Do&Do. 株式会社代表取締役、ab3株式会社取締役の菊池佑太と申します。
https://corp.doando.club/
https://corp.ab3.vision/
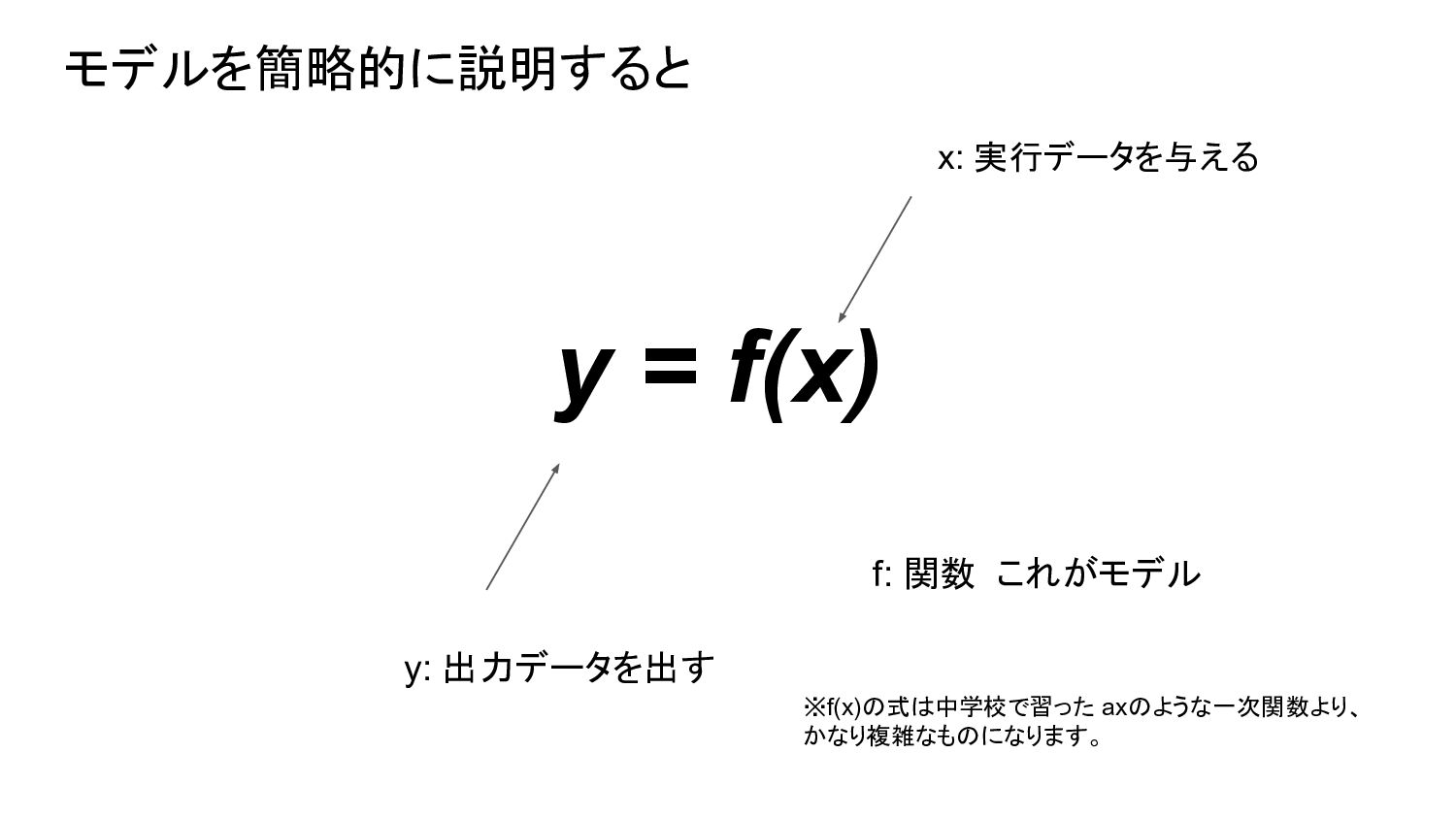
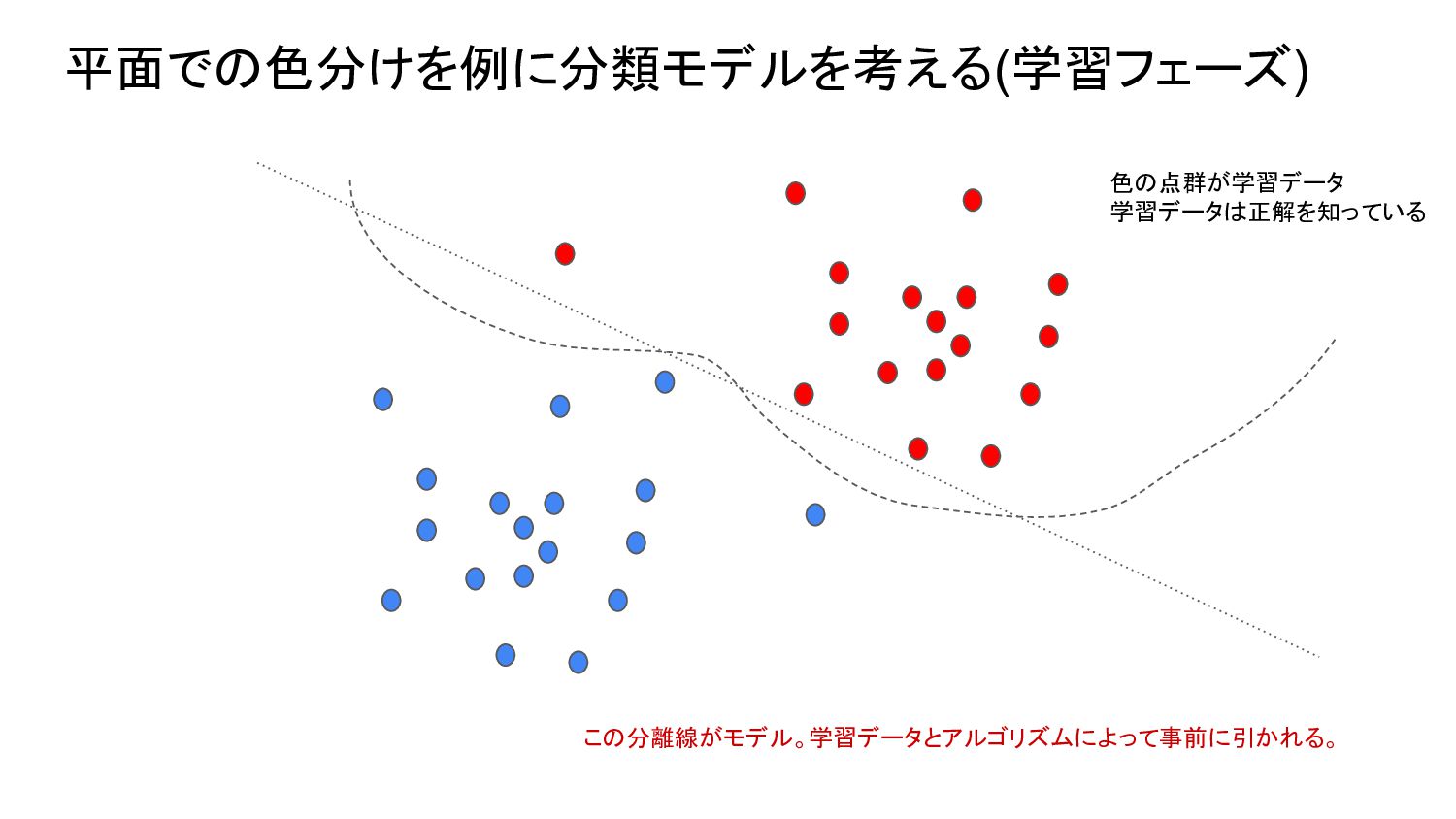
