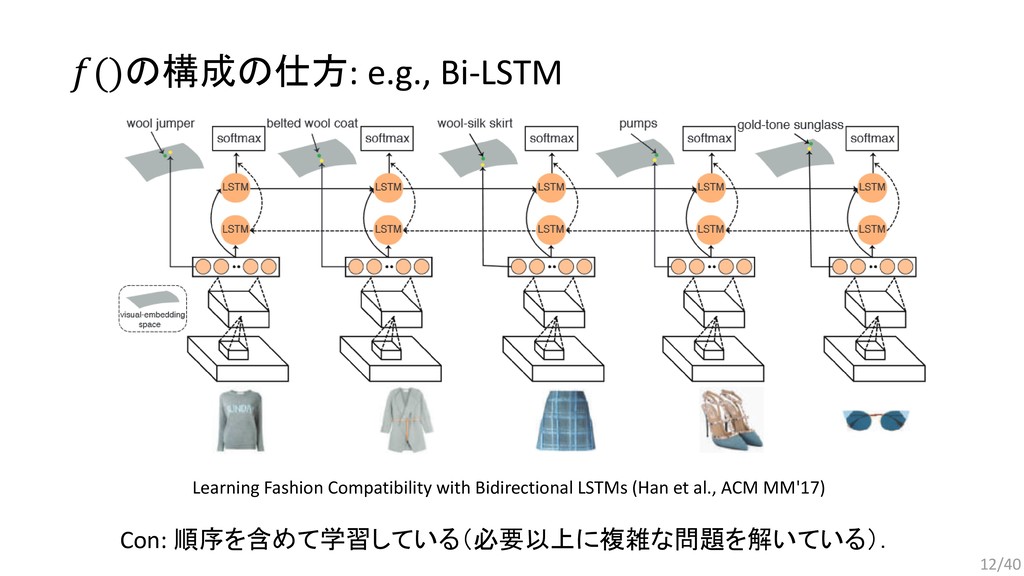
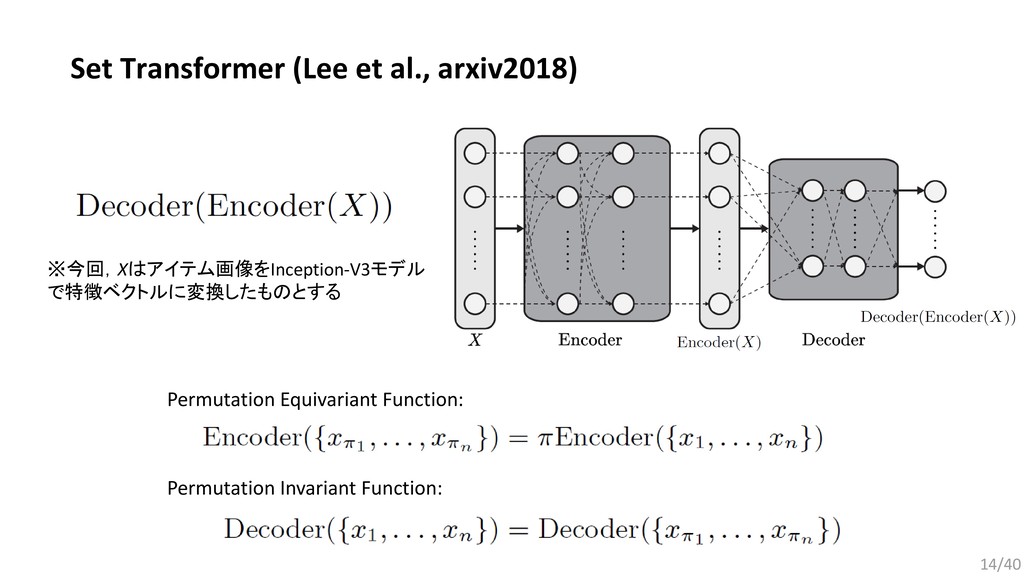
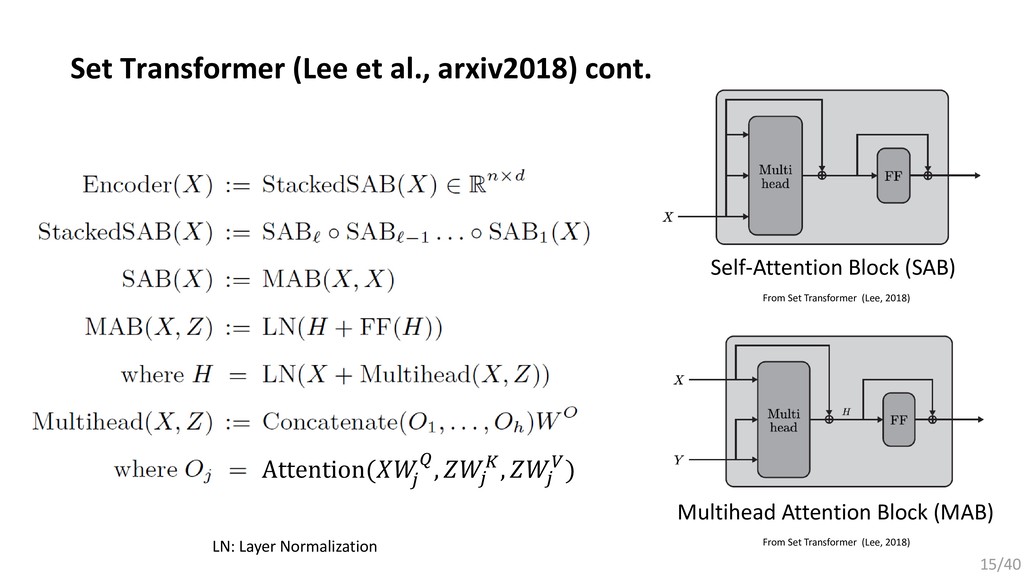
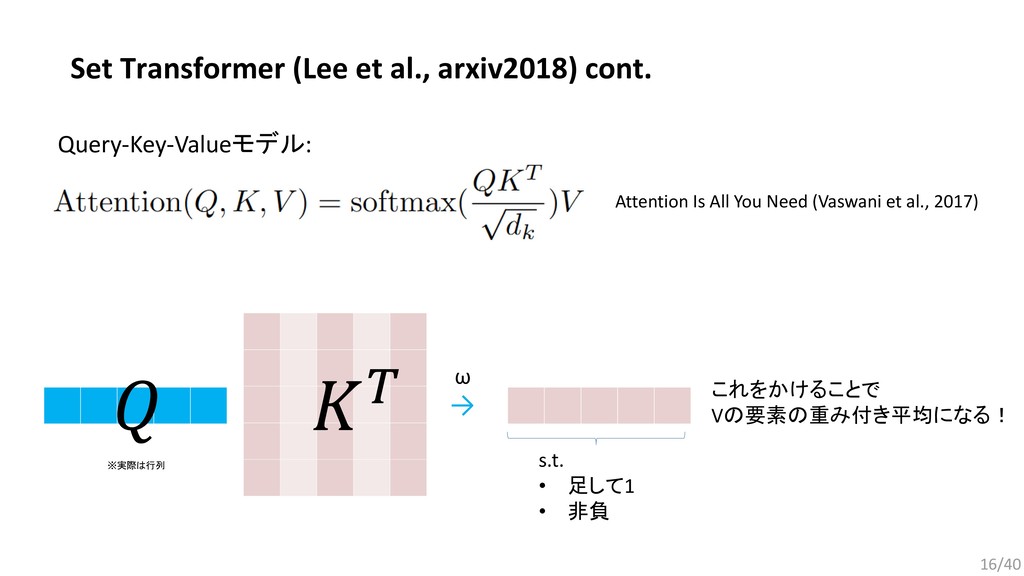
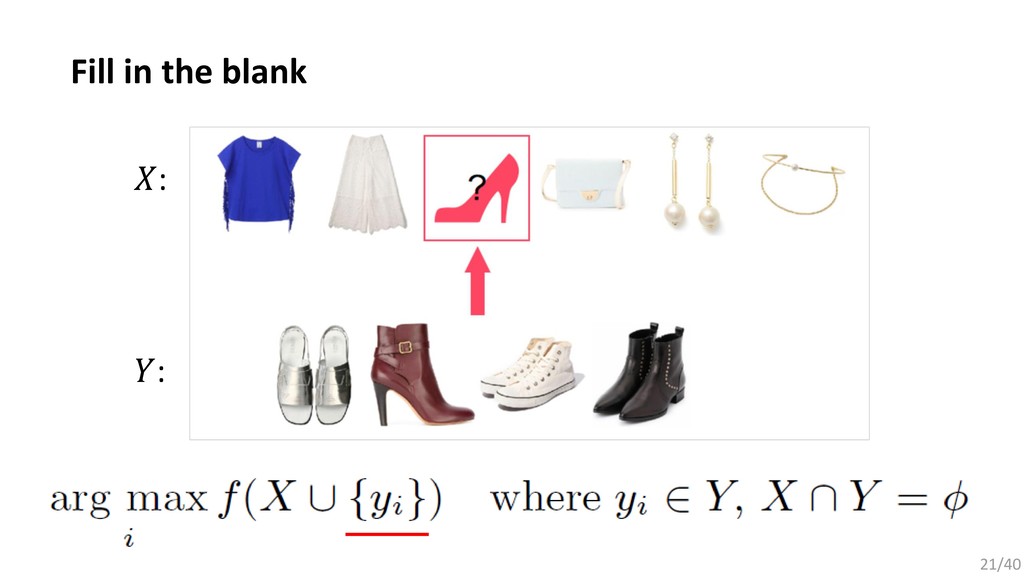
