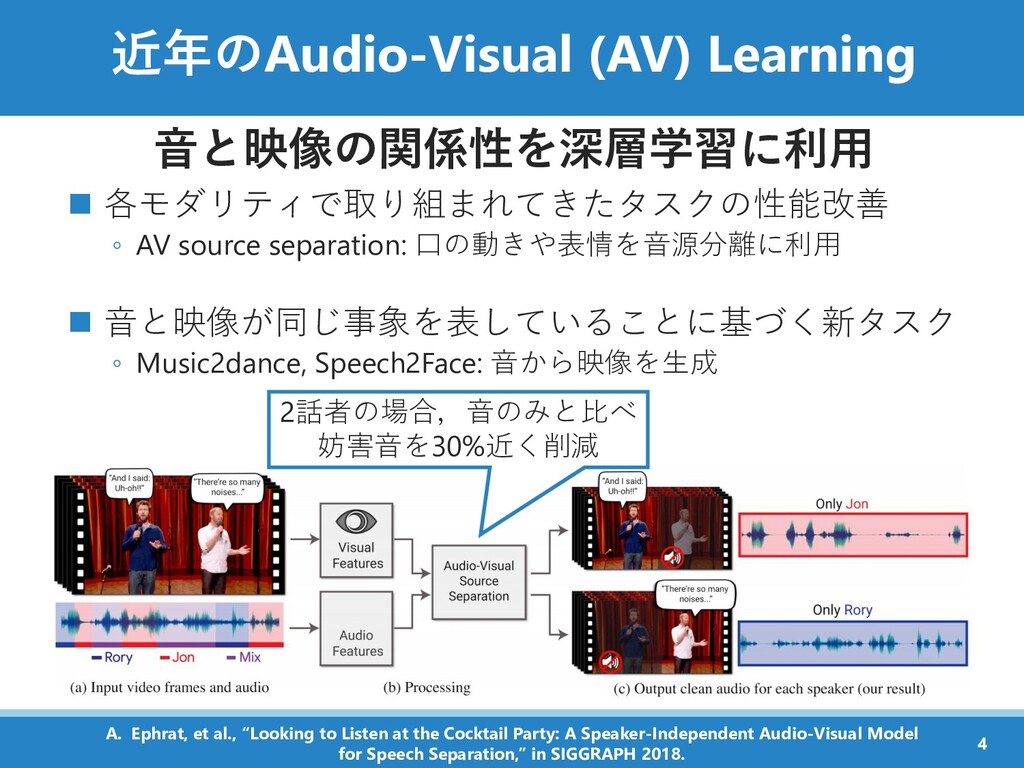
口の動きや表情を音源分離に利用 ◼ 音と映像が同じ事象を表していることに基づく新タスク ◦ Music2dance, Speech2Face: 音から映像を生成 2話者の場合,音のみと比べ 妨害音を30%近く削減 4 A. Ephrat, et al., “Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation,” in SIGGRAPH 2018.
