default database API ◦ Powerful RDBMS capabilities: matches Oracle features ◦ Robust and mature: hardened over 30 years ◦ Fully open source: permissive license, large community ◦ Cloud providers adopting: managed services on all clouds “Most popular database” of 2022 “DBMS of the year” over multiple years 2017 2018 2020
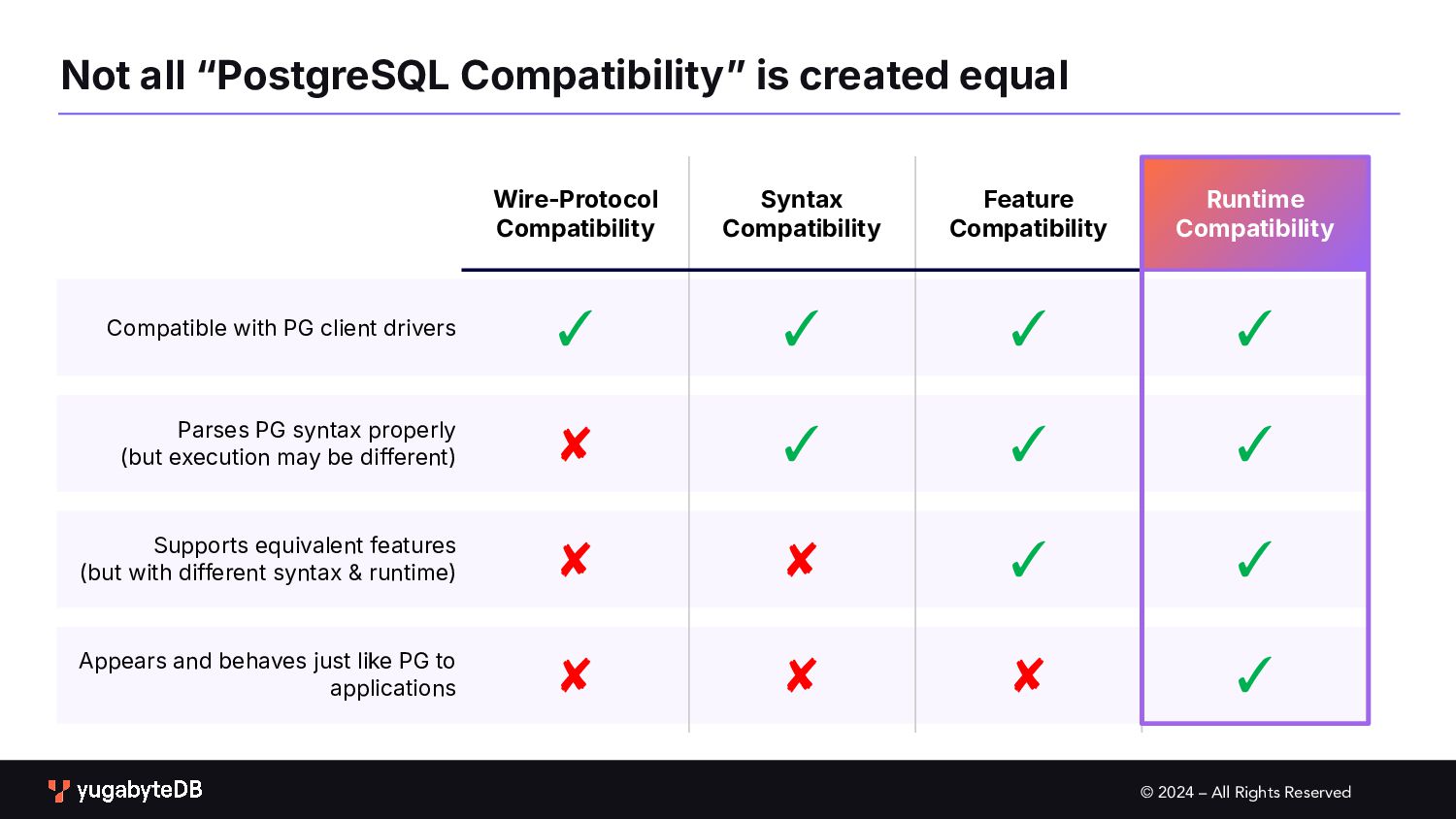
Feature Compatibility Runtime Compatibility Compatible with PG client drivers ✓ ✓ ✓ ✓ Parses PG syntax properly (but execution may be different) ✘ ✓ ✓ ✓ Supports equivalent features (but with different syntax & runtime) ✘ ✘ ✓ ✓ Appears and behaves just like PG to applications ✘ ✘ ✘ ✓ Not all “PostgreSQL Compatibilityˮ is created equal
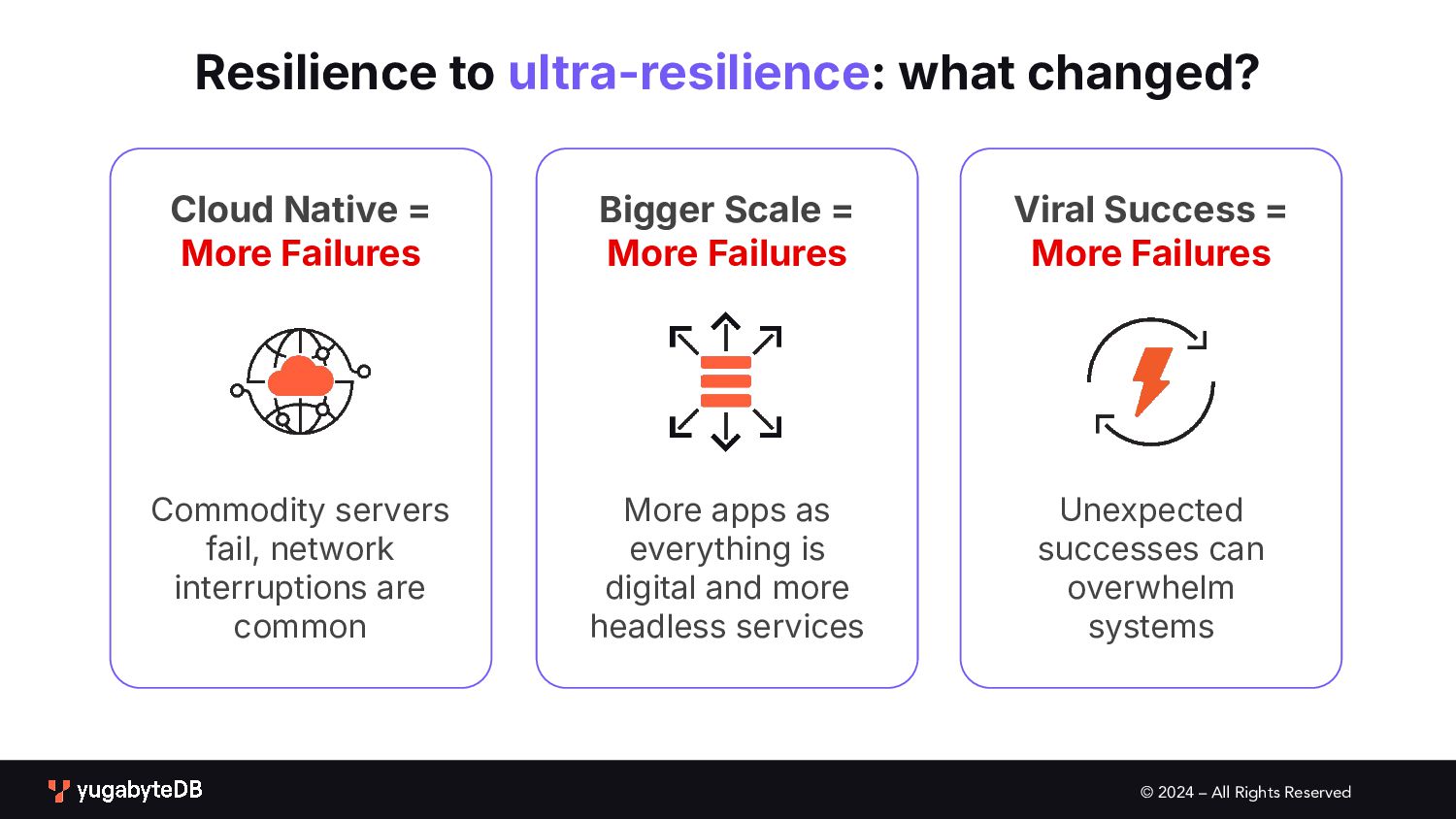
interruptions are common More apps as everything is digital and more headless services Unexpected successes can overwhelm systems Resilience to ultra-resilience: what changed? Cloud Native = More Failures Bigger Scale = More Failures Viral Success = More Failures
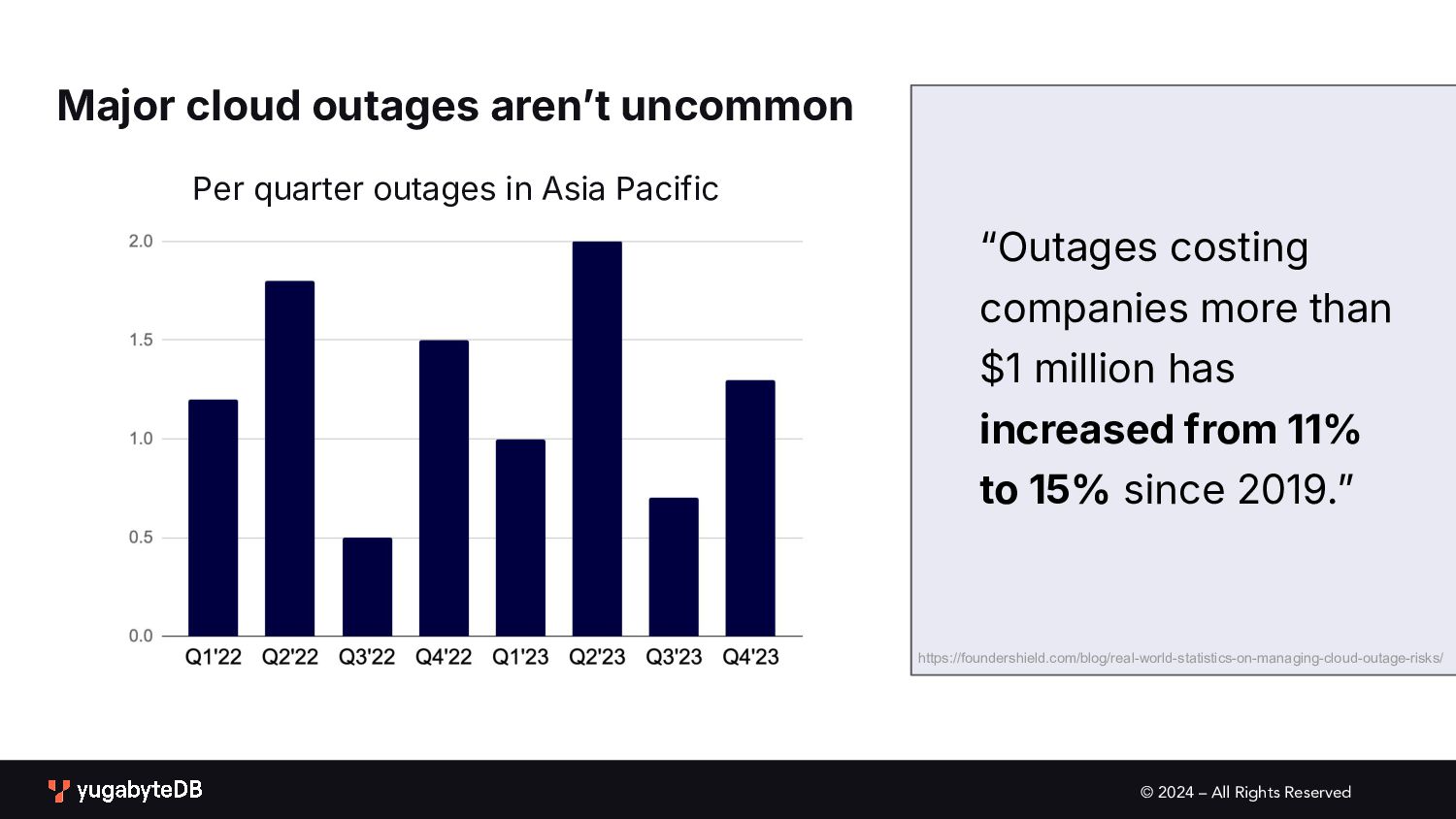
uncommon Per quarter outages in Asia Pacific “Outages costing companies more than $1 million has increased from 11% to 15% since 2019.ˮ https://foundershield.com/blog/real-world-statistics-on-managing-cloud-outage-risks/
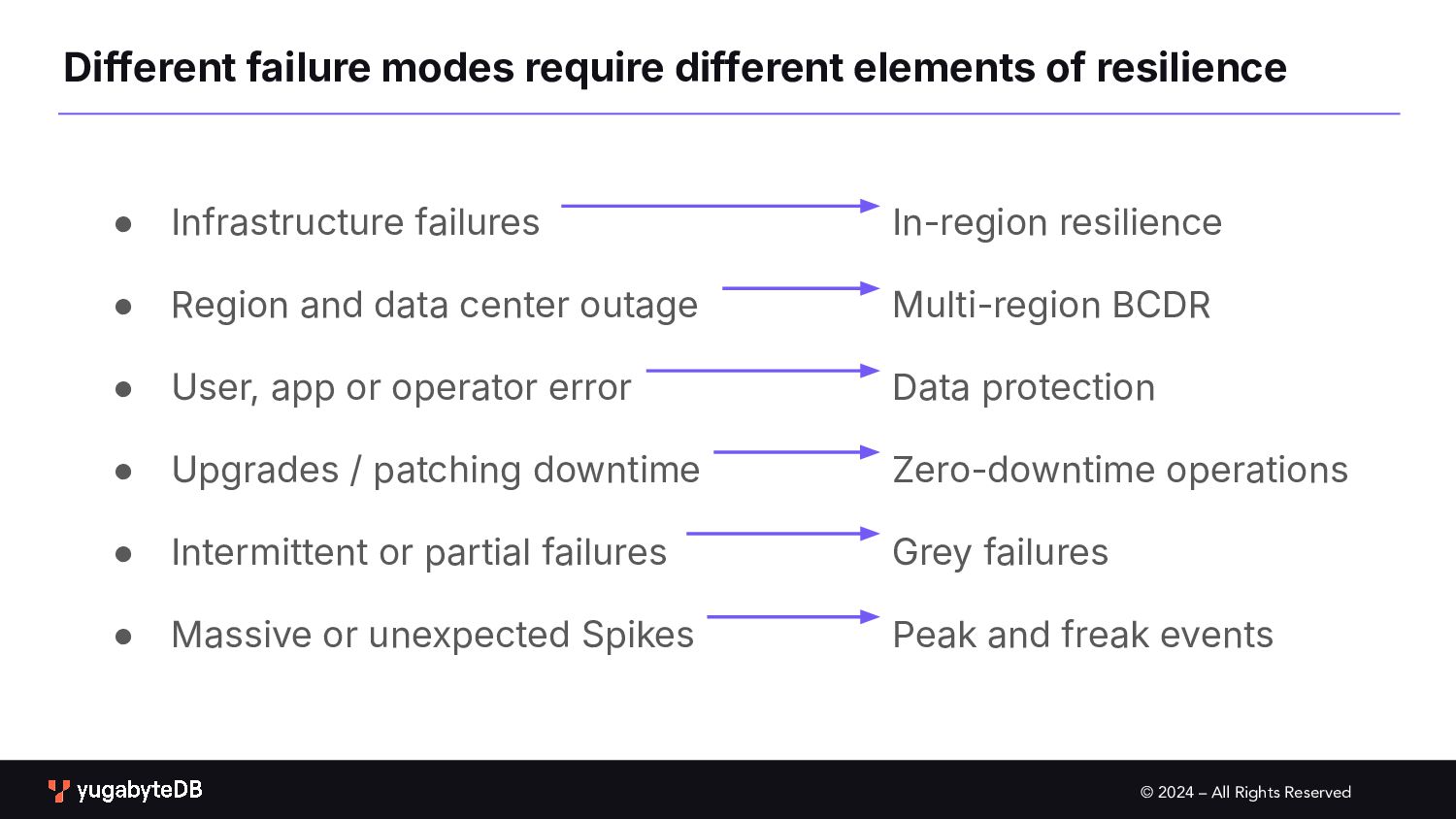
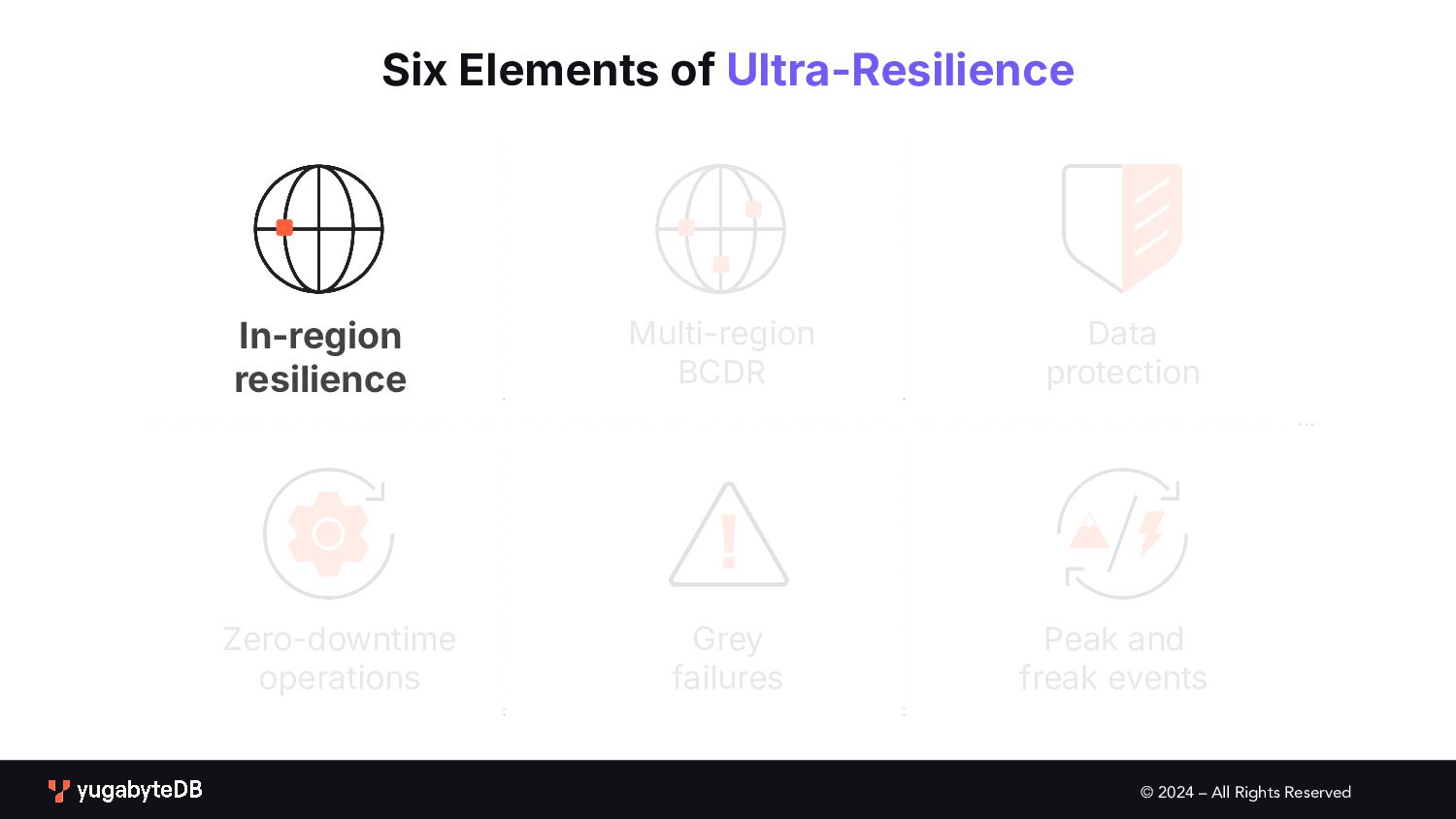
Region and data center outage • User, app or operator error • Upgrades / patching downtime • Intermittent or partial failures • Massive or unexpected Spikes Different failure modes require different elements of resilience In-region resilience Multi-region BCDR Data protection Zero-downtime operations Grey failures Peak and freak events
