Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Logにまつわるエトセトラ
Search
菊池佑太
August 28, 2014
Science
94
0
Share
Logにまつわるエトセトラ
2014.8.28@ヒカラボ 菊池佑太
菊池佑太
August 28, 2014
More Decks by 菊池佑太
See All by 菊池佑太
健康DXサービス「Do」説明資料
yutakikuchi
0
6.3k
AIを活用した事例の現状と今後の予想
yutakikuchi
0
280
Other Decks in Science
See All in Science
タンパク質間相互作⽤を利⽤した⼈⼯知能による新しい薬剤遺伝⼦-疾患相互作⽤の同定
tagtag
PRO
0
200
YouTubeにおける撤回論文の参照実態 / metascience-meetup2026
corgies
3
260
生成AIの現状と展望
tagtag
PRO
0
120
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
900
防災デジタル分野での官民共創の取り組み (1)防災DX官民共創をどう進めるか
ditccsugii
0
630
AI(人工知能)の過去・現在・未来 —AIは人間を超えるのか—
tagtag
PRO
0
180
アクシズを探せ! 各勢力の位置関係についての考察
miu_crescent
PRO
1
280
コミュニティサイエンスの実践@日本認知科学会2025
hayataka88
0
160
やるべきときにMLをやる AIエージェント開発
fufufukakaka
2
1.4k
Bリーグのショットデータを活用した得点期待値モデルの構築 / Construction of expected points model using shot data of B.LEAGUE
konakalab
0
120
ITTF卓球世界ランキングのポイント比を用いた試合結果予測モデルの性能評価 / Performance evaluation of match result prediction models using the point ratio of the ITTF Table Tennis World Ranking
konakalab
0
120
生成AIと司法書士の未来.pdf
tagtag
PRO
0
110
Featured
See All Featured
Typedesign – Prime Four
hannesfritz
42
3k
Designing for Timeless Needs
cassininazir
1
220
WENDY [Excerpt]
tessaabrams
10
37k
Embracing the Ebb and Flow
colly
88
5k
Balancing Empowerment & Direction
lara
6
1.1k
Producing Creativity
orderedlist
PRO
348
40k
Discover your Explorer Soul
emna__ayadi
2
1.1k
New Earth Scene 8
popppiees
3
2.2k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
110k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
160
Odyssey Design
rkendrick25
PRO
2
620
Measuring & Analyzing Core Web Vitals
bluesmoon
9
830
Transcript
1 Log にまつわるエトセトラ 2014.8.28@ ヒカラボ 菊池佑太
2 話しません (´;ω; ` ) • GrowthHack ✔ Retention/ConversionUP 施策
✔ A/B テストによる UI 改善 • 可視化 ✔ BI ツール
3 Log 集計 / 解析 必要な事
4 Web サービス Log 広告 Log
5 Page View (PV) Impression (Imps) Click (CTs) Conversion (CV)
6 アジェンダ 0. 自己紹介 1. Log を記録する 2. Log を集める
3. Log を集計する 4. Log を解析する 5. 質疑応答
7 自己紹介 • 菊池佑太@yutakikuc • EX. Yahoo! AD-Science • 旅行で世界30都市制覇!
• 陸サーファー、時々サーファー • http://d.hatena.ne.jp/yutakikuchi
8 ワイハーのお土産あるお!
