Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Ad-DS Paper Circle #2
Search
Yusuke Kaneko
March 30, 2025
4.5k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Ad-DS Paper Circle #2
広告輪読会第二回スライド
Yusuke Kaneko
March 30, 2025
More Decks by Yusuke Kaneko
See All by Yusuke Kaneko
Ad-DS Paper Circle #1
ykaneko1992
0
7.3k
Ad-DS Paper Circle #3
ykaneko1992
0
4.2k
Ad-DS Paper Circle #4
ykaneko1992
0
4.1k
Ad-DS Paper Circle #5
ykaneko1992
0
3.8k
Ad-DS Paper Circle #6
ykaneko1992
0
3.5k
Ad-DS Paper Circle #7
ykaneko1992
0
3.4k
Ad-DS Paper Circle #8
ykaneko1992
0
3.3k
Ad-DS Paper Circle #9
ykaneko1992
0
3.2k
Ad-DS Paper Circle Intro
ykaneko1992
0
7.6k
Featured
See All Featured
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
760
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
780
Speed Design
sergeychernyshev
33
2k
Typedesign – Prime Four
hannesfritz
42
3.1k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
エンジニアに許された特別な時間の終わり
watany
108
250k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
New Earth Scene 8
popppiees
3
2.4k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
420
Making Projects Easy
brettharned
120
6.7k
Transcript