an order of magnitude higher than other failures • Could be transient failures • May or may not heal automatically • No data loss RPO0 • Very quick recovery (low RTO • Automatically handled without manual intervention What can go wrong… What you want…
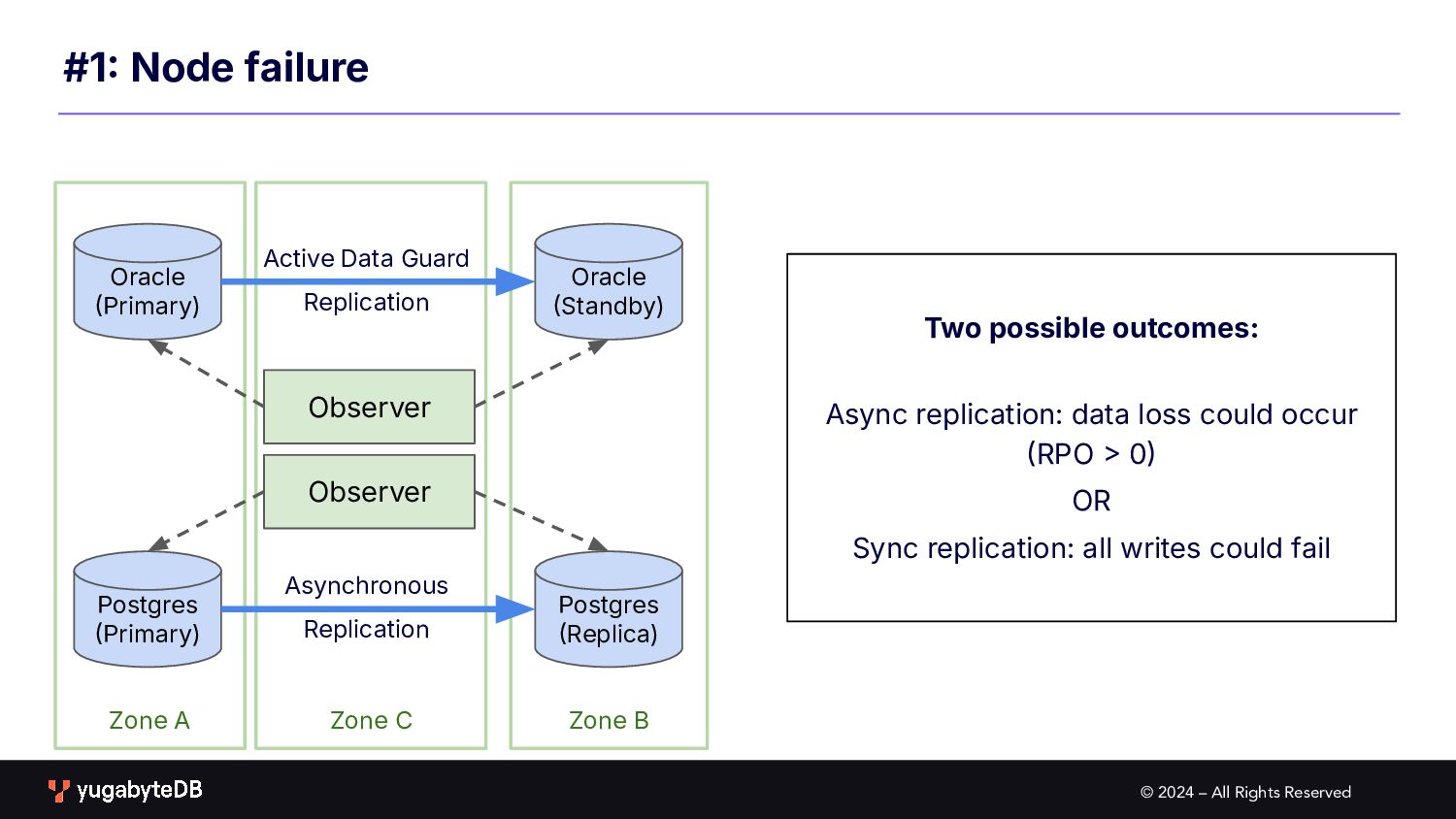
Zone C #1 Node failure Oracle Primary) Oracle Standby) Active Data Guard Replication Postgres Primary) Postgres Replica) Asynchronous Replication Observer Observer Two possible outcomes: Async replication: data loss could occur RPO 0 OR Sync replication: all writes could fail
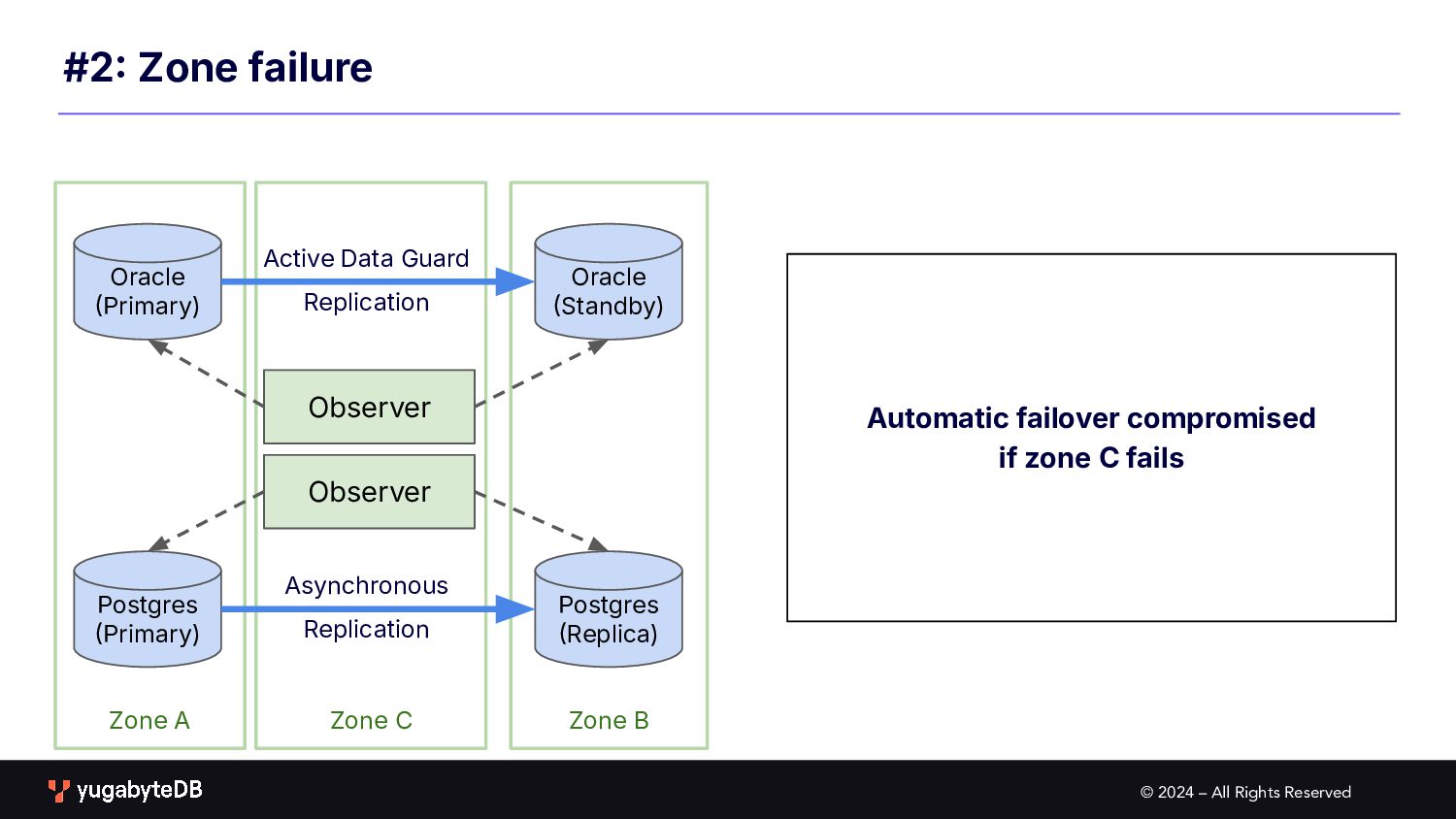
Zone C #2 Zone failure Oracle Primary) Oracle Standby) Active Data Guard Replication Postgres Primary) Postgres Replica) Asynchronous Replication Observer Observer Automatic failover compromised if zone C fails
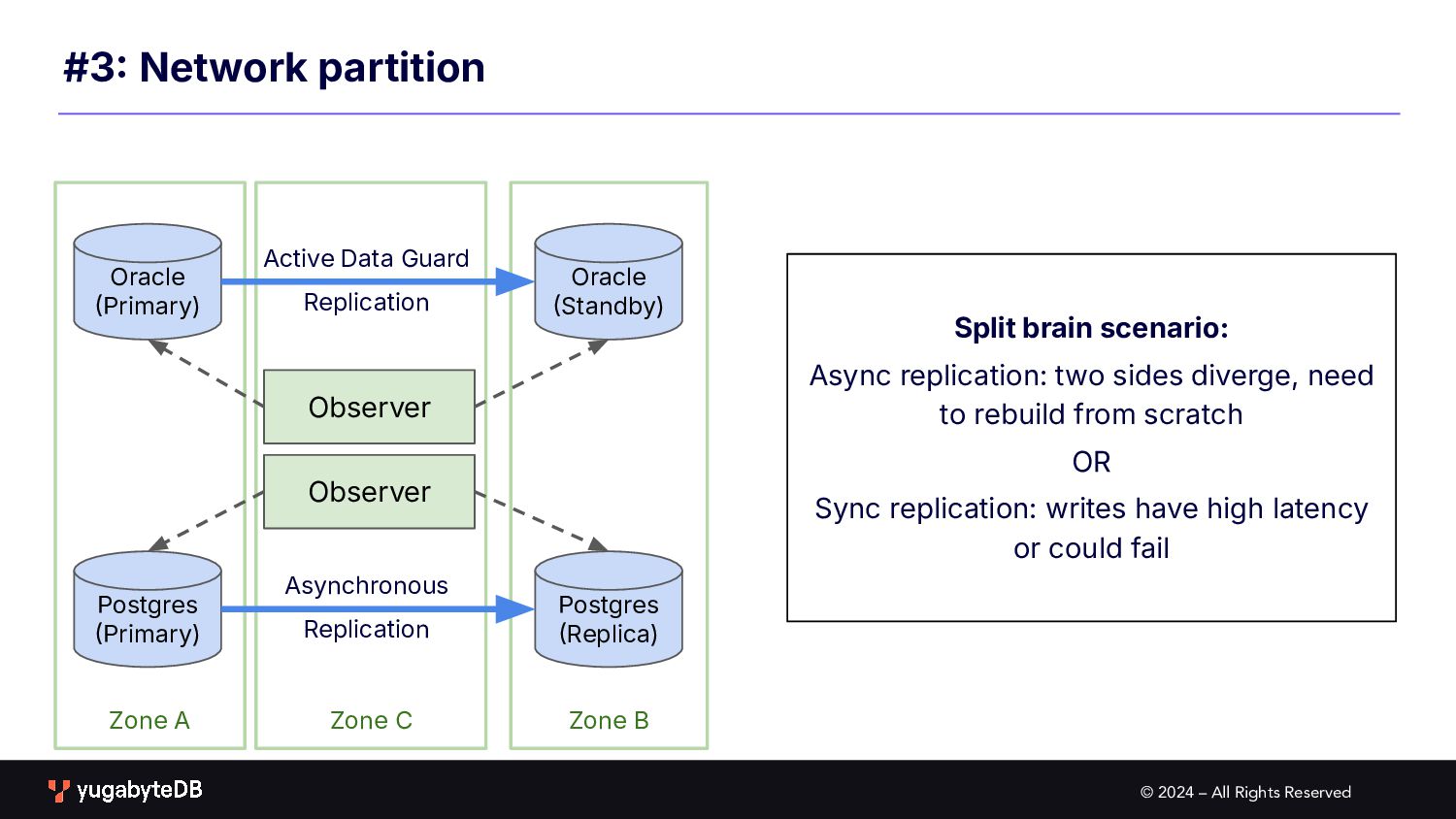
Zone C #3 Network partition Oracle Primary) Oracle Standby) Active Data Guard Replication Postgres Primary) Postgres Replica) Asynchronous Replication Observer Observer Split brain scenario: Async replication: two sides diverge, need to rebuild from scratch OR Sync replication: writes have high latency or could fail
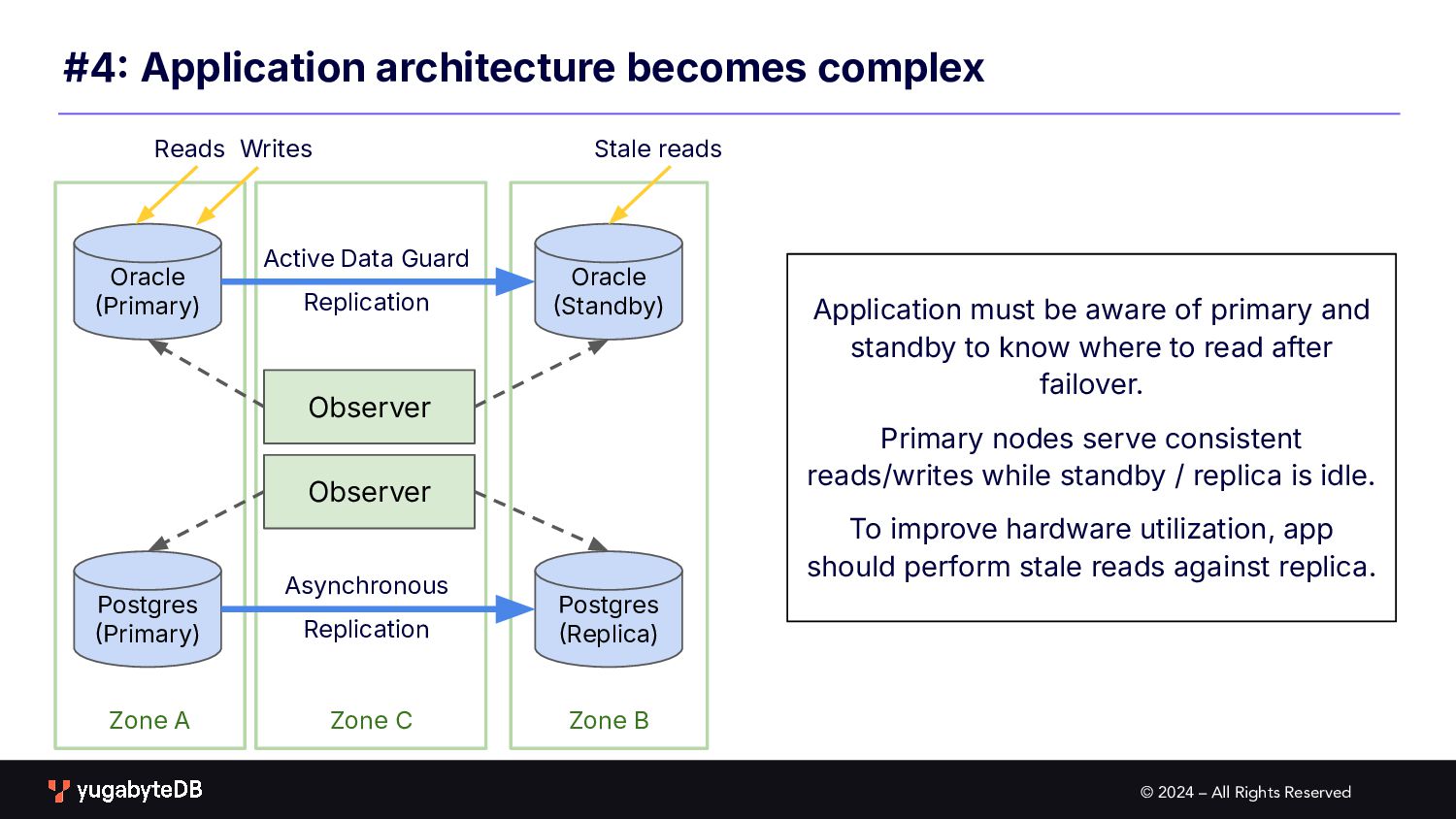
Zone C #4 Application architecture becomes complex Oracle Primary) Oracle Standby) Active Data Guard Replication Postgres Primary) Postgres Replica) Asynchronous Replication Observer Observer Reads Writes Stale reads Application must be aware of primary and standby to know where to read after failover. Primary nodes serve consistent reads/writes while standby / replica is idle. To improve hardware utilization, app should perform stale reads against replica.