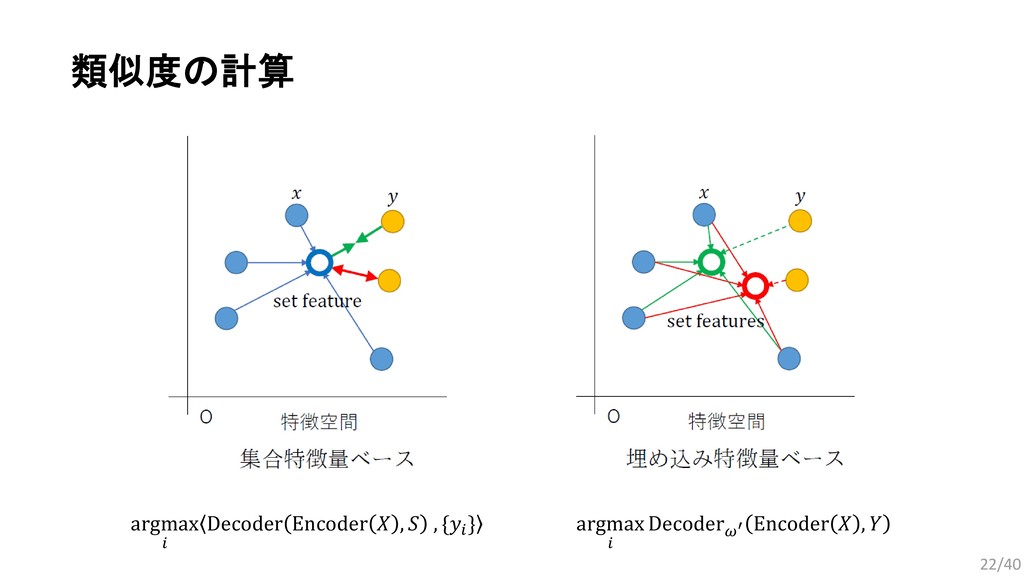
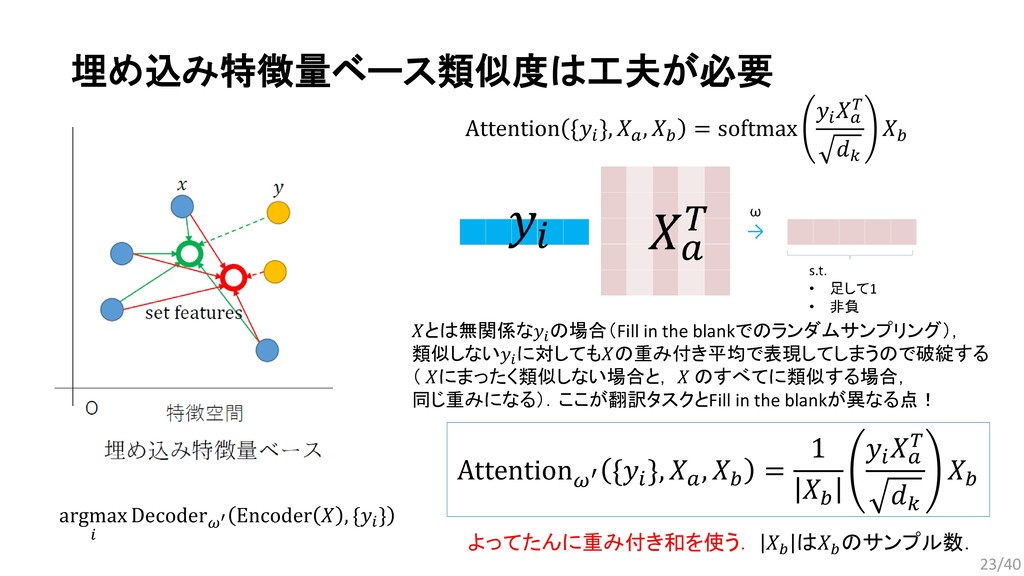
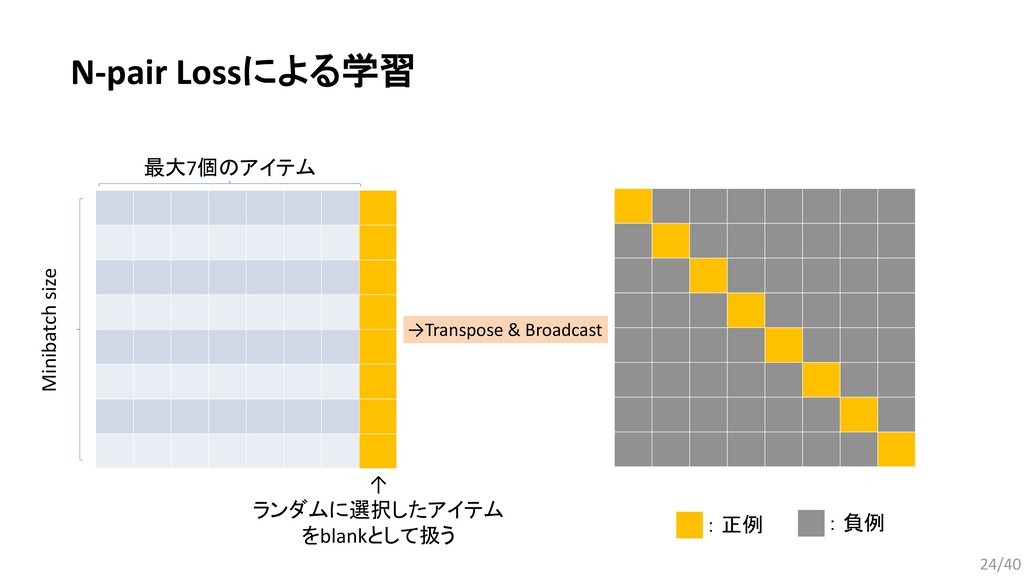
, … , . 要素同士を入れ替えても同じ出力が得られる集合データに適した関数: (2015) Bilinear cnn