以下の講演で使用しました!
人工知能学会 第76回人工知能セミナー, 2018/8/27.
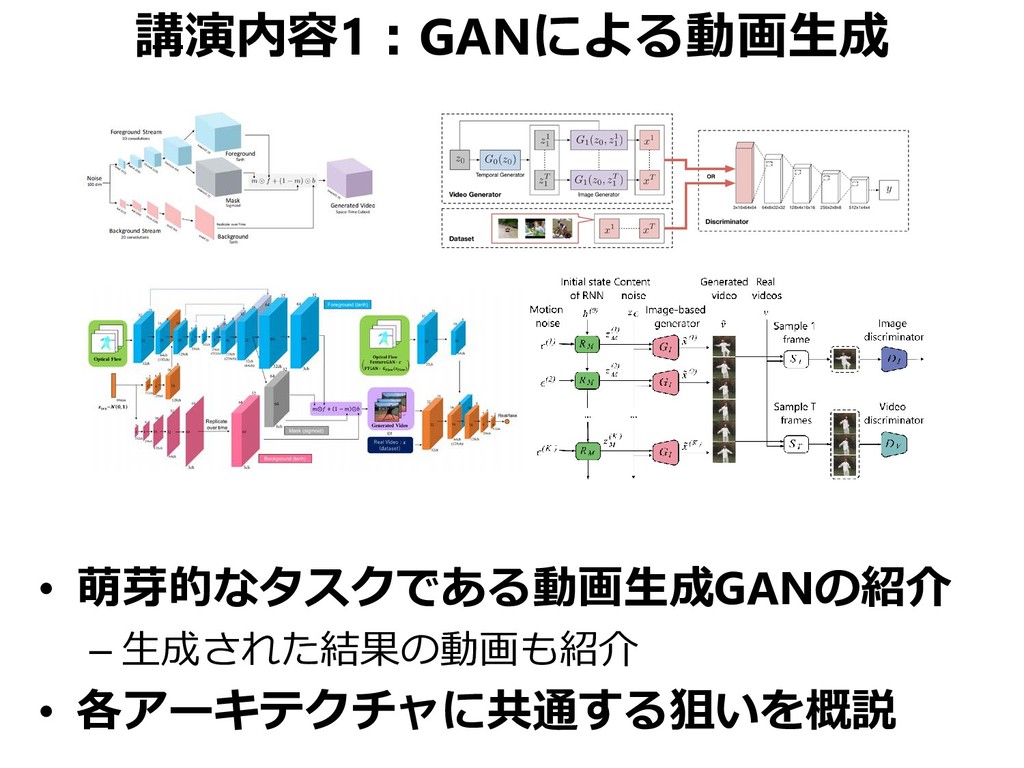
動画生成は文字通り、新規な動画を生成する試みです。まだまだ粗い/奇怪な動画を生成しがちです。
ドメイン適応は、実際に認識・識別させたい何か(ターゲットドメイン)を直接ラベル付けして学習させるデータを用意するのが困難な場合の処方箋の一つです。ラベルが付いているけど微妙にデータの性質が違うソースドメインで学習したモデルを、うまくターゲットドメインでも動くように何とかする技術です。
本講演では
【動画生成】…「時系列的な動き」とその「テクスチャ」に分けて生成するという考え方
【ドメイン適応】…ソースドメインとターゲットドメインの何らかの「ズレ」を無くすという考え方
これらが敵対的学習によって実現されていますよというお話をしました。
{kind=link}
