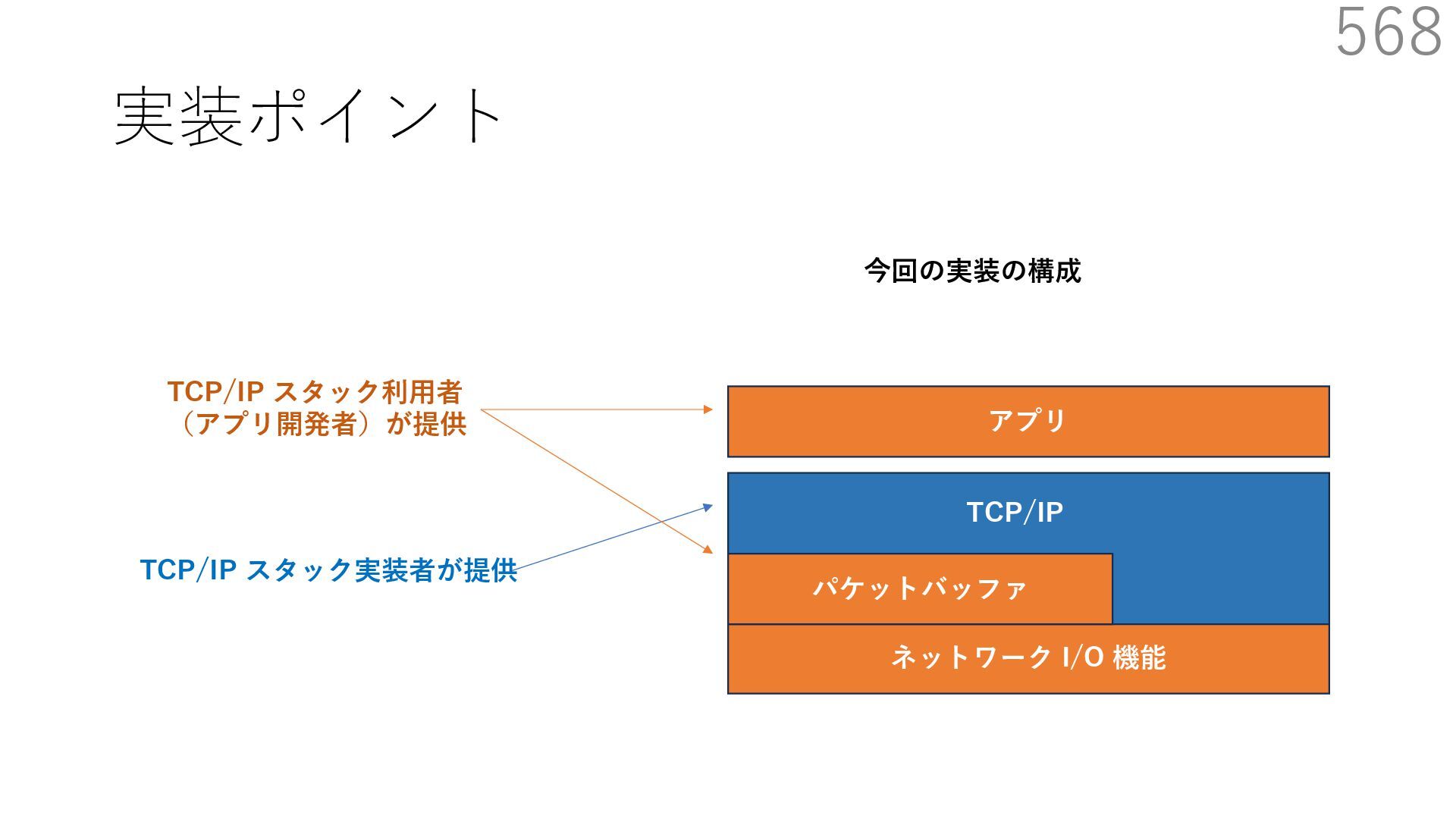
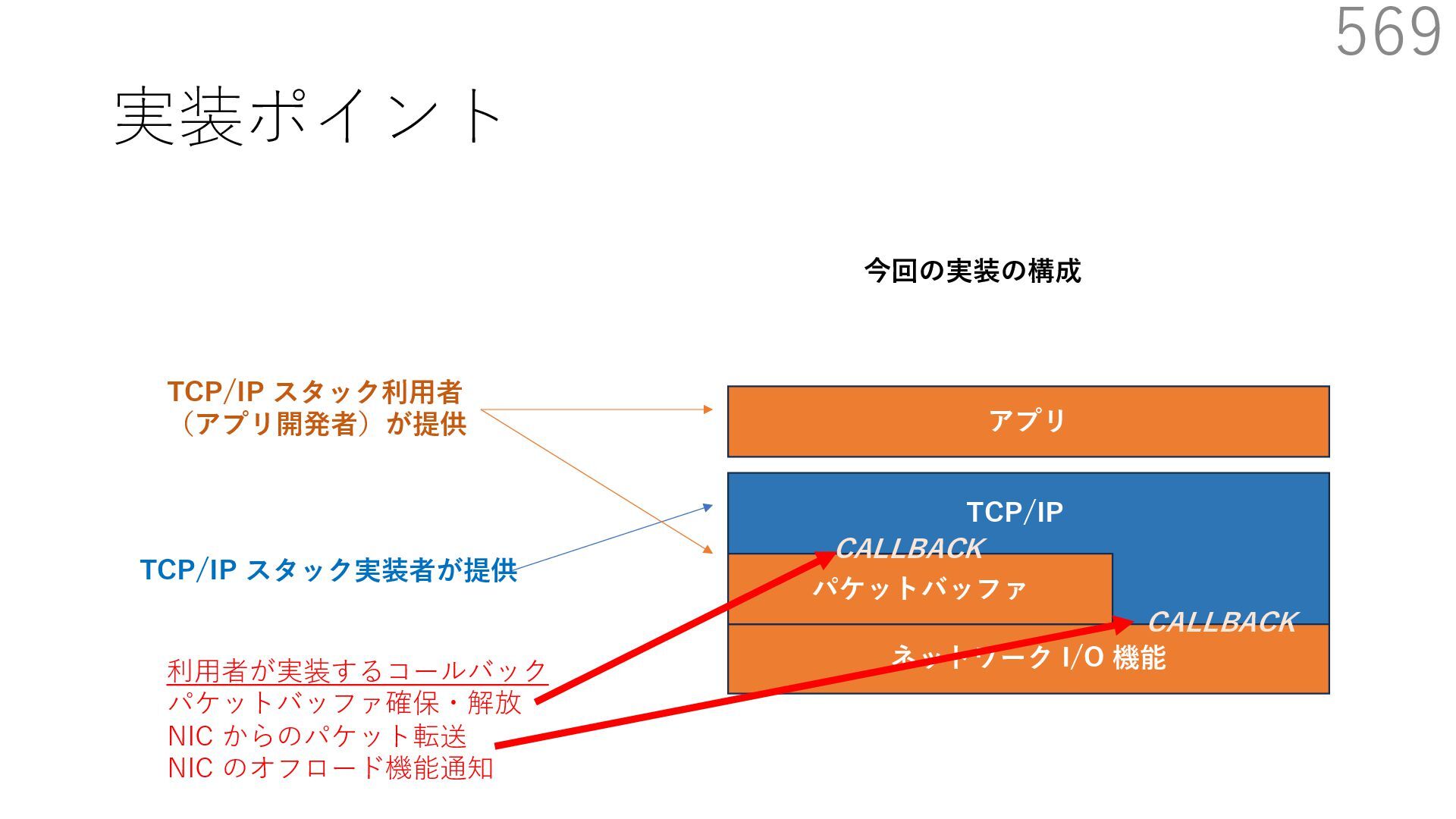
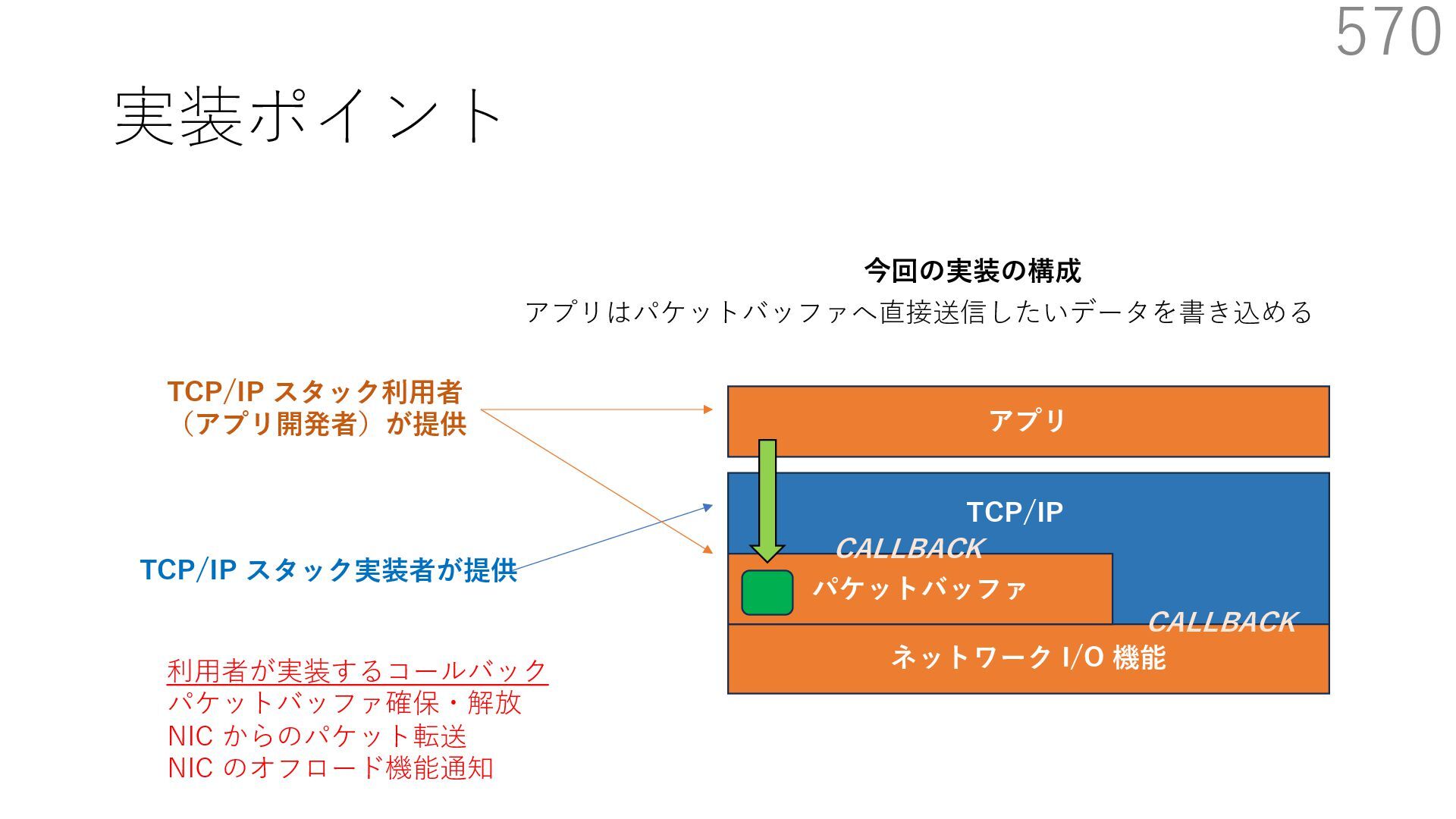
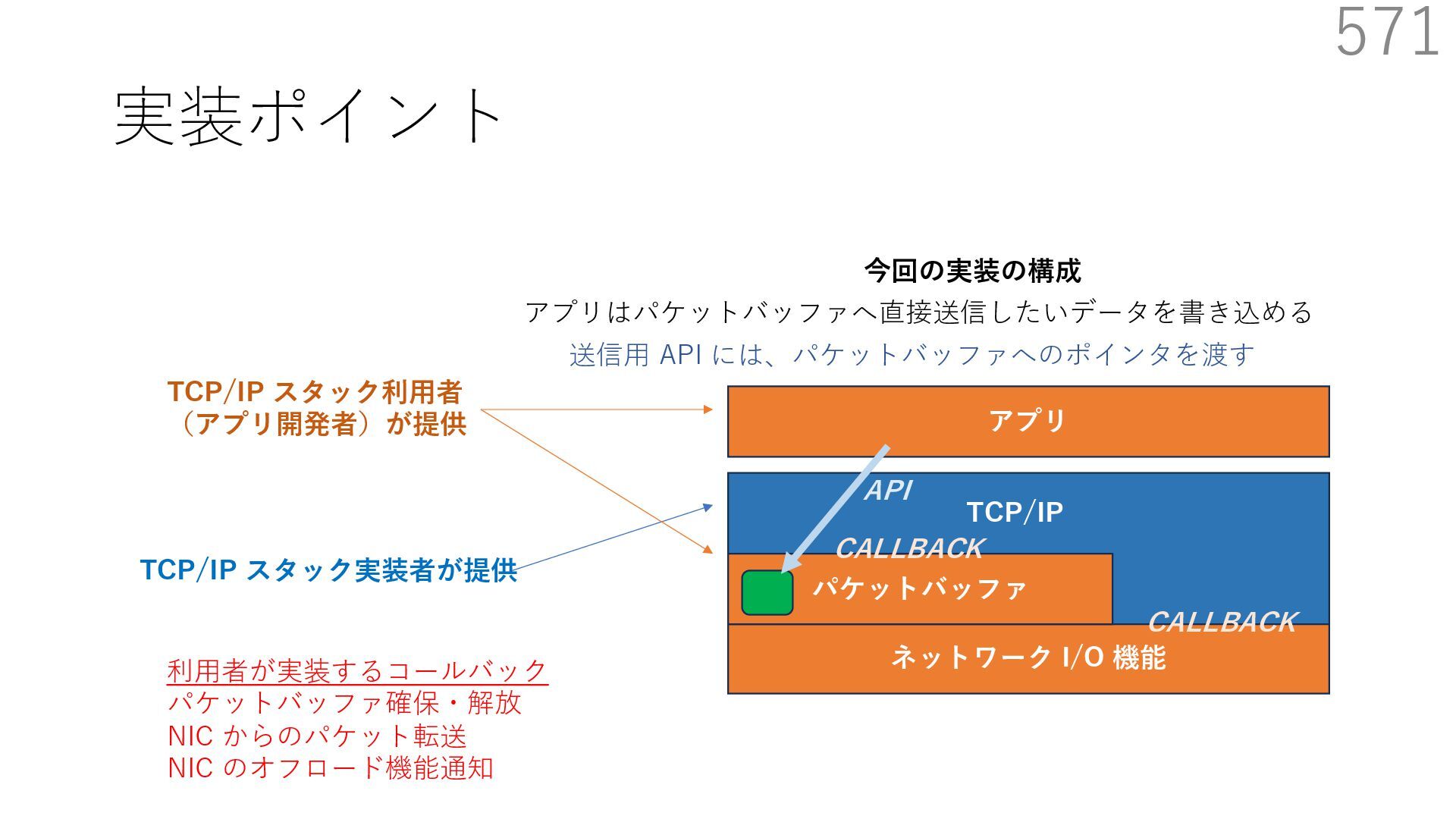
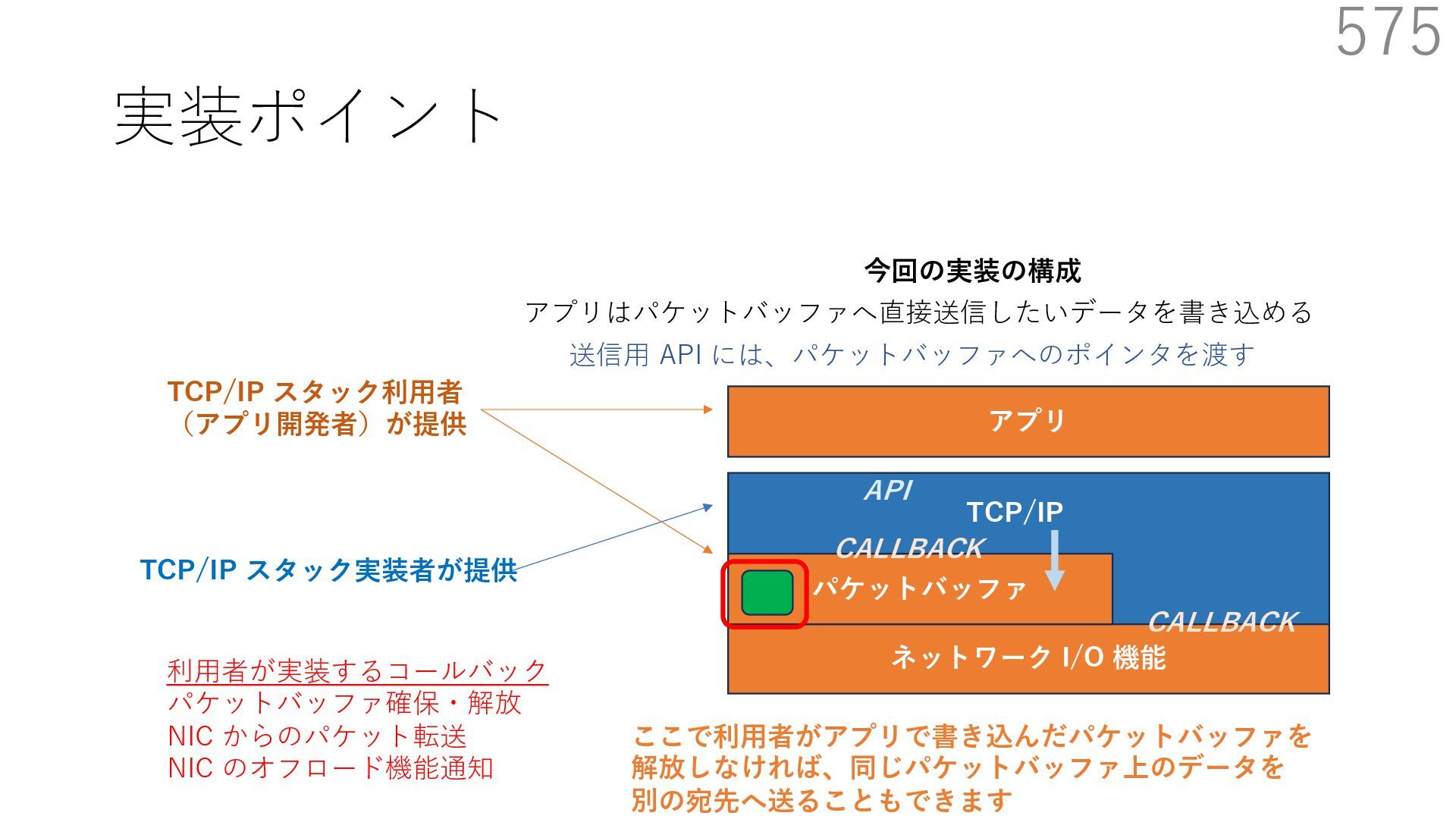
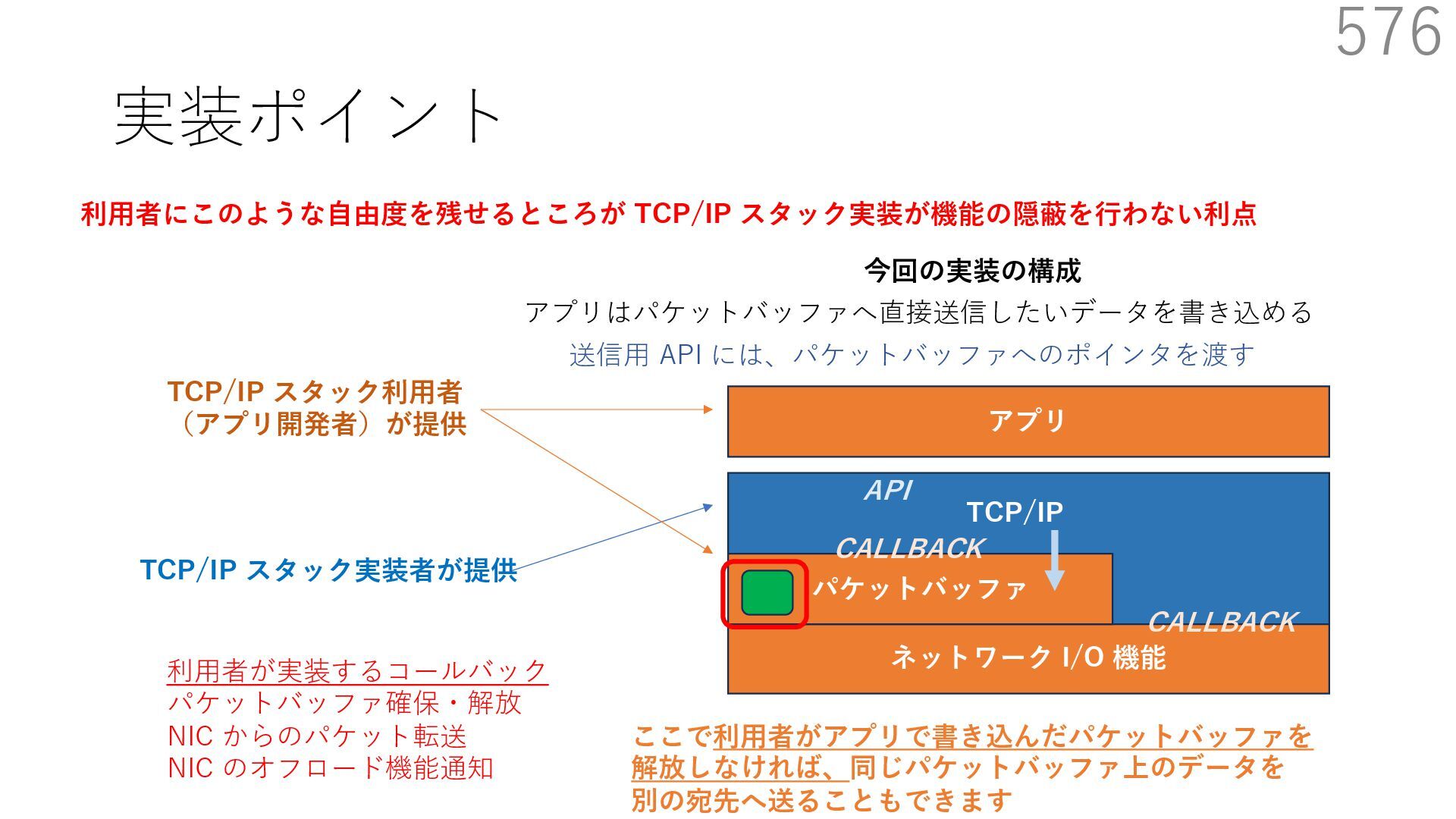
スタック実装者が提供 TCP/IP スタック利⽤者 (アプリ開発者)が提供 CALLBACK CALLBACK 利⽤者が実装するコールバック パケットバッファ確保・解放 NIC からのパケット転送 NIC のオフロード機能通知 アプリはパケットバッファへ直接送信したいデータを書き込める API 送信⽤ API には、パケットバッファへのポインタを渡す
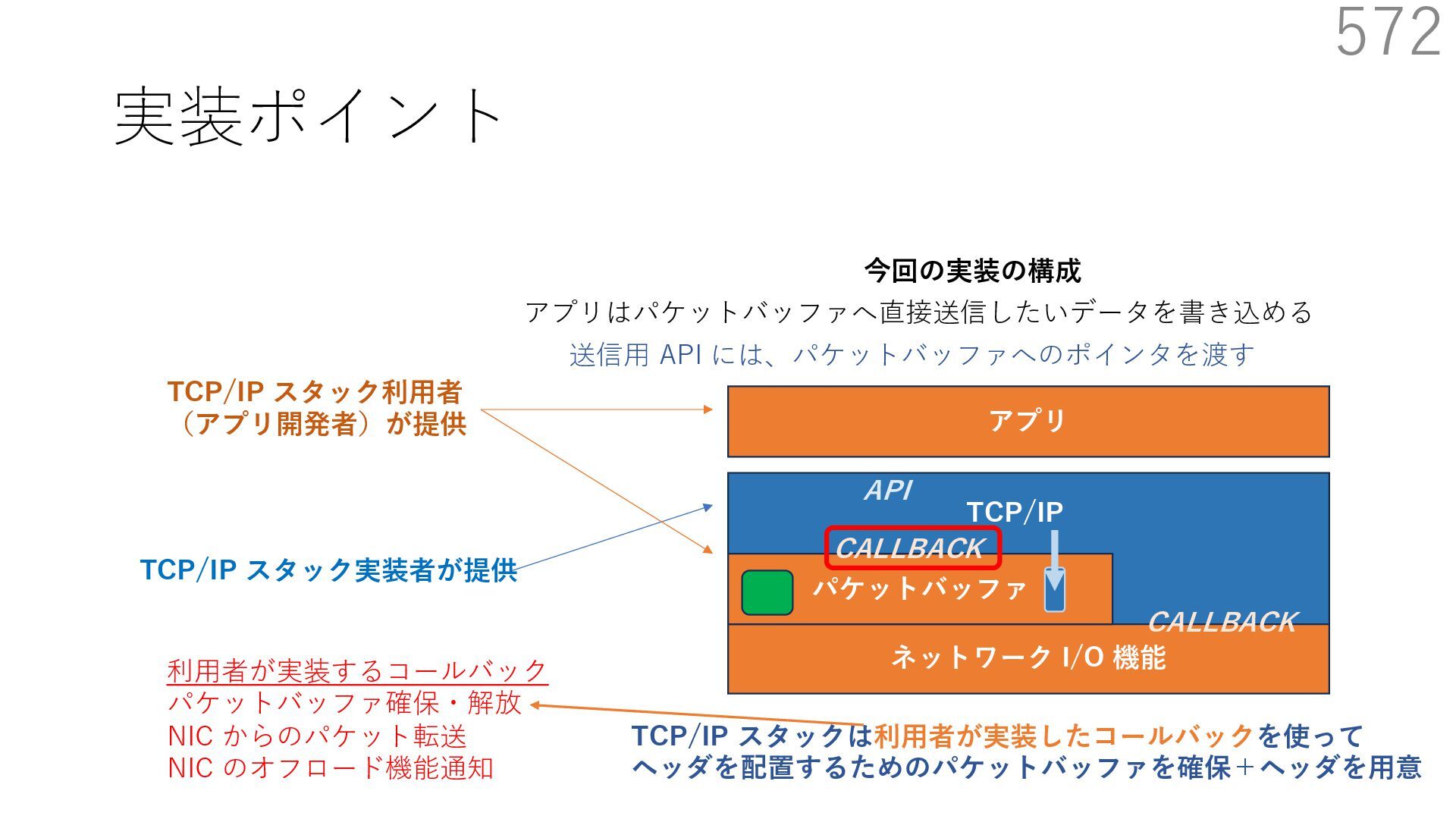
スタック実装者が提供 TCP/IP スタック利⽤者 (アプリ開発者)が提供 CALLBACK CALLBACK 利⽤者が実装するコールバック パケットバッファ確保・解放 NIC からのパケット転送 NIC のオフロード機能通知 アプリはパケットバッファへ直接送信したいデータを書き込める API 送信⽤ API には、パケットバッファへのポインタを渡す TCP/IP スタックは利⽤者が実装したコールバックを使って ヘッダを配置するためのパケットバッファを確保+ヘッダを⽤意
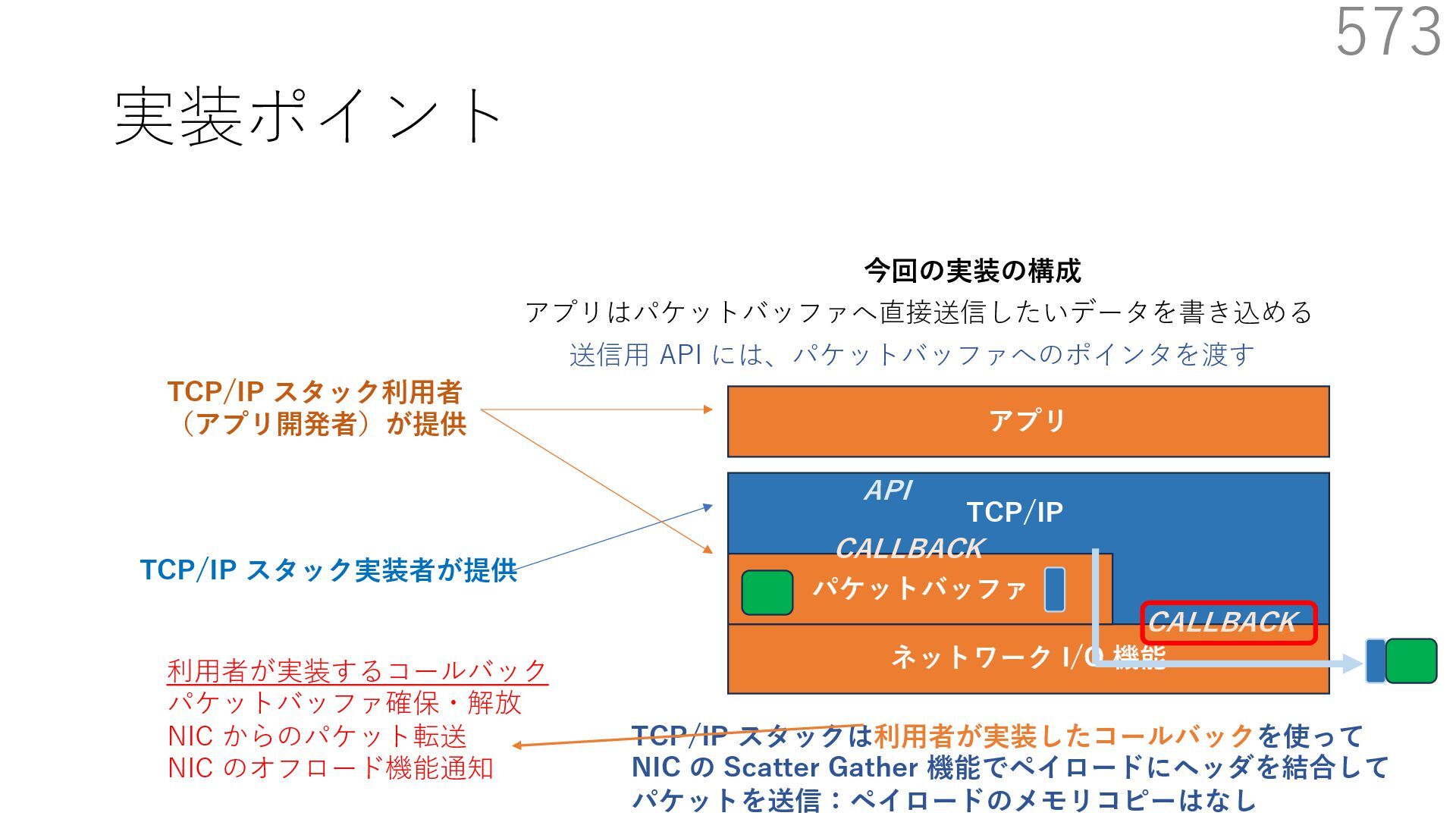
スタック実装者が提供 TCP/IP スタック利⽤者 (アプリ開発者)が提供 CALLBACK CALLBACK 利⽤者が実装するコールバック パケットバッファ確保・解放 NIC からのパケット転送 NIC のオフロード機能通知 アプリはパケットバッファへ直接送信したいデータを書き込める API 送信⽤ API には、パケットバッファへのポインタを渡す TCP/IP スタックは利⽤者が実装したコールバックを使って NIC の Scatter Gather 機能でペイロードにヘッダを結合して パケットを送信:ペイロードのメモリコピーはなし
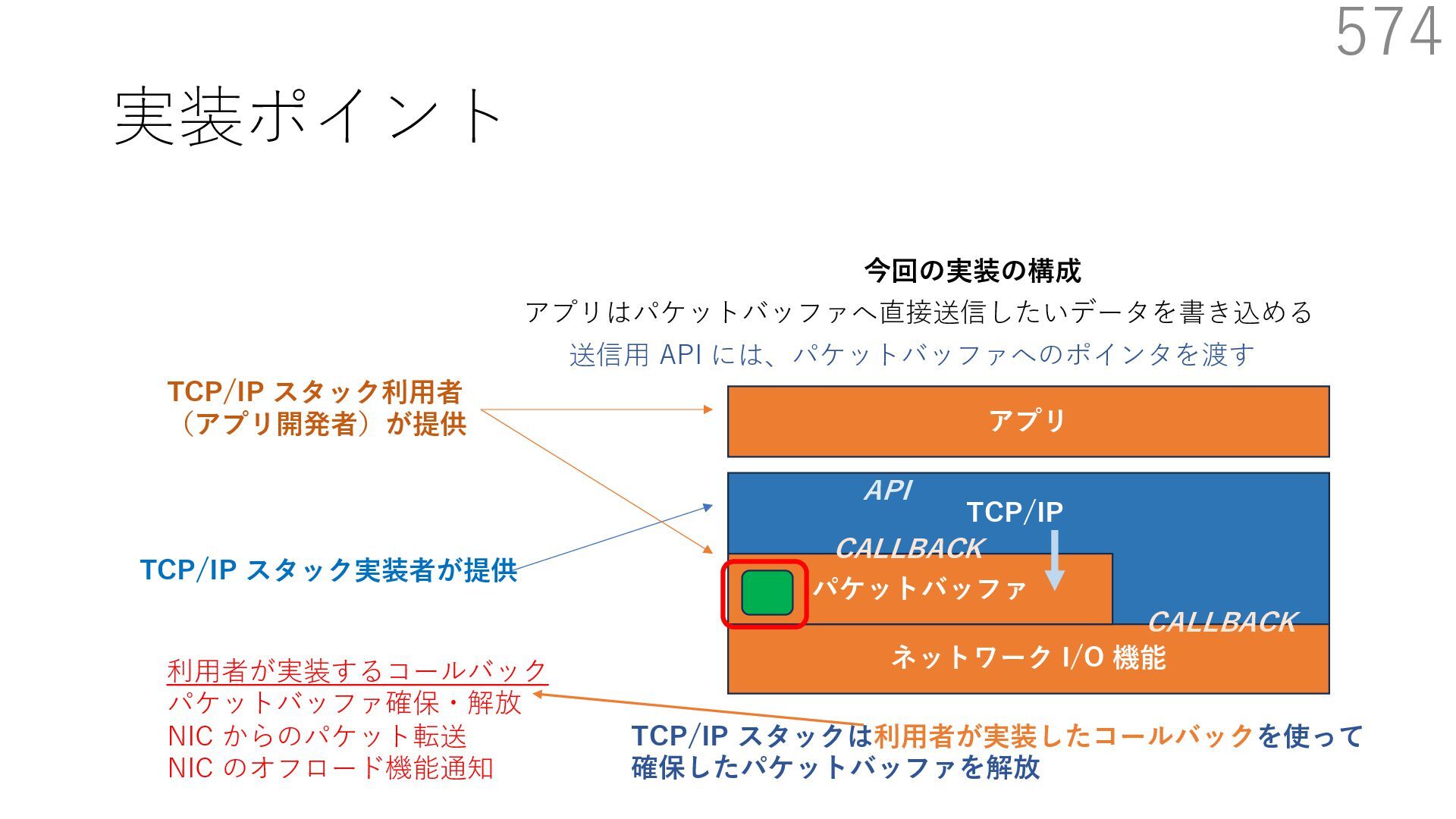
スタック実装者が提供 TCP/IP スタック利⽤者 (アプリ開発者)が提供 CALLBACK CALLBACK 利⽤者が実装するコールバック パケットバッファ確保・解放 NIC からのパケット転送 NIC のオフロード機能通知 アプリはパケットバッファへ直接送信したいデータを書き込める API 送信⽤ API には、パケットバッファへのポインタを渡す TCP/IP スタックは利⽤者が実装したコールバックを使って 確保したパケットバッファを解放
スタック実装者が提供 TCP/IP スタック利⽤者 (アプリ開発者)が提供 CALLBACK CALLBACK 利⽤者が実装するコールバック パケットバッファ確保・解放 NIC からのパケット転送 NIC のオフロード機能通知 アプリはパケットバッファへ直接送信したいデータを書き込める API 送信⽤ API には、パケットバッファへのポインタを渡す ここで利⽤者がアプリで書き込んだパケットバッファを 解放しなければ、同じパケットバッファ上のデータを 別の宛先へ送ることもできます
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
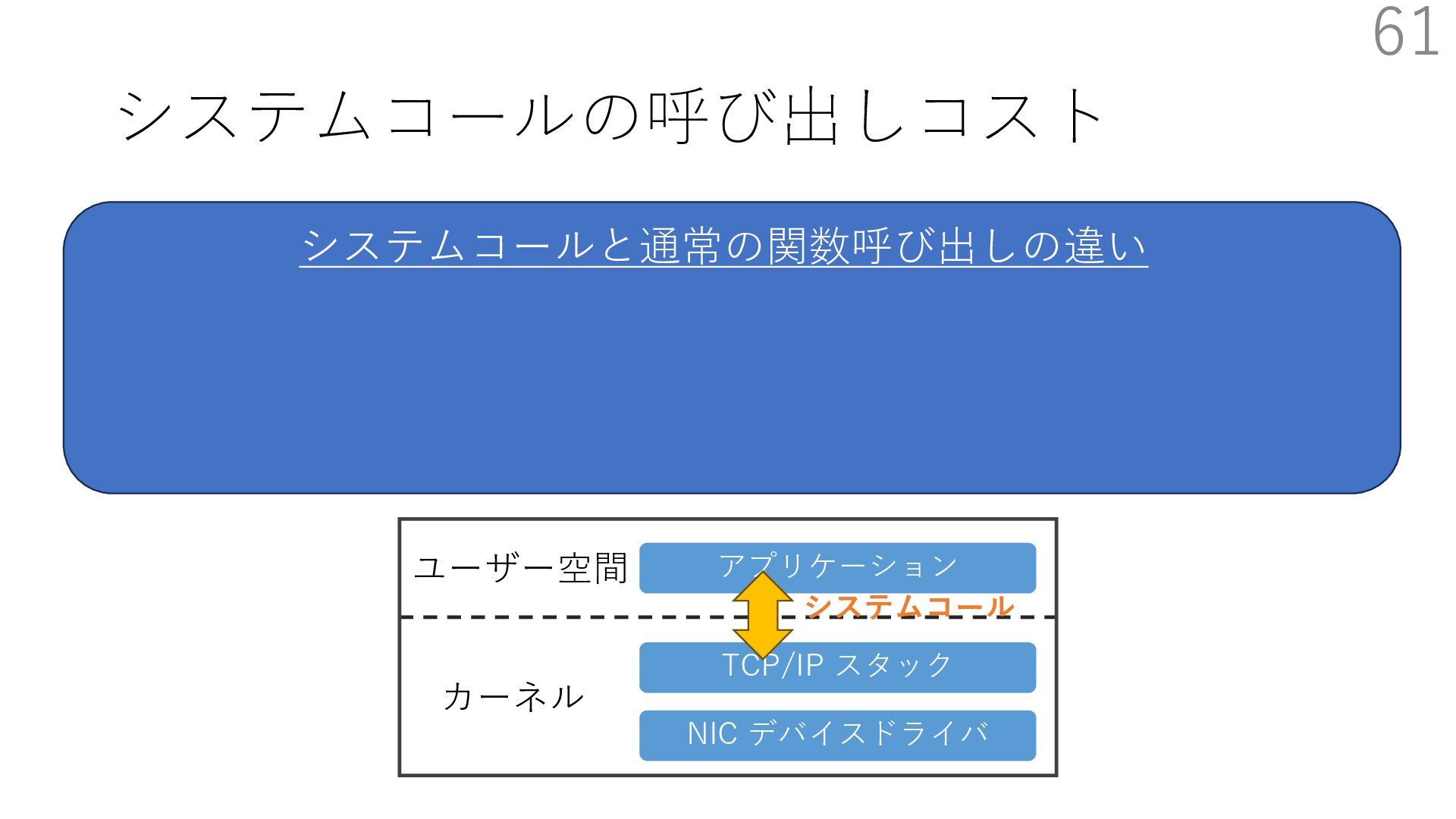{kind=link}
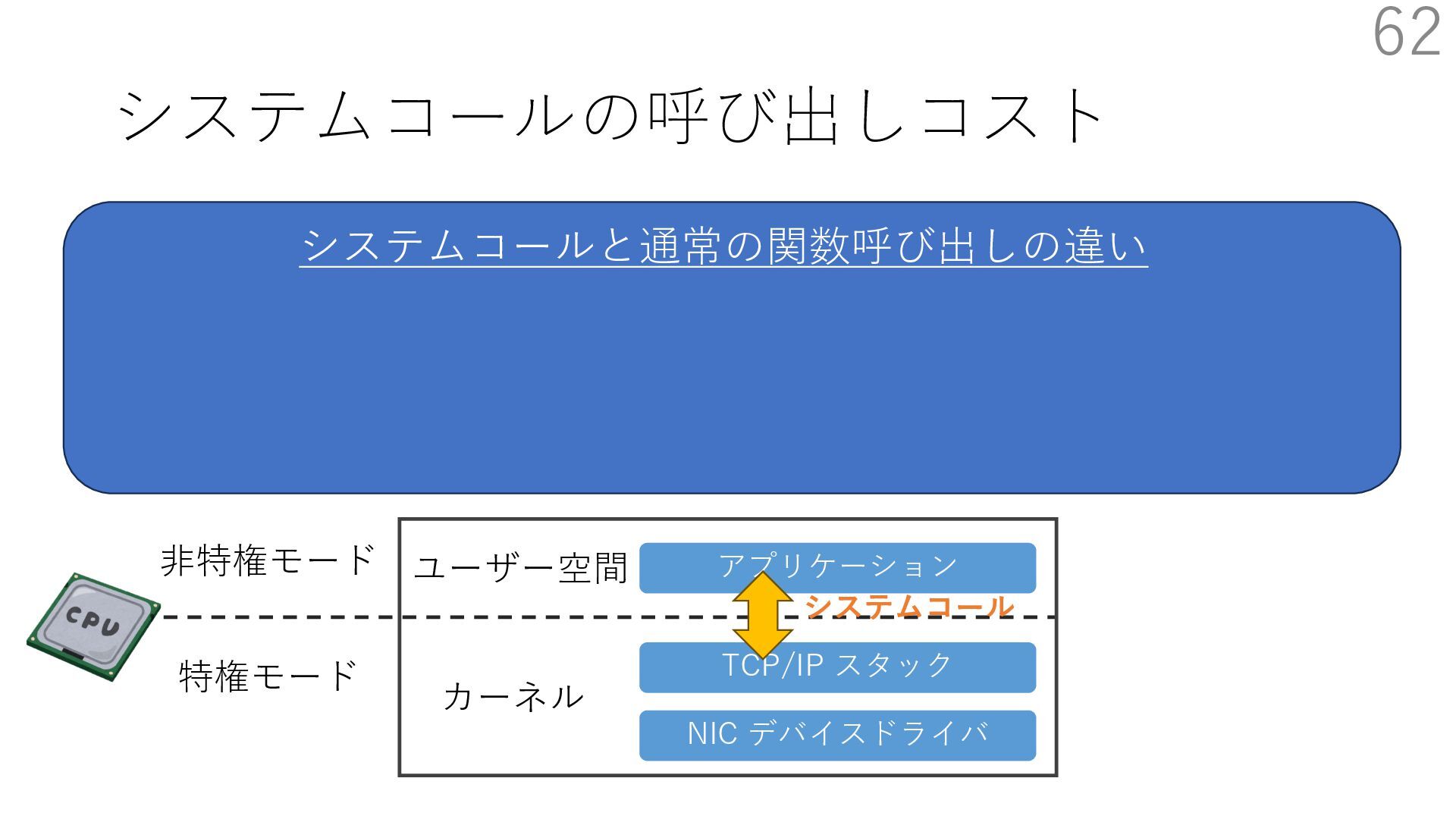{kind=link}
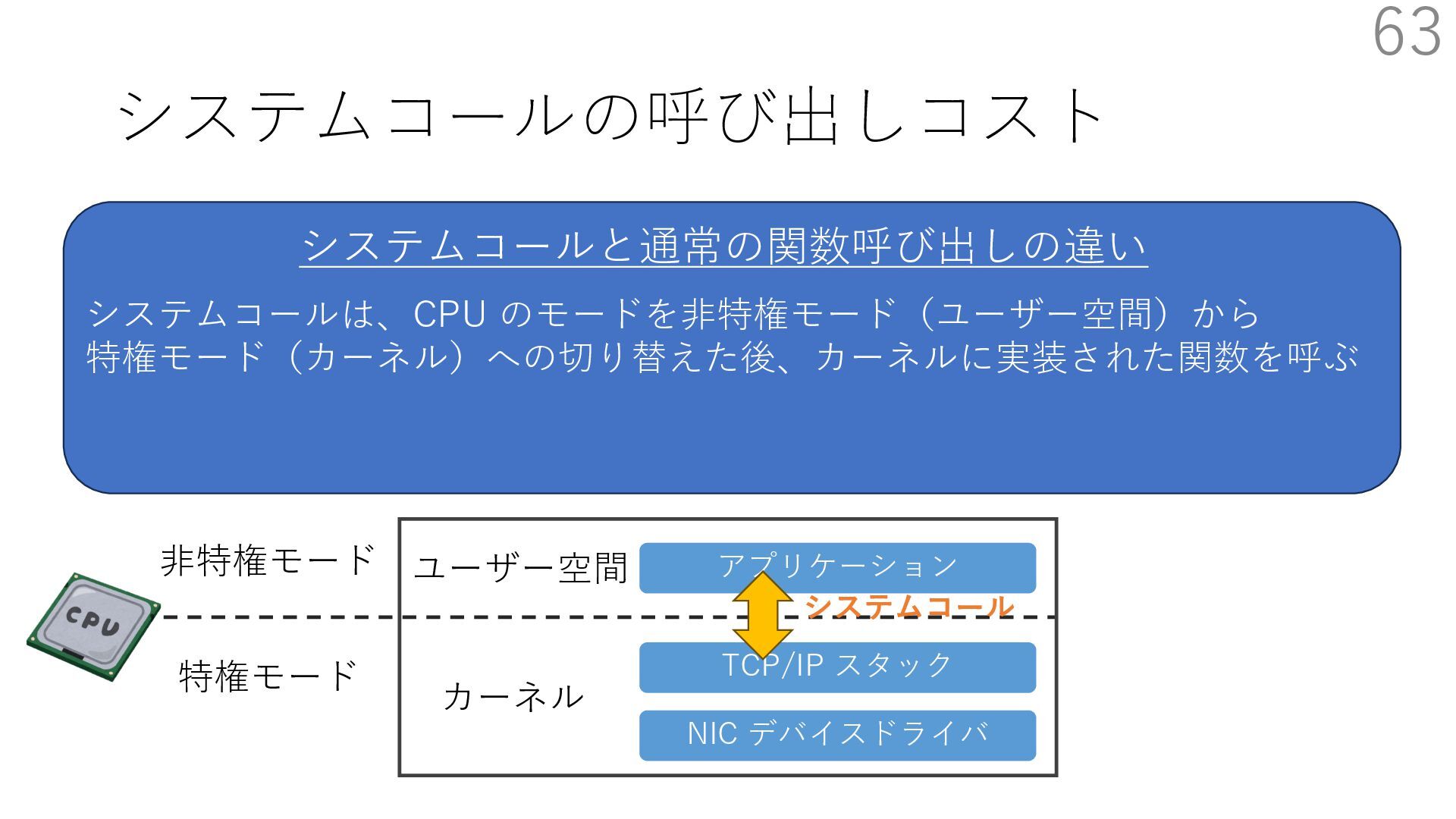{kind=link}
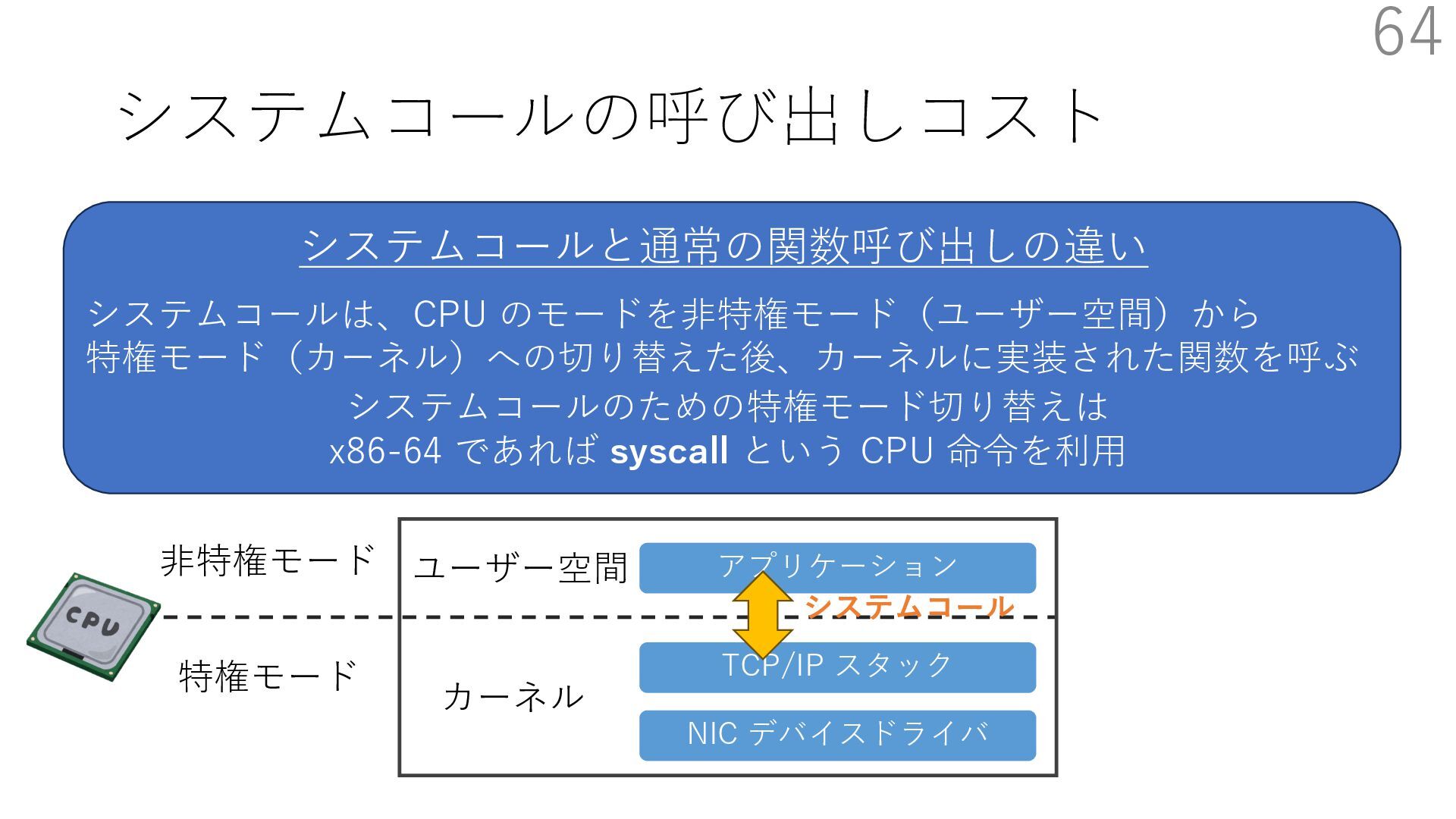{kind=link}