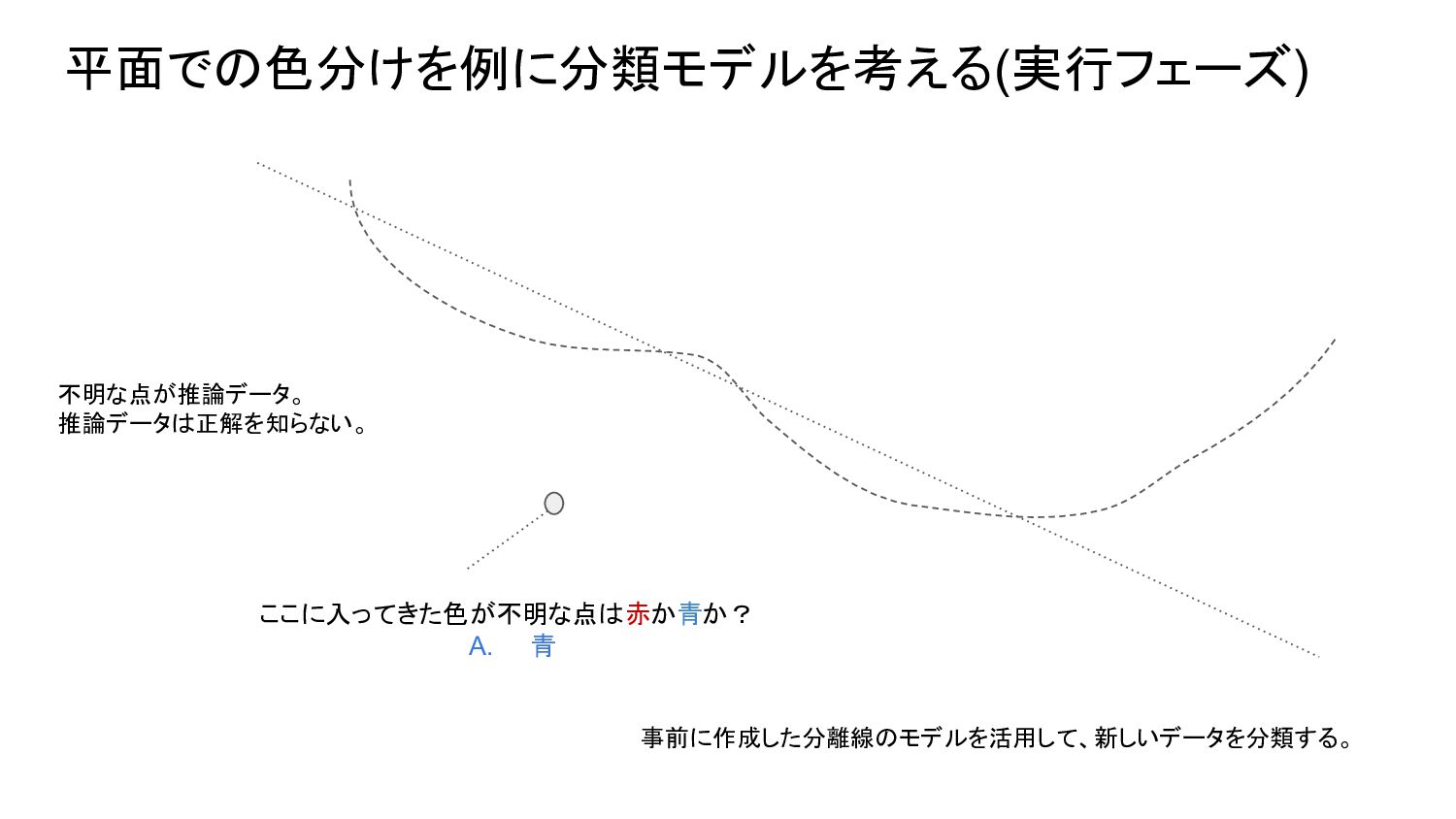
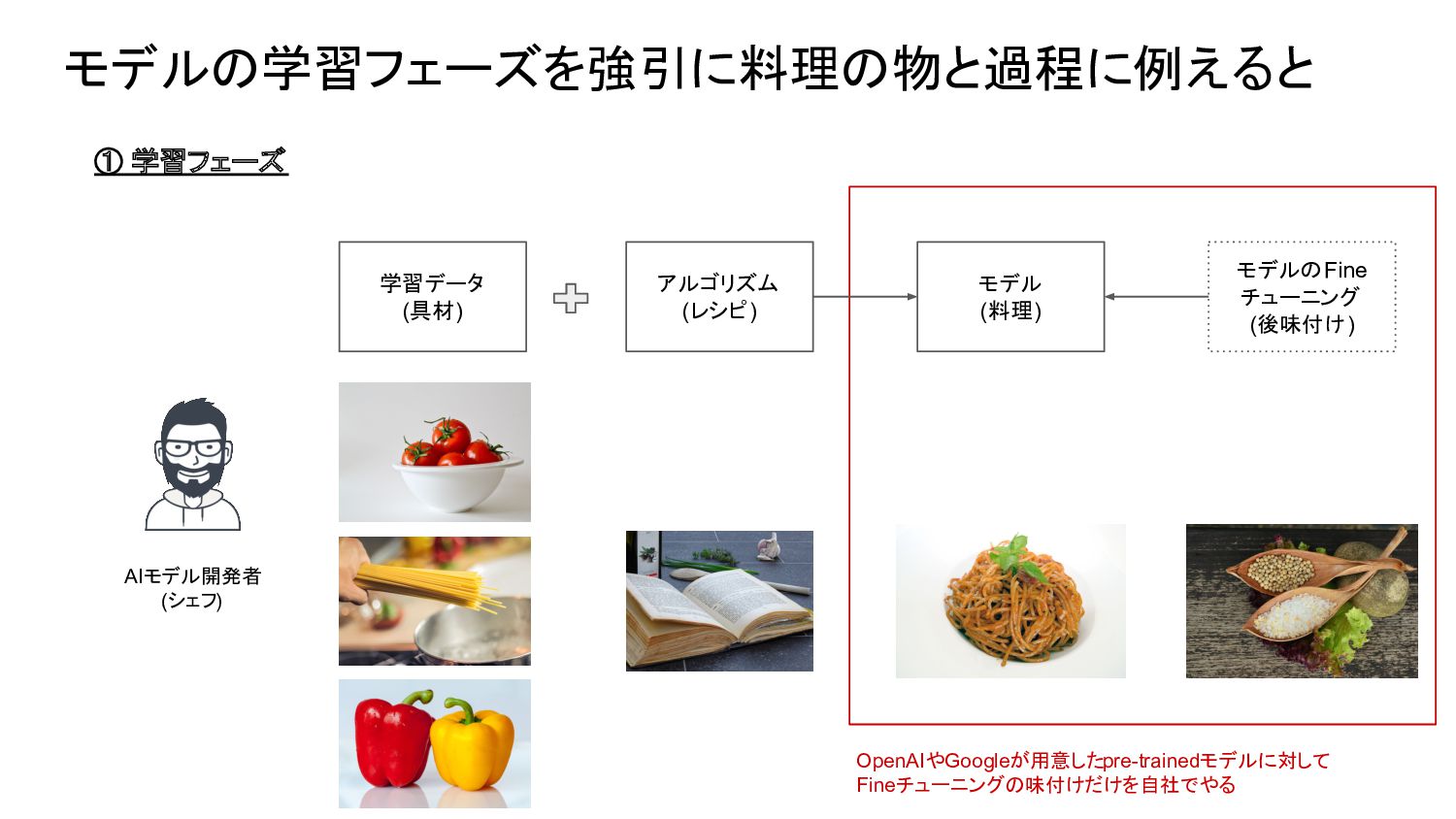
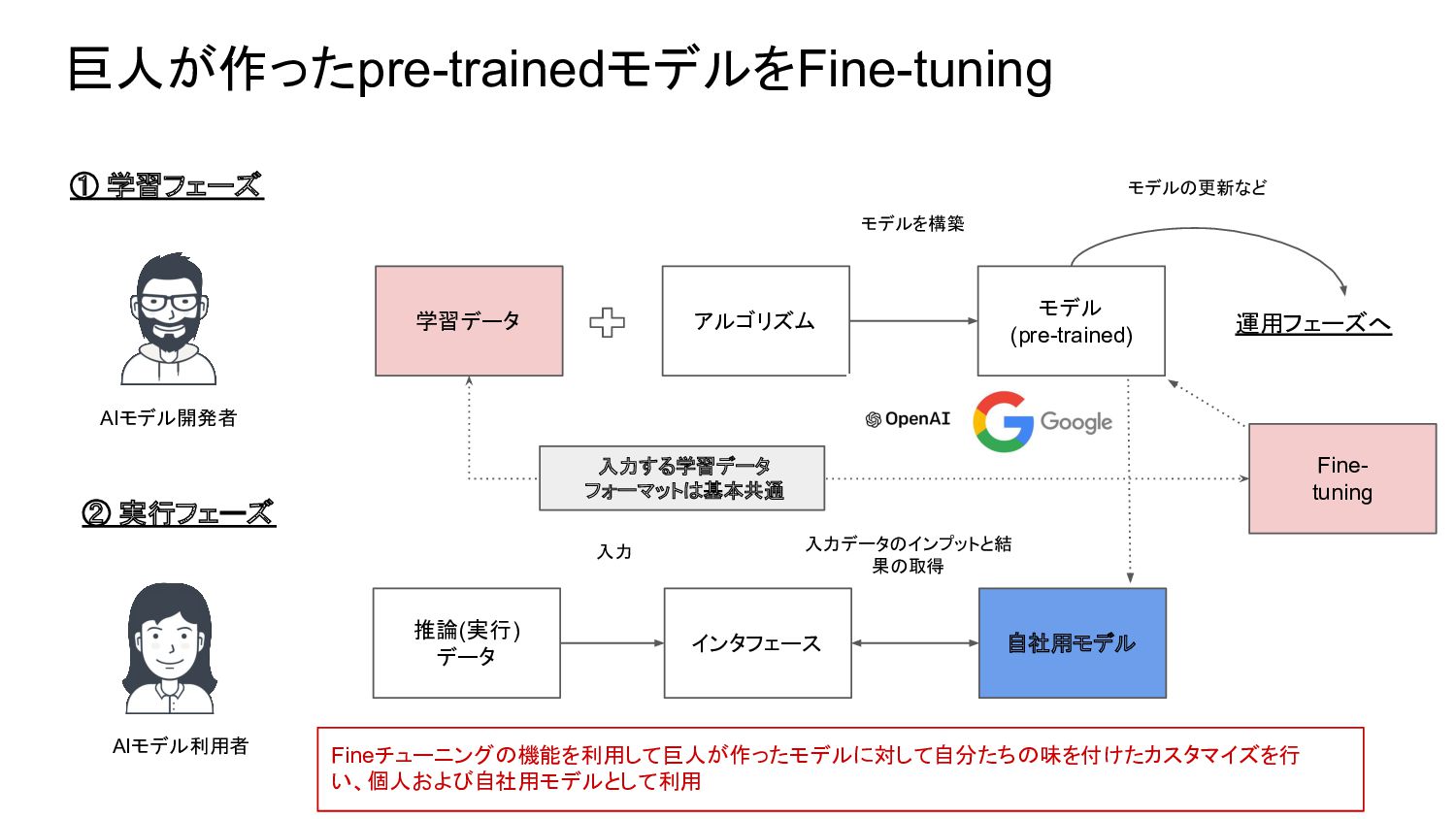
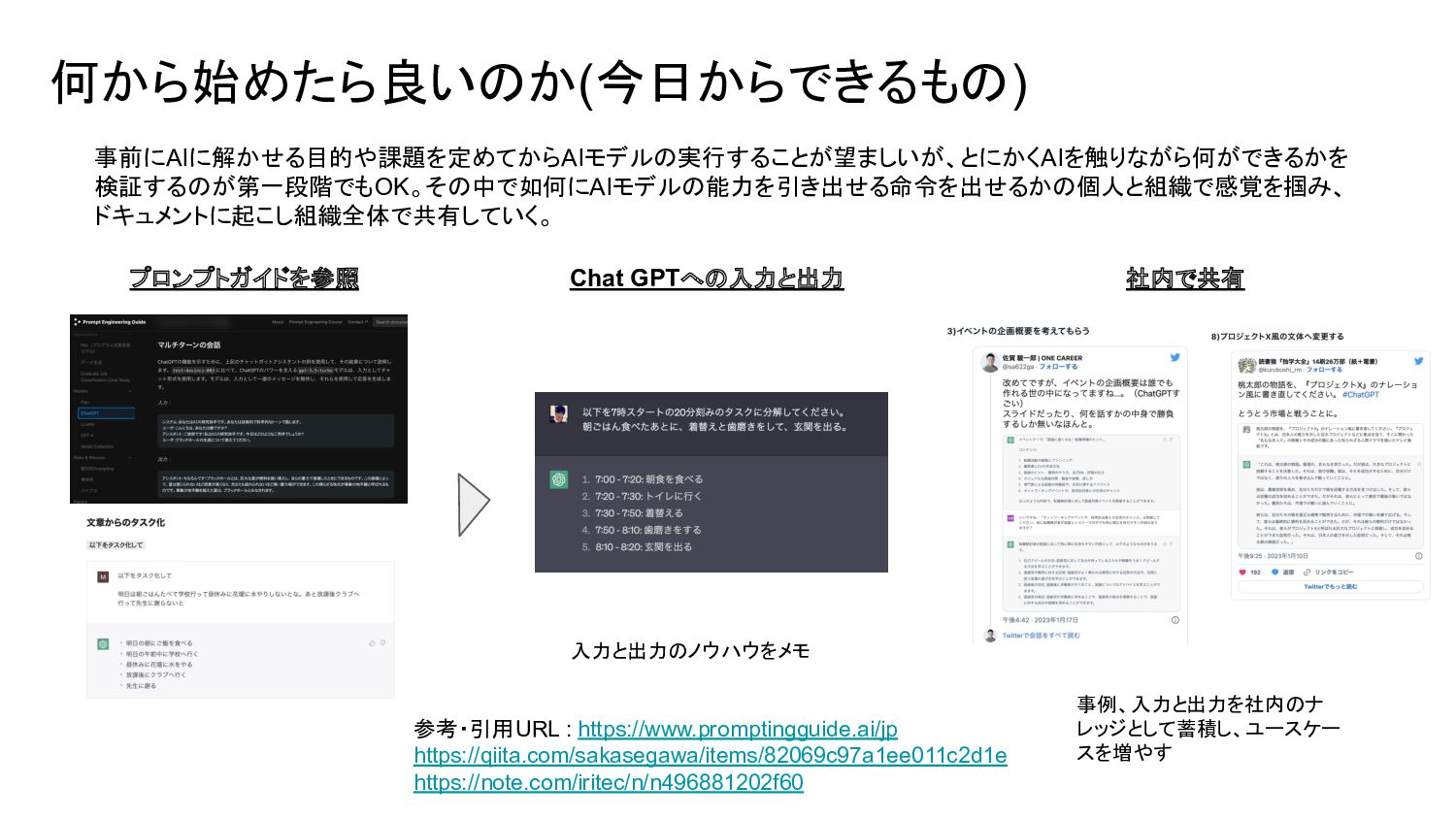