{kind=link}
![車載画像? 実はGANで生成された画像 [Wang+, CVPR 2018]](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_2.jpg){kind=link}
![車載画像? 実はGANで生成された画像 →動画もきれいに生成できる? [Wang+, CVPR 2018]](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_3.jpg){kind=link}
{kind=link}
![教師データの用意は大変 • 例:画像のセマンティックセグメンテーション – Cityscapes [Cordts+, CVPR 2016] – マックスプランク+ダイムラー](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![ラベルからの1024x2048画像生成 綺麗な画像生成→綺麗な動画も生成可能? [Wang+, CVPR 2018]](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_8.jpg){kind=link}
![敵対的学習によるフレーム予測 入力:直近のフレーム 出力:その後のフレーム 拡大しながら生成 [Mathieu+, ICLR 2016]](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
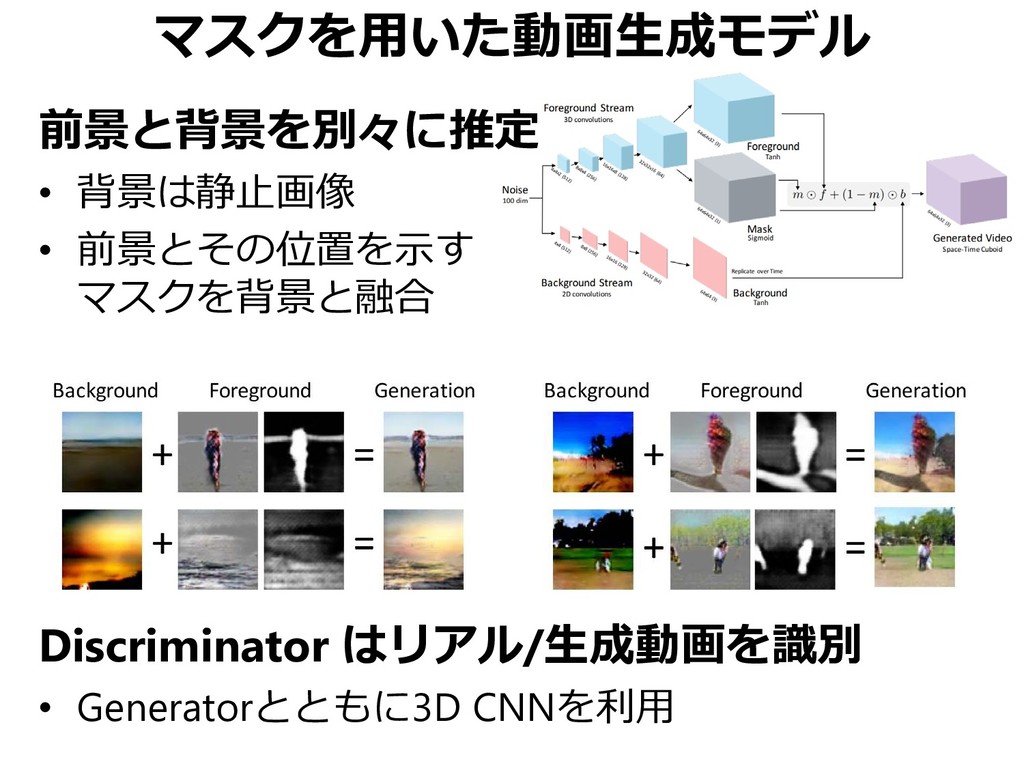
![GAN for Video (VGAN) [Vondrick+, NIPS 2016] ラベル無し動画データセットから シーンダイナミクスをモデリングしたい •](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