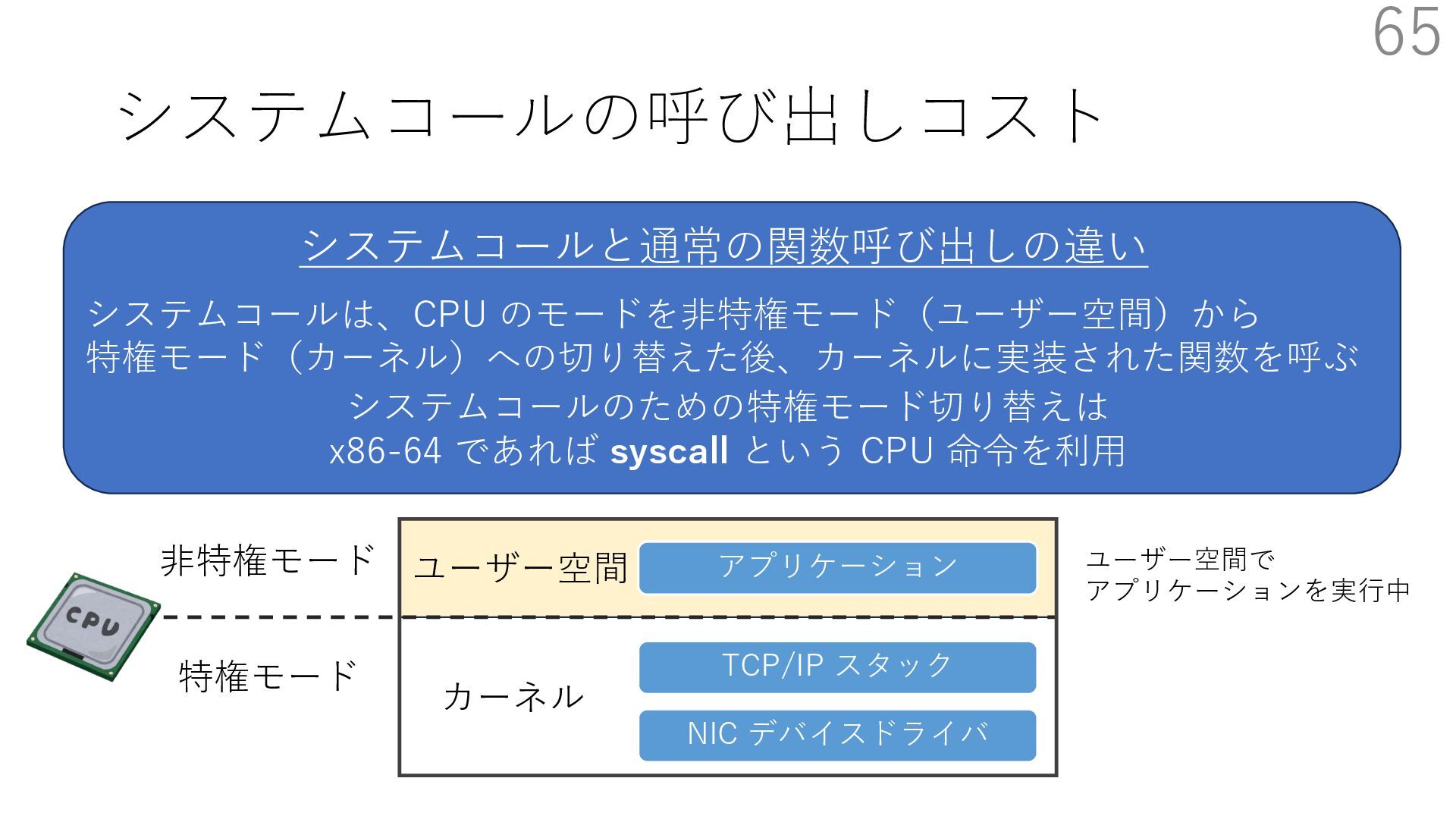{kind=link}
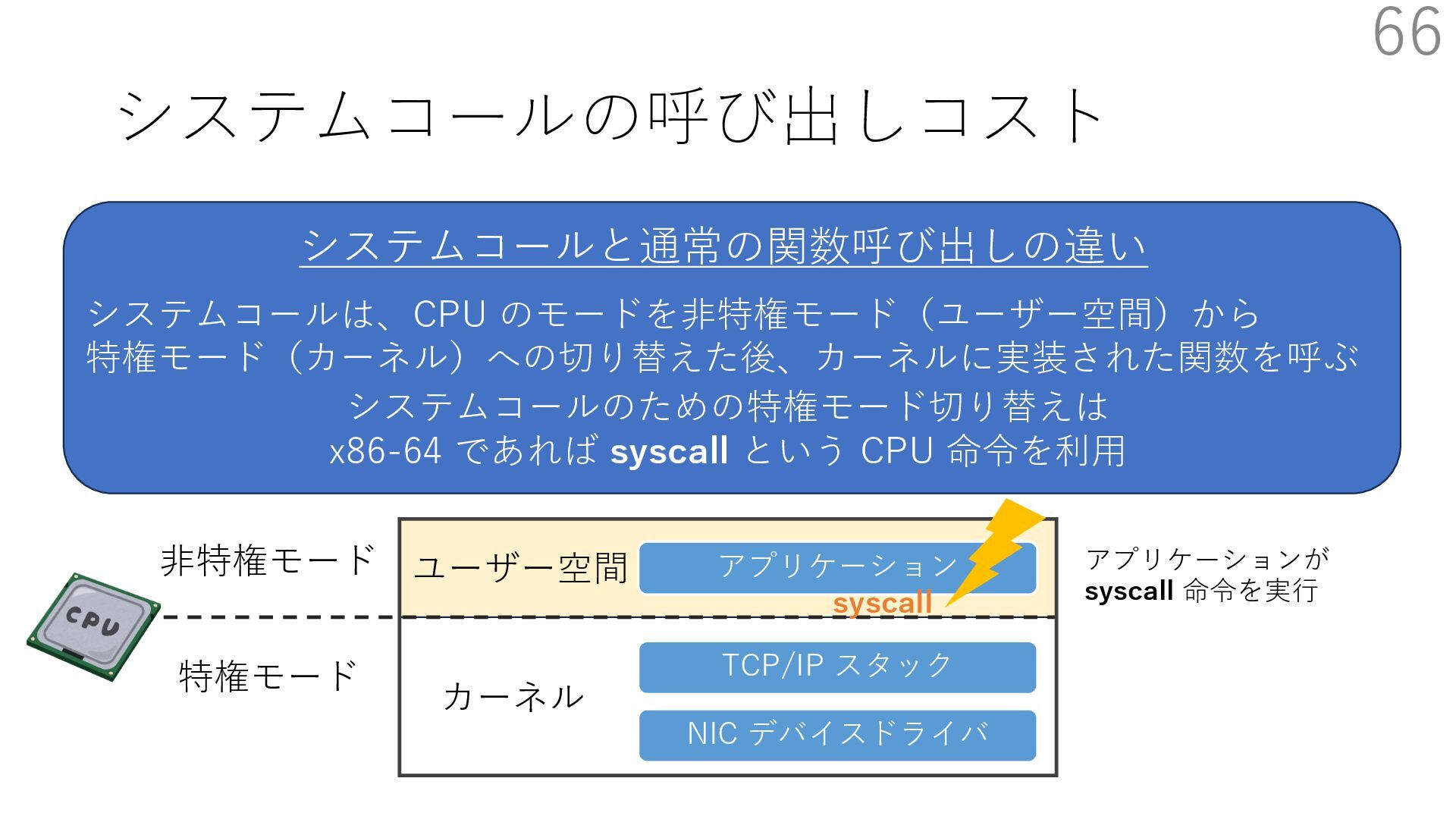{kind=link}
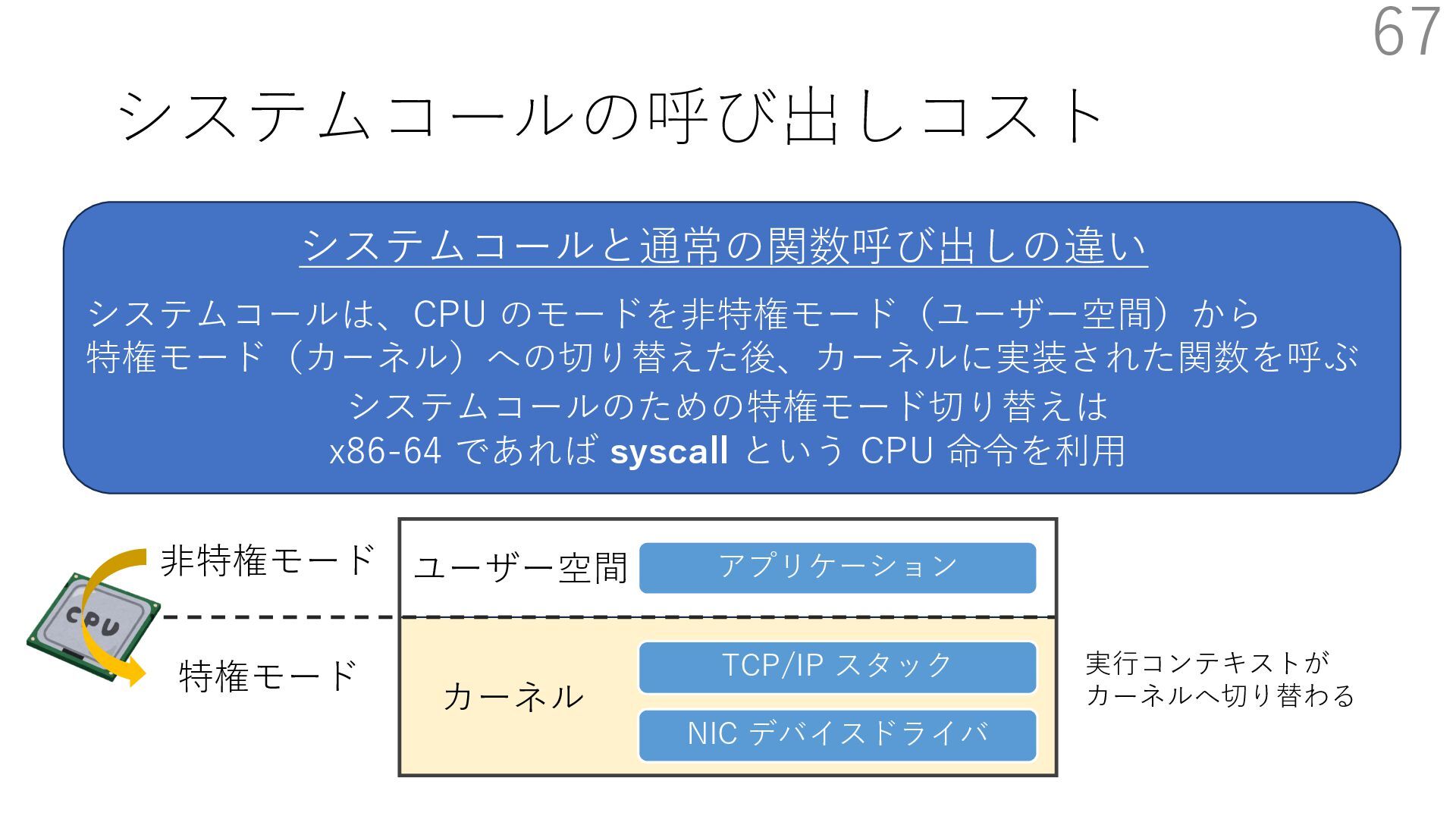{kind=link}
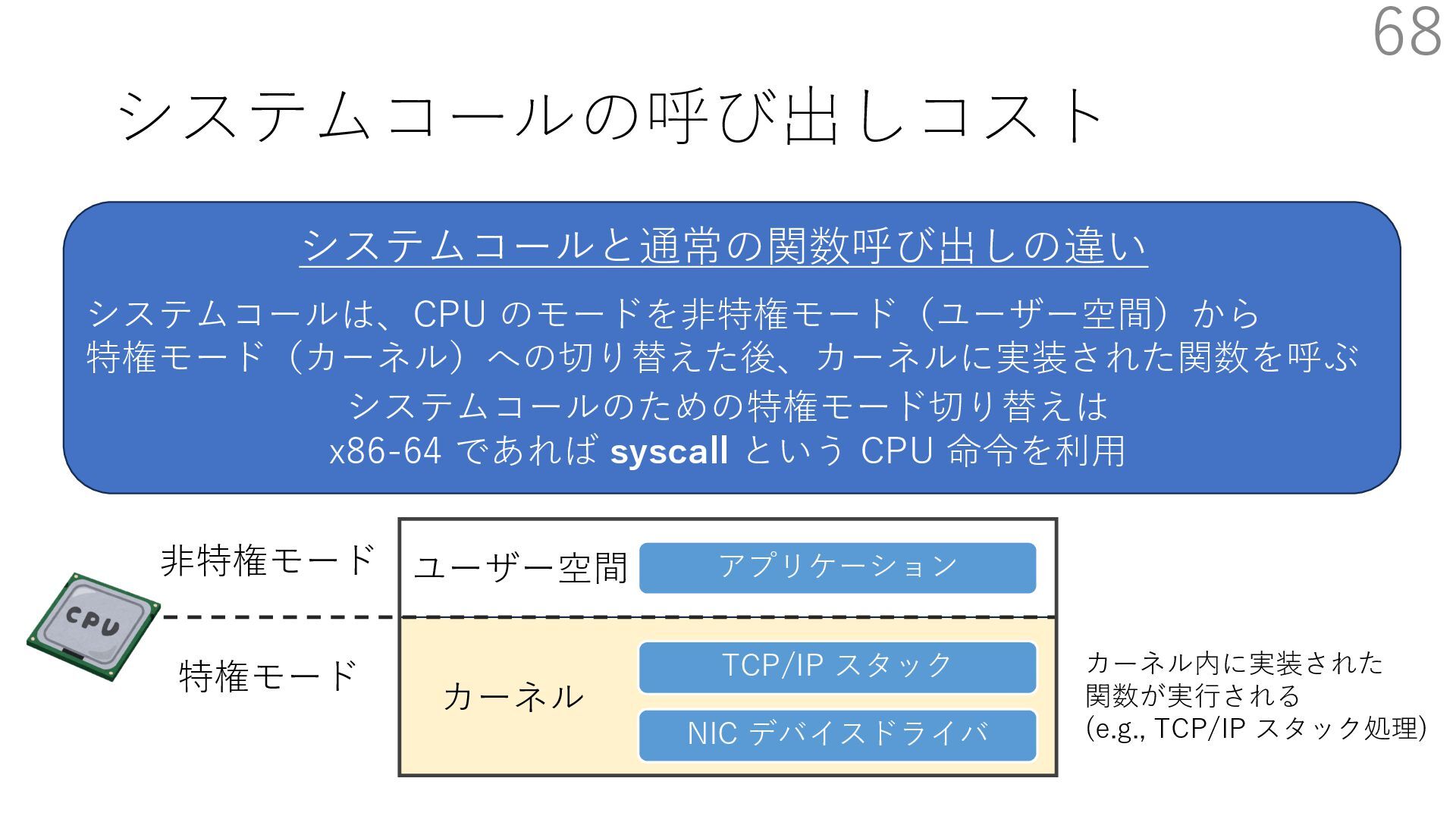{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
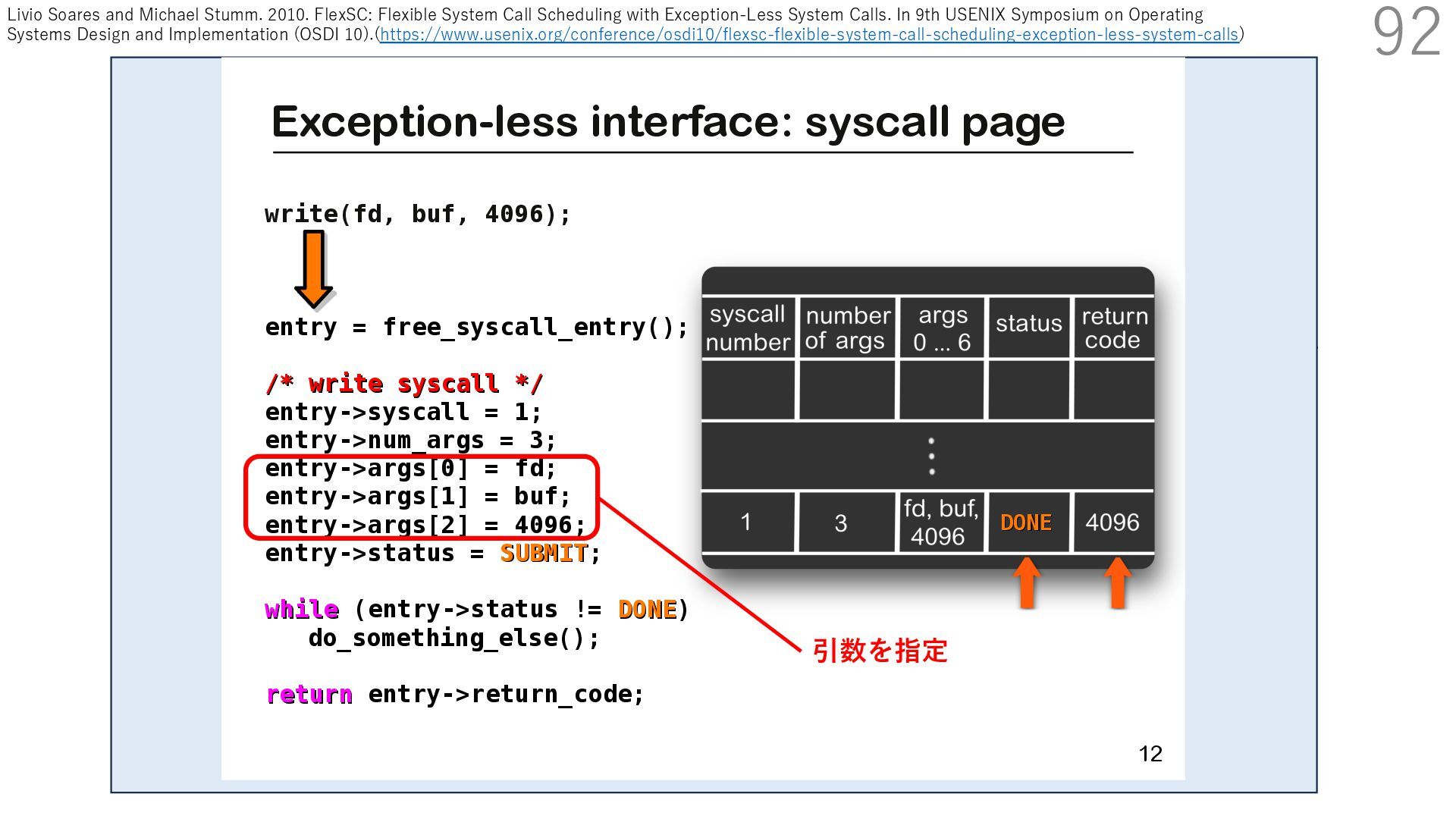{kind=link}
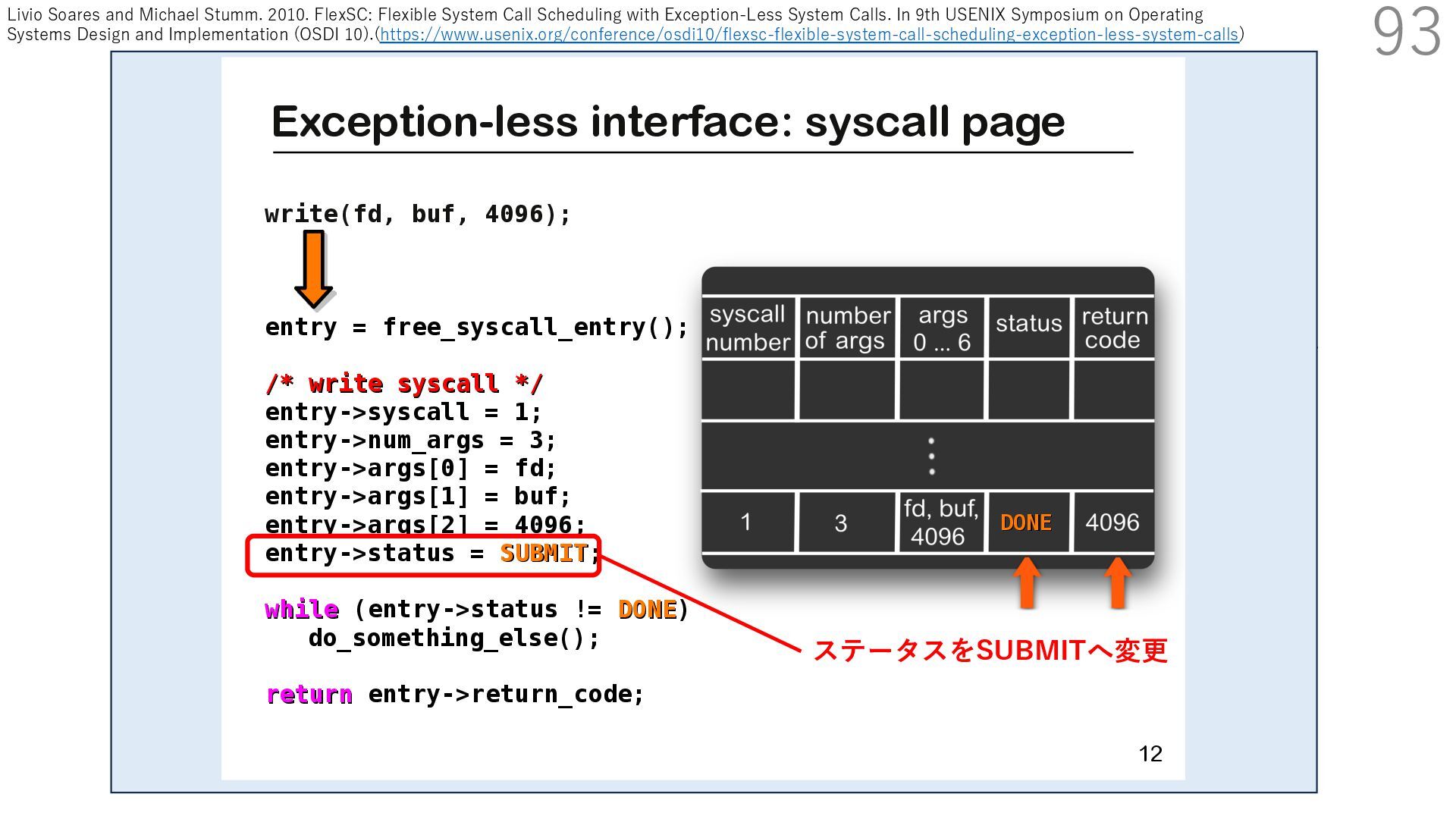{kind=link}
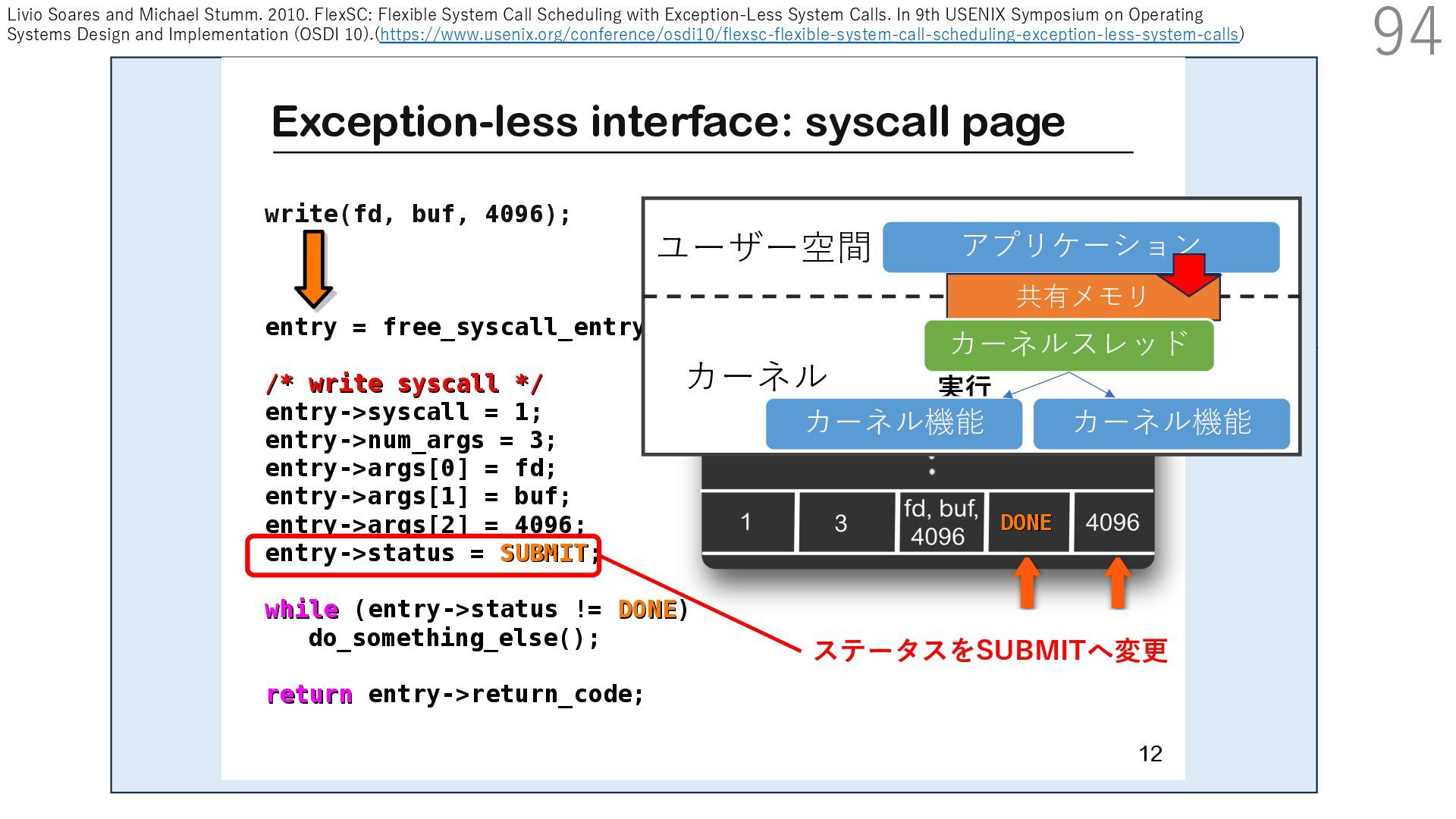{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
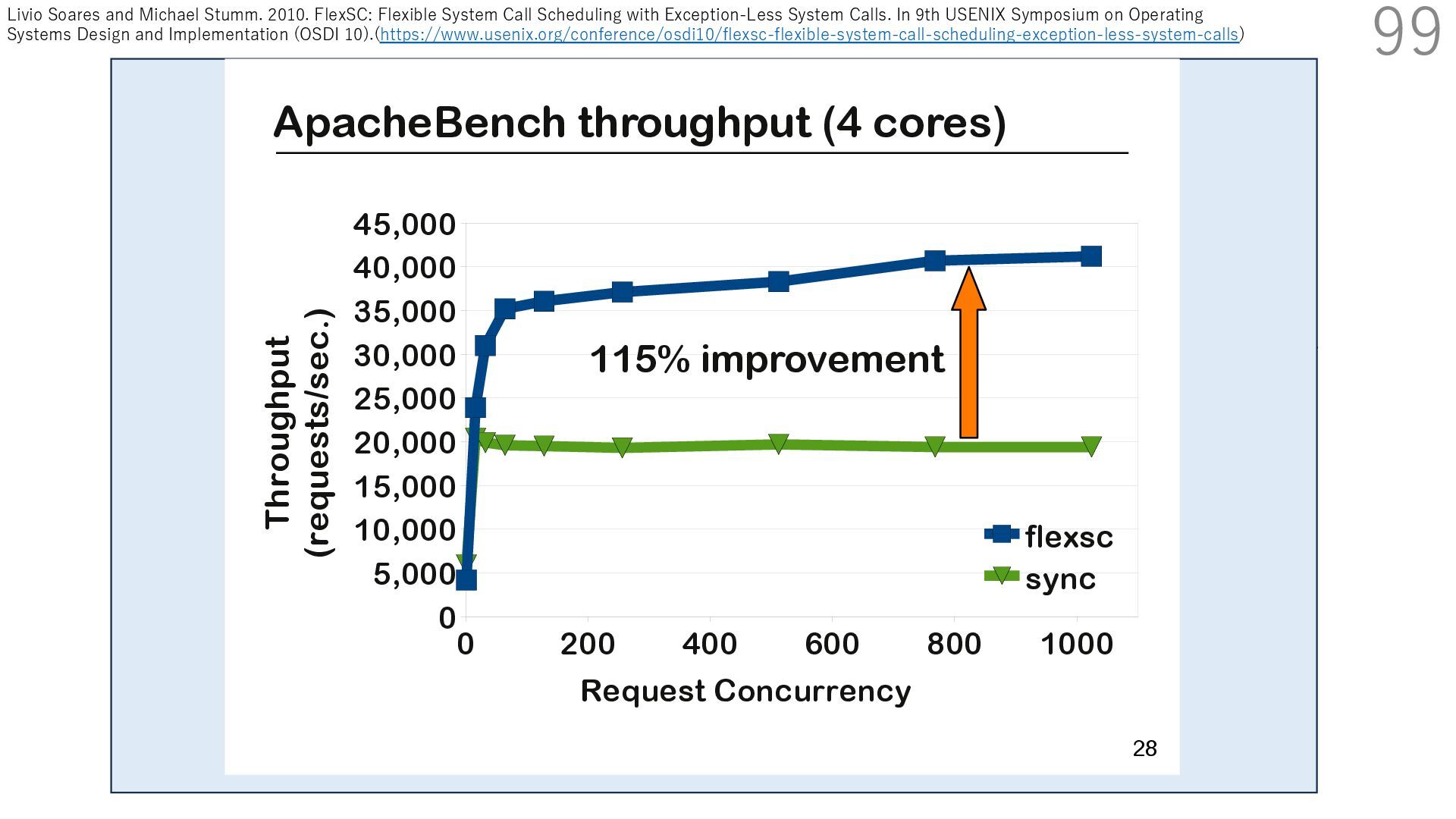{kind=link}
{kind=link}
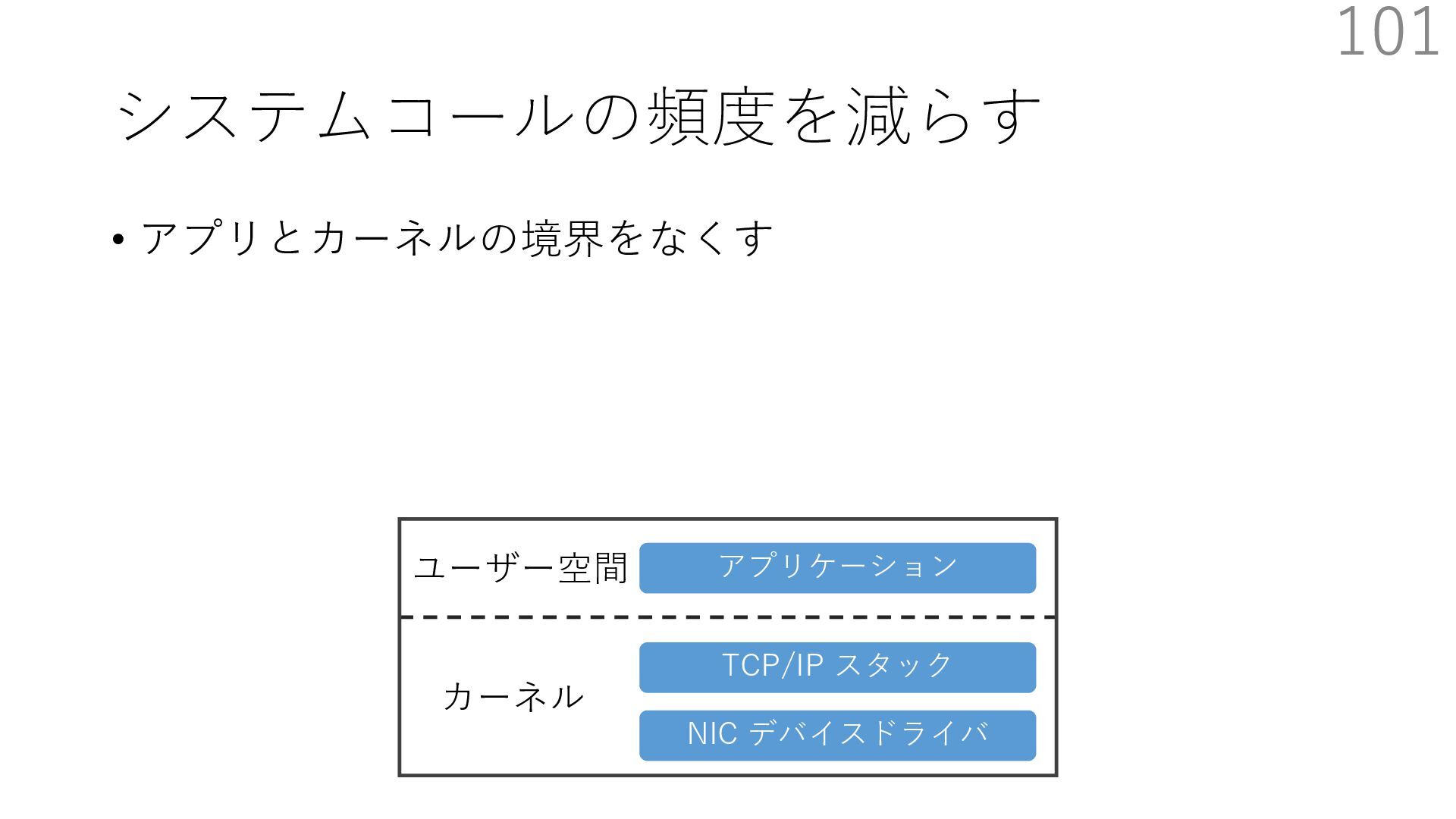{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
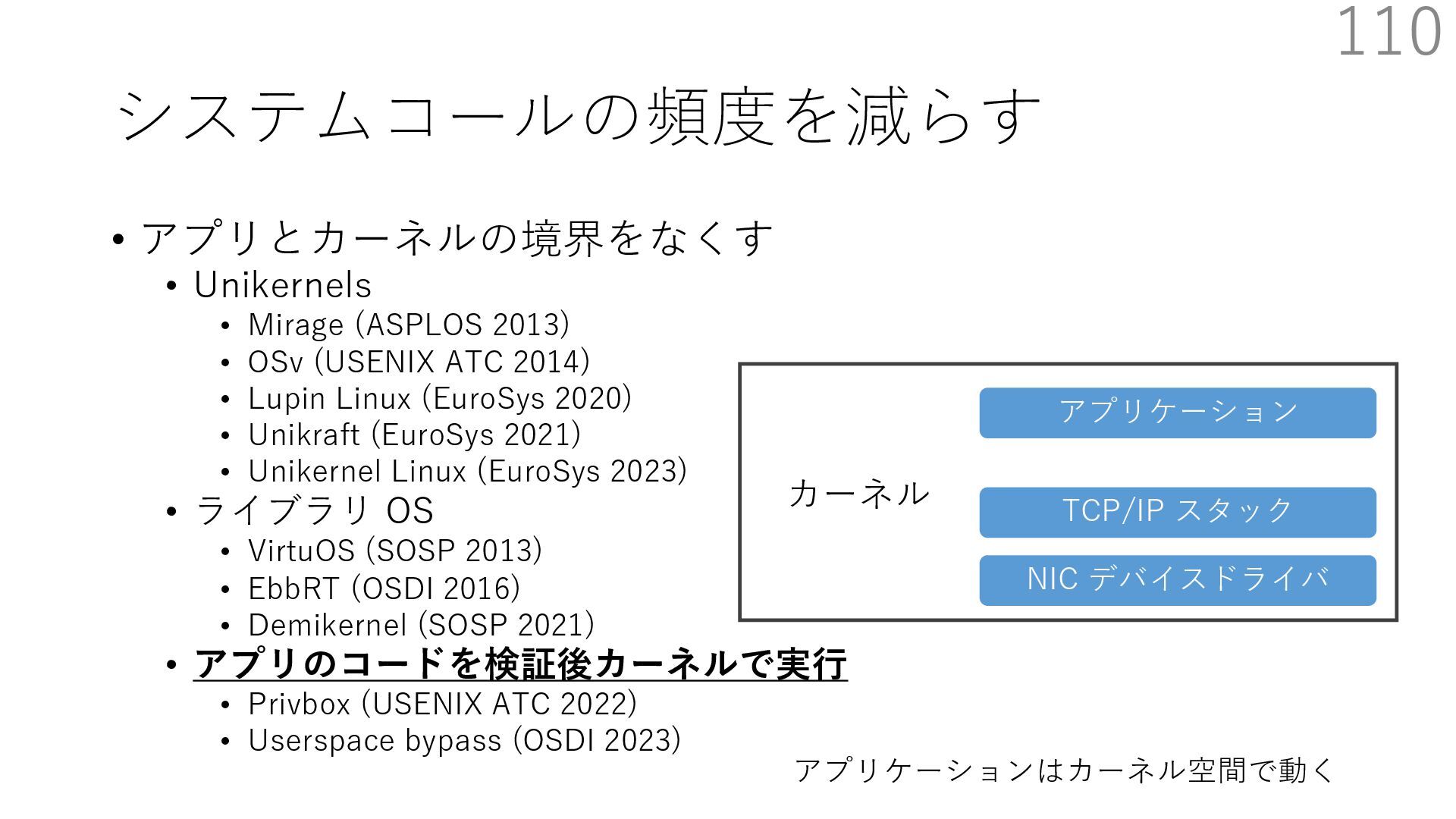{kind=link}
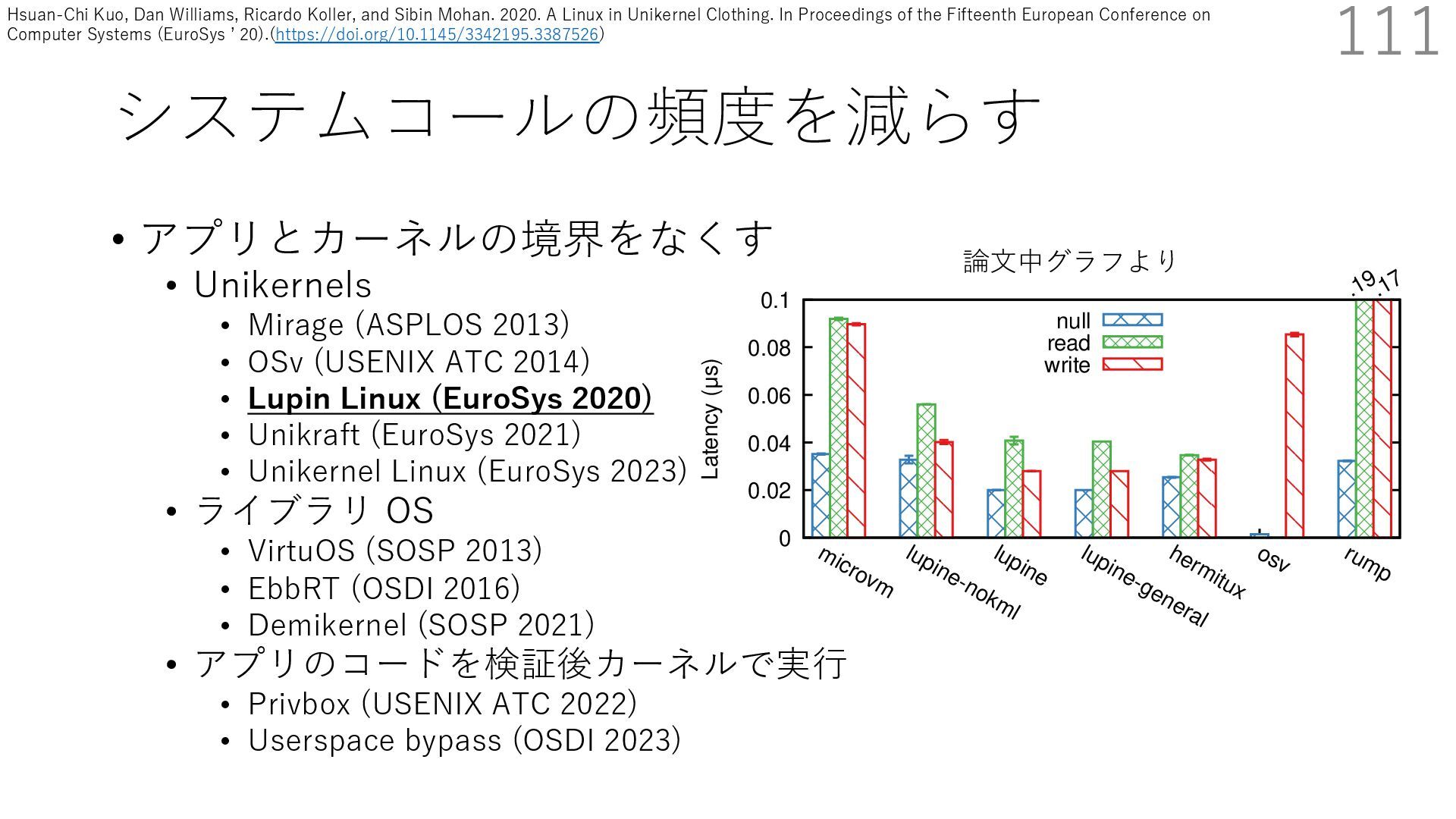{kind=link}
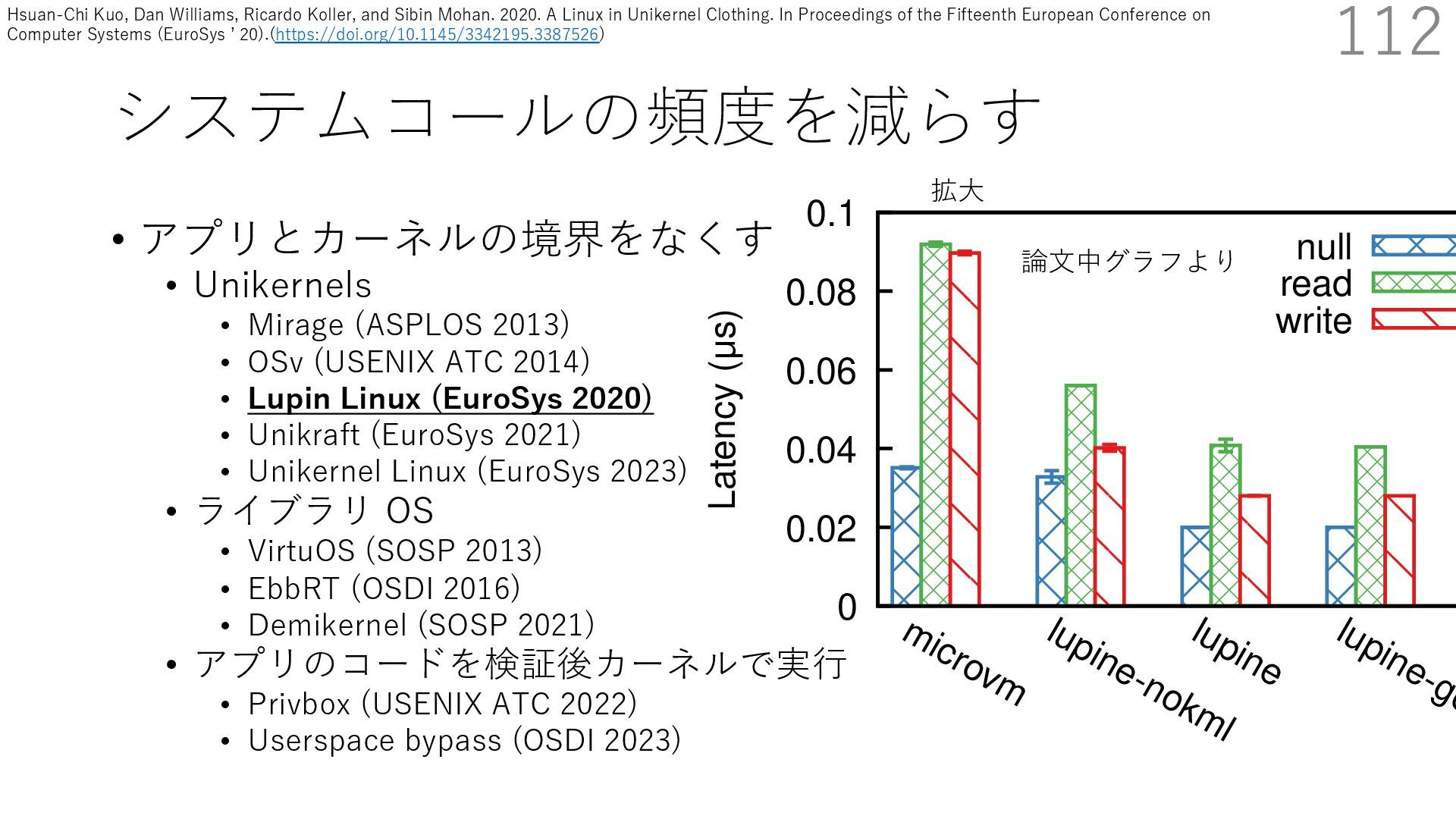{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
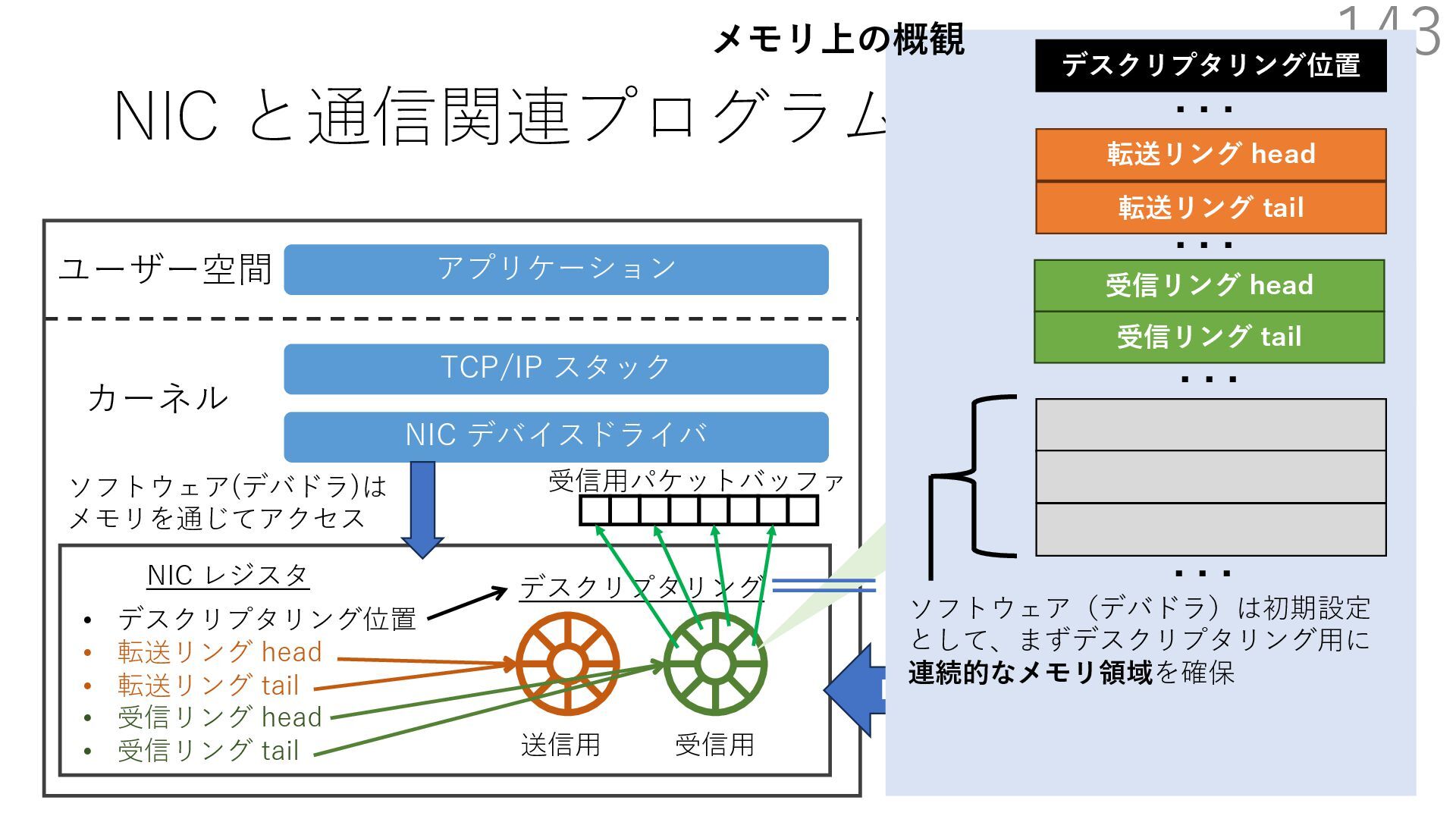{kind=link}
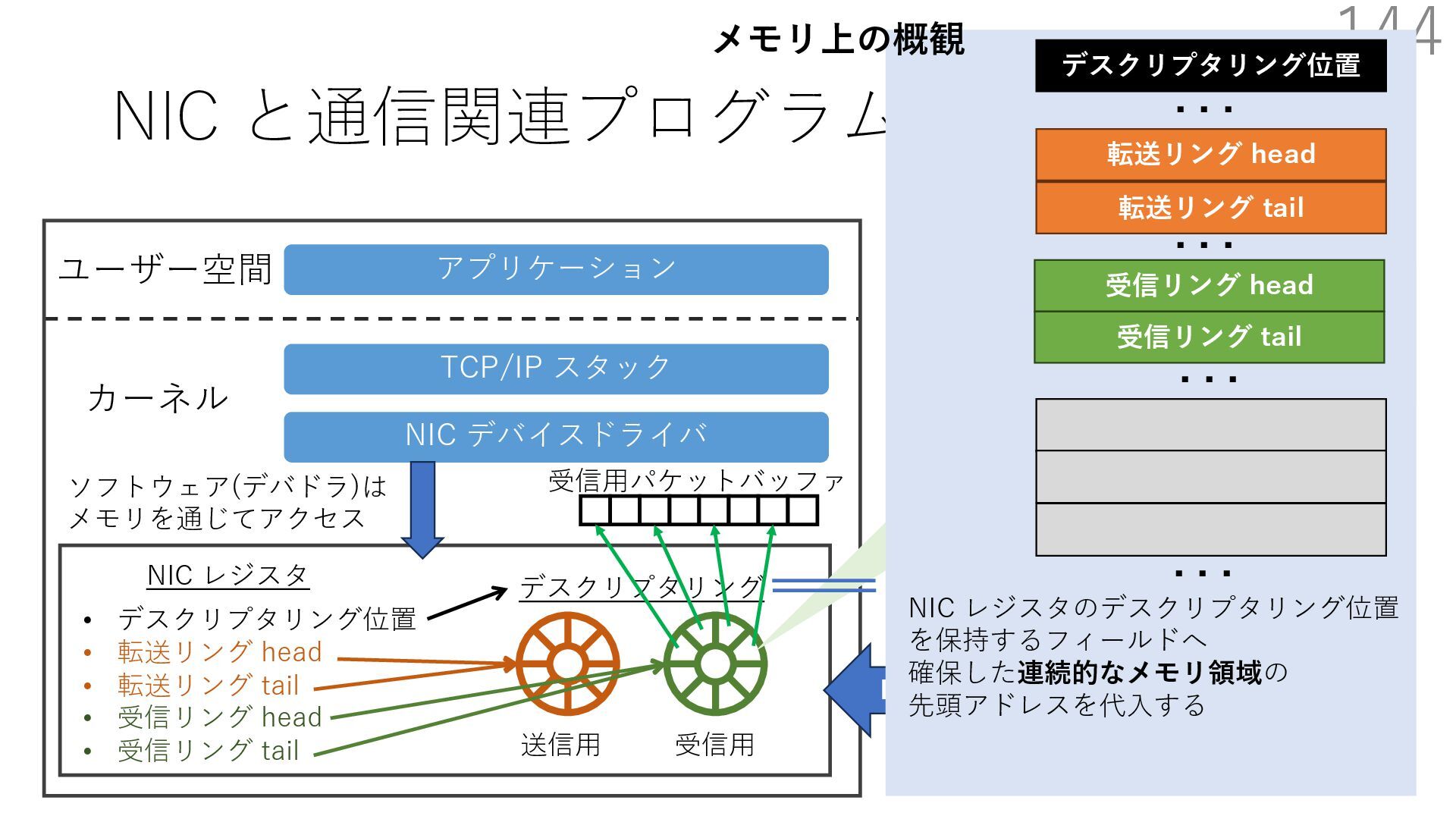{kind=link}
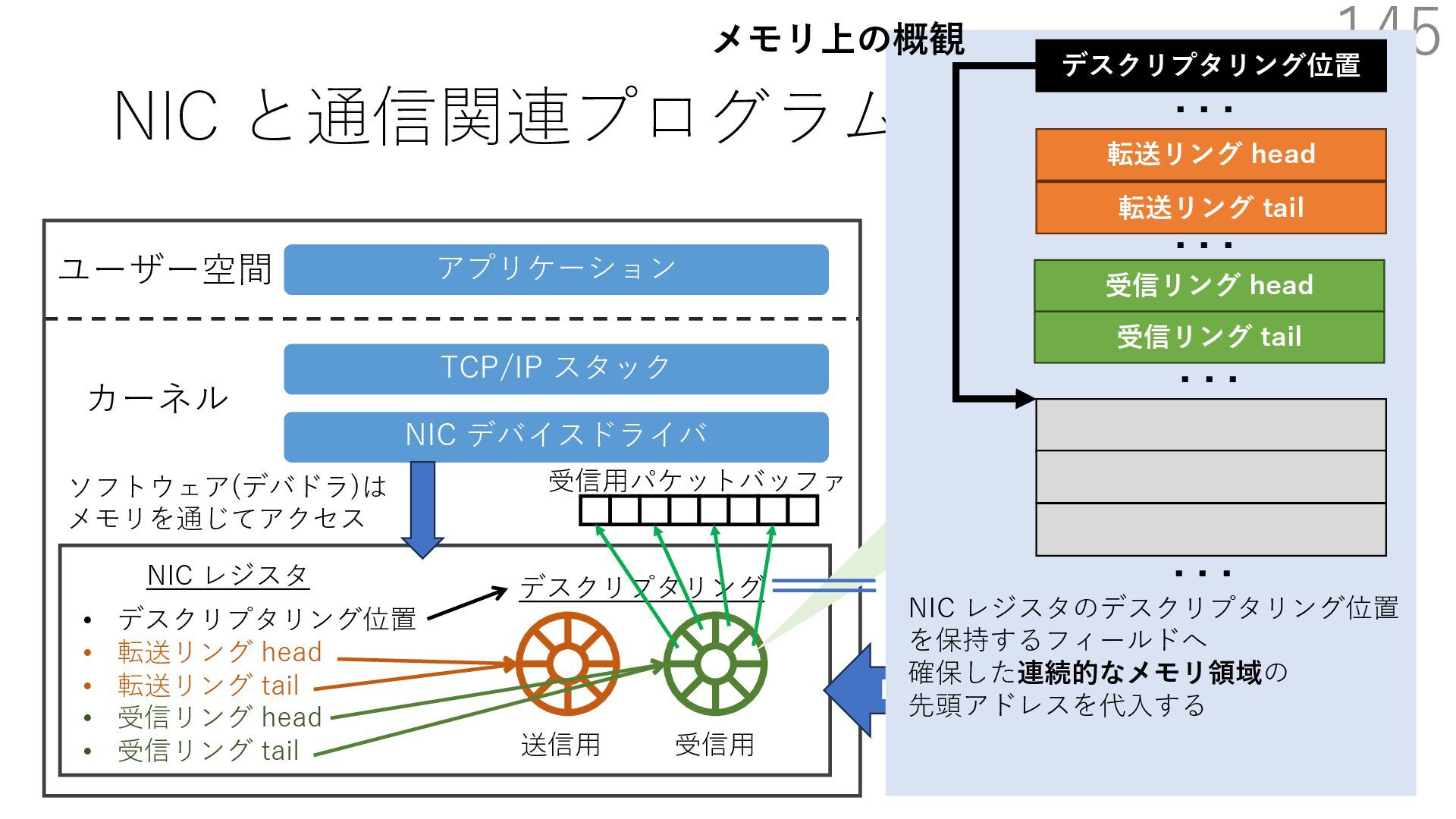{kind=link}
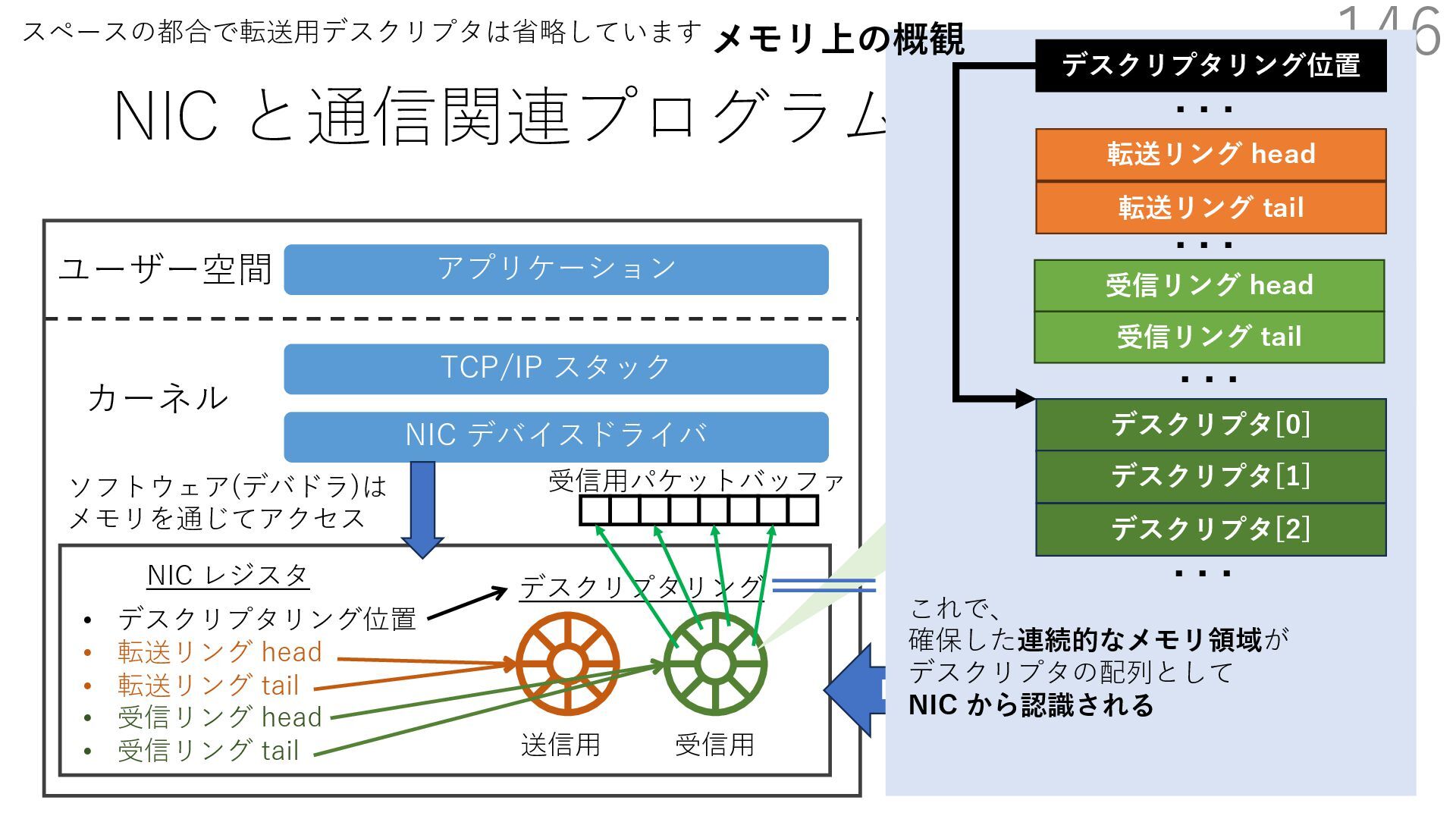{kind=link}
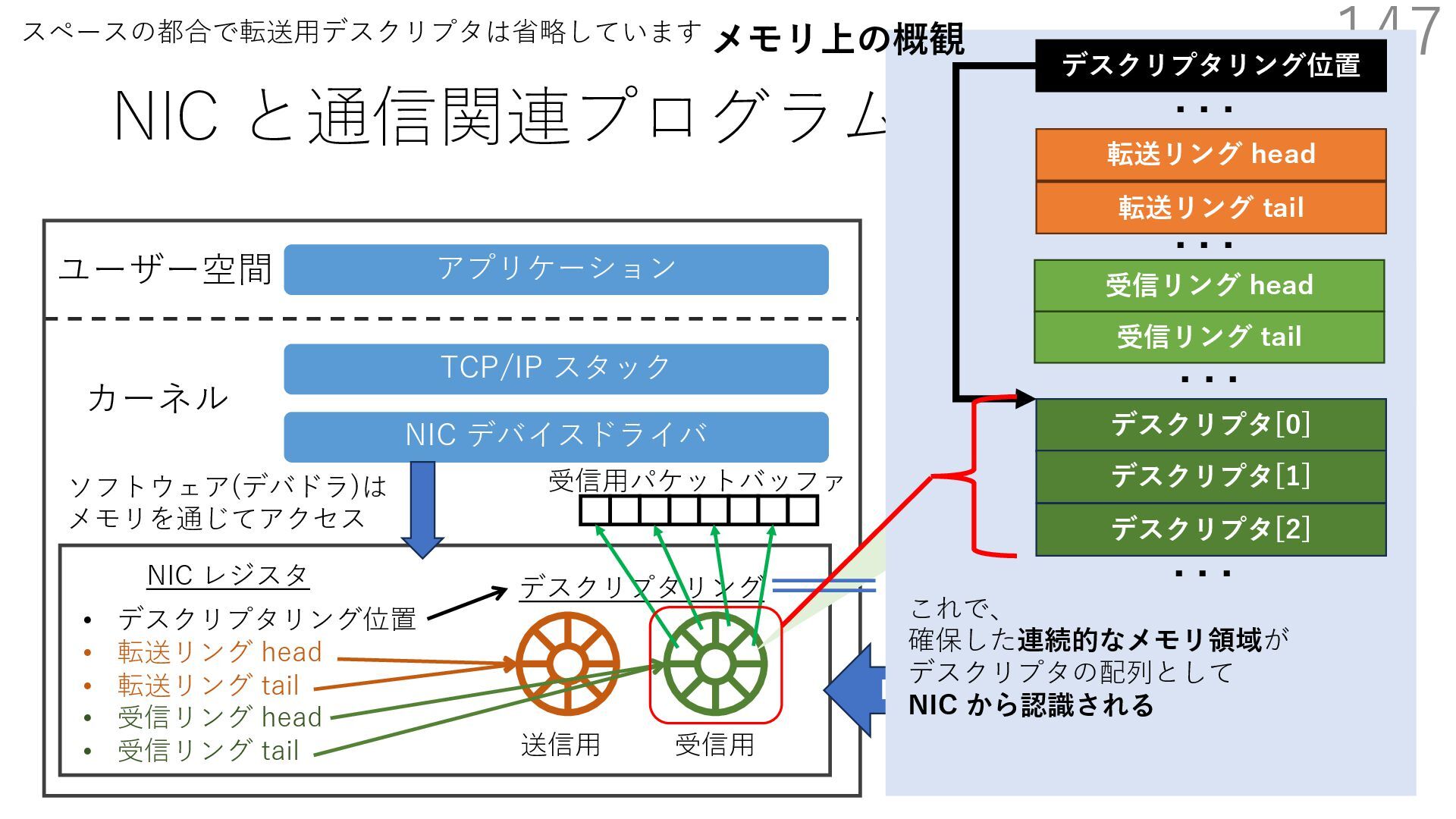{kind=link}
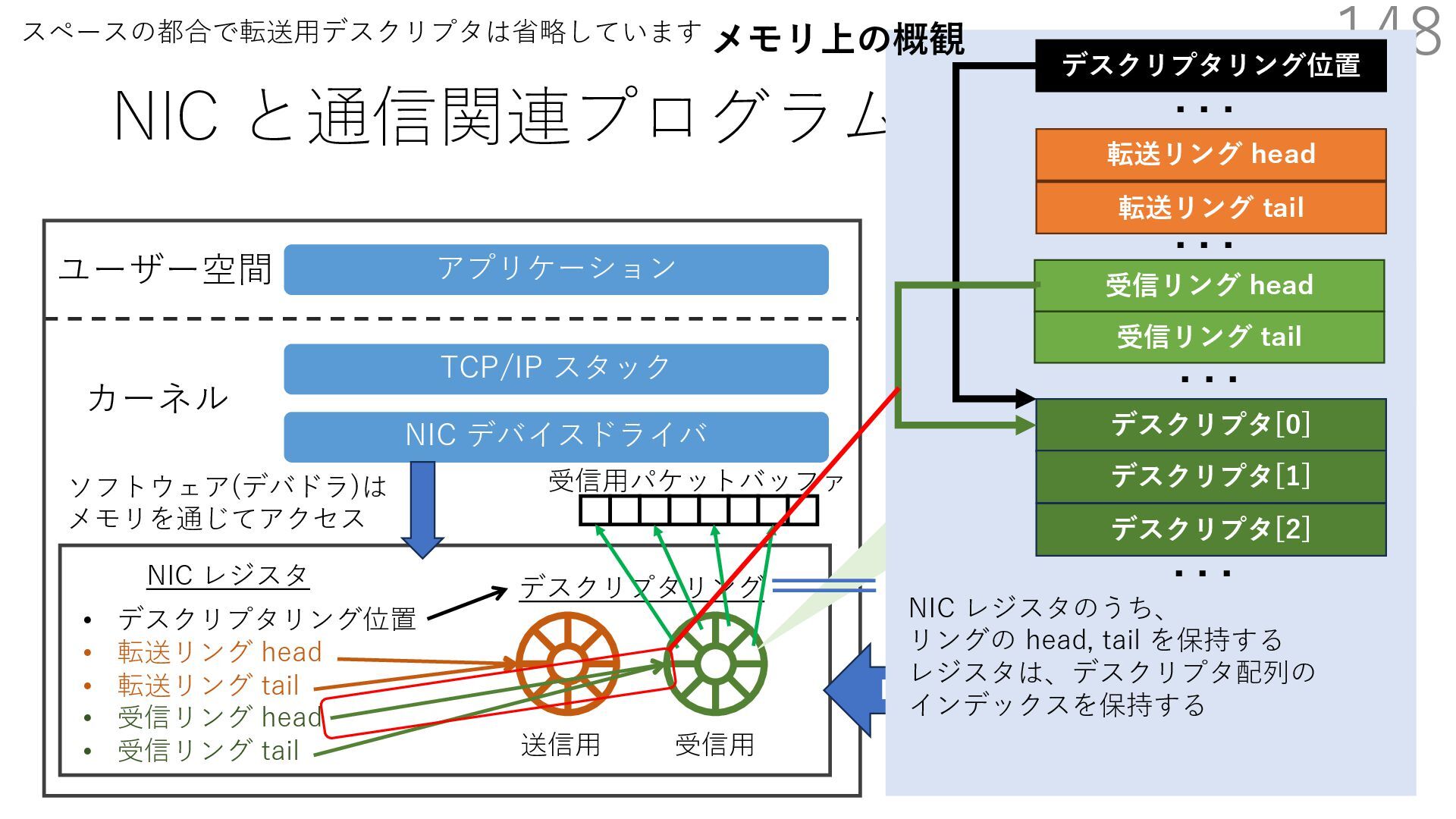{kind=link}
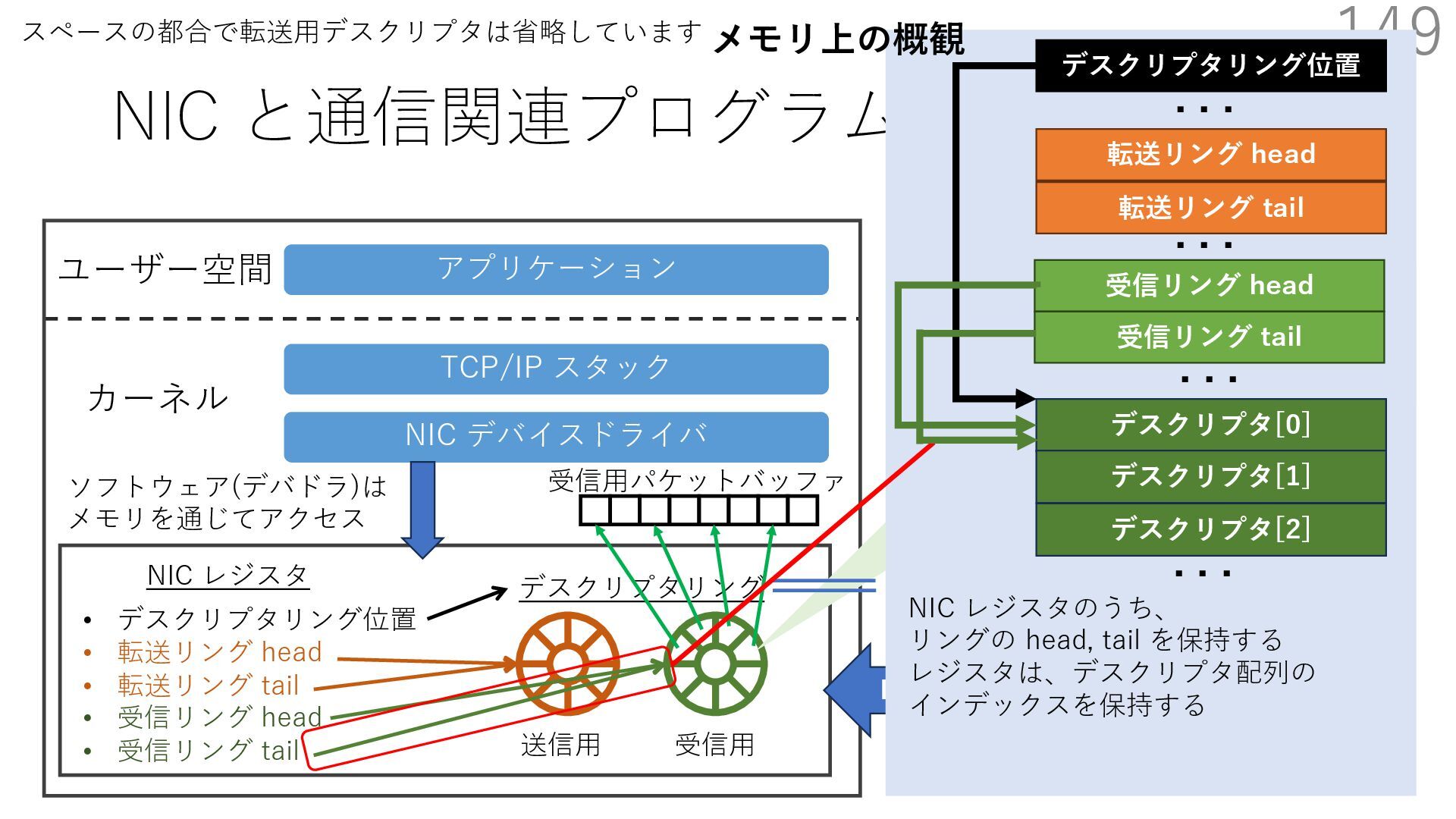{kind=link}
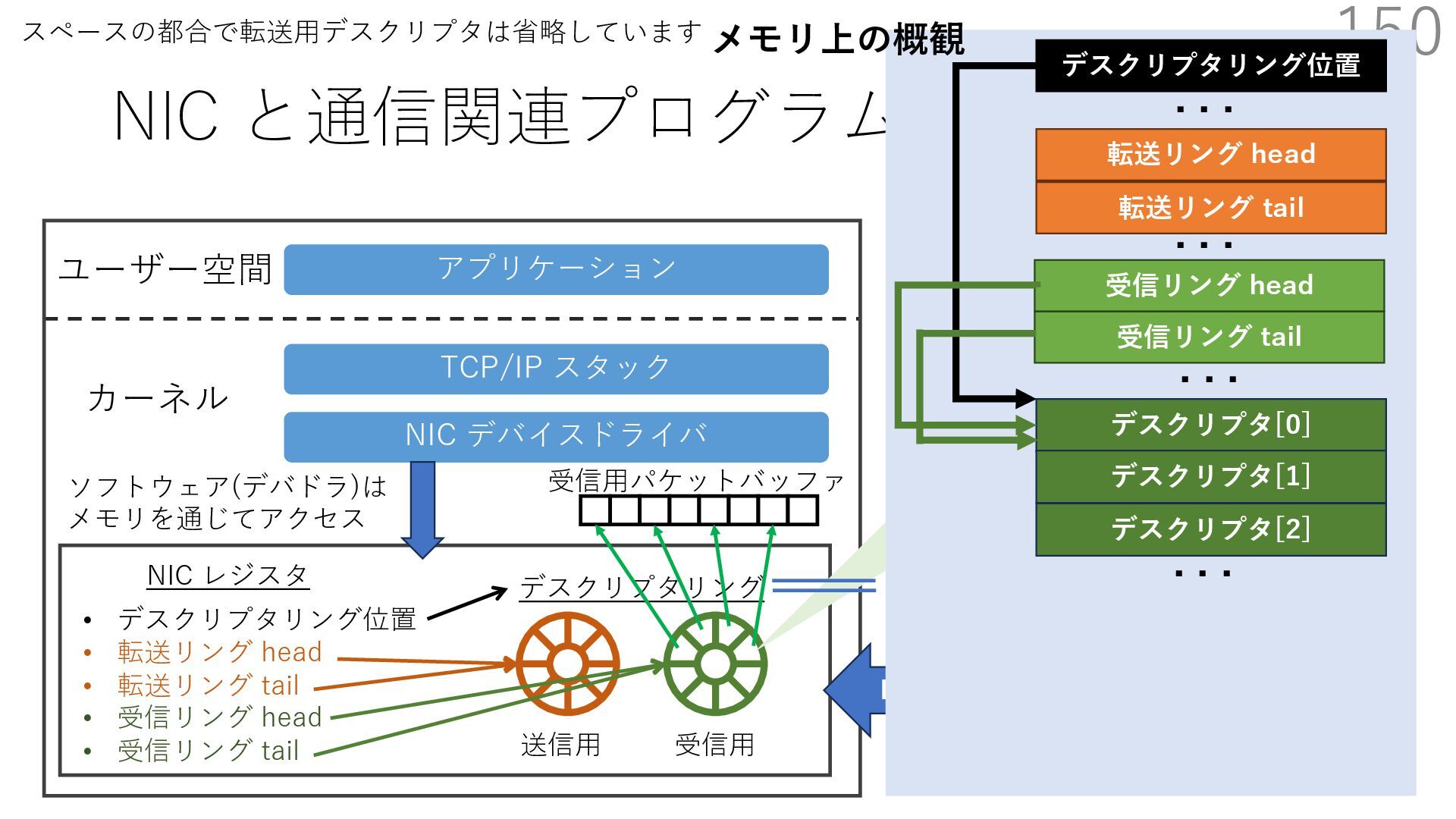{kind=link}
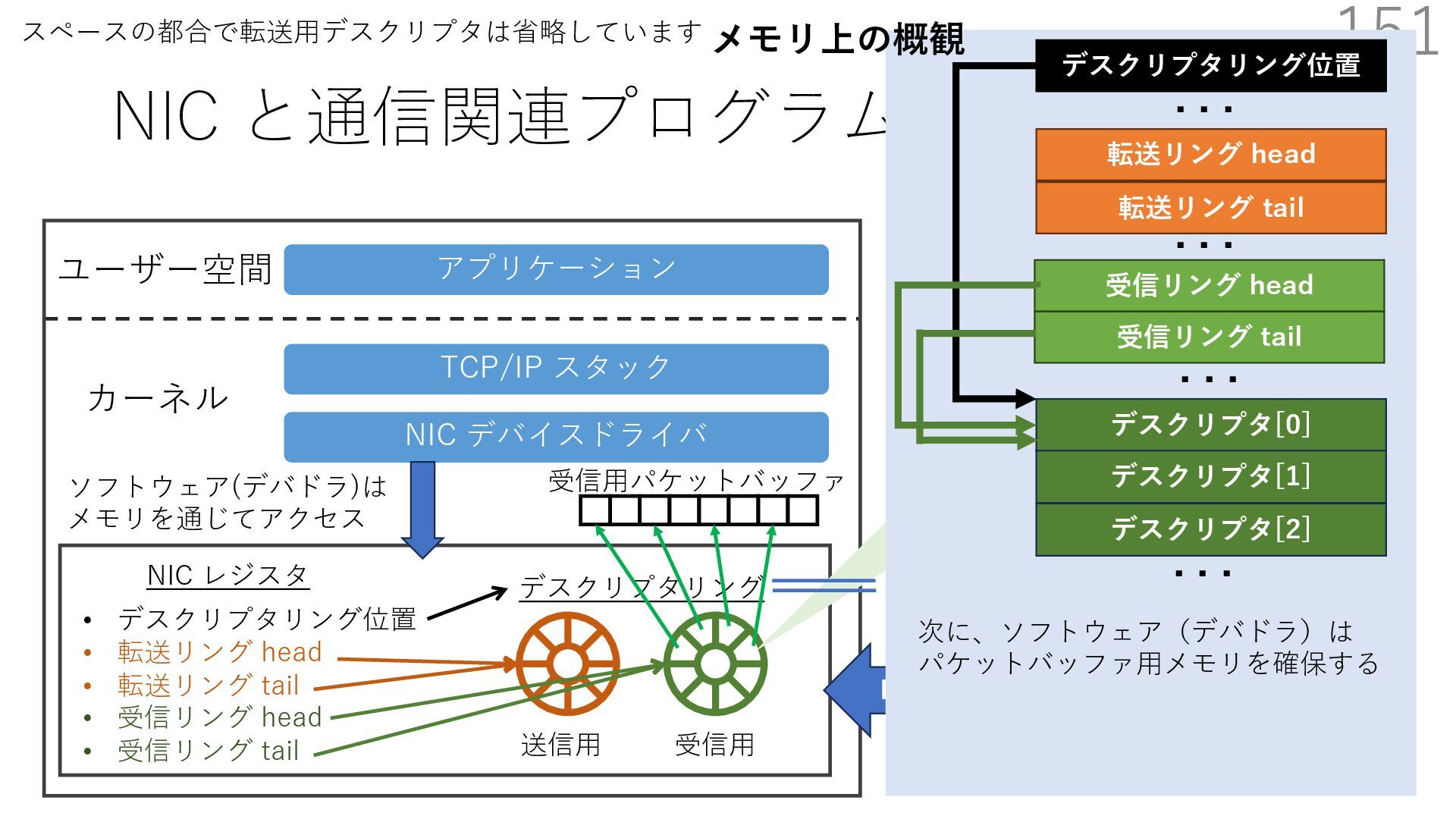{kind=link}
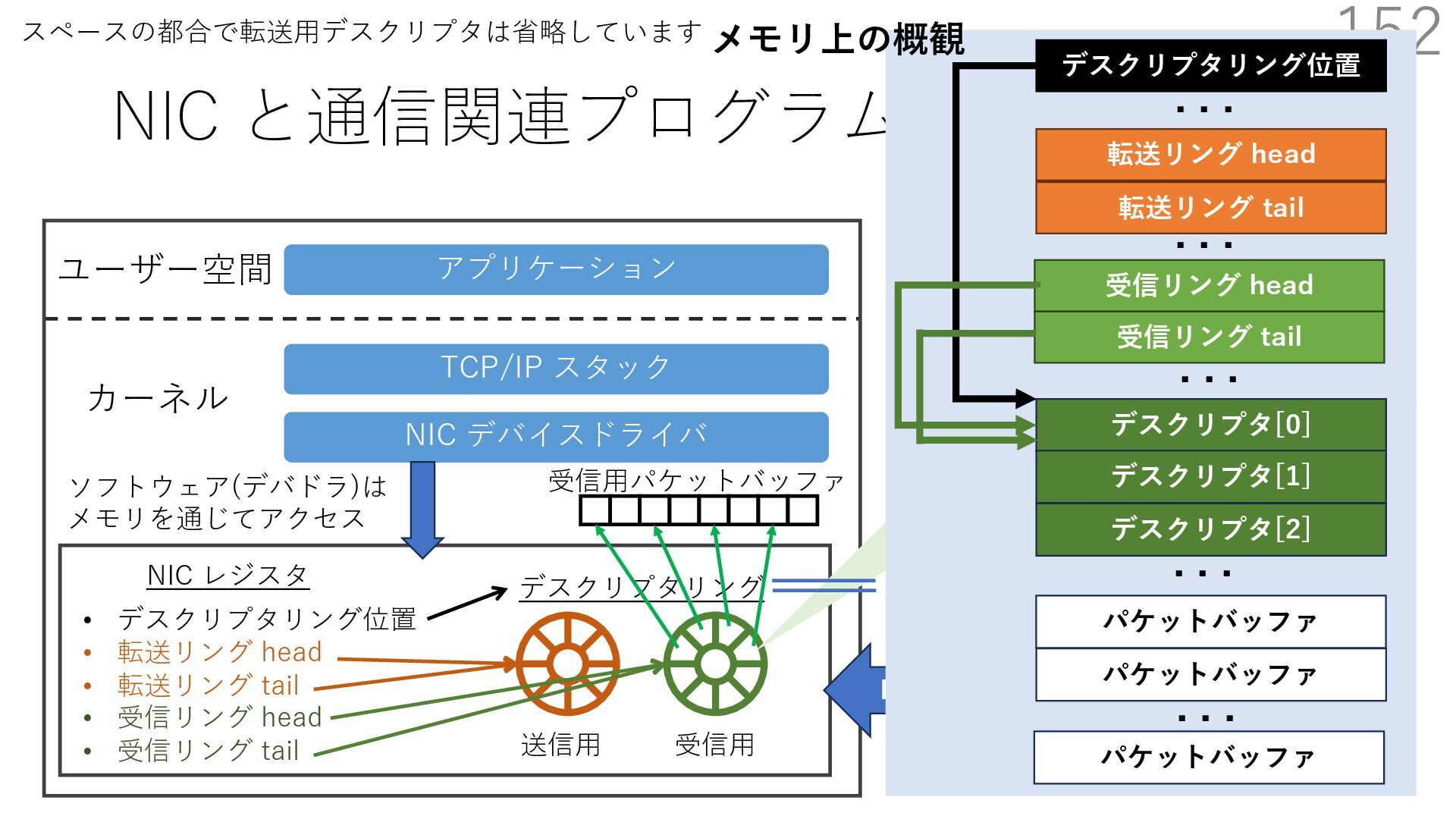{kind=link}
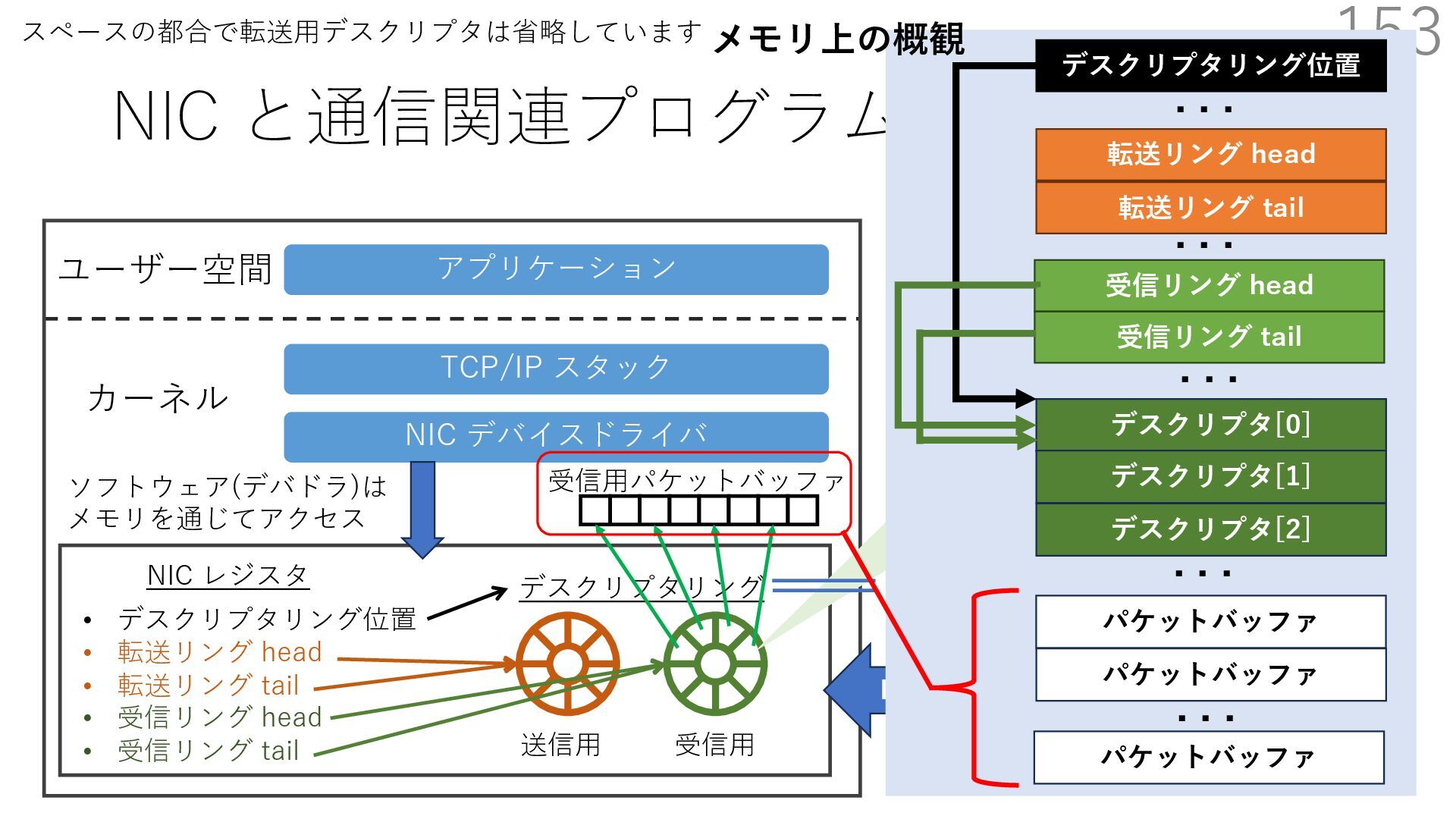{kind=link}
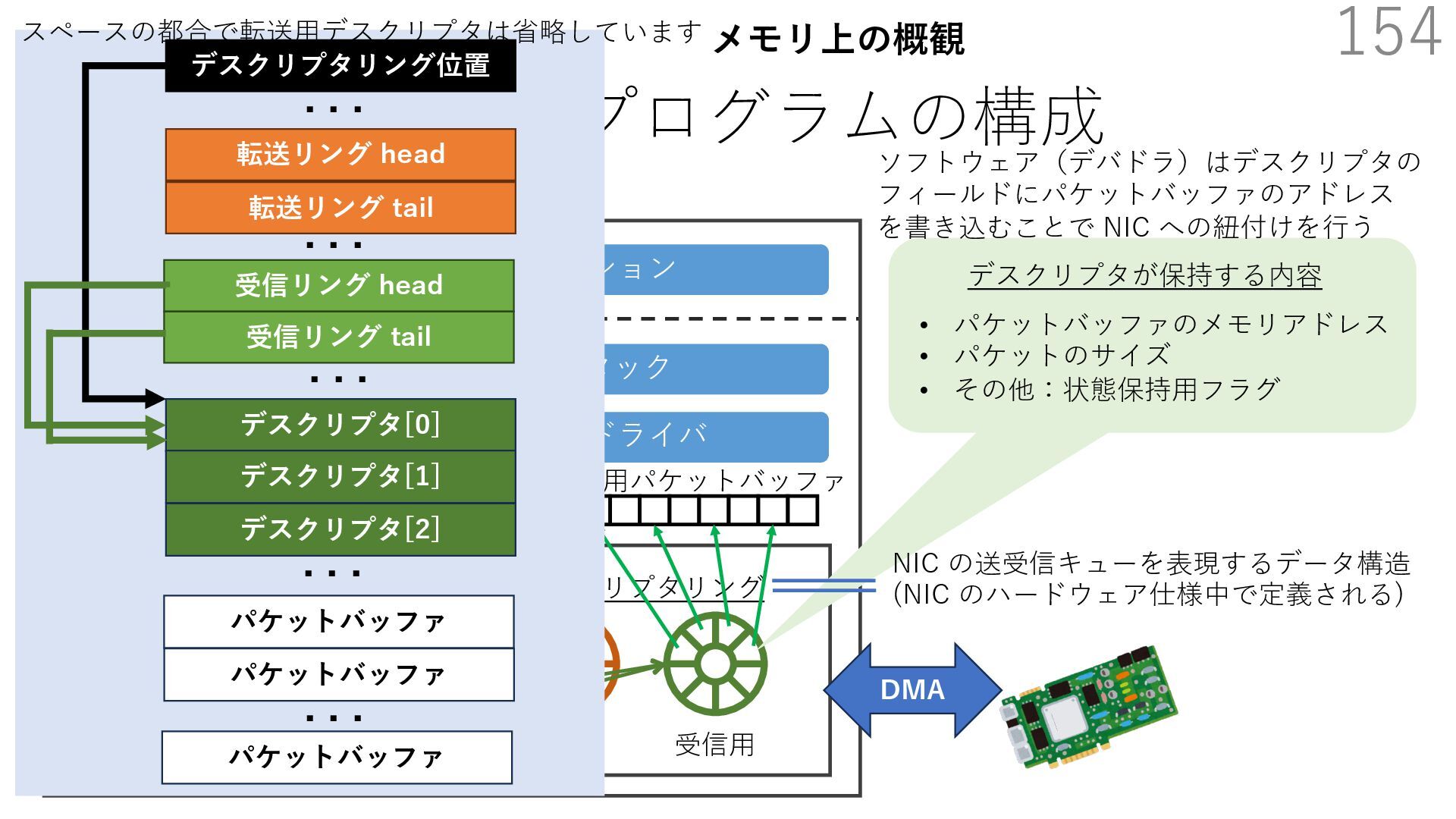{kind=link}
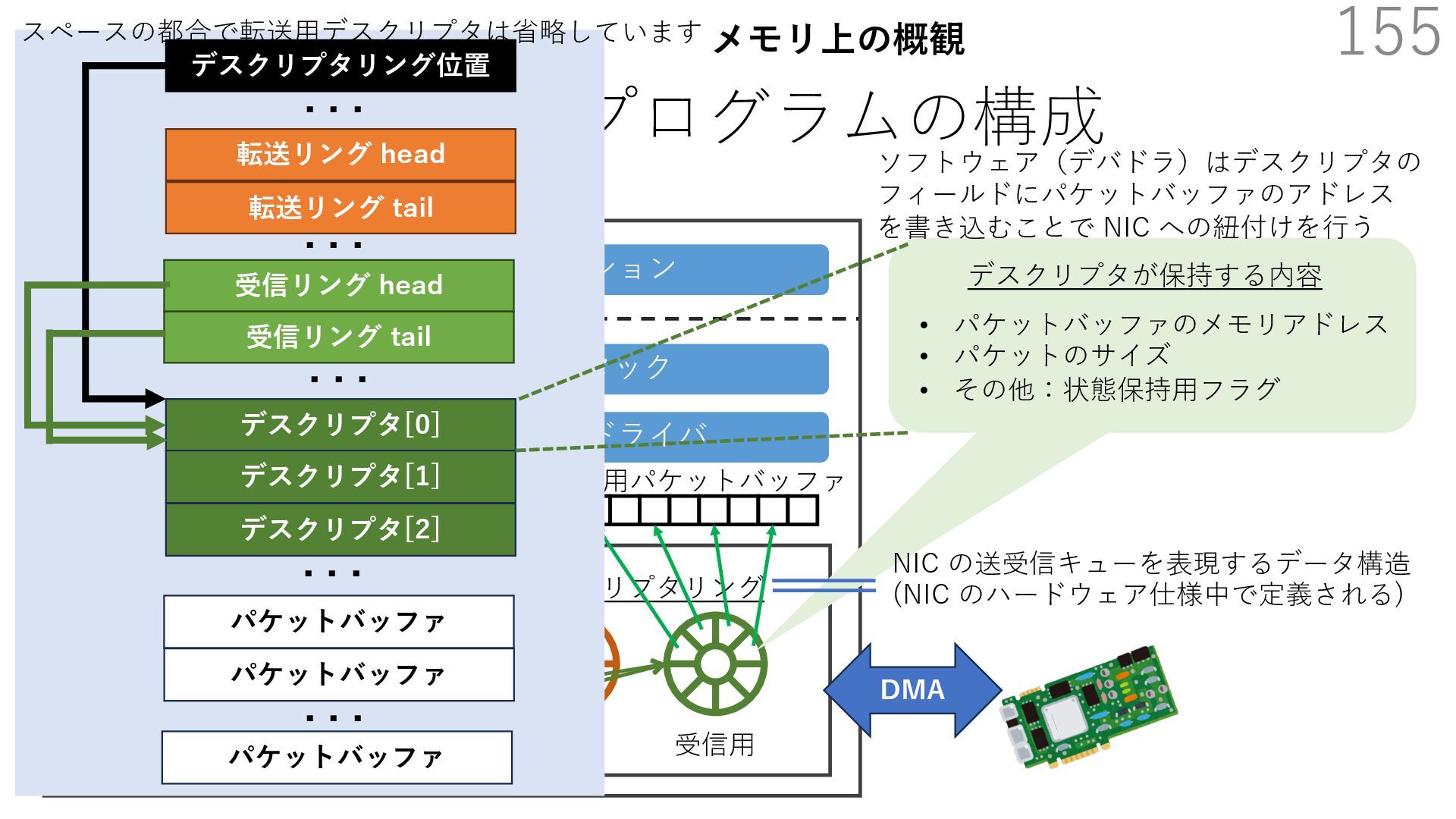{kind=link}
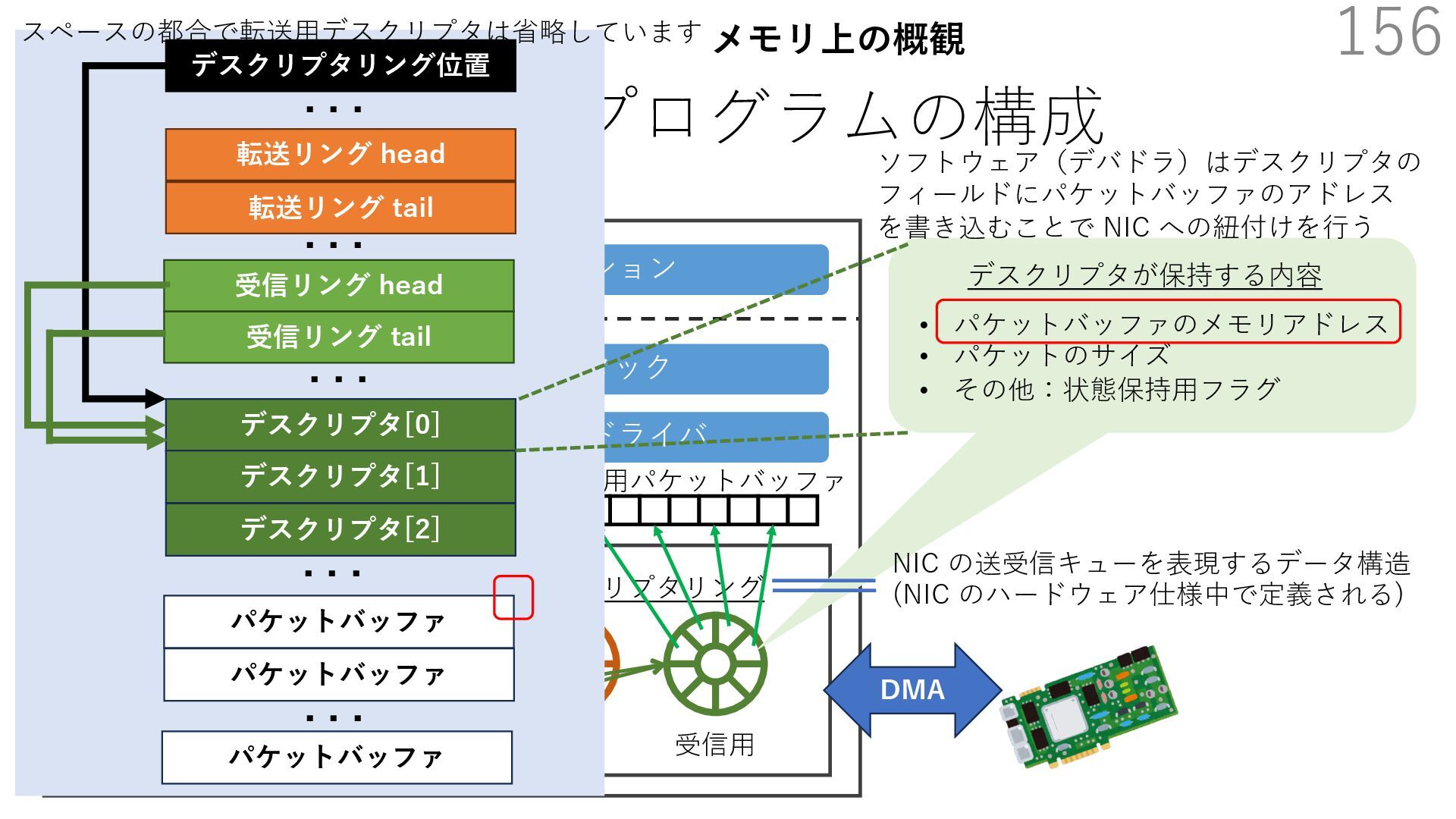{kind=link}
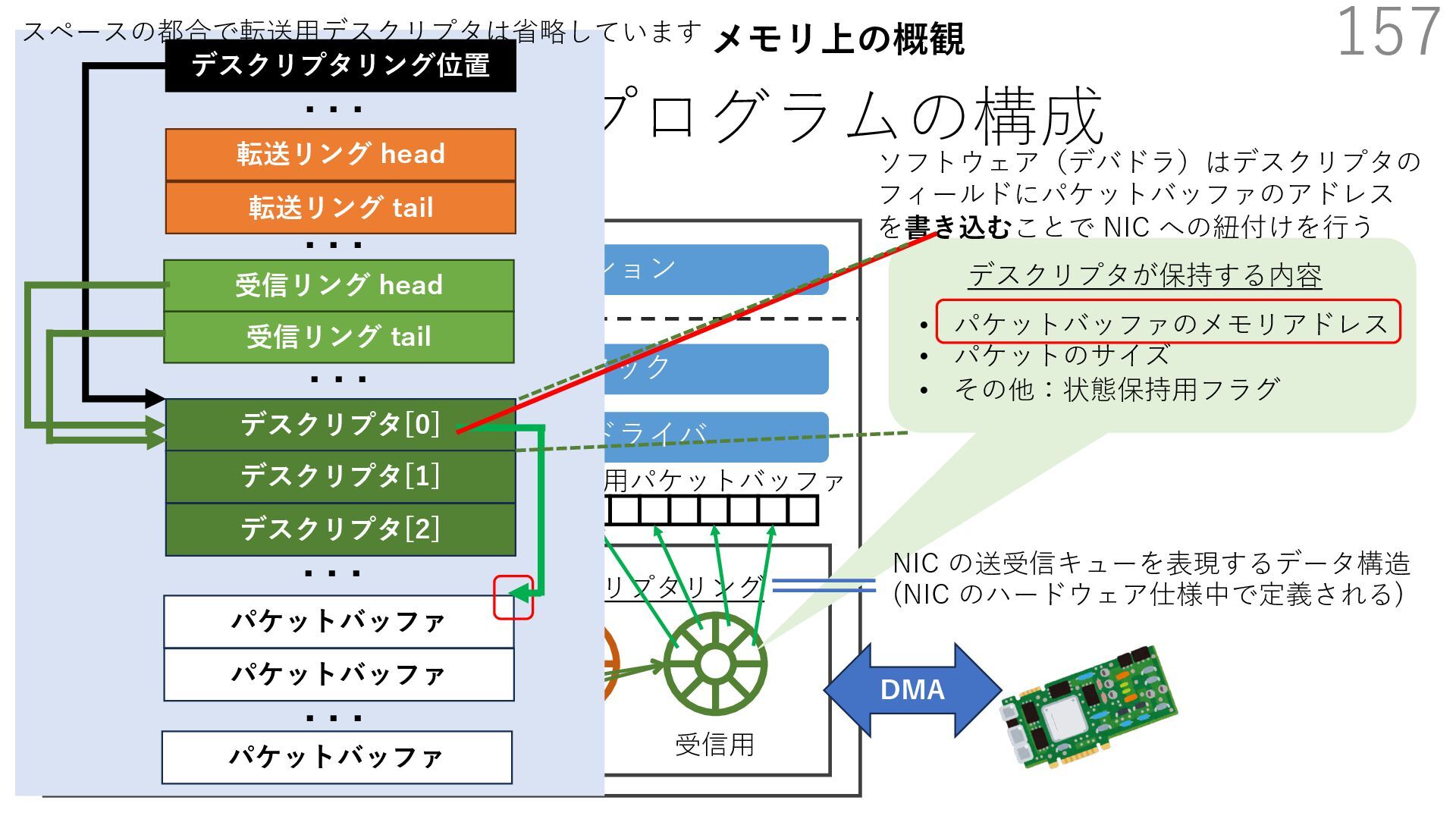{kind=link}
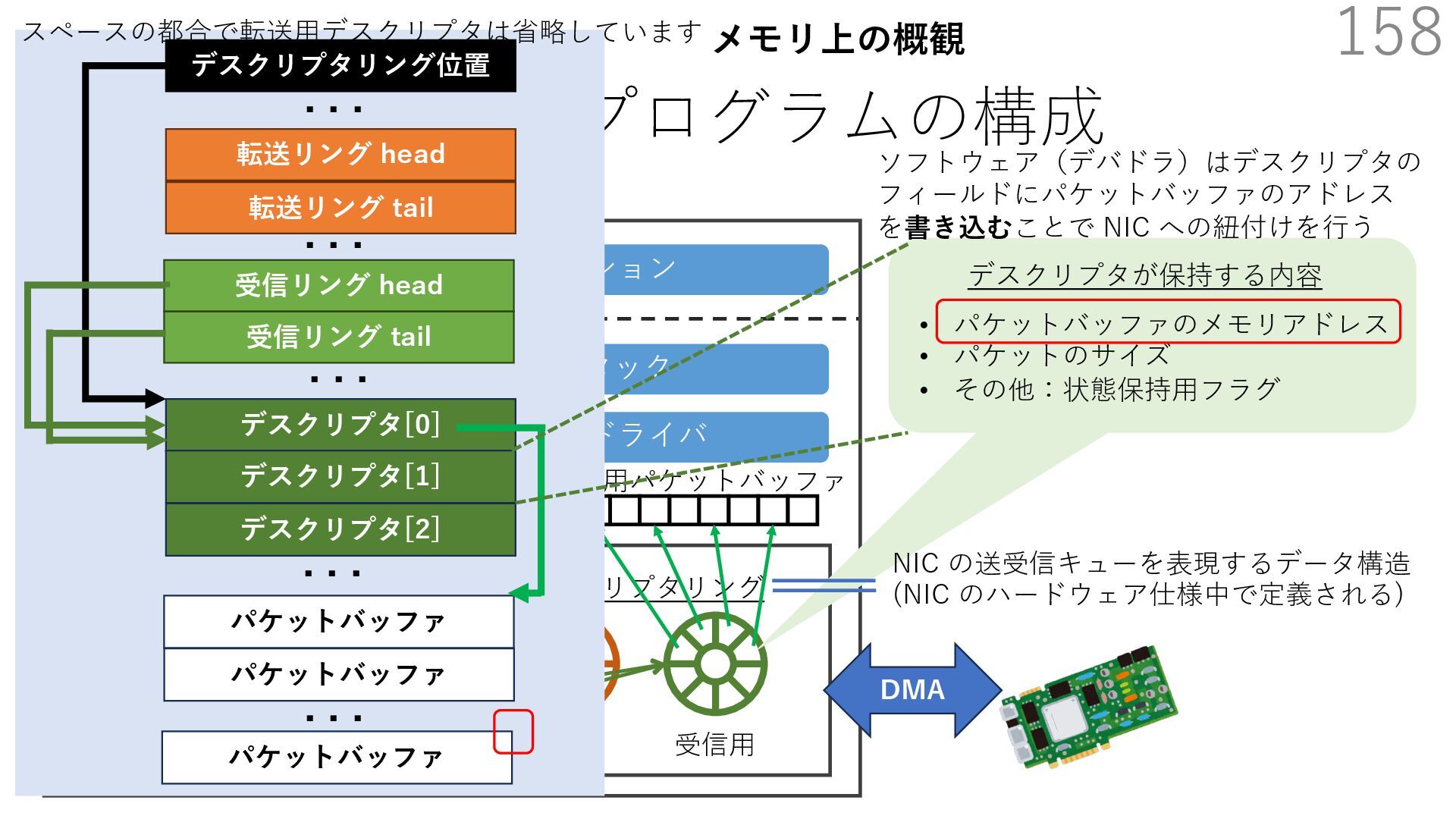{kind=link}
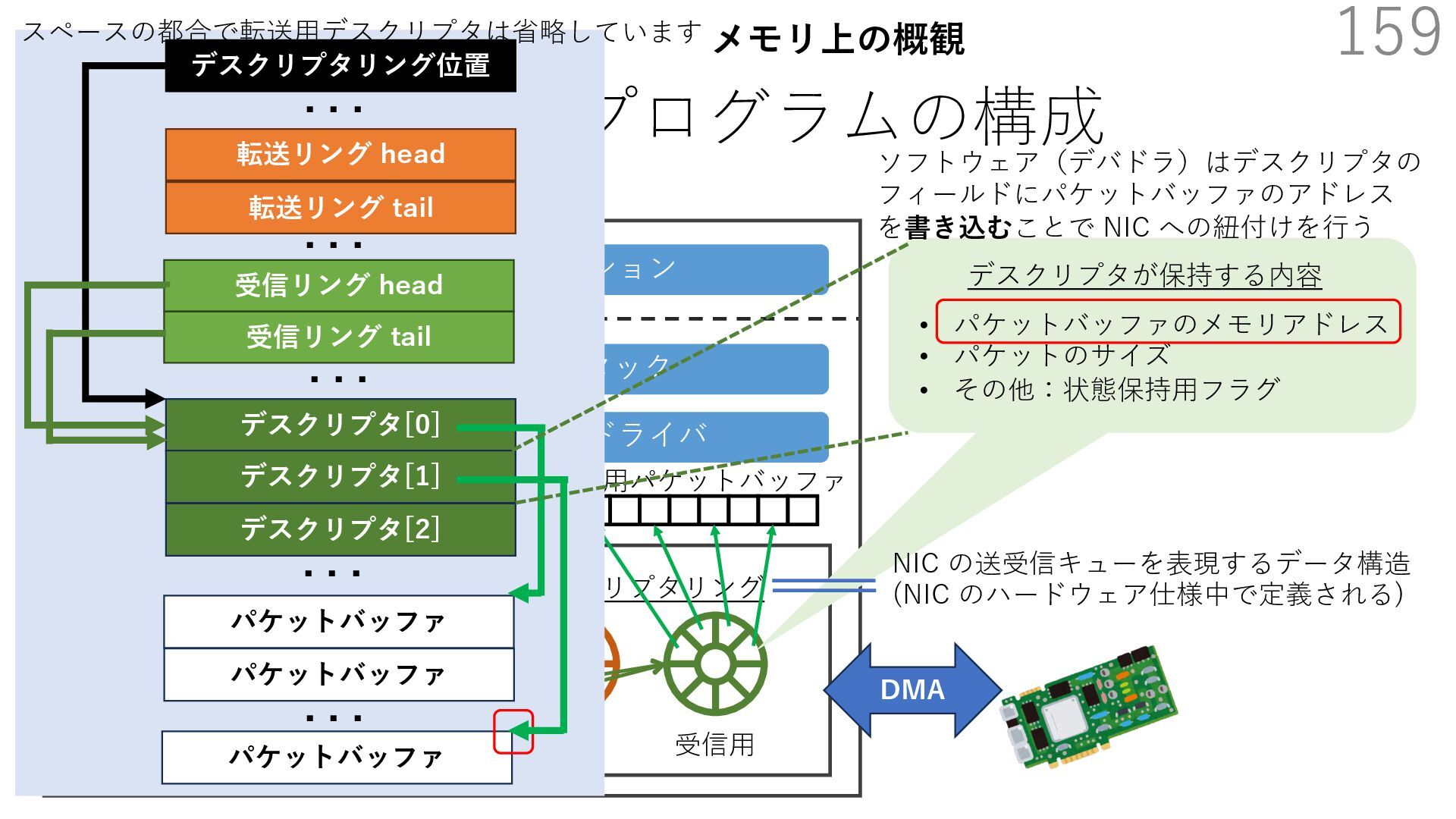{kind=link}
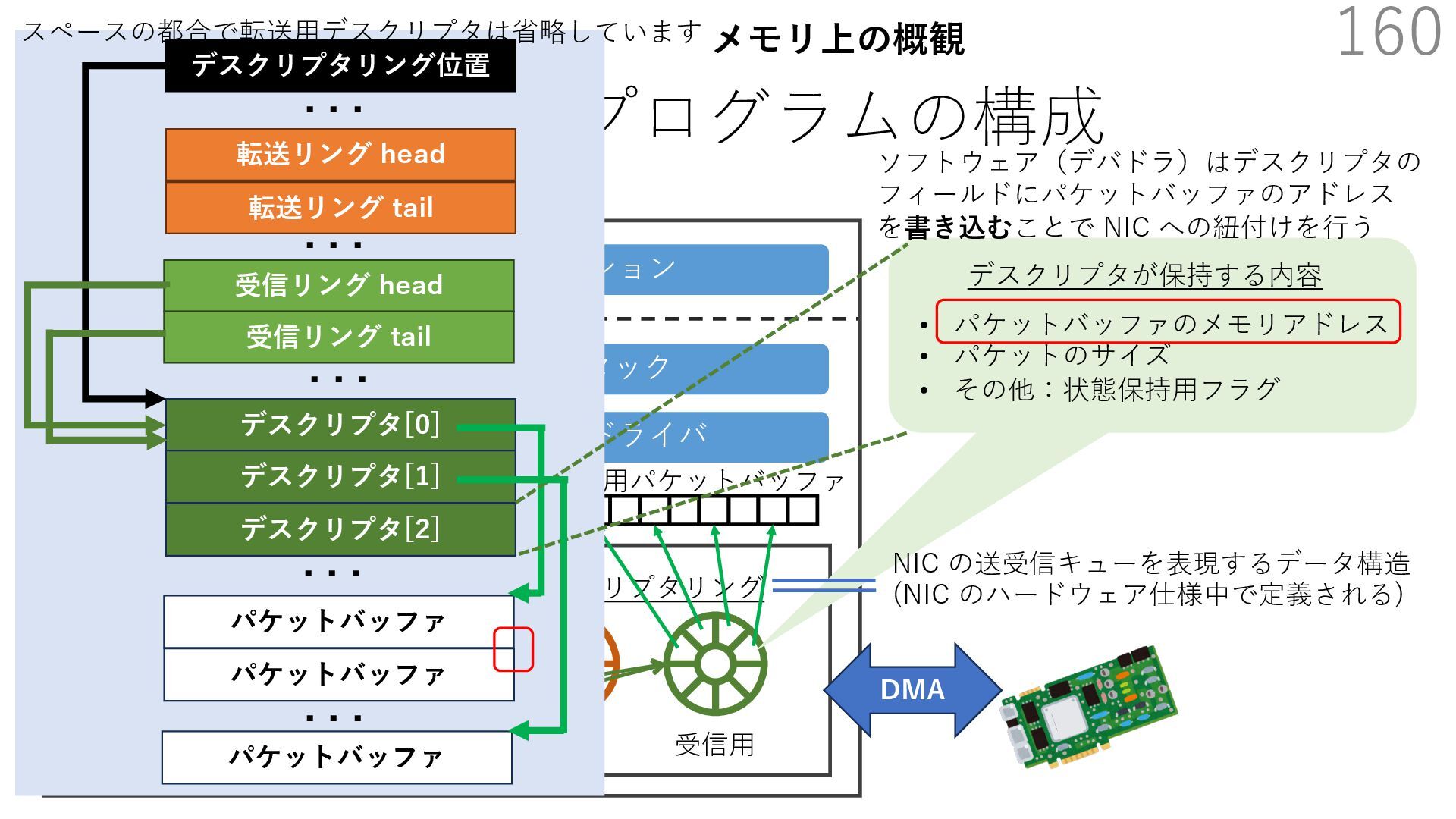{kind=link}
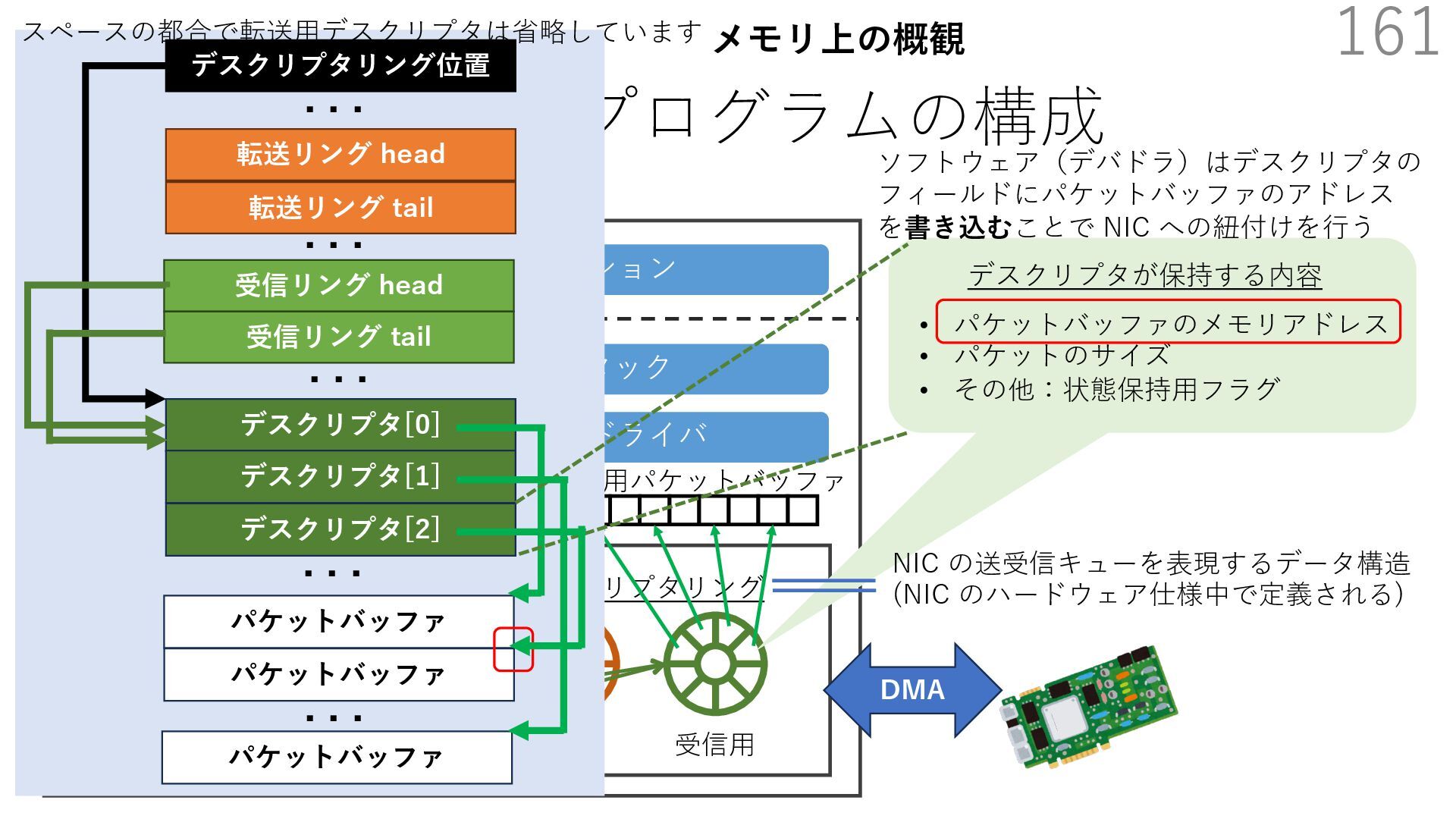{kind=link}