9 経験のあるテクノロジー
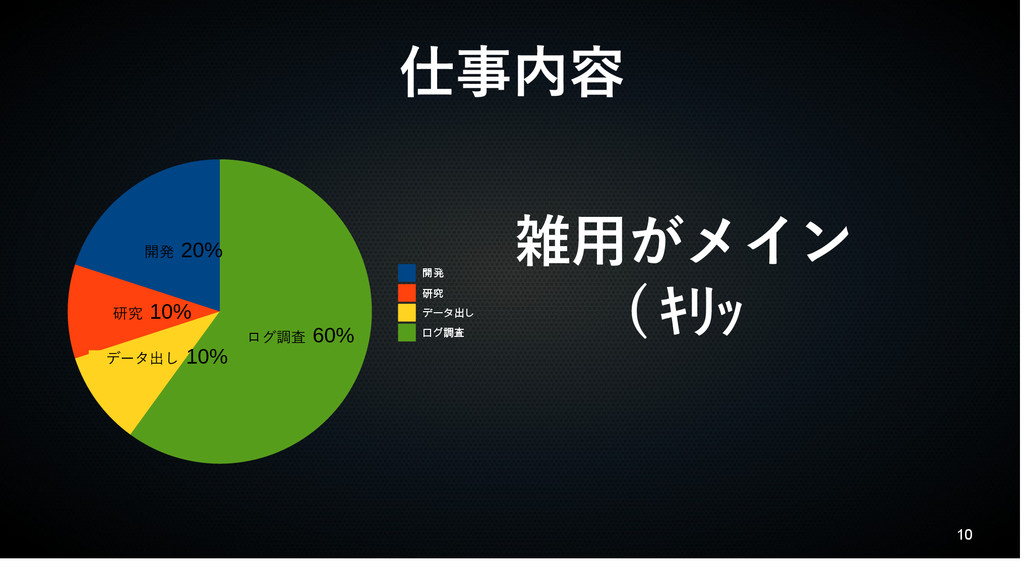
10 仕事内容 開発 20% 研究 10% データ出し 10% ログ調査 60%
開発 研究 データ出し ログ調査 雑用がメイン ( キリッ
11 解決しなければならない 大きな問題
12 Log や Data を軽視する人 /) ///) /
,.= ゙ ''" / / i f ,.r='"-‐' つ_ / / _,.-‐'~ /⌒ ⌒\ / ,i , 二ニ⊃( •) . (•)\ / ノ il ゙フ ::::::⌒ ( __ 人 __ )⌒ ::::: \ , イ「ト、 ,!,!| |r┬-| | / i トヾヽ _/ ィ " \ ` ー '´ / Log はどうでもいいんだよ !!