models for fine-grained visual recognition. (2017) Mining fashion outfit composition using an end-to-end deep learning approach on set data. (2017) Deep sets. (2018) Set Transformer: A framework for Attention-based Permutation-Invariant Neural Networks. 今回は,近年発表されたPermutation Invariant Functionである Set Transformerをファッションデータに応用するための検討を行った. 13/40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
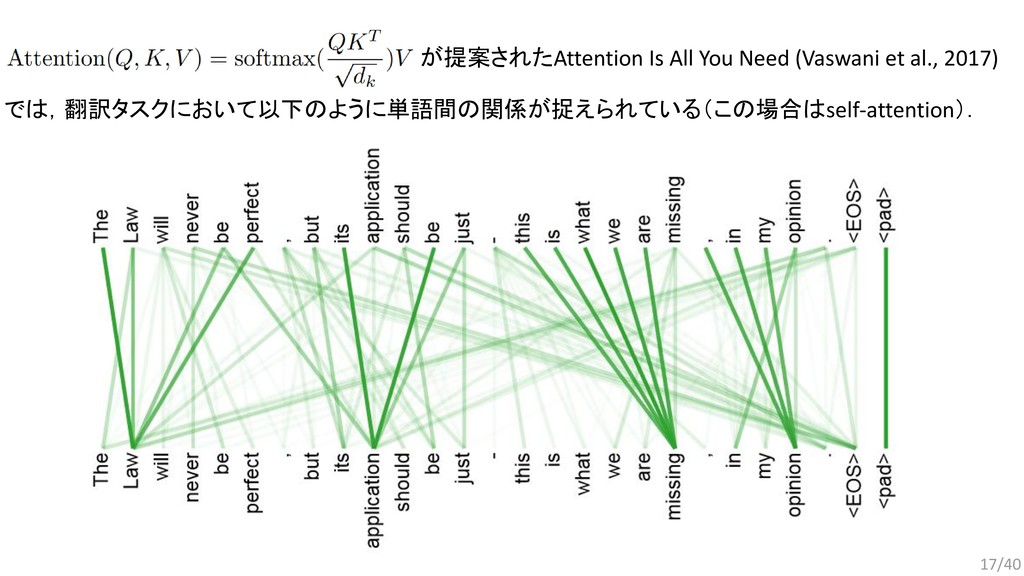{kind=link}
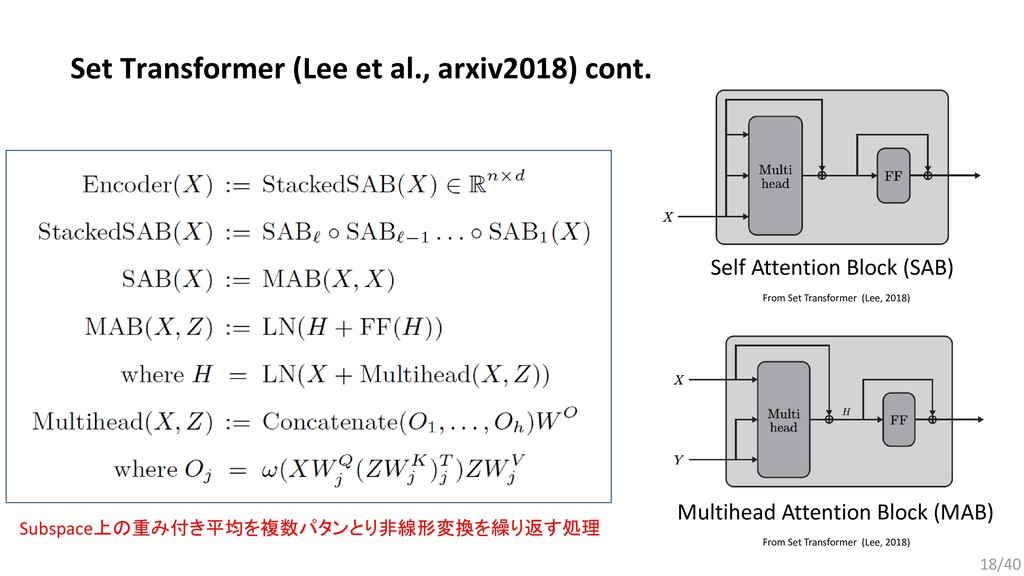{kind=link}
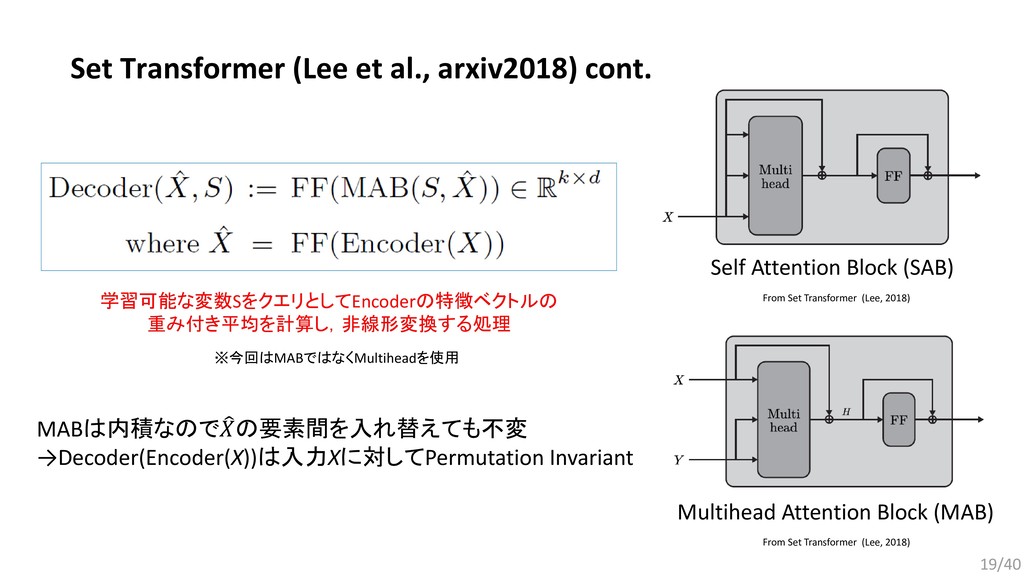{kind=link}