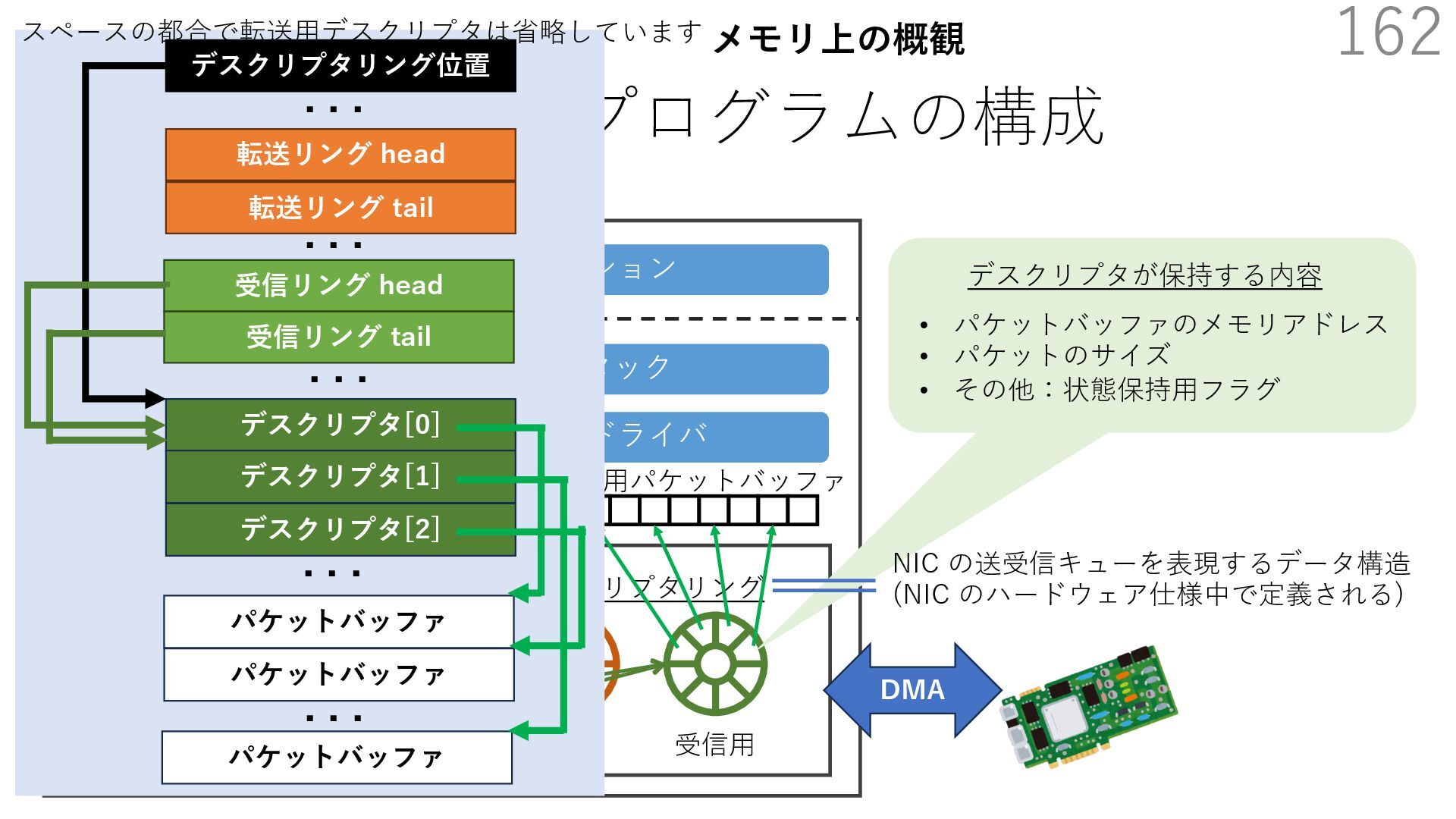{kind=link}
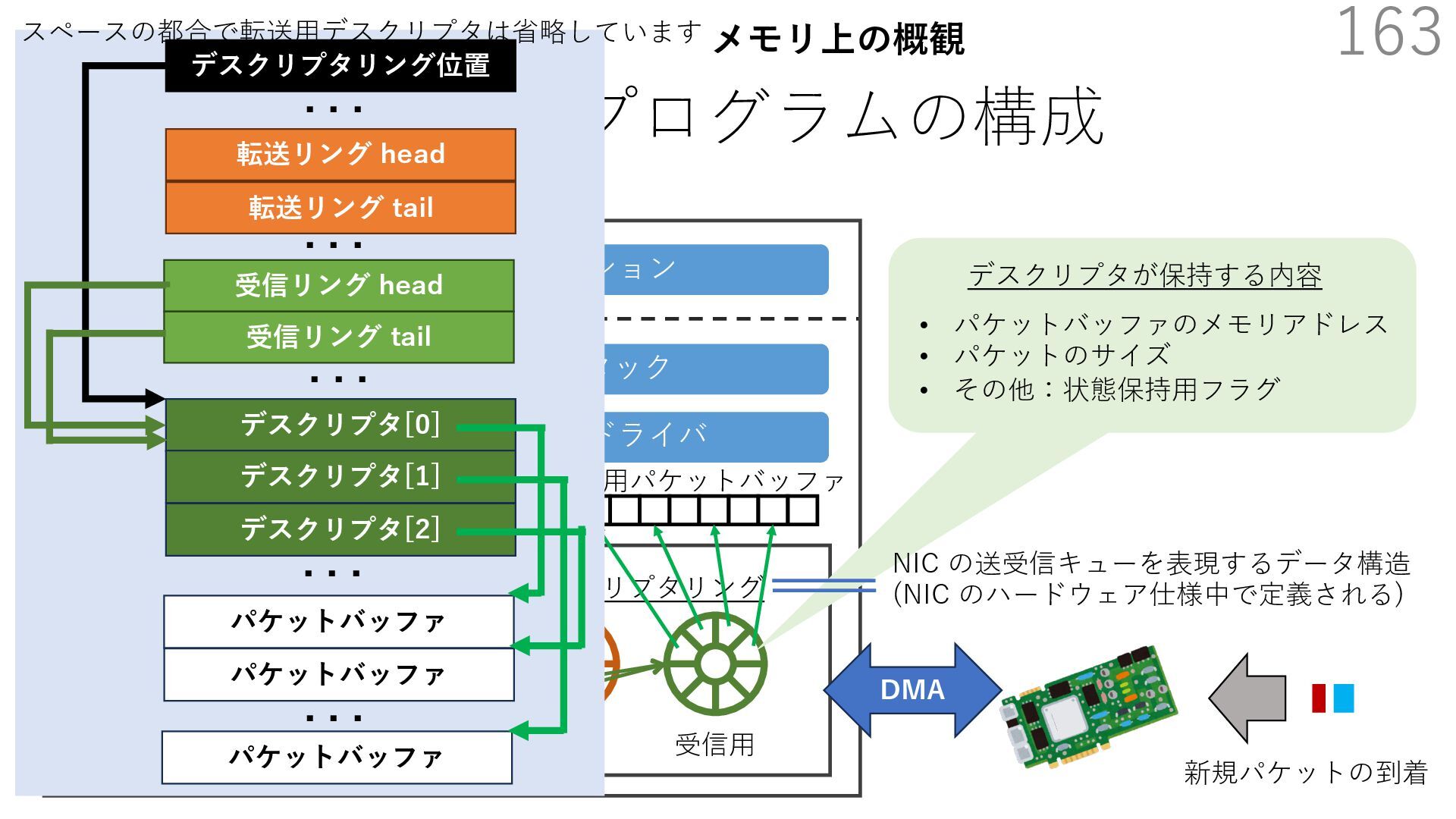{kind=link}
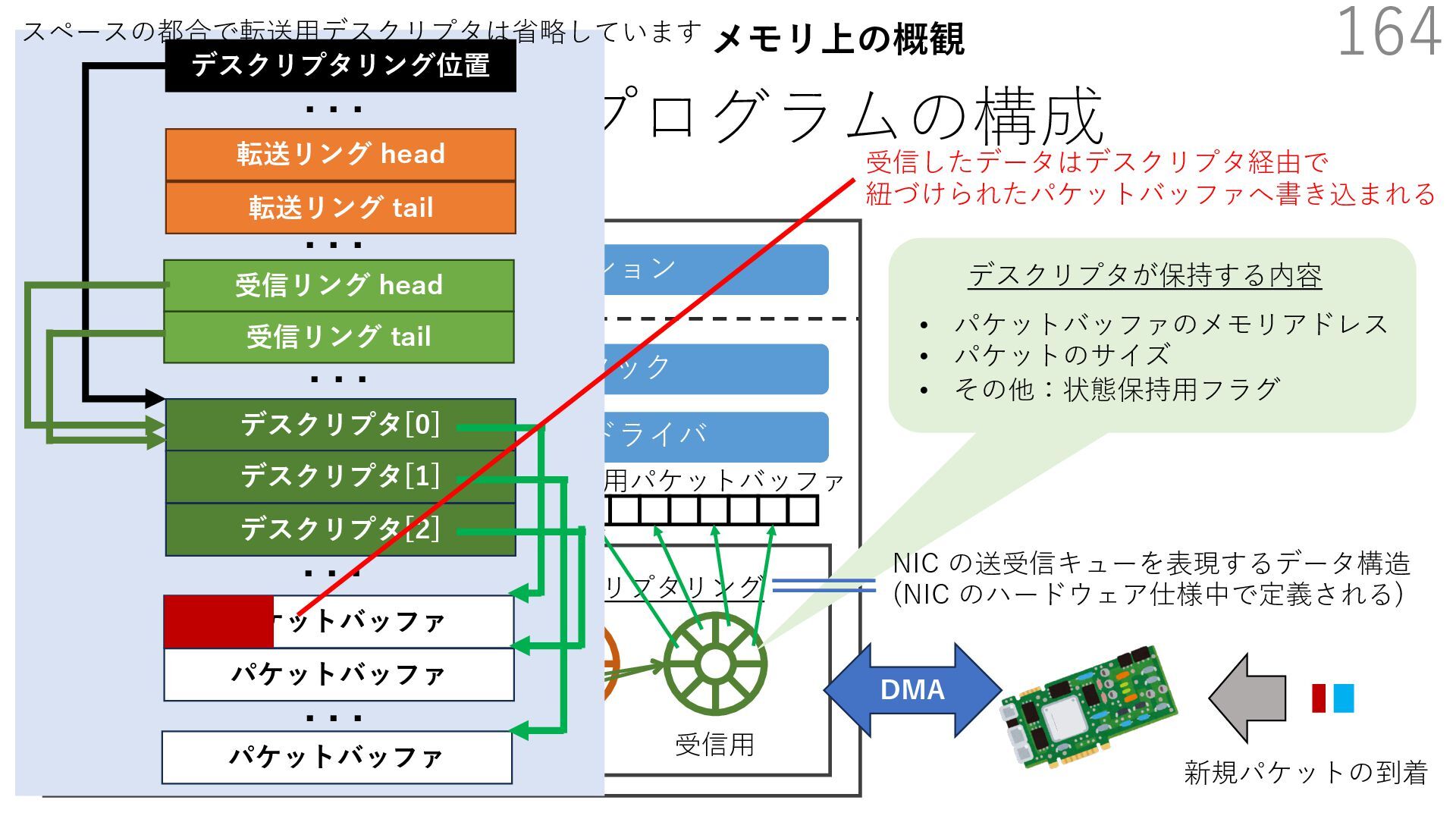{kind=link}
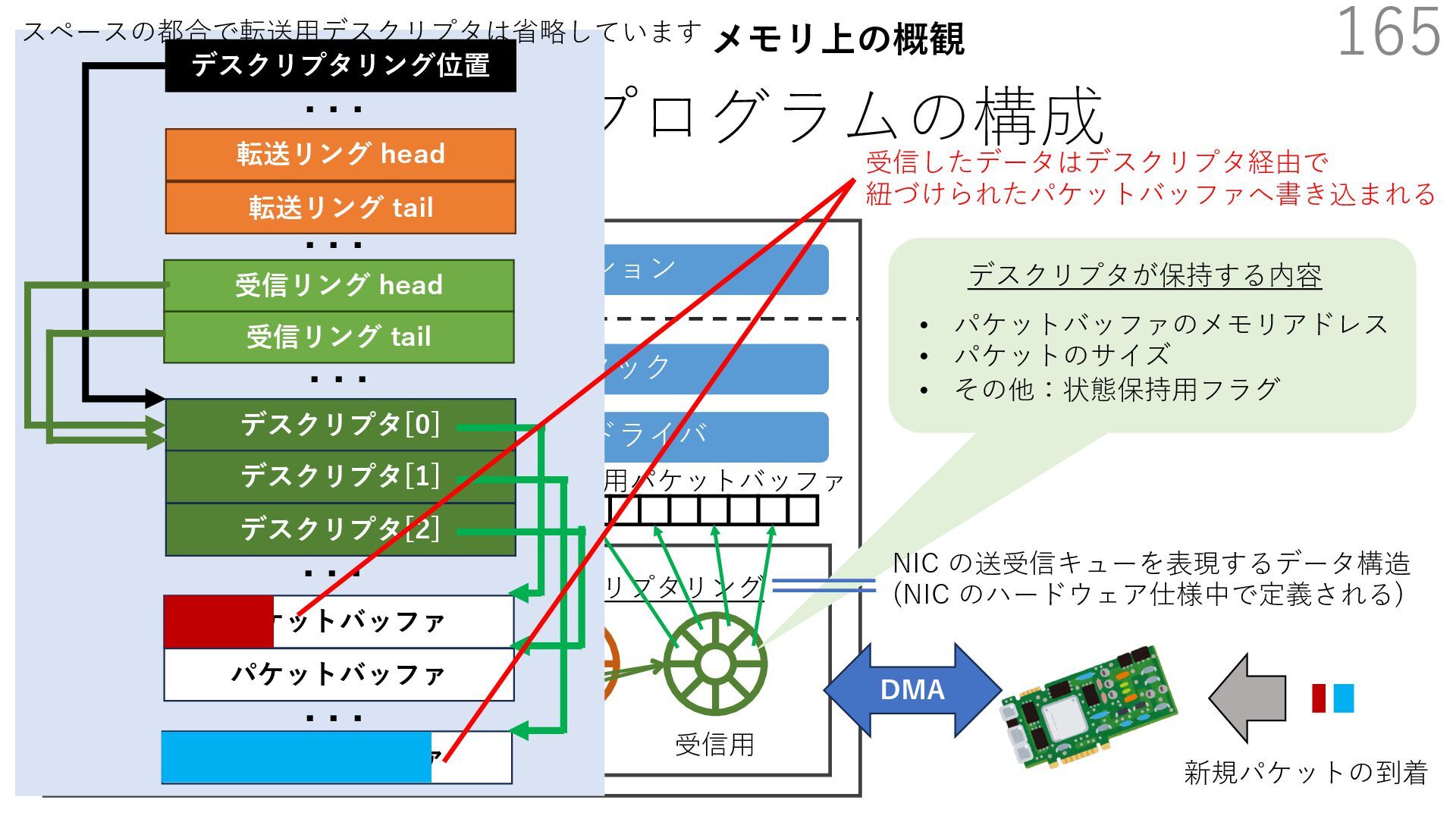{kind=link}
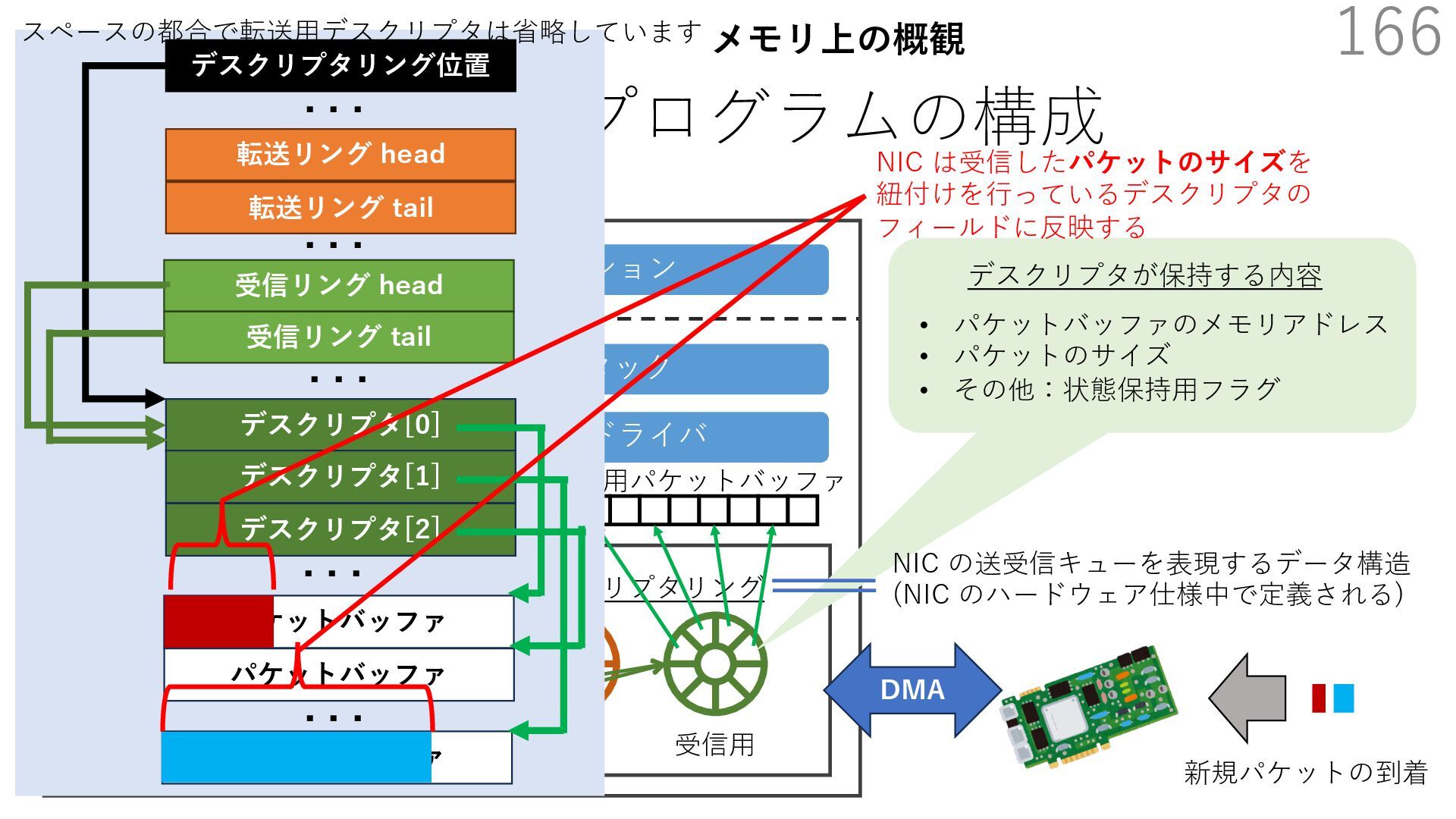{kind=link}
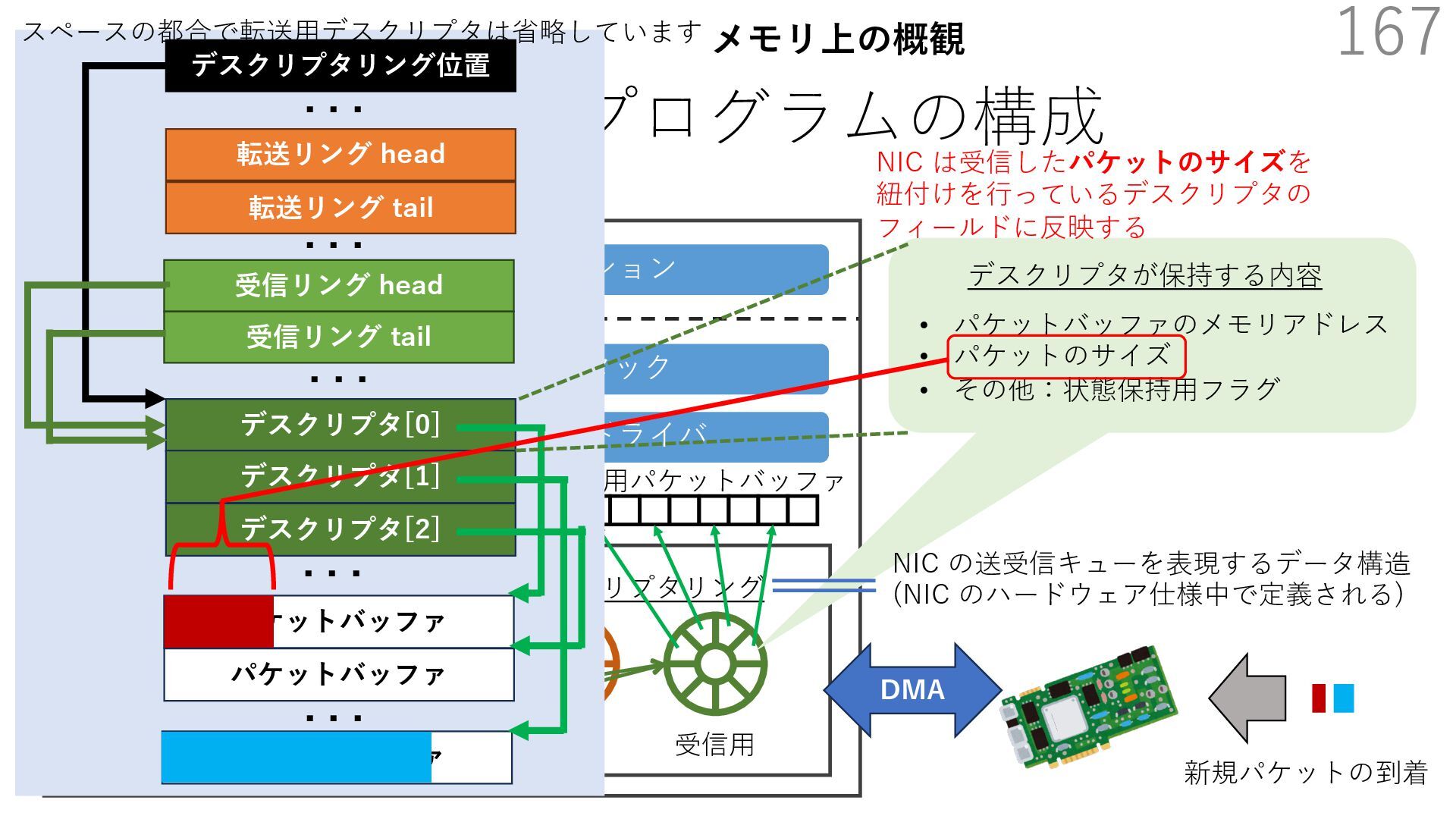{kind=link}
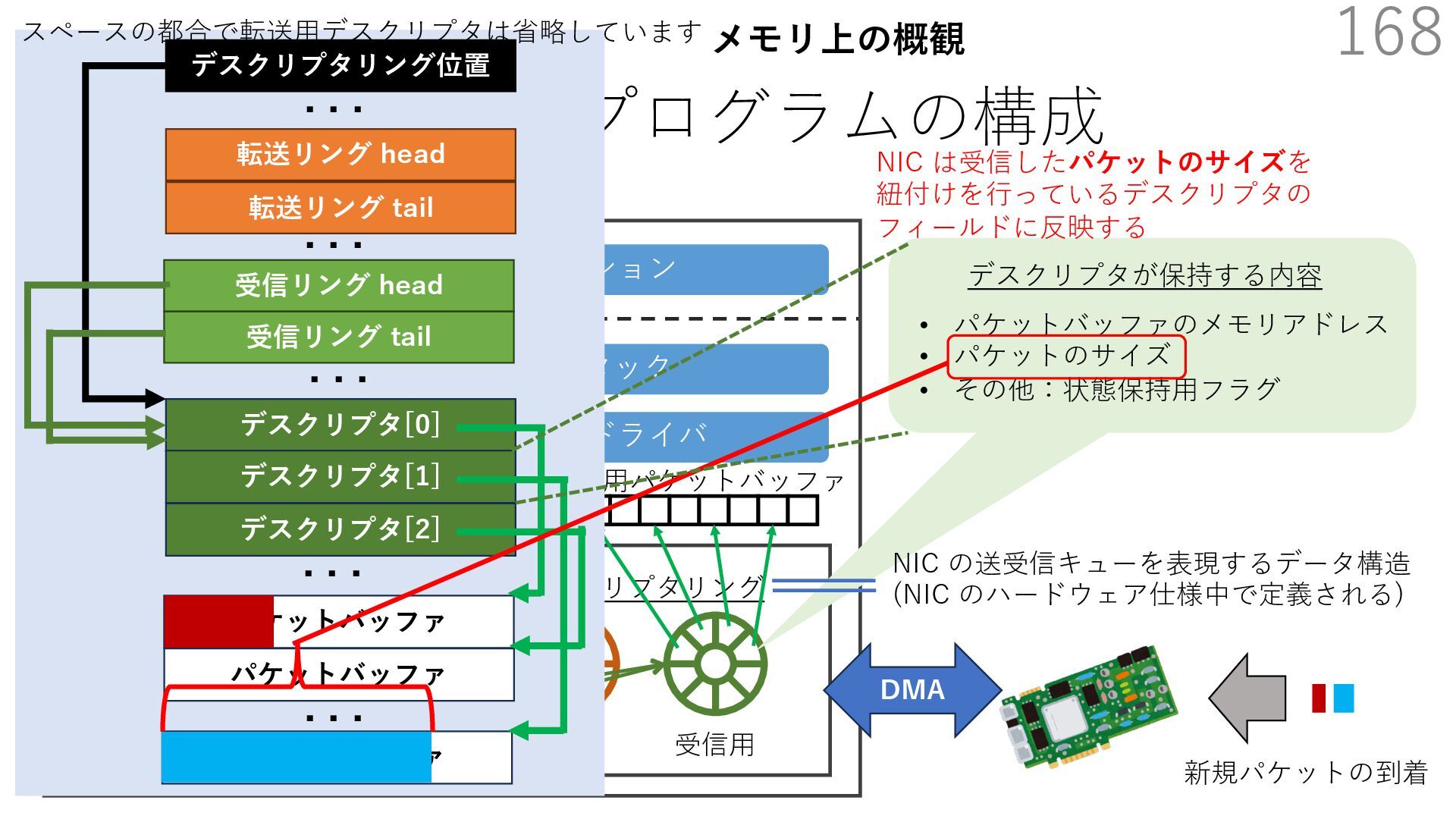{kind=link}
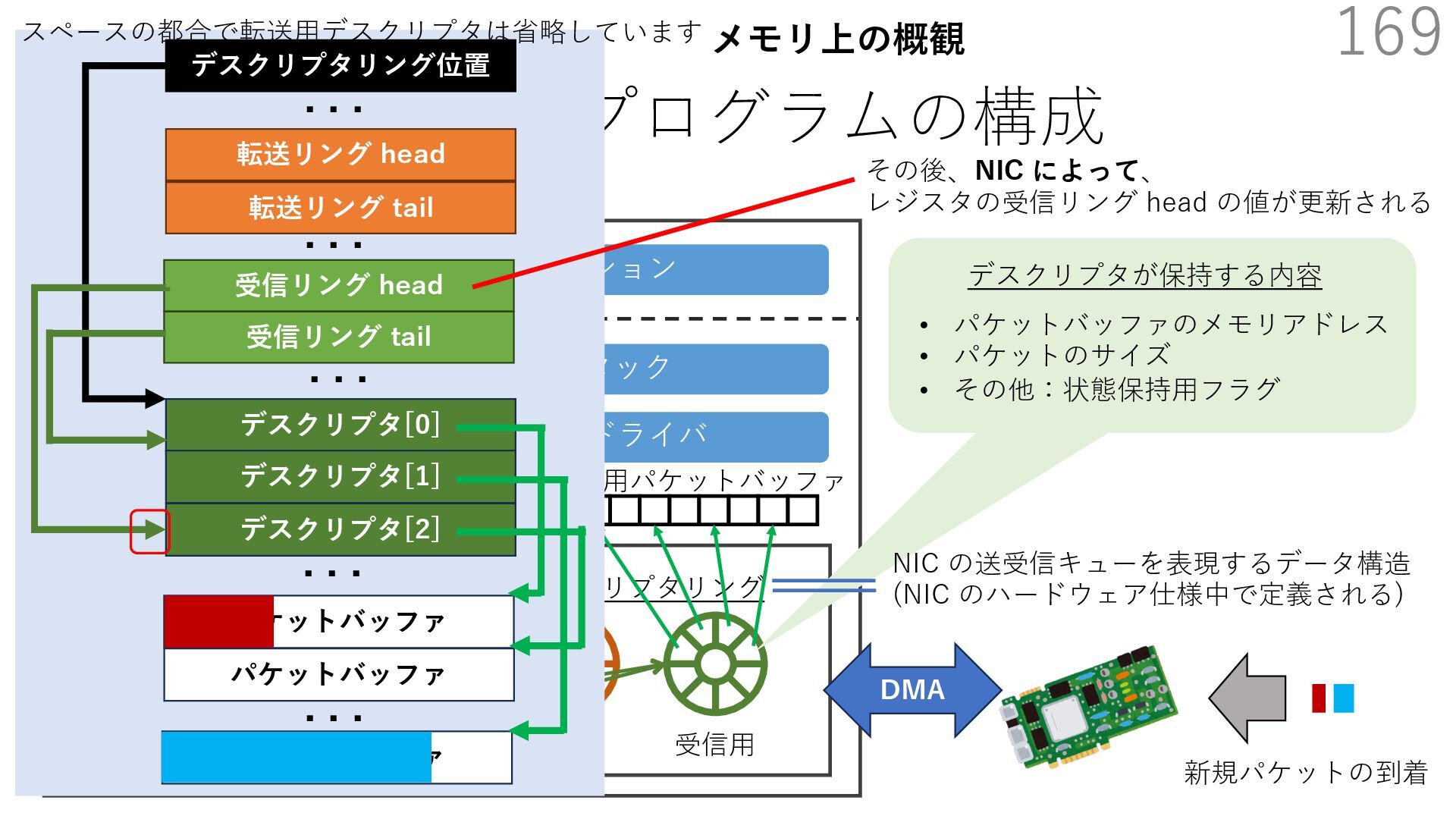{kind=link}
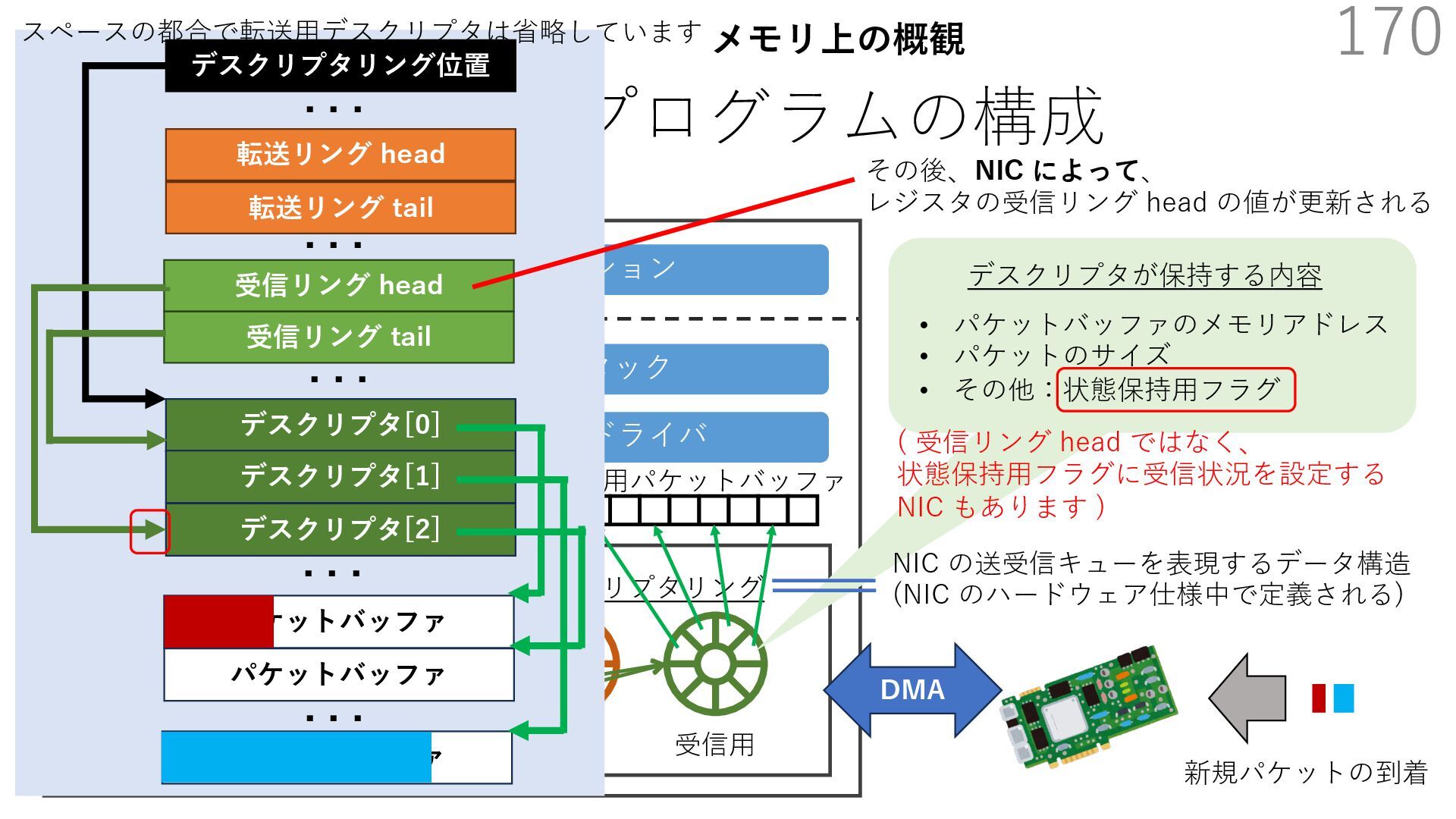{kind=link}
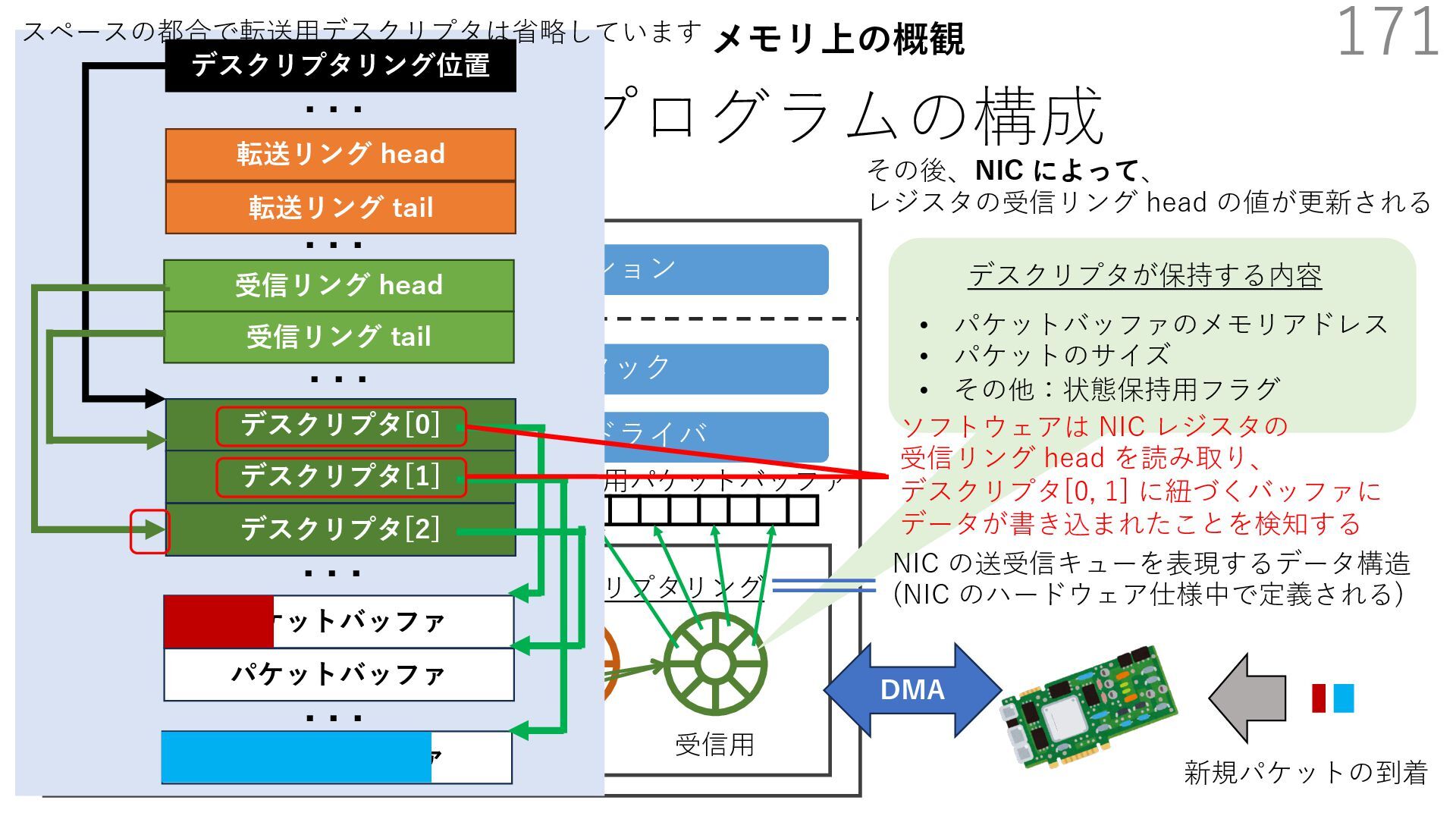{kind=link}
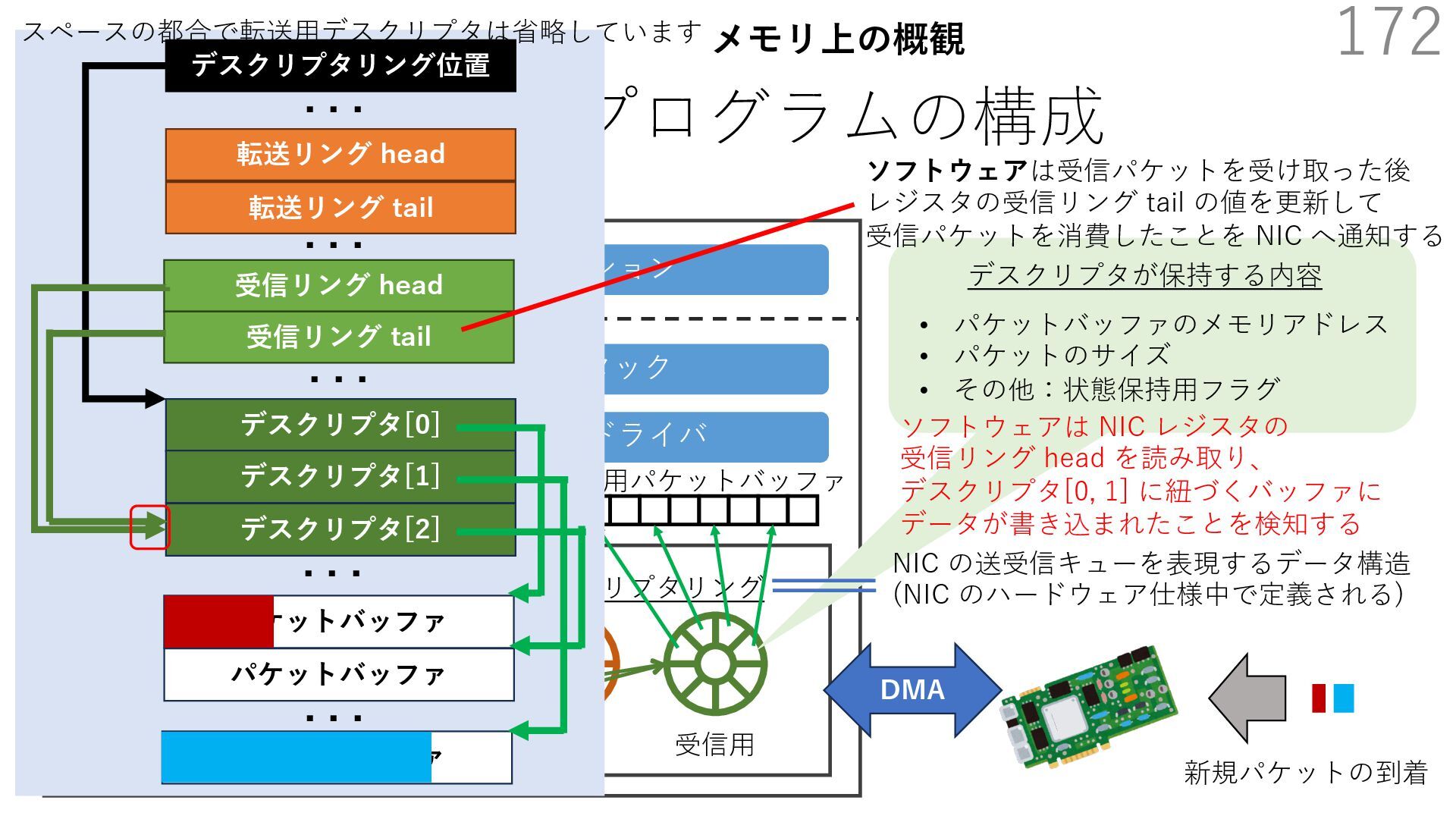{kind=link}
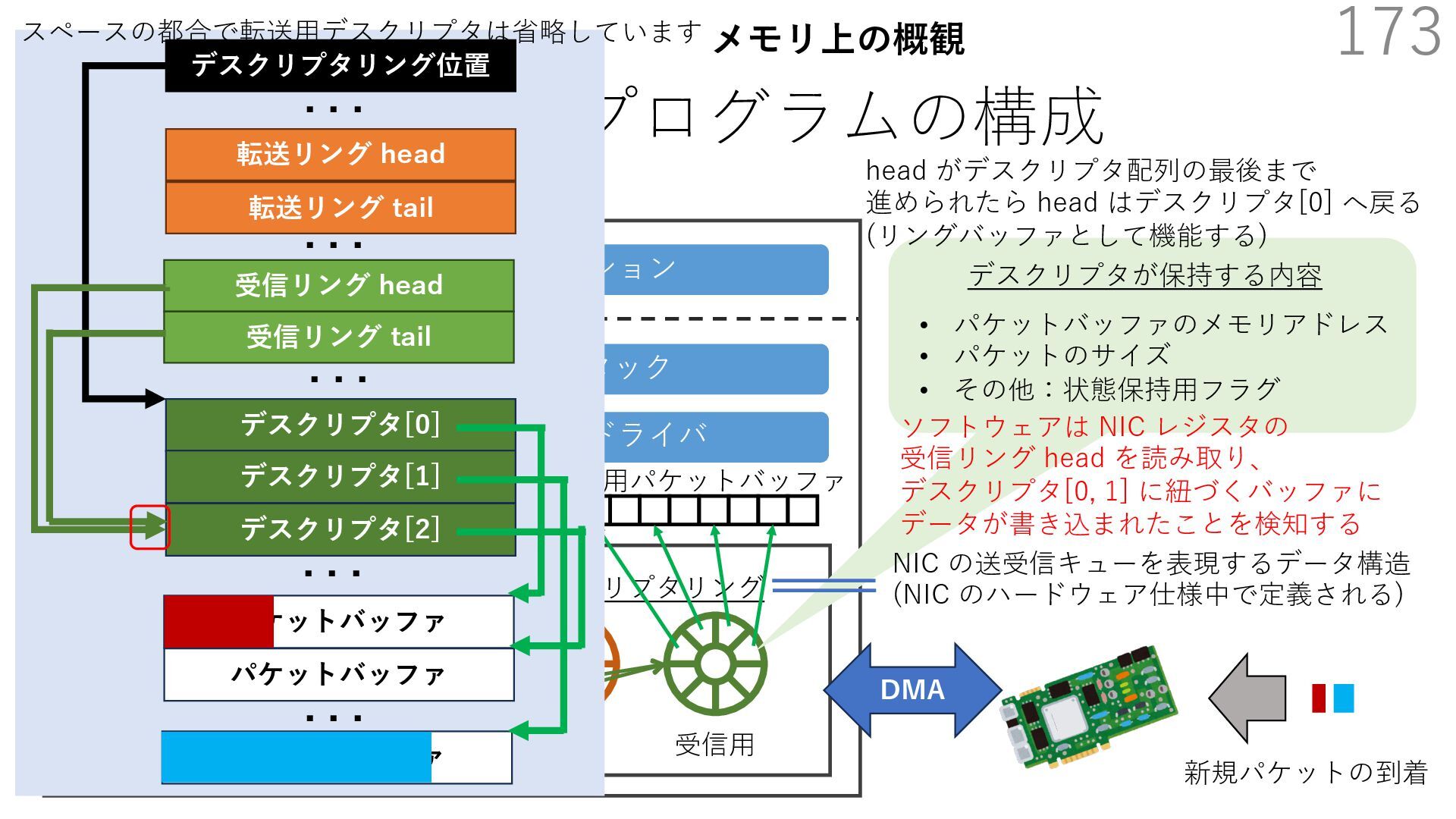{kind=link}
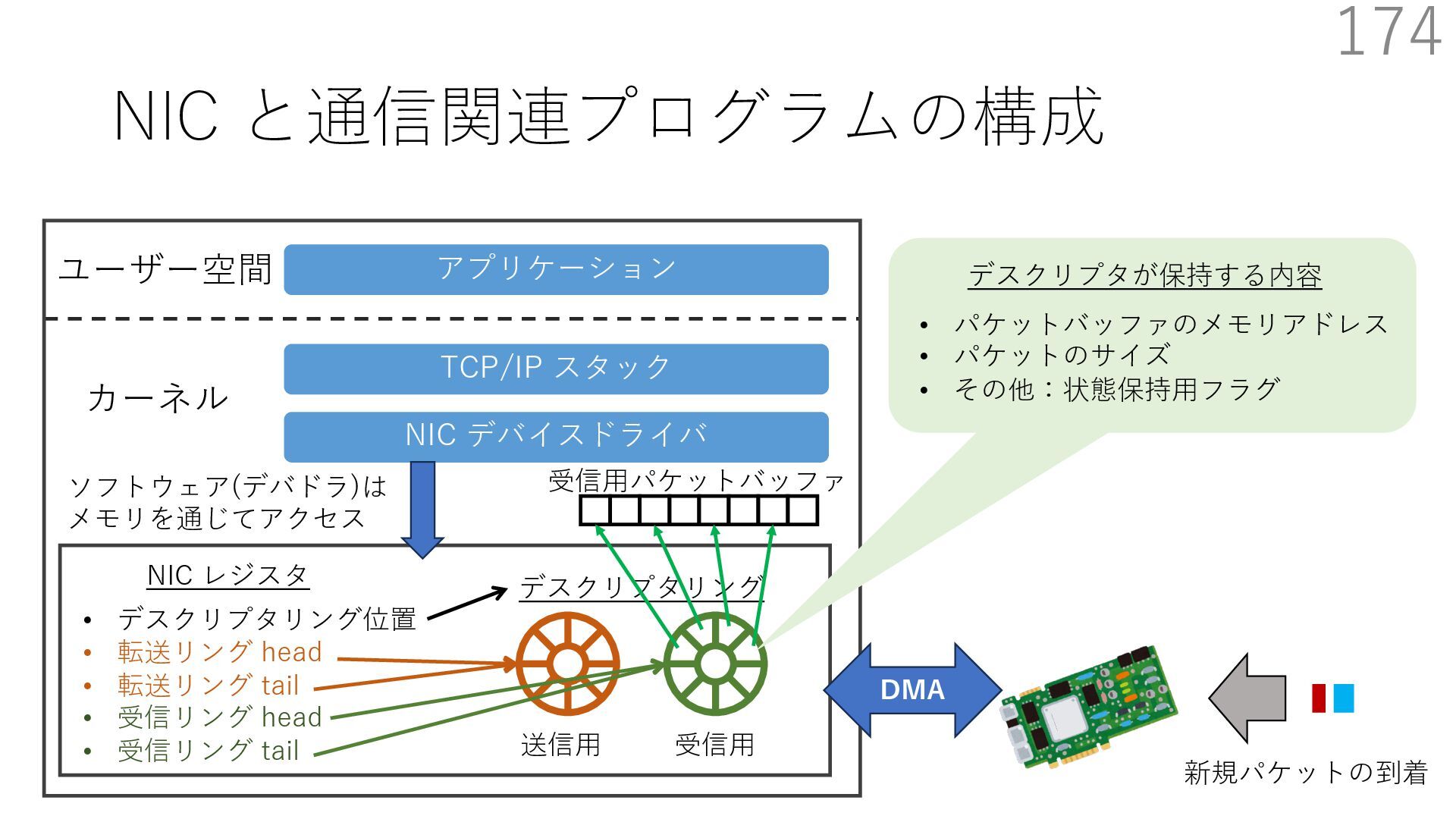{kind=link}
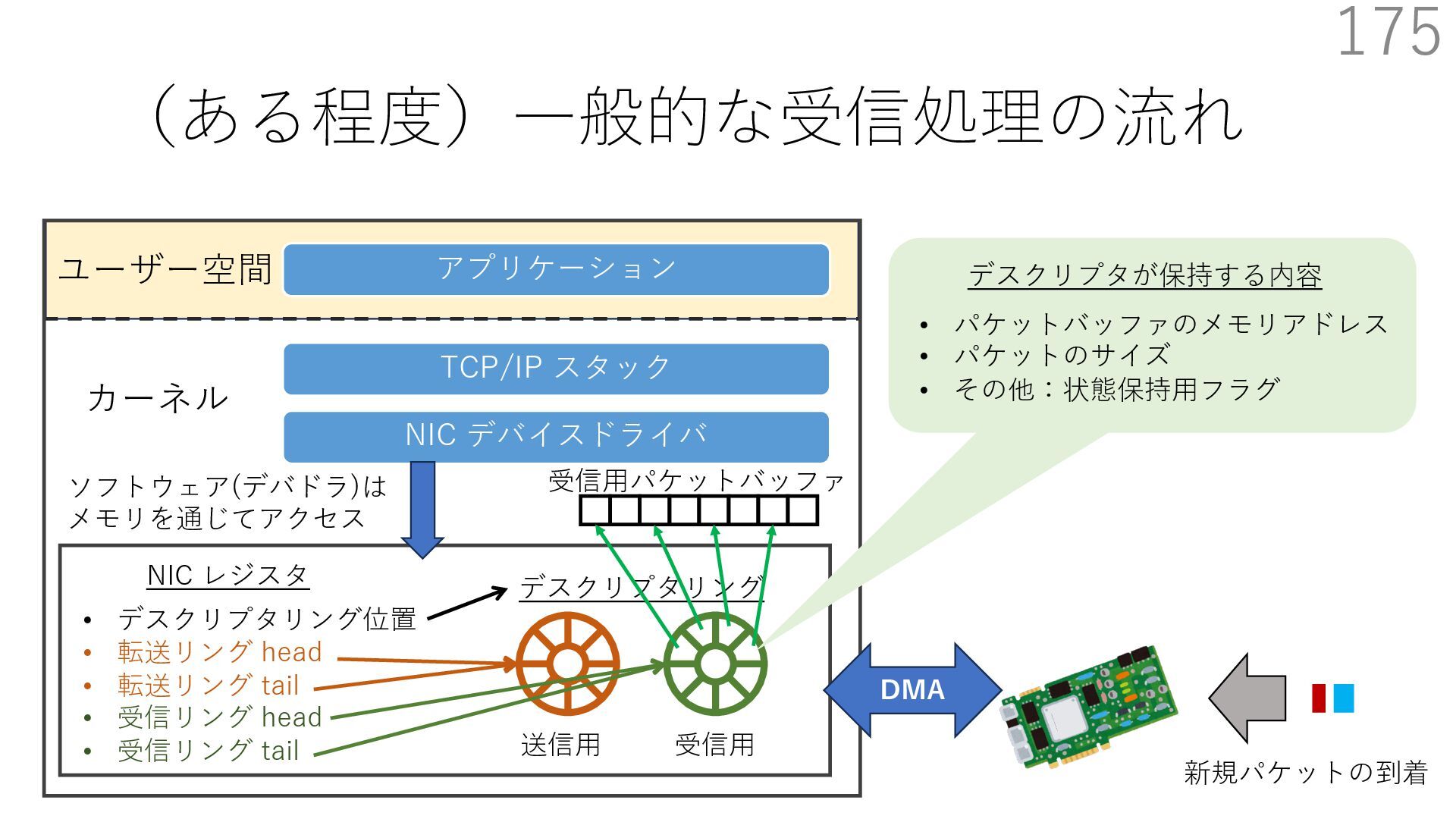{kind=link}
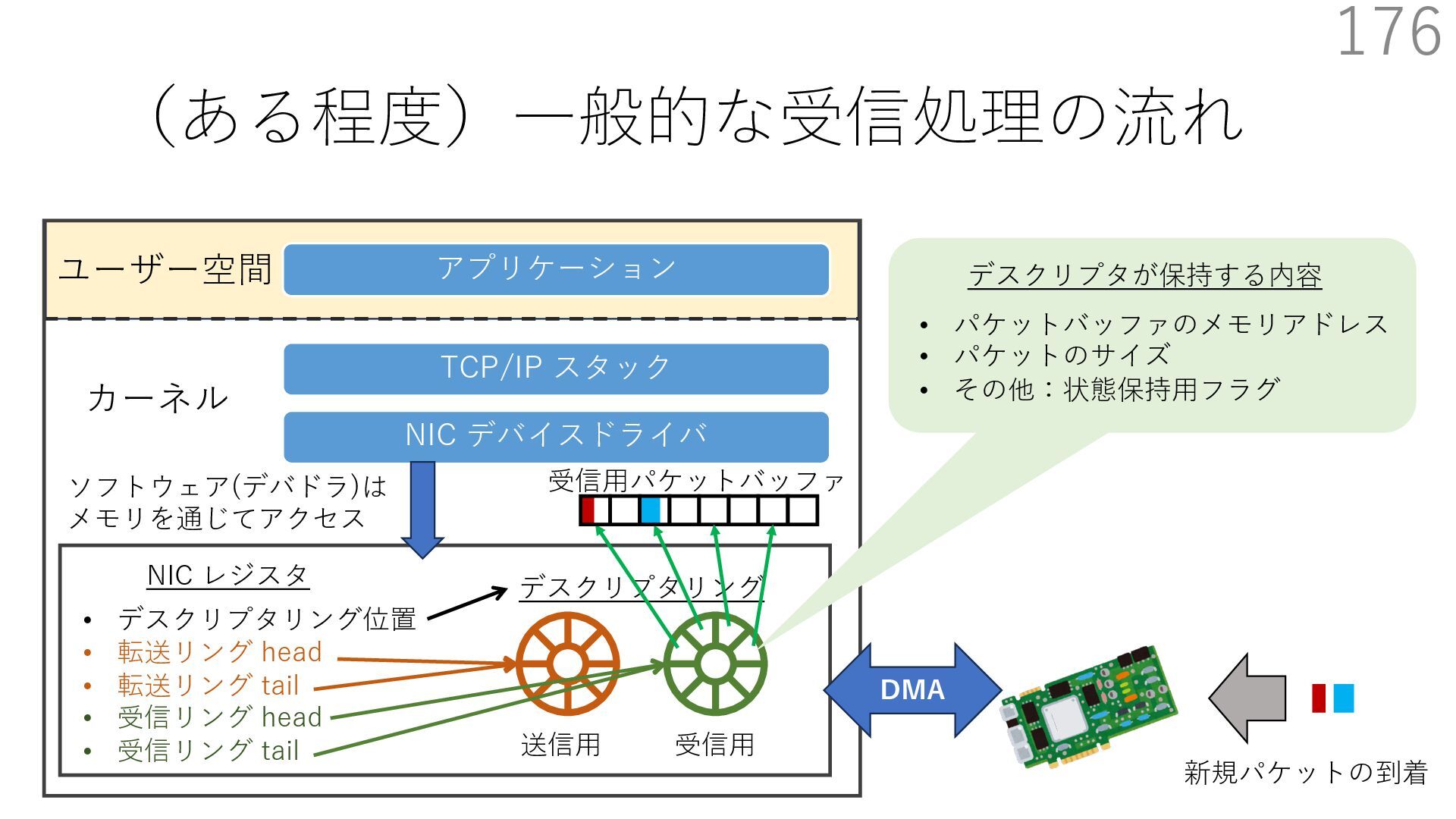{kind=link}
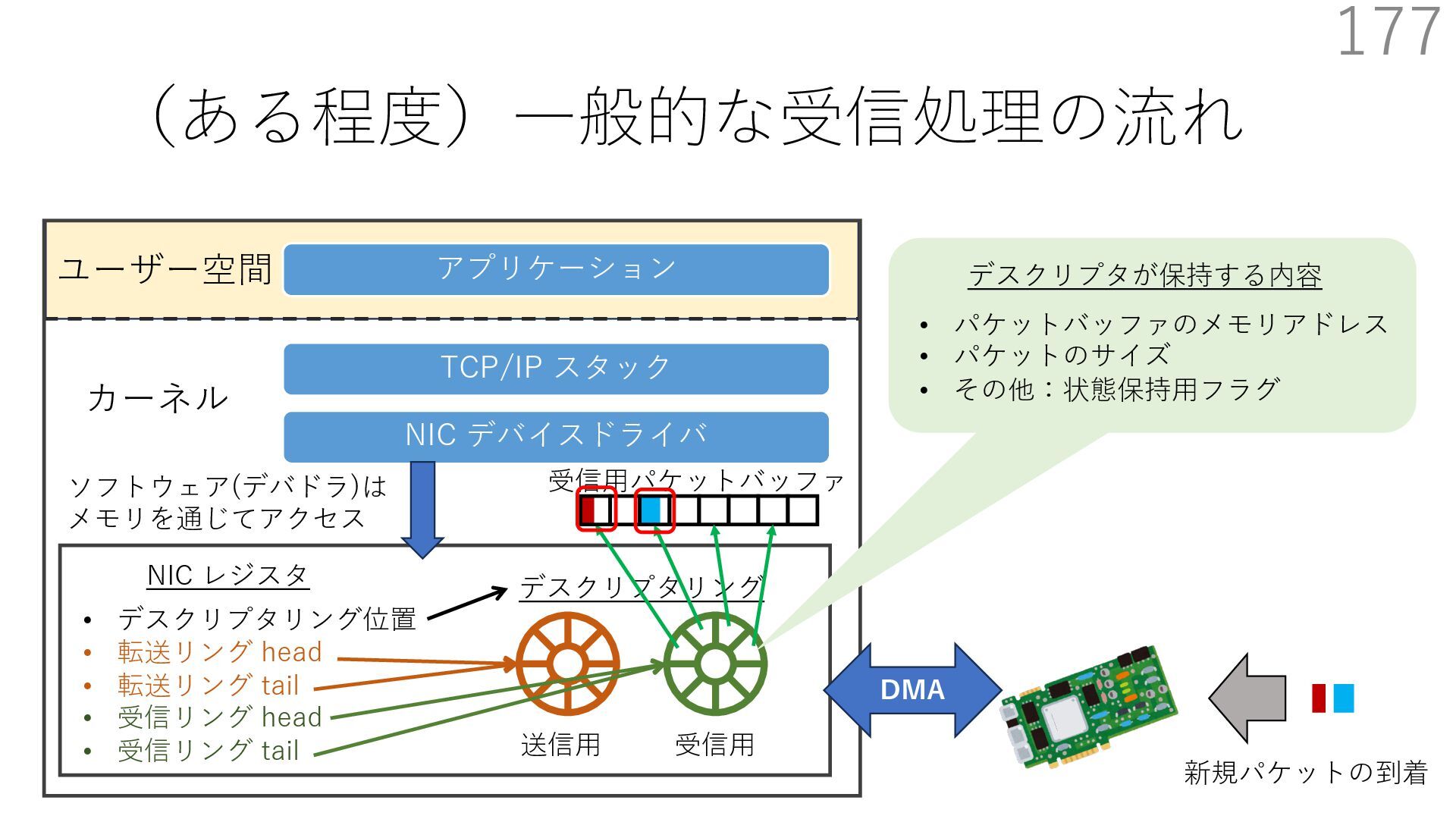{kind=link}
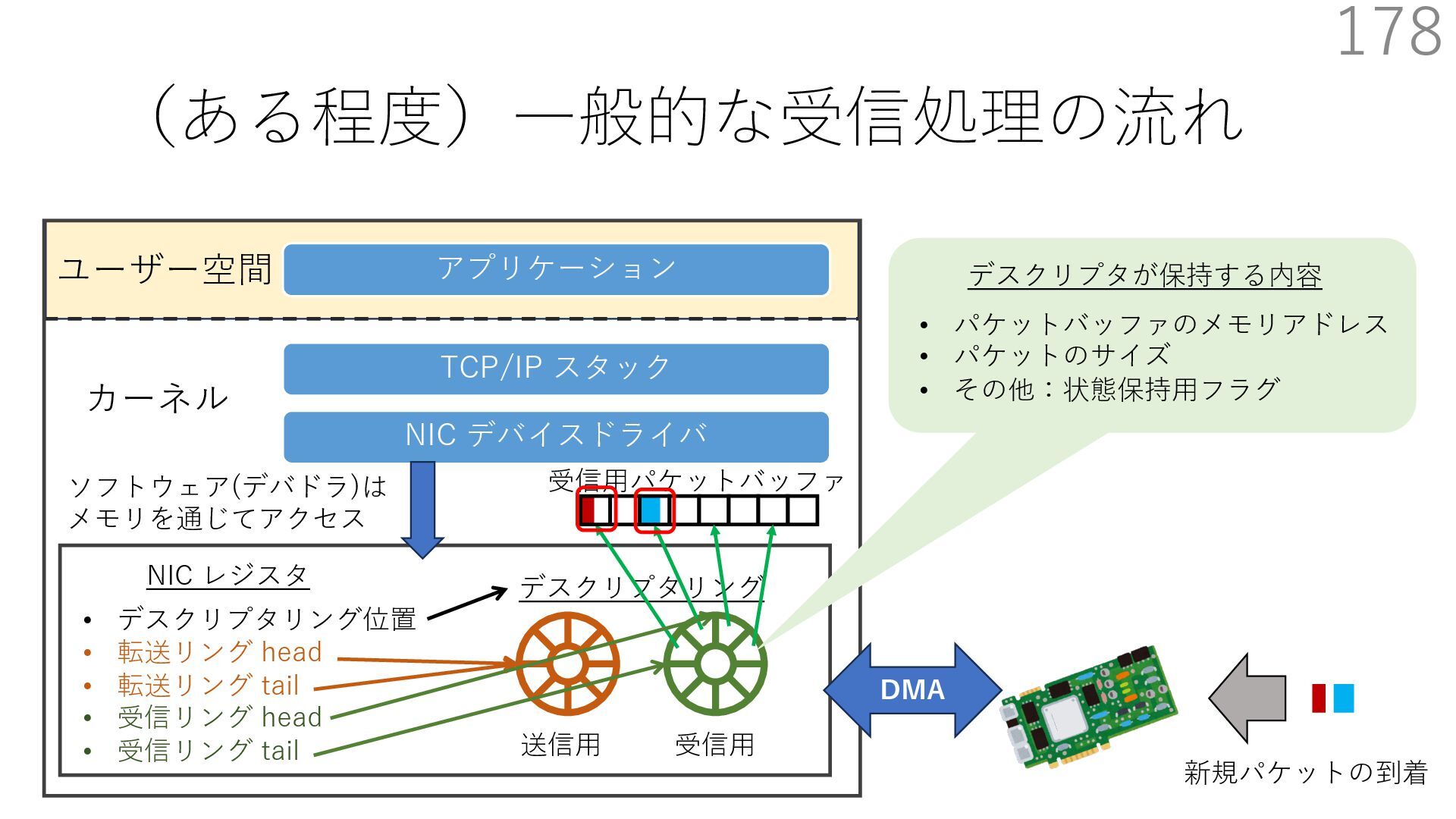{kind=link}
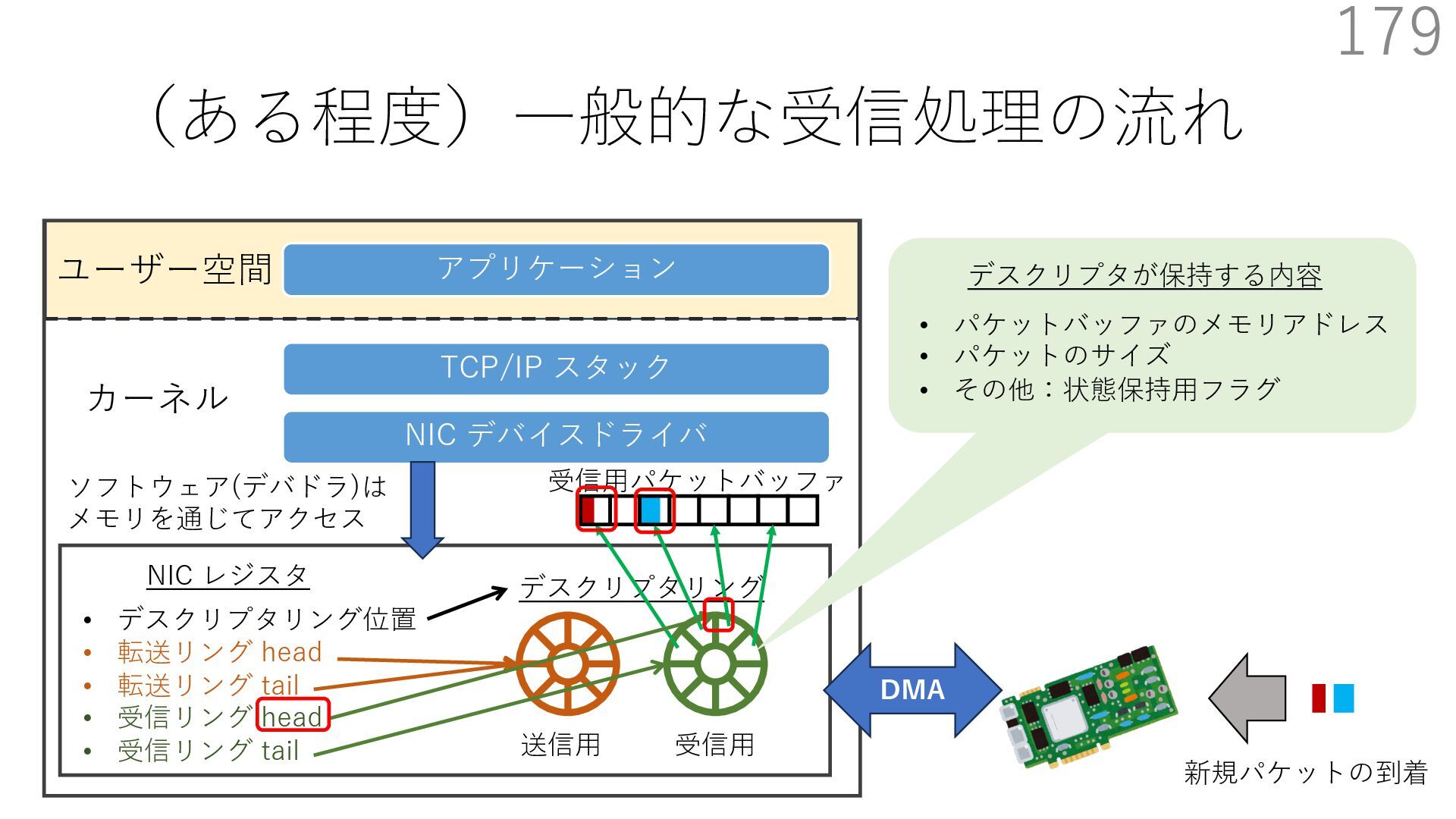{kind=link}
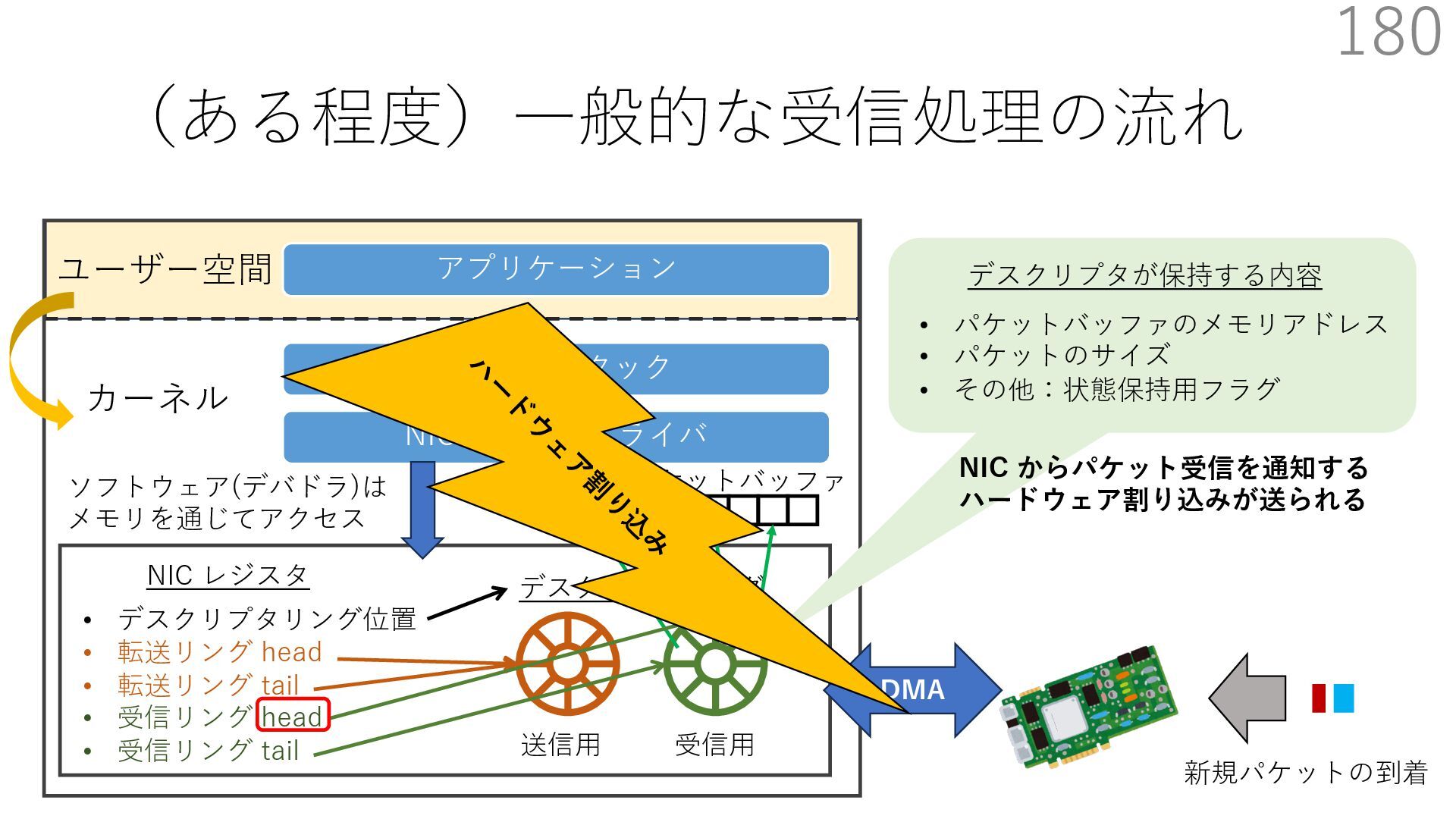{kind=link}
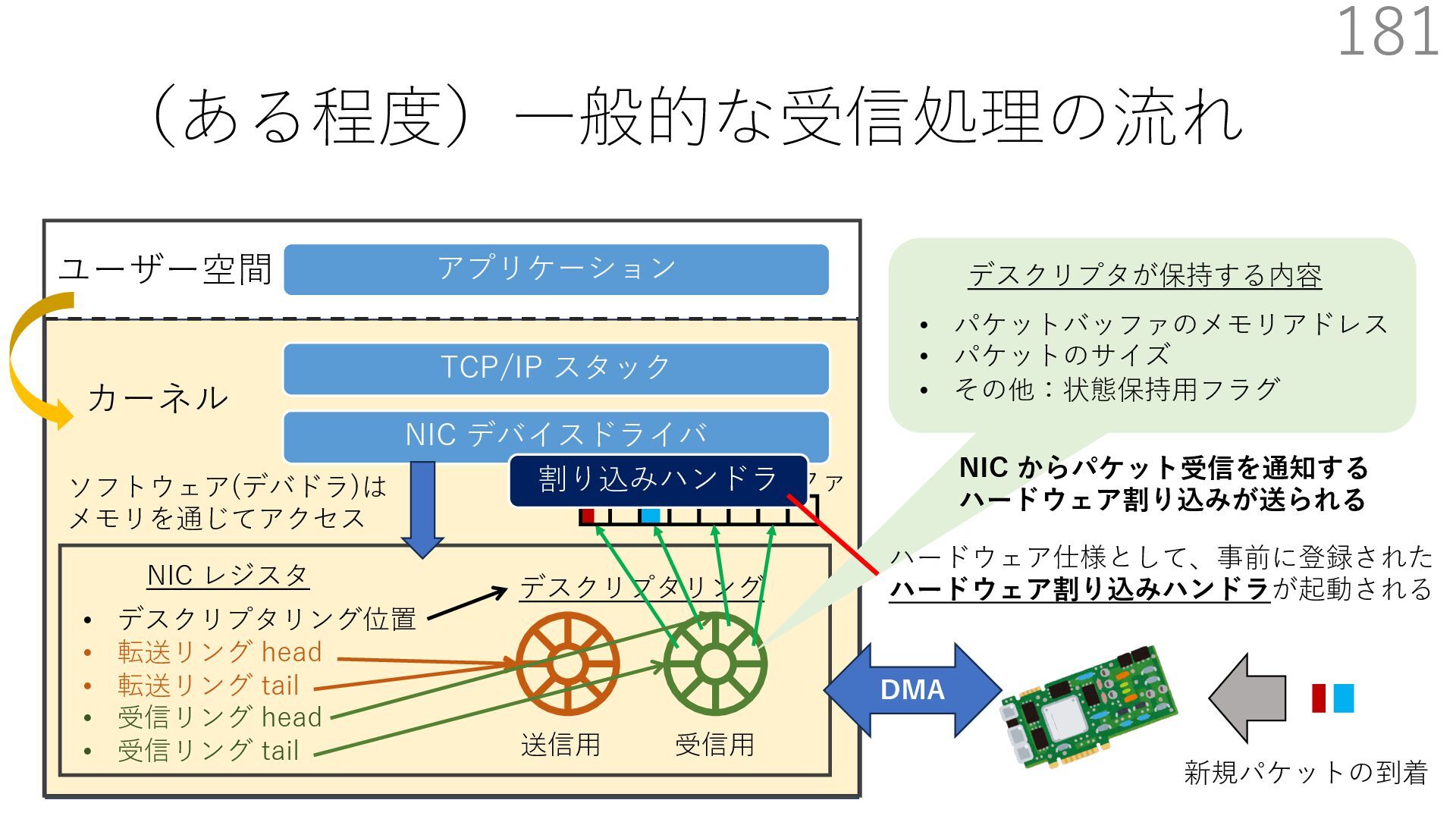{kind=link}
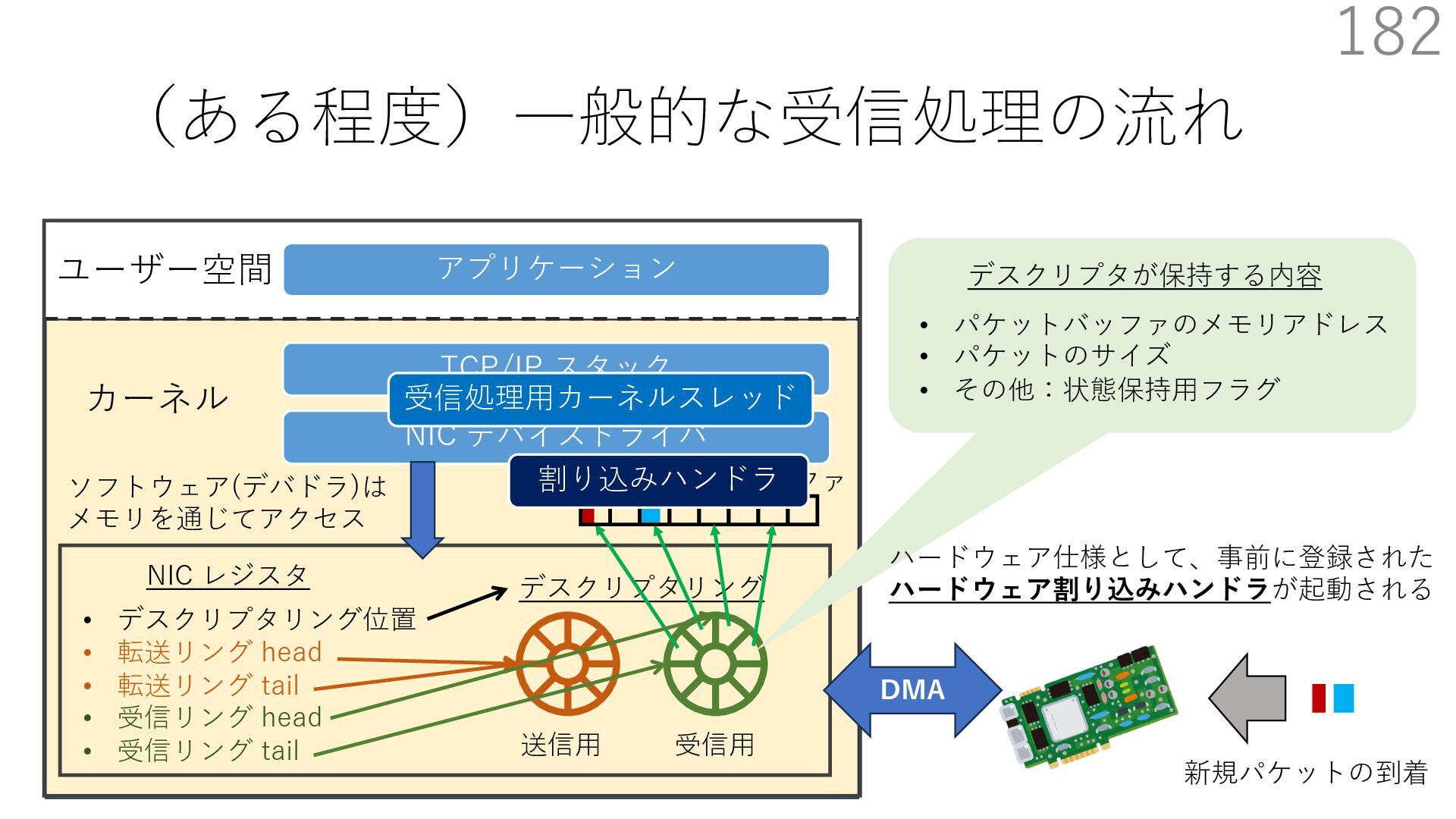{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
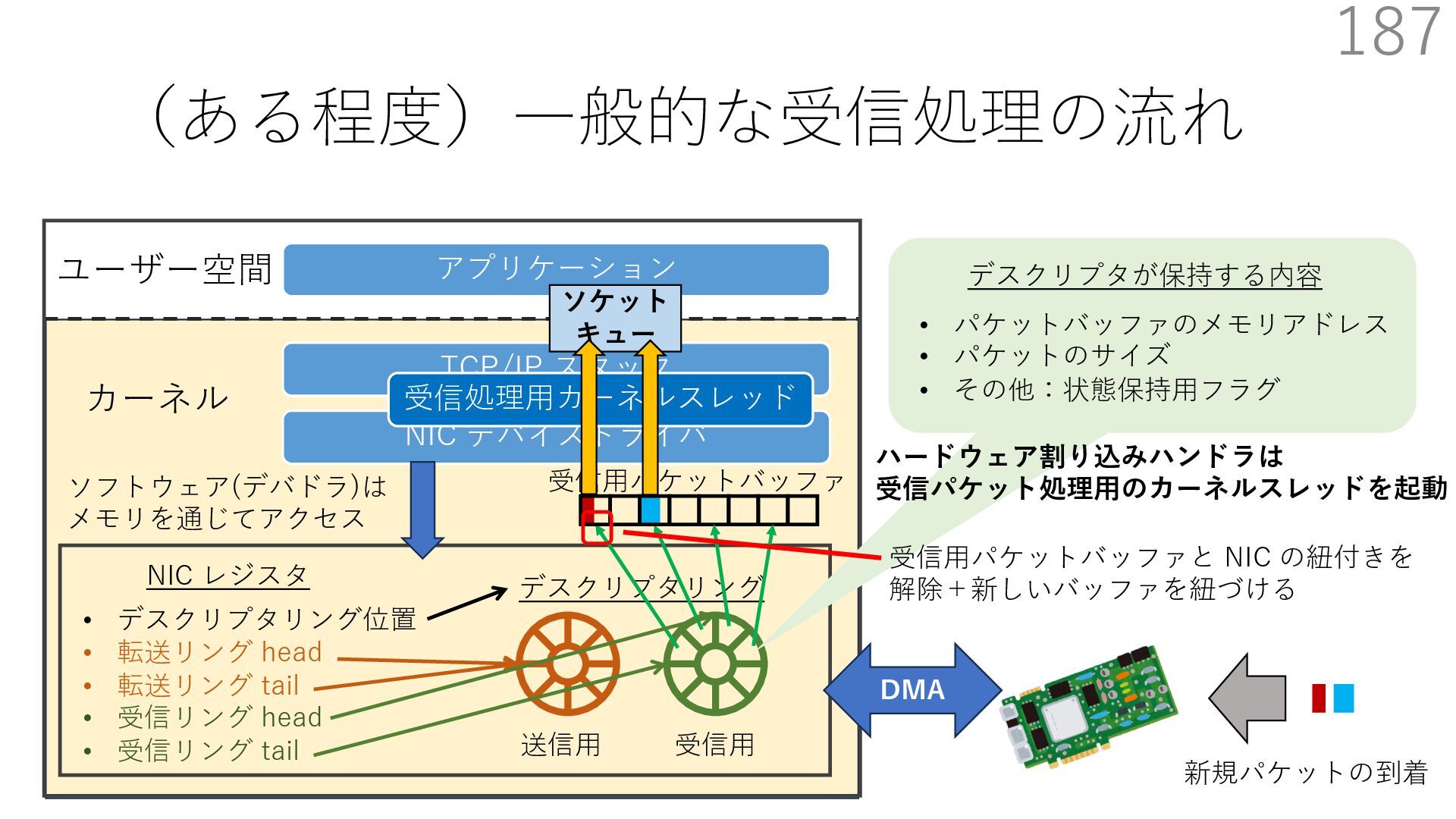{kind=link}
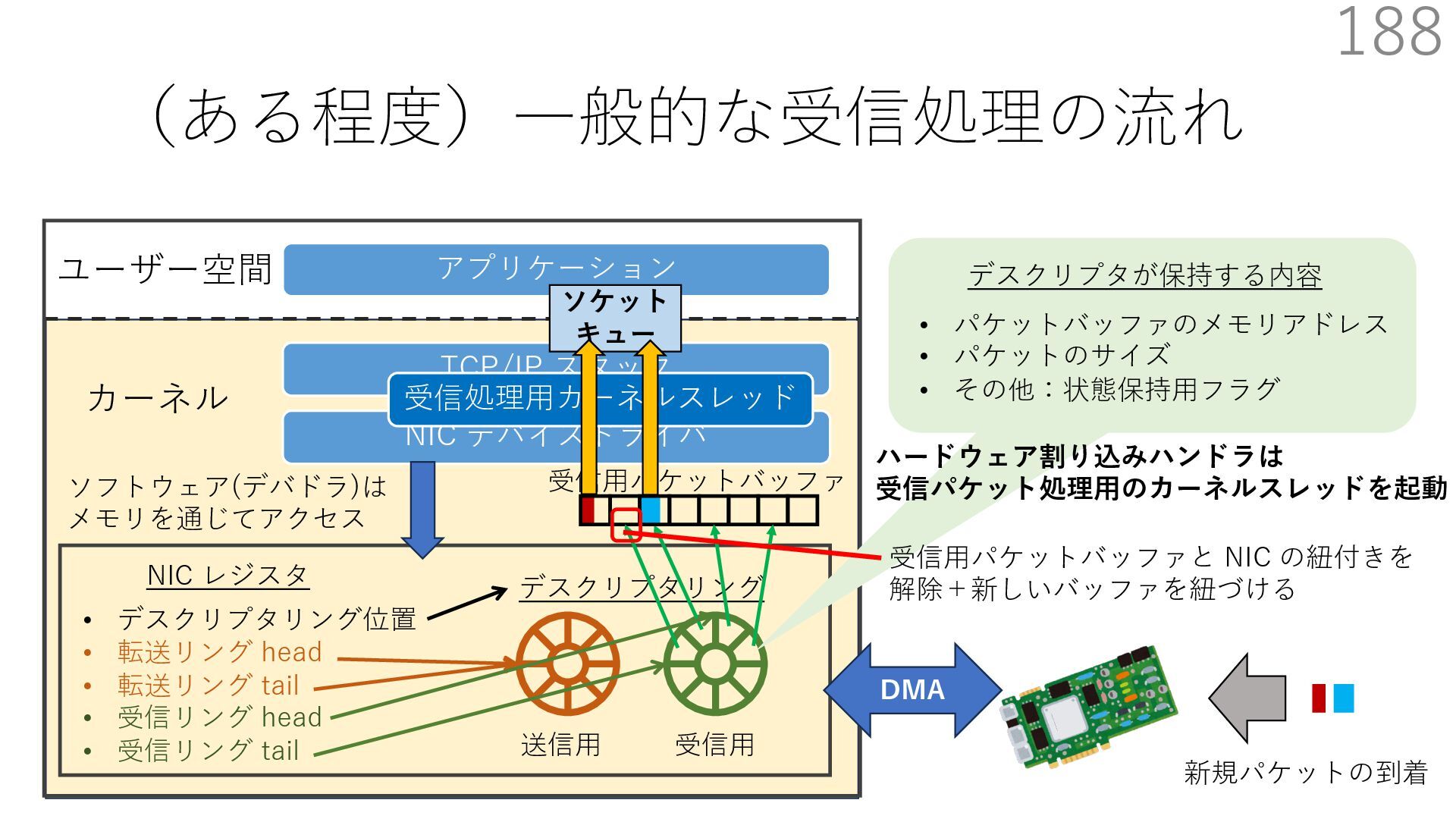{kind=link}
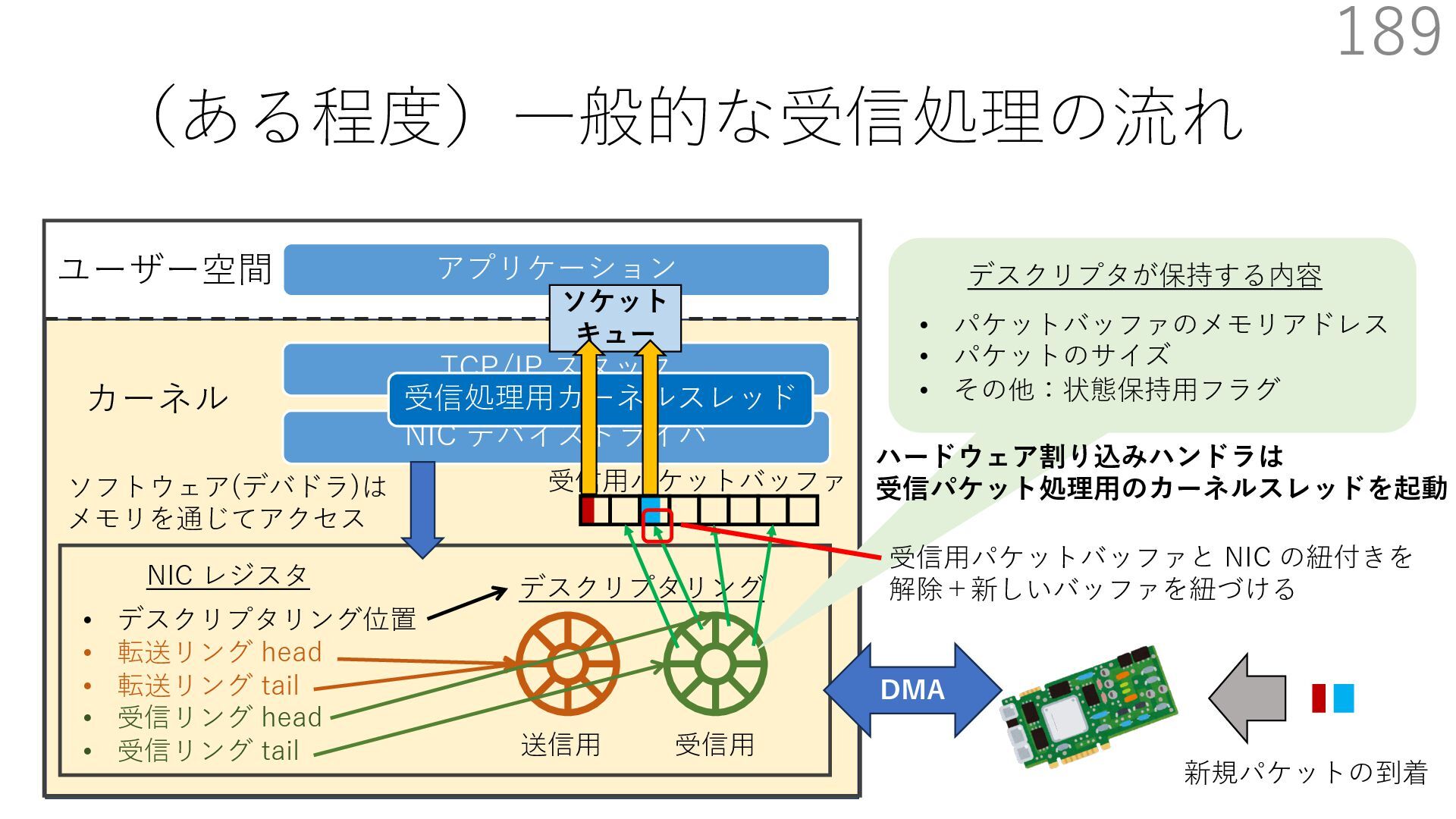{kind=link}
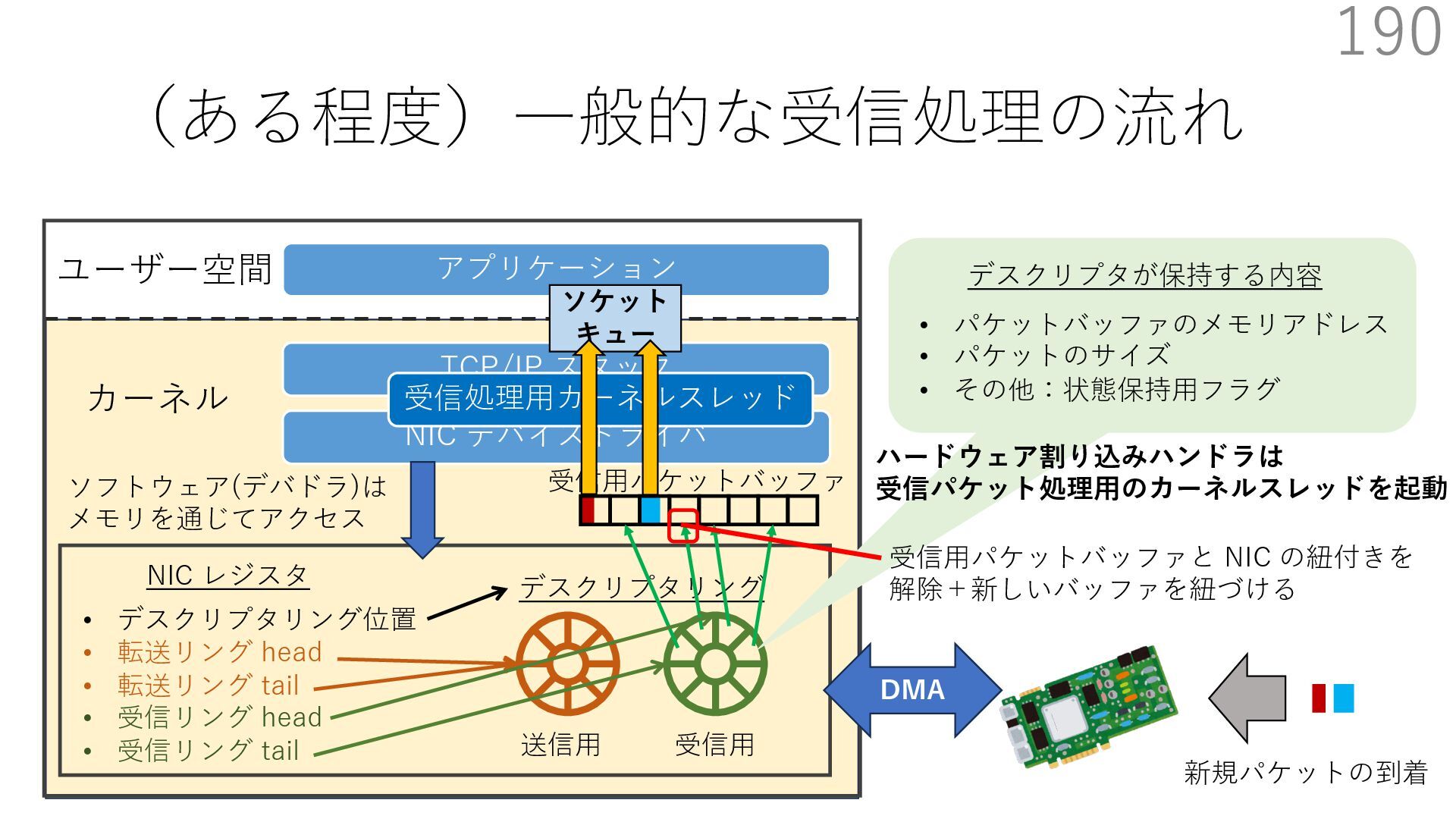{kind=link}
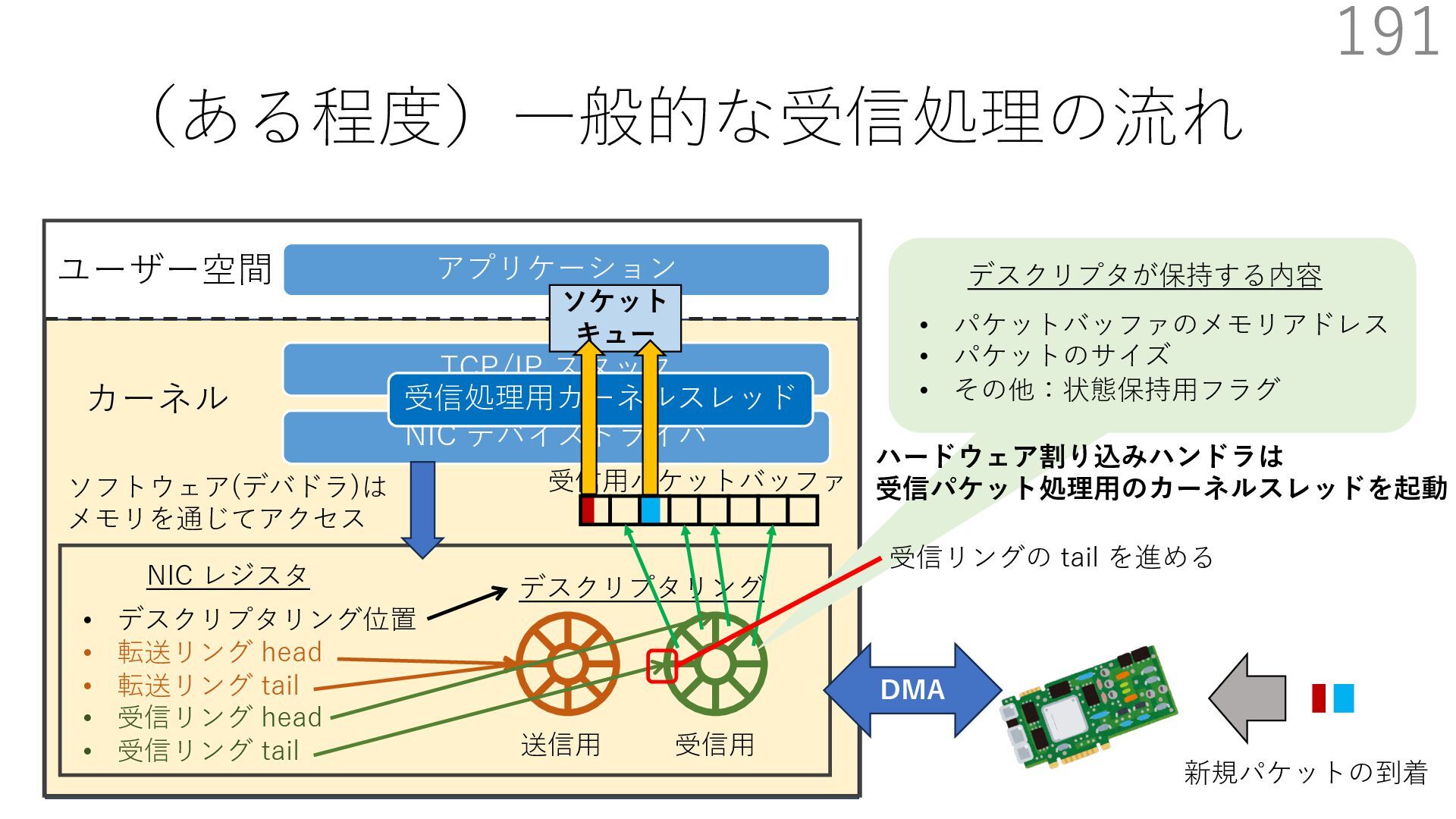{kind=link}
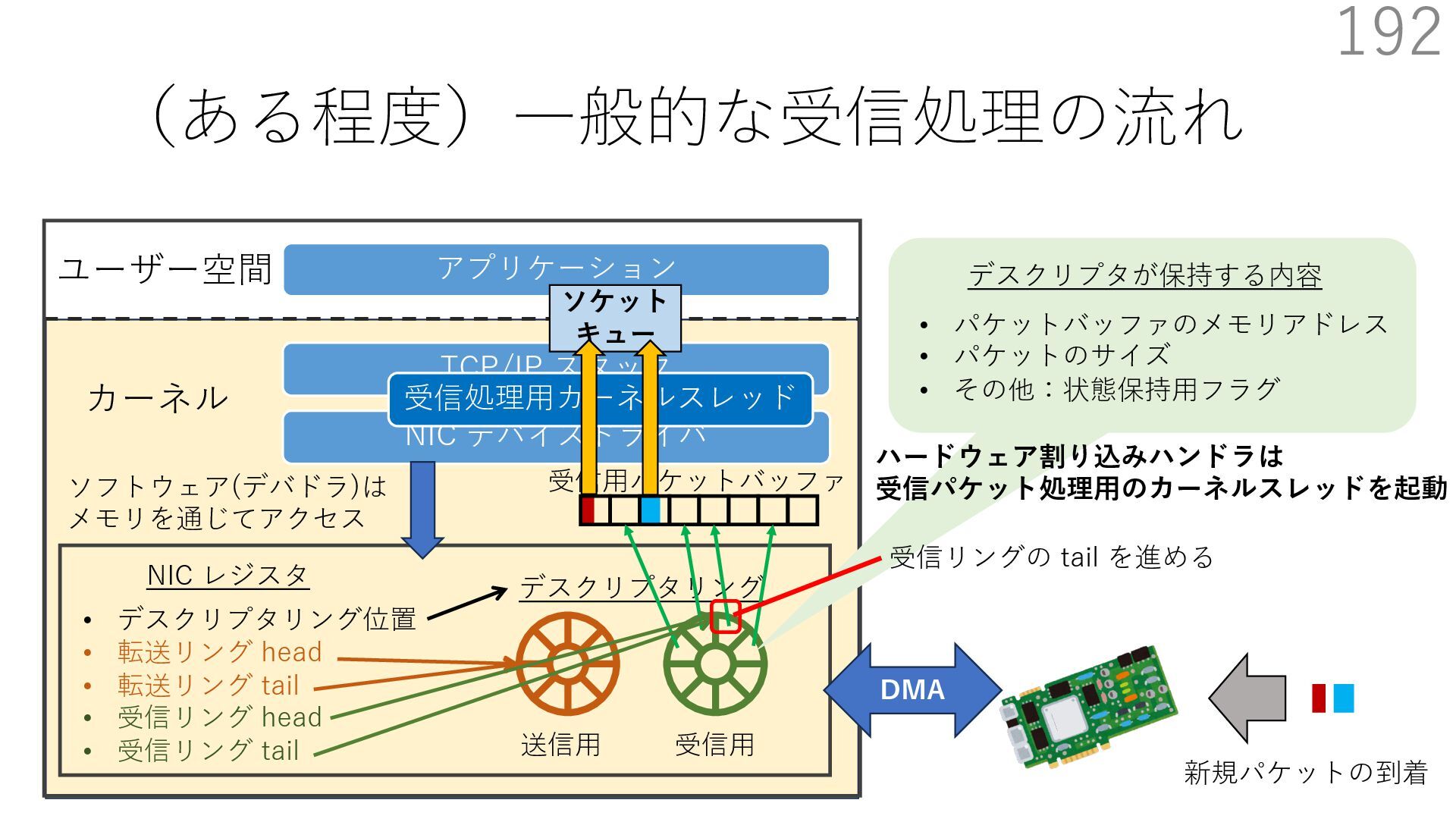{kind=link}
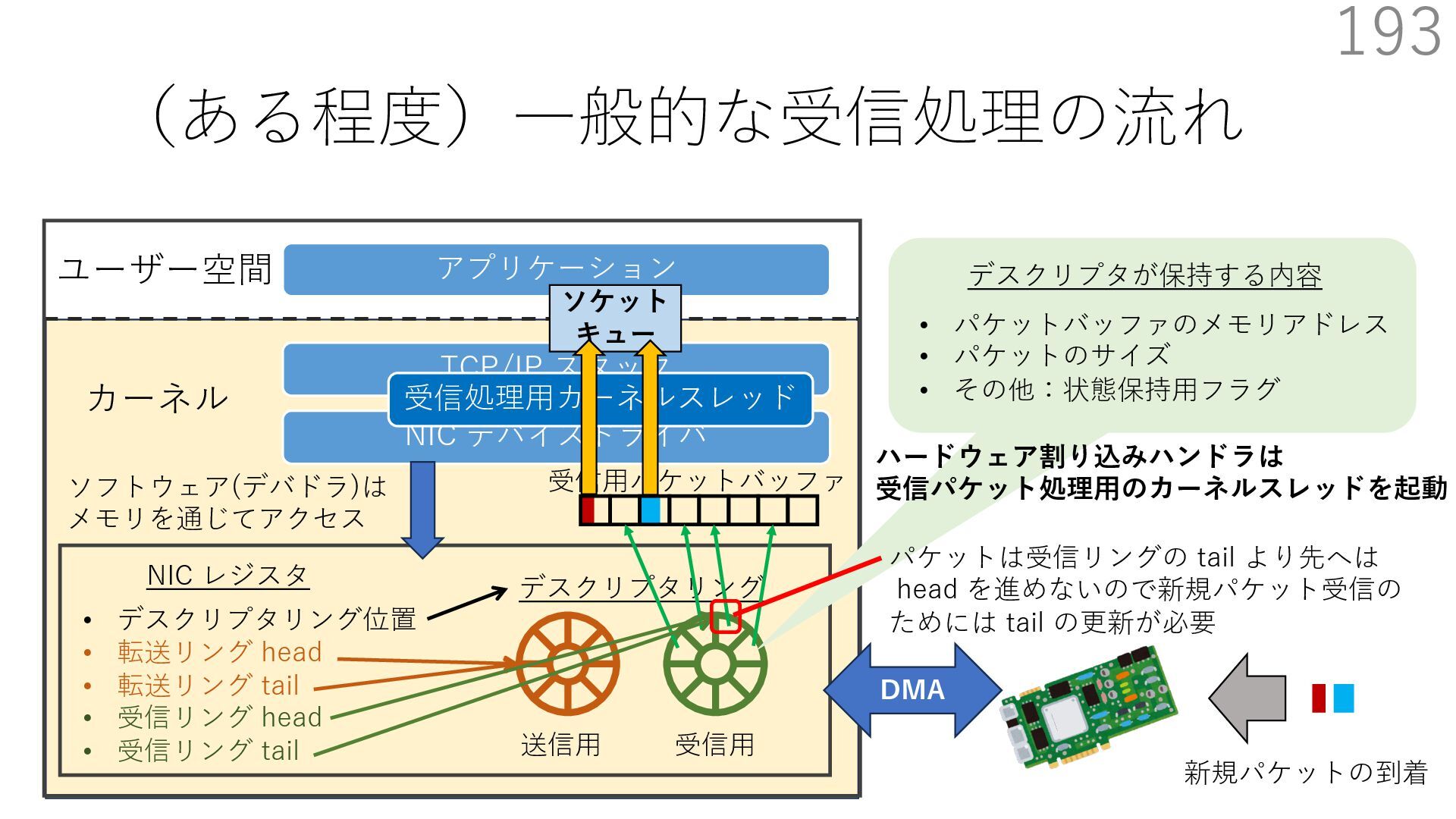{kind=link}
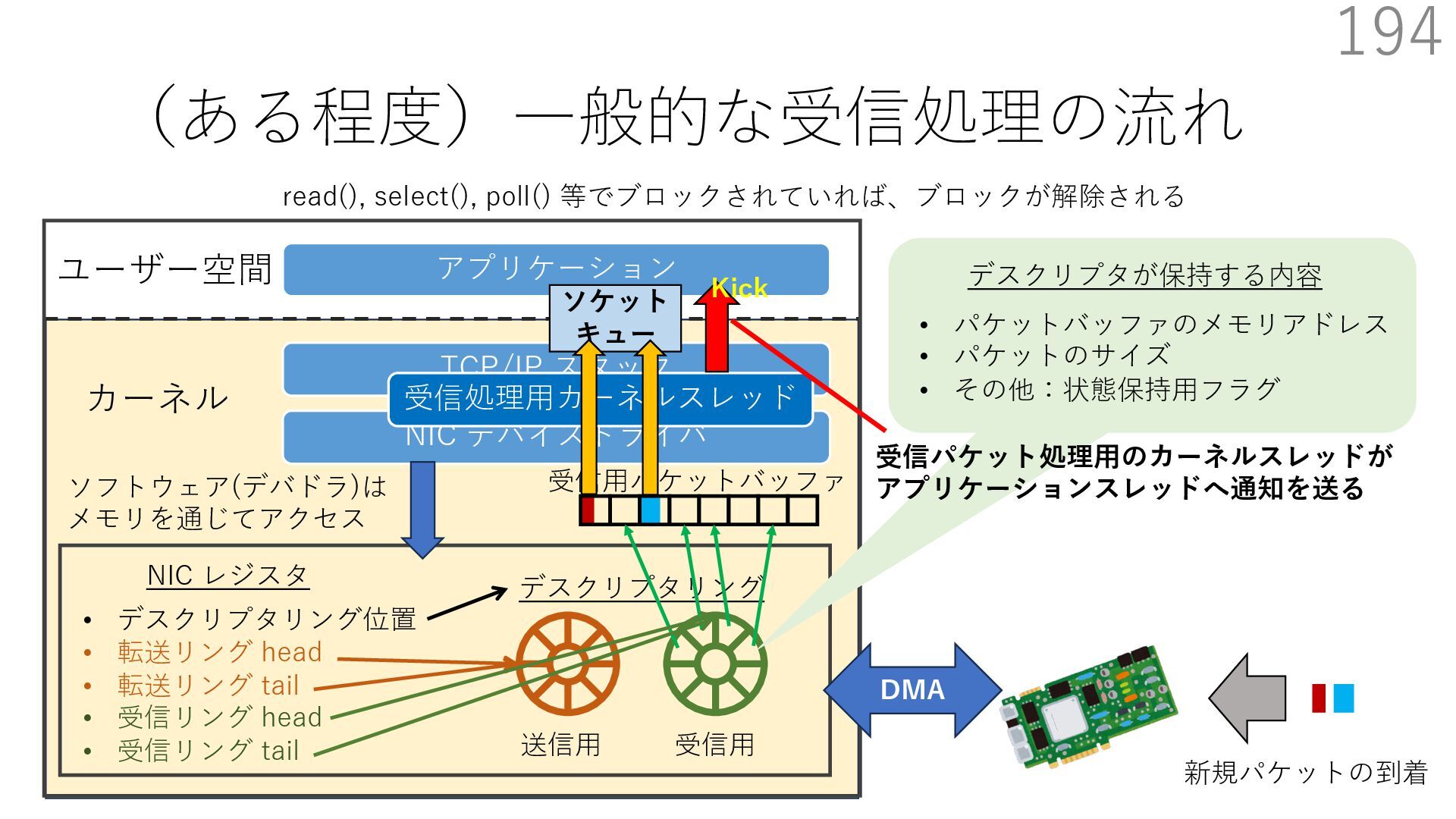{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
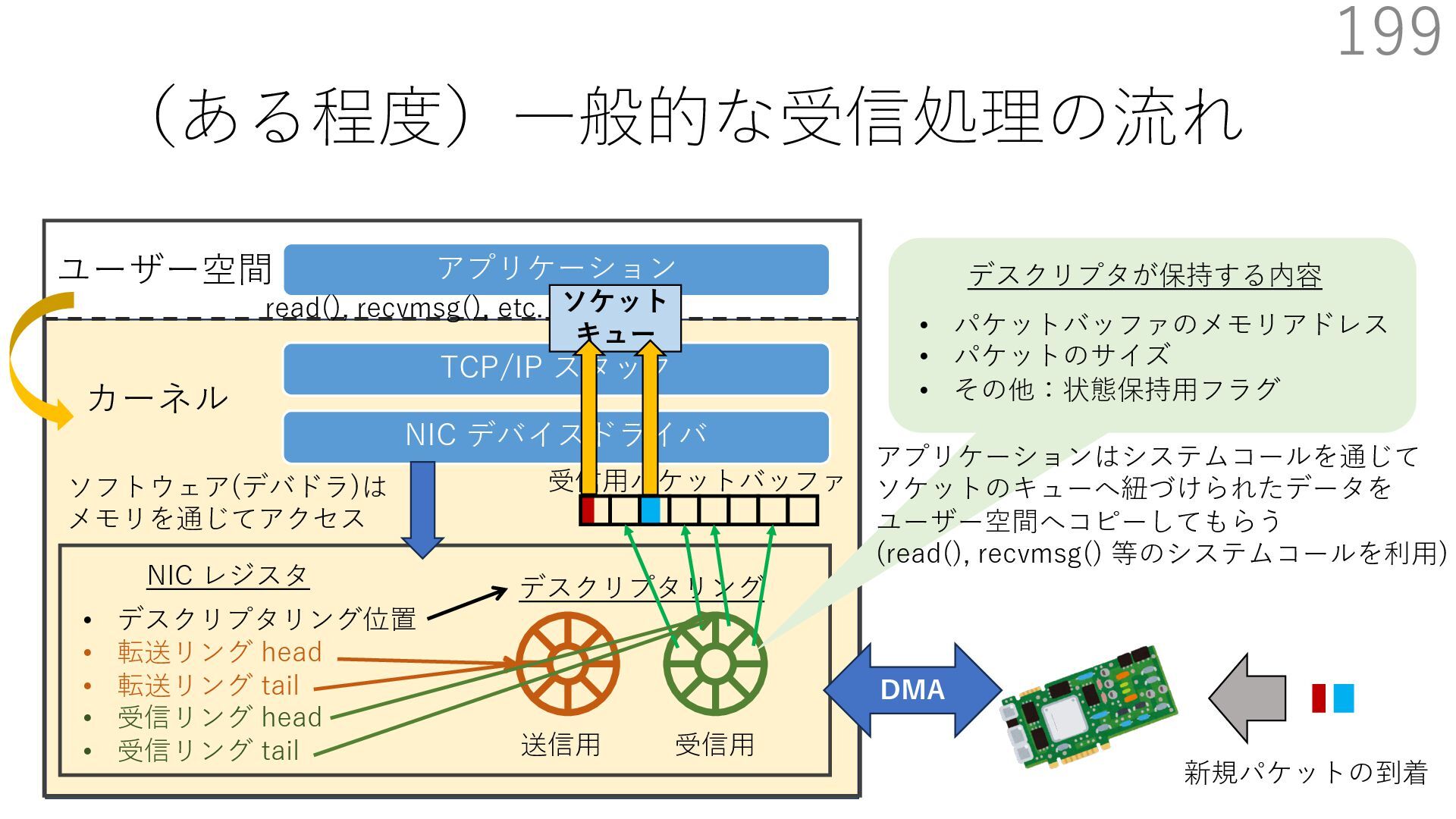{kind=link}
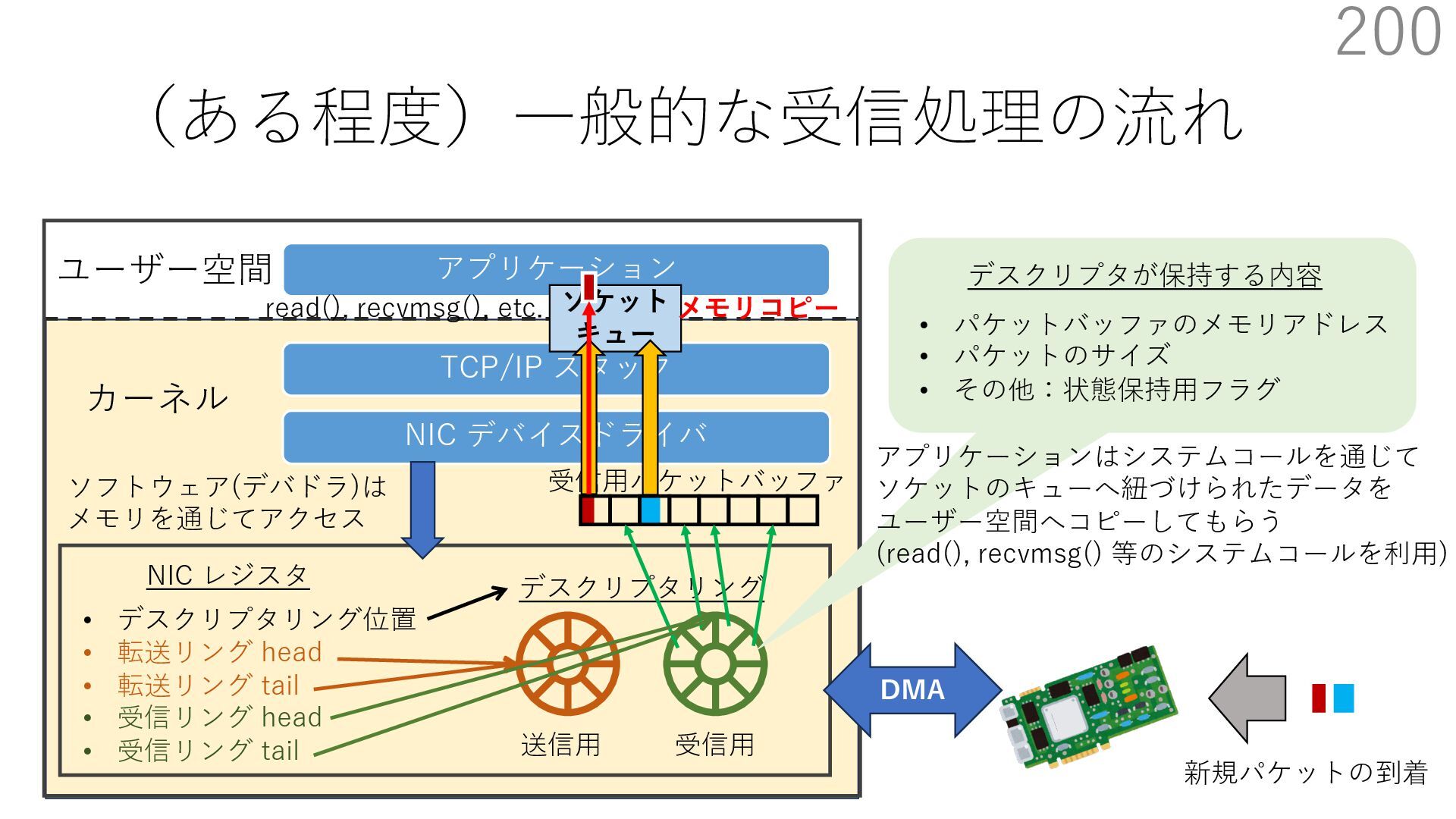{kind=link}
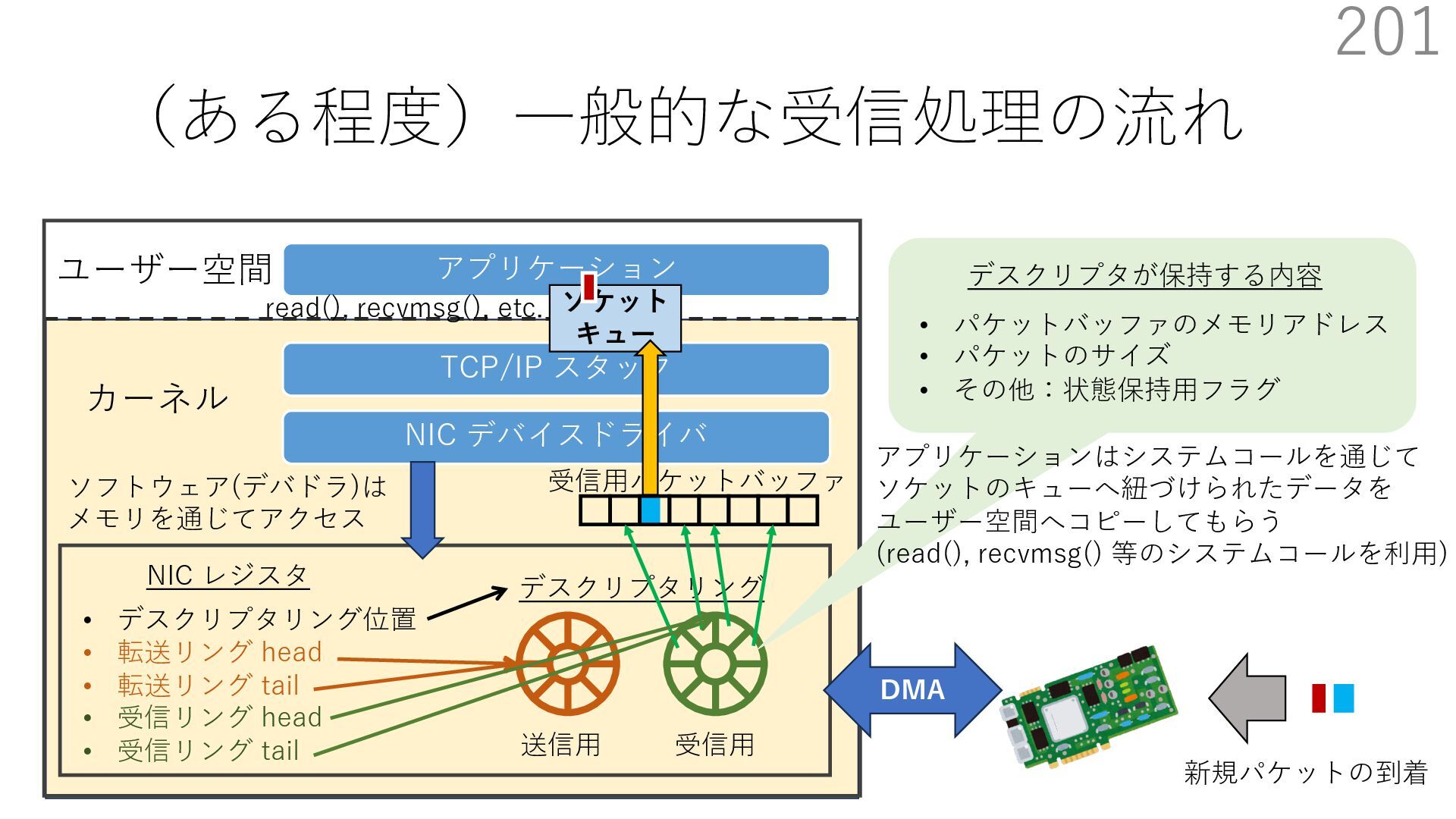{kind=link}
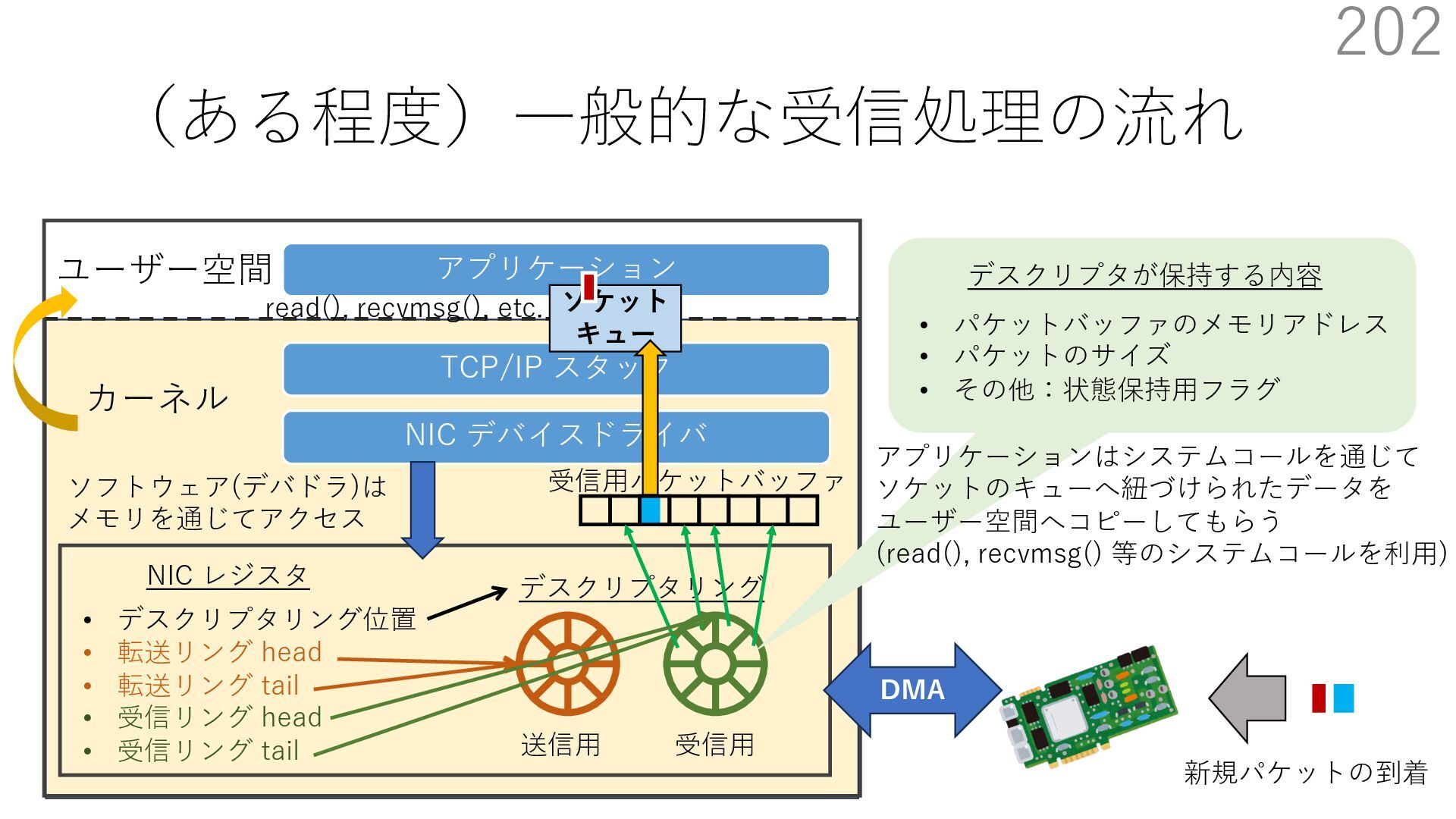{kind=link}