13 Log や Data 取得が後回しにされる理由 • サービスの開発が最優先、 Log は無くても動く •
LogSystem の開発は簡単という誤解 ( 怒 ) • UserData を取得すると User の入力負荷が高くなる • Data 分析方法が分からない
14 Log エンジニアの現場人数 アプリエンジニアの 1/20
15
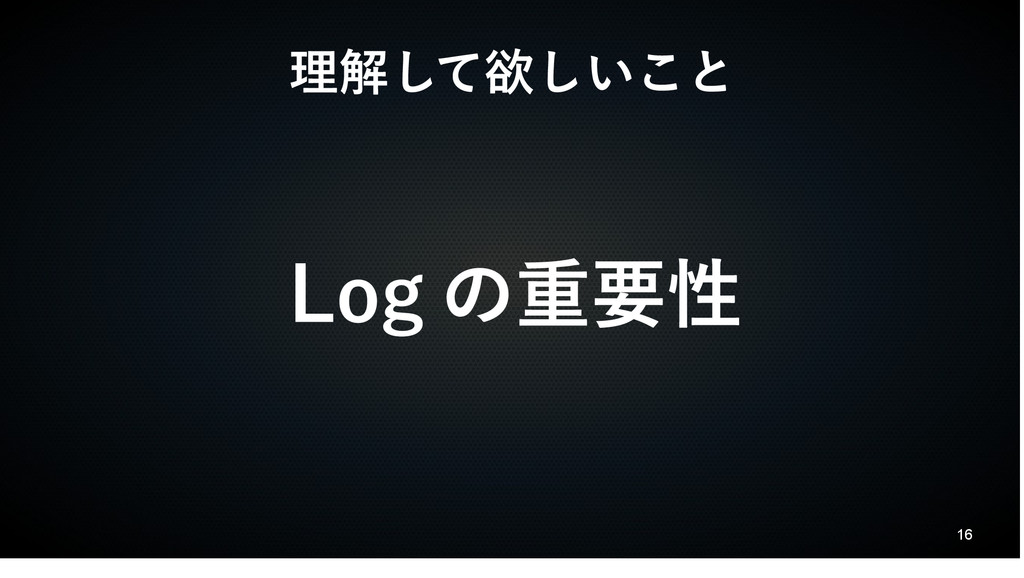
16 理解して欲しいこと Log の重要性
17 アジェンダ 0. 自己紹介 1. Log を記録する 2. Log を集める
3. Log を集計する 4. Log を解析する 5. 質疑応答
18 Log の記録目的 ( 冗談 ) 元気があれば何でもできる! Log があれば何でも分かる!
19 Log の記録目的 ( 真面目 ) Log ≒ Evidence Log
⇒ Next Strategy
20 大事な事なので 2 度言います Log 分析は サービス戦略に繋がる
21 Log の記録で重要な事 3W1H (When,Who,What,How) Log だけで情報が揃うように
22 Log の種類と記録項目 • AccessLog ✔ RequestTime(When), RequestURI(What), Referer(How) ✔
AccessIP , UA ✔ ResponseTime, Status ✔ Cookie(Who) ✔ BrowserID ✔ UserID ✔ UserAttribute ✔ DeviceID(Who)
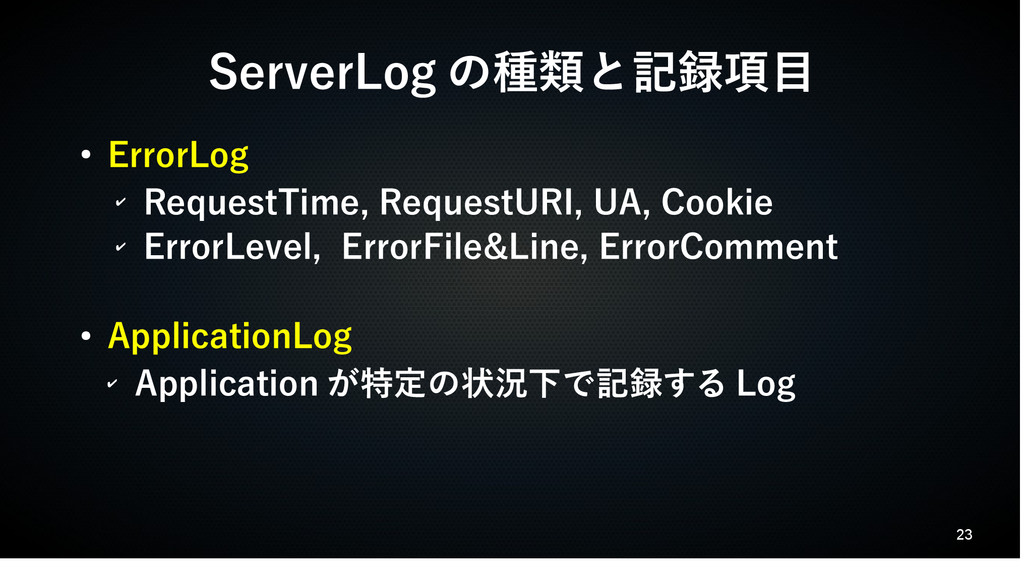
23 ServerLog の種類と記録項目 • ErrorLog ✔ RequestTime, RequestURI, UA, Cookie
✔ ErrorLevel, ErrorFile&Line, ErrorComment • ApplicationLog ✔ Application が特定の状況下で記録する Log
24 BrowserID UserID/Attribute 超重要
25 何が重要なの? ( 後で! )
26 「 mod_oreore 」による BrowserID 発行 • Server への初回アクセス時に Cookie
を発行する • ApacheModule だから Application の実装が不要 • mod_usertrack,mod_session_cookie の不足点をカバー • https://github.com/yutakikuchi/apache_module.git • 30 秒で設定可能
27 UserID/Attribute の記録 • UserID/Attribute は Login をした段階で Cookie に付与
(Application のレイヤーで実装 ) • Hacking されないように変換や暗号化
28 Cookie を Log に落とす
29 Log に落とす Cookie の例 oreore_cookie:id=MTkyLjE2OC41Ni4xMDE0MDkxMTk2ODQ wMzg3MTMyMDE2NTQyNzI1MDMzMTY0OA..&attr=Mjg0Z mUyMzk0Yzg0ZGIzZTIzYTI3N2ExYzhmYTZmMGY3Mzk1MjM 4Ng.. •
id : TimeStamp + LocalIP + ProcessNum + ConnectionNum • attr: UserID + Gender + Age をAES-CBCで暗号化
30 LogFormat • Default(Apache) ::1 - - [08/Feb/2014:21:32:10 +0900] "GET