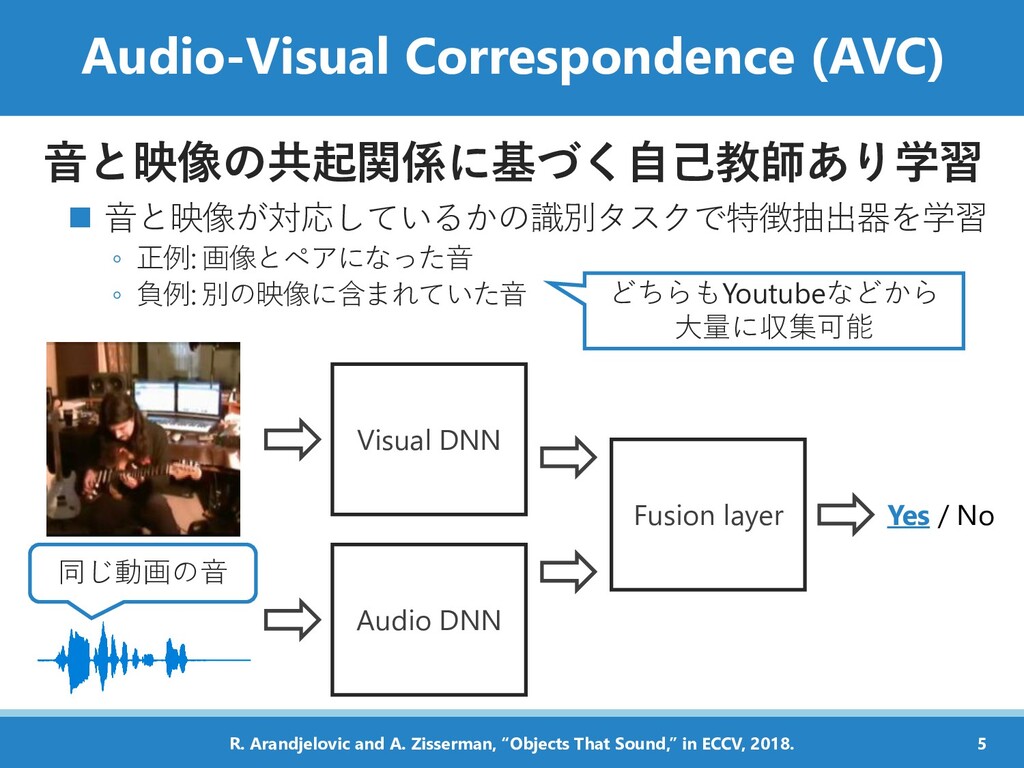
負例: 別の映像に含まれていた音 どちらもYoutubeなどから 大量に収集可能 Visual DNN Audio DNN Fusion layer Yes / No 同じ動画の音 5 R. Arandjelovic and A. Zisserman, “Objects That Sound,” in ECCV, 2018.
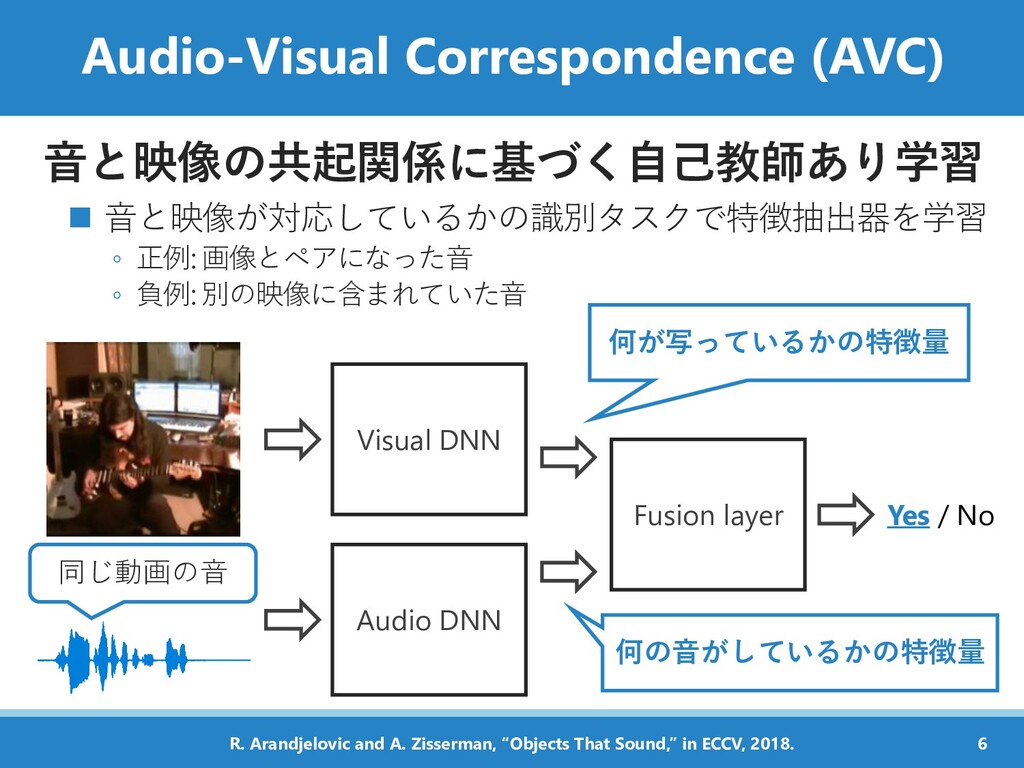
負例: 別の映像に含まれていた音 何の音がしているかの特徴量 Visual DNN Audio DNN Fusion layer Yes / No 同じ動画の音 何が写っているかの特徴量 6 R. Arandjelovic and A. Zisserman, “Objects That Sound,” in ECCV, 2018.