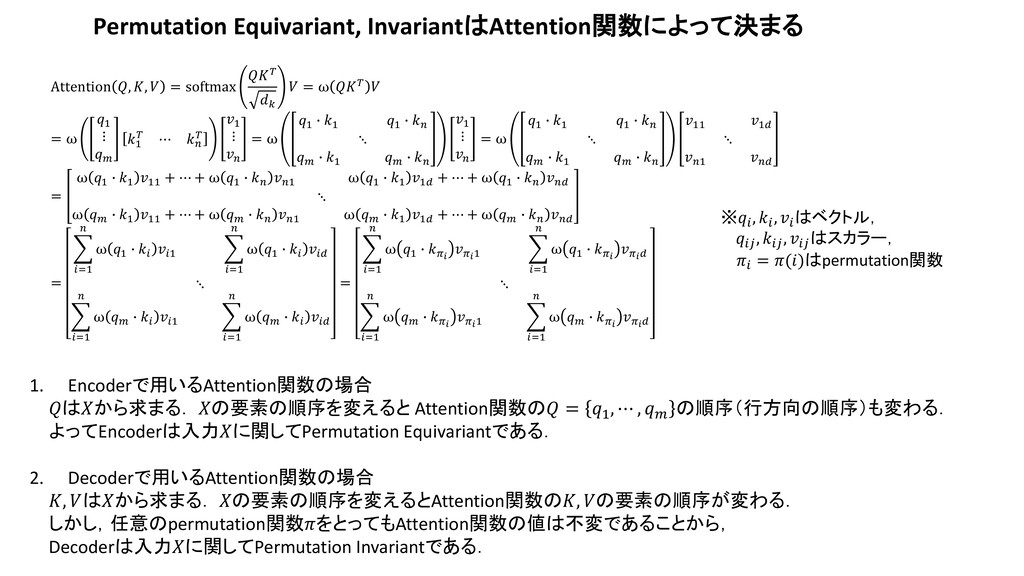{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
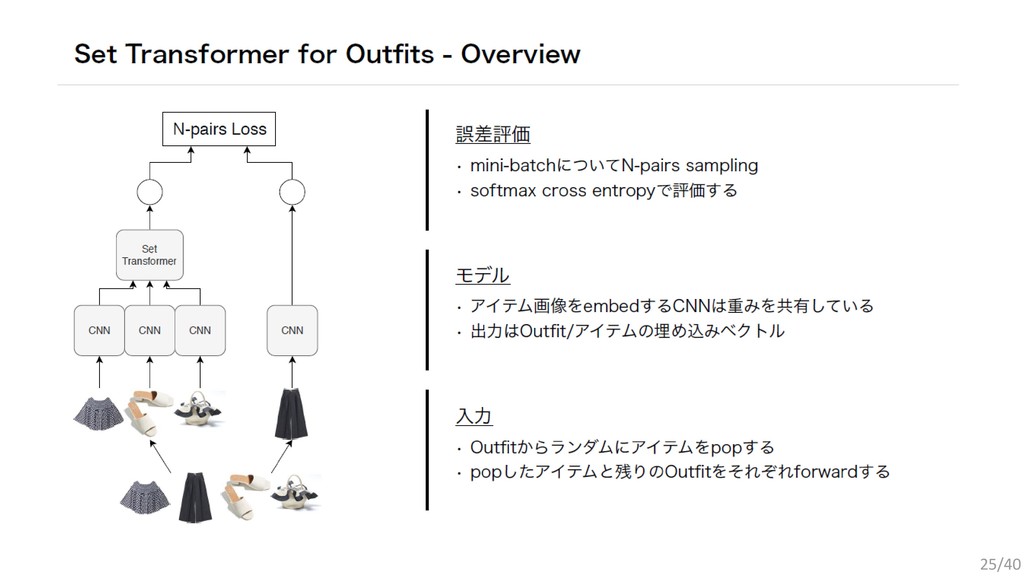{kind=link}
{kind=link}
{kind=link}
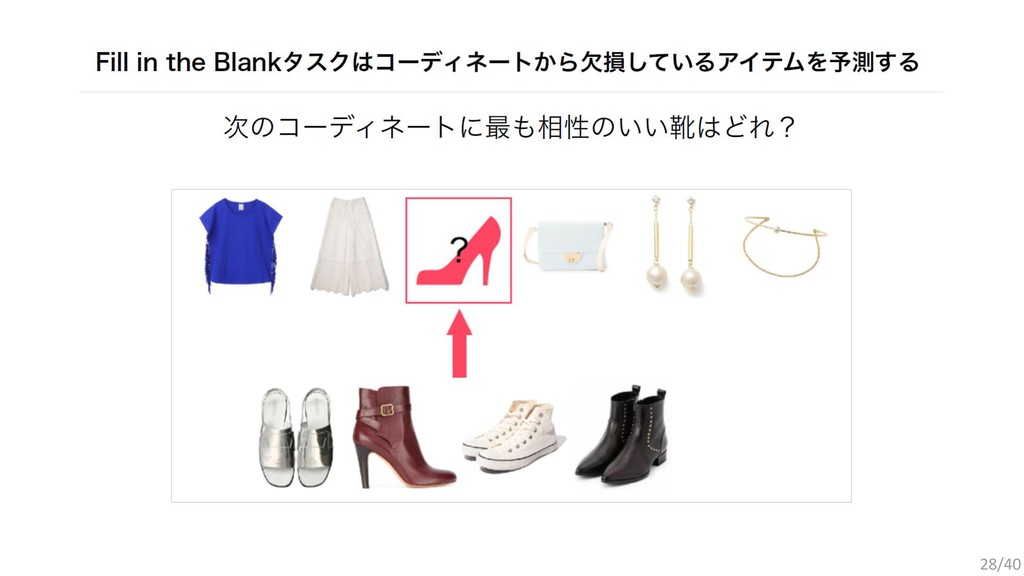{kind=link}