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click
Conversion Rate AI事業本部 協業DXディビジョン 石川喬之
1.自己紹介 2.テーマ紹介 3.論文紹介 4.所感
自己紹介
•入社日 2024 年 1 月中途入社 •前職 ニュースアプリの広告領域でエンジニア •趣味 バスケ🏀, 芸人ラジオ
📻, ビール🍺, 子育て👦 石川 喬之 (いしかわ たかゆき)
テーマ紹介
CVR 予測モデル •CTR 予測モデルに比べて、次の問題を持つ - 正例データが少ない - 遅れ CV の存在
- 学習データと推論データの差異
CVR 予測モデル •CTR 予測モデルに比べて、次の問題を持つ - 正例データが少ない - 遅れ CV の存在
- 学習データと推論データの差異
論文紹介
•論文タイトル Entire Space Multi-Task Model: An Effective Approach for Estimating
Post-Click Conversion Rate •著者情報 Alibaba グループの人々 論文情報
•CVR 予測はランキングシステムにおいて重要な役割をもっている •CVR モデリングにはタスク固有の問題がある 1. セレクションバイアス クリックされたアイテムのみを学習データとする 2. データのスパース性 CTR
タスクに比べて学習データが少ない •Entire Space Multi-task Model (ESMM) を提案する → 空間全体に対して CVR を直接モデル化している → 特徴表現の転移学習戦略を利用している •Taobao のデータを利用した実験によって、ESMM の有効性を検証できた 要旨
•セレクションバイアス問題に対するアプローチ - All Missing As Negative (AMAN) クリックされてないインプレッションを負例として選択するサンプリング戦略。未観測のサンプルを導入することでセレク ションバイアスは排除できるが、予測値は常に過小評価される -
Unbiased method Rejection sampling によって観測値から得られる真の分布に対してモデル化する方法。棄却率の除算で重み付けを行う場合に 不安定になることがある。 •データのスパース性問題に対するアプローチ - hierarchical estimators - オーバーサンプリング 少数クラスのサンプルを増やす手法。サンプリング率に敏感 → それぞれの問題は CVR モデリングのシナリオでは上手く対処されておらず、上記 の方法はいずれも時系列データの情報を利用していない 先行研究
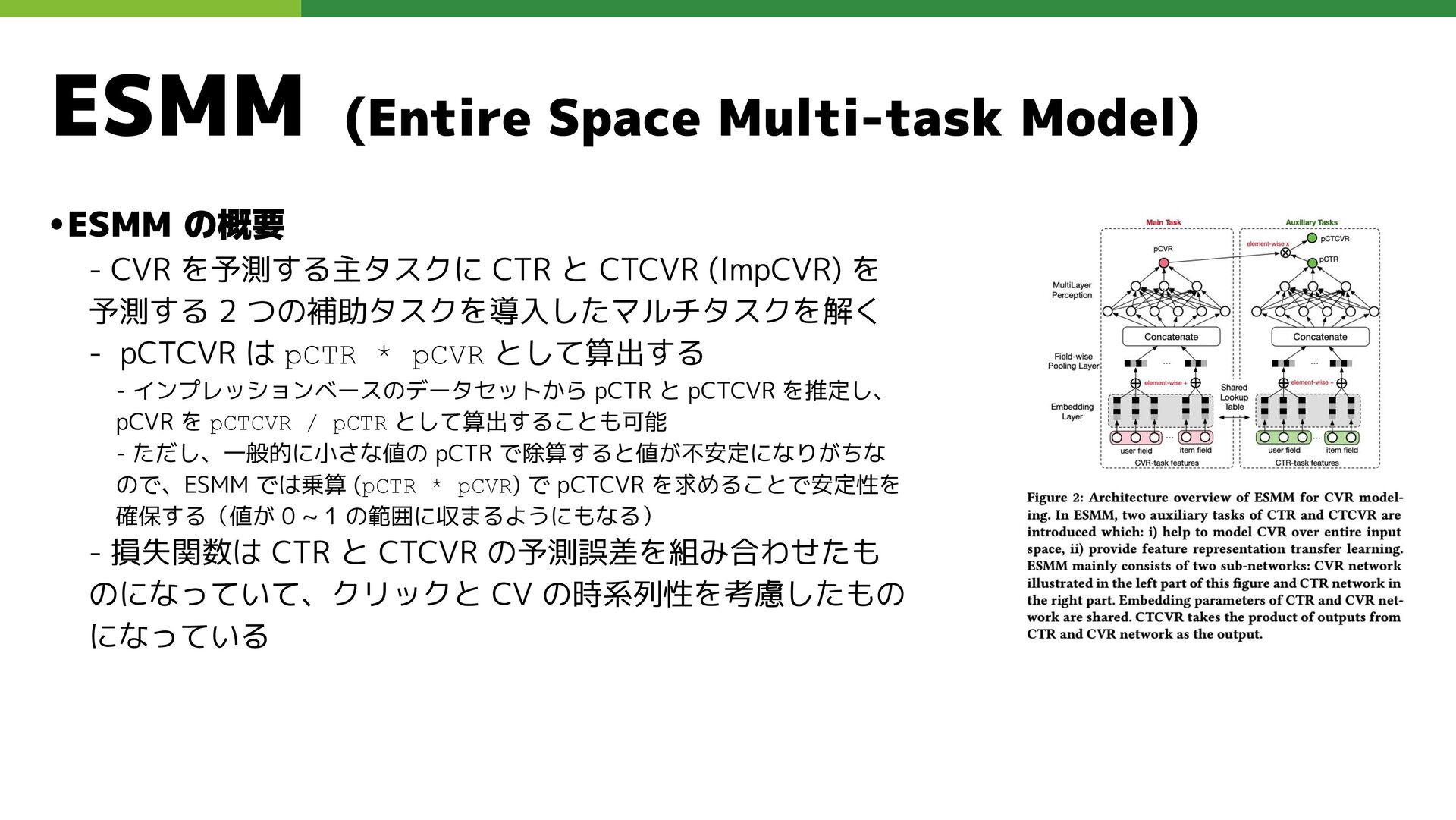
