λ= f(予算) の形式で予算消化速度を調整の指標として使用(FLB、BSLB) b. 🧩 最適な予算消化速度を決定する方法は依然として未解決 2. オークションプロセスをマルコフ決定過程(MDP)として定式化 a. ex. 強化学習(RL)アルゴリズムを使用した予算制約付き入札(RLB) b. 🚧 モデルベースのRLアプローチは、計算コストが高すぎるという課題 4
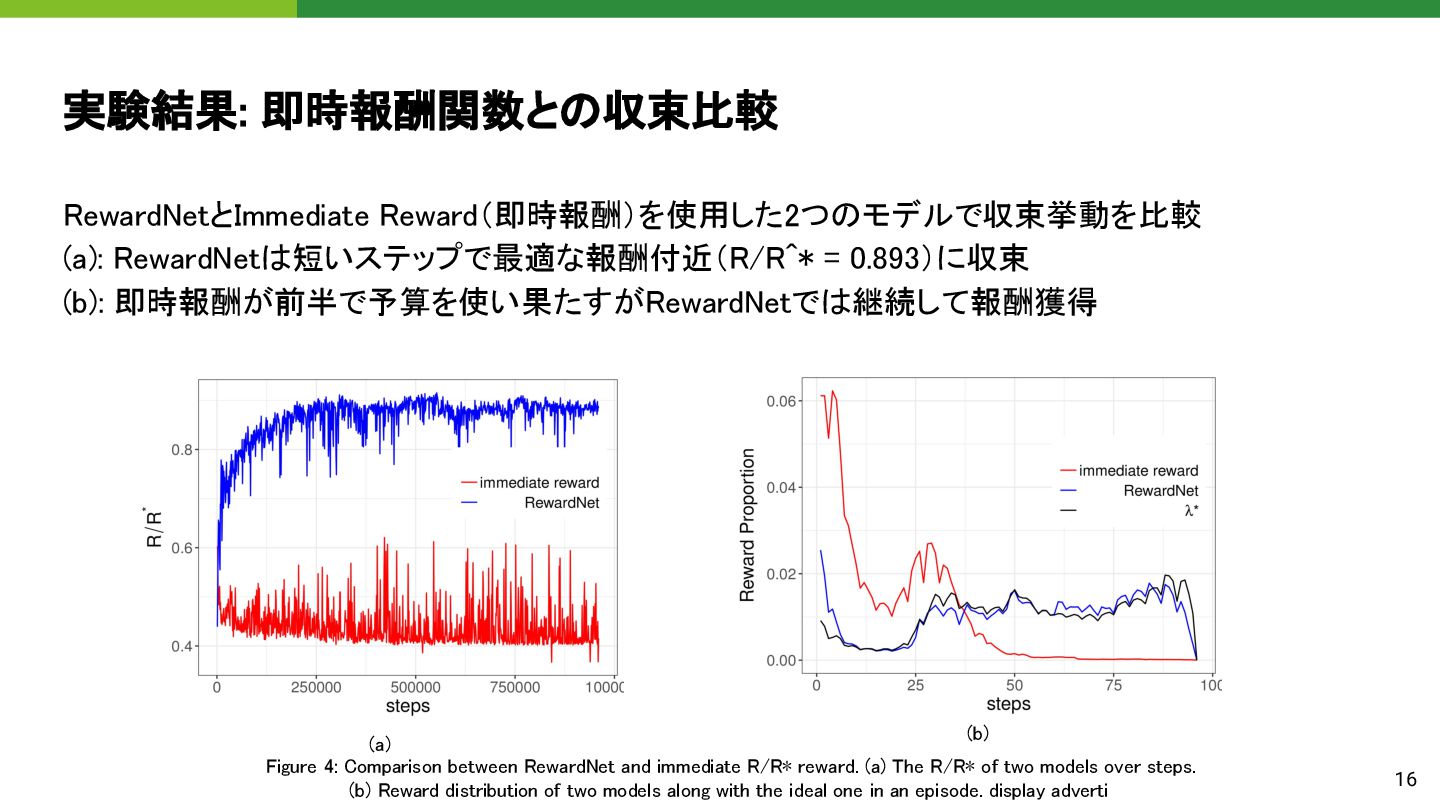
(b): 即時報酬が前半で予算を使い果たすがRewardNetでは継続して報酬獲得 16 Figure 4: Comparison between RewardNet and immediate R/R∗ reward. (a) The R/R∗ of two models over steps. (b) Reward distribution of two models along with the ideal one in an episode. display adverti (a) (b)
