Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Generative Models for Audio Signal Modeling
Search
Yoshiki Masuyama
June 25, 2020
Research
740
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Generative Models for Audio Signal Modeling
Yoshiki Masuyama
June 25, 2020
More Decks by Yoshiki Masuyama
See All by Yoshiki Masuyama
Phase reconstruction by integrating deep learning and signal processing
ymas0315
0
3.6k
Audio-Visual Learning in NeurIPS2020
ymas0315
0
740
Trends in Deep Generative model and Self-supervised Learning at NeurIPS2019
ymas0315
3
2.6k
Other Decks in Research
See All in Research
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
140
nlp2026 In-Context Learningに基づく経路案内のための地理的知識の活用方法に関する検討
takashiinui
0
110
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
510
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
210
Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
satai
3
120
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
600
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
410
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
240
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
120
Featured
See All Featured
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
GitHub's CSS Performance
jonrohan
1033
470k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2.1k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
780
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Designing Experiences People Love
moore
143
24k
Discover your Explorer Soul
emna__ayadi
2
1.2k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
41k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
Generative models for audio signal modeling 升山義紀 1 早稲田大学 及川研究室
自己紹介 2 • 升山義紀 @ymas0315 – 経歴 • 2015.04-2019.03 早稲田大学
基幹理工学部 • 2019.03-現在 同大学院 • 2019.02-2019.09 インターン/アルバイト@LINE • 2019.08-2019.10 インターン@AIST – 研究テーマ • 音響信号処理 (音声強調・分離,位相復元) – 興味のある分野 • クロスモーダル (2.5D Visual Sound, サーベイ発表)
本スライドの内容は個人の解釈であり,誤りの可能性があります. 紹介中の論文および著者ページから図を引用する場合,引用元の 記載を省略します. 3
発表内容 4 • 音響信号の生成モデルとその応用 1. 波形の生成モデル • WaveNet以降の発展 • 画像分野での関連研究との比較
2. スペクトログラムの生成モデル • 高精度なモデリングへ 3. 応用分野 • 音声強調・分離 • 声質変換
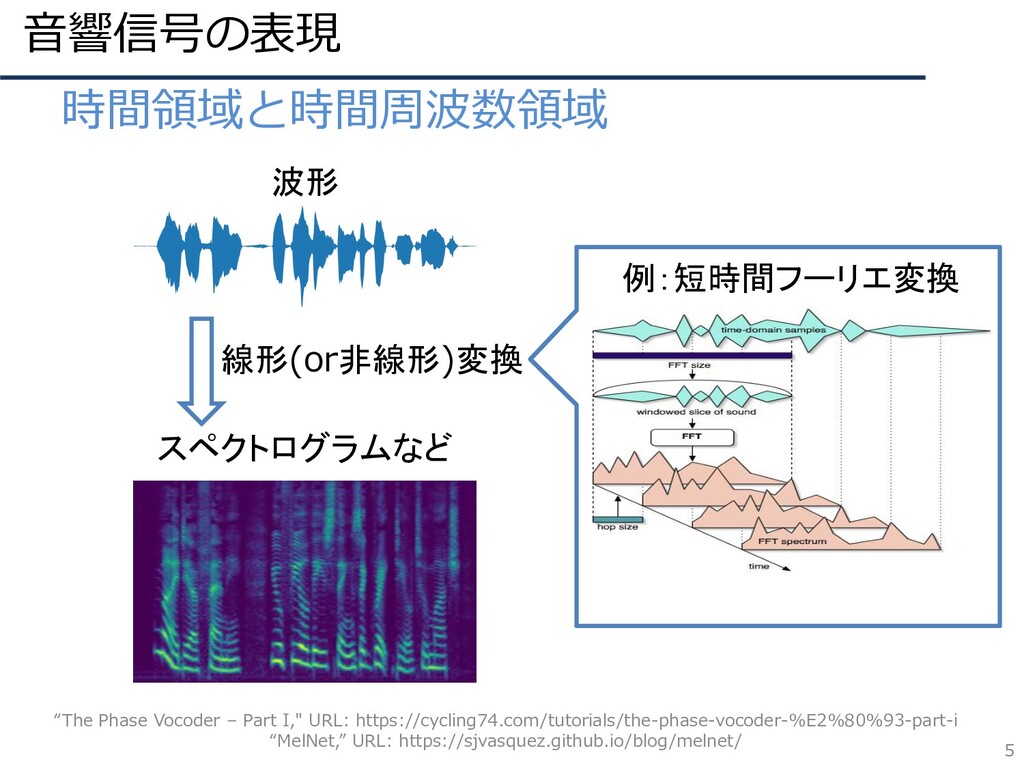
音響信号の表現 5 • 時間領域と時間周波数領域 “The Phase Vocoder – Part I,"
URL: https://cycling74.com/tutorials/the-phase-vocoder-%E2%80%93-part-i “MelNet,” URL: https://sjvasquez.github.io/blog/melnet/ 波形 スペクトログラムなど 線形(or非線形)変換 例:短時間フーリエ変換
発表内容 6 • 音響信号の生成モデルとその応用 1. 波形の生成モデル • WaveNet以降の発展 • 画像分野での関連研究との比較
2. スペクトログラムの生成モデル • より高精度なモデリングへ 3. 応用分野 • 音声強調・分離 • 声質変換
波形のモデルリング 7 • 音声信号の特徴を捉えるための課題 – 長期に渡る依存関係 – 隣接したサンプル間の強い相関 "WaveNet: A
generative model for raw audio," URL: https://deepmind.com/blog/article/wavenet-generative- model-raw-audio