•ESMM の概要 - CVR を予測する主タスクに CTR と CTCVR (ImpCVR) を
予測する 2 つの補助タスクを導入したマルチタスクを解く - pCTCVR は pCTR * pCVR として算出する - インプレッションベースのデータセットから pCTR と pCTCVR を推定し、 pCVR を pCTCVR / pCTR として算出することも可能 - ただし、一般的に小さな値の pCTR で除算すると値が不安定になりがちな ので、ESMM では乗算 (pCTR * pCVR) で pCTCVR を求めることで安定性を 確保する(値が 0 ~ 1 の範囲に収まるようにもなる) - 損失関数は CTR と CTCVR の予測誤差を組み合わせたも のになっていて、クリックと CV の時系列性を考慮したもの になっている ESMM (Entire Space Multi-task Model)
•Feature representation transfer - 埋め込み層によって大規模なスパース入力を低次元ベクトルにマッピングする - ESMM では CVR の埋め込み辞書は
CTR と共有される(特徴表現転移学習) ESMM (Entire Space Multi-task Model)
ESMM (Entire Space Multi-task Model) •ESMM の特性により、CVR 固有の問題を解決でき る -
セレクションバイアス問題 pCTR, pCTCVR はともに全インプレッションのサンプルを 用いて空間全体にわたって推定される - データのスパース性問題 CVRネットワークの特徴表現のパラメータはCTRネットワー クと共有され、より豊富なサンプル (クリックされてないインプレッ ション含めて) で学習される
•データセット Public Dataset : Taobao の特定期間のトラフィックログから 1 % ランダムサンプリング Product
Dataset : 上記のランダムサンプリングされていないもの 有効性の検証 (実験設定)
•比較モデル BASE: シンプルな CVR 予測モデル(図 2 の左側) AMAN: All Missing
As Negative OVERSAMPLING : 少数クラスのサンプルを増やす手法 UNBIASED : 観測値から得られる真の分布に対してモデル化する手法 DIVISION : CTR と CTCVR のネットワークを個別に訓練して除算で算出する ESMM-NS : 軽量版 ESMM(埋め込み層の共有を行わない) ESMM: 今回提唱されたモデル ※ モデル構造は BASE と同じ ReLU, 埋め込み層は 18 次元, MLP の次元数は 360 × 200 × 80 × 2, 最適化手法は Adam 有効性の検証 (実験設定)