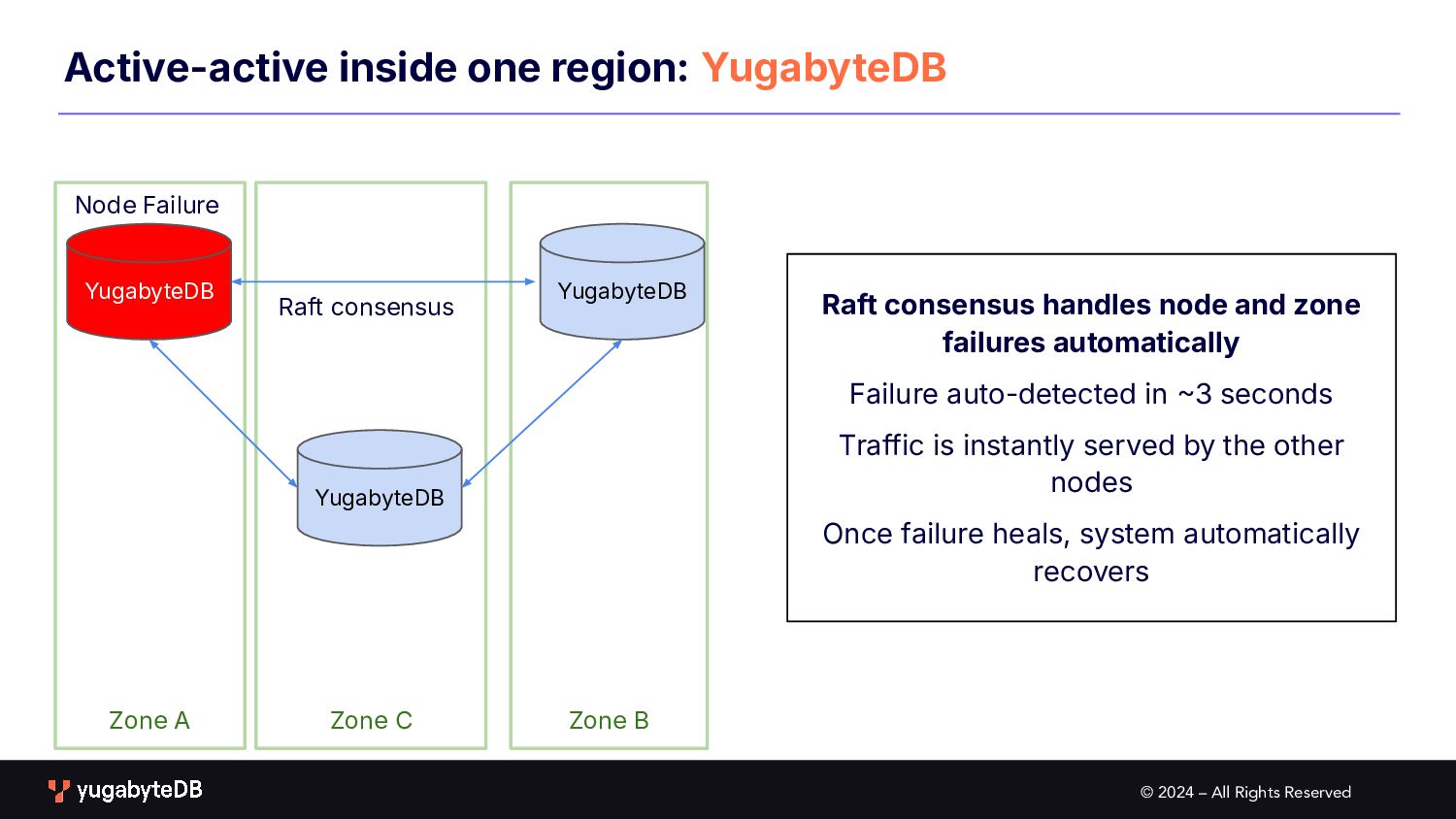
Zone A Active-active inside one region: YugabyteDB YugabyteDB Raft consensus YugabyteDB YugabyteDB Raft consensus handles node and zone failures automatically Failure auto-detected in 3 seconds Traffic is instantly served by the other nodes Once failure heals, system automatically recovers Node Failure
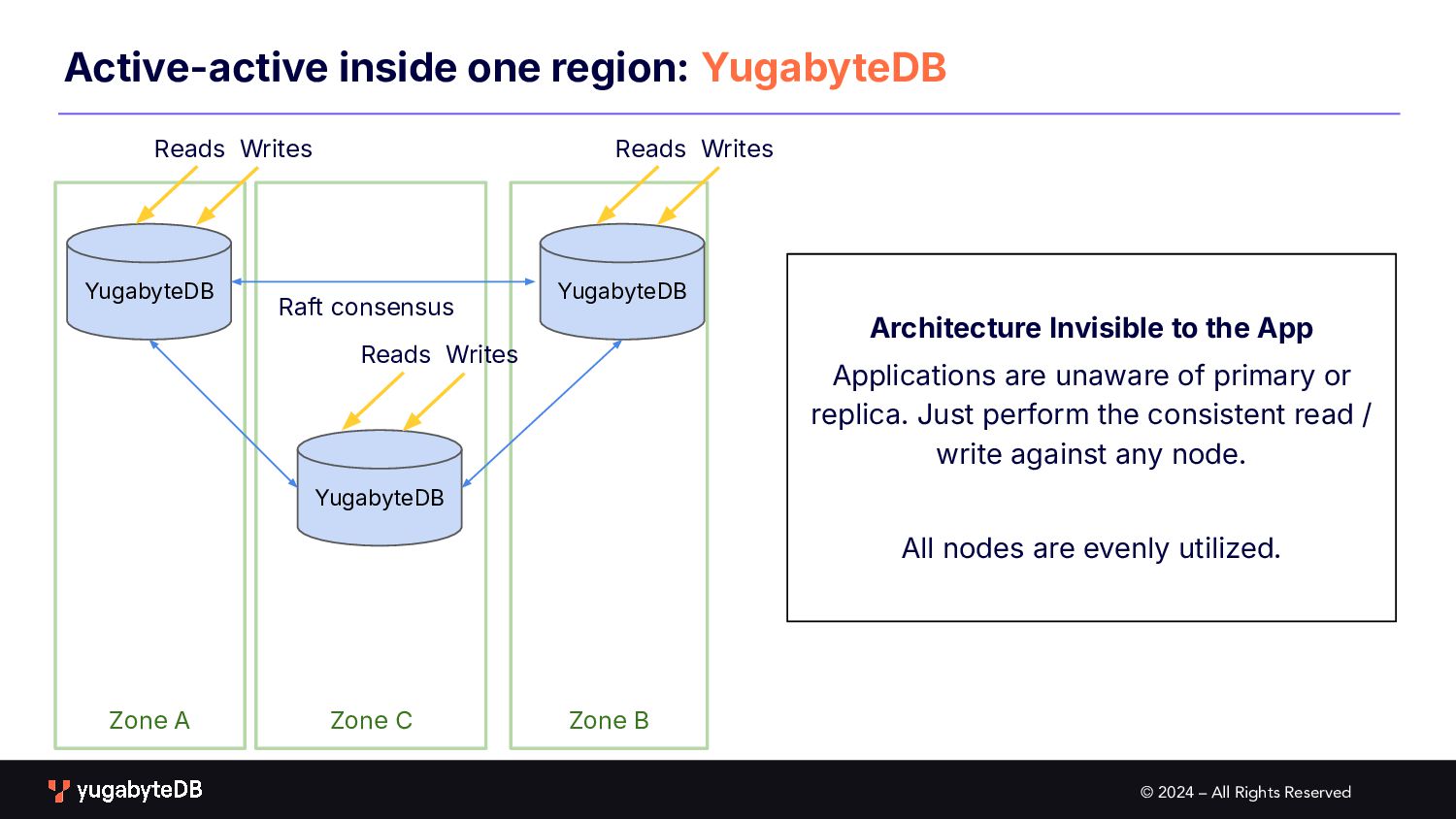
Zone A Active-active inside one region: YugabyteDB YugabyteDB Raft consensus YugabyteDB YugabyteDB Reads Writes Reads Writes Reads Writes Architecture Invisible to the App Applications are unaware of primary or replica. Just perform the consistent read / write against any node. All nodes are evenly utilized.
data center failure—low probability but we see it happen regularly • Failures that last a while • Complex process to “healˮ once the region / DC is back online • Ability to tradeoff between steady-state performance (latency) and potential data loss RPO • Very quick recovery (low RTO • Ability to run DR drills - planned switchover What can go wrong… What you want…
