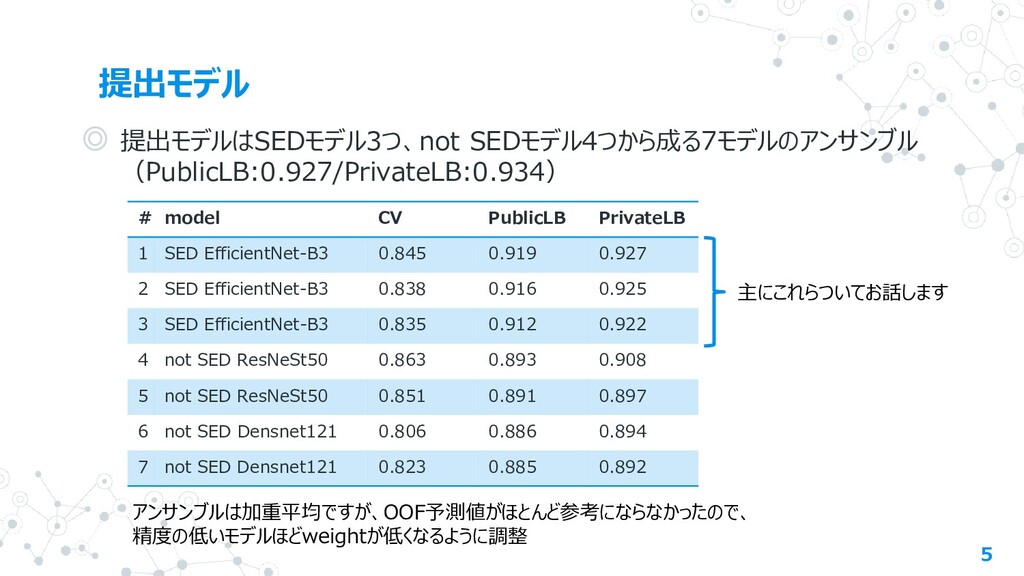
PrivateLB 1 SED EfficientNet-B3 0.845 0.919 0.927 2 SED EfficientNet-B3 0.838 0.916 0.925 3 SED EfficientNet-B3 0.835 0.912 0.922 4 not SED ResNeSt50 0.863 0.893 0.908 5 not SED ResNeSt50 0.851 0.891 0.897 6 not SED Densnet121 0.806 0.886 0.894 7 not SED Densnet121 0.823 0.885 0.892 主にこれらついてお話します アンサンブルは加重平均ですが、OOF予測値がほとんど参考にならなかったので、 精度の低いモデルほどweightが低くなるように調整
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}