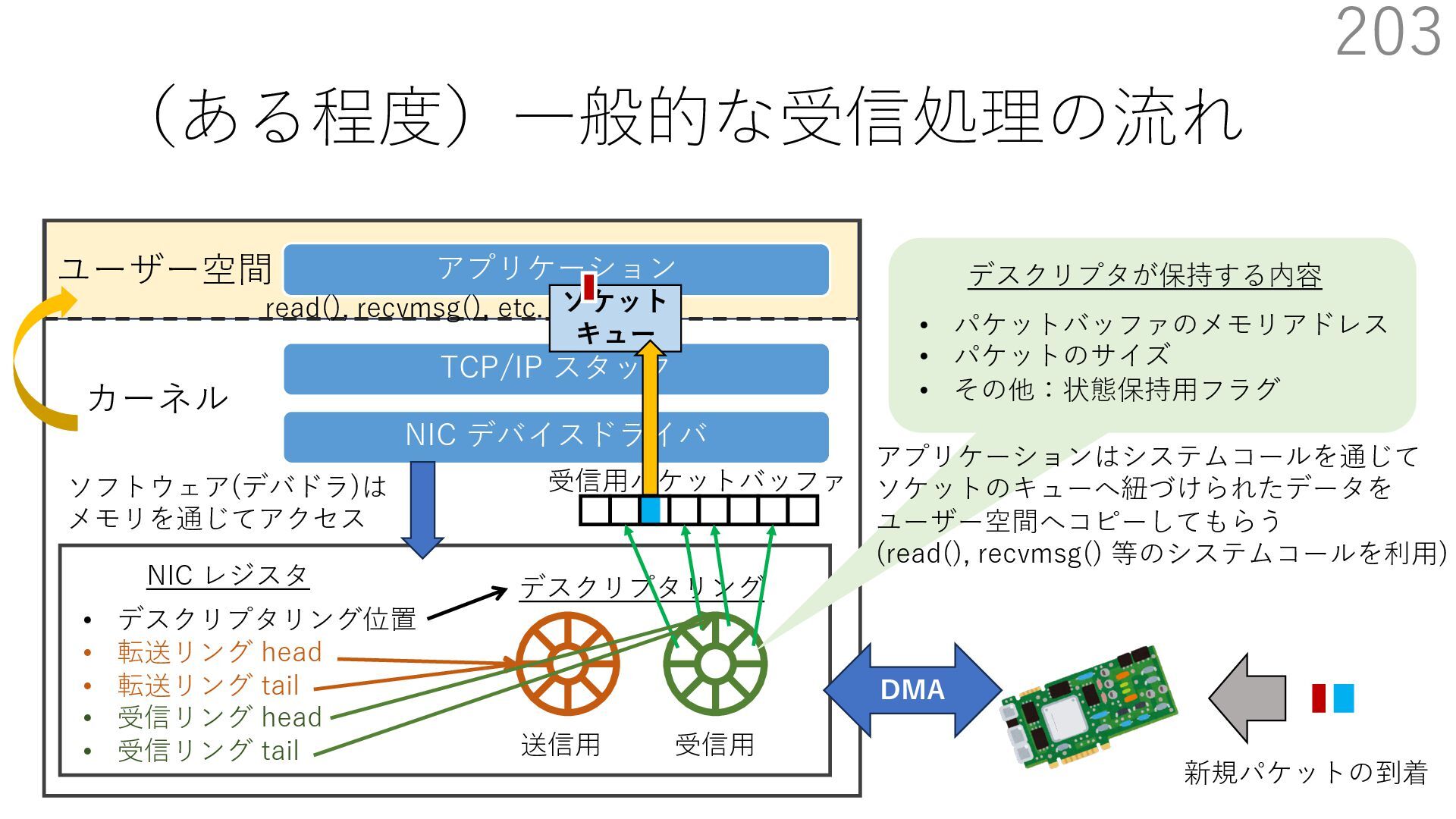{kind=link}
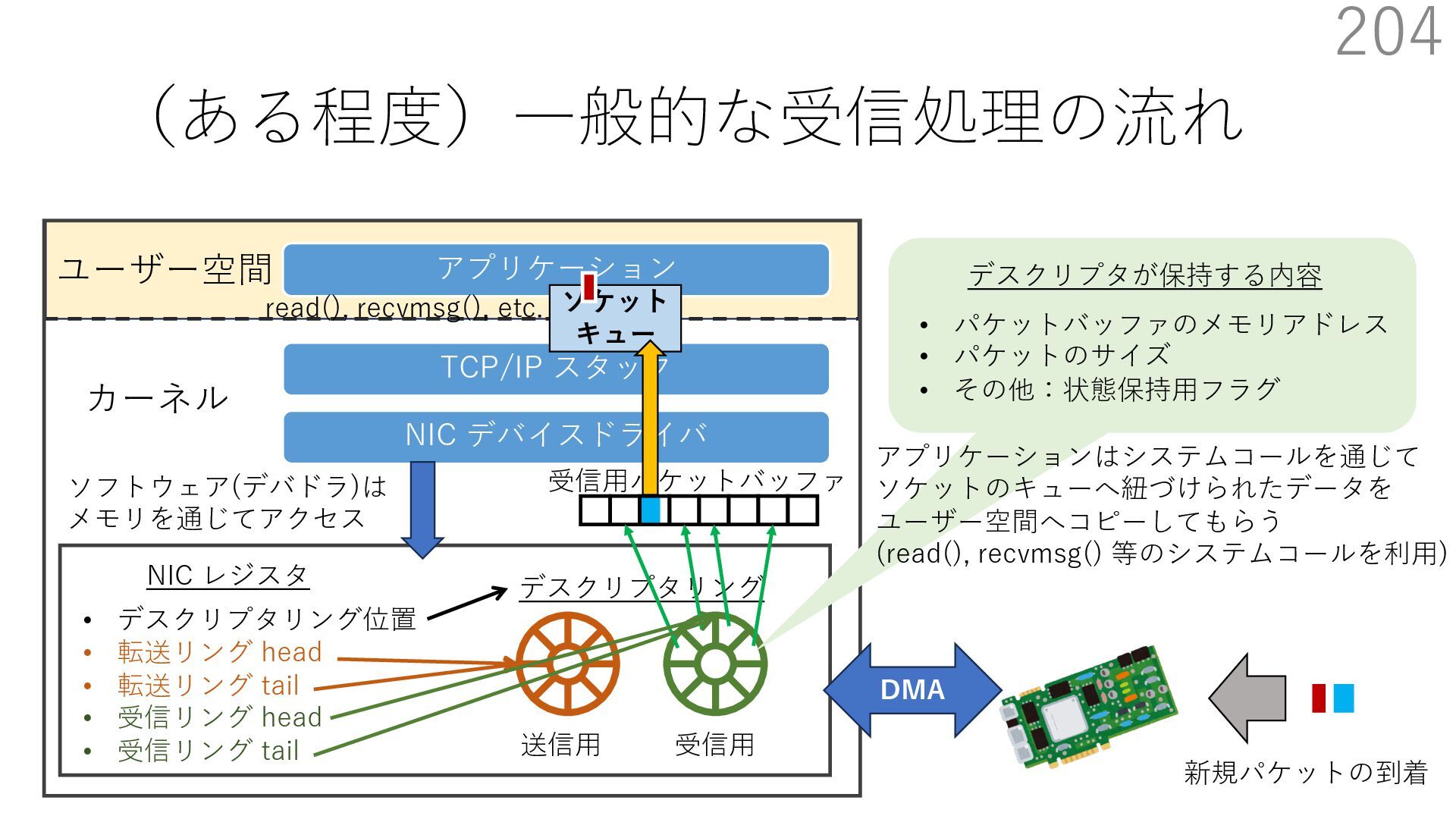{kind=link}
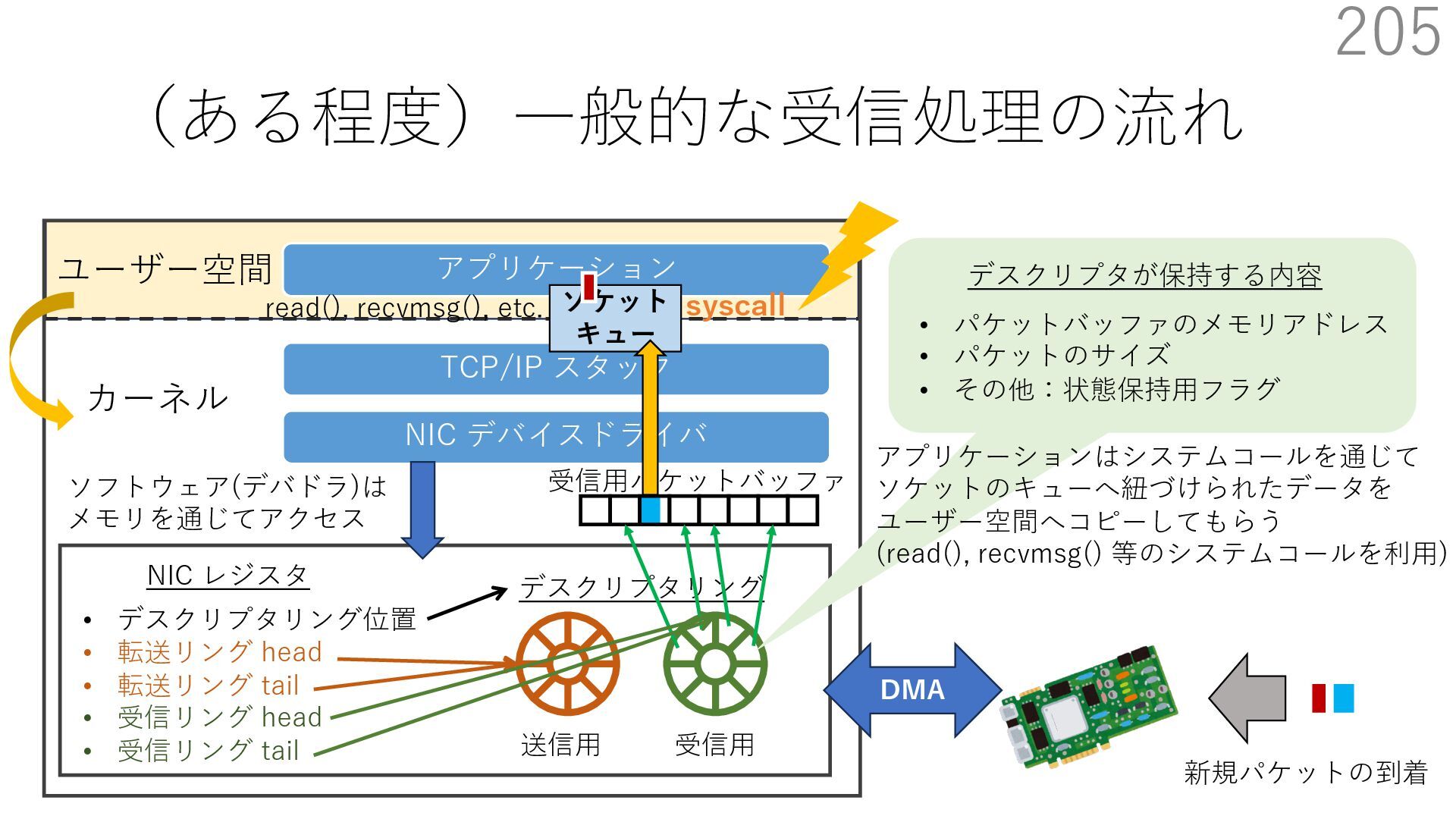{kind=link}
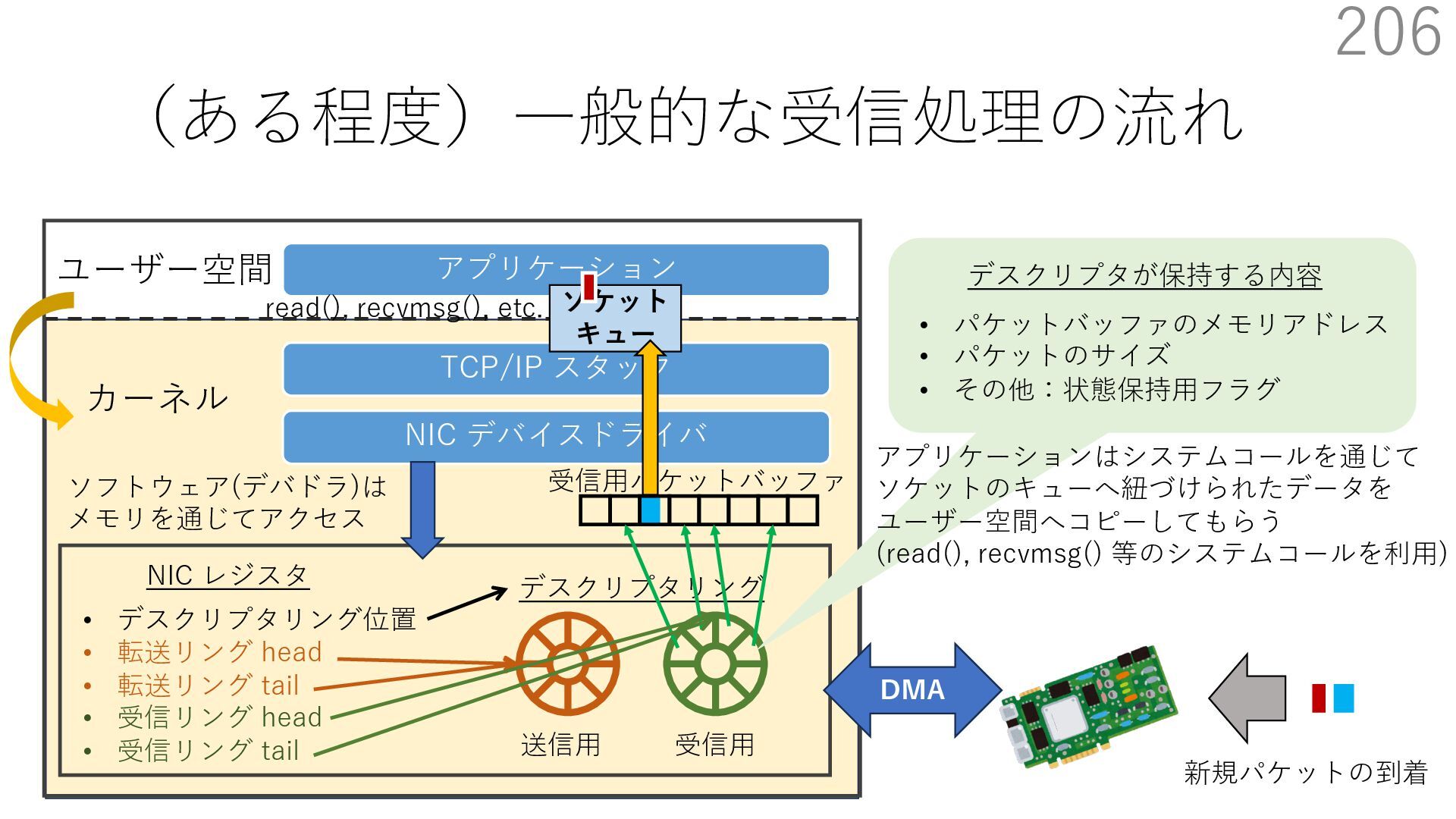{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
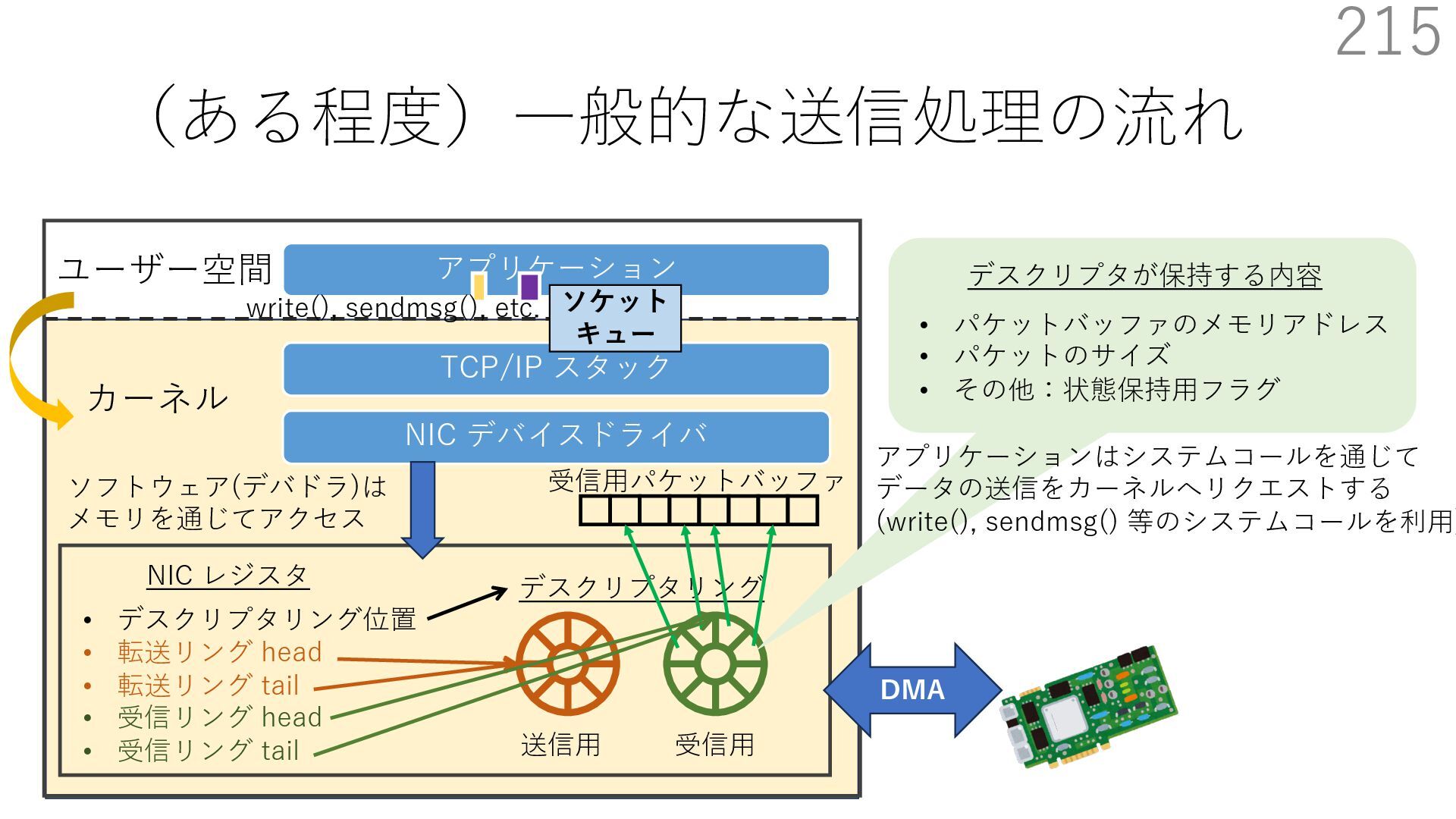{kind=link}
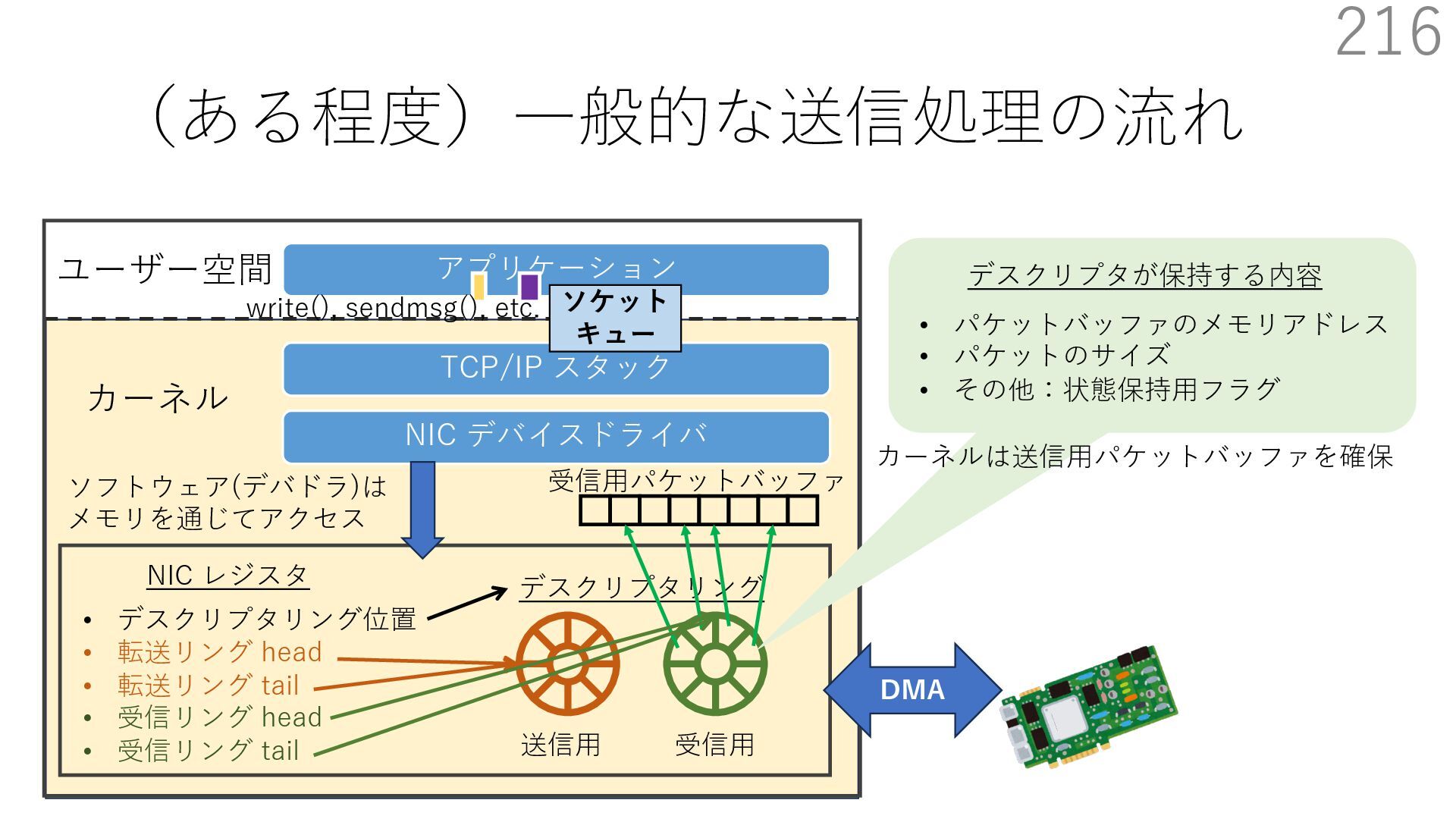{kind=link}
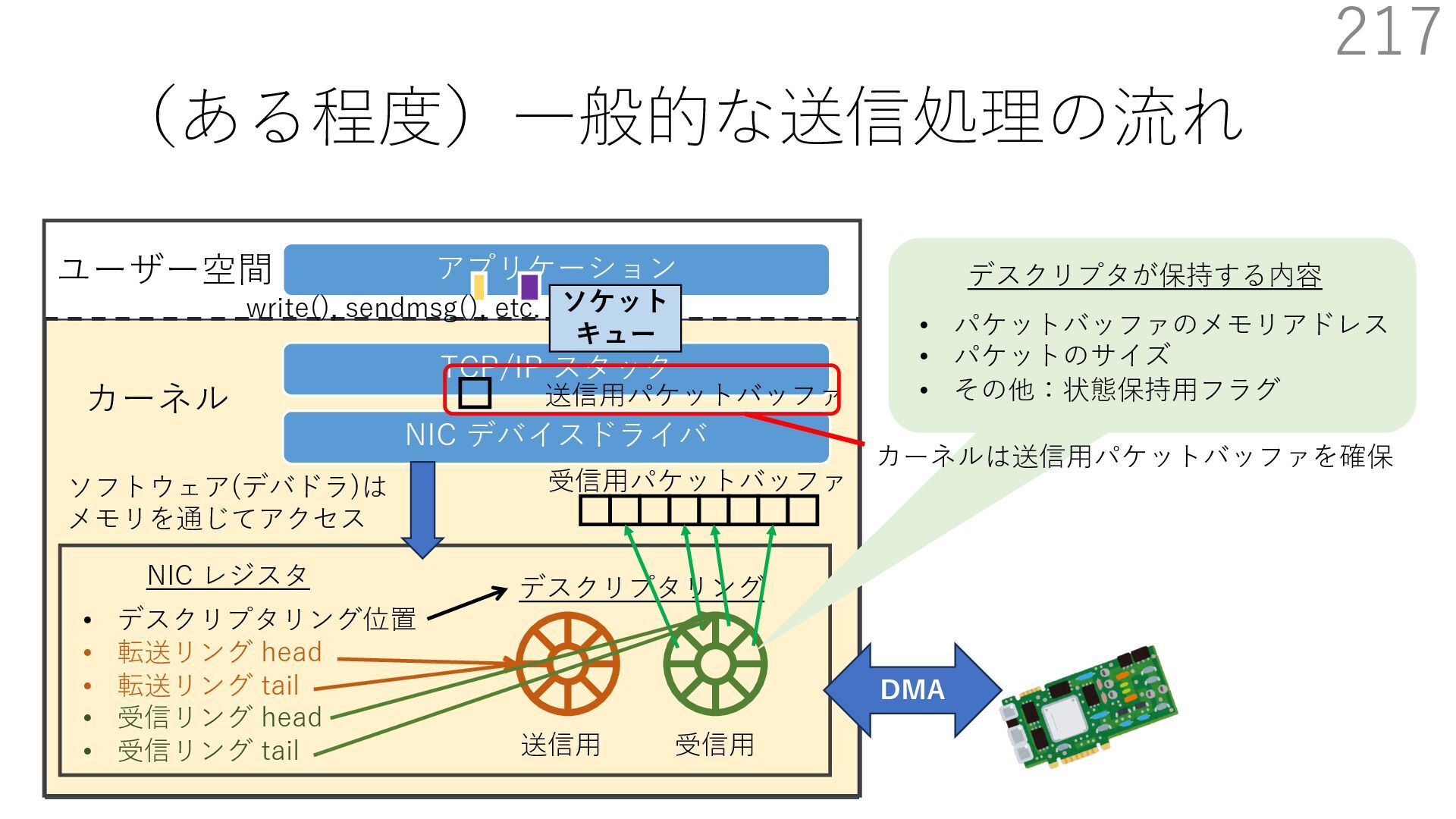{kind=link}
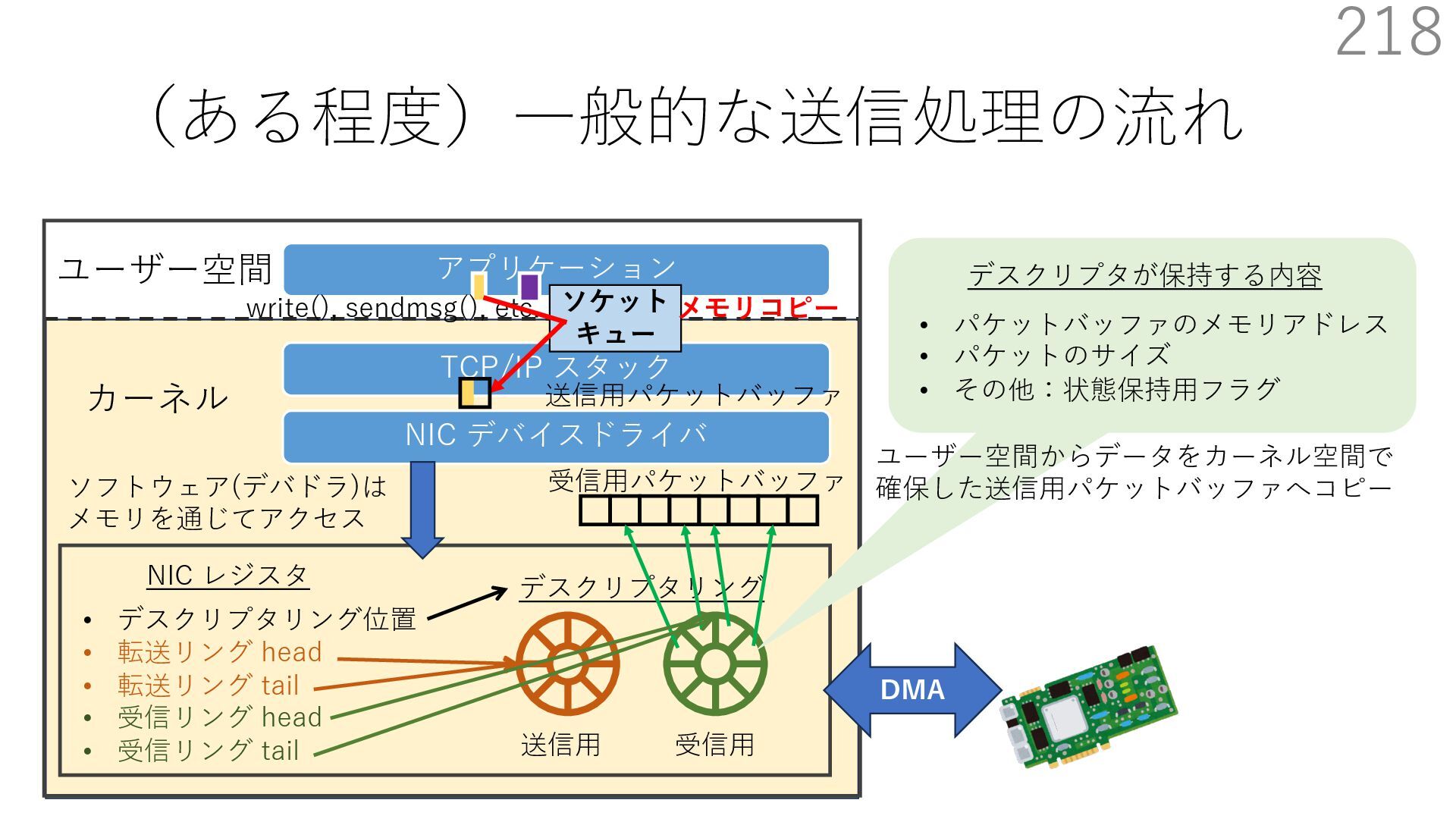{kind=link}
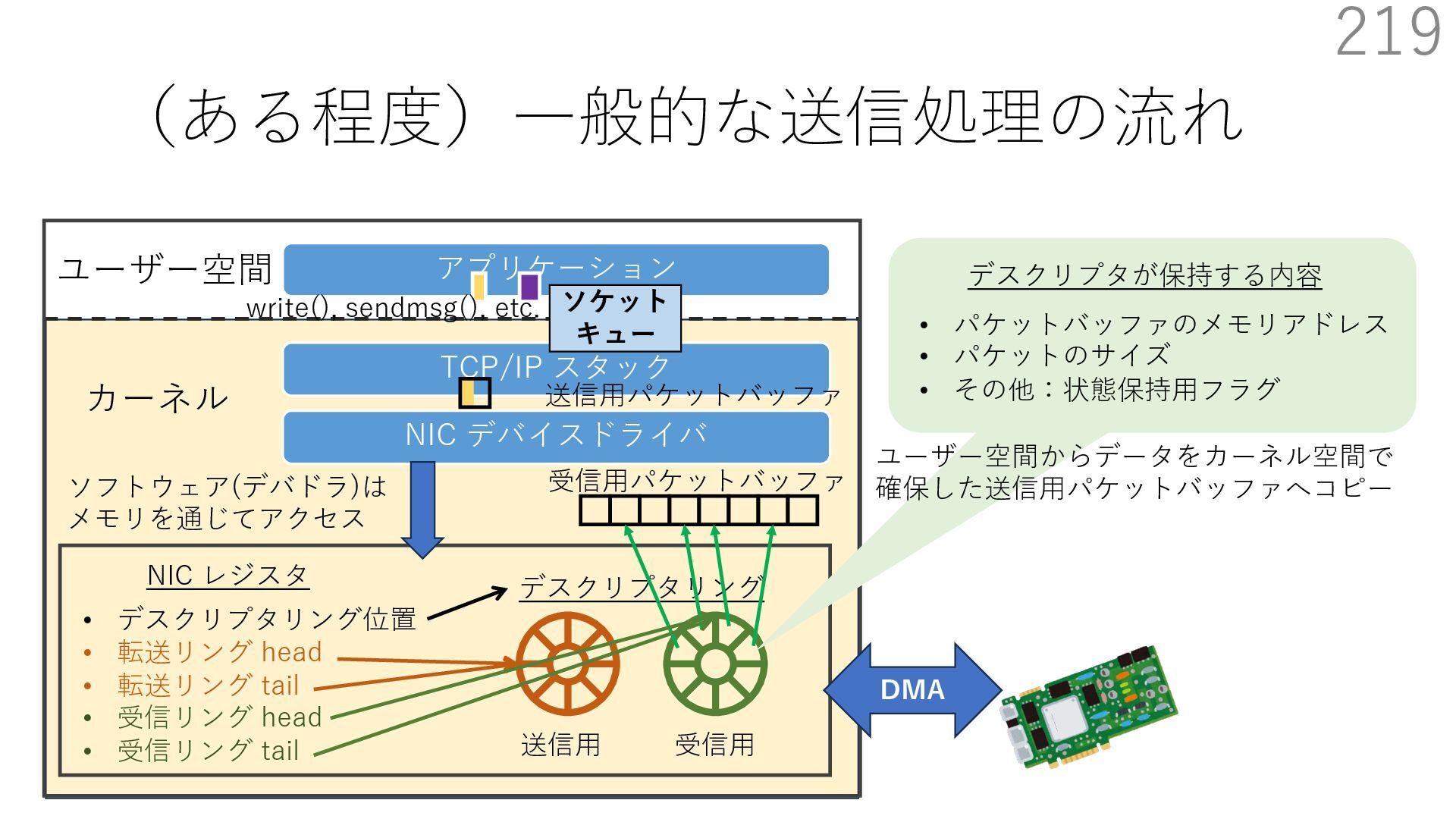{kind=link}
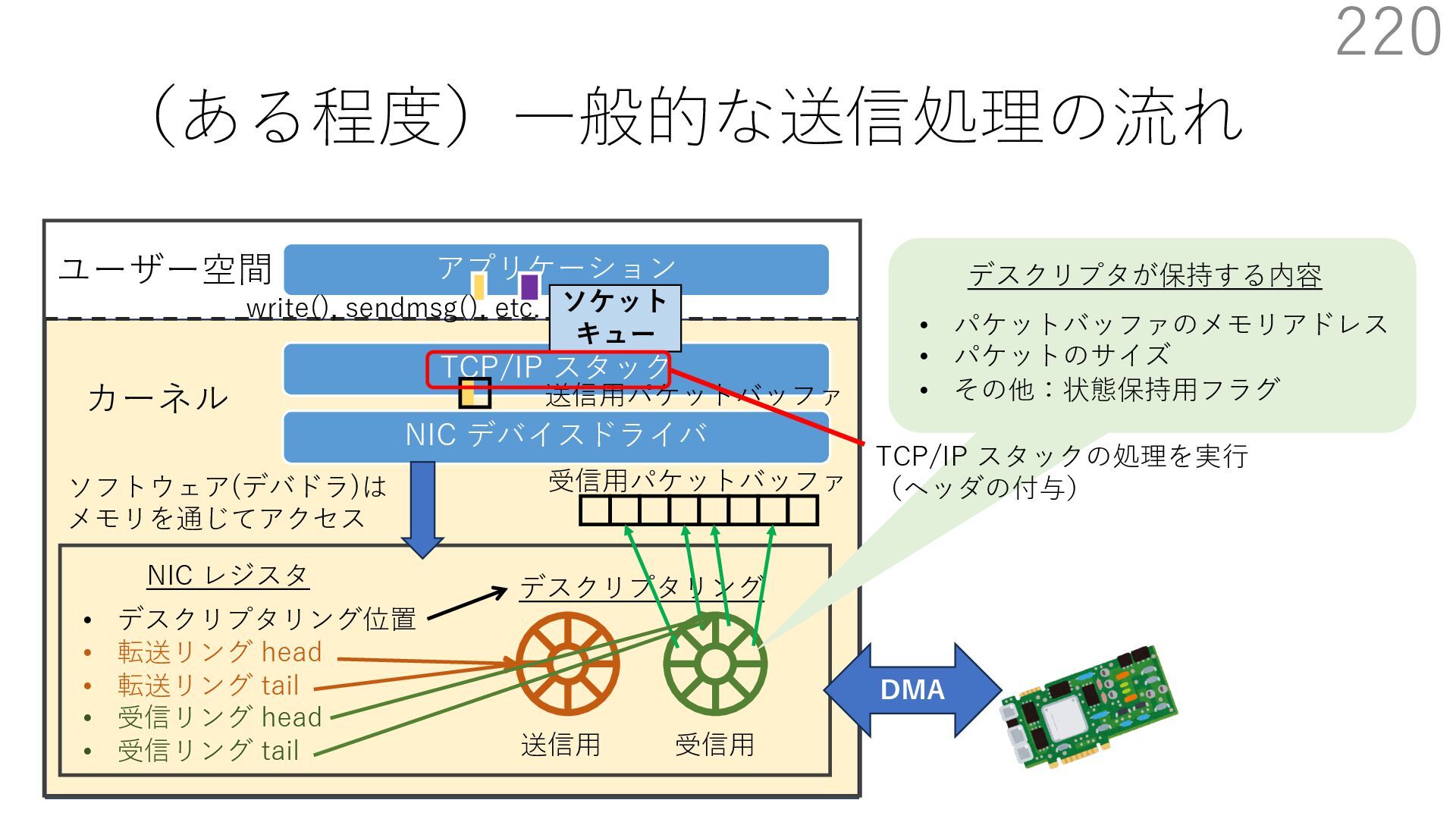{kind=link}
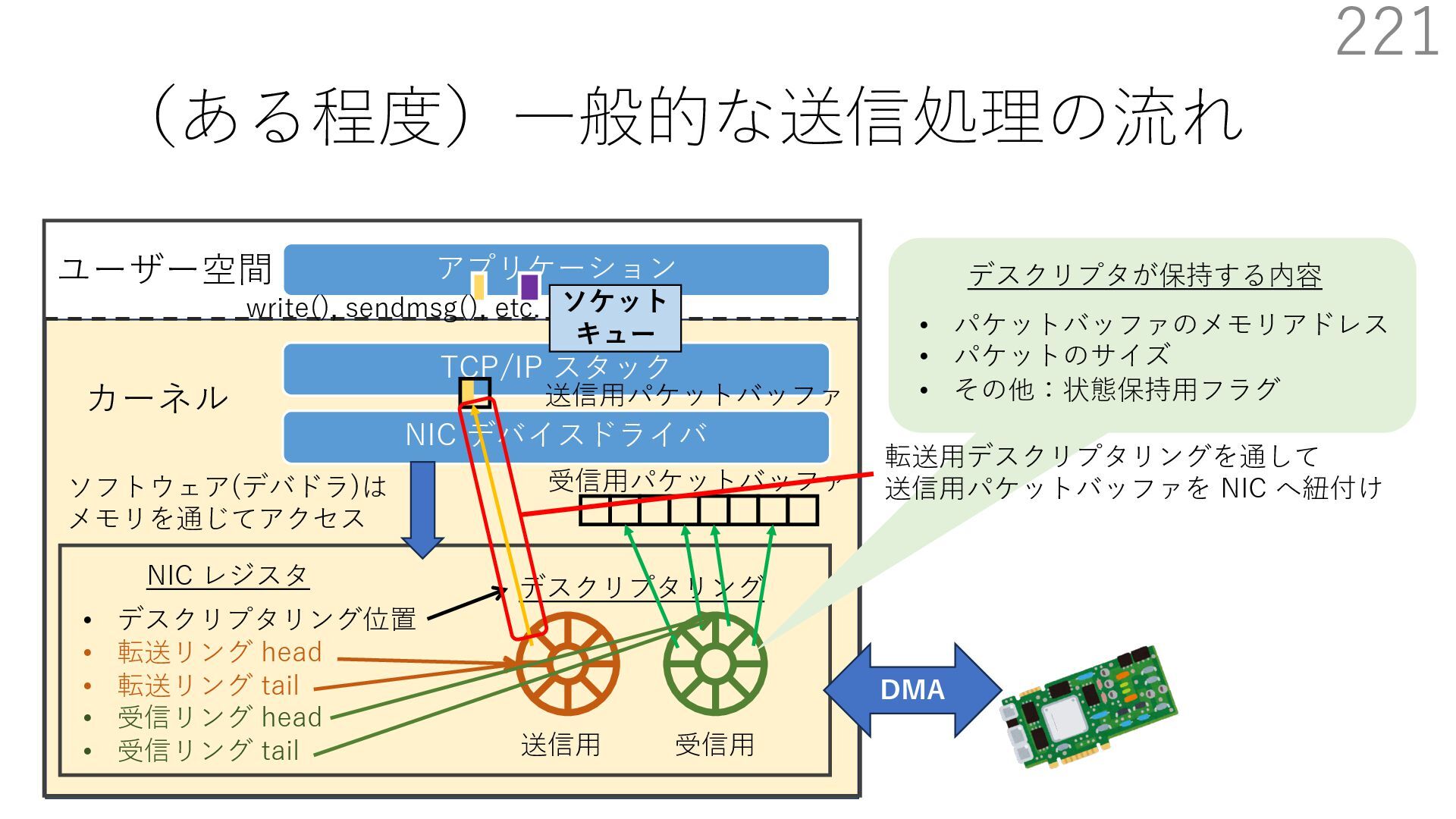{kind=link}
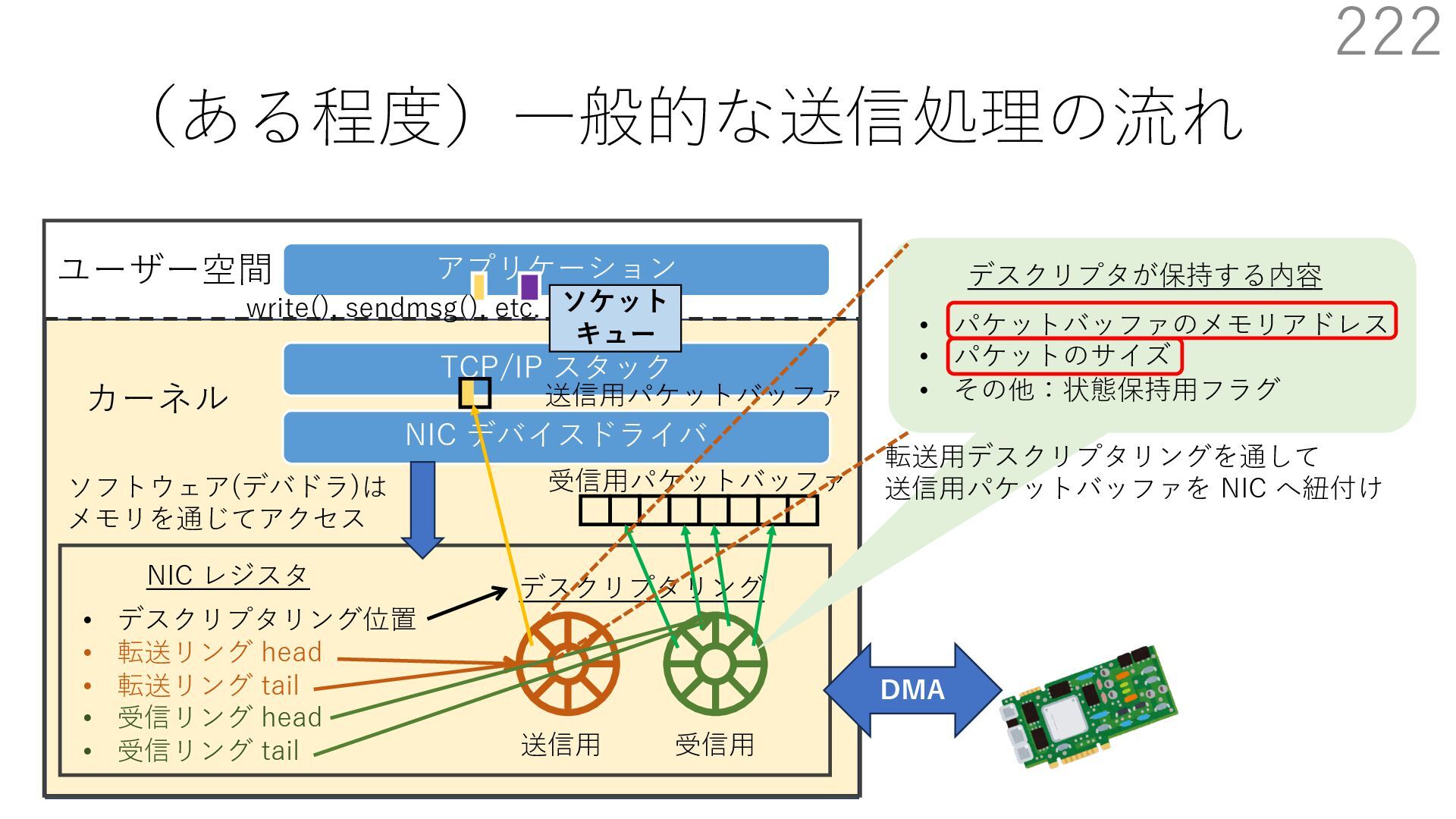{kind=link}
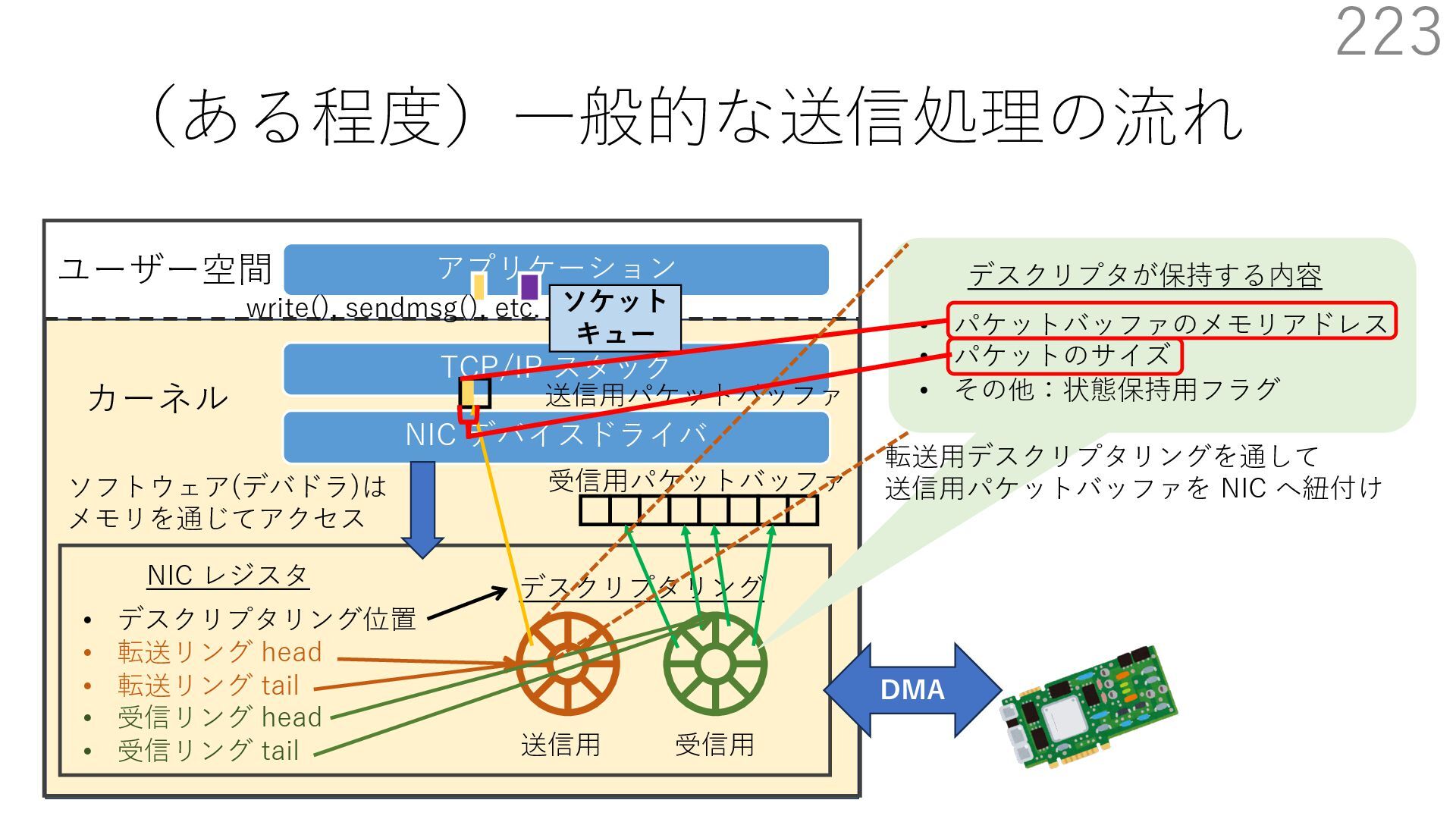{kind=link}
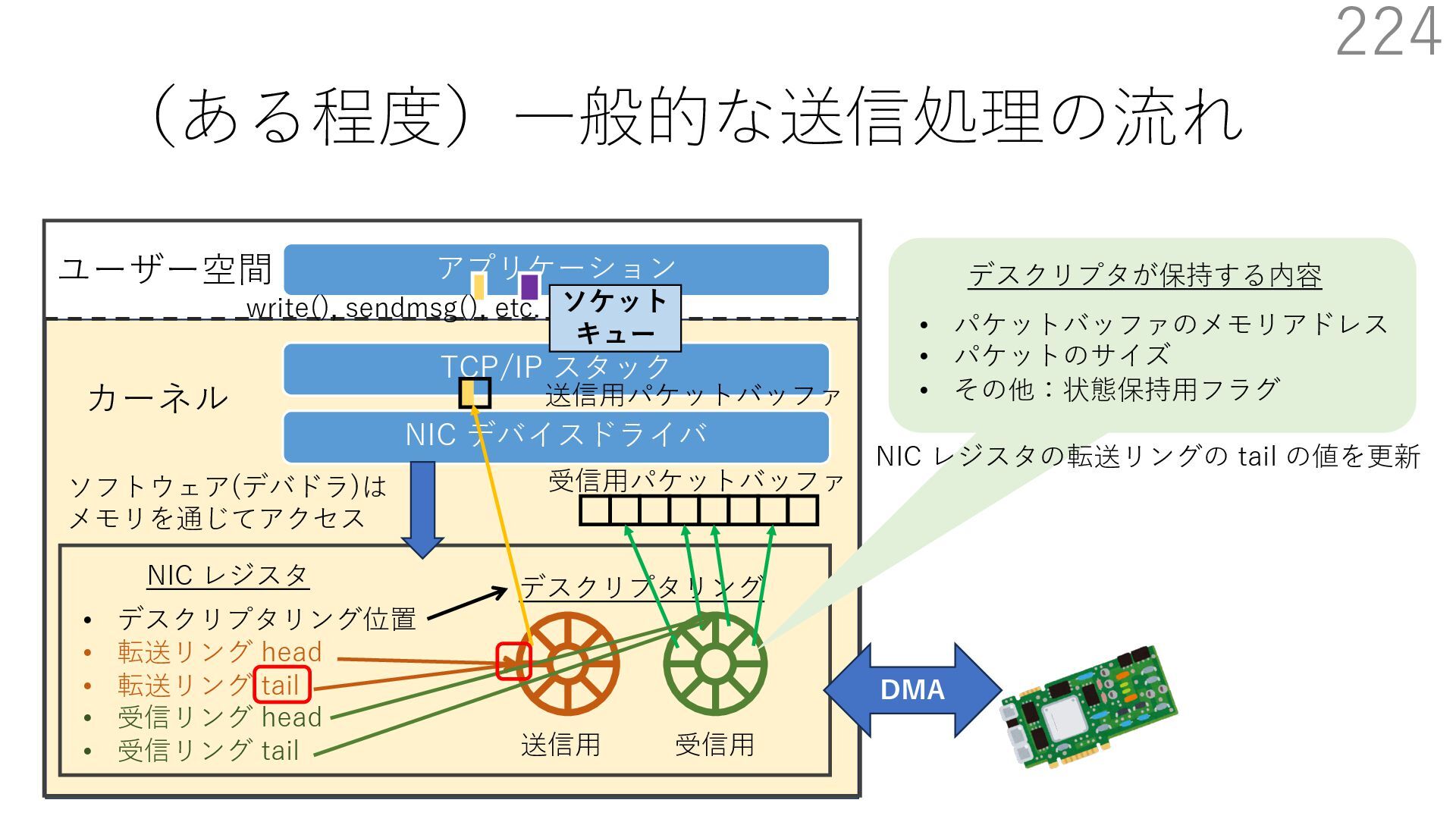{kind=link}
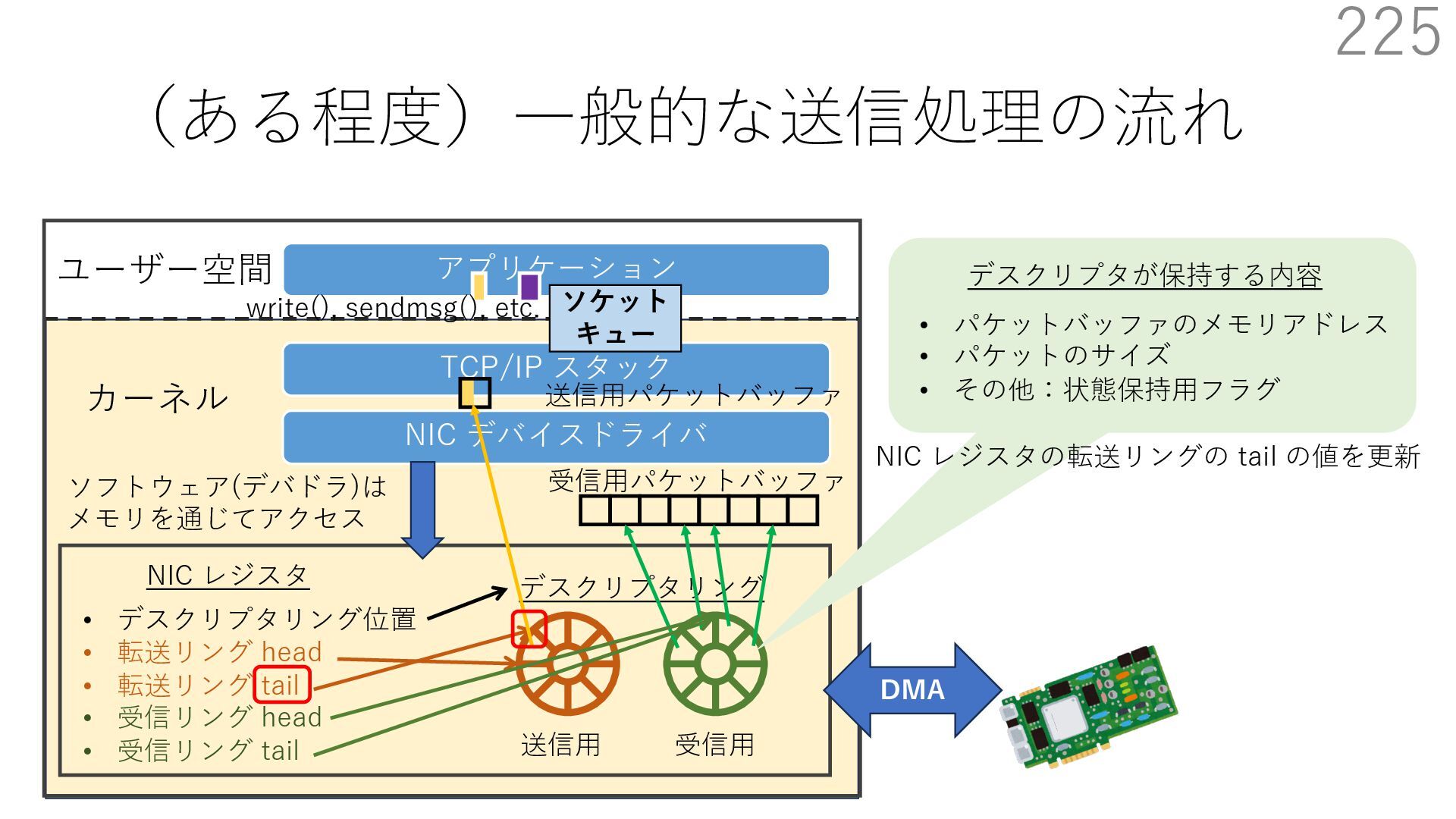{kind=link}
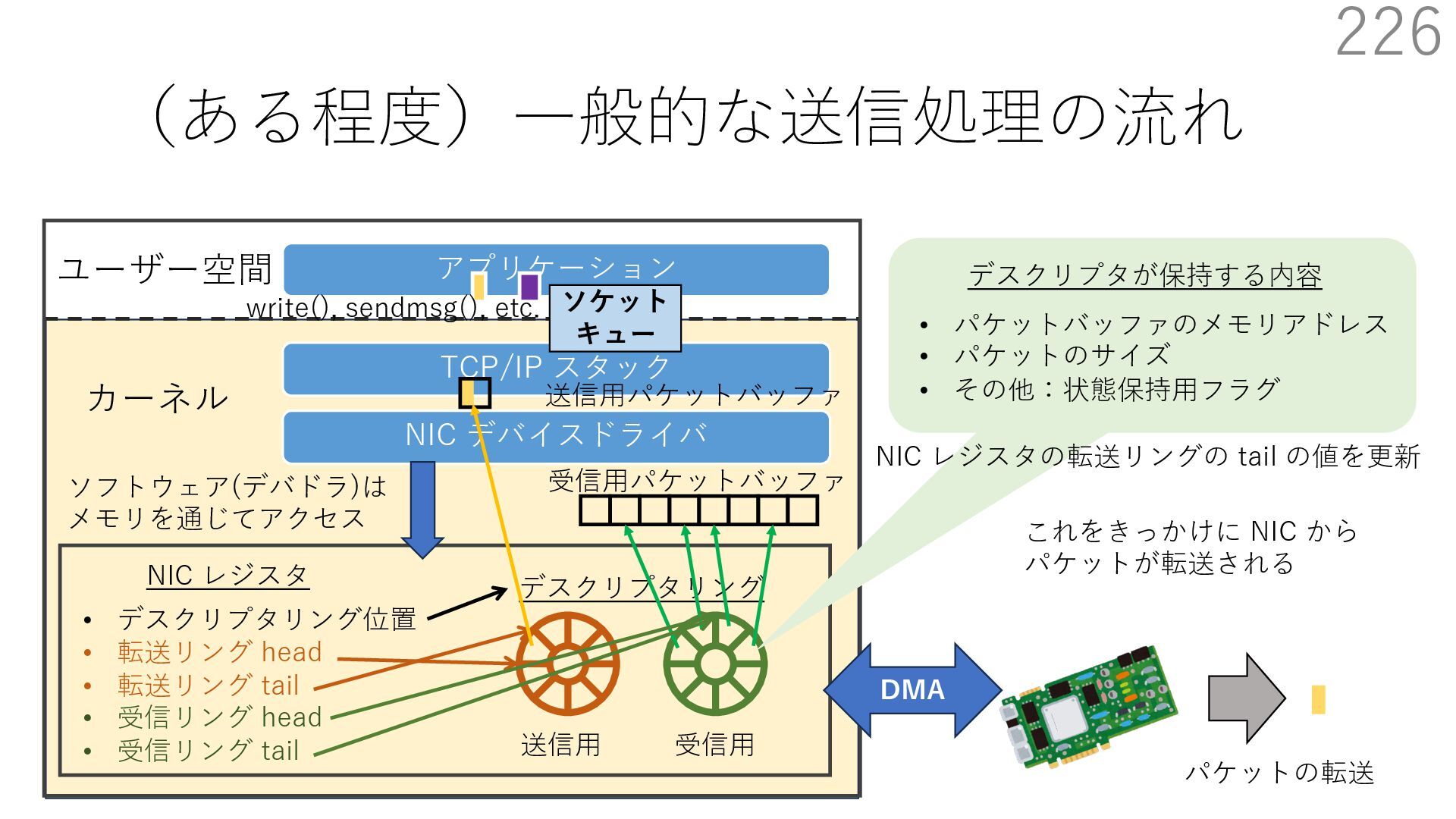{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
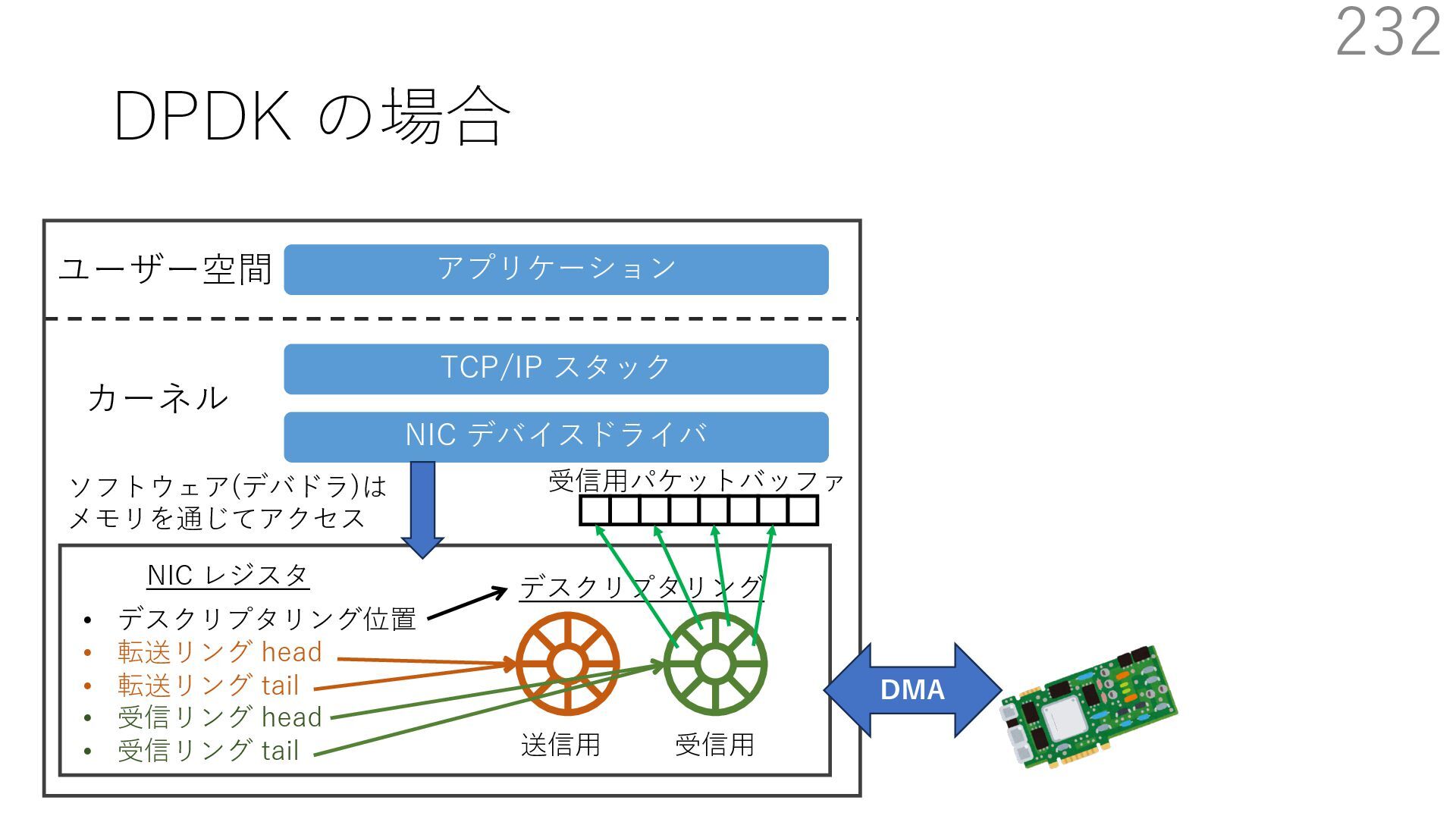{kind=link}
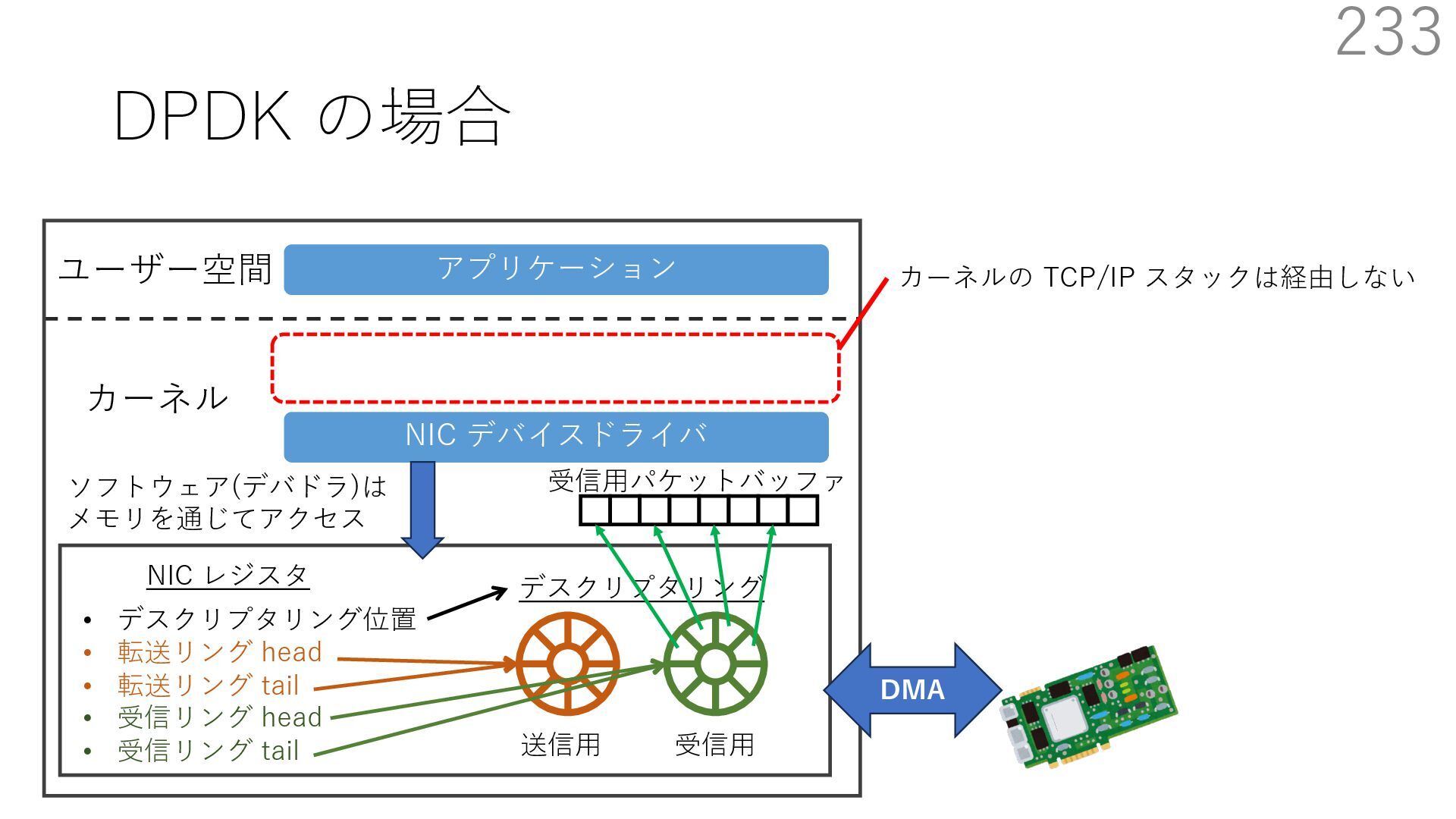{kind=link}
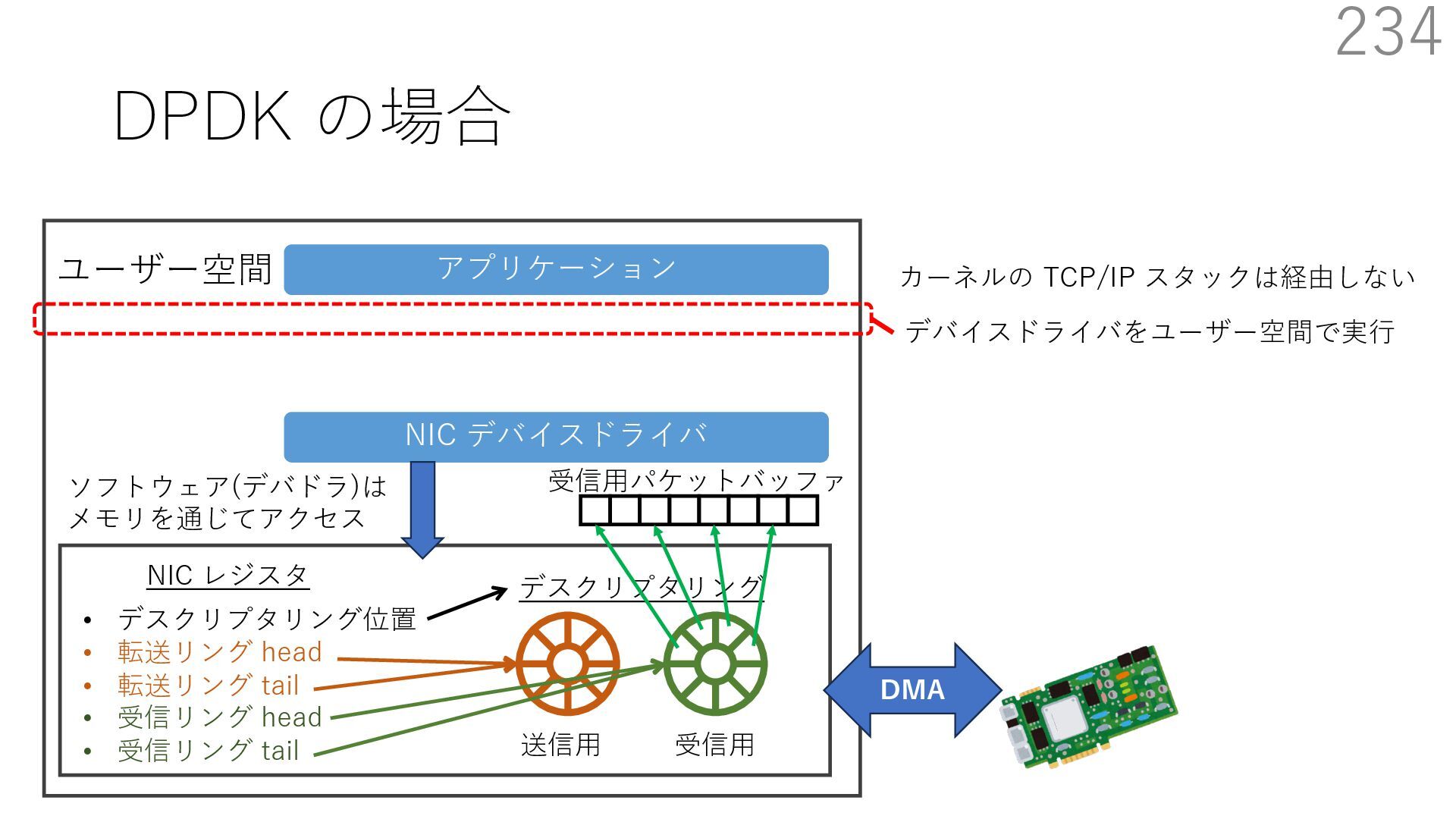{kind=link}
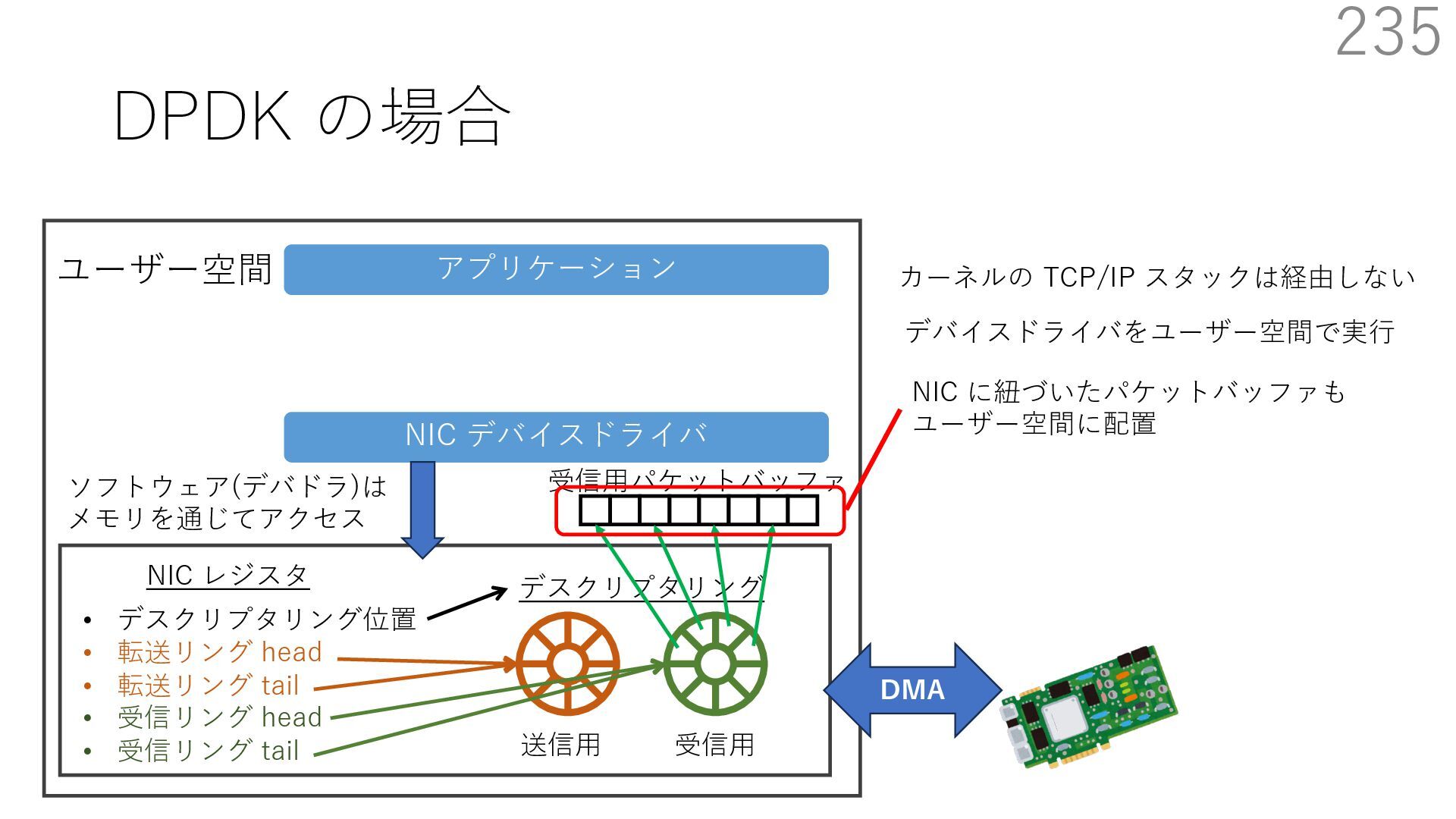{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
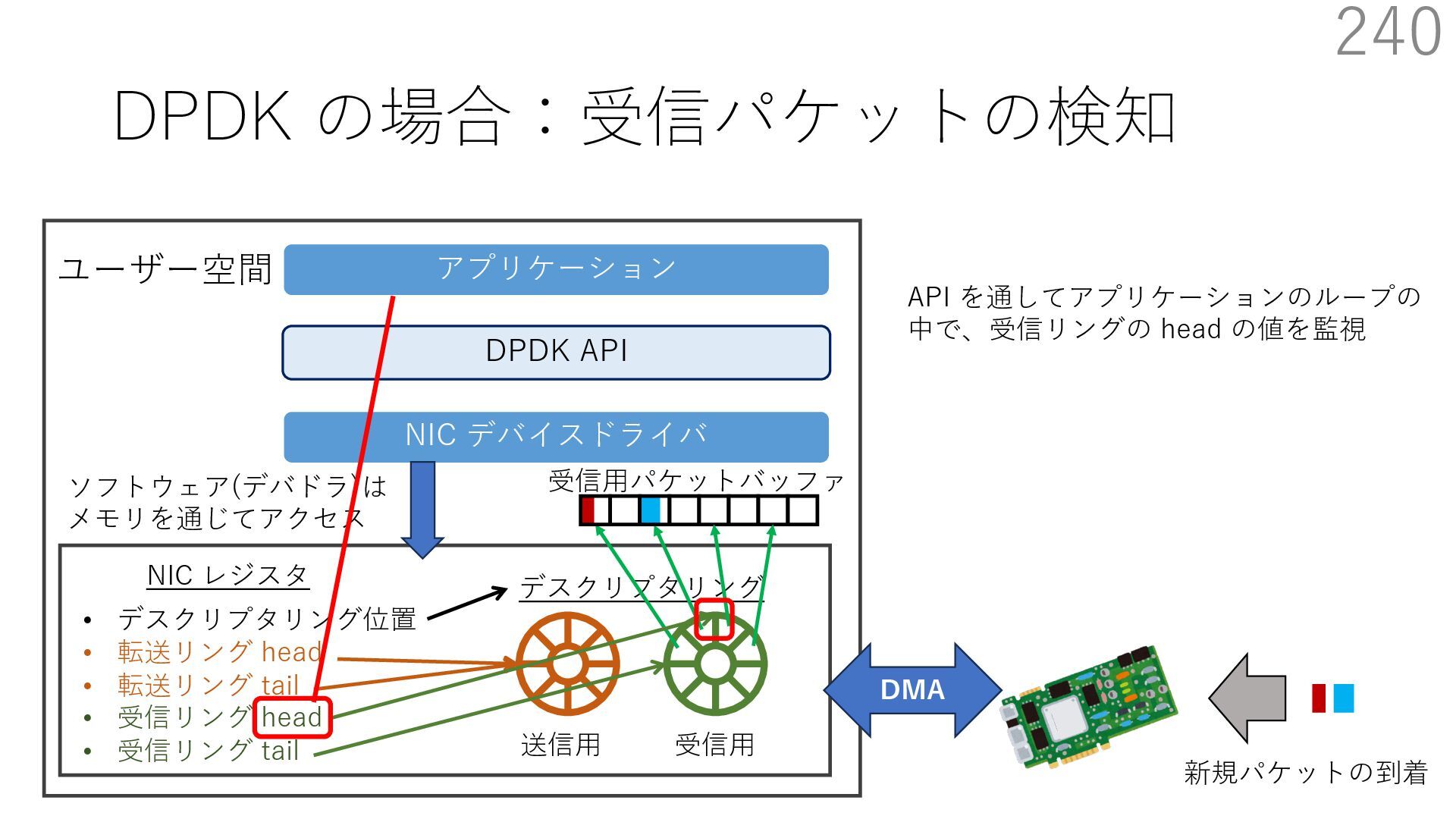{kind=link}
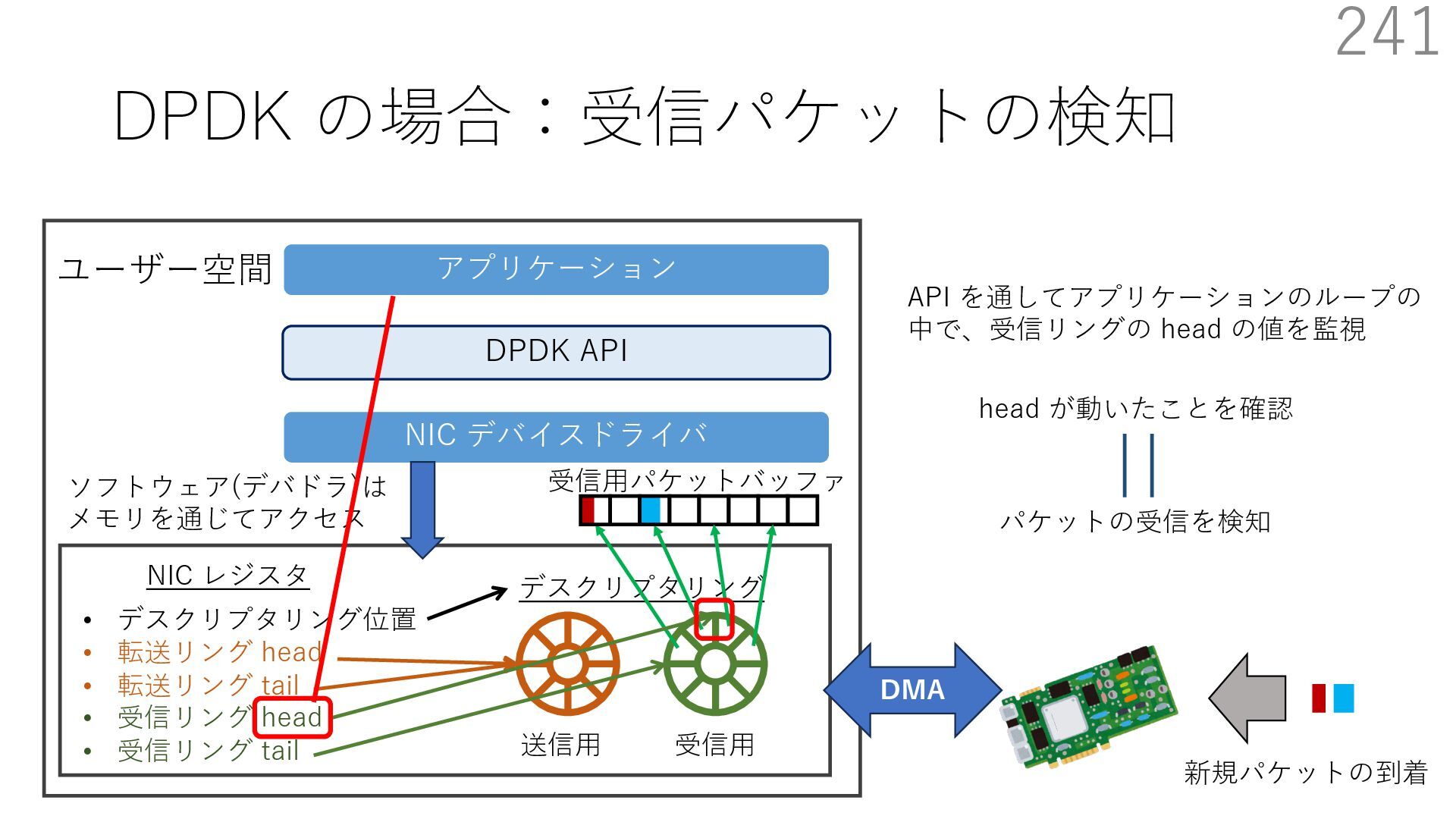{kind=link}
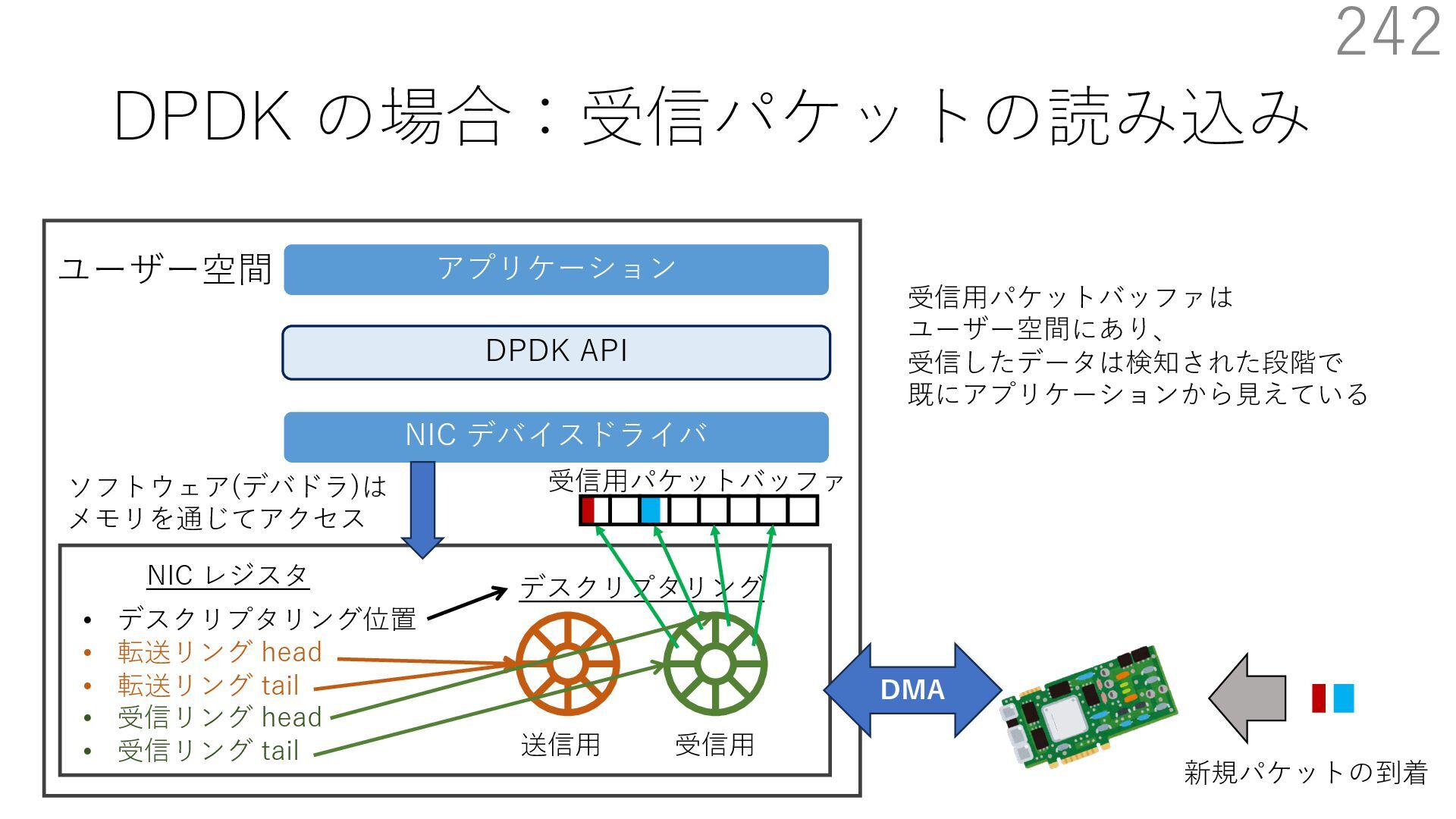{kind=link}
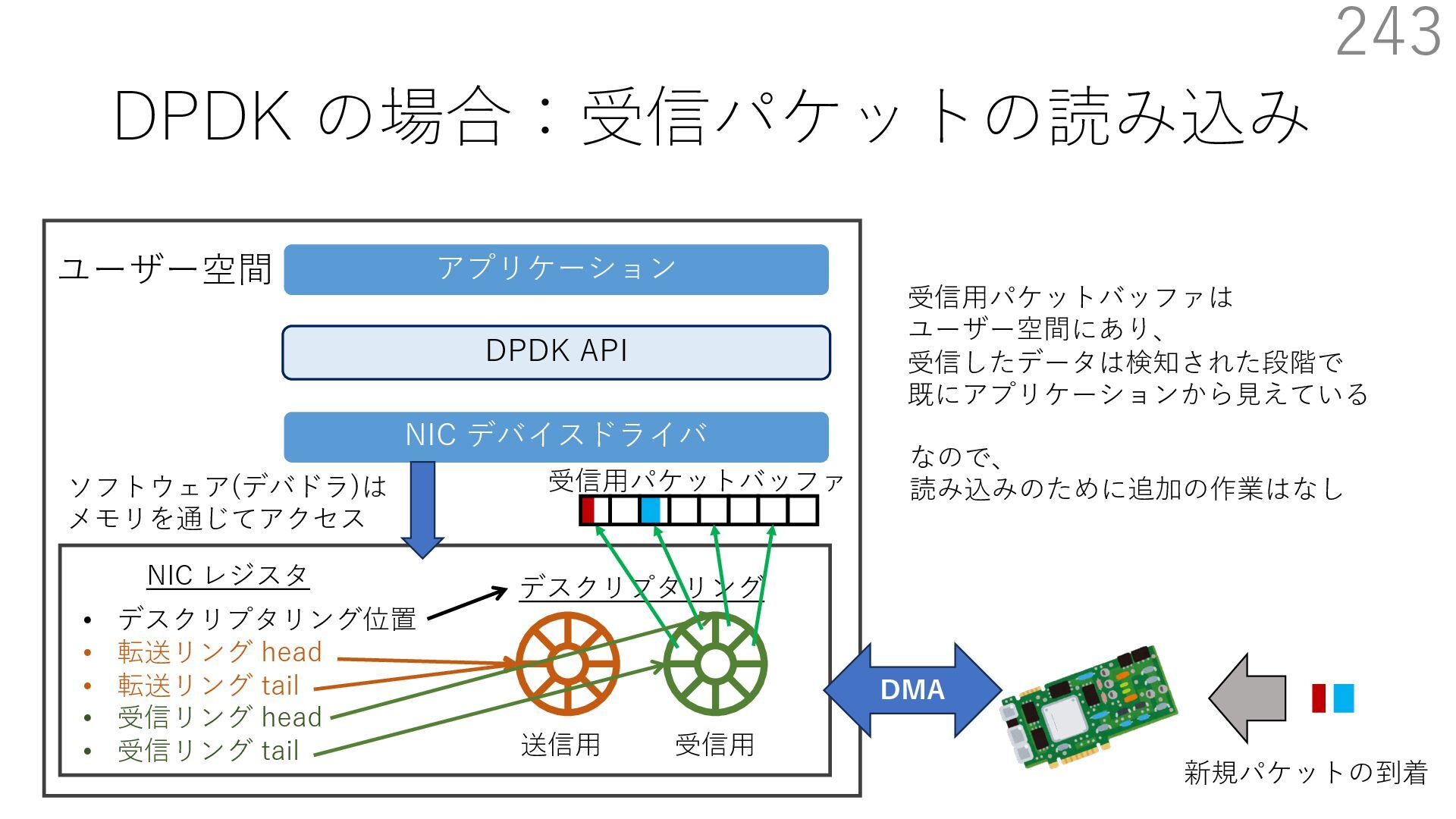{kind=link}
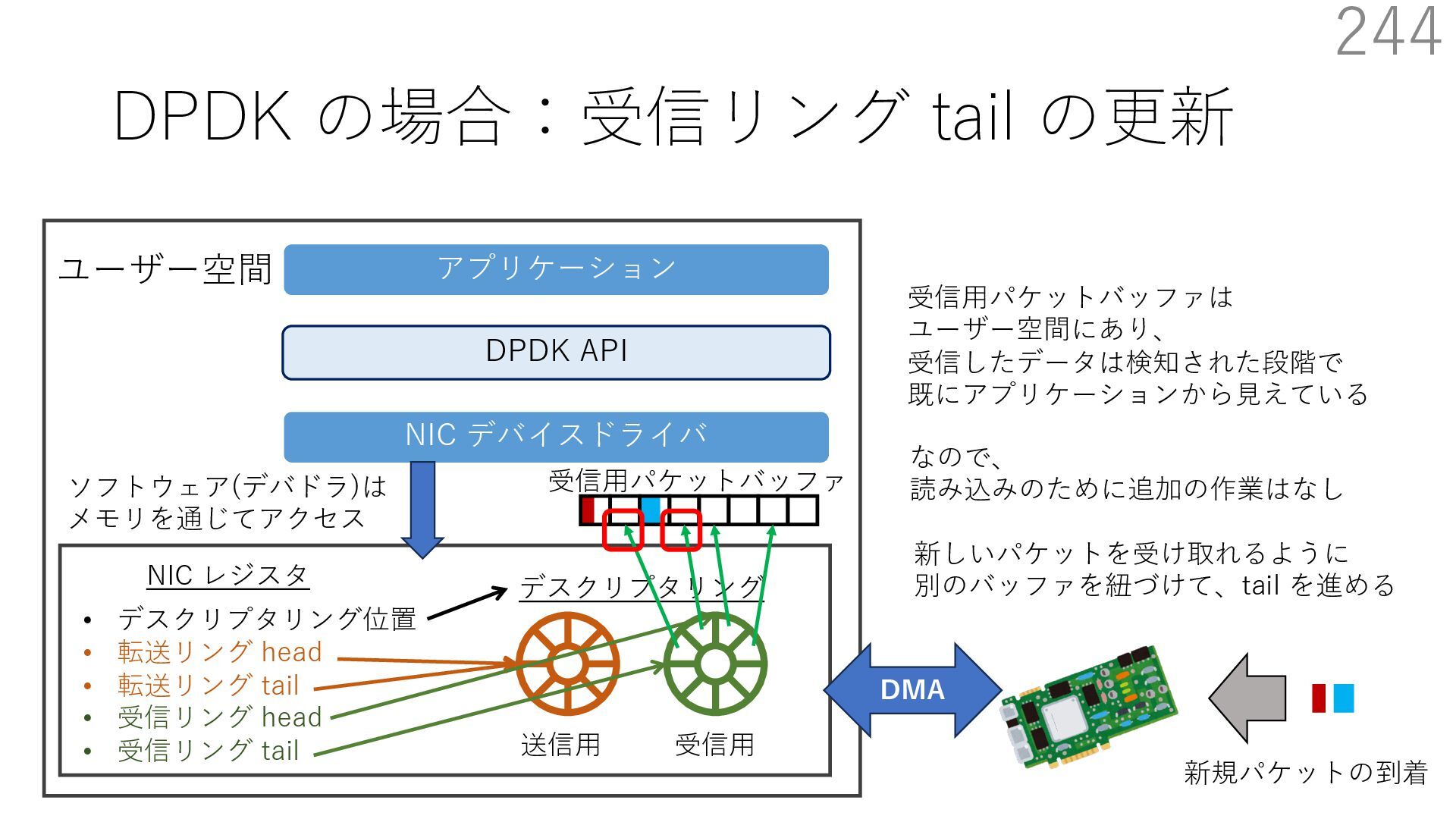{kind=link}
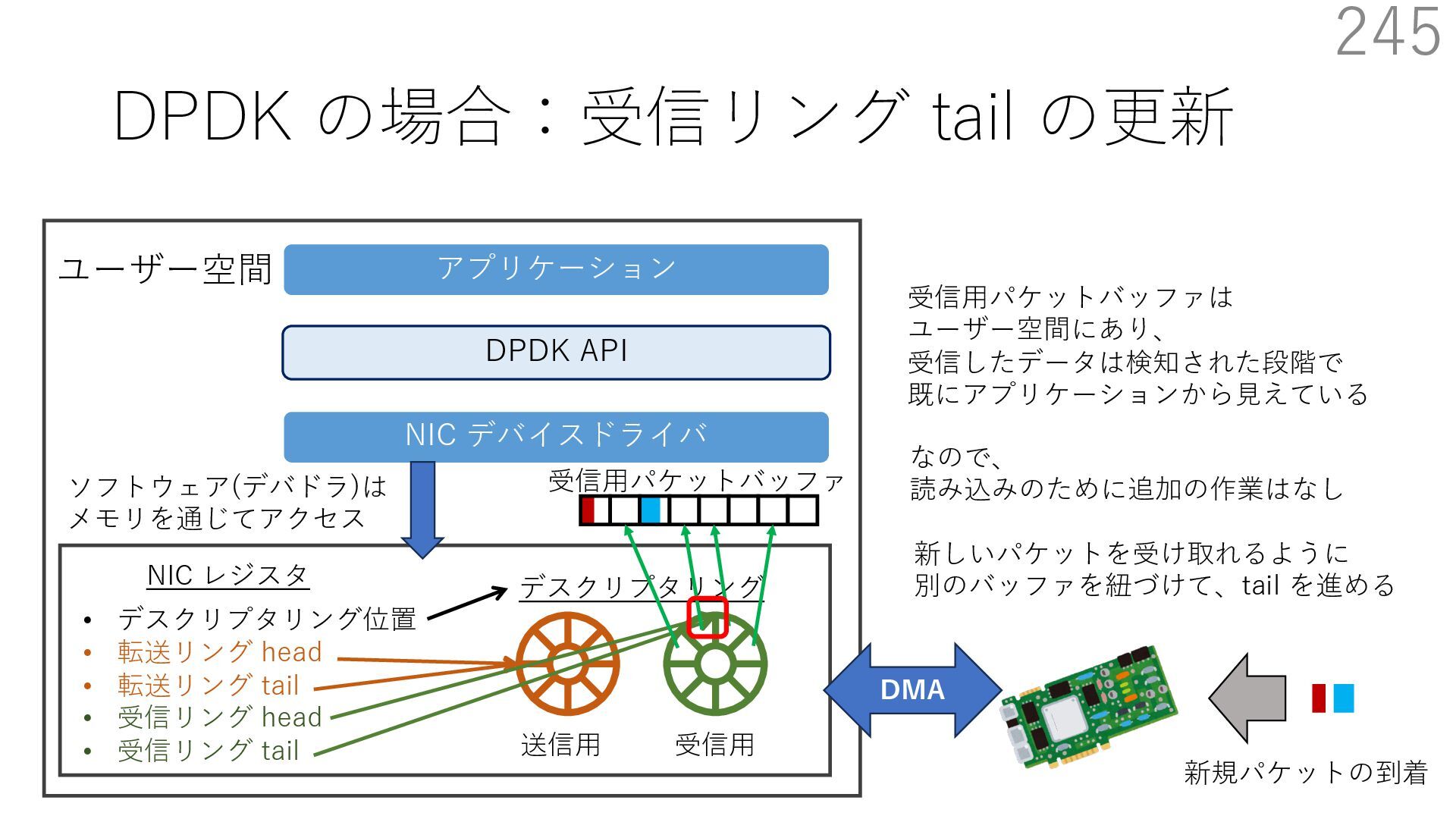{kind=link}
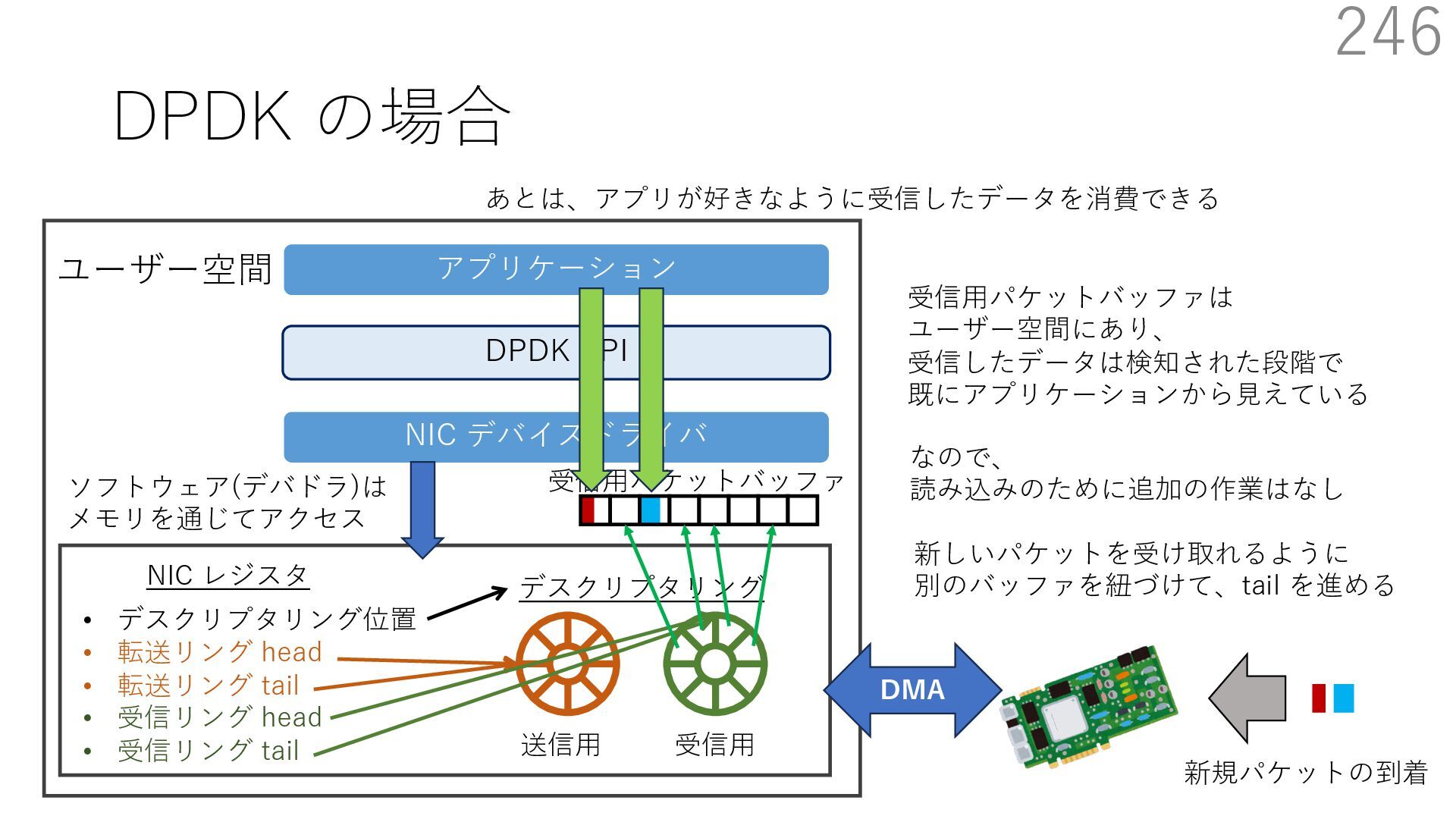{kind=link}
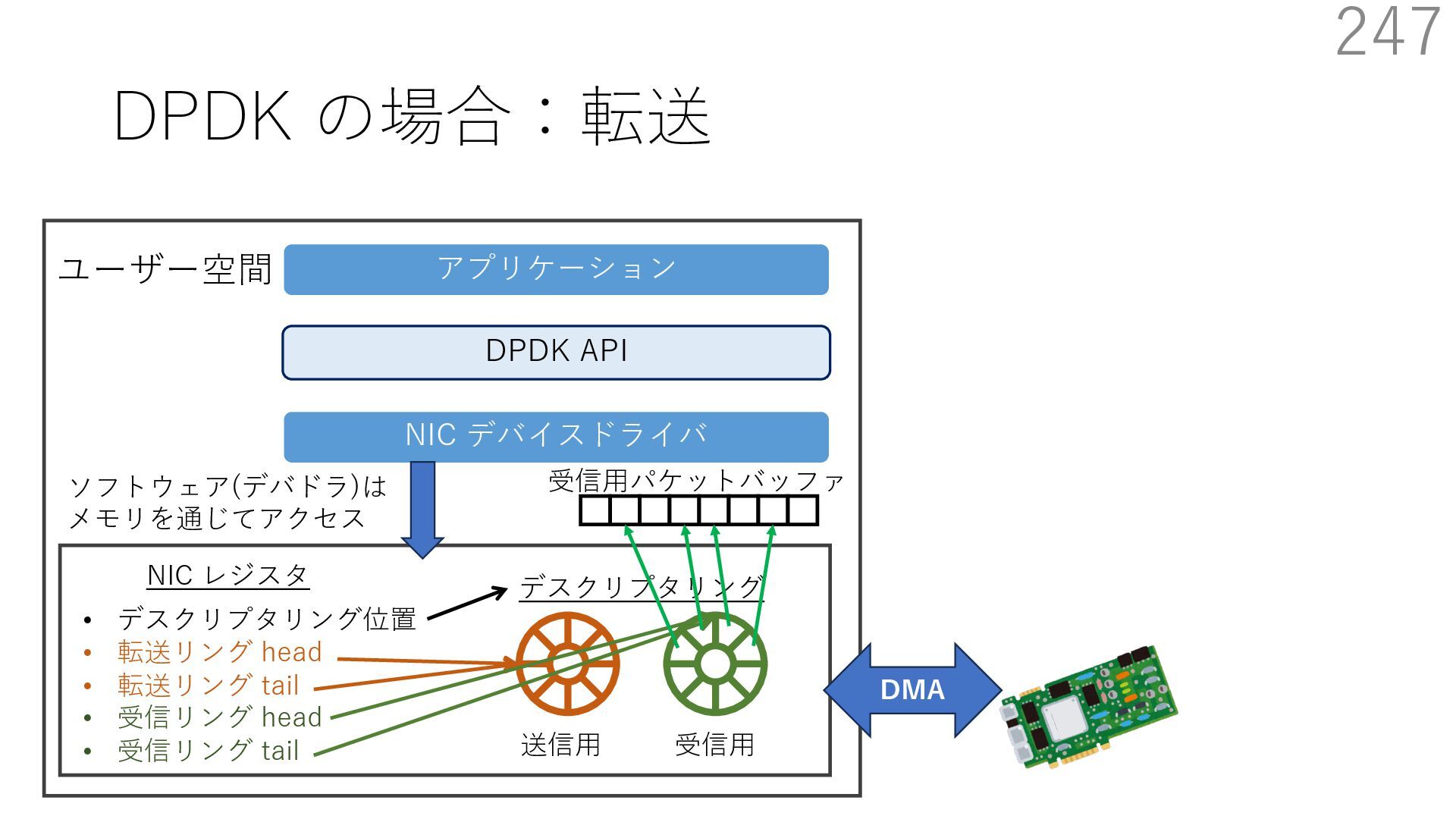{kind=link}
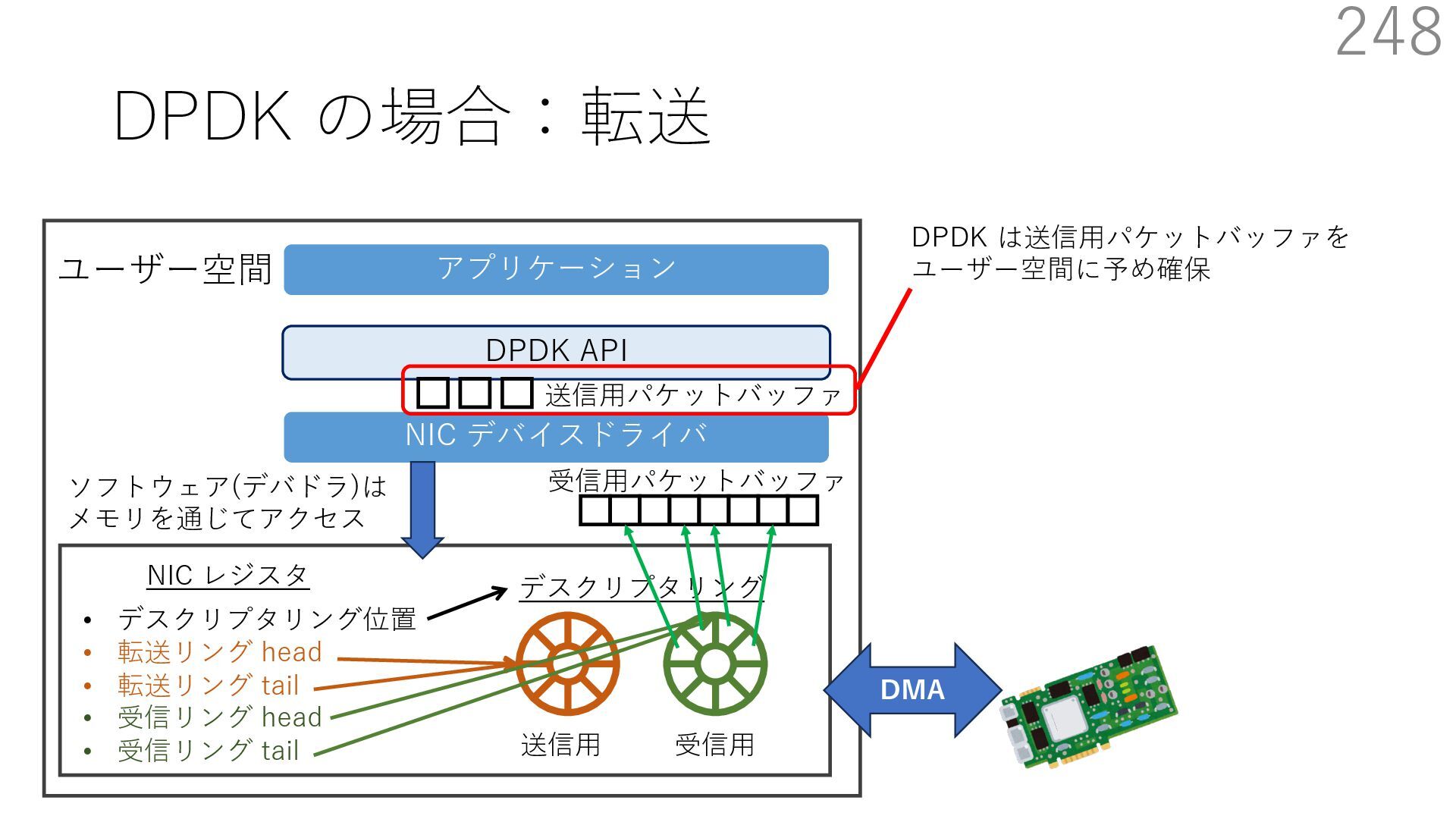{kind=link}
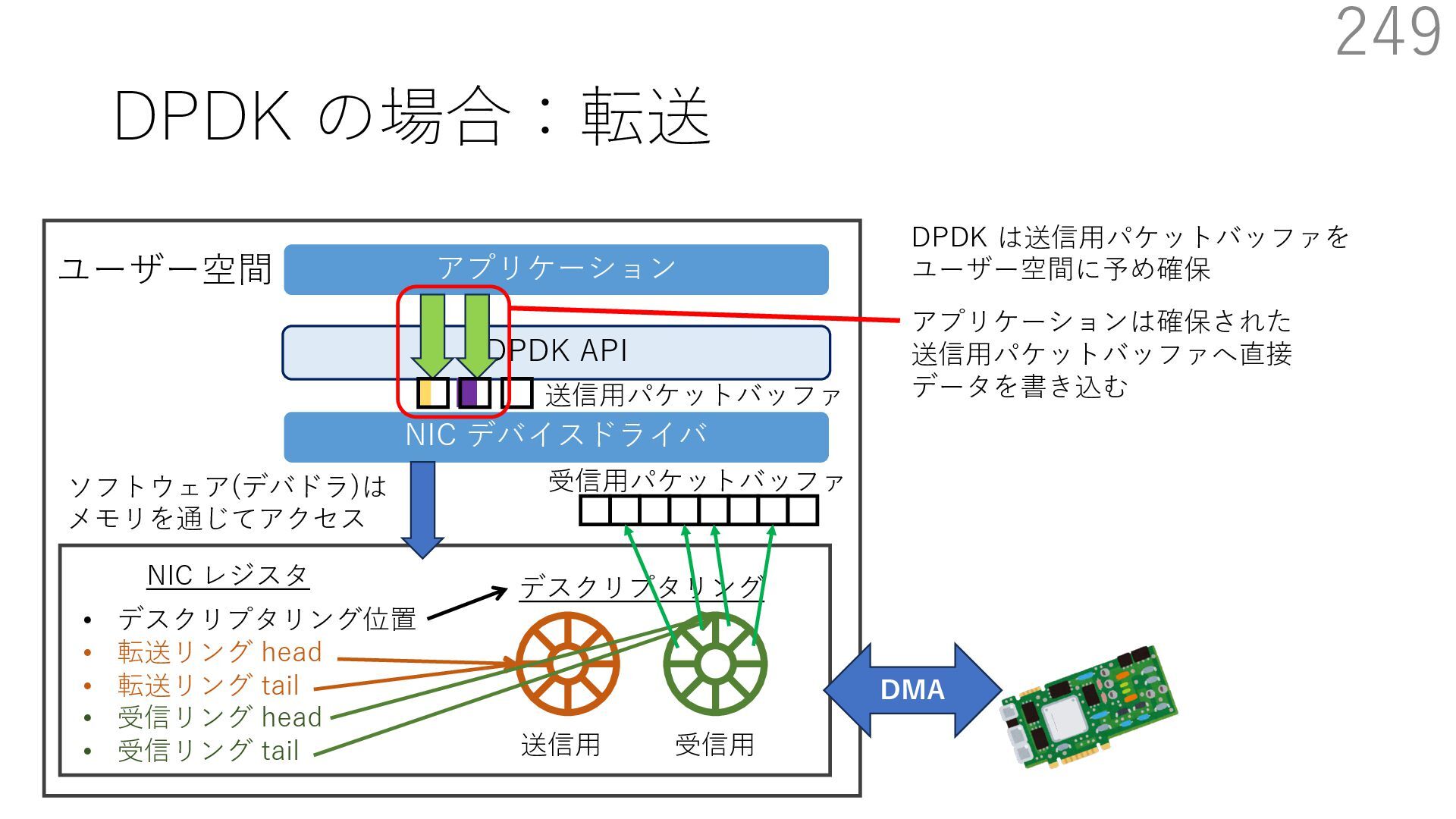{kind=link}
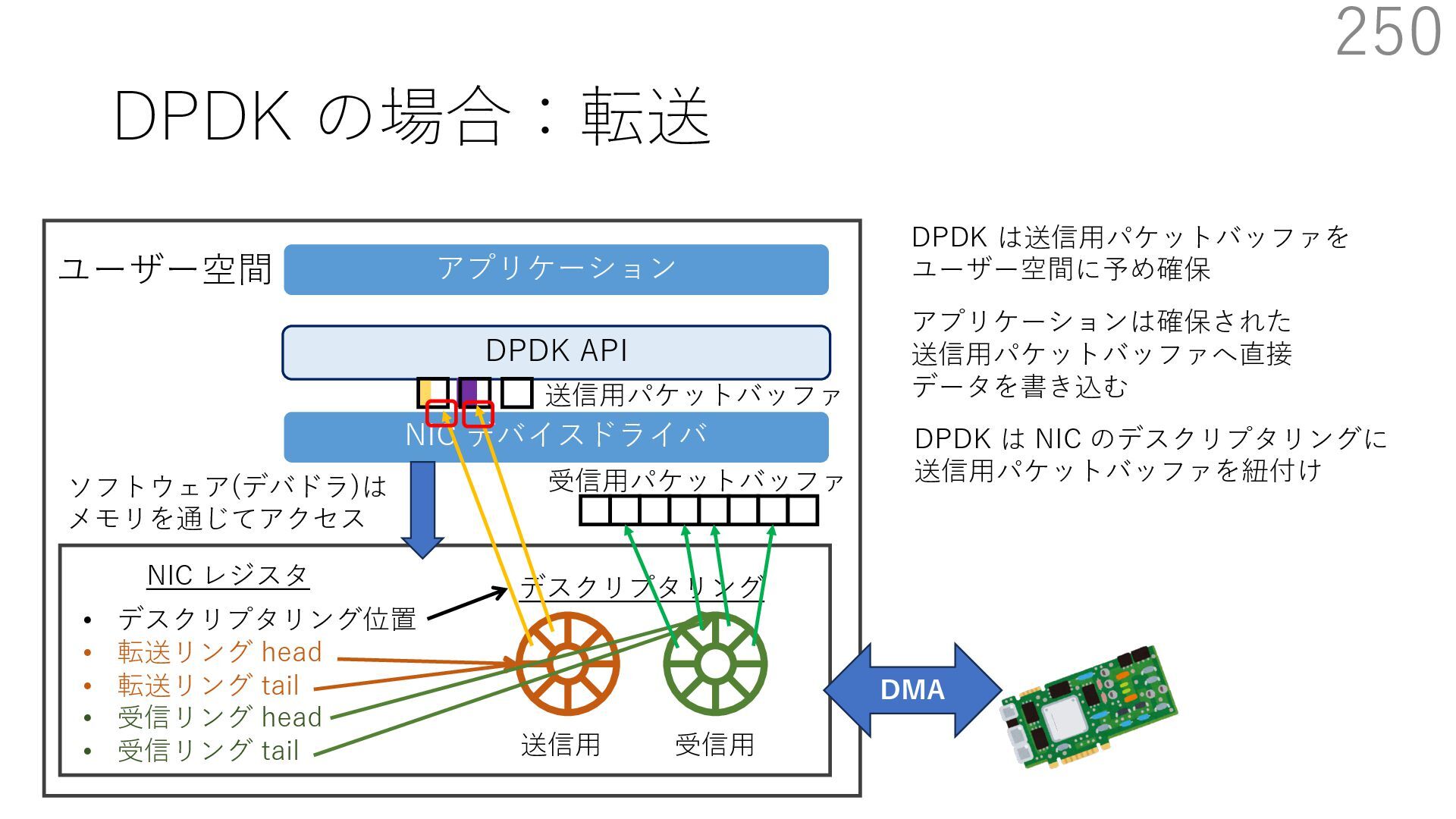{kind=link}
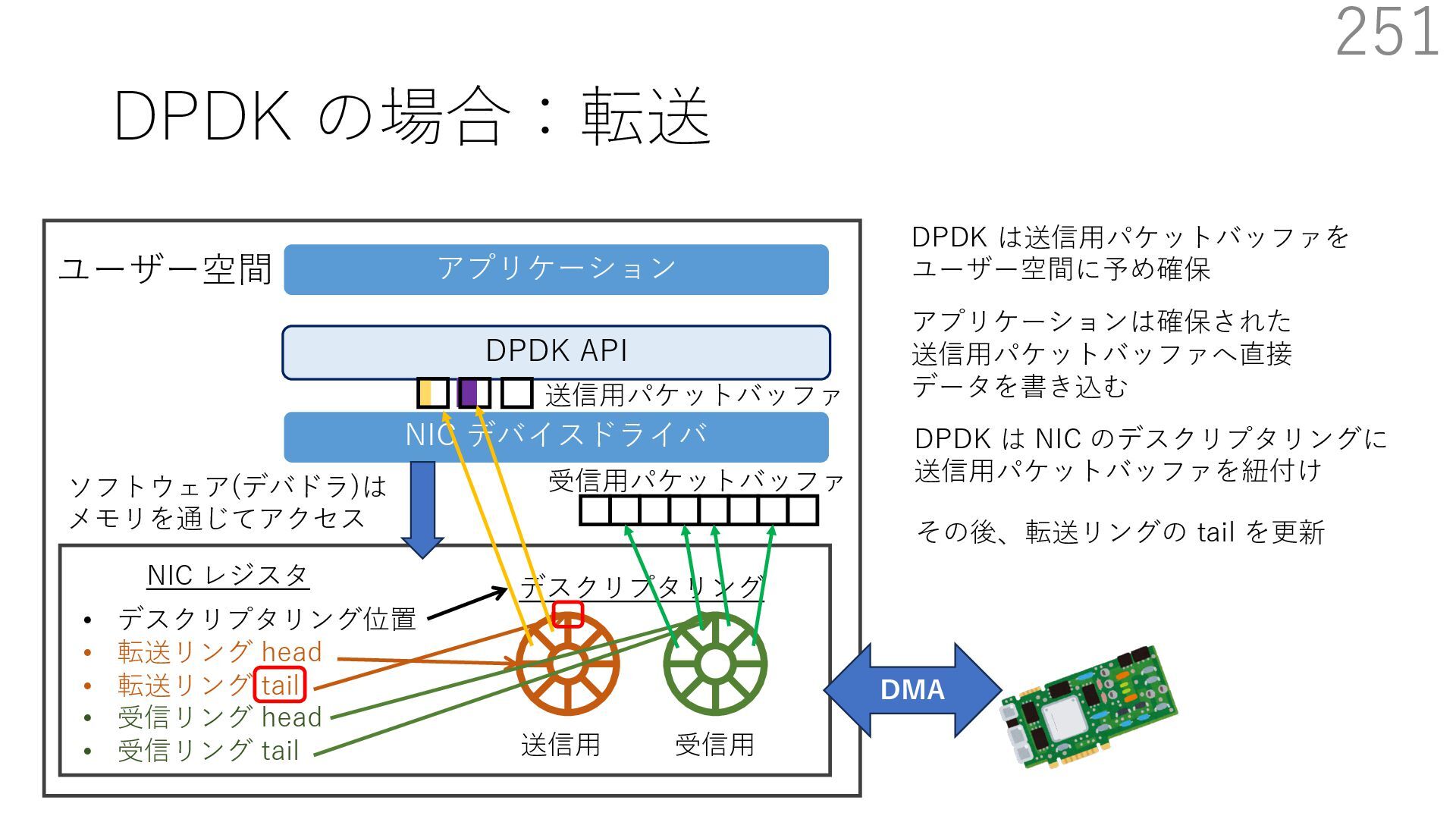{kind=link}