of an application, defining how data flows to deliver functionality Availability Architecture: Design principles and features that ensure continuous operation and minimize downtime Two dimensions to consider
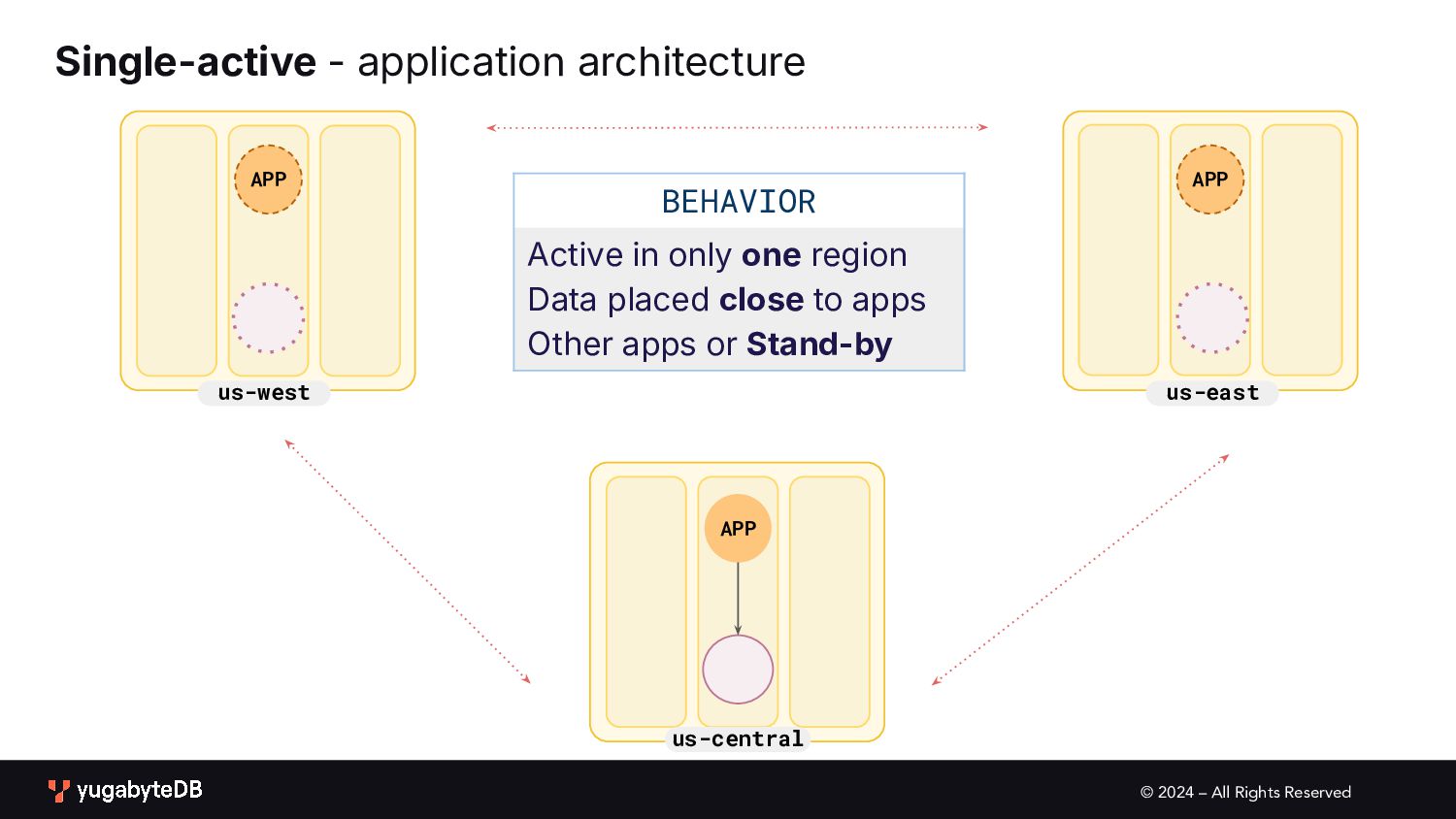
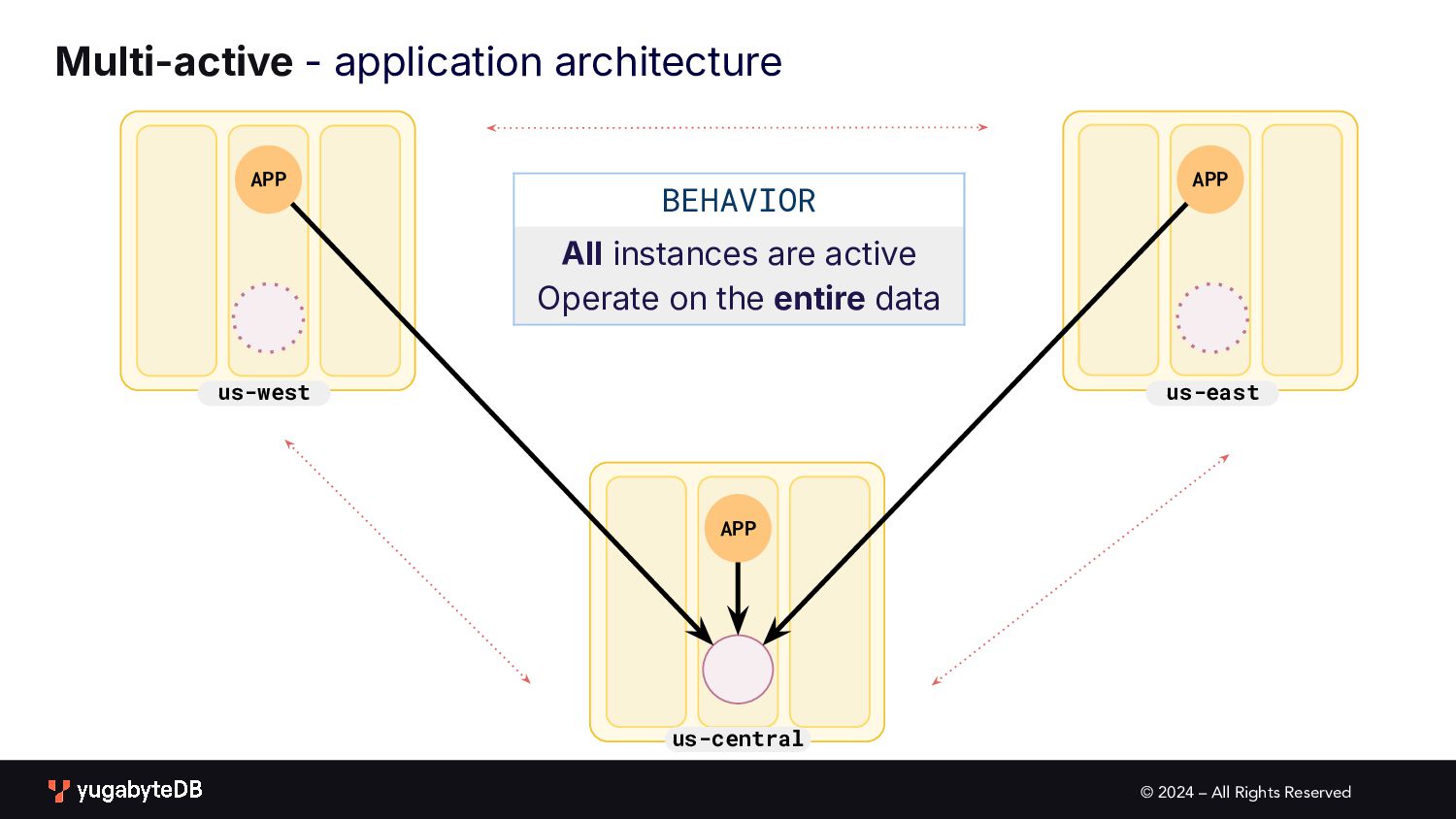
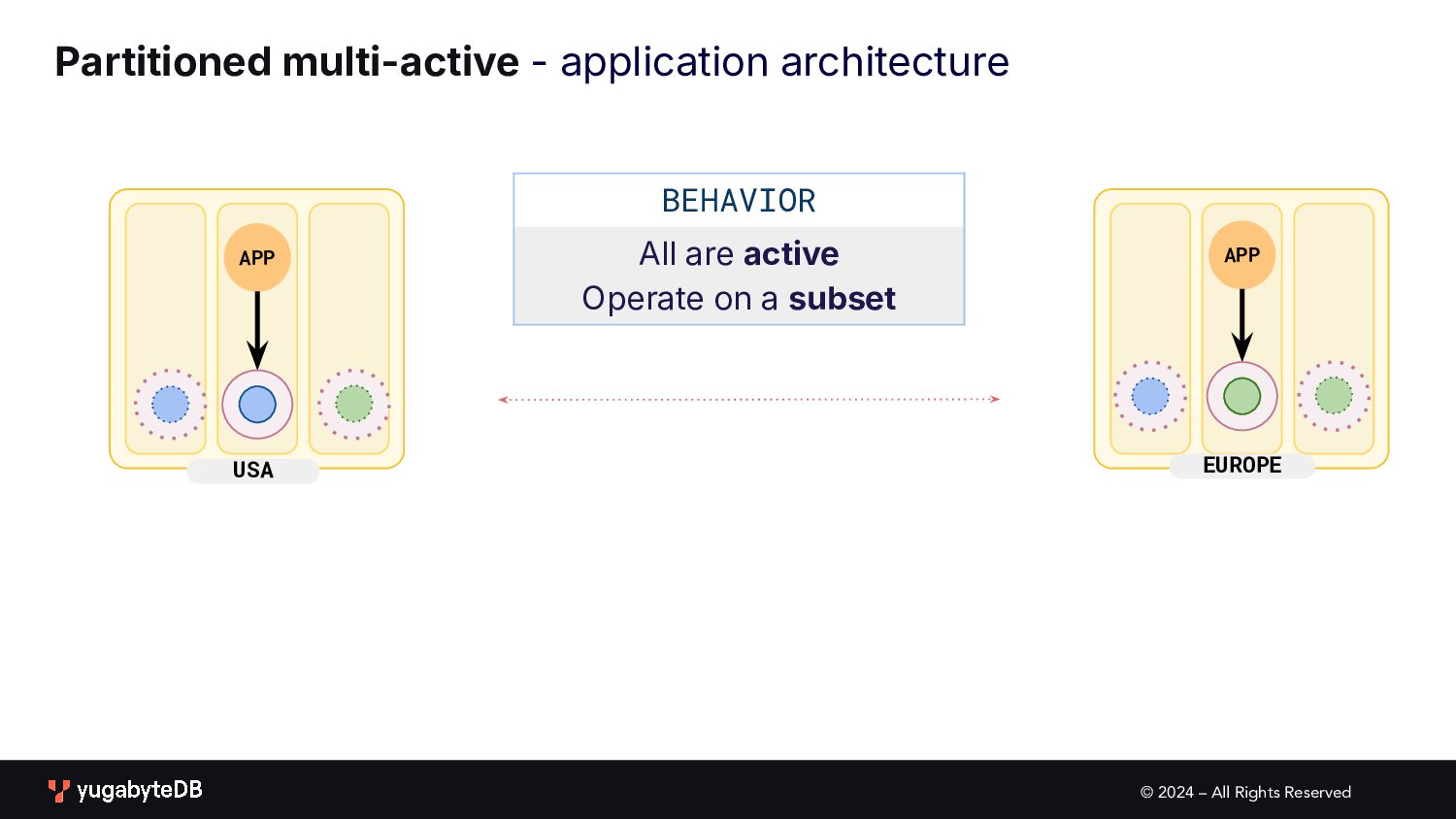
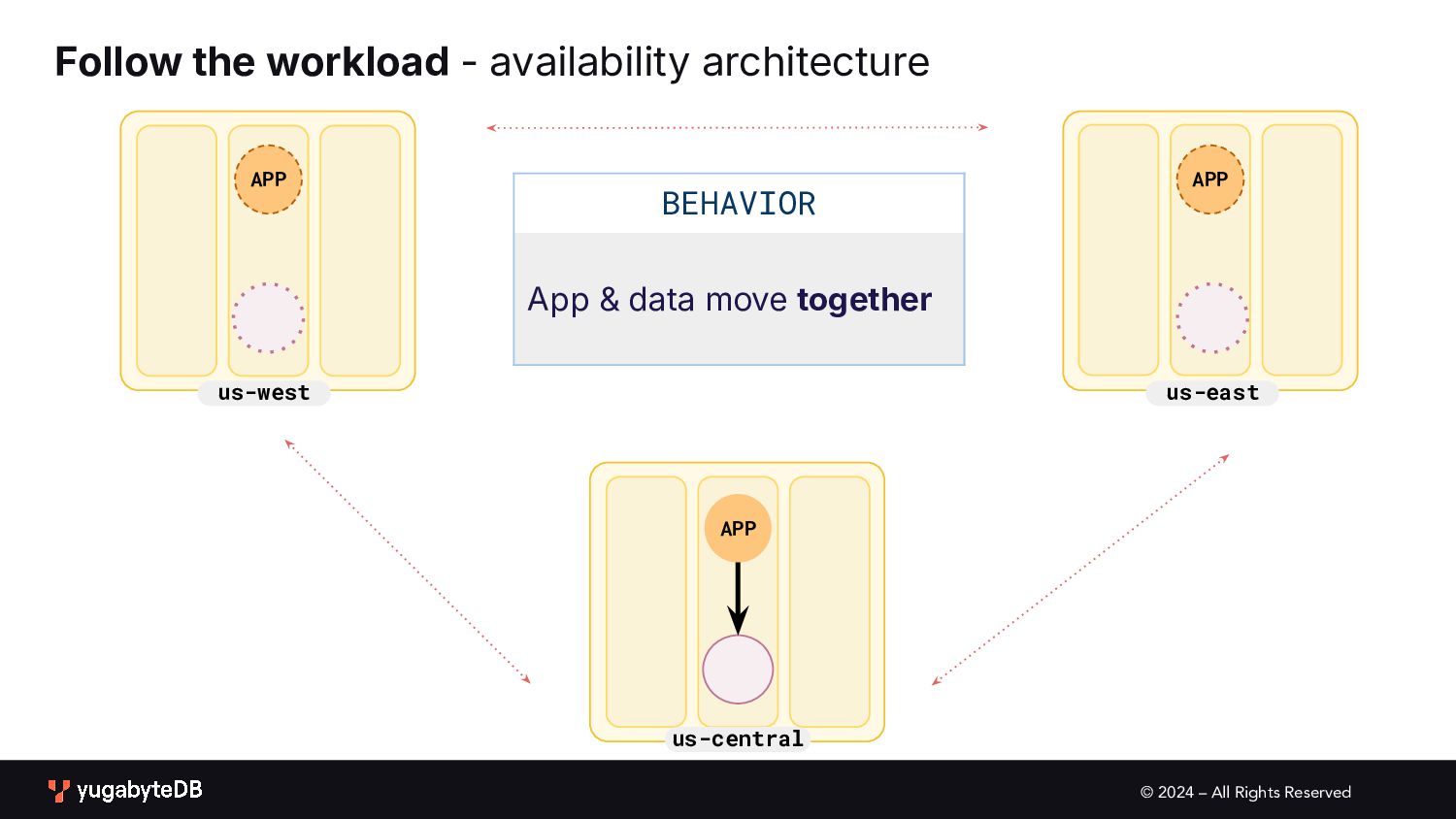
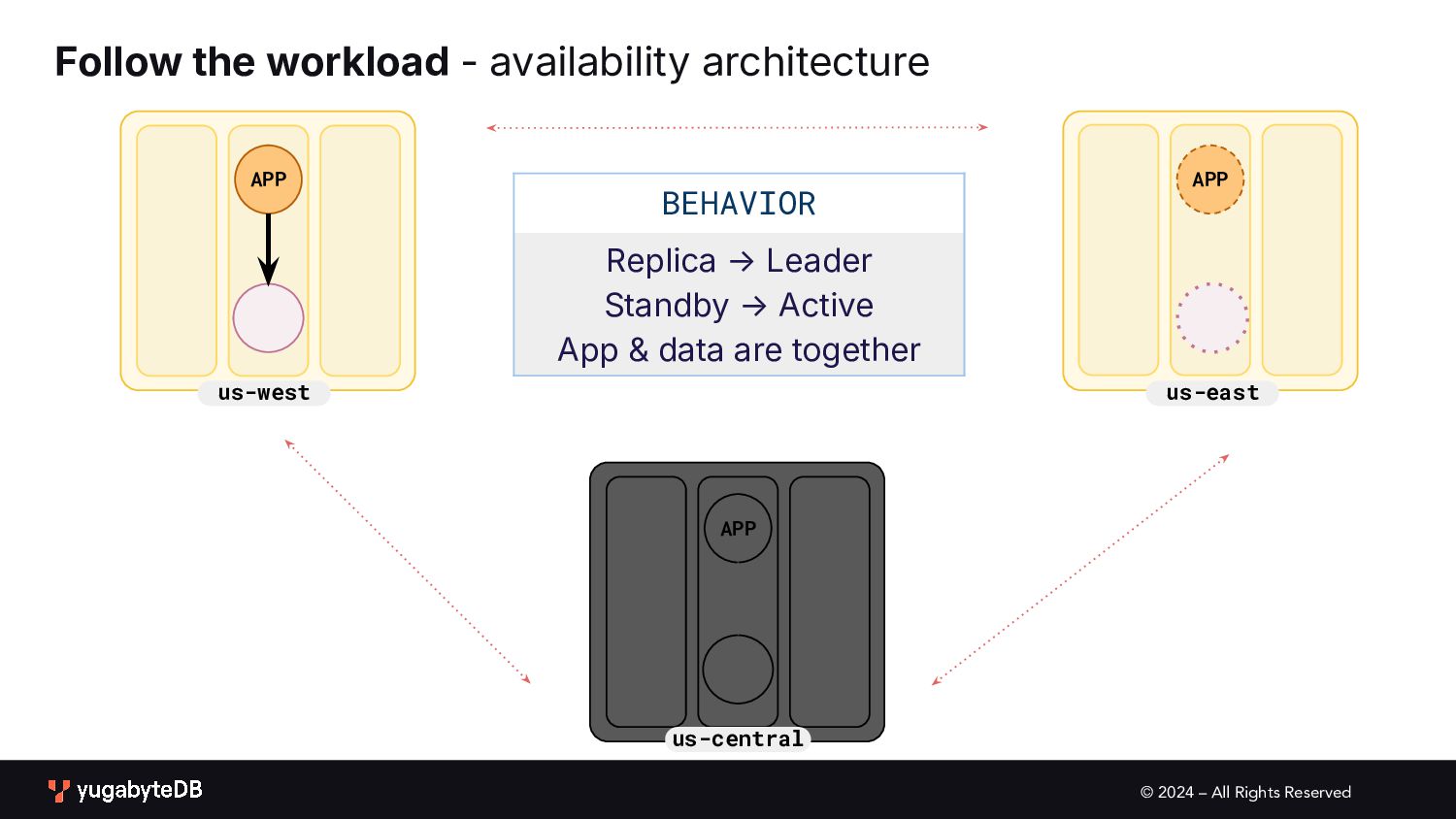
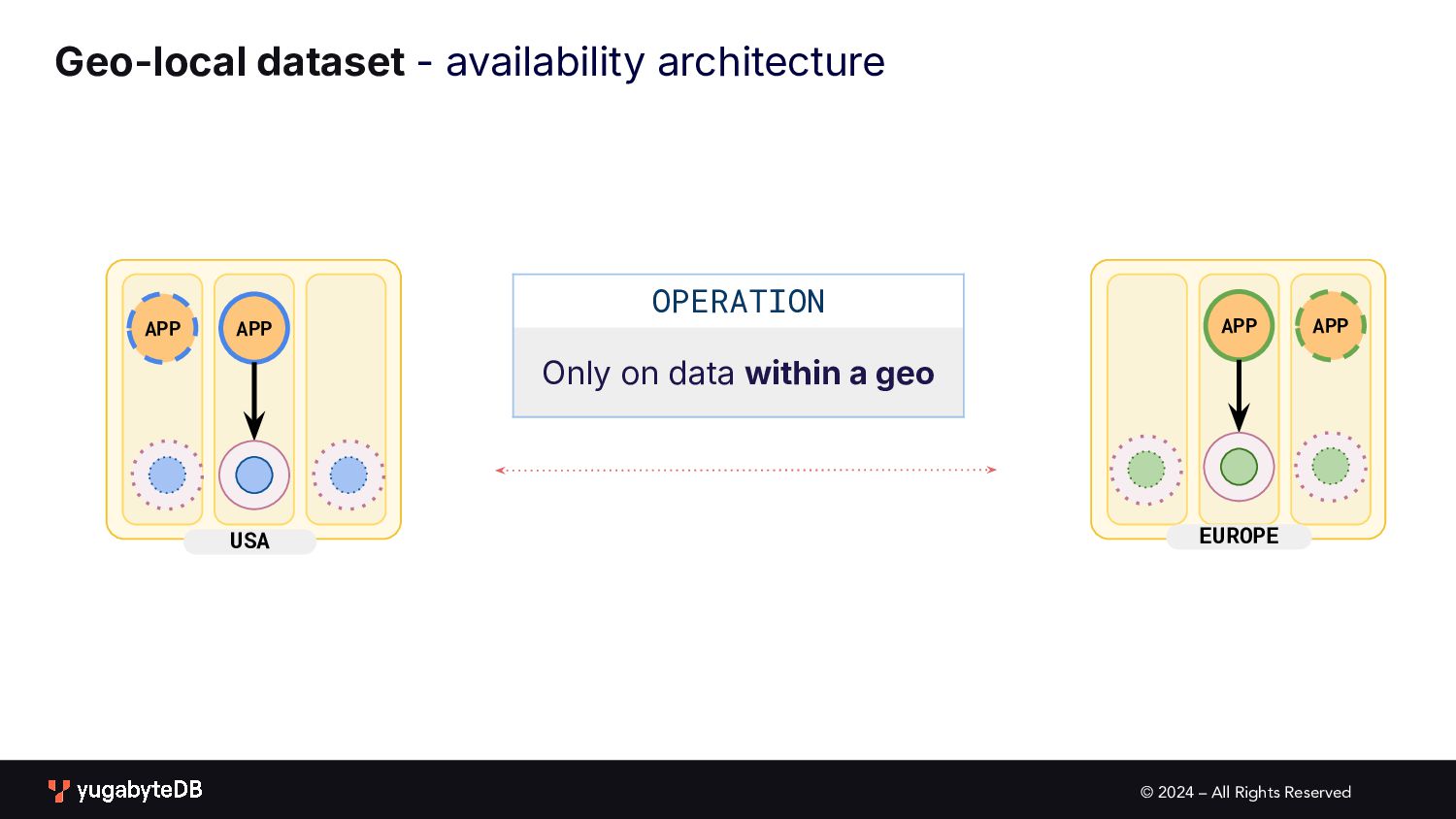
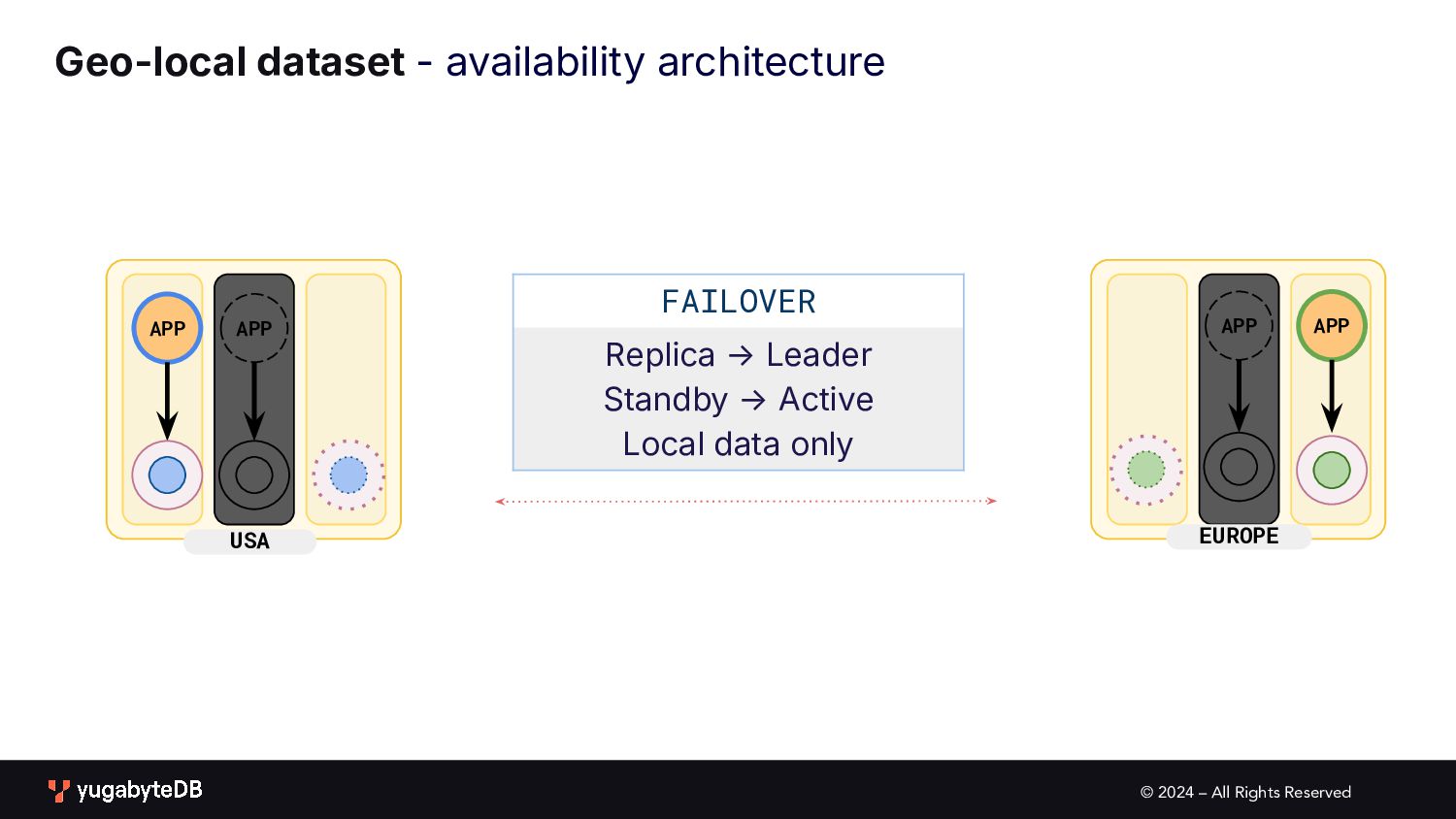
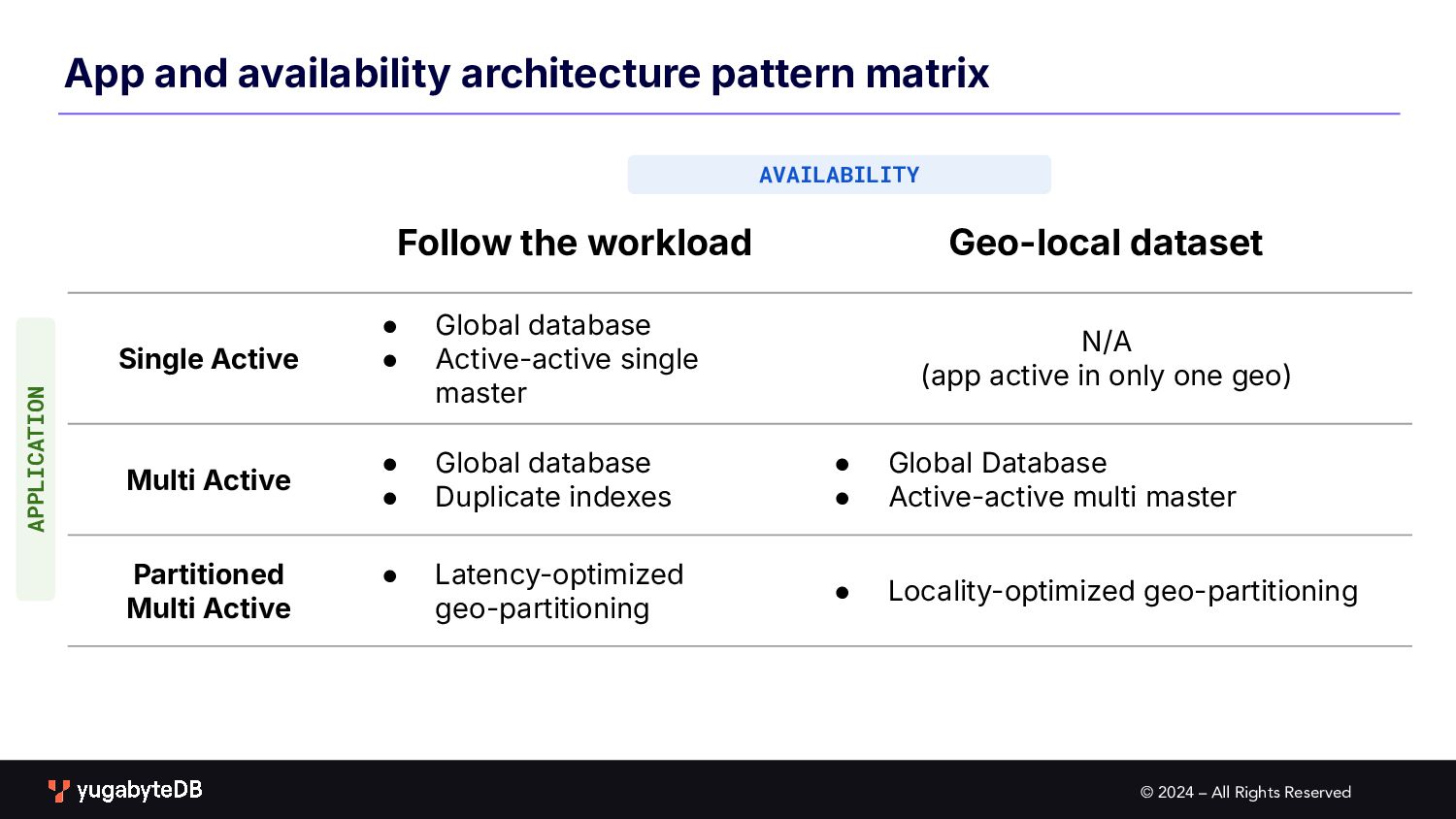
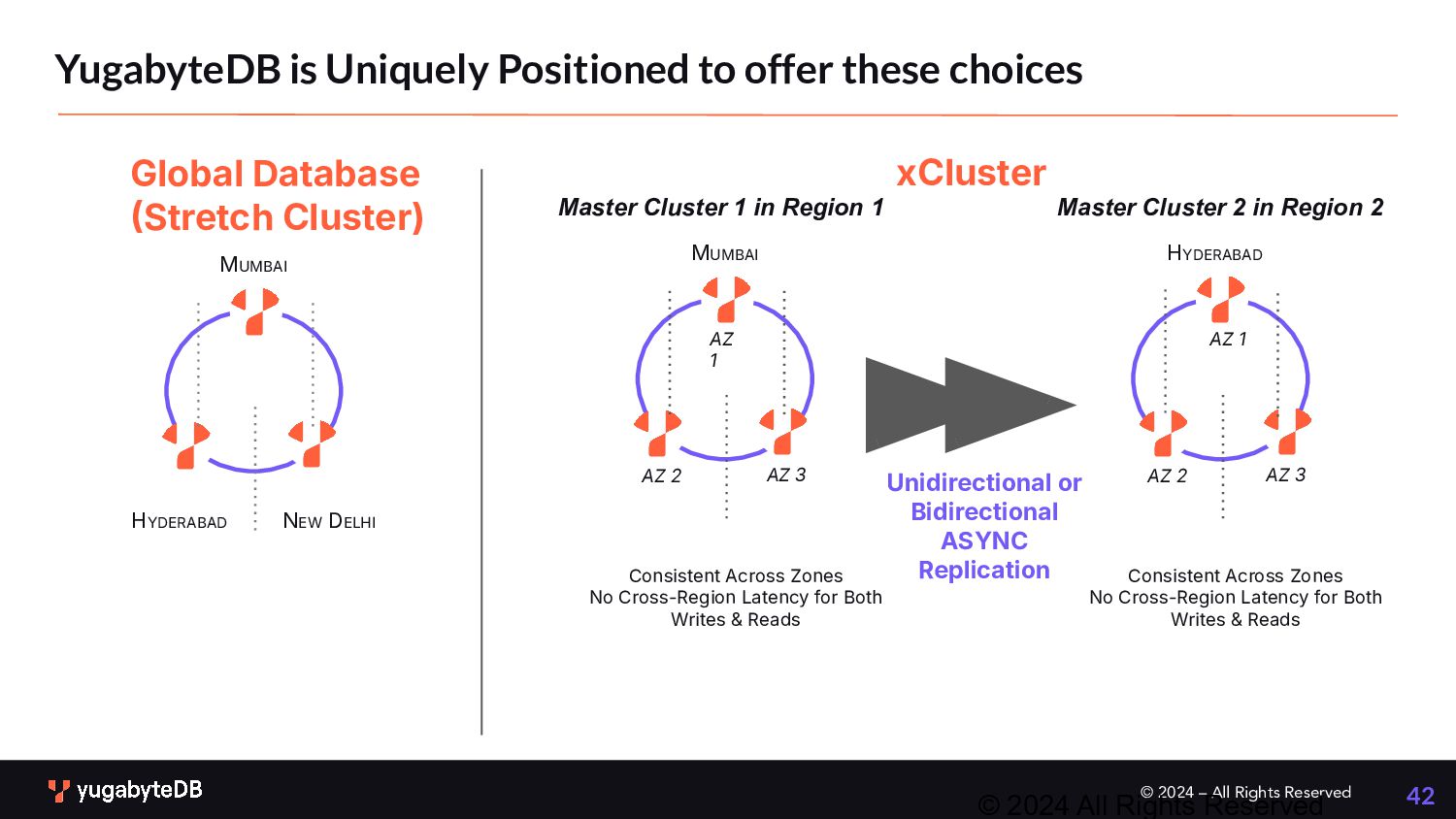
pattern matrix Follow the workload Geo-local dataset Single Active • Global database • Active-active single master N/A (app active in only one geo) Multi Active • Global database • Duplicate indexes • Global Database • Active-active multi master Partitioned Multi Active • Latency-optimized geo-partitioning • Locality-optimized geo-partitioning AVAILABILITY APPLICATION