/ HTTP/1.1" 403 5039 "-" "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.14.0.0 zlib/1.2.3 libidn/1.18 libssh2/1.4.2" • Labeled Tab-Separated Values(LTSV) host:::1<Tab>ident:-<Tab>user:-<Tab>time:[08/Feb/2014:21:32:10 +0900]<Tab>Request:GET / HTTP/1.1<Tab>status: 403 <Tab>size:5039<Tab>referer:-<Tab>agent:curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.14.0.0 zlib/1.2.3 libidn/1.18 libssh2/1.4.2 • ControllCharcter Separeted Values host<^B>::1<^A>ident<^B>-<^A>user<^B>-<^A>time<^B>[08/Feb/2014:21:32:10 +0900]<^A>Request<^B>GET / HTTP/1.1<^A>status<^B> 403 <^A>size<^B>5039<^A>referer<^B>-<^A>agent<^B>curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.14.0.0 zlib/1.2.3 libidn/1.18 libssh2/1.4.2
31 どの Format が良いか? • Log 項目の付け足し / 削除は後から必ず発生する •
付け足しが発生しても Parse 後の順番依存が無い事 • 人目で見ても項目と値が分かり易い LTSVFormat がお勧め
32 LogServer 構成
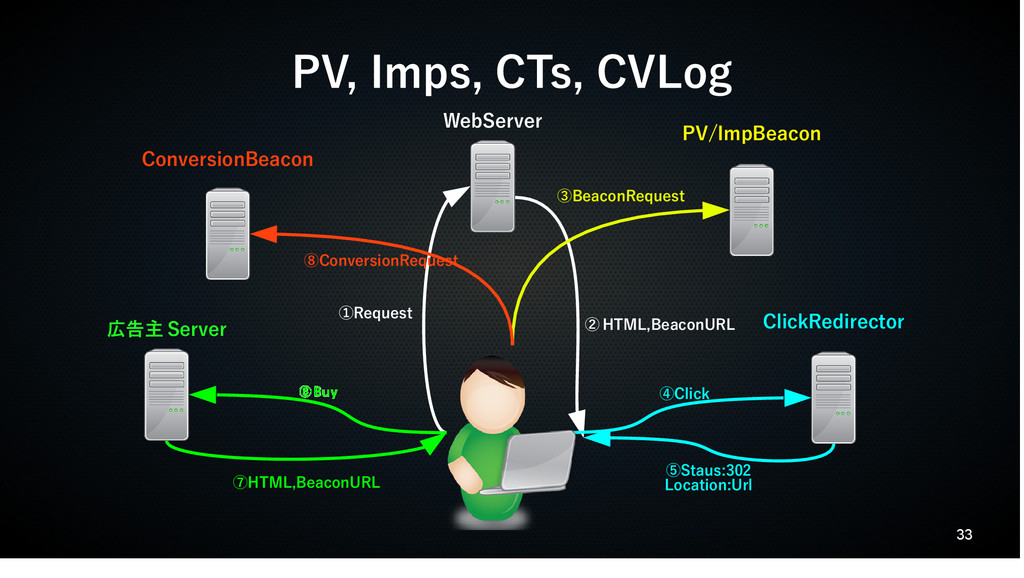
33 PV, Imps, CTs, CVLog ⑤Staus:302 Location:Url ①Request
② HTML,BeaconURL ③BeaconRequest ④Click ⑥Buy ⑦HTML,BeaconURL ⑧ConversionRequest WebServer PV/ImpBeacon ClickRedirector 広告主 Server ConversionBeacon
34 CTs と CVLog 少し詳しく
35 Click 情報 どこに掲載したら Click されたのか
36 導入した Click 検知方法 • 外部 Domain への遷移検知には Redirector を入れる
• Log にどのページのどのリンクが押されたのか記録する ✔ 予約 Parameter(?__uri=hoo&__link=bar_1) ✔ Click 計測用 Cookie(ClickCookie:__uri=hoo&__link=bar_1) ✔ ※Referer は送信しないブラウザがあるので注意 • 識別子の付与は Javascript:Onclick() で出来ると吉 • 集計処理で Parameter の値を CountUP • 識別子の管理が FE と BI ツールで共有が必要 ( 改善ポイント )
37 Click 検知の失敗点 アプリエンジニアの実装にミスが発生する! CTR 集計結果に影響が出る!! 戦略チームから @yutakikuc が怒られる!!! @yutakikuc
がアクセスログから実装ミスをカバーする!!!!