2023.04.26にAIを活用した事例の現状と今後の予想というタイトルで勉強会を実施しました。モデルが構築され、利用するフェーズとプロセスの仕組みの説明を多めにして、それを理解した上で事例の現状と今後の予想の流れを発表しました。
資料に関する質問などは下記のTwitter DMで伺っております。
https://twitter.com/yutakikuchi_
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
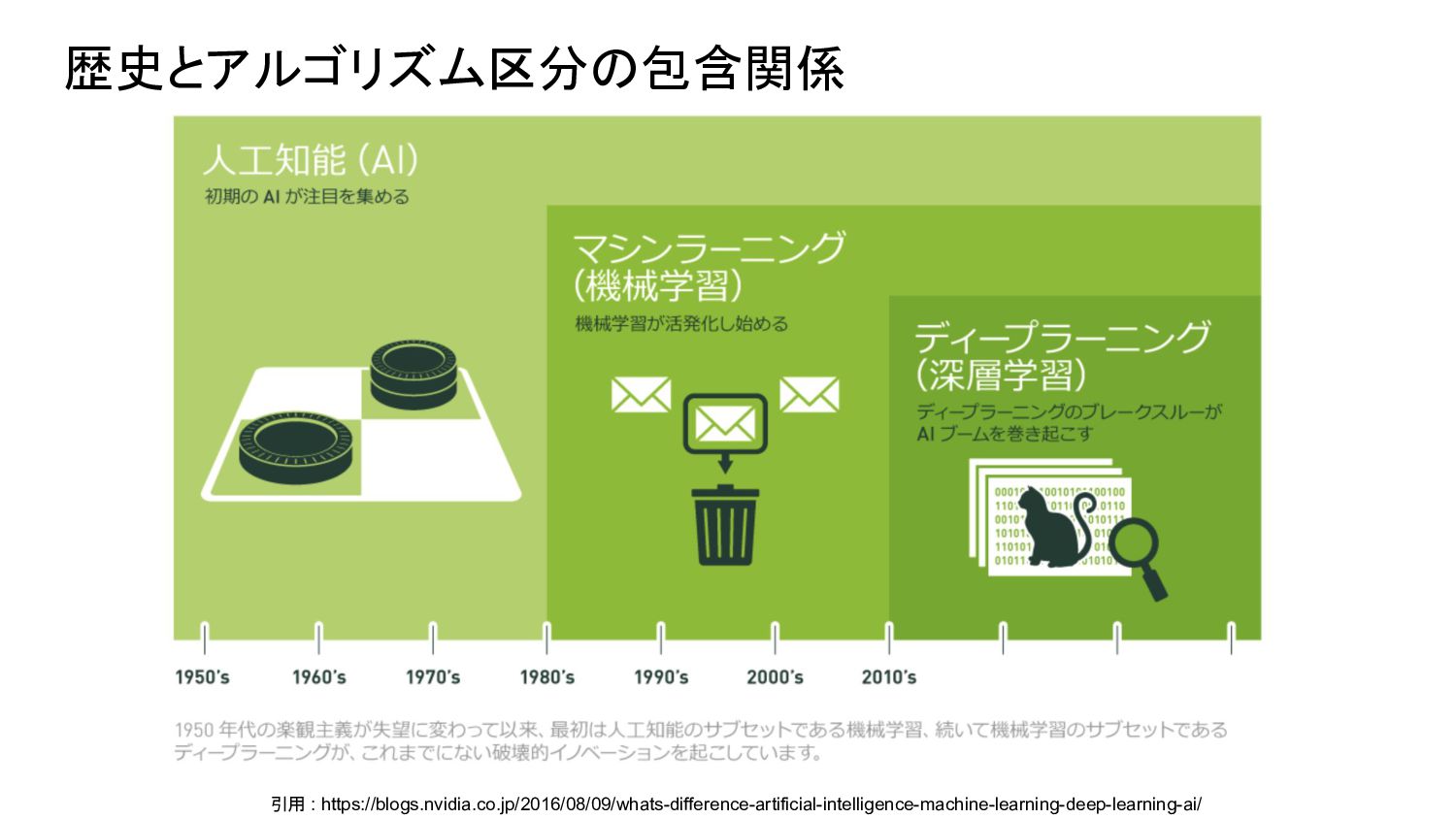{kind=link}
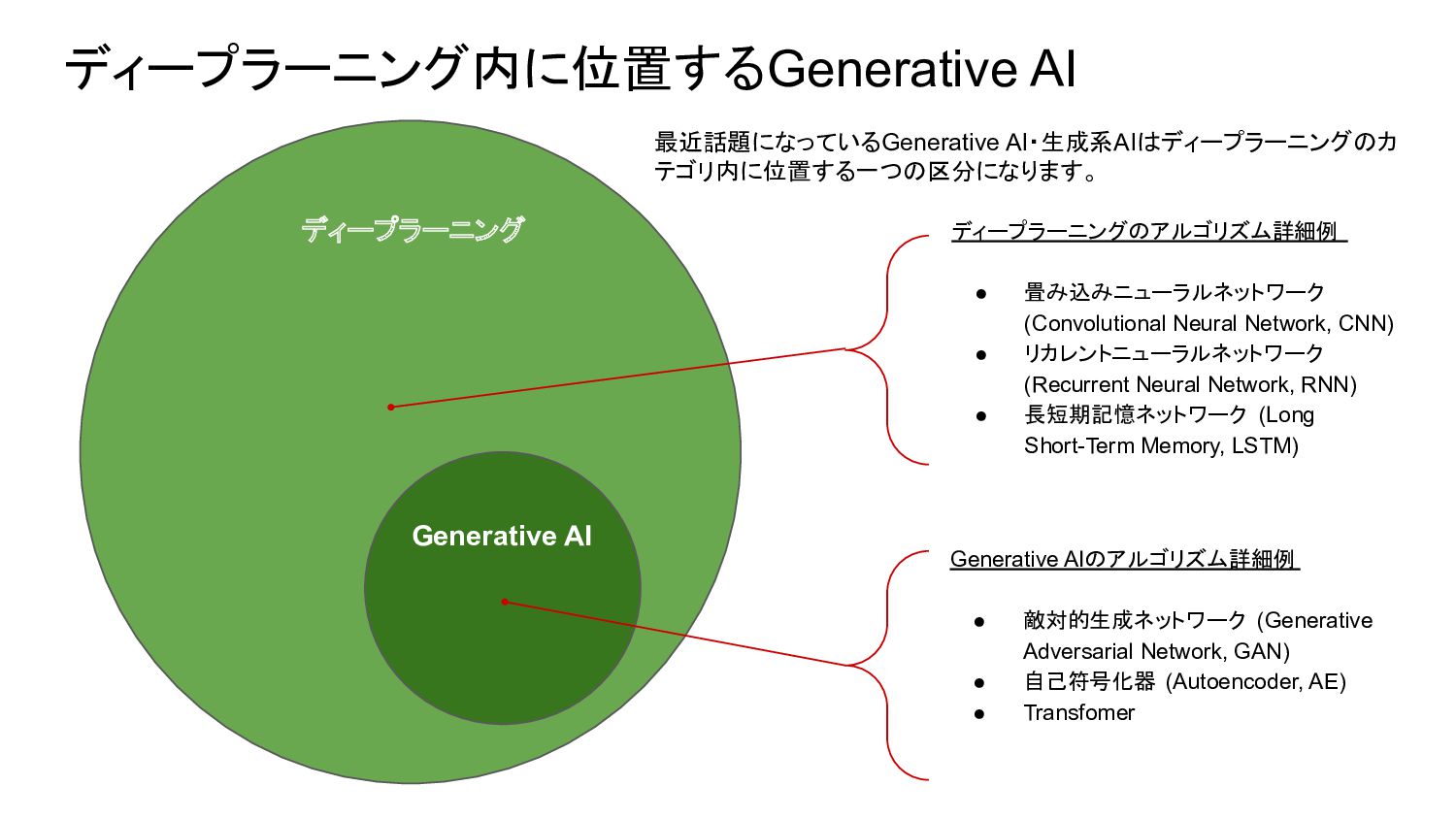{kind=link}
{kind=link}