変遷 8 • WaveNet以降の主な手法 – 自己回帰生成モデルを避け推論を高速化 WaveNet (2016) Parallel WaveNet
(2017) WaveRNN (2018) ClariNet (2018) FloWaveNet (2018) WaveGlow (2018) Real NVP (2016) Glow (2018) IAF (2016) PixelRNN (2016) PixelCNN (2016) PixelCNN++ (2017) Autoregressive IAF Direct flow
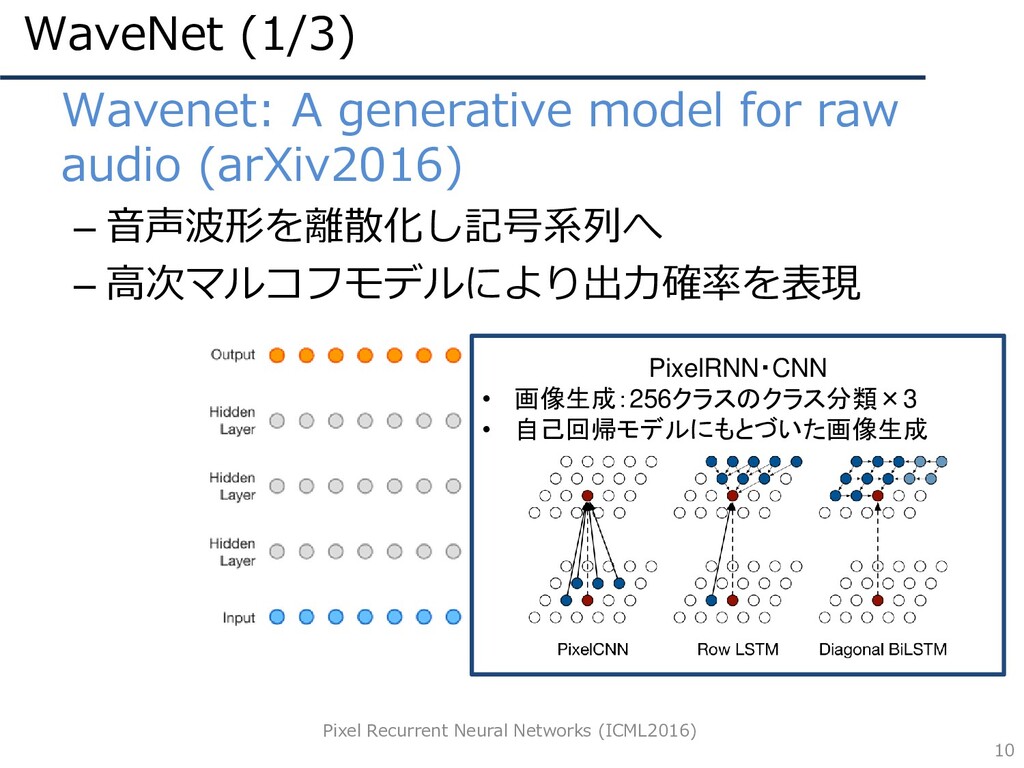
WaveNet (1/3) 9 • Wavenet: A generative model for raw
audio (arXiv2016) – 音声波形を離散化し記号系列へ – 高次マルコフモデルにより出力確率を表現
WaveNet (1/3) 10 • Wavenet: A generative model for raw
audio (arXiv2016) – 音声波形を離散化し記号系列へ – 高次マルコフモデルにより出力確率を表現 Pixel Recurrent Neural Networks (ICML2016) PixelRNN・CNN • 画像生成:256クラスのクラス分類×3 • 自己回帰モデルにもとづいた画像生成
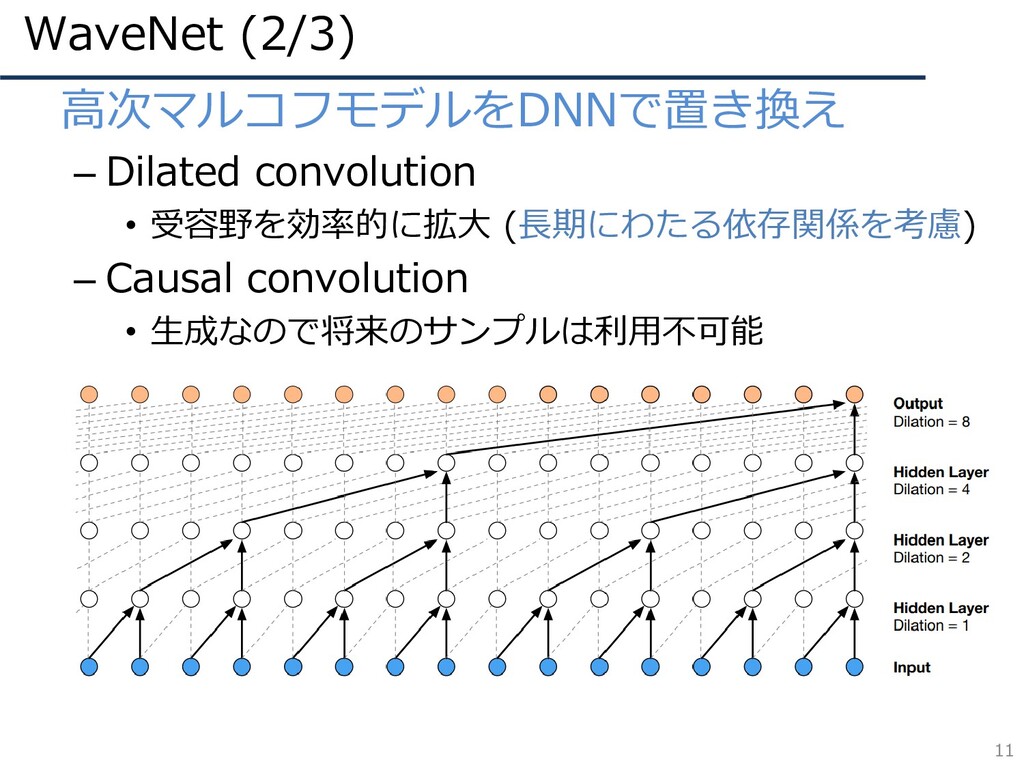
WaveNet (2/3) 11 • 高次マルコフモデルをDNNで置き換え – Dilated convolution • 受容野を効率的に拡大
(長期にわたる依存関係を考慮) – Causal convolution • 生成なので将来のサンプルは利用不可能
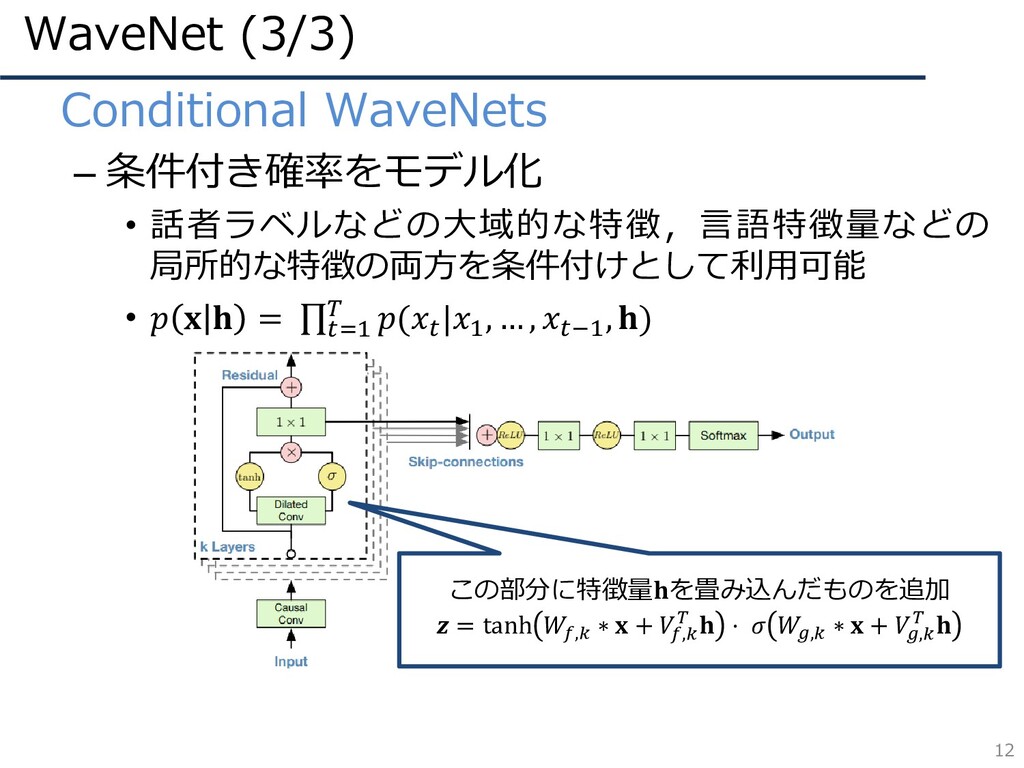
WaveNet (3/3) 12 • Conditional WaveNets – 条件付き確率をモデル化 • 話者ラベルなどの大域的な特徴,言語特徴量などの
局所的な特徴の両方を条件付けとして利用可能 • = ς=1 ( |1 , … , −1 , ) この部分に特徴量を畳み込んだものを追加 = tanh , ∗ + , ⋅ , ∗ + ,
WaveRNN 13 • Efficient Neural Audio Synthesis (ICLR2019) – WaveNetの課題:ネットワークが巨大
– WaveRNN:GRU+2Denseという小規模モデル (特徴づけがあれば小規模DNNで十分?) 他にも音質保持+高速化のテクニック多数 • Dual softmax (上位8bit・下位8bitをわける) • 重みのプルーニング (Sparse WaveRNN) • 生成方法の工夫 (Subscale WaveRNN)
Parallel WaveNet (1/3) 14 • Parallel WaveNet: Fast High-Fidelity Speech