38 CVLog に必要な事 • ( 外部 ) サイトに検知用 Beacon タグを埋め込んでもらう
• Log にどのサイトでどのような CV が発生したのか記録する - Parameter で表現する ( 例 )<img src='http://cbeacon.hikalab.com? siteid=25&productid=13&actionid=2&sign=hikalabo0828' /> • BrowserID 等の Cookie は当然記録する
39 CVLog の活用 • User の購入プロセスの状況把握 • 購入済み商品は Recommend の対象外
• 類似商品の Recommend • 同じような行動履歴の User への Recommend
40 「 Log を記録する」まとめ • Log 分析は戦略に繋がる • BrowserID,User,Attribute の記録
• LTSV Format • CTs,CVLog の記録
41 アジェンダ 0. 自己紹介 1. Log を記録する 2. Log を集める
3. Log を集計する 4. Log を解析する 5. 質疑応答
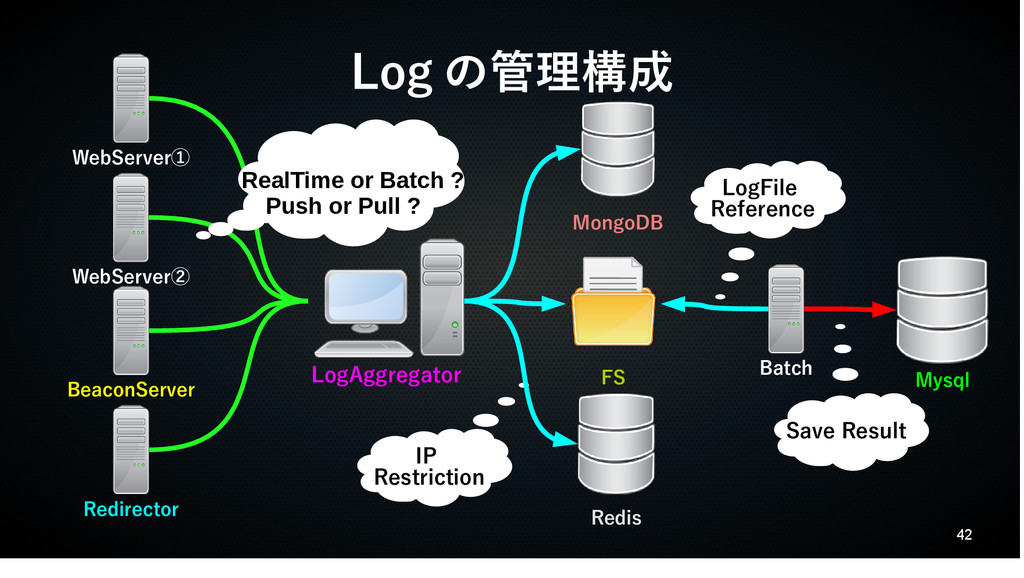
42 Log の管理構成 RealTime or Batch ? Push or Pull
? IP Restriction WebServer① WebServer② BeaconServer Redirector LogAggregator MongoDB FS Redis Batch Mysql LogFile Reference Save Result
43 RealTime or Batch Push or Pull • RealTime(Fluentd,Storm) ✔
即時集計 / 解析 ✔ 一度の転送量を抑える ✗ Batch と比較して転送 / 解析の技術 ハードルが高い • Batch(Rsyslog,[RD]sync) ✔ 定期集計 / 解析 ✔ 安定した集計 ✗ 一度の転送量が多くなる • Push(Fluentd,[RD]Sync) ✔ 送信元 Server が Log 転送する ✔ Log を出力 => 転送が自然な流れ ✗ 送信元 Server の負荷が心配 • Pull(Rsyslog,Storm,[RD]Sync) ✔ 受信元 ServerLog が Log を回収する ✔ メインの設定が受信元 Server で出来 る ✔ 送信元 Server の負荷は軽減 ? ✗ 実装 / 設定が面倒
44 RealTime Log 転送で気をつけたい事 • 処理が詰まらないように (Server 性能の限界を確認しておこう ) •
転送完了したファイル名と Line 数を記録する • HotStandy の用意 • Batch に切り替える手段を用意 • 小規模かつ重要でない Log から導入テストしてみるとか
45 Batch Log 転送で気をつけたい事 • Rotate 処理と転送処理の時間が重なった時の取りこぼし ※ チェックサムの確認 •