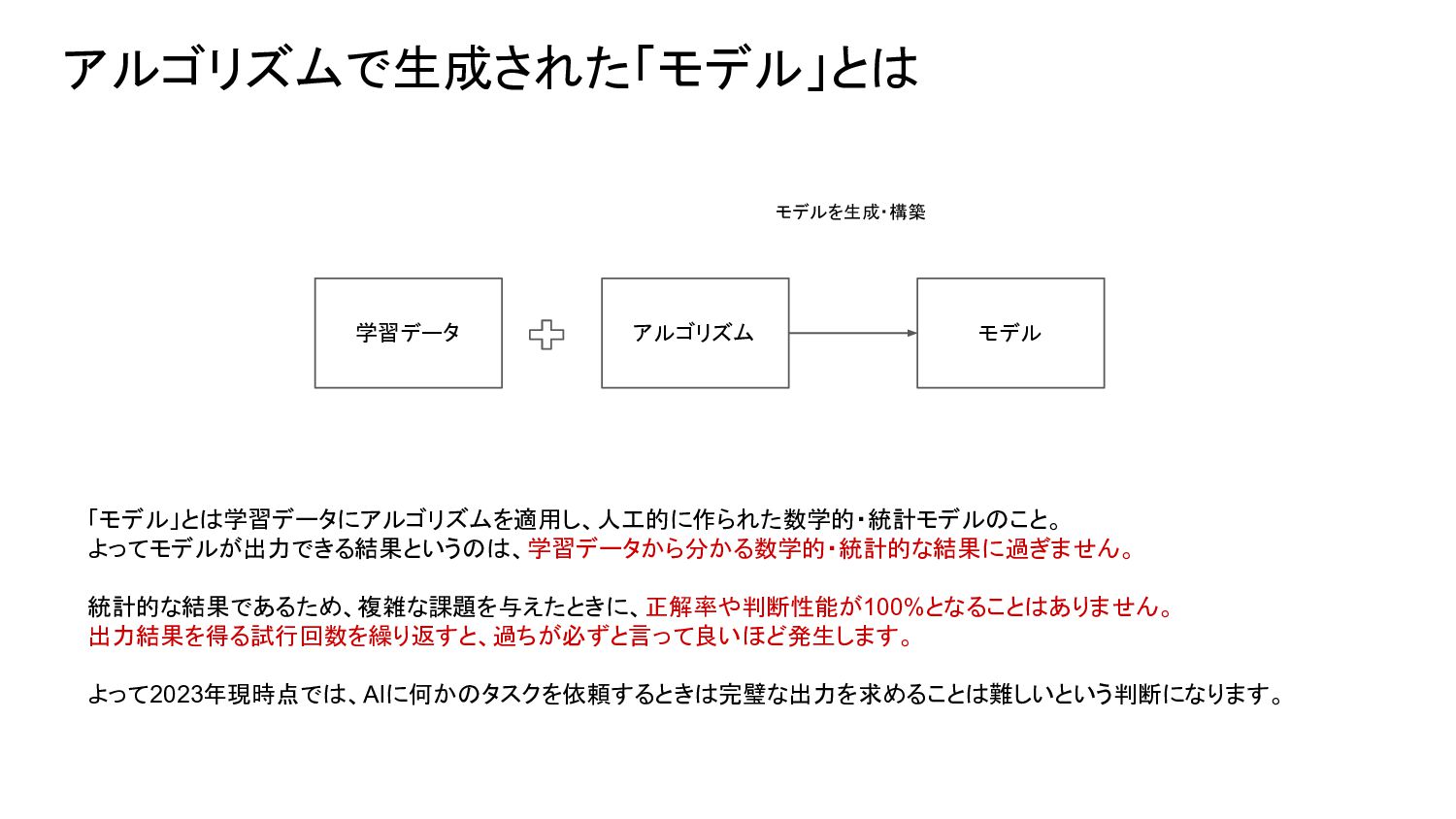{kind=link}
{kind=link}
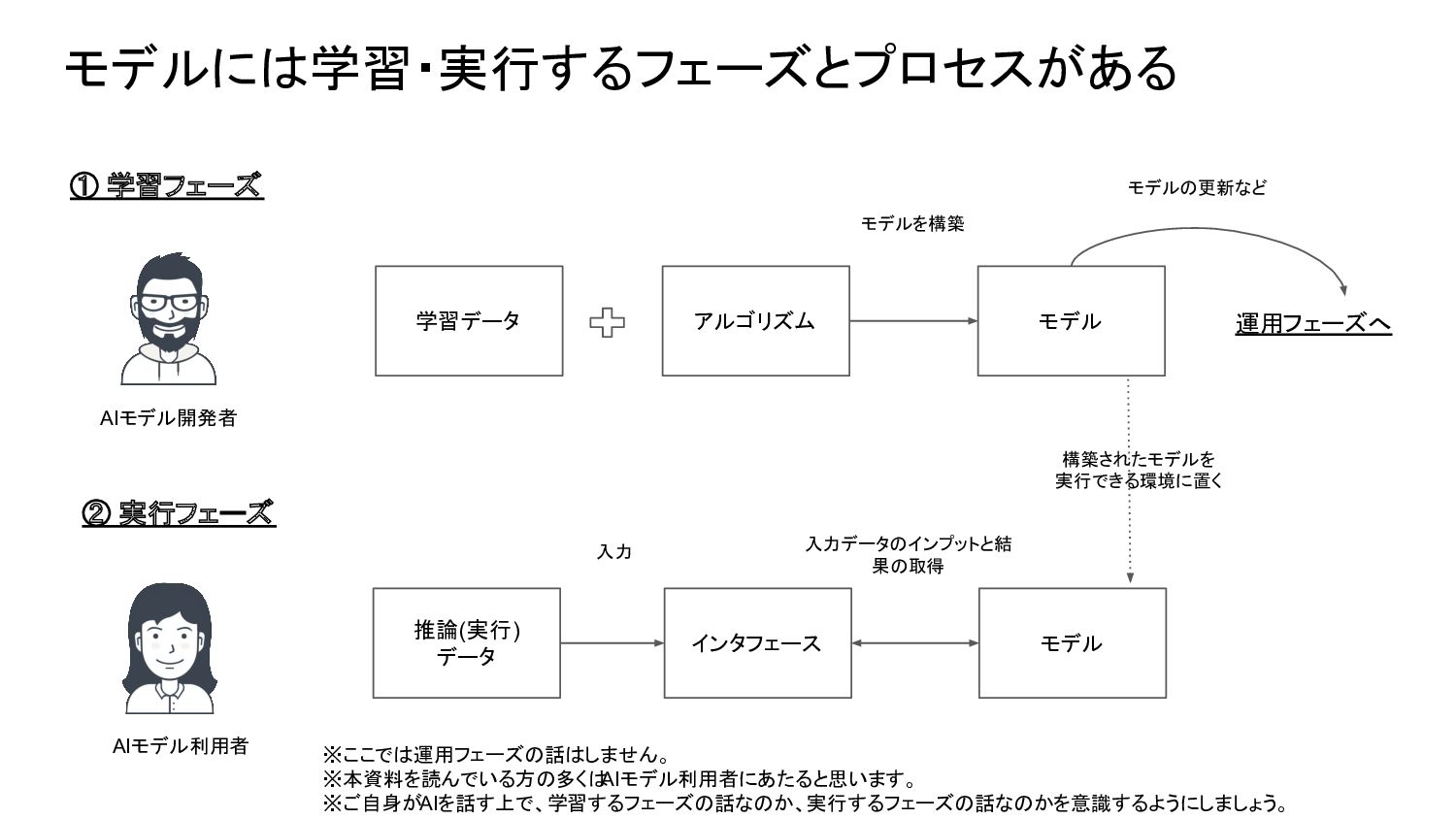{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