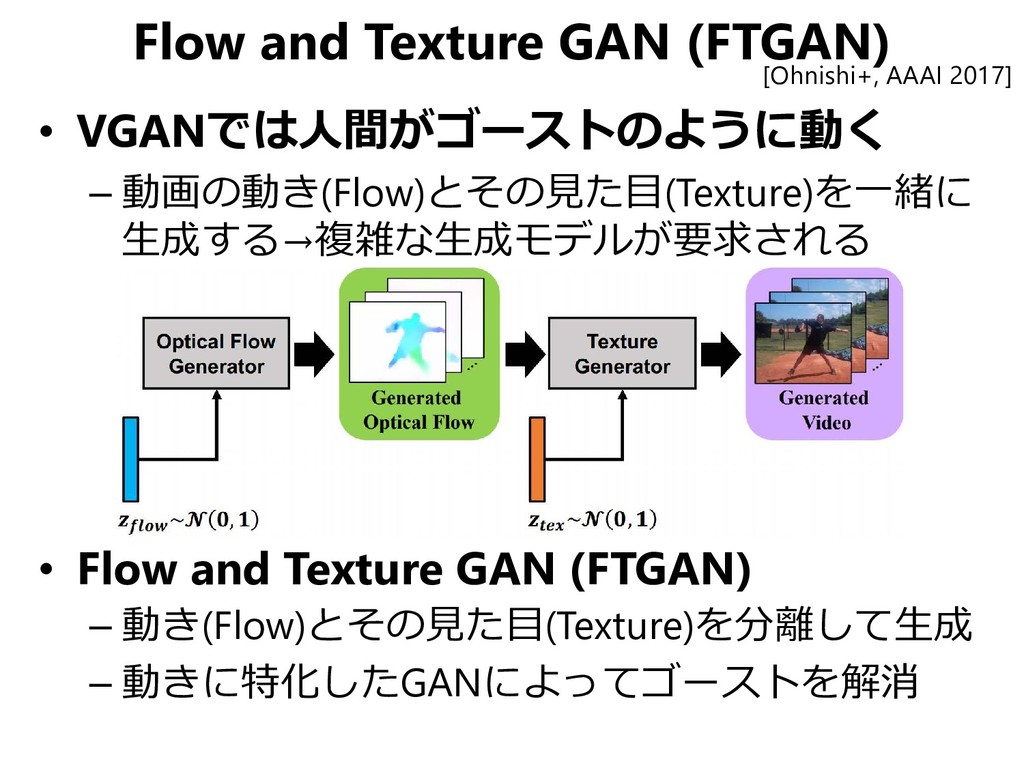
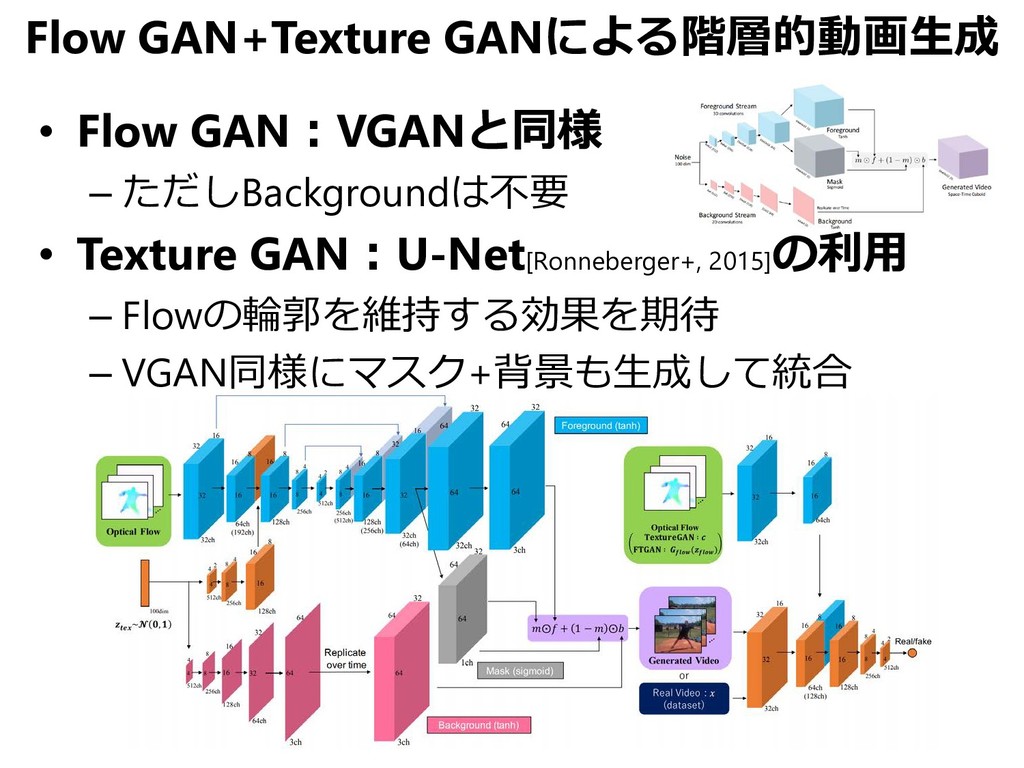
![Temporal GAN (TGAN) [Saito+, ICCV 2017] VGANが奇妙な動きの動画を生成してしまうのは… • 「3D CNNを用いているせい」](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
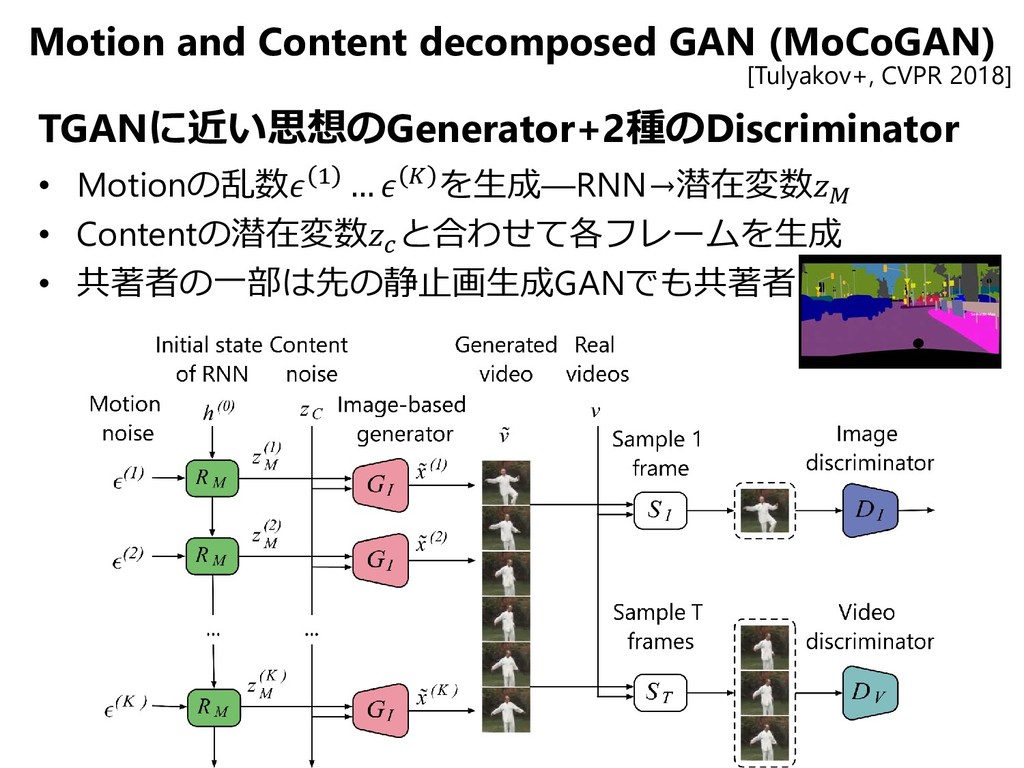{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
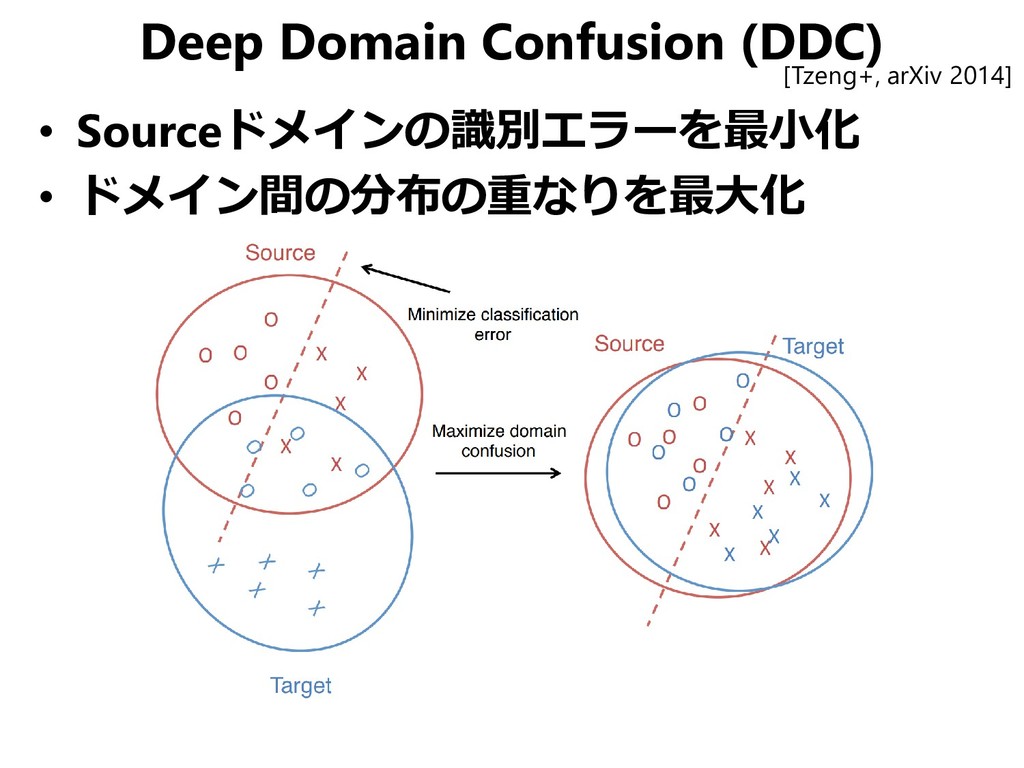{kind=link}