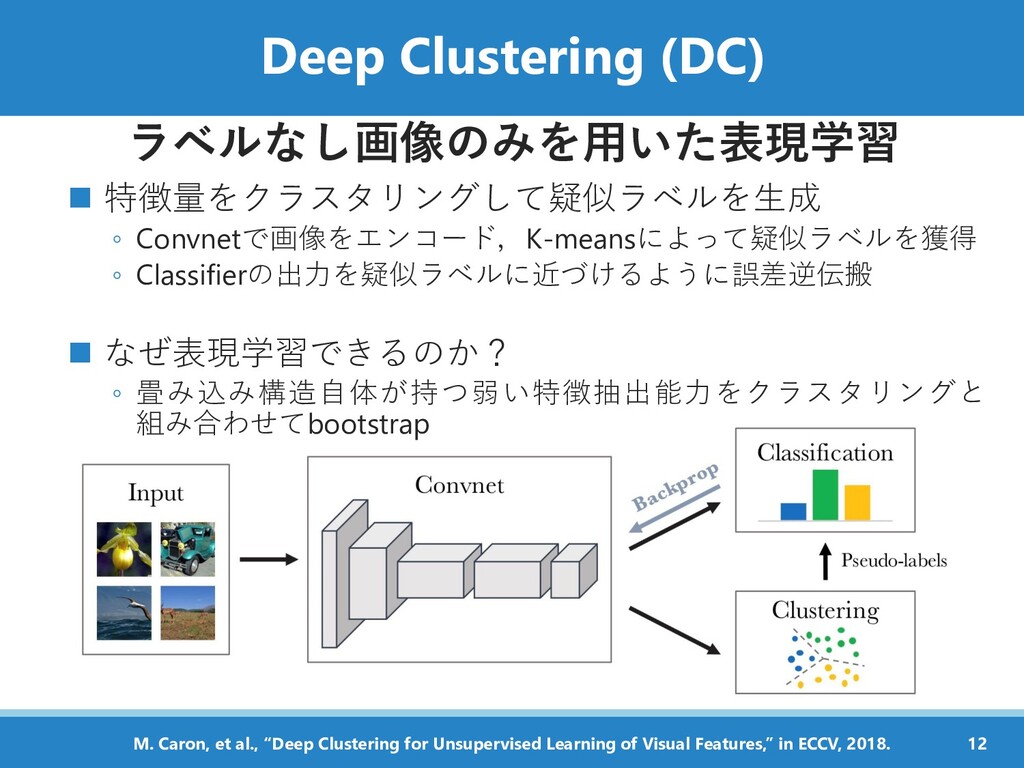
◼ なぜ表現学習できるのか? ◦ 畳み込み構造自体が持つ弱い特徴抽出能力をクラスタリングと 組み合わせてbootstrap 12 M. Caron, et al., “Deep