Synthesis (ICML2018) – WaveNetの課題: • 自己回帰モデルのため推論が並列にできず生成が遅い – Parallel WaveNet: • Inverse Autoregressive flowを用いることで並列に 推論可能 • 教師として利用するWaveNet自体の性能も改善 PixelCNN++ • PixelCNN:softmaxを利用 • PixelCNN++: • mixture of logisticsのパラメータを推定 ⇒ クラス数≠推定すべきパラメータ数
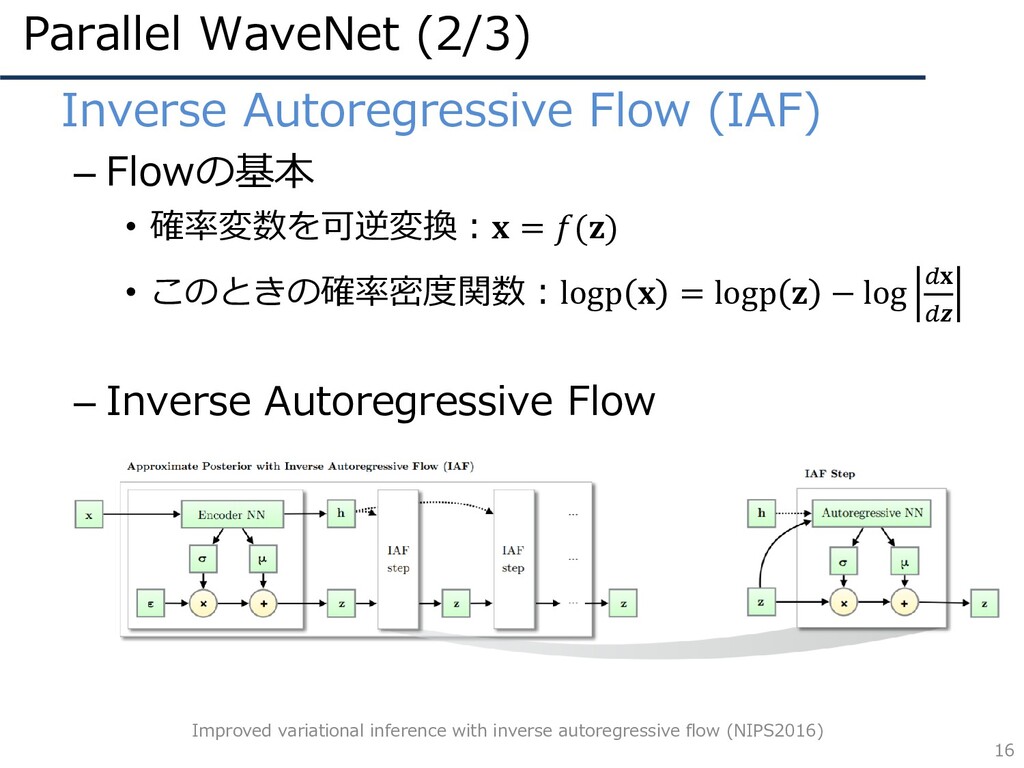
Parallel WaveNet (2/3) 15 • Inverse Autoregressive Flow (IAF) –
Flowの基本 • 確率変数を可逆変換: = () • このときの確率密度関数:logp = logp − log – Inverse Autoregressive Flow • 変数変換を以下のように定義 = ∙ < , + < , • AutoregressiveNNだと が効率的に可能 (ヤコビアンの対角要素の積になり(3) → ())
Parallel WaveNet (2/3) 16 • Inverse Autoregressive Flow (IAF) –
Flowの基本 • 確率変数を可逆変換: = () • このときの確率密度関数:logp = logp − log – Inverse Autoregressive Flow Improved variational inference with inverse autoregressive flow (NIPS2016)
Parallel WaveNet (2/3) 17 • Inverse Autoregressive Flow (IAF) –
Flowの基本 • 確率変数を可逆変換: = () • このときの確率密度関数:logp = logp − log – Inverse Autoregressive Flow • サンプリング:並列に行うことができるため高速 • 学習:尤度の計算が遅い
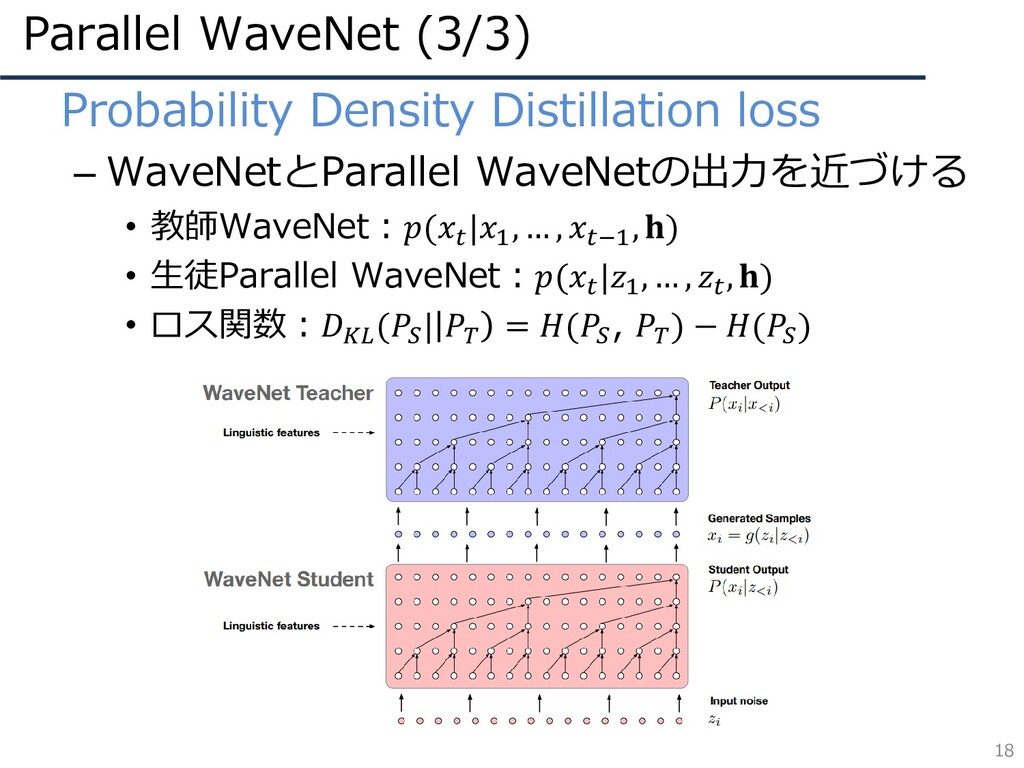
Parallel WaveNet (3/3) 18 • Probability Density Distillation loss –
WaveNetとParallel WaveNetの出力を近づける • 教師WaveNet:( |1 , … , −1 , ) • 生徒Parallel WaveNet:( |1 , … , , ) • ロス関数: ( | = ( , ) − ( )
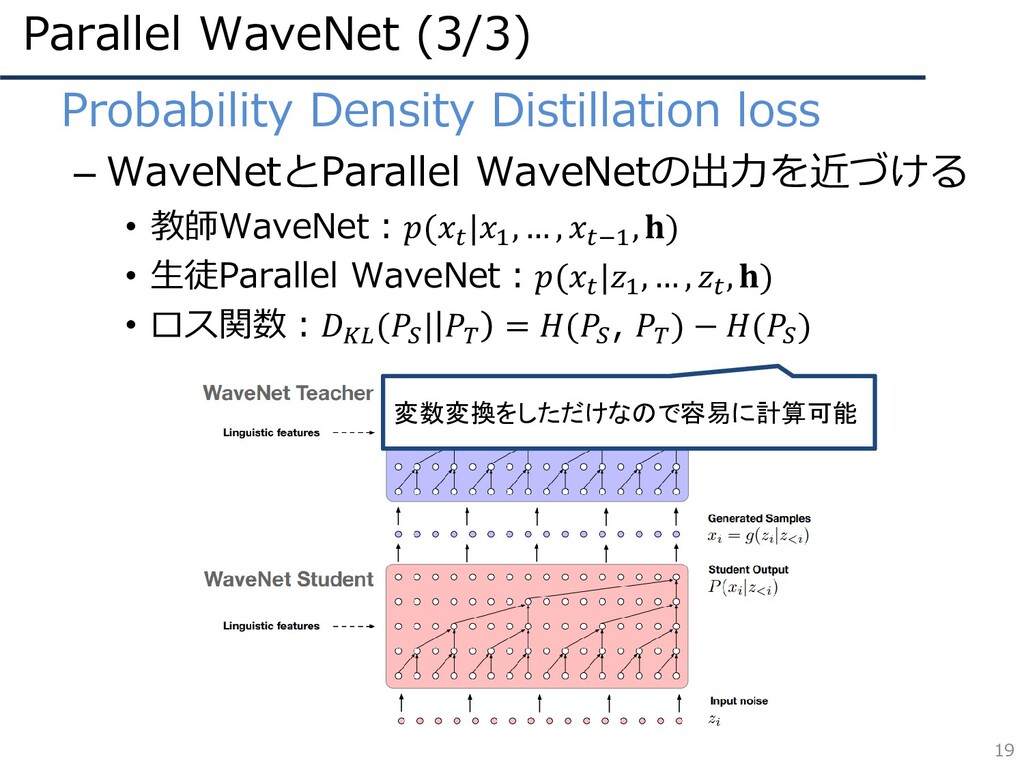
Parallel WaveNet (3/3) 19 • Probability Density Distillation loss –