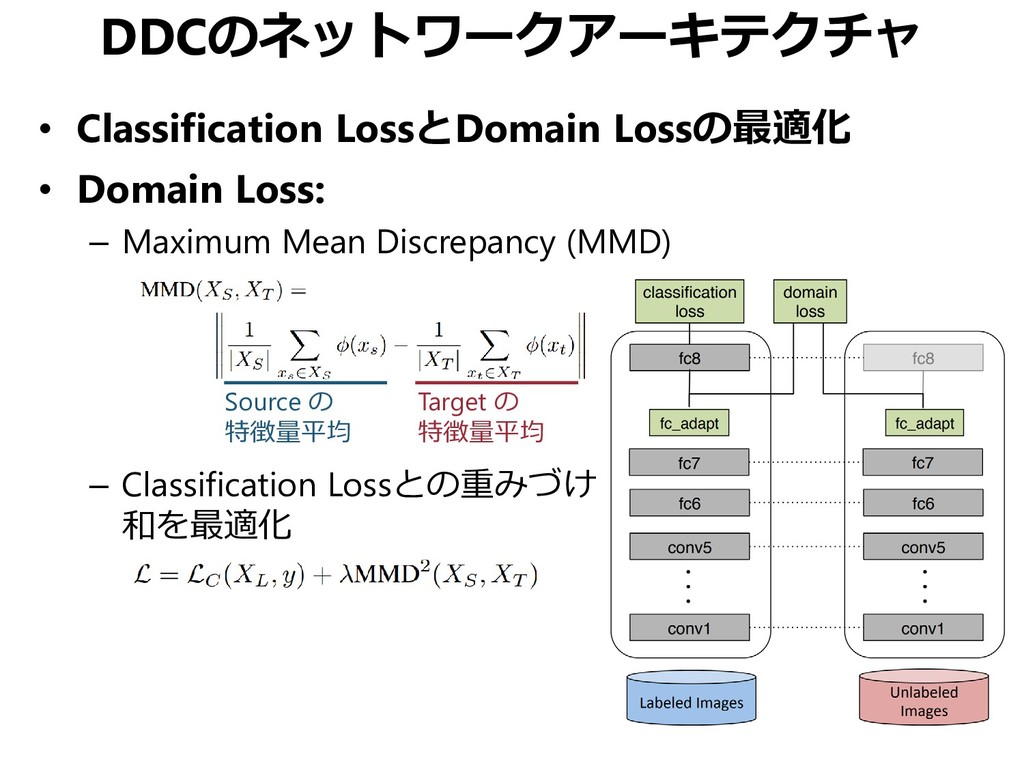{kind=link}
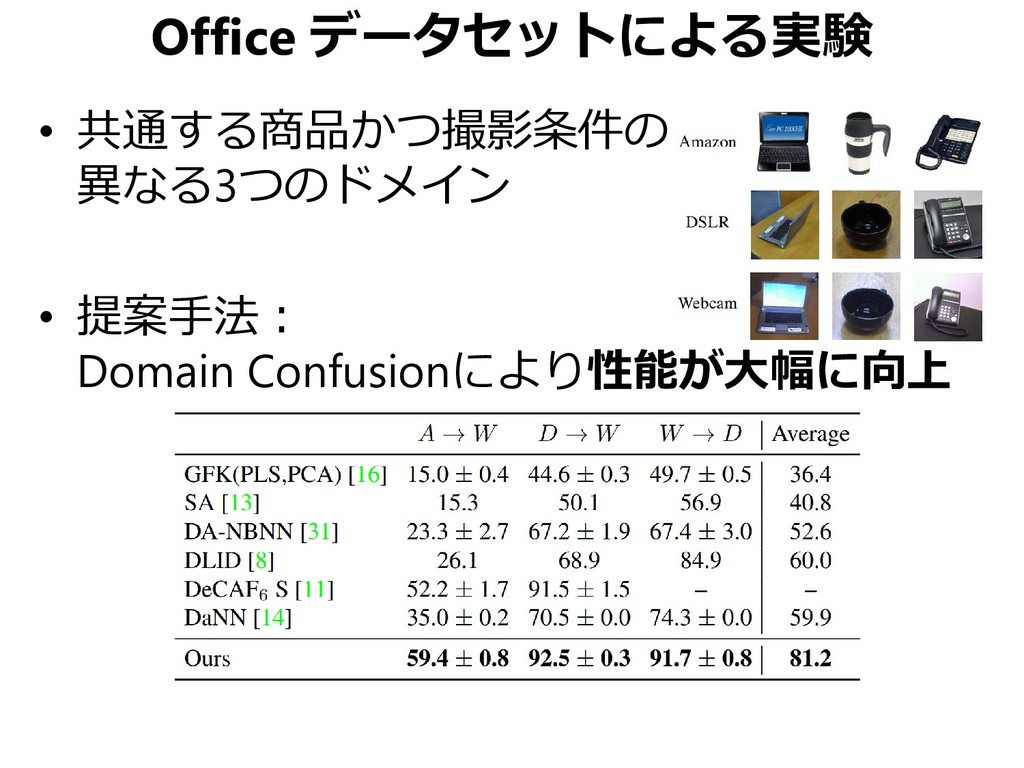{kind=link}
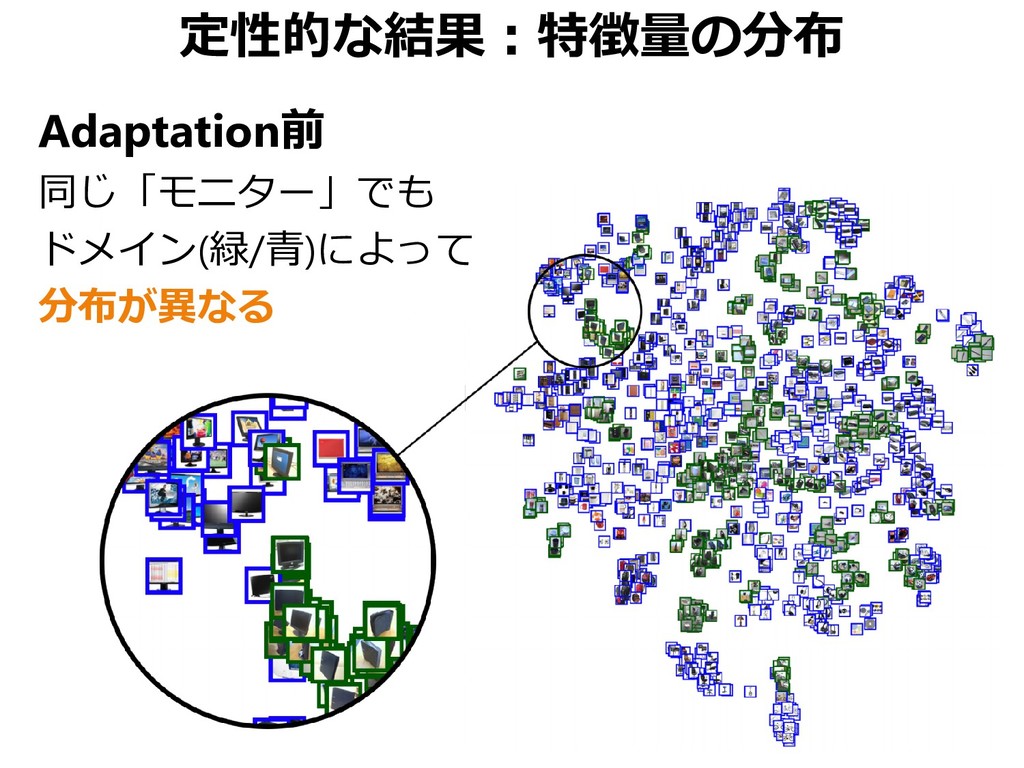{kind=link}
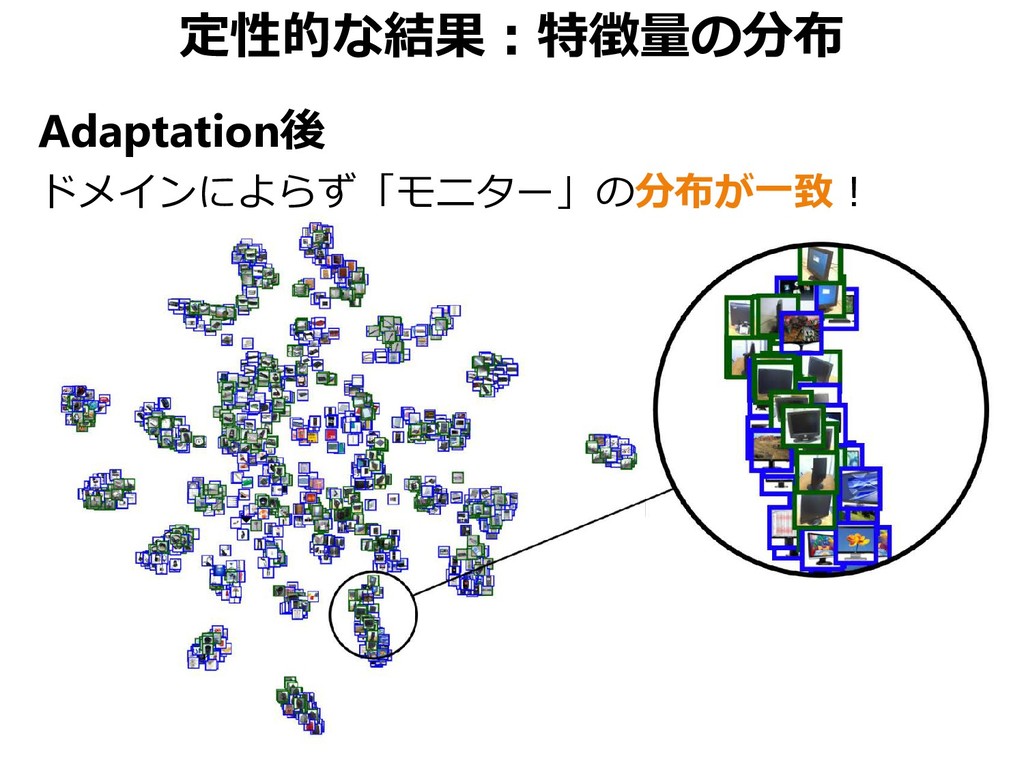{kind=link}
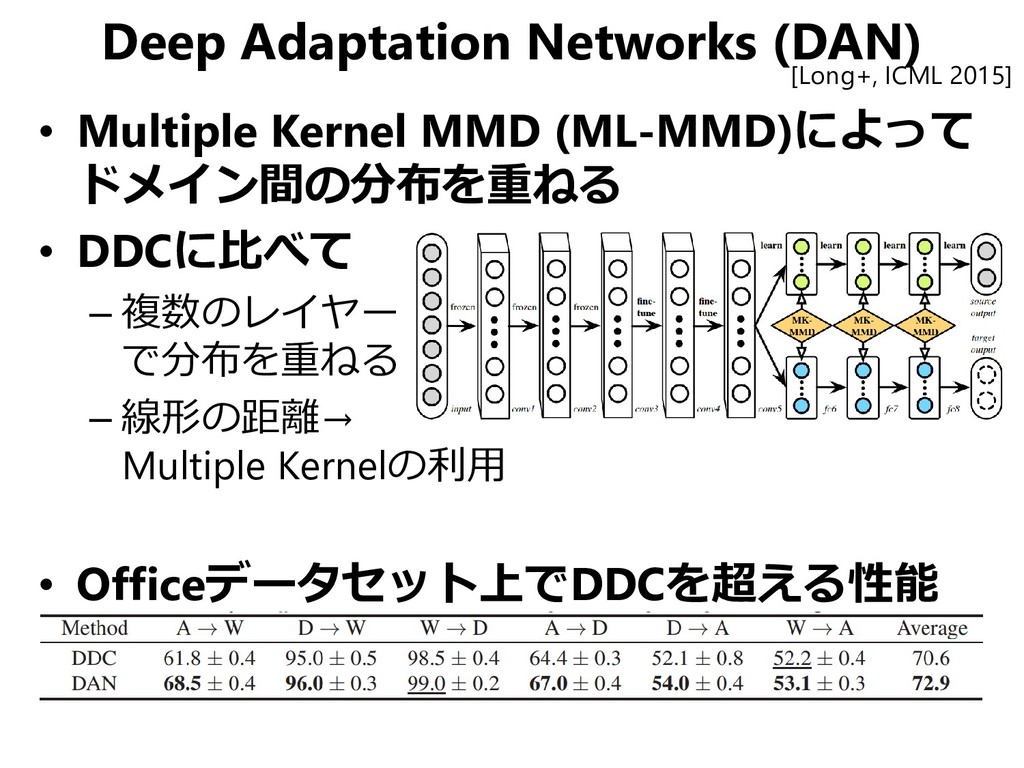{kind=link}
{kind=link}
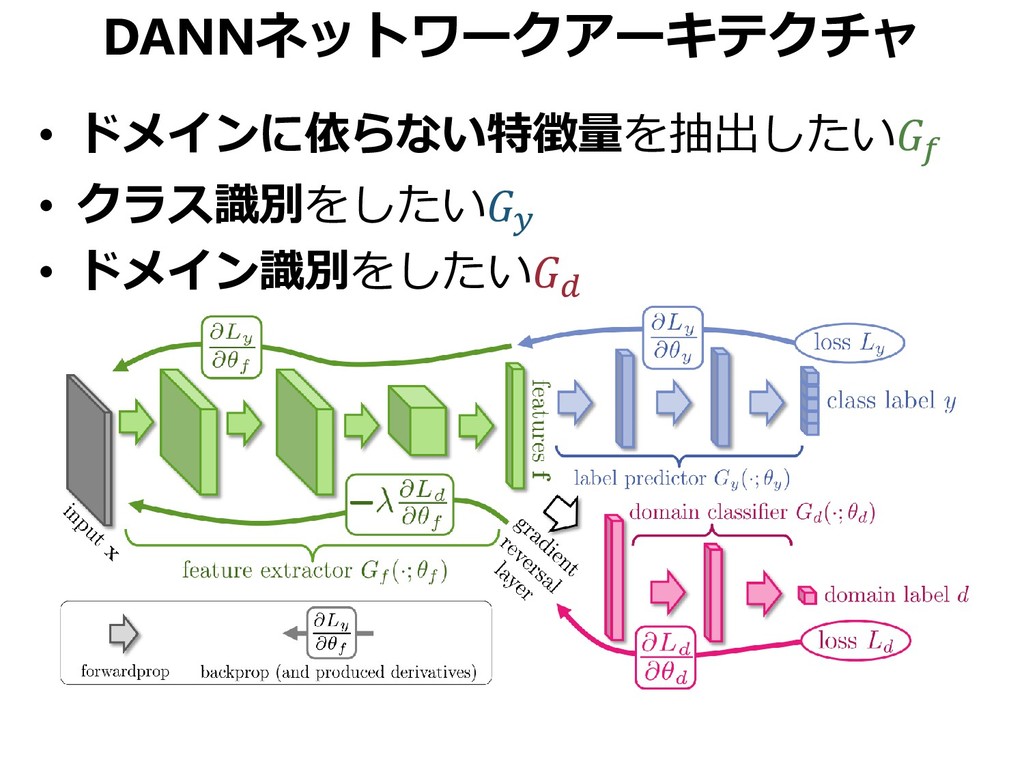{kind=link}
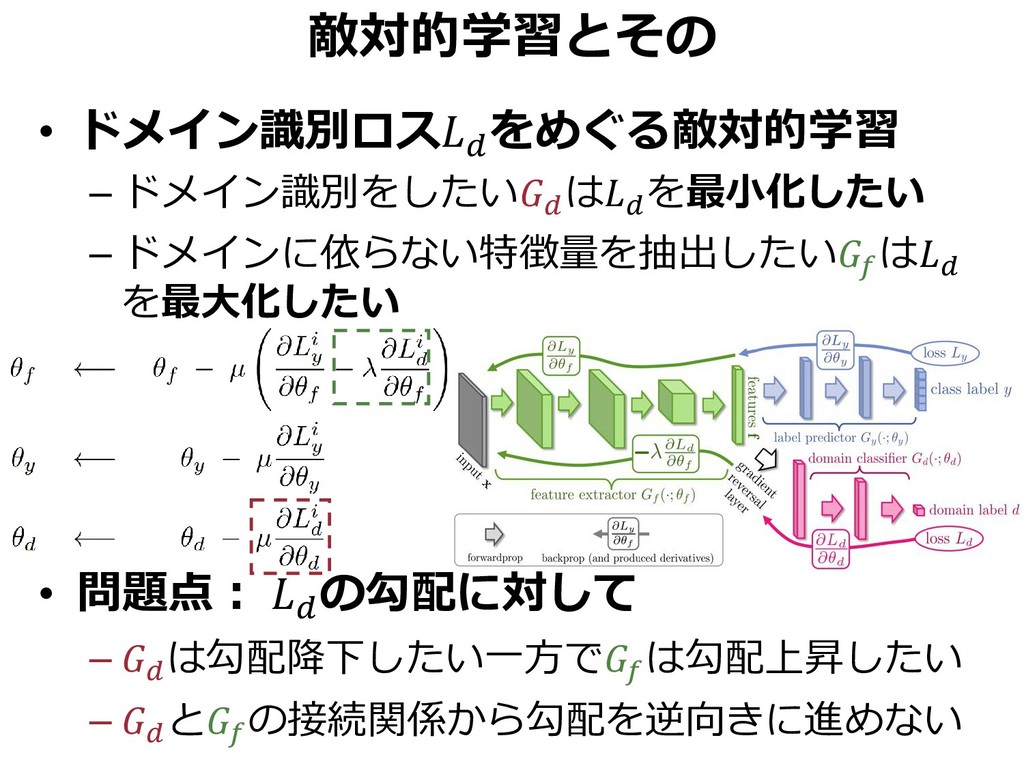{kind=link}
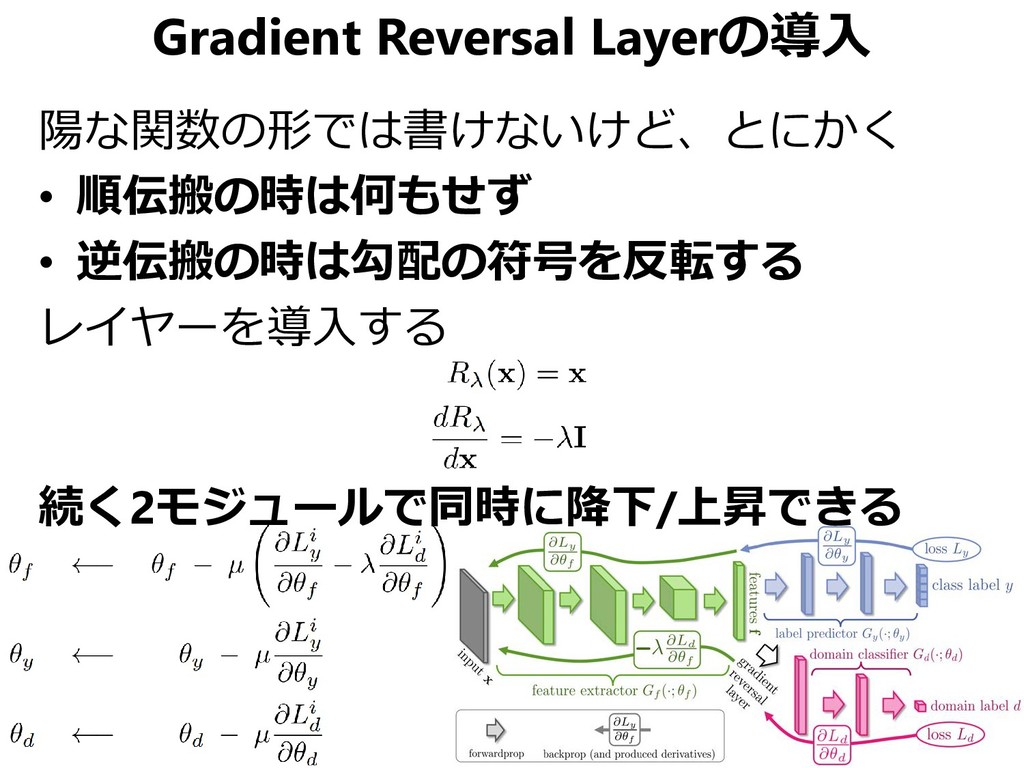{kind=link}