Clustering for Unsupervised Learning of Visual Features,” in ECCV, 2018.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
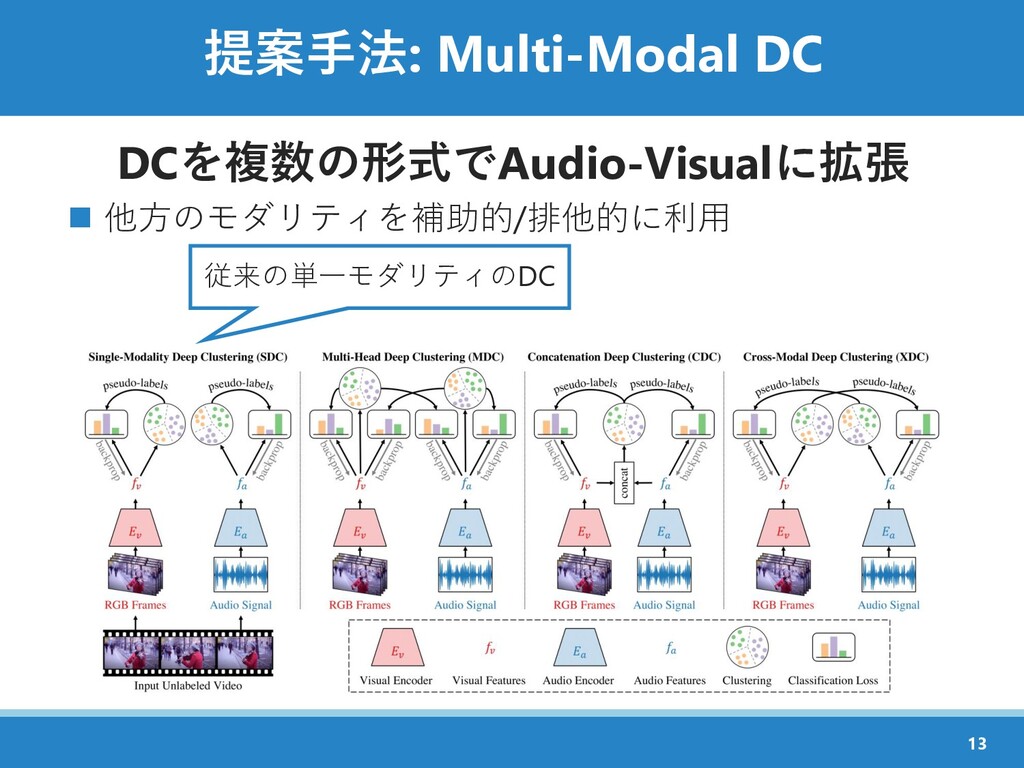{kind=link}
{kind=link}
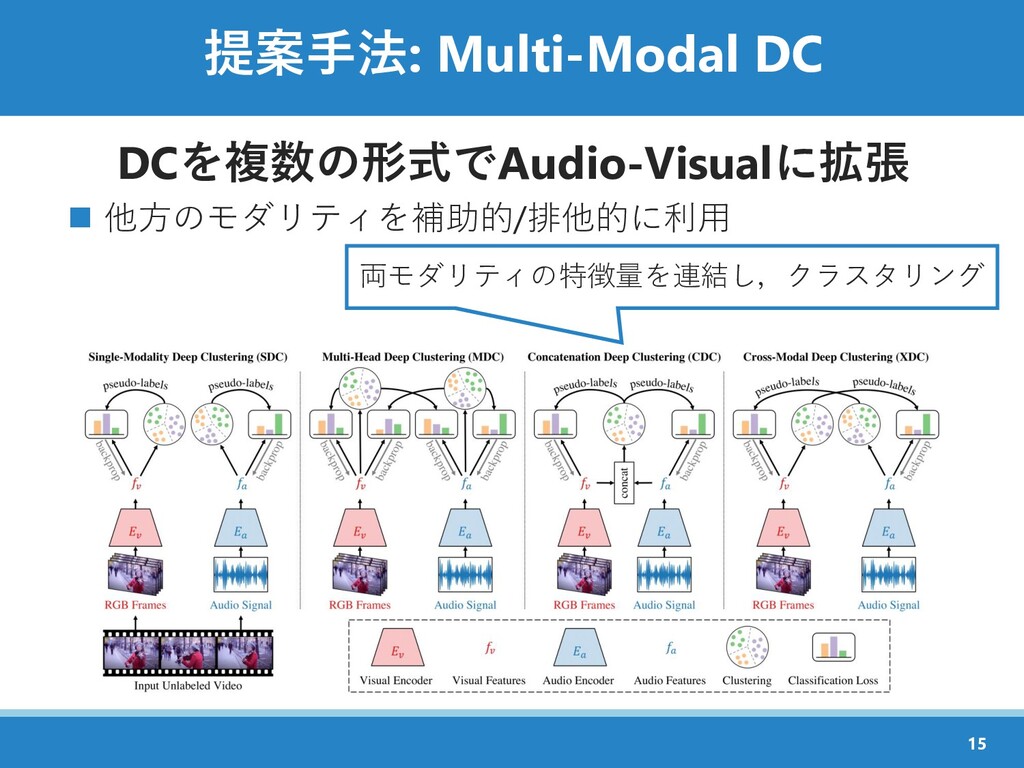{kind=link}
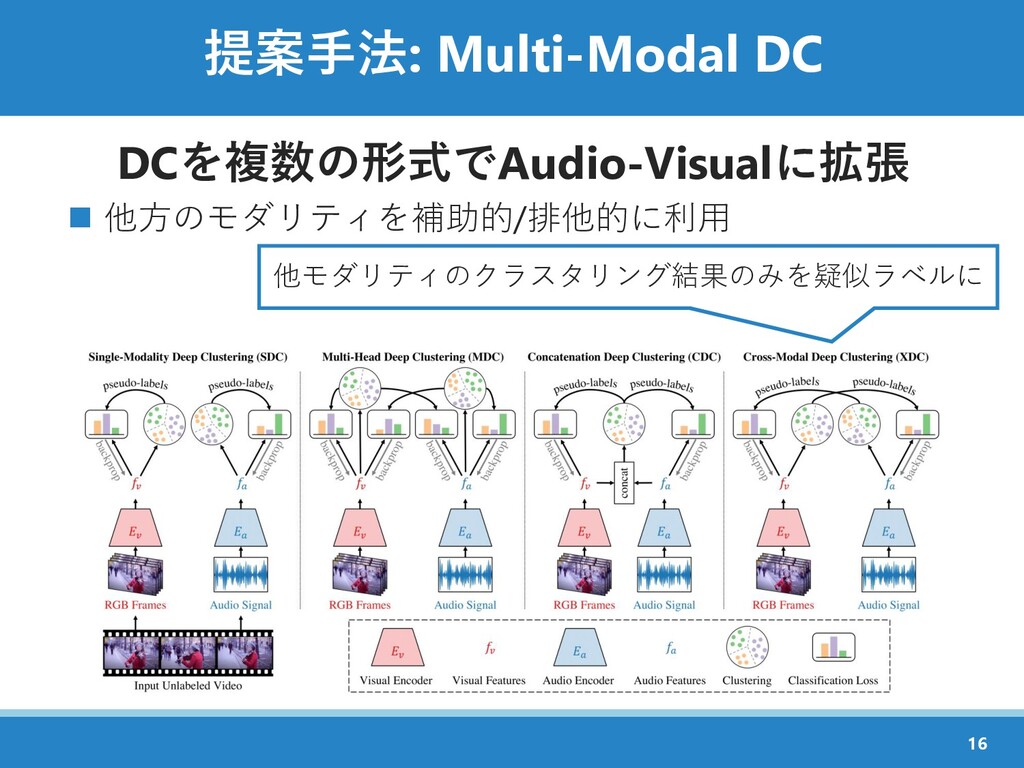