WaveNetとParallel WaveNetの出力を近づける • 教師WaveNet:( |1 , … , −1 , ) • 生徒Parallel WaveNet:( |1 , … , , ) • ロス関数: ( | = ( , ) − ( ) 変数変換をしただけなので容易に計算可能
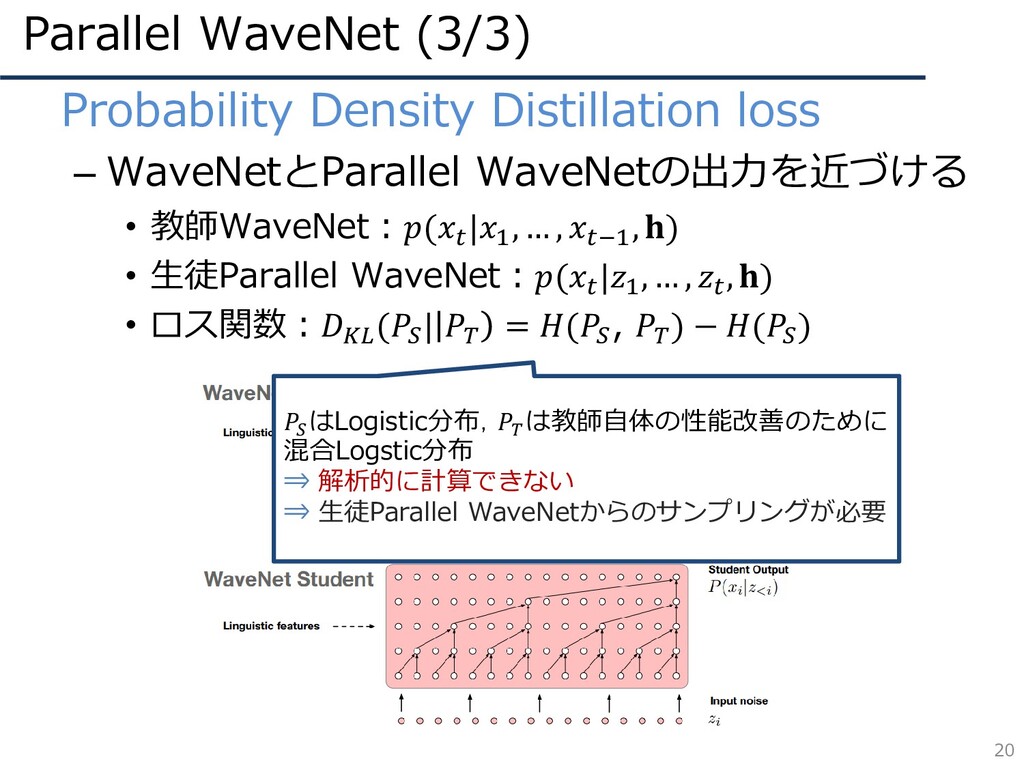
Parallel WaveNet (3/3) 20 • Probability Density Distillation loss –
WaveNetとParallel WaveNetの出力を近づける • 教師WaveNet:( |1 , … , −1 , ) • 生徒Parallel WaveNet:( |1 , … , , ) • ロス関数: ( | = ( , ) − ( ) はLogistic分布, は教師自体の性能改善のために 混合Logstic分布 ⇒ 解析的に計算できない ⇒ 生徒Parallel WaveNetからのサンプリングが必要
ClariNet 21 • ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech
(ICLR2019) – 基本的なアイデアはPralell WaveNetと同じ – ClariNet: • 教師・生徒ともにガウシアンにすることでKL疑距離 最小化が解析的に計算可能 ⇒ サンプリングを回避することで学習が安定 ( | = log + 2 − 2 + − 2 2 • 分散の対数値の二乗誤差をによる正則化を追加
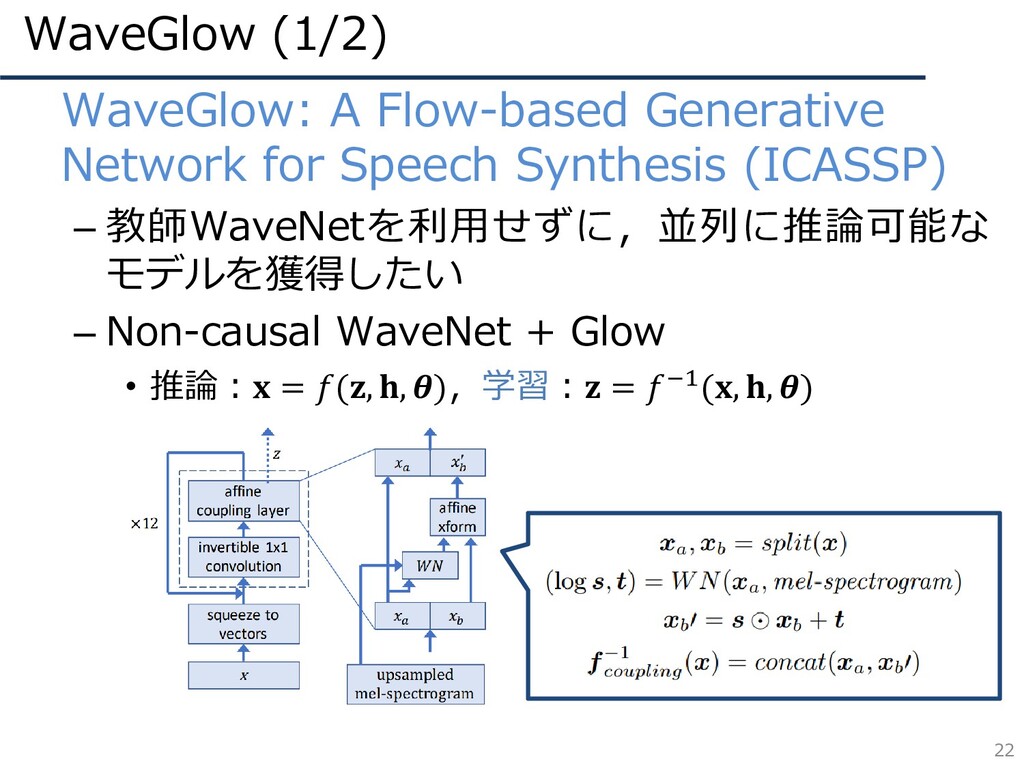
WaveGlow (1/2) 22 • WaveGlow: A Flow-based Generative Network for
Speech Synthesis (ICASSP) – 教師WaveNetを利用せずに,並列に推論可能な モデルを獲得したい – Non-causal WaveNet + Glow • 推論: = (, , ),学習: = −1(, , )
WaveGlow (2/2) 23 • WaveGlow: A Flow-based Generative Network for
Speech Synthesis (ICASSP) – 教師WaveNetを利用せずに,並列に推論可能な モデルを獲得したい – Non-causal WaveNet + Glow • 推論: = (, , ),学習: = −1(, , ) 1×1 invertible convolution • Affine coupling layer のみではチャンネル間の情報は お互いに影響されない • Glowでは1×1 convolutionでチャンネル間の情報を混合
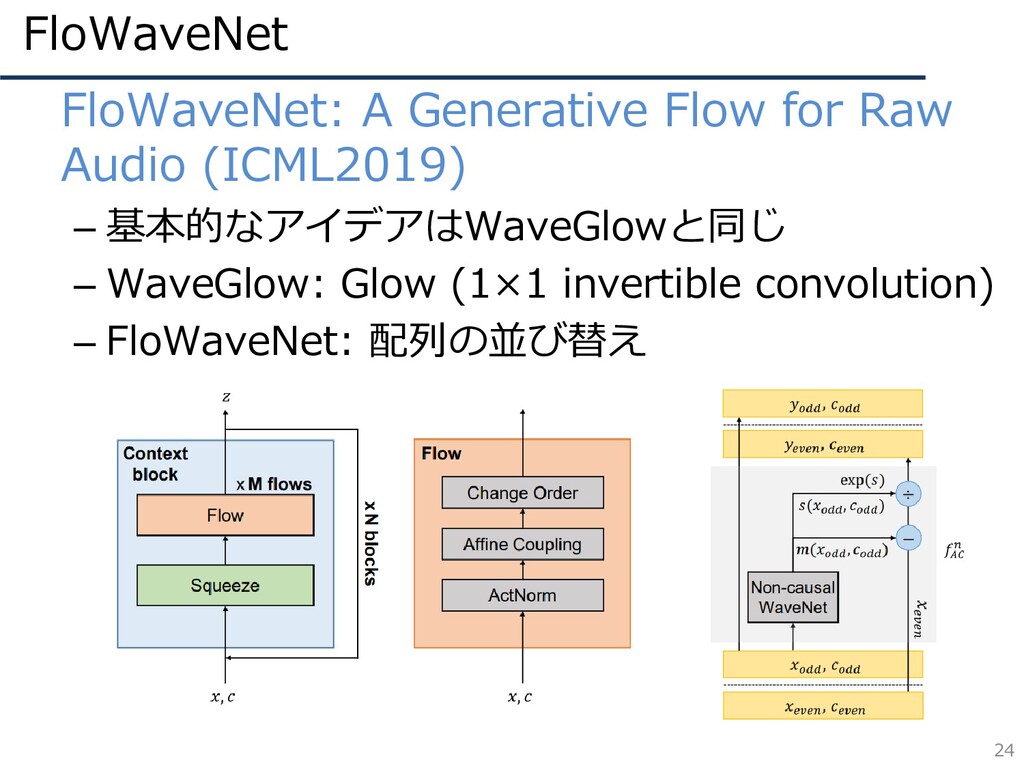
FloWaveNet 24 • FloWaveNet: A Generative Flow for Raw Audio