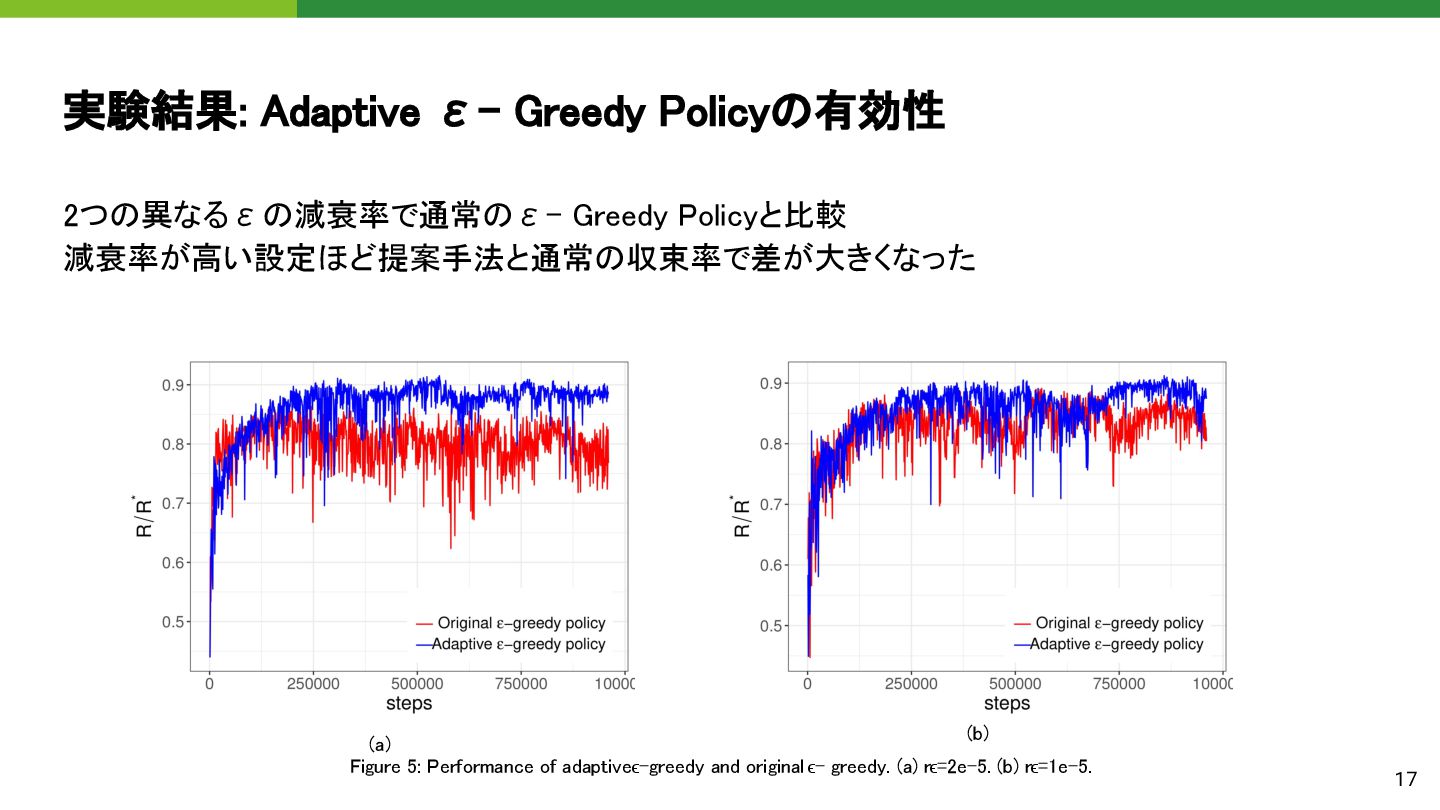
全結合ニューラルネットワーク、3隠れ層、各層100ノード。 2. ハイパーパラメータ設定: a. ミニバッチサイズ: 32 b. リプレイメモリサイズ: 100,000 3. λ調整率: a. 候補: -8%、-3%、-1%、0%、1%、3%、8% 4. ε -greedyポリシー: a. 初期値: 0.9 b. 最終値: 0.05 c. 減衰式: ε = max(0.95 - r_ε* t, 0.05) d. 適応型ポリシー: i. アクション値分布が単峰型でない場合: \epsilon = \max(\epsilon, 0.5) 5. 学習設定: a. ターゲットネットワークの更新: C = 100 ステップごとにθを更新 b. 学習率: 0.001 c. モーメント: 0.95 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}