転送時間が大きくならない事 ※ 複数のデータセンターへの転送 • 冗長化サーバー毎に転送開始時間をづらす • ファイルの圧縮
46 広告配信での実例 Imps : 500,000 、 Clicks : 2000 、
Log 容量: 200M
47 集計の土台 安定した Pull 型 Batch ※Batch は 1 日
1 回 広告主への正確なレポート提出のため Rsync + FuelPHP Task
48 +α Imps,CTs は Push 型 RealTime 集計を準備中 ※Imps 保証数を必要以上に超過させない
RealTime でのリターゲティング Fluentd + fuent-plugin-redis
49 最小構成でも トラフィック問題は 発生せず ... or2
50 冗長化対応での問題 回収先サーバーの 追加設定漏れ
51 「 Log を集める」まとめ • 回収方法の特性を理解 • 集計の土台は Pull 型
Batch で安定稼働 • 配信制御に関わる事は極力 RealTime で
52 アジェンダ 0. 自己紹介 1. Log を記録する 2. Log を集める
3. Log を集計する 4. Log を解析する 5. 質疑応答
53 KPI / KGI
54 原始的な集計 cut -f 2 log.txt | sort | uniq
| wc -l
55 強力なツール ※ 要件が合えば利用
56 強力ツールで出来ない事 • ページ内コンテンツの配信数 • Browser 毎の履歴集計 • 無料では出来る事が限られる •
長期的なログ蓄積には不向き
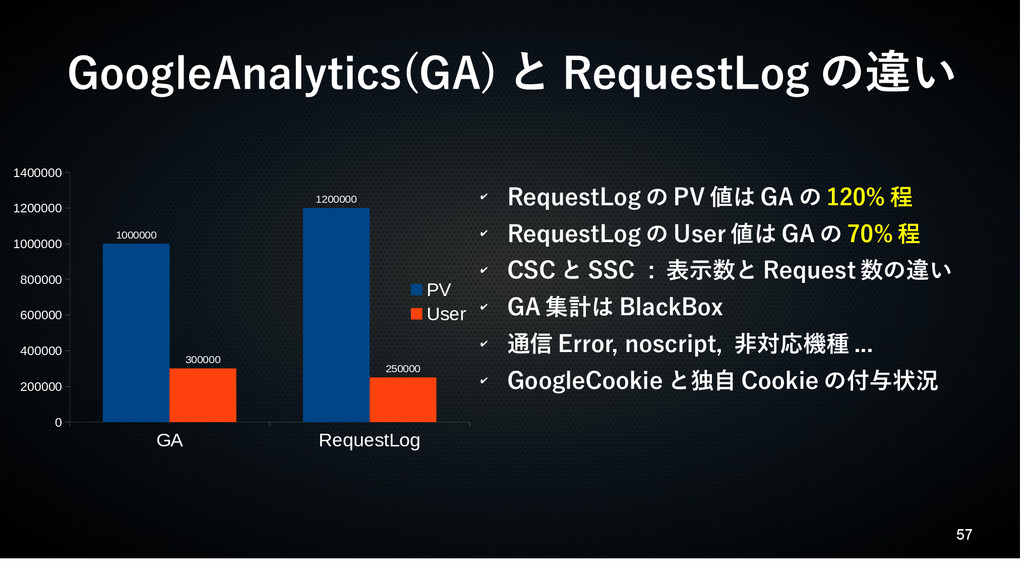
57 GoogleAnalytics(GA) と RequestLog の違い GA RequestLog 0 200000 400000
600000 800000 1000000 1200000 1400000 1000000 1200000 300000 250000 PV User ✔ RequestLog の PV 値は GA の 120% 程 ✔ RequestLog の User 値は GA の 70% 程 ✔ CSC と SSC : 表示数と Request 数の違い ✔ GA 集計は BlackBox ✔ 通信 Error, noscript, 非対応機種 ... ✔ GoogleCookie と独自 Cookie の付与状況
58 独自集計 ツールとの棲み分け 緊急性と重要度の判定
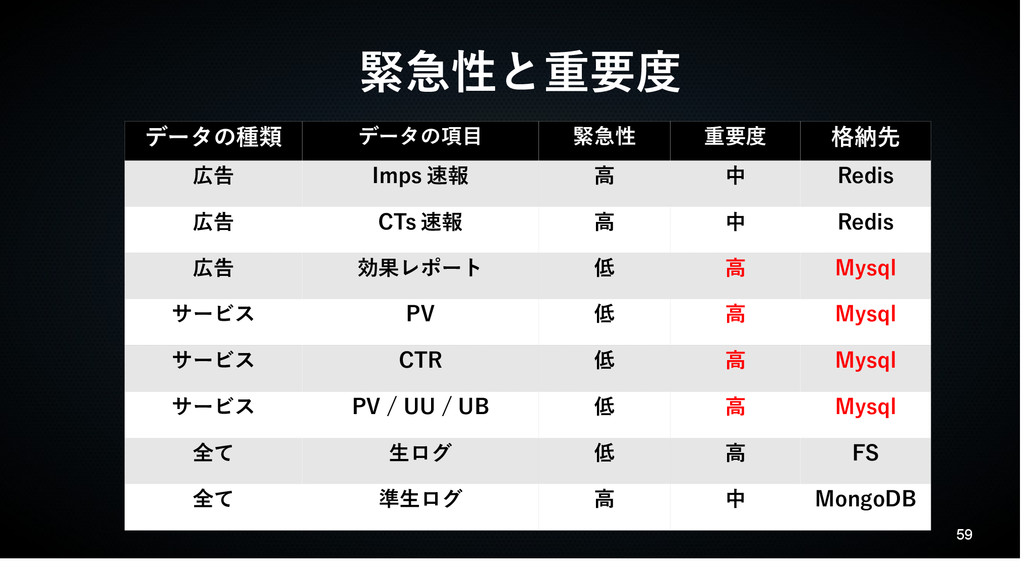
59 緊急性と重要度 データの種類 データの項目 緊急性 重要度 格納先 広告 Imps 速報
高 中 Redis 広告 CTs 速報 高 中 Redis 広告 効果レポート 低 高 Mysql サービス PV 低 高 Mysql サービス CTR 低 高 Mysql サービス PV / UU / UB 低 高 Mysql 全て 生ログ 低 高 FS 全て 準生ログ 高 中 MongoDB