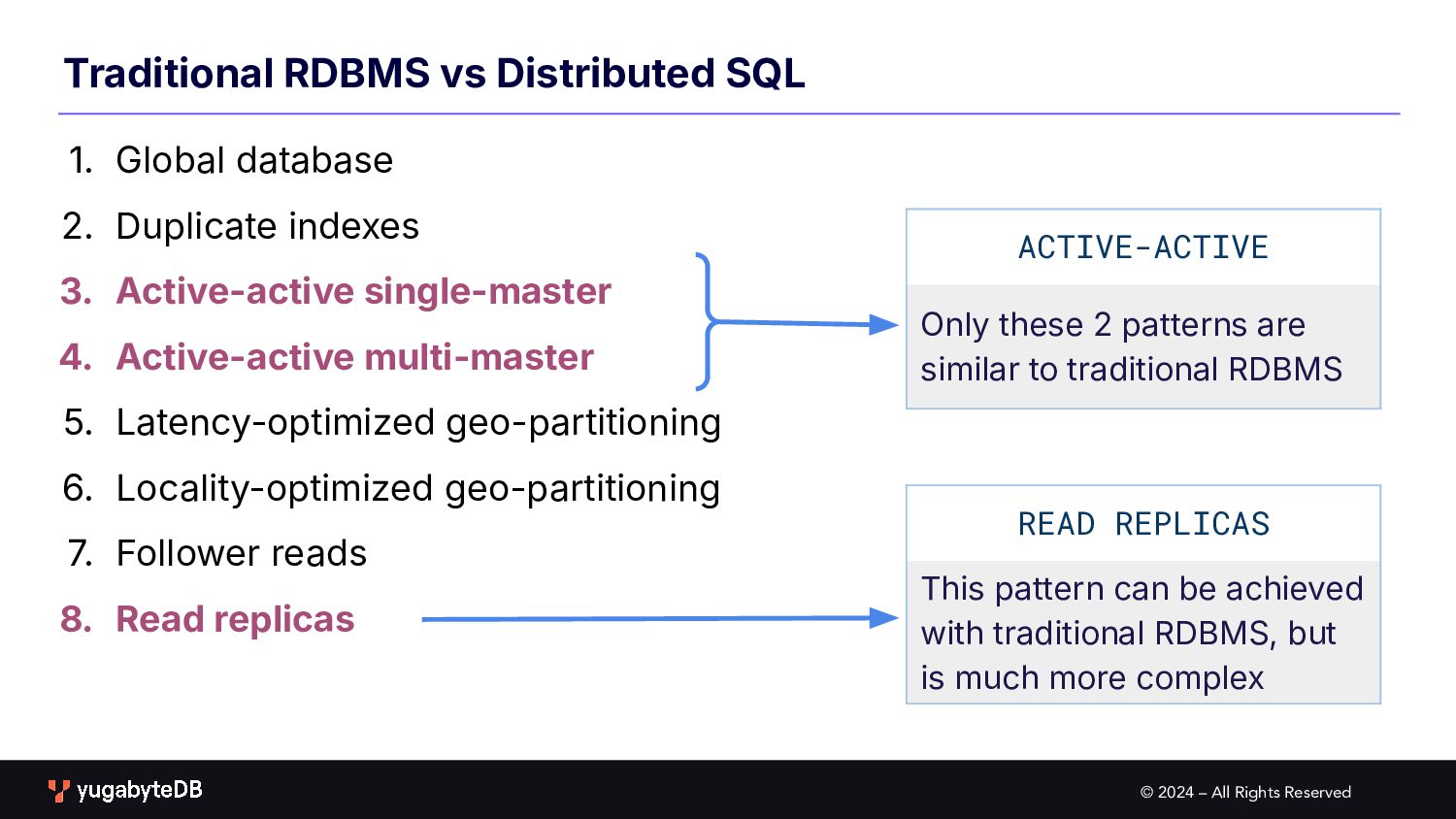
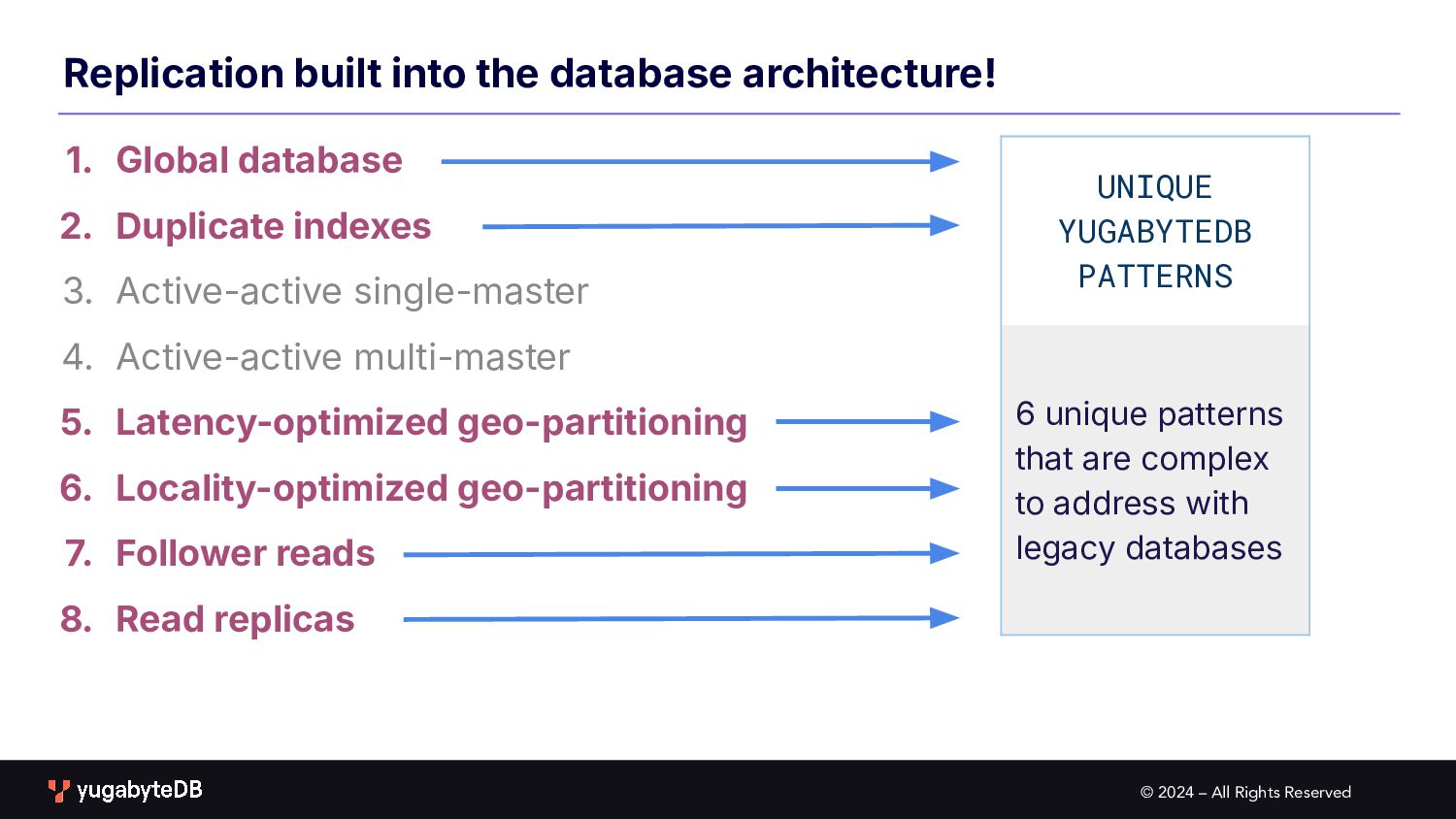
SQL 1. Global database 2. Duplicate indexes 3. Active-active single-master 4. Active-active multi-master 5. Latency-optimized geo-partitioning 6. Locality-optimized geo-partitioning 7. Follower reads 8. Read replicas ACTIVE-ACTIVE Only these 2 patterns are similar to traditional RDBMS READ REPLICAS This pattern can be achieved with traditional RDBMS, but is much more complex
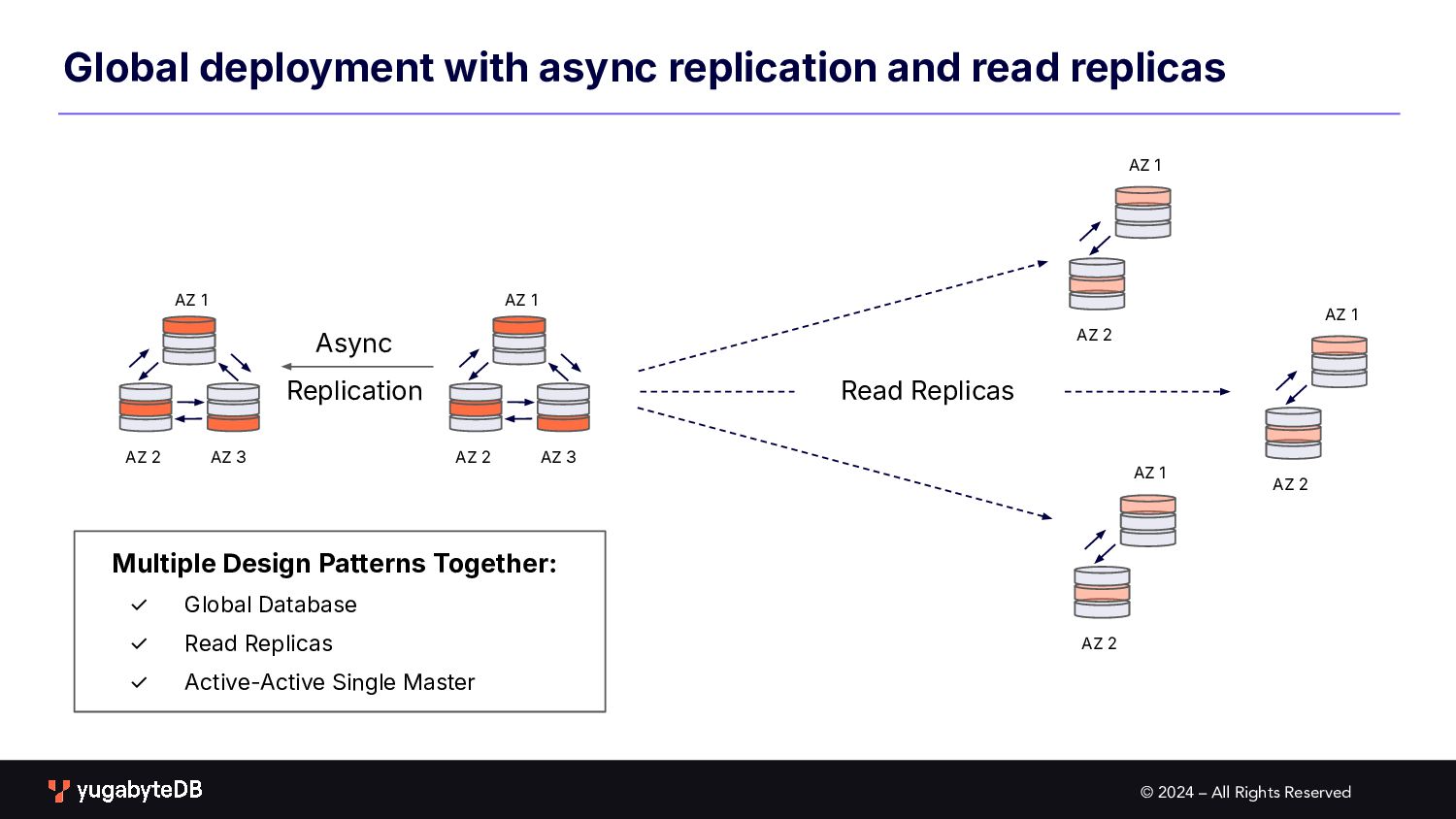
AZ 3 AZ 1 AZ 2 Global deployment with async replication and read replicas AZ 1 AZ 2 AZ 3 AZ 1 AZ 2 AZ 1 AZ 2 Async Replication Read Replicas Multiple Design Patterns Together: ✓ Global Database ✓ Read Replicas ✓ Active-Active Single Master
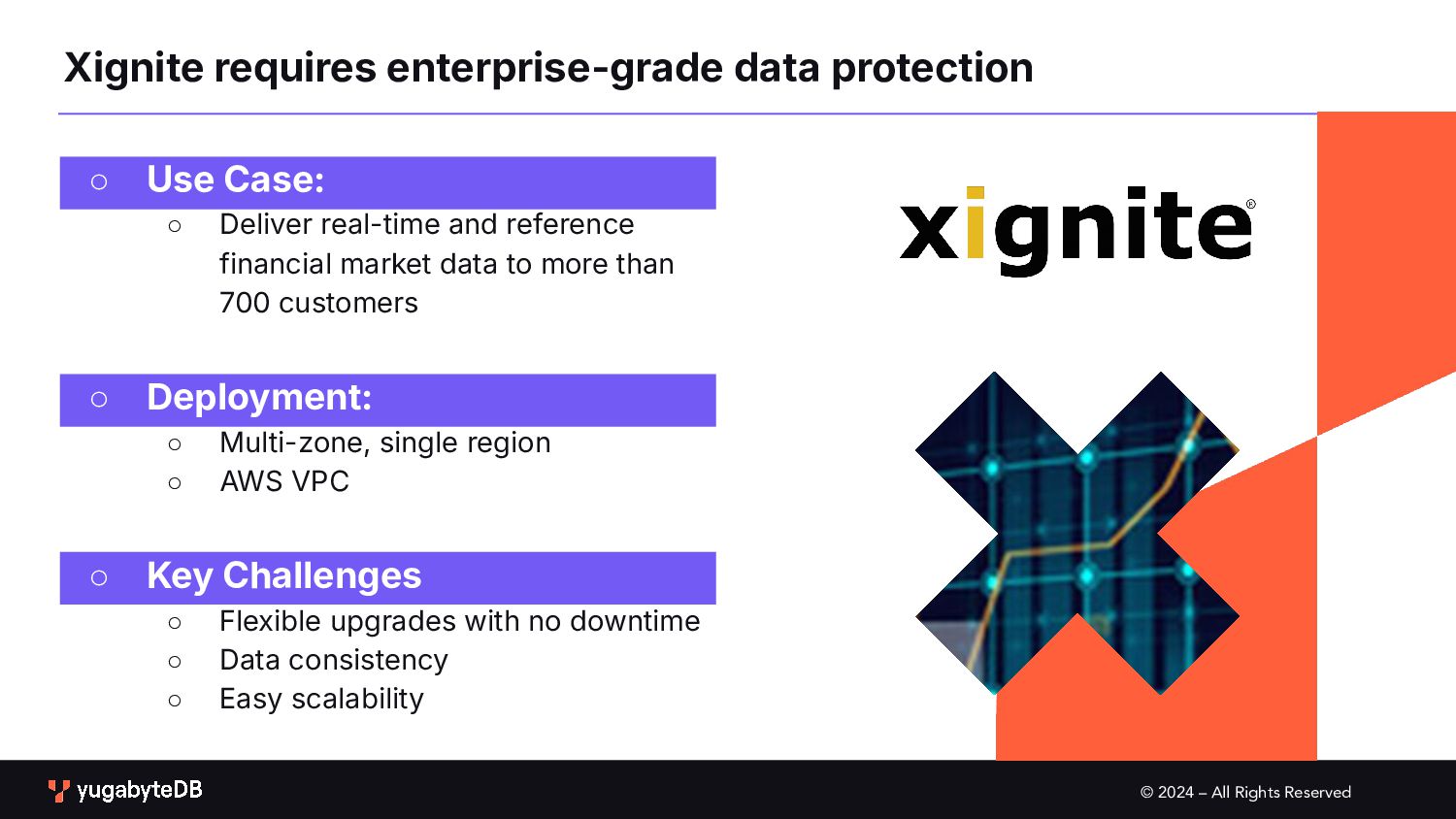