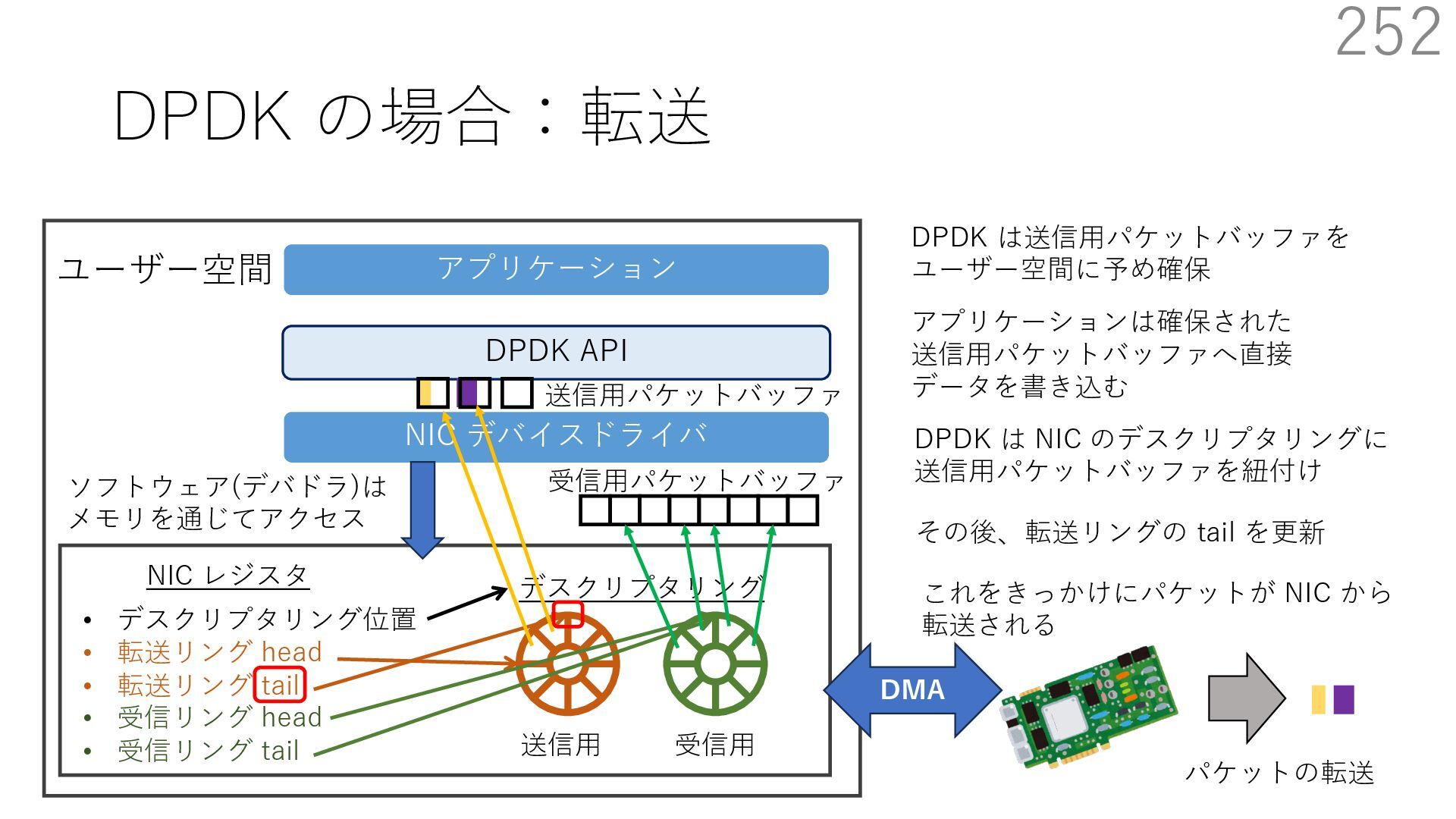{kind=link}
{kind=link}
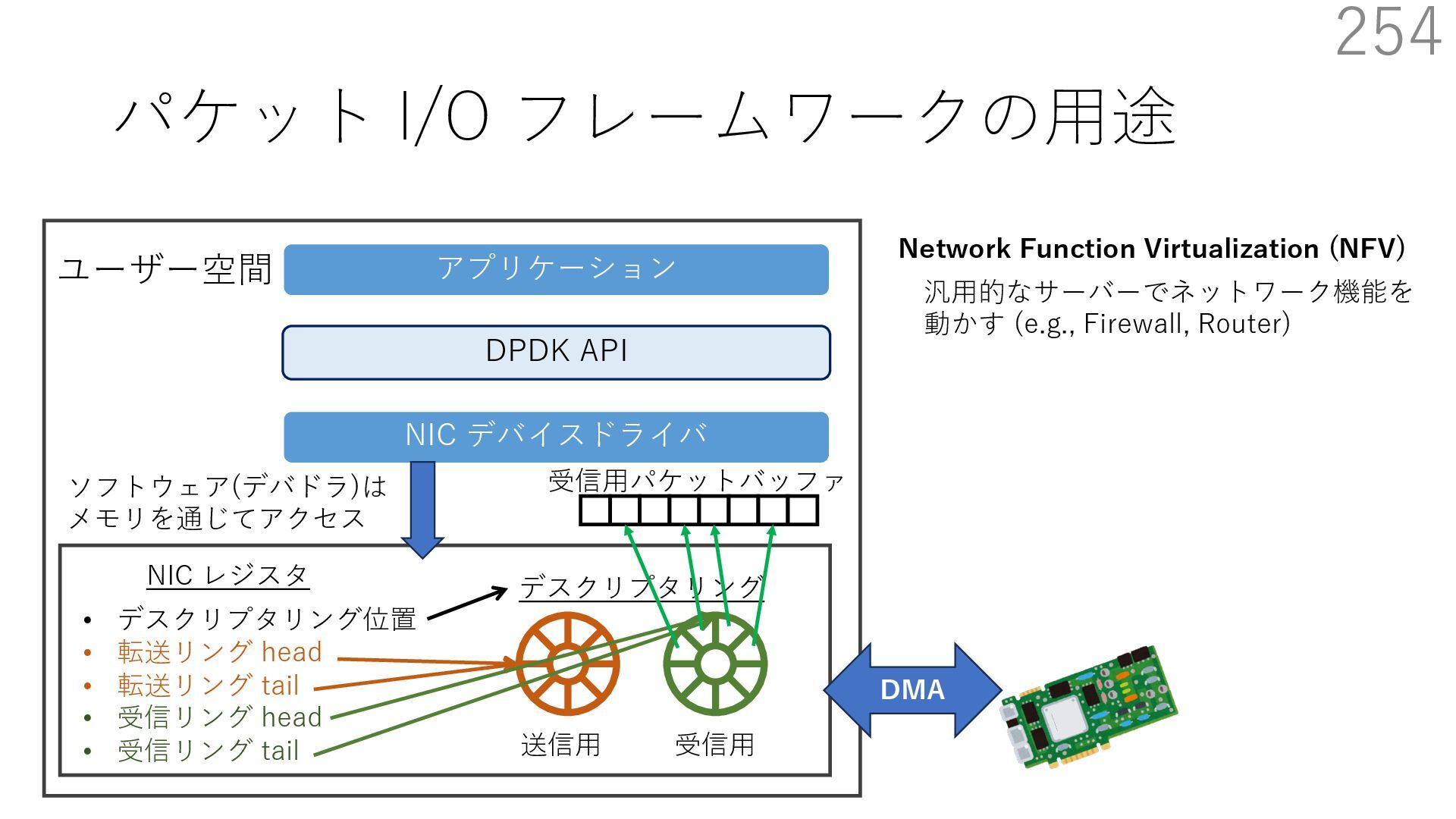{kind=link}
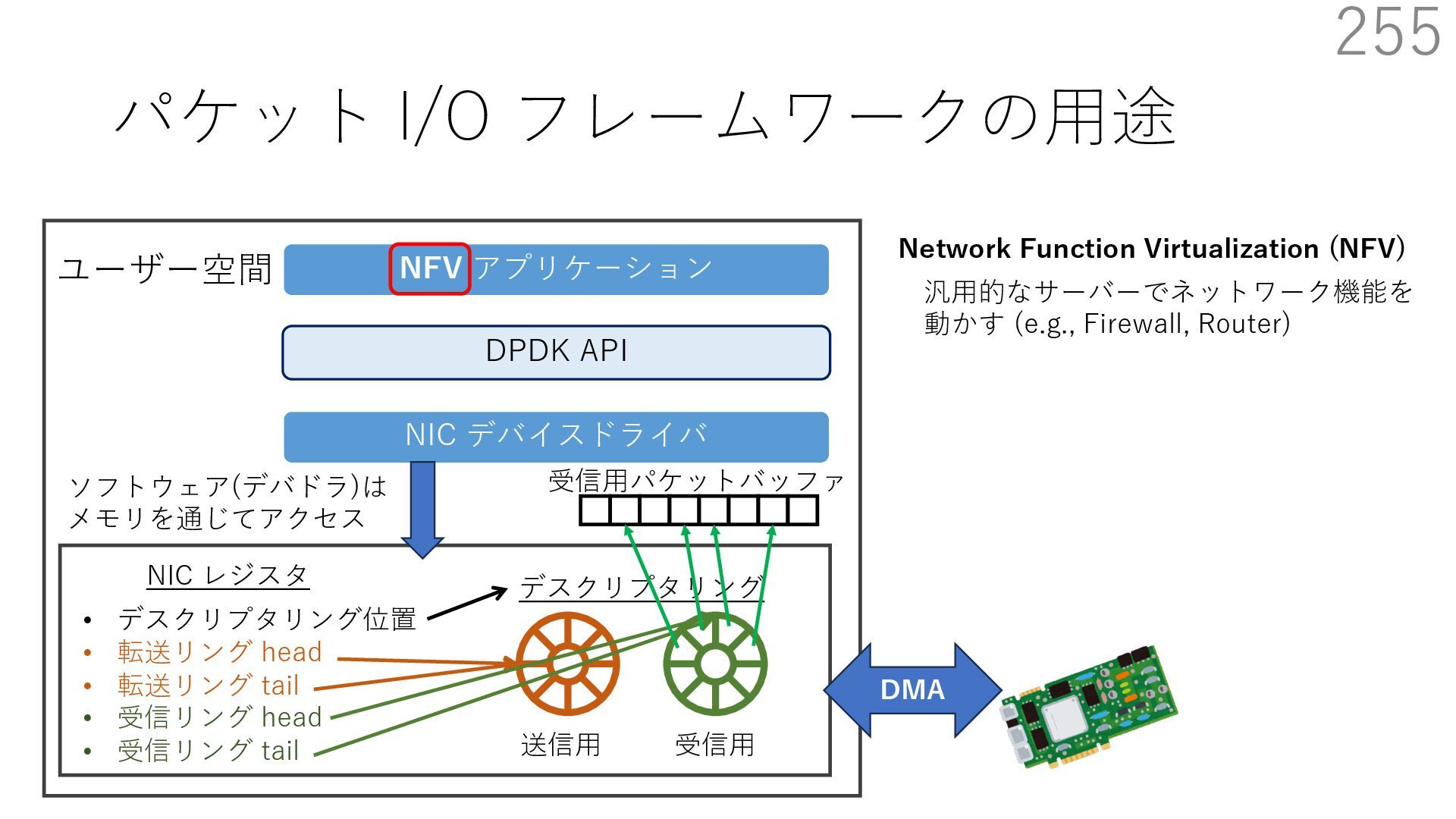{kind=link}
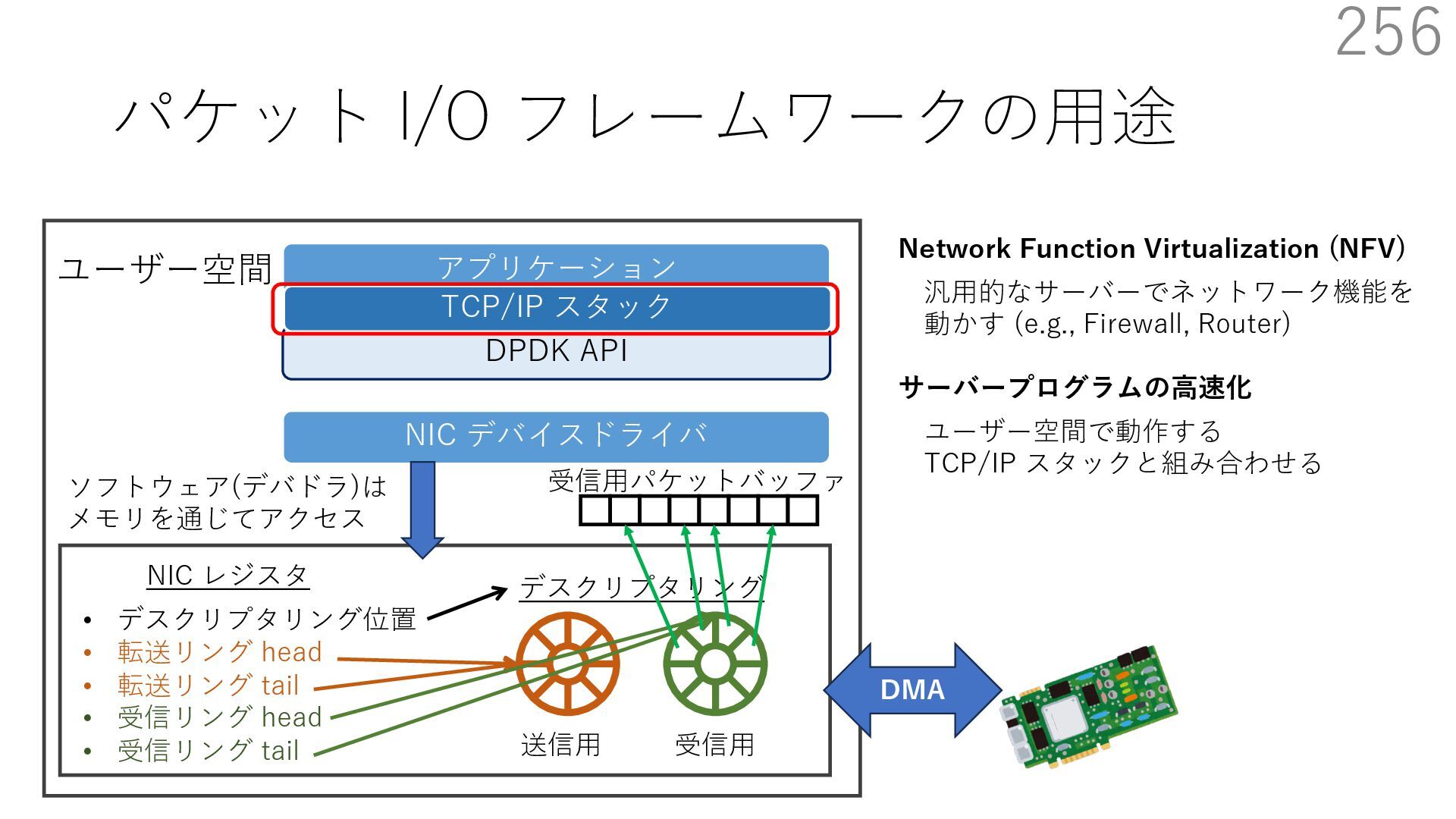{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
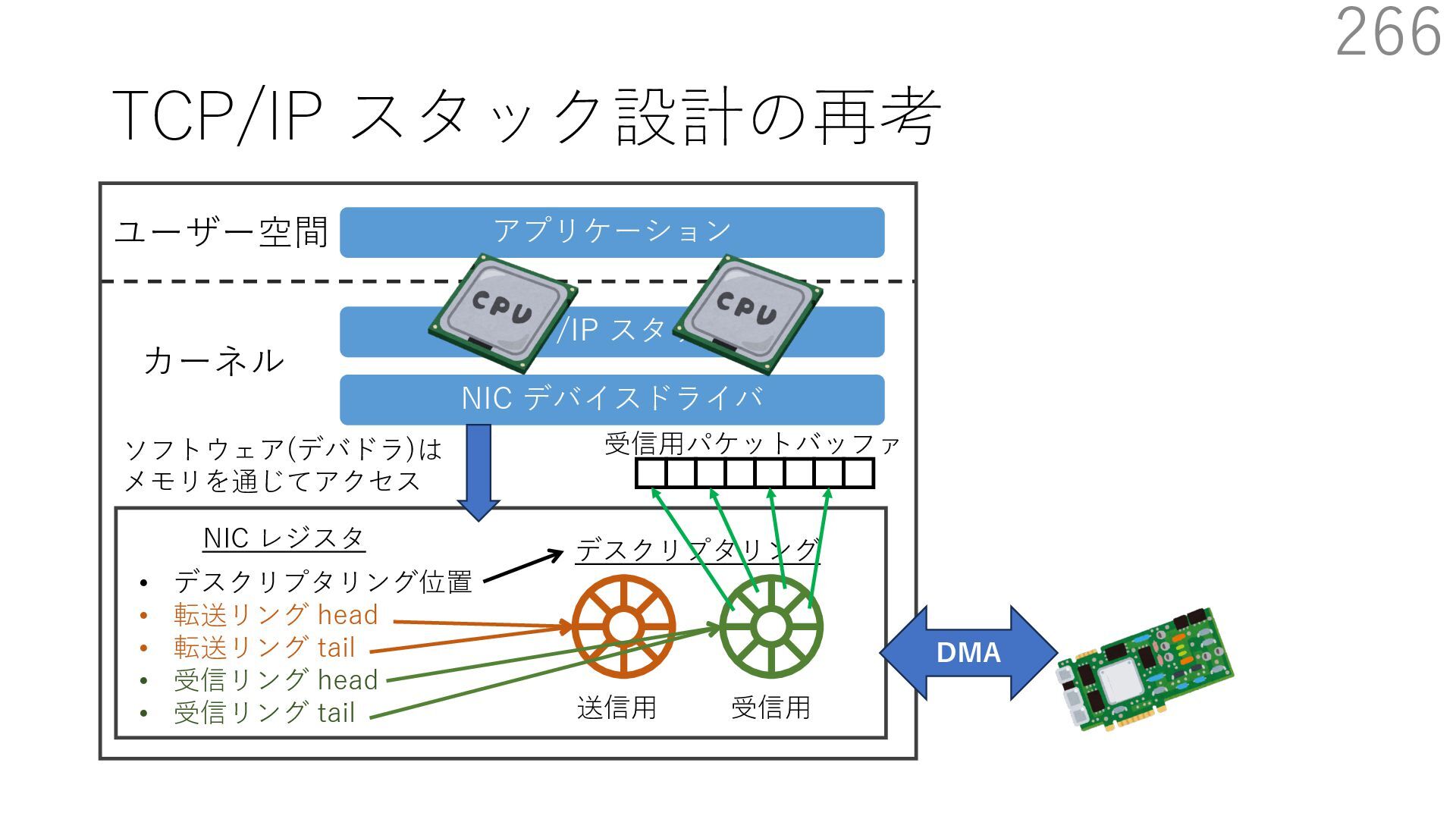{kind=link}
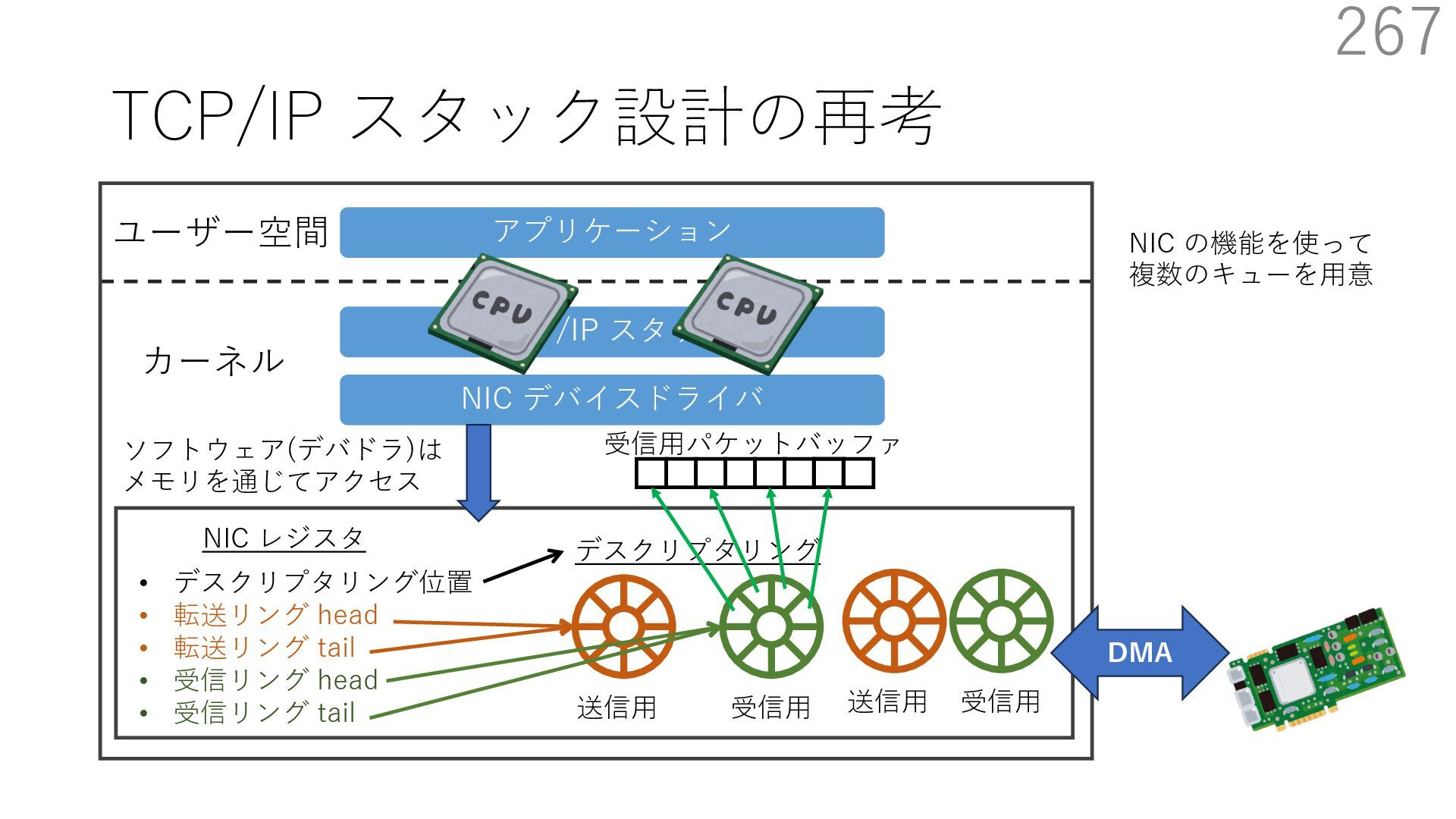{kind=link}
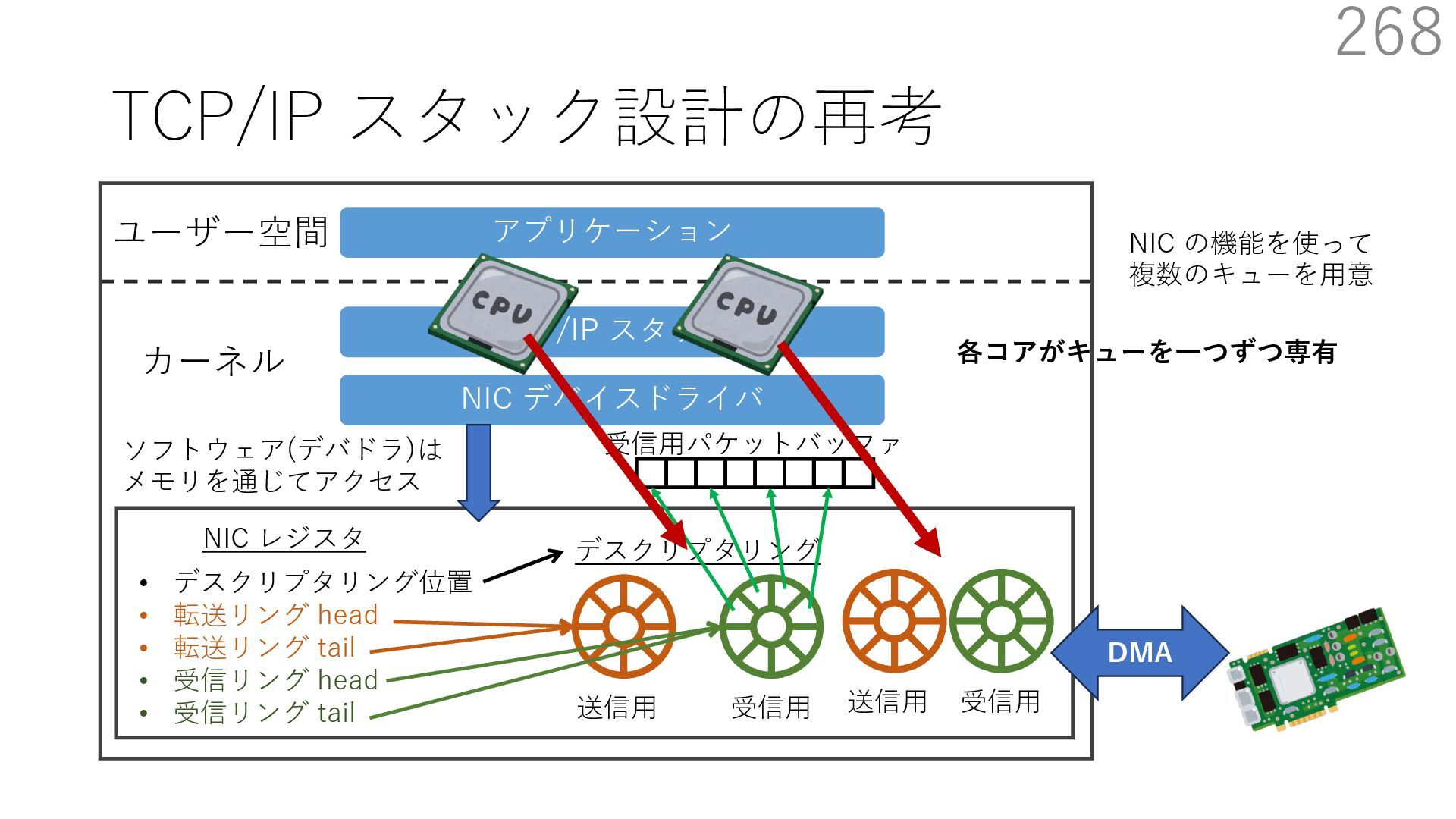{kind=link}
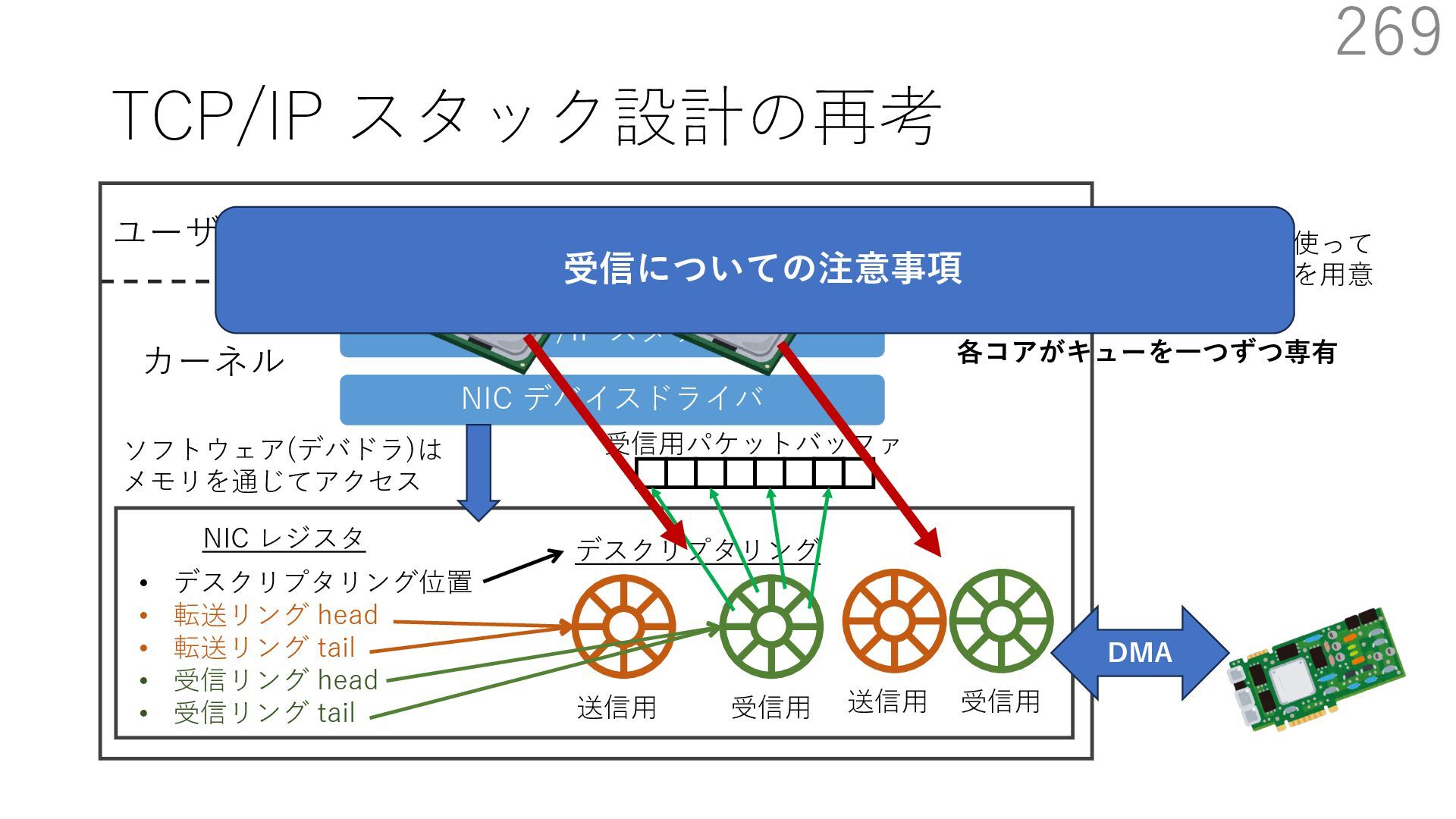{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
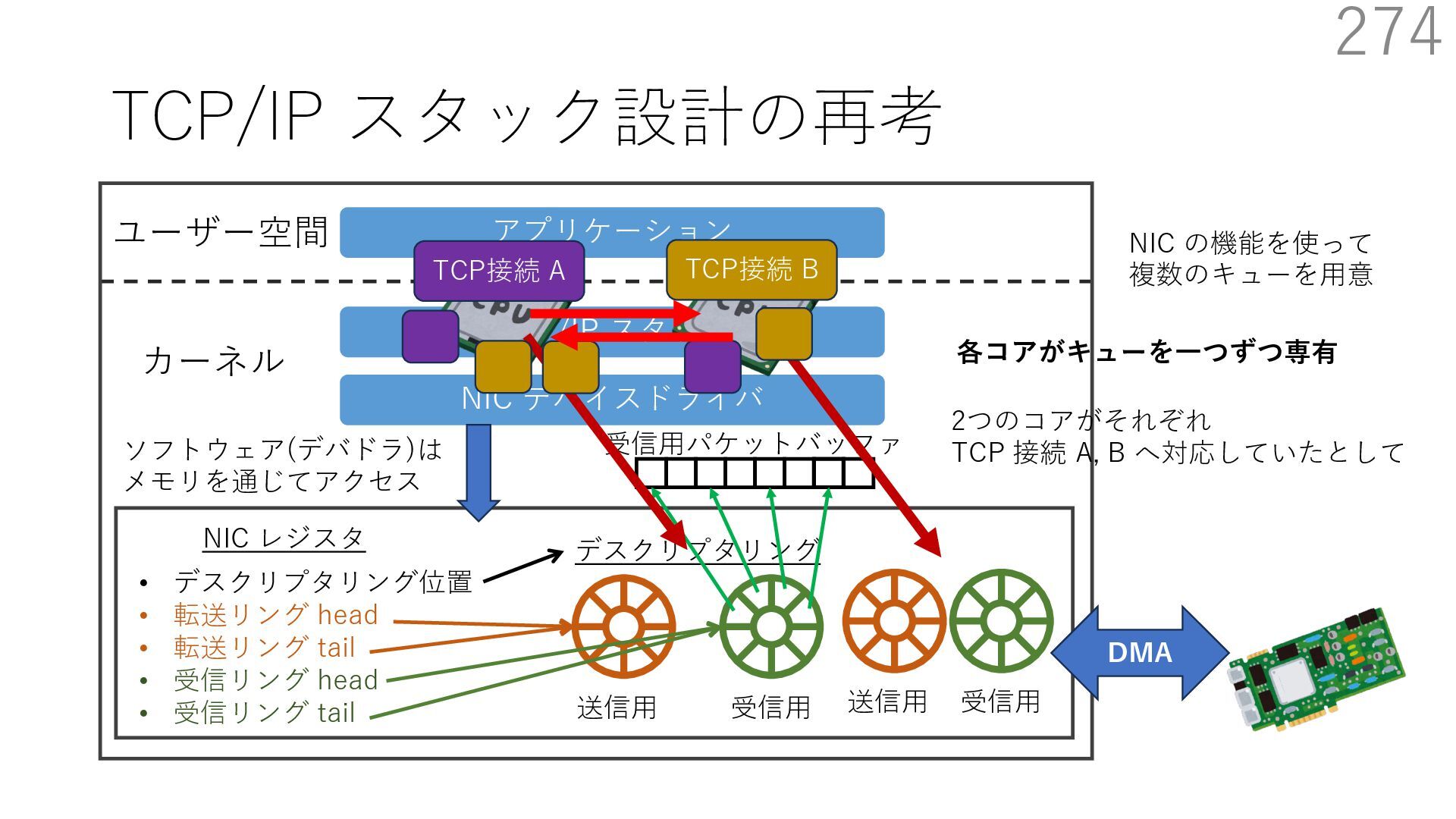{kind=link}
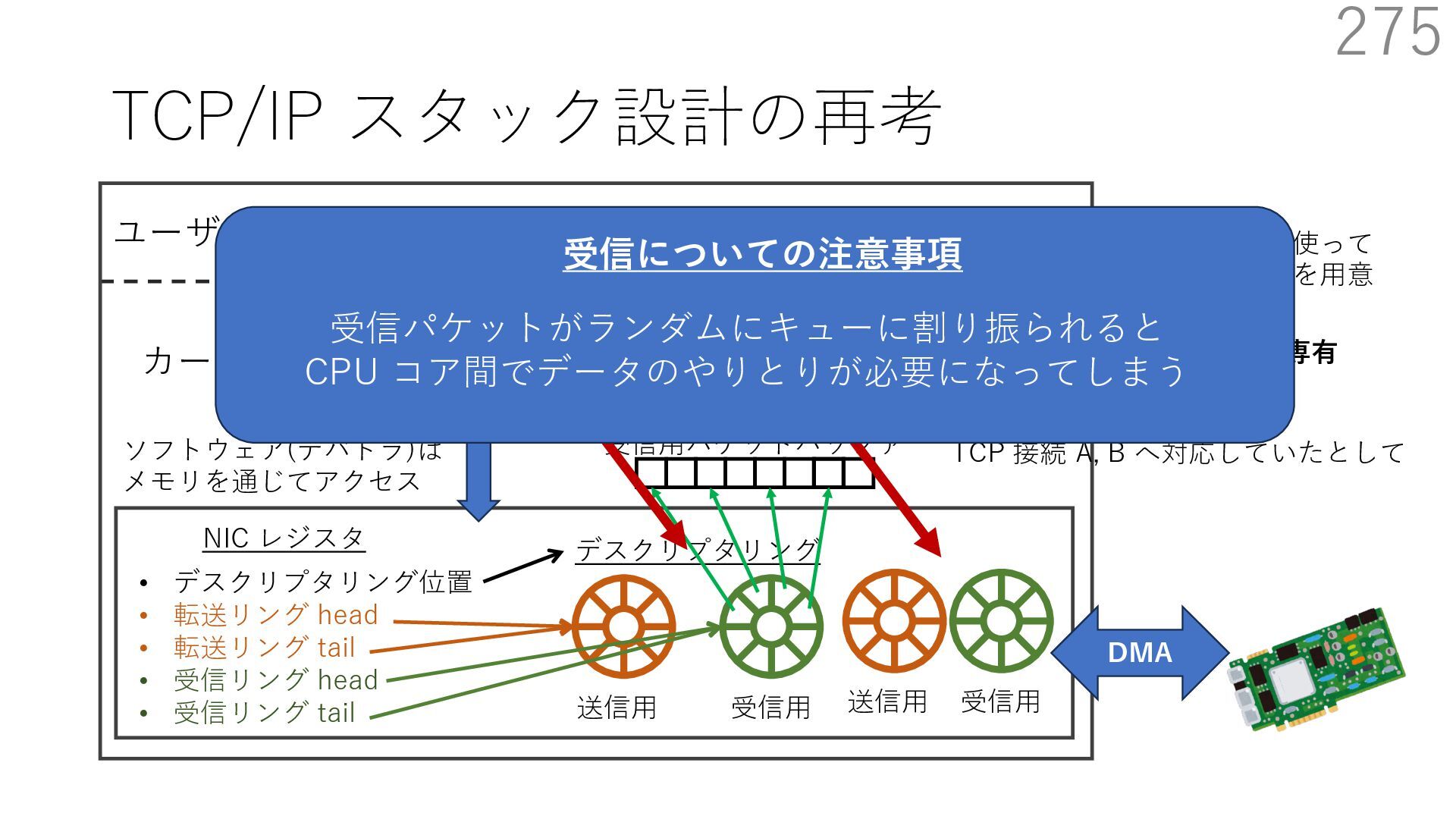{kind=link}
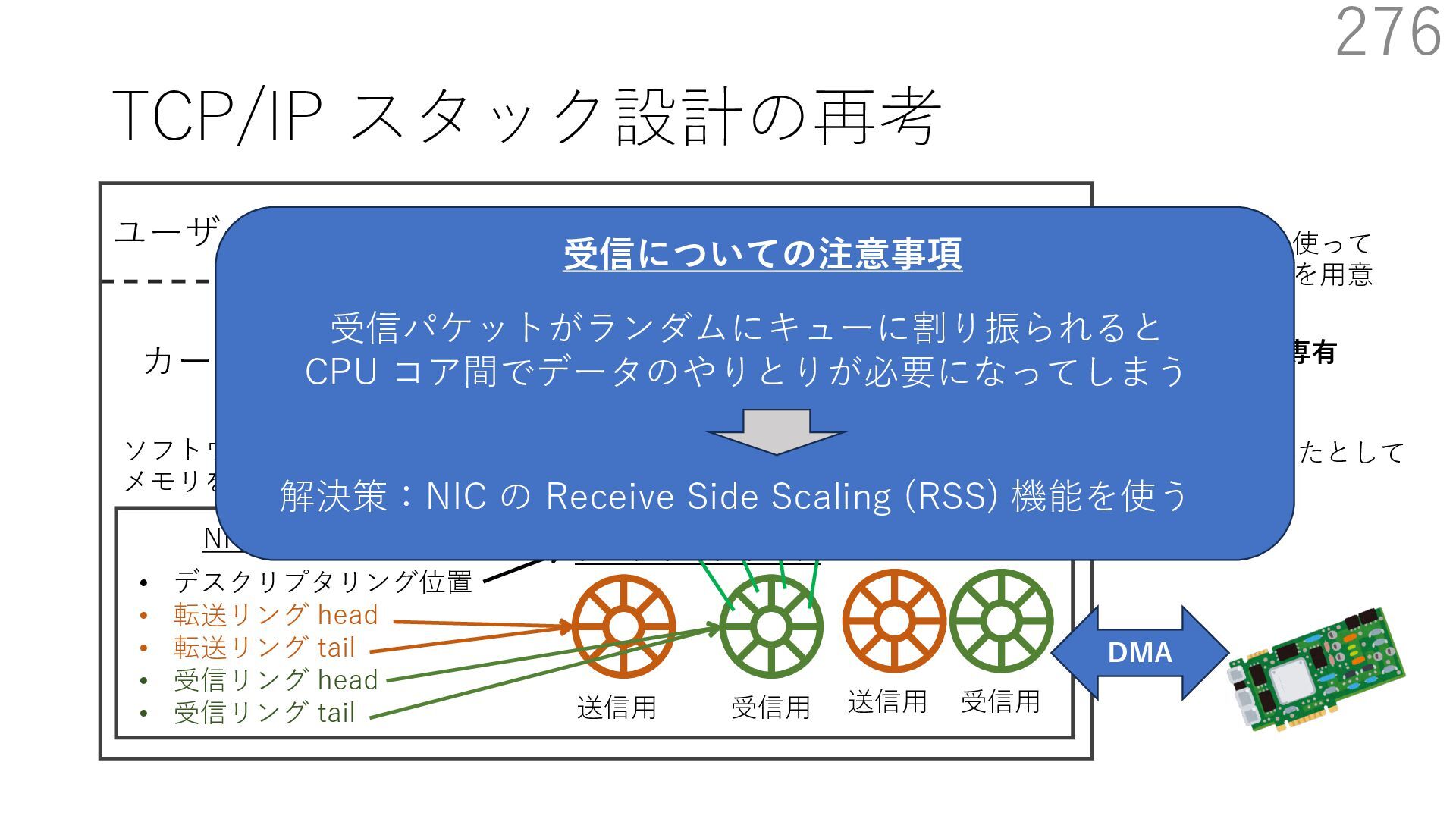{kind=link}
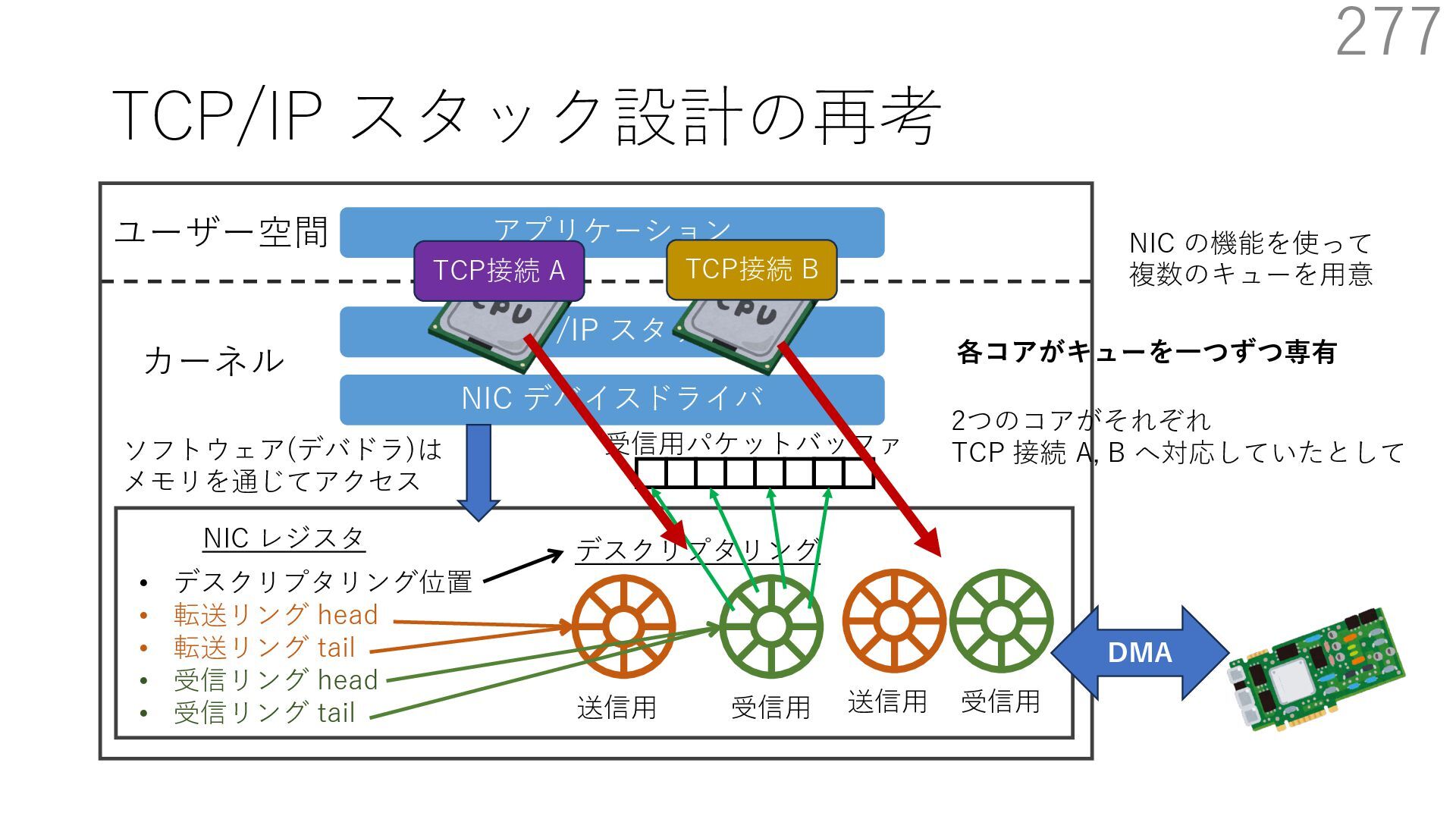{kind=link}
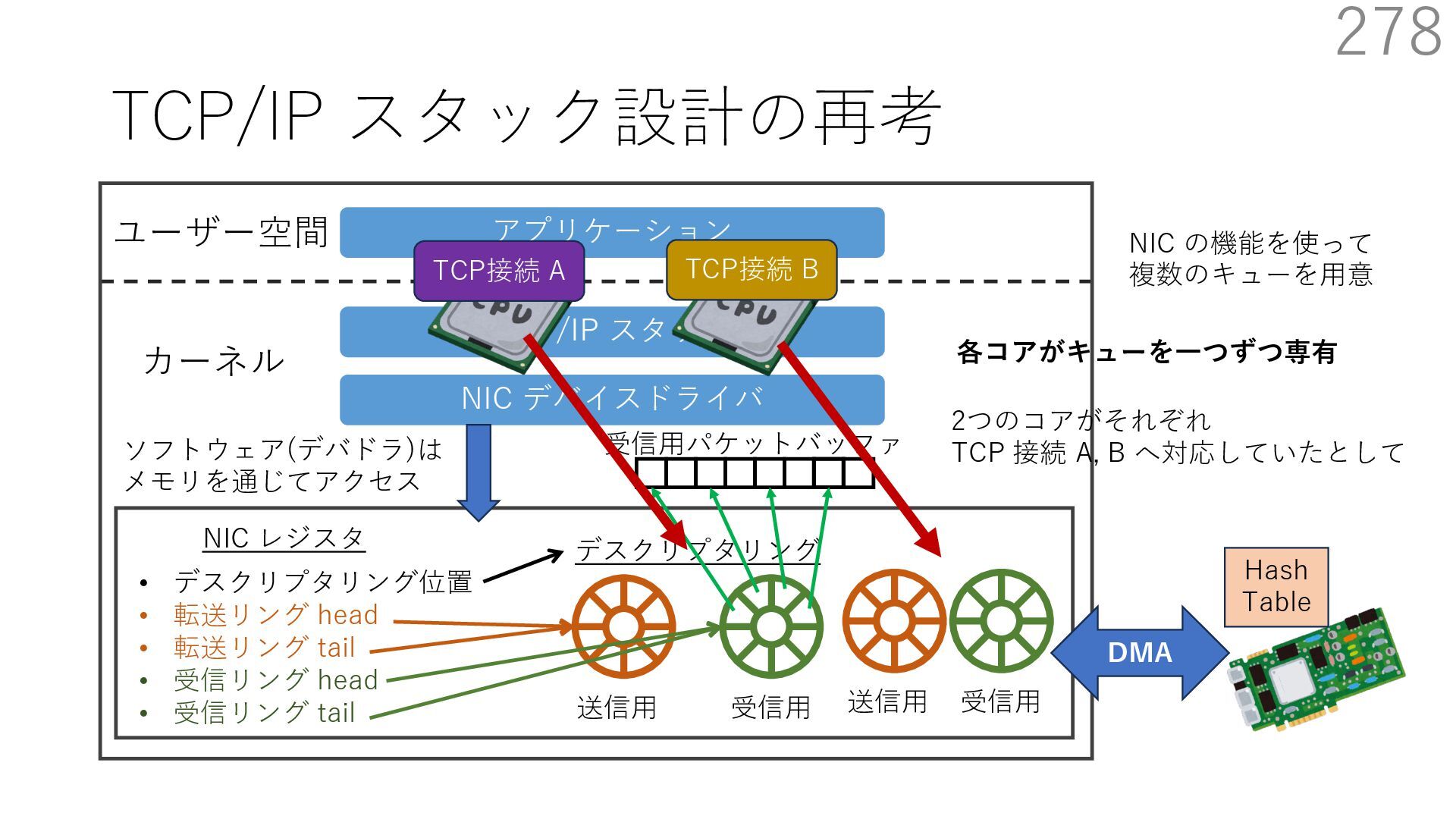{kind=link}
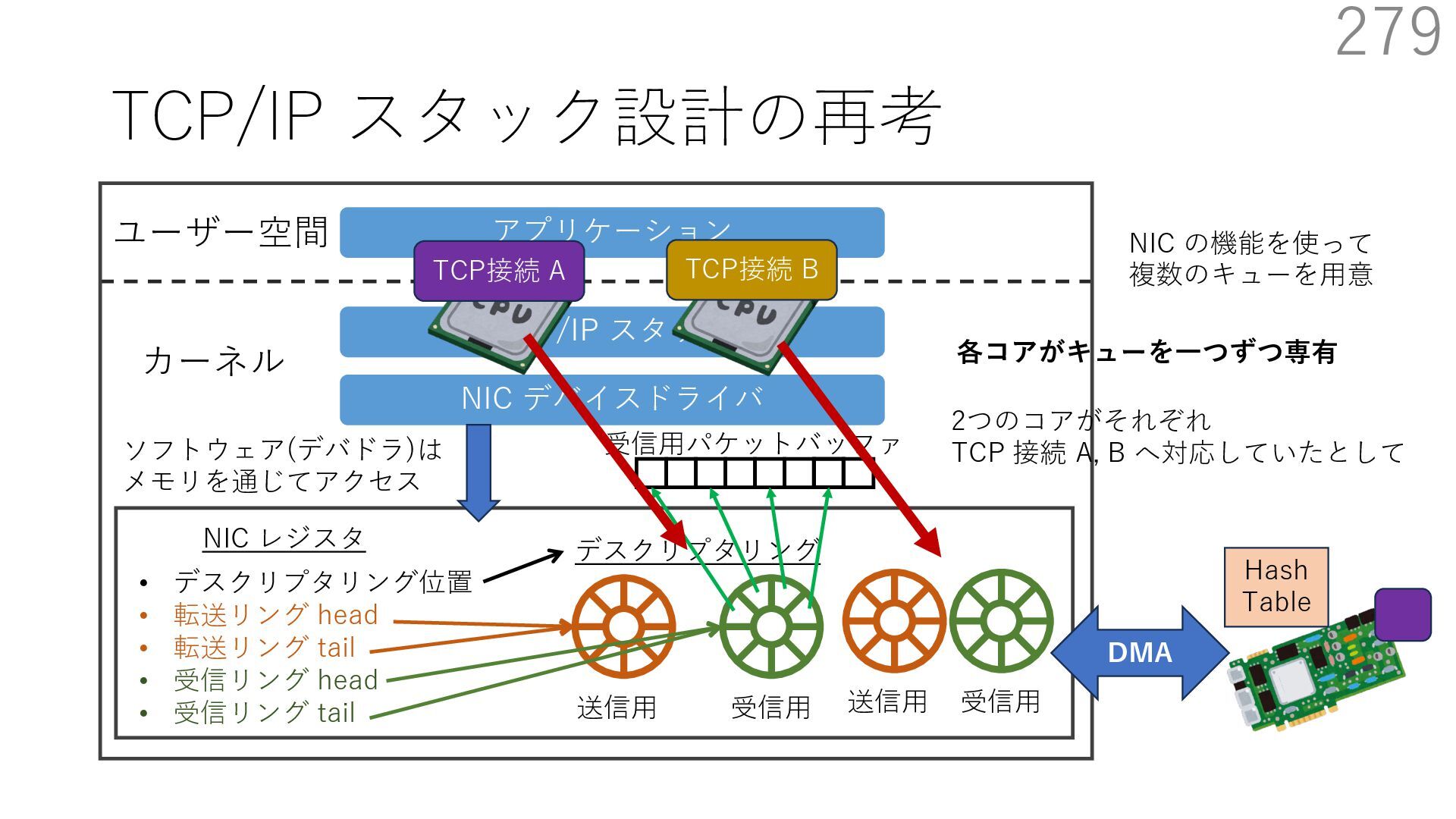{kind=link}
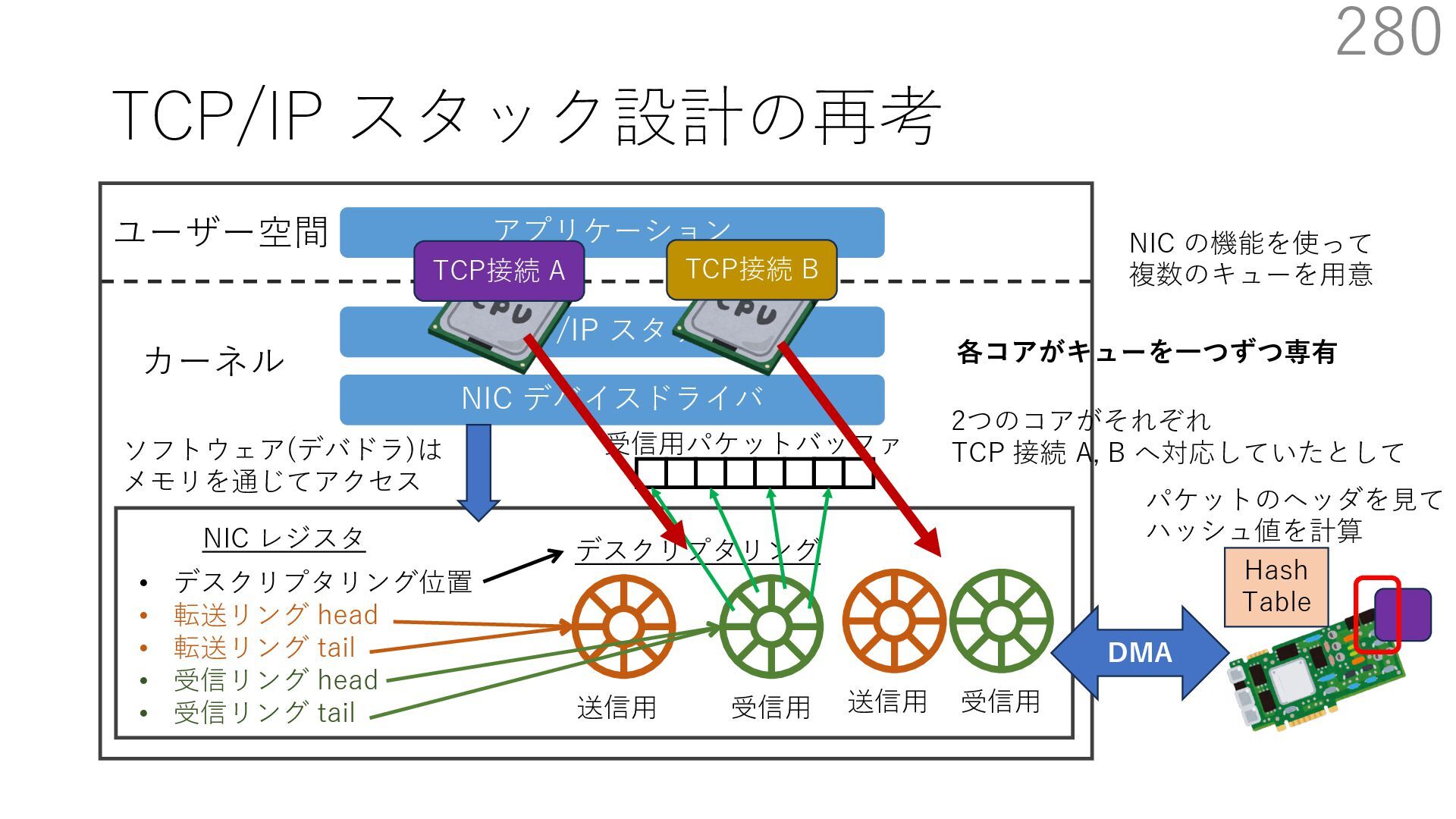{kind=link}
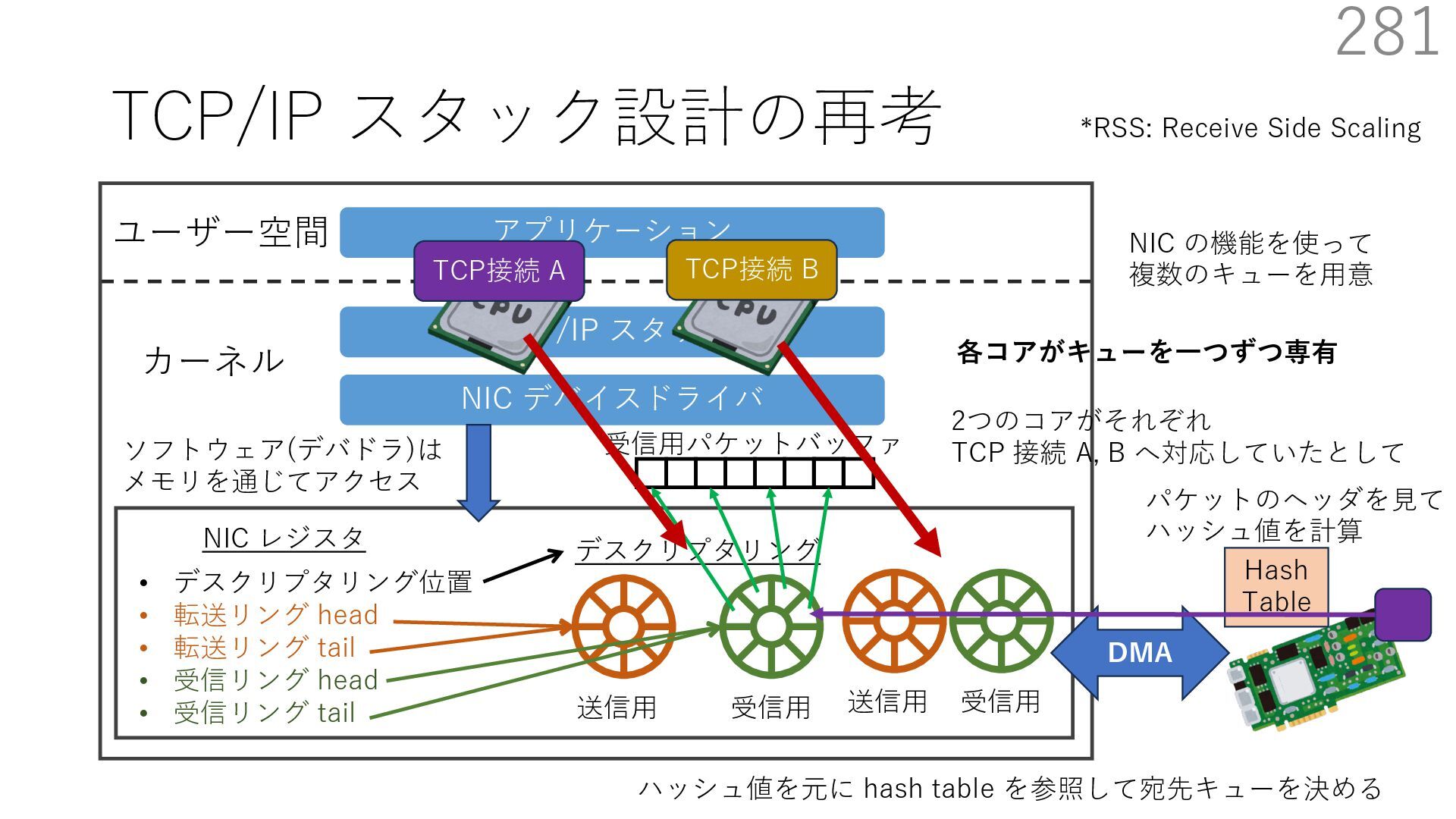{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
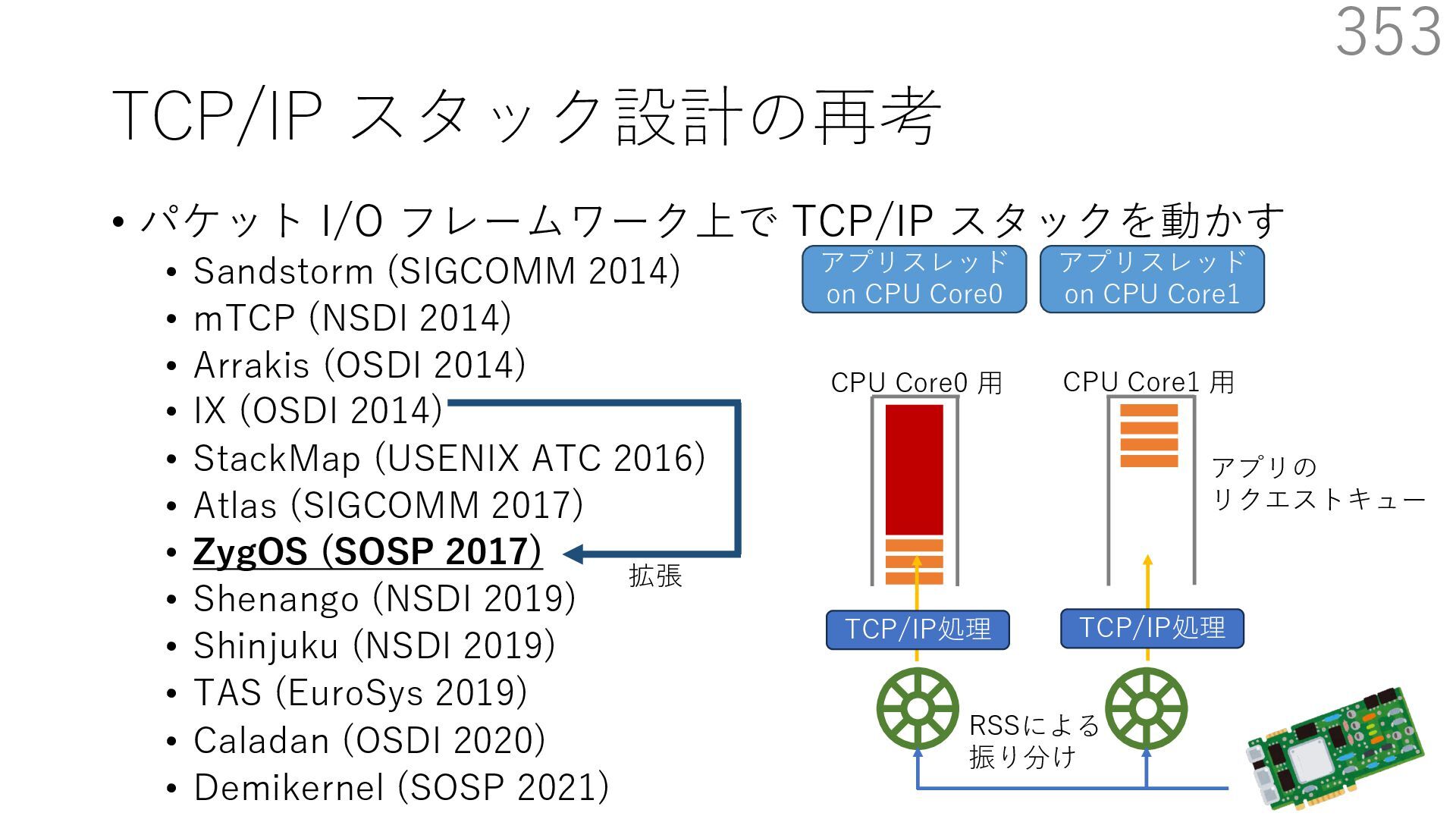{kind=link}
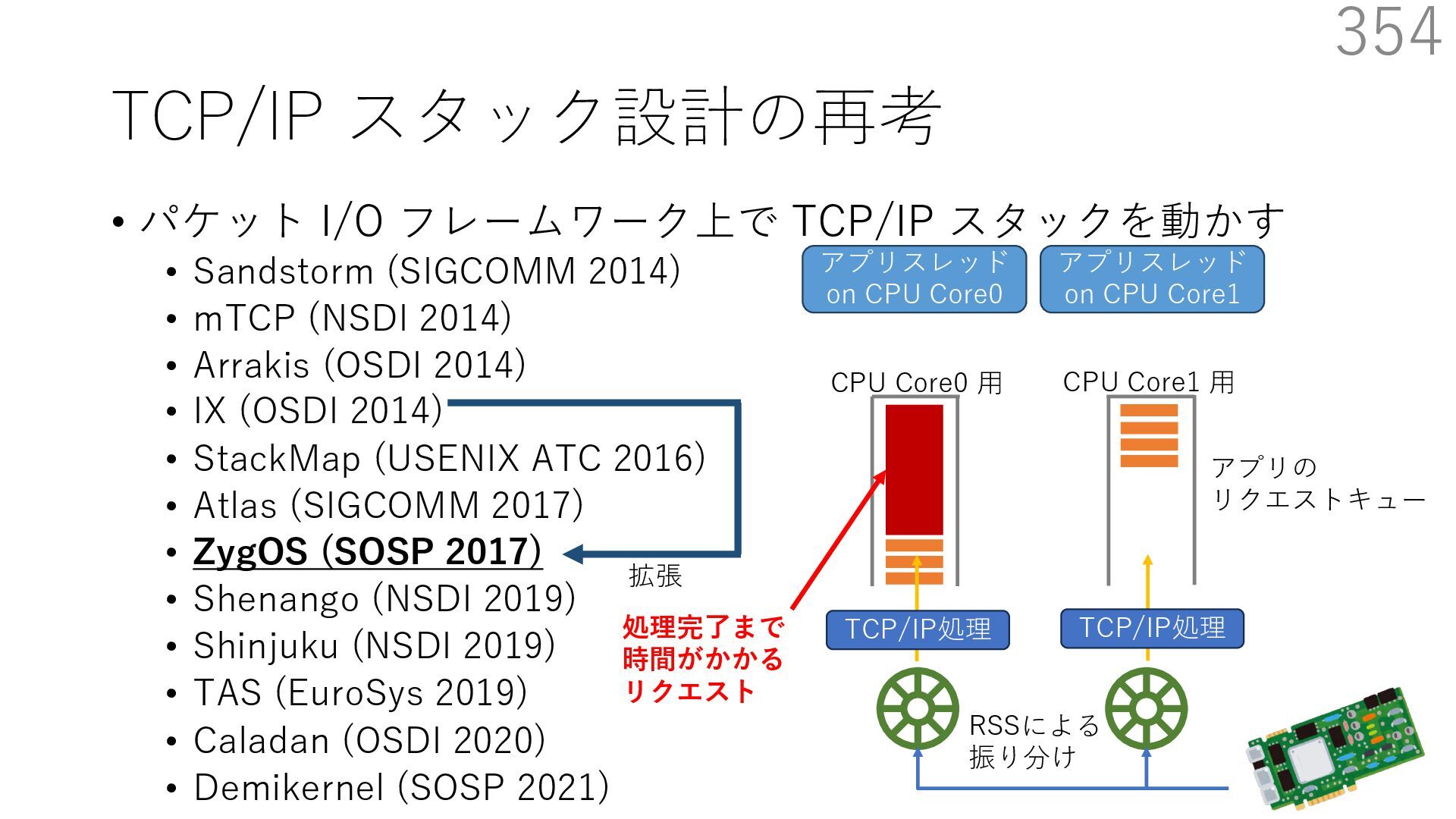{kind=link}
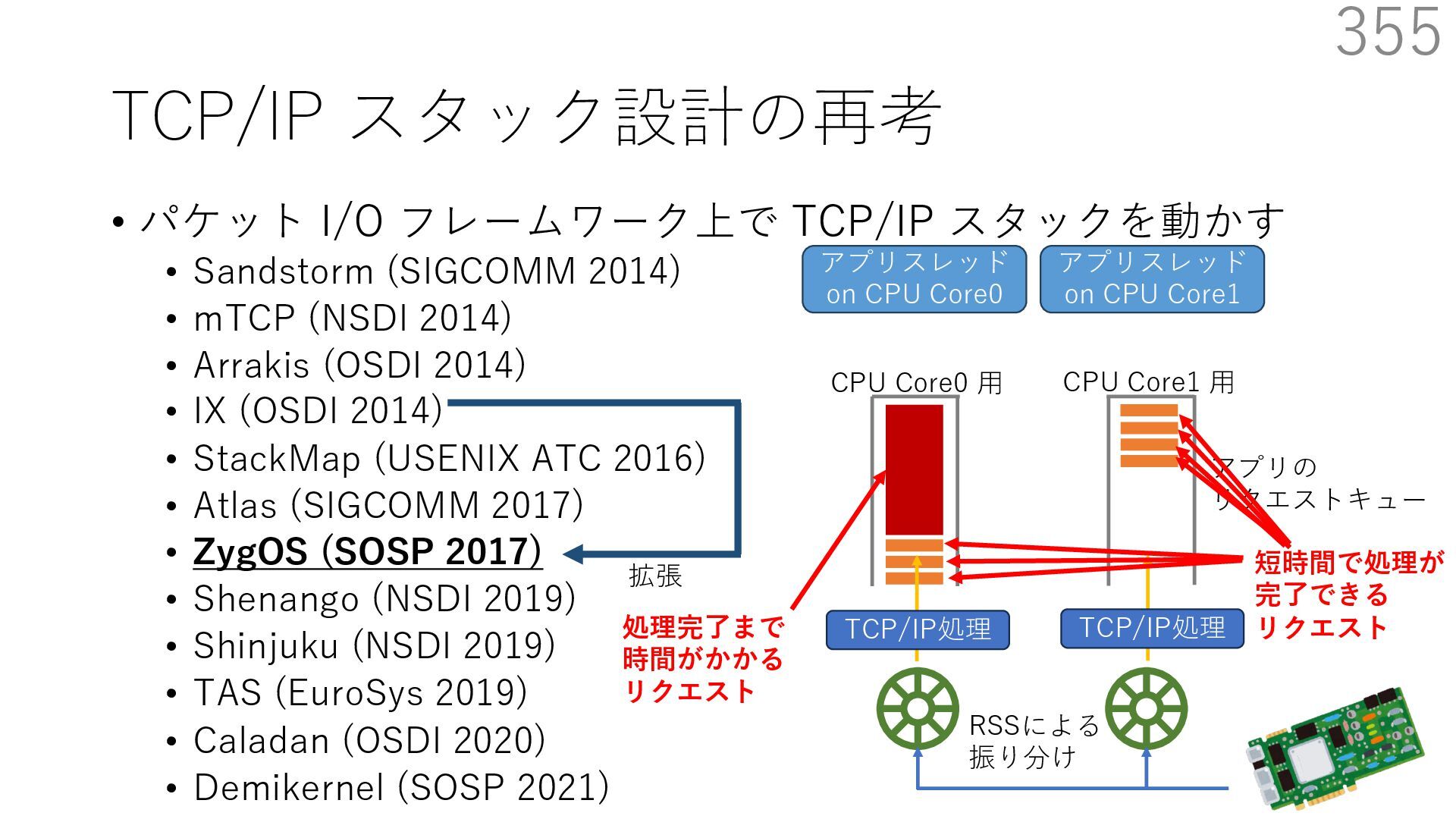{kind=link}
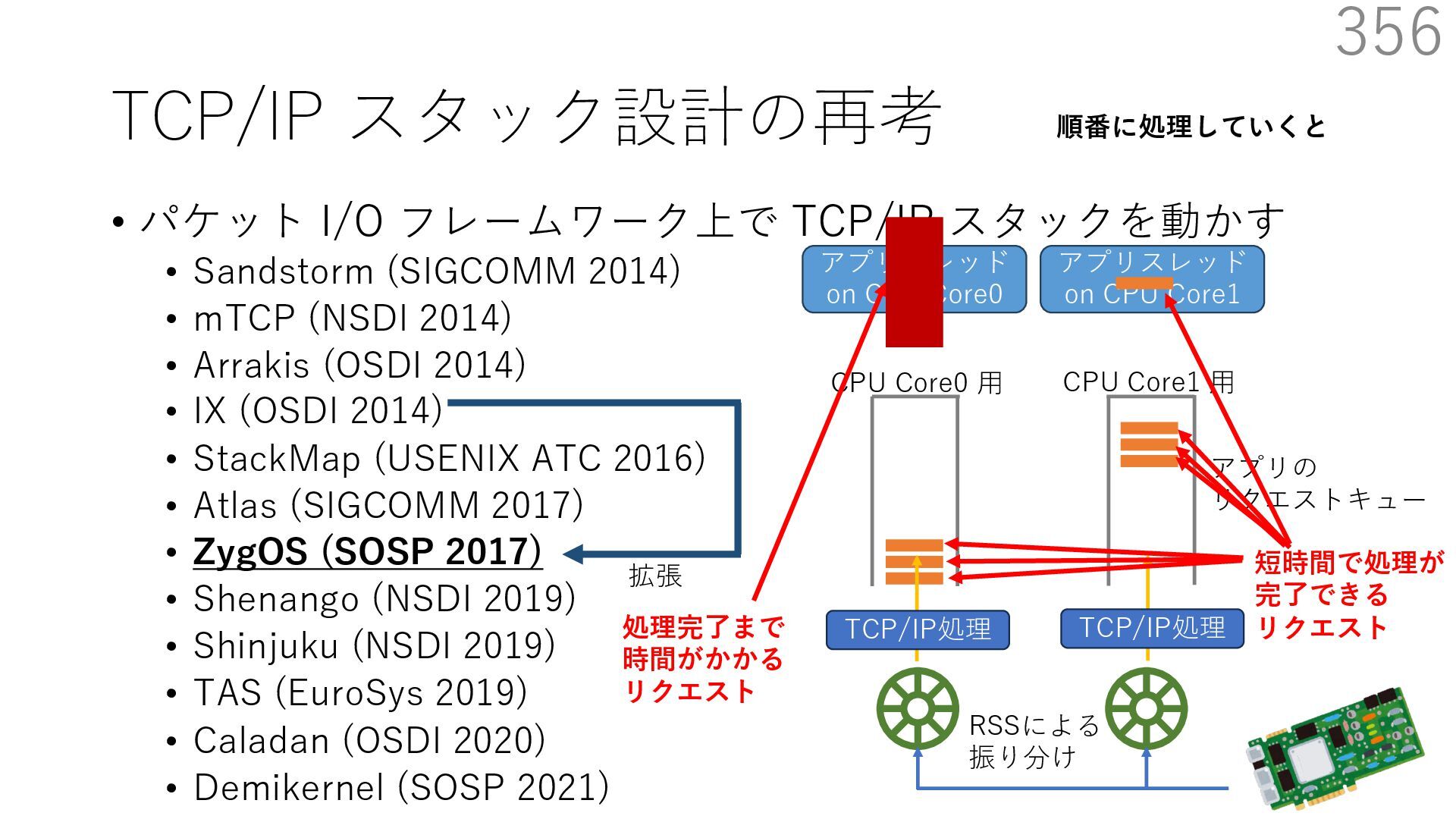{kind=link}
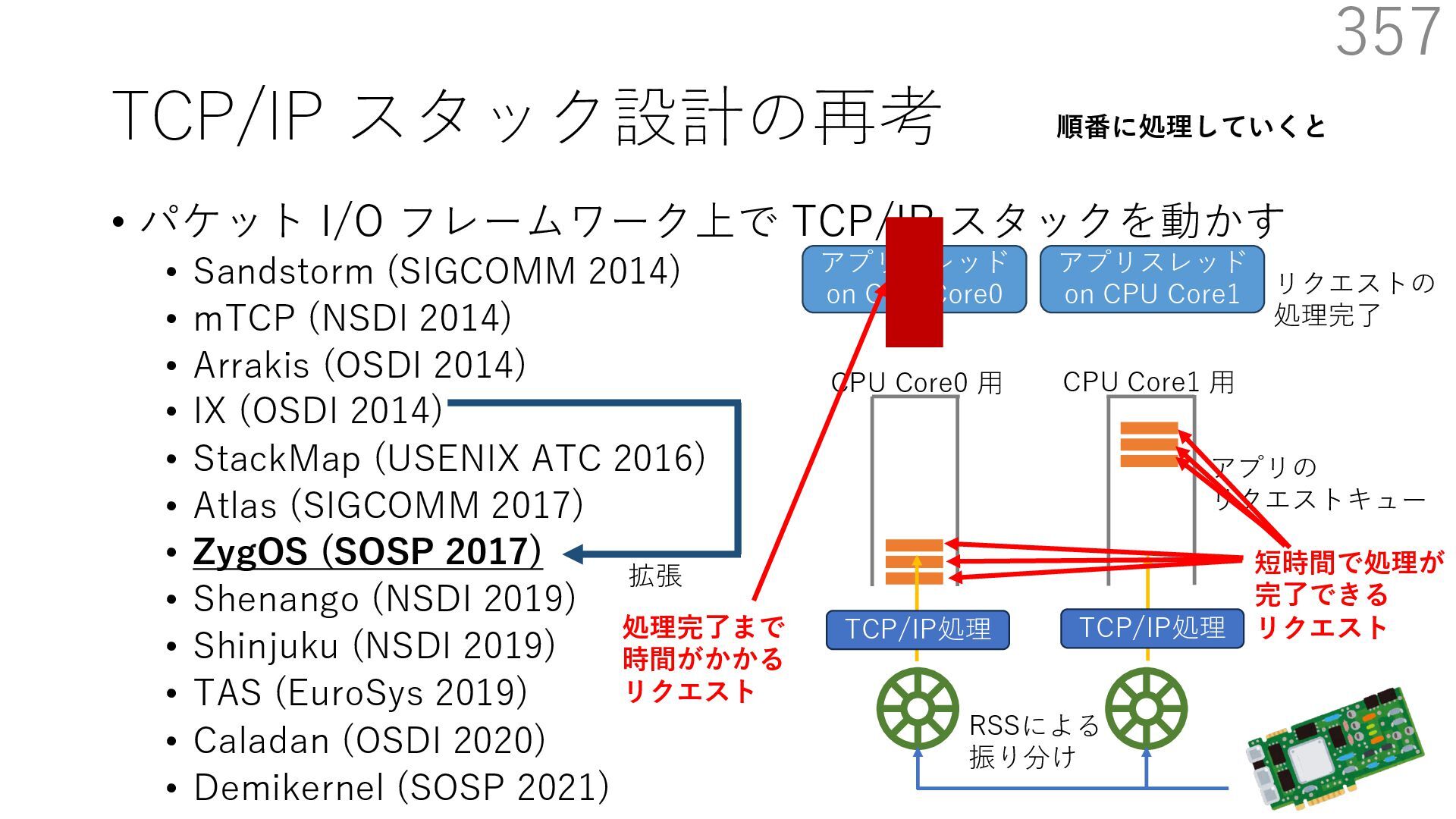{kind=link}
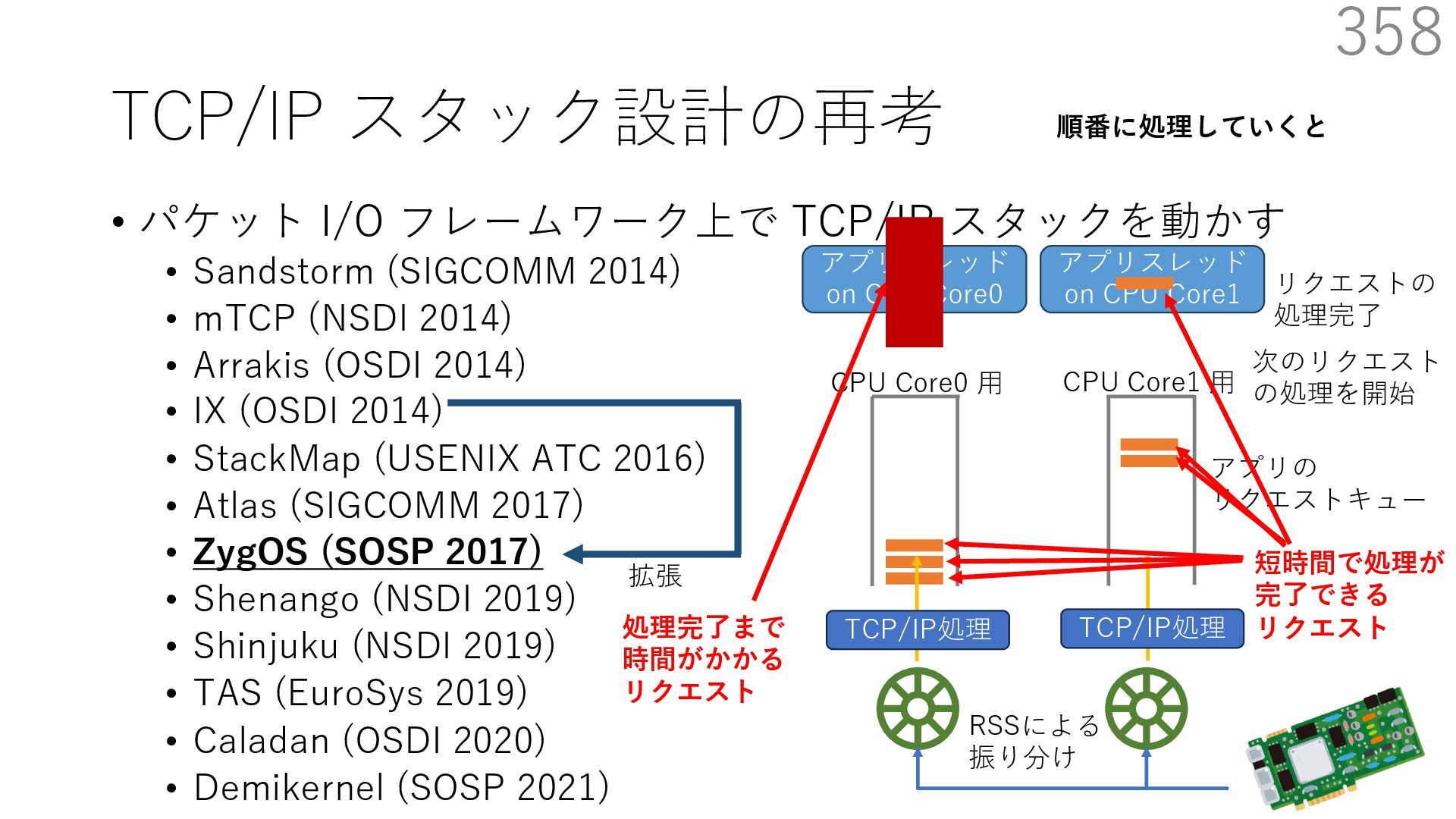{kind=link}
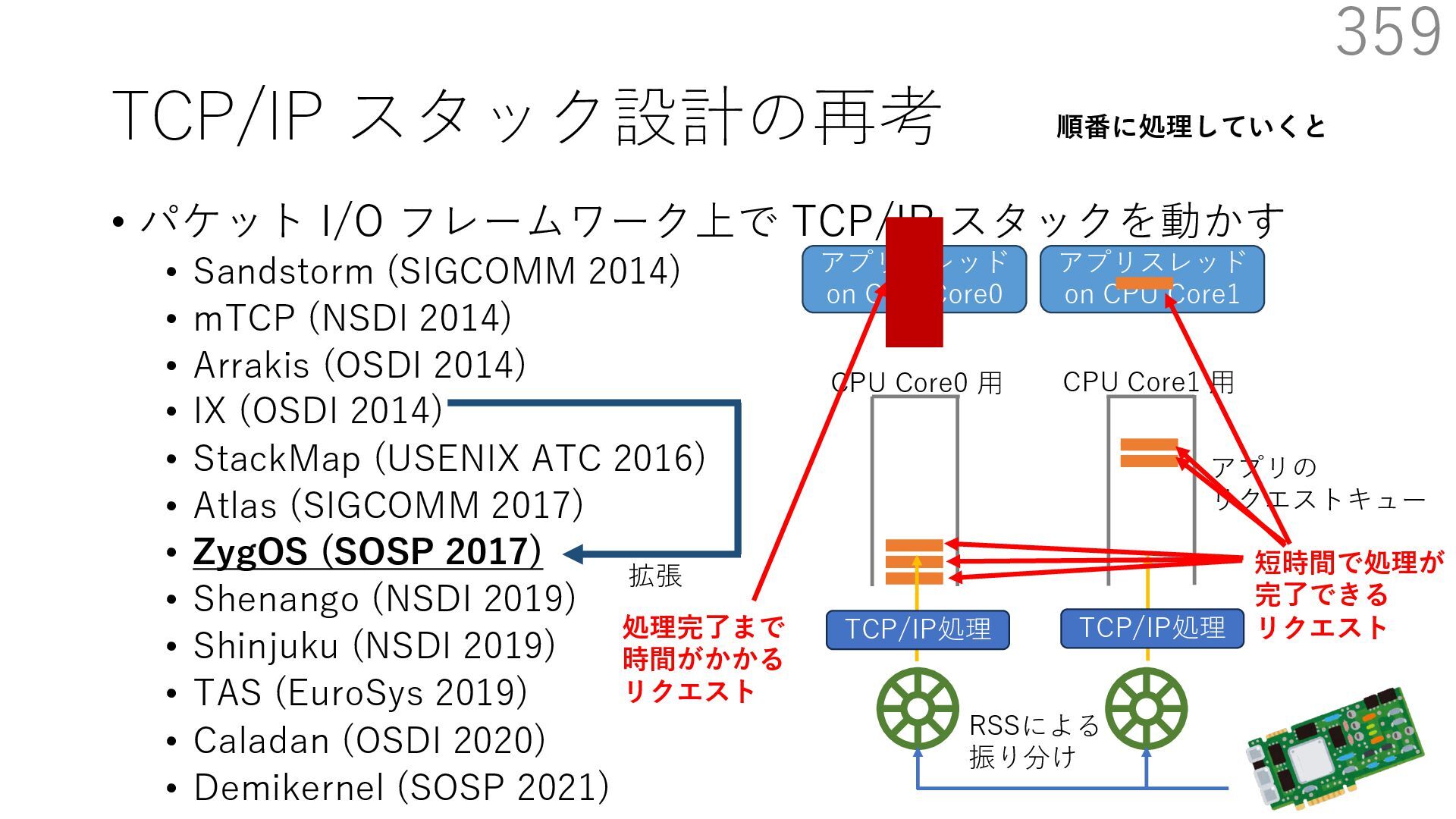{kind=link}
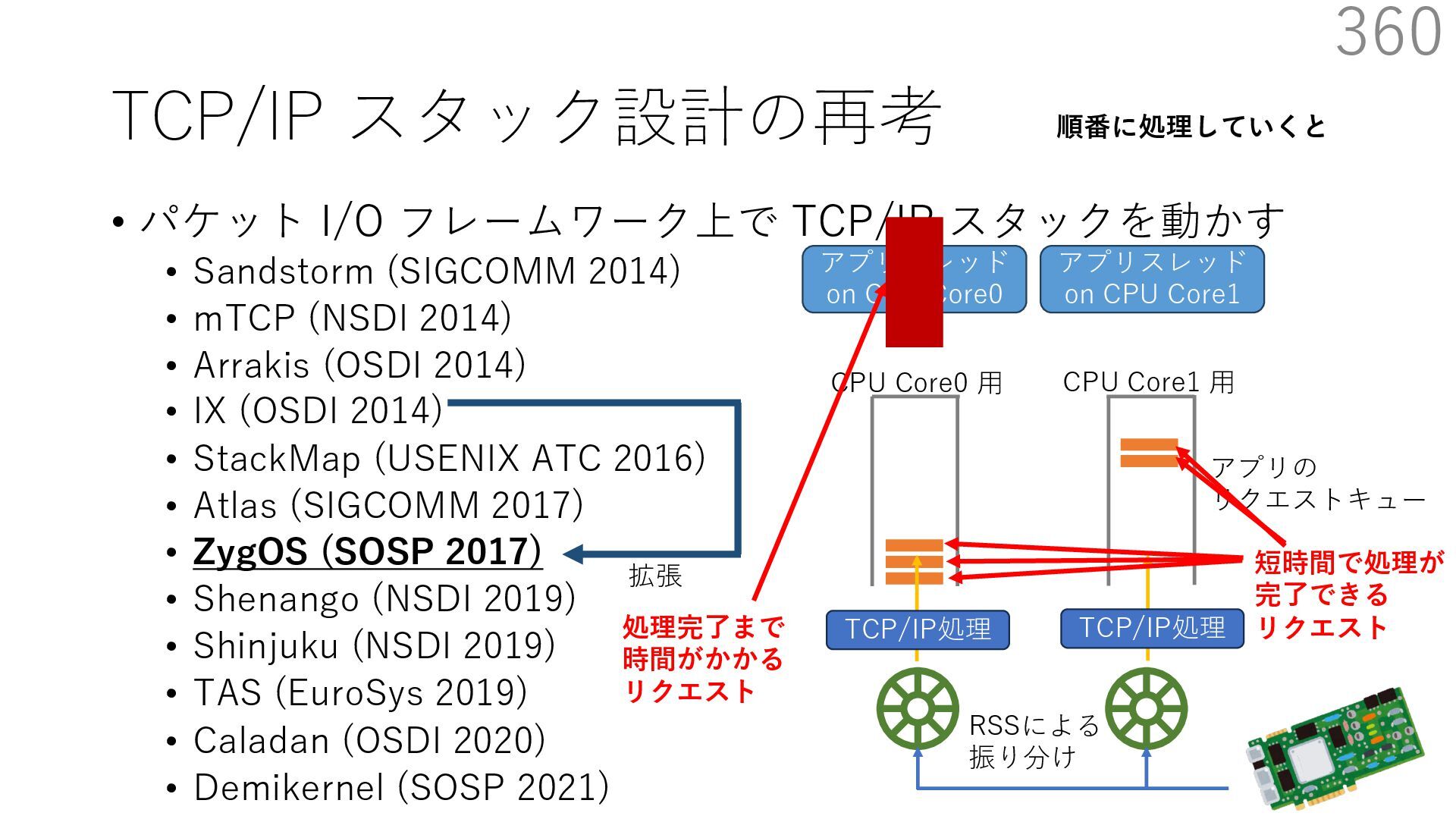{kind=link}
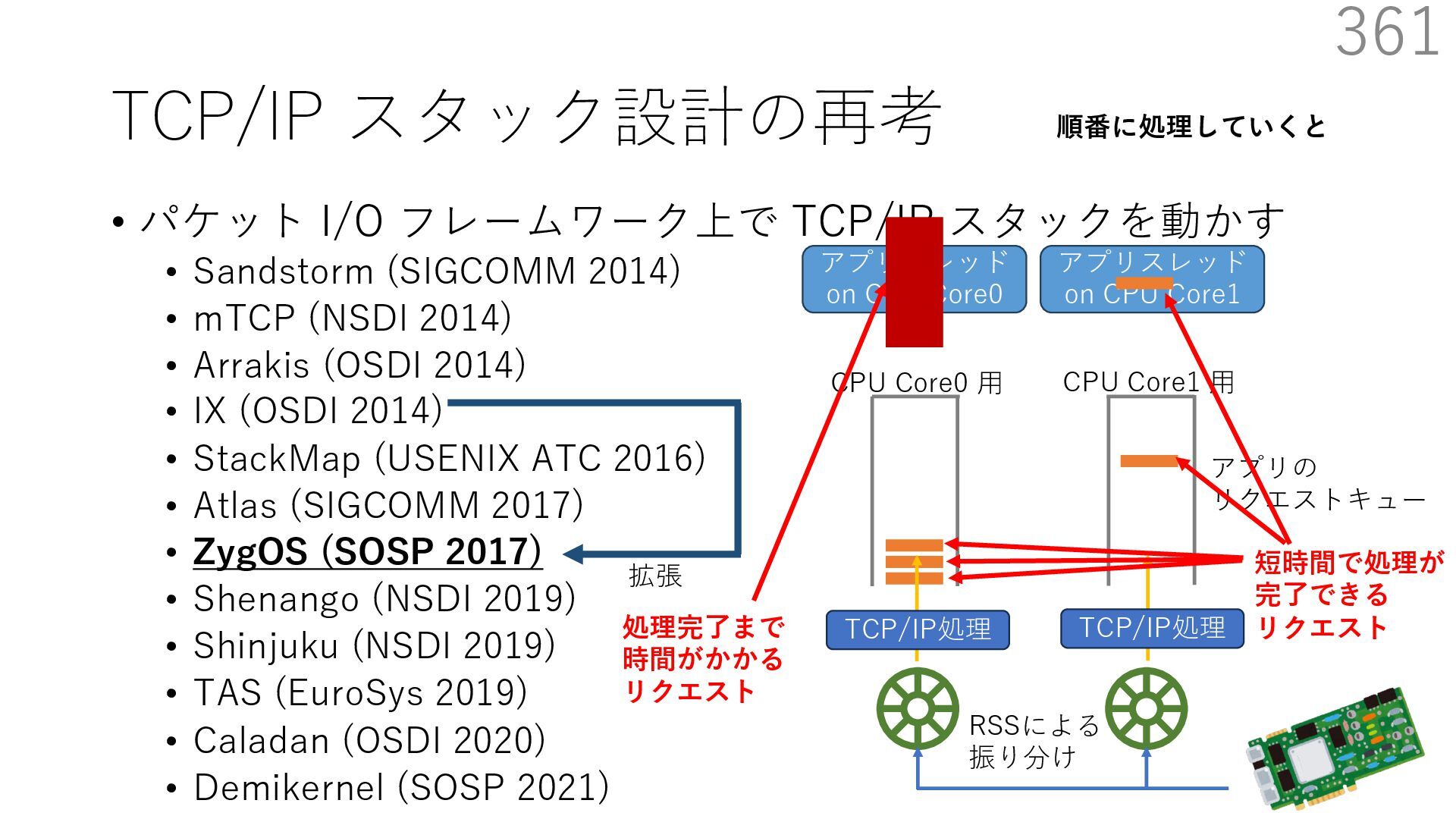{kind=link}
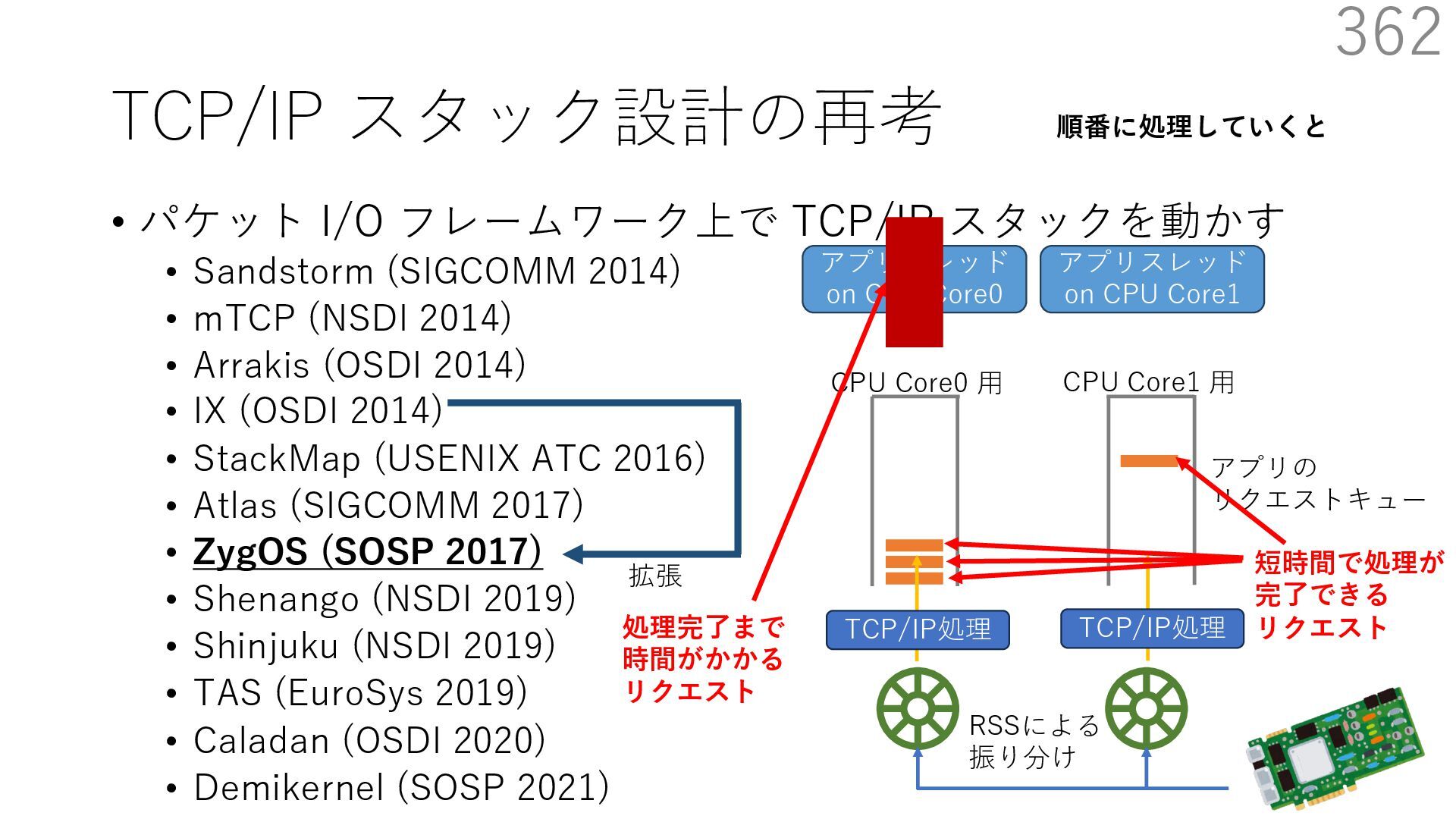{kind=link}
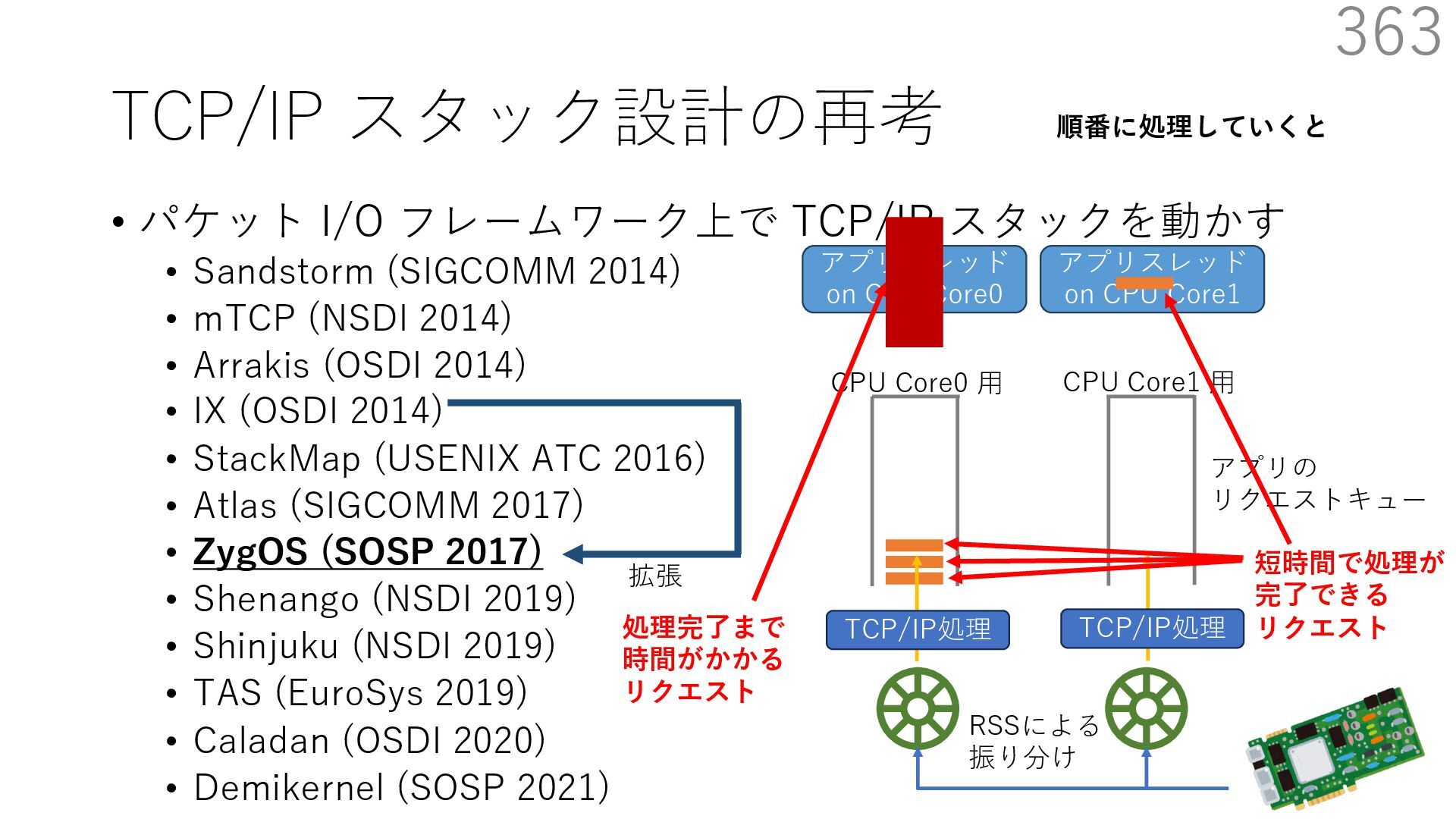{kind=link}
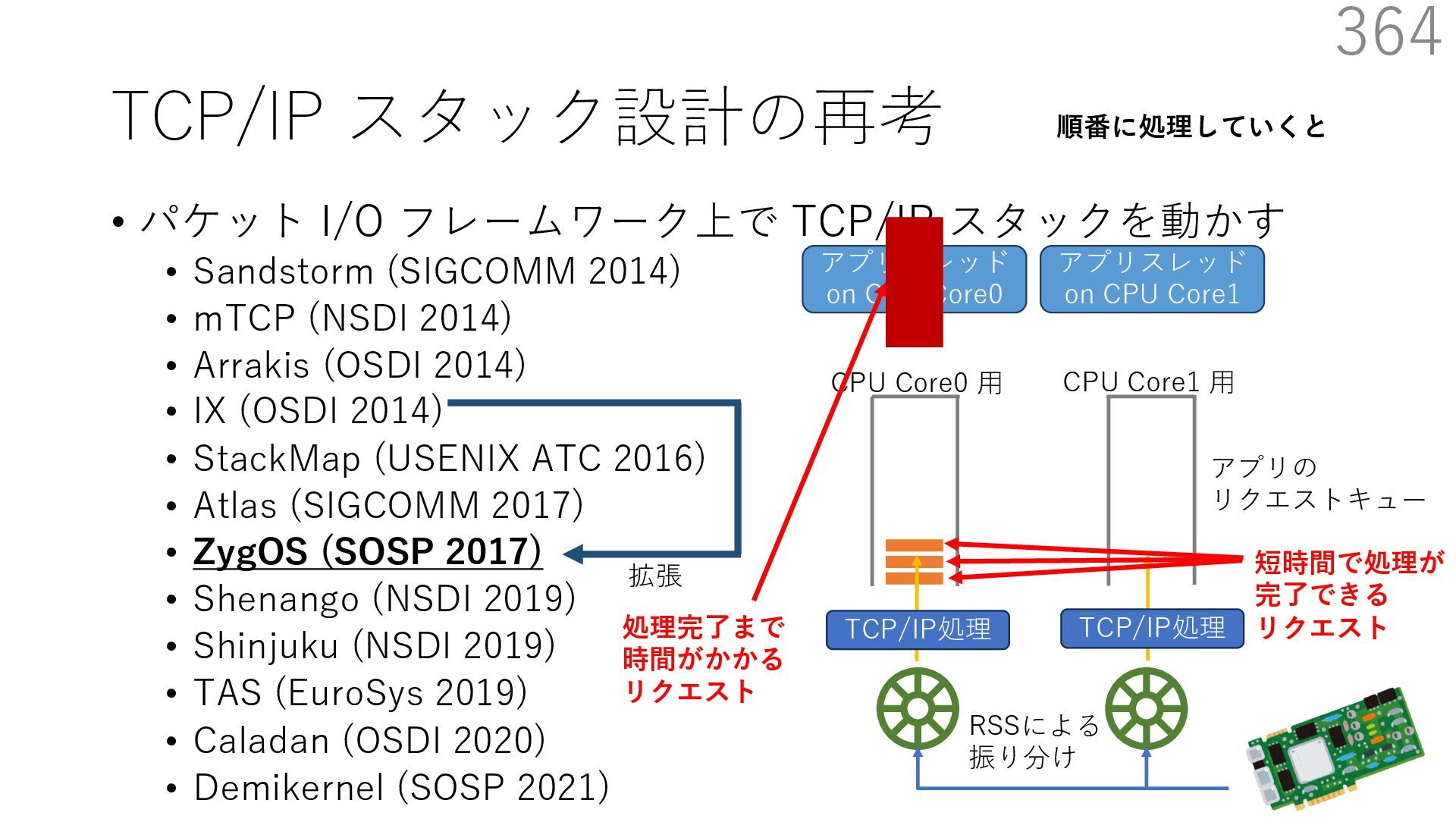{kind=link}
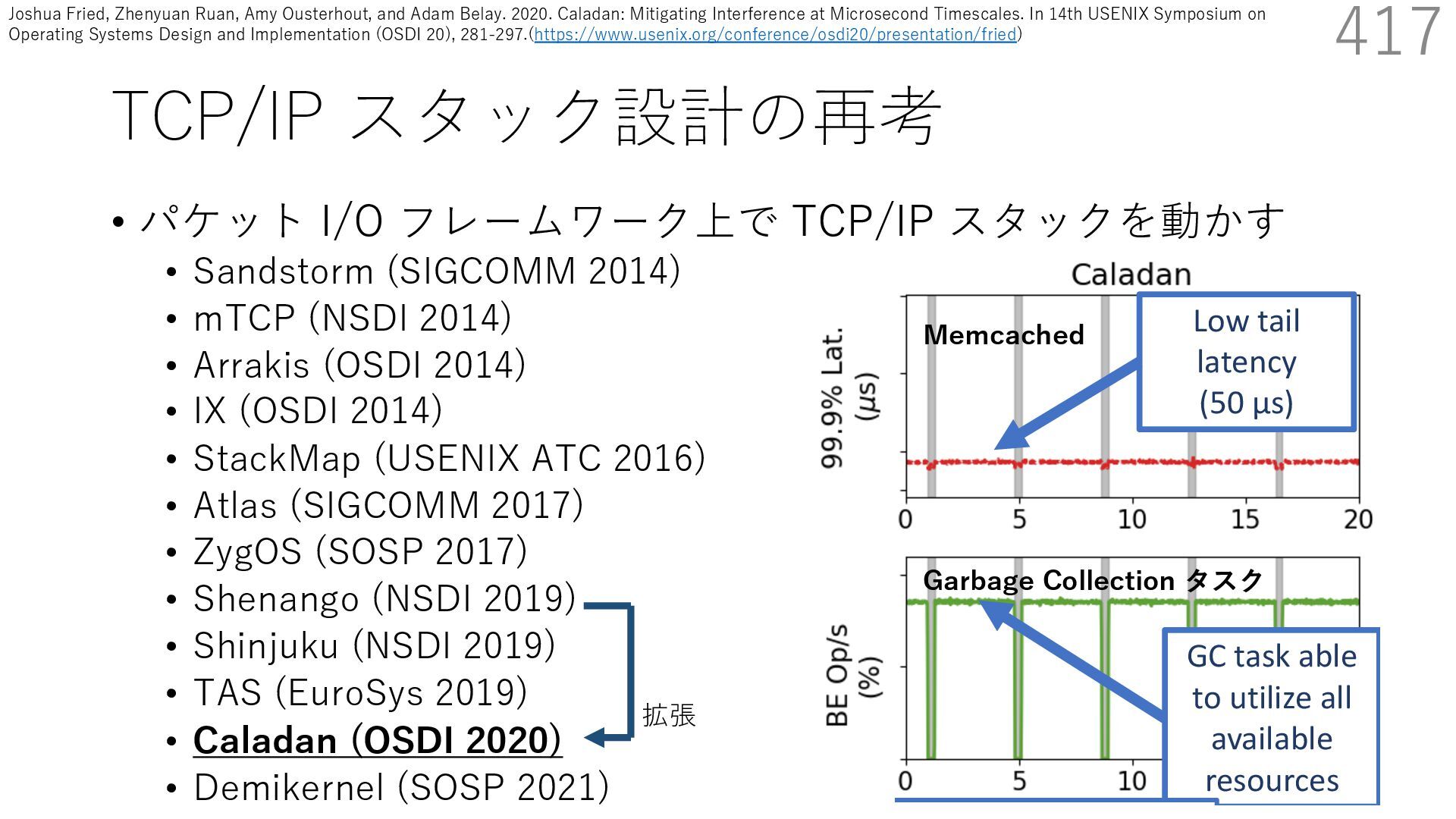
{kind=link}
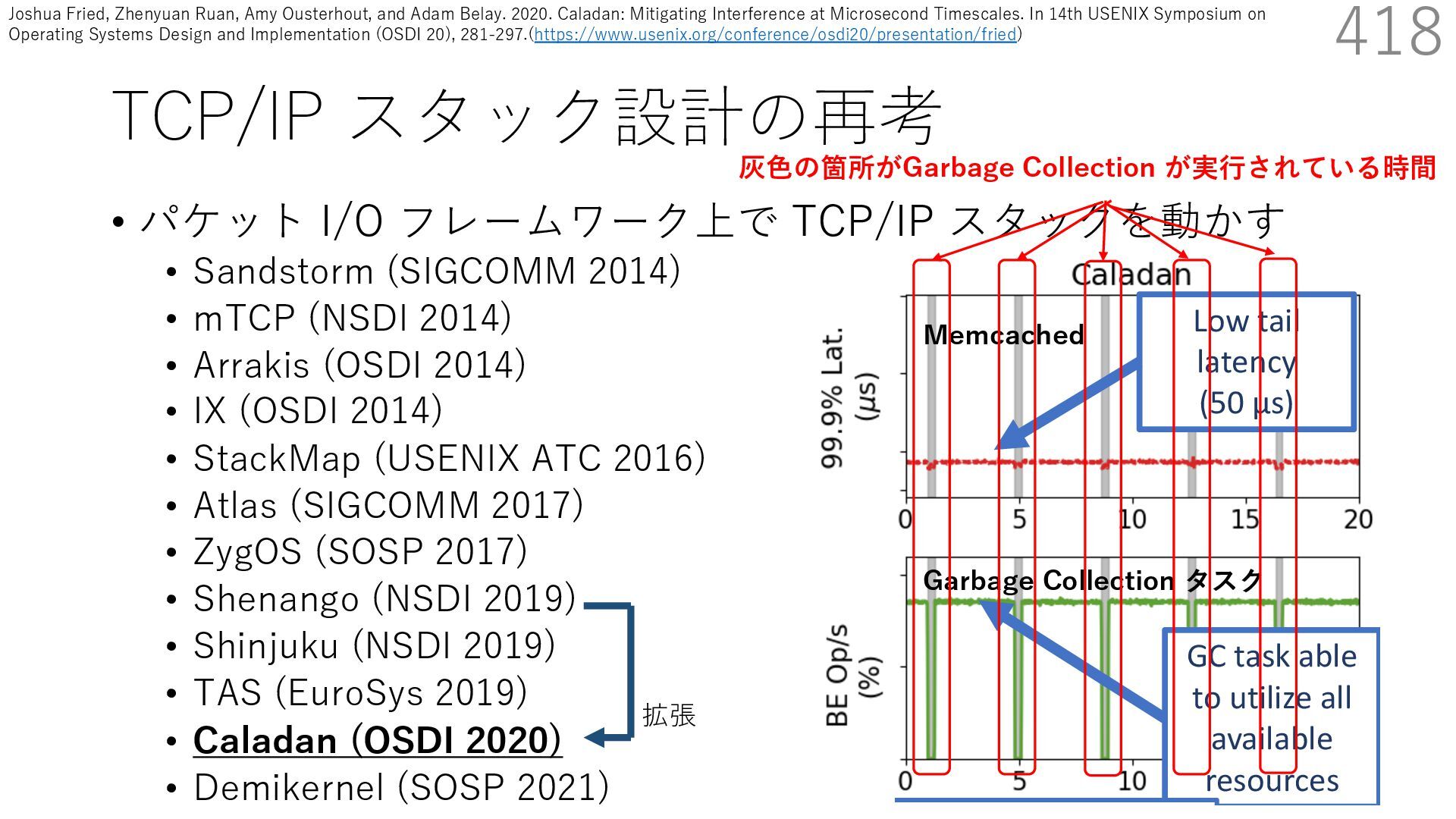
{kind=link}
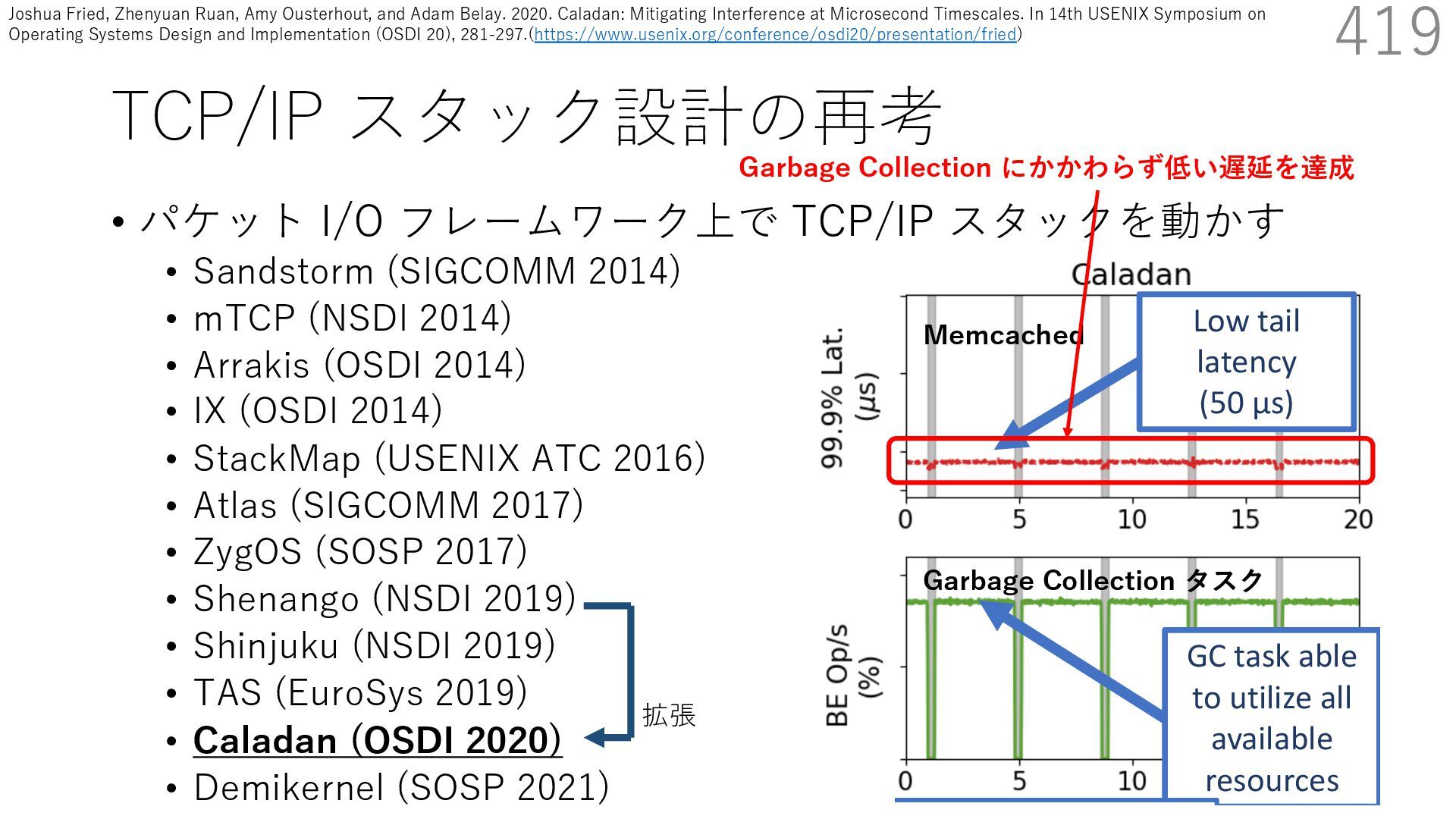
{kind=link}
{kind=link}