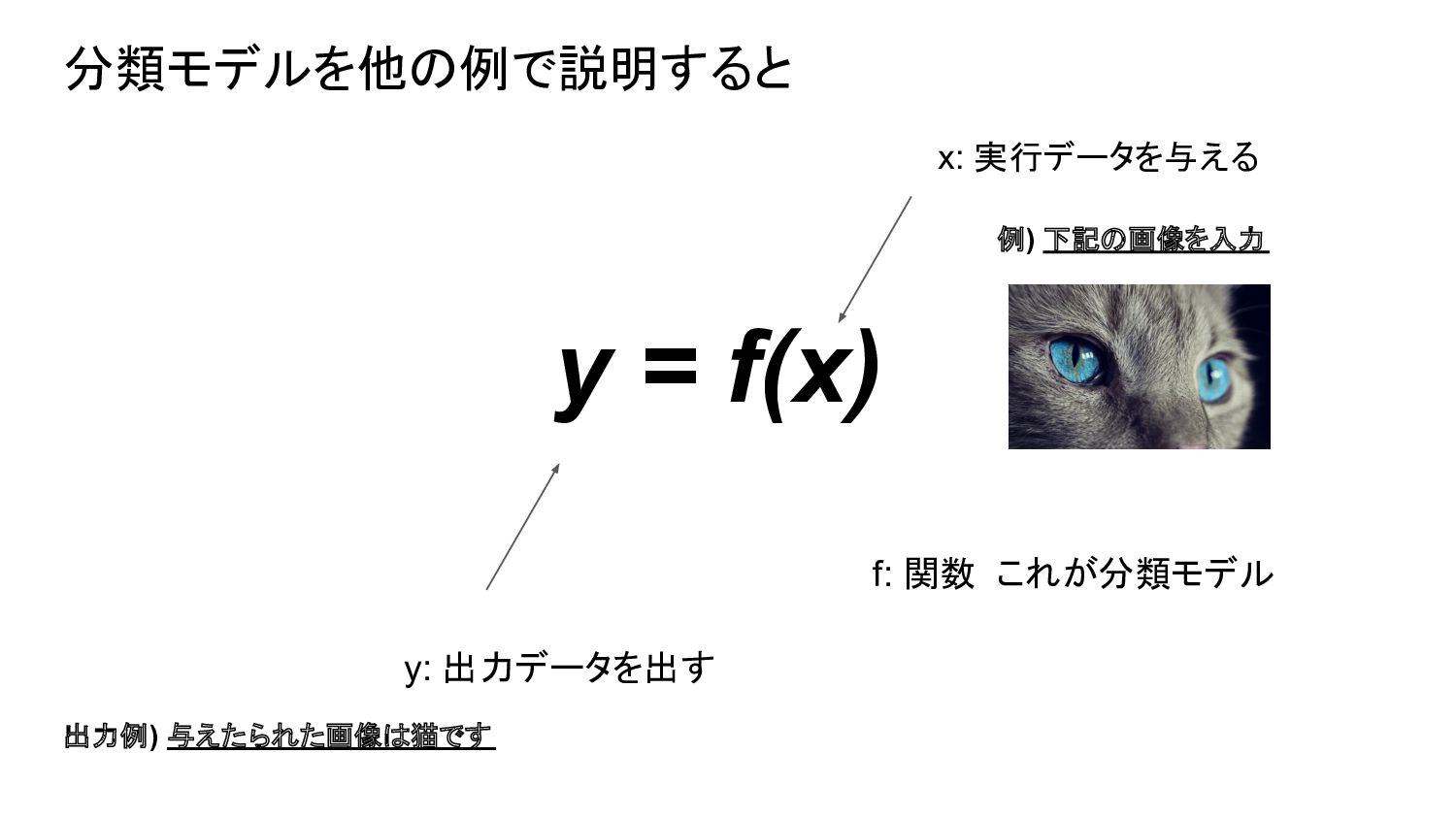{kind=link}
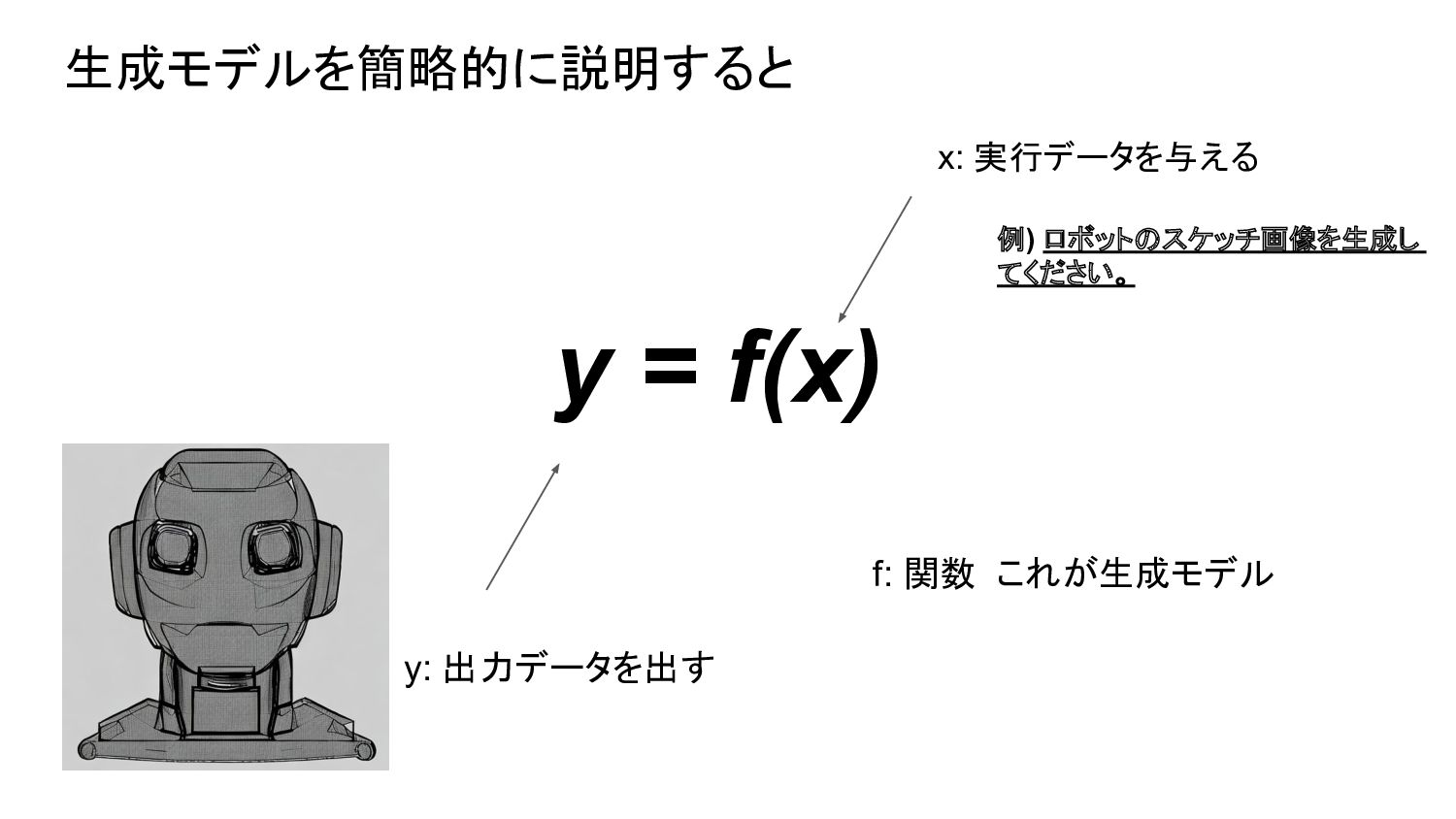{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
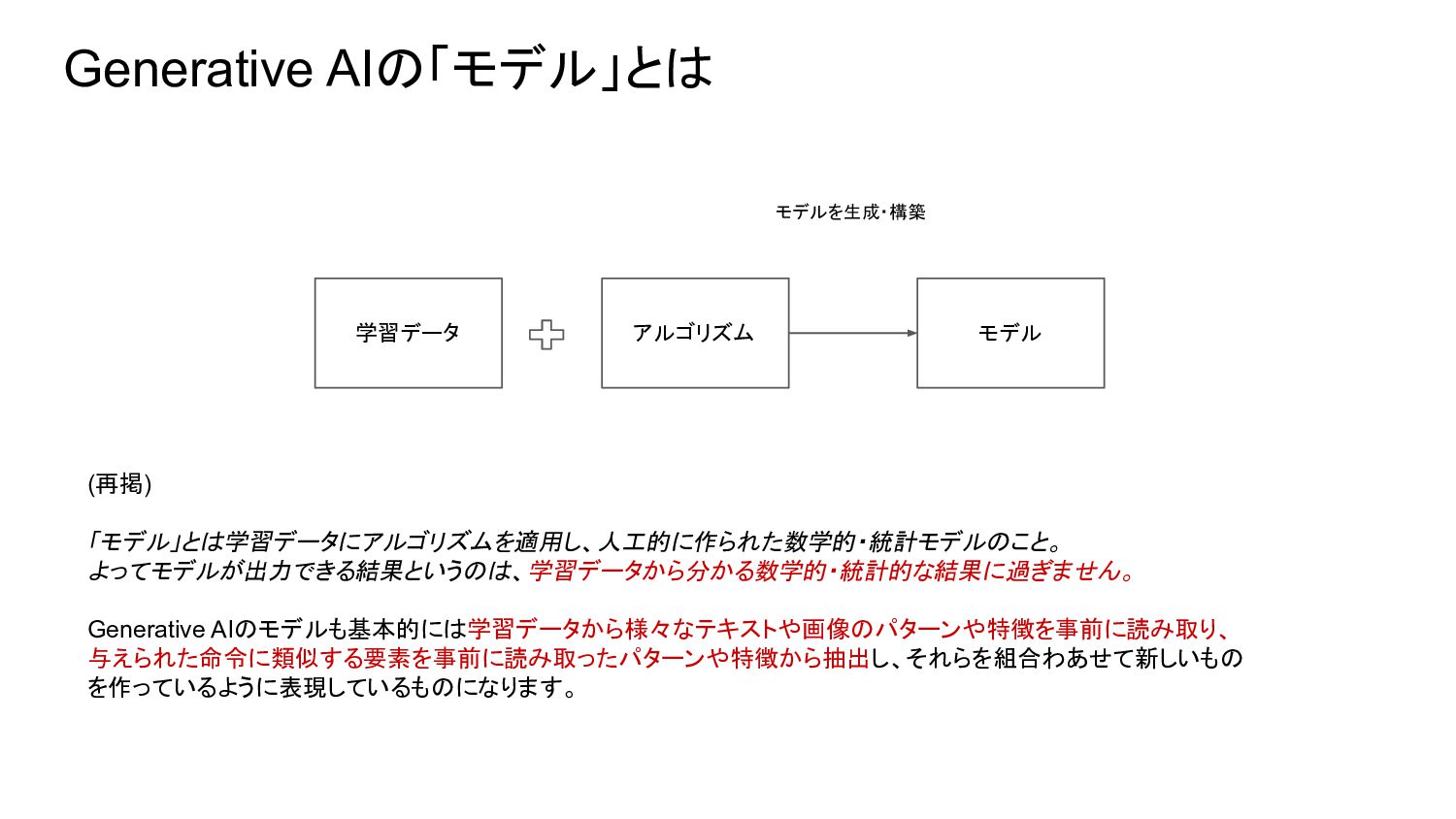{kind=link}