(ICML2019) – 基本的なアイデアはWaveGlowと同じ – WaveGlow: Glow (1×1 invertible convolution) – FloWaveNet: 配列の並び替え
発表内容 25 • 音響信号の生成モデルとその応用 1. 波形の生成モデル • WaveNet以降の発展 • 画像分野での関連研究との比較
2. スペクトログラムの生成モデル • より高精度なモデリングへ 3. 応用分野 • 音声強調・分離 • 声質変換
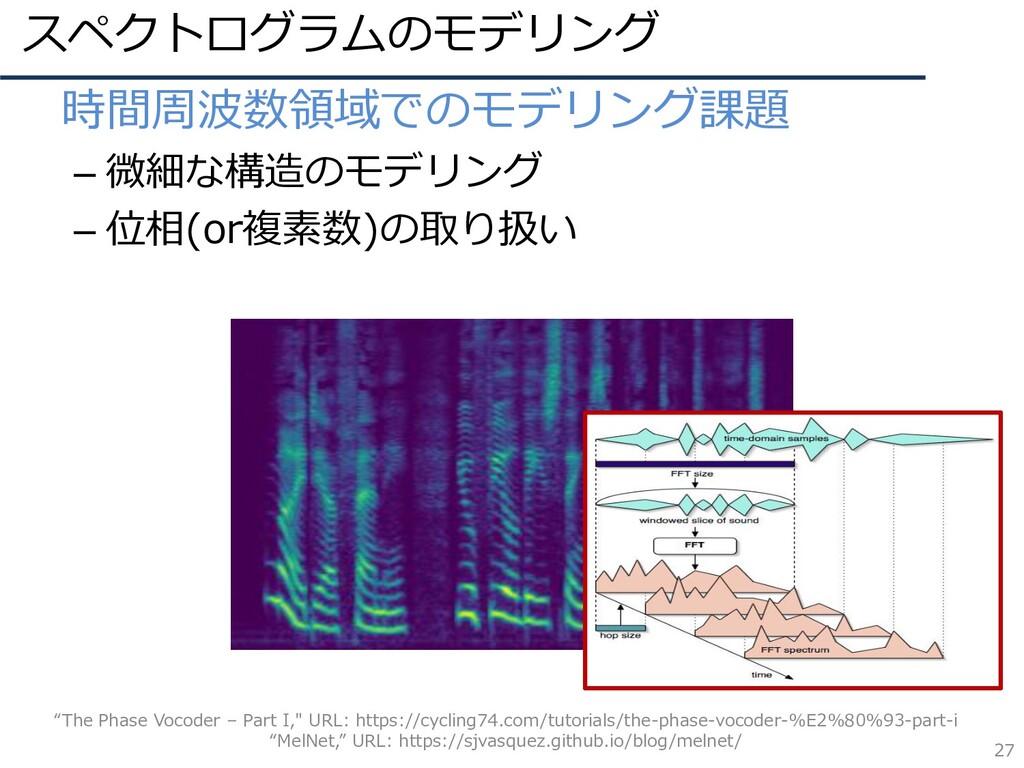
スペクトログラムのモデリング 26 • 時間周波数領域でのモデリング課題 – 微細な構造のモデリング – 位相(or複素数)の取り扱い “The Phase
Vocoder – Part I," URL: https://cycling74.com/tutorials/the-phase-vocoder-%E2%80%93-part-i “MelNet,” URL: https://sjvasquez.github.io/blog/melnet/
スペクトログラムのモデリング 27 • 時間周波数領域でのモデリング課題 – 微細な構造のモデリング – 位相(or複素数)の取り扱い “The Phase
Vocoder – Part I," URL: https://cycling74.com/tutorials/the-phase-vocoder-%E2%80%93-part-i “MelNet,” URL: https://sjvasquez.github.io/blog/melnet/
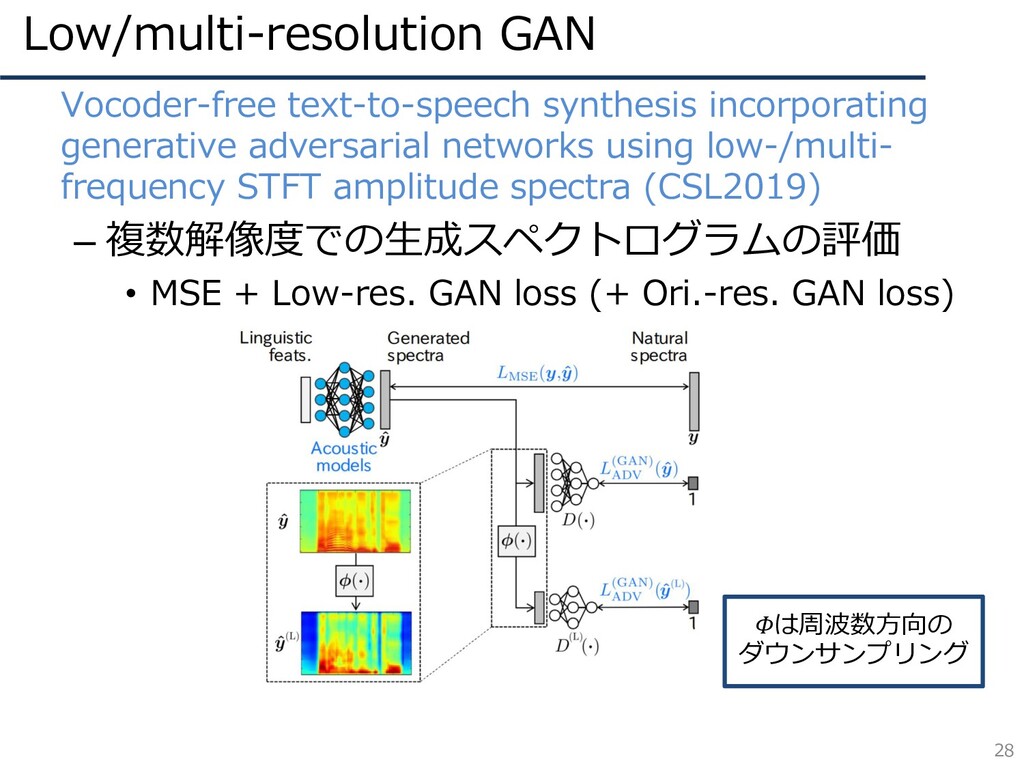
Low/multi-resolution GAN 28 • Vocoder-free text-to-speech synthesis incorporating generative adversarial
networks using low-/multi- frequency STFT amplitude spectra (CSL2019) – 複数解像度での生成スペクトログラムの評価 • MSE + Low-res. GAN loss (+ Ori.-res. GAN loss) Φは周波数方向の ダウンサンプリング
MelNet (1/2) 29 • MelNet: A Generative Model for Audio
in the Frequency Domain (arXiv2019) – より高精度なスペクトログラムのモデリング • 従来より冗長な時間周波数解像度 • スムージングを避けたい ⇒ 自己回帰モデルを適用 • 局所・大域的構造 ⇒ Coarse-to-fine (多段の生成) 4つのRNNでコンテキストをエンコード
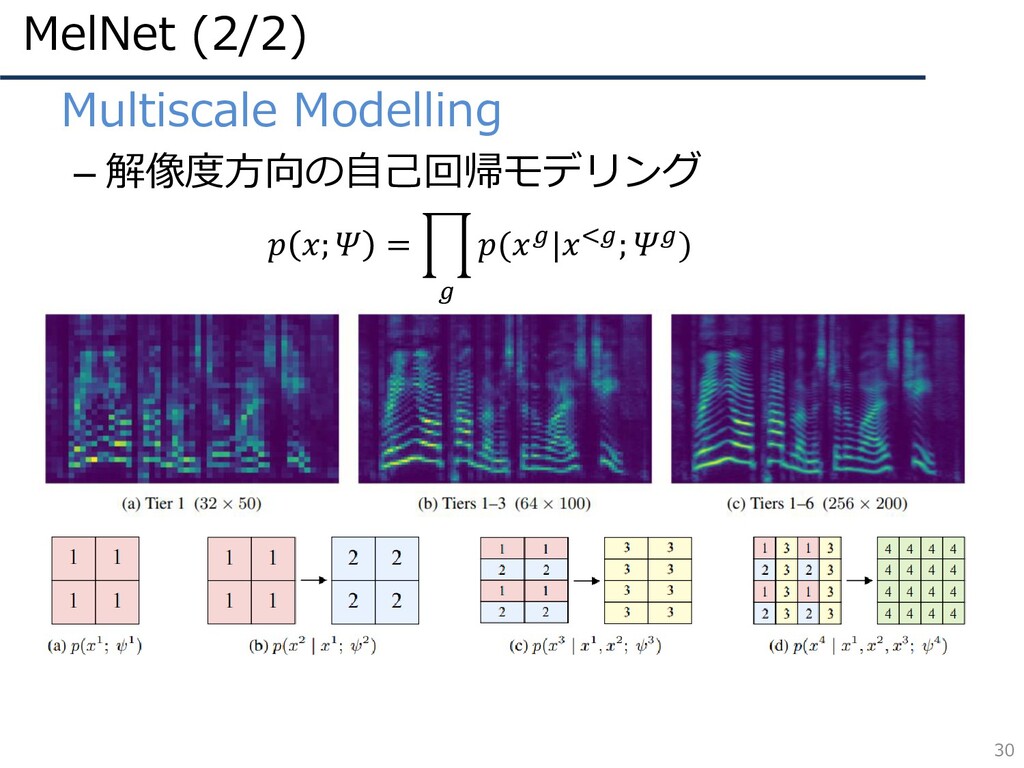
MelNet (2/2) 30 • Multiscale Modelling – 解像度方向の自己回帰モデリング ; =
ෑ (|<; )