{kind=link}
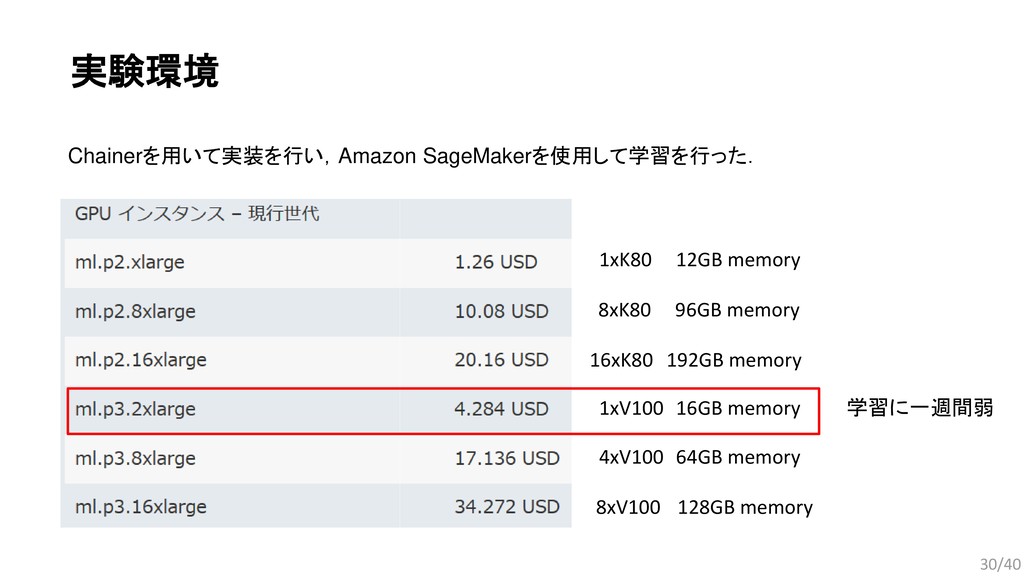{kind=link}
{kind=link}
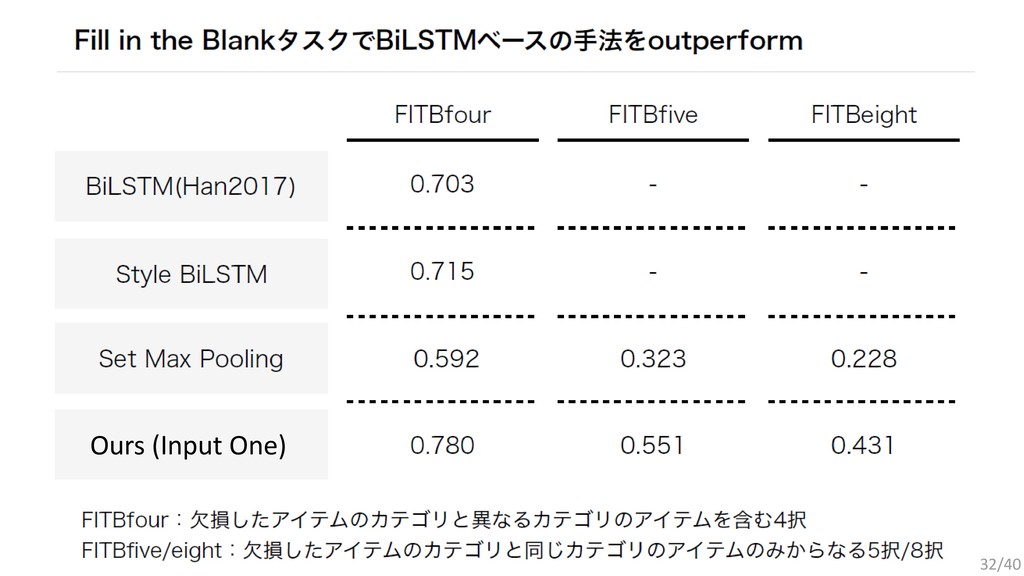{kind=link}
{kind=link}
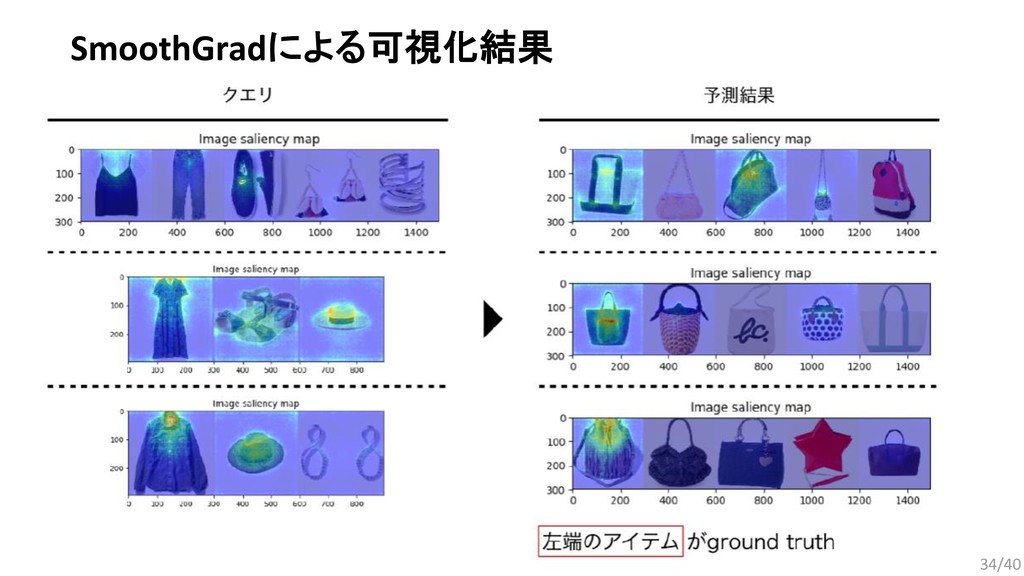{kind=link}