{kind=link}
{kind=link}
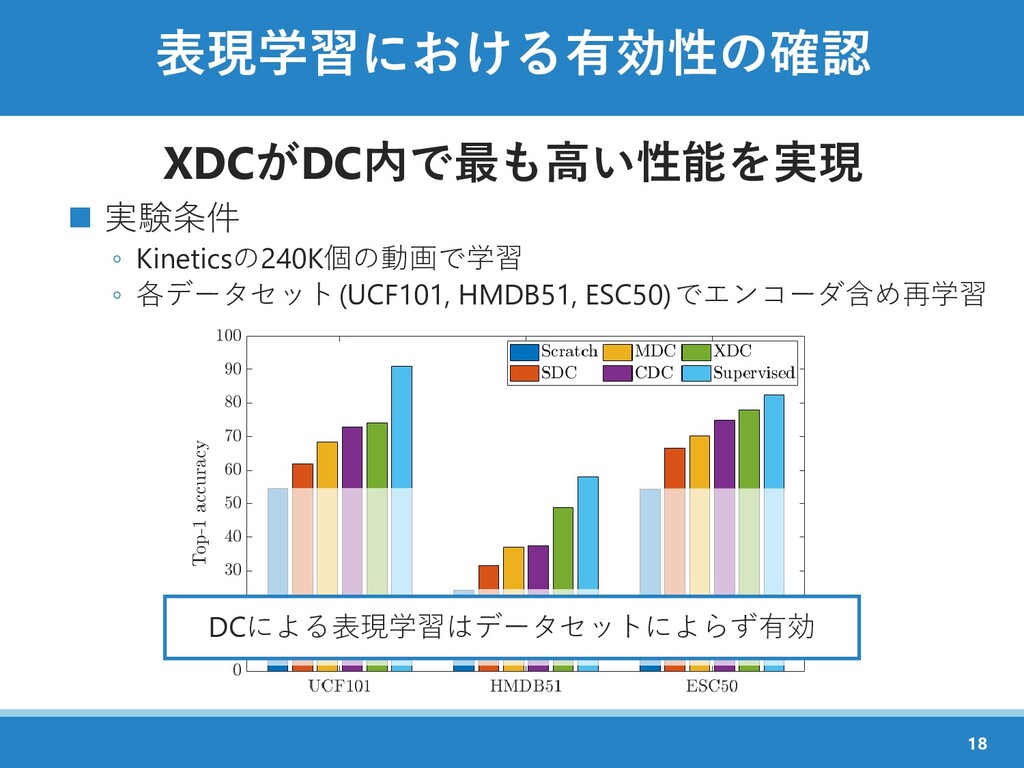{kind=link}
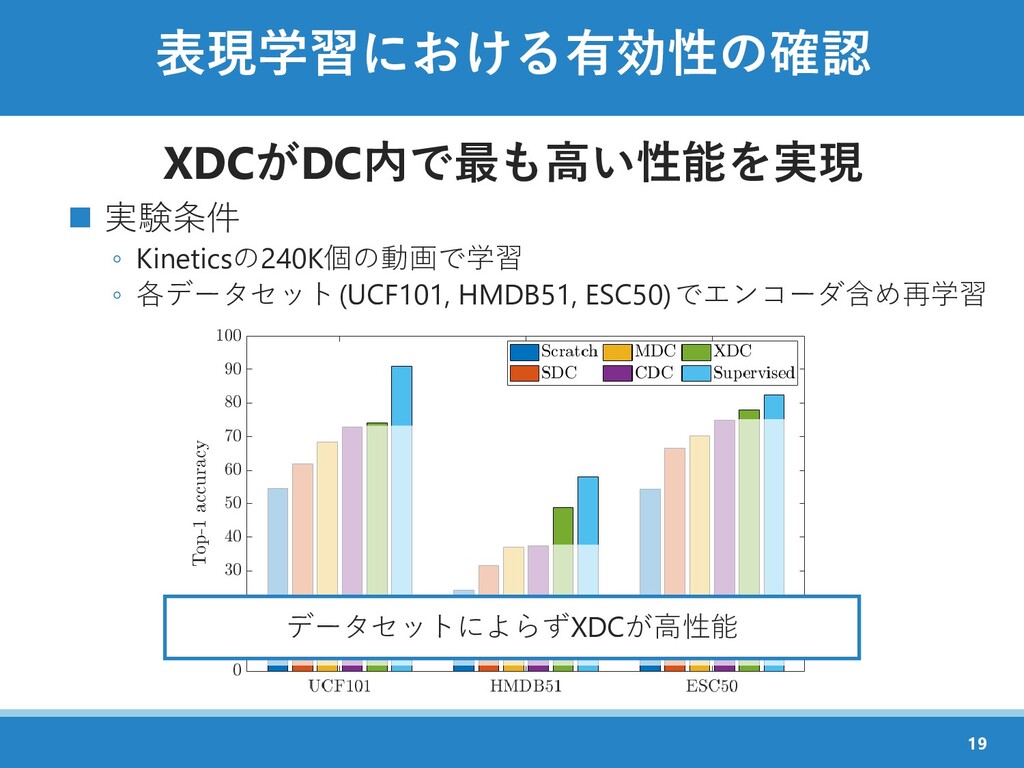{kind=link}