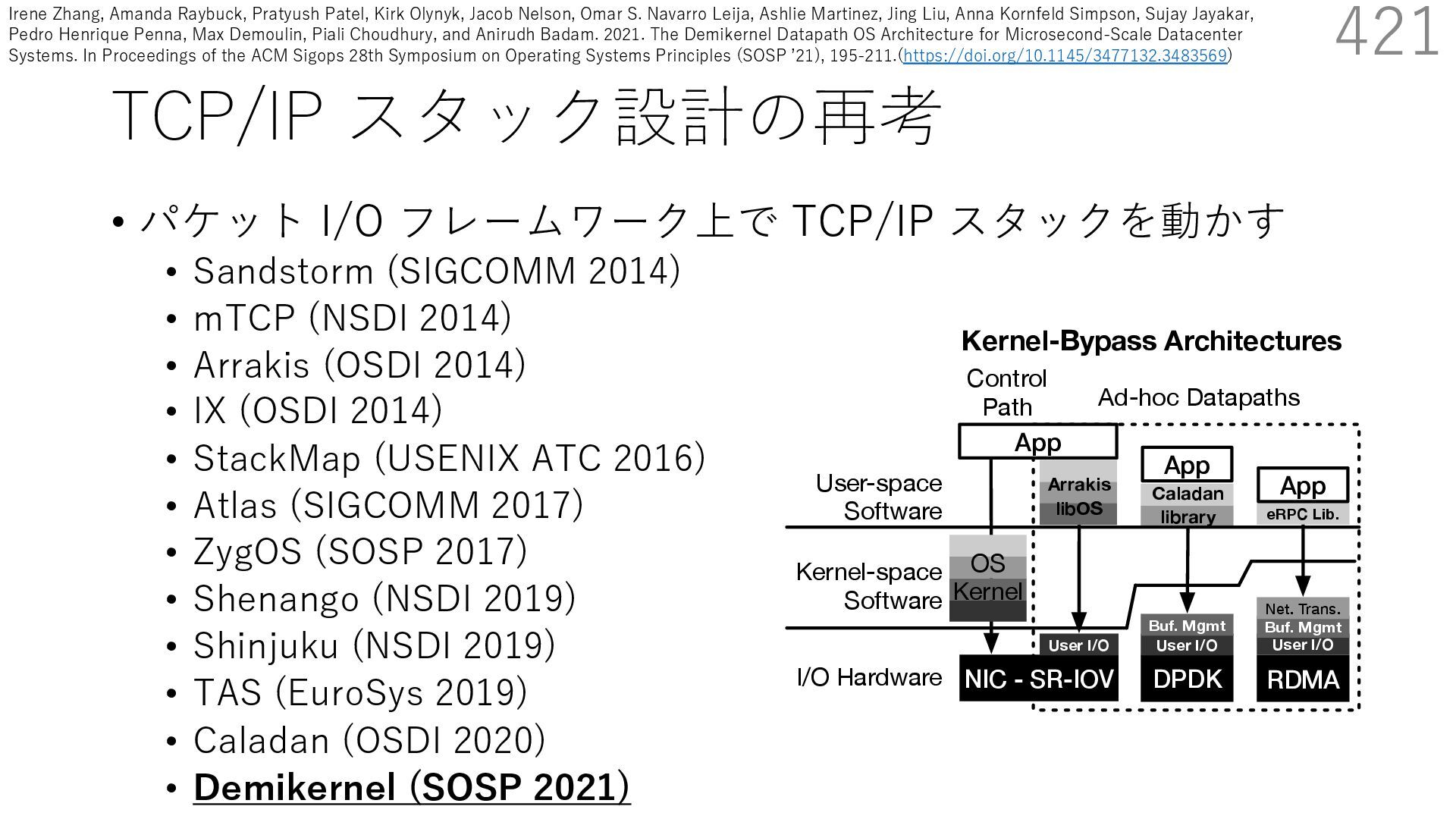
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
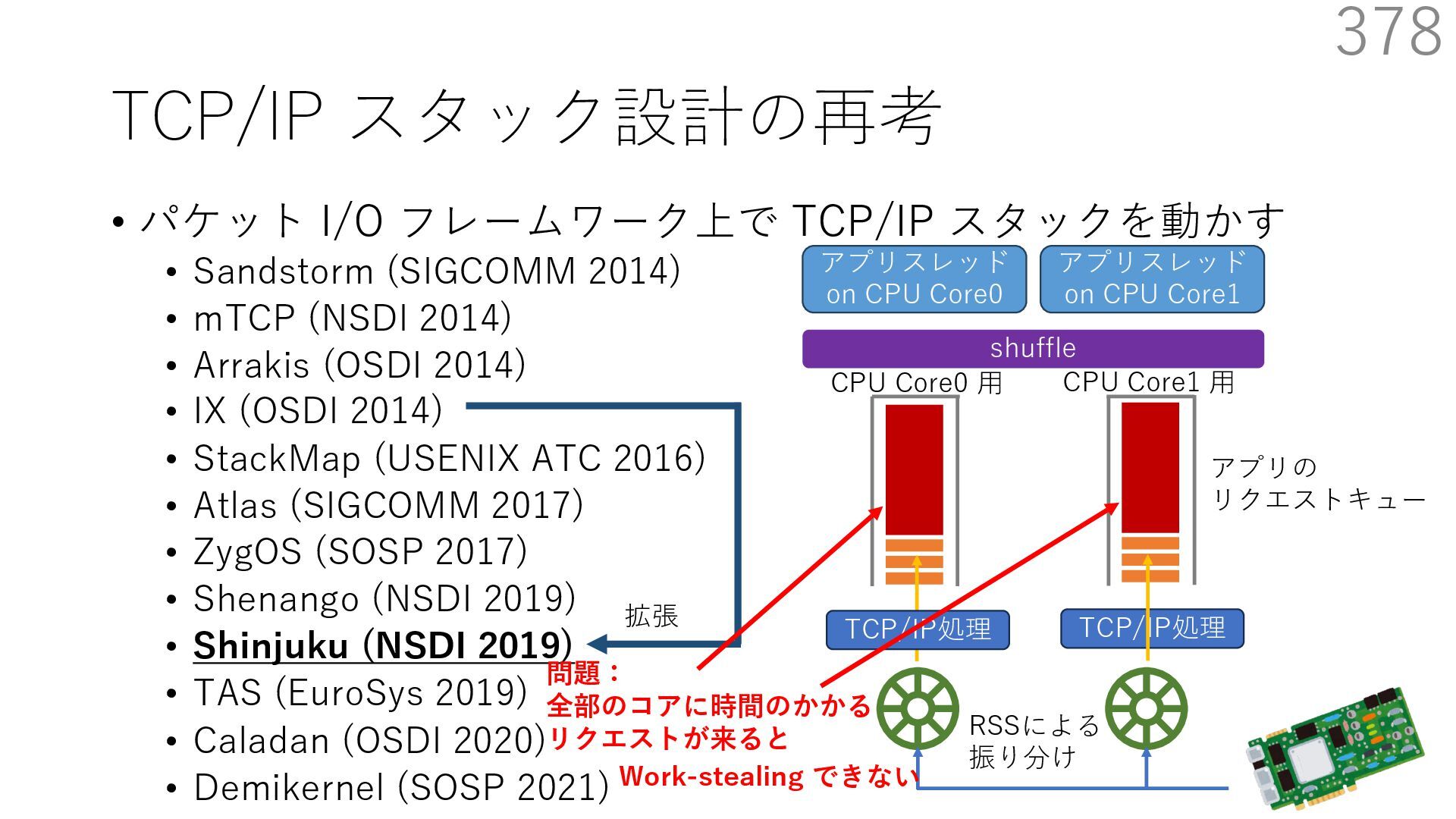{kind=link}
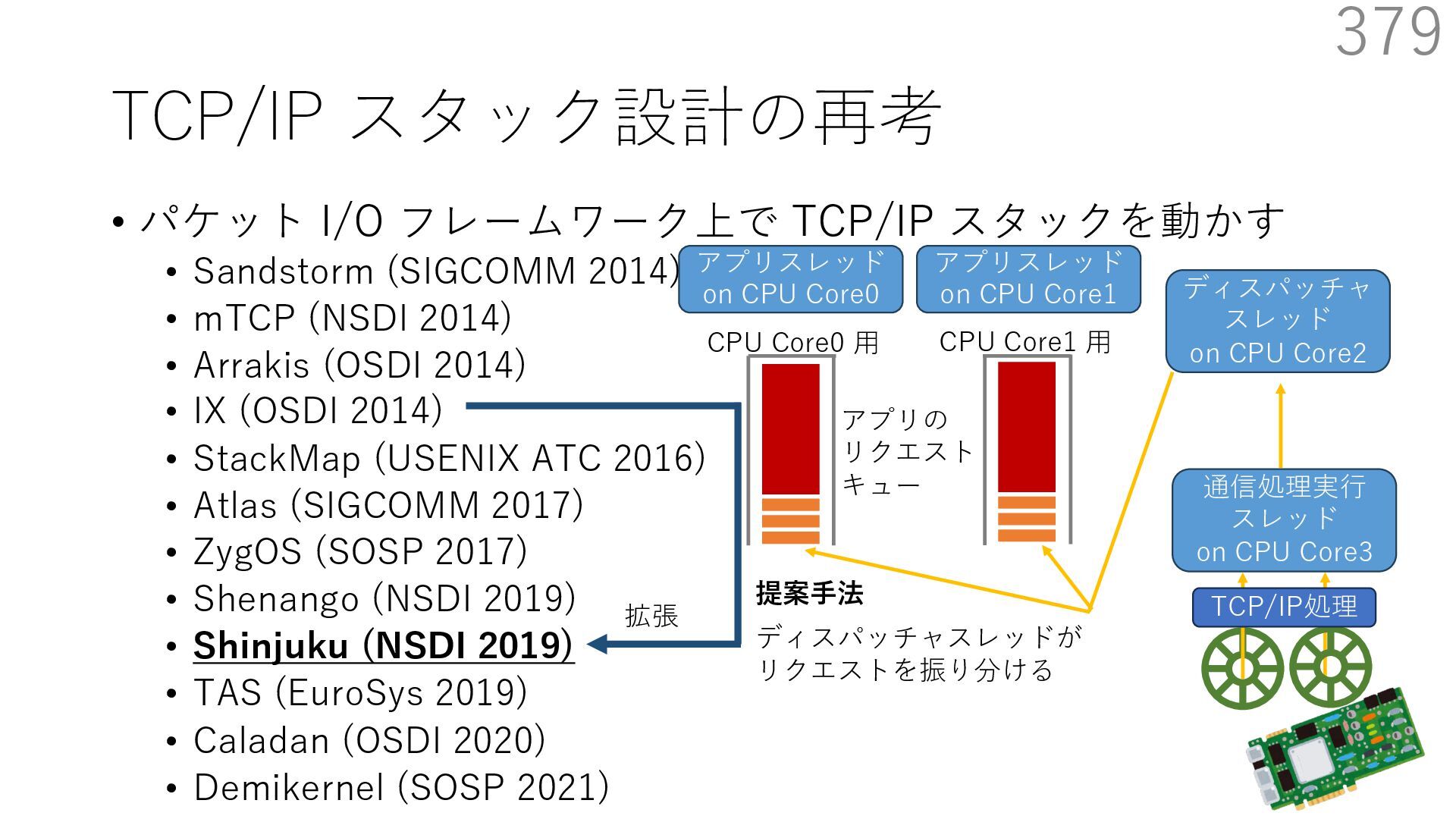{kind=link}
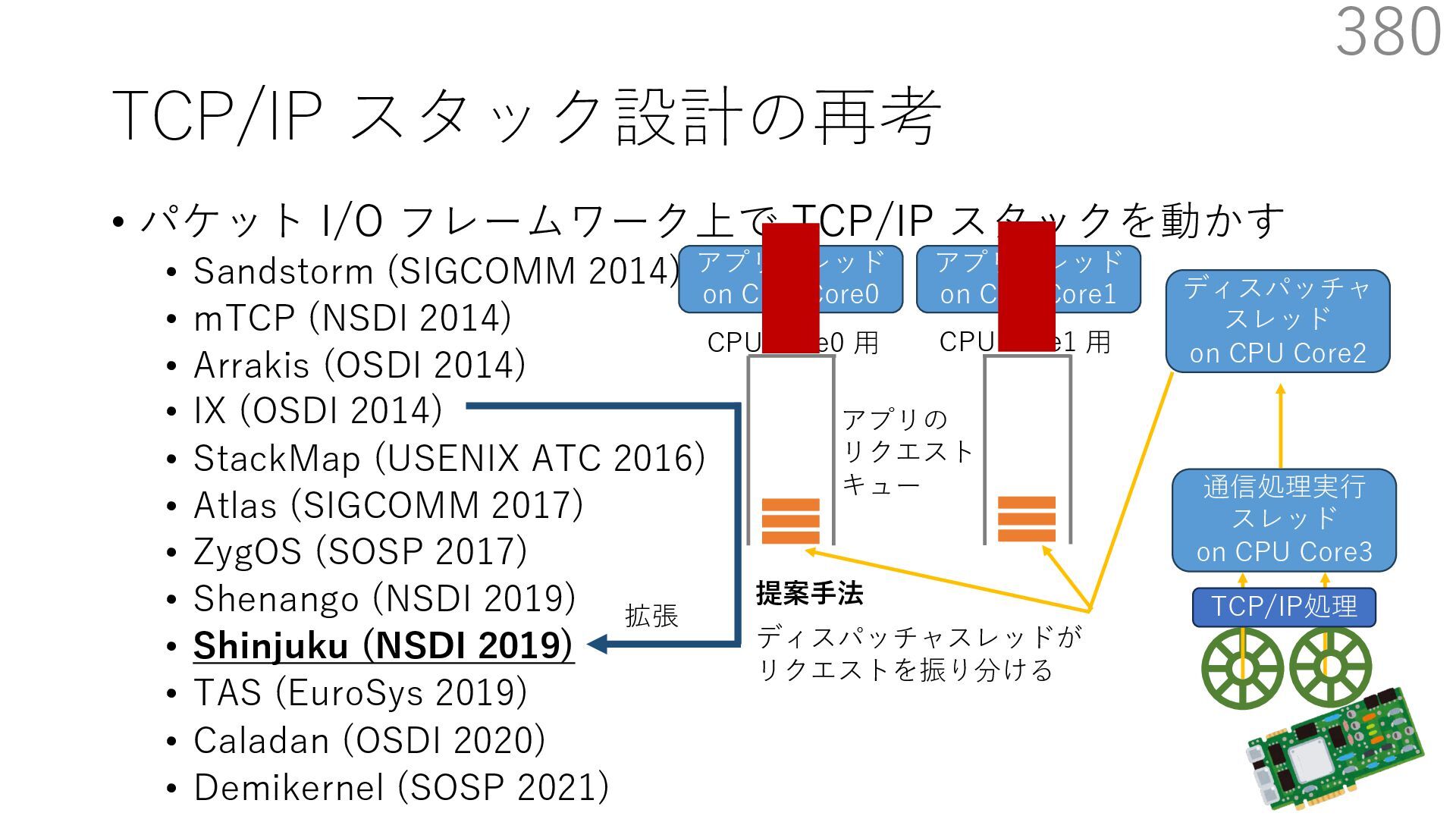{kind=link}
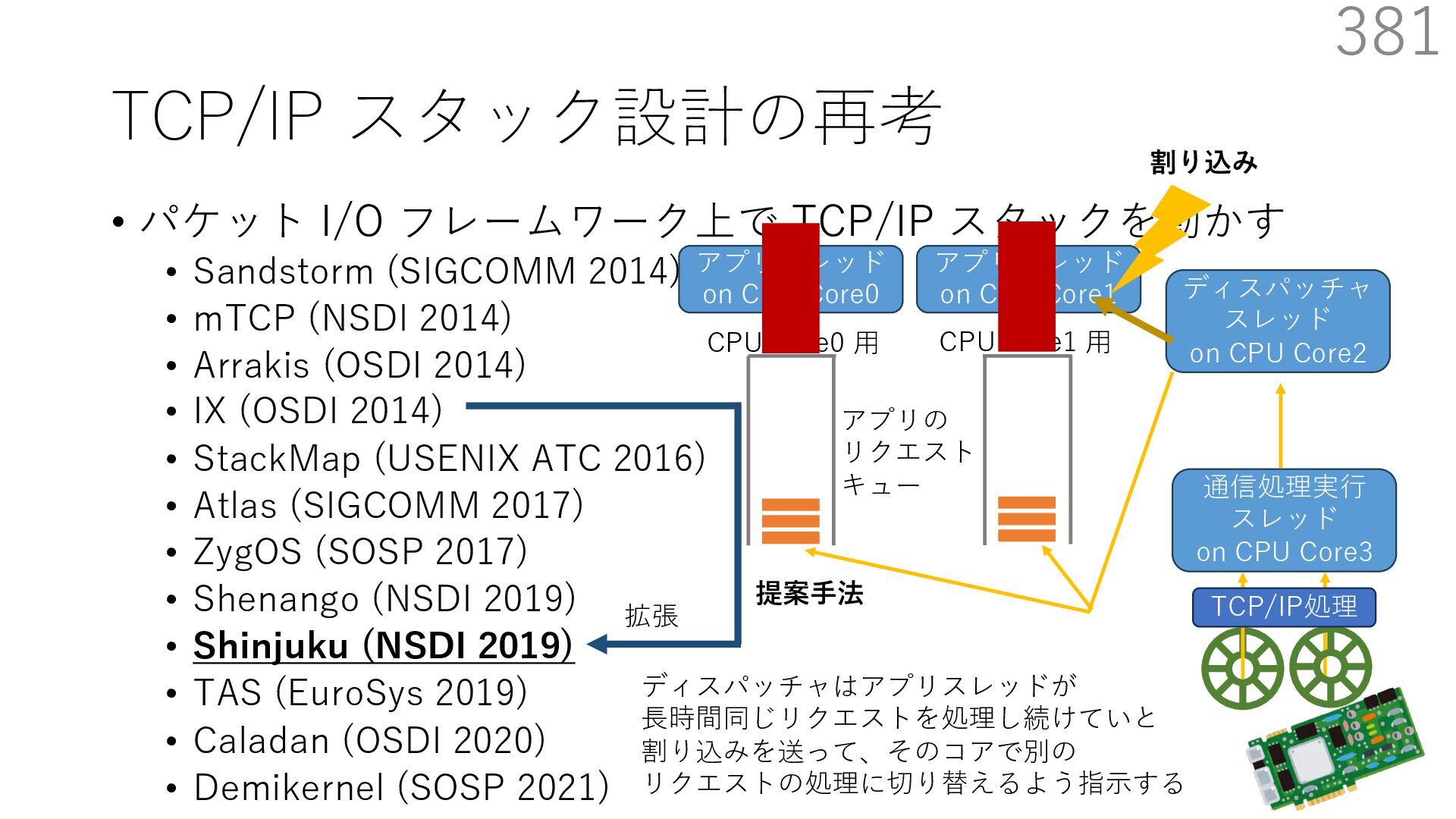{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
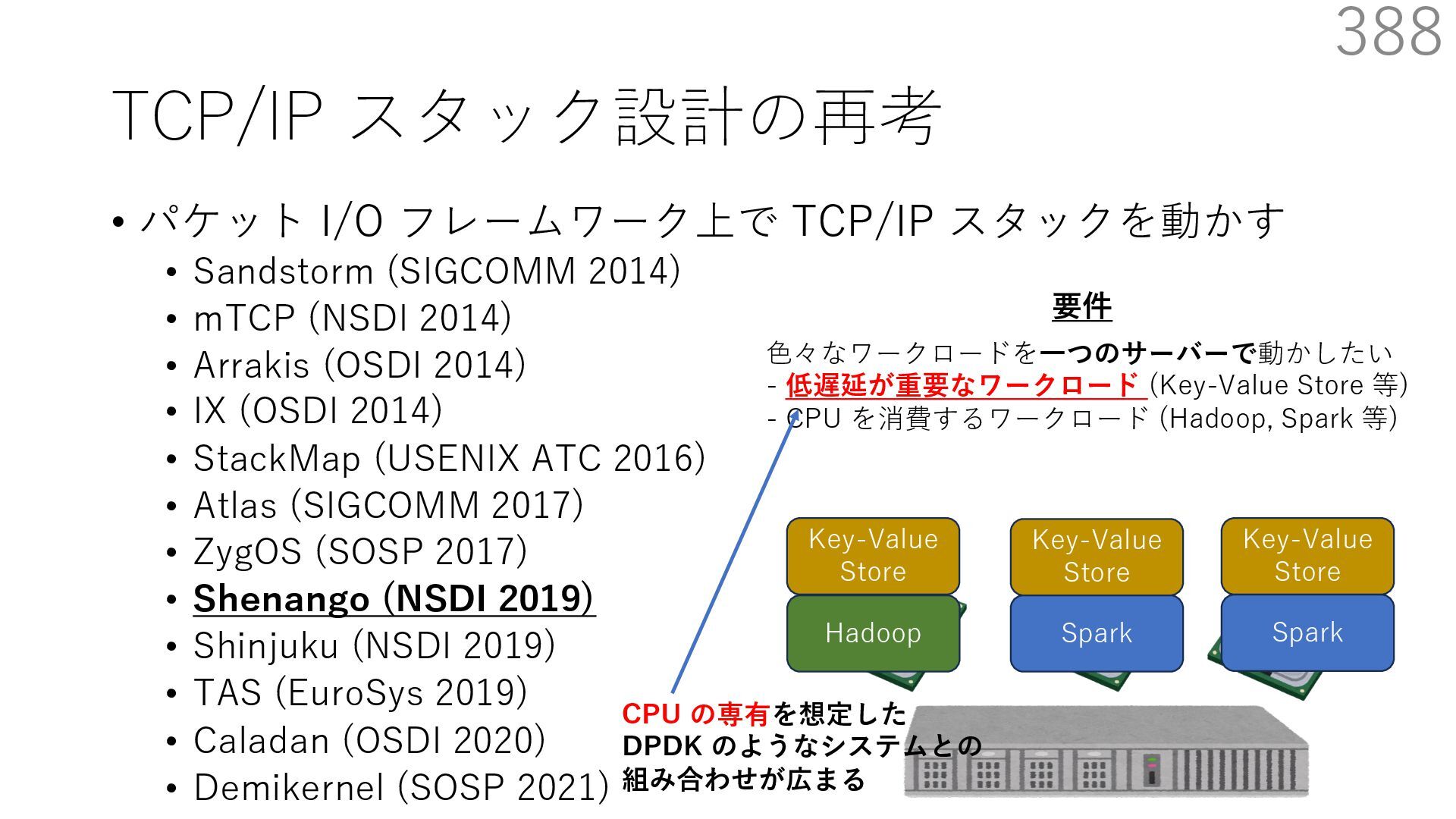{kind=link}
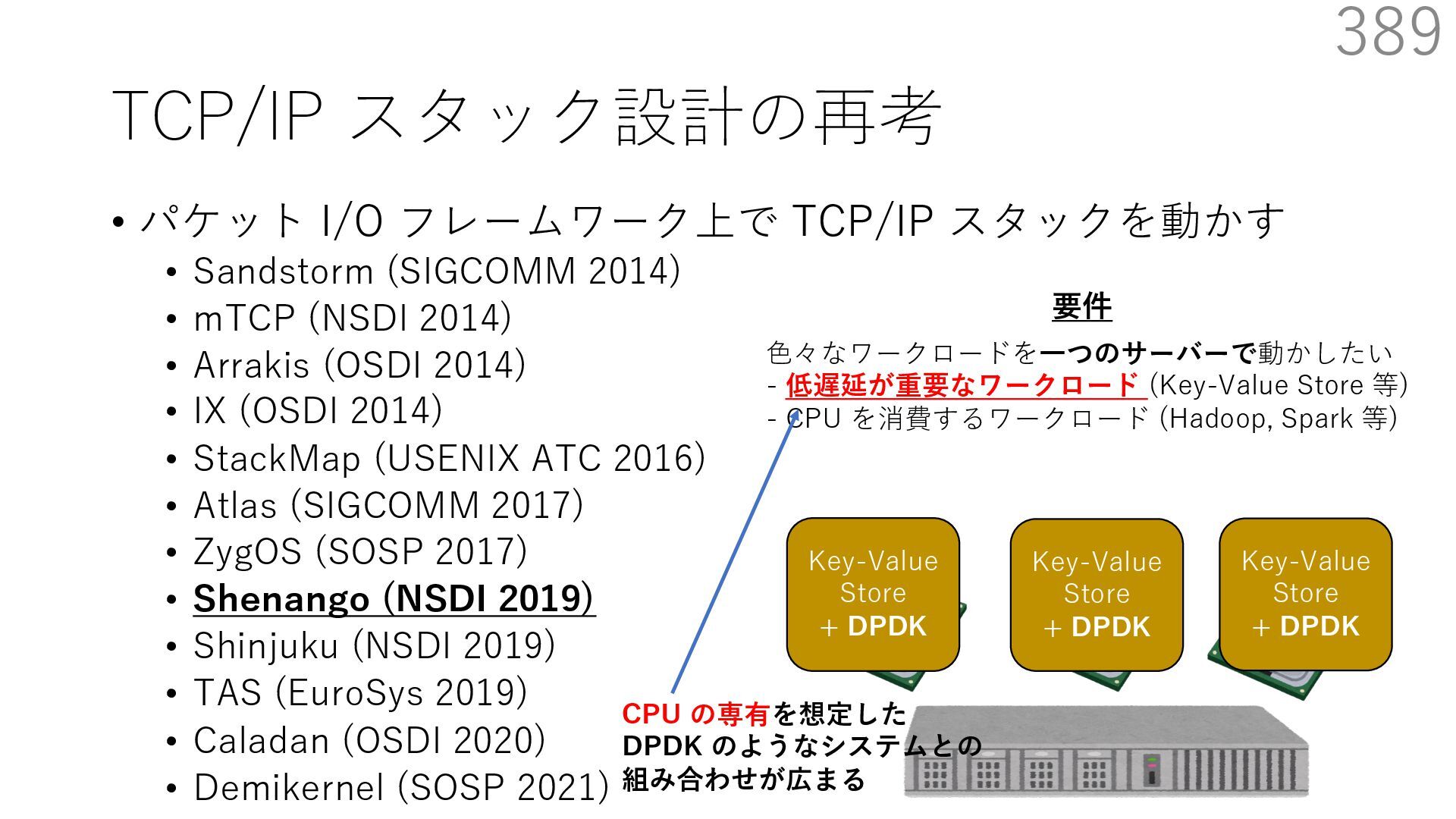{kind=link}
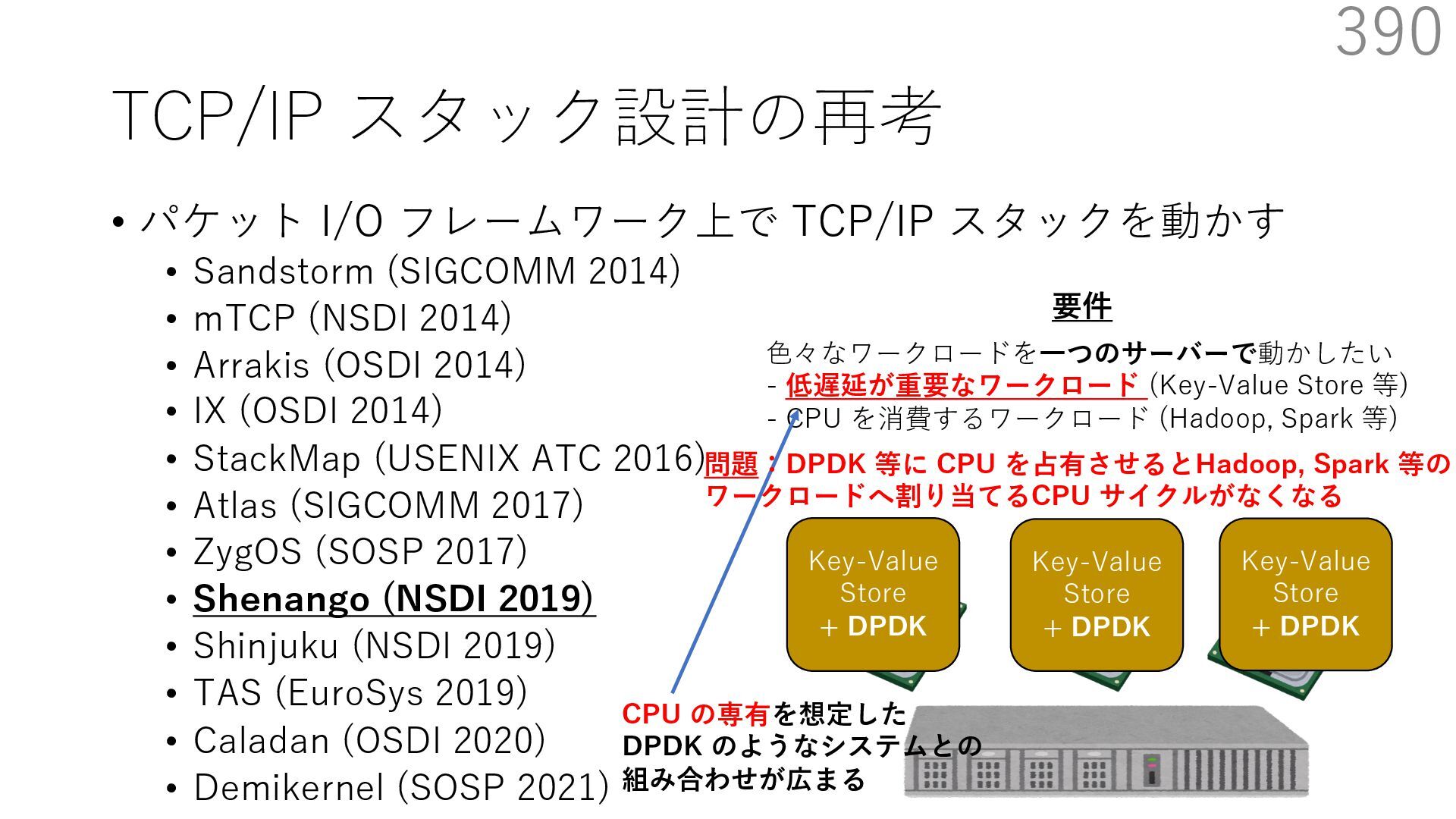{kind=link}
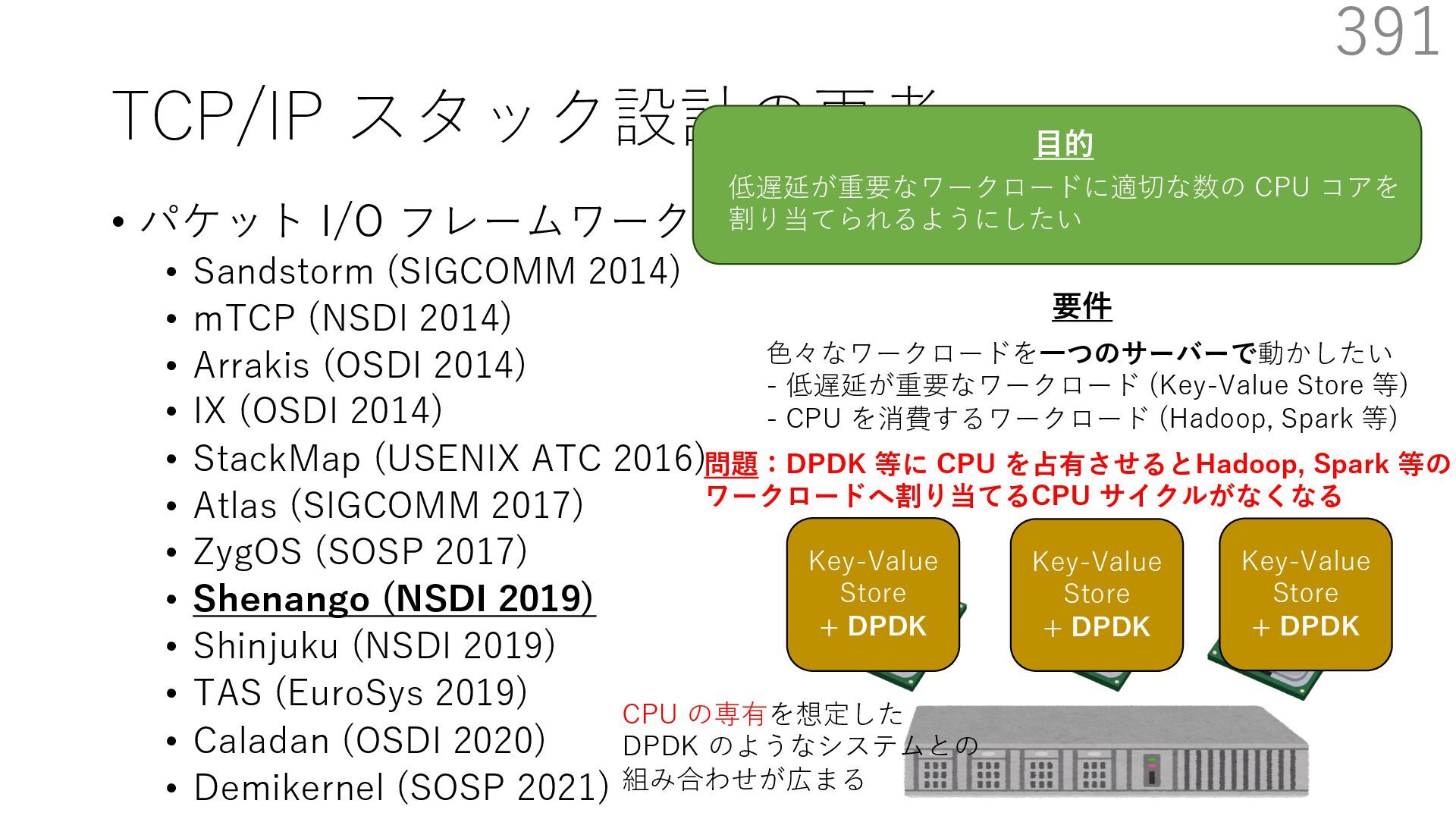{kind=link}
{kind=link}
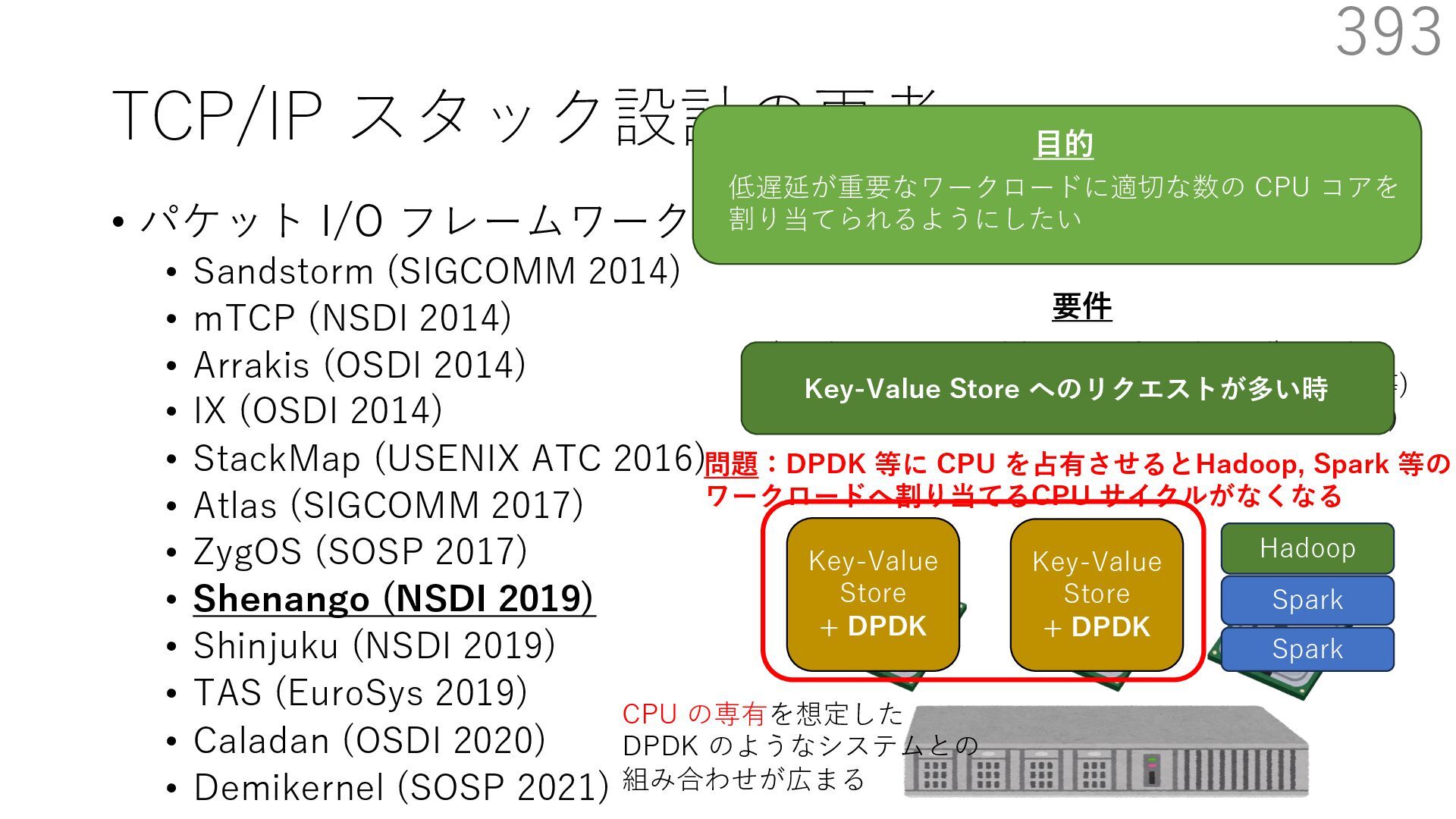{kind=link}
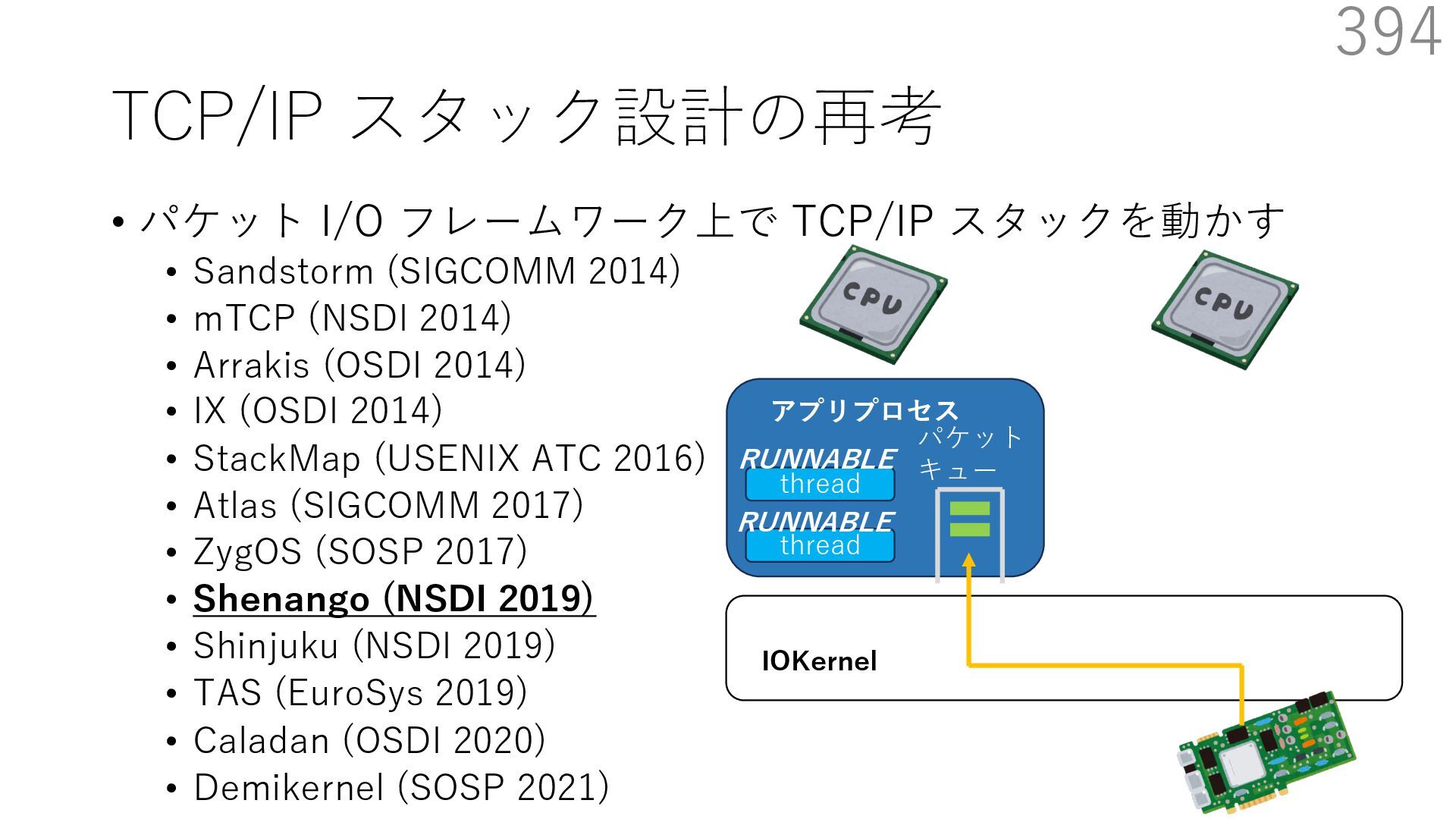{kind=link}
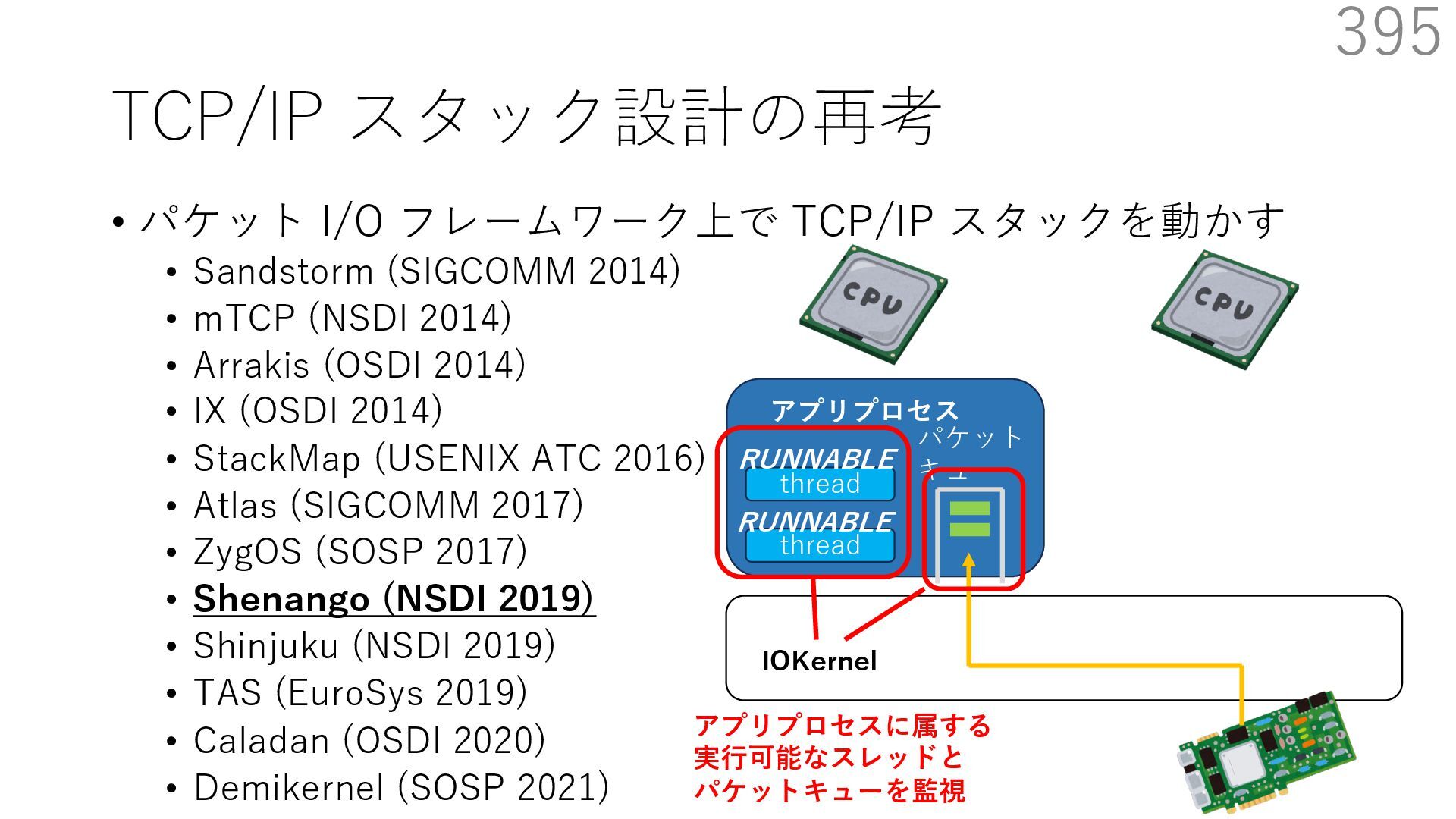{kind=link}
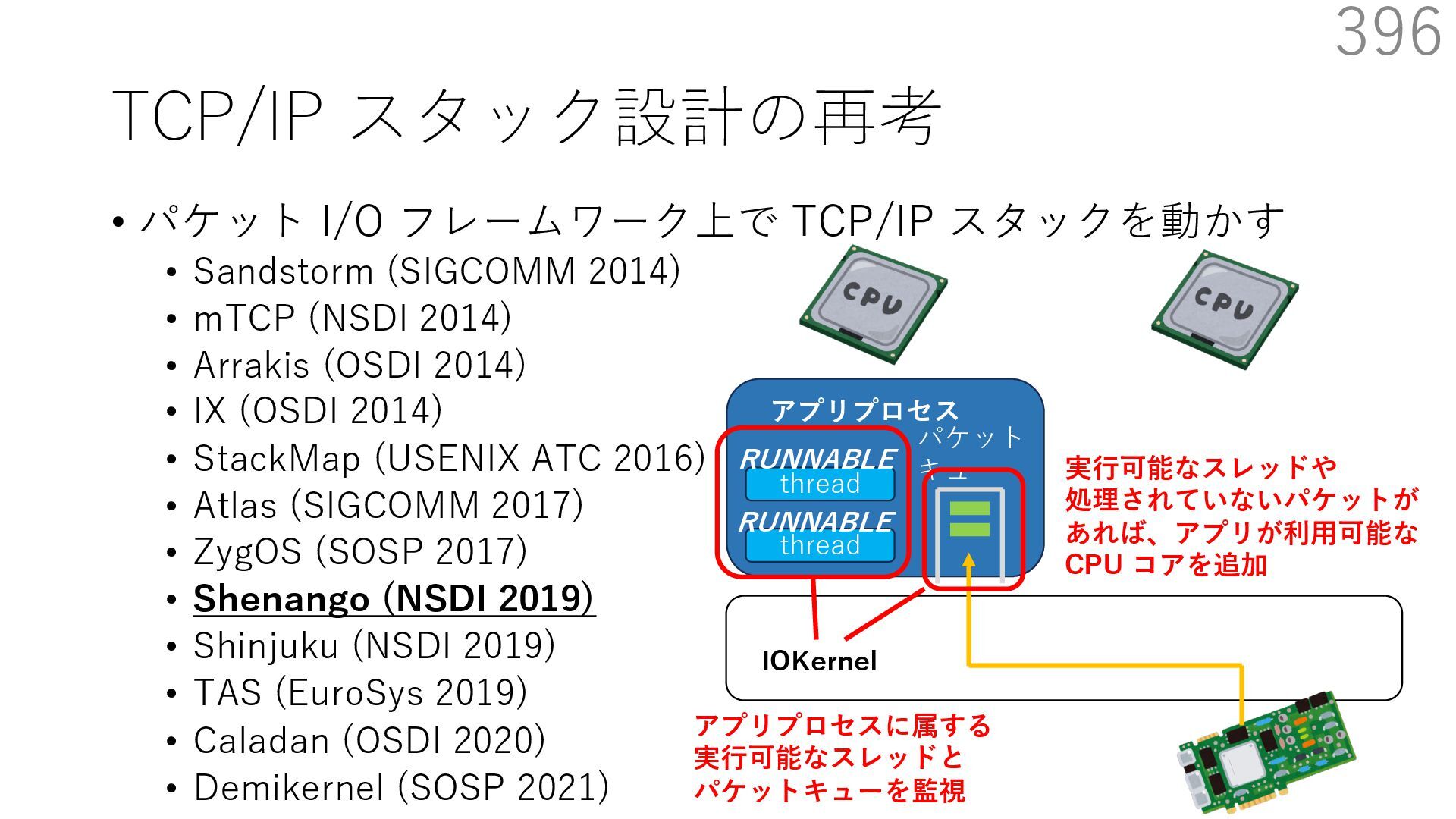{kind=link}
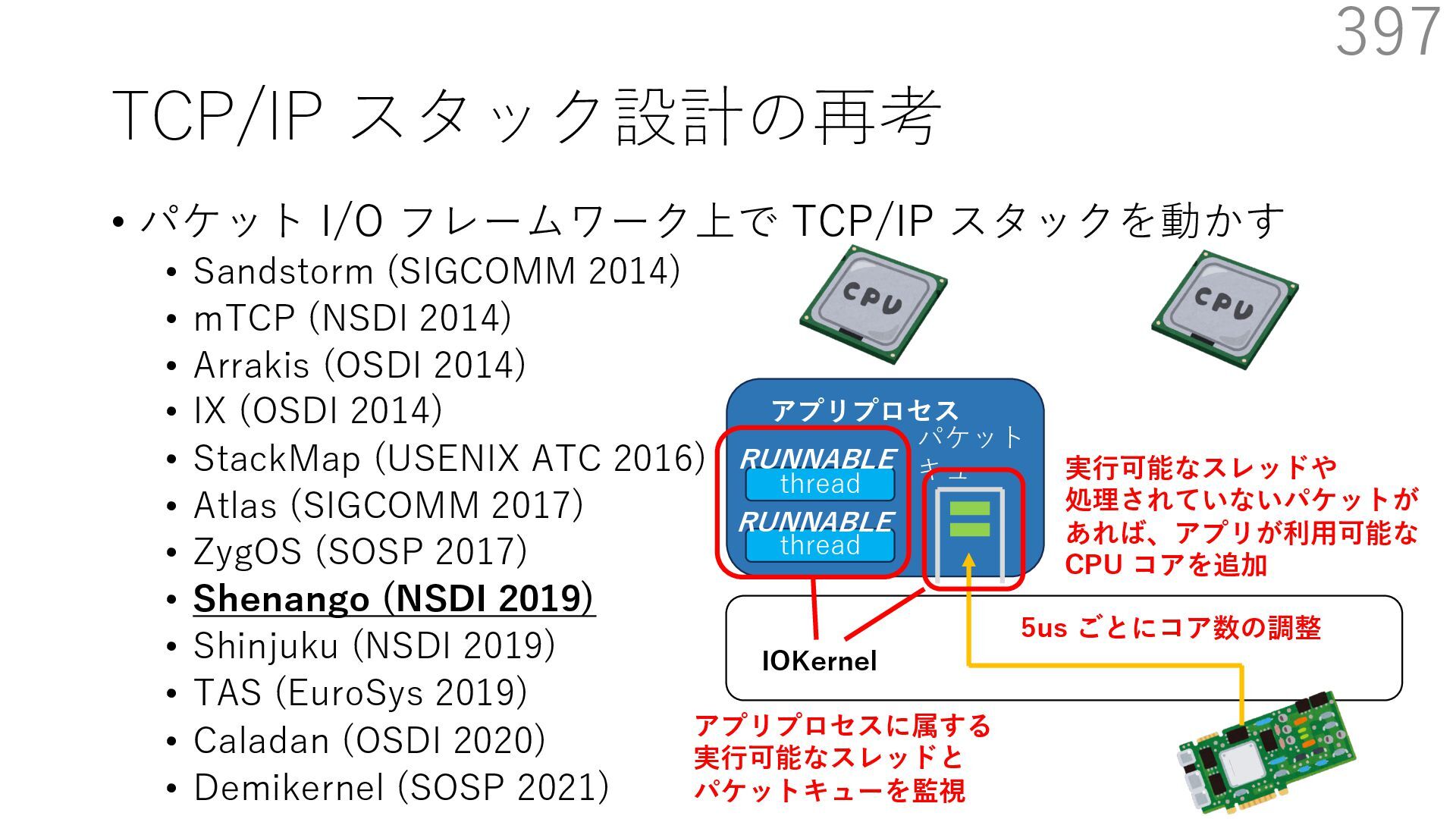{kind=link}
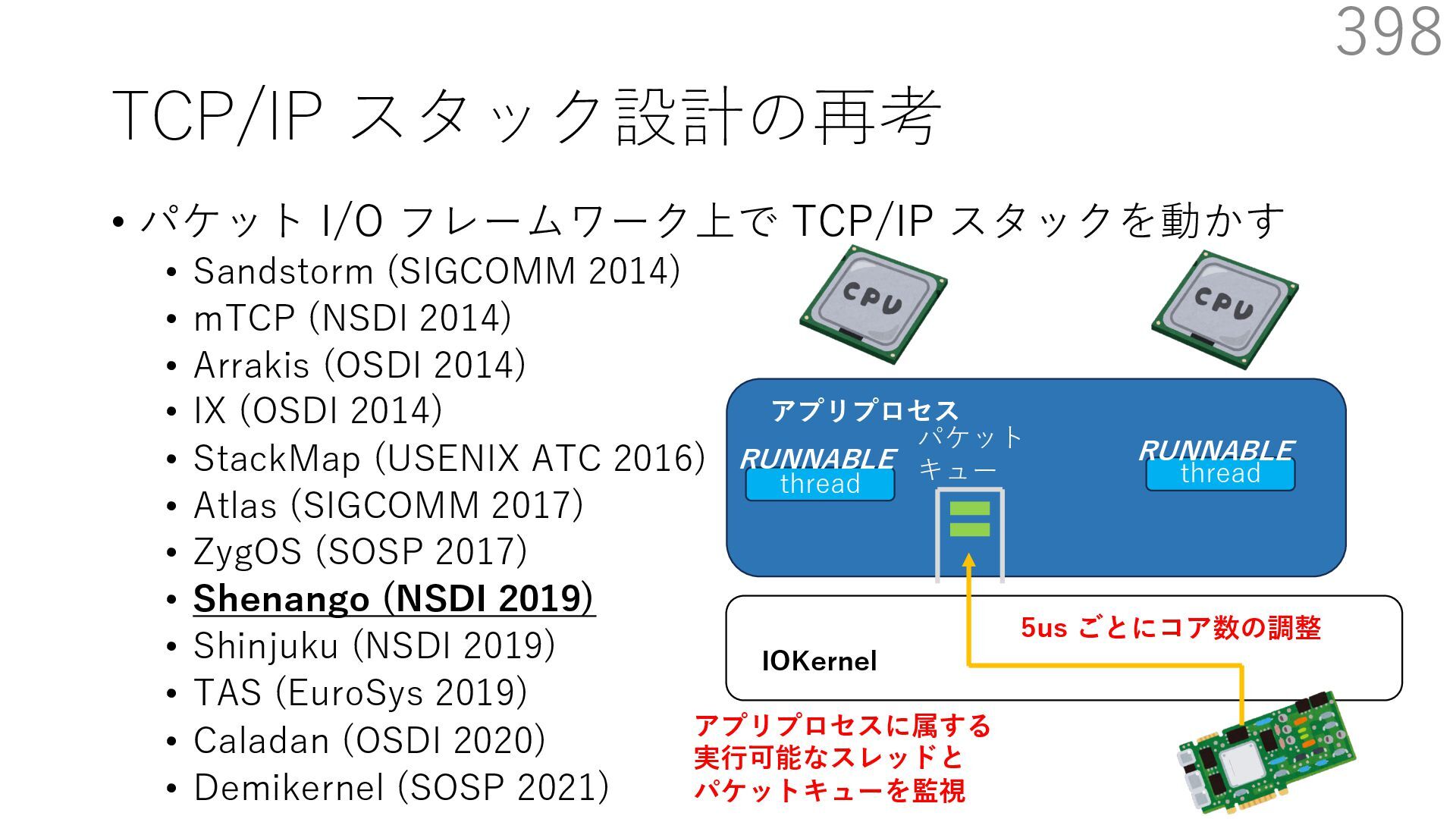{kind=link}
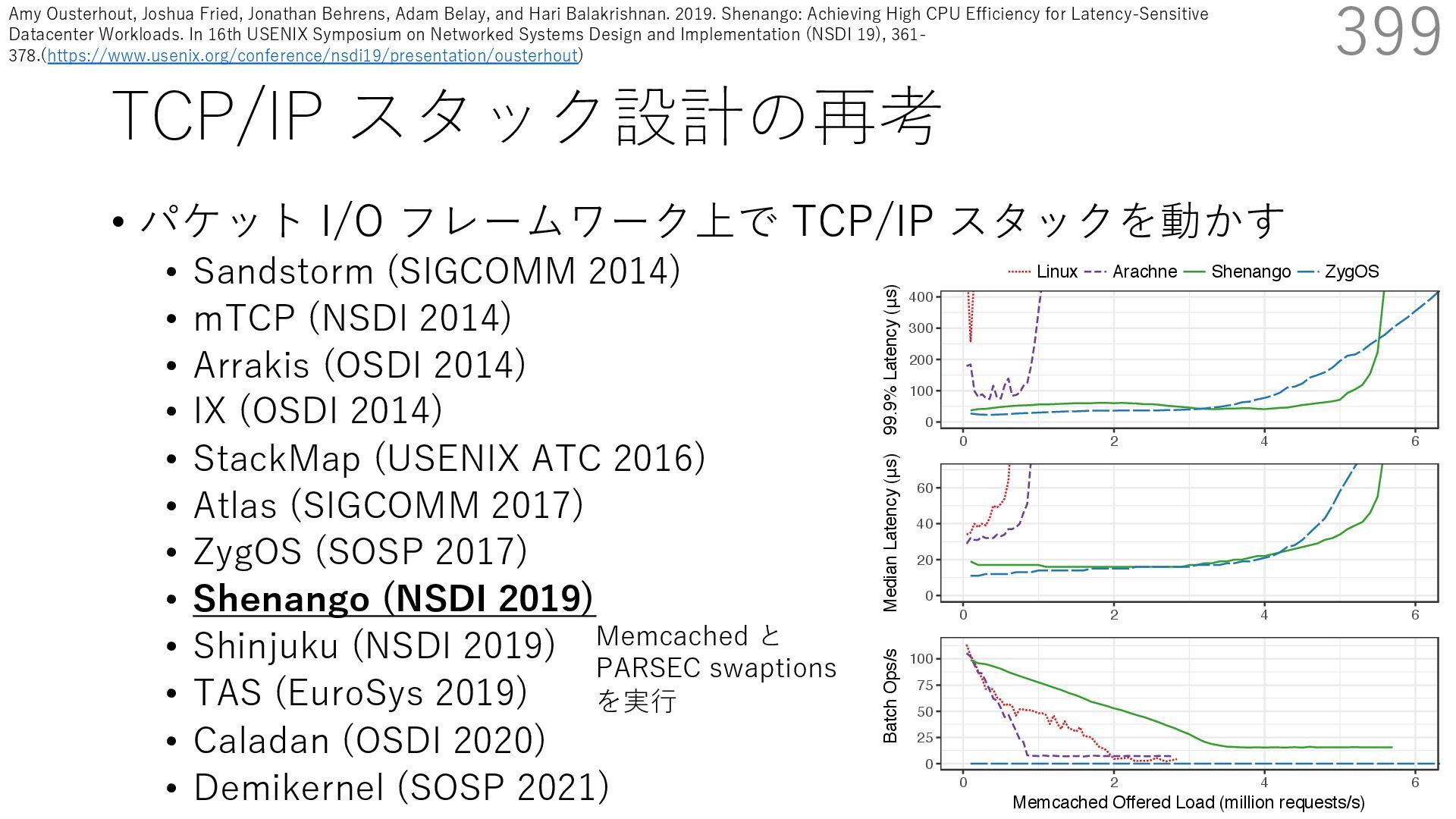{kind=link}
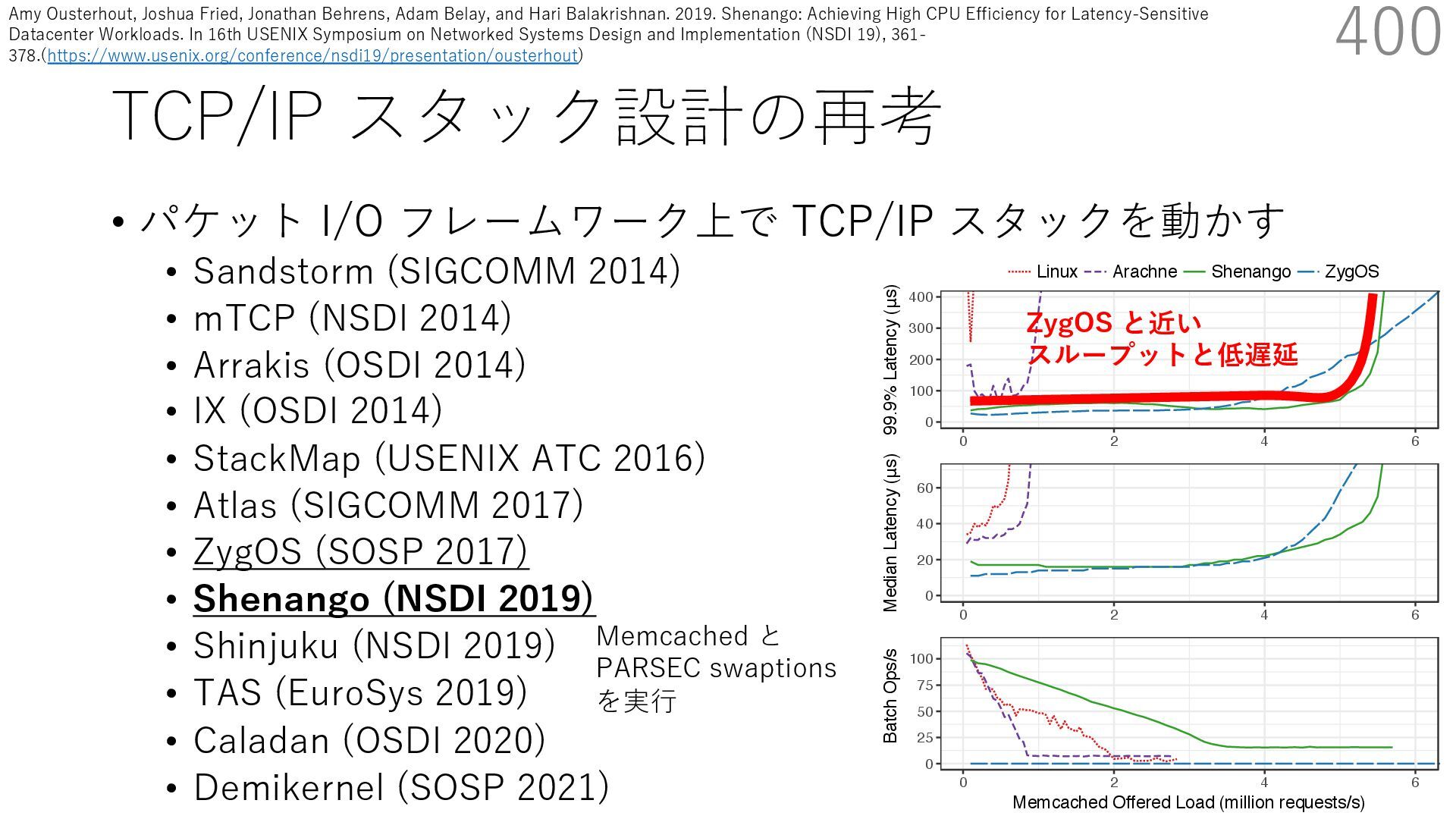{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
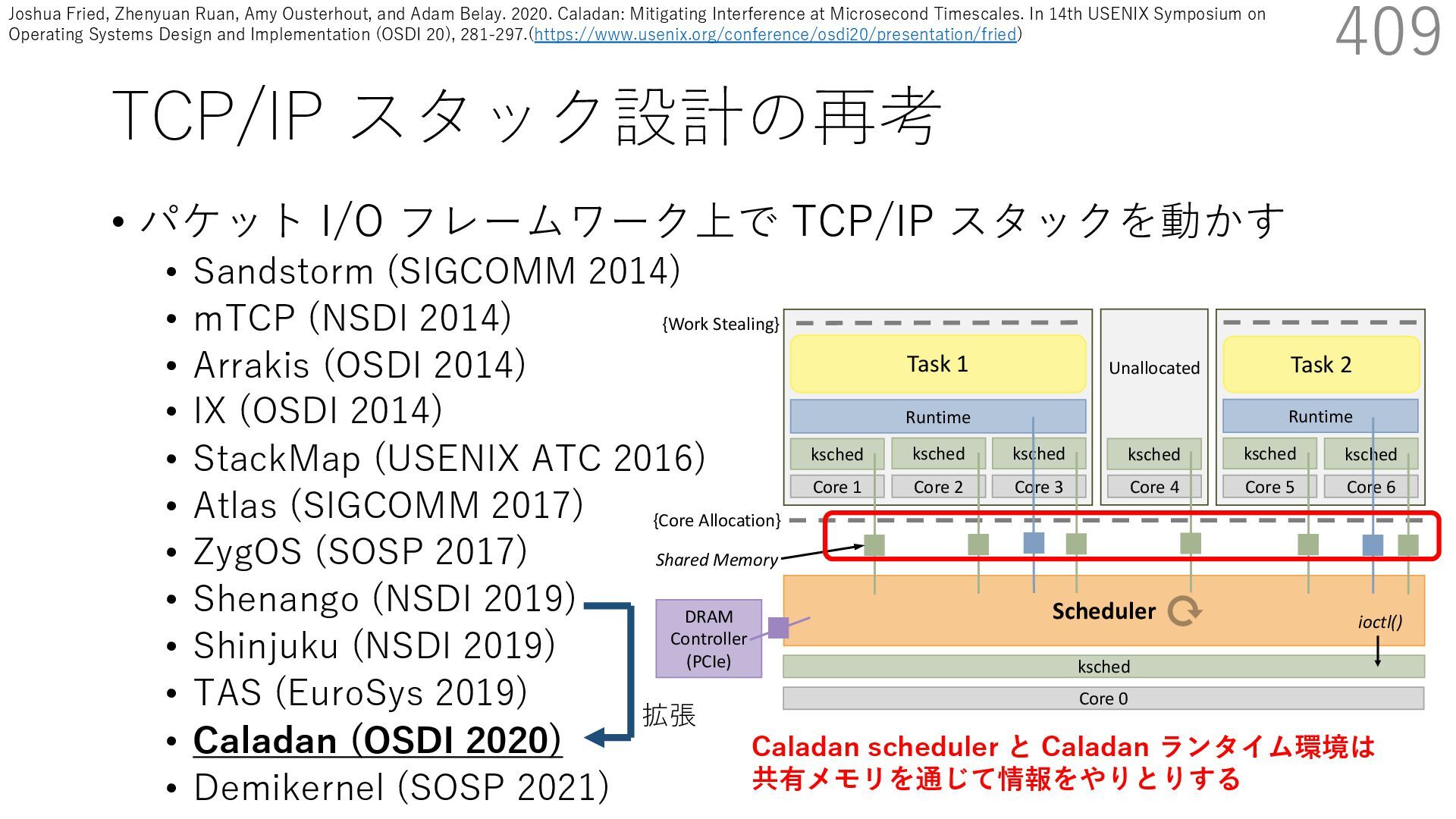{kind=link}
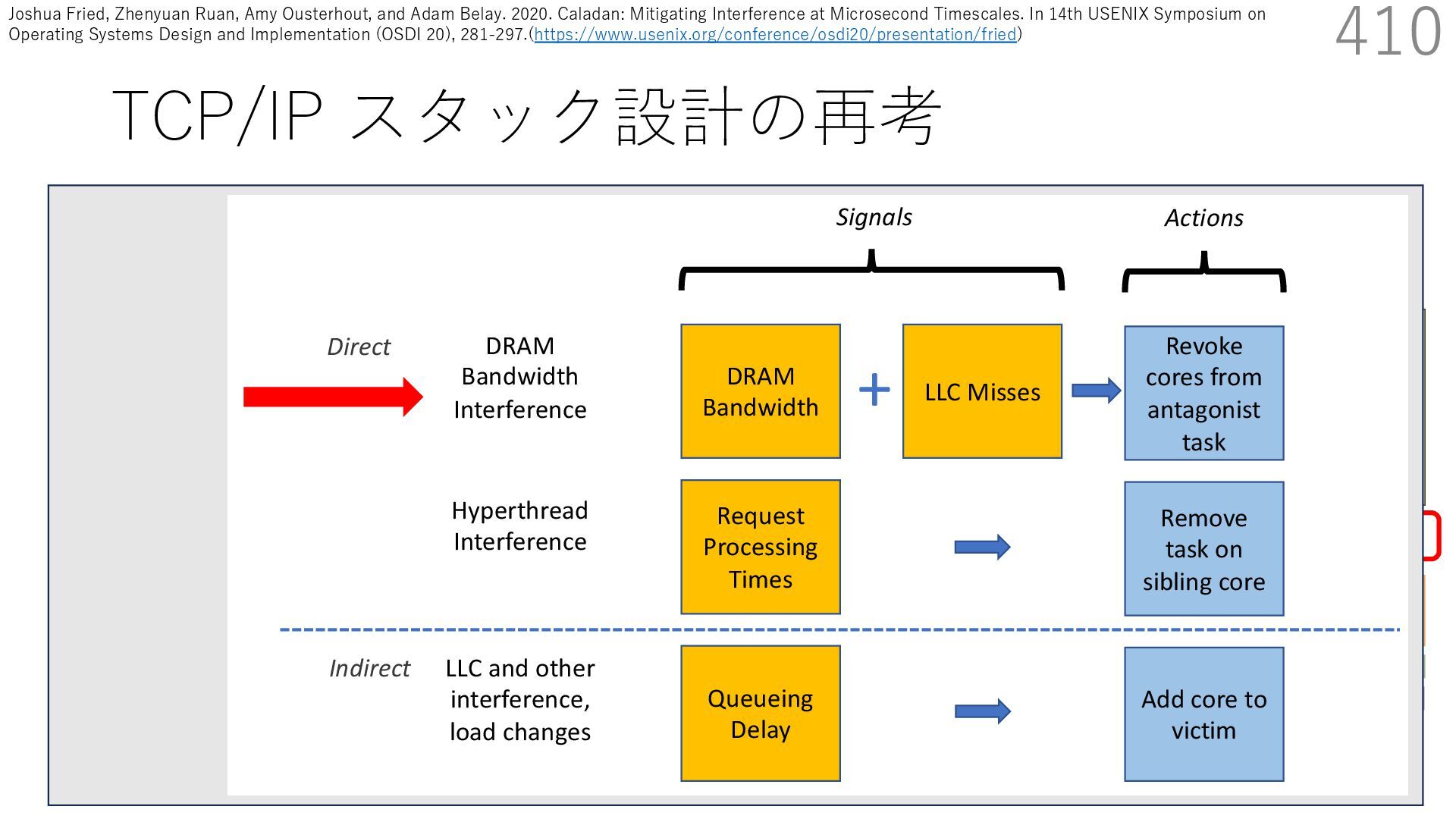{kind=link}
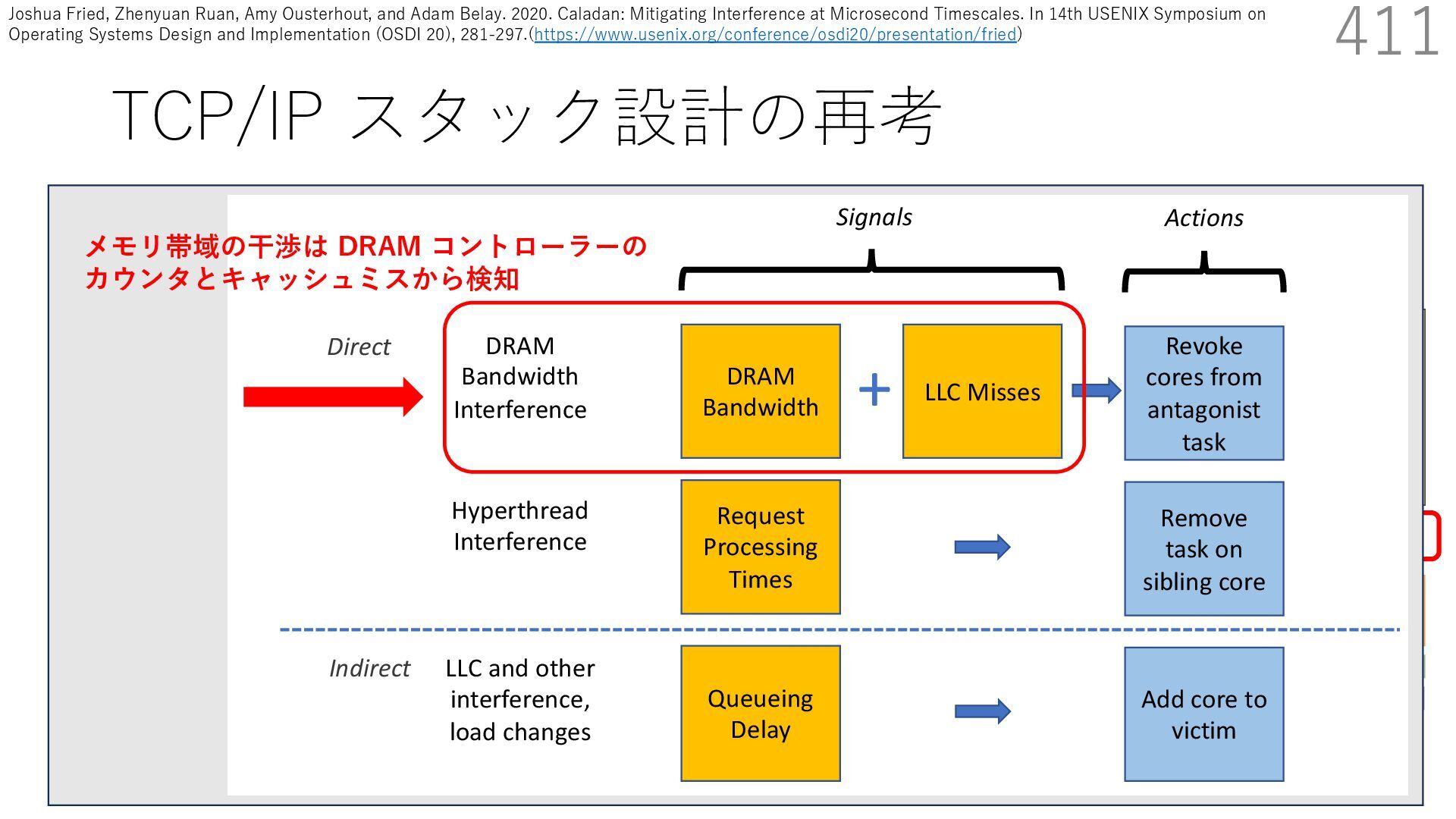{kind=link}
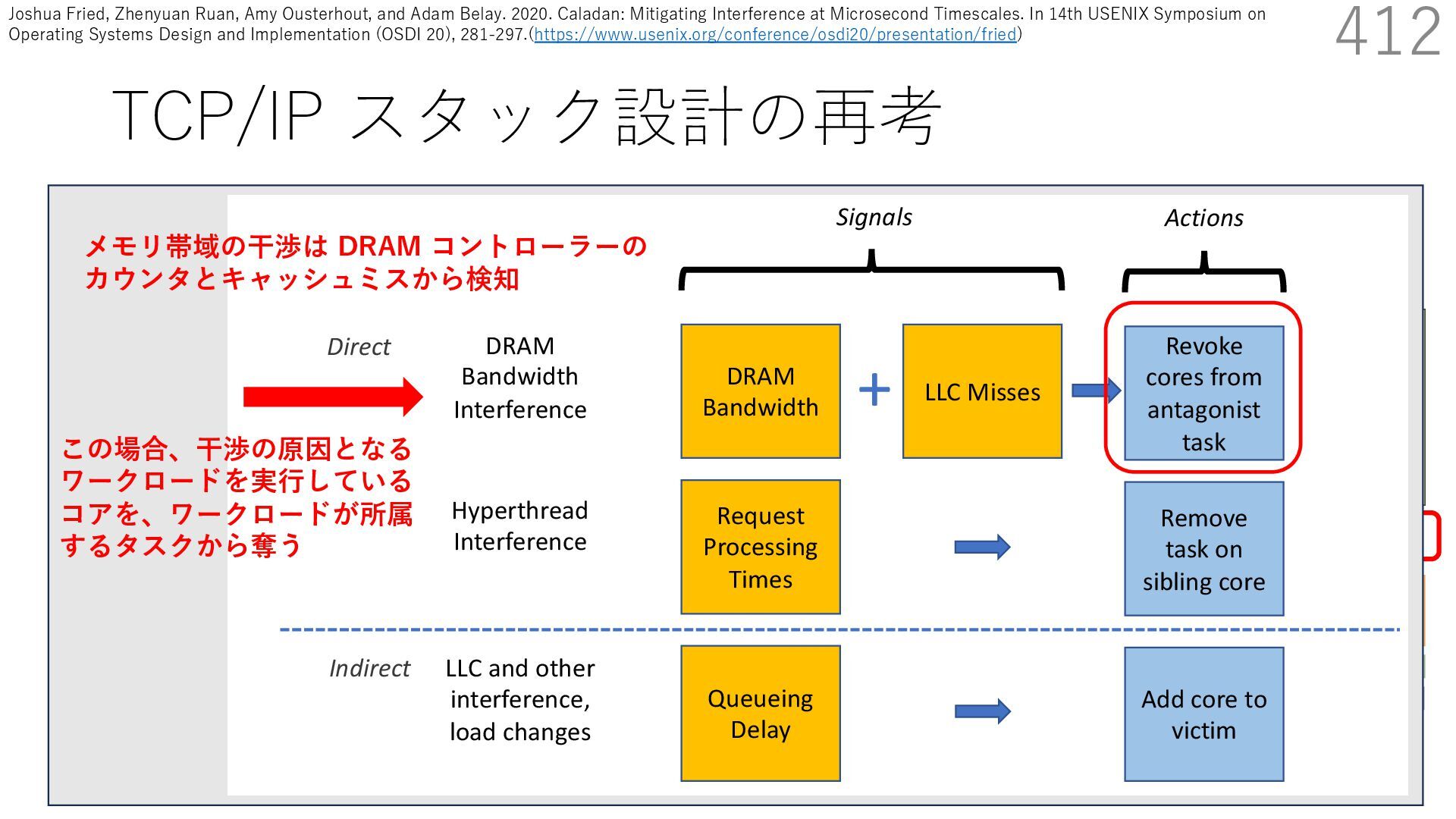{kind=link}
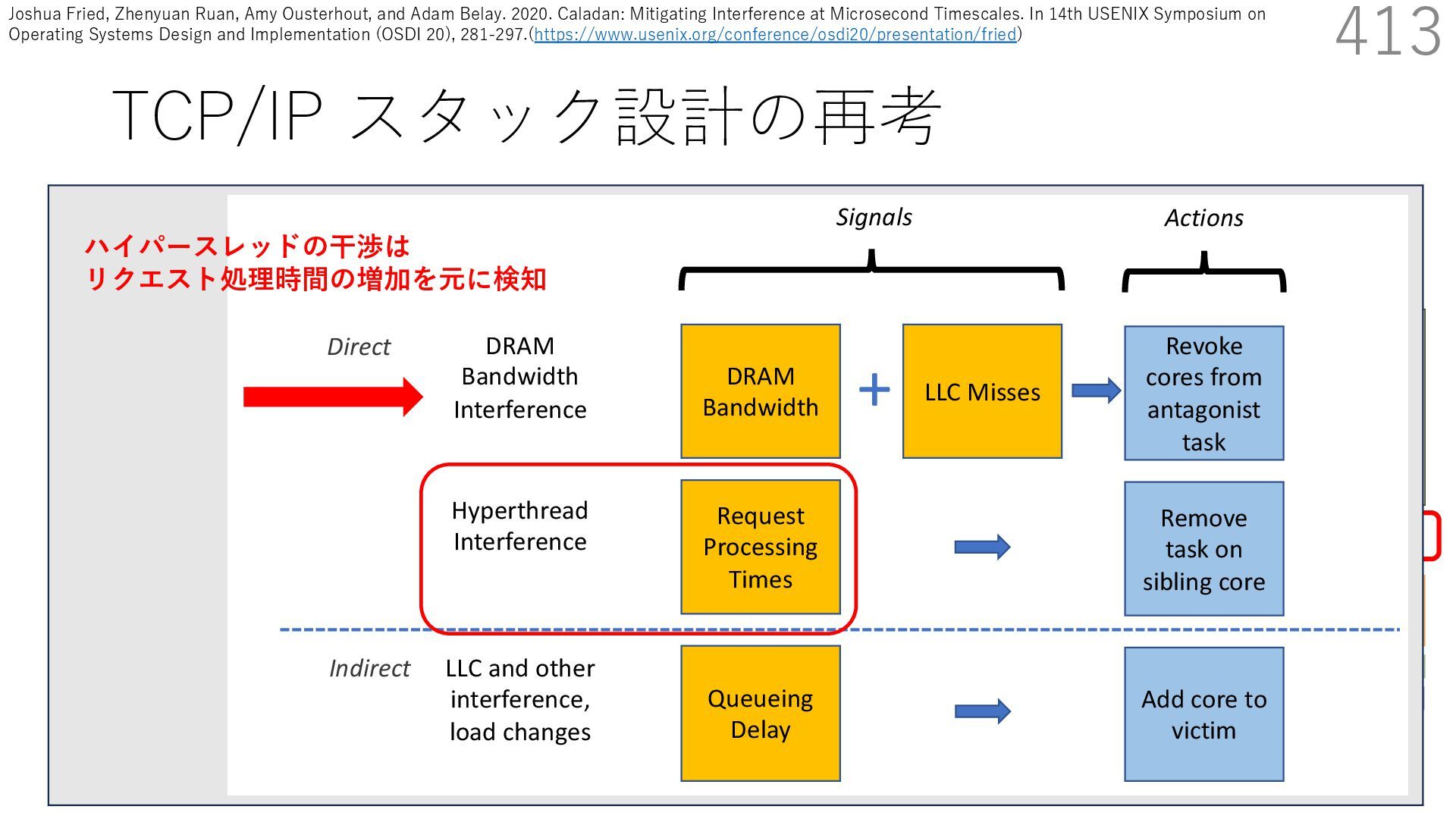{kind=link}
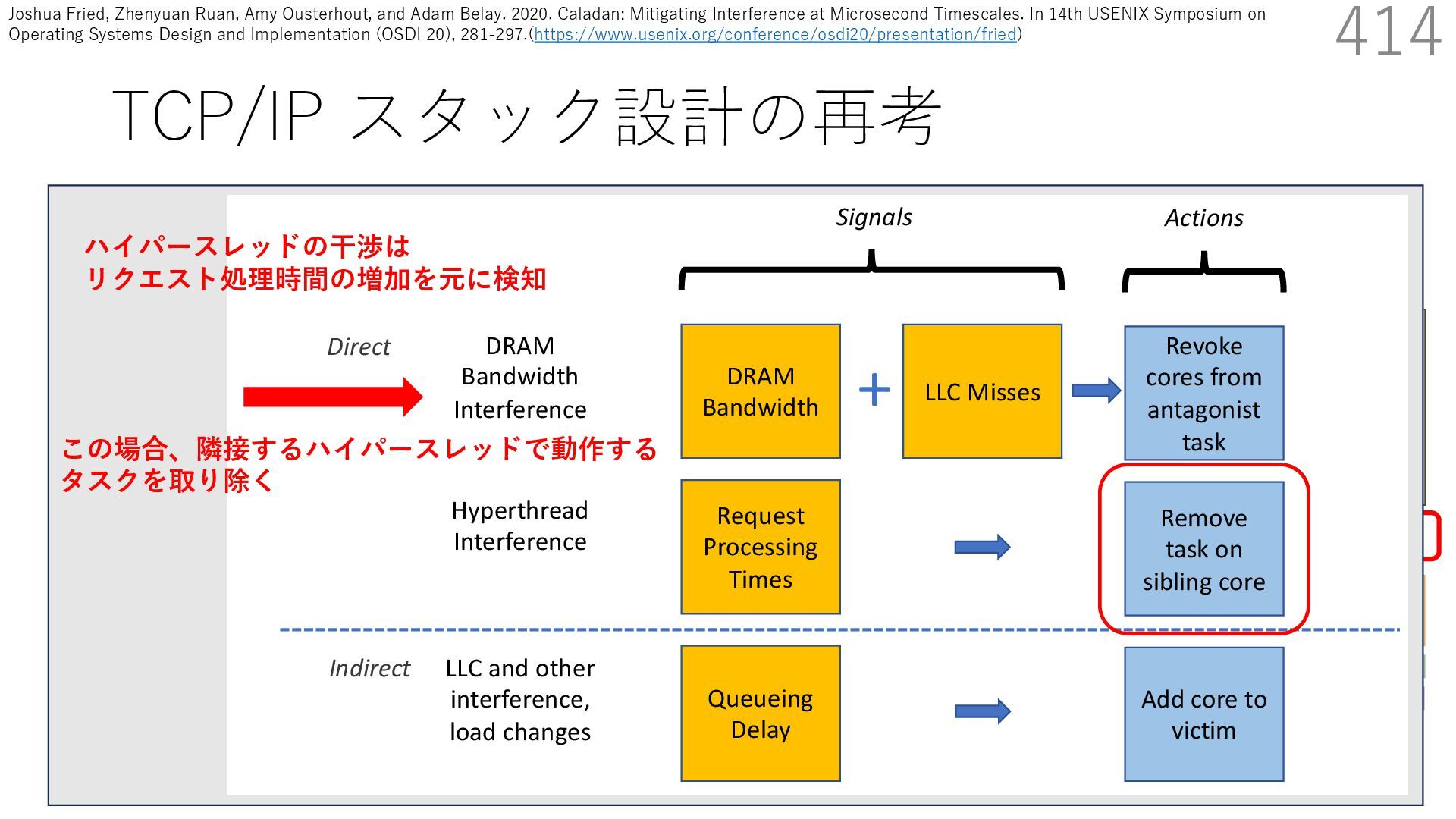{kind=link}
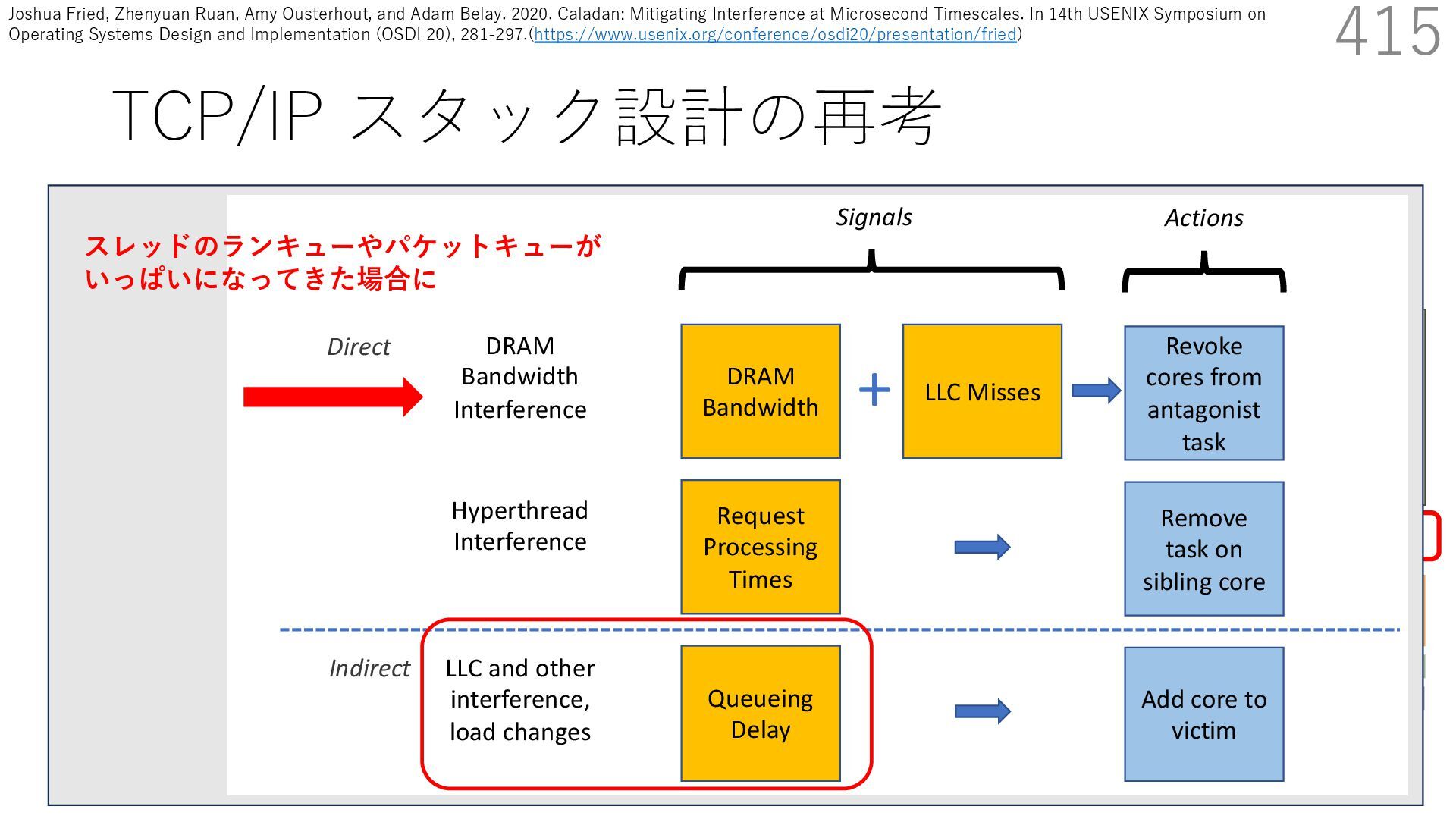{kind=link}
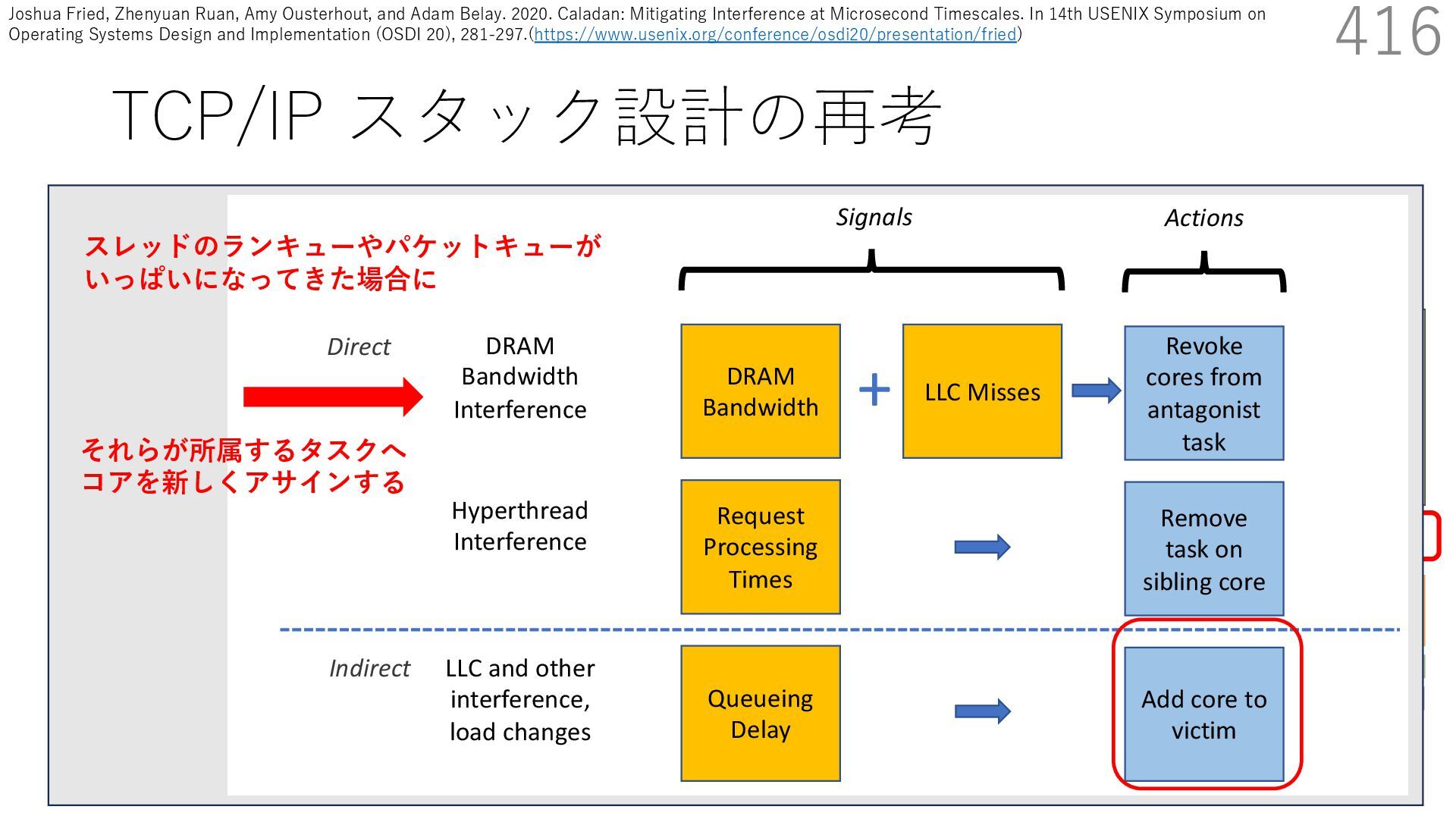{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
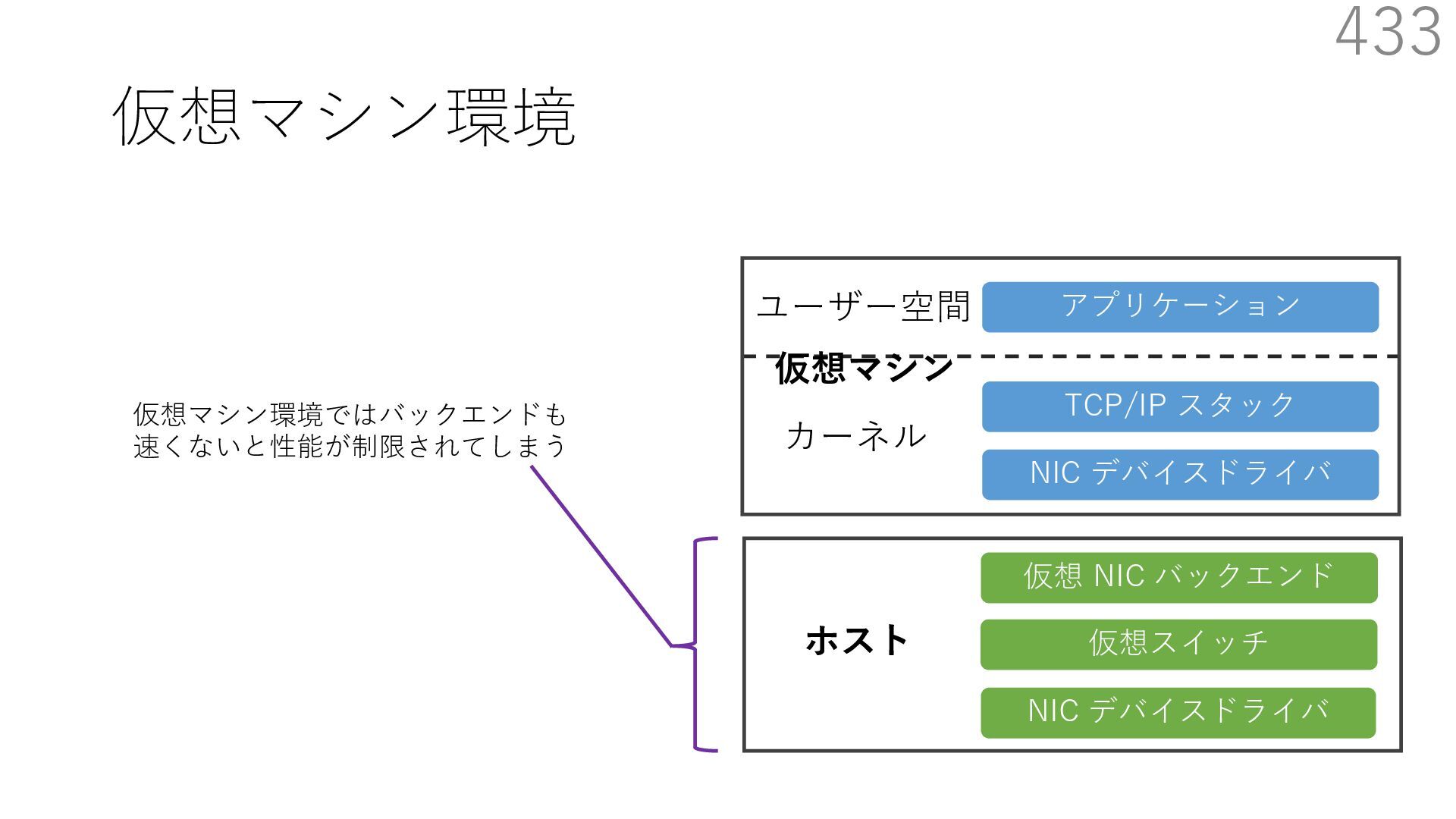{kind=link}
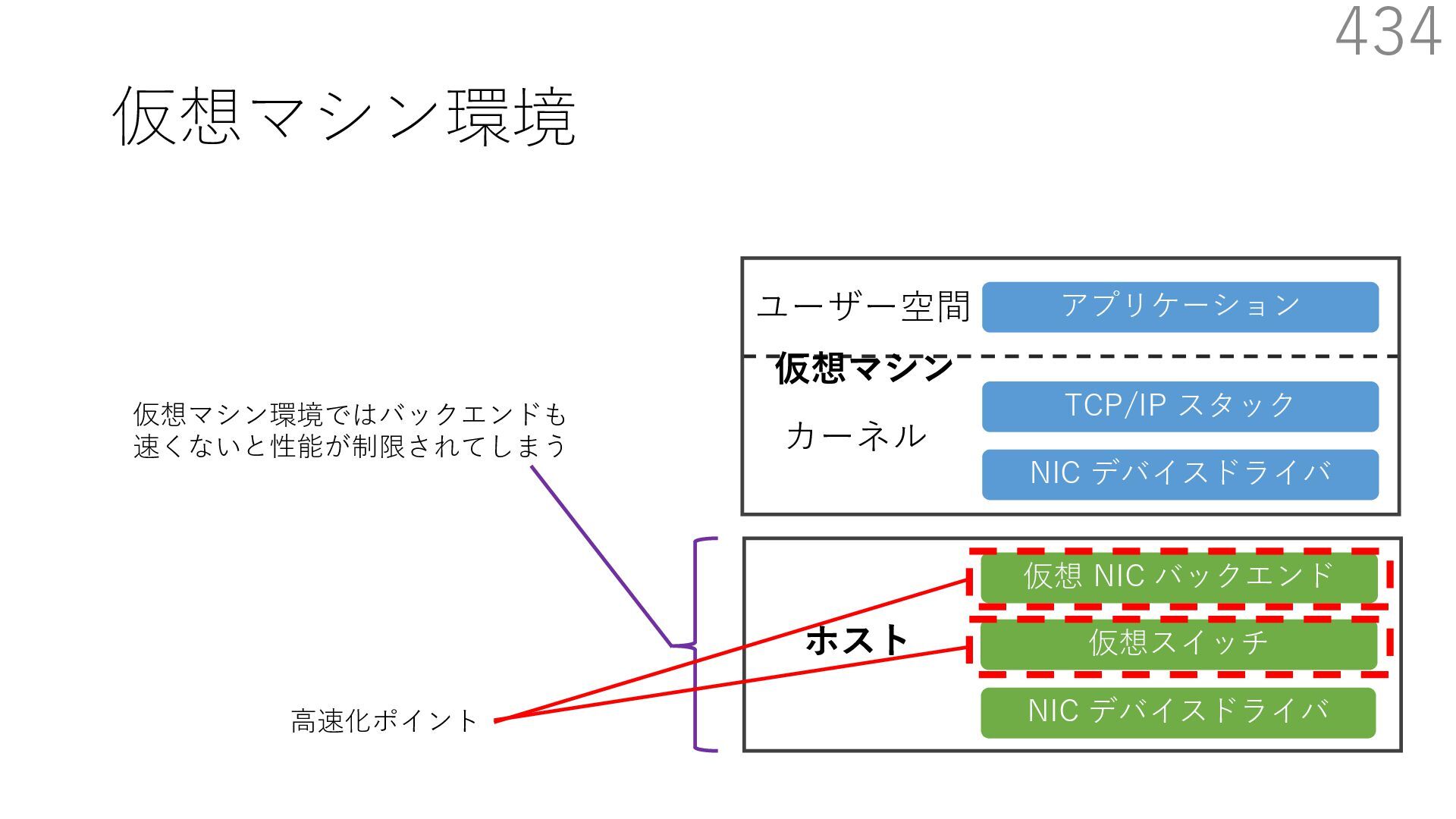{kind=link}
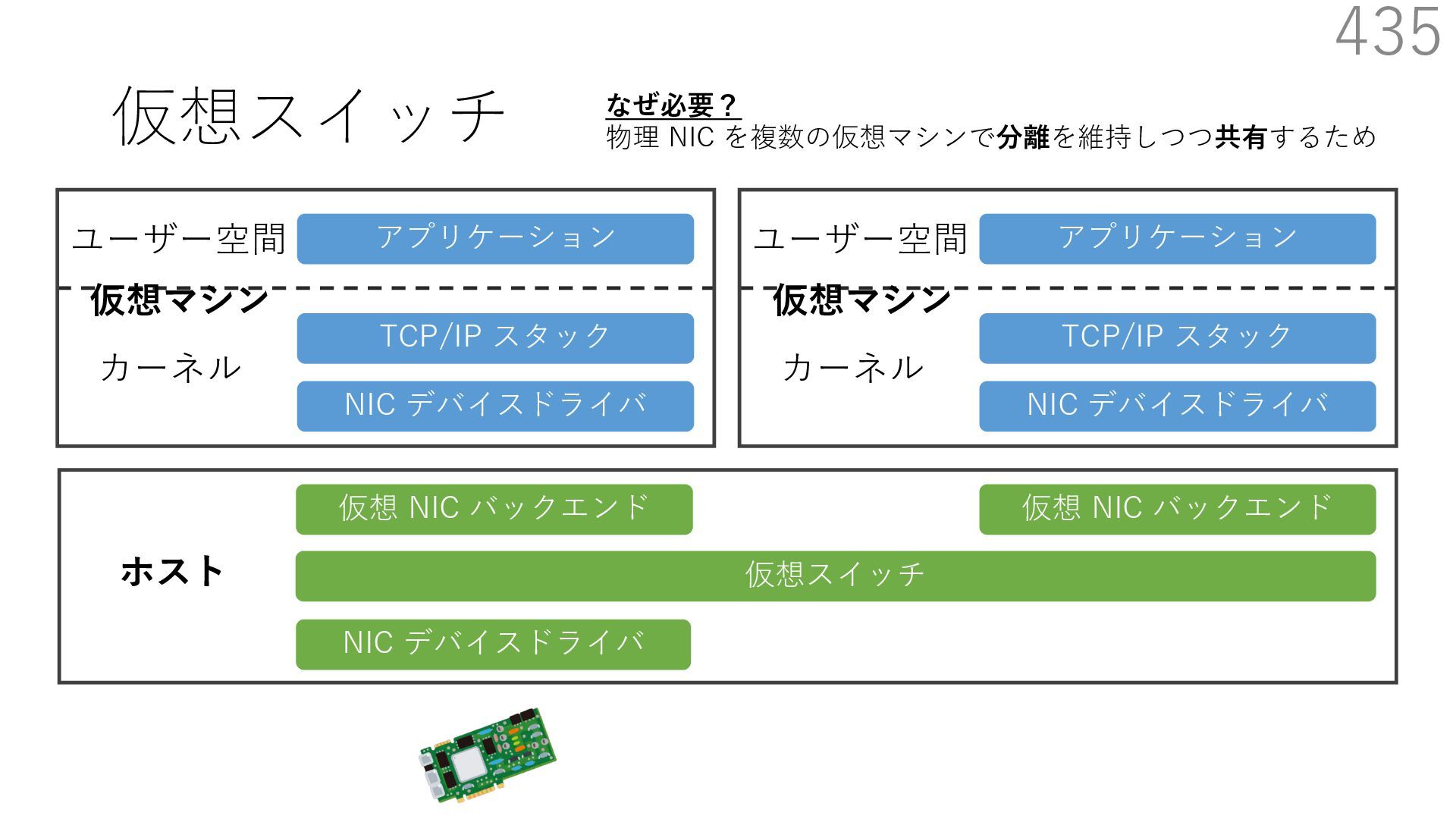{kind=link}
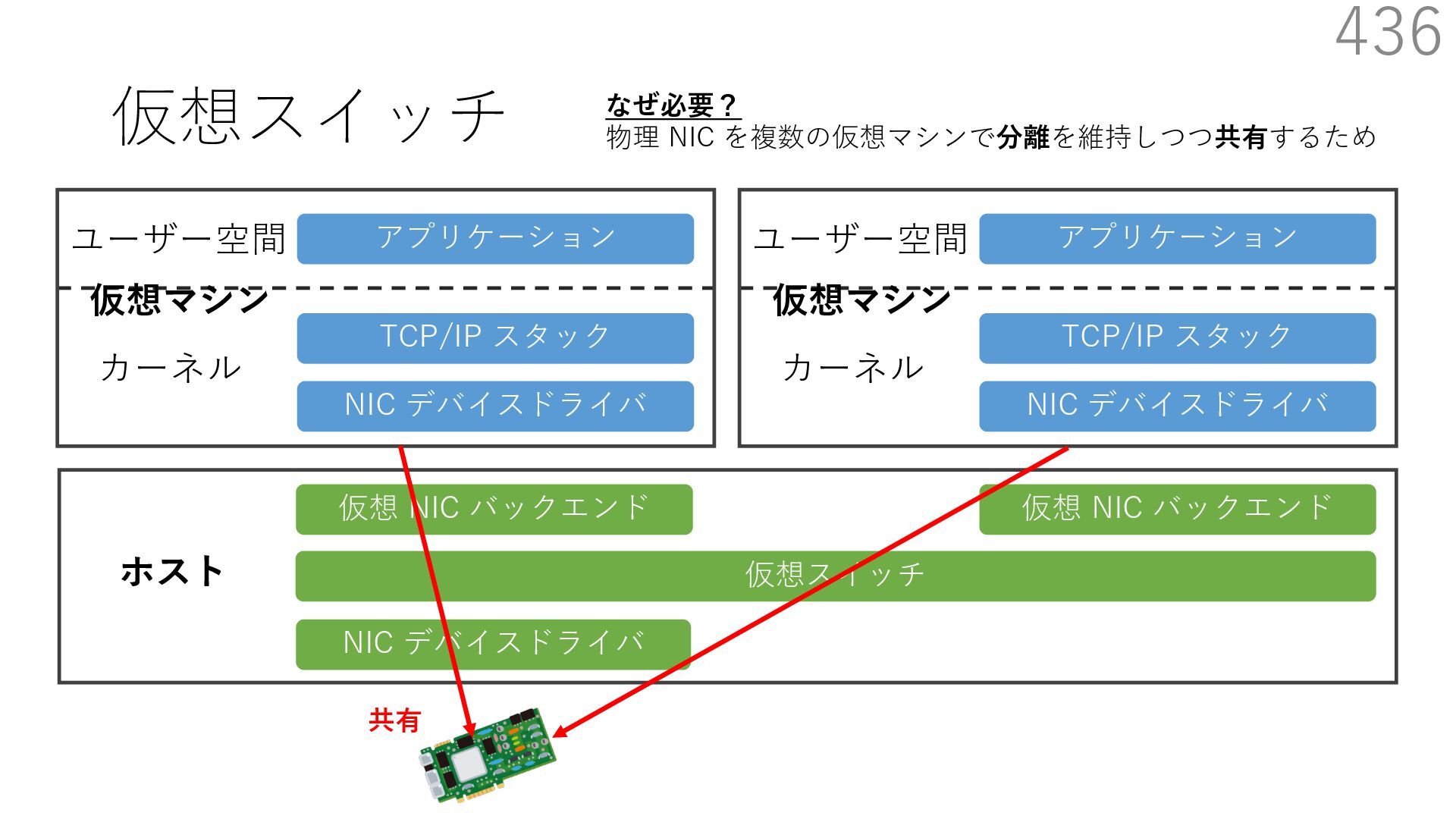{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
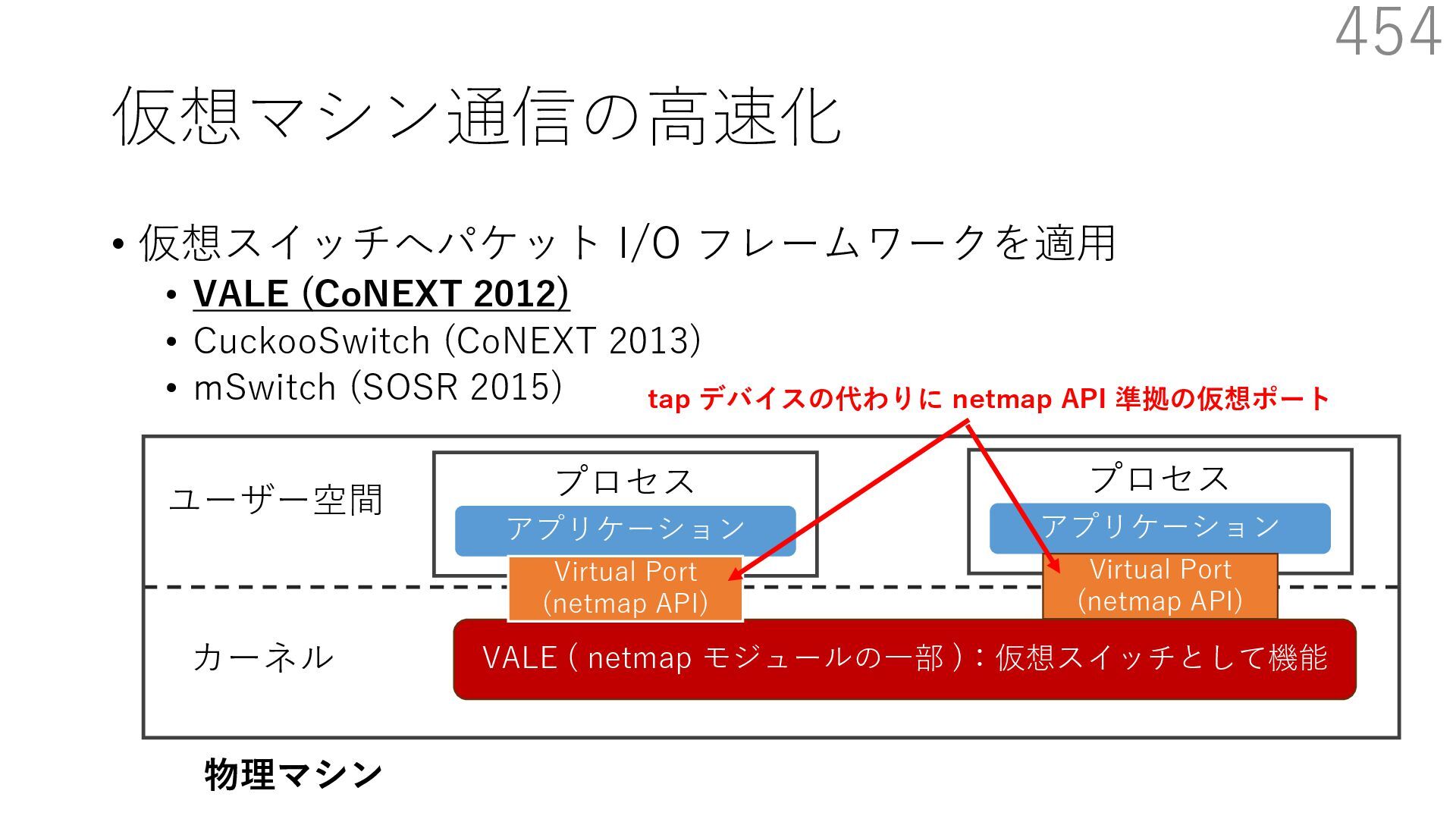{kind=link}