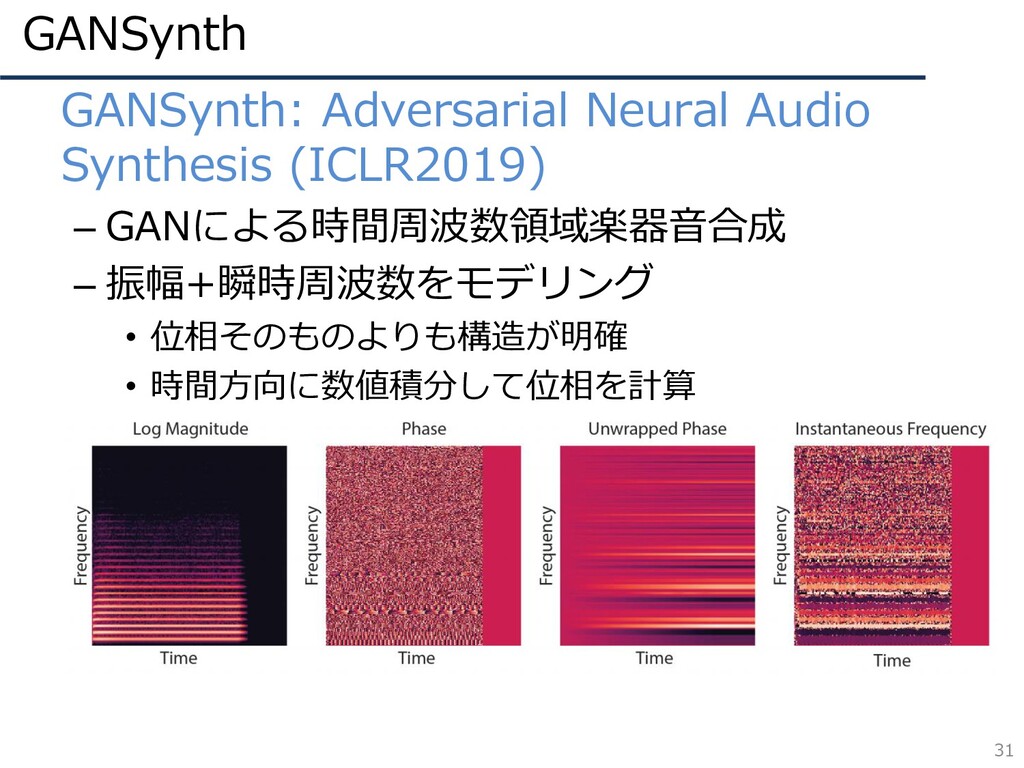
GANSynth 31 • GANSynth: Adversarial Neural Audio Synthesis (ICLR2019) –
GANによる時間周波数領域楽器音合成 – 振幅+瞬時周波数をモデリング • 位相そのものよりも構造が明確 • 時間方向に数値積分して位相を計算
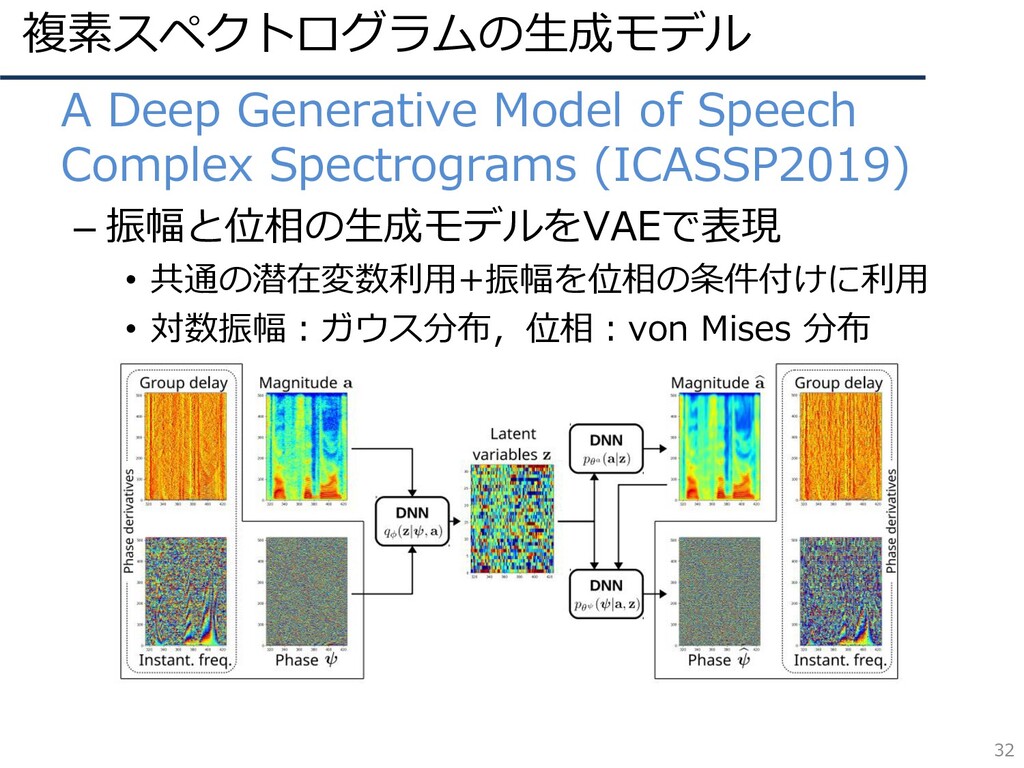
複素スペクトログラムの生成モデル 32 • A Deep Generative Model of Speech Complex
Spectrograms (ICASSP2019) – 振幅と位相の生成モデルをVAEで表現 • 共通の潜在変数利用+振幅を位相の条件付けに利用 • 対数振幅:ガウス分布,位相:von Mises 分布
発表内容 33 • 音響信号の生成モデルとその応用 1. 波形の生成モデル • WaveNet以降の発展 • 画像分野での関連研究との比較
2. スペクトログラムの生成モデル • より高精度なモデリングへ 3. 応用分野 • 音声強調・分離 • 声質変換
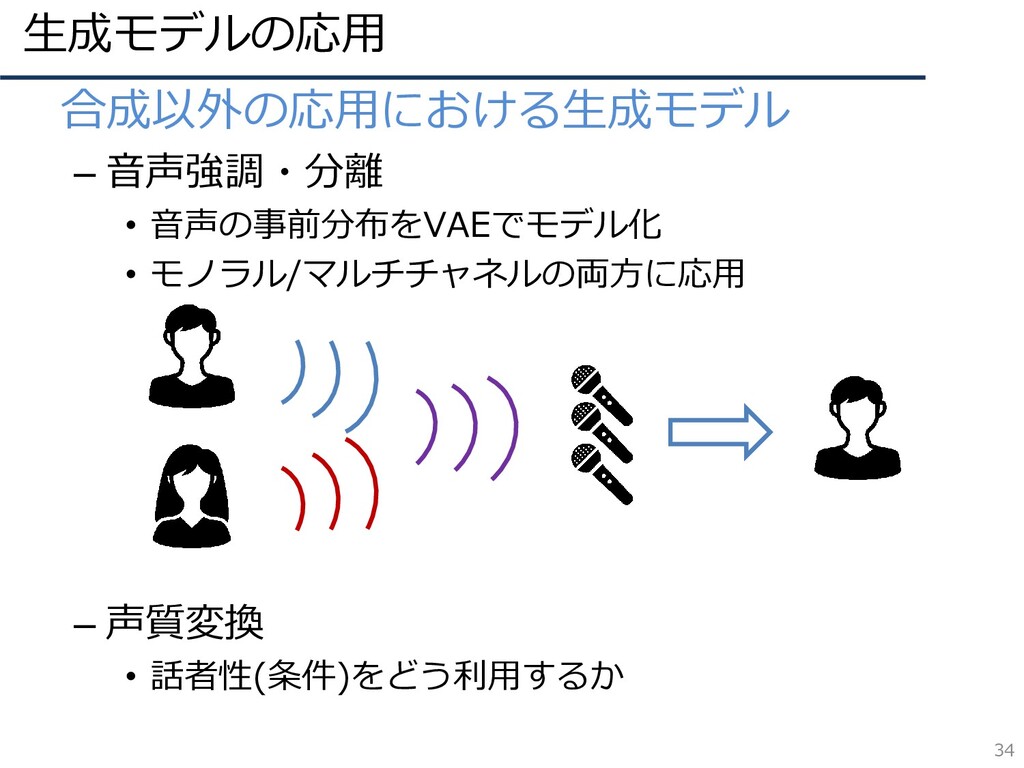
生成モデルの応用 34 • 合成以外の応用における生成モデル – 音声強調・分離 • 音声の事前分布をVAEでモデル化 • モノラル/マルチチャネルの両方に応用
– 声質変換 • 話者性(条件)をどう利用するか
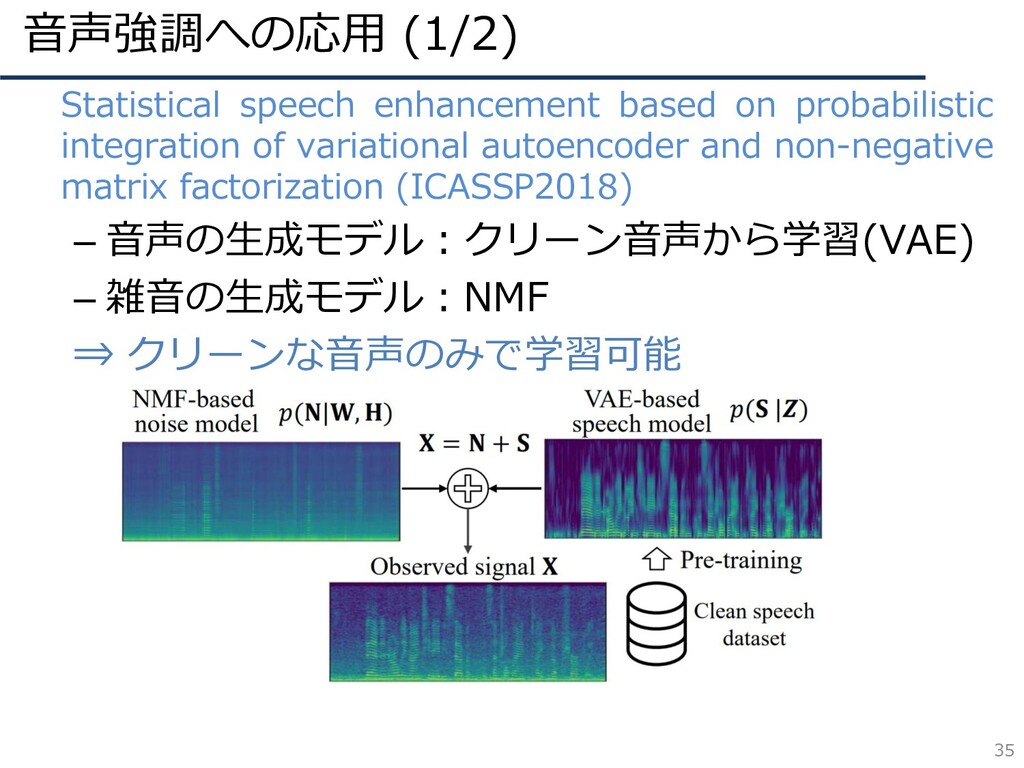
音声強調への応用 (1/2) 35 • Statistical speech enhancement based on probabilistic
integration of variational autoencoder and non-negative matrix factorization (ICASSP2018) – 音声の生成モデル:クリーン音声から学習(VAE) – 雑音の生成モデル:NMF ⇒ クリーンな音声のみで学習可能
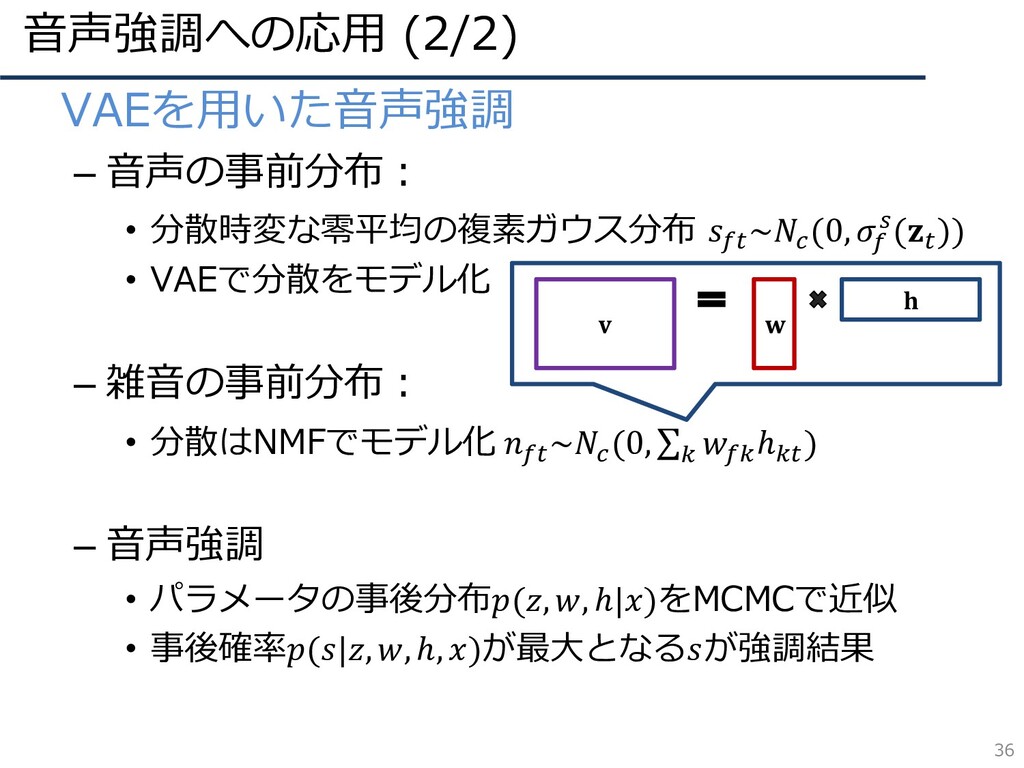
音声強調への応用 (2/2) 36 • VAEを用いた音声強調 – 音声の事前分布: • 分散時変な零平均の複素ガウス分布 ~
(0, ( )) • VAEで分散をモデル化 – 雑音の事前分布: • 分散はNMFでモデル化 ~ (0, σ ℎ ) – 音声強調 • パラメータの事後分布(, , ℎ|)をMCMCで近似 • 事後確率(|, , ℎ, )が最大となるが強調結果
音源分離への応用 (1/3) 37 • Supervised Determined Source Separation with Multichannel
Variational Autoencoder (MIT Press2019) – 複数話者の発話を複数マイクを利用し分離 – Conditional VAE • 話者ラベルで条件づけられた音声の生成モデルをcVAE のデコーダー表現 – 従来の多チャンネル信号処理+DNNのモデリング • 独立成分分析:元信号の独立性を仮定+事前分布が必要 ⇒ 事前分布のところにDNNを適用