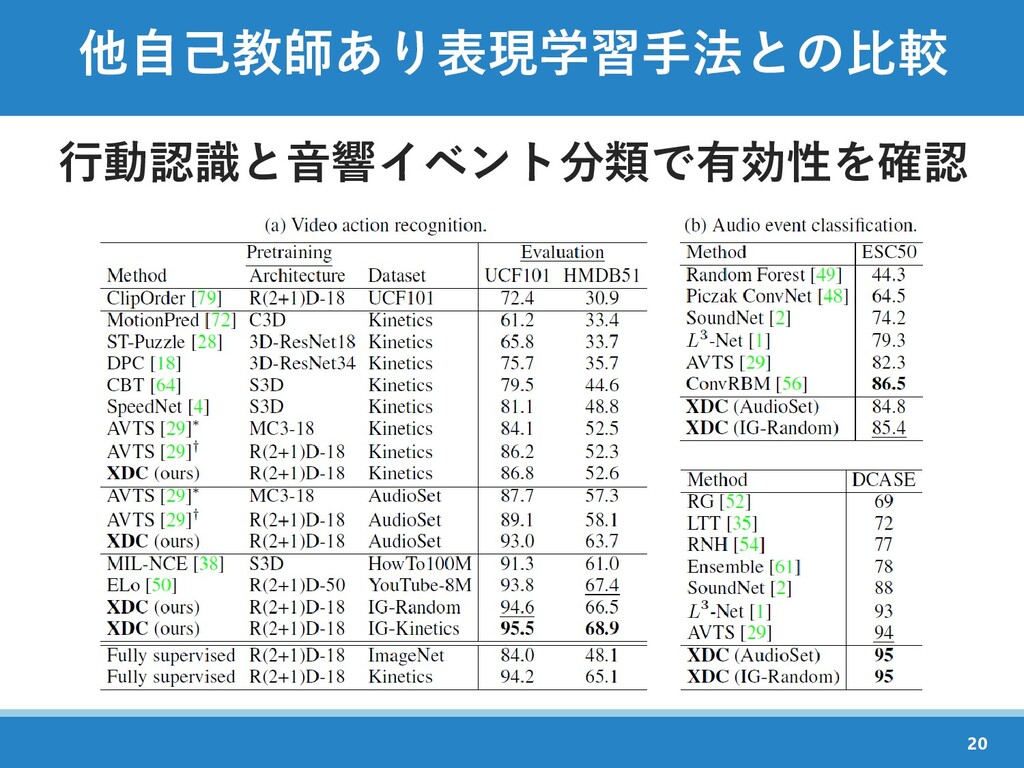{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
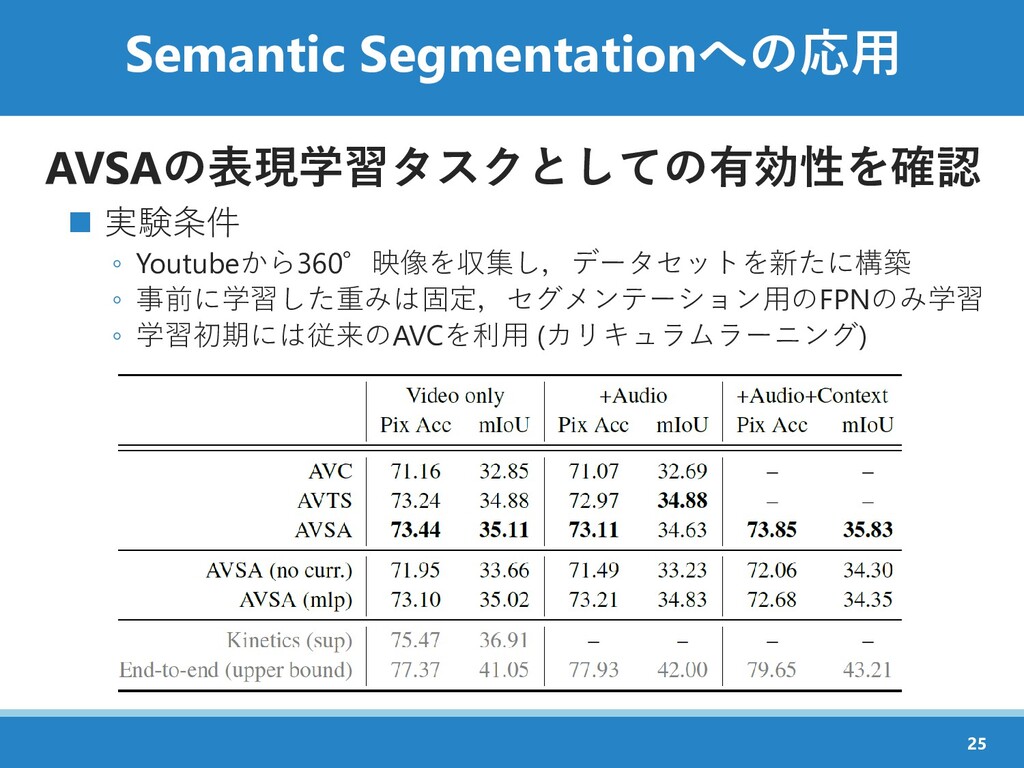