{kind=link}
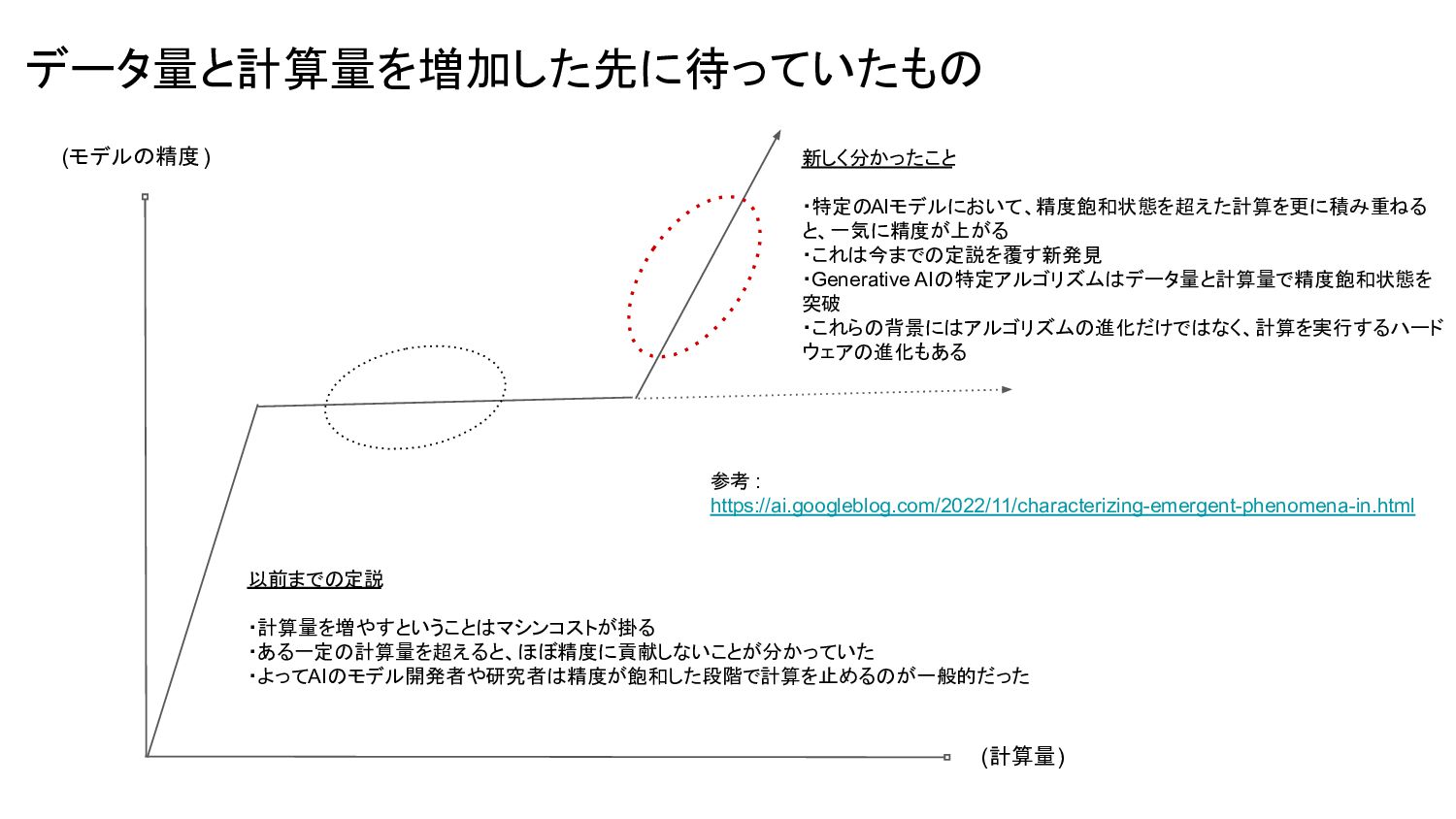{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
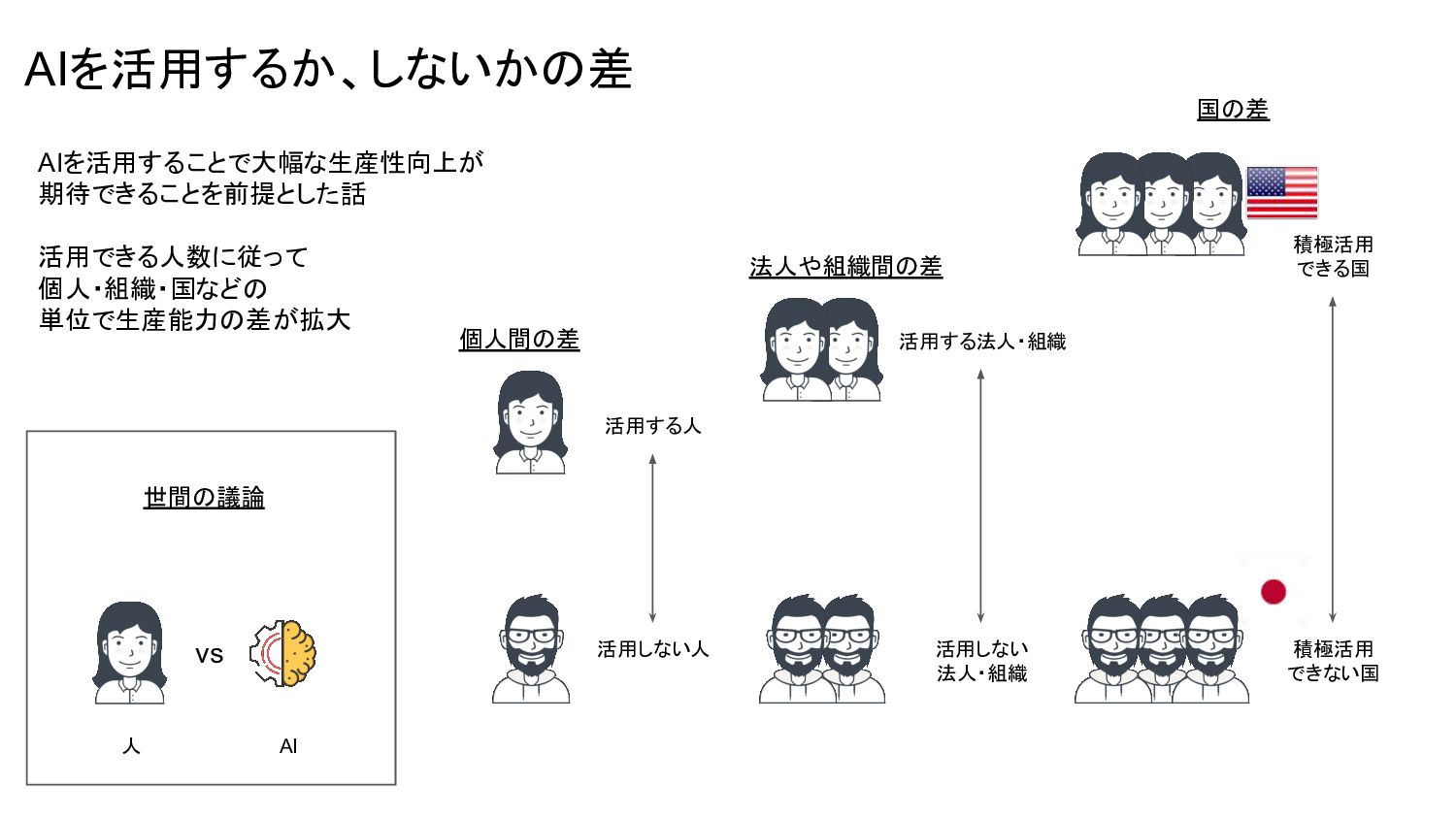{kind=link}