60 Mysql は安定している 心配なのは Write 速度
61 Mysql Table 設計 • テーブル設計 = 集計する項目の決定 • Relationは作らない
– 冗長的な登録は許容 • 古いデータは消す事が前提 – 日付のPartitioningでparge • 複雑な処理は多段集計 – 1次集計Table、2次集計Table
62 Mysql への Write • Batch 処理 ✔ Batch で
OnMemory( 連想配列 ) に集計結果を乗せてから BulkInsert ✔ Hadoop で集計し Sqoop で結果を Import • RealTime 処理 ✔ RunTime で MongoDB へ格納。 MogoDB のデータを Batch で集計 し、 Mysql へ格納 ✔ Mysql の BlackHoleEngine を利用。実体を Slave に ✔ 特定行数を一度 Queue/Summary して、 BulkInsert
63 Redis の利用 • データ管理を Memory と Storage の両方で旨くこなす凄い奴 •
大量データの INSERT/SELECT も Mysql より高速 • Memory と Storage の両方から消えた場合が大変 • 広告の RealTime の Imps 制御で利用 ✔ 超過 Imps は極力発生させたく無い ✔ RealTime で広告 ID と Imps した回数を書き込む ✔ 保険として Batch でも整合性を確認
64 MongoDB の利用 • スキーマ定義が不要でカラム追加の運用も要らない • 大量データのInsertがMysqlより速い(SELECTは同等) • Index, Sharding等の機能もある
• fnd条件指定が簡単でCross集計も可能(例. Android×LoginしているUB数) • 準生ログを保存(BIツールからのみ参照させる) • データが消えるという事例報告がある
65 Performance 担保への最終手段 サンプリング集計 ※ 広告は除く
66 「 Log を集計する」まとめ • 集計の緊急度と重要度で集計方法を変える • Mysql の INSERT
速度が心配 • MongoDB や Redis も導入すると良い
67 アジェンダ 0. 自己紹介 1. Log を記録する 2. Log を集める
3. Log を集計する 4. Log を分析する 5. 質疑応答
68 BrowserID UserID/Attribute 超重要
69 何が重要なの?
70 その① 行動履歴の集約 識別子を key に sort で纏める 行動素性の抽出 MapReduce
との相性
71 その② 分類済み正解データからの推定 BrowserID : 1 UserID : A 女性
× 20 代 BrowserID : 2 UserID : ? 女性 ? 20 代 ? @cosme zexy.net @cosme zexy.net ?