protection ◦ Use Case: ◦ Deliver real-time and reference financial market data to more than 700 customers ◦ Deployment: ◦ Multi-zone, single region ◦ AWS VPC ◦ Key Challenges ◦ Flexible upgrades with no downtime ◦ Data consistency ◦ Easy scalability
application traffic • Reasonably frequent operations • Ability to automate using full-featured APIs • Good observability and integrated smart alerting What you want
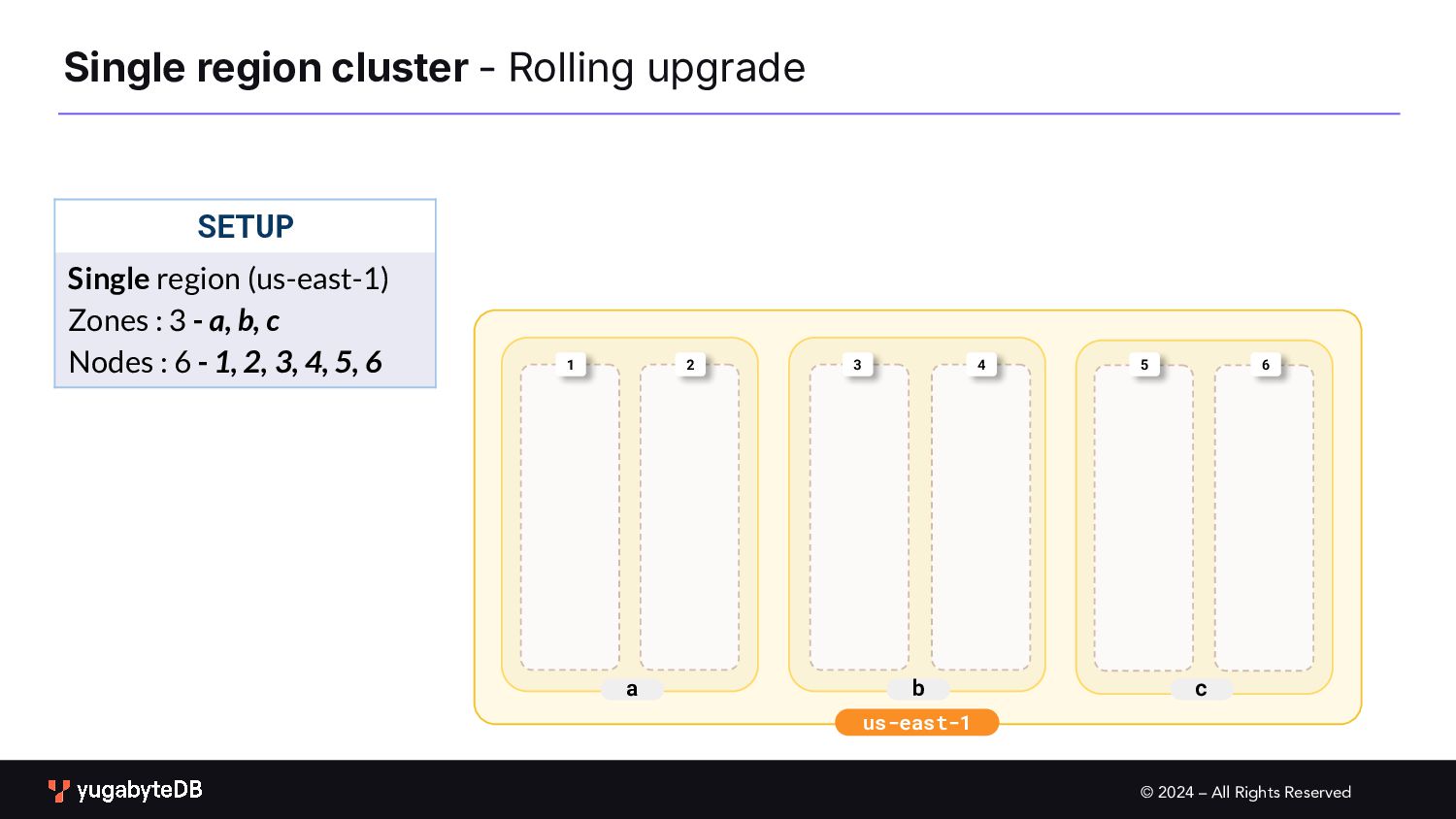
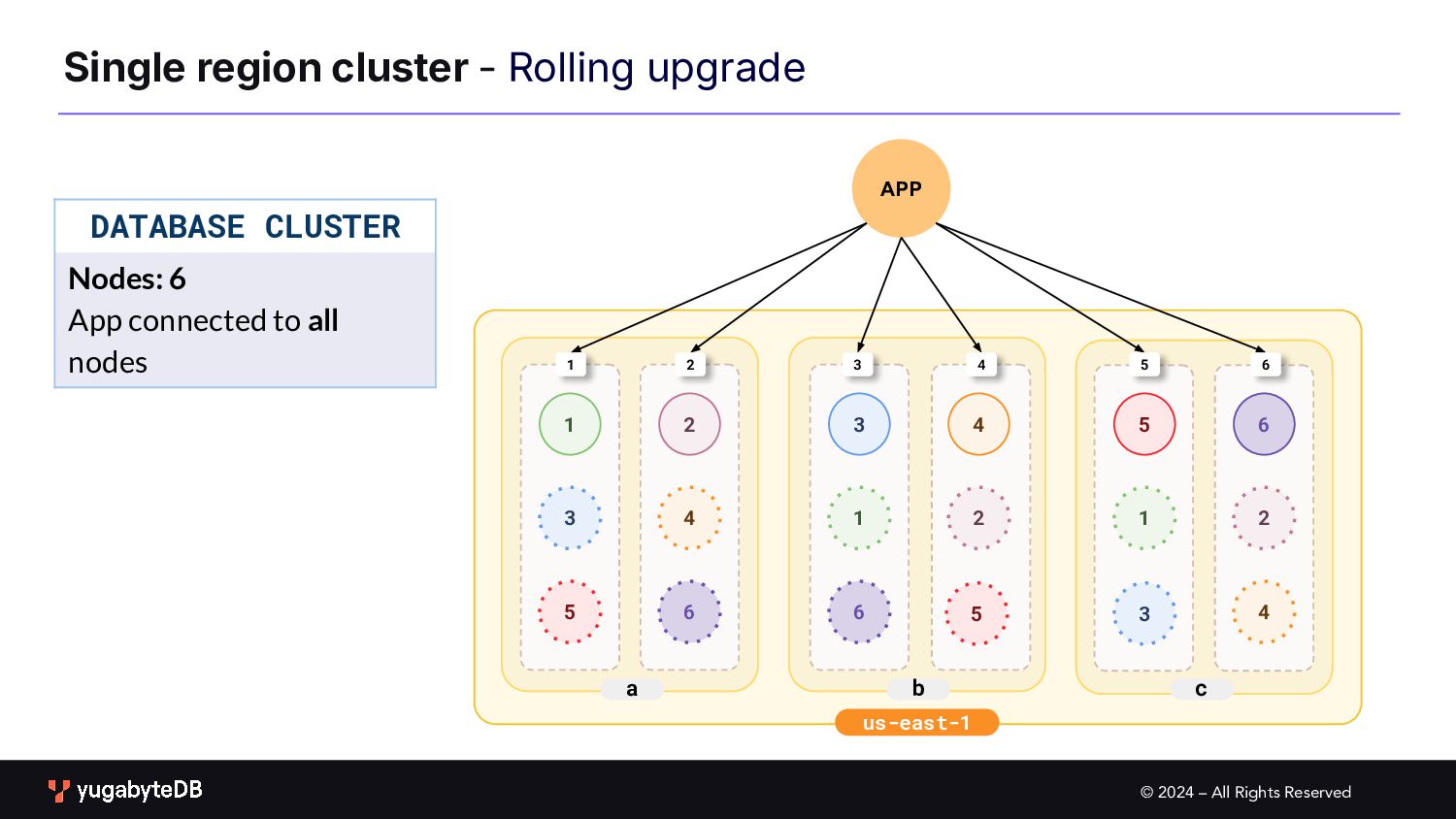
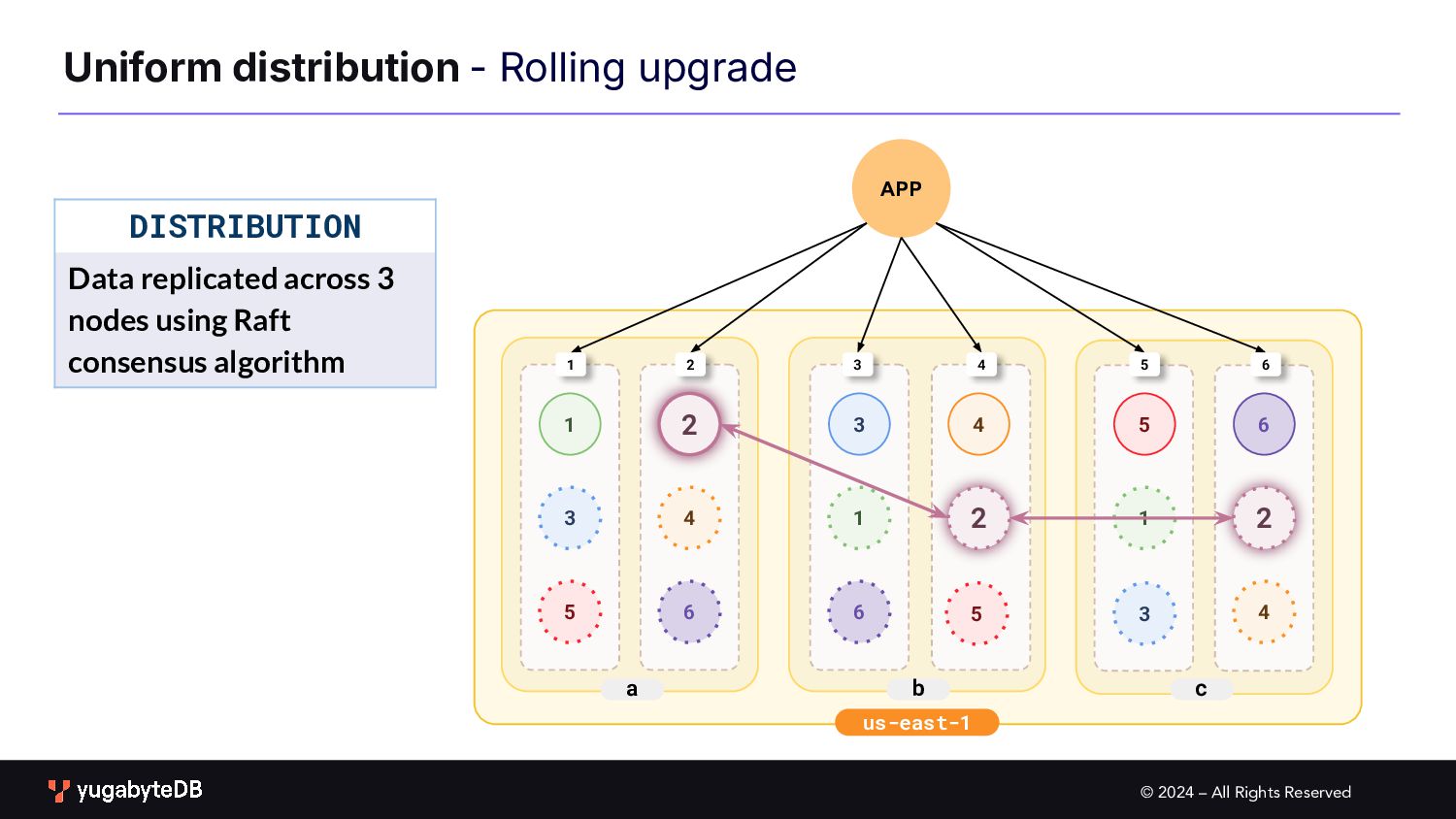
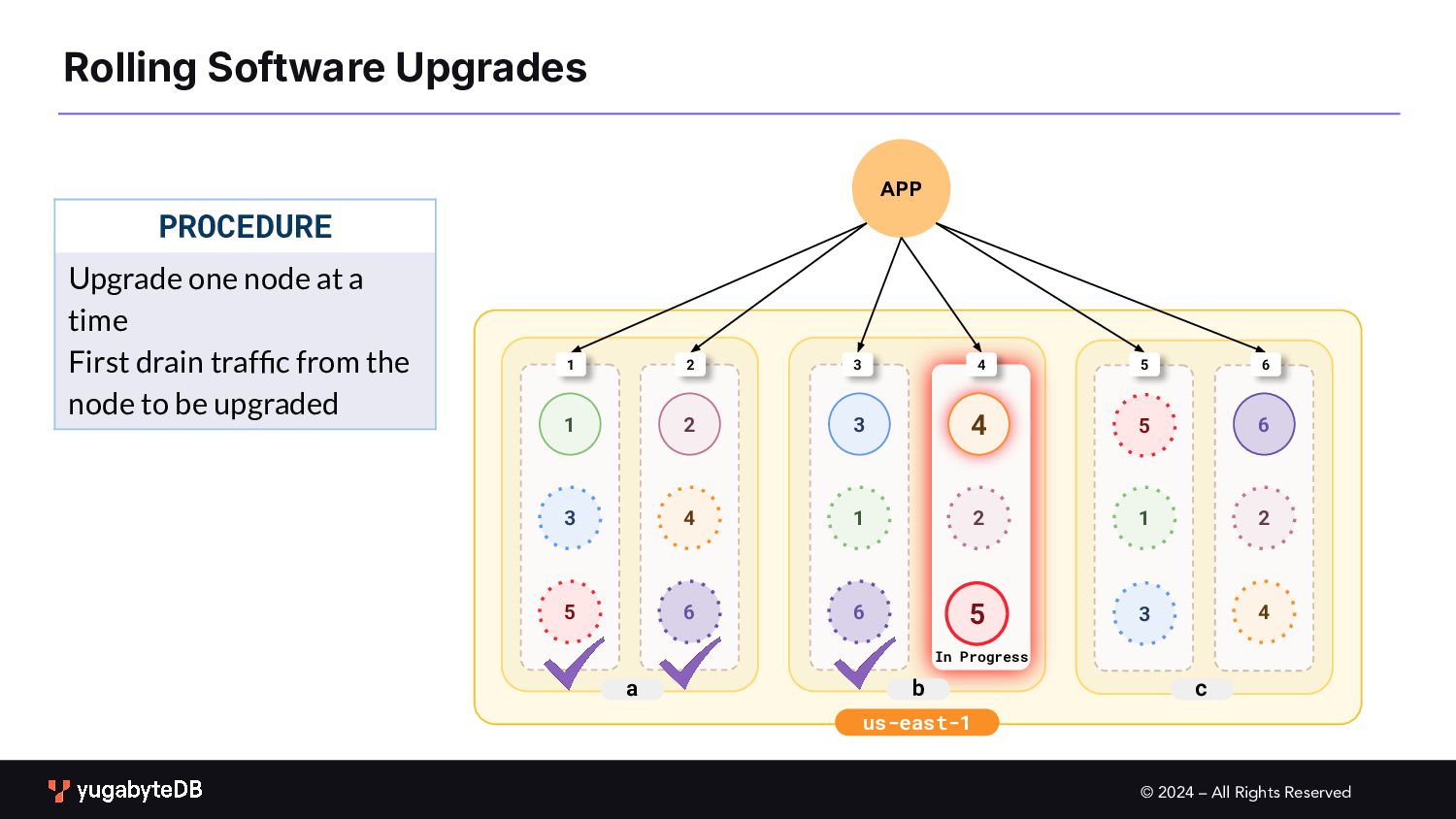
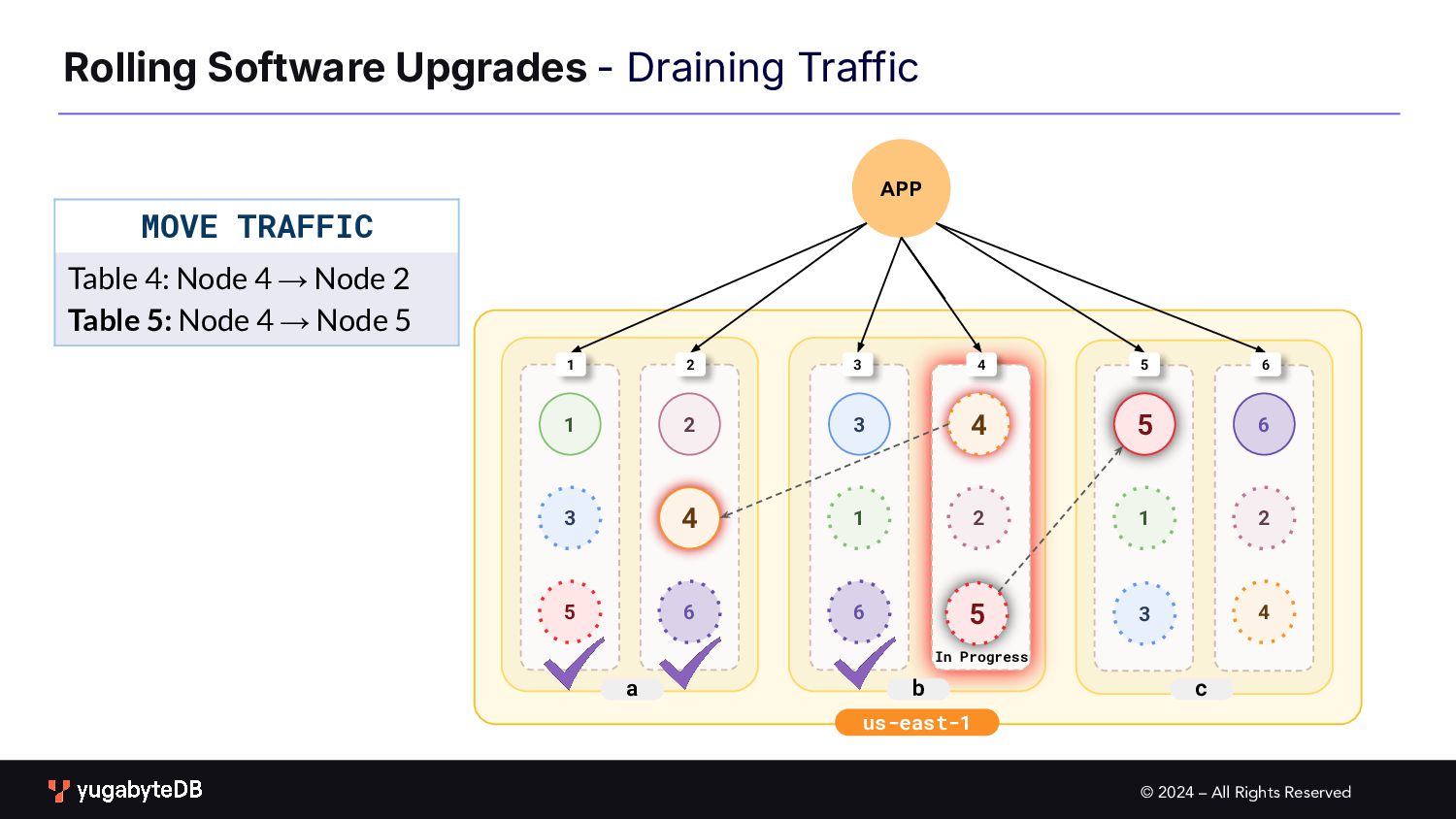
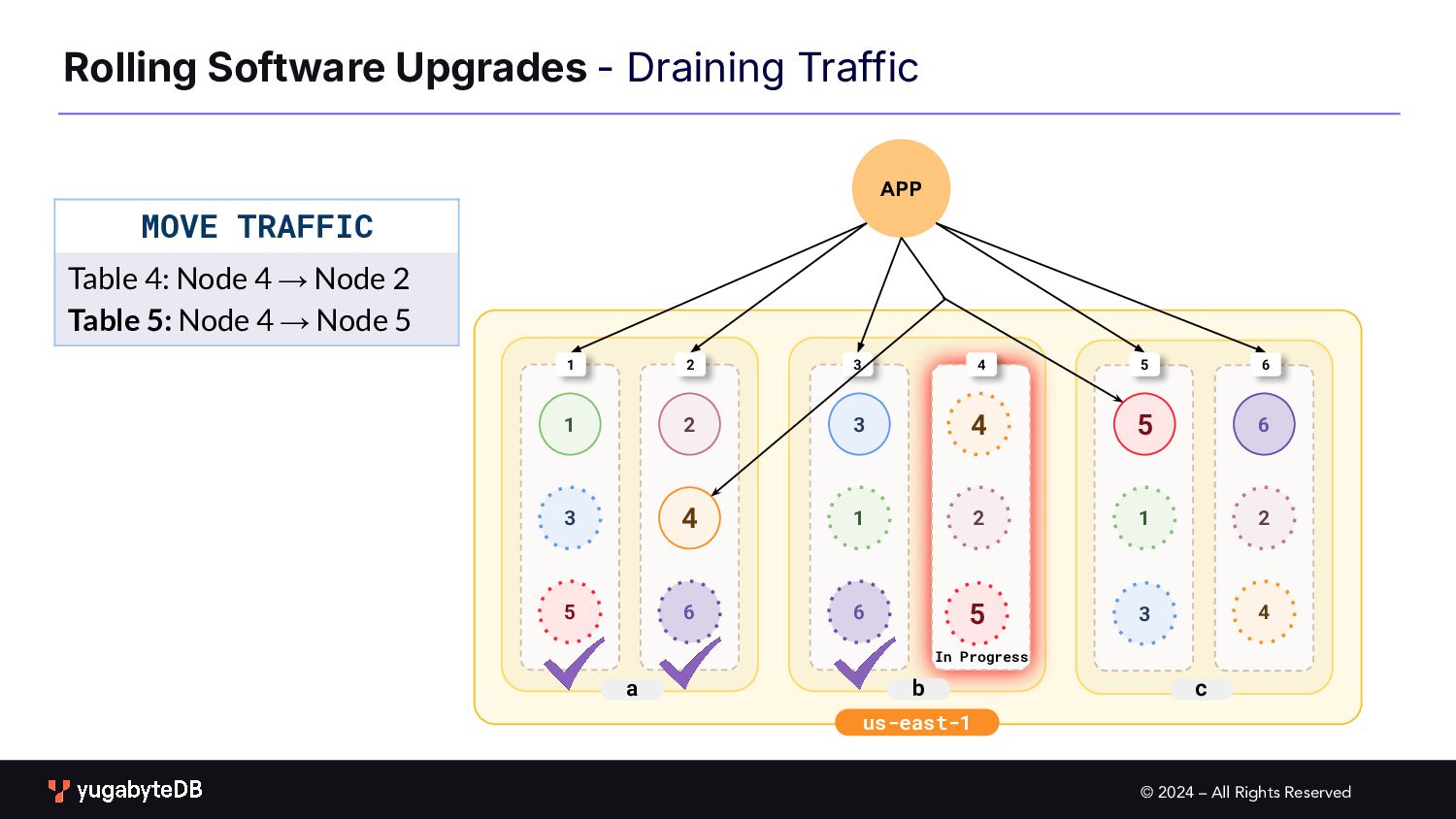
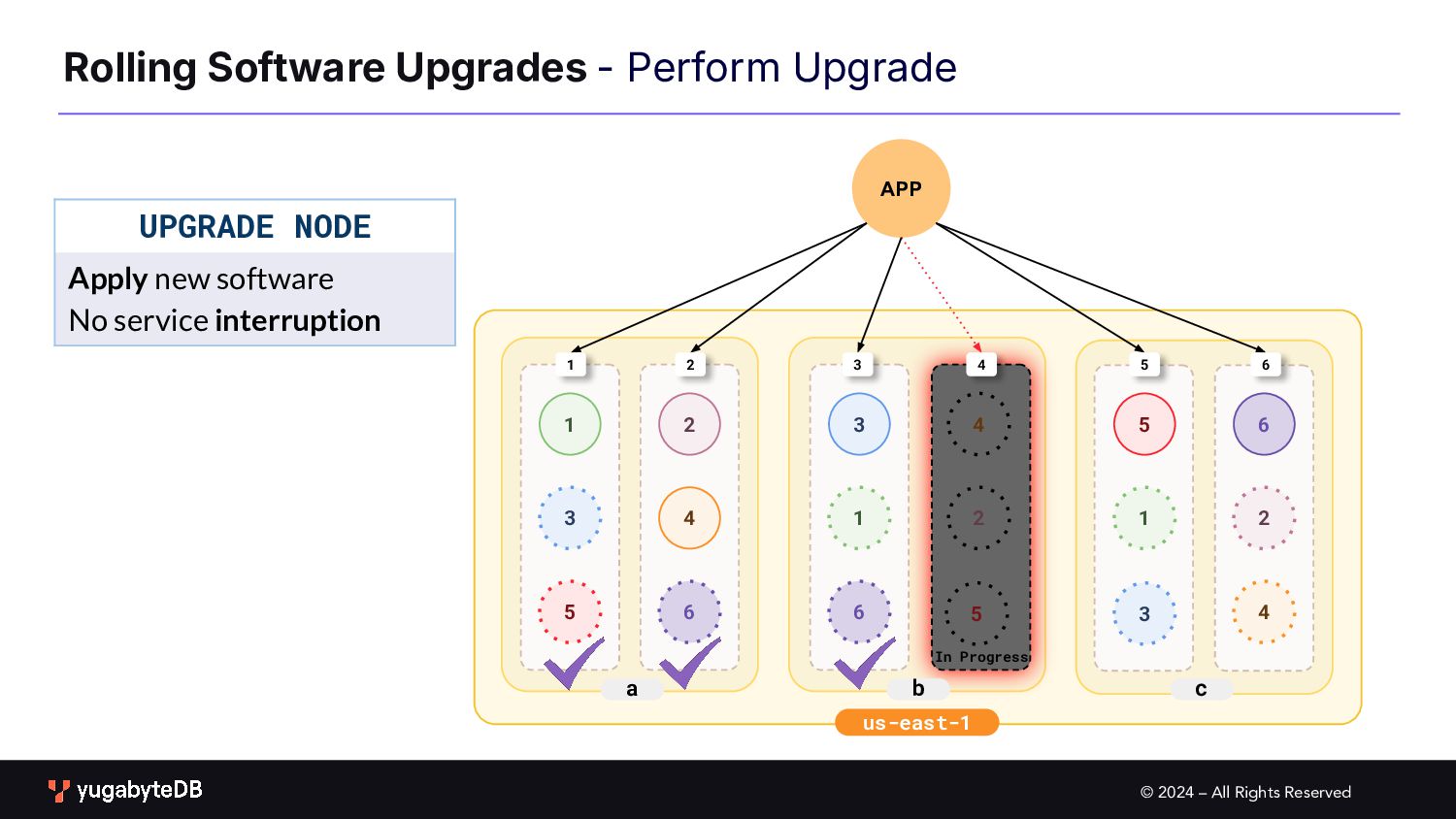
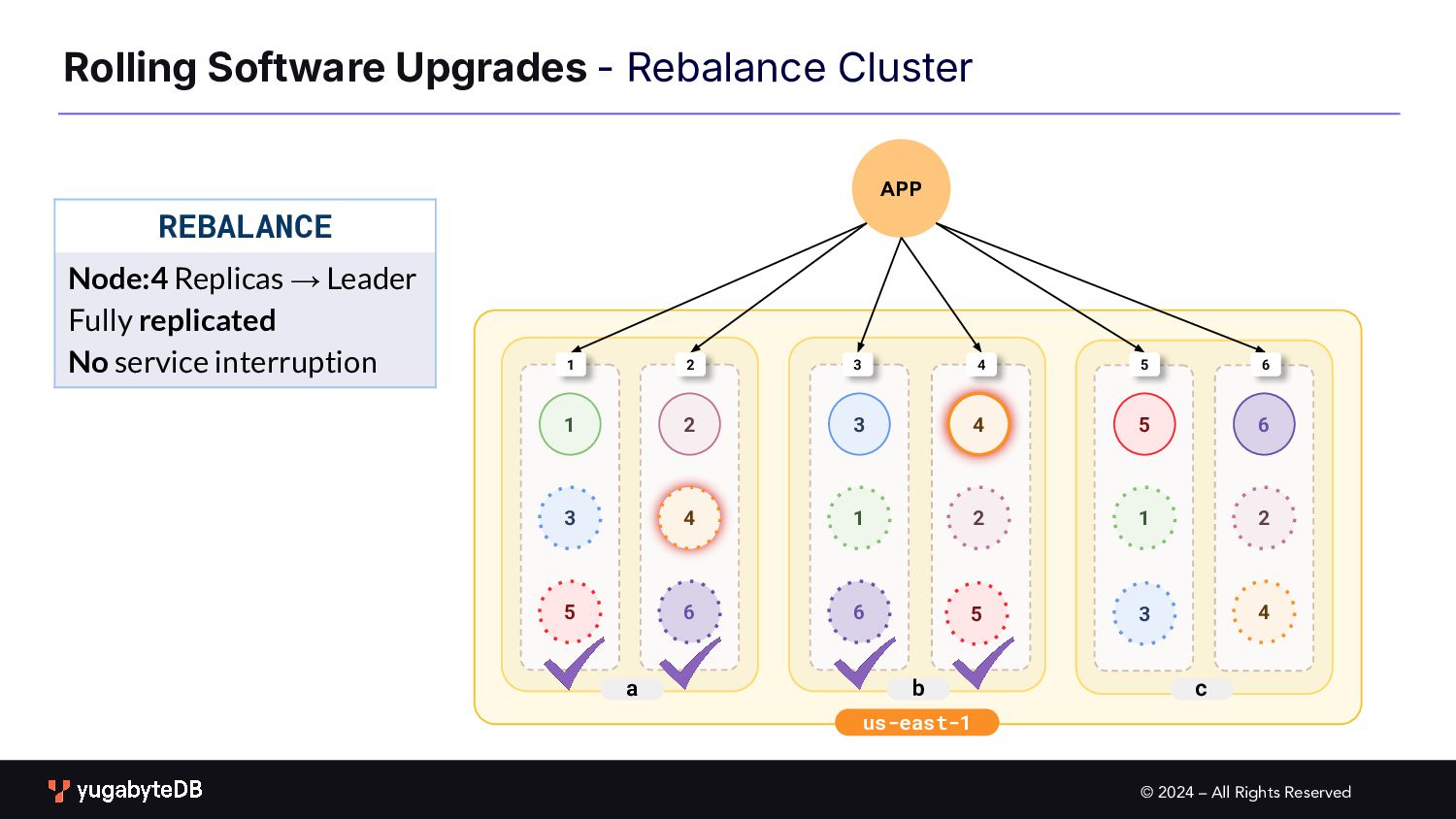
Upgrades b c a 1 2 3 1 2 3 4 4 5 6 6 1 2 3 4 5 6 1 2 3 4 5 6 PROCEDURE Upgrade one node at a time First drain traffic from the node to be upgraded 5 In Progress