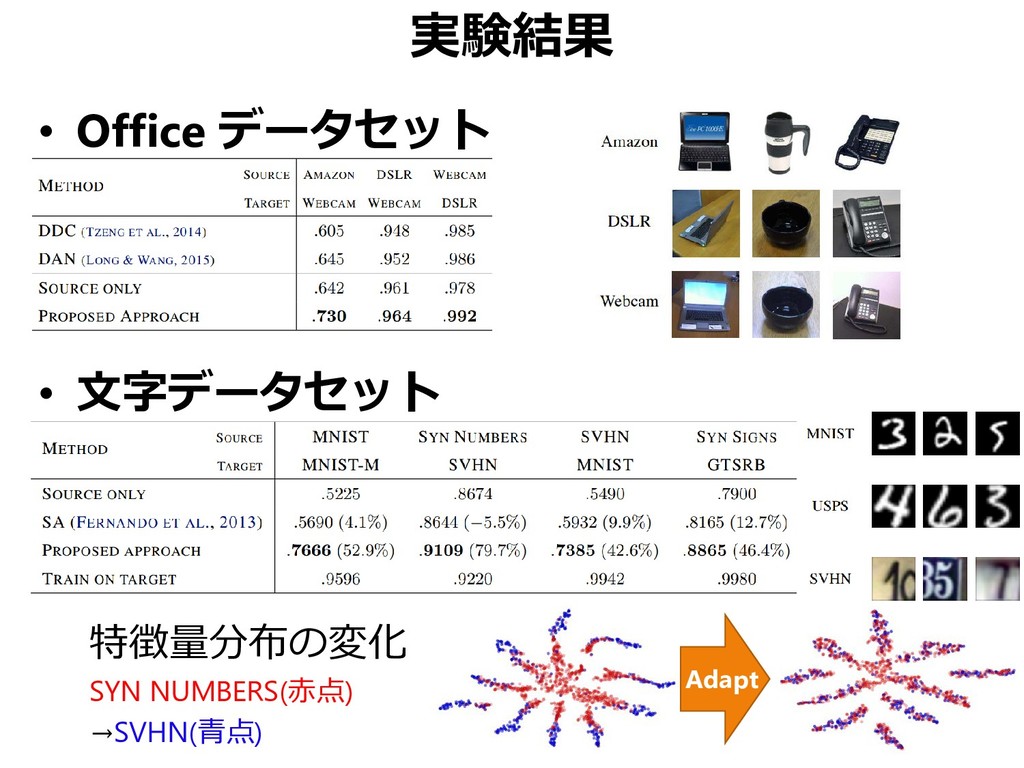{kind=link}
![Adversarial Discriminative Domain Adaptation DANNと同様にドメイン識別器を敵対的学習 [Tzeng+, CVPR 2017]](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_45.jpg){kind=link}
{kind=link}
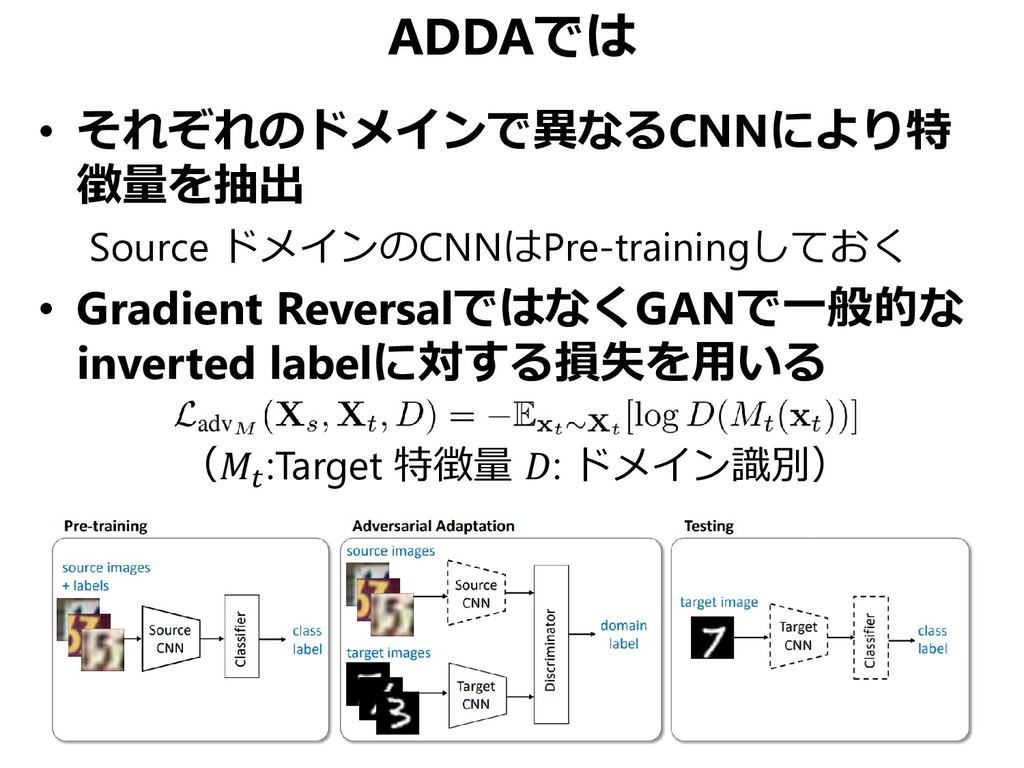{kind=link}
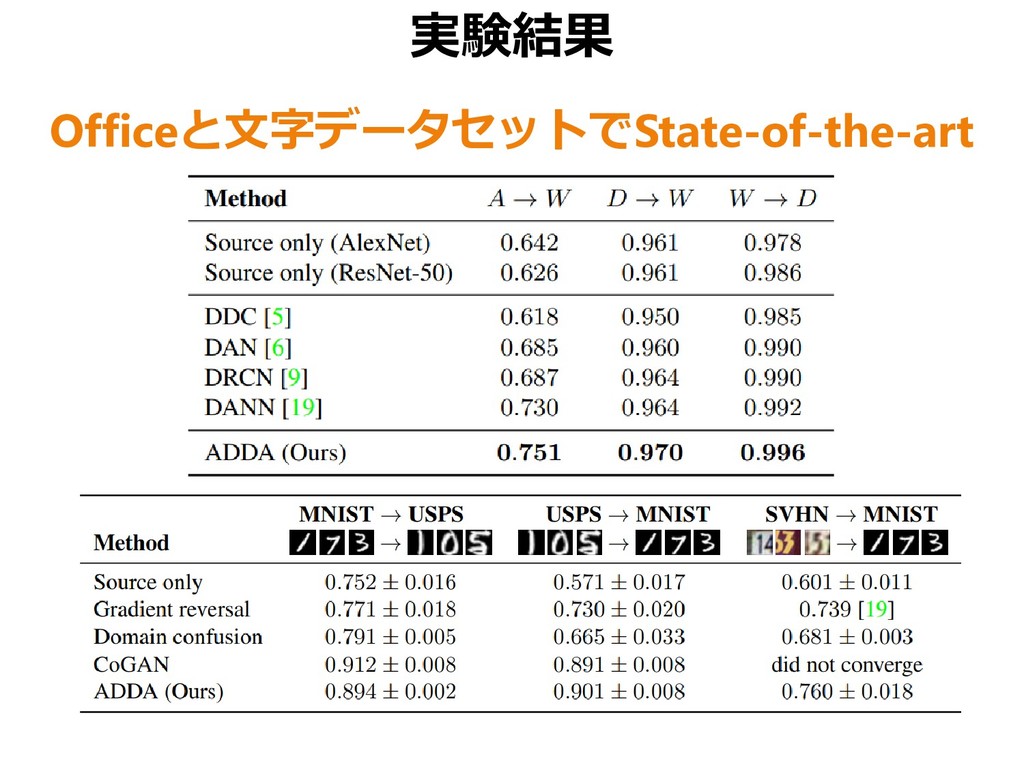{kind=link}
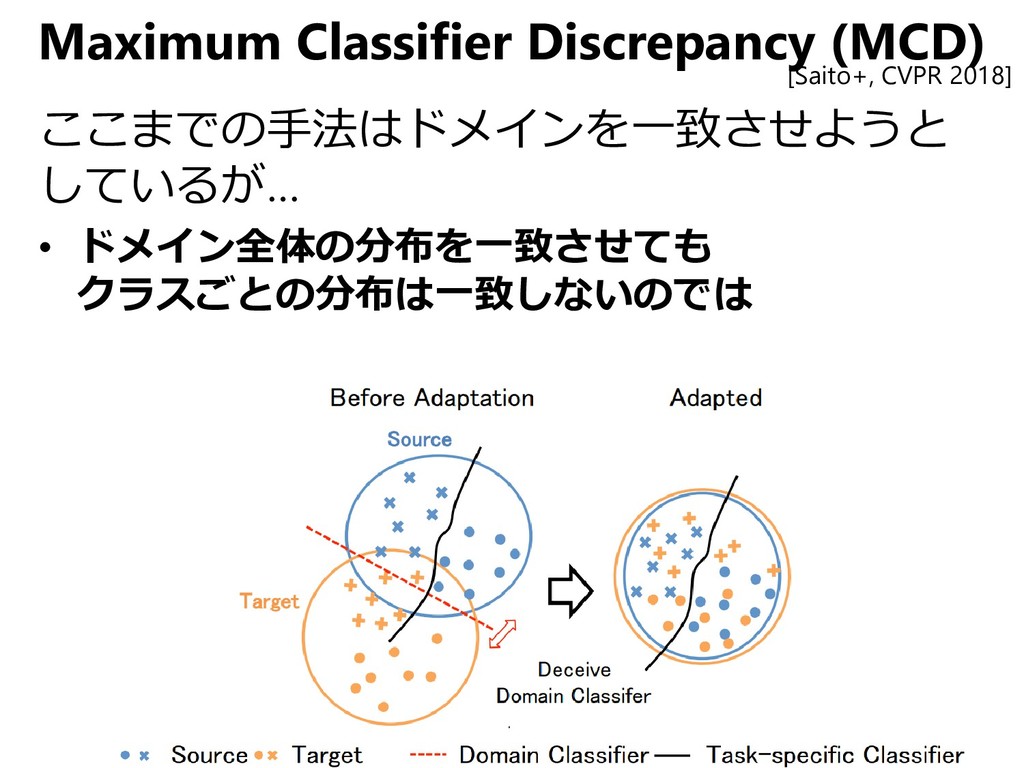{kind=link}
{kind=link}