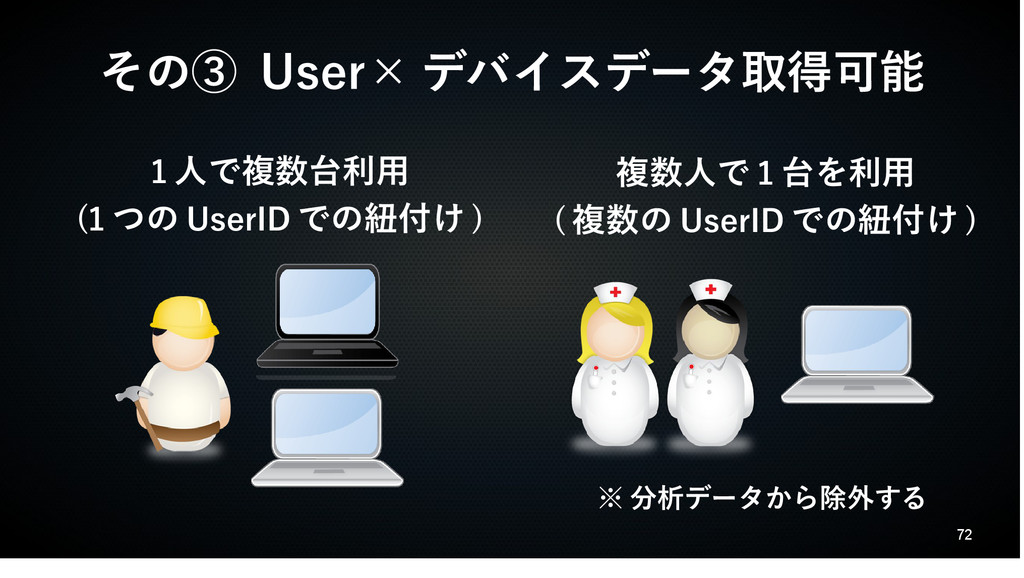
72 その③ User× デバイスデータ取得可能 1 人で複数台利用 (1 つの UserID での紐付け
) 複数人で 1 台を利用 ( 複数の UserID での紐付け ) ※ 分析データから除外する
73 性別推定
74 性別推定 • Userの性別に対してコンテンツや広告をtargetingしたい • 性別が取れるUserは20%以下。※Login必須サイトで無い場合 • 2値分類(random推定でも50%) • 仕組みが単純で高精度が望ましい
• 精度とカバー率の塩梅
75 条件付き確率 • 推定手法の一例 その他決定木やVectorでの分類がある • 仕組みが単純、実装しやすい • 並列分散処理OK •
P(C|D) P: 確率, C:カテゴリ, D:事象 例) 「サッカー」で検索したUserは80%男性である • 対数化や正規化などの処理が最後に必要
76 「 Naive Bayes 」 でぐぐれ!
77 推定 Model 作成と評価 • まずはオフラインで • 素性はスペース区切り検索Query • 訓練データ、推定対象データの準備
(過去28日間) ✔ 訓練データ: 性別が分かるBrowserID×Query ✔ 推定対象データ: 性別が分からないBrowserID×Query ✔ 複数のUserIDが紐づくBrowserIDは対象外 • 訓練データから推定Modelを評価 ✔ K-fold Cross Validation(k-1個のデータセットからModelを作成し、その他1個で精度評 価) • Modelを使って推定対象データから予測 ✔ 男性の確率:90%、女性の確率:10%
78 毎日推定 • 次にオンラインで • 2 年前は Oozie × Pig
で素性抽出 /Model 作成 / 推定を完全自動化 • 今なら hivemall を使いますかね • R 言語でも簡単にできます • BrowserID を基に推定確率を Redis に格納
79 精度とカバー率と配信の閾値 80% は女性と推定 精度 80% 以上のカバー率は 3 割 この人は女性で配信しますか?
配信側の閾値調整
80 気をつけたい事 • 導入後の KPI 変動の監視 ✔ Targeting 増 =>
CTs 増 => CV 下 ✔ 導入前のシミュレーションも欠かさずに行う • 推定 Model の定期的な評価 ✔ 完全自動化での安定運用のため
81 年代 (10 歳区切り ) 推定 マルチ分類への応用
82 「 Log を解析する」まとめ • 分類済み正解データの取得 • 推定により Targeting 数を増やす
• 素性抽出、推定 Model 作成、推定 • 推定確率により配信する / しない
83 以上
84 質疑応答
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![30 LogFormat • Default(Apache) ::1 - - [08/Feb/2014:21:32:10 +0900] "GET](https://files.speakerdeck.com/presentations/8b4e6c4010f101324ddf7ae407783e32/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}