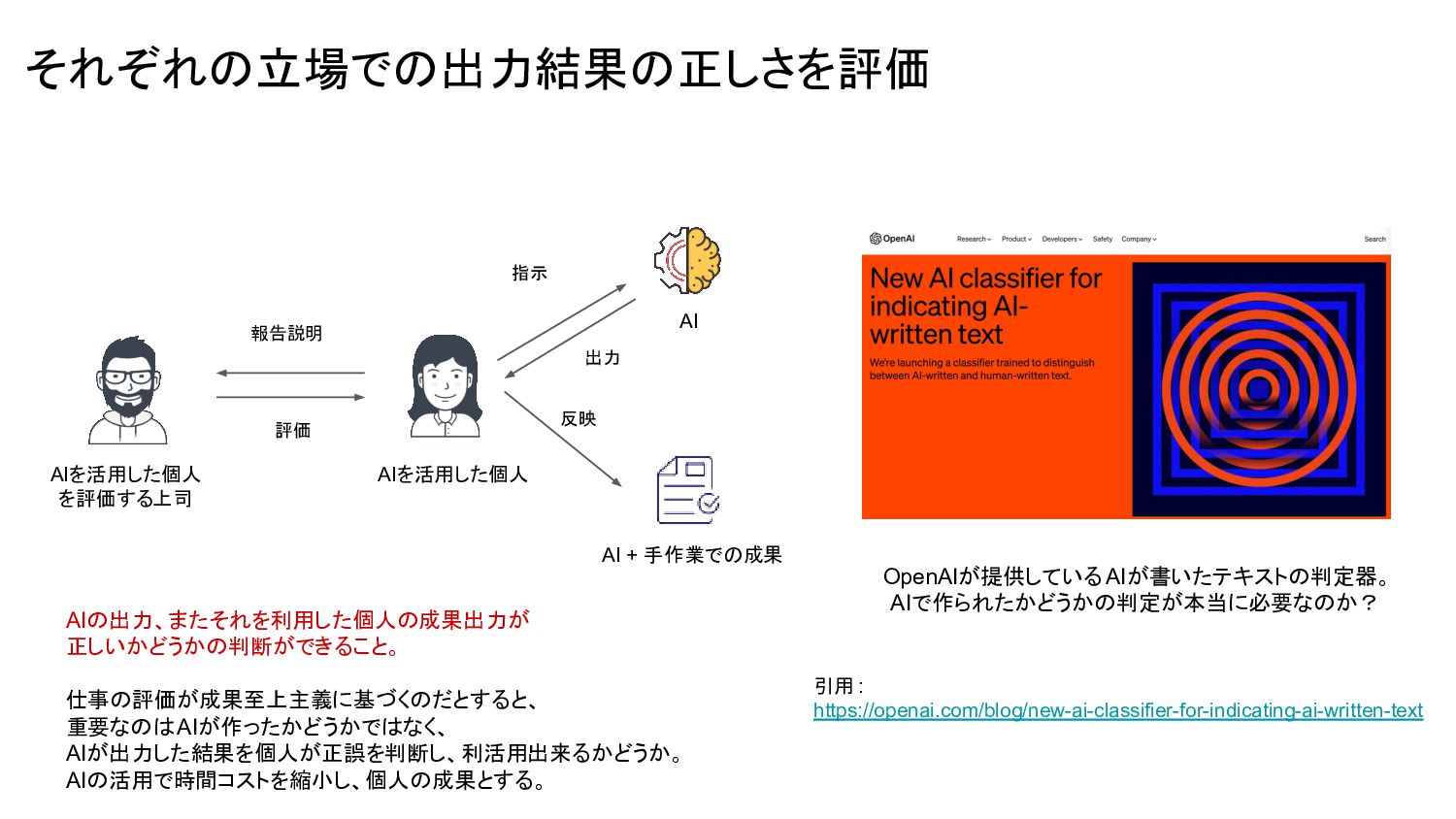{kind=link}
{kind=link}
{kind=link}
{kind=link}
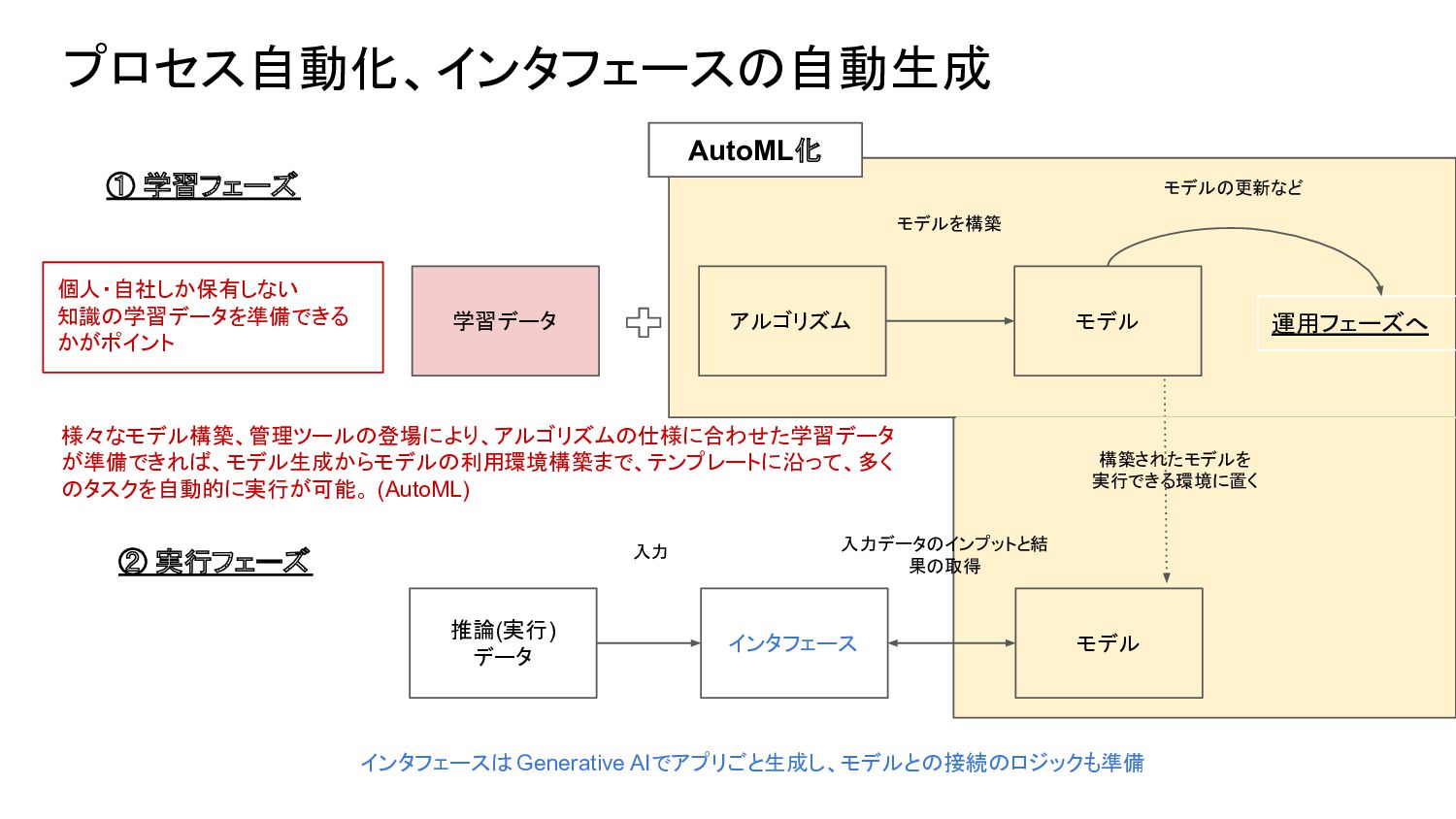{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}