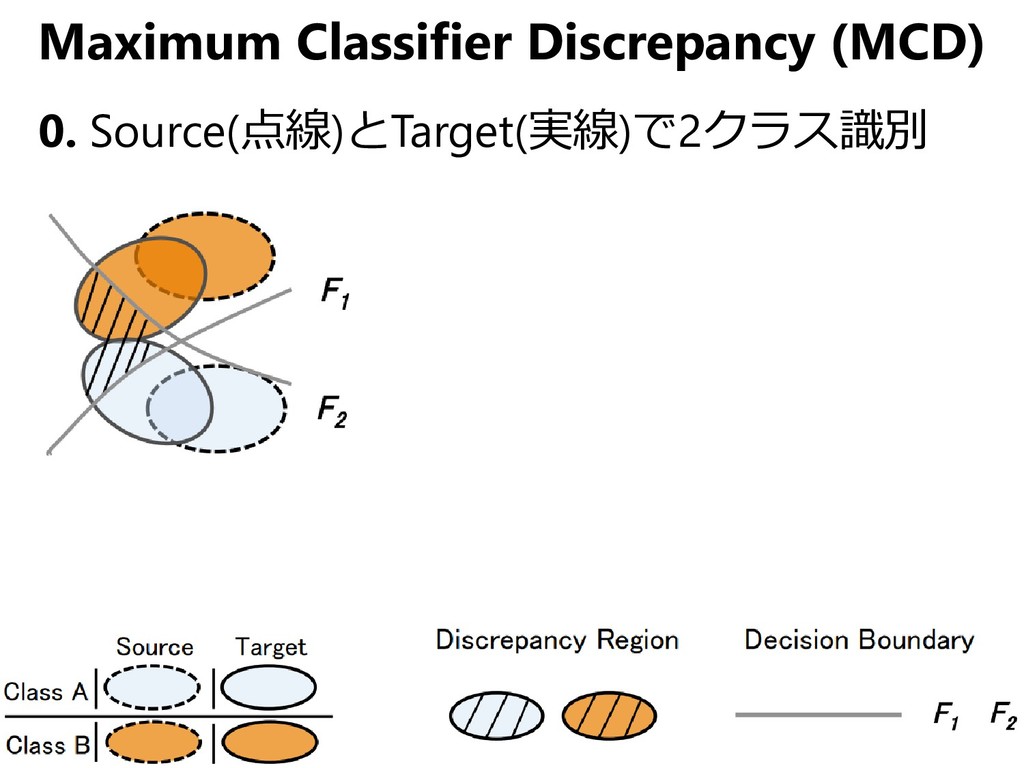{kind=link}
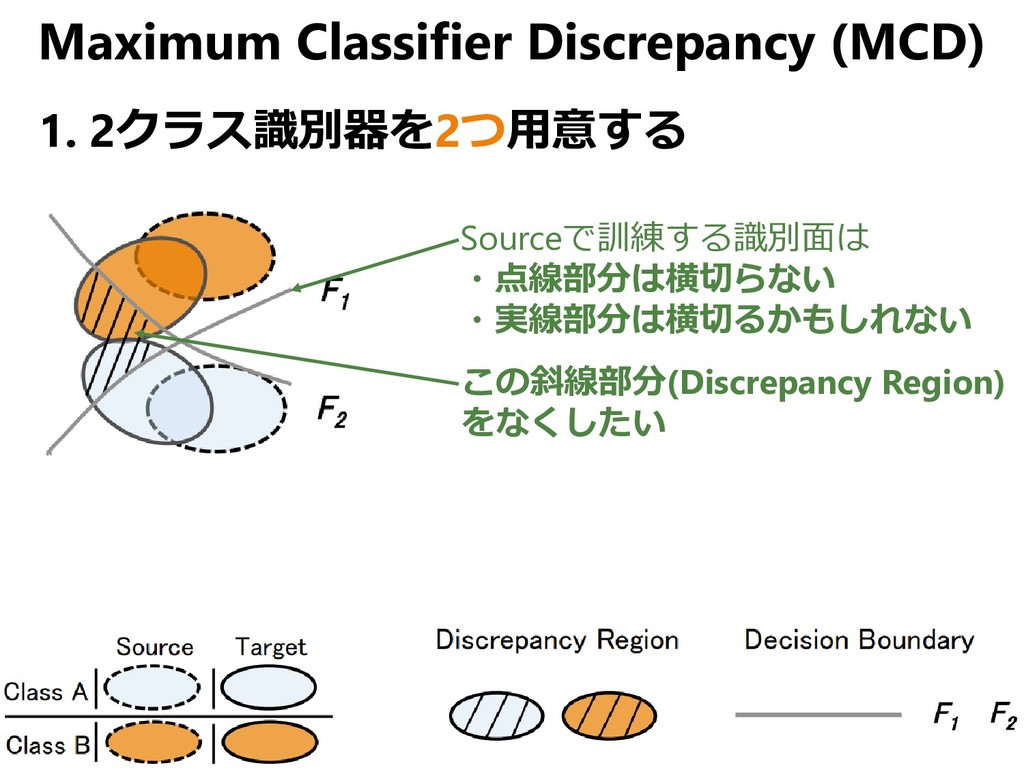{kind=link}
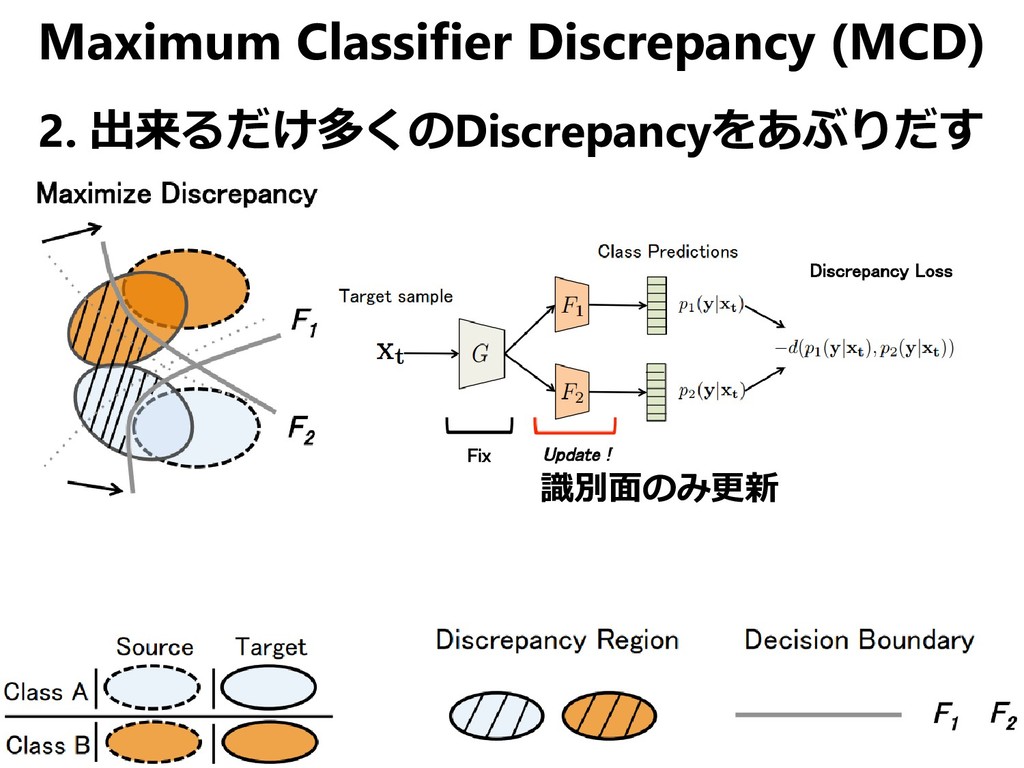{kind=link}
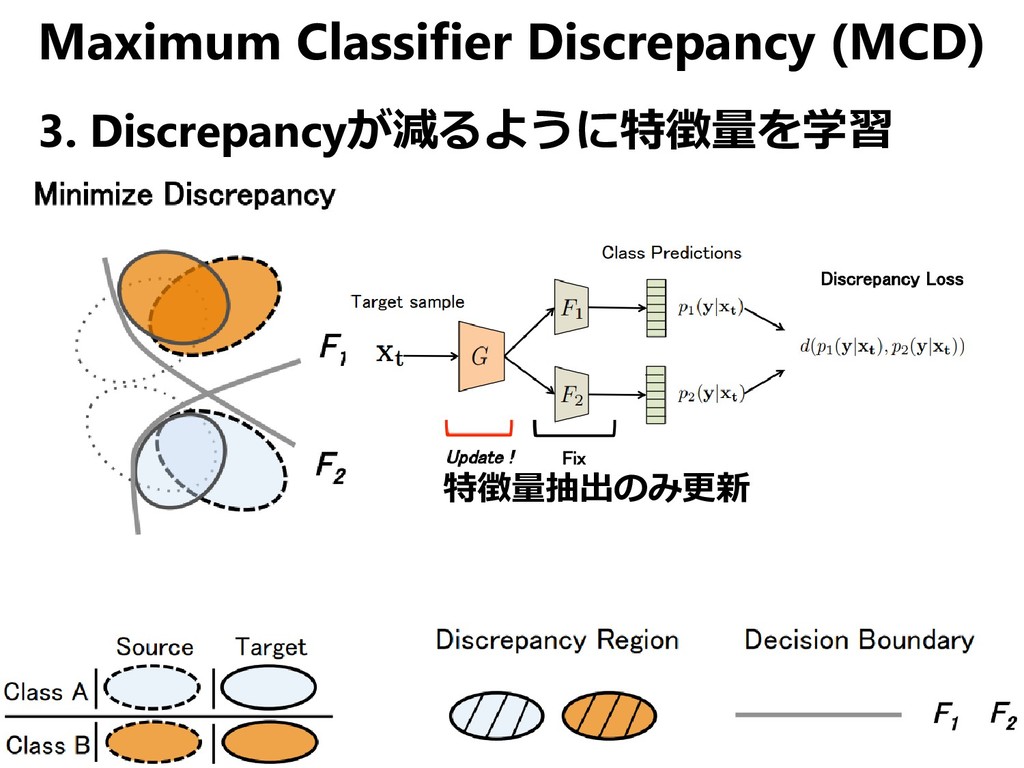{kind=link}
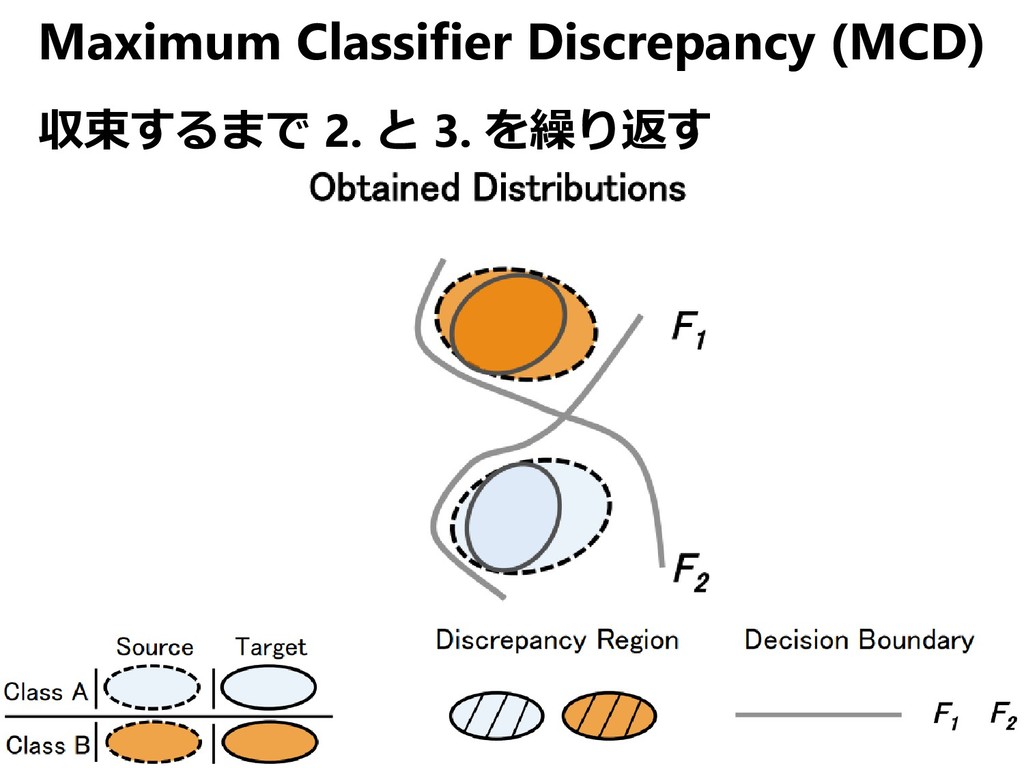{kind=link}
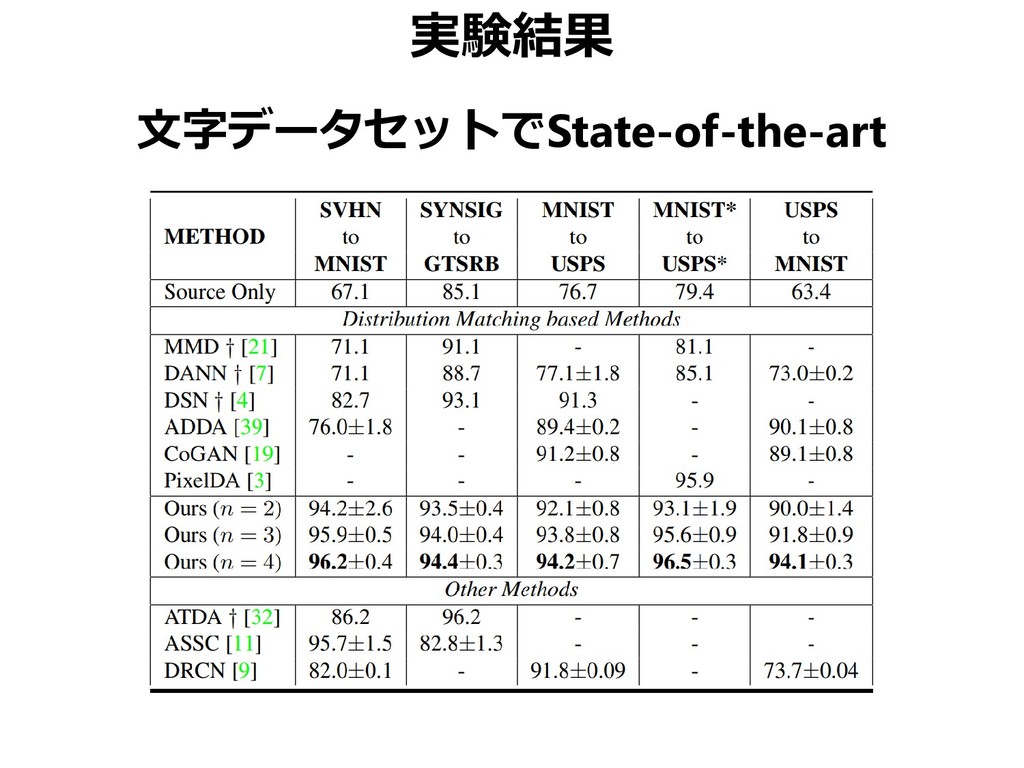{kind=link}
{kind=link}
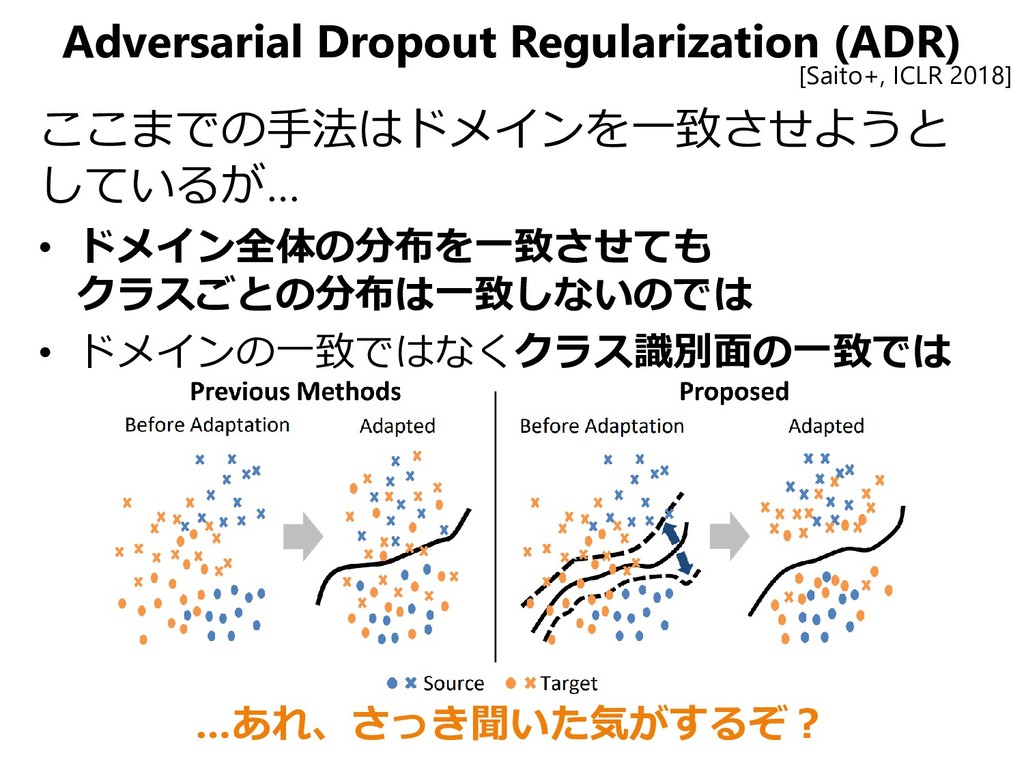{kind=link}
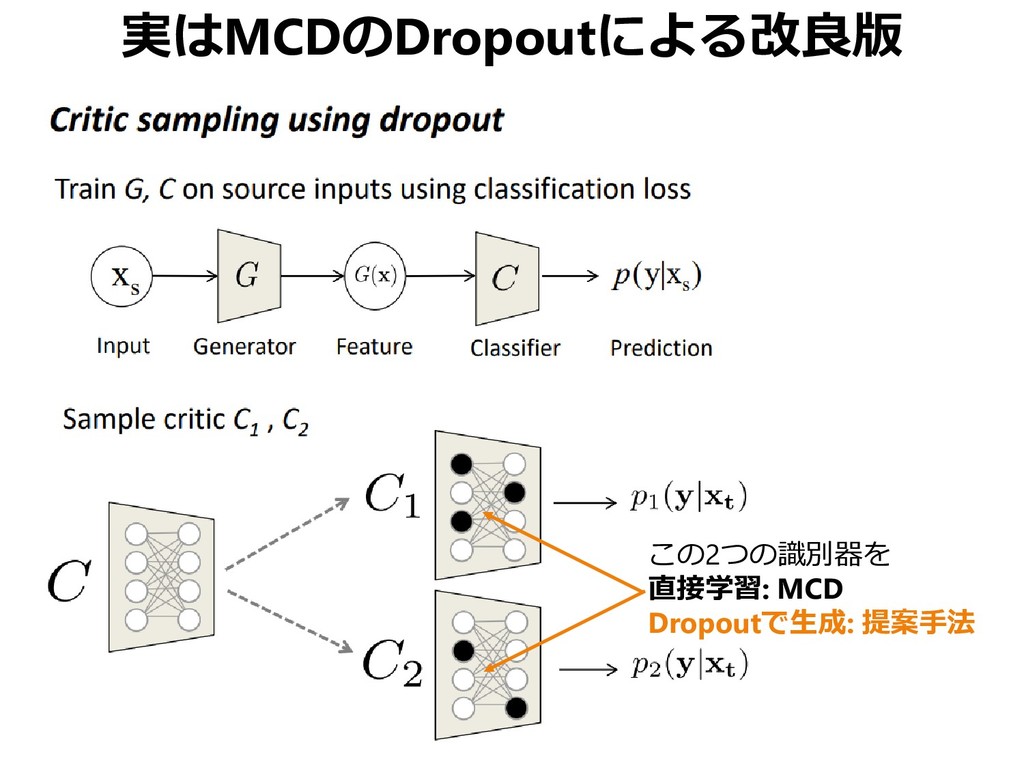{kind=link}