system in single region ◦ IoT-based service to monitor Jakartaʼs water networks and flood system ◦ Online operations with full automation while retaining PostgreSQL features ◦ Deployment: ◦ Multi-zone, single region ◦ On-premises data center
behavior that lead to degraded performance, inconsistencies, or partial outage • Usually subtle and difficult to diagnose and root cause • Often do not trigger immediate alerts or errors—take time to even identify they exist Grey failures: the Achilles' heel of many cloud systems
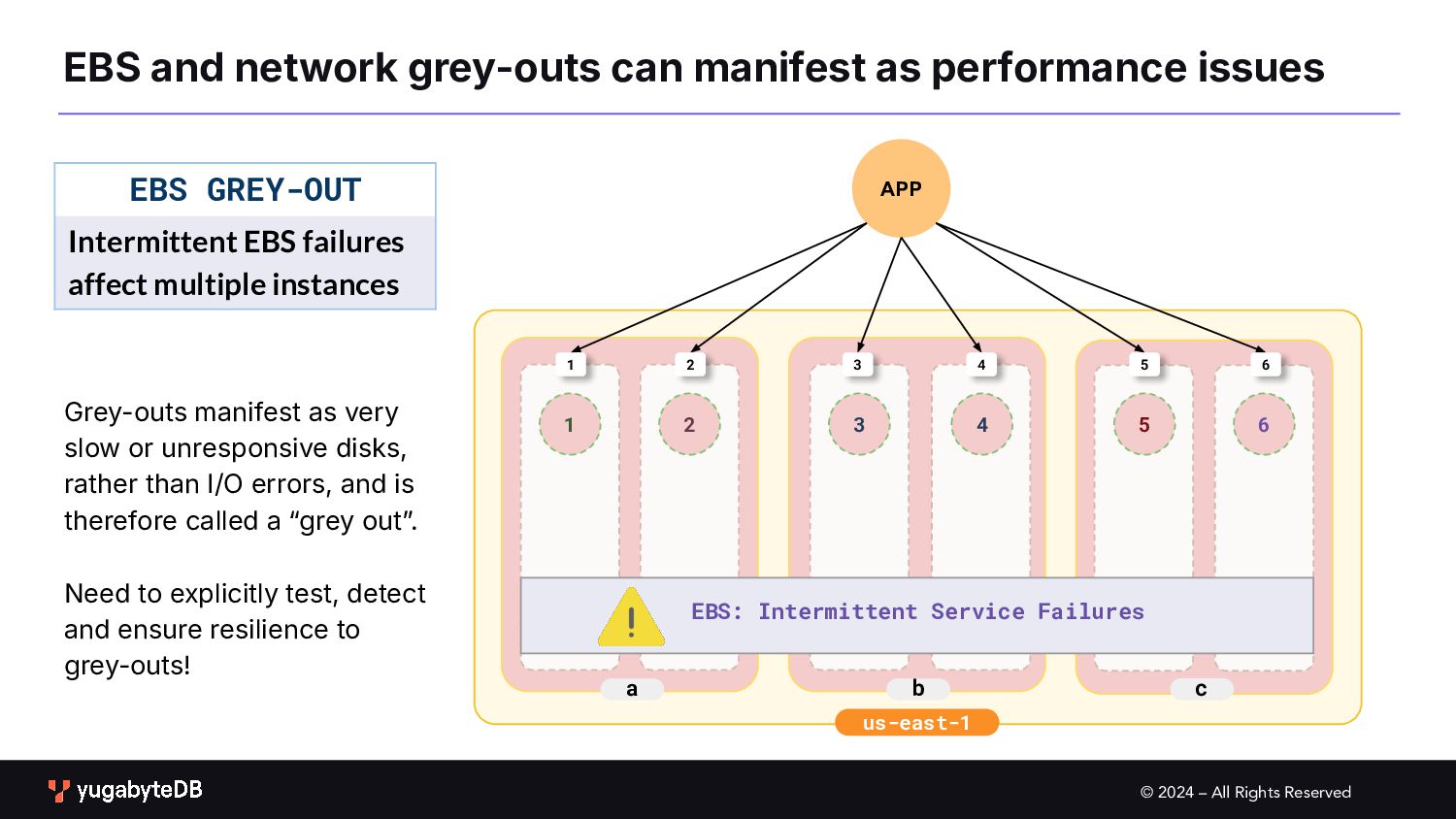
network grey-outs can manifest as performance issues b c a 1 2 3 5 6 1 2 3 4 5 6 EBS GREY-OUT Intermittent EBS failures affect multiple instances EBS: Intermittent Service Failures 4 Grey-outs manifest as very slow or unresponsive disks, rather than I/O errors, and is therefore called a “grey outˮ. Need to explicitly test, detect and ensure resilience to grey-outs!
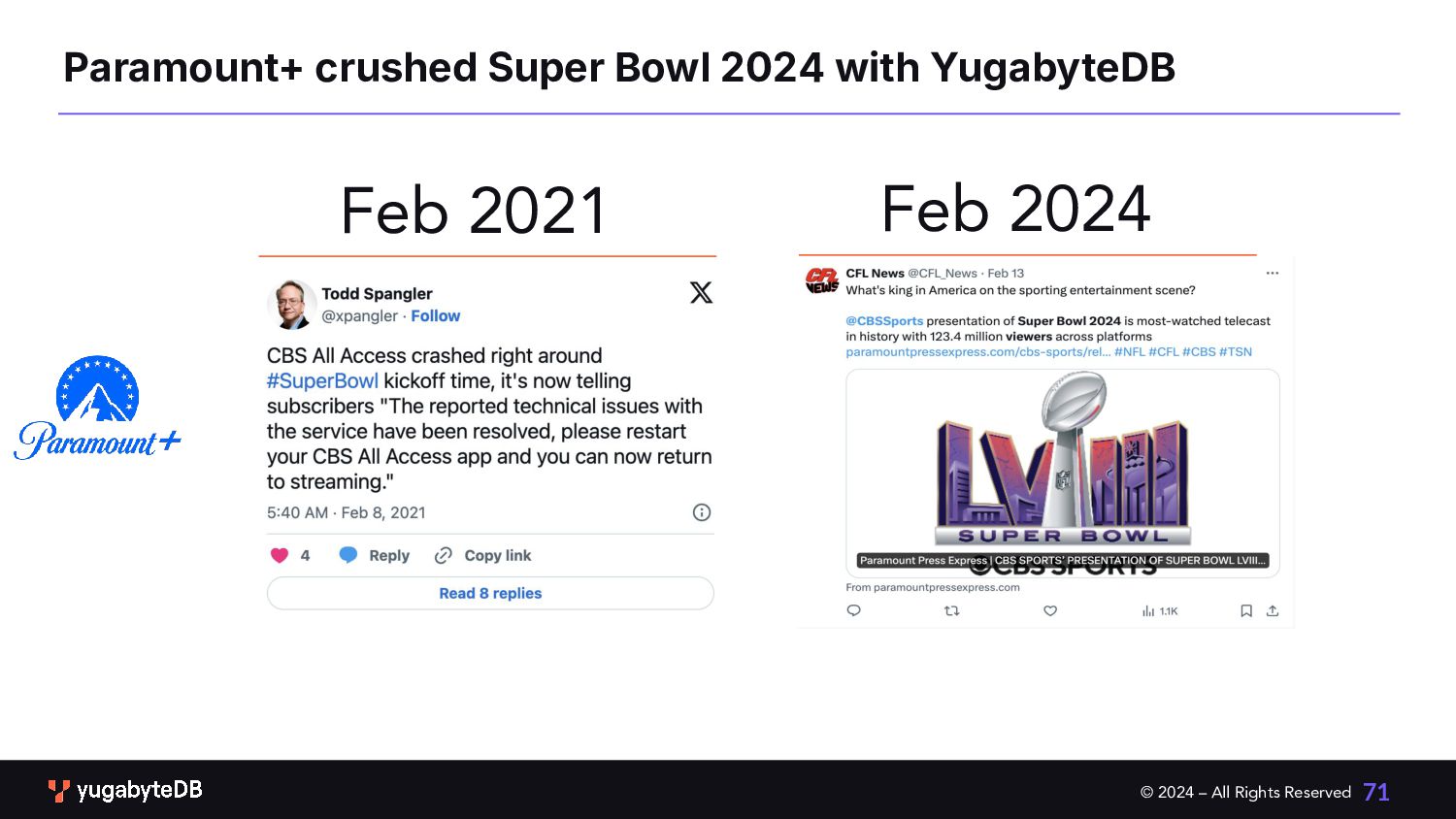