•評価方法 以下の 2 つのタスクに関して AUC で評価する(データは時系列で 2 分割) 1. 従来の
CVR 予測タスク 2. CTCVR 予測タスク pCVR は各モデルで予測、pCTR は BASE モデルと同じモデル構造のモデルで予測し、pCTR × pCVR で算出 有効性の検証 (実験設定)
•パブリックデータセットで評価した 1. BASE モデルを使った 3 モデルの中ではランダムサンプリング の敏感さのためか AMAN のみが悪化した。OVERSAMPLING, UNBIASED
はともに僅かに改善した。 2. 全データを利用した DIVISION, ESMM-NS はともに BASE 比で 大きく改善した。除算による不安定さがない分、ESMM-NS の方が DIVISION より良かった。 3. 特徴表現の転移学習により未クリックデータから学習すること で、ESMM-NS よりもさらに性能改善した。 (ESMM は CVR タスクで BASE モデルよりも AUC で 2.56 ポイント改善) 有効性の検証 (結果)
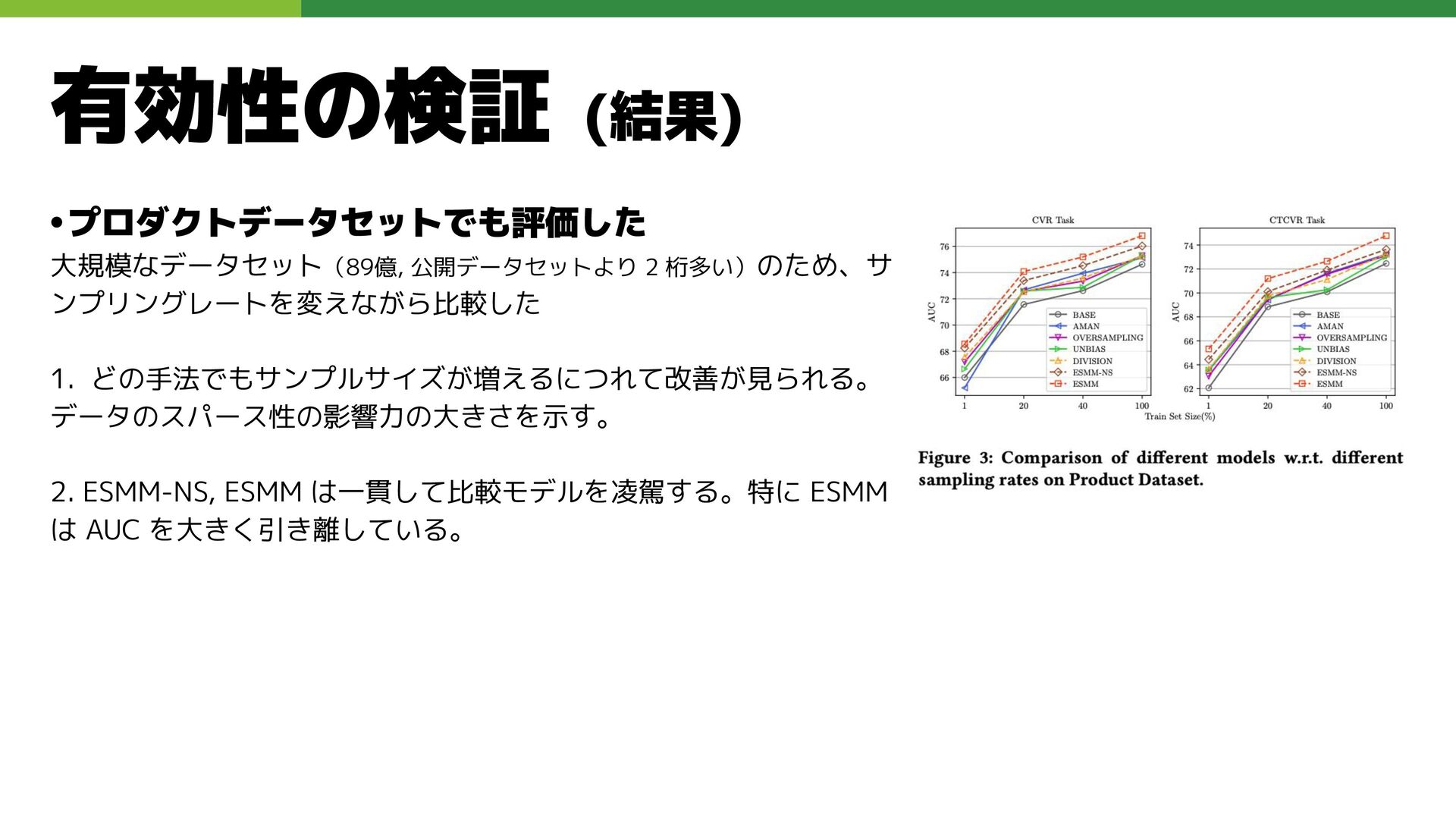
•プロダクトデータセットでも評価した 大規模なデータセット(89億, 公開データセットより 2 桁多い)のため、サ ンプリングレートを変えながら比較した 1. どの手法でもサンプルサイズが増えるにつれて改善が見られる。 データのスパース性の影響力の大きさを示す。 2.
ESMM-NS, ESMM は一貫して比較モデルを凌駕する。特に ESMM は AUC を大きく引き離している。 有効性の検証 (結果)
Conclusion •CVR モデリングタスクのための新しいアプローチ ESMM を提案した •ESMM は CTR と CTCVR
の 2 つの補助タスクによって、CVR モデリングの実務で遭遇するセレク ションバイアスとデータのスパース性の課題にエレガントに対処する •実際のデータセットを用いた実験により、ESMM の優れた性能が実証された Future work •本手法は、時系列データにおけるユーザ行動予測に容易に一般化できる •将来的には、Request → Impression → Click → CV のような多段階のアクションを持つアプリ ケーションにおいて、大域的最適化モデルを設計する予定である まとめ
所感
所感 •入力の時系列データはどのように入れているのか? •CTR と CVR で埋め込み層の重みの共有、上手くいくのか?
ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}