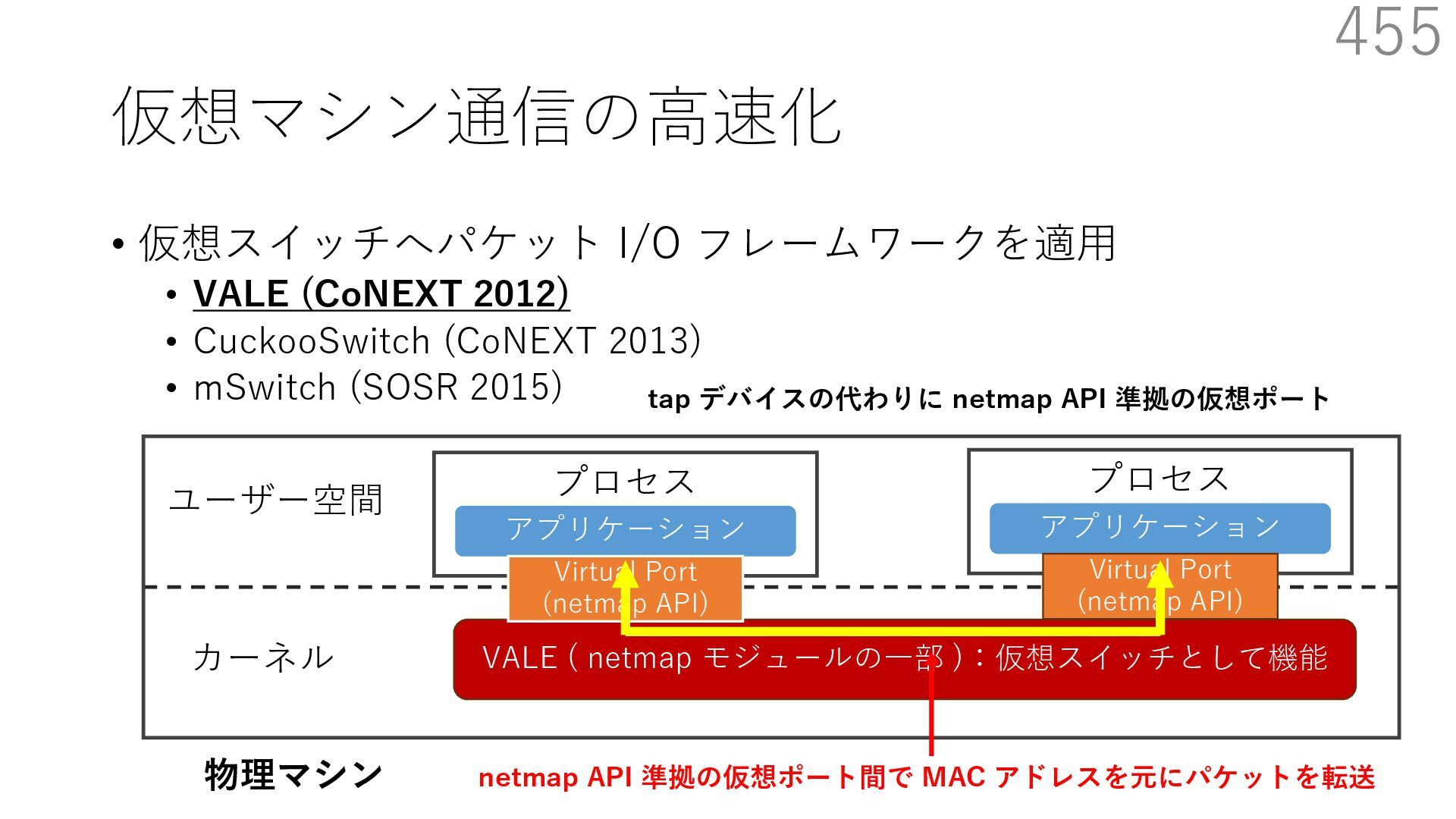{kind=link}
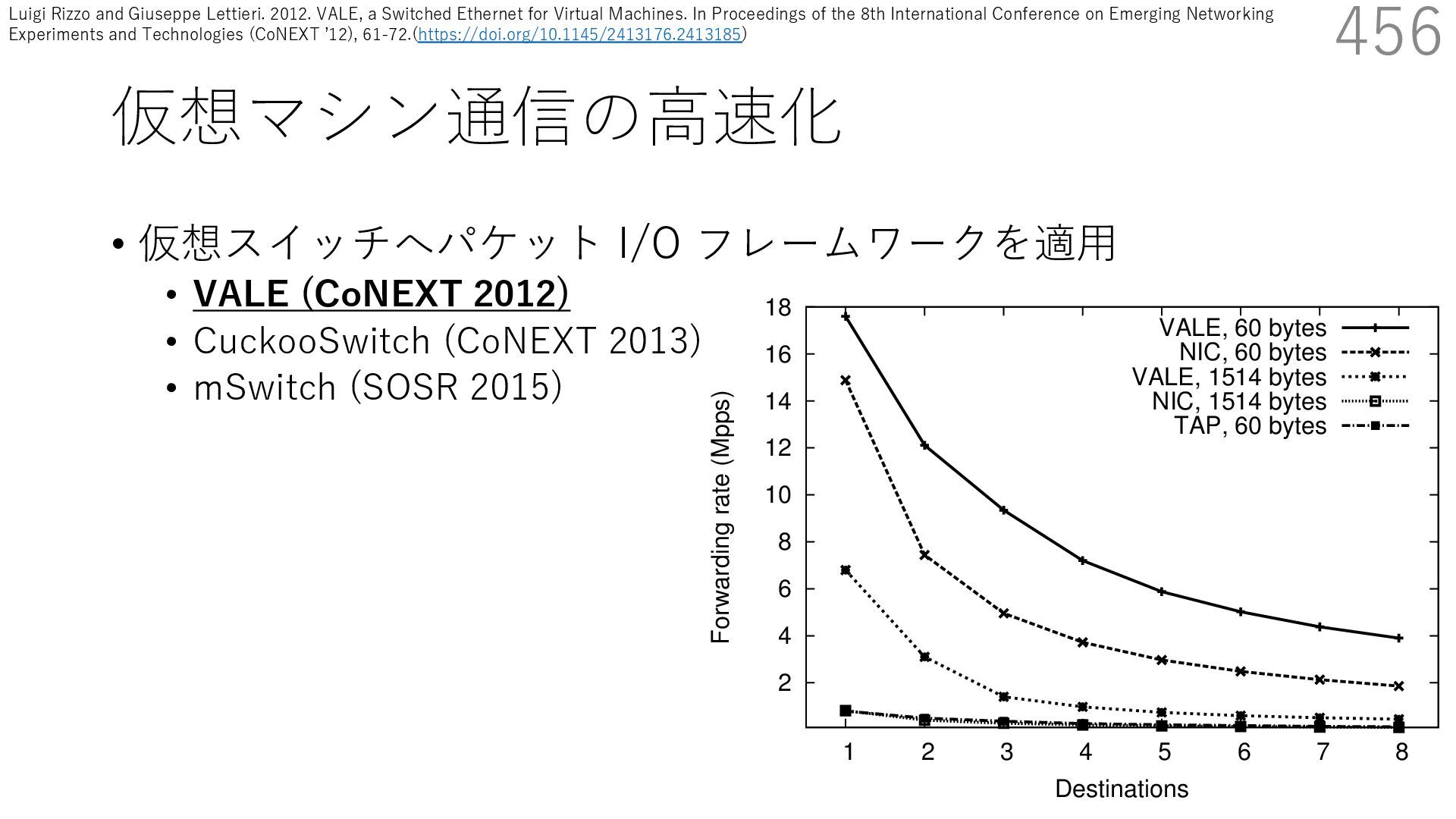{kind=link}
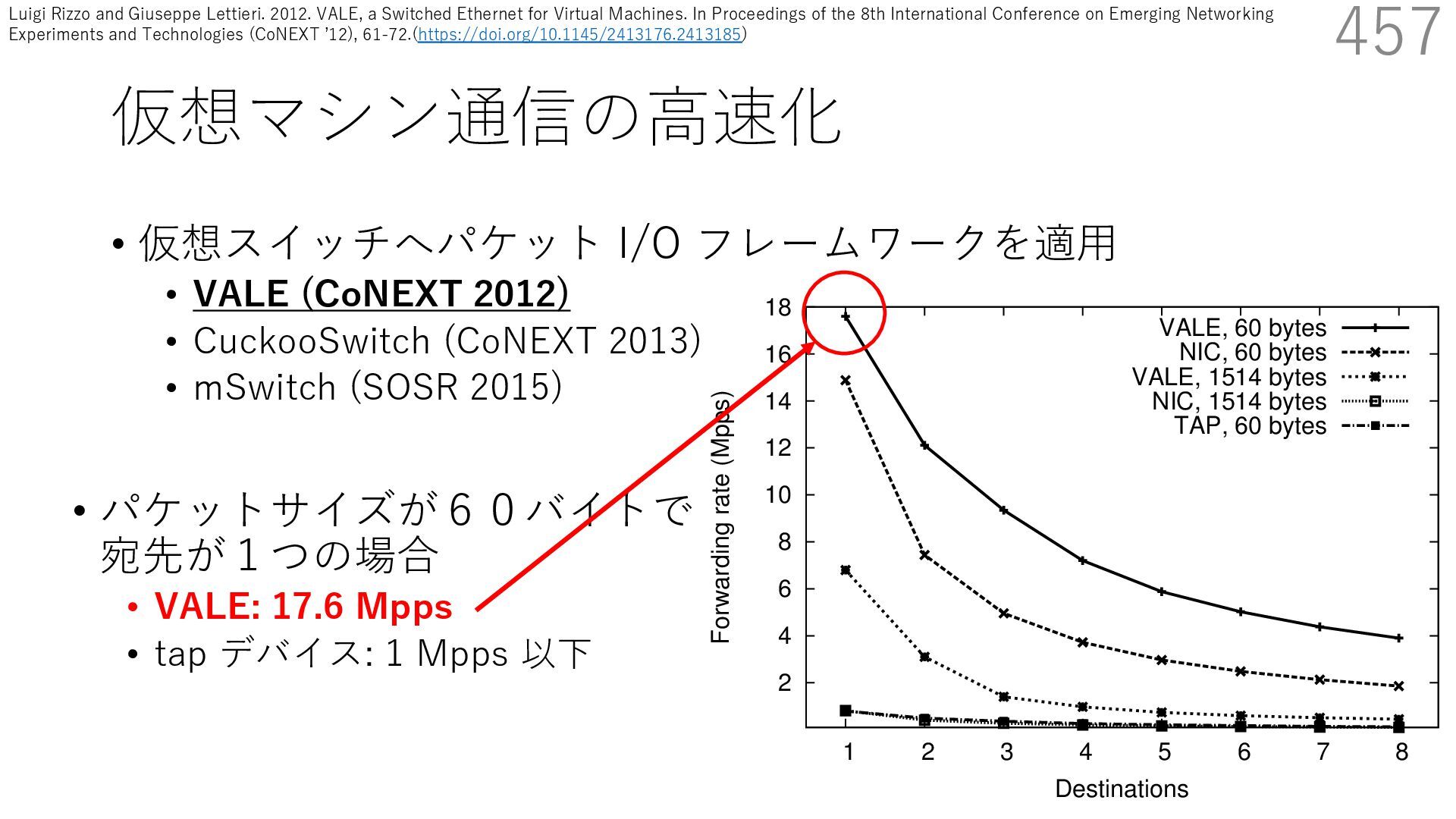{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
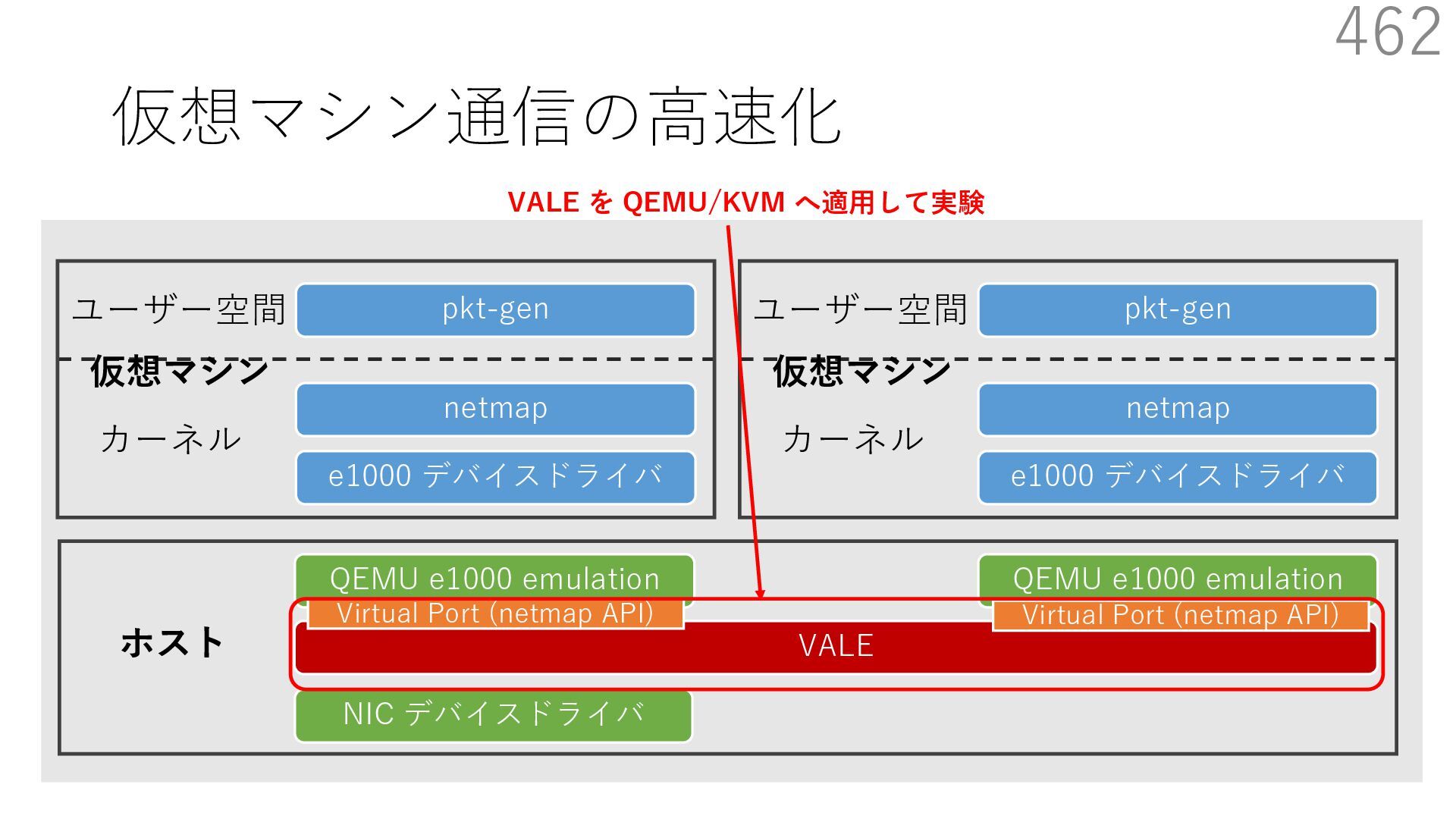{kind=link}
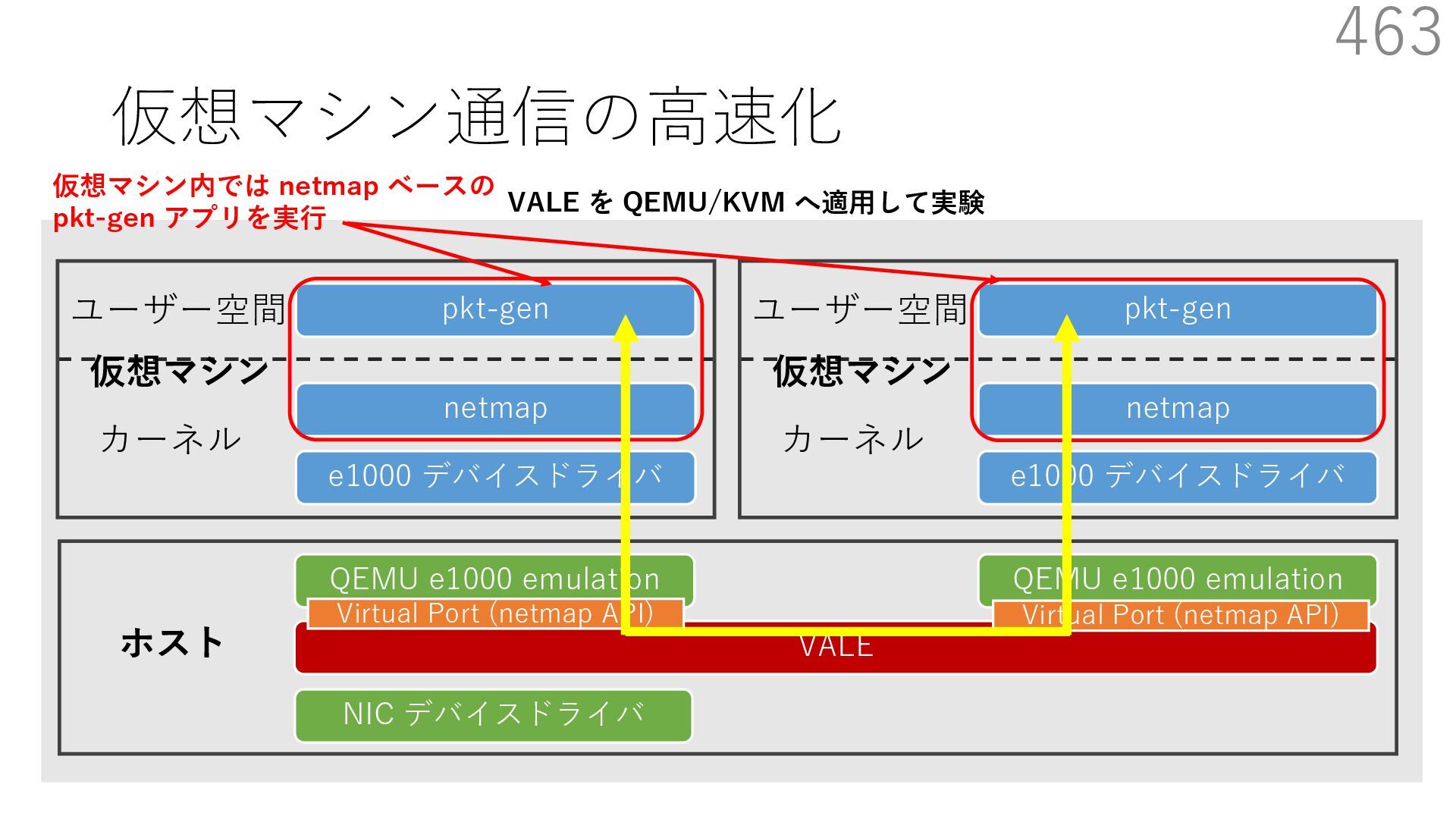{kind=link}
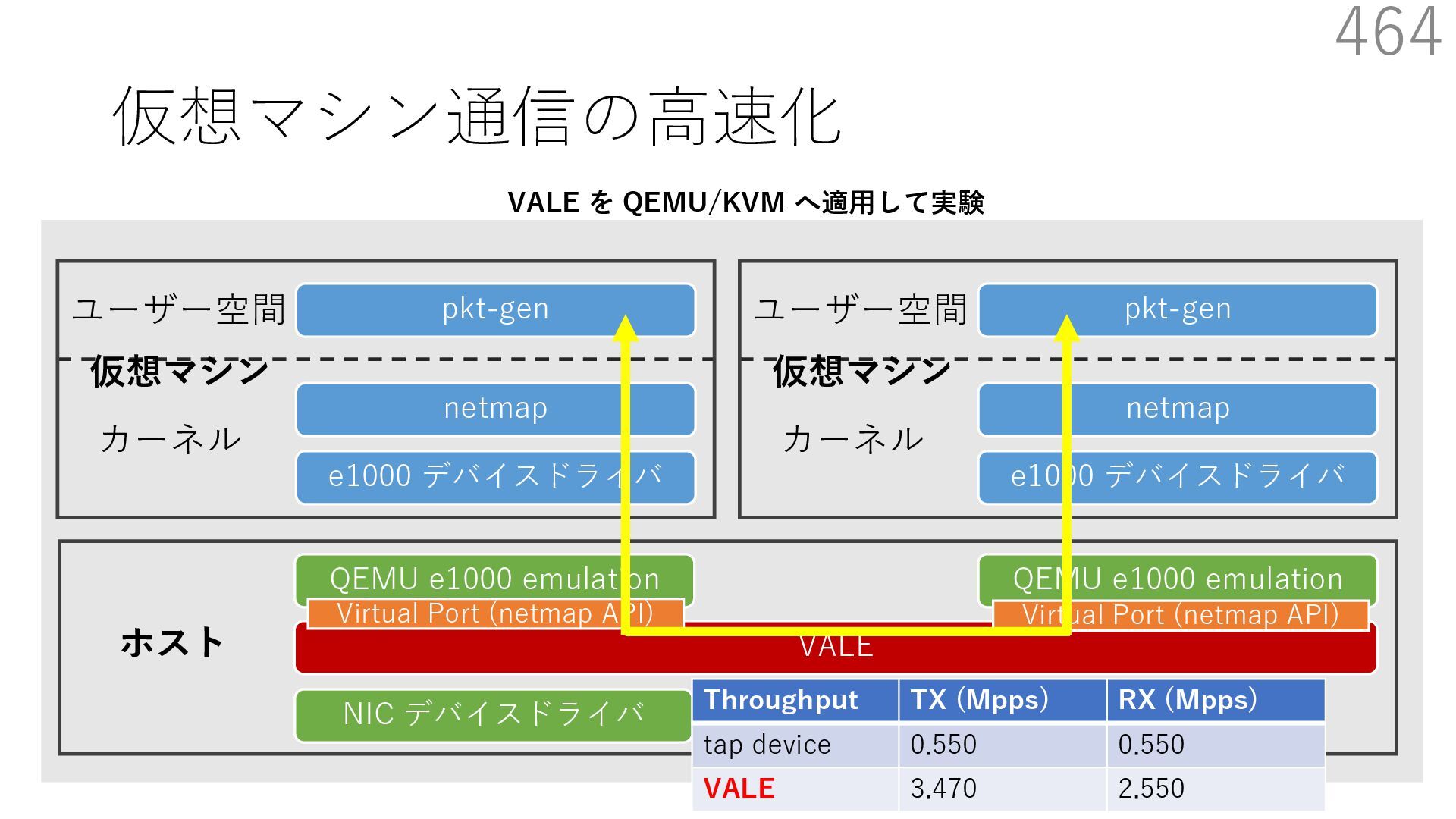{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
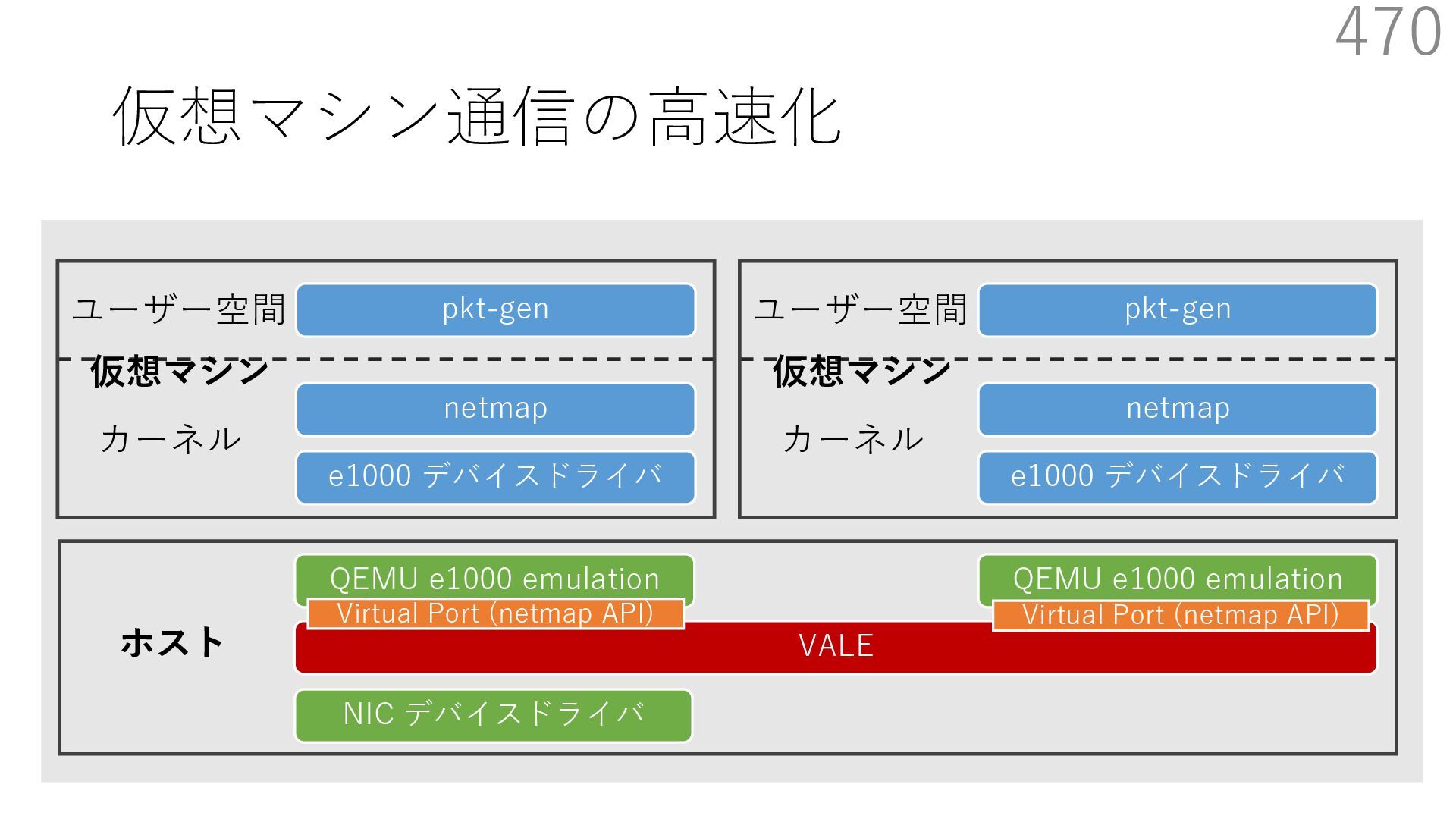{kind=link}
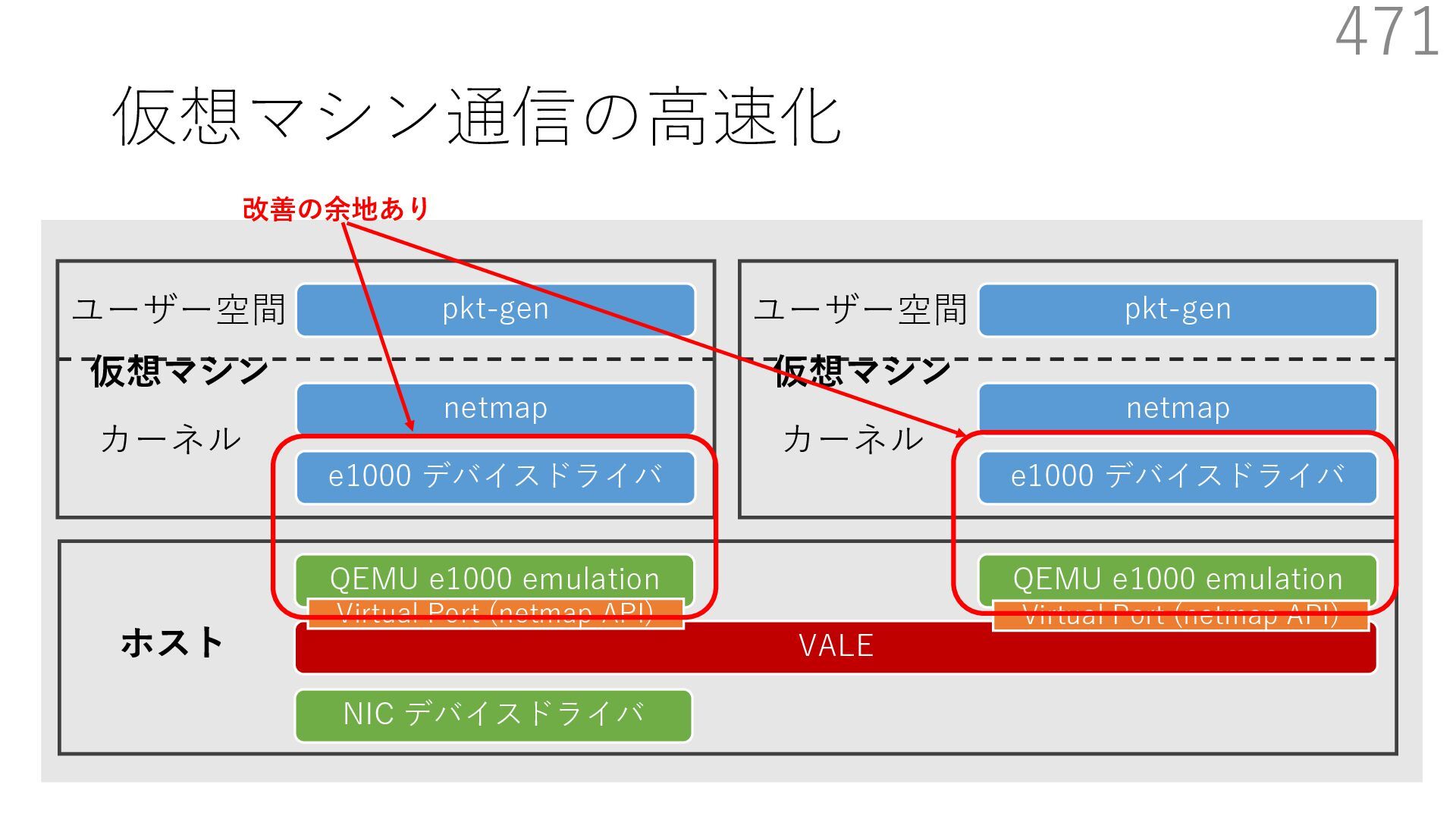{kind=link}
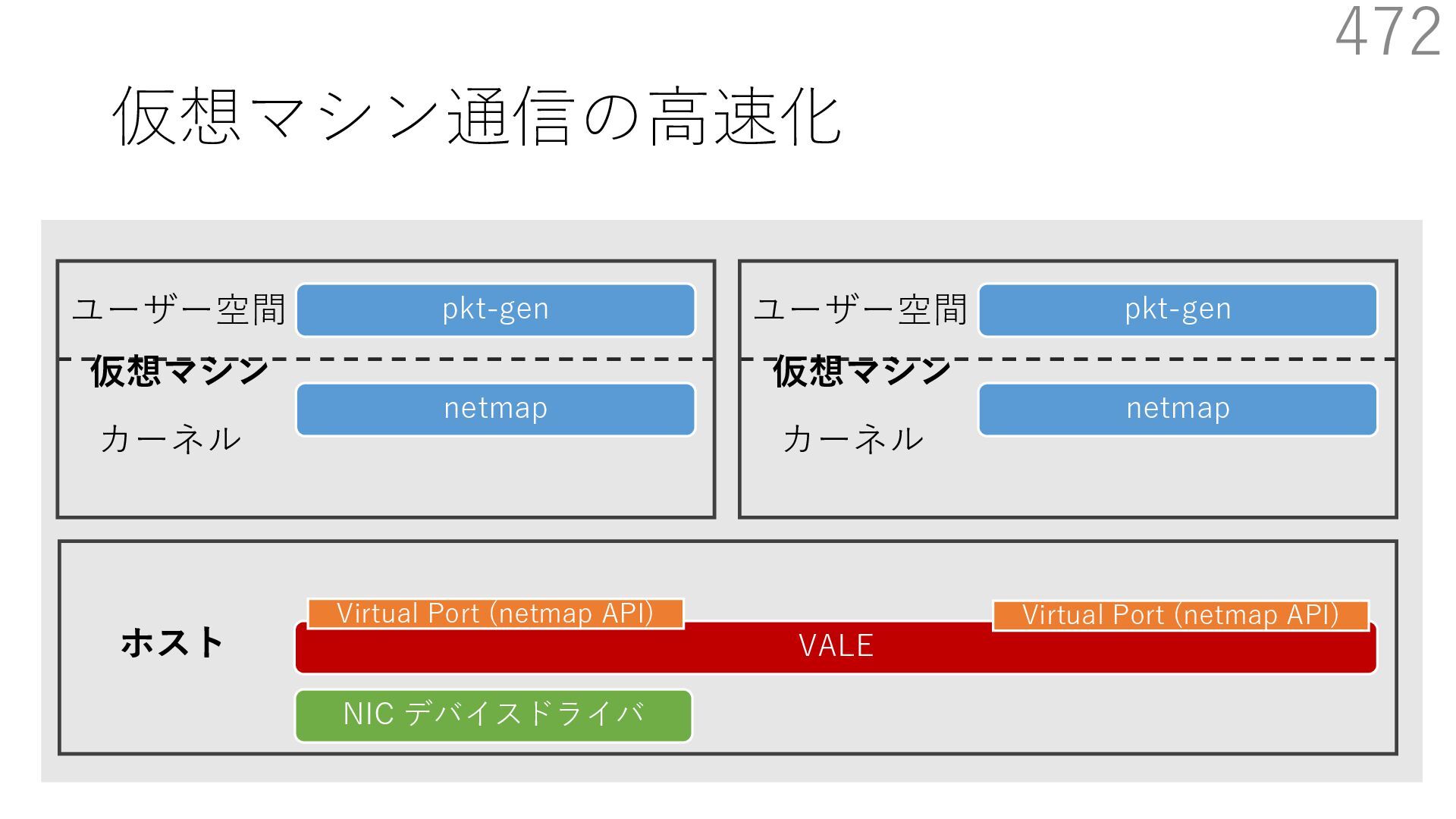{kind=link}
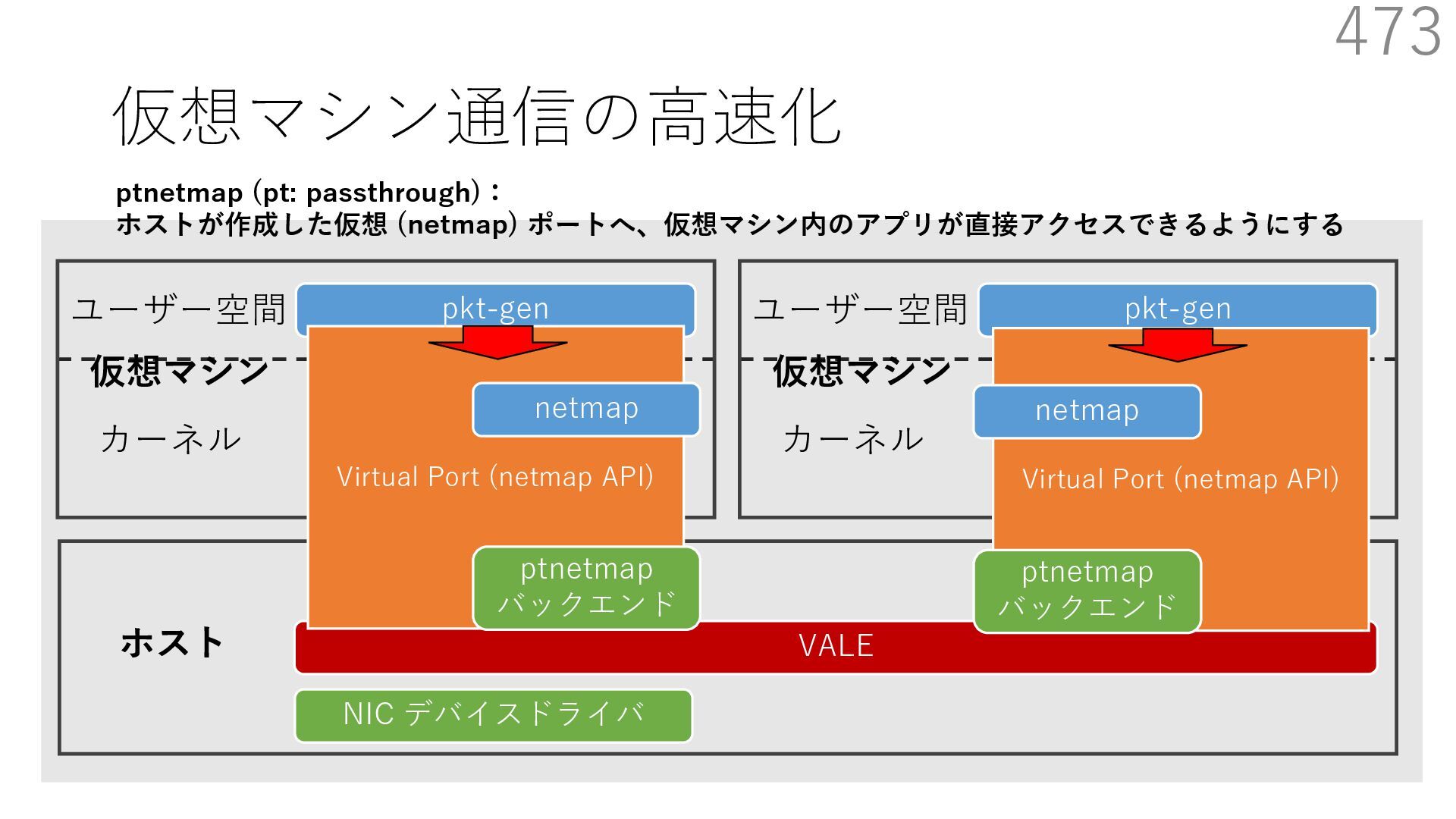{kind=link}
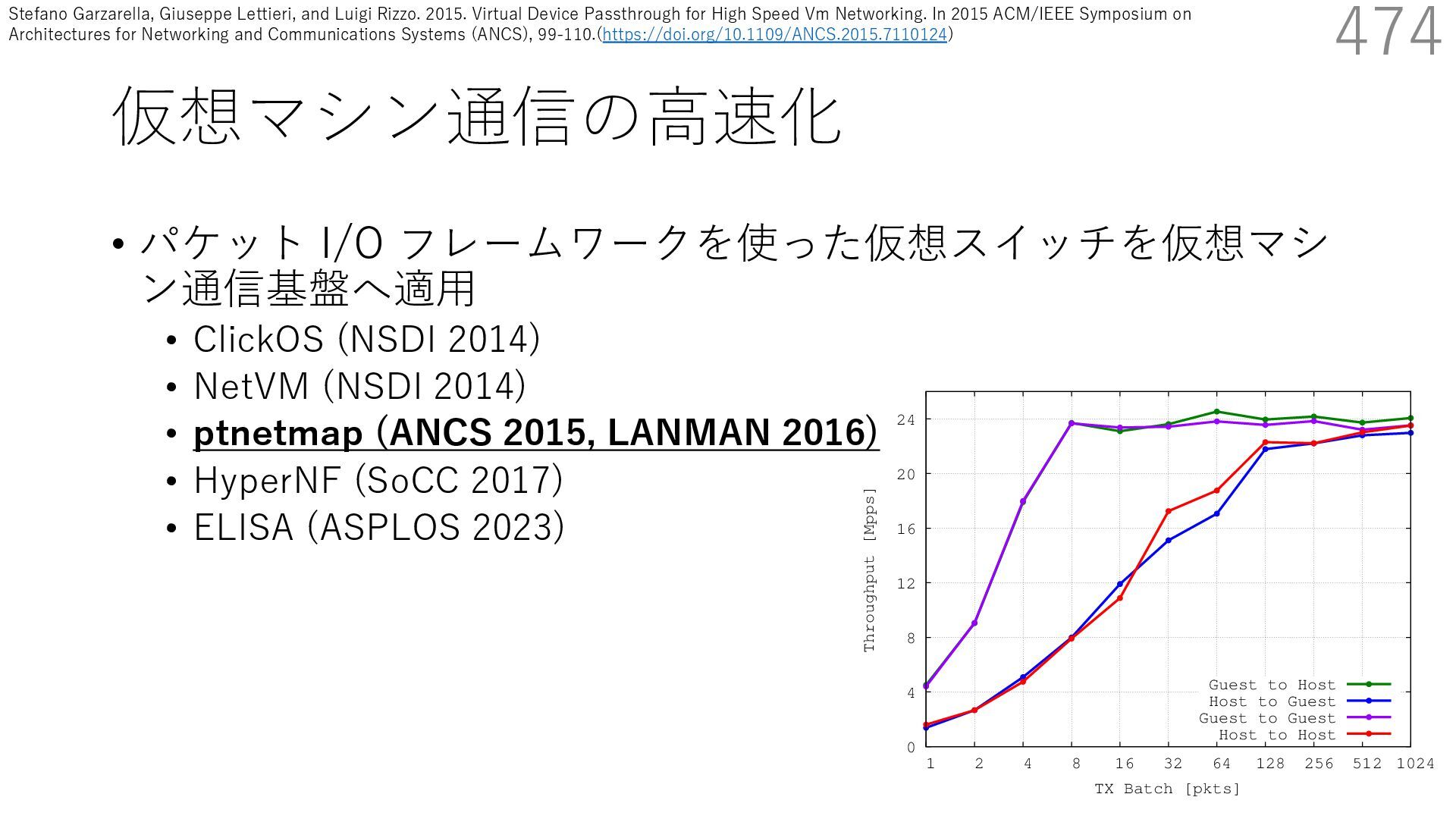{kind=link}
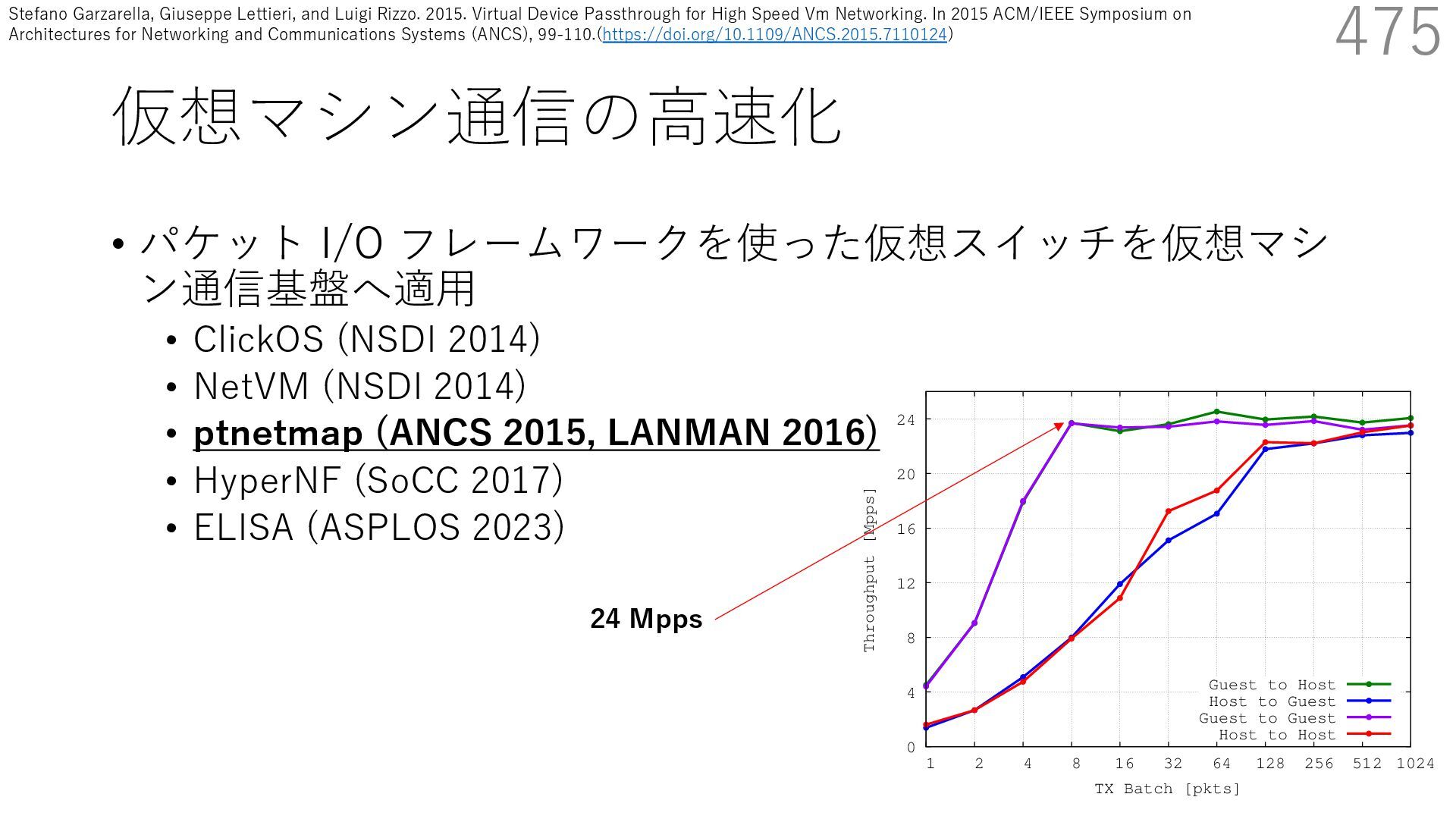{kind=link}
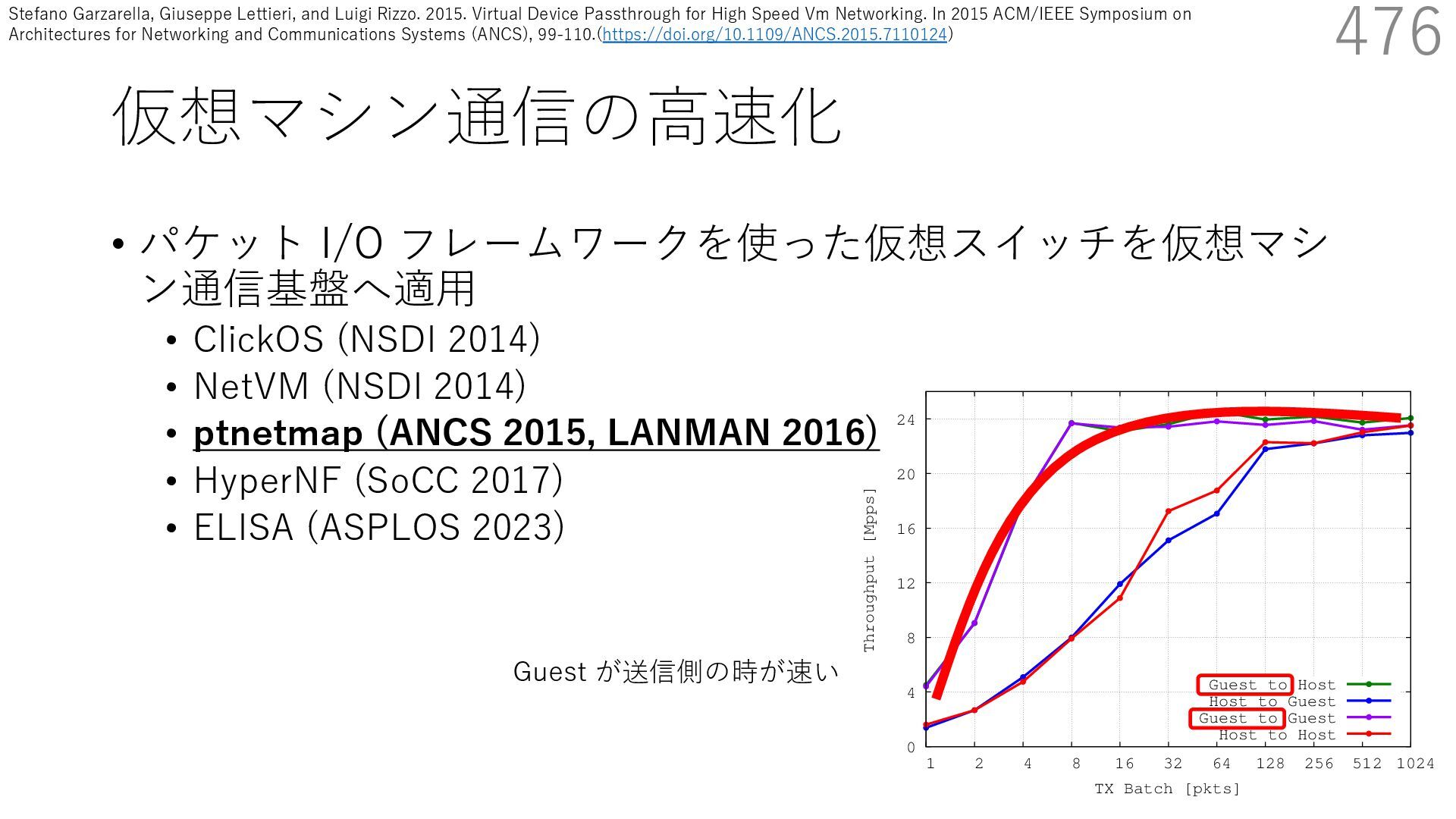{kind=link}
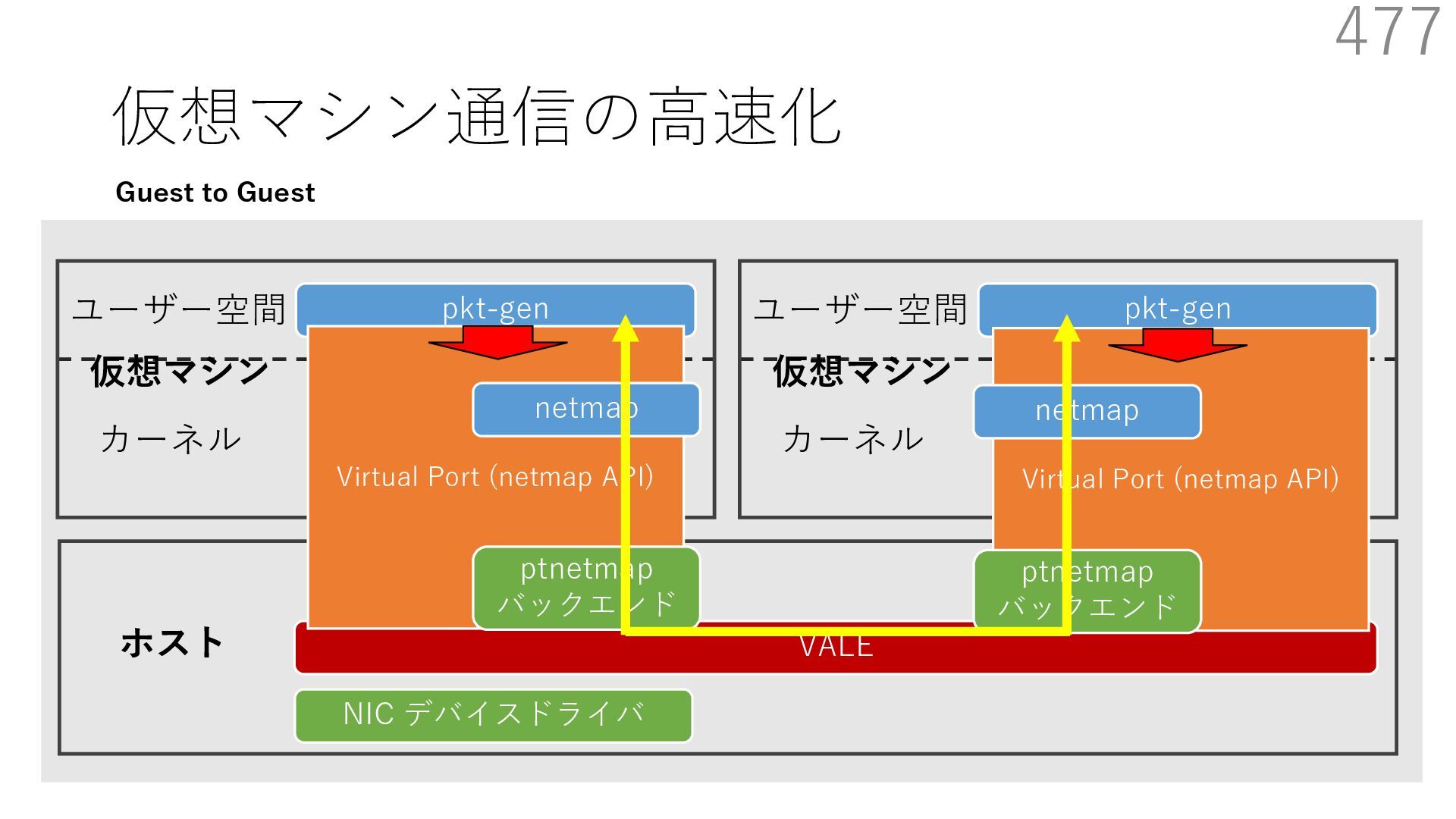{kind=link}
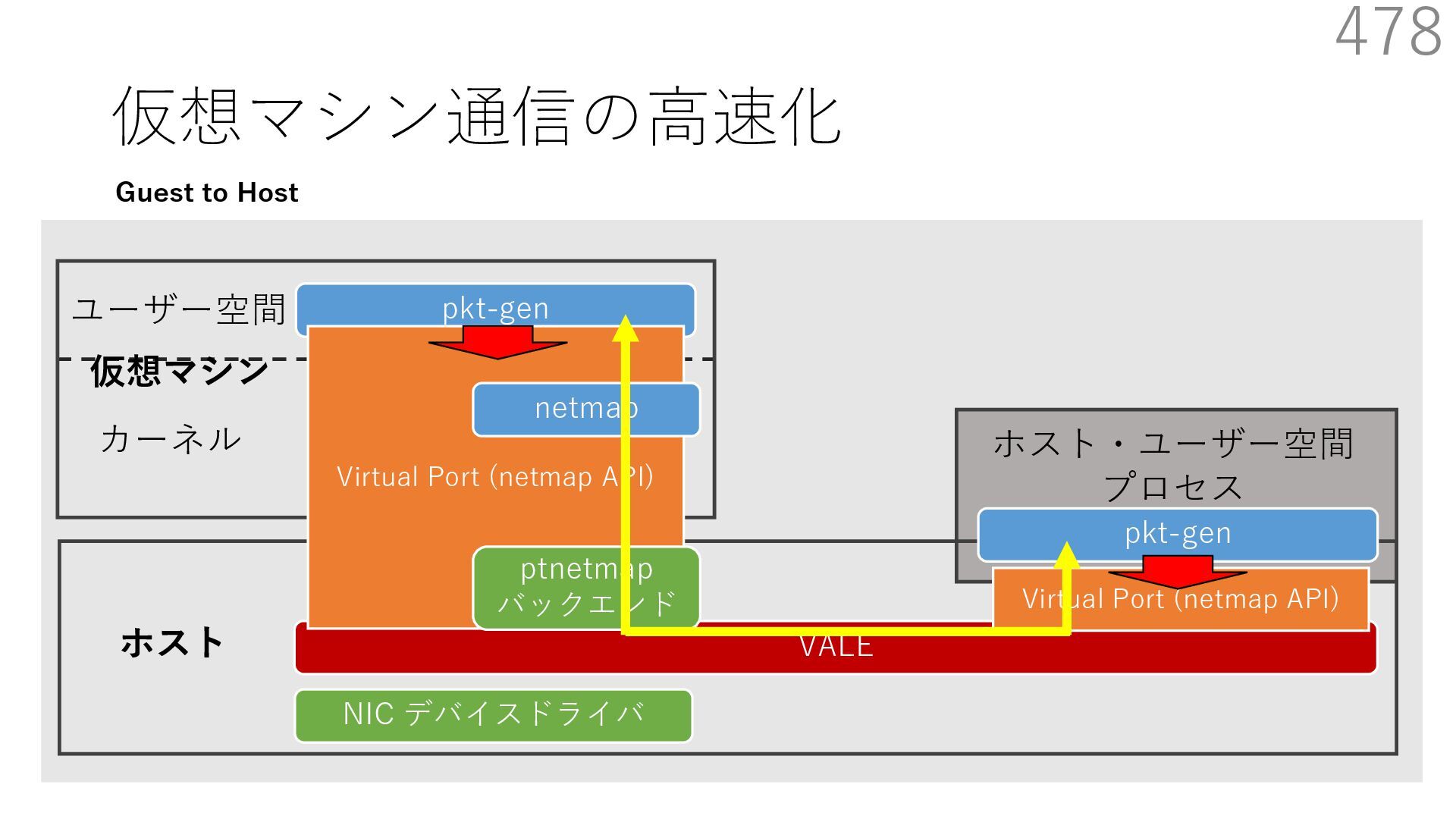{kind=link}
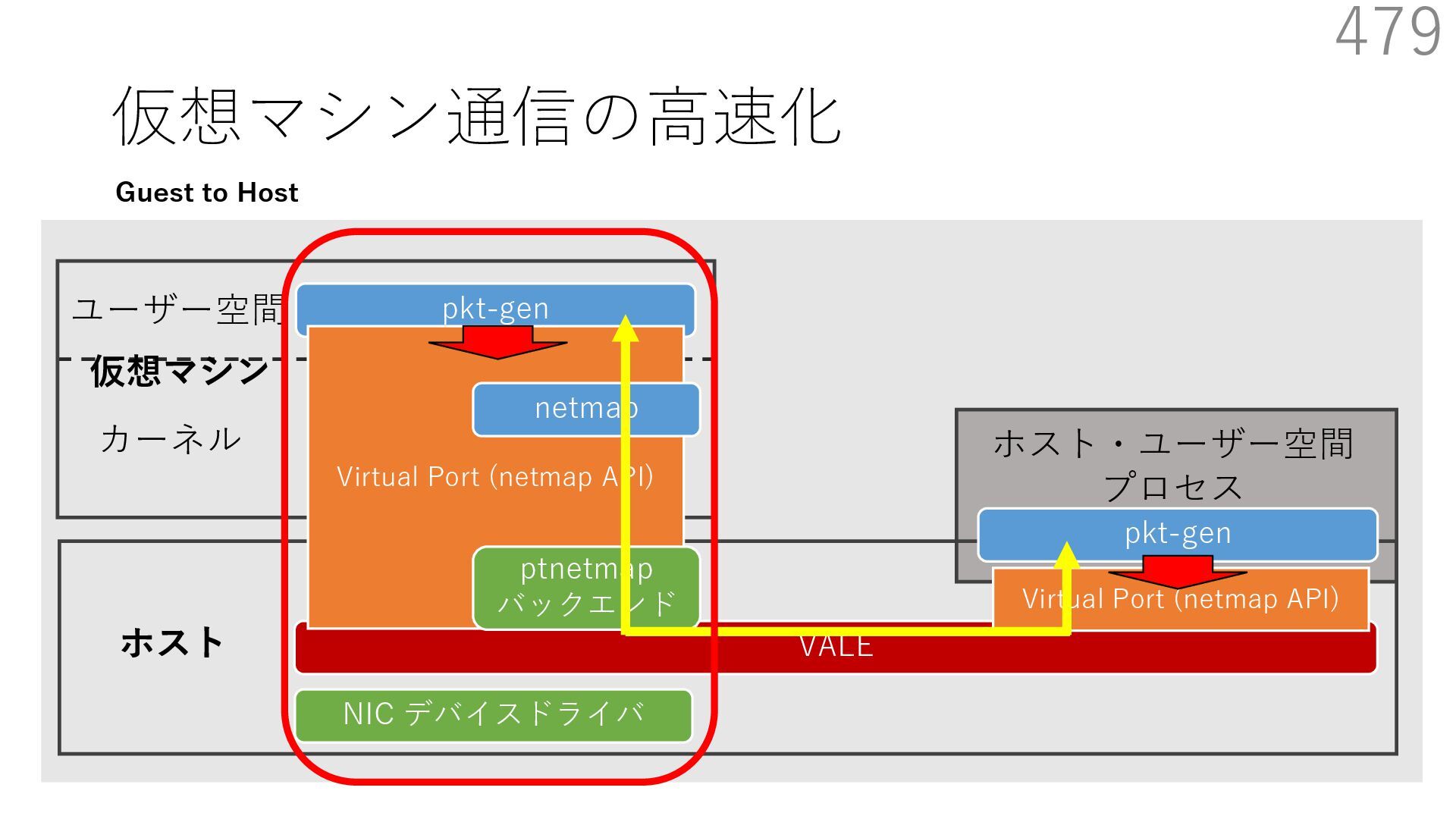{kind=link}
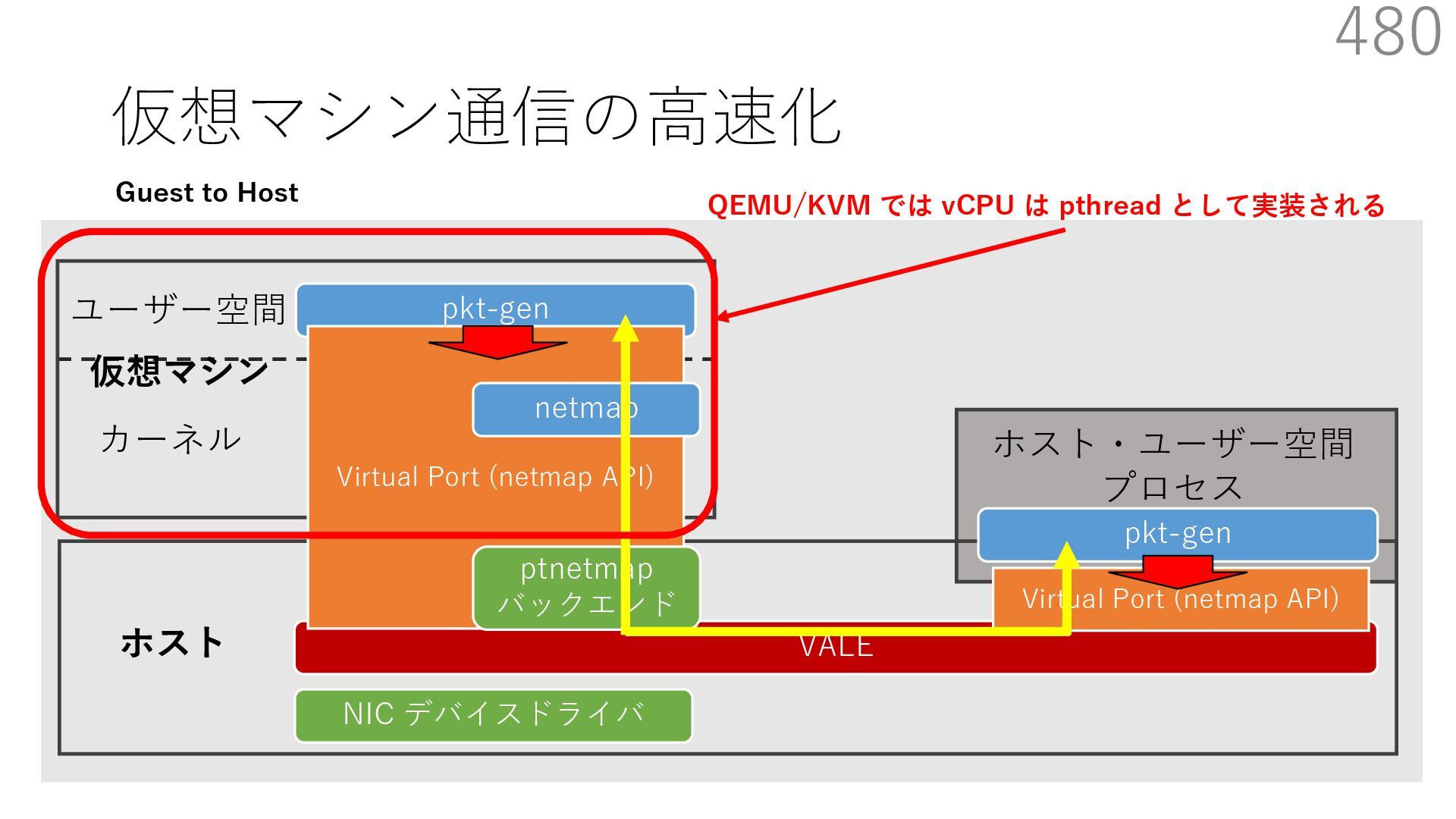{kind=link}
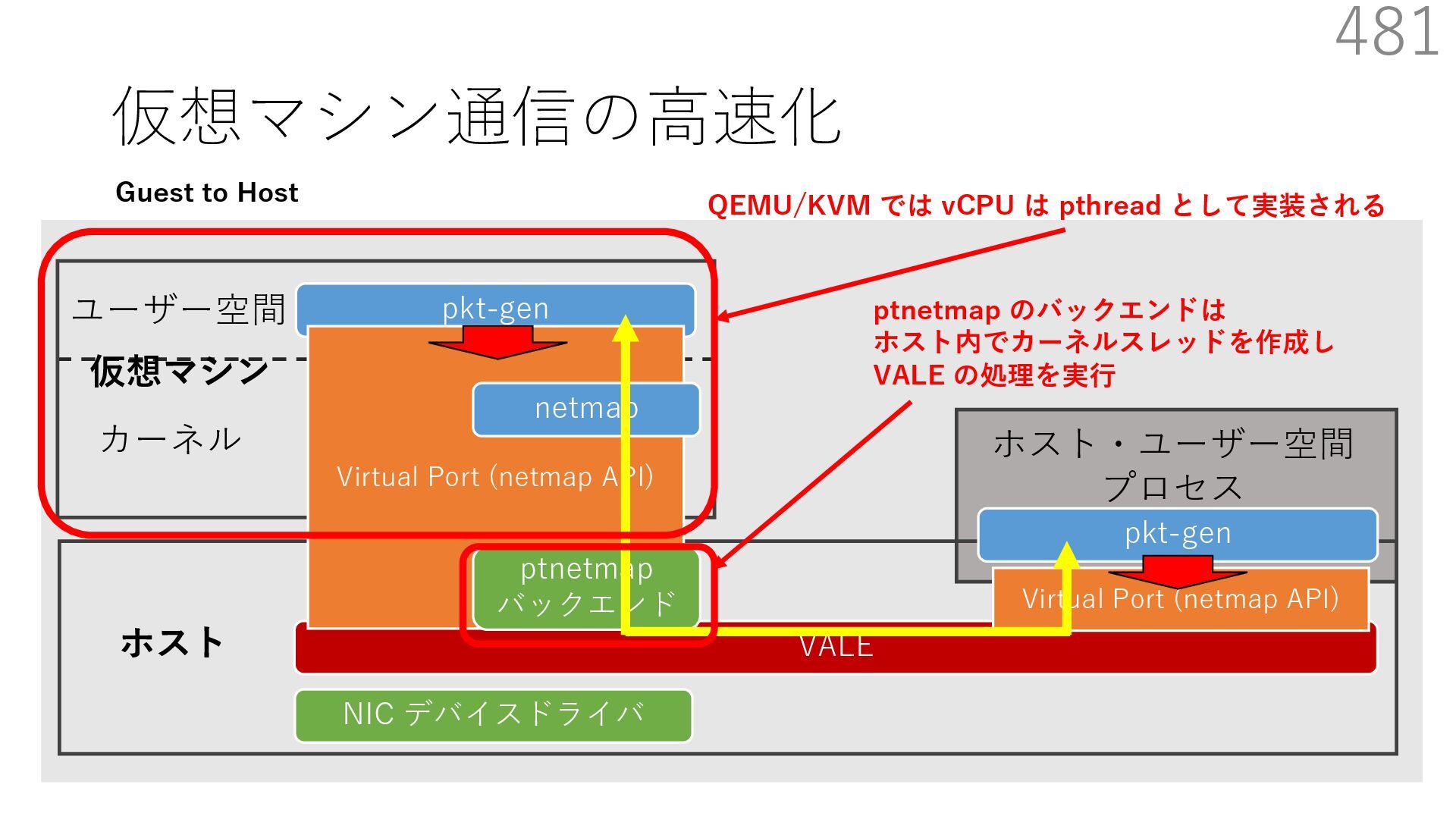{kind=link}
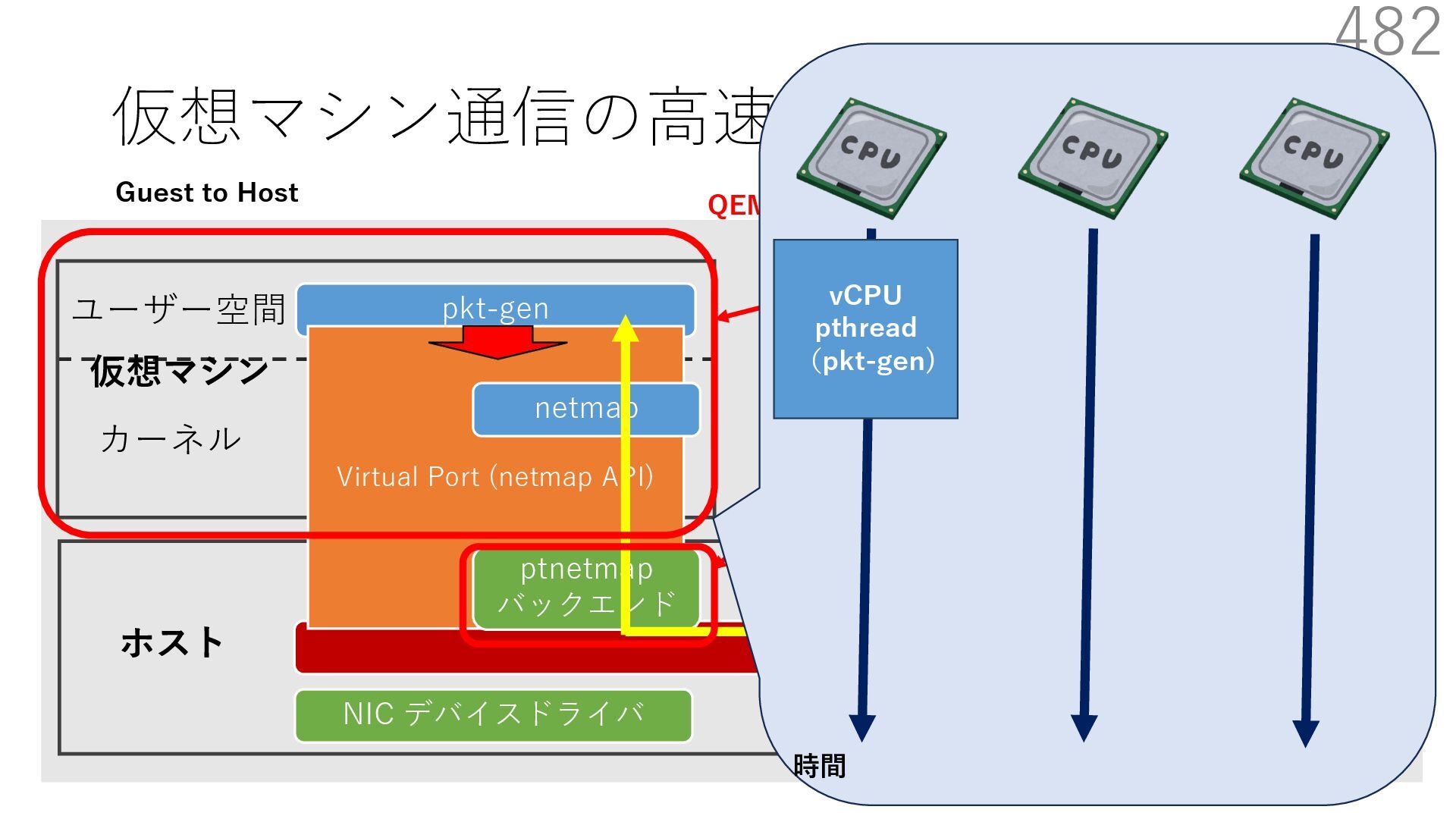{kind=link}
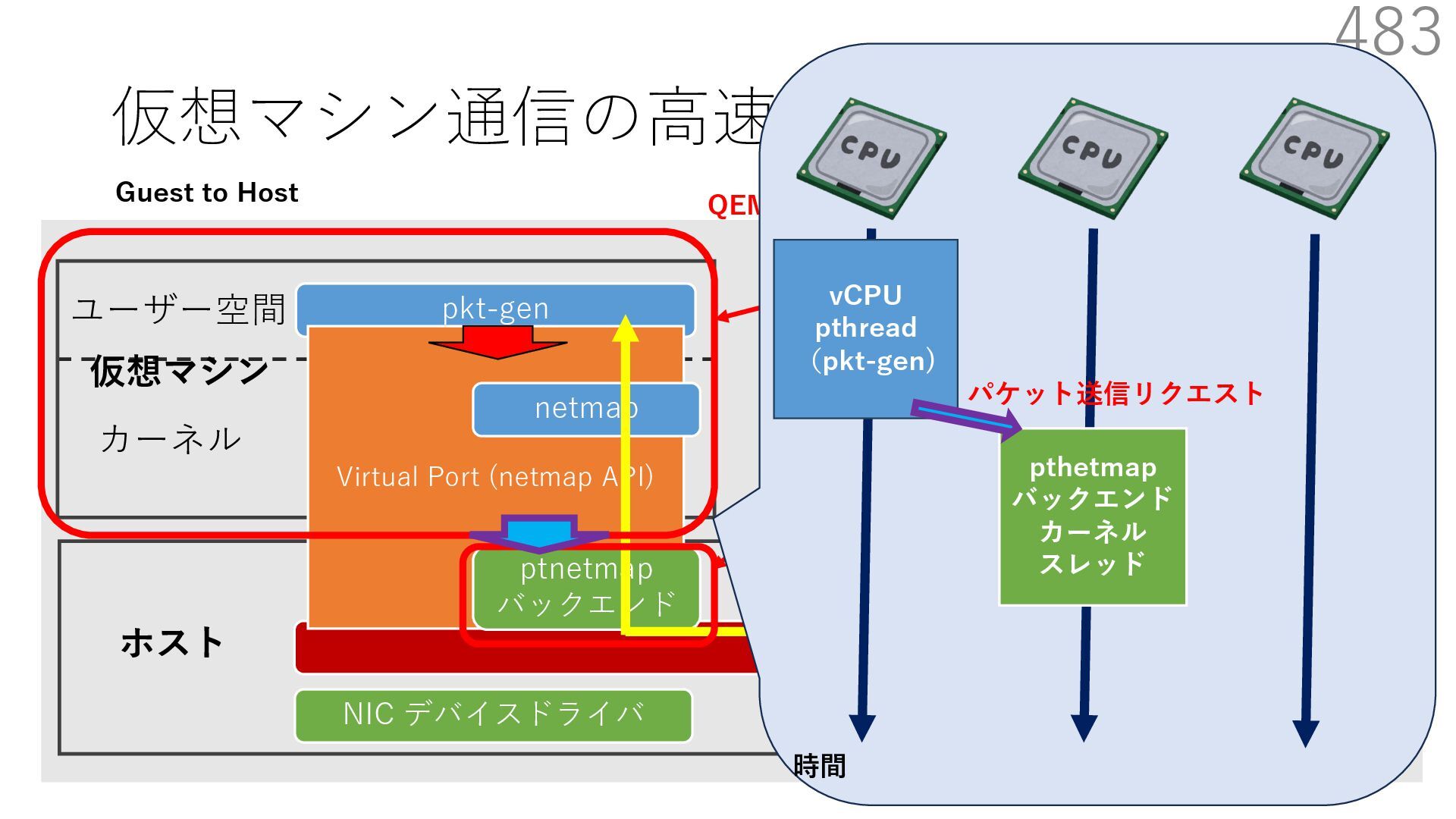{kind=link}
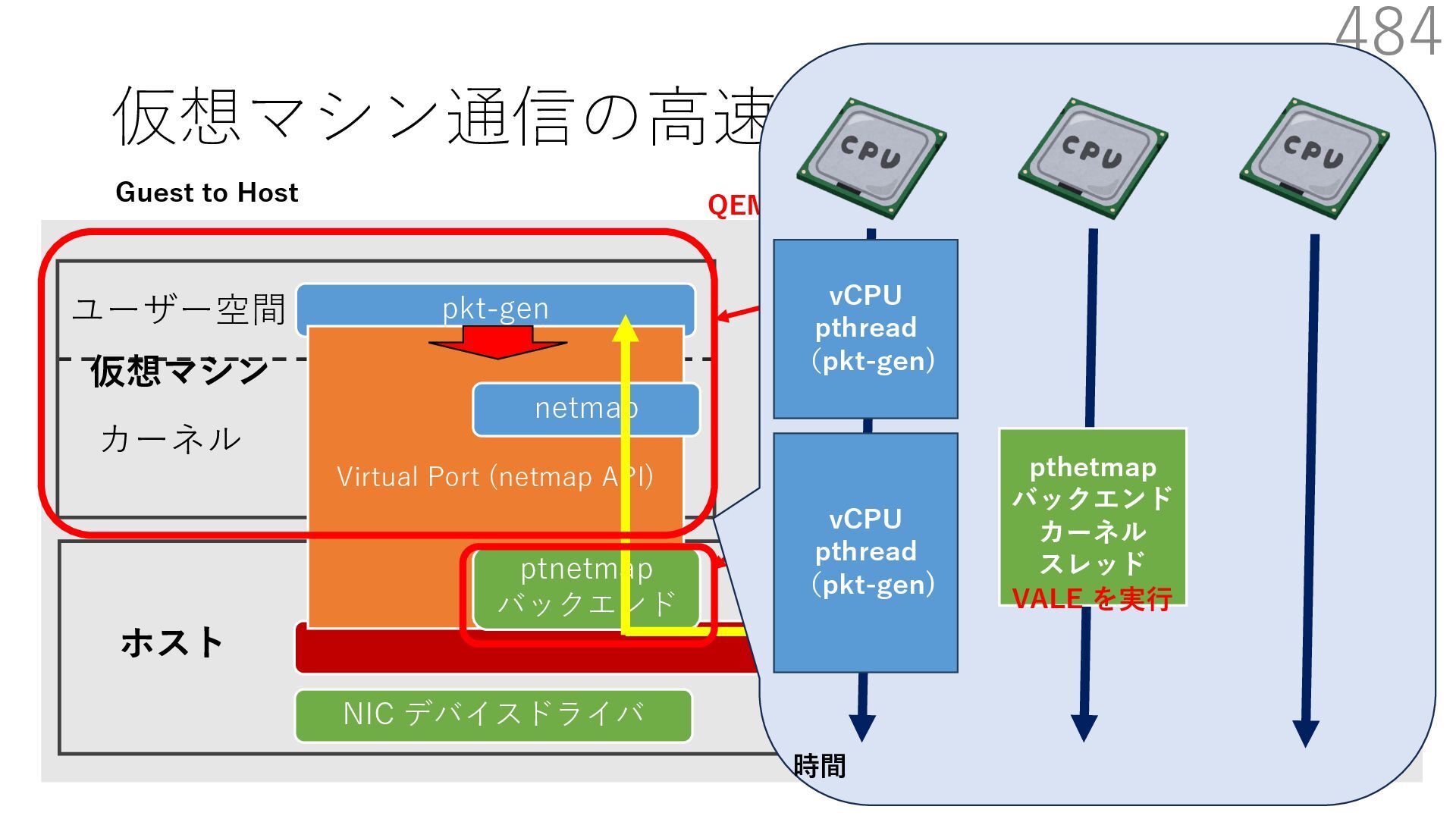{kind=link}
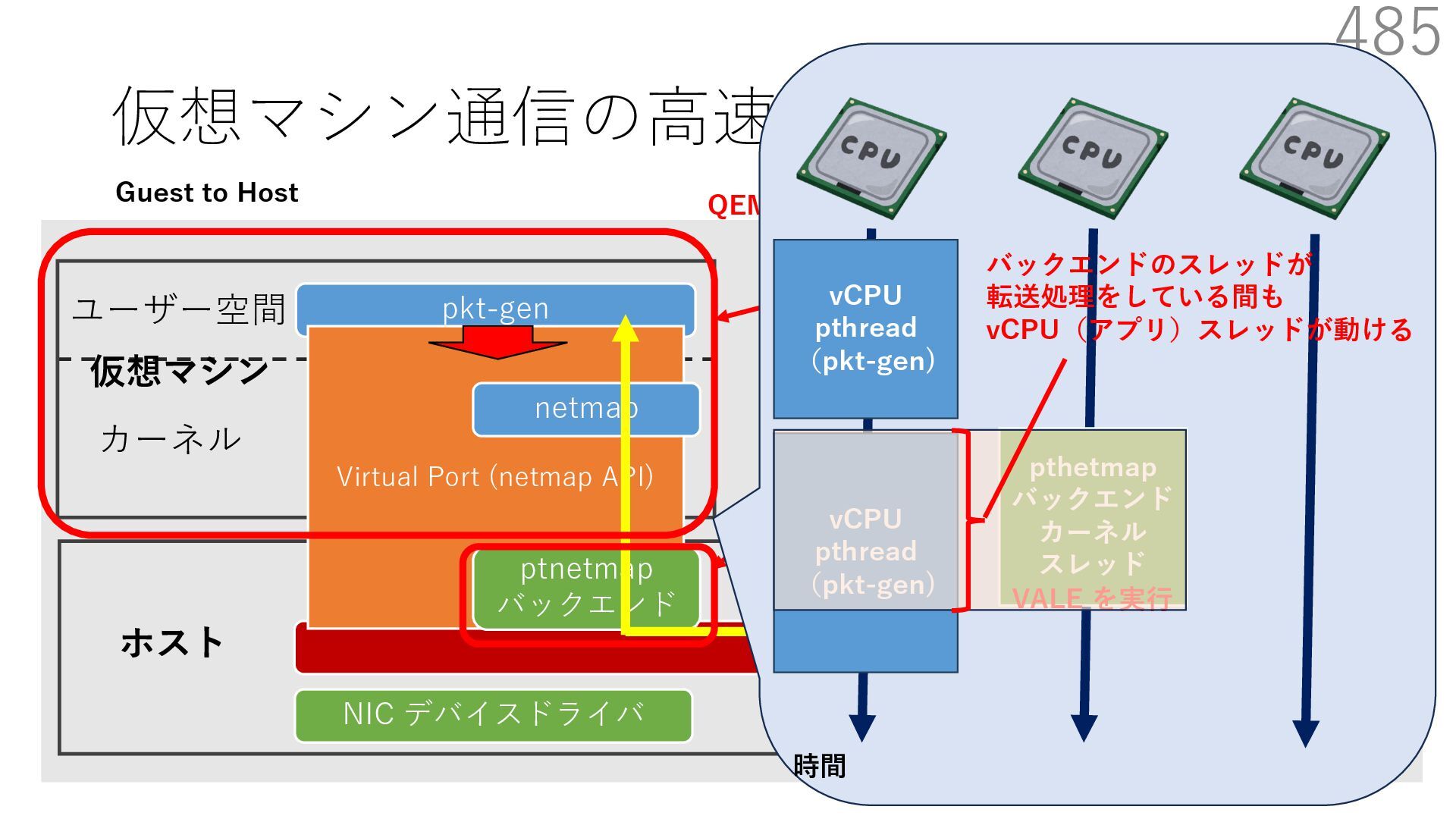{kind=link}
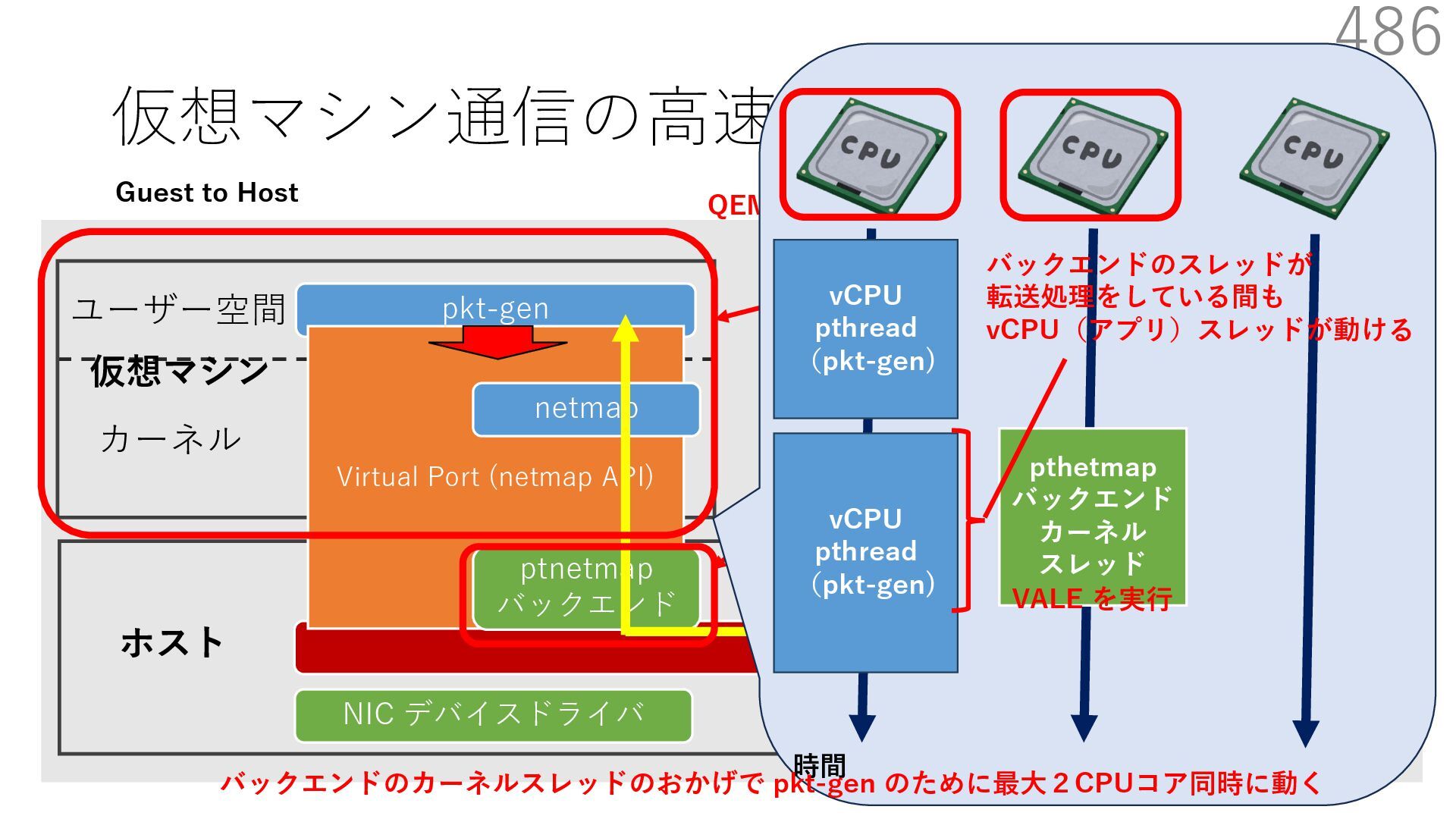{kind=link}
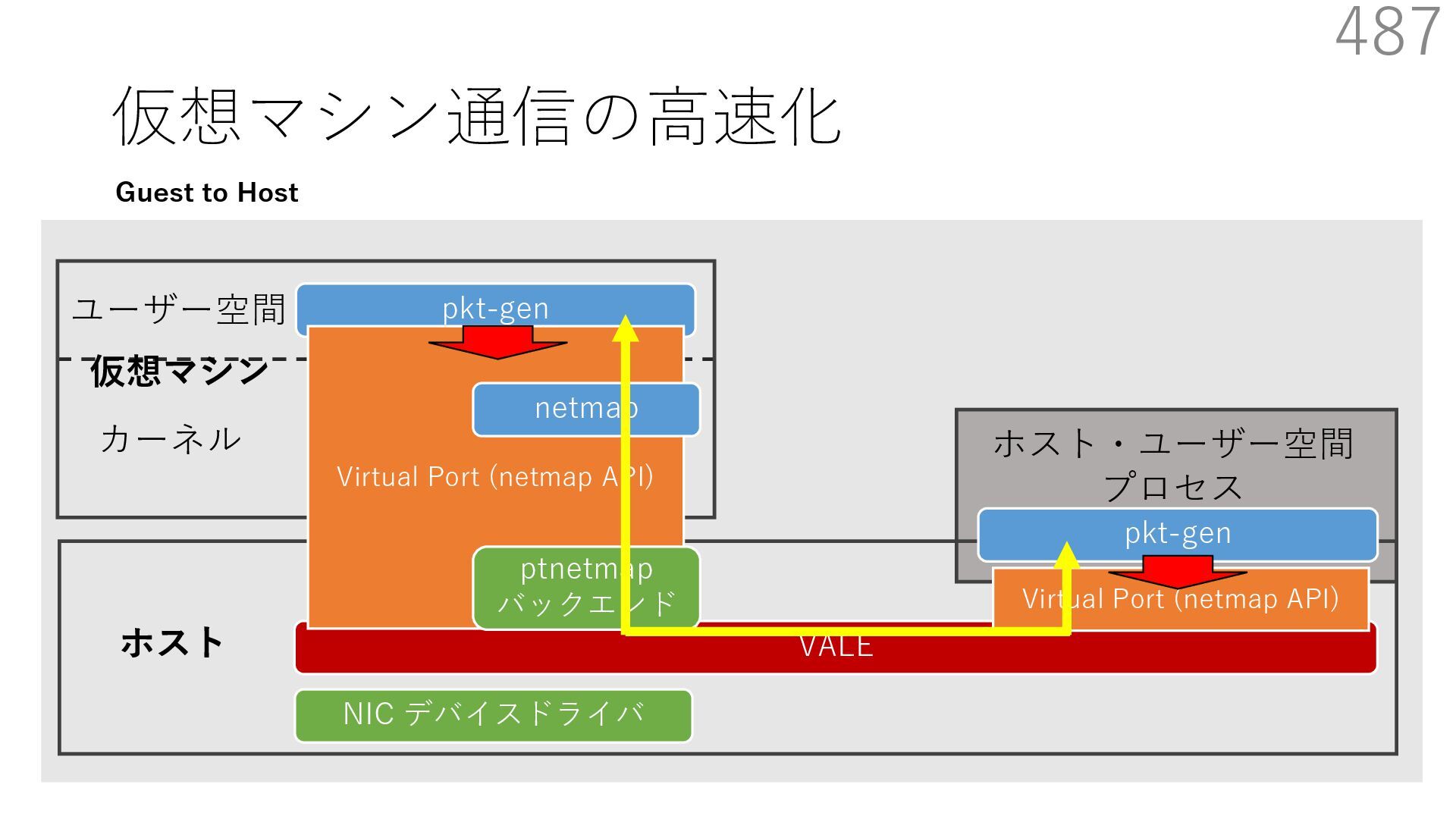{kind=link}
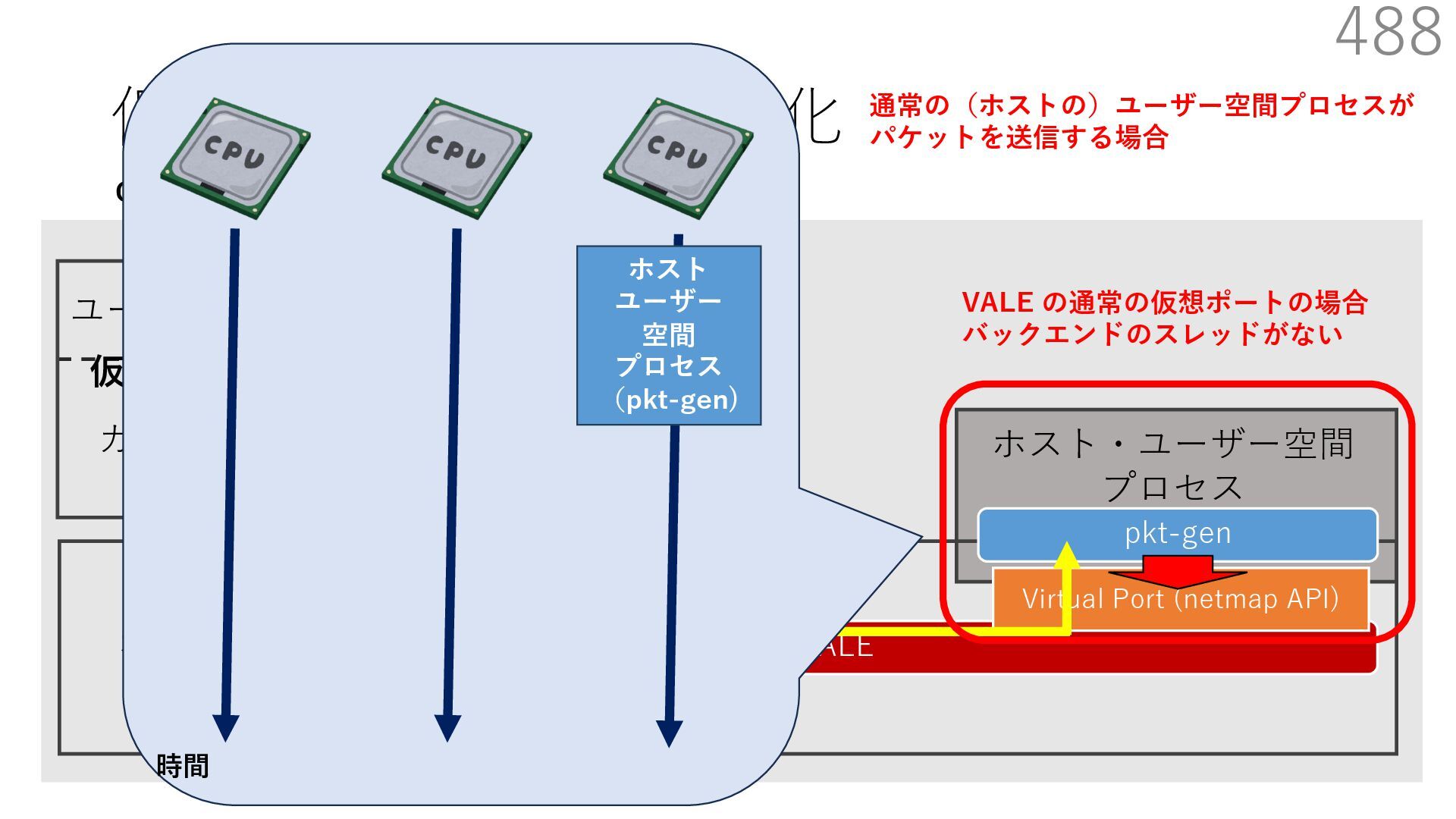{kind=link}
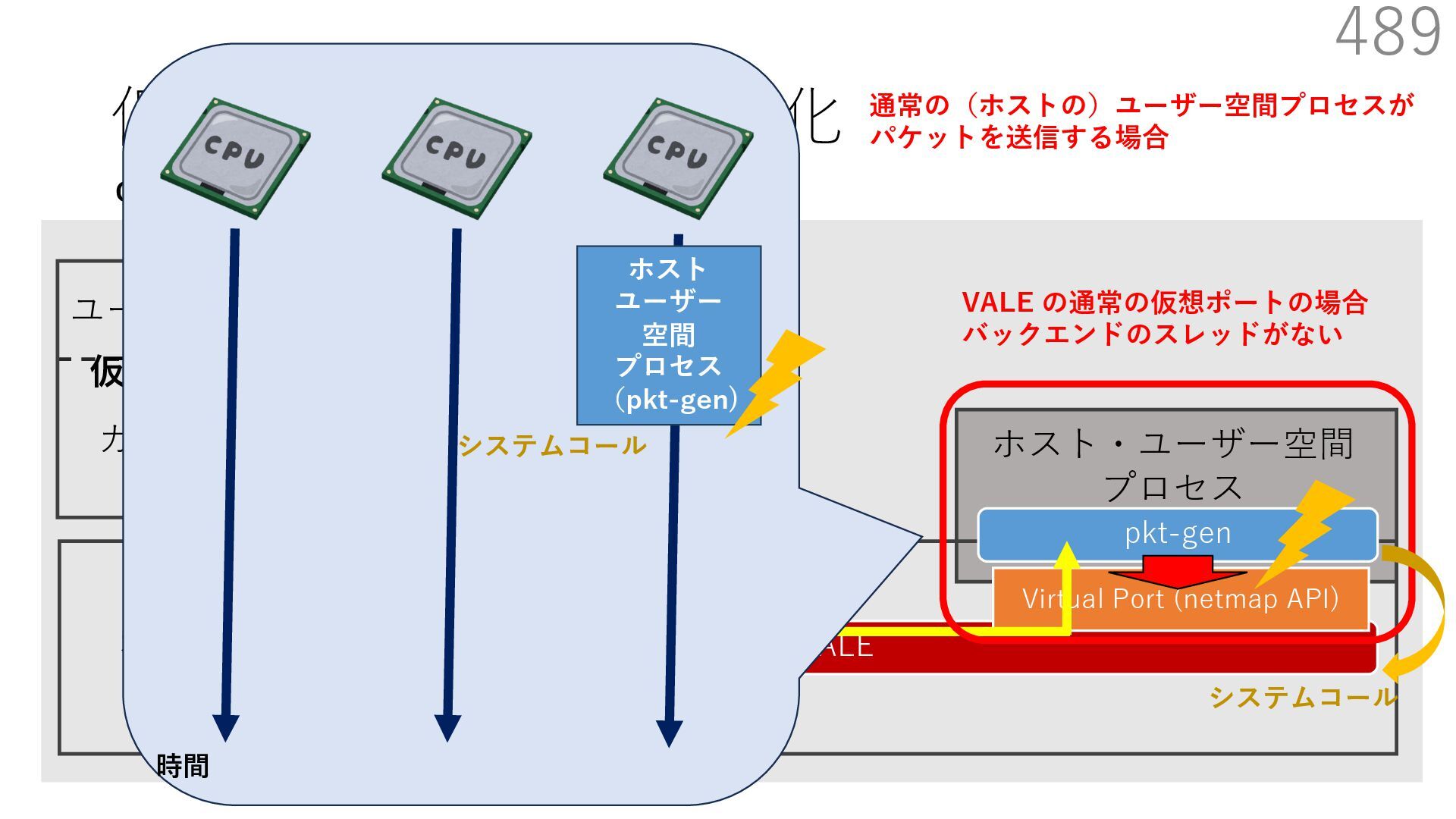{kind=link}
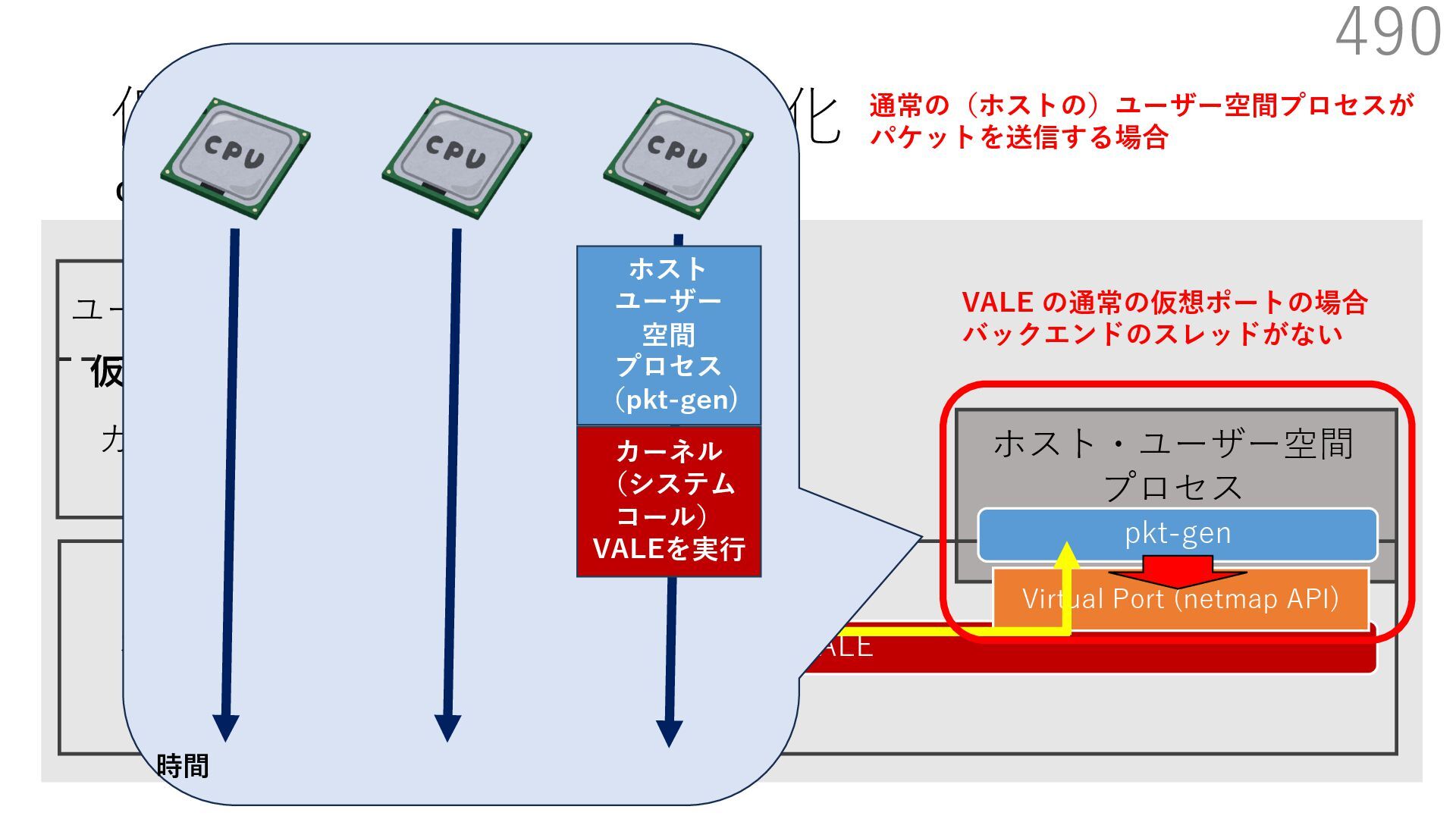{kind=link}
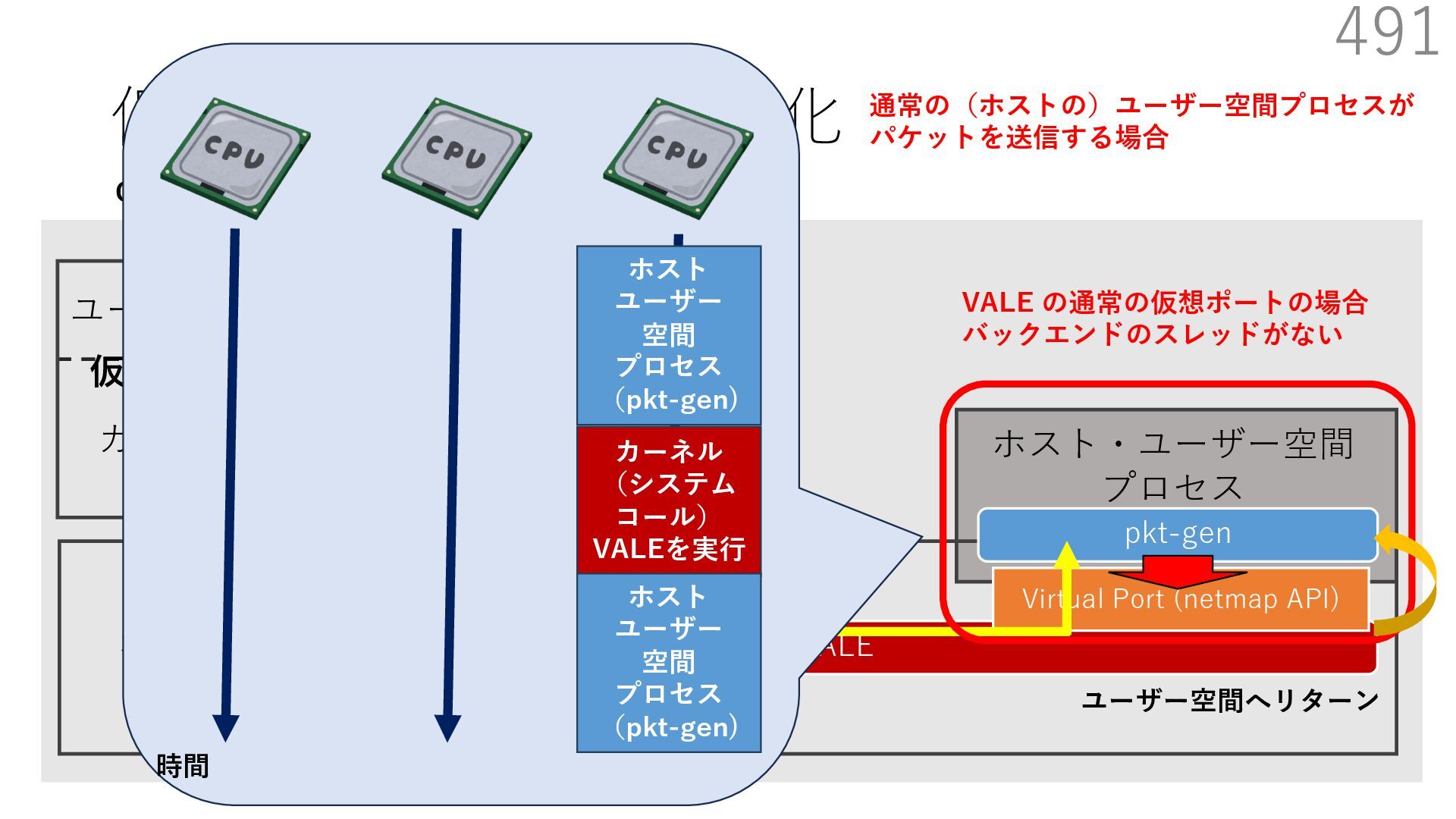{kind=link}
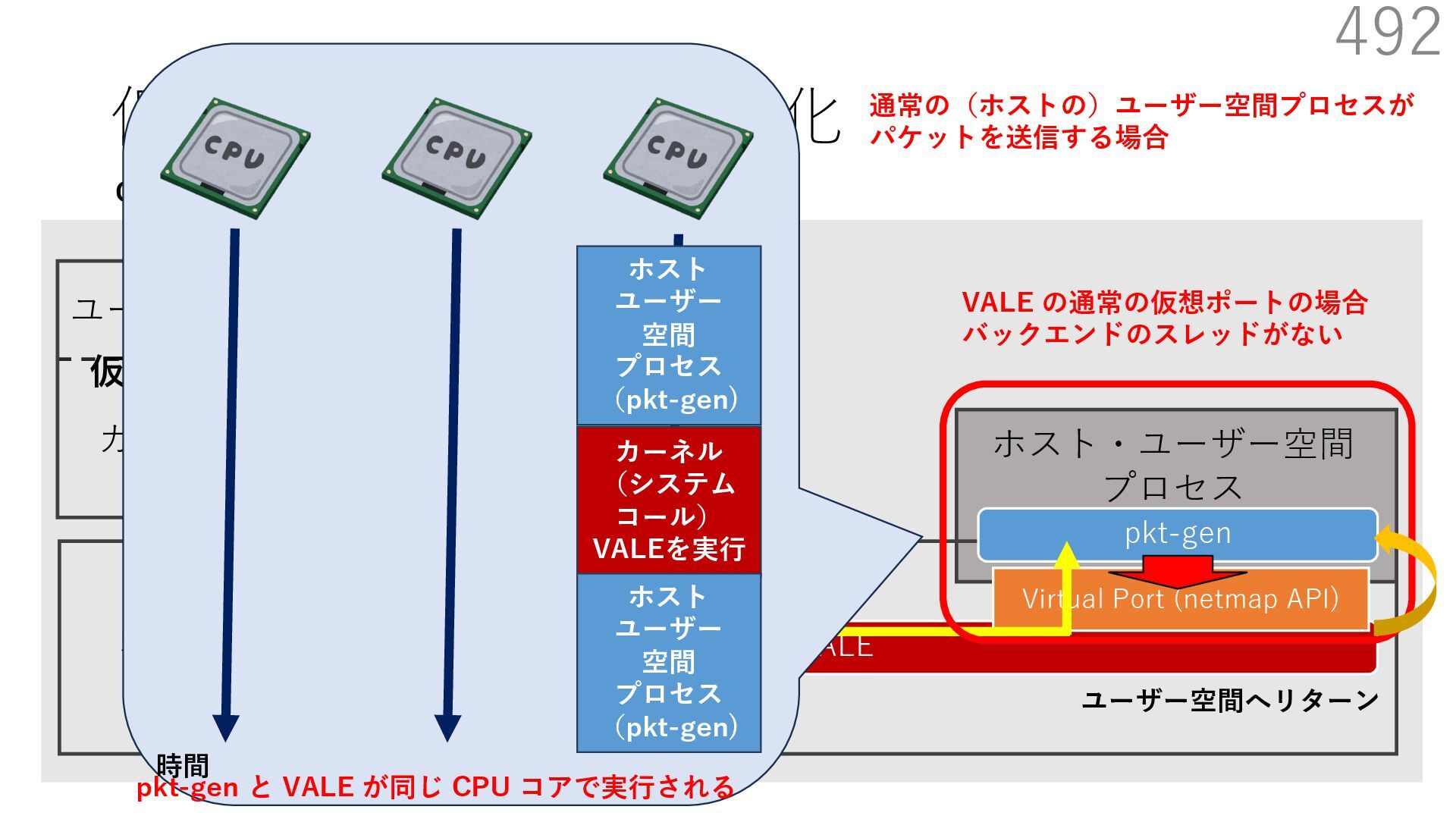{kind=link}
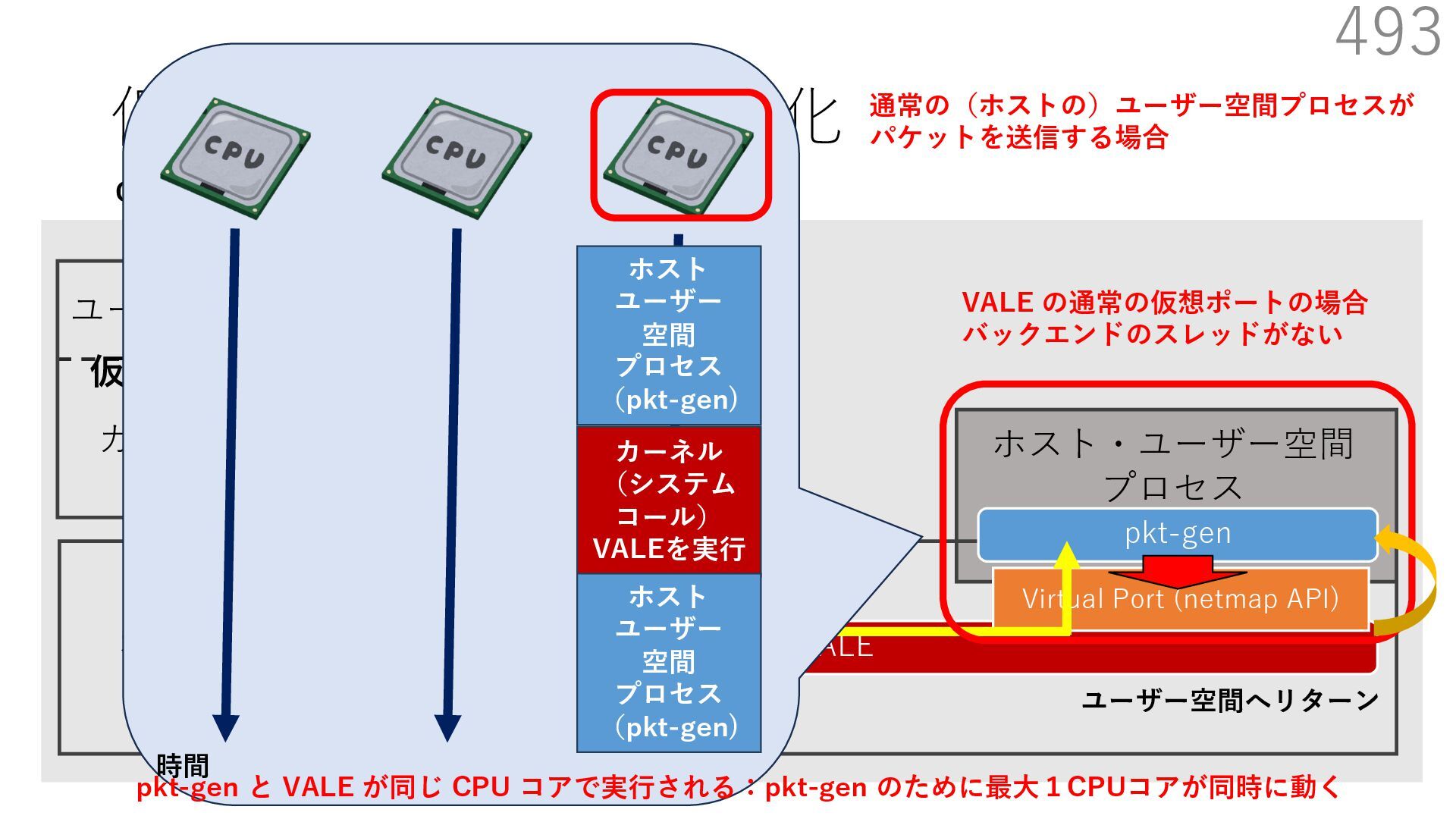{kind=link}
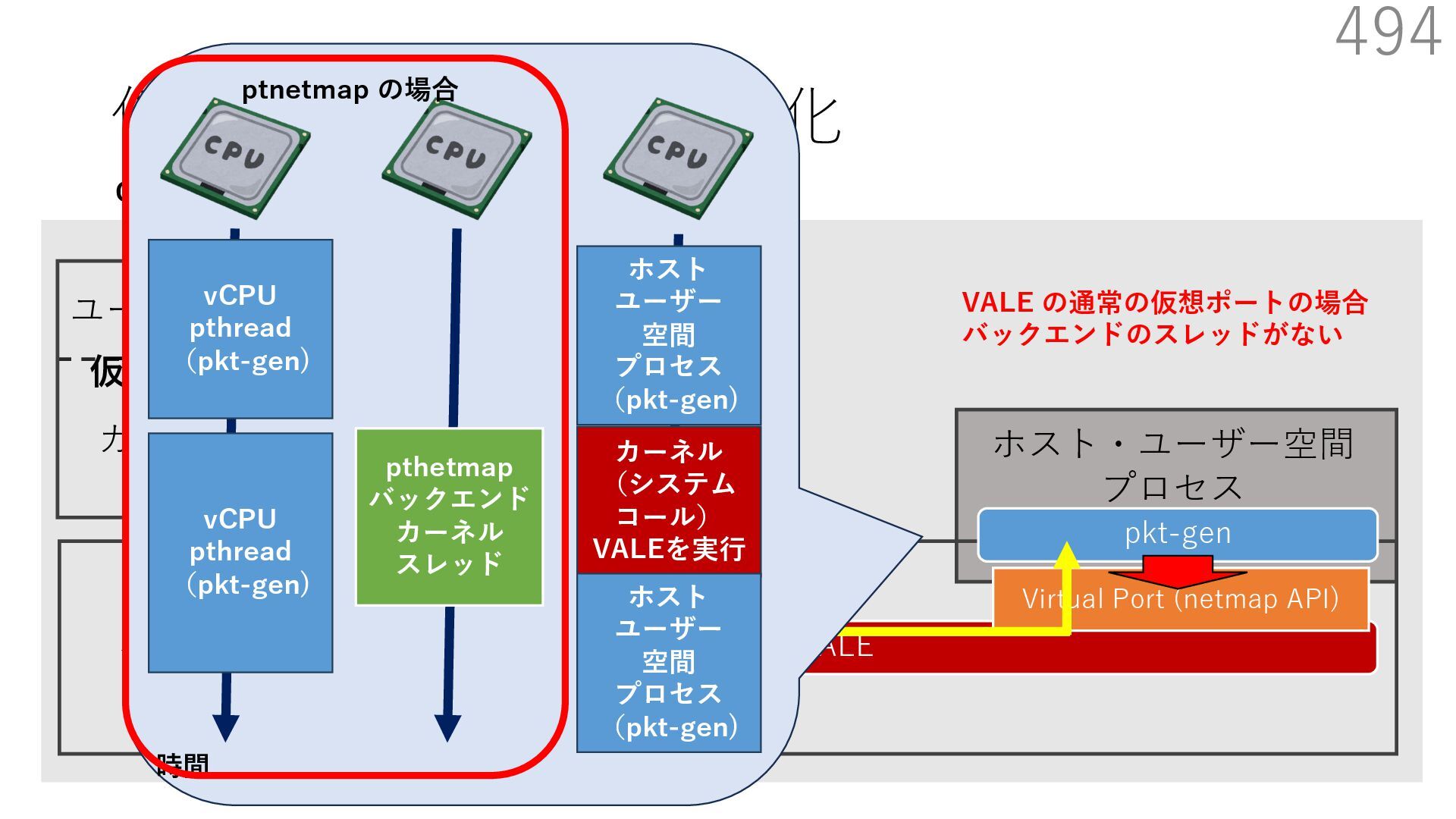{kind=link}
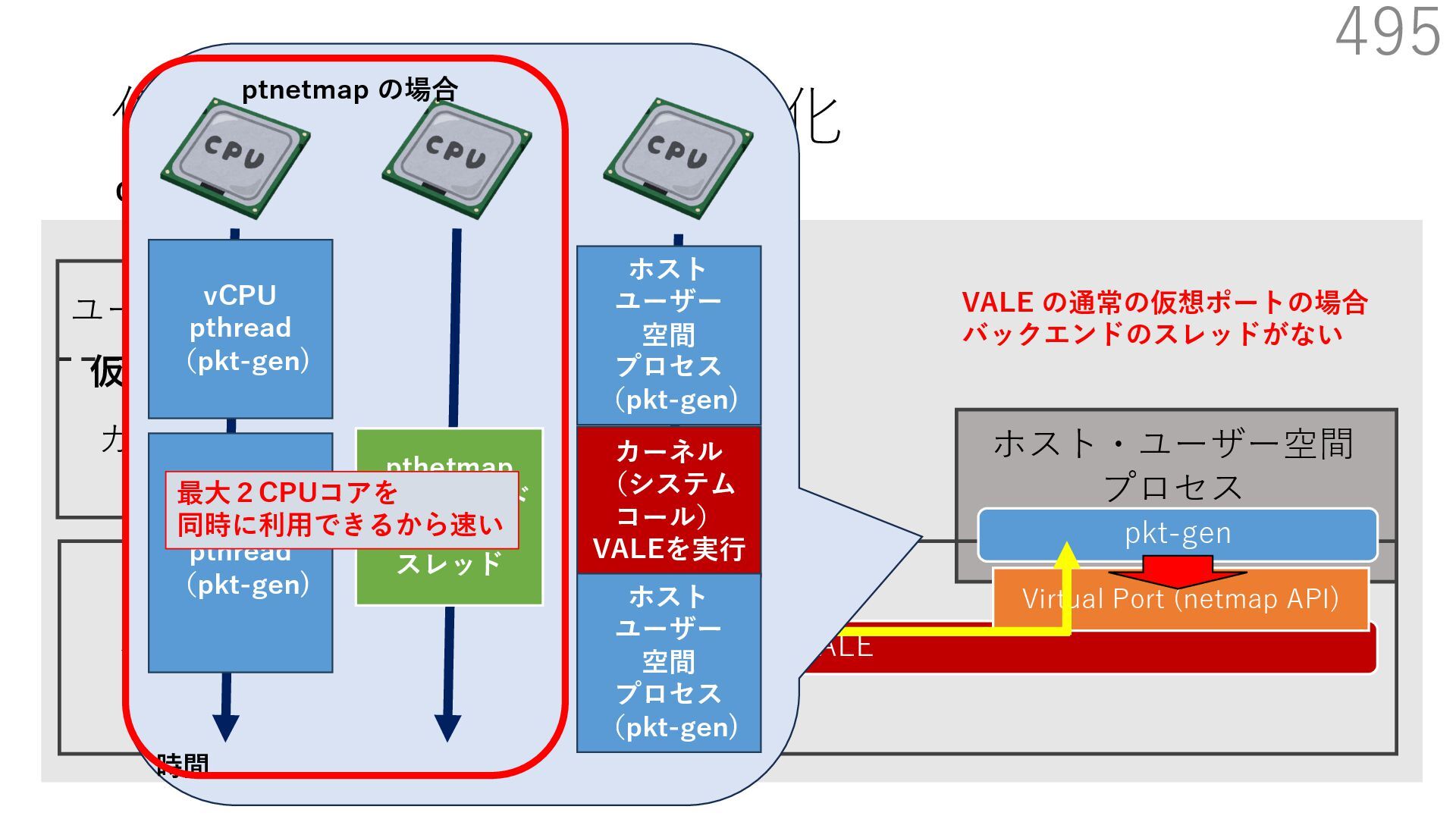{kind=link}
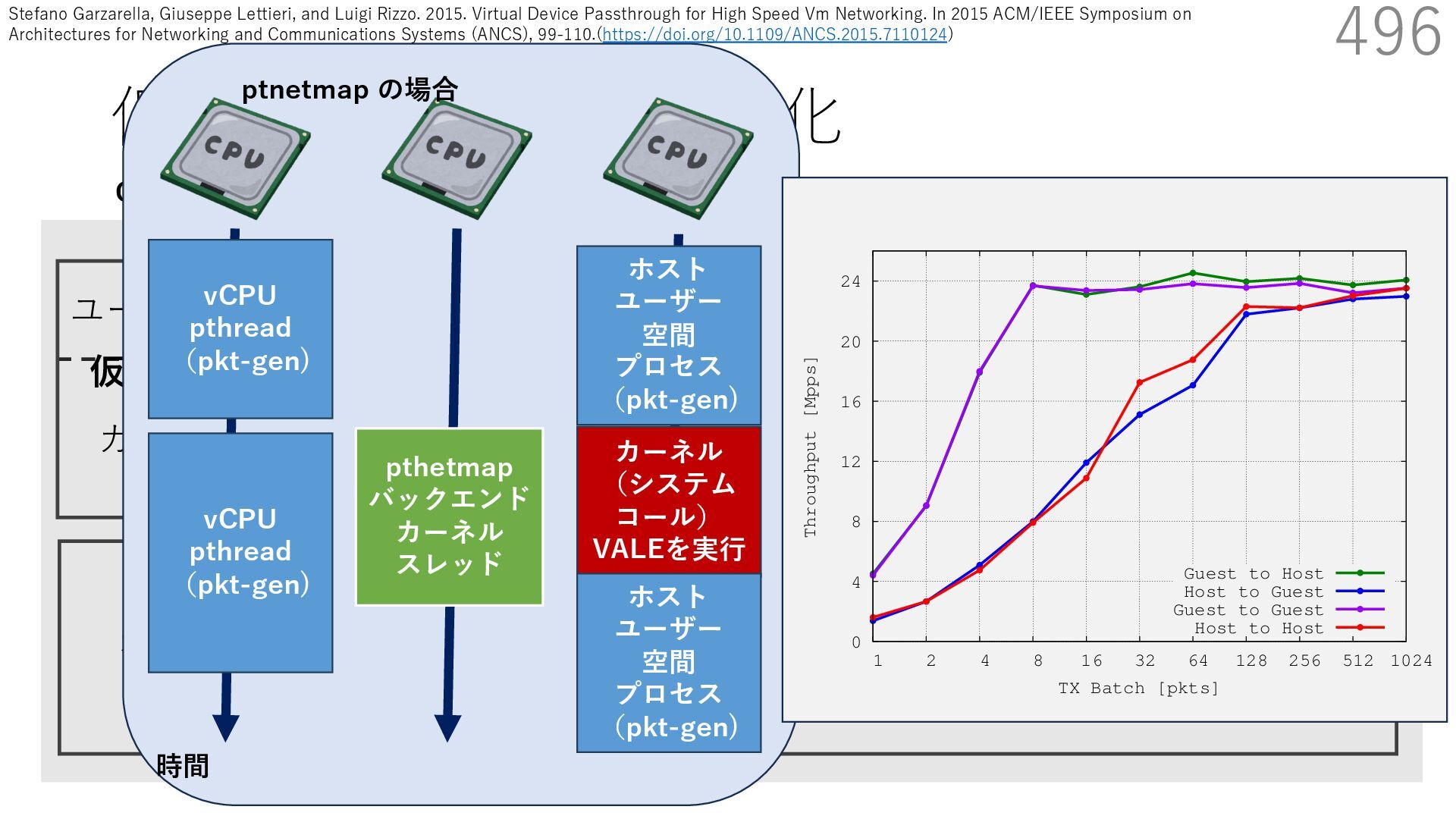{kind=link}