Closer to Their End Users With the anticipated expansion through globalization and release of new services and content, Paramount+ needed a database platform that could perform and scale to support peak demands to provide the best user experience. • Multi-Region/Cloud Deployment ◦ High availability and resilience ◦ Performance at peak scale • Compliance with local laws ◦ Conform to GDPR regulations ◦ Conform to local security laws
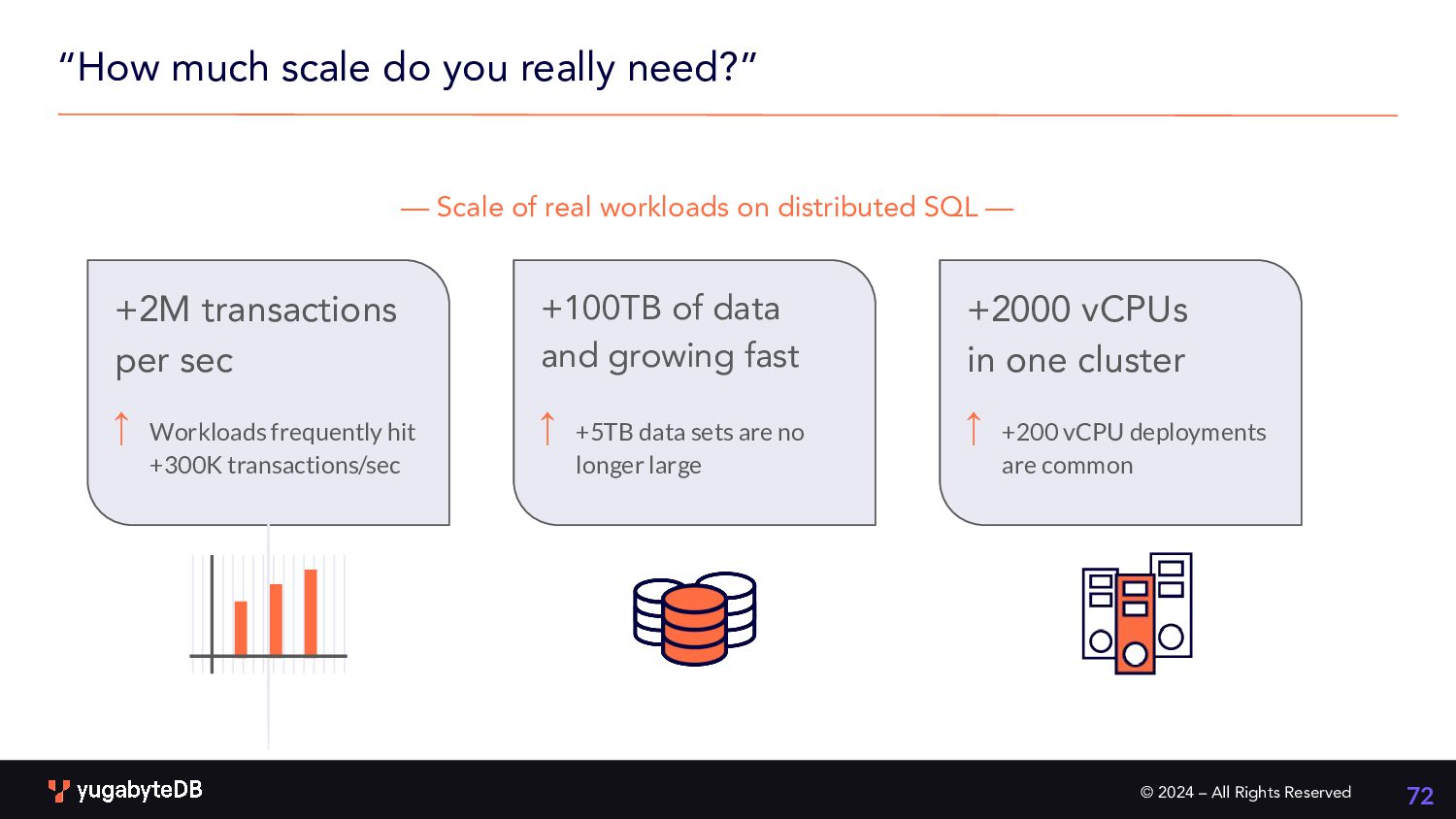
you really need?” 72 +2M transactions per sec Workloads frequently hit +300K transactions/sec ← — Scale of real workloads on distributed SQL — +100TB of data and growing fast +5TB data sets are no longer large ← +2000 vCPUs in one cluster +200 vCPU deployments are common ←
of Ultra-Resilience… In-region resilience Multi-region BCDR Zero-downtime operations Data protection Peak and freak events Grey failures … for No Limits, No Downtime!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}