{kind=link}
{kind=link}
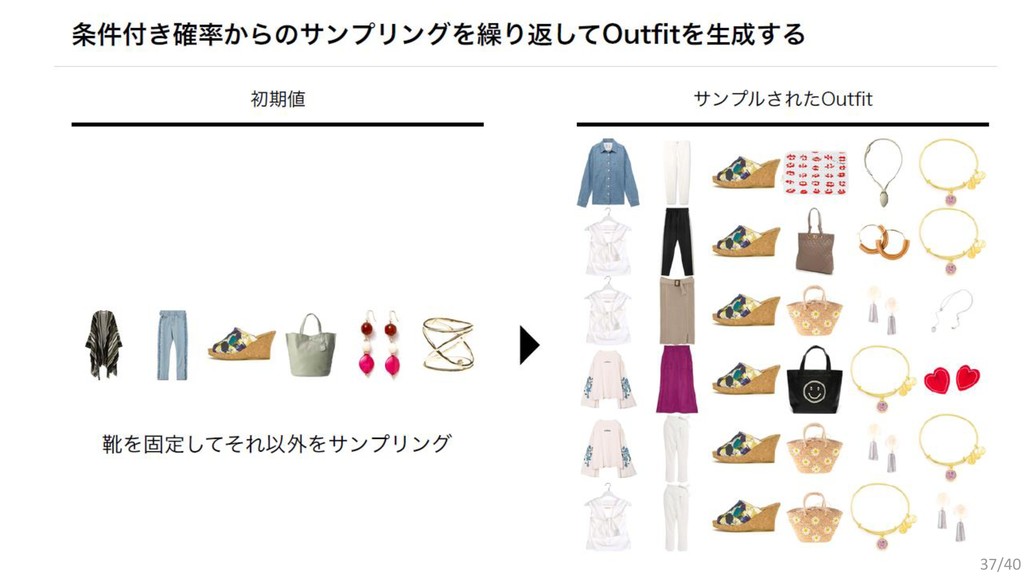{kind=link}
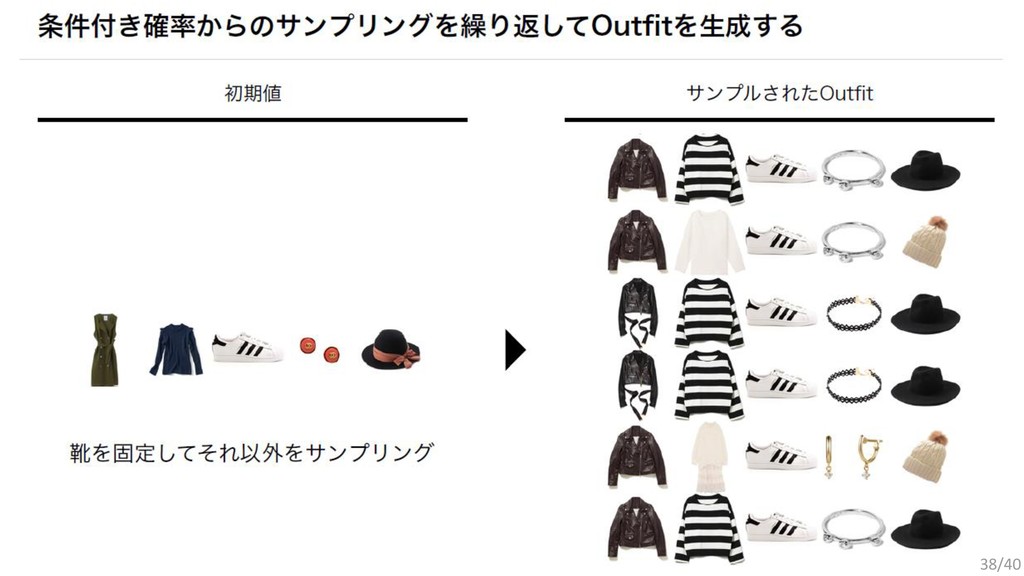{kind=link}
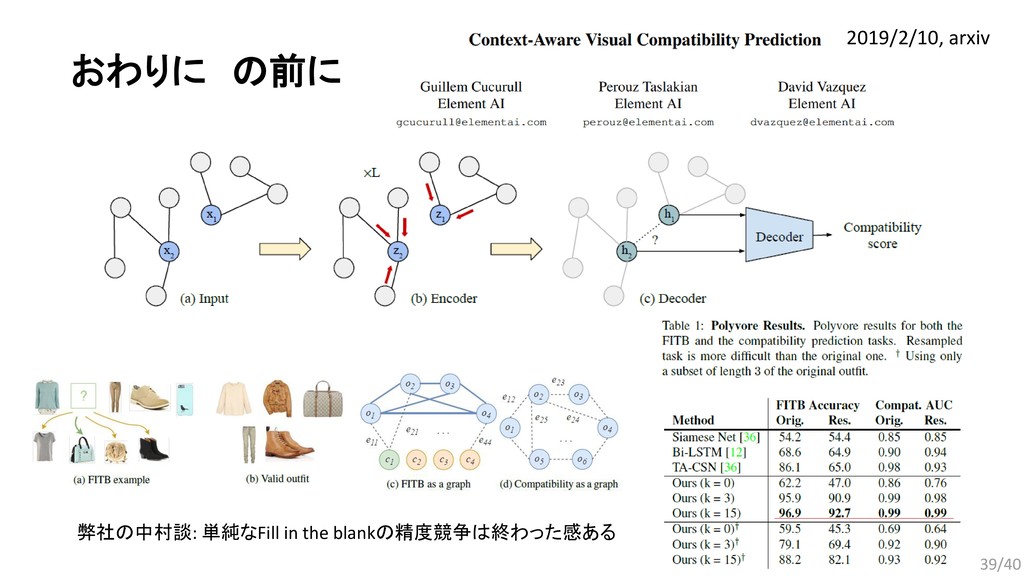{kind=link}
{kind=link}