音源分離への応用 (2/3) 38 • 独立成分分析 – 目的:混合音から元信号1 , 2 を復元
• 混合行列 は未知 (, = , ) • 分離はその逆行列 をかけることで可能 ( が可逆) – モデル • 元音源:各音源独立(, は対角行列) , ~ (0, , ) • 混合音:分離行列を使用すると以下の通り , ~ (0, −1, −) • 分離フィルタを最尤推定
音源分離への応用 (3/3) 39 • MVAE – 分散のモデリング • 時変分散,, の部分をVAEで用いてモデリング
,, = ∙ diag( 2(, )) • 潜在変数, 話者ラベル, スケールパラメータを推定 とは尤度が大きくなるように誤差逆伝播法 で更新
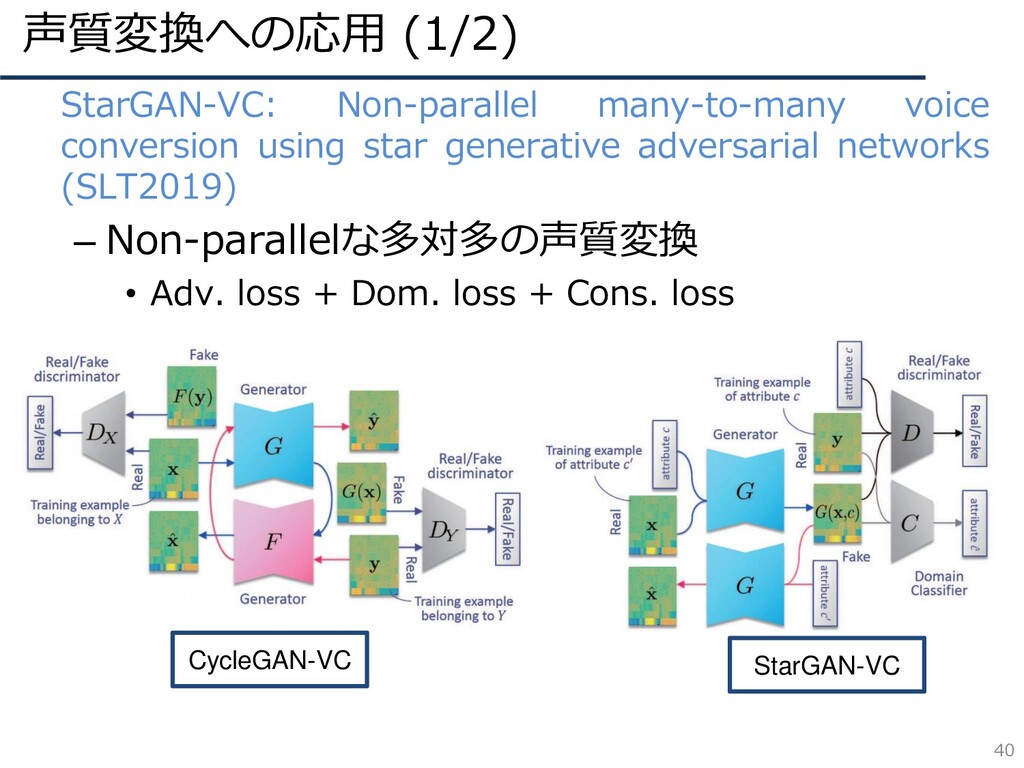
声質変換への応用 (1/2) 40 • StarGAN-VC: Non-parallel many-to-many voice conversion using
star generative adversarial networks (SLT2019) – Non-parallelな多対多の声質変換 • Adv. loss + Dom. loss + Cons. loss CycleGAN-VC StarGAN-VC
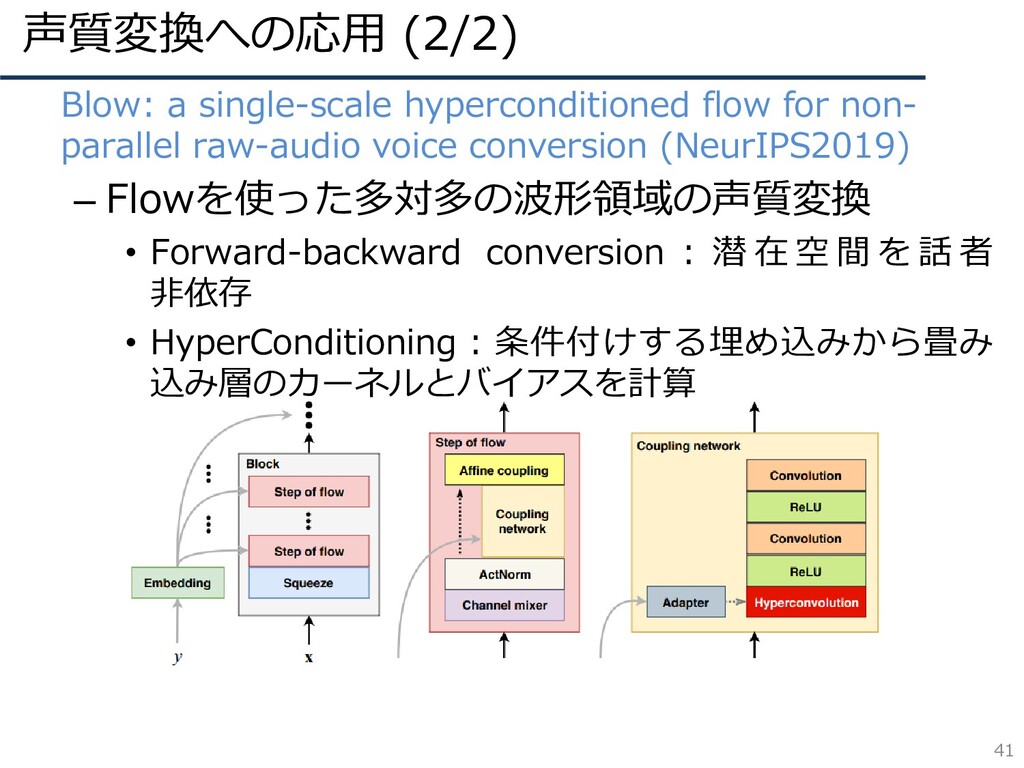
声質変換への応用 (2/2) 41 • Blow: a single-scale hyperconditioned flow for
non- parallel raw-audio voice conversion (NeurIPS2019) – Flowを使った多対多の波形領域の声質変換 • Forward-backward conversion : 潜 在 空 間 を 話 者 非依存 • HyperConditioning:条件付けする埋め込みから畳み 込み層のカーネルとバイアスを計算
Crossmodal Voice Conversion 42 • Crossmodal Voice Conversion (arXiv2019) –
クロスモーダルな生成 • 入力顔画像に合った声質に入力音声を変換 • 入力音声の声質に適合した顔画像を生成 Speech2Face(CVPR2019)は声→顔のみ
まとめ 43 • 音響信号の生成モデルとその応用 1. 波形の生成モデル • Auto regressive modelからFlowへ
2. スペクトログラムの生成モデル • 高精度なモデリングへ(GANやAuto regressive model) 3. 応用分野 • 音声強調・分離(複素ガウス分布の分散の生成モデル) • 声質変換
Interspeech2019 44
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}