{kind=link}
{kind=link}
{kind=link}
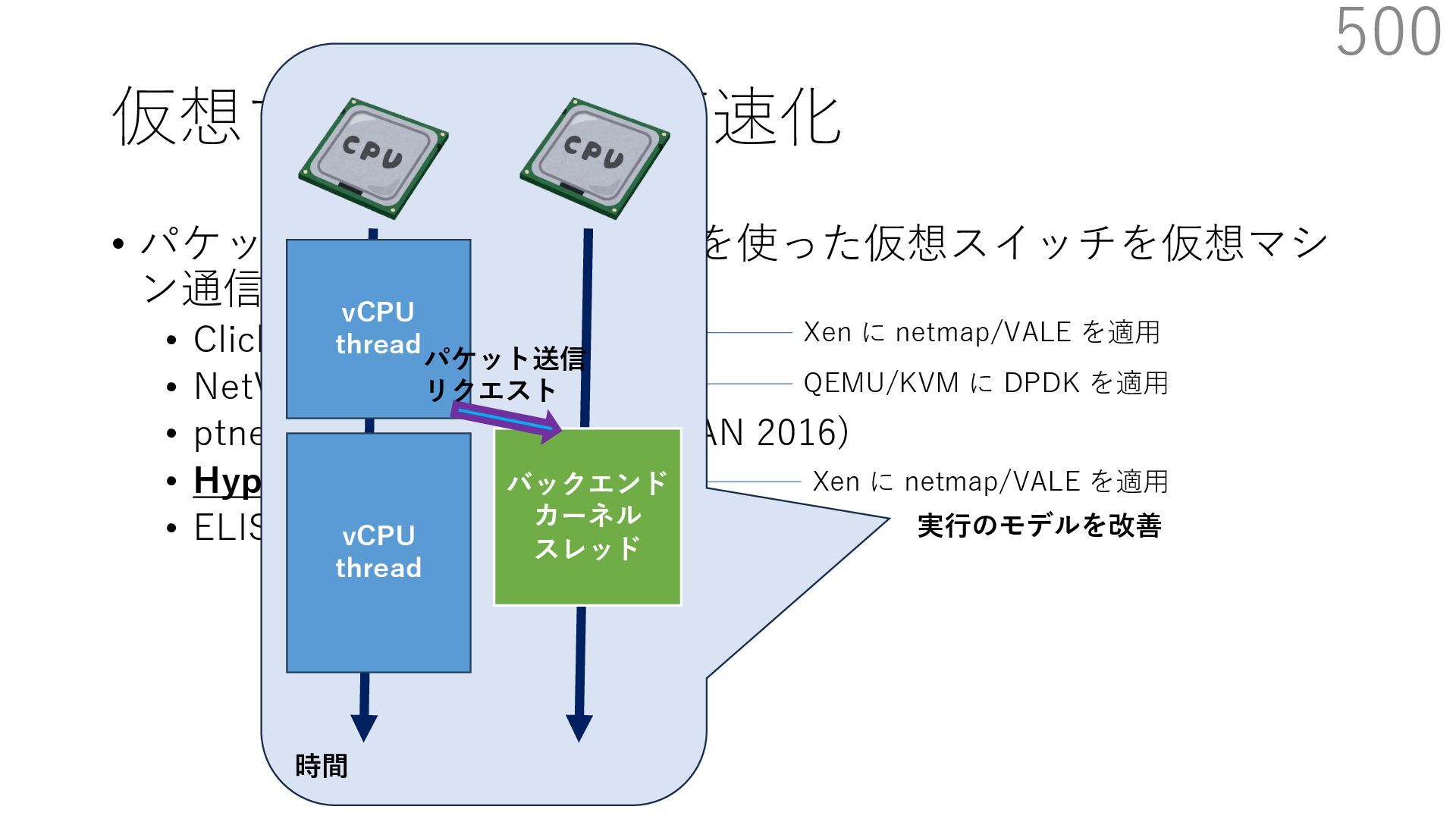{kind=link}
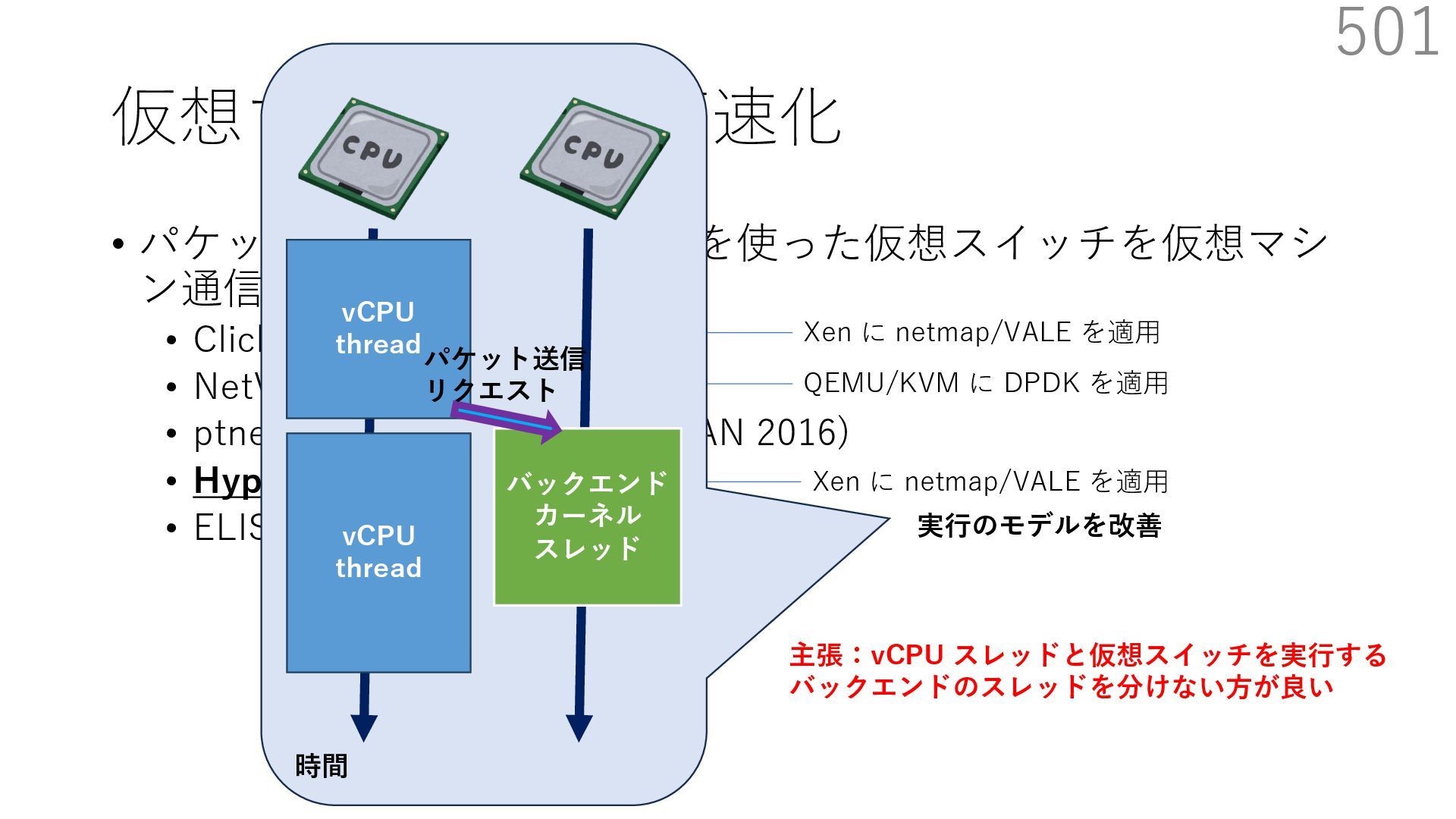{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
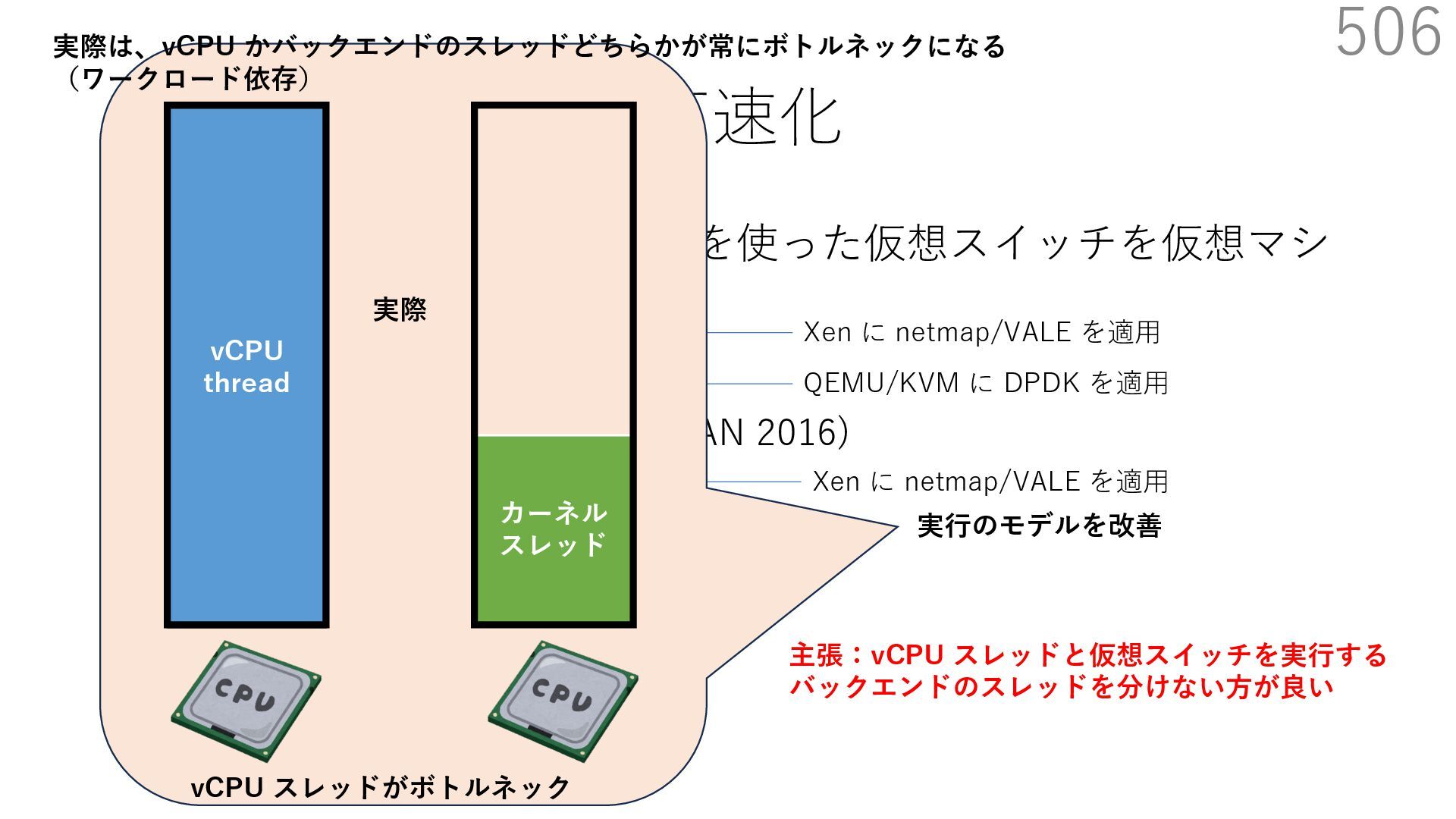{kind=link}
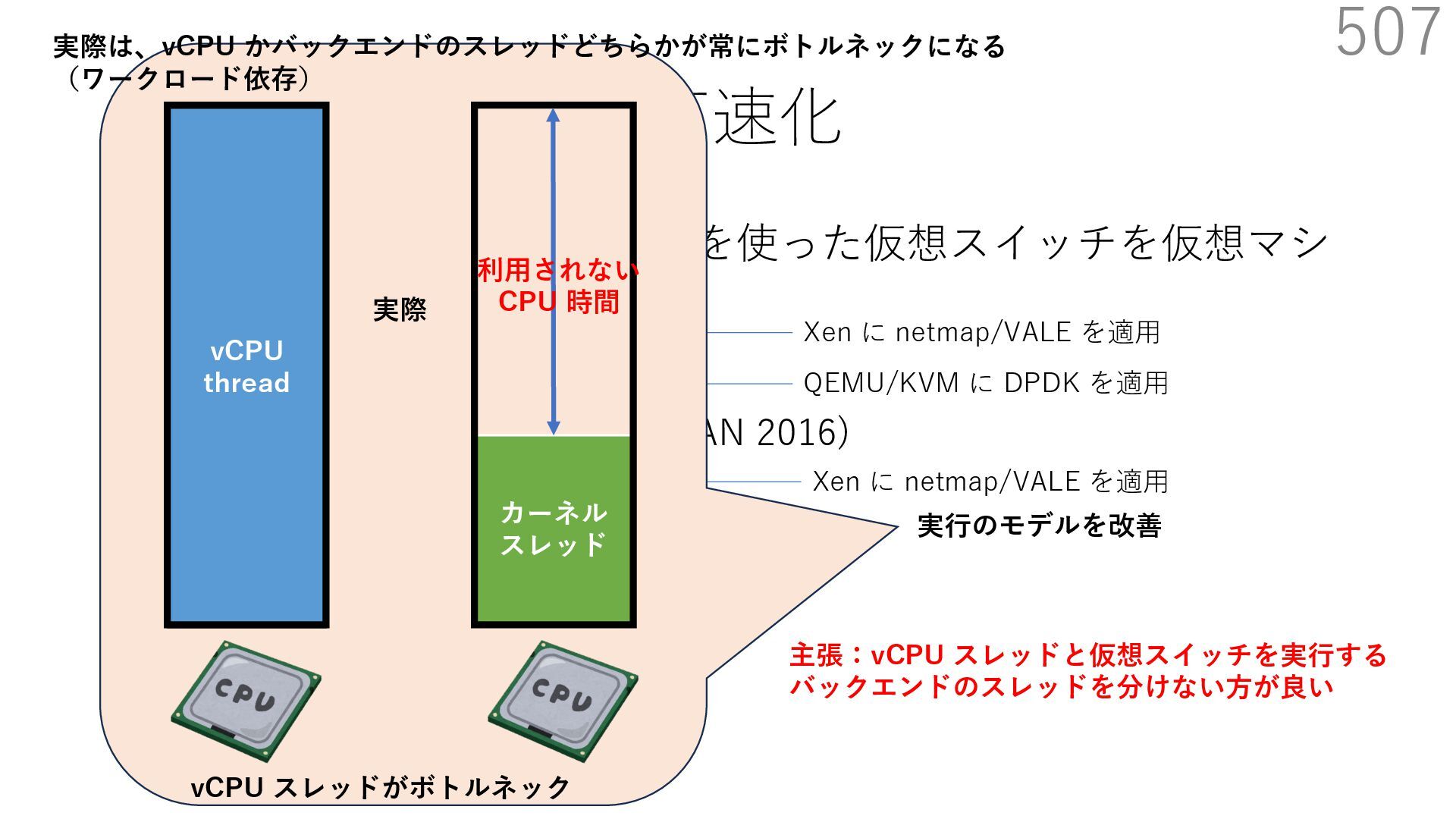{kind=link}
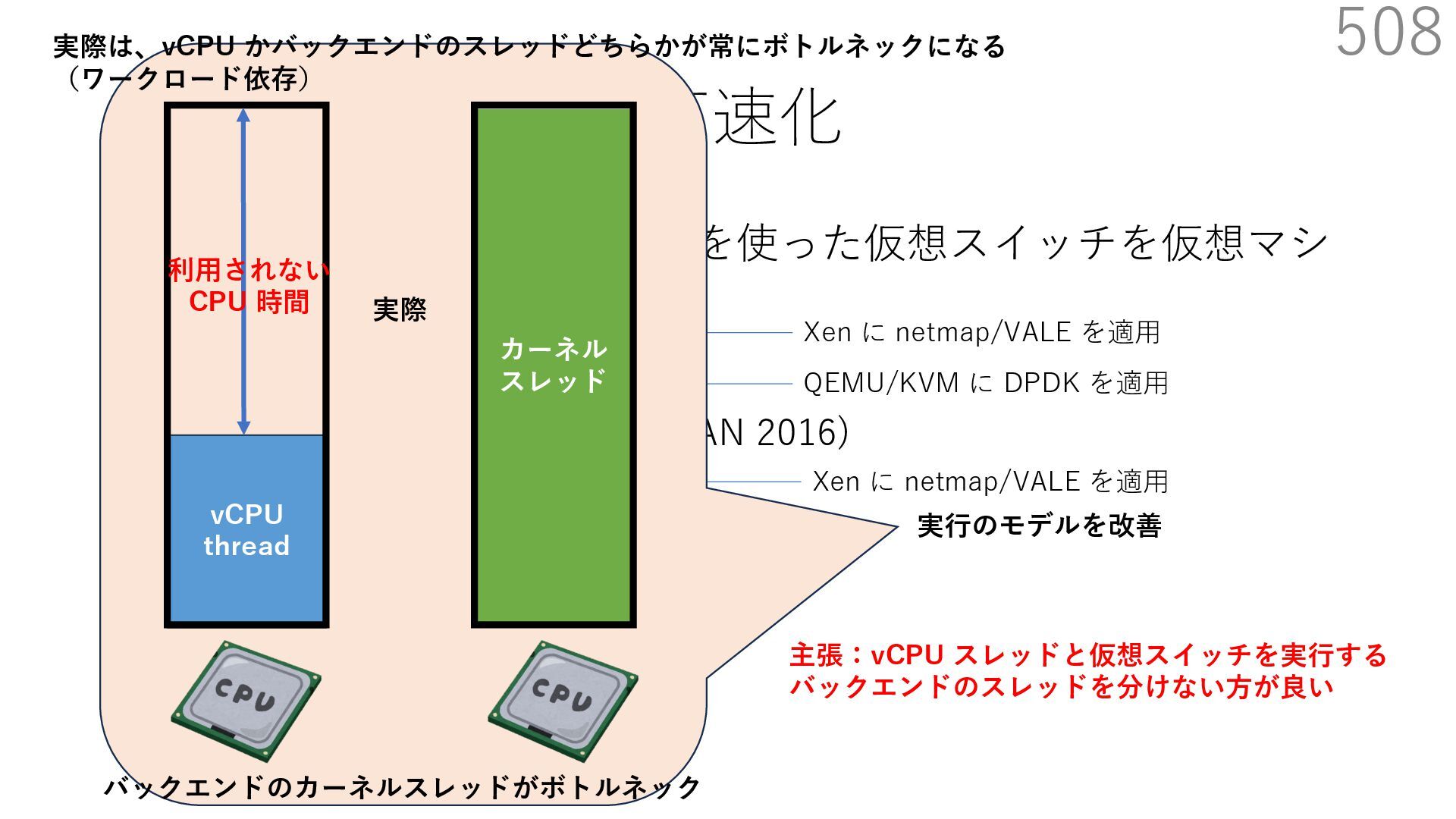{kind=link}
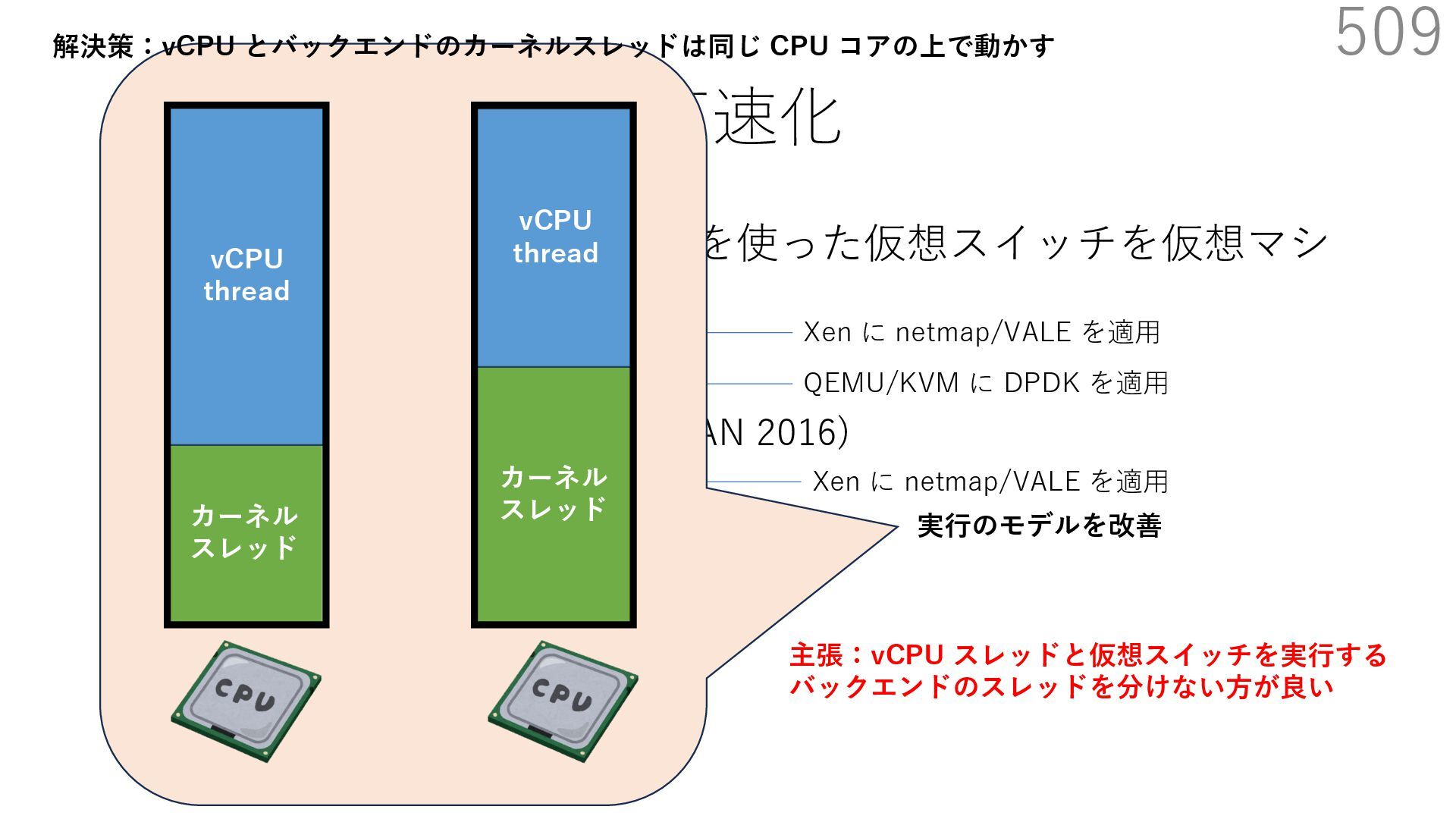{kind=link}
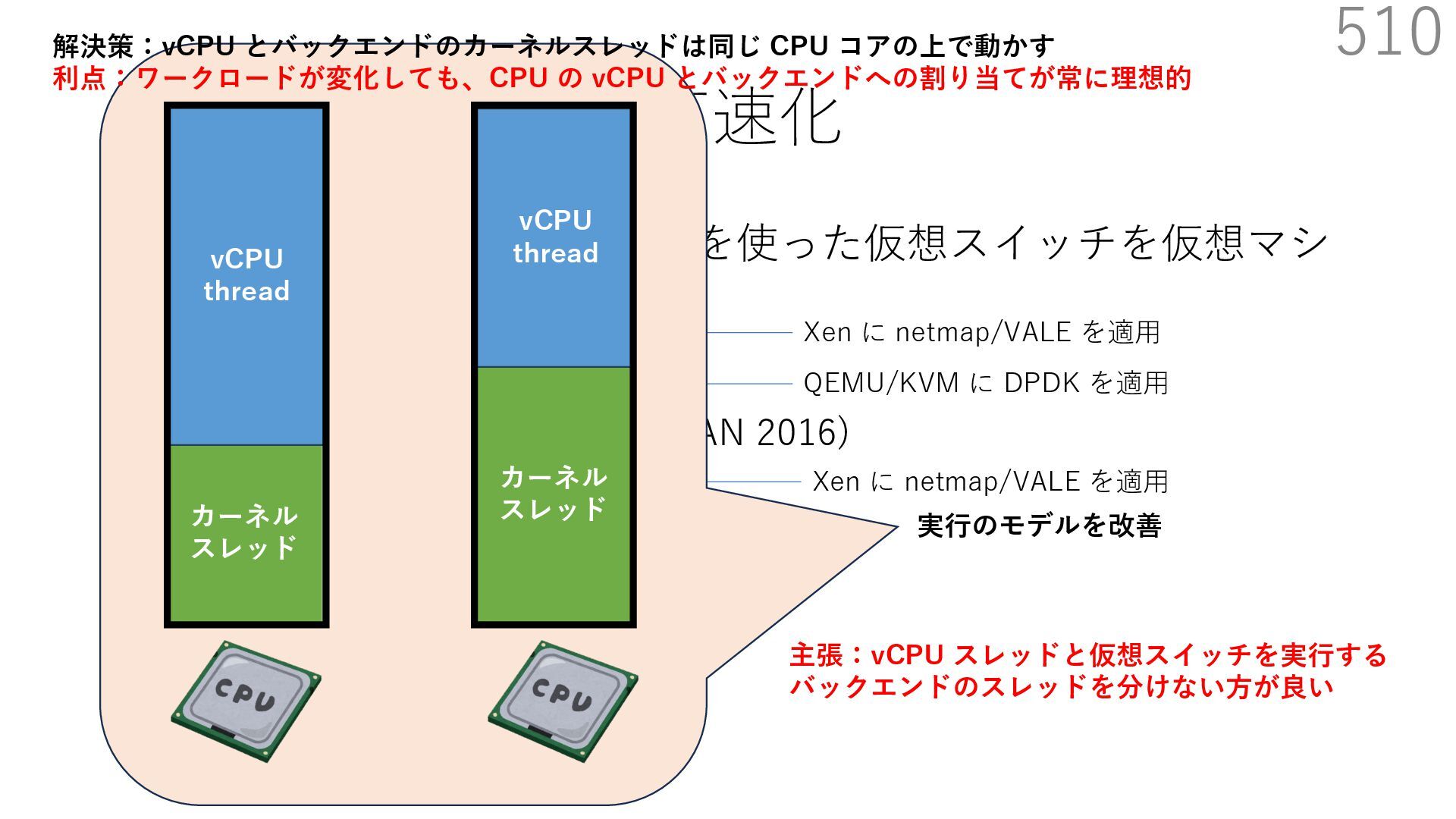{kind=link}
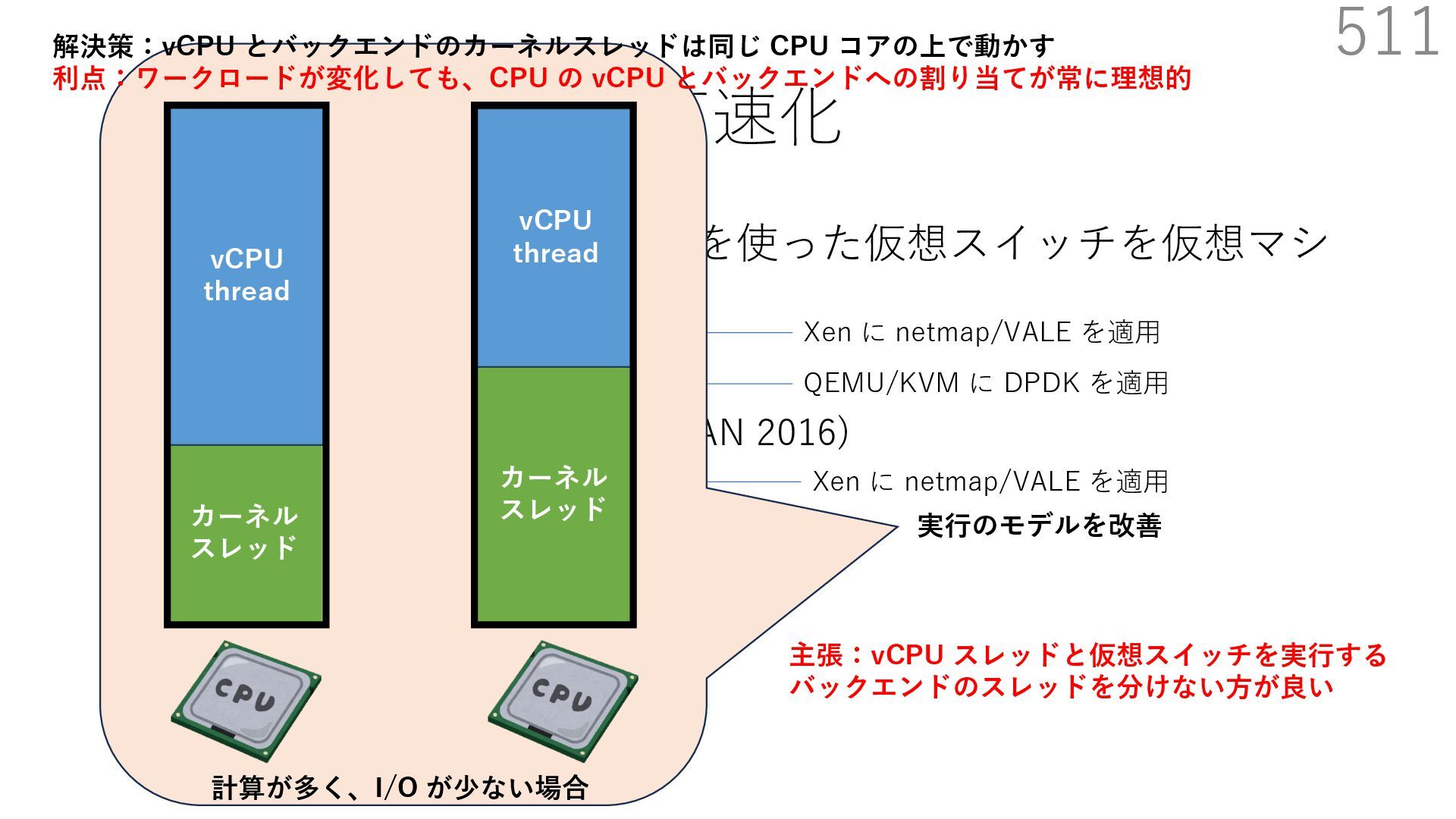{kind=link}
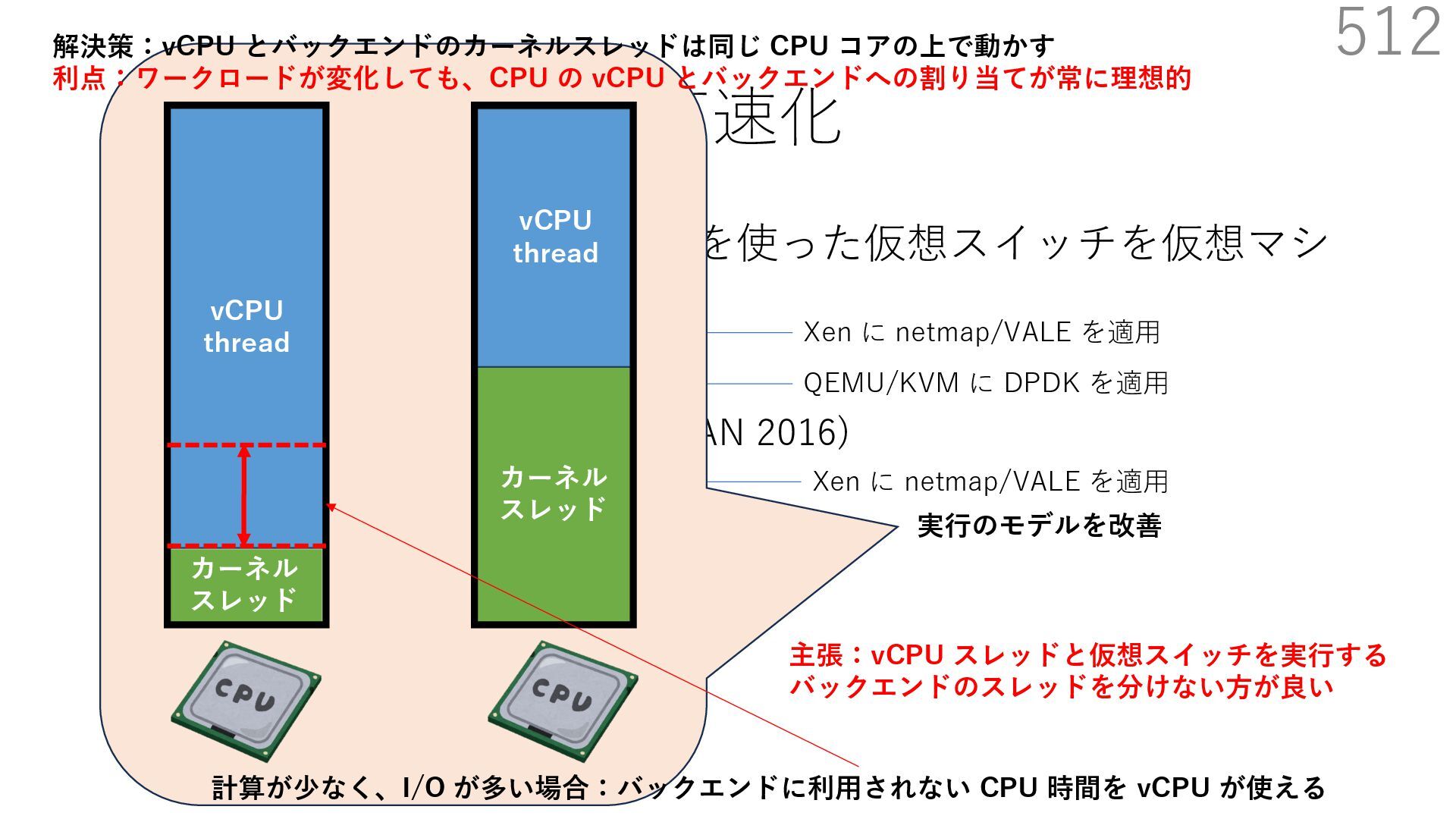{kind=link}
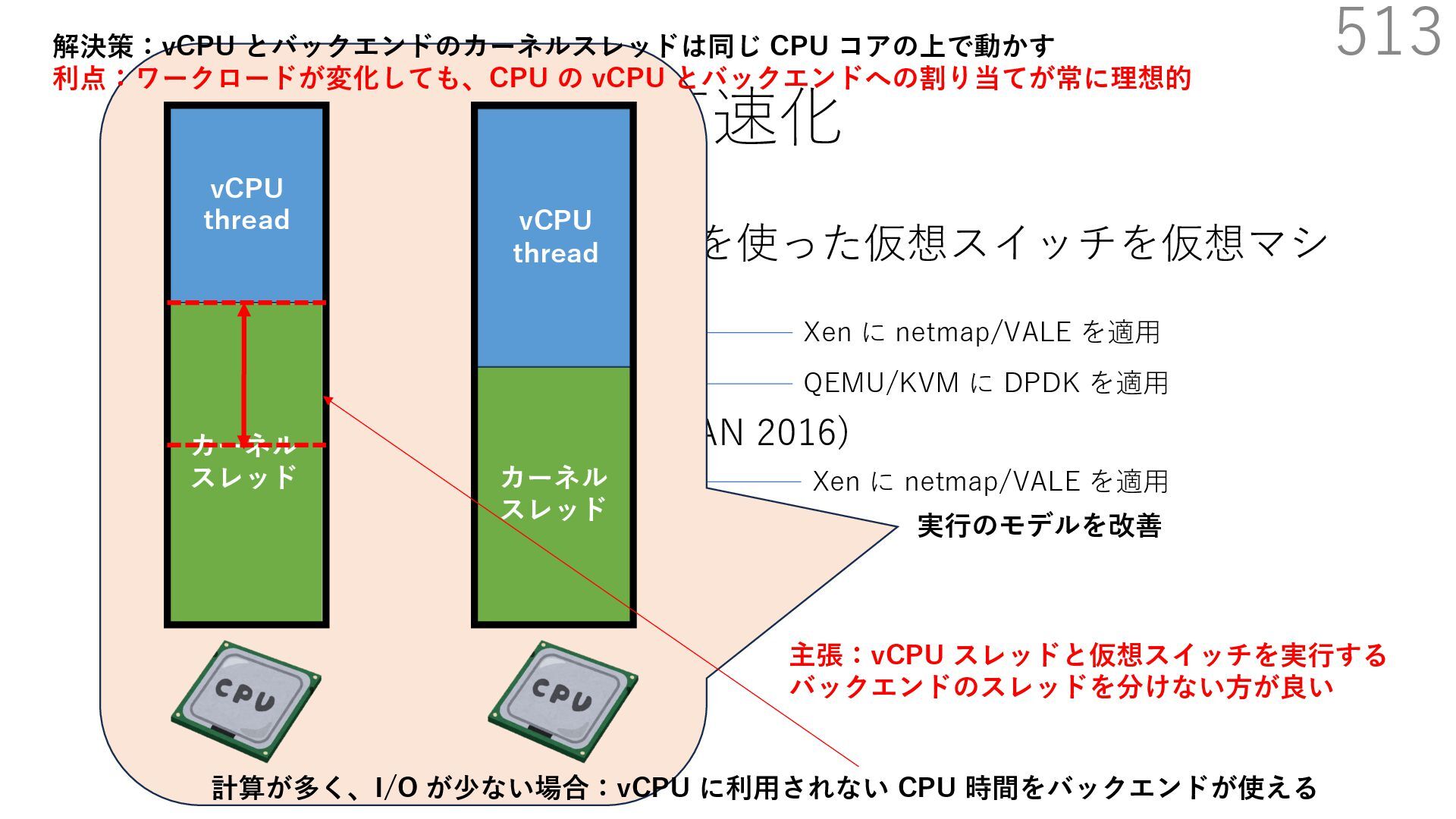{kind=link}
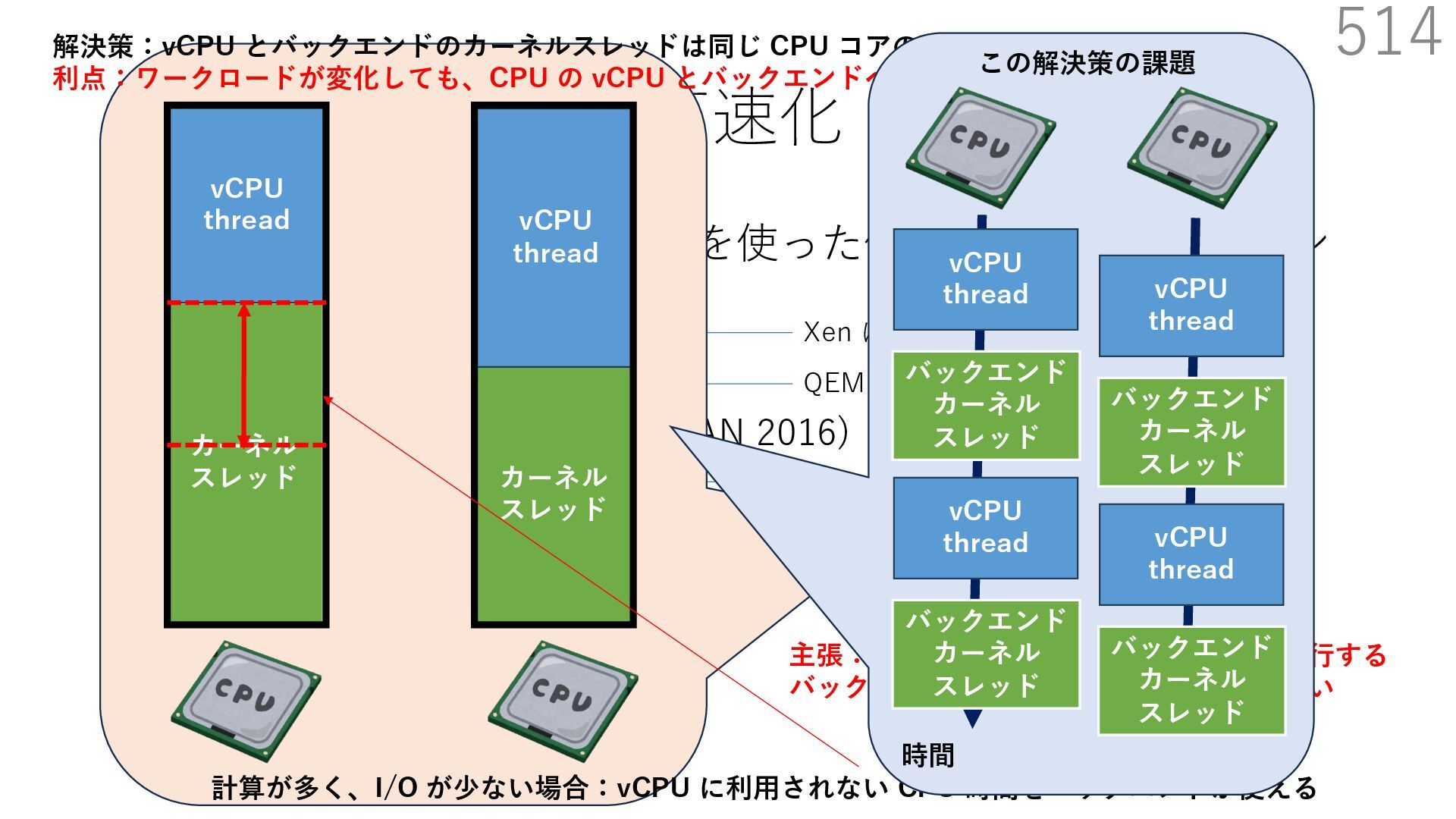{kind=link}
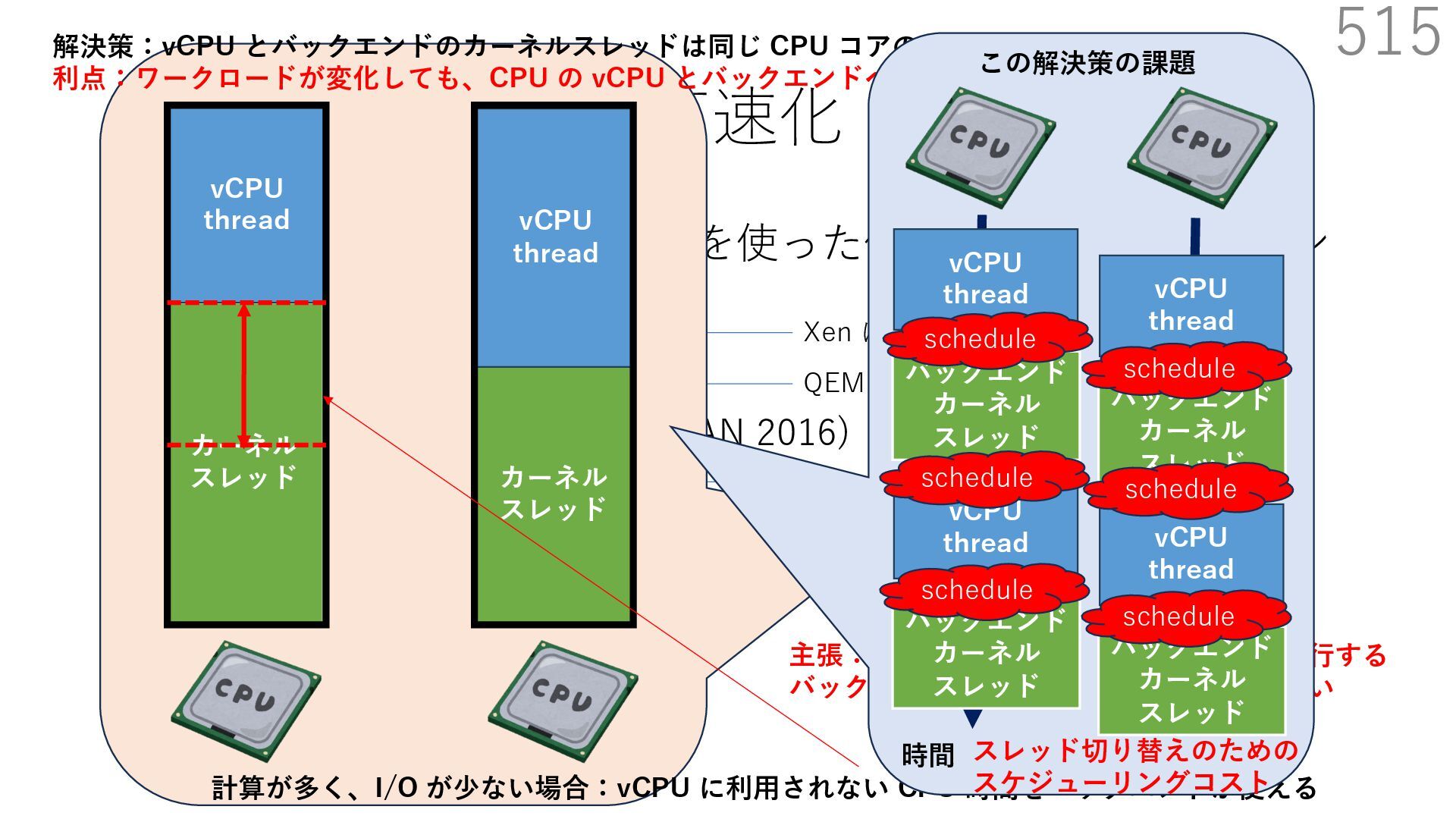{kind=link}
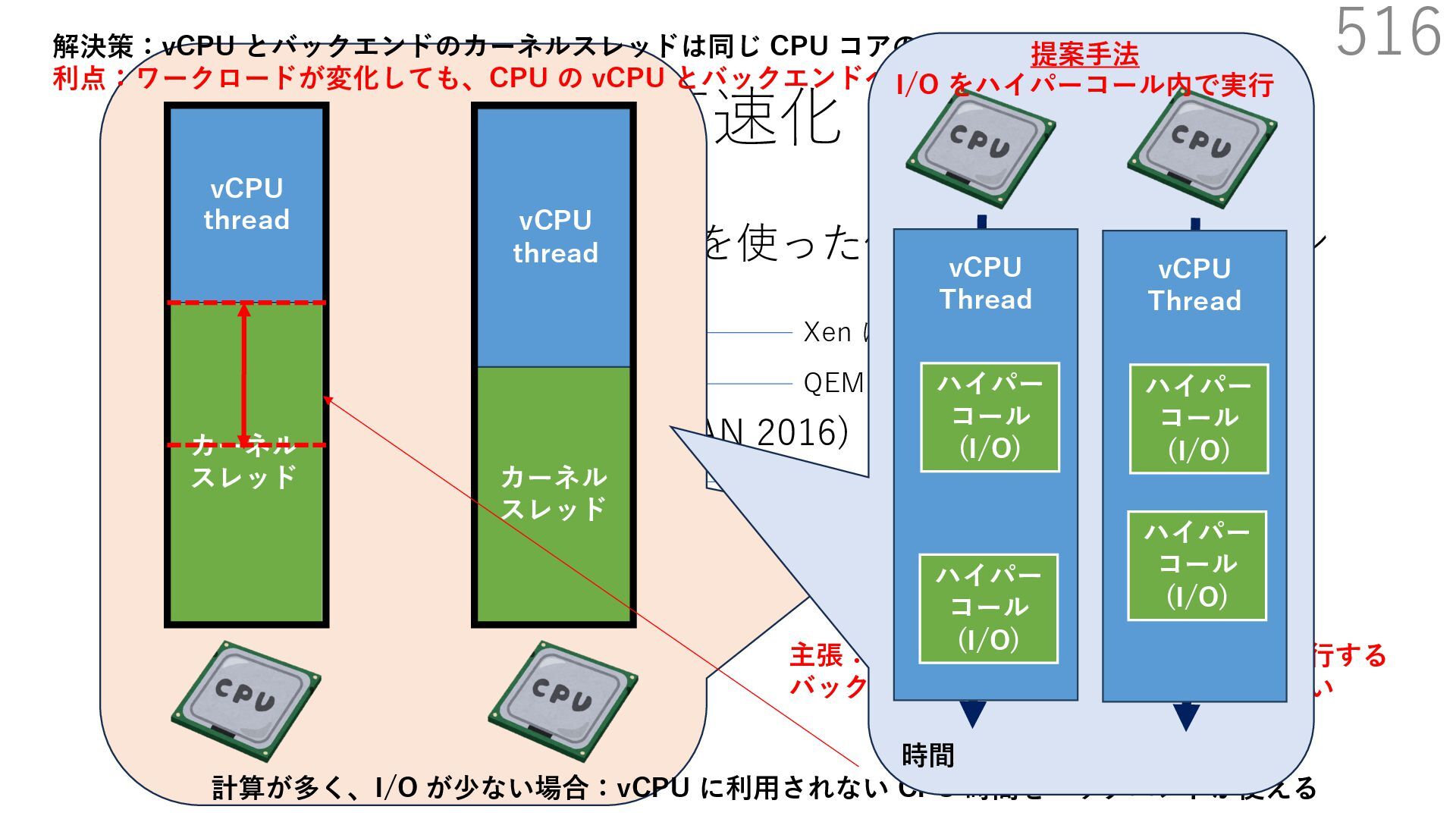{kind=link}
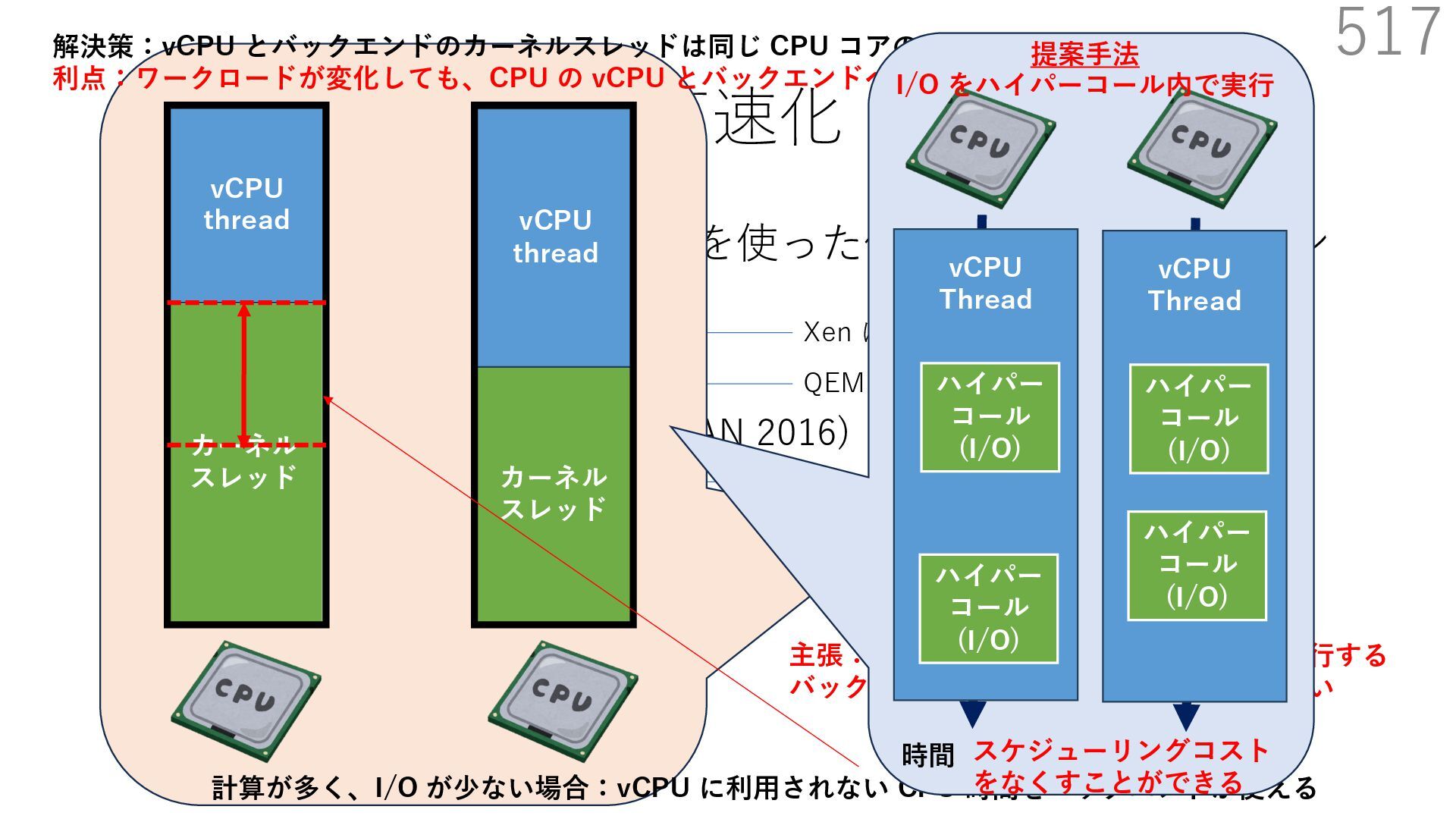{kind=link}
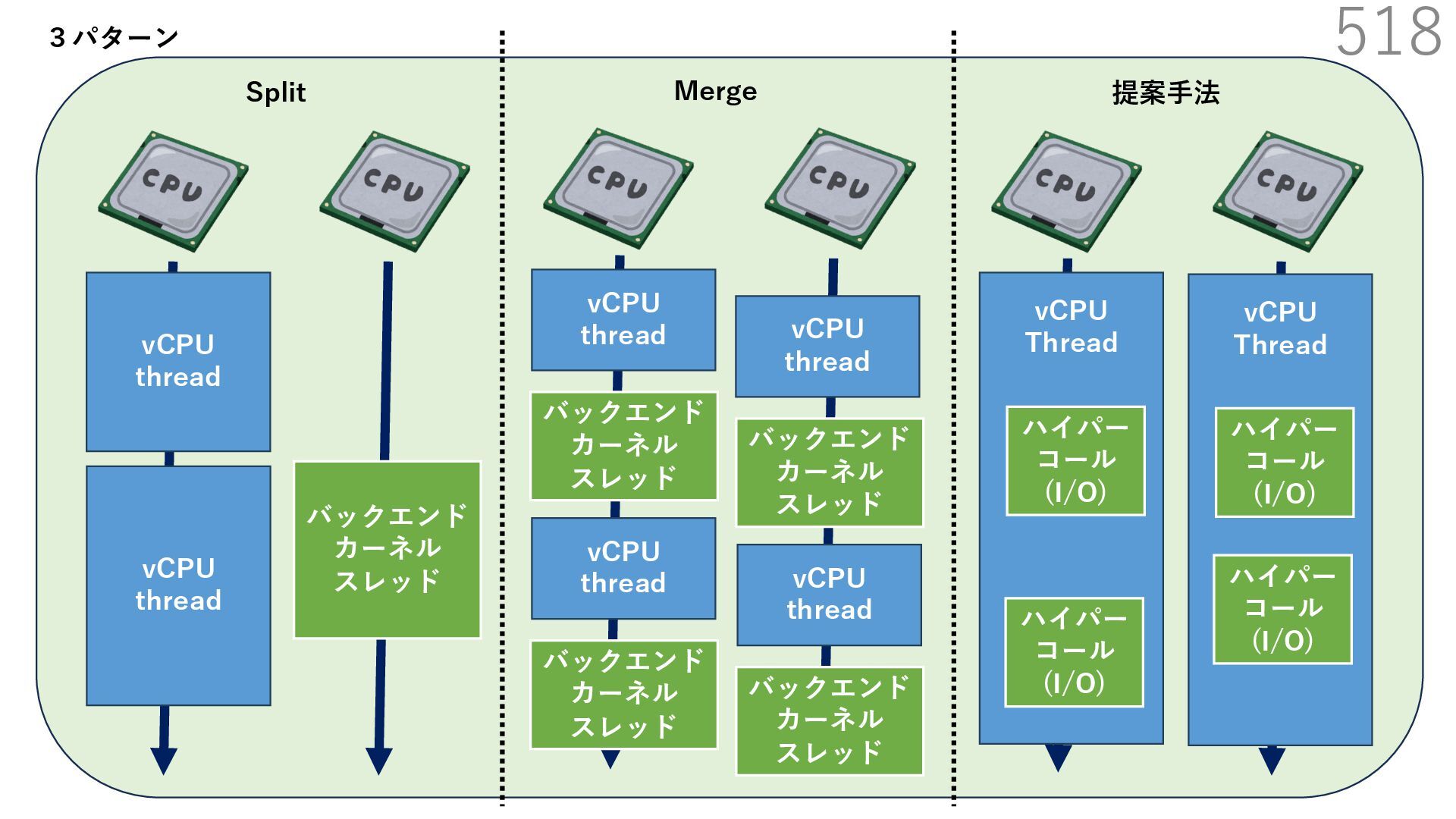{kind=link}
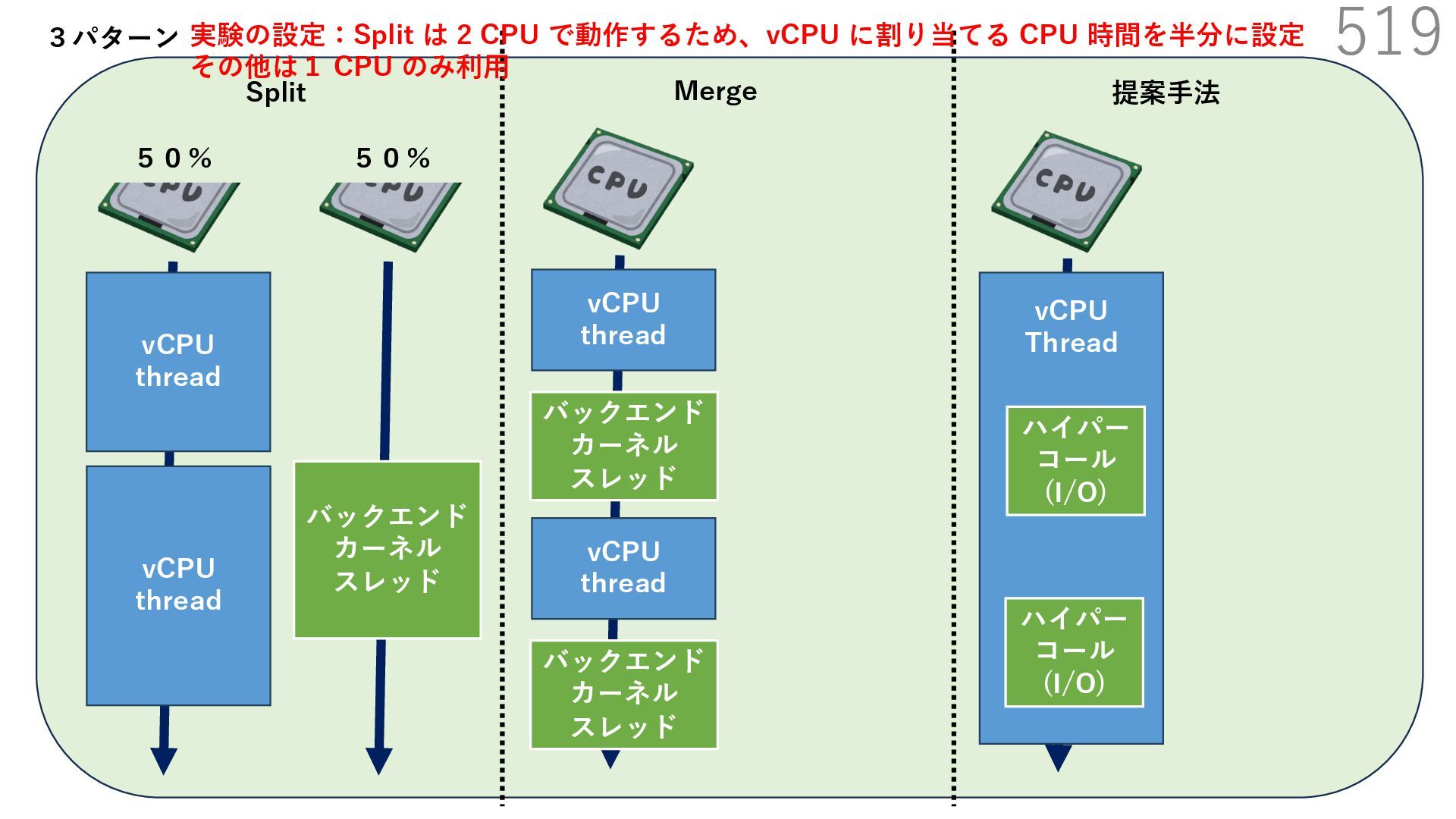{kind=link}
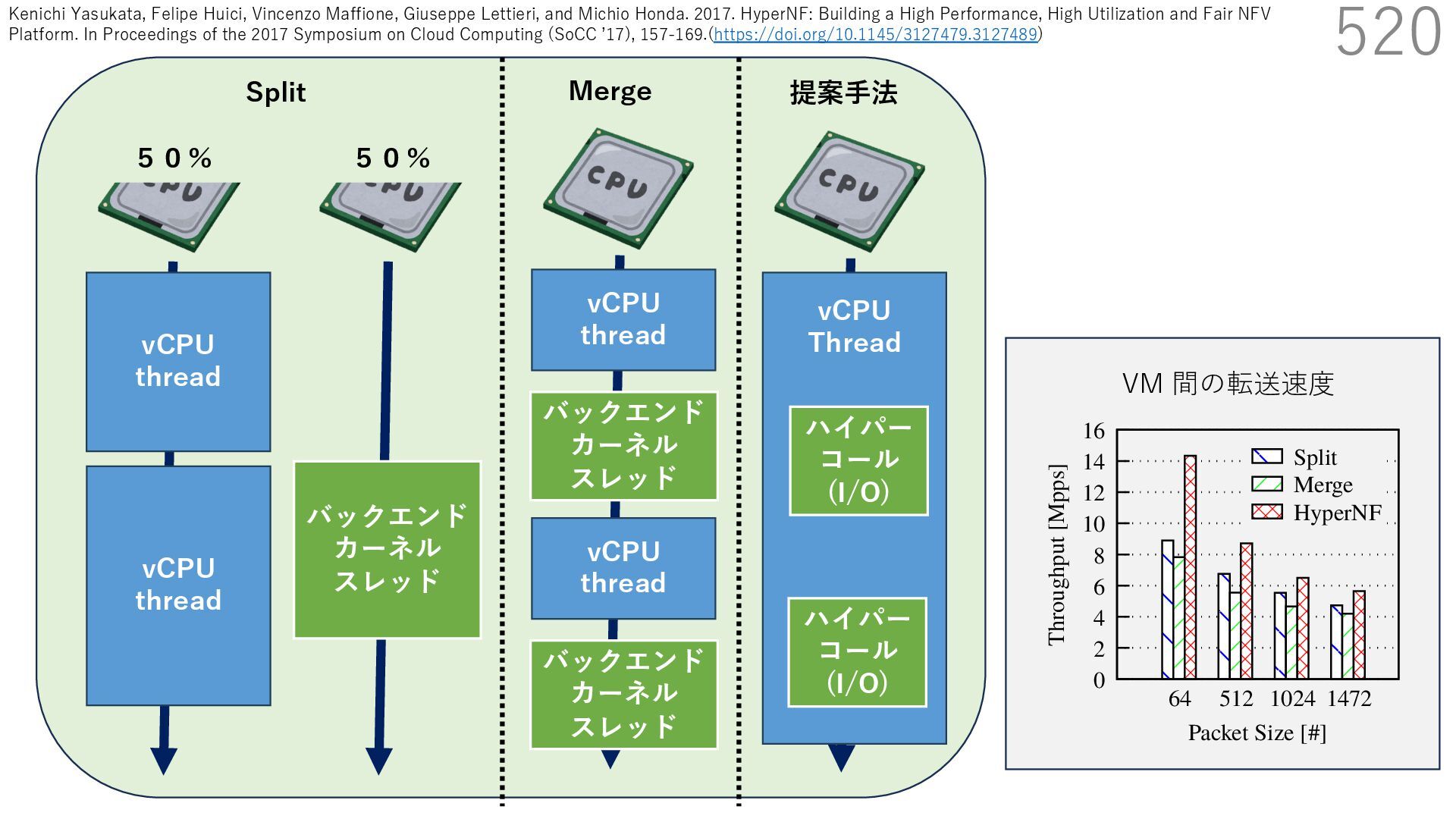{kind=link}
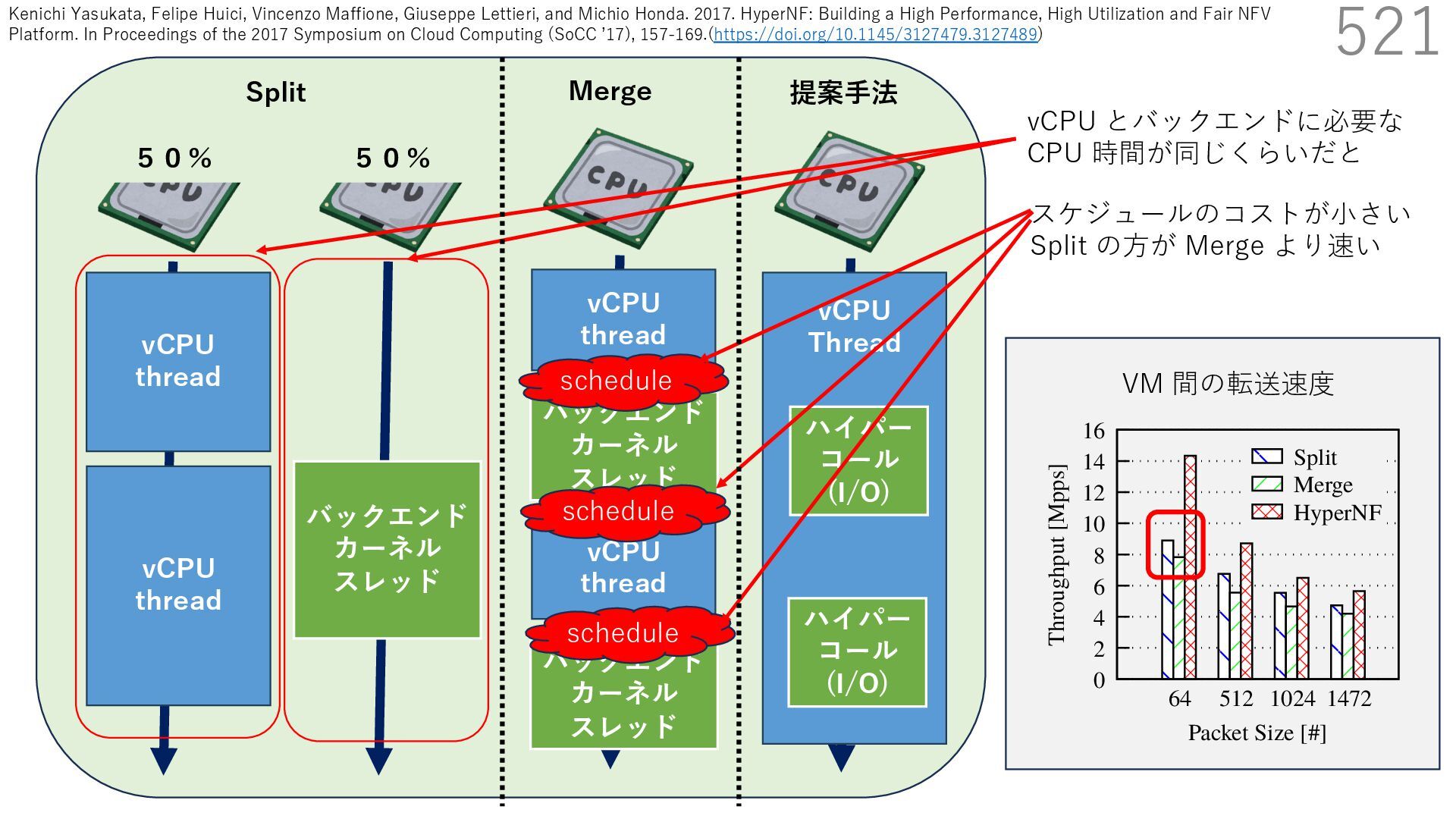{kind=link}
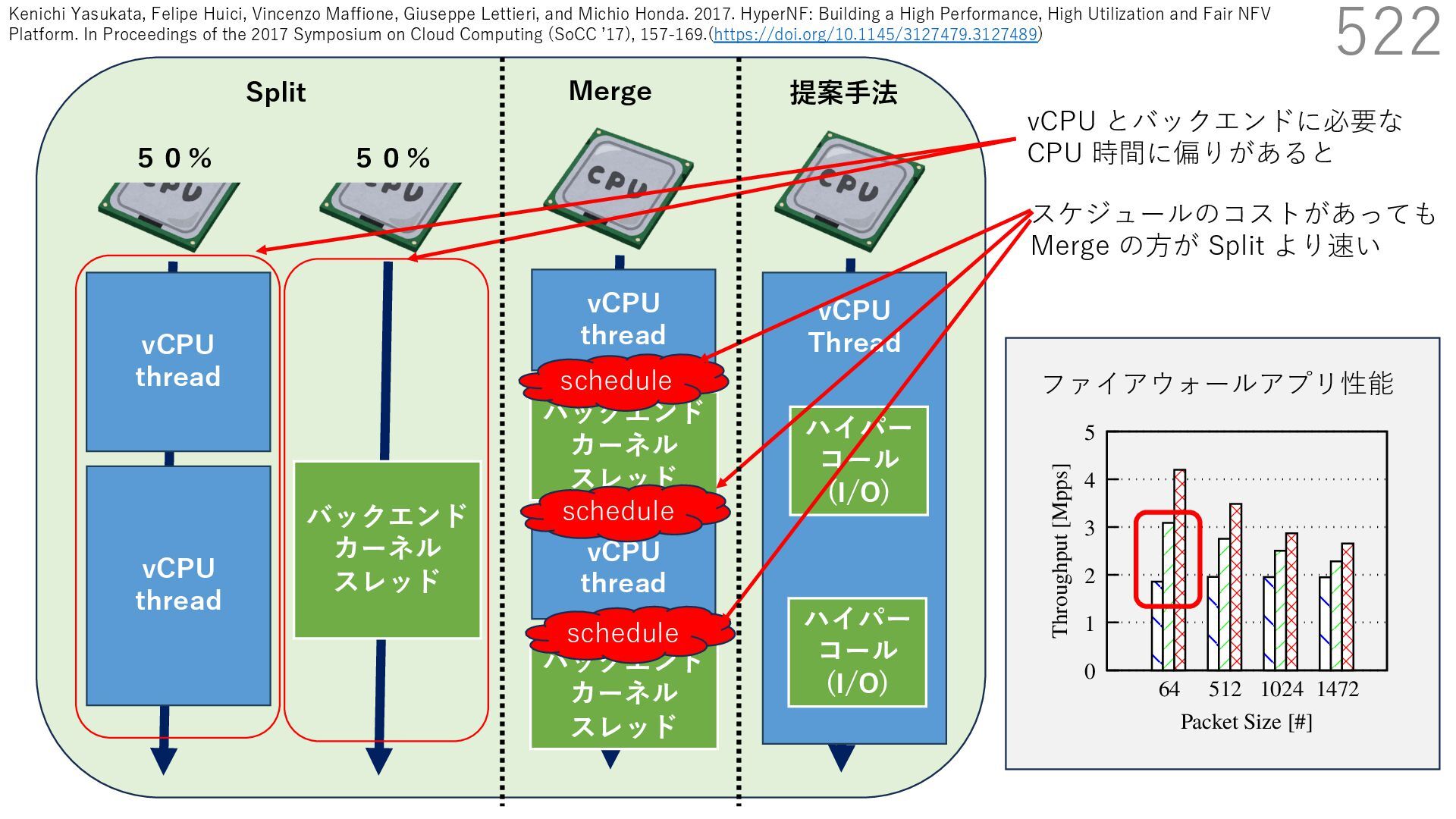{kind=link}
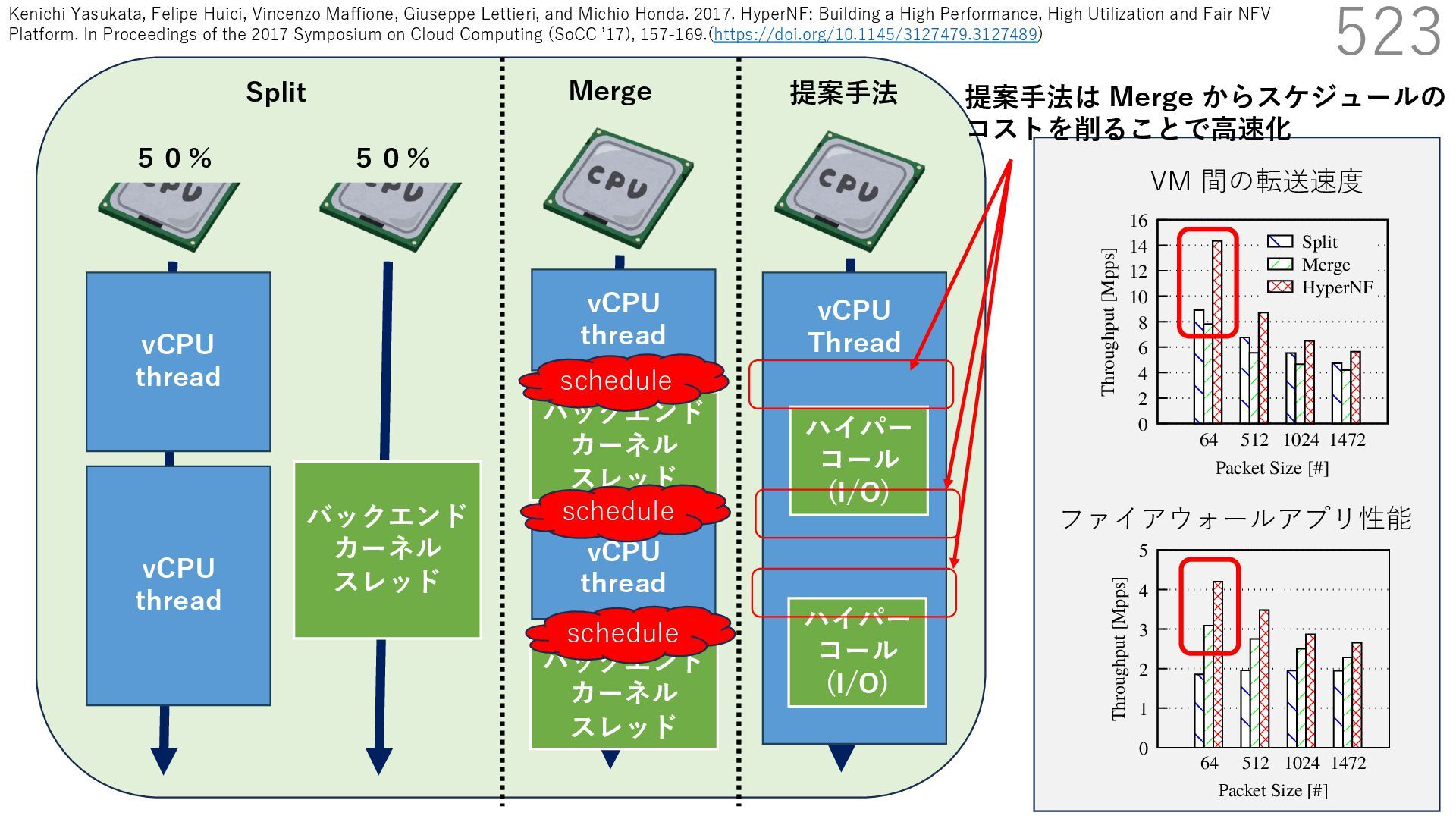{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
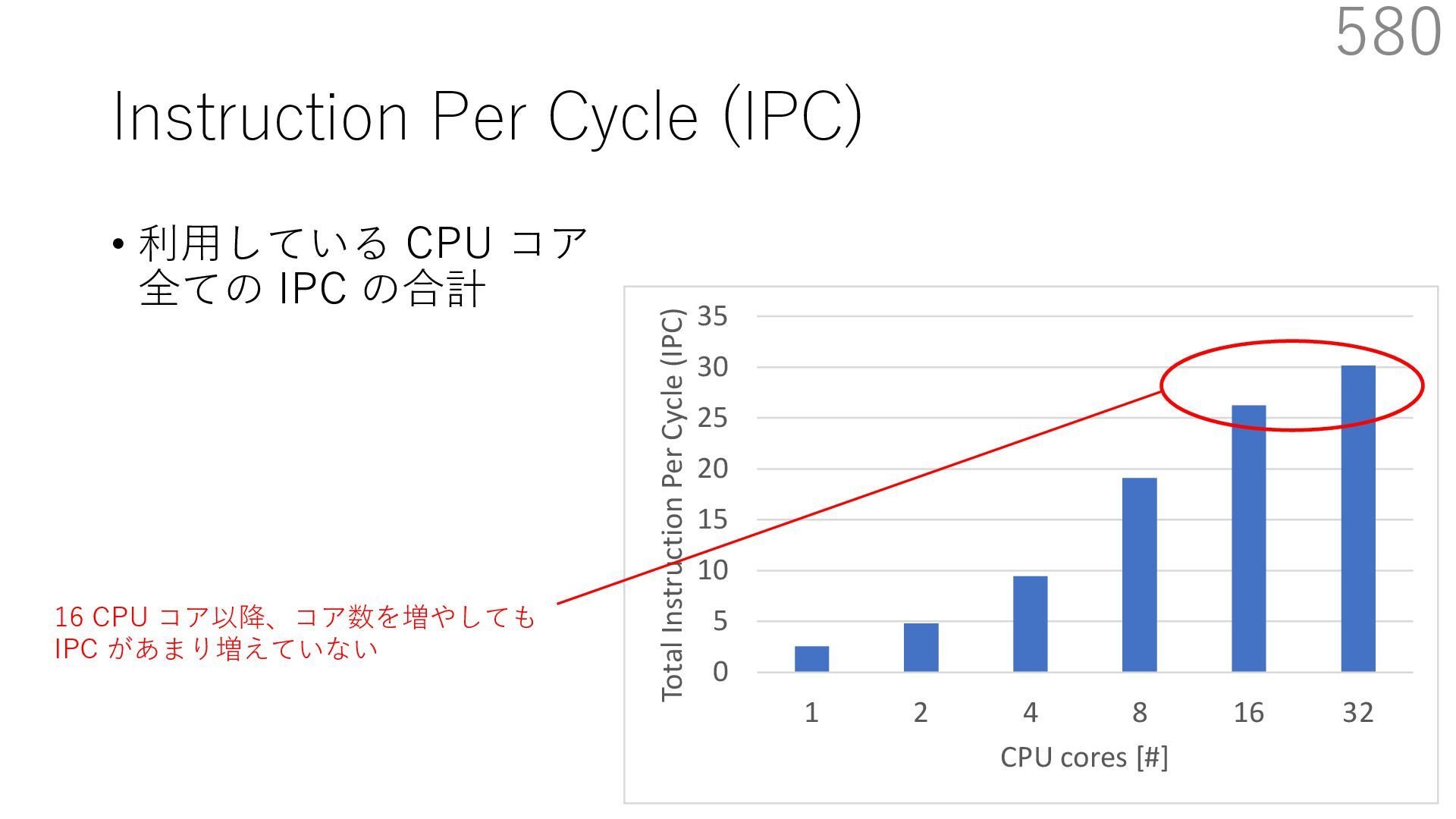
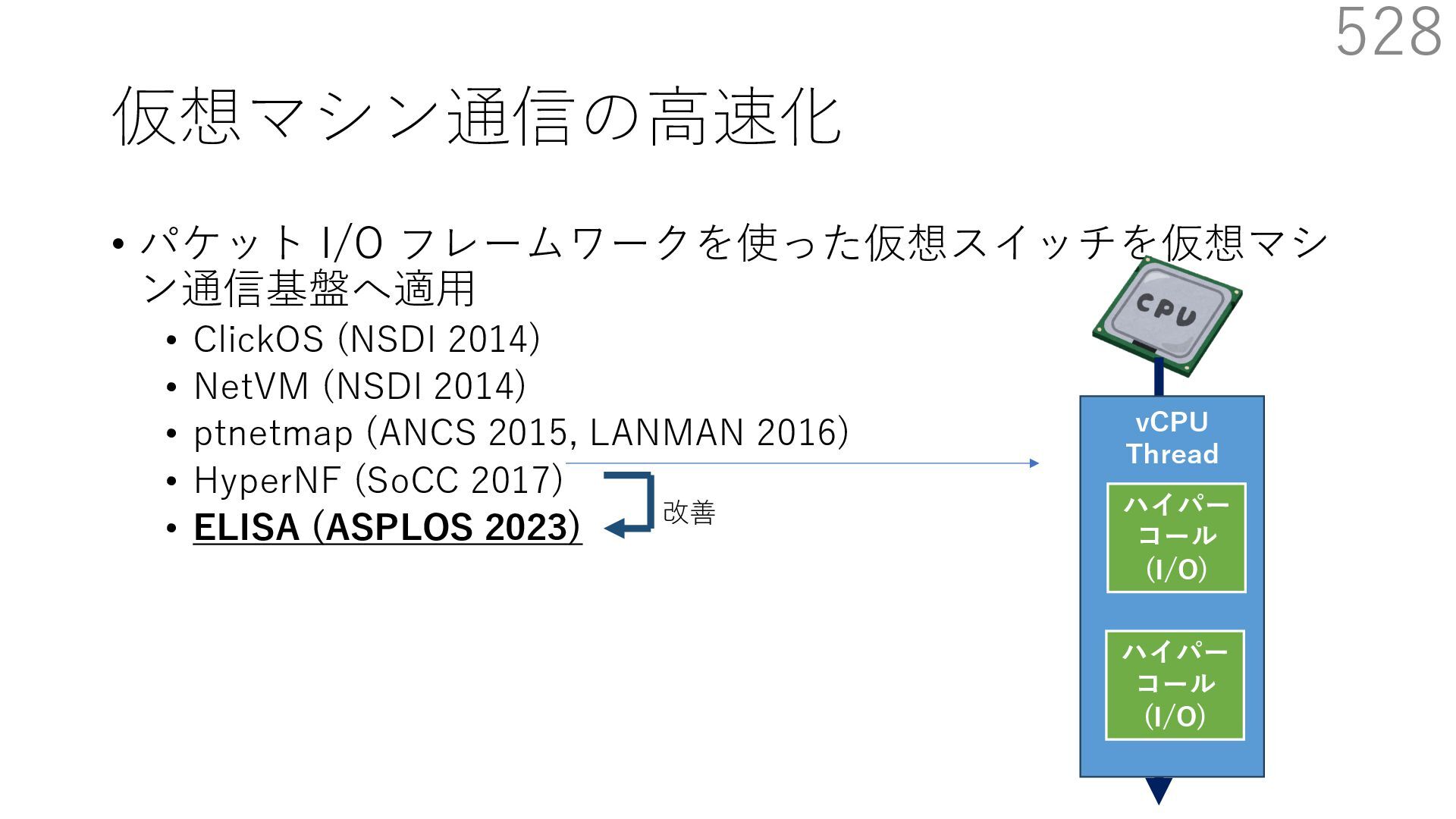{kind=link}
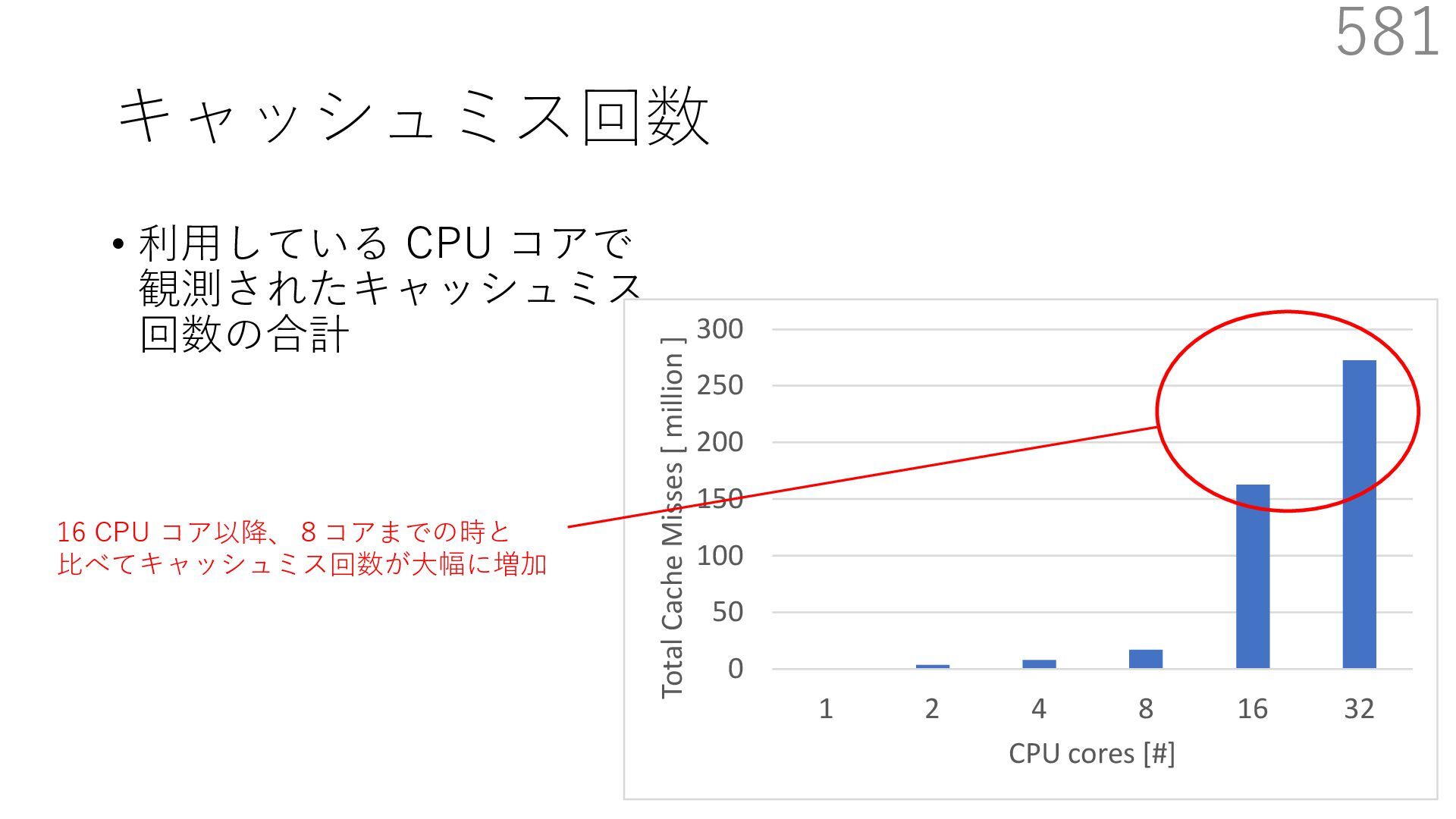
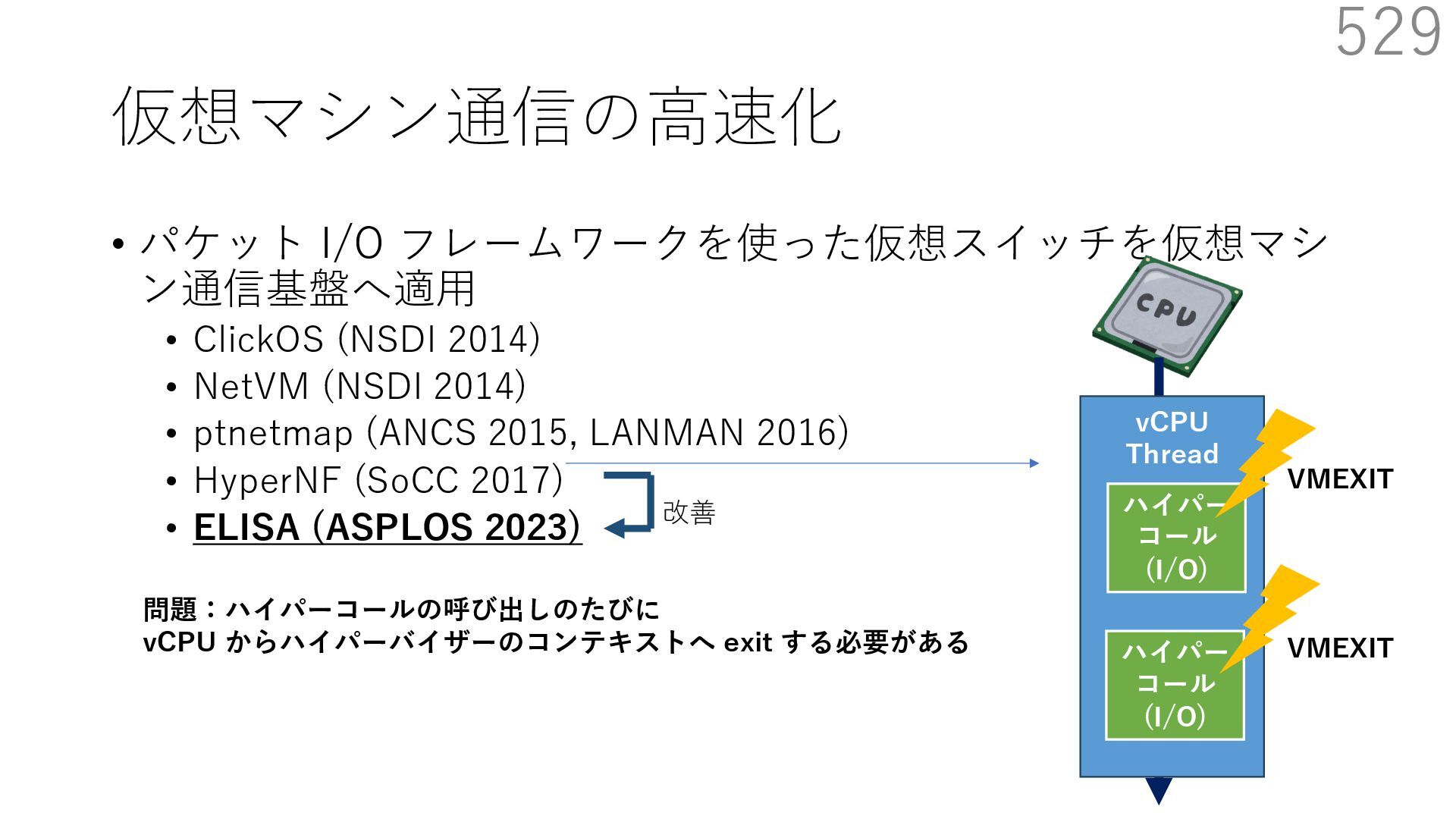{kind=link}
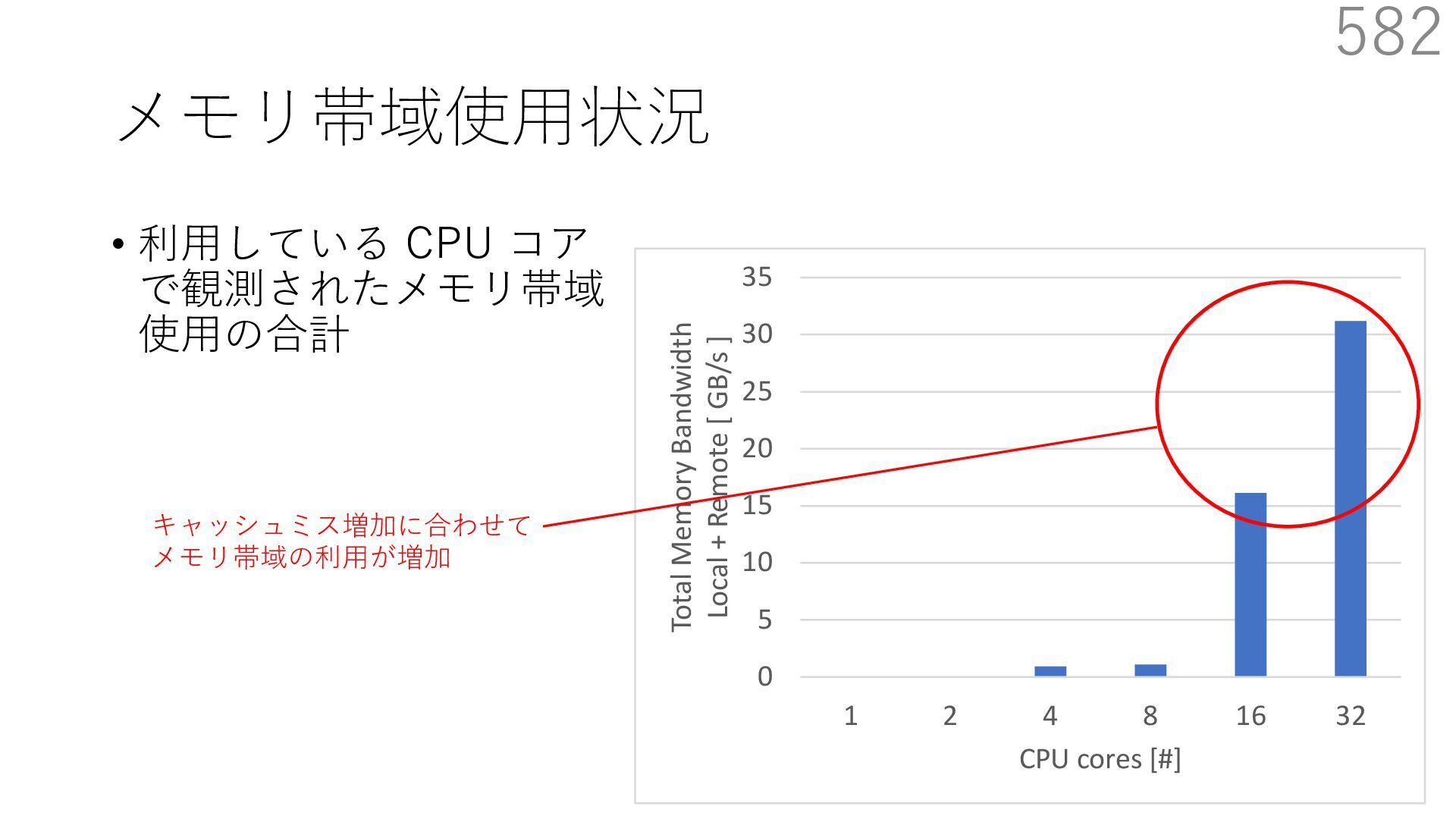
{kind=link}
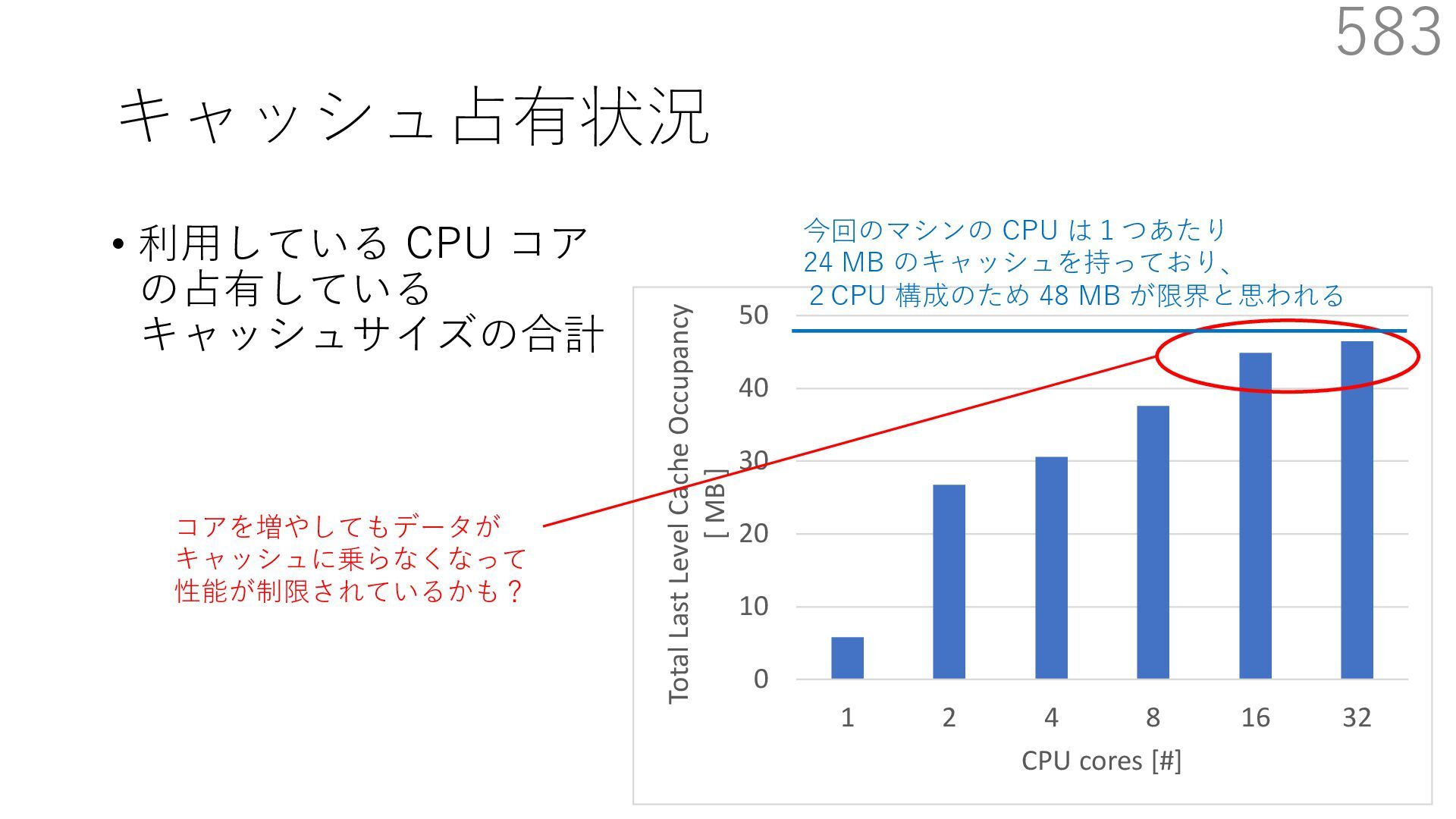
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
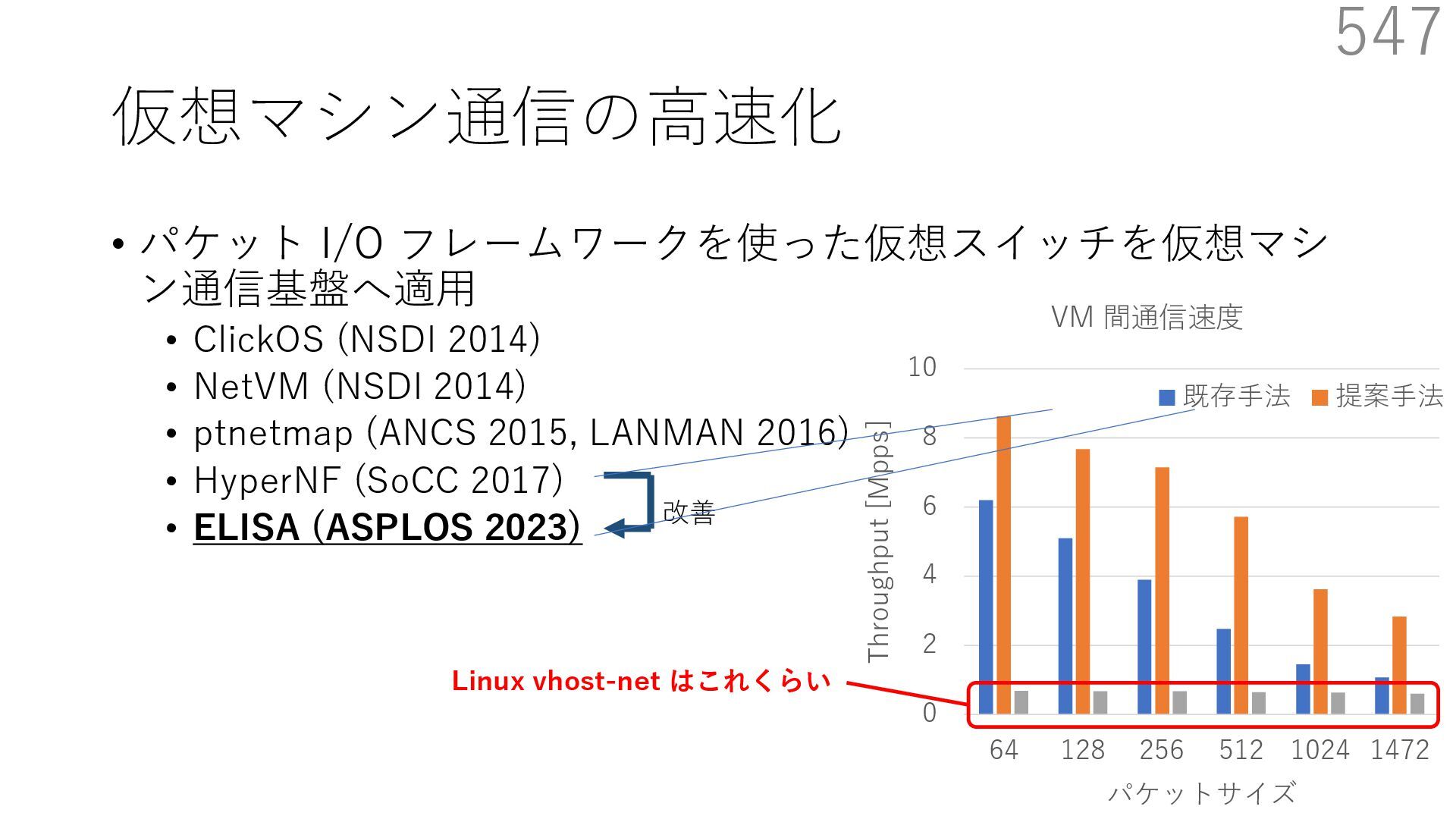{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
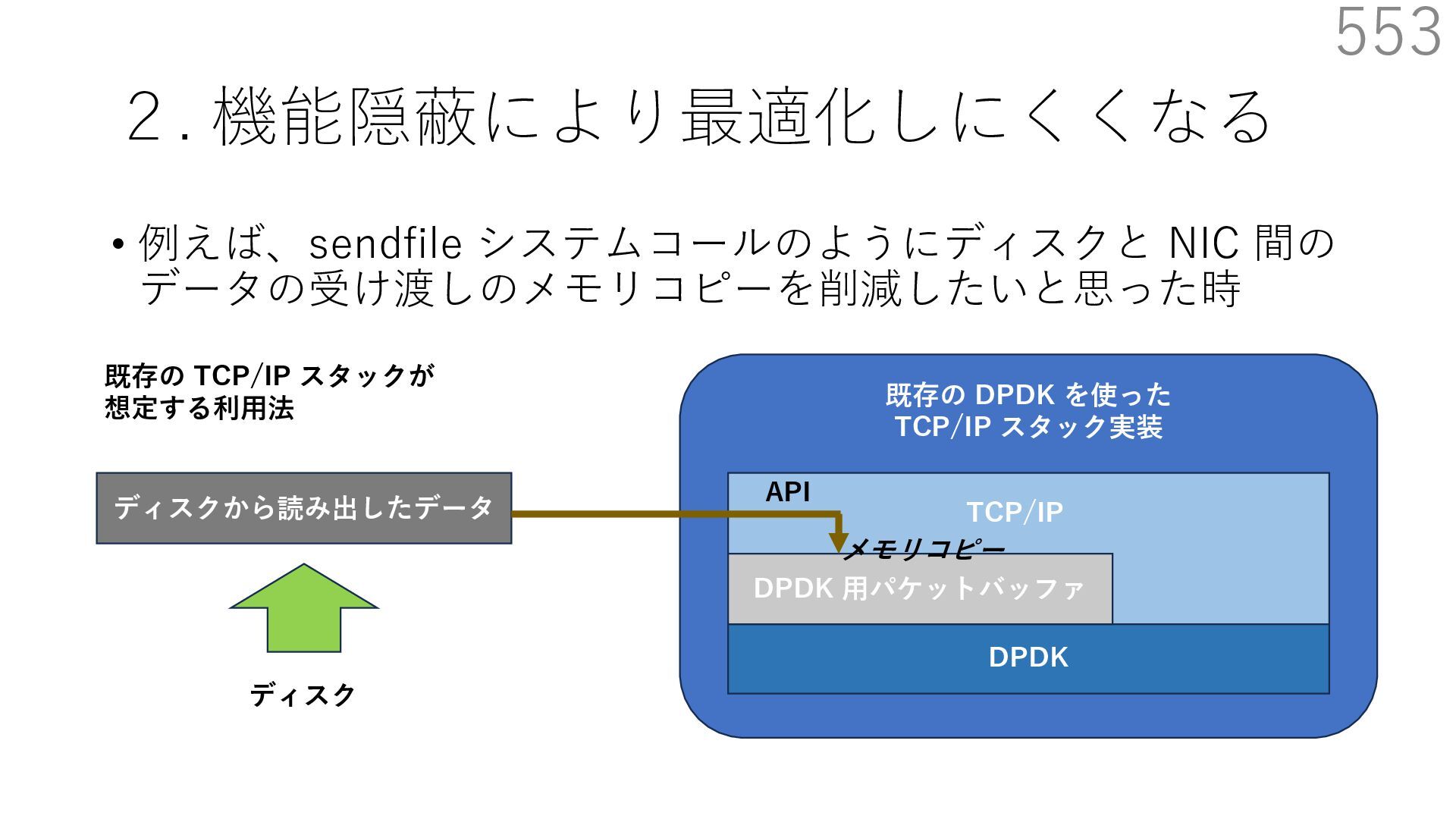{kind=link}
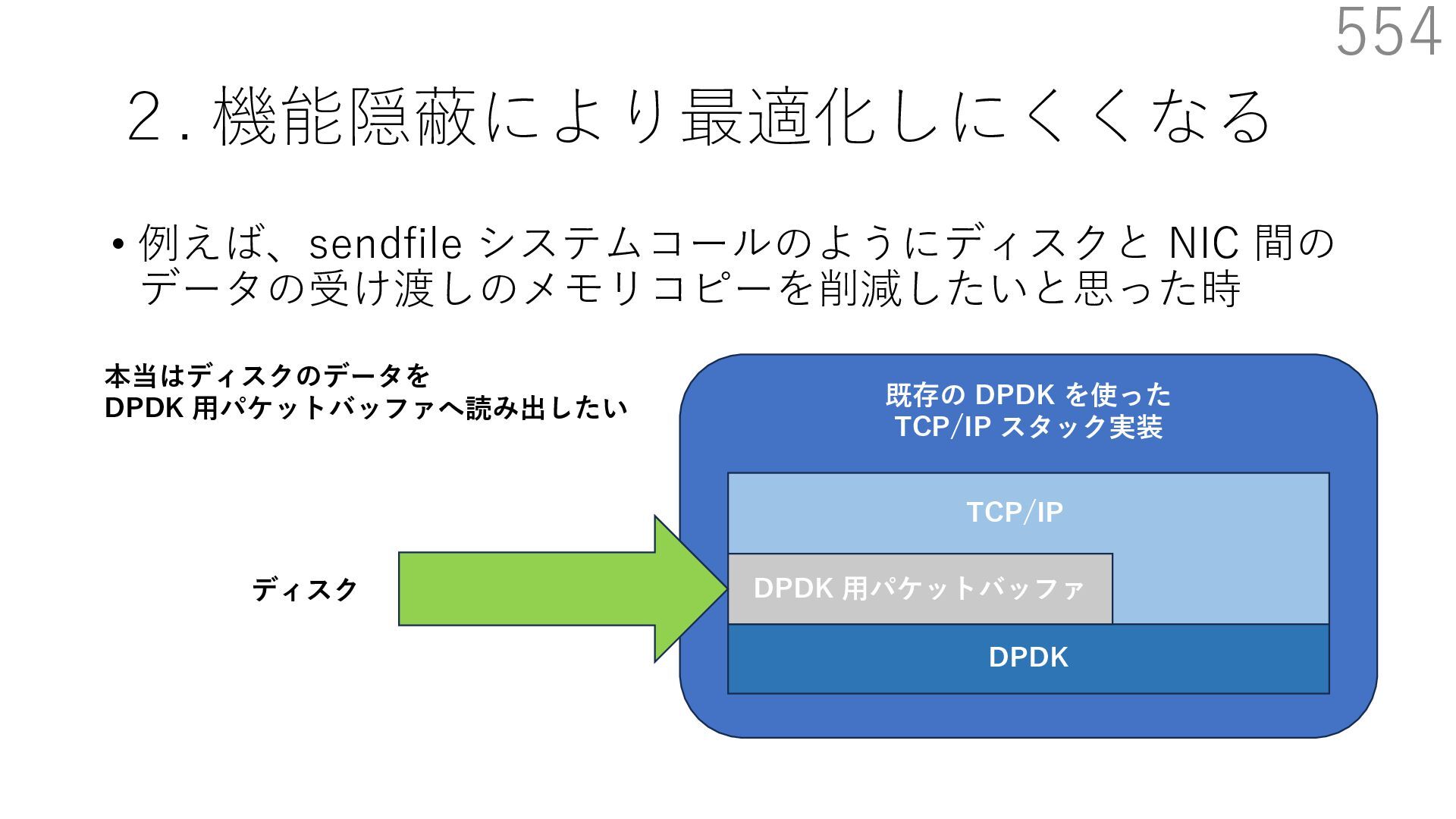{kind=link}
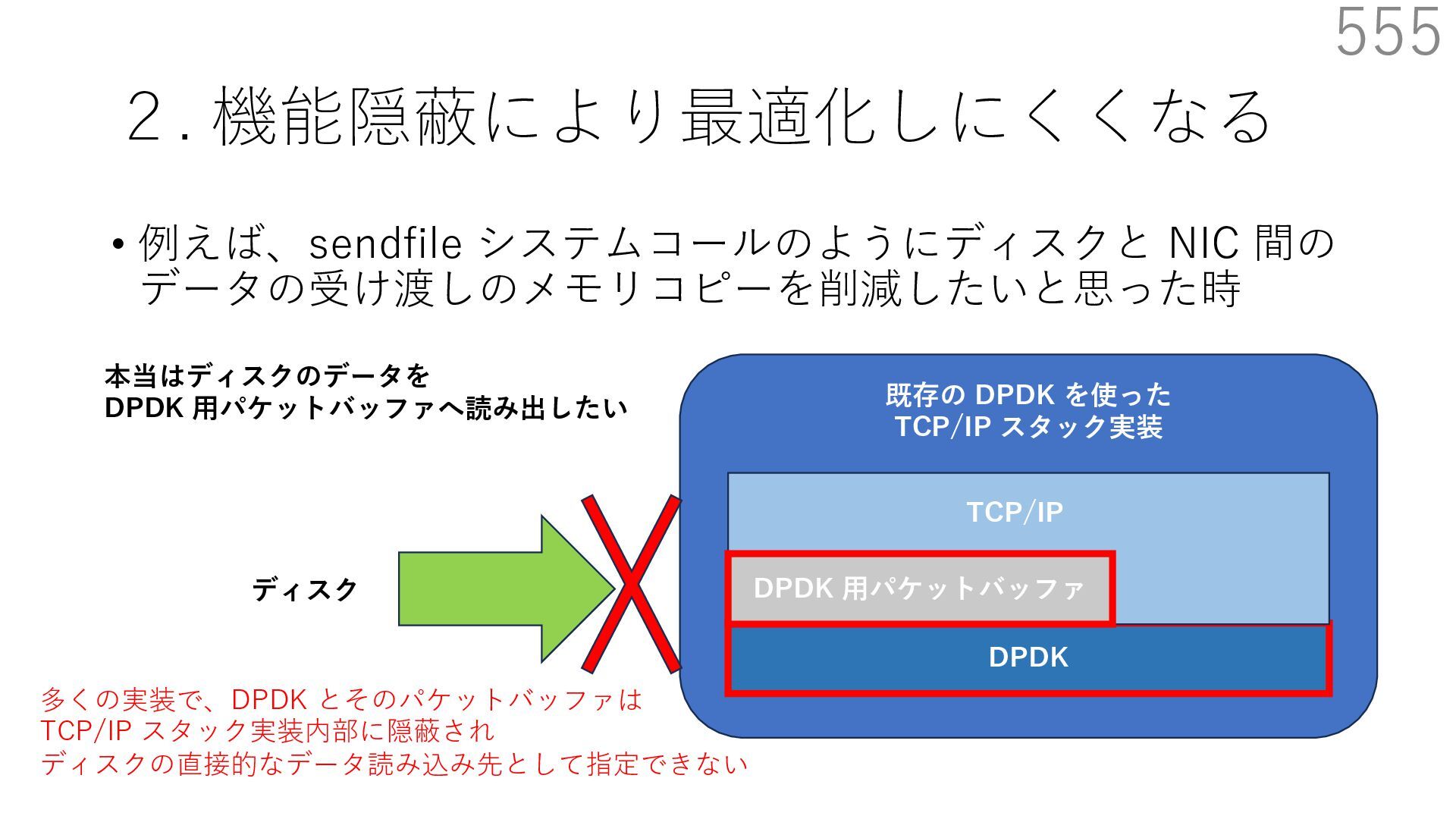{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}