{kind=link}
{kind=link}
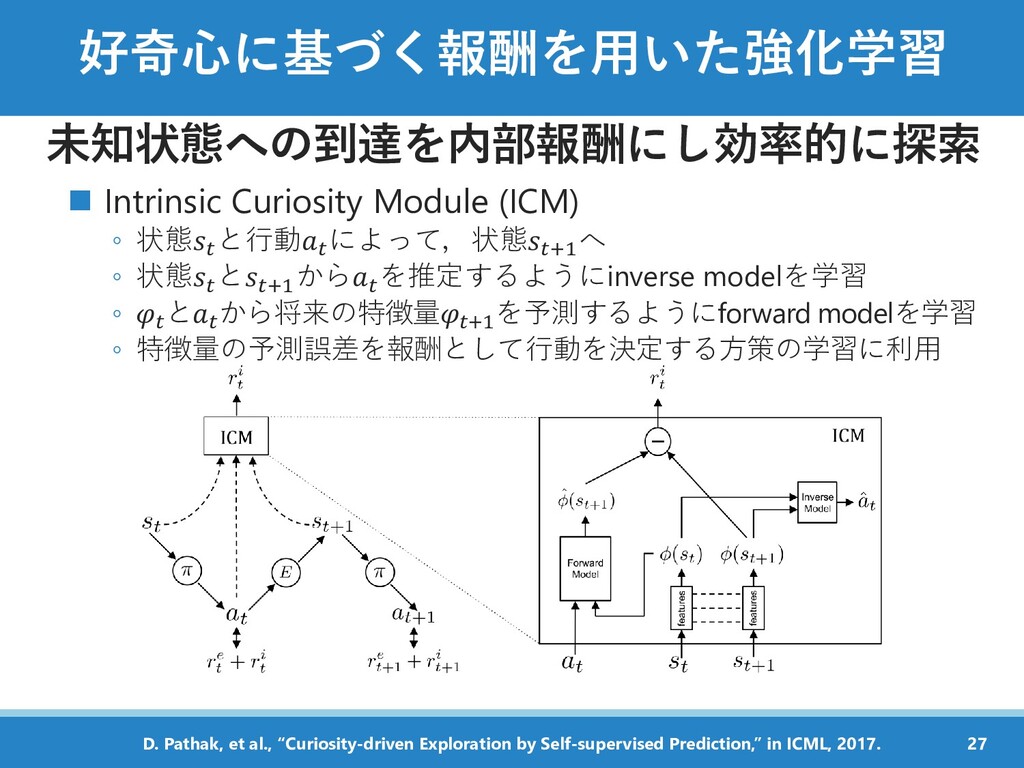{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}