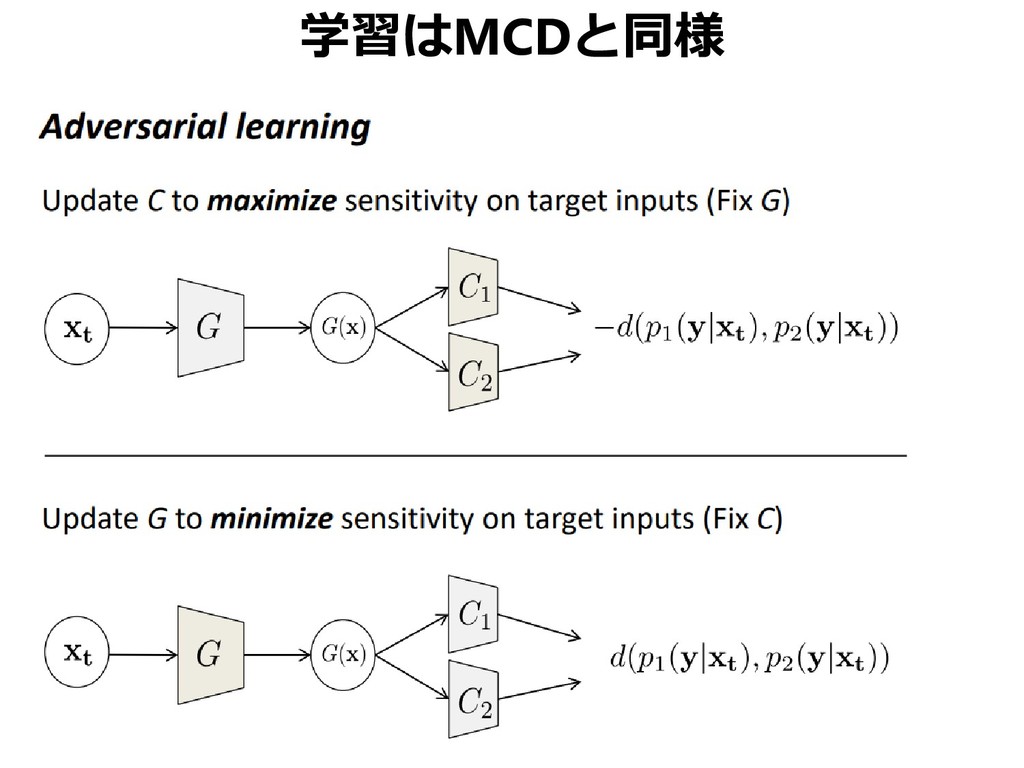{kind=link}
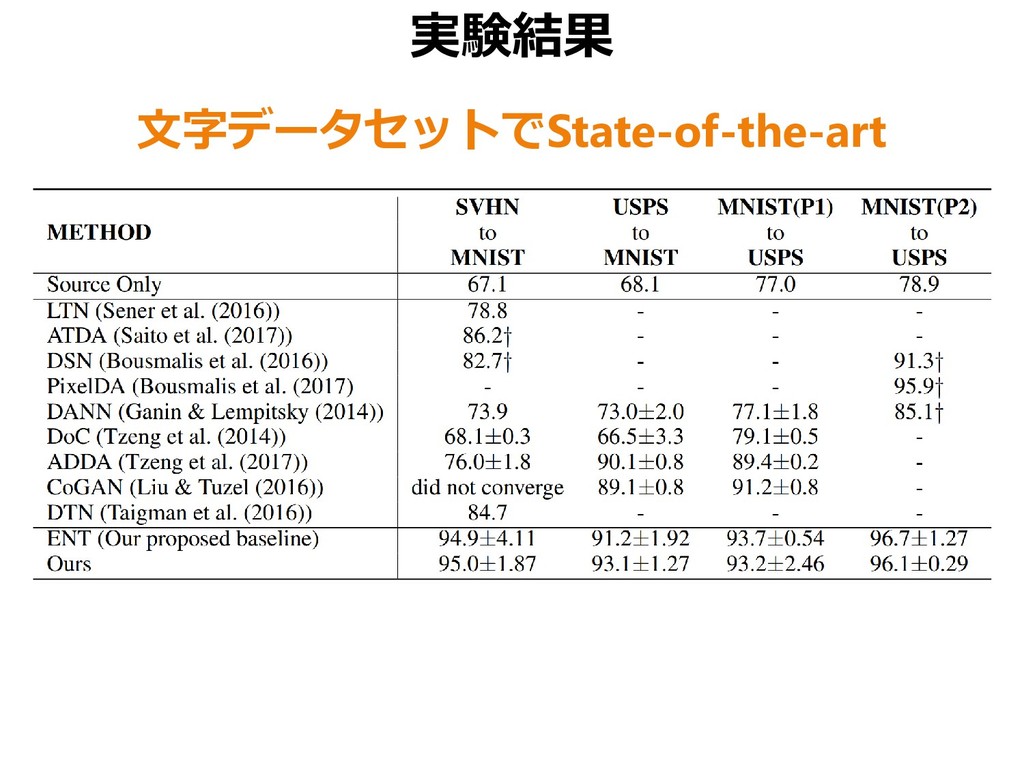{kind=link}
{kind=link}
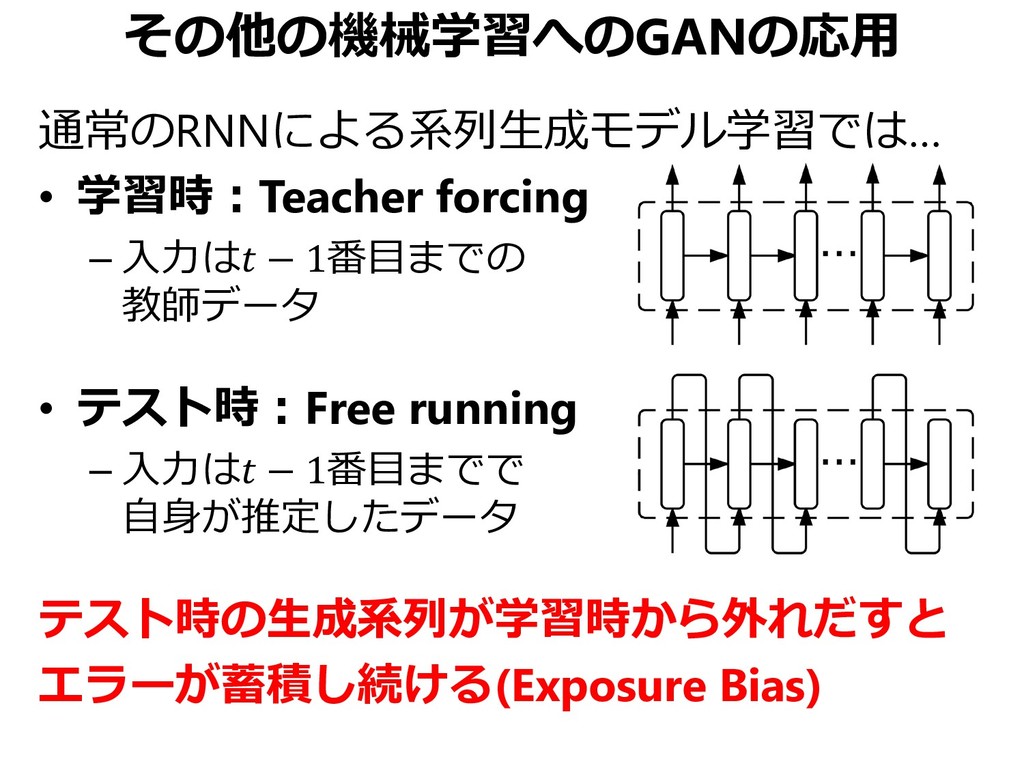{kind=link}
![その他の機械学習へのGANの応用 解決策:Professor Forcing [Goyal+, NIPS 2016] Teacher forcingかFree Runningかわからない状態変数 を出すようにRNNを学習](https://files.speakerdeck.com/presentations/ab563d411a6d4245b2333e0b4cf1505b/slide_64.jpg){kind=link}
{kind=link}